

Abstract
We propose an efficient group sequential monitoring rule for clinical trials. At each interim analysis both efficacy and futility are evaluated through a specified loss structure together with the predicted power. The proposed design is robust to a wide range of priors, and achieves the specified power with a saving of sample size compared to existing adaptive designs. A method is also proposed to obtain a reduced-bias estimator of treatment difference for the proposed design. The new approaches hold great potential for efficiently selecting a more effective treatment in comparative trials. Operating characteristics are evaluated and compared with other group sequential designs in empirical studies. An example is provided to illustrate the application of the method.
Keywords: Decision theory, Group sequential clinical trial design, Loss function, Predicted power, Reduced-bias estimator
1. Introduction
With large numbers of experimental agents in the developing process, there is an increasing need for innovative clinical trial designs that allow effective agents to be identified more efficiently compared with the standard designs. Group sequential designs have the flexibility to use cumulated information to modify the subsequent course of the trial. Monitoring a group sequential clinical trial is a dynamic process. The time of performing an interim analysis in a group sequential trial is a natural time to update and combine the information from prior experience and accumulated data using Bayesian methods. The decision-theoretic approach has the potential ability to concurrently consider efficacy, futility and cost (Berry, 1994). Although there is no explicit specification for the type I and II error rates when determining the maximum sample size, the decisions leading to false-positive and false-negative conclusions may be taken into account through a loss structure to satisfy regulatory settings (Berry and Ho, 1988; and Lewis and Berry, 1994).
In contrast to previous work in the area, Cheng and Shen (2005) proposed an adaptive design using the Bayesian decision-theoretic approach, which allowed the maximum sample size to be random. The design keeps the virtue of the self-designing trial in the frequentist framework (Fisher, 1998; Shen and Fisher, 1999). An algebraic expression that connects the overall type I error rate and the parameters of the loss function was established, so that the desired frequentist properties can be satisfied for regulatory settings. Later, the possibility of inefficient performance by the adaptive designs was raised by Jennison and Turnbull (2006). We recognized the limitations in terms of efficiency in the work of Cheng and Shen (2005), similar to the design of Shen and Fisher (1999). The realized type I error rate is often smaller than the specified significance level. Moreover, the procedures that are based on the non-sufficient statistics may increase the type II error rate with or without the decreased type I error rate. The monitoring procedures for continuing or stopping the trial based on the loss function alone are often not sensitive enough to fully reflect the evidence of operation characteristics at interim analysis. This issue motivated us to search for a more efficient group sequential design within this framework. Our goal of efficient clinical trial design is to minimize the overall sample size while maintaining the specified error rates under regulatory settings (Jennison & Turnbull, 2000, Ch.10). By combining the strengths of the Bayesian approach in establishing a procedure and the frequentist approach in evaluating the procedure, we propose a design that assesses the predicted power and the expected loss at each interim analysis and makes decisions based on these two factors. The maximum sample size is sequentially determined using interim data. The overall type I error rate can be controlled by choosing related designing parameters.
Similar to other sequential clinical trials, the standard estimator of the treatment difference, such as sample mean or posterior mean in this setting, is often biased. Methods in the literature for constructing unbiased or nearly unbiased estimators are not directly applicable to the estimator of parameter following the proposed design because of the random maximum sample size. In this article, we develop a new procedure of estimation aimed at minimizing the bias. The proposed estimation procedure is general and may be applied to other group sequential designs.
The remainder of this article is organized as follows. In Section 2 we present the proposed design, decision rules and the related properties. In Section 3 we derive the critical region and evaluate the frequentist properties with normal responses. We describe a new estimation procedure for the proposed design in Section 4. We conduct a simulation study and compare our inference with the existing adaptive and classical group sequential designs in Section 5. We apply the proposed design to an example in Section 6 and conclude in Section 7.
2. New design and main results
Consider a clinical trial that compares a new treatment T with a control C, where the individual treatment response is XT and the individual control response is XC. For notation simplicity, we assume a design with equal randomization, which can be easily extended to more general two-arm trials. The block size at each stage is 2Bi, i = 1, 2, …, where Bi for each treatment arm is fixed before the trial starts, but the maximum number of blocks is not predetermined and is determined using interim data.
Let X̄Ti and X̄Cibe the observed mean responses in the ith block. Given the parameter of interest, θ, which is a measure of the treatment difference, let
The one-sided hypothesis to be tested is
Within a Bayesian framework, assume that θ has a prior distribution π with E(θ|π) = δ.
2.1. Decision Rule
The loss structures may be devised from the perspective of the investigators, patients, and/or stockholders via the data monitoring committee (Gittins & Pezeshk, 2000). It has become a common practice to include patient advocates on data and safety monitoring committees for the conduct of clinical trials. We define a loss structure consisting of the respective cost of making a false-positive conclusion, a false-negative conclusion, and the cost of the total sample, in which the risk and benefit of the new agent under investigation should be balanced via these cost parameters.
Let D be the decision of either accepting (A) or rejecting (R) null hypothesis. At the jth interim analysis, the loss function is defined by
| (2.1) |
where
K0 is a constant and positive penalty for each unit of h0(θ) when H0 is incorrectly rejected, and K1 is a positive penalty for each unit of h1(θ) when H0 is incorrectly accepted. Here, h0(·) and h1(·) are positive and continuous functions, and the positive loss may change with the actual value of θ. One sensible choice is to allow the loss function to change with the magnitude of θ, such as h0(θ) = h1(θ) = |θ|w + c with c ≥ 0 and w > 0. In this case, the loss to accept the null hypothesis increases as the distance of a positive θ to zero gets larger. Similarly, the loss to reject H0 increases as a negative θ deviates from zero further. The unit cost of each sample, K2, is relative to K0 and K1, which should be much smaller than K0 and K1. Another special case for the type of loss functions is the commonly used 0-Ki loss, with h0(θ) = h1(θ) = 1. Following a common convention that making a false-positive conclusion leads to a more severe penalty than making a false-negative conclusion, we let K0 > K1.
Let
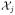 = {X1, …, Xj} be the accumulated data up to step j, where Xj represents data from the jth block. At each interim analysis the study will be terminated for futility or for efficacy if the evidence is strong enough. Otherwise, the study will continue to (j + 1)th block. The loss function related to the above two decisions at the jth interim analysis is defined as the expected loss of stopping the trial and accepting the null hypothesis, that is,
= {X1, …, Xj} be the accumulated data up to step j, where Xj represents data from the jth block. At each interim analysis the study will be terminated for futility or for efficacy if the evidence is strong enough. Otherwise, the study will continue to (j + 1)th block. The loss function related to the above two decisions at the jth interim analysis is defined as the expected loss of stopping the trial and accepting the null hypothesis, that is,
and the predicted loss of continuing the trial to the (j + 1)th block,
| (2.2) |
To better achieve the targeted power while minimizing the total sample size, we incorporate the predicted power into the monitoring rules. We consider this type of the group sequential designs motivated by internal reasons in view of the interim data on the primary endpoint. As discussed by Jennison & Turnbull (2006), it is proper to increase the remaining sample size if continuing as planned would give low conditional power under θ = δ; an interim estimate of θ̂ still represents a worthwhile clinical improvement. In this case, extending the study could ensure the desired power under the estimated effect size. Our goal is to achieve a desired power at an anticipated effective size with the flexibility that the desired power may be preserved at the true effective size (θ) when the true effective size deviates from the anticipated size within a certain extension. Of course, there is a realistic limitation to such a deviation. In our numerical study (Section 5), the values of θ are mostly limited to the set {θ: |θ − δ| < 0.5δ}. Since the proposed design is intended to achieve the desired power at θ, the true efficacy value in a given range, it is natural to use the current posterior mean as an estimator of θ to evaluate the conditional power.
Given data observed up to the jth block, letting δj be the posterior mean of θ given
, the predicted power related to the critical region Rj+1, is defined as P(Rj+1|θ = δj,
), where
| (2.3) |
Definition 2.1
The proposed design follows a two-step decision rule described below, where M is the total number of interim analysis and the procedure starts from j = 1.
If LA(
) ≤ Lcont(
), terminate the trial and accept H0 at the jth step, let M = j.-
If LA(
) > Lcont(
), evaluate the predicted power.If the predicted power P(Rj+1| θ = δj;
) ≥ 1 − β, terminate the trial, let M = j. If E{L(θ, A, M)|
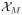 } > E{L(θ, R, M)|
}, reject H0, otherwise accept H0.
} > E{L(θ, R, M)|
}, reject H0, otherwise accept H0.If P(Rj+1|θ = δj,
) < 1 − β, continue the trial to the j + 1th analysis and repeat 1 and 2.
Remark 2.1
In our earlier work (Cheng and Shen, 2005), the decision at block j to stop the trial and reject null hypothesis for efficacy is only based on LR(
) = E{L(θ, R, j)|
}, if it is no greater than Lcont(
). The design parameters, such as penalties for making wrong decisions in the typical decision-theoretic approaches are often searched empirically to match with the specified error rates by trial and error. As a result, the design may not be efficient regarding the sample size. One advantage of using the predicted power directly in the course of procedure is the ability to stop the trial whenever evidence favoring the experimental treatment is sufficient. Otherwise, we continue the trial to gain more information about the treatments. Further comparison is presented in the numerical study section of this paper.
2.2. Properties
Some practical concerns need to be addressed, specifically, whether the trial will be terminated with a finite number of interim analysis and whether the decision rules lead to a correct recommendation with the specified probabilities. The following Theorems 2.1 and 2.2 confirm that these desirable properties hold asymptotically with the proposed design. The proofs of the theorems are given in Appendix A.
Theorem 2.1
Let M be the total number of blocks following the proposed decision procedures. Assuming that the prior density of θ, π(θ), satisfies certain regularity conditions, h0(θ) and h1(θ) are positive and continuous functions of θ, there exists a positive w such that
almost surely, and that K0, K1 and K2 are positive, then
if θ ≠ 0; When θ = 0, P0(M < +∞) = 1 if K1h1(0) < 2BK2, where 2B is the minimum block size.
Theorem 2.1 shows that with probability 1 the trial will be terminated with a finite number of interim analysis. The regularity conditions are specified by Schervish (1995, p. 429).
Theorem 2.2
Under the conditions of Theorem 2.1, let θ* denote the true treatment difference, then
| (2.4) |
almost surely. When θ* > 0, almost surely. When θ* = 0,
The condition on K2 > 0, i.e., a positive cost for enrolling each patient, is critical to avoid unnecessary extension of the trial under H0. Theorem 2.2 ensures that with the proposed monitoring strategies, it is expected that E{L(θ, A)|
} > E{L(θ, R)|
} (since K1h1(θ*) > 0) and the predicted power Pθ* (Rj+1| θ = δj,
) will be near 1 asymptotically under the alternative hypothesis. When the true treatment difference θ* < 0, we should expect that E{L(θ, A)|
}< E{L(θ, R)|
}(since −K0h0(θ*) < 0) and the predicted power remains small, so that the trial will conclude futility with enough data. When θ* = 0, where zero is the boundary value for the two hypotheses, the probability to conclude futility approximates to K0h0(0)=(K1h1(0) + K0h0(0)), which is connected to the type I error rate. For a special case in which h0(0) = h1(0), this limit becomes K0=(K0 + K1). We will give more details of this matter in Section 3.2.
2.3. Computation
There are three key elements in the decision rule, LA(
), Lcont(
), and the predicted power P(Rj+1|θ = δj,
). We derive the computational formulation for each as follows. Given data observed up to the jth block and loss function defined in (2.1), the expected loss of accepting H0 can be expressed as
| (2.5) |
where π (·|
) is the posterior density function of θ given
. Similarly,
| (2.6) |
Expressions (2.5) and (2.6) provide the computational formulation for the two components, E{L(θ, A, j + 1)|
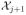 } and E{L(θ, R, j + 1)|
}, of Lcont(
) defined in (2.2). The outside expectation on the right-hand side of (2.2) is determined with respect to the conditional distribution of Xj+1 given
. When F(·|θ) has a density function f(·|θ), the conditional density of Xj+1 given
can be expressed as:
} and E{L(θ, R, j + 1)|
}, of Lcont(
) defined in (2.2). The outside expectation on the right-hand side of (2.2) is determined with respect to the conditional distribution of Xj+1 given
. When F(·|θ) has a density function f(·|θ), the conditional density of Xj+1 given
can be expressed as:
The last element is the predicted power P(Rj+1|θ = δj,
), where Rj+1 is defined in (2.3), and can be expressed as
| (2.7) |
for j = 0, 1, …, M − 1.
3. Applications with normal responses
To illustrate the design procedures in application, we assume that the outcomes follow normal distributions. For simplicity of notation, let
where σ2 is known. (It is not conceptually different with an unknown variance.) The prior distribution for θ is assumed to be N(δ, σ2/B0), where B0 can be interpreted as the equivalent sample size on which the prior information is based (Spiegelhalter et al, 1994). Typically, B0 is much smaller than Bj so that the prior information plays a minor role in the decision process. We let X0 = δ to keep the notation for prior information coherent with that from the interim analysis. After data from the first j blocks are observed, letting , the posterior distribution of θ is , where
are the posterior mean and variance, respectively.
Consider the following function in the loss structure: h0(θ) = h1(θ) = h(θ) = |θ| + c, where c is a nonnegative constant. This function increases linearly with the distance of θ from zero, when an incorrect action is taken. It satisfies the conditions of Theorems 2.1 and 2.2 when cK1 < 2BK2.
3.1. Expected losses and predicted power
For h(θ) = |θ| + c and normal responses, we provide explicit expressions for the three key elements, LA(
), Lcont(
) and the predicted power P(Rj+1|θ = δj,
), in the decision rule through the following three propositions, respectively.
Proposition 3.1
Let h0(θ) = h1(θ) = |θ| + c. We have
| (3.1) |
| (3.2) |
where φ(·) and Φ (·) are the standard normal probability density function and cumulative distribution function, respectively.
Proof
Since the posterior distribution of θ given
follows
, it can be verified that
| (3.3) |
Applying the result of (3.3) to the right-hand side of (2.5). The expression of (3.1) is obtained. By a similar argument, noting that 1 − Φ(x) = Φ(−x), expression (3.2) can be obtained as well.
The computational formula for Lcont(
) defined by (2.2) is derive by the following proposition.
Proposition 3.2
Let h0(θ) = h1(θ) = |θ| + c. Then
| (3.4) |
where .
Proof
Let lD(x|δj) define the integral term of LD(
) given by the right-hand side of (2.5) and (2.6), where D = A or R. Substituting j by j + 1 in equations (3.1) and (3.2), the second term on the right-hand side of each equation gives, respectively, the expression of lA(x|δj) and lR(x|δj) below:
| (3.5) |
Given
and Xj+1 = x, the posterior mean δj+1 satisfies the following recursive equation in terms of δj and x:
It is known that the conditional distribution of Xj+1 given
is also normal, specifically,
Thus, we have (3.4) since .
The next proposition provides a recursive expression for the estimated probability of the rejection region.
Proposition 3.3
Let h0(θ) = h1(θ) = |θ| + c. Then
| (3.6) |
where ξj is the unique solution of the following equation in variable x:
and r = K0=(K0 + K1).
Proof
In view of (3.3) and that h(θ) = |θ|+c, the critical region Rj defined by (2.7) can be expressed as
| (3.7) |
where r = K0=(K0 + K1). For given constants c > 0, s > 0, and 0 < r < 1, it can be verified that the continuous function
| (3.8) |
increases in x, limx→−∞ u(x, s, r) = −∞, and lim x→+∞u(x, s, r) = +∞. By the intermediate value theorem, there exists a unique real number ξj such that
| (3.9) |
where ξj is obtained by solving equation u(x, sj, r) = rc for x. It is easy to see that
| (3.10) |
The posterior mean satisfies the following recursive equation:
In addition to the fact that , we have
| (3.11) |
Following (3.9) through (3.11), the predicted power, P(Rj+1| θ = δj,
), after observing j blocks of data can be expressed as
Hence, (3.6), the following expression for the predicted power, is derived.
The expressions (3.1), (3.4), and (3.6) are computationally straightforward and hence the decision procedures are user-friendly to carry out.
3.2. Connection to type I error rate
Our goal in this section is to find a connection between the type I error rate and K0/K1 in the loss function, so that the operating characteristic can be directly assessed and ensured.
Recall that K0/(K0 + K1) = r, equivalently,
| (3.12) |
The following two terms are defined for the preparation of Proposition 3.4 and its proof.
Let
| (3.13) |
and
| (3.14) |
where
| (3.15) |
Proposition 3.4
Let h0(θ) = h1(θ) = |θ| + c. For K0=K1 defined by (3.13) through (3.12), the probability of having a false positive conclusion is controlled under the nominal significance level α. Moreover, the probability to conclude futility at θ = 0 in Theorem 2.2 with h0(0) = h1(0) is K0=(K0+K1), which is greater than or equal to 1 − α.
Proof
In light of (3.7), the probability to reject the null hypothesis can be expressed as
Since u(x, s, r) defined by (3.8) is increasing in x and linear in s, noting that 0 < s ≤ s1, u(δj/sj, sj, r) > rc leads to
| (3.16) |
we have
| (3.17) |
where ξ = min{u−1(rc, s1, r), u−1(rc, 0, r)}. The last equation holds due to the fact that
For a given upper boundary (e.g. α) to the probability in the right-hand side of (3.17), the corresponding quantile ξ can be derived. Once ξ is obtained, we can calculate r and then the ratio of K0 and K1 subsequently.
Because efficacy is assessed at each interim analysis, we shall use α (j) at the jth interim in order to control the overall type I error rate at α (Slud and Wei, 1982). Let
where α (j) monotonically increases in j and limj→∞ α (j) = α (i.e. α (M) ≤ α). Use the conservative upper boundary α (1) for all j ≥ 1 in the above inequality,
| (3.18) |
which leads to P(Rj|θ = 0) ≤ α (1) < α for all j.
We need to solve the inequality (3.18) for ξ. Following the argument of the first derivative, it can be shown that the component inside of Φ, which is (n0δ − ξσ√nj)/{σ√ (nj − n0)}, as a function of nj, increases when 0 < nj < (ξσ/δ)2 and decreases when (ξσ/δ)2 < nj < ∞. Therefore,
Letting each expression on the right-hand side of the last inequality be less than or equal to α (j), it yields
By using the conservative upper boundary α (1) = α/2 instead of α (j) in the above derivation, (3.13) is verified. Next, we find the algebraic expression for r. In light of (3.16) and (3.17), ξ and r satisfy the equation:
where u is defined by (3.8). For the scenario of max{u(ξ, s1, r), u(ξ, 0, r)} = u(ξ, 0, r) = cΦ(ξ), cΦ(ξ) = rc implies r = Φ(ξ). For the complementary scenario of max{u(ξ, s1, r); u(ξ, 0, r)} = u(ξ, s1, r), it occurs if and only if r ≤ v(ξ), where v(ξ) is defined by (3.15). Hence (3.14) can be verified after working out the algebra in solving u(ξ, s1, r) = rc for r.
In general, the choice of constants Ki depends on the objectives of a trial. In a special case: when hi(θ) = 1 for i =0, 1, K0 and K1 are the costs of making type I and type II errors, respectively, relative to the cost of enrolling a patient, K2.
4. Estimation following the proposed design
After the inference, the estimation of θ is often of interest. It is well known that the naive estimate of θ (sample mean) following a classical group sequential design is biased. This phenomenon also occurs with the posterior mean of θ following the proposed design. Typically, θ is overestimated for trials concluding efficacy and underestimated for trials concluding futility.
We take a different perspective and approach to all existing methods. Since θ is the treatment difference, it is reasonable to assume that the domain of θ, denoted as
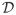 , is bounded and can be predetermined. Let δM and sM be the posterior mean and posterior standard deviation of θ from the original data at the end of the trial that follows the proposed design. We perform a grid search to find a near unbiased estimator of θ in
based on Monte Carlo simulations.
, is bounded and can be predetermined. Let δM and sM be the posterior mean and posterior standard deviation of θ from the original data at the end of the trial that follows the proposed design. We perform a grid search to find a near unbiased estimator of θ in
based on Monte Carlo simulations.
Because the proposed efficient design (ED) is uniquely determined by a set of design parameters, we denote such a design as ED(δ, K0, K1, K2, B0, B1, B, β). Let
be the original data collected under the specified design ED(δ, K0, K1, K2, B0, B1, B, β). To perform a grid search, we divide
into N subintervals with an equal length. The partition is fine enough, so that the midpoint θn in the nth subinterval is representative for the nth interval and θn, n = 1, · · ·, N, should cover the whole
.
Definition 4.1
The simulation based estimation procedure follows:
- For each θn, we simulate one data set from N (θn, σ2/Bi) by applying the same monitoring rules of ED(δ, K0, K1, K2, B0, B1, B, β) as in the original trial. At the end of the simulated trial, compute the posterior mean of θn. To stabilize the estimation, we repeat the procedure for L times and denote the posterior mean from the lth simulation as for each θn. We denote the average of the posterior means from the L simulations as
- When ζMC(θn|L), n = 1,…, N, are computed, the estimator θ̂ will be searched from {θ1,· · ·, θN} with the following criterion: among all candidates in {θ1, · · ·, θN}, ζMC(θ̂|L) is the closest to δM, where δM is the posterior mean obtained from the observed data, i.e.,
(4.1)
We reason that the θ̂ proposed in (4.1) is a reduced-bias estimator. Let g(θ) = Eθ (δM). For any given θn, we have
It is realistic to assume that the
is uniformly bounded when θn takes a value in a predetermined bounded domain
. Based on the above estimation procedure (1), we have
uniformly for θn in
. Moreover,
| (4.2) |
The last equality follows from the facts that
Since Varθ(δM) is free of θn and Varθn {ζMC (θn|L)} = O(1/L), for sufficiently large L, choosing θn to minimize Eθ; θn {ζMC (θn|L) − δM}2, the left-hand side of (4.2), is asymptotically equivalent to choosing θn to minimize {g(θn)−g(θ)}2.
The above proposed estimation procedure has the flavor of a bootstrap procedure in the resampling part (Wang & Leung, 1997). The main difference between our procedure and their procedure is that we use a searching step to locate the estimator of θ that is closest to the posterior estimator; whereas Wang and Leung (1997) used the maximum likelihood estimator.
5. Numerical studies
Using Monte Carlo simulations, we compare the performance of the proposed efficient design (ED) with existing group sequential designs in a similar setting. The OBF design (O’Brien & Fleming, 1979) is a classical group sequential design with a fixed maximum sample size. The self-designing trial of Shen & Fisher (1999) is a frequentist adaptive design, and the Bayesian adaptive design (Cheng & Shen, 2005) is based on the decision-theoretic approach. The ED, Bayes adaptive design and self-designing trials do not enforce a maximum sample size, in contrast to the O’Brien-Fleming (OBF) design, in which the maximum sample size is estimated given the design parameters: δ, α and β.
It is worth noting that the original OBF design is two-sided. DeMets and Ware (1982) extended the results of the OBF design to the one-sided version of the symmetric OBF design. Our numerical study is based on the one-sided boundaries proposed by DeMets and Ware (1982).
For each scenario, the same type I and II error rates, δ, and block sizes are used among the four designs under comparison. The block sizes are prespecified, B0 = 1, Bi = B = 6, for i ≥ 2. For the OBF design, let B1 = B for simplicity. For the remaining three designs, B1 = 15 in order to have a more stable estimator of θ at the first step. The Bayesian adaptive design uses the loss structure with h1(θ) = h0(θ) = 1, while Ki is chosen to achieve the corresponding α and β, respectively. The number of interim analysis of the OBF design is backward derived given the block size B and the fixed maximum sample size. The asymptotic boundary for the one-sided OBF test is obtained from DeMets & Ware (1982) and Shen & Fisher (1999) with the given design parameters.
The values of θ are mostly limited to the set {θ: | θ − δ| < 0.5δ}. For a fair comparison among the methods, the true values of θ are given as fixed when the Xi’s are generated from a normal distribution with σ2 = 1. We used mean θ = 0 under the null hypothesis, and mean θ = 0.5 under the alternative hypothesis. The design parameters are specified as follows: α = 0.025, β = 0.1, and δ = 0.4 or 0.7. Since the type I error rate in the proposed designs depends on K0 and K1 only through the ratio K0/K1, we let K1 = 1 and K0 = r=(1 − r), where r is computed from (3.14). Let h0(θ) = h1(θ) = | θ| + c and c = BK2, which satisfy the conditions of Theorems 2.1 and 2.2.
The empirical type I error rate, power and average sample number (ASN) of each design are summarized in Table 1 with 10,000 repetitions. The proposed efficient design maintains the nominal level at α = 0.025, and achieves the specified power. Among the designs under comparison, the ED is the most robust one to different values of δ. It can achieve the specified power even if δ is considerably optimistically planned, compared with the true θ. When δ (= 0.7) overestimates θ, the ED and Bayesian designs are the two designs that can still maintain the power at 0.9, but the ASN of ED is 17% lower than the ASN of the Bayesian design. When δ is underestimated relative to the true θ (at δ = 0.4), ASNs for ED are at least 25% lower than those for the other designs under the alternative.
Table 1.
The comparison of power and average sample number (ASN) between the proposed design and other group sequential designs with one-sided α = 0.025, B = 6, and true θ = 0 under null and θ = 0.5 under the alternative.
| Design | δ | α̂ | ASNα | 1−β̂ | ASNβ |
|---|---|---|---|---|---|
| OBF | 0.4 | 0.023 | 68.7 | 0.983 | 84.2 |
| Self-designing | 0.4 | 0.010 | 85.4 | 0.923 | 87.2 |
| Bayes Adaptive | 0.4 | 0.014 | 55.3 | 0.949 | 75.0 |
| ED | 0.4 | 0.025 | 42.9 | 0.908 | 55.0 |
| OBF | 0.7 | 0.024 | 26.9 | 0.644 | 38.2 |
| Self-designing | 0.7 | 0.017 | 49.0 | 0.798 | 62.6 |
| Bayes Adaptive | 0.7 | 0.014 | 45.4 | 0.912 | 66.4 |
| ED | 0.7 | 0.019 | 42.7 | 0.901 | 54.8 |
Monte Carlo simulation based on 10,000 repetitions. B0 = 1, B1 = 15, σ = 1, K1 = 1, K2 = 3 * 105, c = BK2, and K0 = r/(1 − r), where r is defined by (3.14). ASNα and ASNβ are average sample sizes under θ = 0 and θ = 0.5, respectively.
While all sequential methods typically lead to savings in sample size compared with the standard fixed sample design, ED performs the best among the designs we investigated. As noted in Table 1, type I error rates of all designs under comparison are under control. The proposed design with assessment of predicted power at each interim analysis results in some further saving in the ASN while achieving the specified power.
The cost of each patient, K2, relative to the cost of making a wrong conclusion is chosen to match the specified power. In general, the larger K2 is, the less power the trial has. We found that K2 should be in the magnitude of 0.15 of K1, the cost of mistakenly concluding a negative trial. The results show that the proposed design is quite robust when K2 varies in the range of 0.15 to 5(0.1)5 over different values of θ and δ. We performed following sensitivity analysis based on simulations (not shown in tables due to space limitation). The role of c is relatively minor other than that c should satisfy the inequality 0 ≤ cK1 < 2K2 min{Bj, j ≥ 1}, which is one of the conditions for Theorem 2.1. The performance of the proposed design is quite robust when c varies within its domain. When the block size is increased from B = 6 to 16, we found that the performances were also similar for the two settings. The only difference is that average sample size increased by 10 under H0 and by 6 under H1 with slightly higher power. Figure 1 shows two histograms of the total number of blocks for the proposed design without a constraint on the maximum number of blocks. Our numerical studies also shows little difference in the error rates or the average sample size if the number of blocks is truncated at 15 for the scenarios shown in the histograms.
Figure 1.

The histogram of the number of blocks as relative frequencies for (a) under H0, θ = 0 and (b) under H1, θ = 0.5. For both (a) and (b), α = 0.025, β = 0.1, δ = 0.5, B1 = 15, B = 8, σ = 1, K2 = 3 * 105, c = BK2, K1 = 1 and K0 = r/(1 − r), where r is defined by (3.14).
We also assess the bias of the proposed estimator and compare it with the posterior mean. Table 2 presents the proposed estimate and the naive posterior mean estimate for θ, along with their empirical estimates of the standard error with β = 0.1, δ = 0.6, and α =.025 or .05. The true underlying θ varies from 0 to 0.6. The grid search was conducted over the predetermined interval [−0.5, 1] with an equal subinterval length of 0.005. To obtain the the reduced-bias estimator, we used 10,000 repetitions for each grid point. The obtained estimator, θ̂, has a substantially reduced bias compared with that of the posterior mean, denoted by δM in Table 2. The standard deviation of the proposed estimators are not significantly different from the standard deviation of the posterior mean.
Table 2.
The comparison of proposed estimate θ̂ and posterior mean δM following an ED with β = 0.1, B = 6 and the assumed treatment difference δ = 0.6.
| α | θ | θ̂ | δM | ||
|---|---|---|---|---|---|
| 0.025 | 0.0 | −0.018 | 0.213 | −0.026 | 0.186 |
| 0.3 | 0.295 | 0.235 | 0.300 | 0.257 | |
| 0.4 | 0.416 | 0.230 | 0.436 | 0.250 | |
| 0.5 | 0.519 | 0.224 | 0.549 | 0.231 | |
| 0.6 | 0.625 | 0.214 | 0.658 | 0.205 | |
| 0.05 | 0.0 | −0.015 | 0.212 | −0.025 | 0.194 |
| 0.3 | 0.304 | 0.235 | 0.320 | 0.258 | |
| 0.4 | 0.425 | 0.230 | 0.455 | 0.244 | |
| 0.5 | 0.523 | 0.219 | 0.558 | 0.218 | |
| 0.6 | 0.616 | 0.218 | 0.645 | 0.202 |
Monte Carlo simulation based on 10,000 repetitions. B0 = 1, B1 = 15, σ = 1, K1 = 1, c = BK2, K2 = 3 * 105 and K0 = r/(1 − r), where r is defined by (3.14).
6. Example
We apply the proposed design to a randomized, placebo-controlled, double-blind trial involving patients with acne papulopustulosa of Plewig’s grade 11–111. Investigators examined the effect of treatment under a combination of 1% chloramphenicol and 0.5% pale sulfonated shale oil versus an alcoholic vehicle (placebo) (Lehmacher & Wassmer, 1999; Fluhr et al., 1998). After 6 weeks of treatment, the level of bacteria was compared to the baseline level for patients in the active treatment group versus those in the placebo group. With α= 0.01 and 1− β = 0.95, h0(θ) = h1(θ) = | θ|+c, we used K2 = 3*105, c = BK2 = 0.00018, K1 = 1 and K0 = r/(1 − r) = 1933.9, where r = 0.9995 is calculated from expression (3.14). Assume that δ = 1 and σ̂0 = 2 based on the prior information. The quantities needed for conducting the proposed design are listed in Table 3, where σ̂j is the sample standard deviation from the cumulatiive data and Pred. Power is the notation for the predicted power P(Rj+1|θ = δj,
). The block means, not cumulative means, are denoted by xj = x̄Tj − x̂Cj.
Table 3.
Illustration of the steps of the ED procedures.
| j | Bj | xj | σ̂j | LA | Lcont | Pred. Power | LR | Decision |
|---|---|---|---|---|---|---|---|---|
| 1 | 12 | 1.549 | 1.861 | 1.507 | 0.210 | 0.946 | Continue | |
| 2 | 6 | 1.580 | 1.932 | 1.530 | 0.051 | 0.997 | 0.061 | Stop; D=R |
In the first interim analysis, LA(
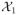 ) = 1.507 > Lcont(
) = 0.210, therefore, the next step is to check the predicted power. Since the predicted power, 0.946, is less than 1 − β = 0.95, the trial continues to the next block. At the second interim analysis, LA(
) = 1.507 > Lcont(
) = 0.210, therefore, the next step is to check the predicted power. Since the predicted power, 0.946, is less than 1 − β = 0.95, the trial continues to the next block. At the second interim analysis, LA(
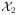 ) > Lcont(
), and the predicted power is 0.997, which is great than 0:95. Therefore, we stop the trial. Because LR(
) = 0.061 < LA(
) = 1.530, the conclusion is to reject H0: θ ≤ 0. The procedure is robust in terms of the choices of δ and σ̂0. When δ varies from 0.5 to 2.5 and σ̂0 varies from 1 to 2.5, the conclusion remains the same and the trial is always terminated after no more than two interim analyses.
) > Lcont(
), and the predicted power is 0.997, which is great than 0:95. Therefore, we stop the trial. Because LR(
) = 0.061 < LA(
) = 1.530, the conclusion is to reject H0: θ ≤ 0. The procedure is robust in terms of the choices of δ and σ̂0. When δ varies from 0.5 to 2.5 and σ̂0 varies from 1 to 2.5, the conclusion remains the same and the trial is always terminated after no more than two interim analyses.
7. Discussion
We have proposed an efficient design with the new aspects of allowing the investigators to evaluate both efficacy and futility at each interim analysis, which leads to a saving in sample size. The one-stage-ahead expected loss and predicted power assessment allow the trial to be terminated once evidence favoring a treatment, or not, is sufficient. The proposed design has the following desirable merits. First, the method can terminate a trial as soon as the evidence is sufficient to show the efficacy of a treatment. Second, the method ensures the control of the type I error rate, which is a practical requirement for trial designs under the regulatory setting, whether Bayesian or frequentist. Third, the proposed method avoids premature decisions with a flexible maximum sample size by relying on the mechanism of assessing the conditional probability. Compared with the other two adaptive designs in simulations, the proposed design is more robust to a range of assumed prior distributions, but more sensitive to the current data.
We have provided a new estimation procedure to obtain a reduced-bias estimator for the parameter of interest. One major advantage of this method is that the estimation procedure takes into account the whole process of the complicated stopping rule through Monte Carlo simulations. The empirical studies have shown that the estimator behaves well under various scenarios. Although this estimation procedure is developed for the proposed design, the methodology of searching for an unbiased parameter estimator may be applied to other Bayesian group sequential designs, as well as classical group sequential designs with the posterior mean replaced by its naive estimate, as in (4.1).
Although we assumed normal observations in illustrating the design, the large sample properties in Section 3 only require independent increments from each block of data to be approximately normally distributed, which will allow extension of the method to outcomes with other distributions and time-to-event outcomes with staggered entry using log-rank type test statistics (Tsiatis et al., 1985 and Shen & Cai, 2003).
The maximum number of blocks is sequentially determined using interim data. When the maximum number of interim analyses is fixed, optimizing the block size B is possible theoretically, but could be difficult computationally. At the first interim analysis, the conditional power can be variable if the size of the first block of data is small. That is why we recommend choosing a relatively larger block size initially, but a constant, smaller block size later. Beyond the initial block, the smaller the block size, the more efficient is the procedure. The most efficient block size would be one, if we do not take the cost of the interim analysis into consideration. But such a fully sequential design after the first block may not be practical in clinical trial conduct. Therefore, we recommend a small block size, such as 5 to 10, after the first block.
We recognize the tradeoff between efficiency and flexibility for clinical trial designs. While being more flexible, the proposed group sequential design may not be the most efficient design as defined in the mathematical sense by Tsiatist and Mehta (2003). As shown in several recent papers (e.g., Bauer, Brannath and Posch, 2001; Brannath, Bauer and Posch, 2006), the most efficient design (in a mathematical sense), however, relies on many underlying assumptions such as the right spending functions and that the sample sizes should be specified a priori. The designs could be poorly underpowered if any of these design parameters were misspecified in the planning phase, which is very likely in practice.
There are different approaches to specifying δ, at which the power is set for group sequential designs, such as using a minimal clinical significant treatment difference (Barber and Jennison, 2002) or an anticipated effective size. Achieving the desired power at the true effective size in a neighborhood of δ has gained more attention for its practicality and flexibility in clinical trial designs in recent years. That is the rationale we use as we set our objectives for the proposed design.
Appendix A. Proofs of Theorems 2.1 and 2.2
For the natural flow of the proofs, we prove Theorem 2.2 first and Theorem 2.1 next.
Proof of Theorem 2.2
We prove (2.4) first. Assume that θ* > 0. For any given positive ε, there exists an N > ε such that h1(θ)=(1 + |θ|w) < ε whenever θ > N. Let
Under the regularity conditions (Schervish, 1995, p. 429, 450),
almost surely and E(|θ |w|
) differs from |θ̂|w by
, where θ̂ is MLE of θ and
. Hence, U is finite almost surely and we have
| (A.1) |
almost surely. A similar argument holds for lim inf. Letting ε approach to zero, we obtain the following inequalities:
Hence,
| (A.2) |
almost surely when θ* > 0. Similarly, we can show the follows:
| (A.3) |
Since
(2.4) is a direct result of (A.2) and (A.3).
For the second part of Theorem 2.2, assuming θ* > 0, since
almost surely, we have
where
Hence,
almost surely.
For the last part of Theorem 2.2, assuming θ* = 0, by a similar argument of (A.1), we have
| (A.4) |
where oε(1) converges to 0 almost surely as j approaches to infinity for any given ε > 0. The last equality of (A.4) follows from the facts that
and
Letting θ̂mj be the MLE and I(θ) be the Fisher information number, we have
| (A.5) |
(Bickel, 2001, p. 339). In light of (A.5),
| (A.6) |
Moreover, converges to Φ(Z) in distribution, where Z follows a standard normal distribution. As a result of (A.4) and (A.6),
Let ε go to zero. Noting that 1 − Φ(Z) follows a uniform distribution on (0, 1) and that the above argument also holds for lim inf, we have
| (A.7) |
Hence, the last part of Theorem 2.2 is proved.
Proof of Theorem 2.1
When θ* < 0, in view of the second equation in expression (A.3),
almost surely. Consequently, Pθ*(M < ∞) = 1.
Next, assuming θ* > 0, the trial stops at M = j if
In the second part of Theorem 2.2, we proved that
almost surely. Subsequently, Pθ*(M < ∞) = 1.
Finally, if θ* = 0 and K1h1(0) < 2Bj+1K2 for j ≥ 1,
| (A.8) |
By a similar argument that yields (A.4) through (A.7), we have
| (A.9) |
The last equality follows from the facts that 1 − Φ(Z) follows a uniform distribution on (0, 1) and that 2Bj+1K2=K1h1(0) > 1. Combining (A.8) and (A.9), we have
which implies P(M < ∞) = 1.
References
- 1.Barber, Jennison Optimal asymmetric one-sided group sequential tests. Biometrika. 2002;89:49–60. [Google Scholar]
- 2.Berry DA. Discussion of a paper by Spiegelhalter, D.J., Freedman, L.S. & Parmar, K.B. Bayesian approaches to randomized trials. J R Statist Soc A. 1994;157:399. [Google Scholar]
- 3.Berry DA, Ho C. One-sided sequential stopping boundaries for clinical trials: a decision-theoretical approach. Biometrics. 1988;44:219–227. [PubMed] [Google Scholar]
- 4.Bickel PJ, Doksum KA. Mathematical Statistics. 2. I. Upper Saddle River, New Jersey: Printice Hall; 2001. [Google Scholar]
- 5.Cheng Y, Shen Y. Bayesian adaptive designs for clinical trials. Biometrika. 2005;92:633–646. [Google Scholar]
- 6.DeMets DL, Ware JH. Asymmetric group sequential boundaries for monitoring clinical trials. Biometrika. 1982;69:661–3. [Google Scholar]
- 7.Fisher L. Self-designing clinical trials. Statist Med. 1998;17:1551–1562. doi: 10.1002/(sici)1097-0258(19980730)17:14<1551::aid-sim868>3.0.co;2-e. [DOI] [PubMed] [Google Scholar]
- 8.Fluhr JW, Gloor M, Merkel W, Warnecke J, Hoffler U, Lehmacher W, Glutsch J. Antibacterial and sebosuppressive efficacy of a combination of chloramphenicol and pale sulfonated shale oil. Arzneimittel-Forschung/Drug Research. 1998;48(I):188–196. [PubMed] [Google Scholar]
- 9.Gittins J, Pezeshk H. How large should a clinical trial be? Statistician. 2000;49:177–187. [Google Scholar]
- 10.Jennison C, Turnbull B. Group Sequential Methods with Applications to Clinical Trials. Chapman and Hall/CRC; 2000. [Google Scholar]
- 11.Jennison C, Turnbull B. Adaptive and nonadaptive group sequential tests. Biometrika. 2006;93:1–21. [Google Scholar]
- 12.Lehmacher W, Wassmer G. Adaptive sample size calculations in group sequential trials. Biometrics. 1999;55:1286–1290. doi: 10.1111/j.0006-341x.1999.01286.x. [DOI] [PubMed] [Google Scholar]
- 13.Lewis RJ, Berry DA. Group sequential clinical trials: a classical evaluation of Baysian decision-theoretic designs. J Am Statist Ass. 1994;89:1528–1534. [Google Scholar]
- 14.O’Brien PC, Fleming TR. A multiple testing procedure for clinical trials. Biometrics. 1979;35:549–556. [PubMed] [Google Scholar]
- 15.Schervish MJ. Theory of Statistics. New York: Springer-Verlag; 1995. [Google Scholar]
- 16.Shen Y, Cai J. Sample size reestimation for clinical trials with censored survival data. J Amer Statist Assoc. 2003;98:418–26. [Google Scholar]
- 17.Shen Y, Fisher L. Statistical inference for self-designing clinical trials with a one-sided hypothesis. Biometrics. 1999;55:190–197. doi: 10.1111/j.0006-341x.1999.00190.x. [DOI] [PubMed] [Google Scholar]
- 18.Slud EV, Wei LJ. Two-sample repeated significance tests based on the modified Wilcoxon statistic. J Am Statist Assoc. 1982;77:862–868. [Google Scholar]
- 19.Spiegelhalter DJ, Freedman LS, Parmar MKB. Bayesian approaches to randomized trials (with discussion) J R Statist Soc A. 1994;157:357–416. [Google Scholar]
- 20.Tsiatis AA, Mehta C. On the inefficiency of the adaptive design for monitoring clinical trials. Biometrika. 2003;90:367–378. [Google Scholar]
- 21.Tsiatis AA, Rosner GL, Tritchler DL. Group sequential tests with censored survival data adjusting for covariates. Biometrika. 1985;72:365–373. [Google Scholar]
- 22.Wang, Leung Bias reduction via resampling for estimation following sequential tests. Sequential Analysis: Design Methods and Applications. 1997;16:249–267. [Google Scholar]