

Abstract
In the present study, we consider the problem of classifying spatial data distorted by a linear transformation or convolution and contaminated by additive random noise. In this setting, we show that classifier performance can be improved if we carefully invert the data before the classifier is applied. However, the inverse transformation is not constructed so as to recover the original signal, and in fact, we show that taking the latter approach is generally inadvisable. We introduce a fully data-driven procedure based on cross-validation, and use several classifiers to illustrate numerical properties of our approach. Theoretical arguments are given in support of our claims. Our procedure is applied to data generated by light detection and ranging (Lidar) technology, where we improve on earlier approaches to classifying aerosols. This article has supplementary materials online.
Keywords: Centroid classifier, Cross-validation, Fourier transform, Inverse transform, Spatial data
1. INTRODUCTION
In the present study, we consider signal classification problems, where the observations are d-dimensional noisy spatial functions Yij, for 1 ≤ i ≤ nj, coming from population Πj, where j = 1 or 2, and which can be modeled as Yij = TXij + δij, where T is a transformation of the function of interest Xij and δij is a random error with zero mean and some correlation structure. Based on training data, the goal is to classify a new noisy data function Y whose class is unknown, as coming from one of Π1 and Π2.
In many instances, the function TXij is the result of a convolution of the function Xij with a blurring source, that is, TXij = ωT * Xij, where * denotes the convolution operator (see Section 2.3) and ωT is a point spread function. There, the function Xij can be reconstructed in part by a (necessarily estimated) deconvolution operation. There is a large statistics literature on deconvolution for image data, and for data of similar type, dating from the 1980s. It includes contributions by Besag (1986), Donoho (1994), Dass and Nair (2003), Qiu (2005, 2007, 2008), and Mukherjee and Qiu (2011). Related research problems arise in spatial statistics, for example, in the contexts of remote sensing (see, e.g., Klein and Press 1992; Cressie and Kornak 2003; Crosilla, Visintini, and Sepic 2007) and statistical signal recovery (see, e.g., Johnstone 1990; Huang and Cressie 2000; Shi and Cressie 2007).
There is also a significant literature on blind deconvolution and estimation of point spread functions. This work includes contributions by Kundur and Hatzinakos (1998), Cannon (1976), Carasso (2001), Galatsanos et al. (2002), Figueiredo and Nowak (2003), Joshi and Chaudhuri (2005), Hall and Qiu (2007a, b), Qiu (2008), Huang and Qiu (2010), and Popescu and Hellicar (2010). However, the problems of deconvolution and point spread function estimation are very different from those of classification, to such an extent that, even if T were known, the methods suggested in this article would still be recommended. It should also be noted that, since neither the function X nor the noise δ is observable, it is not possible to estimate the noise and, hence, to remove it effectively from the observed data Y. In particular, in the problem treated in this article, it is not possible to compute residuals.
In our classification context, it is at least intuitively plausible that if one could recover the function Xij, then one would use that function as the basis for classification, rather than using the noisy convolved function Yij. This idea has been used in the classification of different types of aerosols using long-range infrared light detection and ranging (Lidar) methods (Warren et al. 2008), where deconvolution was used to obtain estimates of the true signal, and the resulting estimates were used as the basis for classification. Our work relates to whether a signal should be deconvolved or correlated errors should be deconvolved before classification, and we shall use Lidar data to illustrate our conclusions. We shall show that there exists a transformation of the noisy convolved function Yij that is appropriate for classification, but that it is not necessarily related to the transformation that would be used to recover the true signal.
The real-data classification problems that motivate this work, all involve just K = 2 populations, and for this reason, and to simplify discussion, we shall confine attention to this case. However, out methodology and theoretical results extend readily to the general case K ≥ 2, using the approach suggested by Friedman (1996).
The article is organized as follows. We introduce our model and ideas in Section 2, and in Section 3, we establish theoretical properties of our procedure. In Section 4, using a variety of classifiers, we apply our approach to simulated data and to the Lidar data mentioned above. Technical arguments are deferred to the supplementary materials.
2. METHODS
2.1 Model and Classification Problem
We observe spatial data functions Yij (r), r ∈
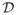 , 1 ≤ i ≤ nj, j = 1, 2, generated by the model
, 1 ≤ i ≤ nj, j = 1, 2, generated by the model
| (2.1) |
where
denotes a d-dimensional spatial grid, or lattice; Xij is the spatial function of interest, T is a linear transformation that blurs the signal; and δij, representing noise, is a component of a correlated stochastic process with zero mean affecting the signal. In this model, the data come from two populations, Π1 and Π2, and, for j = 1, 2, Yij denotes the ith data function drawn from the jth population Πj, where i = 1, …, nj. To simplify notation, we define scale in such a way that
⊂ ℤd, where ℤ is the set of all integers.
The model at Equation (2.1) is appropriate when the observations Yij are, for example, digitized images or Lidar signals. There, T typically represents the accumulated impact of issues such as generalized lens aberrations, atmospheric effects, motion blur, etc., and
is a two- or three-dimensional grid.
Remark 1
It is important to realize that Yij, Xij, and δij are functions defined on
, and that T (and later, the transforms R and Q, which will be defined below) is not a function; it is a functional that maps the function Xij to the function T Xij .
Let Y be a new data value coming from Πk, where k = 1 or 2 is unknown. Our goal is to construct a classifier
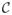 (·) ≡
(·|{Yij}j = 1,2; i = 1,…,nj) from the data Yij that assigns Y to Πk̂, where k̂ =
(Y|{Yij}j = 1,2; i = 1,…,nj) = 1 or 2 is an estimator of k. In the applications we have in mind, where the data are images or Lidar signals, distinguishing between Π1 and Π2 is inherently a problem involving high-dimensional data analysis. In practice, the number of points r at which we observe data Yij(r) can be in the thousands, whereas the training sample sizes, n1 and n2, are often only limited to 20 or 30.
(·) ≡
(·|{Yij}j = 1,2; i = 1,…,nj) from the data Yij that assigns Y to Πk̂, where k̂ =
(Y|{Yij}j = 1,2; i = 1,…,nj) = 1 or 2 is an estimator of k. In the applications we have in mind, where the data are images or Lidar signals, distinguishing between Π1 and Π2 is inherently a problem involving high-dimensional data analysis. In practice, the number of points r at which we observe data Yij(r) can be in the thousands, whereas the training sample sizes, n1 and n2, are often only limited to 20 or 30.
2.2 Deconvolution of the Data Through the Noise Transform
As we indicated in the Introduction, when the functional T is invertible, it is sometimes argued that, instead of applying standard classifiers to the data Yij, one should apply them to inverted data where Y and each Yij are replaced by T−1
Y and T−1
Yij, or rather by regularized versions of them, T̂−1
Y and T̂−1
Yij. That is, classification should be based on
(T̂−1
Y|{T̂−1Yij}j = 1,2; i = 1,…,nj), instead of
(Y|{Yij}j =1,2;i=1,…,nj). Transforming the data by T−1 is a good idea when the goal is to recover the function Xij, since we have T−1
Yij = Xij + T−1
δij, so the transformed data are no longer distorted and contain only additive noise T−1
δij of zero mean. This is only approximately true when using T̂−1, of course; see, for example, Cannon and Hunt (1981) and Hall (1990). However, we argue that when the goal is classification, inverting T is not necessarily a good idea, and a better strategy is to transform the data in such a way that classification performance is improved.
To explore the classification problem further, let εij = T Xij − T μj + δij, where the function μj is defined by μj = Ej(Xij) and Ej denotes expectation, conditional on Xij coming from population j. Then, (2.1) can be written as
| (2.2) |
where Ej(εij) = Ej(δij) = 0. If the processes Xij − μj and δij are also linear, in particular if εij is stationary and Gaussian, as is often approximately the case in practice, then we can write εij = R ξij, where R is another linear transformation and the process ξij is white noise, that is, the random variables ξij(r), for r ∈ ℤd, are uncorrelated and have zero mean and common variance σ2. In this notation, the model in Equation (2.2) can be expressed as
| (2.3) |
so if R is invertible, Equation (2.3) can be written equivalently as
The absence of correlation of ξij, and the constant variances, suggests that, for a variety of classifiers, performance can be improved by working with the data R−1 Y, rather than with Y itself. For example, this is the case when the error process εij in Equation (2.2) is stationary and Gaussian and we use the centroid classifier (see Section 3.1). Indeed, there, the classifier based on such transformed data is Fisher’s linear discriminant, albeit in a much higher-dimensional setting than is usually contemplated, and so, has optimality properties. In particular, this classifier is asymptotically equivalent to applying a likelihood ratio test. More generally, we shall show in Section 3 that in non-Gaussian cases, the optimal transformation, in terms of asymptotic performance of the centroid classifier, is also R−1.
These considerations suggest that, for such classifiers, far from it being a good idea to replace Y and Yij by their deconvolved forms T−1
Y and T−1
Yij, we should replace them by R−1
Y and R−1
Yij and base classification on
(R−1
Y|{R−1
Yij}j = 1,2; i = 1,…,nj). For more general classifiers too, transforming the data prior to applying a classifier can often improve performance, but not when this transform is taken to be T−1. In practice, the optimal transform is unknown and is not necessarily equal to R−1 for each classifier, since the best transform may depend on the particular classifier in use. Likewise, the optimal transform is not necessarily always exactly linear. However, by inverting the Yij’s via a carefully chosen linear transform, which we shall denote by Q−1 in the next section, we can often improve classification performance significantly. We suggest such a practicable inversion technique in the next section, and we construct it from the data in such a way as to optimize classification performance.
2.3 Transforming the Data in Practice
2.3.1 Modeling the Transform
Since the best transform to apply to the data Yij prior to classification is generally not known, it needs to be estimated from the data. However, the sample size is usually too small for estimating this transform without imposing restrictions on it. Motivated by our discussion in the last paragraph of Section 2.2, we model the transform by the inverse Q−1 of a linear transform Q = Qθ, which depends on a low-dimensional vector of parameters θ = (θ1, …, θq), as follows.
Let ωQθ be a nonnegative weight function defined on ℤd and depending on θ. Moreover, let * denote the discrete convolution operation, defined for any two absolutely square summable functions f and g by f * g(r) = Σs∈ℤdf (r − s) g(s). We take Qθ to be the linear transform that maps a function ζ to a function χθ = Qθ ζ defined, for each r ∈ ℤd, by
| (2.4) |
In image analysis terminology, ωQθ is called the spread function of the transform Qθ. The choice of the parameters θ will be treated in Section 2.3.3.
An example of a simple model for ωQθ is the two-parameter family ωp0;θ, where θ = (ρ, ℓ) and ωp0;θ is the ℓ-fold convolution of the probability mass function p0, defined by
| (2.5) |
where and |ρ| < 1 (usually, 0 < ρ < 1). This is the model we used in our numerical work in Section 4, but alternative models and more comments are given in Appendix A.2 in the supplementary materials.
2.3.2 Inverting Q
Since Qθ is defined by a convolution, its inverse is more easily expressed in the Fourier domain. Let ζ be a function defined on ℤd such that Σr∈ℤd|ζ(r)|< ∞. The (discrete) Fourier transform φζ(t), for t ∈ (−π, π)d, is defined by
| (2.6) |
where, on this occasion, . Since the Fourier transform of a convolution between two functions is equal to the product of their Fourier transforms, we deduce from Equation (2.4) that the Fourier transform of the function χθ is given by φχθ = φζ φωQθ.
In this notation, when φωQθ (t) ≠ 0, we can write φζ(t) = φχθ(t)/φωQθ (t). If |φχθ|/|φωQθ is integrable, then Qθ is invertible, and the inverse transform
, obtained by the Fourier inversion theorem, maps the function χθ into the function
defined by (2.8), taking there
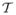 = (−π, π)d. If Qθ is not invertible, we can typically define a generalized inverse,
, by truncating the integral used in Fourier inversion to a small-enough set
⊂ (−π, π)d, for example,
= (−π, π)d. If Qθ is not invertible, we can typically define a generalized inverse,
, by truncating the integral used in Fourier inversion to a small-enough set
⊂ (−π, π)d, for example,
| (2.7) |
with η ∈ (0, π). Thus, in either case, we can write
| (2.8) |
Remark 2
To motivate the selections of
in (2.7), observe that φωQθ (0) equals the sum of the weights ωQθ (r) over r ∈ ℤd, and the ωQθ (r)’s would normally be chosen so that this sum was strictly positive, in fact equal to 1. Therefore, φωQθ (0) ≠ 0, and by continuity, φωQθ (t) ≠ 0 for t in a sufficiently small neighborhood of the origin. Hence, choosing
as in the formulas in (2.7), for sufficiently small η, ensures that the integral at (2.8) is well defined if the function χθ is uniformly bounded.
For example, if we model Qθ by taking ωQθ = ωp0;θ, defined above Equation (2.5), then is particularly easy to calculate. As a matter of fact, by standard calculations, we have
| (2.9) |
for each t = (t1, …, td)T ∈ (−π, π)d, so
| (2.10) |
The integral in Equation (2.10) is well defined if we take
= (−π, π)d, in which case, it simplifies to
| (2.11) |
A very attractive aspect of this choice of Qθ is that we do not need smoothing parameters, such as η at Equation (2.7), to regularize the integral. Further, it can be proved that each integral in Equation (2.11) is equal to a constant, depending only on |sj − rj|, ρ, and ℓ, and which vanishes if |sj − rj| > ℓ. In other words, is a linear combination of values of χθ(s), for s in a neighborhood of r (more precisely, for s such that maxj =1,…,d |sj − rj| ≤ ℓ).
2.3.3 Estimation of Unknown Parameters
Now that we have a practicable representation for the transform to apply to the data before classification, it remains to choose θ. Just as, a priori, it may seem natural to invert the data by T−1, it may also seem natural to choose θ to give a good fit to the data. However, again, our goal here is to classify, and thus, θ should rather be chosen to optimize the performance of the classifier based on . We suggest choosing θ to minimize a cross-validation estimator of error rate.
Specifically, write π1 for the prior probability of Π1, which is typically taken to equal 0.5 if we have no a priori knowledge, or to n1/(n1 + n2) if we believe that the proportion of observations from Π1 in the training sample is representative of that in the population. Define
| (2.12) |
where
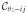 denotes the version of
denotes the version of
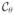 constructed without using Yij, that is,
. Then, ê(θ) estimates the error rate,
constructed without using Yij, that is,
. Then, ê(θ) estimates the error rate,
| (2.13) |
where Pj denotes probability conditional on Y ∈ Πj. We suggest choosing θ to minimize ê(θ).
Remark 3
In cases where the set
cannot be taken equal to (−π, π)d, the classifier can also depend on a small number of parameters defining
, which, if they are unknown, can play the role of a smoothing parameter; see the examples in (2.7). In such cases,
, ê(θ) and e(θ) are replaced by
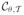 , ê(θ,
) and e(θ,
), respectively, and θ and
re chosen to minimize ê(θ,
).
, ê(θ,
) and e(θ,
), respectively, and θ and
re chosen to minimize ê(θ,
).
3. THEORY
3.1 Centroid Classifier
There exist a variety of standard classifiers that give good performance for high-dimensional data. Here, we discuss detailed theoretical properties in the context of one of the most popular and effective methods, the centroid-based technique; for example, see James and Hastie (2001) and Shin (2008). If
, the centroid method assigns a new value Y, coming from Π1 or Π2, to Π1 (i.e., it puts
(Y) = 1) if Σr∈
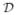 [{Y(r) − Ȳ2(r)}2 − (Y(r) − Ȳ1(r)}2] > 0, and to Π2 (i.e., it puts
(Y) = 2) otherwise. Other classifiers will be discussed in Section 4.4.
[{Y(r) − Ȳ2(r)}2 − (Y(r) − Ȳ1(r)}2] > 0, and to Π2 (i.e., it puts
(Y) = 2) otherwise. Other classifiers will be discussed in Section 4.4.
As already highlighted in Section 2.2, if the errors are stationary, then this classifier is optimized when applied to the data R−1
Yij. Using the representation
for R−1, an approximation to optimal classification involves assigning a new observation Y to Π1 (i.e., putting
(Y) = 1) if and only if Sθ(Y) > 0, where
| (3.1) |
with and where the functions Zθ and Zij;θ are defined by and .
In this notation, the cross-validation technique for choosing θ, described in Equation (2.12) in Section 2.3.3, can be written as
| (3.2) |
where Sθ;−ij denotes the version of Sθ in (3.1) calculated with Z̄j being replaced by . Likewise, the error rate e(θ) in Equation (2.13) can be written as
| (3.3) |
3.2 Main Assumptions
To simplify notation, throughout Section 3, we define scale in such a way that
, in d-variate Euclidean space, has edge width 1, for example,
| (3.4) |
where n ≥ 1. In this setting, #
≍ nd and the training sample sizes, n1 and n2, are interpreted as functions of n. Let
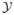 denote the pair of training samples (
denote the pair of training samples (
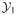 ,
,
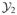 ), with
), with
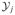 = {Yij, 1 ≤ i ≤ nj}, Yij = (Yij(r):r ∈
). The error rate of our classifier, computed from the training dataset
, is denoted by e(θ) and defined in Equation (3.3). In this section, we give asymptotic formulas for e(θ) and ê(θ), taking
to be a general subset of (−π, π)d. For example,
might be equal to (π, π)d, or to one of the regions defined in Equation (2.7). Theory in cases where cross-validation is used to determine
, as well as θ (see Remark 3 in Section 2.3.3), can be developed at the expense of longer arguments; in the present section, we use cross-validation to optimize over θ but not
, which corresponds to our practical implementation of the method; see Section 4.
= {Yij, 1 ≤ i ≤ nj}, Yij = (Yij(r):r ∈
). The error rate of our classifier, computed from the training dataset
, is denoted by e(θ) and defined in Equation (3.3). In this section, we give asymptotic formulas for e(θ) and ê(θ), taking
to be a general subset of (−π, π)d. For example,
might be equal to (π, π)d, or to one of the regions defined in Equation (2.7). Theory in cases where cross-validation is used to determine
, as well as θ (see Remark 3 in Section 2.3.3), can be developed at the expense of longer arguments; in the present section, we use cross-validation to optimize over θ but not
, which corresponds to our practical implementation of the method; see Section 4.
We develop our theory under three main model assumptions. First, we assume that R maps a function ζ, defined on ℤd, into a function R ζ, defined by
| (3.5) |
Second, we assume that
| (3.6) |
We impose this condition only to avoid long arguments for dealing with potential edge effects. Our conclusions remain valid without it, but the proofs become considerably longer. Finally, we assume that T μ1 − T μ2 = T (μ1 − μ2) is smoother than ωR. More precisely, we assume that T (μ1 − μ2) = α K * ωR, where α is a constant and K is a function supported on
. This assumption ensures that the inverse of the mean of the differences of the observed signals, R−1T(μ1 − μ2), remains bounded. It is imposed only to make our technical arguments simpler and explicit. If it is not satisfied, then, generally speaking, the classification problem becomes simpler, in that the difference between the means of the inverted signals is even larger and, therefore, easier to detect.
We allow the distance between the two transformed means, T μ1 and T μ2, to vary with n, by letting α above depend on n. In particular, we assume that T(μ1 − μ2) = αn K * ωR, where αn is a sequence of positive real numbers bounded above zero. The most important case is that where αn (and hence the distance) decreases with increasing n, since that enables our theoretical arguments to address particularly challenging cases. We also permit the noise variance, , to depend on n. We shall see that the relative sizes of n, αn, and σn interact together to determine the performance of our classifier. Although this interaction is quite complex, to a large extent, it can be represented in terms of the quantity
| (3.7) |
where φωR (t) = Σr∈ℤd
ωR(r) exp(i rTt) is the Fourier transform of ωR and φK (t) = Σr∈
K(r) exp(i rTt) is the Fourier transform of K; here, we used the fact that K is supported on
.
To derive our theoretical results, we also need regularity conditions. These are more technical, and we shall describe them in detail in Appendix B.1 in the supplementary materials; see Equations (B.2)–(B.6).
3.3 Asymptotic Formula for Error Rate
The next theorem describes properties of e(θ) as n diverges. Let Φ denote the standard normal distribution function, and write Θ for a compact set of parameters from which θ is chosen.
Theorem 1
Assume that the data are generated by the model in (2.3), where R is of the form in Equation (3.5) and T is a linear transformation, and that (B.2)–(B.6) hold. Then,
| (3.8) |
where the convergence is in probability.
To elucidate the implications of Theorem 1, observe first that the asymptotic error rate, Φ(−un), in Equation (3.8) is a monotone decreasing function of un. It therefore follows from the formula in Equation (3.7) for un(θ) that the error rate decreases as either the distance, represented by αn, between population means increases or the error variance, , decreases. Moreover, Hölder’s inequality implies that Φ{−un(θ)}, interpreted as a functional of φωQθ, is minimized when φωQθ = φωR, that is, when the transformation Qθ is identical to the actual transformation R.
3.4 Consistency of Cross-Validation Estimator of Error Rate
Recall the definition of ê(θ), the cross-validation estimator of error rate, in Equation (3.2). Theorem 2 shows that ê(θ) shares the same asymptotic property, Equation (3.8), as the actual error rate e(θ), and therefore, is consistent for e(θ), uniformly in θ.
Theorem 2
Assume the conditions of Theorem 1. Then,
| (3.9) |
where the convergence is in probability.
Similarly, it can be proved that if θ = θ̂ is chosen to minimize ê(θ), and used when constructing the classifier, then, under mild additional assumptions, the classifier’s actual error rate will equal minθ∈Θ Φ{−un(θ)} + o(1) as n → ∞.
4. NUMERICAL WORK
4.1 Goals of Simulations
We performed simulation studies to illustrate the following properties:
Transforming the data by T−1 prior to applying a classifier generally does not improve classification performance.
-
Transforming the data using a cross-validation-based transform generally improves classification performance even if is only a rough approximation to the best transform to apply.
(3) The more the errors εij are correlated, the larger is the improvement at (2), especially if the error variance σ2 is large compared with T μj.
The performance of classifiers, applied to data transformed by , improves as the training sample size and/or the fineness of the grid
increases.
4.2 Simulation Setup
4.2.1 Generation of Training Samples
We generated training samples {Y11, …, Y1n1} and {Y21, …, Y2n2}, of sizes n1 = n2 = 10 or n1 = n2 = 25, according to the model
| (4.1) |
for different curves μj, j = 1, 2, and transformations R and T, and with r ∈
⊂ ℝ or r = (r1, r2) ∈
⊂ ℝ2.
We considered four pairs of mean curves μj, for j = 1, 2 (two univariate and two bivariate), each with several features, such as asymmetric peaks and valleys, or sinusoidal components:
μj (r) = |2r − aj|4/5 exp{−5 · 10−4(4r2 − bj)}, where a1 = 5, b1 = 100, a2 = 4, b2 = 80.
, where, c1 = 200, c2 = 190.
, with aj and bj as in (a).
-
μj(r1, r2) = 0.1|4 + 3r2/50|1/5 · exp{−(3r1 + 20)/dj}/{1.2 + cos(1.5r1)} · 1[−20/3,∞)(r1),
where d1 = 40, d2 = 50, and 1[−20/3,∞)(r1) = 1 if r1 ∈ [−20/3, ∞) and 0 otherwise.
In the previous sections, the method was discussed for a grid that had edge width 1. More generally, in our simulations, we also considered examples where the grid has edge width k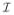 . In that case, the various transformations have to be rescaled by a factor k. More precisely, if a transform F has the form F ξ (r) = Σs∈ℤd
ωF(s) ξ (r − s) on a grid of edge width 1, on a grid of edge width k, it becomes
, where ℤk
. In that case, the various transformations have to be rescaled by a factor k. More precisely, if a transform F has the form F ξ (r) = Σs∈ℤd
ωF(s) ξ (r − s) on a grid of edge width 1, on a grid of edge width k, it becomes
, where ℤk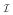 = {s/k, s ∈ ℤ}. Reflecting this discussion, we took
and
= {s/k, s ∈ ℤ}. Reflecting this discussion, we took
and
| (4.2) |
where ωp0;θ is the function defined above (2.5), with θ = θT (ℓT, ρT) or θ = θR = (ℓR, ρR). In our bivariate models (c) and (d), we also considered
| (4.3) |
where, for u ∈ ℤ+, ωM (u) = (θM + 1 − u)/Σu≤θM (θM + 1 − u), with θM being a positive integer.
In each case, we considered several different values of θR in (4.2), or θM in (4.3), and we took the ξij (r) to be independent normal N(0, σ2). Each combination of σ and θR or θM was chosen such that good classification was possible for at least one of the versions of the centroid classifier described below; see Tables A.1–A.3 in Section A.3.1, in the supplementary materials, for all the combinations we considered in practice, and for a measure of signal-to-noise ratio in each case. Finally, we took the parameter θT of the transform T and the grid
where the data are observed as follows:
Model (a): θT = (0.5, 3) and
= {−80, −80 + k, …, 80 − k, 80}.Model (b): θT = (0.5, 2) and
= {−80, −80 + k, …, 80 − k, 80}.Models (c) and (d): θT = (0.25, 2) and
= {−60, −60 + k, …, 60 − k, 60}×{−40, −40 + k, …, 40−k, 40}.
In each case, k = 2 when n1 = n2 = 10, and k = 1 or 2 when n1 = n2 = 25. In particular, when n1 and n2 were increased, we let the grid
become finer by decreasing k from 2 to 1 so as to illustrate point (4) in Section 4.1. We also ran simulations in the unbalanced case, where n1 = 10 and n2 = 25, and obtained results similar to those we shall discuss below; see Figures A.4 and A.5 in Section A.3.4 in the supplementary materials.
For illustration, Figure 1 shows Y11 and Y12 in models (c) and (d), with θR = (0.5, 3). Comparing with Figure 9 in Section 4.5, we can see that model (d) looks similar to our empirical example discussed in Section 4.5.
Figure 1.

Plots of Y11 (left) and Y12 (right), in models (c) (row 1) and (d) (row 2) with θR = (0.5, 3). The online version of this figure is in color.
Figure 9.
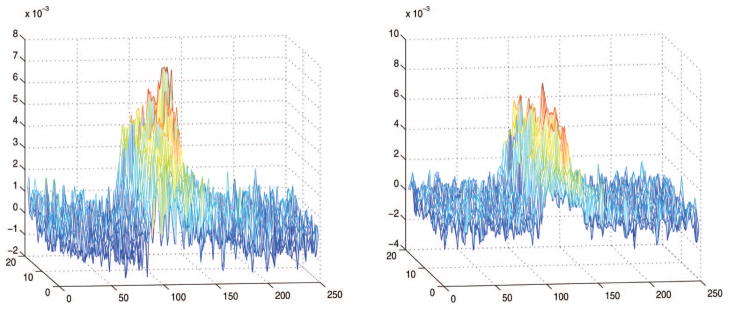
Plots of two background-corrected received data curves from population 1 (left) and population 2 (right), averaged over the 20 bursts, across wavelength and the backscatter spectral range. The online version of this figure is in color.
4.2.2 Model for Qθ, Generation of Test Samples and Estimation of Error Rate
No matter what model we used for R, we systematically modeled Qθ by
| (4.4) |
with θ = (ℓQ, ρQ). This model is flexible, and, as discussed in detail in Section 2.3, it has attractive practical properties such as the fact that we do not need any smoothing parameters to define
in Equation (2.8), which can be taken equal to
= (−π, π)d.
To test our classifier constructed from the training observations Yij, we generated test samples of N = 100 new data curves , of which half came from Π1 and the other half came from Π2, using each time the same model as the one used to generate the Yij’s. We applied several classifiers to three versions of the ’s: the untransformed noisy data , the data , and the data , where Q̂ denotes Qθ̂CV, with Qθ as in (4.4), and with θ = θ̂CV chosen to minimize the cross-validation estimator of the classification error rate, as in Section 2.3.3, where we took π1 = n1/(n1 + n2). When R was of the form in Equation (4.2), we also applied the classifiers to the data .
As indicated above, we chose θ = (ρ, ℓ) to minimize the cross-validation estimator of classification error rate, where we performed the minimization over a bivariate grid of values in the range 0 ≤ ρ ≤ 0.95 and 1 ≤ ℓ ≤ 5. Here, ρ = 0 denotes the identity transform, and when ρ = 0, we do not transform the data. Observe that, in our simulations and examples, the sizes of the training datasets are small, and there is little computational cost. In larger datasets, one would use k-fold cross-validation, that is, the training data would consist of a randomly selected (1 − k−1) × 100% of the data, and the test data, the remaining (100/k)%, with this procedure repeated many times to calculate an overall error rate. Wikipedia has a good description of this approach (http://en.wikipedia.org/wiki/Cross-validation_(statistics)); see also McLachlan, Do, and Ambroise (2004).
In practice, the transform T is often unknown and is not necessarily invertible. In such cases, instead of using T−1, one has to use a regularized estimator T̂−1 constructed from the data (see our real-data illustration). Here, for simplification, we take T as both known and invertible. While this may seem to be unfavorable to our approach, it actually does not matter since our point is to show that T−1 has essentially no role to play in our classification problem, and whether T−1 is known or estimated does not change our conclusions.
In each model, we generated B = 100 training samples, and for each training sample, we generated a test sample of N = 100 new data curves as described above, which we classified in one of the two populations using each of the methods described in the previous paragraph. For each training sample, we calculated the percentage of the new curves that were misclassified by each method. We obtained B = 100 misclassification percentages for each method, and the boxplots shown in Figures 2–8 were computed from these 100 percentages.
Figure 2.
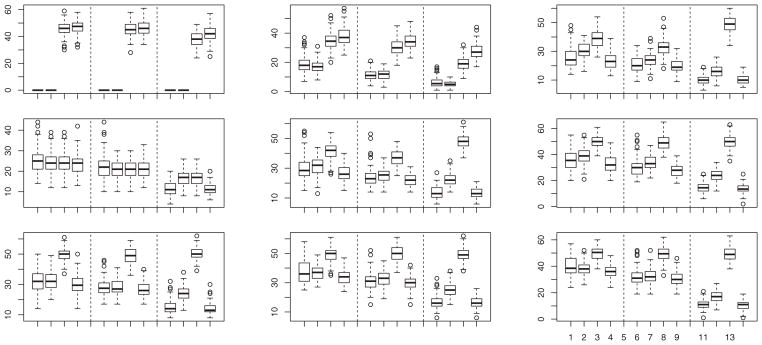
Boxplots of percentage of misclassified observations calculated from 100 simulated samples from model (a) when θR = (ρR, ℓR), with ρR = 0.75, 0.5, and 0.25 in rows 1, 2, and 3, respectively; and ℓR = 3, 2, and 1 in columns 1, 2, and 3, respectively. In each group of 12 boxes, the first four are for n1 = n2 = 10 and k = 2, the next four are for n1 = n2 = 25 and k= 2, and the last four are for n1 = n2 = 25 and k = 1. In each group of four boxes, the data are transformed by Q̂−1 (first box), R−1 (second box), or T−1 (third box), or are untransformed (fourth box).
Figure 8.
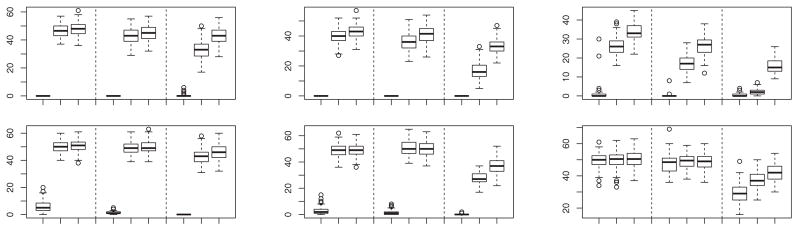
Boxplots of percentage of misclassified observations calculated from 100 simulated samples from models (c) (row 1) and (d) (rows 2) when Rr is of the form at (4.7), with θM,rj = θM + 2 · [2 cos(rj/2)] and θM = 30, 20, and 10 in columns 1, 2, and 3, respectively. In each group of nine boxes, the first three are for n1 = n2 = 10 and k = 2, the next three are for n1 = n2 = 25 and k = 2, and the last three are for n1 = n2 = 25 and k = 1. In each group of three boxes, the data are transformed by Q̂−1 (first box) or T−1 (second box), or are untransformed (third box).
4.3 Simulation Results for Centroid Classifier
4.3.1 Data Coming From the Model in (4.1)
We start by reporting results obtained when applying the centroid classifier described in Section 3.1 to data generated from the model in Equation (4.1). In cases where ê achieved its minimum at several values θ, we broke the ties according to the rule described in Section A.1 in the supplementary materials. The boxplots corresponding to each of the four methods described above, for R of the form in Equation (4.2), are shown in Figures 2–4. We present the results for various values of θR = (ρR, ℓR), for n1 = n2 = 10 and k = 2, n1 = n2 = 25 and k = 2, and for n1 = n2 = 25 and k = 1, where k is the distance between two adjacent univariate components of the grid
. Our finite-sample results support our asymptotic theory, which implies that as n1 and n2 increase (i.e., as training sample size increases) and k decreases (i.e., as the grid
becomes finer), the best results should be obtained by the centroid classifier applied to the data inverted by R−1, of which
is a consistent estimator.
Figure 4.

Boxplots of percentage of misclassified observations calculated from 100 simulated samples from models (c) (rows 1 and 2) and (d) (rows 3 and 4) when θR = (ρR, ℓR), with ρR = 0.85 and 0.5 in rows 1, 3 and 2, 4, respectively; and ℓR = 3, 2, and 1 in columns 1, 2, and 3, respectively. In each group of 12 boxes, the first four are for n1 = n2 = 10 and k = 2, the next four are for n1 = n2 = 25 and k = 2, and the last four are for n1 = n2 = 25 and k = 1. In each group of four boxes, the data are transformed by Q̂−1 (first box), R−1 (second box), or T−1 (third box), or are untransformed (fourth box).
Overall, our results indicate that, in finite samples, it is the latter cross-validation approach that is the most competitive. This is because this method has the ability to optimize performance based on the particular sample at hand. Unsurprisingly, transforming the data through R−1 and brings the most significant improvements when ρR and ℓR are the largest, since it is in these cases that the correlation among the εij’s is the greatest. For smaller values of ρR and ℓR (e.g., ρR = 0.25 and ℓR = 1), the correlation among the εij’s is relatively small, and as a result, in finite samples, the centroid method applied to the untransformed data is often the most competitive approach, although even in these cases, the cross-validation approach remains highly competitive. Of course, in practice, we do not know the transformation R, and our results indicate that cross-validation-based inversion is the method of choice.
4.3.2 Robustness Against Misspecification of R
Next, we illustrate the robustness of the inversion procedure by reporting the results obtained when applying the centroid classifier to the data
, with Q as in Equation (4.4), when the true transform R was of another form, specifically the one in Equation (4.3), where we took θM = 10, 20, or 30. We compare this approach with the centroid-based classifier based on the data
and with the one based on the data
. We show boxplots of the percentage of misclassified data curves in Figure 5, for each of the three methods and for n1 = n2 = 10 and k = 2, n1 = n2 = 25 and k = 2, and n1 = n2 = 25 and k = 1. Our results indicate that even if Qθ at (4.4) is not the exact noise transformation, inverting the data through
can considerably improve on the centroid classifier based on either
or the untransformed data
.
Figure 5.
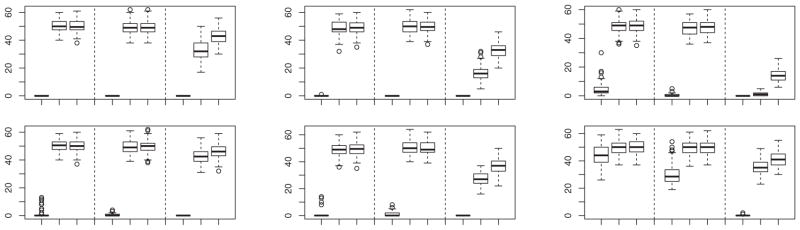
Boxplots of percentage of misclassified observations calculated from 100 simulated samples from models (c) (row 1) and (d) (rows 2) when R is of the form at (4.3), with θM = 30, 20, and 10 in columns 1, 2, and 3, respectively. In each group of nine boxes, the first three are for n1 = n2 = 10 and k = 2, the next three are for n1 = n2 = 25 and k = 2, and the last three are for n1 = n2 = 25 and k = 1. In each group of three boxes, the data are transformed by Q̂−1 (first box) or T−1 (second box), or are untransformed (third box).
4.3.3 Robustness Against the Stationarity Assumption
In practice, the model in Equation (4.1) is often an approximation to the model that generated the data. In this section, to investigate the effect of nonstationarity of the errors on our procedure, we report results of simulations where the data Yij were generated from the model
| (4.5) |
with the fixed transform R replaced by a transform Rr, depending on r.
In the univariate case, instead of R in Equation (4.2), we used
| (4.6) |
with θr = (ρr, ℓ), where ρr = ρ + 0.1 cos(r/α) (we considered two cases: α = 2 and α = 10) and ρ and ℓ are as in the previous section. In the bivariate case, instead of using the transform R in Equation (4.3) with constant θM, we used the transform
| (4.7) |
where, for u ∈ ℤ+ and j = 1, 2, ωM,rj (u) = (θM,rj + 1 − u)/Σu≤θM,rj (θM,rj + 1 − u), with θM,rj = θM + 2 · [α cos(rj/2)] (we considered two cases: α = 2 and α = 4), θM is as in the previous section, and, for any real number x, we use [x] to denote the integer closest to x.
Although, here, the errors Rr ξij (r) were nonstationary, we inverted the data in the same way as before, using the transform . Figures 6 and 7 show boxplots of the percentage of misclassified curves for the centroid classifier constructed from the data , Yij, and T−1 Yij, where Yij was generated as in Equation (4.5), with μj from model (a) and model (b), respectively, Rr as in (4.6), and α = 2. For the case α = 10, see Figures A.1 and A.2 in the supplementary materials. Figure 8 shows similar results for the bivariate models (c) and (d), when the data were generated according to (4.5), with Rr as in Equation (4.7) and α = 2; see Figure A.3 in the supplementary materials for the case α = 4. These results indicate that our inversion method can improve classification performance significantly even when the errors are not exactly stationary; it usually does not degrade performance more than a little.
Figure 6.
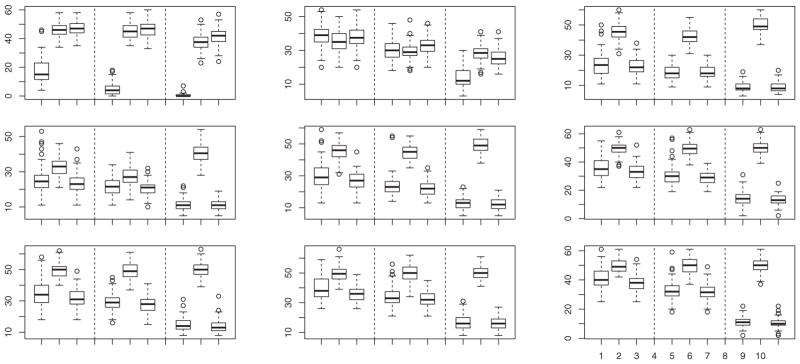
Boxplots of percentage of misclassified observations calculated from 100 simulated samples from model (a) when θR = (ρR,r, ℓR), with ρR,r = ρR + 0.1 cos(r/2); ρR = 0.75, 0.5, and 0.25 in rows 1, 2, and 3, respectively; and ℓR = 3, 2, and 1 in columns 1, 2, and 3, respectively. In each group of nine boxes, the first three are for n1 = n2 = 10 and k = 2, the next three are for n1 = n2 = 25 and k 2, and the last three are for n1 = n2 = 25 and k = 1. In each group of three boxes, the data are transformed by Q̂−1 (first box) or T−1 (second box), or are untransformed (third box).
Figure 7.

Boxplots of percentage of misclassified observations calculated from 100 simulated samples from model (b) when θR = (ρR,r, ℓR), with ρR,r= ρR + 0.1 cos(r/2); ρR = 0.75, 0.5, and 0.25 in rows 1, 2, and 3, respectively; and ℓR = 3, 2, and 1 in columns 1, 2, and 3, respectively. In each group of nine boxes, the first three are for n1 = n2 = 10 and k = 2, the next three are for n1 = n2 = 25 and k = 2, and the last three are for n1 = n2 = 25 and k = 1. In each group of three boxes, the data are transformed by Q̂−1 (first box) or T−1 (second box), or are untransformed (third box).
4.4 Other Classifiers
Although it is beyond the scope of this article to develop theory for all types of classifiers, and derive the theoretically optimal transform for each of them, we argue that our conclusions extend to other classifiers. To illustrate this, we also implemented two other classifiers often employed in high-dimensional and functional data problems, which we applied to the four versions of the data: Yij, T−1 Yij, R−1 Yij, and , with θ̂CV chosen to minimize the cross-validation estimate of classification error. Namely, we used the support vector machine (SVM) classifier with a linear kernel (svmtrain in MATLAB) and the logistic classifier applied to the partial least-square (PLS) projection of the data (here, data refer to any of the four versions, transformed or not, of the data); see Delaigle and Hall (2012b) and Section A.3.3 in the supplementary materials for more details on the logistic classifier, and see Delaigle and Hall (2012a) for properties of PLS in the functional context.
Boxplots summarizing the results of our simulations, in the same settings as for the centroid classifier, are shown in Figures A.6–A.11 in Section A.3.5 in the supplementary materials. From these figures, we can see that the results obtained with these two classifiers are very similar to those obtained with the centroid classifier. In other words, inverting by T−1 usually did not improve the results, and, in general, inverting by the transform , chosen by cross-validation from the data, improved the results significantly (compared with using the data Yij or T −1 Yij) or, when the latter worked well, transforming the data by did not degrade performance much.
As already noted, the best transform to apply generally depends on the particular classifier. However, an attractive aspect of our methodology is that the suggested inversion, , is chosen to minimize a cross-validation estimator of classification error. Therefore, our approach is very flexible, since in a general setting, it approximates the inverse transform that optimizes classification.
4.5 Empirical Example
We have access to data from a small experiment involving long-range infrared Lidar methods. Briefly, the idea is to discriminate between two types of aerosols that have been emitted and are to be detected by Lidar: those that are biological in nature and those that are nonbiological. There are 29 curves available to us, with n1 = 15 nonbiological and n2 = 14 biological signals.
The process involves a signal or waveform sent out in a series of bursts, and received Lidar data were observed. Some of the bursts were sent before the aerosol was released, and these were used to background-correct the received signal after the aerosol was released. For each sample, the data used here are the background-corrected received signals for a burst, 19 wavelengths, and 250 backscatter time points. In our illustrative analysis, we followed the procedure described below for 20 bursts collected almost simultaneously in the middle of the release period and then averaged over the bursts before classification. Thus, in our notation, Yij consists of the two-dimensional collection of background-corrected received signals over the wavelengths and the backscatter time points for the ith sample within the j th aerosol class. These observed data are the convolution of a true signal, the Lidar response function for a delta-pulse transmitter, with the transmitted signal. If we write
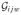 (t) for this true signal for wavelength w at backscatter time point t, Rijw(t) for the background-corrected received signal, and
(t) for this true signal for wavelength w at backscatter time point t, Rijw(t) for the background-corrected received signal, and
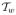 (t) for the transmitted signal, then, using an integral approximation to the discrete convolution, the signal we observe is
(t) for the transmitted signal, then, using an integral approximation to the discrete convolution, the signal we observe is
where ξijw(t) has mean zero. If we define
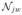 (t) = E{
(t)},
, and
, then we have that the observed data are given by Rijw(t) =
(t) = E{
(t)},
, and
, then we have that the observed data are given by Rijw(t) =
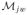 (t) +
(t) +
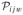 (t), where
(t) has mean zero. In our notation, Yij, μj, T μj, and εij are the collection of Rijw(t),
(t),
(t), and
(t) over the wavelengths and backscatter ranges, respectively, but averaged across 20 bursts. It is readily observed that the transformation T μj is linear. Two typical observed average curves for each population are given in Figure 9.
(t), where
(t) has mean zero. In our notation, Yij, μj, T μj, and εij are the collection of Rijw(t),
(t),
(t), and
(t) over the wavelengths and backscatter ranges, respectively, but averaged across 20 bursts. It is readily observed that the transformation T μj is linear. Two typical observed average curves for each population are given in Figure 9.
We considered three approaches. The first simply used the observed data Yij. The second was our method applied to the
, where Qθ had the form as in Equation (4.4). In the third, for each burst and each wavelength, we deconvolved to estimate
(t) using the Wiener–Helstrom method described by Warren et al. (2008), and averaged over the bursts. In each case, since we could not generate new data, we estimated the misclassification error rate (i.e., misclassification percentage) by cross-validation. In other words, as in the case of the procedure described in Section 2.3.3, we built the classifier from all but one of the 29 curves, classified that curve in one of the two populations (nonbiological or biological), and averaged the results over all 29 curves.
For the centroid classifier, the cross-validation estimator of the misclassification error rate was 34.5% for the first approach based on nontransformed data, 24.1% for our cross-validation-based inversion approach, and 34.5% for the third approach based on inversion of T. For the SVM and logistic regression classifiers, the estimator of the misclassification error rate was 37.9% (SVM) or 27.6% (logistic) when the classifier was based on nontransformed data, 17.2% (SVM) or 21% (logistic) when the classifier was based on our cross-validation-based inversion method, and 58.6% (SVM) or 31% (logistic) when the classifier was based on inversion of T. For all three classifiers, the reduction in the misclassification error rate obtained by our cross-validation-based data inversion illustrates the significant improvement that can be obtained by inverting the data through a data-driven transform chosen to minimize an estimator of classification error.
Supplementary Material
Figure 3.
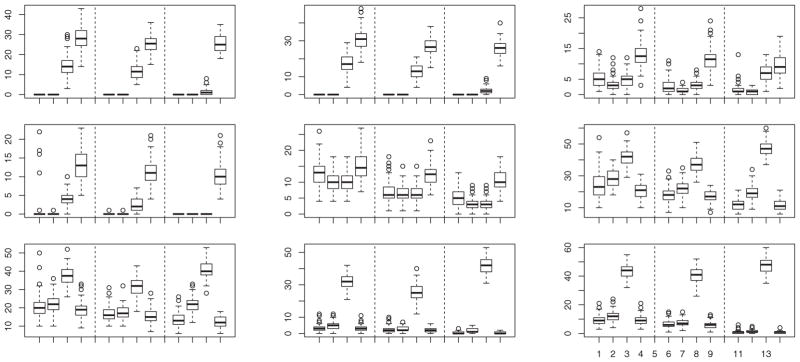
Boxplots of percentage of misclassified observations calculated from 100 simulated samples from model (b) when θR = (ρR, ℓR), with ρR = 0.75, 0.5, and 0.25 in rows 1, 2, and 3, respectively; and ℓR = 3, 2, and 1 in columns 1, 2, and 3, respectively. In each group of 12 boxes, the first four are for n1 = n2 = 10 and k = 2, the next four are for n1 = n2 = 25 and k = 2, and the last four are for n1 = n2 = 25 and k = 1. In each group of four boxes, the data are transformed by Q̂−1 (first box), R−1 (second box), or T−1 (third box), or are untransformed (fourth box).
Acknowledgments
Carroll’s research was supported by a grant from the National Cancer Institute (R37-CA057030) and in part by award number KUS-CI-016-04, made by King Abdullah University of Science and Technology (KAUST) and by the National Science Foundation (DMS-0914951). Delaigle’s research was supported by grants and a Queen Elizabeth II Fellowship from the Australian Research Council, and Hall’s research was supported by a Federation Fellowship, a Laureate Fellowship, and grants from the Australian Research Council.
Footnotes
Section A contains details about numerical implementation, and additional simulation results. Section B contains regularity conditions and a proof of the theorems.
Contributor Information
Raymond Carroll, Email: carroll@stat.tamu.edu, Department of Statistics, Texas A&M University, College Station, TX 77843-3143.
Aurore Delaigle, Email: a.delaigle@ms.unimelb.edu.au, Department of Mathematics and Statistics, University of Melbourne, VIC 3010, Australia.
Peter Hall, Email: halpstat@ms.unimelb.edu.au, Department of Mathematics and Statistics, University of Melbourne, VIC 3010, Australia.
References
- Besag J. On the Statistical-Analysis of Dirty Pictures. Journal of the Royal Statistical Society, Series B. 1986;48:259–302. [Google Scholar]
- Cannon M. Blind Deconvolution of Spatially Invariant Image Blurs With Phase. IEEE Transactions on Acoustics, Speech and Signal Processing. 1976;24:58–63. [Google Scholar]
- Cannon TM, Hunt BR. Image Processing by Computer. Scientific American. 1981;245:214–225. [Google Scholar]
- Carasso AS. Direct Blind Deconvolution. SIAM Journal on Applied Mathematics. 2001;61:1980–2007. [Google Scholar]
- Cressie N, Kornak J. Spatial Statistics in the Presence of Location Error With an Application to Remote Sensing of the Environment. Statistical Science. 2003;18:436–456. [Google Scholar]
- Crosilla F, Visintini D, Sepic F. An Automatic Classification and Robust Segmentation Procedure of Spatial Objects. Statistical Methods and Applications. 2007;15:329–341. [Google Scholar]
- Dass SC, Nair VN. Edge Detection, Spatial Smoothing, and Image Reconstruction with Partially Observed Multivariate Data. Journal of the American Statistical Association. 2003;98:77–89. [Google Scholar]
- Delaigle A, Hall P. Methodology and Theory for Partial Least Squares Applied to Functional Data. The Annals of Statistics. 2012a;40:322–352. [Google Scholar]
- Delaigle A, Hall P. Componentwise Classification and Clustering of Functional Data. Biometrika. 2012b;99(2):299–313. [Google Scholar]
- Donoho DL. Statistical Estimation and Optimal Recovery. The Annals of Statistics. 1994;22:238–270. [Google Scholar]
- Figueiredo MAT, Nowak RD. An EM Algorithm for Wavelet-Based Image Restoration. IEEE Transactions on Image Processing. 2003;12:906–916. doi: 10.1109/TIP.2003.814255. [DOI] [PubMed] [Google Scholar]
- Friedman JH. Another Approach to Polychotomous Classification. Technical Report. 1996 available at http://www-stat.stanford.edu/jhf/ftp/poly.pdf.
- Galatsanos NP, Mesarović VZ, Molina R, Katsaggelos AK, Mateos J. Hyperparameter Estimation in Image Restoration Problems With Partially Known Blurs. Optical Engineering. 2002;41:1845–1854. [Google Scholar]
- Hall P. Optimal Convergence Rates in Signal Recovery. The Annals of Probability. 1990;18:887–900. [Google Scholar]
- Hall P, Qiu P. Blind Deconvolution and Deblurring in Image Analysis. Statistica Sinica. 2007a;17:1483–1509. [Google Scholar]
- Hall P, Qiu P. Nonparametric Estimation of a Point Spread Function in Multivariate Problems. The Annals of Statistics. 2007b;35:1512–1534. [Google Scholar]
- Huang HC, Cressie N. Deterministic/Stochastic Wavelet Decomposition for Recovery of Signal From Noisy Data. Technometrics. 2000;42:262–276. [Google Scholar]
- Huang XF, Qiu P. Blind Deconvolution for Jump-Preserving Curve Estimation. Mathematical Problems in Engineering [online] 2010:Article No. 350849. doi: 10.1155/2010/350849. [DOI] [Google Scholar]
- James G, Hastie T. Functional Linear Discriminant Analysis for Irregularly Sampled Curves. Journal of the Royal Statistical Society, Series B. 2001;63:533–550. [Google Scholar]
- Johnstone IM. Speed of Estimation in Positron Emission Tomography and Related Inverse Problems. The Annals of Statistics. 1990;18:251–280. [Google Scholar]
- Joshi MV, Chaudhuri S. Joint Blind Restoration and Surface Recovery in Photometric Stereo. Journal of the Optical Society of America. 2005;A22:1066–1076. doi: 10.1364/josaa.22.001066. [DOI] [PubMed] [Google Scholar]
- Klein R, Press SJ. Adaptive Bayesian Classification of Spatial Data. Journal of the American Statistical Association. 1992;87:844–851. [Google Scholar]
- Kundur D, Hatzinakos D. A Novel Blind Deconvolution Scheme for Image Restoration Using Recursive Filtering. IEEE Transactions on Signal Processing. 1998;46:375–389. [Google Scholar]
- McLachlan GJ, Do KA, Ambroise C. Analyzing Microarray Gene Expression Data. Hoboken, NJ: Wiley; 2004. [Google Scholar]
- Mukherjee PS, Qiu P. 3-D Image Denoising by Local Smoothing and Nonparametric Regression. Technometrics. 2011;53:196–208. [Google Scholar]
- Popescu DC, Hellicar AD. Point Spread Function Estimation for a Terahertz Imaging System. EURASIP Journal on Advances in Signal Processing [online] 2010:Article No. 575817. doi: 10.1155/2010/575817. [DOI] [Google Scholar]
- Qiu P. Image Processing and Jump Regression Analysis. New York: Wiley; 2005. [Google Scholar]
- Qiu P. Jump Surface Estimation, Edge Detection, and Image Restoration. Journal of the American Statistical Association. 2007;102:745–756. [Google Scholar]
- Qiu P. A Nonparametric Procedure for Blind Image Deblurring. Computational Statistics and Data Analysis. 2008;52:4828–4841. [Google Scholar]
- Shi T, Cressie N. Global Statistical Analysis of MISR Aerosol Data: A Massive Data Product From NASA’s Terra Satellite. Environ-metrics. 2007;18:665–680. [Google Scholar]
- Shin H. An Extension of Fisher’s Discriminant Analysis for Stochastic Processes. Journal of Multivariate Analysis. 2008;99:1191–1216. [Google Scholar]
- Warren RE, Vanderbeek RG, Ben-David A, Ahl JL. Simultaneous Estimation of Aerosol Cloud Concentration and Spectral Backscatter From Multiple-Wavelength Lidar Data. Applied Optics. 2008;47:4309–4320. doi: 10.1364/ao.47.004309. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.