

Summary
This article examines group testing procedures where units within a group (or pool) may be correlated. The expected number of tests per unit (i.e., efficiency) of hierarchical- and matrix-based procedures is derived based on a class of models of exchangeable binary random variables. The effect on efficiency of the arrangement of correlated units within pools is then examined. In general, when correlated units are arranged in the same pool, the expected number of tests per unit decreases, sometimes substantially, relative to arrangements that ignore information about correlation.
Keywords: Composite sampling, Epitope mapping, Exchangeable binary random variables, Group testing, HIV, Matrix testing, Pooled testing
1. Introduction
Group testing is a method used to reduce the average number of tests needed to identify cases of a disease in a population. The first use of group testing was proposed by Dorfman (1943). Dorfman proposed pooling blood samples of groups of men inducted into the military, and testing the combined samples for antigens to identify the presence of syphilis. If the combined samples tested negative for the antigens, the men were declared syphilis free with only one test. Otherwise, samples from each man were tested individually. Specimen pooling or group testing has been applied to screening for various infectious diseases and has also found broader application in many other areas (see Kim et al., 2007, and references therein). Group testing can also be used to reduce the average number of tests needed to estimate the prevalence of a disease, but this article focuses on case identification.
Dorfman’s two-stage procedure has been generalized to three or more stages. If the initial (or “master”) pool tests positive, the specimens may be pooled into smaller nonoverlapping subpools. If a subpool tests positive, individuals can be tested, or subpools can be divided further into smaller nonoverlapping subpools nested within the previous subpool. This is known as a hierarchical procedure (Johnson, Kotz, and Wu, 1991). Another common group testing algorithm is an array-based procedure (Phatarfod and Sudbury, 1994). In the simplest scenario, a group of n2 units (specimens) is arranged into an n × n matrix, and pools of size n are constructed from units in each row or column. The 2n row and column pools are then tested, and positive units are identified by testing the units at the intersections of positive row and column pools.
Prior research regarding group testing procedures typically assumes individual units are independent. This assumption may not be reasonable in certain situations. For example, in the infectious disease setting, responses to a screening test may be positively correlated for individuals from the same geographical area or the same household. A second example arises in HIV vaccine development, where group testing methods are used to detect T-cell responses to specific epitopes induced by a candidate vaccine (Malhotra et al., 2007a, 2007b; Yan et al., 2007). T-cell responses to one or more peptides are identified by using ELISpot, intracellular cytokine staining, or other assays. Li et al. (2006) developed a potential T-cell epitope peptide set designed to contain epitopes found in commonly circulating strains of HIV. The peptide set is made of 15-mer peptides, some of which overlap by 10 or more amino acids. It is reasonable to expect T-cell responses from the same individual to be correlated for overlapping peptides. Indeed, Malhotra et al. (2007a) observed that T cells of HIV infected individuals can recognize multiple peptides containing variants of the same epitope. Roederer and Koup (2003) evaluated possible group testing procedures for this setting using Monte Carlo simulation, but did not consider that T-cell responses may be correlated. Below we show that accounting for this correlation when using group testing for case identification can reduce the average number of tests needed to identify all peptides that elicit a T-cell response.
Some group testing models allow for the probability a unit tests positive (the “prevalence”) to vary between units. Typically these models assume individual responses are independent conditional on the unit-specific prevalence (e.g., see Bilder, Tebbs, and Chen, 2010). The unit-specific prevalences will not generally be known but in some settings may be estimated with reasonable accuracy and precision based on observed covariates. In the absence of knowledge of the unit-specific prevalences, heterogeneity in the prevalences can induce correlation between units. Below we consider an approach to modeling correlation that does not require (i) (estimates of) unit-specific prevalence or (ii) assuming conditional independence.
2. Preliminaries
Suppose that a unit is either positive or negative with respect to some binary trait. For example, the unit could represent an individual with or without disease, or a peptide to which T cells respond or do not respond. Also suppose there is a test that attempts (perhaps with error) to classify units or pools of units as positive or negative, where a pool is considered positive if at least one unit in the pool is positive. The efficiency of a group testing procedure is defined as the expected number of tests per unit required to classify all units as either positive or negative. To evaluate the efficiency, one must calculate the probabilities that pools of units do not have any positive responses. These calculations require knowledge about correlation among units within each pool. Suppose there are n units total which can be partitioned into l clusters of size m and the following assumption holds:
Assumption 1
Units in different clusters are independent, and the joint distribution of the true classification of units in the same cluster is the same for all clusters.
Without loss of generality, let X̃ = (X1, …, Xm) be a vector of binary random variables representing the true classification of units in a particular cluster, where Xi = 1 if unit i in that cluster is positive, and Xi = 0 otherwise. Let , let x̃ be a possible realization of X̃, and let ẋ be the sum of the values of x̃. Let be a subvector of any m′ elements of X̃ where m′ ∈ {1, …, m} and let . Deriving the efficiency of a group testing procedure requires assumptions about the distribution of X̃. A class of models for X̃ is defined below by Assumptions 2 and 3 below via the factorization pr(X̃ = x̃) = pr(Ẋ = ẋ)pr(X̃ = x̃ ∣ Ẋ = ẋ).
Assumption 2
Units within a cluster are exchangeable in the sense that
for any permutation (γ1, γ2, … , γm) of the set of integers {1, 2, …, m}.
Because the Xi’s are binary, Assumption 2 implies for ẋ = 0, …, m, so the distribution of X̃ is fully identified by the distribution of Ẋ.
Assumption 3
The distribution of Ẋ can be expressed as a mixture of binomial distributions such that for ẋ = 0, …, m
| (1) |
where for any function g, and π is a random variable with support [0, 1] and cumulative distribution function F.
Note there are connections between Assumption 3 and de Finetti’s Theorem. In particular, if the cluster X̃ can be viewed as a subset of an infinite sequence of exchangeable binary random variables, then Assumption 3 and Lemma 2, below, follow immediately from de Finetti’s Theorem (de Finetti, 1975). In settings motivating this work, such as the epitope mapping studies, the focus is on clusters of finite size, in which case (1) does not hold in general. Nonetheless, (1) is not a particularly strong assumption in settings where X̃ can be viewed as subset of a finite sequence of exchangeable binary random variables of length k ≥ m, for in that case the distribution of Ẋ can be approximated by a mixture of binomial random variables with error going to zero at rate k−1 (Diaconis, 1977). For example, in epitope mapping studies, a set of m exchangeable peptides might be envisaged as a subset of a larger set of k exchangeable peptides.
The lemmas below establish certain properties about the family of distributions under Assumptions 2 and 3 that are used in evaluating the efficiencies derived in Sections 3 and 4. Let E(Xi) = p be the probability that any unit i is positive and let cor(Xi, Xj) = σ be the pairwise correlation between any two units i and j for i ≠ j. We refer to p as the prevalence. Lemma 1 shows that any distribution of exchangeable binary random variables approaches a known limiting distribution as σ approaches one. Lemma 2 shows that the distribution of a subset of units from an exchangeable cluster where (1) holds is of the same form as the distribution of the units in the cluster. By specifying a distribution for π where the first and second moments are p and σ p (1 − p) + p2, respectively, the distribution of a vector of exchangeable binary random variables with specified marginal means and pairwise correlations is defined by Lemma 3. Proofs of the lemmas are given in the Web Appendix A.
Lemma 1
Under Assumption 2, as σ approaches 1 the distribution of Ẋ converges to a two-point distribution, where pr(Ẋ = 0) → 1 − p and pr(Ẋ = m) → p.
Lemma 2
Under Assumptions 2 and 3, the distribution of Ẋ′ is a mixture of binomial distributions of the same form as Ẋ, such that
| (2) |
for ẋ′ = 1, …, m′.
Lemma 3
Under Assumptions 2 and 3, if E(π) = p and E(π2) = σ p(1 − p) + p2, then E(Xi) = p for all i and cor(Xi, Xj) = σ for all i ≠ j.
The models defined by Assumption 3 can be viewed as random effect models where units within the same cluster are positive with (unknown) probability π, with π varying between clusters according to distribution F. In the sequel, three particular models are considered to examine how the efficiencies of group testing procedures are affected by correlated responses. The first is a beta-binomial model where π has a beta distribution with mean p and variance σ p(1 − p). The second model is from Madsen (1993) who described multiple distributions that can be used to model exchangeable binary data. One of those models can be constructed by letting π = p with probability 1 − σ, π = 0 with probability σ(1 − p), and π = 1 with probability σp; this will be referred to as the Madsen model. This model can be thought of as arising from a situation where there are two types of clusters: one type where units are independent, and another type where units all perfectly correlated and behave exactly the same, either all positive or all negative. In both types of clusters, the probability of a particular unit being positive is p. A cluster is of the first type with probability 1 − σ and is of the second type otherwise. A third model, described in Morel and Neerchal (1997), can be constructed by letting with probability p and with probability 1 − p. In the comparisons described below, the Morel–Neerchal model tended to yield efficiencies between the beta-binomial and Madsen models (results not shown).
The efficiency derivations in Sections 3 and 4 below rely on the following additional notation and assumptions. Let q0 = 1 and qm′ = pr(Ẋ′ = 0) denote the probability that m′ units from the same cluster are negative for m′ ∈ {1, …, m}. For the three models above q1 = 1 − p and qm′ is given by (2) with ẋ′ = 0. Let T denote the number of tests required by a particular group testing procedure to classify n units as positive or negative. To allow for test error (i.e., false positive or false negative test results), assume pools with at least one positive unit test positive with probability Se and that pools with no positive units test negative with probability Sp; we refer to Se and Sp as test sensitivity and specificity. The special case of no test error corresponds to Se = Sp = 1. Web Appendix B provides further details regarding assumptions about test error.
3. Hierarchical Procedures
3.1 Notation and Efficiency of General Hierarchical Procedures
Consider a hierarchical procedure where n1 = n units are combined to form a master pool. In the first stage, the master pool is tested, and if it tests positive, w2 nonoverlapping pools of n2 units are each tested in the second stage. In a two-stage procedure, n2 = 1 and each unit in a master pool that tests positive is tested individually. In a general h stage procedure, for each pool that tests positive in stage s − 1, ns −1/ns nonoverlapping pools of ns units are tested. There are a total of ws = n1/ns pools that could be tested at stage s if all of the pools in the previous stages test positive. At the hth stage each pool is made up of individual units, so nh = 1. The total number of tests T = T1 + … + Th, where Ts is a random variable representing the number of tests at stage s. The efficiency of a hierarchical procedure is . The master pool is always tested, so E(T1) is always one.
Let if the ith pool in the sth stage has at least one truly positive unit, and 0 otherwise. For a particular arrangement of clusters, let msik be the number of units from cluster k in pool i of stage s for k = 1, …, l. In general,
| (3) |
is the probability that pool i in stage s is truly positive. Let Vsi = 1 if the ith pool in the sth stage tests positive and let Vsi = 0 otherwise (i.e., if the pool tests negative or is not tested). For s > 1, which can be evaluated by noting
| (4) |
and for s > 1
| (5) |
where in general, for t < s, it denotes the pool in stage t containing the units from pool i in stage s. Equation (5) can be evaluated using the following results:
and for s > 2
where and for s > 1.
To determine the efficiency of a particular hierarchical procedure, (4) and (5) are evaluated based on the arrangement of clusters. For the cluster arrangements considered in Sections 3.2 and 3.3 below and for any arrangement where the units are independent, the efficiency calculation is simplified because pr(Vsi = 1) is the same for all i and therefore E(Ts) = ws pr(V(s−1)i = 1). Johnson et al. (1991) derive the efficiency for a hierarchical procedure with independent units where sensitivity and specificity can depend on the stage. If units are independent, is equivalent to their equation (6.19) when sensitivity and specificity are constant for all stages.
3.2 Nested Hierarchical Arrangement
Suppose clusters of size m are arranged such that all units from the same cluster are in the same pool for stages 1 to h′ − 1. Also, suppose for stages h′ to h, all units in the same pool are members of the same cluster. That is, msik = m or 0 for s < h′, and msik = ns or 0 for s ≥ h′ where h′ ∈ {2, 3, …, h}. Figure 1a shows an example of an h = 3 stage procedure where m = 6, n1 = 12, n2 = 3, and the numbers 1 and 2 denote cluster membership. At stage 2, all six units from the same cluster cannot fit in pools of size 3, but all units in the same pool are from the same cluster, so h′ = 2. Call this a nested hierarchical arrangement. By (3), if 1 < s ≤ h′ then for all i, and if h′ < s ≤ h then for all i.
Figure 1.
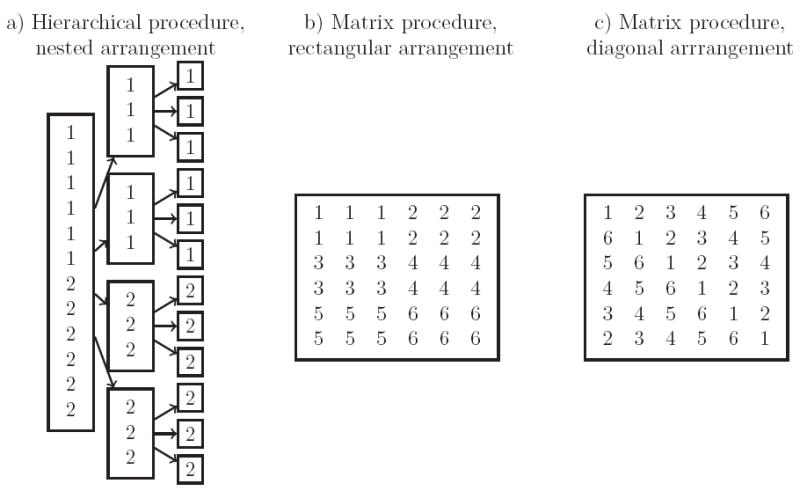
Illustrations of the construction hierarchical and matrix procedures.
3.3 Random Hierarchical Arrangement
Suppose units are arranged in a way that is independent of their cluster membership. Let M̃si· be the random vector of length l of the number of units from each cluster 1, …, l in pool i in stage s. Let each possible arrangement of the n1 units have the same probability, so M̃si· has a multivariate hypergeometric distribution such that
| (6) |
where m̃si ·t = (msi1t, …, msilt) is the tth possible value of M̃si· for . Then
| (7) |
and therefore
| (8) |
When n1 is large, the number of possible arrangements becomes very large, and the exact calculation for (8) is computationally difficult. Monte Carlo simulation can be used to approximate (8). First values of M̃(s−1)i· are repeatedly sampled from a multivariate hypergeometric distribution according to (6). Then the conditional probability (7) is evaluated for each sample. Finally, one minus the sample mean of the conditional probabilities will approximate (8).
3.4 Comparison of Hierarchical Arrangements
For a two-stage hierarchical procedure with a nested arrangement, if Se = Sp = 1, the expected number of tests is E(T) = 1 + E(T2), where . If σ = 0 then and the efficiency for all models equals as in Dorfman (1943). Figure 2 illustrates the efficiency of a two-stage hierarchical procedure for the beta-binomial and Madsen models for different values of σ as a function of m when Se = Sp = 1. For large clusters the expected tests per unit is reduced substantially as σ increases. When σ = 0.99, the efficiencies for both models are almost identical, which is consistent with Lemma 1. See Web Figures 1 and 2 for similar results when Se and Sp are less than 1.
Figure 2.
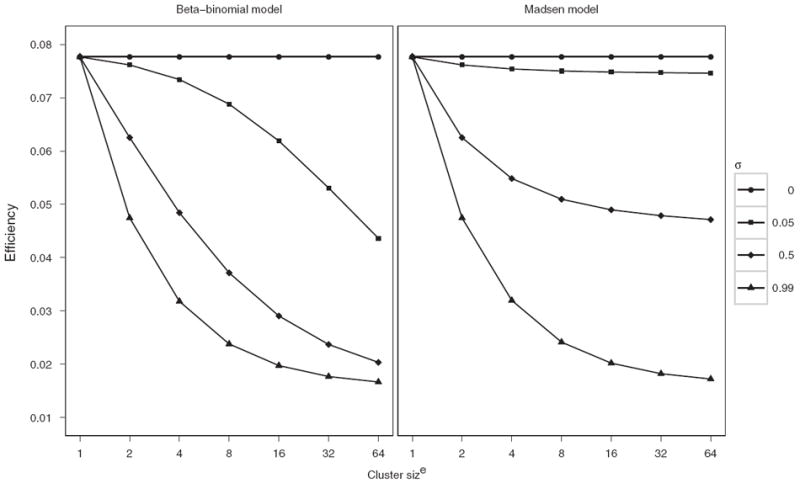
Efficiencies for a two-stage hierarchical procedure where Se = Sp = 1, n1 = 64 and p = 0.001 by cluster size m, pairwise correlation σ, and model.
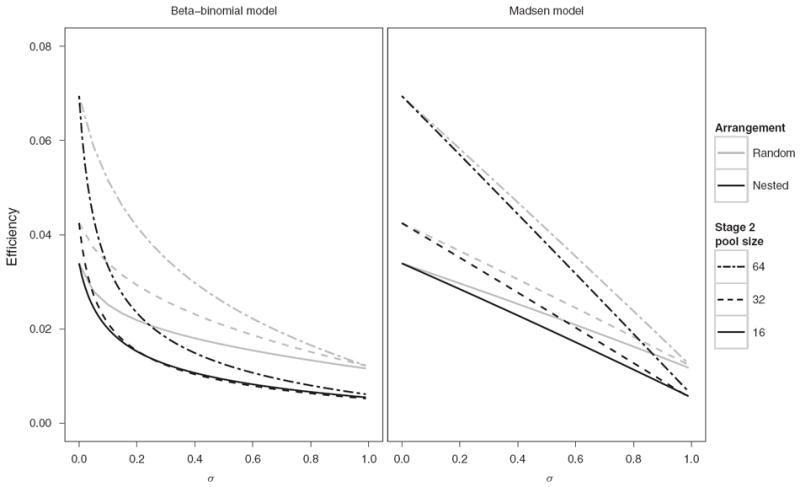
For a three-stage hierarchical procedure with a nested arrangement where all units from the same cluster fit into the same pool in stages 1 and 2 (i.e., h′ = 3) and Se = Sp = 1, the expected number of tests for stage 2 has the same form as in the two-stage procedure above. Similarly, the expected number of tests for the third stage is so . Figure 3 compares the efficiencies of three-stage hierarchical nested and random arrangements by stage two pool size, n2, as a function of σ. Efficiencies for the random arrangements were obtained by Monte Carlo simulation. In all cases in Figure 3 the nested arrangements have better efficiency than random arrangements for σ > 0. Similar results when Se and Sp are less than 1 are given in Web Figures 3 and 4.
Figure 3.
Efficiencies for three-stage hierarchical procedures where Se = Sp = 1, n1 = 256, p = 0.001, and m = 32 by pairwise correlation σ, stage two pool size n2, arrangement, and model.
4. Matrix Procedures
4.1 Notation and Efficiency of General Matrix Procedures
Consider a matrix-based procedure where n = rc units are arranged in a matrix with r rows and c columns. First, r row pools and c column pools are tested. If any rows and columns test positive, then units at the intersections of positive rows and columns are tested. Let Yij be 1 if the unit in the ith row and the jth column is truly positive and 0 otherwise, let , and let for i = 1, …, r and j = 1, …, c. Let Ri and Cj denote the observed responses for the tests corresponding to the ith row and the jth column, respectively. If sensitivity or specificity is not one, some columns might test positive while all rows test negative, or the opposite. If this occurs, assume no further tests are carried out such that the unit at the intersection of row i and column j is tested only if Ri = Cj = 1. This is the procedure used in Precopio et al. (2008). In general, for an r × c matrix, the expected number of tests equals
| (9) |
Let mi·k be the number of units from cluster k in row i; let m·jk be the number of units from cluster k in column j; and let mijk be the number of units from cluster k in either row i or column j. Then (9) can be evaluated by noting
| (10) |
where
and
| (11) |
Let m̃i·· = (mi ·1, …, mi ·l), let m̃·j· = (m·j 1, …, m·j l), and let m̃i j · = (mi j 1, …, mi j l). If the ordered values of m̃i ·· and m̃i′·· are equal, the ordered values of m̃·j· and m̃·j′· are equal, and the ordered values of m̃i j· and m̃i′j′· are equal for all i ≠ i′ and j ≠ j′, then pr(Ri = Cj = 1) is the same for all i and j, and (9) reduces to
| (12) |
If Se = Sp = 1 and all units are independent, then σ = 0 and the expected tests per unit is as in Phatarfod and Sudbury (1994).
4.2 Rectangular Arrangement
In a rectangular arrangement, clusters of m units are arranged in submatrices of dimension r′ × c′ so m = r′ c′. These submatrices are arranged in a matrix of dimensions r × c. The number of rows r is assumed to be divisible by r′ and the number of columns c is assumed to be divisible by c′. Figure 1b shows an example of a 6 × 6 matrix procedure where m = 6, r′ = 2, and c′ = 3. Again, the numbers in the figure represent cluster membership. In a rectangular arrangement, clusters are arranged in a way that (12) holds, and , , and . If Se = Sp = 1,
4.3 Diagonal Arrangement
In a diagonal arrangement, assume r = c = m. Clusters of size m are arranged on diagonals of a matrix such that each row and each column have exactly one unit from each cluster. More precisely, for any i ∈ {1, …, r − 1} and j ∈ {1, …, c − 1}, the responses Yij and Y(i+1)(j +1) will correspond to units from the same cluster in a diagonal arrangement. See Figure 1c for an example where r = c = m = 6. Clusters can wrap such that the last unit in a row of the matrix is a member of the same cluster as the first unit in the next row of the matrix. In this arrangement, clusters are arranged in a way that (12) hold and , , and . If Se = Sp = 1,
4.4 Random Arrangement
Now consider the case where units are arranged in a matrix randomly in a way that is independent of cluster membership. Let M̃i·· be the random vector of the number of units from each cluster 1, …, l in row i, let M̃·j· be the random vector of the number of units from each cluster 1, …, l in column j, and let M̃i j · be the random vector of the number of units from each cluster 1, …, l in either row i or column j. Each possible arrangement of n units has the same probability, so M̃i ·· has a multivariate hypergeometric distribution such that
where m̃i ··t = (mi ·1t, …, mi ·l t) is the tth possible vector of values of m̃i ··t, .
From (11) it follows that , implying
Additionally, and can be calculated in an analogous way. Similar to calculating in a randomly arranged hierarchical procedure, calculating , , and becomes computationally infeasible as n increases, and Monte Carlo simulation can be used to approximate each of these probabilities. The efficiency, E(T)/n, can then be calculated by (10) and (12).
4.5 Comparison of Matrix Arrangements
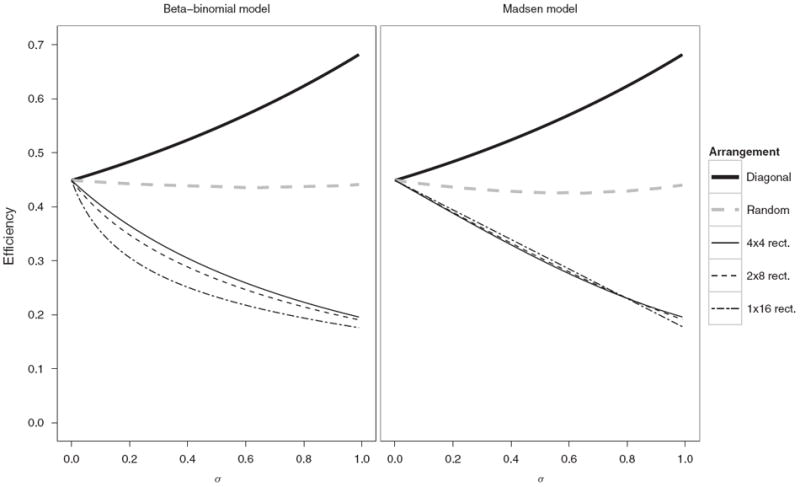
Figure 4 shows the expected tests per unit for a square matrix of size 16 × 16 with clusters of size 16 for different rectangular arrangements, a diagonal arrangement, and a random arrangement, where Se = Sp = 1. Efficiencies for the random arrangement were obtained by Monte Carlo simulation. For rectangular arrangements, the expected number of tests per unit decreases as σ increases. For the beta-binomial model, the expected tests per unit is lowest when clusters are arranged in a row, and the expected tests per unit increases as the arrangement of clusters moves from a single row to a 4 × 4 square. For the Madsen model, the rectangular arrangements perform about the same. Intuitively, a diagonal arrangement will perform worse than a rectangular arrangement, because positive responses in the same cluster will be in different rows and columns, and therefore more individual testing will be required. This intuition is supported by Figure 4, where the diagonal arrangement performs much worse than the other arrangements as σ increases. In the diagonal arrangement, the most units from the same cluster that are tested together is two. The joint distribution for a cluster of size two is fully specified by the first and second moments, so the efficiency for the diagonal arrangement is the same for both models. The efficiency for the randomly arrangement is worse than the rectangular arrangements, but better than the diagonal arrangement in this case. Similar results when Se and Sp are less than 1 are given in Web Figures 5 and 6.
Figure 4.
Efficiencies for a 16 × 16 matrix procedure where p = 0.05, Se = Sp = 1 and clusters are of size m = 16 by arrangement, pairwise correlation σ, and model.
5. Application
Malhotra et al. (2007a) used a 9 × 10 matrix procedure to evaluate T-cell responses to 90 peptides. The matrix algorithm was used to test for peptide responses for each of 23 subjects in the study, so there were a total of 2030 T-cell responses to classify. The peptides were made up of 15 amino acids, with some pairs of peptides overlapping by 10 or more amino acids. To illustrate the potential gain in efficiency when clusters are arranged strategically for group testing, we consider the efficiency of the 9 × 10 matrix procedure for different possible peptide arrangements. Assume the 90 peptides can be partitioned into groups of size 5 or 10 such that T-cell responses to each group of peptides form an exchangeable cluster with positive pairwise correlations. Such clusters might be formed by grouping peptides coded by the same gene (e.g., nef) or grouping peptides with similar amino acid sequences. From Figure 2A of Malhotra et al. (2007a), there were a total of 151 positive responses to the set of 90 peptides for all subjects. Therefore suppose for this illustration the probability of a positive T-cell responses is 0.07 (i.e., ≈ 151/2030).
Figure 5 shows the efficiency of the 9 × 10 matrix procedure if the clusters are in a rectangular arrangement compared to a random arrangement when Se = Sp = 1. Efficiencies for the random arrangements were obtained by Monte Carlo simulation. For the rectangular arrangements, the clusters of size 5 are arranged in submatrices of size 1 × 5 and the clusters of size 10 are arranged in submatrices of size 1 × 10. For both of these cluster sizes, the rectangular arrangements have a substantial gain in efficiency over the random arrangements. For example, at σ = 0.4 for m = 5, the efficiency for the rectangular arrangement is 0.39 versus 0.48 for the random arrangement from the beta-binomial model, resulting in 0.09 fewer tests per peptide on average. For each of the 23 subjects, 90 peptides are evaluated, so there is a potential savings of about 186 tests by strategically arranging peptides within a matrix. In the presence of test error similar but slightly less savings would be expected (Web Figures 7 and 8). Malhotra et al. (2007a) only examined peptides associated with the Nef gene, but other studies evaluate a much larger number of peptides across the HIV genome (Russell et al., 2003; Koup et al., 2010). For such large scale studies, the savings from a strategic arrangement of peptides can be substantial.
Figure 5.
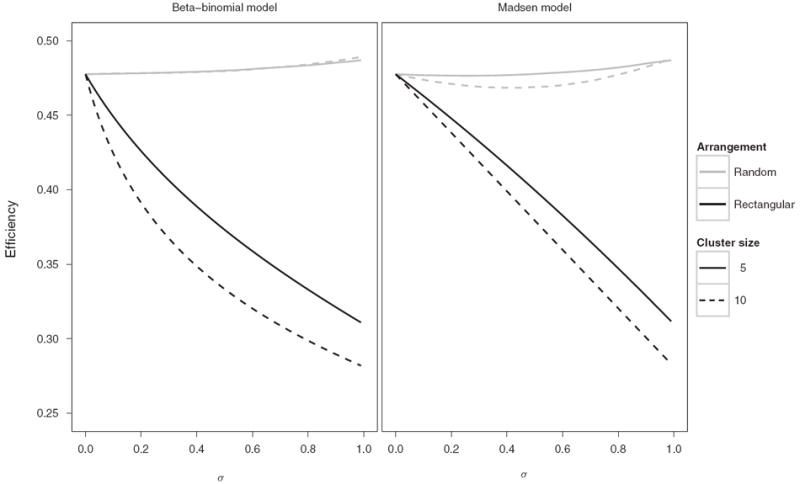
Efficiencies for a 9 × 10 matrix procedure where p = 0.07, Se = Sp = 1 by pairwise correlation σ, cluster size m, arrangement, and model.
6. Discussion
This article provides closed form expressions for hierarchicaland matrix-based group testing procedures when units within clusters are correlated. These results allow investigation into the effect of correlation and the arrangement of clusters on a procedure’s efficiency. For the three models of exchangeable binary random variables considered, we found that if units from the same cluster are tested together, then the efficiency of a particular procedure can be improved, sometimes substantially, relative to random arrangements, which ignore information about cluster membership.
The feasibility of incorporating information on correlation into the design of particular group testing studies will depend on the setting. In the epitope mapping example, pools of peptides are typically constructed in a single or few large batches. Then epitope mapping studies are conducted by repeating a standard deconvolution algorithm over various sets of specimens (one at a time), e.g., individual sera from participants in an HIV vaccine trial. Because the peptide pools are constructed in batches ahead of time, information on correlation between peptides can easily be utilized when deciding which peptides to combine into pools. Correlation estimates can be obtained through prior experiments in similar settings, public databases (Taylor and Flower, 2007) or prediction models for T-cell epitopes (Lin et al., 2008). In infectious disease screening applications, individual level covariate information can be incorporated into pooling algorithms to improve efficiency (e.g., see Bilder et al., 2010). In such settings where individual level covariates are used to design the pooling algorithm it should be feasible to account for correlation between individuals as well. To facilitate such designs, an R package gtcorr, available at http://cran.r-project.org/, has been developed, which calculates the efficiencies of hierarchical and matrix group testing procedures for the beta-binomial, Madsen, and Morel–Neerchal cluster models.
Throughout this article clusters were assumed to be of equal size with the same distribution (Assumption 1), contain exchangeable units (Assumption 2), and have a distribution within a particular class (Assumption 3). Assumption 1 is helpful for ease of presentation but in fact the efficiency derivations in Sections 3.1 and 4.1 are sufficiently general that this assumption is not required. For instance, (9)-(11) can be used to evaluate the efficiency of any matrix algorithm with varying cluster sizes and different prevalences between clusters. To account for cluster-specific prevalences, the terms qmi ·k, qm·j k, and qmi j k in (11) should be computed using (2) for ẋ′ = 0 and π equal to the prevalence for cluster k. The R package gtcorr allows for clusters of various size and different prevalences between clusters. As discussed in Section 2, Assumption 3 is not a particularly strong assumption. In future research, models that do not assume exchangeable units within clusters (Assumption 2) could be considered. Some empirical investigation regarding violations of Assumption 2 is given in Web Appendix C. These results demonstrate that efficiency estimates obtained when incorrectly assuming an exchangeable correlation structure may be fairly accurate in some settings.
Supplementary Material
Acknowledgments
SDL and MGH were supported by NIH grant R01 AI029168. The authors thank the editor, associate editor, two anonymous reviewers, and Elena Bordonali for helpful comments.
Footnotes
Supplementary Materials
Web Appendices and Figures referenced in Sections 2–6 are available under the Paper Information link at the Biometrics website http://www.biometrics.tibs.org.
References
- Bilder C, Tebbs J, Chen P. Informative retesting. Journal of the American Statistical Association. 2010;105:942–955. doi: 10.1198/jasa.2010.ap09231. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Finetti B. Theory of Probability A Critical Introductory Treatment. Vol. 2. London: John Wiley & Sons; 1975. [Google Scholar]
- Diaconis P. Finite forms of de Finetti’s theorem on exchangeability. Synthese. 1977;36:271–281. [Google Scholar]
- Dorfman R. The detection of defective members of large populations. The Annals of Mathematical Statistics. 1943;14:436–440. [Google Scholar]
- Johnson NL, Kotz S, Wu X. Inspection Errors for Attributes in Quality Control. London: Chapman and Hall/CRC; 1991. [Google Scholar]
- Kim H, Hudgens MG, Dreyfuss JM, Westreich DJ, Pilcher CD. Comparison of group testing algorithms for case identification in the presence of test error. Biometrics. 2007;63:1152–1163. doi: 10.1111/j.1541-0420.2007.00817.x. [DOI] [PubMed] [Google Scholar]
- Koup RA, Roederer M, Lamoreaux L, Fischer J, Novik L, Nason MC, Larkin BD, Enama ME, Ledgerwood JE, Bailer RT, Mascola JR, Nabel GJ, Graham BS VRC 009 and VRC 010 Study Teams. Priming immunization with DNA augments immunogenicity of recombinant adenoviral vectors for both HIV-1 specific antibody and T-cell responses. PloS ONE. 2010;5:e9015, 1–15. doi: 10.1371/journal.pone.0009015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li F, Malhotra U, Gilbert PB, Hawkins NR, Duerr AC, McElrath JM, Corey L, Self SG. Peptide selection for human immunodeficiency virus type 1 CTL-based vaccine evaluation. Vaccine. 2006;24:6893–6904. doi: 10.1016/j.vaccine.2006.06.009. [DOI] [PubMed] [Google Scholar]
- Lin H, Ray S, Tongchusak S, Reinherz E, Brusic V. Evaluation of MHC class I peptide binding prediction servers: applications for vaccine research. BMC Immunology. 2008;9:1–13. doi: 10.1186/1471-2172-9-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Madsen R. Generalized binomial distributions. Communications in Statistics—Theory and Methods. 1993;22:3065–3086. [Google Scholar]
- Malhotra U, Li F, Nolin J, Allison M, Zhao H, Mullins J, Self S, McElrath M. Enhanced detection of human immunodeficiency virus type 1 (HIV-1) Nef-specific T cells recognizing multiple variants in early HIV-1 infection. Journal of Virology. 2007a;81:5225–5237. doi: 10.1128/JVI.02564-06. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Malhotra U, Nolin J, Mullins J, McElrath M. Comprehensive epitope analysis of cross-clade Gag-specific T-cell responses in individuals with early HIV-1 infection in the US epidemic. Vaccine. 2007b;25:381–390. doi: 10.1016/j.vaccine.2006.07.045. [DOI] [PubMed] [Google Scholar]
- Morel J, Neerchal N. Clustered binary logistic regression in teratology data using a finite mixture distribution. Statistics in Medicine. 1997;16:2843–2853. doi: 10.1002/(sici)1097-0258(19971230)16:24<2843::aid-sim627>3.0.co;2-f. [DOI] [PubMed] [Google Scholar]
- Phatarfod RM, Sudbury A. The use of a square array scheme in blood testing. Statistics in Medicine. 1994;13:2337–2343. doi: 10.1002/sim.4780132205. [DOI] [PubMed] [Google Scholar]
- Precopio M, Butterfield T, Casazza J, Little S, Richman D, Koup R, Roederer M. Optimizing peptide matrices for identifying T-cell antigens. Cytometry Part A. 2008;73:1071–1078. doi: 10.1002/cyto.a.20646. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roederer M, Koup RA. Optimized determination of T cell epitope responses. Journal of Immunological Methods. 2003;274:221–228. doi: 10.1016/s0022-1759(02)00423-4. [DOI] [PubMed] [Google Scholar]
- Russell N, Hudgens M, Ha R, Havenar-Daughton C, McElrath M. Moving to human immunodeficiency virus type 1 vaccine efficacy trials: Defining T cell responses as potential correlates of immunity. The Journal of Infectious Diseases. 2003;187:226–242. doi: 10.1086/367702. [DOI] [PubMed] [Google Scholar]
- Taylor P, Flower D. Immunoinformatics and computational vaccinology: A brief introduction. In: Darren F, Jon T, editors. Silico Immunology. New York, NY: Springer US; 2007. pp. 23–46. [Google Scholar]
- Yan J, Yoon H, Kumar S, Ramanathan M, Corbitt N, Kutzler M, Dai A, Boyer J, Weiner D. Enhanced cellular immune responses elicited by an engineered HIV-1 subtype B consensus-based envelope DNA vaccine. Molecular Therapy. 2007;15:411–421. doi: 10.1038/sj.mt.6300036. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.