

Abstract
In compressed sensing, one takes 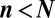 samples of an N-dimensional vector
samples of an N-dimensional vector 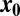 using an
using an 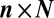 matrix A, obtaining undersampled measurements
matrix A, obtaining undersampled measurements 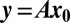 . For random matrices with independent standard Gaussian entries, it is known that, when
. For random matrices with independent standard Gaussian entries, it is known that, when 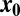 is k-sparse, there is a precisely determined phase transition: for a certain region in the (
is k-sparse, there is a precisely determined phase transition: for a certain region in the (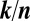 ,
,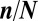 )-phase diagram, convex optimization
)-phase diagram, convex optimization 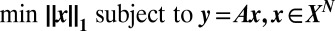 typically finds the sparsest solution, whereas outside that region, it typically fails. It has been shown empirically that the same property—with the same phase transition location—holds for a wide range of non-Gaussian random matrix ensembles. We report extensive experiments showing that the Gaussian phase transition also describes numerous deterministic matrices, including Spikes and Sines, Spikes and Noiselets, Paley Frames, Delsarte-Goethals Frames, Chirp Sensing Matrices, and Grassmannian Frames. Namely, for each of these deterministic matrices in turn, for a typical k-sparse object, we observe that convex optimization is successful over a region of the phase diagram that coincides with the region known for Gaussian random matrices. Our experiments considered coefficients constrained to
typically finds the sparsest solution, whereas outside that region, it typically fails. It has been shown empirically that the same property—with the same phase transition location—holds for a wide range of non-Gaussian random matrix ensembles. We report extensive experiments showing that the Gaussian phase transition also describes numerous deterministic matrices, including Spikes and Sines, Spikes and Noiselets, Paley Frames, Delsarte-Goethals Frames, Chirp Sensing Matrices, and Grassmannian Frames. Namely, for each of these deterministic matrices in turn, for a typical k-sparse object, we observe that convex optimization is successful over a region of the phase diagram that coincides with the region known for Gaussian random matrices. Our experiments considered coefficients constrained to 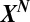 for four different sets
for four different sets 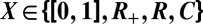 , and the results establish our finding for each of the four associated phase transitions.
, and the results establish our finding for each of the four associated phase transitions.
Keywords: sparse recovery, universality in random matrix theory equiangular tight frames, restricted isometry property, coherence
Compressed sensing aims to recover a sparse vector 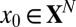 from indirect measurements
from indirect measurements 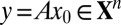 with
with 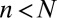 , and therefore, the system of equations
, and therefore, the system of equations 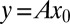 is underdetermined. Nevertheless, it has been shown that, under conditions on the sparsity of
is underdetermined. Nevertheless, it has been shown that, under conditions on the sparsity of  , by using a random measurement matrix A with Gaussian i.i.d entries and a nonlinear reconstruction technique based on convex optimization, one can, with high probability, exactly recover
, by using a random measurement matrix A with Gaussian i.i.d entries and a nonlinear reconstruction technique based on convex optimization, one can, with high probability, exactly recover  (1, 2). The cleanest expression of this phenomenon is visible in the large
(1, 2). The cleanest expression of this phenomenon is visible in the large 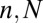 asymptotic regime. We suppose that the object
asymptotic regime. We suppose that the object 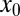 is k-sparse—has, at most, k nonzero entries—and consider the situation where
is k-sparse—has, at most, k nonzero entries—and consider the situation where 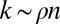 and
and 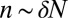 . Fig. 1A depicts the phase diagram
. Fig. 1A depicts the phase diagram 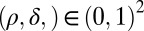 and a curve
and a curve 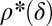 separating a success phase from a failure phase. Namely, if
separating a success phase from a failure phase. Namely, if 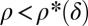 , then with overwhelming probability for large N, convex optimization will recover
, then with overwhelming probability for large N, convex optimization will recover 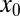 exactly; however, if
exactly; however, if 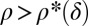 , then with overwhelming probability for large N convex optimization will fail. [Indeed, Fig. 1 depicts four curves
, then with overwhelming probability for large N convex optimization will fail. [Indeed, Fig. 1 depicts four curves 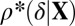 of this kind for
of this kind for 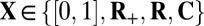 —one for each of the different types of assumptions that we can make about the entries of
—one for each of the different types of assumptions that we can make about the entries of 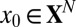 (details below).]
(details below).]
Fig. 1.

The four fundamental phase transitions for compressed sensing with Gaussian matrices in (A) ε–δ and (B) ρ–δ coordinates: R (black), C (red), 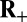 (blue), and
(blue), and 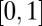 (green).
(green).
How special are Gaussian matrices to the above results? It was shown, first empirically in ref. 3 and recently, theoretically in ref. 4, that a wide range of random matrix ensembles exhibits precisely the same behavior, by which we mean the same phenomenon of separation into success and failure phases with the same phase boundary. Such universality, if exhibited by deterministic matrices, could be very important, because certain matrices, based on fast Fourier and fast Hadamard transforms, lead to fast and practical iterative reconstruction algorithms, even in the very large N setting, where these results would have greatest impact. In certain fast algorithms like FISTA (5) and AMP (6), such matrices are simply applied implicitly and never need to be stored explicitly, saving space and memory accesses; the implicit operations often can be carried out in order 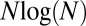 time rather than the naive order
time rather than the naive order 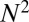 time typical with random dense matrices. Also, certain deterministic systems (7) have special structures that enable especially fast reconstruction in especially large problems.
time typical with random dense matrices. Also, certain deterministic systems (7) have special structures that enable especially fast reconstruction in especially large problems.
In this paper, we show empirically that randomness of the matrix A is not required for the above phase transition phenomenon.* Namely, for a range of deterministic matrices, we show that the same phase transition phenomenon occurs with the same phase boundary as in the Gaussian random matrix case. The probability statement is now not on the matrix, which is deterministic, but instead, on the object to be recovered; namely, we assume that the positions of the nonzeros are chosen purely at random. Our conclusion aligns with theoretical work pointing in the same direction by Tropp (8), Candès and Plan (9), and especially, Donoho and Tanner (10) discussed below; however, the phenomenon that we document is both much broader and more precise and universal than what currently available theory could explain or even suggest. The deterministic matrices that we study include many associated with fast algorithms, and therefore, our results can be of real practical significance. The section Surprises also identifies two anomalies uncovered by the experiments.
Methods
For each of the deterministic matrix sequences 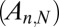 under study and each choice of coefficient set
under study and each choice of coefficient set 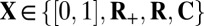 , we investigated the hypothesis that the asymptotic phase transition boundary is identical to the known boundary for Gaussian random matrices. To measure the asymptotic phase plane at a point
, we investigated the hypothesis that the asymptotic phase transition boundary is identical to the known boundary for Gaussian random matrices. To measure the asymptotic phase plane at a point 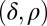 , we chose a sequence of tuples
, we chose a sequence of tuples 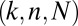 such that
such that 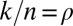 and
and 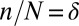 , and we performed a sequence of experiments, one for each tuple. In each experiment, we performed Monte Carlo draws of random k-sparse objects
, and we performed a sequence of experiments, one for each tuple. In each experiment, we performed Monte Carlo draws of random k-sparse objects 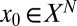 , attempted to recover
, attempted to recover 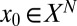 from
from 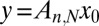 , and documented the ratio
, and documented the ratio 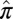 of successes to trials. Our raw empirical observations, thus, consist of a list of entries of the form
of successes to trials. Our raw empirical observations, thus, consist of a list of entries of the form 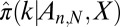 associated with carefully chosen locations
associated with carefully chosen locations 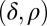 in the phase plane. This section discusses details of creation and subsequent analysis of these empirical observations.
in the phase plane. This section discusses details of creation and subsequent analysis of these empirical observations.
Deterministic Matrices Under Study.
The different matrices that we studied are listed in Table 1. A simple example is the 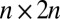 Spikes and Sines matrix (11–13),
Spikes and Sines matrix (11–13), 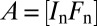 , where Fn is usual discrete Fourier transform matrix. Our list includes numerous tight frames, obeying
, where Fn is usual discrete Fourier transform matrix. Our list includes numerous tight frames, obeying 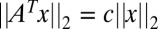 ; several are equiangular tight frames, with the smallest possible coherence
; several are equiangular tight frames, with the smallest possible coherence 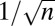 [i.e., the maximal inner product between normalized columns (12)] (14–16). Not all of our frames are maximally incoherent; we consider a so-called Affine Chirp frame with coherence
[i.e., the maximal inner product between normalized columns (12)] (14–16). Not all of our frames are maximally incoherent; we consider a so-called Affine Chirp frame with coherence 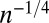 , which is neither tight nor equiangular. Our experiments began as assigned coursework for a course on compressed sensing at Stanford University; they considered the matrices labeled Spikes and Sines (SS), Spikes and Hadamard (SH), and Grassmannian Frame (GF), which served as simple examples of deterministic measurement matrices in that course. After our initial experiments made the basic discovery reported here, we extended our experiments to other matrices. The second stage of experiments involved the deterministic matrices labeled Paley Tight Frame (PETF), Delsarte-Goethals (DG), and Linear Chirp Frame (LC), which were extensively studied in recent years by researchers at Princeton University, especially Robert Calderbank and others. The Spikes and Noiselets (SN), Affine Plane Chirps (AC), and Cyclic matrices were added in a third stage of refinement; their selection was based on personal interests and knowledge of the authors. We emphasize that there are no unreported failures. Namely, we report results for all ensembles that we studied; we are not limiting our reports to those results that seem to support our claims, while holding back information about exceptions. The observed exceptions are disclosed in the section Surprises below.
, which is neither tight nor equiangular. Our experiments began as assigned coursework for a course on compressed sensing at Stanford University; they considered the matrices labeled Spikes and Sines (SS), Spikes and Hadamard (SH), and Grassmannian Frame (GF), which served as simple examples of deterministic measurement matrices in that course. After our initial experiments made the basic discovery reported here, we extended our experiments to other matrices. The second stage of experiments involved the deterministic matrices labeled Paley Tight Frame (PETF), Delsarte-Goethals (DG), and Linear Chirp Frame (LC), which were extensively studied in recent years by researchers at Princeton University, especially Robert Calderbank and others. The Spikes and Noiselets (SN), Affine Plane Chirps (AC), and Cyclic matrices were added in a third stage of refinement; their selection was based on personal interests and knowledge of the authors. We emphasize that there are no unreported failures. Namely, we report results for all ensembles that we studied; we are not limiting our reports to those results that seem to support our claims, while holding back information about exceptions. The observed exceptions are disclosed in the section Surprises below.
Table 1.
Matrices considered here and their properties
| Label | Name | Natural δ | Coherence | Tight frame | Equiangular | Definition | Refs. |
| SS | Spikes and Sines | 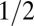 |
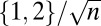 |
Yes | No | Eq. S1 | 12, 13, 17 |
| SH | Spikes and Hadamard | 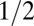 |
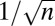 |
Yes | No | Eq. S2 | 17 |
| SN | Spikes and Noiselets | 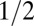 |
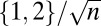 |
Yes | No | Eq. S3 | 43 |
| PETF | Paley Tight Frame | 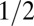 |
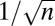 |
Yes | No | SI Appendix | 16 |
| GF | Grassmannian Frame | 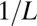 |
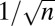 |
Yes | Yes | Eq. S4 | 14 |
| DG | Delsarte-Goethals | 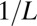 |
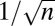 |
Yes | Yes | Eq. S6 | 15, 36 |
| LC | Linear Chirp Frame | 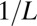 |
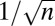 |
Yes | Yes | Eq. S5 | 15, 44 |
| AC | Affine Plane Chirps | 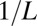 |
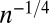 |
No | No | Eq. S7 | 45 |
| CYC | Cyclic | 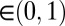 |
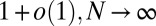 |
No | No | Eq. 2 | 41, 42 |
Generation of Pseudorandom Sparse Objects.
For 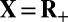 , R, and C, a vector
, R, and C, a vector 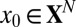 is called k-sparse if
is called k-sparse if 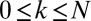 and
and 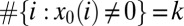 . For case
. For case 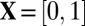 ,
, 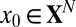 is k-sparse if
is k-sparse if 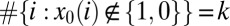 ; this notion was called k-simple in the work by Donoho and Tanner (10). We abuse language in the case
; this notion was called k-simple in the work by Donoho and Tanner (10). We abuse language in the case 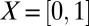 by saying that entries of
by saying that entries of  not in
not in 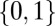 are nonzeros, whereas entries in
are nonzeros, whereas entries in 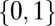 are zeros.
are zeros.
In our experiments, pseudorandom k-sparse objects  were generated as follows.
were generated as follows.
Random positions of nonzeros. The positions of the k nonzeros are chosen uniformly random without replacement.
Values at nonzeros. For
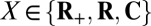 , the nonzero entries have values i.i.d uniformly distributed in the unit amplitude set
, the nonzero entries have values i.i.d uniformly distributed in the unit amplitude set 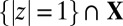 . Thus, for
. Thus, for 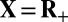 , the nonzeros are all equal to one; for R, they are
, the nonzeros are all equal to one; for R, they are 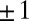 with signs chosen by i.i.d fair coin tossing, and for C, the nonzeros are uniformly distributed on the unit circle. For
with signs chosen by i.i.d fair coin tossing, and for C, the nonzeros are uniformly distributed on the unit circle. For 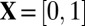 , the values not equal to zero or one are uniformly distributed in the unit interval
, the values not equal to zero or one are uniformly distributed in the unit interval 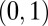 .
.Values at zeros. For
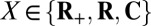 , the zeros have value zero. For
, the zeros have value zero. For 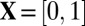 , the zeros have values chosen uniformly at random from
, the zeros have values chosen uniformly at random from 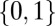 .
.
Convex Optimization Problems.
Each Monte Carlo iteration in our experiments involves solving a convex optimization problem, in which we attempt to recover a given k-sparse object from 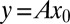 . Each of the four specific constraint sets
. Each of the four specific constraint sets 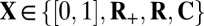 leads to a different convex program for sparse recovery of
leads to a different convex program for sparse recovery of 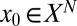 . For each specific choice of X, we solve
. For each specific choice of X, we solve
where 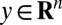 and
and 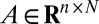 .
.
When X is one of 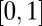 ,
, 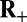 , or R, the corresponding
, or R, the corresponding 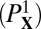 can be reduced to a standard linear program and solved by a simplex method or an interior point method; in case R, the problem
can be reduced to a standard linear program and solved by a simplex method or an interior point method; in case R, the problem 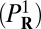 is sometimes called Basis Pursuit (17). The case C is a so-called second-order cone problem (18).
is sometimes called Basis Pursuit (17). The case C is a so-called second-order cone problem (18).
Probability of Exact Recovery.
For a fixed matrix A, let 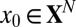 be a random k-sparse object. Let
be a random k-sparse object. Let 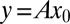 , and therefore, notwithstanding the deterministic nature of A,
, and therefore, notwithstanding the deterministic nature of A, 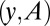 is a random instance of
is a random instance of 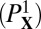 . Define
. Define
This quantity is the same for a wide range of random k-sparse 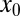 , regardless of details of their amplitude distributions, provided that they obey certain exchangeability and centrosymmetry properties.
, regardless of details of their amplitude distributions, provided that they obey certain exchangeability and centrosymmetry properties.
Estimating the Probability of Exact Recovery.
Our procedure follows the procedure in ref. 3. For a given matrix A, coefficient type X, and sparsity k, we conduct an experiment with the purpose of estimating 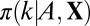 using M Monte Carlo trials. In each trial, we generate a pseudorandom k-sparse vector
using M Monte Carlo trials. In each trial, we generate a pseudorandom k-sparse vector 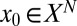 as described above and compute the indirect underdetermined measurements
as described above and compute the indirect underdetermined measurements 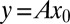 .
. 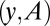 gives an instance of
gives an instance of 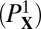 , which we supply to a solver, and obtains the result
, which we supply to a solver, and obtains the result 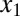 . We compare the result
. We compare the result 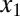 with
with 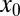 . If the relative error
. If the relative error 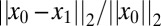 is smaller than a numerical tolerance, we declare the recovery a success; if not, we declare it a failure. (In this paper, we used an error threshold of 0.001.) We, thus, obtain M binary measurements
is smaller than a numerical tolerance, we declare the recovery a success; if not, we declare it a failure. (In this paper, we used an error threshold of 0.001.) We, thus, obtain M binary measurements 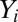 , indicating success or failure in reconstruction. The empirical success fraction is then calculated as
, indicating success or failure in reconstruction. The empirical success fraction is then calculated as
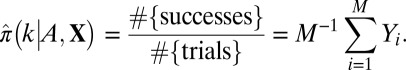 |
These raw observations are generated by our experiments.
Asymptotic Phase Transition.
Let 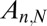 be an
be an 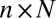 random matrix with i.i.d Gaussian entries, and consider a sequence of tuples
random matrix with i.i.d Gaussian entries, and consider a sequence of tuples 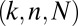 with
with 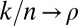 and
and 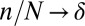 . Then (1),
. Then (1),
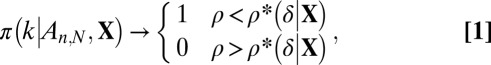 |
where the convergence is almost sure (10, 19–22).
Now let 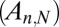 denote a sequence of deterministic matrices under study, with the same shape/sparity tuples
denote a sequence of deterministic matrices under study, with the same shape/sparity tuples 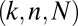 as in the Gaussian case just mentioned. The hypothesis that we investigate is that expression 1 still holds. There is precedent: the theorem below shows, for the case
as in the Gaussian case just mentioned. The hypothesis that we investigate is that expression 1 still holds. There is precedent: the theorem below shows, for the case 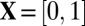 , that if each
, that if each 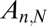 is a matrix with its columns in general position in
is a matrix with its columns in general position in 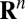 , expression 1 holds.
, expression 1 holds.
Empirical Phase Transitions.
The hypothesis that 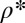 marks the large N-phase transition boundary of each deterministic matrix sequence under study is investigated as follows. The empirical phase transition point is obtained by fitting a smooth function
marks the large N-phase transition boundary of each deterministic matrix sequence under study is investigated as follows. The empirical phase transition point is obtained by fitting a smooth function 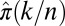 (e.g., a probit function) to the empirical data
(e.g., a probit function) to the empirical data 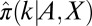 and finding the empirical 50% response point
and finding the empirical 50% response point 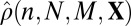 —the value of ρ solving:
—the value of ρ solving:
Examples are in Fig. S1. Under the hypothesis that expression 1 holds not only for Gaussian matrices but also for our sequence of deterministic matrices 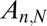 , we have
, we have
Consequently, in data analysis, we will compare the fitted values 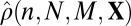 with
with 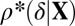 .
.
Computing.
We used a range of convex optimizers available in the MATLAB environment:
CVX: A modeling system for disciplined convex programming by Grant and Boyd (23), Grant et al. (24), and Grant and Boyd (25) supporting two open-source interior-point solvers: SeDuMi and SDPT3.
ASP: A software package for sparse solutions by Friedlander and Saunders (26); its main solver BPdual (27) uses an active-set method to solve the dual of the regularized basis pursuit denoise (BPDN) problem based on dense QR factors of the matrix of active constraints, with only the R factor being stored and updated.
FISTA: A fast iterative soft-thresholding algorithm for solving the BPDN problem. A MATLAB implementation of the algorithm is available from the authors (5).
SPGL1: A solver by van den Berg and Friedlander (28, 29) for the large-scale BPDN problem based on sampling the so-called Pareto curve; it uses the Spectral Gradient Projection method.
Mosek: A commercial optimization toolbox that offers both interior-point and primal simplex solvers (30).
Zulfikar Ahmed also translated our code into python and used the general purpose solver package CVXOPT by Anderson and Vandeberghe (31). We verified the robustness of our results across solvers. We found that SPGL1, with the settings that we used, did not match the other solvers, giving consistently lower phase transitions; therefore, we did not use it in the results reported here. In practice, most of our results were obtained using CVX by participants in the Stanford University graduate class Stat 330/CME 362.
Results
The data that we obtained in our experiments have been deposited (32, 33); they are contained in a text file with more than 100,000 lines, each line reporting one batch of Monte Carlo experiments at a given 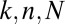 ,
, 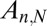 , and X. Each line documents the coefficient field X, the type of matrix ensemble, the matrix size, the sparsity level, the number of Monte Carlo trials, and the observed success fraction. The file also contains metadata identifying the solver and the researcher responsible for the run. In all, more than 15 million problem solutions were obtained in this project.
, and X. Each line documents the coefficient field X, the type of matrix ensemble, the matrix size, the sparsity level, the number of Monte Carlo trials, and the observed success fraction. The file also contains metadata identifying the solver and the researcher responsible for the run. In all, more than 15 million problem solutions were obtained in this project.
Our overall database can be partitioned into several subsets, which address three general questions.
Broad Phase Diagram Survey.
In such a survey, we systematically sample the empirical success frequency 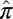 over a
over a 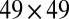 grid covering the full-phase diagram
grid covering the full-phase diagram 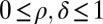 , including regions where we already know that we will see either all failures or all successes (an example is given in Fig. 2). For a matrix type definable only when
, including regions where we already know that we will see either all failures or all successes (an example is given in Fig. 2). For a matrix type definable only when 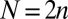 (i.e., undersampling rate
(i.e., undersampling rate 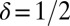 ), we considered 49 equispaced ρ-values in
), we considered 49 equispaced ρ-values in 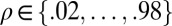 (Fig. S1 shows an example). The GF, DG, LC, and AC frames naturally allow N of the form
(Fig. S1 shows an example). The GF, DG, LC, and AC frames naturally allow N of the form 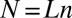 for whole-number L; in such cases, we sampled
for whole-number L; in such cases, we sampled 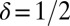 ,
, 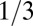 , etc. (Eq. S2). In Figs. 2–4, the two-phase structure is evident.
, etc. (Eq. S2). In Figs. 2–4, the two-phase structure is evident.
Fig. 2.

Empirical (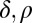 )-phase diagram for the cyclic ensemble. Vertical axis:
)-phase diagram for the cyclic ensemble. Vertical axis: 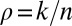 . Horizontal axis:
. Horizontal axis: 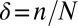 . Shaded attribute gives fraction of successful reconstructions. Red, 100%; blue, 0%. Dashed line, asymptotic Gaussian prediction
. Shaded attribute gives fraction of successful reconstructions. Red, 100%; blue, 0%. Dashed line, asymptotic Gaussian prediction 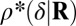 . In this experiment,
. In this experiment, 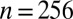 ,
, 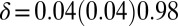 .
.
Fig. 3.
Partial  -phase diagram for chirping frames AC (green), LC (blue), and GF (black). Panels show different coefficient fields: (A) real (
-phase diagram for chirping frames AC (green), LC (blue), and GF (black). Panels show different coefficient fields: (A) real (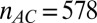 ,
, 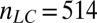 ,
, 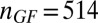 ), (B) complex (
), (B) complex (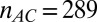 ,
, 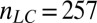 ,
, 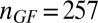 ), and (C) positive (
), and (C) positive (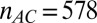 ,
, 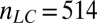 ,
, 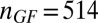 ). In each panel, symbols (=, −, ., +, #) correspond to probability range
). In each panel, symbols (=, −, ., +, #) correspond to probability range 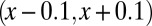 for
for 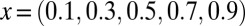 , respectively. Symbols are shifted horizontally to minimize overstrike. For example, all three columns on the x axis near
, respectively. Symbols are shifted horizontally to minimize overstrike. For example, all three columns on the x axis near 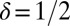 actually refer to data located on the vertical
actually refer to data located on the vertical 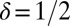 line.
line.
Fig. 4.
Partial  -phase diagram for DG frames. Panels show different coefficient fields: (A) positive (
-phase diagram for DG frames. Panels show different coefficient fields: (A) positive ( ), (B) real (
), (B) real (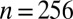 ), and (C) complex (
), and (C) complex (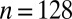 ). In each panel, symbols (=, −, ., +, #)/colors (violet, red, yellow, green, blue) correspond to probability range
). In each panel, symbols (=, −, ., +, #)/colors (violet, red, yellow, green, blue) correspond to probability range 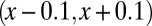 for
for 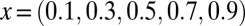 , respectively.
, respectively.
Precise Positioning of Phase Transition.
To address our main hypothesis regarding the agreement of phase transition boundaries, we measure 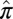 at points
at points 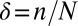 and
and 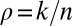 in the phase plane
in the phase plane 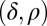 , which we expect to be maximally informative about the location of the phase transition. In fact, the informative locations in binomial response models correspond to points where the probability of response is nearly 50%; hence, we sample heavily for
, which we expect to be maximally informative about the location of the phase transition. In fact, the informative locations in binomial response models correspond to points where the probability of response is nearly 50%; hence, we sample heavily for 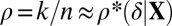 . Figs. S1–S3 show examples comparing the fitted phase transition with the Gaussian theoretical ones. In brief, the results are broadly consistent in all cases with the Gaussian theory, with deviations following a familiar and expected pattern.
. Figs. S1–S3 show examples comparing the fitted phase transition with the Gaussian theoretical ones. In brief, the results are broadly consistent in all cases with the Gaussian theory, with deviations following a familiar and expected pattern.
Finite-N Scaling.
The Gaussian theory is asymptotic as 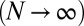 (19–21, 34), and in general, even with Gaussian random matrices, the large N theory cannot be expected to match empirical data to within the usual naive SEs (21). Instead, one observes, at finite problem sizes, a finite transition zone of width
(19–21, 34), and in general, even with Gaussian random matrices, the large N theory cannot be expected to match empirical data to within the usual naive SEs (21). Instead, one observes, at finite problem sizes, a finite transition zone of width 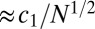 and a small displacement of the empirical phase transition away from the asymptotic Gaussian phase transition of size
and a small displacement of the empirical phase transition away from the asymptotic Gaussian phase transition of size 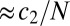 . Analysis techniques used in ref. 21 motivated Figs. S1 and S2. Visual inspection shows that, as N increases, the data become increasingly consistent with the Gaussian
. Analysis techniques used in ref. 21 motivated Figs. S1 and S2. Visual inspection shows that, as N increases, the data become increasingly consistent with the Gaussian 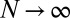 prediction. In brief, the results are consistent with a transition zone width that tends to zero and a transition offset that also tends to zero as N increases.
prediction. In brief, the results are consistent with a transition zone width that tends to zero and a transition offset that also tends to zero as N increases.
Discussion
Rigorous Analysis Justifying Our Approach.
In one of four coefficient situations that we study—the case where coefficients in 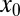 are real and bounded:
are real and bounded: 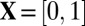 —Donoho and Tanner (10) have proven that, for every reasonable matrix, the same probability distribution holds in finite samples. In consequence, the Gaussian theory, which describes one specific random matrix ensemble, actually describes all reasonable deterministic matrices.
—Donoho and Tanner (10) have proven that, for every reasonable matrix, the same probability distribution holds in finite samples. In consequence, the Gaussian theory, which describes one specific random matrix ensemble, actually describes all reasonable deterministic matrices.
Theorem (10).
Suppose that A is a fixed matrix with its N columns in general position†
in
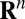 . Then
. Then
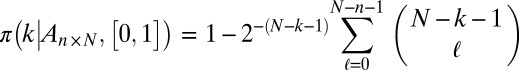 |
This probability is independent of the matrix A for A ranging through an open dense set in the space of 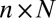 matrices. In addition to motivating our conclusion, it gives a valuable check on our analysis techniques, because it provides the exact expression
matrices. In addition to motivating our conclusion, it gives a valuable check on our analysis techniques, because it provides the exact expression
and the exact distribution of 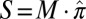 as binomial
as binomial 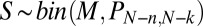 .
.
It also motivates our analysis technique. From the binomial form of 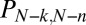 , one can see that
, one can see that
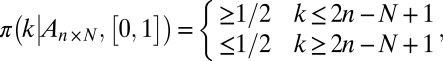 |
and therefore, for any sequence of matrices 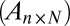 all in general position, our experimental method will recover the correct phase transition:
all in general position, our experimental method will recover the correct phase transition:
The theorem also motivates the finite-N scaling analysis. Using the exact binomial law 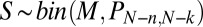 , we conclude that, for large N, the 97.5% success point
, we conclude that, for large N, the 97.5% success point 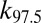 satisfies
satisfies 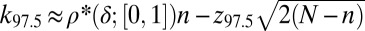 , whereas the 2.5% success point
, whereas the 2.5% success point 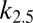 satisfies
satisfies 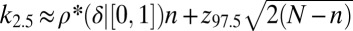 , where
, where 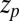 denotes the pth percentile of the standard normal (
denotes the pth percentile of the standard normal (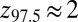 ). Hence, one sees that the transition zone between complete failure and complete success has a width roughly
). Hence, one sees that the transition zone between complete failure and complete success has a width roughly 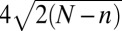 , thereby justifying our fitting power laws in n to the observed transition width.
, thereby justifying our fitting power laws in n to the observed transition width.
Finally, the universality of the phase transition 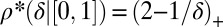 across all deterministic matrices with columns in general position motivates the thrust of this whole project.
across all deterministic matrices with columns in general position motivates the thrust of this whole project.
Asymptotic Analysis.
Tropp (8) and Candès and Plan (9) obtained initial theoretical results on the problem of a single large matrix. They consider a sequence of matrices 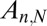 and for each fixed problem size
and for each fixed problem size 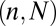 , a random
, a random 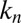 -sparse
-sparse 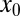 , which they try to recover from measurements
, which they try to recover from measurements 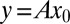 . Their methods apply to all of the matrix families that we have considered here, because our matrices all have low coherence. They give conditions on the aspect ratio
. Their methods apply to all of the matrix families that we have considered here, because our matrices all have low coherence. They give conditions on the aspect ratio 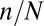 , the coherence of
, the coherence of 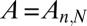 , and
, and 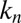 , such that, with high probability,
, such that, with high probability, 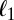 minimization will correctly recover
minimization will correctly recover 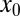 . Their results are ultimately qualitative in that, for a wide variety of matrices, they predict that there will be a success phase for small
. Their results are ultimately qualitative in that, for a wide variety of matrices, they predict that there will be a success phase for small 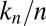 . However, their results are unable to shed light on the size or shape of the success region. In contrast, we show here that the region is asymptotically the same for certain deterministic matrices as the region for random Gaussian measurement matrices. Separately, Howard et al. (35) and Calderbank et al. (36) pointed to the analogy between compressed sensing and random coding in information theory and observed that average-case reconstruction performance of a deterministic sensing matrix can be expected to be very good, even for some matrices with poor worst-case performance.
. However, their results are unable to shed light on the size or shape of the success region. In contrast, we show here that the region is asymptotically the same for certain deterministic matrices as the region for random Gaussian measurement matrices. Separately, Howard et al. (35) and Calderbank et al. (36) pointed to the analogy between compressed sensing and random coding in information theory and observed that average-case reconstruction performance of a deterministic sensing matrix can be expected to be very good, even for some matrices with poor worst-case performance.
Restricted Isometry Properties of Deterministic Matrices.
In recent work, several authors have constructed deterministic matrices obeying the so-called restricted isometry property (RIP) of Candès and Tao (2). Such matrices, if they could be built for sufficiently high k (relative to 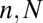 ) would guarantee sparse recovery in a particularly strong sense: every k-sparse
) would guarantee sparse recovery in a particularly strong sense: every k-sparse 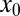 would be recoverable. This statement would be a deterministic and not a probabilistic one. Bourgain et al. (37) are the current record holders in deterministic RIP constructions; they have constructed matrices obeying RIP for k slightly§ larger than
would be recoverable. This statement would be a deterministic and not a probabilistic one. Bourgain et al. (37) are the current record holders in deterministic RIP constructions; they have constructed matrices obeying RIP for k slightly§ larger than 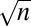 (37). This result is still far too weak to imply anything close to the empirically observed phase transitions or the known strong neighborliness phase transition for the case of Gaussian matrices.
(37). This result is still far too weak to imply anything close to the empirically observed phase transitions or the known strong neighborliness phase transition for the case of Gaussian matrices.
Calderbank et al. (36) introduced a notion of statistical RIP (StRIP) and constructed a number of deterministic matrices with StRIP. Such matrices guarantee sparse recovery in the same sense as used in this paper (i.e., according to statistical statements across random k-sparse objects with random positions for the nonzeros). However, to our knowledge, existing arguments are not able to derive precise phase transitions from StRIP; they only show that there is some region with high success but do not delineate precisely the regions of success and failure.
Table 1 lists several deterministic matrices obeying StRIP. Indeed, Calderbank et al. (36) used group theory to provide sufficient conditions for a sensing matrix to satisfy StRIP. Subsequently, Jafarpour (15) showed that the coherence property introduced in ref. 38 in conjunction with the tightness of the frame honors the requirements given in ref. 36 and therefore, provides sufficient conditions for StRIP. Combining these arguments, the matrices in Table 1 labeled SS, SH, SN, PETF, GF, DG, and LC obey StRIP for sufficiently large problem sizes. Refs. 15, 38, and 39 have additional discussion on the conditioning and null-space structure of these matrices. We show here that, for all these ensembles, the success region is empirically consistent with the theoretical region for random Gaussian matrices.
Other Ensembles.
We studied several matrix ensembles not mentioned so far. For example, we used the same simulation framework and software to study random Gaussian matrices, partial Fourier matrices, and partial Hadamard matrices; our results are in line with earlier reports of Donoho and Tanner (3). We also considered several variations of the SS example based on Discrete Cosine Transforms (DCTs) of types I, II, III, and IV and the discrete Hartley transform. Finally, because of their importance to the theory of convex polytopes, we also considered the cyclic matrices when 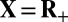 . All of the deterministic matrices that we considered yielded experimental data consistent with asymptotic agreement of the empirical phase transition and the theoretical phase transition in the Gaussian case—with exceptions noted immediately below.
. All of the deterministic matrices that we considered yielded experimental data consistent with asymptotic agreement of the empirical phase transition and the theoretical phase transition in the Gaussian case—with exceptions noted immediately below.
Surprises.
We were surprised by two anomalies.
Positive coefficients, solver for signed coefficients.
We can apply the signed solver [i.e., the solver for 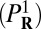 ] even when the coefficients are nonnegative. For several of the matrices that we considered, the phase transition that will be observed is the one that is universal for signed coefficients
] even when the coefficients are nonnegative. For several of the matrices that we considered, the phase transition that will be observed is the one that is universal for signed coefficients 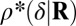 . However, in several cases, we observed instead a phase transition at
. However, in several cases, we observed instead a phase transition at 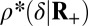 , although the problem solved did not assume nonnegative structure. Table 2 presents a list of matrices with this positive adaptivity property. We learned from this phenomenon that, to observe universal signed behavior in the signed case, for some matrices A, it was necessary to make sure that the object
, although the problem solved did not assume nonnegative structure. Table 2 presents a list of matrices with this positive adaptivity property. We learned from this phenomenon that, to observe universal signed behavior in the signed case, for some matrices A, it was necessary to make sure that the object 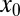 did not always obey
did not always obey 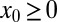 . For some other matrices, the signed solver gave the same phase transition regardless of whether the nonzeros contained both positive and negative values or only positive values. For conditions under which the sign pattern does not affect reconstruction, see ref. 40.
. For some other matrices, the signed solver gave the same phase transition regardless of whether the nonzeros contained both positive and negative values or only positive values. For conditions under which the sign pattern does not affect reconstruction, see ref. 40.
Table 2.
Evidence for the positive adaptivity property
| Label | Name | δ | 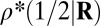 |
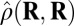 |
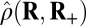 |
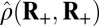 |
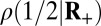 |
| SS | Spikes and Sines | 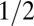 |
0.386 | 0.3914 | 0.5621 | 0.5624 | 0.558 |
| SH | Spikes and Hadamard | 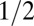 |
0.386 | 0.3942 | 0.5716 | 0.5687 | 0.558 |
| SN | Spikes and Noiselets | 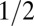 |
0.386 | 0.3677 | 0.5531 | 0.5605 | 0.558 |
| LC | Linear Chirp Frame | 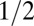 |
0.386 | 0.3865 | 0.5614 | 0.5576 | 0.558 |
| AC | Affine Plane Chirps | 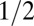 |
0.386 | 0.3866 | 0.5609 | 0.5582 | 0.558 |
Note that 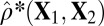 means the phase transition observed when the solver assumes
means the phase transition observed when the solver assumes 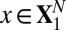 , whereas the object actually obeys
, whereas the object actually obeys 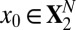 . Thus, the notation
. Thus, the notation 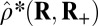 means the empirical phase transition that we observed when we ran the solver for signed objects, but in fact, the object was nonnegative. Data were taken at
means the empirical phase transition that we observed when we ran the solver for signed objects, but in fact, the object was nonnegative. Data were taken at 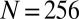 and 25 Monte Carlo repetitions at each grid point. SEs of estimated phase transition yield 2 SE error bars of width ∼ 0.01 (compare with Fig. S2).
and 25 Monte Carlo repetitions at each grid point. SEs of estimated phase transition yield 2 SE error bars of width ∼ 0.01 (compare with Fig. S2).
Cyclic matrix, positive coefficients.
Assuming n is even and 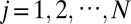 , the cyclic matrix is defined as (41, 42) (Eq. 2)
, the cyclic matrix is defined as (41, 42) (Eq. 2)
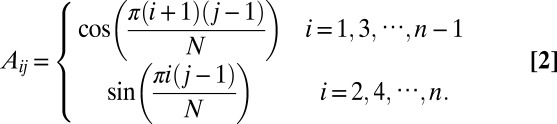 |
As discussed in ref. 42, in the case of nonnegative coefficients 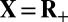 and assuming
and assuming 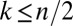 nonzeros in
nonzeros in 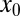 , there is a unique solution to
, there is a unique solution to 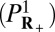 :
: 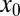 . Consequently, the phase transition associated with this matrix must obey
. Consequently, the phase transition associated with this matrix must obey 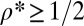 for every δ. Empirically, we do not observe
for every δ. Empirically, we do not observe 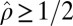 ; we, instead, observe
; we, instead, observe 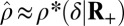 exactly as with other matrices! (See Fig. 1.)
exactly as with other matrices! (See Fig. 1.)
In short, although the theory of cyclic polytopes seemingly forbids it, our observations are consistent with large-N universality of the Gaussian-based formula. Remember that we are considering the behavior of numerical algorithms and that the cyclic matrix contains many very poorly conditioned subsets of k-columns. Possibly, numerical ill-conditioning is responsible for the failure of the predictions from polytope theory.
Limits to Universality.
We emphasize that, although the prediction from Gaussian theory applies to many matrices, we do not expect it to apply to all matrices, the theorem quoted from ref. 10 notwithstanding.
Conclusions
For an important collection of large deterministic matrices, the behavior of convex optimization in recovering random k-sparse objects is accurately predicted by the theoretical expressions that are known for the case of Gaussian random matrices. Evidence is presented for objects with coefficients over each of the sets 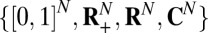 when the convex optimization problem is appropriately matched and the positions and signs of the nonzeros are randomly assigned.
when the convex optimization problem is appropriately matched and the positions and signs of the nonzeros are randomly assigned.
Standard presentations of compressed sensing based on RIP suggest to practitioners that good deterministic matrices for compressed sensing are as yet unavailable, and possibly will be available only after much additional research. We use instead the notion of phase transition, which measures, in a straightforward way, the probability of exact reconstruction. We show here that reconstruction of sparse objects by convex optimization works well for certain deterministic measurement matrices—in fact, just as well as for true random matrices. In particular, our demonstration covers several explicit deterministic matrices for which fast transforms are known.
Supplementary Material
Acknowledgments
We would like to thank Michael Saunders and Michael Friedlander for providing us with a prerelease version of the optimization software ASP. This work was partially supported by National Science Foundation Grant DMS 0906812 (American Reinvestment and Recovery Act). Part of the work was done when S.J. was a research scientist at Yahoo! Research. Sam Gross held an NSF-DMS VIGRE fellowship, and Young Choi was supported by Army Grant W911NF-07-2-0027-1. Kevin S. Raines was supported by National Science Foundation Grant DGE 1147470 as well as the Stanford Humanities and Sciences Fellowship. Mainak Choudhury was supported by a 3Com Corp. Stanford Graduate Fellowship. Carlos Sing-Long was partially supported by a Fulbright-CONICYT scholarship.
Footnotes
The authors declare no conflict of interest.
Data deposition: The data reported in this paper are available at http://purl.stanford.edu/wp335yr5649.
See Commentary on page 1146.
1A complete list of the Stat 330/CME 362 Collaboration can be found in SI Text.
*This research began as a class project at Stanford University by students of Stat 330/CME 362, which was taught by D.L.D. in Fall of 2011 (Teaching Assistant: M.G.). The basic discovery was a joint effort of all of the participants. Independently, S.J. made a similar discovery in studying Delsarte-Goethals frames for his thesis.
†A collection of vectors in 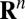 is said to be in general position if no subcollection of, at most, n vectors is linearly dependent.
is said to be in general position if no subcollection of, at most, n vectors is linearly dependent.
§I.e., 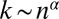 , with
, with 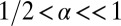 .
.
This article contains supporting information online at www.pnas.org/lookup/suppl/doi:10.1073/pnas.1219540110/-/DCSupplemental.
References
- 1.Donoho DL. Compressed sensing. IEEE Trans Inf Theory. 2006;52(4):1289–1306. [Google Scholar]
- 2.Candès EJ, Tao T. Decoding by linear programming. IEEE Trans Inf Theory. 2005;51(1):4203–4215. [Google Scholar]
- 3.Donoho D, Tanner J. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Philos Transact A Math Phys Eng Sci. 2009;367(1906):4273–4293. doi: 10.1098/rsta.2009.0152. [DOI] [PubMed] [Google Scholar]
- 4.Bayati M, Lelarge M, Montanari A. Universality in polytope phase transitions and message passing algorithms. 2012 arXiv:1207.7321. [Google Scholar]
- 5.Beck A, Teboulle M. Fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J Imaging Sci. 2009;2(1):183–202. [Google Scholar]
- 6.Donoho DL, Maleki A, Montanari A. Message-passing algorithms for compressed sensing. Proc Natl Acad Sci USA. 2009;106(45):18914–18919. doi: 10.1073/pnas.0909892106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Howard S, Calderbank R, Searle S. Conference on Information Sciences and Systems (CISS) Piscataway, NJ: IEEE; 2008. Fast reconstruction algorithm for deterministic compressive sensing using second order reed-muller codes; pp. 11–15. [Google Scholar]
- 8.Tropp J. On the conditioning of random subdictionaries. Appl Comput Harmon Anal. 2008;25(1):1–24. [Google Scholar]
- 9.Candès EJ, Plan Y. Near-ideal model selection by ℓ1 minimization. Ann Stat. 2009;37(5A):2145–2177. [Google Scholar]
- 10.Donoho D, Tanner J. Counting the faces of randomly-projected hypercubes and orthants, with applications. Discrete Comput Geom. 2010;43(3):522–541. [Google Scholar]
- 11.Donoho DL, Stark PB. Uncertainty principles and signal recovery. SIAM J Appl Math. 1989;49(3):906–931. [Google Scholar]
- 12.Donoho DL, Huo X. Uncertainty principles and ideal atomic decomposition. IEEE Trans Inf Theory. 2001;47(7):2845–2862. [Google Scholar]
- 13.Tropp J. On the linear independence of spikes and sines. J Fourier Anal Appl. 2008;14(5-6):838–858. [Google Scholar]
- 14.Strohmer T, Heath R. Grassmannian frames with applications to coding and communication. Appl Comput Harmon Anal. 2003;14(3):257–275. [Google Scholar]
- 15.Jafarpour S. 2011. Deterministic compressed sensing. PhD thesis (Princeton University, Princeton)
- 16.Bandeira A, Fickus M, Mixon D, Wong P. The road to deterministic matrices with the restricted isometry property. 2012 arXiv:12021234. [Google Scholar]
- 17.Chen S, Donoho D, Saunders M. Atomic decomposition by Basis Pursuit. SIAM J Sci Comput. 1999;20(1):33–61. [Google Scholar]
- 18.Boyd S, Vandenberghe L. Convex Optimization. Cambridge, United Kingdom: Cambridge Univ Press; 2004. [Google Scholar]
- 19.Donoho D. High-dimensional centrally symmetric polytopes with neighborliness proportional to dimension. Discrete Comput Geom. 2006;35(4):617–652. [Google Scholar]
- 20.Donoho DL, Tanner J. Neighborliness of randomly projected simplices in high dimensions. Proc Natl Acad Sci USA. 2005;102(27):9452–9457. doi: 10.1073/pnas.0502258102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Donoho D, Tanner J. Counting faces of randomly-projected polytopes when the projection radically lowers dimension. J Amer Math Soc. 2009;22(1):1–53. [Google Scholar]
- 22.Maleki A, Anitoriy L, Yang Z, Baraniuk R. Asymptotic analysis of complex lasso via complex approximate message passing (camp) 2011 arXiv:11080477v1. [Google Scholar]
- 23.Grant M, Boyd S. 2010. CVX: Matlab Software for Disciplined Convex Programming, Version 1.21. Available at http://cvxr.com/cvx. Accessed December 12, 2012.
- 24.Grant M, Boyd S, Ye Y. Disciplined convex programming. In: Liberti L, Maculan N, editors. Global Optimization: From Theory to Implementation, Nonconvex Optimization and Its Applications. New York: Springer; 2006. pp. 155–210. [Google Scholar]
- 25.Grant M, Boyd S. CVX Users’ Guide for CVX Version 1.22. 2012. Available at http://cvxr.com/cvx/cvx_usrguide.pdf. Accessed December 12, 2012. [Google Scholar]
- 26.Friedlander M, Saunders M. ASP: A Set of Matlab Functions for Solving Basis Pursuit-Type Problems. 2010. Available at http://www.cs.ubc.ca/˜mpf/asp. Accessed December 14, 2012. [Google Scholar]
- 27.Friedlander M, Saunders M. 2011. A Dual Active-Set Quadratic Programming Method for Finding Sparse Least-Squares Solutions, Department of Computer Science, University of British Columbia. Available at http://www.cs.ubc.ca/~mpf/asp. Accessed December 15, 2012.
- 28.van den Berg E, Friedlander MP. Probing the pareto frontier for basis pursuit solutions. SIAM J Sci Comput. 2008;31(4):890–912. [Google Scholar]
- 29.van den Berg E, Friedlander MP. 2007. SPGL1: A Solver for Large-Scale Sparse Reconstruction. Available at http://www.cs.ubc.ca/labs/scl/spgl1. Accessed December 12, 2012.
- 30.Mosek APS. Mosek Optimization Software. 2012. Available at http://www.mosek.com. Accessed December 12, 2012.
- 31. Andersen M, Vandeberghe L (2012) CVXOPT. Available at http://abel.ee.ucla.edu/cvxopt/index.html. Accessed December 27, 2012.
- 32. Monajemi H, Jafarpour S, Gavish, M {Stat 330/CME 362} Collaboration, Donoho DL (2012) Data for the article Deterministic Matrices Matching the Compressed Sensing Phase Transitions of Gaussian Random Matrices. Available at http://purl.stanford.edu/wp335yr5649. Accessed December 14, 2012.
- 33. Monajemi H, Jafarpour S, {Stat 330/CME 362} Collaboration, Gavish M, Donoho D (2012) RunMyCode Companion Website for Deterministic Matrices Matching the Compressed Sensing Phase Transitions of Gaussian Random Matrices. Available at http://www.runmycode.org/CompanionSite/Site190. Accessed December 27, 2012.
- 34.Donoho D, Tanner J. Precise undersampling theorems. Proc IEEE. 2010;98(6):913–924. [Google Scholar]
- 35.Howard S, Calderbank A, Searle S. Proceedings of 42nd Annual IEEE Conference on Information Sciences and Systems. Piscataway NJ: IEEE; 2008. A fast reconstruction algorithm for deterministic compressive sensing using second order reed-muller codes; pp. 11–15. [Google Scholar]
- 36.Calderbank AR, Howard S, Jafarpour S. Construction of a large class of deterministic matrices that satisfy a statistical restricted isometry property. IEEE J Sel Top Signal Process. 2010;4(2):358–374. [Google Scholar]
- 37.Bourgain J, Dilworth S, Ford K, Konyagin S, Kutzarova D. Explicit constructions of RIP matrices and related problems. Duke Math J. 2011;159(1):145–185. [Google Scholar]
- 38.Bajwa W, Calderbank R, Jafarpour S. Proceedings of the 48th Annual Allerton Conference on Communication, Control, and Computing. NJ: IEEE Piscataway; 2010. Revisiting model selection and recovery of sparse signals using one-step thresholding; pp. 977–984. [Google Scholar]
- 39.Jafarpour S, Duarte MF, Calderbank AR. IEEE International Symposium on Information Theory (ISIT) Cambridge, MA: IEEE; 2012. Beyond worst-case reconstruction in deterministic compressed sensing; pp. 1852–1856. [Google Scholar]
- 40.Bajwa W, Calderbank R, Jafarpour S. Why Gabor frames? Two fundamental measures of coherence and their role in model selection. arXiv:1006.0719. 2010 [Google Scholar]
- 41.Grünbaum B. Convex Polytopes. 2003. Graduate Texts in Mathematics, Vol 221 (Springer, New York), 2nd Ed. [Google Scholar]
- 42.Donoho DL, Tanner J. Sparse nonnegative solution of underdetermined linear equations by linear programming. Proc Natl Acad Sci USA. 2005;102(27):9446–9451. doi: 10.1073/pnas.0502269102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Coifman R, Meyer Y, Geschwind F. Noiselets. Appl Comput Harmon Anal. 2001;10(1):27–44. [Google Scholar]
- 44.Applebaum L, Howard S, Searle S, Calderbank R. Chirp sensing codes: Deterministic compressed sensing measurements for fast recovery. Appl Comput Harmon Anal. 2009;26(2):283–290. [Google Scholar]
- 45.Gurevich S, Hadani R, Sochen N. The finite harmonic oscillator and its associated sequences. Proc Natl Acad Sci USA. 2008;105(29):9869–9873. doi: 10.1073/pnas.0801656105. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.