

Abstract
We introduce a new method for detecting communities of arbitrary size in an undirected weighted network. Our approach is based on tracing the path of closest‐friendship between nodes in the network using the recently proposed Generalized Erds Numbers. This method does not require the choice of any arbitrary parameters or null models, and does not suffer from a system‐size resolution limit. Our closest‐friend community detection is able to accurately reconstruct the true network structure for a large number of real world and artificial benchmarks, and can be adapted to study the multi‐level structure of hierarchical communities as well. We also use the closeness between nodes to develop a degree of robustness for each node, which can assess how robustly that node is assigned to its community. To test the efficacy of these methods, we deploy them on a variety of well known benchmarks, a hierarchal structured artificial benchmark with a known community and robustness structure, as well as real‐world networks of coauthorships between the faculty at a major university and the network of citations of articles published in Physical Review. In all cases, microcommunities, hierarchy of the communities, and variable node robustness are all observed, providing insights into the structure of the network.
Introduction
The topology of networks occurring in biological or chemical [1], [2], social [3], [4], political [5], or technological [6] systems can give profound insights into a variety of important aspects of these systems, such as the processes that generated the network [7], the stability of the system [8] or the properties of processes occurring on it [9]. An important aspect of common real‐world networks is that of community structure [10], where subsets of the network are densely connected internally and weakly connected externally. Nodes in the same community have more in common than those in distinct communities, reflected in the topology of denser intracommunity edges than inter‐community edges. However, the detection of communities in networks without apriori knowledge of their structure is highly nontrivial, and methods for community detection have recently attracted a great deal of interest.
Perhaps the most common approach for community detection in networks is based on modularity maximization [11], [12]. Each node i in a network of N nodes and M edges is assigned to a single community, 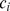 , with the partition chosen to maximize
, with the partition chosen to maximize
| (1) |
where  is the weight of the edge between nodes i and j,
is the weight of the edge between nodes i and j, 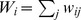 is the strength of node i,
is the strength of node i, 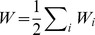 , and
, and 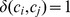 if
if 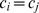 and 0 otherwise. For an unweighted network,
and 0 otherwise. For an unweighted network,  0 or 1, where
0 or 1, where 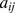 is the adjacency matrix, and thus
is the adjacency matrix, and thus  is the degree of the node. Modularity compares the network in question to a randomly generated network with each node constrained to have the same strength, and is maximized by a partition into communities
is the degree of the node. Modularity compares the network in question to a randomly generated network with each node constrained to have the same strength, and is maximized by a partition into communities 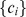 that have a higher intra‐community weight than would be expected randomly. This choice of a random network acts as a null model, although other choices are possible [13], and a wide variety of numerical approaches for efficiently computing the maximal partition exist, including statistical mechanical methods [14], bisection algorithms [11], and other greedy searches [15], [16]. While modularity maximization is both intuitive and accurate in a variety of settings,
that have a higher intra‐community weight than would be expected randomly. This choice of a random network acts as a null model, although other choices are possible [13], and a wide variety of numerical approaches for efficiently computing the maximal partition exist, including statistical mechanical methods [14], bisection algorithms [11], and other greedy searches [15], [16]. While modularity maximization is both intuitive and accurate in a variety of settings, 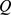 has a natural system‐size resolution limit [17], [13] if the number of nodes becomes large
has a natural system‐size resolution limit [17], [13] if the number of nodes becomes large 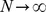 , but the typical strength
, but the typical strength 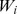 of all nodes remains finite, the total strength
of all nodes remains finite, the total strength 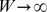 and the second term in the sum in Eq. 1 becomes small since
and the second term in the sum in Eq. 1 becomes small since  and
and 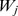 do not diverge. Thus, modularity maximization may not detect small communities in large networks due to this resolution limit. Simple methods to overcome this limitation include the introduction of a resolution parameter [14], [13]
do not diverge. Thus, modularity maximization may not detect small communities in large networks due to this resolution limit. Simple methods to overcome this limitation include the introduction of a resolution parameter [14], [13]
 , with the redefinition of
, with the redefinition of 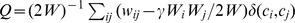 , or multiresolution methods [18] which impose a self‐loop of strength r on the network i.e.
, or multiresolution methods [18] which impose a self‐loop of strength r on the network i.e. 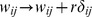 in Eq. 1. Both of these approaches overcome the problem of a resolution limit by introducing an arbitrary parameter in detecting community structure that must be tuned. Alternate approaches to community detection avoid a resolution limit through other means, such as thresholding the resistance distance between nodes, with nodes having low resistance distance between each other belonging to the same community [19], maximizing the fitness of each node in a greedy fashion [20], creating block models to detect communities if the number of expected communities is exactly known [21], or refining communities by finding statistically significant nodes [22]. In all these approaches, at least one free parameter is required to detect the communities, which may be useful in giving the ability to tune the resolution at which communities are detected, but with no a‐priori method for determining the correct value that leads to a meaningful partition.
in Eq. 1. Both of these approaches overcome the problem of a resolution limit by introducing an arbitrary parameter in detecting community structure that must be tuned. Alternate approaches to community detection avoid a resolution limit through other means, such as thresholding the resistance distance between nodes, with nodes having low resistance distance between each other belonging to the same community [19], maximizing the fitness of each node in a greedy fashion [20], creating block models to detect communities if the number of expected communities is exactly known [21], or refining communities by finding statistically significant nodes [22]. In all these approaches, at least one free parameter is required to detect the communities, which may be useful in giving the ability to tune the resolution at which communities are detected, but with no a‐priori method for determining the correct value that leads to a meaningful partition.
In this paper, we develop a new parameter‐free, resolution‐limit‐free method for community detection, most easily understood intuitively in the context of a social network a person belongs in the same community as his or her closest friend the node to which he or she has the greatest measure of closeness, discussed below. Our method requires a way to measure closeness or friendship between nodes in a network, and a variety of such measures are available [23]. We will focus primarily on a recently proposed non‐metric measure of closeness [24], the Generalized Erds Numbers GENs, which have been found useful in a variety of contexts in understanding the structure of network topology. This closest‐friend community detection method is shown to be able to accurately detect communities in a variety of widely used benchmarks, in some cases outperforming some modularitymaximizing detection schemes in real world networks with a known correct partition. We also extend the method to detect community structure at a lower resolution macrocommunities formed from higher resolution microcommunities without appealing to a free parameter. Our approach has the advantages of being intuitively accessible, free of arbitrary parameters, and able to accurately find communities in complex networks. We leverage our chosen measure of closeness between nodes in determining the robustness of assignment of each node into its community rather than a global measure of the quality of the partition using modularity. Finally, our approach is applied to a citation network and a coauthorship network, and the complex hierarchical structure of each network is examined in detail.
Methods
Communities from Closeness
In a network with community structure, nodes in a community have a higher density of edges internally to other nodes in their community than they do externally. While one approach to community detection maximizes global quality functions that depend on the density of edges [10], we could alternatively search for high densities of edges locally to find communities. Such a local method may use an appropriate measure of closeness between nodes, with close nodes having multiple short‐length paths between one another implying a locally high density of edges see below for examples. In the context of a social network, for example, it is natural to expect that closest friends those who feel closest to one to another given a measure of closeness should be found in the same community. Such an expectation can be enforced by determining the closest friend CF of each node i, denoted  , and requiring them to be in the same community. In other words, node i is assigned to the same community as the node to which it is topologically closest. The closest friend of
, and requiring them to be in the same community. In other words, node i is assigned to the same community as the node to which it is topologically closest. The closest friend of 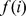 denoted
denoted 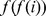 is also found in this community, and we generate a path of closest friendship
is also found in this community, and we generate a path of closest friendship  halting when a self‐intersection occurs after which the cycle would repeat. Nodes i and j that share elements of their closest friend paths i.e.
halting when a self‐intersection occurs after which the cycle would repeat. Nodes i and j that share elements of their closest friend paths i.e.  will all trace to the same central loop, and each of the elements of
will all trace to the same central loop, and each of the elements of 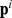 and
and 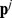 are placed in the same community. If the closeness measure is well chosen such that a higher density of edges implies a stronger feeling of closeness, the closest friend paths for nodes in each community will remain within the correct communities, allowing for an accurate partition of the network discussed further in Supplementary Information S1. This approach has the advantage of generating a single partition rather than a tree of many possible partitions from which the correct partition must be chosen, commonly used in clustering algorithms and without a system‐size resolution limit [17], [13], and therefore unambiguously chooses a natural partition of the network.
are placed in the same community. If the closeness measure is well chosen such that a higher density of edges implies a stronger feeling of closeness, the closest friend paths for nodes in each community will remain within the correct communities, allowing for an accurate partition of the network discussed further in Supplementary Information S1. This approach has the advantage of generating a single partition rather than a tree of many possible partitions from which the correct partition must be chosen, commonly used in clustering algorithms and without a system‐size resolution limit [17], [13], and therefore unambiguously chooses a natural partition of the network.
Despite the simplicity of our method, there exist pathological network topologies may require modification of the algorithm in order to accurately detect the community structure. As a simple example, a node that is connected to every other node in the network will be everyones closest friend, regardless of the topology of the rest of the network, and only one community will be detected using our approach see Supplementary Information S1 for further discussion. Failure of the detection algorithm in this case can be avoided by searching for the closest unpopular friend CUF, where the CUF is detected by sorting the closest friends of node i in descending order of node degree, and choosing the first node 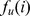 who has degree less than or equal to the next‐closest node. This ensures that we avoid nodes with extremely high degree the popular close friends, who may have many out‐of‐community connections, and choose
who has degree less than or equal to the next‐closest node. This ensures that we avoid nodes with extremely high degree the popular close friends, who may have many out‐of‐community connections, and choose  to be a node that is simultaneously a a close friend but not necessarily the closest and b less likely to have out‐of‐community edges. The path of closest friendship is modified to be
to be a node that is simultaneously a a close friend but not necessarily the closest and b less likely to have out‐of‐community edges. The path of closest friendship is modified to be 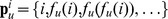 , and community detection proceeds as described above. We note that neither the CF nor CUF approaches depend on the graph being Hamiltonian the particular path
, and community detection proceeds as described above. We note that neither the CF nor CUF approaches depend on the graph being Hamiltonian the particular path 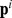 or
or 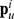 need not span the entire graph for any starting node i and must not, if there is to be more than one community. Additional modifications to both the CF and CUF methods are required due to community fracture communities may be split into two or more disjoint pieces due to the random fluctuations of the edges [25] see Supplementary Information S1 for further discussion. Fractured communities may occur for any community detection algorithms, and a greedy approach to detect and merge fractured communities is described in Supplementary Information S1.
need not span the entire graph for any starting node i and must not, if there is to be more than one community. Additional modifications to both the CF and CUF methods are required due to community fracture communities may be split into two or more disjoint pieces due to the random fluctuations of the edges [25] see Supplementary Information S1 for further discussion. Fractured communities may occur for any community detection algorithms, and a greedy approach to detect and merge fractured communities is described in Supplementary Information S1.
Choosing a Closeness Measure
Before we apply the CF or CUF method for community detection, we must choose a measure of closeness between nodes in that network, with the only requirement being that nodes i and j are closer if there is a higher density of edges multiple shortranged paths between them. We focus on the use of a recently developed closeness measure, the Generalized Erds numbers [24] GENs, created with two simple principles in mind i connections from node j to nodes that feel close to a specified node nodes k with low 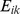 are more important than connections to other nodes, and ii a connection of high weight from j to some node k should make node j feel more close to node k and less close to node i. This second expectation is natural if closeness is defined with a limited resource in mind, such as the time spent between people in a social or coauthorship network [24]. These expectations naturally lead to a weighted harmonic mean [24], with
are more important than connections to other nodes, and ii a connection of high weight from j to some node k should make node j feel more close to node k and less close to node i. This second expectation is natural if closeness is defined with a limited resource in mind, such as the time spent between people in a social or coauthorship network [24]. These expectations naturally lead to a weighted harmonic mean [24], with 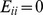 and
and
with 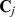 the set of nodes that are connected to j.
the set of nodes that are connected to j. 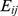 is not a distance metric as
is not a distance metric as 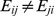 , a desirable property because unpopular low degree or low weight individuals may feel close to popular high weight nodes, but not vice‐versa. The GENs are computed numerically by setting
, a desirable property because unpopular low degree or low weight individuals may feel close to popular high weight nodes, but not vice‐versa. The GENs are computed numerically by setting 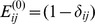 and iteratively computing
and iteratively computing 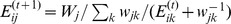 , halting when
, halting when 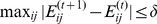 for some tolerance
for some tolerance  we used
we used 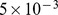 . Computing the closeness between all pairs of nodes i and j will scale as
. Computing the closeness between all pairs of nodes i and j will scale as 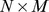 , and is the slowest step in detecting communities using the CF or CUF approaches.
, and is the slowest step in detecting communities using the CF or CUF approaches.
To see how our closeness measure works in detecting communities in a network with known community structure, we examine the Girvan‐Newman benchmark [1], [12] in Fig. 1a, which consists of four equal‐sized communities of 32 nodes, each with  edges leading out of the community and
edges leading out of the community and 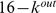 edges within the community. The connectivity between communities can also be described by the mixing parameter
edges within the community. The connectivity between communities can also be described by the mixing parameter  , with detection of the correct communities becoming difficult when
, with detection of the correct communities becoming difficult when 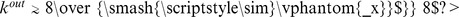 or
or 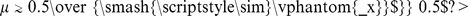 . The level of agreement between the detected and correct partition is quantified using the normalized mutual information [10]
. The level of agreement between the detected and correct partition is quantified using the normalized mutual information [10]
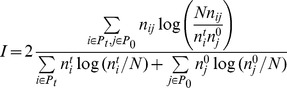 |
(2) |
with 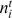 the number of nodes in community i of the trial partition
the number of nodes in community i of the trial partition  ,
, 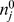 is the number in community j of the true partition
is the number in community j of the true partition  , and
, and 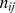 is the number simultaneously occurring in i and j of
is the number simultaneously occurring in i and j of 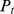 and
and 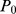 . In Fig. 1a, we see that the accuracy of the CUF approach does depend on the choice of closeness measure, where we compare the performance of the GEN measure with others [23] such as the overlap measure
. In Fig. 1a, we see that the accuracy of the CUF approach does depend on the choice of closeness measure, where we compare the performance of the GEN measure with others [23] such as the overlap measure 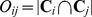 with
with 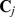 the set of neighbors of j and the Jacard coefficient
the set of neighbors of j and the Jacard coefficient  . Similarly, in real‐world networks with an apriori known community structure shown in Fig. 1b such as the Football network [1], the Political Blogs network [26], and the Political Books network [27] see Supplementary Information S1, both the GENs and overlap are consistently more accurate in community detection than greedy modularity maximization. Because the GENs are the most accurate on both real world and artificial networks of all of the closeness measures attempted, we choose to focus on them as our measure of closeness in the rest of the paper.
. Similarly, in real‐world networks with an apriori known community structure shown in Fig. 1b such as the Football network [1], the Political Blogs network [26], and the Political Books network [27] see Supplementary Information S1, both the GENs and overlap are consistently more accurate in community detection than greedy modularity maximization. Because the GENs are the most accurate on both real world and artificial networks of all of the closeness measures attempted, we choose to focus on them as our measure of closeness in the rest of the paper.
Figure 1. Benchmarks of the community detection algorithm.

a shows the mutual information between the detected and true partitions for varying 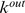 and for different closeness measures on the Girvan‐Newman benchmark [1], [12]. Up and down triangles show modularity maximization using a greedy [16] implemented in Mathematica and Potts model [14], [32] for comparison with the CUF method implemented using the Jacard Coefficients black circles, GENs red squares and overlap blue stars as closeness measures. b Percent improvement of the CUF approach over a greedy modularity maximization [16] using the GENs red, overlap blue, and Jacard Coefficients black as a closeness measure for real world networks with a correct partition known apriori. Taken together, a and b suggest the GENs are typically more accurate measure of closeness. c‐f show the CUF method implemented on the benchmark of Lancichinetti, Fortunato and Radicchi for varying k,
and for different closeness measures on the Girvan‐Newman benchmark [1], [12]. Up and down triangles show modularity maximization using a greedy [16] implemented in Mathematica and Potts model [14], [32] for comparison with the CUF method implemented using the Jacard Coefficients black circles, GENs red squares and overlap blue stars as closeness measures. b Percent improvement of the CUF approach over a greedy modularity maximization [16] using the GENs red, overlap blue, and Jacard Coefficients black as a closeness measure for real world networks with a correct partition known apriori. Taken together, a and b suggest the GENs are typically more accurate measure of closeness. c‐f show the CUF method implemented on the benchmark of Lancichinetti, Fortunato and Radicchi for varying k, 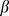 and
and  compare to Fig. 5 and 7 of Ref. [28]. The CUF method performs well for
compare to Fig. 5 and 7 of Ref. [28]. The CUF method performs well for 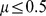 , although modularity maximization is more accurate as is the case in a, and beings to fail significantly for
, although modularity maximization is more accurate as is the case in a, and beings to fail significantly for 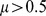 as expected. g shows the multiresolution modularity [18]
as expected. g shows the multiresolution modularity [18]
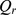 of the high solid black line and low dashed blue line resolution partitions using our CUF algorithm, alongside the maximum modularity determined via simulated annealing. The modularity maximizing solutions transition smoothly between the coarser partition for small r and the finer partition for larger r as expected, indicating that our CUF method does indeed detect the two levels of hierarchy accurately without appealing to arbitrary parameters.
of the high solid black line and low dashed blue line resolution partitions using our CUF algorithm, alongside the maximum modularity determined via simulated annealing. The modularity maximizing solutions transition smoothly between the coarser partition for small r and the finer partition for larger r as expected, indicating that our CUF method does indeed detect the two levels of hierarchy accurately without appealing to arbitrary parameters.
Additional Benchmarks of Community Detection
As a systematic test of the method on a more complex benchmark, apply our detection method to the benchmark of Lancichinetti, Fortunato, and Radicchi [28]. Communities are of variable size with the size s of each drawn from a power law distribution, 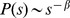 and the degree of each node is drawn from a scale free distribution as well
and the degree of each node is drawn from a scale free distribution as well 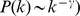 . Each node has on average a fraction
. Each node has on average a fraction 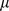 of its edges within its assigned community and
of its edges within its assigned community and 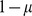 edges outside of its community. The complex structure of this network makes community detection non‐trivial, but as seen in Fig. 1c‐f our method is accurately able to reconstruct the correct partition for various values of
edges outside of its community. The complex structure of this network makes community detection non‐trivial, but as seen in Fig. 1c‐f our method is accurately able to reconstruct the correct partition for various values of 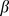 ,
,  , and
, and  for
for 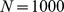 and 50 realizations of the network for each data point. So long as
and 50 realizations of the network for each data point. So long as 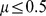 , we typically find the normalized mutual information
, we typically find the normalized mutual information 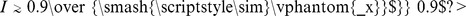 , indicating a good agreement with the correct partition. Our approach produces partitions that are less accurate than the results reported in Fig. 5 of Ref. [28], in accordance with the observations in Fig. 1a that the method underperforms modularity maximization when the correct partition is also modularity maximizing. However, the CUF method still performs admirably, with the additional benefits of no fitting parameters or resolution limits.
, indicating a good agreement with the correct partition. Our approach produces partitions that are less accurate than the results reported in Fig. 5 of Ref. [28], in accordance with the observations in Fig. 1a that the method underperforms modularity maximization when the correct partition is also modularity maximizing. However, the CUF method still performs admirably, with the additional benefits of no fitting parameters or resolution limits.
Hierarchical Communities
In many cases [29], [20] networks have community structure at multiple resolutions, begging the question of how to detect such a hierarchical community structure. Instead of using a tunable resolution parameter whose correct values are unknown apriori, the CFCUF method naturally suggests a simpler approach to iteratively coarse grain the network using a highresolution partition detected as described above and then reapply our detection method on the lower resolution network. Communities in the high‐resolution partition act as coarse grained nodes, and the average closeness felt between communities serves to determine closest friends. If the GENs are chosen as the measure of closeness, the averages are taken as 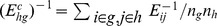 , where
, where 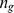 is the number of nodes in
is the number of nodes in 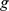 . While the choice of a method of coarse graining the network implies an additional degree of freedom in our algorithm, it is important to note the differences between the CUF method and modularity maximization with a variable resolution parameter. In the CFCUF method, the resolution can not be tuned continuously by choosing different closeness measures or methods of coarse graining. Rather, the choice of measure and method set an optimal apriori resolution for hierarchical community detection, which is likely to be robust to changes in the method if the closeness measure and the coarse graining method are well chosen.
. While the choice of a method of coarse graining the network implies an additional degree of freedom in our algorithm, it is important to note the differences between the CUF method and modularity maximization with a variable resolution parameter. In the CFCUF method, the resolution can not be tuned continuously by choosing different closeness measures or methods of coarse graining. Rather, the choice of measure and method set an optimal apriori resolution for hierarchical community detection, which is likely to be robust to changes in the method if the closeness measure and the coarse graining method are well chosen.
The accuracy of our hierarchical detection method on a commonly used artificial benchmark, implemented in Ref. [18], is shown in Fig. 1g, with additional benchmarks discussed further in Supplementary Information S1. A network of 256 nodes is formed from 16 communities of 16 nodes each, in turn composed of 4 macrocommunities containing 4 communities each. Each node has on average 13 edges within its community and 4 edges outside of its community but within its macrocommunity, and 1 edge outside of its macrocommunity. This is similar to the Reichardt and Bornholdt [14], [20] benchmark discussed in Supplementary Information S1 and adapted in the next section. We compare the partitions detected using the CUF algorithm with a simulated annealing maximization of the multiresolution modularity that is, Eq. 1 with  , where r is a resolution parameter ranging from
, where r is a resolution parameter ranging from 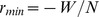 to
to  . The average modularity
. The average modularity 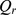 for the modularity maximizing partition is shown by the red points in Fig. 1g, and this modularity maximizing partition transitions smoothly between the high‐resolution communities detected using our CUF algorithm for large r and the low‐resolution coarse grained using our hierarchical algorithm for small r. Additional analysis of a similar benchmark for our hierarchical detection algorithm can be found in Supplementary Information S1.
for the modularity maximizing partition is shown by the red points in Fig. 1g, and this modularity maximizing partition transitions smoothly between the high‐resolution communities detected using our CUF algorithm for large r and the low‐resolution coarse grained using our hierarchical algorithm for small r. Additional analysis of a similar benchmark for our hierarchical detection algorithm can be found in Supplementary Information S1.
Robustness of Individual Nodes
It is desirable that any method for community detection be relatively robust to small changes in network connectivity. Modularity may be used to assess the quality of a partition on a global level at a particular resolution, but not the robustness of a individual node. The assignment of node i to a particular community may be fragile non‐robust if it a has few edges within its assigned community i.e. small 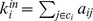 or b has a small ratio of in‐community and out‐of‐community edges i.e. small
or b has a small ratio of in‐community and out‐of‐community edges i.e. small 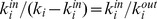 . It is useful to incorporate both of these elements into a single measure, which we call the degree of robustness
. It is useful to incorporate both of these elements into a single measure, which we call the degree of robustness 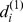 is the number of the
is the number of the 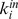 nodes to which i feels closest that are in is microcommunity. Nodes with high robustness can be considered the core of their community, since of all of the nodes in the community they have the largest number of close friends amongst the other community members. In networks with a hierarchical community structure, nodes may have varying robustness at each resolution. Nodes that are robustly assigned to a microcommunity may have a fragile assignment to its macro‐community, and vice versa. To assess the robustness at each level of the hierarchy, we can compute
nodes to which i feels closest that are in is microcommunity. Nodes with high robustness can be considered the core of their community, since of all of the nodes in the community they have the largest number of close friends amongst the other community members. In networks with a hierarchical community structure, nodes may have varying robustness at each resolution. Nodes that are robustly assigned to a microcommunity may have a fragile assignment to its macro‐community, and vice versa. To assess the robustness at each level of the hierarchy, we can compute 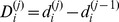 , where
, where 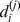 is the robustness of a node i at the
is the robustness of a node i at the 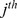 resolution in the hierarchy, setting
resolution in the hierarchy, setting 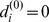 for notational convenience so that
for notational convenience so that 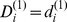 . Nodes with small
. Nodes with small  are weakly connected to the other nodes in their community i.e. their assignment to the micro‐ or macrocommunity is fragile, regardless of the robustness in communities of other resolutions. Note that the normalized degree of robustness
are weakly connected to the other nodes in their community i.e. their assignment to the micro‐ or macrocommunity is fragile, regardless of the robustness in communities of other resolutions. Note that the normalized degree of robustness 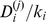 is useful in detecting nodes on the boundary between communities having many edges, but few close friends in their assigned community, but that
is useful in detecting nodes on the boundary between communities having many edges, but few close friends in their assigned community, but that 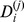 more directly indicates robustness as the number of strong in‐community edges. At each level of resolution, the average robustness of any community can be estimated as
more directly indicates robustness as the number of strong in‐community edges. At each level of resolution, the average robustness of any community can be estimated as 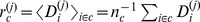 .
.
An Artificial Benchmark with Variable Robustness
In order to introduce variable node robustness into an artificial benchmark, we modify the benchmark of Reichardt and Bornholdt [14], [20] similar to that in Fig. 1g which includes 512 nodes, 16 microcommunities of 32 nodes, and 4 macrocommunities of 128 nodes see Supplementary Information S1 for more details. Each node i has on average 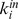 edges connecting it to its microcommunity,
edges connecting it to its microcommunity, 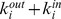 edges in its macrocommunity, and
edges in its macrocommunity, and 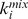 edges outside of its macrocommunity. In order to modify the benchmark to allow for variable node robustness, we choose
edges outside of its macrocommunity. In order to modify the benchmark to allow for variable node robustness, we choose 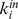 ,
, 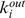 , and
, and 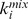 to depend on i in a simple fashion, depending on the macrocommunity it is assigned to labelled A–D in Fig. 2a and an asymmetry parameter
to depend on i in a simple fashion, depending on the macrocommunity it is assigned to labelled A–D in Fig. 2a and an asymmetry parameter 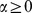 , with
, with 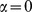 corresponding to the standard Reichardt‐Bornholdt benchmark [14] see the table in the caption of Fig. 2 and discussion in Supplementary Information S1. This modified benchmark allows us to examine the effectiveness of the multilevel hierarchical community detection as well as the utility of the degree of robustness
corresponding to the standard Reichardt‐Bornholdt benchmark [14] see the table in the caption of Fig. 2 and discussion in Supplementary Information S1. This modified benchmark allows us to examine the effectiveness of the multilevel hierarchical community detection as well as the utility of the degree of robustness  .
.
Figure 2. Benchmarks with variable node robustness.

a A snapshot of the benchmark with hierarchical community structure and variable node robustness at 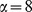 . The behavior of the nodes as a function of
. The behavior of the nodes as a function of  and
and 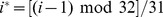 is described in the table, with
is described in the table, with 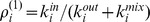 the average in‐out ratio at the microcommunity resolution, and
the average in‐out ratio at the microcommunity resolution, and 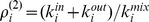 is the in‐out ratio at the macrocommunity resolution. In the table, down arrows, up arrows, and dashes denote increasing, decreasing, and constant values respectively of the quantities on average. b and e show the in‐degrees at each resolution,
is the in‐out ratio at the macrocommunity resolution. In the table, down arrows, up arrows, and dashes denote increasing, decreasing, and constant values respectively of the quantities on average. b and e show the in‐degrees at each resolution, 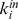 for microcommunities and
for microcommunities and 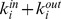 for macrocommunities. Likewise, c and f show the ratio of in‐ and out‐degrees at each resolution,
for macrocommunities. Likewise, c and f show the ratio of in‐ and out‐degrees at each resolution, 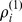 and
and 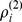 . d shows the degrees of robustness
. d shows the degrees of robustness 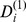 at the micro‐scale and g shows the robustness
at the micro‐scale and g shows the robustness  on the macro‐scale. The behavior of the degrees of robustness at both resolutions agrees with the expectations in most cases if the in‐degrees or in‐ to out‐degrees decrease, the nodes become less robust.
on the macro‐scale. The behavior of the degrees of robustness at both resolutions agrees with the expectations in most cases if the in‐degrees or in‐ to out‐degrees decrease, the nodes become less robust.
Table 1.
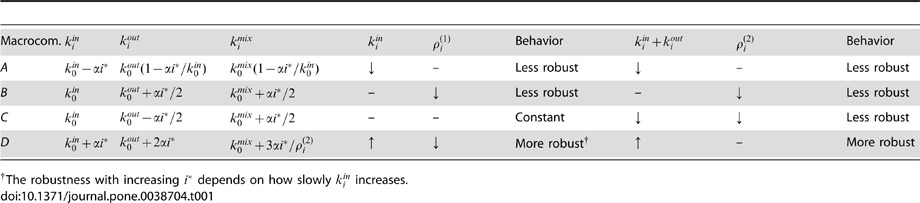
| Macrocom. |
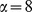
|
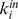
|
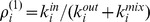
|
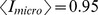
|
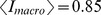
|
Behavior |

|

|
Behavior |
| A |

|
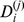
|
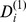
|
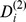
|
Less robust |
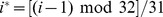
|
Less robust | ||
| B |
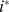
|
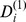
|
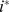
|

|
Less robust |
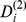
|
Less robust | ||
| C |
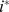
|
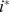
|
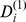
|
Constant |
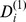
|
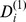
|
Less robust | ||
| D |
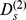
|
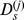
|
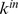
|
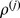
|

|
More robust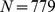
|
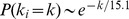
|
More robust |
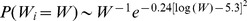 The robustness with increasing
The robustness with increasing 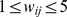 depends on how slowly
depends on how slowly 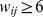 increases.
increases.
An example of the benchmark is shown explicitly in Fig. 2a for , for which the in, out, and mixdegrees of nodes vary significantly with i see the caption of Fig. 2. Fig. 2bc show the indegrees and inout ratios for the highest resolution of the hierarchy and ef for the coarsest resolution, with a decrease in implying a node is less connected to its community and a decrease in indicating a node is highly connected to nodes outside of its community. When we apply our community detection algorithm, the CUF approach recovers the correct partition with a mutual information of on the microscale and on the macroscale see eq. 2 at . The mutual information at each scale increases for for decreasing , but begins to drop rapidly near . The high value of the mutual information shows that the CUF algorithm accurately detects the intended communities for reasonably large asymmetry in the community structure see Supplementary Information S1 for further hierarchical benchmarking.
The benchmark shows that the degree of robustness accurately determines nodes that are less robustly assigned to their intended community at both levels of resolution shown in Fig. 2d and g. Nodes in macrocommunity A are less connected to the network overall and are less robustly assigned at all scales, with and unsurprisingly both and are decreasing with as expected. In macrocommunity B, nodes have a constant incommunity degree and a decreasing ratio of in to outofcommunity degree at each scale, so nodes should be less robust with increasing . While the expected decrease in robustness is clearly observed for , at the macroscale there is a slight but unexpected increase in the robustness of each node as increases. This is due to errors in the macroscale community detection, with macrocommunity B being the most difficult to detect of all of them. Nodes in macrocommunity C have constant in‐degree and in‐out ratio at the micro‐scale with the corresponding robustness nearly constant, but at the macro‐scale are less robust with both the in‐degree and in‐out ratio decreasing leading to an expected decrease in with increasing . Finally, the nodes on the micro‐scale in macrocommunity D simultaneously have increasing in‐degree but decreasing in‐out ratio with increasing . While we find the degree of robustness increasing, the rate of increase of depends on the interplay between the increased robustness due to more in‐community edges and the decreased robustness due to more out‐of‐community edges. in macrocommunity B and D and in macrocommunity D are both clear examples of the dependence of the rate of increase in on both and . The successes in correctly determining not only the hierarchical community structure but also node robustness of this simple benchmark suggest that our approach may be fruitfully applied to complex real world networks with hierarchical structure.
Results and Discussion
The Harvard Coauthorship Network
Turning now to real examples, we look at the network of scientific journals which we expect can be divided into sub‐fields at varying resolutions. We construct a network from publications found in the Digital Access to Scholarship at Harvard DASH repository, a database of journals, book chapters, and conference proceedings uploaded by Harvard faculty. The available metadata includes the authors and the journal of publication, which we use to generate a weighted network with each journal as a node. The weight of the edge between nodes i and j, , is the number of article pairs that have at least one author in common, with one article published in journal i and the other in journal j. The largest connected component of this network comprising journals as nodes, shown in Fig. 3a has a complex structure while the degree of each node the number of edges with non‐zero weight is exponentially distributed, , the strength of each node is log‐normally distributed, with a good fit given by see Fig. 3b‐c. It is interesting to note that an exponentially distributed degree sequence is indicative of network growth without preferential attachment [30], while log‐normally distributed strengths may indicate growth with a localized preferential attachment in the weight see ref. [31] and below for further discussion. This may illuminate some of the details of how a publication network grows while authors preferentially publish in high‐profile journals or proceedings leading to the fat tail on the strength distribution, they may choose to publish in new or lower profile journals if necessary leading to the exponential, non‐preferential attachment distribution of the degree sequence.
Figure 3. The network of journals from the DASH data.

a Low weight edges with are shown in blue, while higher weight nodes are shown in red. Nodes are ordered in order of descending macrocommunity size, then descending microcommunity size, and finally in descending strength. The 36 microcommunities are denoted by the smaller black squares, while the 6 macrocommunities are shown in the larger thick black squares. Some microcommunities are labelled with their two most robust nodes having largest  . The degree distribution of the DASH data in b is exponential, while the distribution of node strengths in c appears to be log‐normal. In d, the average robustness of nodes in the microcommunities
. The degree distribution of the DASH data in b is exponential, while the distribution of node strengths in c appears to be log‐normal. In d, the average robustness of nodes in the microcommunities 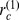 , thick bars of varying color and macrocommunities
, thick bars of varying color and macrocommunities  , thin black bars for the DASH data. In d, the bar for Mathematical Sciences 2 MS2 is cut off, having a very high average degree of robustness of
, thin black bars for the DASH data. In d, the bar for Mathematical Sciences 2 MS2 is cut off, having a very high average degree of robustness of  .
.
In Fig. 3a, 36 microcommunities in the DASH network are found, and in most cases an inspection of the group memberships showed the members of each community were related a full list is found in Supplementary Information S1. It is worth noting that using a Potts model approach to modularity maximization [14], [32] with resolution 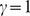 yields 32 distinct microcommunities, and the partitions generated by the two methods share much in common, suggesting the CUF results are reasonable. The hierarchical detection scheme shows that each of the microcommunities falls into 6 natural macrocommunities see Fig. 3a. The two largest macrocommunities show a division between the Physical Sciences physics, biology, chemistry, and geology and the Mathematical Sciences pure mathematics, economics, and computer science. Three additional macrocommunities consist of a combination of Philosophy and the History of Science, Linguistics, and Law, and a final macrocommunity having no obvious meaning on inspection see Supplementary Information S1 for the member journals of each community. We note that this hierarchical partition is not easily detected using the Potts modularity maximization approach even for
yields 32 distinct microcommunities, and the partitions generated by the two methods share much in common, suggesting the CUF results are reasonable. The hierarchical detection scheme shows that each of the microcommunities falls into 6 natural macrocommunities see Fig. 3a. The two largest macrocommunities show a division between the Physical Sciences physics, biology, chemistry, and geology and the Mathematical Sciences pure mathematics, economics, and computer science. Three additional macrocommunities consist of a combination of Philosophy and the History of Science, Linguistics, and Law, and a final macrocommunity having no obvious meaning on inspection see Supplementary Information S1 for the member journals of each community. We note that this hierarchical partition is not easily detected using the Potts modularity maximization approach even for 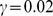 , there are still 23 microcommunities detected via modularity maximization. Thus, the partition into distinct scientific fields naturally arises from the coarse graining in our approach, but is difficult to detect using modularity methods alone. Further coarse graining shows that there is no additional hierarchical structure to be found in the DASH network.
, there are still 23 microcommunities detected via modularity maximization. Thus, the partition into distinct scientific fields naturally arises from the coarse graining in our approach, but is difficult to detect using modularity methods alone. Further coarse graining shows that there is no additional hierarchical structure to be found in the DASH network.
The average robustness of the nodes in each community of the DASH data is very heterogeneous the multi‐colored bars in Fig. 3d, which can be of use in determining which microcommunities are held together weakly, either because of the complex network topology involving the nodes in the community or due to an incorrect partitioning of the network. Many of the detected communities have few nodes, and are correspondingly less robust on average. Even some large communities have low average robustness, which could indicate an incorrect assignment or an unexpected network topology around a community. For example, Phys. Sci. 5 PS5 in Fig. 3d consists of 26 journals, with a very small average degree of robustness of 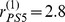 . The surprisingly low robustness of PS5 is not due to sparse connections between nodes within the community the average degree of nodes in PS5,
. The surprisingly low robustness of PS5 is not due to sparse connections between nodes within the community the average degree of nodes in PS5,  , but is because of the fact that these journals are highly connected externally
, but is because of the fact that these journals are highly connected externally 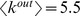 .
.
The robustness of a nodes assignment to its macrocommunity the thin black bars in Fig. 3d is not determined by how robustly assigned it is to its microcommunity. The average robustness 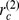 gives an indication of how strongly a microcommunity is attached to its macrocommunity, and we find that PhilosophyHistory 1 PH1 is the most weakly assigned, with
gives an indication of how strongly a microcommunity is attached to its macrocommunity, and we find that PhilosophyHistory 1 PH1 is the most weakly assigned, with 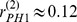 , despite the very robust assignment of the nodes in the microcommunity
, despite the very robust assignment of the nodes in the microcommunity 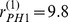 . Two journals in PH1 are very strongly connected to the Mathematical Sciences macrocommunity so much weight is directed to Math. Sci. from PS1, while many journals in PH1 are more weakly connected to the journals in its own macrocommunity so more edges are directed towards Philosophy and History. The degree of robustness is thus able to home in on microcommunities that may be on the boundary between macrocommunities and identifying particularly complex topologies.
. Two journals in PH1 are very strongly connected to the Mathematical Sciences macrocommunity so much weight is directed to Math. Sci. from PS1, while many journals in PH1 are more weakly connected to the journals in its own macrocommunity so more edges are directed towards Philosophy and History. The degree of robustness is thus able to home in on microcommunities that may be on the boundary between macrocommunities and identifying particularly complex topologies.
The Physical Review Citation Network
Another real‐world network where one may expect a hierarchical structure is that of a citation network independent of their journal of publication, with an expectation of divisions between fields and sub‐fields as was observed in the DASH network. We examine the citation network of articles published in the Physical Review journals [33], [31], with articles as nodes and citations between articles as edges. Citations naturally form directed edges a citation between i and j does not imply a citation between j and i, but to apply our methods we study the undirected 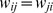 version. The degree distribution of this network has been previously shown to be log‐normally distributed [31], which may indicate the underlying dynamics of the growth of the network. Network growth coupled with with preferential attachment produces a scale free degree distribution [30], [7], but Redner [33] has noted that a modified, locally defined preferential attachment process explains the emergence of a log‐normally distributed data. Rather than citing the most important papers, an author chooses to cite either a randomly chosen paper or one of the citations of that paper with the latter likely to be highly cited [34]. The lognormal distribution is also observed in the highly‐cited subset of the network considered see below for further discussion, suggesting that this smaller sample is reasonably representative of the structure of the full network.
version. The degree distribution of this network has been previously shown to be log‐normally distributed [31], which may indicate the underlying dynamics of the growth of the network. Network growth coupled with with preferential attachment produces a scale free degree distribution [30], [7], but Redner [33] has noted that a modified, locally defined preferential attachment process explains the emergence of a log‐normally distributed data. Rather than citing the most important papers, an author chooses to cite either a randomly chosen paper or one of the citations of that paper with the latter likely to be highly cited [34]. The lognormal distribution is also observed in the highly‐cited subset of the network considered see below for further discussion, suggesting that this smaller sample is reasonably representative of the structure of the full network.
Applying the CUF method to the Physical Review network detects four distinct hierarchies of community structure, ranging from the finest resolution of numerous small microcommunities to the coarsest resolution with two large macrocommunities see Fig. 4ac for a schematic ranging from coarsest to finest. At the highest resolution, 266 communities are detected, and the partition has the modularity 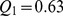 at
at 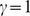 . This is in reasonable agreement with a similar previously studied Phys. Rev. network [33] with 274 detected communities and a modularity of
. This is in reasonable agreement with a similar previously studied Phys. Rev. network [33] with 274 detected communities and a modularity of 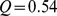 , suggesting that this fine resolution partition of the more current data is reasonable. High‐modularity partitions are also detected using our coarse graining method, with the modularities
, suggesting that this fine resolution partition of the more current data is reasonable. High‐modularity partitions are also detected using our coarse graining method, with the modularities  for the 62 communities on the second level of the hierarchy and
for the 62 communities on the second level of the hierarchy and 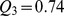 for the 11 communities at the third level see Fig. 4a‐b. The final level of coarse graining does not produce a very high modularity with
for the 11 communities at the third level see Fig. 4a‐b. The final level of coarse graining does not produce a very high modularity with 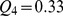 for two macrocommunities, but the meaning of the partition recognizable on inspection of the component communities for its distinction between earth‐bound and cosmological research. At each level of hierarchy, the partitioning is both reasonable from a scientific perspective as well as generally producing a large modularity, suggesting that CUF approach is able to discern the natural partitions of the network without need for a resolution parameter.
for two macrocommunities, but the meaning of the partition recognizable on inspection of the component communities for its distinction between earth‐bound and cosmological research. At each level of hierarchy, the partitioning is both reasonable from a scientific perspective as well as generally producing a large modularity, suggesting that CUF approach is able to discern the natural partitions of the network without need for a resolution parameter.
Figure 4. The hierarchical community structure of the Physical Review network.

a‐c shows a progressively coarsened view of the network, with the text labels of the communities composed of the most statistically significant words found in the titles of the articles in the communities. a shows the microcommunity structure of 148 nodes, with b a zoomed‐out picture of the 625 nodes in one macrocommunity of the second level of the hierarchy, and c the full network showing the final two levels of hierarchy. d shows the degree distribution as well as the distribution of node robustness at each level of the hierarchy shown log‐linear in the inset. Black circles show the degree distribution, which is log‐normally distributed [31] the best fit is the black line. The distribution of robustness on the micro‐scale, 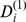 , is shown with the blue squares, while the distribution for the other hierarchical degrees of robustness
, is shown with the blue squares, while the distribution for the other hierarchical degrees of robustness 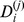 are all quite similar shown with the up triangles, down triangles, and stars. The initial decay of the robustness is well‐fit by an exponential in all cases with the best fit for each shown as lines.
are all quite similar shown with the up triangles, down triangles, and stars. The initial decay of the robustness is well‐fit by an exponential in all cases with the best fit for each shown as lines.
The distribution of the degrees of robustness found in the Physical Review network is shown in Fig. 4d, along side the degree distribution of the nodes. As mentioned earlier, the degree distribution is well fit by a log‐normal distribution [31]
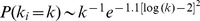 , with a fatter tail than exponential but vanishing faster than a power law. The distribution of node robustness
, with a fatter tail than exponential but vanishing faster than a power law. The distribution of node robustness 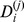 , which indicates how robustly the node i is assigned at the
, which indicates how robustly the node i is assigned at the 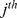 level of the hierarchy, decays much more rapidly for large
level of the hierarchy, decays much more rapidly for large  for all four of the hierarchical levels. At the finest resolution blue squares in Fig. 4d, the degrees of robustness are well fit by an exponential decay
for all four of the hierarchical levels. At the finest resolution blue squares in Fig. 4d, the degrees of robustness are well fit by an exponential decay 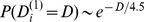 , and although the tail beyond
, and although the tail beyond  incorporating below 2.5 of the nodes is slower than exponential, it remains faster than log‐normal. The far more rapid decay of the degrees of robustness suggest that highly‐cited papers have applications in a wide variety of fields i.e. are have many out‐of‐community edges. The robustness of the nodes at the lower‐resolution partitions are all similar to one another triangles and stars in Fig. 4d, all satisfying an exponential initial decay of
incorporating below 2.5 of the nodes is slower than exponential, it remains faster than log‐normal. The far more rapid decay of the degrees of robustness suggest that highly‐cited papers have applications in a wide variety of fields i.e. are have many out‐of‐community edges. The robustness of the nodes at the lower‐resolution partitions are all similar to one another triangles and stars in Fig. 4d, all satisfying an exponential initial decay of 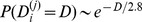 over a somewhat shorter range. Each node has roughly the same robustness on each level of the hierarchy, suggesting that an equal fraction of nodes are involved in forming the edges of the different levels of the hierarchies.
over a somewhat shorter range. Each node has roughly the same robustness on each level of the hierarchy, suggesting that an equal fraction of nodes are involved in forming the edges of the different levels of the hierarchies.
Conclusions
In this paper, we have described a new and intuitive method for detecting hierarchical community structure in complex networks that does not rely on free parameters or require advanced knowledge of the number or size of the communities. Given a method for measuring the closeness between two nodes in a network, one can trace a path of closest friendship that defines a high‐resolution partition of the community, resulting in a method with 1 reasonable computational complexity in comparison to other methods [10], 2 easy detection of multiple levels of community structure without the need for an unknown apriori resolution parameter [17], [13], and 3 a simple yet powerful method of measuring the robustness of the assignment of an individual node to its community. We must note that there are also limitations to our approach, including the free choice of a closeness measure, pathological network topologies which, for example, necessitates the use of the CUF over the CF see Supplementary Information S1, and the requirement that no community can be formed from only one node. Despite these possible limitations, the advantages of our approach in automatically detecting and evaluating hierarchical community structure are significant. Using the recently proposed Generalized Erds Numbers [24] as a closeness measure which performs better than other measures in benchmarks we examined two real world systems where a hierarchical community structure is naturally expected a coauthorship network defined by the DASH data and a citation network generated from the Physical Review data. Our approach is able to detect a high‐resolution partition of each dataset that is composed of well defined communities of variable size, and an inspection of the member nodes suggests that the partition is meaningful in both the DASH‐ and Phys. Rev. networks. Our coarse graining method of detecting hierarchy finds a reasonable macrocommunity partition for the DASH data with each of the macrocommunities clearly linked upon inspection, with this coarse‐grained partition not obviously detected using modularity maximization. By examining the degree of robustness of these communities on the micro‐ and macro‐scale, we are able to rapidly home in on the most interdisciplinary communities those with many significant connections to other communities. The Phys. Rev. citation network naturally partitions into four distinct hierarchies of communities without any apriori assumption of the correct number of hierarchies, with the nodes in the communities generally related to each other upon inspection. The ability to find communities of arbitrary size, detect the structure of a natural and system‐defined number of hierarchies, and locate particularly insular or interdisciplinary communities are all significant advantages of our method, and clearly displayed in the analysis of both the DASH and Phys. Rev. networks.
Supporting Information
Acknowledgments
We would like to thank Reinhard Engels for providing us with a easily processed copy of the DASH data, Levi Dudte for many useful conversations on the methods and paper, and the Wyss Institute for Biologically Inspired Engineering at Harvard.
Footnotes
Competing Interests: The authors have declared that no competing interests exist.
Funding: The authors have no support or funding to report.
References
- 1.Girvan M, Newman M. Community structure in social and biological networks. Proceedings of the National Academy of Sciences of the United States of America. 2002;99:7821. doi: 10.1073/pnas.122653799. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Bilke S, Peterson C. Topological properties of citation and metabolic networks. Physical Review E. 2001;64:36106. doi: 10.1103/PhysRevE.64.036106. [DOI] [PubMed] [Google Scholar]
- 3. Castellano C, Fortunato S, Loreto V. 2009. Statistical physics of social dynamics. Reviews of modern physics 81 591 – 646 [Google Scholar]
- 4. Barabsi A, Jeong H, Nda Z, Ravasz E, Schubert A, et al. 2002. Evolution of the social network of scientific collaborations. Physica A Statistical Mechanics and its Applications 311 590 – 614 [Google Scholar]
- 5. Porter M, Mucha P, Newman M, Friend A. 2007. Community structure in the united states house of representatives. Physica A Statistical Mechanics and its Applications 386 414 – 438 [Google Scholar]
- 6.Yan K, Fang G, Bhardwaj N, Alexander R, Gerstein M. Comparing genomes to computer operating systems in terms of the topology and evolution of their regulatory control networks. Sciences STKE. 2010;107:9186. doi: 10.1073/pnas.0914771107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Barabsi A, Albert R. Emergence of scaling in random networks. Science. 1999;286:509. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- 8. Albert R, Jeong H, Barabasi A. 2000. Error and attack tolerance of complex networks. Nature 406 378 – 382 [DOI] [PubMed] [Google Scholar]
- 9. Moore C, Newman M. 2000. Epidemics and percolation in small‐world networks. Physical Review E 61 5678– 5682 [DOI] [PubMed] [Google Scholar]
- 10. Fortunato S. 2010. Community detection in graphs. Physics Reports 486 75 – 174 [Google Scholar]
- 11.Newman M. Modularity and community structure in networks. Proceedings of the National Academy of Sciences. 2006;103:8577. doi: 10.1073/pnas.0601602103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Newman M, Girvan M. Finding and evaluating community structure in networks. Physical Review E. 2004;69:26113. doi: 10.1103/PhysRevE.69.026113. [DOI] [PubMed] [Google Scholar]
- 13. Kumpula J, Saramki J, Kaski K, Kertesz J. 2007. Limited resolution in complex network community detection with potts model approach. The European Physical Journal B 56 41 – 45 [Google Scholar]
- 14.Reichardt J, Bornholdt S. Statistical mechanics of community detection. Physical Review E. 2006;74:16110. doi: 10.1103/PhysRevE.74.016110. [DOI] [PubMed] [Google Scholar]
- 15.Newman M. Fast algorithm for detecting community structure in networks. Physical Review E. 2004;69:066133. doi: 10.1103/PhysRevE.69.066133. [DOI] [PubMed] [Google Scholar]
- 16.Clauset A. Finding local community structure in networks. Phys Rev E. 2005;72:026132. doi: 10.1103/PhysRevE.72.026132. [DOI] [PubMed] [Google Scholar]
- 17.Fortunato S, Barthlemy M. Resolution limit in community detection. Proceedings of the National Academy of Sciences. 2007;104:36. doi: 10.1073/pnas.0605965104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Arenas A, Fernandez A, Gomez S. Analysis of the structure of complex networks at different resolution levels. New Journal of Physics. 2008;10:053039. [Google Scholar]
- 19. Wu F, Huberman B. 2004. Finding communities in linear time a physics approach. The European Physical Journal B‐Condensed Matter and Complex Systems 38 331 – 338 [Google Scholar]
- 20.Lancichinetti A, Fortunato S, Kertsz J. Detecting the overlapping and hierarchical community structure in complex networks. New Journal of Physics. 2009;11:033015. [Google Scholar]
- 21.Karrer B, Newman M. Stochastic blockmodels and community structure in networks. Phys Rev E. 2011;83:016107. doi: 10.1103/PhysRevE.83.016107. [DOI] [PubMed] [Google Scholar]
- 22.Lancichinetti A, Radicchi F, Ramasco JJ, Fortunato S. Finding statistically significant communities in networks. PLoS One. 2011;6:e18961. doi: 10.1371/journal.pone.0018961. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Liben–Nowell D, Kleinberg J. 2007. The link prediction problem for social networks. Journal of the American Society for Information Science and Technology 58 1019 – 1031 [Google Scholar]
- 24.Morrison G, Mahadevan L. Asymmetric network connectivity using weighted harmonic averages. Europhys Lett. 2011;93:40002. [Google Scholar]
- 25.Guimera R, Sales‐Pardo M, Amaral LAN. Modularity from fluctuations in random graphs and complex networks. Phys Rev E. 2008;70:025101. doi: 10.1103/PhysRevE.70.025101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Adamic LA, Glance N. The political blogosphere and the 2004 us election. Proceedings of the WWW‐2005 Workshop on the Weblogging Ecosystem. 2005.
- 27.Krebs V. Network data website. Available http://www-personal.umich.edu/~mejn/netdata/, maintained by M. E. J. Newman. Accessed 2012 Jun 1.
- 28.Lancichinetti A, Fortunato S, Radicchi F. Benchmark graphs for testing community detection algorithms. Phys Rev E. 2008;78:46110. doi: 10.1103/PhysRevE.78.046110. [DOI] [PubMed] [Google Scholar]
- 29.Sales‐Pardo M, Guirmera R, Moreira AA, Amaral LAN. Extracting the hiearchical organization of complex systems. Proc Natl Acad Sci. 2007;104:15224. doi: 10.1073/pnas.0703740104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Barabasi AL, Albert R, Jeong H. Mean‐field theory for scale‐free networks. Physica A. 1999;272:173. [Google Scholar]
- 31.Redner S. Citation statistics from 110 years of physical review. Physics Today. 2005;58:49. [Google Scholar]
- 32.Csrdi G, Nepusz T. The igraph software package for complex network research. InterJournal Complex Systems. 2006. 1695
- 33.Chen P, Redner S. Community structure of the physical review citation network. J Infometrics. 2010;4:278. [Google Scholar]
- 34.Feld SL. Why your friends have more friends than you do. Amer J Sociol. 1991;96:1464. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.