

Abstract
We describe a novel approach to nonparametric point and interval estimation of a treatment effect in the presence of many continuous confounders. We show the problem can be reduced to that of point and interval estimation of the expected conditional covariance between treatment and response given the confounders. Our estimators are higher order U-statistics. The approach applies equally to the regular case where the expected conditional covariance is root-n estimable and to the irregular case where slower non-parametric rates prevail.
Keywords: Minimax, U-statistics, Influence functions, Nonparametric, Semi-parametric, Robust Inference
1. Introduction
We consider perhaps the central problem in biostatistics, epidemiology, and econometrics: the estimation of a treatment effect in the presence of a high dimensional vector X of confounding covariates. To this end, for a binary treatment A and a response Y, let τ be the variance weighted average treatment effect
where a simple calculation establishes the equality in the first line, and γ(x) is the average treatment effect among subjects with X = x under the assumption of no unmeasured confounding (ignorable treatment assignment given X).
Our motivation for τ as our functional of interest is as follows. The most common model for estimation of a causal effect assumes γ (X) = β does not depend on X wp 1, which is unlikely to hold exactly. Most semiparametric estimators of β, including those of Robinson (1988) and Donald and Newey (1994), converge in probability to τ even if the assumption γ (X) = β is false. An alternative motivation is considered by Crump et al. (2006).
We now show that point and interval estimators for τ can be constructed from point and interval estimators for the numerator E [cov(Y, A|X)] of τ. As a consequence, until Section 6, the paper is devoted to constructing point and interval estimators for E [cov(Y, A|X)]. In Section 6, we translate these estimators into estimators for τ.
For any fixed τ* ∈ R, define Y (τ*) = Y − τ* A and the corresponding functional
τ is the unique solution to ψ(τ*) = 0. Suppose that we can construct point estimators ψ̂(τ*) and (1 − α) interval estimators for ψ(τ*). Then τ̂ satisfying ψ̂ (τ̂) = 0 is an estimator of τ. Further, a (1 − α) confidence set for τ is the set of τ* for which a (1 − α) interval estimator for ψ (τ*) contains zero. Until Section 6, we take τ* = 0, and consider inference for the expected conditional covariance ψ ≡ E [cov {Y, A|X}].
Henceforth, we assume we observe N iid copies of O = (Y, A, X) such that the marginal distribution FO of X has a Lebesgue density f in Rd that has a compact support. We assume FO is contained in a nonparametric model M (Θ) = {F(·; θ); θ ∈ Θ}, indexed by the (infinite dimensional) parameter θ ∈ Θ. In this notation, our parameter of interest is the unique solution τ (θ) to ψ (τ*, θ) = 0 with ψ(τ*, θ) ≡ Eθ [covθ(Y (τ*), A|X)] and, until Section 6, we consider inference on
We let b: x ↦ b(x) = E [Y|X = x], p: x ↦ p(x) = E [A|X = x], and f: x ↦ f(x) denote the components of θ corresponding to the conditional expectations of Y and A given X = x and the density of the marginal distribution FX of X. Our model M (Θ) places no restrictions on FO, other than (i) bounds on the Lp norms of these functions to insure all integrals are bounded and (ii) explicit smoothness bounds that specify that b(x), p(x), and f(x) are in known Hölder classes βb, βp, and βf. Informally, a function h(x) is in a Hölder class βh if all partial derivatives of h(·) up to order ⌊βh⌋ exist and are bounded by a constant Ch and the partial derivatives of order ⌊βh⌋ are Hölder with exponent βh − ⌊βh⌋ and bound Ch. Recall that a function q(x) is Hölder with exponent a and bound c if |q(x) − q(x*)| < c|x − x*|a with a < 1 for all x, x*. A formal definition of our model and of a Hölder class are given in the web-supplement.
Robins et al. (2009b) proved that in model M (Θ)
| (1) |
is a necessary condition for the existence of a –consistent estimator of ψ(θ).
We introduce a novel class of point and interval estimators for ψ (θ) that can be applied in both the “regular” case where condition (1) holds and in the “irregular” case where condition (1) does not hold. Our novel estimators are U-statistics. In previous work we derived these estimators using an abstract theory of higher order influence functions (Robins (2004), Robins et al. (2008) and Robins et al. (2009a)). In this paper we derive these estimators using a much more accessible bias correction procedure.
In section 2 we assume that condition (1) holds. However Robins and Ritov (1997) argue that, in epidemiologic studies in which the dimension d of X is not small, the large sample behavior of estimators derived under asymptotics that assumes condition (1) often fails to provide an accurate guide to their actual finite sample behavior; therefore we study the irregular case in Section 3.
For two sequences of random variables XN and YN, the notation XN ≲ YN means XN ≤ CYN for a constant C that is fixed in the context. The notations XN ≍ YN mean XN ≲ YN and YN ≲ XN. The notations XN ~ YN and XN ≪ YN mean that and . For convenience, we will drop the N subscript and write X and Y for XN and YN.
2. Failure of First Order Inference in The Regular Case
By definition, an estimator ψ̂ is a regular asymptotically linear (RAL) estimator of ψ(θ) if and only if
| (2) |
| (3) |
Here U1 (θ) is the so called first order influence function of ψ (θ). By Slutsky’s theorem N1/2(ψ̂ − ψ (θ)) is asymptotically normal with mean zero and variance var {U1 (θ)}. Thus a RAL estimator converges to ψ (θ) at rate . Consider the plug-in estimator ψ (θ̂) and the one step estimator , where θ̂ is a rate-optimal nonparametric estimator of θ (i.e of FO, Härdle et al. (1998)). If ψ (θ̂) is RAL then so is the one step estimator but not vice-versa, as the onestep estimator may have smaller asymptotic bias with the same asymptotic variance (Bickel et al. (1998)).
In this paper, we require a modified version of the one step estimator in which b̂, p̂, f̂, and thus θ̂ are estimated from a separate, randomly-chosen training sample of size N – n, and the modified one-step estimator is , where the sum is over the n subjects in the estimation sample. The original one step estimator and ψ̂1 will generally have the same rate of convergence and order of asymptotic bias if (N − n) ≍ n (which we assume to be true unless stated otherwise). This modification is made because Hölder classes with β < d/2 are not Donsker (Van der Vaart and Wellner (1996)). Henceforth, all expectations and variances are to be interpreted as conditional on the training sample and thus are random, although for convenience, we sometimes suppress this fact in the notation, especially for variances.
Conditional on the training sample, the estimator ψ̂1 is the sum of n independent random variables. Hence, it is conditionally asymptotically normal with mean Eθ[(b(X) − b̂(X))(p(X) − p̂(X))] + ψ(θ) and variance of order
(Bickel et al. (1998)). Thus, the interval
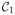 = ψ̂1 ± zα/2s.e.(ψ̂1) is a honest asymptotic confidence interval if and only if the maximal bias
is oP(n−1/2), where the subscript p reflects the randomness in BI(ψ̂1) due to the training sample. Thus, BI(ψ̂1) is of smaller order than s.e.(ψ̂1) ≍ n−1/2. Here BI(ψ̂1, θ) = Eθ[(b(X) − b̂(X))(p(X) − p̂(X))] is the bias under θ. A formal definition of a honest asymptotic confidence interval is given in the web-supplement. In addition, ψ̂1 has a uniform convergence rate of
(i.e. is
-consistent) if and only if
.
= ψ̂1 ± zα/2s.e.(ψ̂1) is a honest asymptotic confidence interval if and only if the maximal bias
is oP(n−1/2), where the subscript p reflects the randomness in BI(ψ̂1) due to the training sample. Thus, BI(ψ̂1) is of smaller order than s.e.(ψ̂1) ≍ n−1/2. Here BI(ψ̂1, θ) = Eθ[(b(X) − b̂(X))(p(X) − p̂(X))] is the bias under θ. A formal definition of a honest asymptotic confidence interval is given in the web-supplement. In addition, ψ̂1 has a uniform convergence rate of
(i.e. is
-consistent) if and only if
.
If b̂ and p̂ are rate optimal estimators of b and p, they have convergence rates and . Hence, (i.e., when (N − n) ≍ n). Hence even when condition (1) holds, BI(ψ̂1) can exceed OP(n−1/2). For example, if βb = βp then for BI(ψ̂1) to be OP(n−1/2) requires that βb + βp ≥ d. In fact, if βp = 0 holds, then BI(ψ̂1) ≫ n−1/2 for any finite βb. Thus, to construct a uniform -consistent estimator for ψ (θ) whenever condition (1) holds, we require an estimator with smaller bias than ψ̂1. To achieve this, we will subtract from ψ̂1 a bias correction term which estimates the bias BI(ψ̂1, θ).
3. Second Order U-statistics Estimators
3.1. The Estimator
To motivate our bias correction term, suppose that X were categorical with known probability mass function f. Define the residuals ε̂i ≡ Yi − b̂(Xi), Δ̂j ≡ Aj − p̂(Xj), and kernel function . Then is an unbiased estimator of BI(ψ̂1, θ). Since f is unknown, we use Kf̂ (Xi, Xj) instead. By analogy, for X continuous, if we could find a “kernel” Kf,∞ (x, X) such that
| (4) |
then the statistic would be unbiased for BI(ψ̂1, θ).
A kernel satisfying eq. (4) is referred to as a Dirac delta function wrt to the measure FX and is known not to exist in L2 [FX] × L2 [FX]. However, the above motivates the construction of a class of estimators for BI(ψ̂1, θ) using “truncated Dirac kernels”.
Let {zl (·)} ≡ {zl (x); l = 1, 2, …} be dense in L2(μ) with μ the Lebesgue measure and let z̄k (x)T = (z1 (x), …, zk (x)). Define, for f̂ a component of θ̂, φ̄k (X) = (Ef̂[z̄k (X) z̄k (X)T])−1/2 z̄k (X) so Ef̂[φ̄k (X) φ̄k (X)T] = Ik×k. Here f̂ is a rate optimal estimator of f with convergence rate in Lq (μ) for q finite. Let Kf̂,k (Xi, Xj) = φ̄k (Xi)T φ̄k (Xj). Then, for any h(x), the projection Πf̂[h(x)|z̄k (x)] ≡ Πf̂[h(x)|lin{z̄k(x)}] under f̂ of h(x) onto the subspace lin{z̄k(x)} spanned by the elements of z̄k (x) is Ef̂[Kf̂,k (x, X) h(X)]. Thus, by definition, Kf̂,k (x, X), is the associated projection kernel. Note that Πf̂[h(x)|z̄k(x)] = Πf̂[h(x)|φ̄k (x)] since lin{z̄k(x)} and lin{φ̄k (x)} are equal.
Kf̂,k (x, X) is a truncated at k approximation to Kf̂,∞ (x, X) in the sense that, with f̂ substituted for f, it satisfies eq. (4) for r(x) ∈ lin{z̄k (x)}. Our bias corrected estimator is then
3.2. Bias and Variance Properties of ψ̂2,k
The bias of ψ̂2,k is given in the following theorem proved in the web-supplement. The bias can be decomposed into the sum of two terms-the truncation bias and the estimation bias. The truncation bias is due to the truncated at k approximation Kf,k (Xi, Xj) to Kf,∞ (Xi, Xj), whereas the estimation bias comes from using b̂(Xi), p̂(Xi), and f̂(Xi) to estimate b(Xi), p(Xi) and f(Xi).
In the following, since f ∈ θ, we can and sometimes do write the projection operator Πf as Πθ. Let be the projection under θ of h(X) onto the orthocomplement of lin{z̄k (X)} = lin{φ̄k (X)}.
Theorem 1
Suppose regularity conditions (A.1)– (A.2) of the web-supplement hold. Then the (conditional) bias BI (ψ̂2,k, θ) ≡ Eθ[ψ̂2,k] − ψ (θ) equals TBk (θ) + EB2,k (θ) where
| (5) |
and
| (6) |
The next theorem, proved in the web-supplement, derives the orders of TBk (θ) and EB2,k (θ) for a choice of Z̄k ≡ z̄k (X), that provides optimal uniform approximation error of order k−β/d for any function h(x) of a d-dimensional x in a Hölder class with exponent β. That is is of order k−β/d in sup norm. Polynomial, spline and suitable wavelet bases all satisfy this assumption.
Theorem 2
Suppose that regularity conditions (A.1) – (A.3) of the web-supplement are satisfied. Then with BI (ψ̂2,k) = supθ∈Θ|BI(ψ̂2,k, θ)|, TBk = supθ∈Θ{TBk (θ)}, EB2 = supθ∈Θ|EB2,k (θ)|,
| (7) |
| (8) |
Note the order of the maximal bias of EB2,k (θ) does not depend on k. The theorem is proved in the web-supplement. A heuristic argument is as follows. If, as is always possible, our optimal estimates of b̂(x) and p̂(x) are in lin{z̄k (x)} = lin{φ̄k (x)}, then TBk (θ) depends on the product of and , which is . Next, noting
and
we observe that EB2,k (θ) is a product of terms in (b(X) − b̂(X)), (p(X) − p̂(X)) and (f(X) − f̂(X)).
The following theorem proved in the web-supplement gives the order of the (conditional) variance of ψ̂2,k.
Theorem 3
Assume (A.1) – (A.3) are satisfied, then conditional on the training sample,
| (9) |
3.3. Convergence Rate of the Optimal Estimator in the Class ψ̂2,k: k ∈
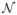 }
}
3.3.1. The regular case - Eq. (1) holds
In this subsection, condition (1) holds so N−1/2 is a lower bound on the rate of convergence.
Lemma 4
Given (1) and (N − n) ≍ n, (i) ψ̂2,n ≡ ψ̂2,k=n converges at rate n−1/2 (and thus is rate minimax) if and only if
| (10) |
and (ii) no estimator ψ̂2,k converges at rate n−1/2 if ψ̂2,n does not.
Proof
has variance of order O(n−1) only if k = O (n). Among all ψ̂2,k with k = O (n), is minimized for k ≍ n, proving (ii). Further TBn = Op(n−1/2) by condition (1). Finally, when (10) holds, EB2 = Op(n−1/2). Hence ψ̂2,n converges at rate n−1/2.
Recall ψ̂1 has maximal bias BI(ψ̂1) ≲ n−1/2 (and thus converges at rate n−1/2) if and only if . As an example, with , the bias of ψ̂1 shrinks to zero at rate ; in contrast, ψ̂2,n converges at rate n−1/2 as long as . Thus the second order U-statistic added to ψ̂1 to form ψ̂2,n has reduced the bias to Op(n−1/2) without any increase in the order of the variance since k/n2 ≍ 1/n when k ≍ n.
In Section 4, we shall construct an estimator that converges at the minimax rate of n−1/2 when eq. (1) holds, even though neither ψ̂1 nor ψ̂2,n converges at rate n−1/2 because (10) fails to hold and so EB2 ≫ n−1/2.
Finally suppose that eqs. (1) and (10) hold with strict inequalities. Then TBn and EB2 are op(n−1/2). Hence, with (N − n) ≍ n, N1/2(ψ̂2,n − ψ (θ)) is asymptotically normal with mean zero and finite variance. However ψ̂2,n does not achieve the optimal constant as its asymptotic variance exceeds the semiparametric variance bound varθ[U1 (θ)]. This deficiency can be remedied by no longer choosing (N − n) ≍ n. Specifically, arguing as on page 379 in Robins et al. (2009b), if we make the ratio (N − n)/N to be of order 1/log (N) rather than of order 1 and take keff ≍ n/log(n), then ; hence ψ̂2,keff is asymptotically linear and normal with variance varθ [U1 (θ)] and thus semi-parametric efficient.
3.3.2. The irregular case - Eq. (1) does not hold
Suppose condition (1) does not hold. In that case Robins et al. (2009b) proved that a lower bound for the minimax rate is . The following Lemma shows that, if
| (11) |
holds, ψ̂2,k* with is rate minimax.
Lemma 5
If (11) holds, i) ψ̂2,k* converges at rate , which is thus minimax and (ii) no estimator ψ̂2,k converges at this rate if ψ̂2,k* does not.
Proof
Consider ψ̂2,k* with . The standard error and the truncation bias TBk* of ψ̂2,k* both are of order , proving (ii). When (11) also holds, .
In Section 4, we construct an estimator that, often converges faster (and never slower) than ψ̂2,k*, when (11) does not hold, although the rate remains slower than .
4. U-Statistic estimators
We next show that we can construct a new estimator that subtracts from ψ̂2,k a third order U-statistic, denoted by , which estimates the estimation bias EB2,k (θ) of ψ̂2,k. In fact we show that we can iterate this process to construct new estimators that subtract from ψ̂m−1,k a mth order U-statistic , which estimates the estimation bias EBm−1,k (θ) of ψ̂m−1,k. In the web-supplement we prove the following theorem
Theorem 6
Under assumptions (A.1) – (A.3) and with each zl (x) the tensor product of elements of a univariate compact wavelet basis with optimal approximation properties, for m = 3, …, the estimator has (i) truncation bias TBk (θ) for all m, (ii) estimation bias EBm,k (θ) of smaller order than EBm−1,k (θ), total bias BI(ψ̂m,k, θ) ≡ Eθ[ψ̂m,k] − ψ(θ) = TBk (θ) + EBm,k (θ) and (iii) variance of the same order as ψ̂2,k when k = O (n) but of greater order than that of ψ̂m−1,k when k ≫ n. Here
| (12) |
Specifically
| (13) |
| (14) |
| (15) |
Remark 1
The assumption that each zl (x) is the tensor product of compact wavelets is only used in the proof of (iii) for technical reasons. We expect that (iii) holds for many other bases.
Remark 2
In this notation we could write with .
4.1. Convergence Rate of the Optimal Estimator in the Class {ψ̂m,k: m = 2, …, k ∈
}
4.1.1. The regular case - Eq. (1) holds
In this subsection, condition (1) holds so N−1/2 is a lower bound on the rate of convergence.
Lemma 7
Given condition (1), βf > 0, and (N − n) ≍ n, ψ̂mopt,n ≡ ψ̂mopt,k=n converges at rate n−1/2 (and thus is rate minimax) where mopt is the smallest integer for which .
Proof
Since ρm increases without bound as m → ∞, mopt always exists when βf > 0 and EBmopt is . Further and by condition (1).
The key point is the same as in the case discussed in Section 3.3. The U-statistic terms of ψ̂mopt,n reduce the order of the estimation bias below , and yet do not increase the order of the variance or truncation bias. Thus by introducing the U-statistic estimators of arbitrarily large order m, we are able to construct -consistent estimators for ψ (θ) for any value of βf > 0, as long as condition (1) holds.
Although ψ̂mopt,n fails to be semiparametric efficient this defficiency can be remedied as follows.
Lemma 8
Assume condition (1) holds with a strict inequality. Let (N − n)/N=1/log(N) so n = N (1 − 1/log(N))]. Let mopt* be the smallest integer for which , and keff ≍ n/log (n). Then (i) ψ̂mopt*,keff has TBkeff = op(N−1/2), (ii) EBmopt* = op (N−1/2), and (iii) ; hence ψ̂mopt*,keff is semiparametric efficient.
4.1.2. The irregular case - Eq. (1) does not hold
Suppose condition (1) does not hold so estimation of ψ(θ) at rate N−1/2 is not possible. For any fixed m ≥ 2, let
be the value of k equating the order
of var[ψ̂m,k] to the order k−2(βb+βp)/d of
. (Note k* of Sec 3.3 is k* (2)). Thus
. ψ̂m,k*(m) has the optimal rate in the class {ψ̂m,k: k ∈
} since
does not depend on k. This rate is
The optimal estimator in the class {ψ̂m,k: m = 2, …; k ∈
} is thus ψ̂meff,,k*(meff) with meff the minimizer of r (m). As discussed in Section 3.3, if condition (11) holds, then meff = 2, and ψ̂meff,,k*(meff) attains the minimax convergence rate
. If (11) fails to hold, ψ̂meff,,k*(meff) will not be minimax (Robins et al. (2008)).
5. Confidence Interval Construction
In the regular case where (1) holds with a strict inequality and βf > δ, it follows from Lemma 8 that an honest asymptotic 1 − α confidence interval for ψ (θ) whose width shrinks at rate n−1/2 is the Wald interval . where
and zα is the upper α–quantile of a N (0, 1) distribution.
Consider now the irregular case. A necessary condition for an ψ̂ to center a honest Wald interval is that the order of its bias be less than that of the standard error. The estimator ψ̂meff,,k*(meff) fails to satisfy this condition as its maximal estimation bias EBmeff can dominate its standard error. However the condition is satisfied by the estimator ψ̂meff,k̃(meff) with meff as above and k̃ (meff) equal to the k that equates the variance . The log n factor insures that the order of the standard error exceeds that of the bias. Furthermore ψ̂meff,k̃(meff) converges at the same rate as the estimator ψ̂meff,,k*(meff) up to a log factor.
In Theorem 10 of the web-supplement we show that, if an estimator ψ̂m,k in our class has bias of lower order than the standard deviation, then, for k ≫ n, is conditionally (given the training sample) and unconditionally uniformly asymptotically normal with mean zero and variance that can be consistently estimated. It follows that is an honest asymptotic 1 − α confidence interval for ψ (θ) whose width shrinks at rate , where the formula for is given in Theorem 10 of the web-supplement. Thus, the interval
shrinks as fast as any interval Cm,k in our class.
6. Inference on τ(θ)
Recall from Section 1 that our ultimate functional of interest, τ (θ) = Eθ[covθ(Y, A|X)]/Eθ [varθ (A|X)], is the unique solution to the equation ψ(τ, θ) = 0 where ψ(τ, θ) = Eθ [{Y (τ) − b(X, τ)}{A − p(X)}] with b (τ): x → b (x, τ) ≡ E[Y(τ) | X = x] and Y (τ) = Y − τA. We assume it is b (τ) for τ = τ (θ) that is known to lie in the Hölder class of smoothness βb rather than the function b.
Consider first the irregular case where condition 1 fails to hold. As discussed in Section 1, {τ: 0 ∈ Cmeff,k̃(meff) (τ)} is an honest asymptotic 1− α confidence set for τ (θ), where Cm,k (τ) and ψ̂m,k (τ) are Cm,k and ψ̂m,k with Y replaced by Y (τ). Furthermore, it follows from Theorem 6.1 of Robins et al. (2009b) that the width of the confidence set {τ: 0 ∈ Cmeff,k̃(meff) (τ)} or τ (θ) shrinks with increasing n at the same rate as does the confidence interval Cmeff,k̃(meff) (τ) for ψ (τ, θ). Finally, let τ̂meff,k̃(meff) be the solution to ψ̂meff,k̃(meff) (τ) = 0. Then, a Taylor expansion around τ (θ), shows that is asymptotically normal with mean zero and a finite variance.
In the regular case where condition 1 holds and βf > δ, we conclude by a similar argument that τ̂mopt*,keff solving ψ̂mopt*,keff(τ) = 0 is a semiparametric efficient estimator of τ(θ) with influence function , where U1 (θ, τ) = {Y (τ) − b(X, τ)}{A − p(X)} − ψ (τ, θ) is the efficient influence function of the functional ψ (τ, θ).
7. Discussion
Although this paper breaks important new ground, many difficult issues remain. First, we have assumed the maximal possible roughness (as encoded in Hölder exponents and constants) of the nuisance functions p, b, and f to be known apriori. In practice, different subject matter experts will clearly disagree as to the maximal roughness; in addition, the actual smoothnesses of the nuisance functions cannot be empirically estimated. Thus it would be important to have methods that adapt to the unknown smoothness of these functions. However, for honest confidence intervals, the degree of possible adaption to unknown smoothness is small. Therefore an analyst needs to report a mapping from apriori smoothness assumptions encoded in Hölder exponents and constants (or in other measures of smoothness) to the associated (1 − α) honest confidence intervals proposed in this paper. Such a mapping is finally only useful if substantive experts can approximately quantify their informal opinions concerning the smoothness of p, b, and f using a measure of smoothness offered by the analyst. It is an open question which, if any, smoothness measure is suitable for this purpose.
In the irregular case, our results are for rates of convergence. We currently have few results on the constants in front of those rates.
Finally, a general software program to calculate our estimators must first construct a non-parametric d-dimensional density estimator f̂ and then compute the k×k matrix {Ef̂[z̄k (X) z̄k (X)T]}−1 by numerical integration followed by matrix inversion. As, in practice, k can easily be 500,000, we have yet to solve these computational challenges.
Supplementary Material
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Bhattacharya RN, Ghosh JK. A class of U-statistics and asymptotic normality of the number of k-clusters. Journal of Multivariate Analysis. 1992;43:300–330. [Google Scholar]
- Bickel P, Klaassen C, Ritov Y, Wellner J. Efficient and adaptive estimation for semiparametric models. Springer Verlag; 1998. [Google Scholar]
- Crump RK, Hotz VJ, Imbens GW, Mitnik OA. Working Paper. National Bureau of Economic Research; 2006. Moving the Goalposts: Addressing Limited Overlap in the Estimation of Average Treatment Effects by Changing the Estimand; p. 330. [Google Scholar]
- Donald S, Newey W. Series estimation of semilinear models. Journal of Multivariate Analysis. 1994;50:30–40. [Google Scholar]
- Härdle W, Kerkyacharian G, Picard D, Tsybakov A. Wavelets, approximation, and statistical applications. Springer; New York: 1998. [Google Scholar]
- Robins J. Optimal structural nested models for optimal sequential decisions. Proceedings of the Second Seattle Symposium in Biostatistics: Analysis of Correlated Data; Springer; 2004. p. 189. [Google Scholar]
- Robins J, Li L, Tchetgen E, van der Vaart A. Working Paper. Department of Biostatistics, Harvard School of Public Health; 2007. Higher order influence functions and minimax estimation of nonlinear functionals. [Google Scholar]
- Robins J, Li L, Tchetgen E, van der Vaart A. Higher order influence functions and minimax estimation of nonlinear functionals. IMS Lecture Notes–Monograph Series Probability and Statistics Models: Essays in Honor of David A. Freedman. 2008;2:335–421. [Google Scholar]
- Robins J, Li L, Tchetgen E, van der Vaart A. Quadratic semi-parametric Von Mises calculus. Metrika. 2009a;69:227–247. doi: 10.1007/s00184-008-0214-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins J, Tchetgen E, Li L, van der Vaart A. Semiparametric minimax rates. Electronic Journal of Statistics. 2009b;3:1305–1321. doi: 10.1214/09-EJS479. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins JM, Ritov Y. Toward a curse of dimensionality appropriate (CODA) asymptotic theory for semi-parametric models. Statistics in Medicine. 1997;16:285–319. doi: 10.1002/(sici)1097-0258(19970215)16:3<285::aid-sim535>3.0.co;2-#. [DOI] [PubMed] [Google Scholar]
- Robinson P. Root-N-consistent semiparametric regression. Econometrica: Journal of the Econometric Society. 1988;56:931–954. [Google Scholar]
- Van der Vaart A, Wellner J. Weak convergence and empirical processes. Springer Verlag; 1996. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.