

Abstract
Variable numbers of tandem repeats (VNTR) typing is widely used for studying the bacterial cause of tuberculosis. Knowledge of the rate of mutation of VNTR loci facilitates the study of the evolution and epidemiology of Mycobacterium tuberculosis. Previous studies have applied population genetic models to estimate the mutation rate, leading to estimates varying widely from around 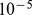 to
to 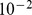 per locus per year. Resolving this issue using more detailed models and statistical methods would lead to improved inference in the molecular epidemiology of tuberculosis. Here, we use a model-based approach that incorporates two alternative forms of a stepwise mutation process for VNTR evolution within an epidemiological model of disease transmission. Using this model in a Bayesian framework we estimate the mutation rate of VNTR in M. tuberculosis from four published data sets of VNTR profiles from Albania, Iran, Morocco and Venezuela. In the first variant, the mutation rate increases linearly with respect to repeat numbers (linear model); in the second, the mutation rate is constant across repeat numbers (constant model). We find that under the constant model, the mean mutation rate per locus is
per locus per year. Resolving this issue using more detailed models and statistical methods would lead to improved inference in the molecular epidemiology of tuberculosis. Here, we use a model-based approach that incorporates two alternative forms of a stepwise mutation process for VNTR evolution within an epidemiological model of disease transmission. Using this model in a Bayesian framework we estimate the mutation rate of VNTR in M. tuberculosis from four published data sets of VNTR profiles from Albania, Iran, Morocco and Venezuela. In the first variant, the mutation rate increases linearly with respect to repeat numbers (linear model); in the second, the mutation rate is constant across repeat numbers (constant model). We find that under the constant model, the mean mutation rate per locus is 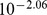 (95% CI:
(95% CI: 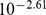 ,
,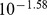 )and under the linear model, the mean mutation rate per locus per repeat unit is
)and under the linear model, the mean mutation rate per locus per repeat unit is 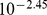 (95% CI:
(95% CI: 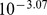 ,
,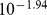 ). These new estimates represent a high rate of mutation at VNTR loci compared to previous estimates. To compare the two models we use posterior predictive checks to ascertain which of the two models is better able to reproduce the observed data. From this procedure we find that the linear model performs better than the constant model. The general framework we use allows the possibility of extending the analysis to more complex models in the future.
). These new estimates represent a high rate of mutation at VNTR loci compared to previous estimates. To compare the two models we use posterior predictive checks to ascertain which of the two models is better able to reproduce the observed data. From this procedure we find that the linear model performs better than the constant model. The general framework we use allows the possibility of extending the analysis to more complex models in the future.
Author Summary
Genetically typing the bacterium responsible for tuberculosis is useful for understanding the evolutionary and epidemiological characteristics of the disease. Typing methods based on variable number tandem repeat (VNTR) loci are increasingly being used. These loci, which are composed of repeated units, mutate by increasing or decreasing in the number of these repeats. Knowledge of the mutation rate of molecular markers facilitates the epidemiological interpretation of the observed genetic variation in a sample of bacterial isolates. Few studies have examined the rate of mutation at these markers and estimates to date have varied considerably. To address this problem we develop a stochastic model of evolution of these markers and then estimate their mutation rate using approximate Bayesian computation. We examine two alternative forms of the mutation process. The observed data are from four published data sets of tuberculosis bacterial isolates sampled in Albania, Iran, Morocco and Venezuela. We find that these markers have fairly high rates of mutation compared with estimates from previous studies.
Introduction
Mycobacterium tuberculosis, the bacterial pathogen that causes tuberculosis, latently infects one third of the world's population and is responsible for the highest mortality rate of any single bacterial pathogen [1]. Recent advances in genotyping techniques have increased our ability to discriminate among M. tuberculosis isolates, helping to shed light on the genetic diversity, demographics and evolution of this pathogen [2], [3]. For instance, Pepperell et al. [4], [5] suggested that the restricted diversity in this bacterial species is likely the result of population bottlenecks and founder effects. Genotyping or fingerprinting also refines our understanding of the epidemiological characteristics of the disease in a population, for example by revealing the extent of local transmission and factors associated with this transmission (e.g., [6]).
Frequently used methods for genetic fingerprinting of M. tuberculosis include restriction fragment length polymorphism typing based on mobility of the insertion sequence IS 6110 [7] and spoligotyping which exploits variation at the Direct Repeat or CRISPR locus [8]. More recently, a multilocus typing method based on variable numbers of tandem repeats (VNTR) has been developed for M. tuberculosis [9]–[11]. These loci are minisatellites, and are also known as mycobacterial interspersed repetitive units (MIRUs). We will refer to these as “VNTR loci”.
VNTR-based methods are increasing in importance and efforts are being made to standardise the loci used [9]. The larger the number of loci used, the greater the discrimination among isolates resulting in a large number of smaller clusters of identical profiles in a sample. The early standard of 5 locus VNTR typing lacked the discriminatory power of IS6110-typing but comparative studies have shown that using at least 12 loci can have comparable or better discrimination relative to IS6110 [12]–[14]. An advantage of using VNTR is that if the mutation rate is low there is the possibility of adding more loci to increase discriminatory power [10].
Inferences about transmission are sensitive to the degree of genetic clustering, which is a function of the mutation rate of the marker [15]. It is therefore important to have accurate estimates of the mutation rate of VNTR loci. Knowledge of the mutation rate of VNTR also allows calibration of the molecular clock to make inferences about the evolutionary history of M. tuberculosis, for instance, the time until the most recent common ancestor of a clade [3].
A standard model for the evolution of VNTR loci is the stepwise mutation model [16], [17], which has successfully been used to describe microsatellite evolution in eukaryotes (e.g. [18]). The stepwise mutation model has also been applied to VNTR evolution in M. tuberculosis
[19], leading to estimates of the rate of mutation. Such estimates in the literature vary widely from 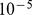 per locus per year [19] to
per locus per year [19] to 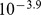 per locus per year [3] to
per locus per year [3] to 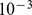 –
–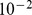 [20]. This wide variation in estimates has led to debate in the literature [21]–[24]. Taking a model-based approach can help to resolve this question. It allows our understanding of biological mechanisms underlying VNTR evolution to be incorporated into the analysis, while providing a natural framework for model validation and criticism. Similarly, examination of multiple data sets under the same models and methods could provide support or otherwise for resulting estimates.
[20]. This wide variation in estimates has led to debate in the literature [21]–[24]. Taking a model-based approach can help to resolve this question. It allows our understanding of biological mechanisms underlying VNTR evolution to be incorporated into the analysis, while providing a natural framework for model validation and criticism. Similarly, examination of multiple data sets under the same models and methods could provide support or otherwise for resulting estimates.
In this study we estimate the mutation rate of VNTR markers by developing a stochastic stepwise mutation process of the evolution of genotypes through gains and losses of repeat numbers [16], [19] embedded in a model of disease transmission [25]. We consider and evaluate two alternative formulations of the stepwise mutation model under a Bayesian statistical framework, applying our methods to four geographically distinct data sets. Our study provides a posterior estimate of the VNTR mutation rate under an explicit model of evolution placed within an epidemiological context.
Methods
Model of the dynamics of infection and mutation of VNTR loci
In the model of disease transmission we use, 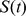 tracks the number of individuals who are susceptible to infection and
tracks the number of individuals who are susceptible to infection and 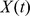 tracks infectious individuals, where
tracks infectious individuals, where  is time measured in years. For simplicity, we assume a population of fixed size
is time measured in years. For simplicity, we assume a population of fixed size 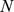 . Let
. Let 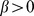 be the rate of transmission and
be the rate of transmission and 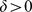 be the rate of death or recovery. First consider a deterministic model where the dynamics are given by
be the rate of death or recovery. First consider a deterministic model where the dynamics are given by
| (1) |
We start the process with a single infected individual (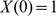 ). Define
). Define 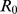 to be the basic reproductive ratio, that is, the number of cases resulting from a single infectious case in a wholly susceptible population. For this model,
to be the basic reproductive ratio, that is, the number of cases resulting from a single infectious case in a wholly susceptible population. For this model, 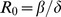 . The analytical solution of Equation (1) can be written as
. The analytical solution of Equation (1) can be written as
| (2) |
The steady state of the infectious population is
We use this deterministic model as the basis for a continuous-time stochastic model that incorporates mutation at VNTR loci. The transition rates of this model, summarised in Table 1, are as follows: the rate of new infections is 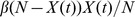 and the rate out of the infectious class from death or recovery is
and the rate out of the infectious class from death or recovery is  . An infection event increases
. An infection event increases 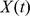 by 1 while a death-or-recovery event decreases
by 1 while a death-or-recovery event decreases 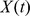 by 1. Each infection is associated with a bacterial genotype by which we mean the set of repeat states across all loci considered in a VNTR typing technique, determined for a particular isolate. Let
by 1. Each infection is associated with a bacterial genotype by which we mean the set of repeat states across all loci considered in a VNTR typing technique, determined for a particular isolate. Let 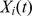 be the number of individuals infected with bacterial genotype
be the number of individuals infected with bacterial genotype  so that
so that
where 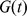 is the number of distinct genotypes in the population at time
is the number of distinct genotypes in the population at time  .
.
Table 1. Transition rates in the stochastic model.
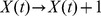
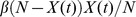
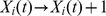
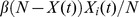
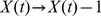
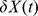
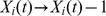
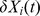
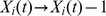
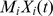
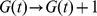
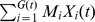
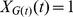
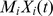
*: If an existing genotype is re-created by mutation, the count of that genotype is incremented instead. Note that the increment 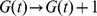 occurs before the assignment
occurs before the assignment 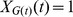 .
.
We apply the stepwise mutation model to describe VNTR mutation [16], [17], [19] in which an event results in a unit increase or decrease in the number of repeats at a locus. We define  to be the mutation rate per infectious case for genotype
to be the mutation rate per infectious case for genotype  so that the transition rate for mutation of genotype
so that the transition rate for mutation of genotype  is
is 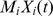 . A mutation event results in either a new genotype, or a pre-existing genotype in the population (i.e., homoplasy). In the event of mutation to a new genotype, the number of individuals from the mutating genotype decreases by 1 and the number of individuals in the new class becomes 1. In the case of homoplasy, the number of individuals in the mutating genotype decreases by 1 while the number of individuals in the existing class increases by 1. In either case the total number of infected cases,
. A mutation event results in either a new genotype, or a pre-existing genotype in the population (i.e., homoplasy). In the event of mutation to a new genotype, the number of individuals from the mutating genotype decreases by 1 and the number of individuals in the new class becomes 1. In the case of homoplasy, the number of individuals in the mutating genotype decreases by 1 while the number of individuals in the existing class increases by 1. In either case the total number of infected cases, 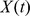 , does not change.
, does not change.
We consider two alternative ways to specify VNTR mutation. In the first model, the mutation rate at a locus is proportional to the number of repeats at that locus. In this linear model, the per-locus mutation rate increases linearly with the number of repeats at the locus. In the second constant model, the mutation rate the per-locus mutation rate is constant and thus not dependent on repeat number. Defining 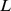 to be the number of loci,
to be the number of loci,  to be the number of repeats at locus
to be the number of repeats at locus 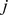 for genotype
for genotype  , and
, and 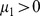 to be the rate of mutation at a locus with a single repeat, under the linear model
to be the rate of mutation at a locus with a single repeat, under the linear model
Under the constant model
where  is the per locus mutation rate and where the indicator function
is the per locus mutation rate and where the indicator function 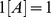 if
if 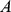 is true and 0 otherwise. In both models the boundary condition
is true and 0 otherwise. In both models the boundary condition 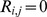 is an absorbing state in that a locus with zero repeats cannot gain or lose repeats.
is an absorbing state in that a locus with zero repeats cannot gain or lose repeats.
The process starts at time 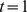 with a single infected individual and the population evolves until time
with a single infected individual and the population evolves until time 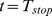 . The initial individual has genotype given by
. The initial individual has genotype given by  , which we call the founding genotype. At time
, which we call the founding genotype. At time 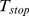 a sample of size
a sample of size  is taken from the population. We simulate this process using the Gillespie exact algorithm [26] so that the time between events is distributed exponentially, with parameter
is taken from the population. We simulate this process using the Gillespie exact algorithm [26] so that the time between events is distributed exponentially, with parameter 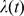 , where
, where
Given an event, the probability of a specific outcome is proportional to the rate of that outcome, so that
Given a mutation event, the probability of mutation in an individual with genotype  is
is
and given a mutation event in genotype  , the probability that it occurs at locus
, the probability that it occurs at locus 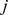 under the linear model is
under the linear model is
and under the constant model is
We assume that given a mutation event at locus 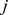 in genotype
in genotype  , the probability of repeat gain is equal to the probability of repeat loss, following [3], [19].
, the probability of repeat gain is equal to the probability of repeat loss, following [3], [19].
Inference procedure
We implement a standard Bayesian analysis of model parameters using approximate Bayesian computation (ABC) [27]–[29]. ABC methods permit approximate Bayesian inference when numerical evaluation of the posterior distribution is either computationally prohibitive or not available, and have been successfully applied to problems in molecular epidemiology [30]–[34].
Intuitively, given a candidate parameter vector, 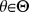 , prior distribution
, prior distribution 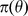 and model likelihood
and model likelihood 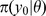 with observed data
with observed data 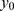 , ABC methods proceed by generating an artificial dataset from the model
, ABC methods proceed by generating an artificial dataset from the model 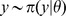 and then reducing the dataset to a low dimensional vector of summary statistics,
and then reducing the dataset to a low dimensional vector of summary statistics, 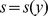 . If
. If  is similar to the same vector of statistics obtained from the observed data,
is similar to the same vector of statistics obtained from the observed data, 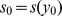 , then
, then  could have credibly reproduced the observed data under the model. As such, the parameter vector is then retained as part of the approximate posterior, otherwise it is discarded. More precisely, the posterior obtained under ABC methods is given by
could have credibly reproduced the observed data under the model. As such, the parameter vector is then retained as part of the approximate posterior, otherwise it is discarded. More precisely, the posterior obtained under ABC methods is given by
| (3) |
where 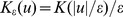 is a standard smoothing kernel with scale parameter
is a standard smoothing kernel with scale parameter 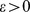 . As
. As  becomes small, the approximation (3) becomes increasingly accurate, although computational overheads increase. If the vector of summary statistics are informative for the model parameters, then this posterior distribution approximates the true posterior distribution so that
becomes small, the approximation (3) becomes increasingly accurate, although computational overheads increase. If the vector of summary statistics are informative for the model parameters, then this posterior distribution approximates the true posterior distribution so that 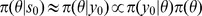 . See e.g. [30], [31], [35], [36] for further description of ABC methods.
. See e.g. [30], [31], [35], [36] for further description of ABC methods.
The parameter vector for the constant model above is 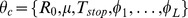 where
where  is the repeat structure of the founding genotype in the simulation. For the linear model we have
is the repeat structure of the founding genotype in the simulation. For the linear model we have  . Except where this may cause confusion, we will refer to a non-model-specific parameter vector as
. Except where this may cause confusion, we will refer to a non-model-specific parameter vector as  .
.
Conditional on the parameter vector  , and following simulation under the model, a sample of size
, and following simulation under the model, a sample of size  individuals is drawn from the resulting population. Summary statistics,
individuals is drawn from the resulting population. Summary statistics,  , are then computed, determined as quantities expected to be highly informative regarding the model parameters. Using lower case letters (e.g.
, are then computed, determined as quantities expected to be highly informative regarding the model parameters. Using lower case letters (e.g. 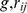 ) to denote sample-based values of the population-level counterparts (e.g.
) to denote sample-based values of the population-level counterparts (e.g. 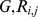 ), the summary statistics include the number of distinct genotypes in the sample,
), the summary statistics include the number of distinct genotypes in the sample, 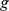 , and the set of
, and the set of 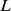 sample means of repeats at each locus
sample means of repeats at each locus
for 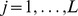 , which is expected to contain information about the initial repeat numbers
, which is expected to contain information about the initial repeat numbers  for some time after the founding case. Here,
for some time after the founding case. Here, 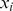 denotes the number of individuals in the sample with genotype
denotes the number of individuals in the sample with genotype  , and
, and 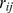 denotes the within-sample number of repeats at locus
denotes the within-sample number of repeats at locus 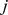 for genotype
for genotype  . The final two statistics are based on the ANOVA decomposition
. The final two statistics are based on the ANOVA decomposition 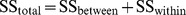 given by
given by
where 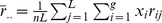 , from which
, from which 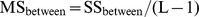 and
and 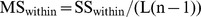 can be computed. These two statistics are expected to be informative about the mutation rate between and within loci. The complete vector of summary statistics is then given by
can be computed. These two statistics are expected to be informative about the mutation rate between and within loci. The complete vector of summary statistics is then given by
To complete the model specification, we set the parameter  to
to 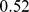 , following [32], [37]. This death/recovery rate is the sum of the death rate due to tuberculosis, the death rate due to other causes, and the recovery rate from tuberculosis. We chose an informative prior distribution for
, following [32], [37]. This death/recovery rate is the sum of the death rate due to tuberculosis, the death rate due to other causes, and the recovery rate from tuberculosis. We chose an informative prior distribution for 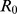 based on the study of the basic reproductive value of tuberculosis by Blower et al. [38]. We use a distribution approximating the histogram in Figure 3a in reference [38] which has a mean of 5.16 and a standard deviation of 2.82, and in particular define the prior of
based on the study of the basic reproductive value of tuberculosis by Blower et al. [38]. We use a distribution approximating the histogram in Figure 3a in reference [38] which has a mean of 5.16 and a standard deviation of 2.82, and in particular define the prior of 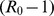 to be a gamma distribution with a shape parameter of
to be a gamma distribution with a shape parameter of 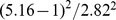 and a scale parameter of
and a scale parameter of 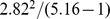 . The priors for
. The priors for 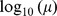 ,
, 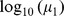 ,
, 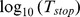 and
and  are uniform with wide ranges as shown in Table 2.
are uniform with wide ranges as shown in Table 2.
Figure 3. Marginal posterior estimates for 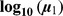 ,
, 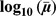 and
and  .
.

Here 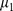 is the per-locus mutation rate for a locus with a single repeat under the linear model;
is the per-locus mutation rate for a locus with a single repeat under the linear model; 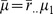 is the same quantity scaled by the mean number of repeats observed in the sample;
is the same quantity scaled by the mean number of repeats observed in the sample; 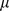 is the per-locus mutation rate for any repeat number under the constant model.
is the per-locus mutation rate for any repeat number under the constant model.
Table 2. Prior distributions and initial sampling distributions for each model parameter.
| Parameter | Prior distribution | Initial sampling distribution |
|
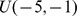
|
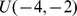
|
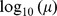
|
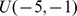
|
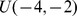
|

|
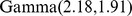
|
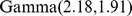
|
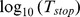
|
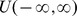
|
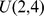
|
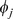
|
Uniform on 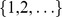
|
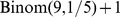
|
Initial sampling distributions are utilised in the ABC simulations (see Text S1).
We examine the effectiveness of the ABC inference procedure by evaluating its ability to recover accurate estimates of the mutation rate based on data generated under the constant and linear models We simulated a population of 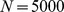 individuals with
individuals with 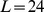 loci,
loci, 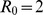 ,
, 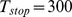 , and considered a range of mutation rates under each model varying across orders of magnitude
, and considered a range of mutation rates under each model varying across orders of magnitude  and
and 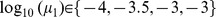 . The number of repeats of the founding genotype were initialised as
. The number of repeats of the founding genotype were initialised as 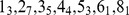 (determined as random draws from
(determined as random draws from 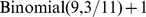 ), where
), where 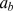 denotes
denotes 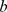 loci with repeat number
loci with repeat number  . Based on a sample of size
. Based on a sample of size 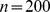 we generated data under each mutation rate value, and obtained weighted samples from the ABC posterior approximations
we generated data under each mutation rate value, and obtained weighted samples from the ABC posterior approximations 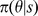 (c.f. 3) using a population-based ABC algorithm, following [32], [39], [40]. The technical algorithmic details are given in Text S1.
(c.f. 3) using a population-based ABC algorithm, following [32], [39], [40]. The technical algorithmic details are given in Text S1.
The estimated posterior distributions of 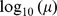 and
and 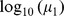 using the simulated data are shown in Figure 1. These results indicate that mutation rates can generally be recovered accurately, with the true parameter values lying in regions of high posterior density close to the posterior mode, and with a clear location shift in the density with varying mutation rate. Higher precision can be attained by using a larger sample size, although
using the simulated data are shown in Figure 1. These results indicate that mutation rates can generally be recovered accurately, with the true parameter values lying in regions of high posterior density close to the posterior mode, and with a clear location shift in the density with varying mutation rate. Higher precision can be attained by using a larger sample size, although 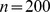 already represents a sample larger than the real datasets used for this study (c.f. Table 3). In the ABC setting, posterior precision can also be improved by reducing the kernel scale parameter
already represents a sample larger than the real datasets used for this study (c.f. Table 3). In the ABC setting, posterior precision can also be improved by reducing the kernel scale parameter  in (3) or by the inclusion of more summary statistics [30], [31], [35], [36], although each of these can substantially increase computational overheads. Improving the precision of posterior parameter estimates for given summary statistics is currently an area of active ABC research [41].
in (3) or by the inclusion of more summary statistics [30], [31], [35], [36], although each of these can substantially increase computational overheads. Improving the precision of posterior parameter estimates for given summary statistics is currently an area of active ABC research [41].
Figure 1. Marginal posterior distributions for 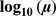 and
and 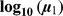 using simulated data.
using simulated data.
Plots show the marginal posterior distribution of  (left) and
(left) and  (right) using four simulated data sets generated from the constant (left) and linear (right) VNTR models. The known values of
(right) using four simulated data sets generated from the constant (left) and linear (right) VNTR models. The known values of 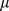 and
and 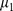 used to generate the data,
used to generate the data, 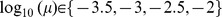 and
and 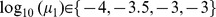 , are indicated by vertical lines.
, are indicated by vertical lines.
Table 3. Summary of data sets analysed in this study.
| Country | TB incidence* | Loci | Isolates | Collection period | Source |
| Albania | 15 | 24 | 100 | 2006–2007 | [42] |
| Iran | 19 | 15 | 154 | 2004–2005 | [43] |
| Morocco | 92 | 12 | 153 | 1997–1998 | [11] |
| Venezuela | 33 | 24 | 67 | 1997–2007 | [44] |
*: per 100,000 per year. Data from [57].
Data
We selected recently published VNTR loci data sets from studies undertaken in four countries: Albania [42], Iran [43], Morocco [11] and Venezuela [44]. We chose data sets with a high number of isolates largely from the same clade, a high number of VNTR loci in the typing method, and relatively short periods of isolate collection. The data from Albania and Venezuela are based on 24-locus typing, and the data from Iran and Morocco are based on 15 and 12 loci respectively. A summary of these data are provided in Table 3, along with the incidence of tuberculosis for each country.
As an initial exploratory examination of these data, we computed gene diversity [45] (also known as virtual heterozygosity), for each locus in each data set. This statistic is given by 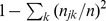 where
where 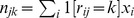 is the number of isolates with repeat size
is the number of isolates with repeat size 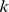 at locus
at locus 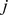 . Figure 2 (left plots) shows the empirical cumulative distribution function of gene diversity across loci for each of the data sets. There is no obvious bimodality in these distributions. This feature is consistent with a common process generating diversity, compared to, for example, the potential bi- or multi-modality in the empirical cumulative distribution function arising from a multi-modal distribution of mutation rates. Similarly, plotting the proportion of VNTR states per locus per repeat (right plots of Figure 2) reveals that while some loci are more variable than others, there is no obvious separation between loci exhibiting high and low variation.
. Figure 2 (left plots) shows the empirical cumulative distribution function of gene diversity across loci for each of the data sets. There is no obvious bimodality in these distributions. This feature is consistent with a common process generating diversity, compared to, for example, the potential bi- or multi-modality in the empirical cumulative distribution function arising from a multi-modal distribution of mutation rates. Similarly, plotting the proportion of VNTR states per locus per repeat (right plots of Figure 2) reveals that while some loci are more variable than others, there is no obvious separation between loci exhibiting high and low variation.
Figure 2. Genetic diversity of VNTR loci for each published dataset.

Left plots: Empirical cumulative distribution function of gene diversity across loci. The gene diversity is computed at each locus as  where
where 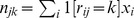 is the number of isolates with repeat size
is the number of isolates with repeat size 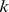 at locus
at locus 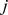 . Right plots: Heat-map diversity, following Aminian et al (2009), illustrating the proportion of tandem repeats for each locus (ordered according to the original study).
. Right plots: Heat-map diversity, following Aminian et al (2009), illustrating the proportion of tandem repeats for each locus (ordered according to the original study).
Results
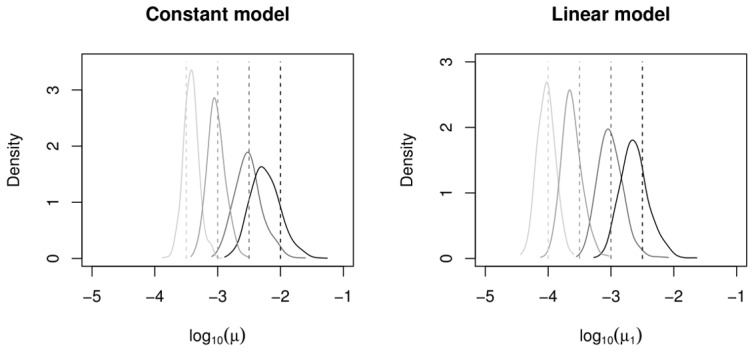
Figure 3 shows the marginal posterior distribution of the mutation rate of VNTR loci for each of the four data sets analysed. In the case of the linear model we also show (middle panel of Figure 3) the posterior of 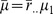 , the per-locus mutation rate
, the per-locus mutation rate 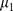 at repeat size 1 scaled by the average repeat number
at repeat size 1 scaled by the average repeat number 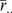 of each dataset to provide estimates of the mean per-locus mutation rate in a population with the same distribution of repeats as found in each sample. The posterior means of the mutation rate under the two models, along with 95% central credibility intervals are given in Table 4. The mean per-locus mutation rate at a locus with a single repeat from the four data sets under the linear model is
of each dataset to provide estimates of the mean per-locus mutation rate in a population with the same distribution of repeats as found in each sample. The posterior means of the mutation rate under the two models, along with 95% central credibility intervals are given in Table 4. The mean per-locus mutation rate at a locus with a single repeat from the four data sets under the linear model is 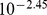 , and under the constant model the mean per-locus rate is
, and under the constant model the mean per-locus rate is 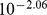 . Note that the prior distributions of the mutation parameters are uniform on a logarithmic (base 10) scale, and so Figure 3 displays the posterior distributions on this scale.
. Note that the prior distributions of the mutation parameters are uniform on a logarithmic (base 10) scale, and so Figure 3 displays the posterior distributions on this scale.
Table 4. Bayesian posterior estimates for mutation rate.
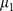
|
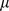
|
|||
| Country | mean | 95% credible interval | mean | 95% credible interval |
| Albania |
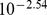
|
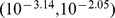
|
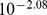
|
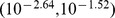
|
| Iran |
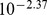
|
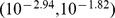
|
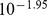
|
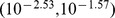
|
| Morocco |
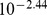
|
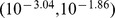
|
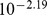
|
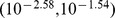
|
| Venezuela |
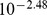
|
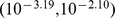
|
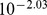
|
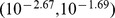
|
To evaluate the suitability of the constant and linear models to describe the observed data, we follow [36], [46], [47] and implement posterior predictive model checks. This approach examines the predictive distribution of specified validation statistics (based on data-generation under the fitted models) expected to be informative about various model aspects. Comparing the predictive distribution of these statistics with the same statistics derived from the observed data, enables some degree of discrimination between models. To avoid confusing model fitting with model assessment, these statistics should be different from those used in the ABC model fitting process.
Unlike the constant model, the mutation rate increases with repeat number under the linear model, and so we expect variation in repeat numbers to increase with repeat numbers. Our model assessment statistics aim to capture these differences from the data. Specifically, we focus on measures of the spread of repeats over the loci. Defining
where 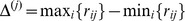 , and
, and
where 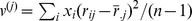 , and
, and 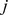 indexes loci as before, we consider the maximum (over loci) range (
indexes loci as before, we consider the maximum (over loci) range (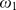 ), the difference between maximum and minimum range (
), the difference between maximum and minimum range (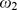 ), maximum variance (
), maximum variance (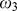 ) and the difference between maximum and minimum variance (
) and the difference between maximum and minimum variance (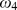 ).
).
Under the linear model, the distributions of these statistics are expected to be shifted to higher values compared to the constant model. We also fit a simple linear regression to each data set with the standard deviation of repeat number at a locus as the response variable and the mean repeat number at a locus as the predictor variable. Based on this fit, we consider
where 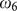 is the fitted standard deviation in repeats at a locus with a mean repeat number of one. These statistics are expected to be informative in that the slope should be positive under the linear model and near zero under the constant value, and the intercept should be low under the linear model and high under the constant model.
is the fitted standard deviation in repeats at a locus with a mean repeat number of one. These statistics are expected to be informative in that the slope should be positive under the linear model and near zero under the constant value, and the intercept should be low under the linear model and high under the constant model.
Figure 4 displays the predictive distributions of 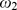 versus
versus 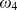 under both models. The observed data statistics are indicated by a cross (
under both models. The observed data statistics are indicated by a cross ( ). If the cross does not lie within the body of the predictive distribution, this suggests that the model and data are inconsistent with respect to aspects of the data captured by these statistics. The lower four panels present these diagnostics for artificial data generated under both models. The linear data (lower images) can be seen to be inconsistent with the constant model, but consistent with the linear model. The constant data (middle images) appear to be consistent with both models. As such, these diagnostics are able to reject the constant model when the data is generated by the linear model. In terms of the actual empirical data, the top plots in Figure 4 are based on the data from Albania. Clearly, the constant model is insufficient to describe the variation in repeat numbers inherent in the data. The linear model is better able to account for the observed pattern of repeat variation, although it is still imperfect. The posterior predictive distributions using the data sets from the other three countries were very similar to those of the Albanian data set (not shown).
). If the cross does not lie within the body of the predictive distribution, this suggests that the model and data are inconsistent with respect to aspects of the data captured by these statistics. The lower four panels present these diagnostics for artificial data generated under both models. The linear data (lower images) can be seen to be inconsistent with the constant model, but consistent with the linear model. The constant data (middle images) appear to be consistent with both models. As such, these diagnostics are able to reject the constant model when the data is generated by the linear model. In terms of the actual empirical data, the top plots in Figure 4 are based on the data from Albania. Clearly, the constant model is insufficient to describe the variation in repeat numbers inherent in the data. The linear model is better able to account for the observed pattern of repeat variation, although it is still imperfect. The posterior predictive distributions using the data sets from the other three countries were very similar to those of the Albanian data set (not shown).
Figure 4. Posterior predictive model checks.
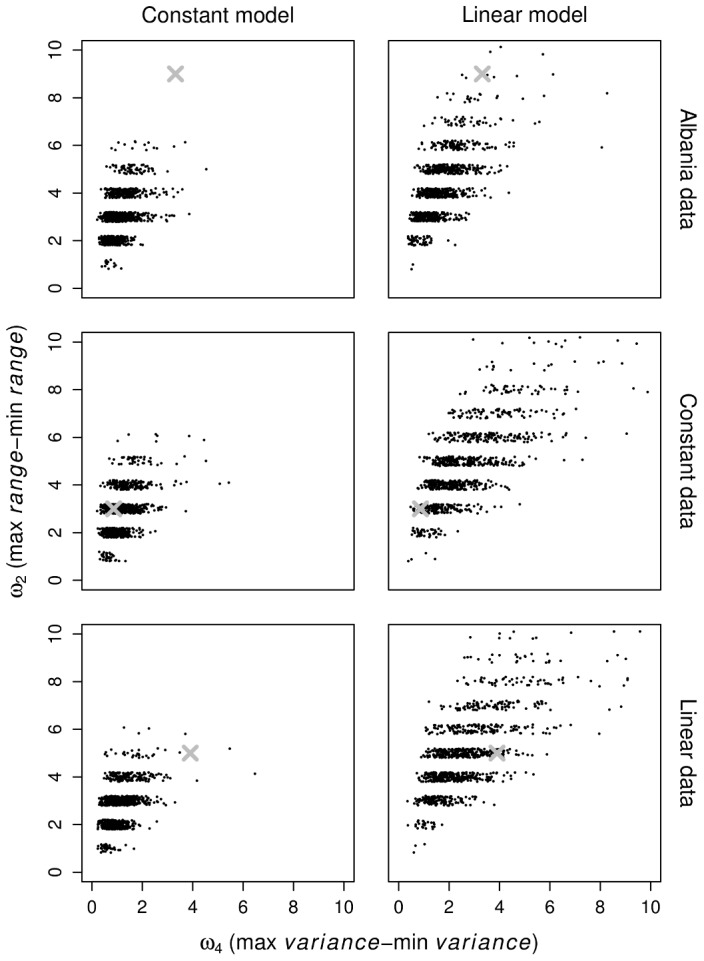
Scatterplots of the posterior predictive distributions of  (the difference between maximum and minimum range of repeat numbers over loci), versus
(the difference between maximum and minimum range of repeat numbers over loci), versus  (the same quantity substituting variance for range). Columns represent constant (left) and linear (right) models. Rows represent the Albanian dataset (top), artificially generated data from the constant model (middle) and artificially generated data from the linear model (bottom). The
(the same quantity substituting variance for range). Columns represent constant (left) and linear (right) models. Rows represent the Albanian dataset (top), artificially generated data from the constant model (middle) and artificially generated data from the linear model (bottom). The  indicates the statistics derived from the observed dataset.
indicates the statistics derived from the observed dataset.
The question of whether the linear model is adequate is examined further in Figure 5 which shows a posterior predictive check of  versus
versus  under the linear model for each of the analysed data sets. In each case, the observed data lie on the periphery of the predictive densities. Although the linear model is partially able to reproduce these statistics, this analysis shows that there is room for improvement.
under the linear model for each of the analysed data sets. In each case, the observed data lie on the periphery of the predictive densities. Although the linear model is partially able to reproduce these statistics, this analysis shows that there is room for improvement.
Figure 5. Further posterior predictive model checks.
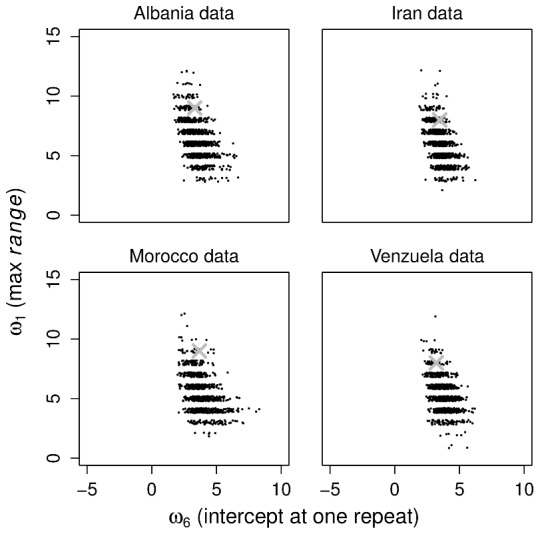
Scatterplots of the posterior predictive distributions of 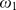 (the maximum range of repeat numbers over loci) versus
(the maximum range of repeat numbers over loci) versus 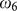 (the intercept at one repeat) under the linear model, for each observed dataset. The
(the intercept at one repeat) under the linear model, for each observed dataset. The  indicates the statistics derived from the observed dataset.
indicates the statistics derived from the observed dataset.
Discussion
We have analysed VNTR data from four tuberculosis studies using a model combining marker mutation and disease transmission processes, within a Bayesian framework. Our analysis shows that the VNTR mutation rate is likely to be relatively high – the posterior mean is higher than some previous estimates obtained in the literature [3], [19] and closer to more recent estimates [20]. The four data sets, which are from different geographic regions, yielded very similar estimates. Such agreement of estimates is expected if there is a common mechanism of mutation across data sets.
Previous work by two of us [20] used standard equilibrium results of the infinite alleles model to describe mutation at multiple VNTR loci, and used estimates of other markers (IS6110 and spoligotyping) to calibrate the VNTR rates. That population genetic approach did not account for evolution of VNTRs as a stepwise mutation process. It therefore did not account for homoplasy, though this problem is mitigated by the inclusion of multiple VNTR loci. Further, the underlying dynamics did not include any epidemiological details. Nevertheless, it allowed us to analyse a large number of data sets in the literature to provide a ballpark estimate of VNTR mutation rates. In contrast to that and other prior work, here we used a model that explicitly and simultaneously accounts for the mutation process of the marker and the disease dynamics, and we explored two alternative models of mutation. In addition, the stepwise mutation model used here allows mutation events to re-generate existing VNTR profiles, thereby accounting for homoplasy [48].
In the debate over the magnitude of VNTR mutation rates [3], [21]–[24] it has been noted that if loci are classified as less variable and more variable, then lower values would be estimated from the former category of loci. This raises the question of whether classification of loci into two categories of rates is supported by an underlying bimodal distribution whose modes correspond to low and high levels of polymorphism. In examining gene diversity, which is a measure of polymorphism, across loci in each data set (Figure 2) we did not observe any obvious break separating less and more variable loci. We have therefore pooled all loci and obtained an estimate of the rate of an arbitrary locus, rather than for a subset of slow or fast evolving loci. If hypermutable VNTR loci exist and are excluded from estimation procedures, using the remaining loci would clearly yield a lower mutation rate.
Our use of the linear model is a step towards resolving this issue. The linear relationship by which more units of a repeat are more prone to mutation naturally creates variation in rates. In fact, in assessing the ability of each of our two mutation models to describe the data, we found that the linear model performs better than the constant model (Figure 4). We note that the average mutation rate 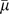 under the linear model was estimated to be very close to the mutation rate
under the linear model was estimated to be very close to the mutation rate 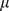 in the constant model; in this sense our analysis is robust to the exact form of the mutation model.
in the constant model; in this sense our analysis is robust to the exact form of the mutation model.
Despite the linear model outperforming the constant model, a posterior predictive goodness-of-fit analysis revealed some evidence that the linear model did not fit the data perfectly (Figure 5). While previous studies of eukaryote minisatellites agree with a linear relationship between repeat number and mutation rate [49], some studies of eukaryote microsatellites indicate a more complex relationship between repeat number and mutation rate [50]–[53]. We investigated a third model in which the mutation rate increases exponentially with repeat number, but the results are very similar to those of the linear model (Figure S3 in Text S1). Future work might adopt a per locus mutation rate that grows non-linearly with repeat number. A drawback of this possibility would be the added complexity and dimensionality of the model with the need to estimate further parameters in a framework that is already computationally intensive. An alternative approach might be to construct a hierarchical Bayesian model of mutation rates in which each locus is associated with its own rate according to some distribution, akin to the analysis of Bazin et al. [54].
We have used a simple model to avoid overfitting the data. However, it is possible to extend the model in future studies to incorporate further complexity and realism. One such detail is the reactivation of latent infection, which could be described by a susceptible-exposed-infected (SEI) model in which a proportion of cases progress directly to disease [38]. We performed preliminary simulations from a stochastic version of such a model (details in Text S1). We consider the number of distinct genotypes since this is one of the statistics we use in the inference and it is known to be informative for mutation rate in similar models [55], [56]. Figure S2 in Text S1 shows how the number of distinct genotypes in a sample varies with the mutation rate under both models. The latent reactivation model was able to generate statistics close to the observed statistic. The points in the region of the observed statistic are near the posterior density generated under the original model. While this is suggestive that a latency model would produce similar estimates, a full Bayesian analysis would be required to address this issue. The lack of latency is a limitation of our study which should be addressed in future research.
Migration is another factor which a more realistic multi-deme population model might incorporate. The interplay between migration and mutation may affect the resulting estimates of the mutation rate. For example, migration from regions with genetically very different clades of M. tuberculosis occurs at a high rate would lead to over-estimation of the mutation rate. Our approach based on the approximate Bayesian computation framework makes future directions such as this and those relating to the mutation process feasible.
Supporting Information
Additional technical details of the algorithm used in the Bayesian analysis, the stochastic model of latent tuberculosis reactivation, and the mutation model of VNTR with an exponential increase in rate with respect to repeat number.
(PDF)
Acknowledgments
We thank anonymous reviewers for their suggestions.
Footnotes
The authors have declared that no competing interests exist.
This work was supported by an Australian Postgraduate Award to RZA. MMT and SAS are supported by the Australian Research Council under the Discovery Project scheme (DP0987302 and DP1092805). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.World Health Organization. Global tuberculosis control 2010. World Health Organization; 2010. [Google Scholar]
- 2.Hershberg R, Lipatov M, Small PM, Sheffer H, Niemann S, et al. High functional diversity in Mycobacterium tuberculosis driven by genetic drift and human demography. PLoS Biol. 2008;6:e311. doi: 10.1371/journal.pbio.0060311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Wirth T, Hildebrand F, Allix-Béguec C, Wölbeling F, Kubica T, et al. Origin, spread and demography of the Mycobacterium tuberculosis complex. PLoS Pathog. 2008;4:e1000160. doi: 10.1371/journal.ppat.1000160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Pepperell C, Hoeppner V, Lipatov M, Wobeser W, Schoolnik GK, et al. Bacterial genetic signatures of human social phenomena among M. tuberculosis from an Aboriginal Canadian population. Mol Biol Evol. 2010;27:427–440. doi: 10.1093/molbev/msp261. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Pepperell CS, Granka JM, Alexander DC, Behr MA, Chui L, et al. Dispersal of Mycobacterium tuberculosis via the Canadian fur trade. Proc Natl Acad Sci U S A. 2011;108:6526–6531. doi: 10.1073/pnas.1016708108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Sails AD, Barrett A, Sarginson S, Magee JG, Maynard P, et al. Molecular epidemiology of Mycobacterium tuberculosis in East Lancashire 2001–2009. Thorax. 2011;66:709–713. doi: 10.1136/thx.2011.158881. [DOI] [PubMed] [Google Scholar]
- 7.Thierry D, Brisson-Noel A, Vincent-Levy-Frebault V, Nguyen S, Guesdon JL, et al. Characterization of a Mycobacterium tuberculosis insertion sequence, IS6110, and its application in diagnosis. J Clin Microbiol. 1990;28:2668–2673. doi: 10.1128/jcm.28.12.2668-2673.1990. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Kamerbeek J, Schouls L, Kolk A, van Agterveld M, van Soolingen D, et al. Simultaneous detection and strain differentiation of Mycobacterium tuberculosis for diagnosis and epidemiology. J Clin Microbiol. 1997;35:907–914. doi: 10.1128/jcm.35.4.907-914.1997. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Supply P, Allix C, Lesjean S, Cardoso-Oelemann M, Rusch-Gerdes S, et al. Proposal for standardization of optimized mycobacterial interspersed repetitive unit-variable-number tandem repeat typing of Mycobacterium tuberculosis. J Clin Microbiol. 2006;44:4498–4510. doi: 10.1128/JCM.01392-06. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Oelemann MC, Diel R, Vatin V, Haas W, Rüsch-Gerdes S, et al. Assessment of an optimized mycobacterial interspersed repetitive- unit-variable-number tandem-repeat typing system combined with spoligotyping for population-based molecular epidemiology studies of tuberculosis. J Clin Microbiol. 2007;45:691–697. doi: 10.1128/JCM.01393-06. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Tazi L, El Baghdadi J, Lesjean S, Locht C, Supply P, et al. Genetic diversity and population structure of Mycobacterium tuberculosis in Casablanca, a Moroccan city with high incidence of tuberculosis. J Clin Microbiol. 2004;42:461–466. doi: 10.1128/JCM.42.1.461-466.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Sola C, Filliol I, Legrand E, Lesjean S, Locht C, et al. Genotyping of the Mycobacterium tuberculosis complex using MIRUs: association with VNTR and spoligotyping for molecular epidemiology and evolutionary genetics. Infect Genet Evol. 2003;3:125–133. doi: 10.1016/s1567-1348(03)00011-x. [DOI] [PubMed] [Google Scholar]
- 13.Valcheva V, Mokrousov I, Narvskaya O, Rastogi N, Markova N. Utility of new 24-locus variable-number tandem-repeat typing for discriminating Mycobacterium tuberculosis clinical isolates collected in Bulgaria. J Clin Microbiol. 2008;46:3005–3011. doi: 10.1128/JCM.00437-08. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Smittipat N, Billamas P, Palittapongarnpim M, Thong-On A, Temu MM, et al. Polymorphism of variable-number tandem repeats at multiple loci in My-cobacterium tuberculosis. J Clin Microbiol. 2005;43:5034–5043. doi: 10.1128/JCM.43.10.5034-5043.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Tanaka MM, Francis AR. Methods of quantifying and visualising outbreaks of tuberculosis using genotypic information. Infect Genet Evol. 2005;5:35–43. doi: 10.1016/j.meegid.2004.06.001. [DOI] [PubMed] [Google Scholar]
- 16.Ohta T, Kimura M. A model of mutation appropriate to estimate the number of electrophoretically detectable alleles in a finite population. Genet Res. 1973;22:201–204. doi: 10.1017/s0016672300012994. [DOI] [PubMed] [Google Scholar]
- 17.Shriver MD, Jin L, Chakraborty R, Boerwinkle E. VNTR allele frequency distributions under the stepwise mutation model: A computer simulation approach. Genetics. 1993;134:983–993. doi: 10.1093/genetics/134.3.983. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Cornuet JM, Beaumont MA, Estoup A, Solignac M. Inference on microsatellite mutation processes in the invasive mite, varroa destructor, using reversible jump Markov chain Monte Carlo. Theor Popul Biol. 2006;69:129–144. doi: 10.1016/j.tpb.2005.07.005. [DOI] [PubMed] [Google Scholar]
- 19.Grant A, Arnold C, Thorne N, Gharbia S, Underwood A. Mathematical modelling of Mycobacterium tuberculosis VNTR loci estimates a very slow mutation rate for the repeats. J Mol Evol. 2008;66:565–574. doi: 10.1007/s00239-008-9104-6. [DOI] [PubMed] [Google Scholar]
- 20.Reyes JF, Tanaka MM. Mutation rates of spoligotypes and variable number tandem repeat loci in Mycobacterium tuberculosis. Infect Genet Evol. 2010;10:1046–1051. doi: 10.1016/j.meegid.2010.06.016. [DOI] [PubMed] [Google Scholar]
- 21.Supply P, Niemann S, Wirth T. On the mutation rates of spoligotypes and variable numbers of tandem repeat loci of Mycobacterium tuberculosis: Continued when tuning matters. Infect Genet Evol. 2011;11:1191–1191. doi: 10.1016/j.meegid.2010.12.009. [DOI] [PubMed] [Google Scholar]
- 22.Supply P, Niemann S, Wirth T. On the mutation rates of spoligotypes and variable numbers of tandem repeat loci of Mycobacterium tuberculosis. Infect Genet Evol. 2011;11:251–252. doi: 10.1016/j.meegid.2010.12.009. [DOI] [PubMed] [Google Scholar]
- 23.Tanaka MM, Reyes JF, et al. Mutation rate of VNTR loci in Mycobacterium tuberculosis: Response to Supply et al. Infect Genet Evol. 2011;11:1189–1190. doi: 10.1016/j.meegid.2011.01.014. [DOI] [PubMed] [Google Scholar]
- 24.Tanaka MM, Reyes JF. VNTR mutation in Mycobacterium tuberculosis: Lower rates for less variable loci. Infect Genet Evol. 2011;11:1192–1192. [Google Scholar]
- 25.Jacquez JA, Simon CP. The stochastic SI model with recruitment and deaths I. Comparison with the closed SIS model. Math Biosci. 1993;117:77–125. doi: 10.1016/0025-5564(93)90018-6. [DOI] [PubMed] [Google Scholar]
- 26.Gillespie DT. Exact stochastic simulation of coupled chemical reactions. J Phys Chem. 1977;81:2340–2361. [Google Scholar]
- 27.Tavare S, Balding DJ, Grifiths RC, Donnelly P. Inferring coalescence times from DNA sequence data. Genetics. 1997;145:505–518. doi: 10.1093/genetics/145.2.505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Beaumont MA, Zhang W, Balding DJ. Approximate Bayesian computation in population genetics. Genetics. 2002;162:2025–2035. doi: 10.1093/genetics/162.4.2025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Marjoram P, Molitor J, Plagnol V, Tavaré S. Markov chain Monte Carlo without likelihoods. Proc Natl Acad Sci U S A. 2003;100:15324–15328. doi: 10.1073/pnas.0306899100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Beaumont MA. Approximate Bayesian computation in evolution and ecology. Ann Rev Ecol Sys. 2010;41:379–406. [Google Scholar]
- 31.Bertorelle G, Benazzo A, Mona S. ABC as a exible framework to estimate demography over space and time: some cons, many pros. Mol Ecol. 2010;19:2609–2625. doi: 10.1111/j.1365-294X.2010.04690.x. [DOI] [PubMed] [Google Scholar]
- 32.Luciani F, Sisson SA, Jiang H, Francis AR, Tanaka MM. The epidemiological fitness cost of drug resistance in Mycobacterium tuberculosis. Proc Natl Acad Sci U S A. 2009;106:14711–14715. doi: 10.1073/pnas.0902437106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Tanaka MM, Francis AR, Luciani F, Sisson SA. Using approximate Bayesian computation to estimate tuberculosis transmission parameters from genotype data. Genetics. 2006;173:1511–1520. doi: 10.1534/genetics.106.055574. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Drovandi CC, Pettitt AN. Estimation of parameters for macroparasite population evolution using approximate Bayesian computation. Biometrics. 2011;67:225–233. doi: 10.1111/j.1541-0420.2010.01410.x. [DOI] [PubMed] [Google Scholar]
- 35.Sisson SA, Fan Y. Likelihood-free Markov chain Monte Carlo. In: Brooks SP, Gelman A, Jones G, Meng XL, editors. Handbook of Markov chain Monte Carlo. Chapman and Hall/CRC Press; 2011. pp. 319–341. [Google Scholar]
- 36.Csillery K, Blum MGB, Gaggiotti OE, Francois O. Approximate Bayesian computation (ABC) in practice. Trends Ecol Evol. 2010;25:410–418. doi: 10.1016/j.tree.2010.04.001. [DOI] [PubMed] [Google Scholar]
- 37.Cohen T, Murray M. Modeling epidemics of multidrug-resistant M. tubercu-losis of heterogeneous fitness. Nat Med. 2004;10:1117–1121. doi: 10.1038/nm1110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Blower S, Mclean A, Porco T, Small P, Hopewell P, et al. The intrinsic transmission dynamics of tuberculosis epidemics. Nat Med. 1995;1:815–821. doi: 10.1038/nm0895-815. [DOI] [PubMed] [Google Scholar]
- 39.Sisson SA, Fan Y, Tanaka MM. Sequential Monte Carlo without likelihoods. Proc Natl Acad Sci U S A. 2007;104:1760–1765. doi: 10.1073/pnas.0607208104. Errata (2009), 106, 16889. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Peters GW, Fan Y, Sisson SA. On sequential Monte Carlo, partial rejection control and approximate Bayesian computation. Stat Comput : in press 2012 [Google Scholar]
- 41.Fearnhead P, Prangle D. Constructing summary statistics for approximate Bayesian computation: Semi-automatic ABC. J Roy Stat Soc B. 2012;74:419–474. [Google Scholar]
- 42.Tafaj S, Zhang J, Hauck Y, Pourcel C, Hafizi H, et al. First insight into genetic diversity of the Mycobacterium tuberculosis complex in Albania obtained by multilocus variable-number tandem-repeat analysis and spoligotyping reveals the presence of Beijing multidrug-resistant isolates. J Clin Microbiol. 2009;47:1581–1584. doi: 10.1128/JCM.02284-08. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Asgharzadeh M, Khakpour M, Salehi TZ, Kafil HS. Use of mycobacterial interspersed repetitive unit-variable-number tandem repeat typing to study Mycobacterium tuberculosis isolates from East Azarbaijan province of Iran. Pak J Biol Sci. 2007;10:3769–3777. doi: 10.3923/pjbs.2007.3769.3777. [DOI] [PubMed] [Google Scholar]
- 44.Abadía E, Sequera M, Ortega D, Méndez M, Escalona A, et al. Mycobacterium tuberculosis ecology in Venezuela: epidemiologic correlates of common spoligotypes and a large clonal cluster defined by MIRU-VNTR-24. BMC Infect Dis. 2009;9:122–134. doi: 10.1186/1471-2334-9-122. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Nei M. Analysis of gene diversity in subdivided populations. Proc Natl Acad Sci U S A. 1973;70:3321–3323. doi: 10.1073/pnas.70.12.3321. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Gelman A, Meng XL, Stern HS. Posterior predictive assessment of model fitness via realized discrepancies. Stat Sinica. 1996;6:733–807. [Google Scholar]
- 47.Thornton K, Andolfatto P. Approximate Bayesian inference reveals evidence for a recent, severe bottleneck in a Netherlands population of Drosophila melanogaster. Genetics. 2006;172:1607–1619. doi: 10.1534/genetics.105.048223. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Reyes JF, Chan CHS, Tanaka MM. Impact of homoplasy on variable numbers of tandem repeats and spoligotypes in Mycobacterium tuberculosis. Infect Genet Evol. 2012;12:811–818. doi: 10.1016/j.meegid.2011.05.018. [DOI] [PubMed] [Google Scholar]
- 49.Buard J, Bourdet A, Yardley J, Dubrova Y, Jeffreys A. Inuences of array size and homogeneity on minisatellite mutation. EMBO J. 1998;17:3495–3502. doi: 10.1093/emboj/17.12.3495. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Dieringer D, Schlötterer C. Two distinct modes of microsatellite mutation processes: evidence from the complete genomic sequences of nine species. Genome Res. 2003;13:2242–2251. doi: 10.1101/gr.1416703. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Lai Y, Sun F. The relationship between microsatellite slippage mutation rate and the number of repeat units. Mol Biol Evol. 2003;20:2123–2131. doi: 10.1093/molbev/msg228. [DOI] [PubMed] [Google Scholar]
- 52.Kelkar Y, Tyekucheva S, Chiaromonte F, Makova K. The genome-wide determinants of human and chimpanzee microsatellite evolution. Genome Res. 2008;18:30–38. doi: 10.1101/gr.7113408. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Seyfert A, Cristescu M, Frisse L, Schaack S, Thomas W, et al. The rate and spectrum of microsatellite mutation in Caenorhabditis elegans and Daphnia pulex. Genetics. 2008;178:2113–2121. doi: 10.1534/genetics.107.081927. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Bazin E, Dawson KJ, Beaumont MA. Likelihood-free inference of population structure and local adaptation in a Bayesian hierarchical model. Genetics. 2010;185:587–602. doi: 10.1534/genetics.109.112391. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Ewens WJ. The sampling theory of selectively neutral alleles. Theor Popul Biol. 1972;3:87–112. doi: 10.1016/0040-5809(72)90035-4. [DOI] [PubMed] [Google Scholar]
- 56.Blum MGB, Nunes MA, Prangle D, Sisson SA. A comparative review of dimension reduction methods in approximate Bayesian computation. 2012. http://arxiv.org/abs/1202.3819.
- 57.World Health Organization. Tuberculosis Country Profiles: Epidemiology and Strategy. 2009. http://www.who.int/tb/country/data/profiles/en/index.html.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Additional technical details of the algorithm used in the Bayesian analysis, the stochastic model of latent tuberculosis reactivation, and the mutation model of VNTR with an exponential increase in rate with respect to repeat number.
(PDF)