

Abstract
Learning a second language as an adult is particularly effortful when new phonetic representations must be formed. Therefore the processes that allow learning of speech sounds are of great theoretical and practical interest. Here we examined whether perception of single formant transitions, that is, sound components critical in speech perception, can be enhanced through an implicit task-irrelevant learning procedure that has been shown to produce visual perceptual learning. The single-formant sounds were paired at sub-threshold levels with the attended targets in an auditory identification task. Results showed that task-irrelevant learning occurred for the unattended stimuli. Surprisingly, the magnitude of this learning effect was similar to that following explicit training on auditory formant transition detection using discriminable stimuli in an adaptive procedure, whereas explicit training on the subthreshold stimuli produced no learning. These results suggest that in adults learning of speech parts can occur at least partially through implicit mechanisms.
Languages differ in their phonetic repertoire, that is, in the set of speech sounds that are used to form words and thus to convey distinctions in meaning. Infants learn the speech sounds of their linguistic environment in their first year of life by attending to sound differences that are related to meaning differences and ignoring inconsequential sound differences (Jusczyk, 1997). This results in more efficient processing of speech sounds used in their language and less efficient processing of other sounds (Kuhl et al., 2008). Language acquisition, in general, and phonetic learning, in particular, appear to rely heavily on implicit learning mechanisms that extract statistical regularities organized at many different levels (Perruchet & Pacton, 2006; Saffran, Werker, & Werner, 2006). For example, humans' sensitivity to the distributional frequencies of the acoustic input affects word segmentation and phonetic categorization (Maye, Werker, & Gerken, 2002; Saffran, Newport, & Aslin, 1996). These powerful statistical mechanisms are modulated by attentional and motivational factors (Kuhl, Tsao, & Liu, 2003) as well as contingent positive reinforcements (Goldstein, King, & West, 2003; Gros-Louis, Goldstein, & West, 2006). However very little is known regarding the mechanisms that guide phonetic learning in adults.
Despite initial nondiscriminability, adults can learn to distinguish new phonetic contrasts (for review see Bradlow, 2008; Pisoni, Lively, & Logan, 1994). Substantial and long-lasting gains are seen (Lively, Pisoni, Yamada, Tohkura, & Yamada, 1994), generalizing to some extent to production (Bradlow, Pisoni, Yamada, & Tohkura, 1997), though this learning is limited to achieving performance levels well below native levels. A well-studied example concerns learning of the English /r/-/l/ distinction by Japanese adults. American English /r/ differs mostly from /l/ in the frequency of the third spectral peak (third formant or F3; see Figure 1), which is very low for /r/ but as high as possible for /l/ (Stevens, 1998). Although this is not the only acoustic difference between /r/ and /l/, variation in F3 onset and transition is sufficient for native speakers of American English to discriminate between /r/ and /l/ (O'Connor, Gerstman, Liberman, Dalattre, & Cooper, 1957; Yamada & Tohkura, 1990). Also, Japanese listeners who are unable to discriminate English /r/ from /l/ exhibit difficulty in differentially processing F3 in the acoustic context of a syllable (Yamada & Tohkura, 1990).
Figure 1.
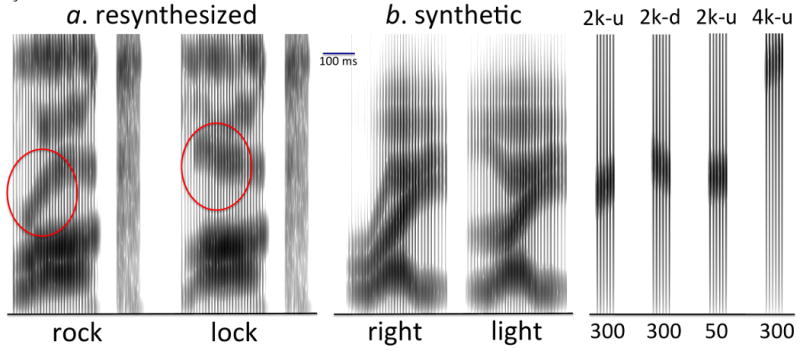
English /r/-/l/ distinction and examples of our formant transition stimuli. Left: spectrograms of LPC-resynthesized “lock” and “rock” stimuli based on natural recordings, from McCandliss et al (2002). These sounds differ mainly in the 3rd spectral prominence (formant; circled in red). Middle: spectrograms of synthetic “right” and “light” stimuli (excluding the final /t/ burst) based on the specifications of Yamada & Tohkura (1990). Note the initial steady-state and transition difference in the 3rd formant. Right: spectrograms of synthesized single formant transitions used in our study, including examples from different conditions. 2k/4k refers to 2600 Hz vs. 4600 Hz endpoint center frequency; u/d refers to upward vs. downward sweep direction; 50/300 refers to the extent of the transition sweep in Hz within the 70-ms stimulus duration. All spectrograms are plotted to the same scale, extending from 0 to 5000 Hz in the vertical direction; the common horizontal scale is indicated by a 100-ms segment.
Phonetic training regimes for adults differ dramatically in their methods and in their underlying assumptions regarding the mechanisms involved in learning. Phonetic learning has been found through explicit phonetic training with focused attention on the stimulus differences, explicit category labels, and performance feedback (Bradlow, 2008; Loebach & Pisoni, 2008; Pisoni et al., 1994; Vallabha & McClelland, 2007). It is also seen under natural settings after prolonged experience in a non-native phonetic, linguistic and social environment (Flege, 2003), where learning of the critical differences that distinguish phonetic contrasts emerges largely unintentionally. Phonetic training studies generally employ explicit training procedures, with participants focusing their attention on distinguishing the phonetic contrasts and receiving response feedback (Loebach & Pisoni, 2008; McCandliss, Fiez, Protopapas, Conway, & McClelland, 2002). Some degree of learning without external feedback is possible when stimuli are made discriminable through exaggeration (McCandliss et al., 2002), a finding consistent with Hebbian learning mechanisms (Grossberg, 1978, 1987; Gutnisky, Hansen, Iliescu, & Dragoi, 2009; Vallabha & McClelland, 2007) reinforcing the distinct percepts produced by exaggerated stimuli (Vallabha & McClelland, 2007). However, a reliably larger gain and more rapid improvement was found in training with feedback (compared to training without feedback), indicating that the simple Hebbian-learning account is “at best, incomplete” (McCandliss et al., 2002, p. 104).
Here we examine how novel approaches to perceptual learning may shed light on the mechanisms involved in adult phonetic learning. We consider a recent model of task-irrelevant perceptual learning (TIPL) (Seitz & Watanabe, 2005), which views perceptual learning as the result of systematic coincidences between (a) stimulus-driven representations upon exposure to environmental stimuli and (b) diffuse signals elicited upon successful task performance. In this model, stimulus features are represented and available for reinforcement learning whether attended or not. This representation is pre-perceptual in that it may occur below limens of detectability or discriminability. The “success signals” that modulate learning may be elicited by external rewards (Seitz, Kim, & Watanabe, 2009) or by internally generated performance evaluation in lieu of feedback (Seitz & Watanabe, 2009). A key prediction of this model is that in the course of performing a task, the individual learns unattended stimulus features, in addition to attended stimuli, that coincide with successful performance, because the modulating signal is not tied to the specific stimulus features causing its elicitation. This model is consistent with neural models of learning, attention, and motivation during reinforcement learning (Dranias, Grossberg, & Bullock, 2008; Grossberg & Merrill, 1996), while it stands in contrast to frameworks in which learning is gated by task-directed attentional factors (Ahissar & Hochstein, 1993).
The present work extends the TIPL procedure into the auditory domain, addressing, in particular, the sound property that is most important for distinguishing /r/ from /l/. We used subthreshold single formant transitions as unattended, task-irrelevant, stimuli that were presented in a temporally correlated manner within sequences of task-relevant animal sounds (see Figure 2 for task schematic). We found that after 10 days of training on the serial auditory presentation (SAP) animal sound identification task, subjects improved at discriminating formant transitions that had been temporally paired with targets of the SAP task. Notably, the magnitude of the threshold improvements found from the TIPL procedure was comparable to that achieved through explicit training with feedback for the same auditory distinction.
Figure 2.
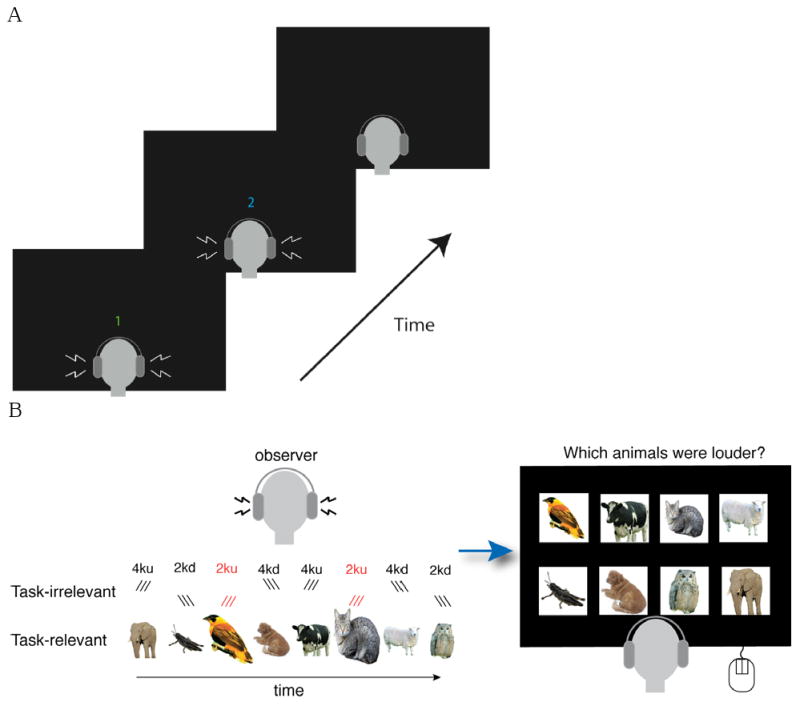
Task schematics. A, schematic of two-interval formant transition detection task; observer heard two sounds and had to report whether the first or second sound contained the formant sweep. B, schematic of SAP task; observer heard 8 sounds and had to click on the two pictures that corresponded to the two louder sounds (indicated in cartoon by larger animals; bird and cat) in the sequence. Task-irrelevant formant transition stimuli were presented three times during each animal sound, as indicated by triple lines (/ for upward sweeks and \ for downward sweeps; with higher elevation indicating higher frequencies), with formant transistions paired with task-targets shown in red.
Method
Participants
32 adults (18-35 years old), with normal hearing and normal or corrected-to-normal vision, participated in the study. In the TIPL training, 16 subjects participated, 4 in each of 4 conditions. Of these, 8 were native English speakers, 6 native Japanese speakers (one had an English speaking parent), and 2 native Chinese speakers. In the adaptive training, 8 subjects participated, 4 in each of 2 conditions, including 5 native English speakers, 1 native Japanese speaker, 1 native Korean speaker, and 1 native Italian speaker. In the explicit training, 8 more subjects participated, 4 in each of 2 conditions, including 4 native English speakers and 4 native Chinese speakers. One participant in the explicit training group for 2ku was dropped from the study due to his extremely poor performance on the pretest (initial average threshold of 800 Hz in the 2ku condition) and thus only 7 participants were included in the explicit training data set reported below. We observed no differences in learning based upon language background, as non-native English speakers in each condition showed qualitatively similar results as the native English speakers in the same conditions. Participants were naïve as to the purpose of the experiments. Informed consent was obtained according to the requirements of the Boston University and University of California at Riverside, Institutional Review Boards.
Stimuli
Formant transitions were 70 ms long and were created by passing a constant-amplitude train of 7 impulses spaced 10 ms apart through a simple resonator with center frequency continuously varied (linearly interpolated for every sample at a rate of 22050 Hz) from an initial value (specified below) to a final value of either 2600 or 4600 Hz and a constant bandwidth of 260 or 460 Hz, respectively, resulting in sounds with a single spectral peak transition at a constant fundamental frequency of 100 Hz and an approximate intensity of 63.7 dBA SPL. Resonating frequencies at stimulus onset were determined following transition detection threshold estimation (see below). For the training, onset frequencies were set at subthreshold values of 2475 (condition “2k-up”), 2725 (2k-down), 4400 (4k-up), and 4800 (4k-down) Hz for the first 8 participants. For the second 8 participants values were chosen at ∼80% of the threshold level of the first group resulting in values of 2500 (2k-up), 2750 (2k-down), 4300 (4k-up), and 5100 (4k-down). Thus the total extent of the formant sweep over the 70 ms was 125 (100), 125 (150), 200 (300), and 200 (500) Hz, for the 2k-up, 2k-down, 4k-up, and 4k-down conditions, respectively (values for the second group in parenthesis). Reference constant-profile single-formant stimuli for each condition were constructed with a constant resonating frequency equal to the fixed endpoint value of the corresponding set (2600 Hz for 2k and 4600 Hz for 4k).
Stimuli for the SAP task were eight identifiable animal sounds (dog, cat, cow, bird, elephant, sheep, cricket, and owl) downloaded from http://www.seaworld.org/animal-info/sound-library/index.htm (Supplemental Figure 4 displays spectrograms of these sounds). Sounds were equated in duration at 500 ms, using 10-ms square-sine on and off ramps as needed, and in intensity, to the extent possible, at approximately 62.4 dBA SPL.
Procedure
The experiment consisted of four phases: practice, pre-test, training sessions, and post-test. In practice sessions, participants were familiarized with the formant transition stimuli and with the psychoacoustic threshold estimation procedure. There were two endpoint-frequency conditions (termed 2k and 4k; see “Stimuli”) crossed with two sweep-direction conditions (up and down), resulting in four detection conditions, each run once during practice. The pre-test was conducted on the day following practice. In this session, formant transition detection thresholds were estimated 4 times (in nonconsecutive runs) for each condition. In the 10 training sessions, taking place over 10 consecutive days, participants carried out the SAP animal sound identification task. Finally, the post-test was identical to the pre-test.
Formant transition detection task (practice and test sessions)
Formant transition detection thresholds were determined psychoacoustically in a two-interval forced-choice task presenting one formant sweep and one stimulus with a constant spectral profile (fixed resonator) at each trial, in random order. Participants pressed “1” or “2” on the keyboard to indicate the interval of the sweeping stimulus. Stimuli differed only in resonator center frequency, determined adaptively in a modified variable-step staircase procedure based on accelerated stochastic approximation (Treutwein, 1995), with c=400 (starting step size 250 Hz and initial sweep extent of 600 Hz) and target correct response probability .75. The procedure was terminated at 15 reversals unless a maximum of 60 trials was reached first. Thresholds were calculated by linear averaging of the extent of formant sweep for the last 12 response reversals (or as many as available, if fewer). Thresholds were determined in separate runs for 2k-up, 2k-down, 4k-up, and 4k-down conditions. Accuracy feedback was given in the practice session only.
TIPL training sessions
The TIPL training involved SAP of eight animal sounds with 50ms interstimulus interval (ISI). After each trial, participants reported the two louder animal sounds in the sequence by clicking (in the correct order) on two of eight animal pictures displayed on the screen (Figure 2). The order of eight animal sounds and the two animals chosen as targets was randomized across trials. A two-component adaptive procedure was applied to the amplitude of the two target sounds during this task. First, an adaptive staircase affected the amplitude increment of the target items (after each correct trial dB increment over base was multiplied by .95 and after incorrect trials divided by .9025). Due to extreme differences in spectral profiles among the animal sounds, intensity levels were adaptively varied independently based on identification performance for each animal separately. Thus, a second staircase applied a multiplier for each individual animal sound (dB increment multiplied by .995 or divided by .9925). This procedure achieved consistent performance across participants and animal sounds (Supplemental Figure 2). No accuracy feedback was given.
Throughout training, formant transition sounds were presented simultaneously (linearly added) with the animal sounds. For each participant, a specific subthreshold formant transition (2ku, 2kd, 4ku, or 4kd) was added to the targets of every trial (paired sound), and the other three formant sweeps were added to the distractors (nonpaired sounds), such that the four different formant transitions were presented an equal number of times in each trial. The choice of paired sound was counterbalanced across participants. Given that the animal sounds were presented for 500ms each and the formant transitions were only 70ms in duration, each formant transition was presented 3 times during a single animal sound presentation, with a 72.5ms ISI between formant presentations. During the 10 days of training, each participant heard the paired formant sounds 3 times with 2 animals in each trial, totaling 18000 individual presentations of the subthreshold single formant sweep over 3000 trials (300 trials per session).
The base level of the animal sounds was approximately 62.4 dBA and the paired formant stimuli were presented at 55.1 dBA with combined intensity of the formant + animal sound of about 63.4 dBA for nontargets. For targets, the animal component of the sound was elevated by the aforementioned adaptive procedure as follows: It = If + (1.0 + to× ta) × Ia (If : formant sweep level; Ia : animal sound base level; to : overall threshold; ta: animal sound-specific threshold).
Explicit training sessions
Explicit training was designed to test the possibility that the subthreshold stimuli are learnable when attended and externally rewarded. The single formant stimulus stream was based on that used in TIPL training, thus consisting of two target triplets and six nontarget triplets. The two target triplets (which were paired with the louder animal sounds in TIPL) were the same formant transitions in each trial as they were in TIPL. The other six stimuli were sets of three identical single-formant sounds with constant spectral profiles, their formant frequency being fixed at the endpoint frequency of the corresponding stimuli used in TIPL, thus being identical to the constant-profile reference stimuli used in testing. Only two frequency conditions were used in explicit training (2kd and 2ku, counterbalanced across subjects).
To minimize confusion of the participants, we removed the animal sounds from the auditory stream and replaced them with a sequence of animal pictures. The participants' task was to report the two animals that were paired with the formant transitions, using the same response screen as in TIPL. Due to the unchanged structure of presentation of the target stimuli, each subthreshold single-formant sweep was presented 18000 times, as many as in TIPL, in the same number of trials.
Adaptive training sessions
Procedures for standard adaptive training were similar to the other training conditions in terms of scheduling and testing, and similar to the test sessions in terms of the stimulus-response interaction. Participants conducted the same practice and pre- and post-training test sessions, however only the 2ku and 2kd sounds were used. Each participant conducted 5 training sessions on separate days in which either the 2ku or 2kd formant was trained (4 participants in each group). The training was identical to the test sessions with the exception that response accuracy feedback was given after each trial. Participants conducted 8 repetitions of the threshold estimation procedure in each training session, for a maximum of 2400 individual presentations of single-formant sweeps and potential corresponding rewards.
Results
The results from 16 subjects who conducted the SAP task show that the training task remained difficult and that subjects underwent task-related learning in identifying the loudest animal sounds (thresholds for each day shown in Supplemental Figure 1). Threshold decrease across sessions was significant by two-way repeated measures ANOVA (F(9, 1248) = 39.18, p < .001). Loudness thresholds for different animal sounds were significantly different (F(7, 1248) = 71.84, p < .001), however identification accuracy was highly similar across animal sounds (F(7, 1248) = 1.18, p = .312) presumably due to the target-specific adaptive procedure (see Supplemental Figure 2 for performance on each target-type).
Mean formant transition detection thresholds before and after training are shown in Figure 3. Threshold values were higher than formant sweep extents used during training, confirming that formant transitions presented during training were indeed subthreshold. There were no significant differences in pre-training thresholds between paired and unpaired conditions (paired samples t-test, averaging distance from mean pre-training threshold for each condition, t(15) = 1.25, p = .231; the same results were obtained comparing ratios to condition means, t(15) = 1.26, p = .226).
Figure 3.
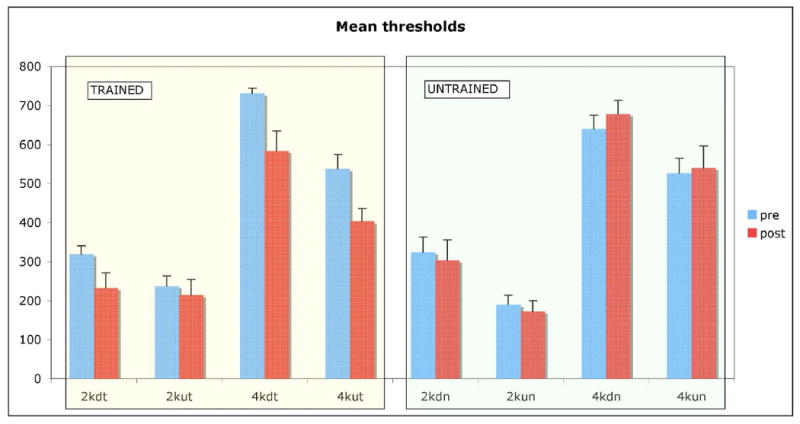
Formant sweep extent detection performance (mean thresholds, in Hz) for each condition, before and after training. “Trained” (t) refers to sweeps paired with target animal sounds during training and “untrained” (n) refers to sweeps paired with nontargets (averaged across the corresponding subjects in each case). Error bars show standard error.
Our main interest was to see whether learning would occur specifically for formant transitions paired with the SAP targets, that is, whether significant differences would emerge between post-training and pre-training thresholds in the paired condition (Figure 4). A significant decrease was found in detection thresholds for formant transitions paired with targets (t(15) = −2.3, p = .037, paired samples t-test), but not for formant transitions paired with nontargets (t(47) = .17, p = .87). There was also a significant difference in learning between formant transitions paired with targets and formant transitions paired with nontargets (t(15) = −2.75, p = .015, paired samples t-test of paired sound threshold change vs. average of unpaired sounds). These results confirm that task-irrelevant learning occurred for acoustic components that distinguish speech sounds even when the dimension undergoing learning remained unattended and subthreshold.
Figure 4.

Change in formant sweep extent detection thresholds between test sessions, before vs. after training, as a proportion (percentage) of pre-training threshold, in Hz. Paired, average change across the 2kd, 2ku, and 4kd, 4ku conditions for formant transitions paired with SAP targets. Control, average threshold change for formant transitions not paired with targets in the SAP task. Paired 2k, average change of 2kd and 2ku thresholds from task-irrelevant training. Trained 2k, average change of 2kd and 2ku thresholds from adaptive training. RSAP 2k, average change of 2kd and 2ku thresholds from explicit training. Error bars show standard error.
The results of 7 subjects in the explicit training group are plotted in the far right (Trained RSAP 2k) of Figure 4. We found no evidence that these subjects were able to improve their formant transition detection sensitivity through this procedure, even though they experienced the exact same number of stimulus presentations per day, using the same target stimuli, over the same number of days as the implicit training group.
In the adaptive training group, performance improvements asymptoted within 5 days (Supplemental Figure 3 shows day-by-day performance). The degree of learning was not significantly different from that found after implicit, task-irrelevant training (t(14) = .14, p = .89; unpaired t-test of trained 2k threshold changes between groups). Effect sizes (Cohen's d) were 1.1 and 0.9 in the adaptively and implicitly trained group, respectively (see “trained 2IFC 2k” and “paired 2k” in Figure 4). As with implicit training, performance benefits were specific to the trained formant transition in the adaptive training group (t(7) = −2.8, p = .026, paired samples t-test of trained sound threshold change vs. untrained threshold change).
Discussion
Our results show that detection thresholds of auditory formant transitions can be lowered implicitly by pairing these sounds with the targets of an unrelated task. Neither attention nor awareness of the critical stimulus property (i.e., change in spectral peak) is necessary to achieve an increase in sensitivity to sweep extents of formant transitions.
While the sweep extents of the formant transitions used during TIPL were below participants' thresholds, the presence of these formant transition stimuli was perceptible. During debriefing at the end of the experiment, some participants noted that they heard “clicking sounds”. However, no participant could indicate any relationship between the formant transitions and the animal sound targets. Also while the loudness of the targets was increased relative to the distractors, the formant transitions were presented at constant amplitude, therefore the target-paired formants were presumably more difficult to identify than the others. Furthermore, we used a fully balanced design, in which formant sounds were counterbalanced across participants, performance was controlled with an adaptive staircase, and each formant transition condition was presented simultaneously with each animal sound (both as target and distractor) an equal number of times. These factors give us confidence that learning obtained through our procedure cannot be explained by selective attention to particular formant transitions during the training procedure.
There were two differences in the auditory stimuli between the explicit and implicit group, namely the absence of animal sounds and the constant profile of the nontarget single-formant stimuli in the explicit group. Both of these differences were expected to provide a learning advantage to the explicit group, because there was less interference from other sounds and no confusability of the direction of spectral change, respectively. Yet, there was no evidence for learning in the explicit group, suggesting that explicit attention may be insufficient for (or even detrimental to; see Choi, Seitz, & Watanabe, 2009) the formation of higher sensitivity representations of the subthreshold stimuli. An additional potential difference is that, in the implicit group, loud animal sounds may have acted as internal feedback generators, reinforcing almost every presentation of the target single-formant sweeps, whereas in the explicit group, reinforcing external feedback occurred only in the rare instances in which participants guessed correctly which were the target stimuli. Therefore both the role and the source of feedback warrant further scrutiny in future work.
While the magnitude of learning was similar between the implicit and adaptive groups, there were substantial differences between the stimuli and the procedures, favoring learning in the adaptive group. Specifically, in adaptive training stimuli were consistently presented at or above discrimination threshold during training, and were individually rewarded at a high rate of performance, whereas in implicit training stimuli were consistently presented at subthreshold levels and there was no specific external reward associated with their presentation. Moreover, the adaptive procedure tracked the participants' performance by adjusting the sweep extent and thus maintaining difficulty in the trained task at a near-optimal level for perceptual improvement (Amitay, Irwin, Hawkey, Cowan, & Moore, 2006). On the other hand, implicit training lasted for 10 days, with more stimulus presentations per day than adaptive training, which only lasted five days. However, there was evidence of asymptotic performance in adaptive training, suggesting that further training might have had little or no additional learning effect.
Because of the notorious difficulty Japanese listeners face with the English /r/–/l/ distinction, it has been considered as a testing ground for different nonnative phonetic training approaches. An important lesson from such training paradigms is that variability in training is critical for achieving transfer of stimulus-specific learning to new speakers, new sound tokens, and new phonetic environments (e.g. Bradlow, 2008; Lively, Logan, & Pisoni, 1993; McCandliss et al., 2002). Feedback is generally considered necessary for learning. However, when the critical acoustic differences are artificially exaggerated, making them more easily identifiable, learning is possible without performance feedback, as Hebbian learning mechanisms presumably reinforce the distinct percepts that are produced by the exaggerated stimuli, resulting in separate categories (McCandliss et al., 2002; Vallabha & McClelland, 2007). The Hebbian account cannot provide a complete account of phonetic category learning, because feedback markedly improves learning (e.g. Vallabha & McClelland, 2007). Tricomi et al. (2006) suggested that the strong activation of the caudate nucleus observed in phonetic training conditions with feedback (but not without feedback) can explain aspects of adult phonetic learning under laboratory conditions, and, perhaps, aspects of first language learning under natural settings. These findings and suggestions on the role of feedback in adult nonnative phonetic training and, perhaps, in first language acquisition, can be better understood within Seitz and Watanabe's perceptual learning model in which learning occurs due to the coincidence of stimulus driven activity and the release of nonspecifically acting reinforcement and motivational signals (Grossberg & Merrill, 1996; Seitz & Watanabe, 2005).
Both task-relevant and task-irrelevant learning contribute to our understanding of how a brain solves the stability-plasticity dilemma; that is, how a brain can learn quickly without catastrophic forgetting. Adaptive Resonance Theory (Carpenter, 2001; Grossberg, 1980, 2007) explains how laminar neocortical circuits enable both intercortical attentive feedback from higher cortical levels and intracortical pre-attentive feedback from superficial layers of the same cortical region to accomplish this goal. The intracortical feedback loops self-stabilize slow perceptual learning without attention or awareness, and thus provide a plausible mechanism for the task-irrelevant learning observed in the current study. The cooperation and competition among these distinct but interacting pre-attentive and attentive processes provides a framework for investigating the conditions under which task-irrelevant learning can occur, without being inhibited by the “biased competition” properties of focused attention. For example, task-irrelevant learning may fail to engage the ART mismatch-reset process. New category learning could occur due to an interaction of filtering, competition, and intracortical resonance without the benefit of mismatch-mediated search and vigilance control processes. Further research will be required to verify this prediction.
An important question is whether task-irrelevant perceptual learning would benefit Japanese listeners. While our results cannot support strong claims regarding this issue, it should be noted that 6 of the TIPL group participants were native Japanese speakers. We found that 5 of them showed learning for the paired formant transition, with an average improvement of 23.2% ±9.5%, while one showed a 23.1% degradation of performance. These results suggest that the procedure is effective for native Japanese speakers as it is for native English speakers. However, the threshold improvements for both native English and Japanese speakers in both training paradigms (implicit and explicit) were specific to formant transitions that were trained. Specificity of learning is typical of studies of perceptual learning, which have shown that performance improvements often do not transfer to untrained stimuli (for review see Fahle, 2004). These specificity effects are often considered as evidence that the learning effects result from changes in the sensory representation of the trained stimuli (Ahissar & Hochstein, 2004; Fahle, 2004) or in the read-out from the sensory areas (Dosher & Lu, 1998). The observation of specificity in our study is also in line with the aforementioned requirement for variability in training tokens in order for learning to generalize to untrained conditions (speakers, context, etc.) and suggests that L2 phonetic learning may be more akin to general perceptual learning. Along these lines, the fact that learning of the formant transitions is specific to frequency and sweep direction suggests that for TIPL to be effective for L2 phonetic learning, a range of simple distinctions from the new language's phonetic repertoire, such as both upward and downward formant transitions at a range of relevant frequencies, would need to be trained. Given this, further research will be required before clear benefits to L2 learners can be achieved.
The fact that the magnitude of learning was similar between the implicit and adaptive trainings is at first glance surprising. While it is conceivable that learning in the two paradigms is due to independent mechanisms (Poldrack et al., 2001), an alternative explanation is that much learning achieved through explicit training occurs implicitly. That is, learning from the adaptive task is due to subjects' performance yielding an appropriate schedule of reinforcement to the learned stimuli, not simply due to their explicit attention towards the stimuli. Recent research of visual learning shows that attention to stimuli can actually hinder perceptual learning (Gutnisky et al., 2009; Tsushima, Seitz, & Watanabe, 2008). This finding that benefits in the perception of formant transitions achieved through task irrelevant learning are as large as in explicit adaptive training may imply that learning of speech sounds may generally be achieved through implicit learning mechanisms.
This view of learning as emerging unintentionally, through task-irrelevant use, within a rich phonetic, linguistic and social context, although ecologically appealing, until now, has not been explored experimentally. For example, traditional training paradigms for adult second language learners in non-native phonetic contrasts use training procedures with explicit category labels and feedback after each stimulus presentation (Lively et al., 1993; Logan, Lively, & Pisoni, 1991). Obviously this is not how infants and adults learn new sounds. An interesting exception to traditional training techniques is a recent study by Wade and Holt (2005). Subjects acquired unintentionally new auditory categories after playing a 30-minute “game,” during which different nonspeech tokens of distinct sound categories were systematically correlated with the appearance of discrete targets. Such training paradigms have important implications for our understanding of how sensory learning is achieved by the brain and can inform how best to teach people to improve their sensory skills.
Supplementary Material
Acknowledgments
We thank Erin M. Ingvalson and Lori L. Holt of Carnegie Mellon University for providing formant specifications for synthesizing r/l based on Yamada & Tohkura (1990) and for useful discussion. We also thank Daniel Khafi and Shao-Chin Hung for help conducting the experiments.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Aaron R. Seitz, University of California, Riverside
Athanassios Protopapas, Institute for Language & Speech Processing, Greece.
Yoshiaki Tsushima, Harvard University.
Eleni L. Vlahou, Institute for Language & Speech Processing, Greece
Simone Gori, University of Padua.
Stephen Grossberg, Boston University.
Takeo Watanabe, Boston University.
References
- Ahissar M, Hochstein S. Attentional control of early perceptual learning. Proc Natl Acad Sci U S A. 1993;90(12):5718–5722. doi: 10.1073/pnas.90.12.5718. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ahissar M, Hochstein S. The reverse hierarchy theory of visual perceptual learning. Trends Cogn Sci. 2004;8(10):457–464. doi: 10.1016/j.tics.2004.08.011. [DOI] [PubMed] [Google Scholar]
- Amitay S, Irwin A, Hawkey DJC, Cowan JA, Moore DR. A comparison of adaptive procedures for rapid and reliable threshold assessment and training in naive listeners. Journal of the Acoustical Society of America. 2006;119(3):1616–1625. doi: 10.1121/1.2164988. [DOI] [PubMed] [Google Scholar]
- Bradlow AR. Training non-native language sound patterns. In: Hansen J, Zampini M, editors. Phonology and second language acquisition. Philadelphia, PA: John Benjamins; 2008. pp. 287–308. [Google Scholar]
- Carpenter GA. Neural-network models of learning and memory: leading questions and an emerging framework. Trends in Cognitive Sciences. 2001;5:114–118. doi: 10.1016/s1364-6613(00)01591-6. [DOI] [PubMed] [Google Scholar]
- Choi H, Seitz AR, Watanabe T. When attention interrupts learning: inhibitory effects of attention on TIPL. Vision Res. 2009;49(21):2586–2590. doi: 10.1016/j.visres.2009.07.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dosher BA, Lu ZL. Perceptual learning reflects external noise filtering and internal noise reduction through channel reweighting. Proc Natl Acad Sci U S A. 1998;95(23):13988–13993. doi: 10.1073/pnas.95.23.13988. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dranias MR, Grossberg S, Bullock D. Dopaminergic and non-dopaminergic value systems in conditioning and outcome-specific revaluation. Brain Res. 2008;1238:239–287. doi: 10.1016/j.brainres.2008.07.013. [DOI] [PubMed] [Google Scholar]
- Fahle M. Perceptual learning: a case for early selection. J Vis. 2004;4(10):879–890. doi: 10.1167/4.10.4. [DOI] [PubMed] [Google Scholar]
- Flege J. Assessing constraints on second-language segmental production and perception. In: Meyer A, Schiller N, editors. Phonetics and phonology in language comprehension and production: Differences and similarities. Berlin: Mouton de Gruyter; 2003. pp. 319–355. [Google Scholar]
- Goldstein MH, King AP, West MJ. Social interaction shapes babbling: testing parallels between birdsong and speech. Proc Natl Acad Sci U S A. 2003;100(13):8030–8035. doi: 10.1073/pnas.1332441100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gros-Louis J, West MJ, Goldstein MH, King AP. Mothers provide differential feedback to infants' prelinguistic sounds. International Journal of Behavioral Development. 2006;30(6):509–516. [Google Scholar]
- Grossberg S. A theory of human memory: Self-organization and performance of sensory-motor codes, maps, and plans. In: R R, Snell F, editors. Progress in theoretical biology. New York: Academic Press; 1978. pp. 233–374. [Google Scholar]
- Grossberg S. How does a brain build a cognitive code? Psychological Review. 1980;87:1–51. doi: 10.1007/978-94-009-7758-7_1. [DOI] [PubMed] [Google Scholar]
- Grossberg S. Competitive learning: From interactive activation to adaptive resonance. Cognitive Science. 1987;11:23–63. [Google Scholar]
- Grossberg S. Consciousness CLEARS the mind. Neural Networks. 2007;20:1040–1053. doi: 10.1016/j.neunet.2007.09.014. [DOI] [PubMed] [Google Scholar]
- Grossberg S, Merrill JWL. The hippocampus and cerebellum in adaptively timed learning, recognition, and movement. Journal of Cognitive Neuroscience. 1996;8:257–277. doi: 10.1162/jocn.1996.8.3.257. [DOI] [PubMed] [Google Scholar]
- Gutnisky DA, Hansen BJ, Iliescu BF, Dragoi V. Attention Alters Visual Plasticity during Exposure-Based Learning. Curr Biol. 2009 doi: 10.1016/j.cub.2009.01.063. [DOI] [PubMed] [Google Scholar]
- Jusczyk PW. The discovery of spoken language. Cambridge, Mass: MIT Press; 1997. [Google Scholar]
- Kuhl PK, Conboy BT, Coffey-Corina S, Padden D, Rivera-Gaxiola M, Nelson T. Phonetic learning as a pathway to language: new data and native language magnet theory expanded (NLM-e) Philos Trans R Soc Lond B Biol Sci. 2008;363(1493):979–1000. doi: 10.1098/rstb.2007.2154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kuhl PK, Tsao FM, Liu HM. Foreign-language experience in infancy: effects of short-term exposure and social interaction on phonetic learning. Proc Natl Acad Sci U S A. 2003;100(15):9096–9101. doi: 10.1073/pnas.1532872100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lively SE, Logan JS, Pisoni DB. Training Japanese listeners to identify English /r/ and /l/. II: The role of phonetic environment and talker variability in learning new perceptual categories. J Acoust Soc Am. 1993;94(3 Pt 1):1242–1255. doi: 10.1121/1.408177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loebach JL, Pisoni DB. Perceptual learning of spectrally degraded speech and environmental sounds. J Acoust Soc Am. 2008;123(2):1126–1139. doi: 10.1121/1.2823453. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Logan JS, Lively SE, Pisoni DB. Training Japanese listeners to identify English /r/ and /l/: a first report. J Acoust Soc Am. 1991;89(2):874–886. doi: 10.1121/1.1894649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maye J, Werker JF, Gerken L. Infant sensitivity to distributional information can affect phonetic discrimination. Cognition. 2002;82(3):B101–111. doi: 10.1016/s0010-0277(01)00157-3. [DOI] [PubMed] [Google Scholar]
- McCandliss BD, Fiez JA, Protopapas A, Conway M, McClelland JL. Success and failure in teaching the [r]-[l] contrast to Japanese adults: tests of a Hebbian model of plasticity and stabilization in spoken language perception. Cogn Affect Behav Neurosci. 2002;2(2):89–108. doi: 10.3758/cabn.2.2.89. [DOI] [PubMed] [Google Scholar]
- O'Connor JD, Gerstman LJ, Liberman AM, Dalattre PC, Cooper FS. Acoustic cues for the perception of initial /w,r,l/ in English. Word. 1957;13:25–43. [Google Scholar]
- Perruchet P, Pacton S. Implicit learning and statistical learning: one phenomenon, two approaches. Trends Cogn Sci. 2006;10(5):233–238. doi: 10.1016/j.tics.2006.03.006. [DOI] [PubMed] [Google Scholar]
- Pisoni DB, Lively SE, Logan JS. Perceptual learning of nonnative speech contrasts: Implications for theories of speech perception. In: Goodman JC, Nusbaum HC, editors. The development of speech perception: The transition from speech sounds to spoken words. Cambridge: MIT Press; 1994. [Google Scholar]
- Poldrack RA, Clark J, Pare-Blagoev EJ, Shohamy D, Creso Moyano J, Myers C, Gluck MA. Interactive memory systems in the human brain. Nature. 2001;414(6863):546–550. doi: 10.1038/35107080. [DOI] [PubMed] [Google Scholar]
- Saffran JR, Newport EL, Aslin RN. Word segmentation: The role of distributional cues. Journal of Memory and Language. 1996;35:606–621. [Google Scholar]
- Saffran JR, Werker J, Werner L. The infant's auditory world: Hearing, speech, and the beginnings of language. In: Siegler R, Kuhn D, editors. Handbook of Child Development. New York: Wiley; 2006. pp. 58–108. [Google Scholar]
- Seitz A, Watanabe T. A unified model for perceptual learning. Trends Cogn Sci. 2005;9(7):329–334. doi: 10.1016/j.tics.2005.05.010. [DOI] [PubMed] [Google Scholar]
- Seitz AR, Kim D, Watanabe T. Rewards evoke learning of unconsciously processed visual stimuli in adult humans. Neuron. 2009;61(5):700–707. doi: 10.1016/j.neuron.2009.01.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seitz AR, Watanabe T. The phenomenon of task-irrelevant perceptual learning. Vision Res. 2009;49(21):2604–2610. doi: 10.1016/j.visres.2009.08.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stevens K. Acoustic phonetics. Cambridge: MIT Press; 1998. [Google Scholar]
- Treutwein B. Adaptive psychophysical procedures. Vision Res. 1995;35(17):2503–2522. [PubMed] [Google Scholar]
- Tsushima Y, Seitz AR, Watanabe T. Task-irrelevant learning occurs only when the irrelevant feature is weak. Curr Biol. 2008;18(12):R516–517. doi: 10.1016/j.cub.2008.04.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vallabha GK, McClelland JL. Success and failure of new speech category learning in adulthood: consequences of learned Hebbian attractors in topographic maps. Cogn Affect Behav Neurosci. 2007;7(1):53–73. doi: 10.3758/cabn.7.1.53. [DOI] [PubMed] [Google Scholar]
- Wade T, Holt LL. Incidental categorization of spectrally complex non-invariant auditory stimuli in a computer game task. J Acoust Soc Am. 2005;118(4):2618–2633. doi: 10.1121/1.2011156. [DOI] [PubMed] [Google Scholar]
- Yamada RA, Tohkura Y. Perception and production of syllable-initial English /r/ and /l/ by native speakers of Japanese. Proceedings of the 1st International Conference on Spoken Language Production; Kobe, Japan. 1990. pp. 757–760. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.