

Abstract
We provide a novel and completely different approach to dimension-reduction problems from the existing literature. We cast the dimension-reduction problem in a semiparametric estimation framework and derive estimating equations. Viewing this problem from the new angle allows us to derive a rich class of estimators, and obtain the classical dimension reduction techniques as special cases in this class. The semiparametric approach also reveals that in the inverse regression context while keeping the estimation structure intact, the common assumption of linearity and/or constant variance on the covariates can be removed at the cost of performing additional nonparametric regression. The semiparametric estimators without these common assumptions are illustrated through simulation studies and a real data example. This article has online supplementary material.
Keywords: Estimating equations, Nonparametric regression, Robustness, Semiparametric methods, Sliced inverse regression
1. INTRODUCTION
Dimension reduction has been an active field of statistical research for the last 20 years and continues to be important due to the increasingly large amount of available covariates in various scientific areas. The goal of dimension reduction is to identify one or multiple directions represented by a matrix β, so that the response Y relates to the covariate vector x only through a few linear combinations xTβ. When the conditional distribution depends on xTβ, it is a problem of estimating the central space (Cook 1998); when the conditional mean E(Y | x) depends on xTβ, it is a problem of estimating the central mean space (Cook and Li 2002).
Started with the ingenious idea of sliced inverse regression (SIR) in the seminal article by Li (1991), many highly effective methods in the area of dimension reduction have been developed. For identifying the central space, see, for example, sliced average variance estimation (SAVE) (Cook and Weisberg 1991) and directional regression (DR) (Li and Wang 2007) and their variations such as kernel inverse regression (Zhu and Fang 1996), CANCOR analysis (Fung et al. 2002), and so on. These methods extend the inverse regression idea and are promising in recovering the central space. However, they all rely on certain conditions. These conditions mainly include the linearity condition, where E(x | xTβ) is assumed to be a linear function of x, and the constant variance condition, where cov(x | xTβ) is assumed to be a constant matrix. These conditions are not always satisfied, and sometimes could imply stringent assumptions on the joint distribution of x. To be precise, SIR requires the linearity condition; SAVE and DR require both the linearity condition and the constant variance condition. If the covariates do not satisfy these two conditions, current practice often relies on transformation (Box and Cox 1964) or reweighting (Cook and Nachtsheim 1994), which can restore these conditions sometimes. Li and Dong (2009) and Dong and Li (2010) successfully remove the linearity condition from the dimension-reduction problems while their estimators remain to be the inverse regression type. This is no doubt a great advancement. The residual issue is that they assumed E(x | xTβ) to be a polynomial function of xTβ and they still required the constant variance condition. These remaining requirements can still be stringent and difficult to check in practice. Zhu and Zeng (2006) introduced a dimension-reduction method to identify the central subspace through using Fourier transformations. Their method, however, requires one to estimate the joint probability density function (pdf) of x, which is typically infeasible in a high-dimensional environment. To circumvent this difficulty, they assumed x to be multivariate normal in implementations. Adapting the idea of minimum average variance estimation (MAVE) (Xia et al. 2002), Xia (2007) proposed a similar procedure (dMAVE) to recover the central space, and Wang and Xia (2008) proposed sliced regression (SR) for dimension reduction. However, their methods estimate the distribution function nonparametrically and heavily rely on the implicit assumption that all the covariates are continuous. Because all the existing dimension-reduction methods impose either the above two conditional moment conditions or distributional assumptions on the covariate vector in one form or another, new dimension-reduction methods which are free of any of these assumptions are highly in demand, particularly when some covariates are discrete or categorical.
Similarly, a large amount of literature exists for identifying the central mean space. For example, when the central mean space is one dimensional, Li and Duan (1989) suggested using the ordinary least squares (OLS), assuming x to satisfy the linearity condition. Härdle and Stoker (1989) and Power, Stock, and Stoker (1989) proposed the average derivative estimation, which requires x to be continuous. Horowitz and Härdle (1996) proposed a method that allows some covariates to be discrete; however, the number of levels in discrete variables cannot be large. Ichimura (1993) and Härdle, Hall, and Ichimura (1993) suggested using nonlinear least squares, which are essentially special cases of our proposal which will be described in the following. When the central mean space is possibly two or more dimensional, Xia et al. (2002) proposed the minimum average variance estimation method, which, similar to the constructive approach in Xia (2007) and the sliced regression in Wang and Xia (2008), requires x to be continuous. Li (1992) and Cook and Li (2002) proposed the method of principal Hessian directions which requires x to satisfy both the linearity condition and the constant variance condition, which are not always satisfied in practice. Assuming conditional normality of x on Y, Cook and Forzani (2009) proposed a likelihood-based method, and in the context of classification, Hernández and Velilla (2005) estimated the dimension reduction space via minimizing a criterion function which involves kernel density estimation. Yin and Cook (2005); Yin, Li, and Cook (2008); and Park, Sriram, and Yin (2010) proposed a method to recover the dimension-reduction space via minimizing a Kullback–Leibler distance.
In this article, we provide a completely different viewpoint for looking at the dimension-reduction problems. Our approach is through semiparametrics, which has not been considered in the literature. By casting the dimensional-reduction problem in the semiparametric framework, the dimension-reduction problems become semiparametric estimation problems. Therefore, powerful semiparametric estimation and inference tools become applicable. We use the geometric approach in Bickel et al. (1993) and Tsiatis (2006) to analyze these problems and derive the space of the influence functions. This enables us to construct a rich class of estimators. Many of the existing dimension-reduction methods turn out to be special cases in this class. In fact, the complete class of influence functions provide all the possible consistent estimators.
A direct consequence of the semiparametric analysis is the relaxation of the linearity condition and the constant variance condition. Using the semiparametric construction, we reveal that these conditions are not structurally necessary. Consequently, in all these existing dimension-reduction procedures, we can remove these two conditions, and instead replace the assumed quantity with nonparametric estimation of the corresponding conditional expectations. Thus, the semiparametric derivation allows us to obtain the dimension reduction spaces without any distributional assumption on the covariate vector. Another advantage of the semiparametric analysis is that we do not require all the covariates to be continuous.
In summary, the contributions of this article are:
We introduce a novel and drastically different approach to the dimension-reduction field. We anticipate to stimulate deeper and richer literature in this direction.
We derive the complete class of influence functions, which guarantees to yield all possible root-n consistent estimators for the column space of β. We demonstrate how to obtain several most popular dimension-reduction methods from this class. This further reveals the underlying connection between these different methods and provides a different and natural motivation for their construction.
We completely eliminate the linearity condition, the constant variance condition, the condition on the quadratic form of the covariates, or, in fact, any moment conditions on the covariates at all.
We eliminate the redundant continuity conditions on the covariates. The new approach can be readily used even when some covariates are categorical or discrete.
The outline of this article is the following. In Section 2, we describe the semiparametric approach to the central space estimation and derive a rich class of estimators. We establish their link and generalization to several existing dimension-reduction methods in Section 3. The analysis for central mean space estimation is given in Section 4. We explain the implementation details on estimation and on selecting the dimension of the central space/central mean space in Section 5. Extensive simulation studies are conducted in Section 6 to demonstrate the practical performance and the method is implemented in a real data example in Section 7. We finish the article with a brief discussion in Section 8. Technical derivations are collected in an appendix and the online supplementary document.
2. ESTIMATING THE CENTRAL SUBSPACE VIA SEMIPARAMETRICS
Let x be a p × 1 covariate vector and Y a univariate response variable. The goal of sufficient dimension reduction (Cook 1998) is to seek a matrix β such that
| (1) |
where denotes the conditional distribution function of Y given x. (1) implies that the response variable Y relates to x only through linear combinations xTβ. The column space of β satisfying (1) is called a dimension-reduction subspace. Because the dimension-reduction subspace is not unique, our primary interest is the central subspace, which is defined as the intersection of all dimension-reduction subspaces, provided that the intersection itself is a dimension-reduction subspace (Cook 1998).
Following the convention in the area of dimension reduction, we denote by SY|x the central subspace and assume β to satisfy βTcov(x)β = Id. Note that β is more restrictive than before, however to avoid introducing a new notation, we keep the same notation. We also assume SY|x exists and is unique. Here, the number of columns in β, denoted by d, is the dimension of SY|x and is often referred to as the structural dimension. Our goal is to find SY|x through finding β ∈ ℝp × d which satisfies (1). To focus on the main issues of the dimension-reduction problems, we assume throughout our article that the covariate vector x satisfies E(x) = 0 and cov(x) = Ip. This assumption causes no loss of generality, thanks to an invariance property of the central subspace (Cook 1998, p. 106).
In model (1), the likelihood of one random observation (x, Y) is
where η1 is a probability mass function (pmf) of x or a pdf of x, or a mixture, depending on whether x contains discrete variables, and η2 is the conditional pmf/pdf of Y on x. Treating η1, η2 as infinite-dimensional nuisance parameters while β as the parameter of interest, this can be viewed as a semiparametric estimation problem. The essential idea in semiparametrics is to construct estimators through deriving influence functions. Influence functions can be viewed as normalized elements in a so called nuisance tangent space orthogonal complement Λ⊥. Thus, if one can successfully derive Λ⊥, one at least has the hope of characterizing the influence functions and constructing estimators. Because semiparametrics is not a familiar tool in the dimension-reduction community, we give a general and more precise explanation in Appendix 0. It is not a simple and straightforward tool to grasp and to master, and interested readers are encouraged to refer to Bickel et al. (1993) and Tsiatis (2006) for in-depth understanding. In model (1), using the semiparametric analysis, we characterize the space of the span of all possible score functions, had η1, η2 been replaced by all possible parametric submodels, to find the nuisance tangent space. We then derive its orthogonal complement to obtain
See the detailed derivation in Appendix 1. The form of Λ⊥ permits many possibilities for constructing consistent estimating equations. For example, for any functions g(Y, xTβ) and α(x), we can choose f(Y, x) to be
Here, f(Y, x) satisfies E{f(Y, x) | xTβ, Y} = 0 and is thus a valid element in Λ⊥. Therefore, a general class of estimating equations can be obtained using the sample version of
| (2) |
The resulting estimate is obviously -consistent (Newey 1990).
Remark 1. Equation (2) is only one convenient way to construct elements in Λ⊥. Other constructions are also possible. For example, an arbitrary linear combination
also provides a -consistent estimator because it is a valid element in Λ⊥.
Remark 2. It is easy to see that solving (2) does not necessarily yield a unique solution. Theoretically, as long as we choose g and α so that the matrix A in Theorem 1 has rank p(p − d) and B is bounded, solving (2) can yield a basis of SY|x, although the basis may not be unique; and as long as the dimension-reduction problem is identifiable, such g and α always exist. Regarding the issue of multiple solutions in practice, there are two aspects to it. First, in a typical estimating equation approach, multiple roots issue presents a challenge. This problem almost always exists in a finite sample, even under the condition that at the population level a unique solution exists. There is no established method to handle it as far as we know. Almost in all the situations, empirical methods are used to select the most sensible root among several roots. Second, uniquely in the context of dimension reduction, even if the targeted central space SY|x is unique, its basis—which is what we solve for—is not. Fortunately, this level of multiple roots issue is not a concern. As any particular choice of the basis will yield the same space, and the space is what we really aim for.
In Appendix 2, we show that (2) has a double robustness property, in that the consistency is doubly assured by the term g − E(g | xTβ) and the term α − E(α | xTβ). We can misspecify either E{g(Y, xTβ) | xTβ} or E{α(x) | xTβ}, the estimator obtained from (2) will still be consistent. Specifically, if we replace E{α(x) | xTβ} with an arbitrary function h(xTβ), then (2) becomes
which still yields a consistent estimator. Similarly, if we replace E{g(Y, xTβ) | xTβ} with an arbitrary function h(xTβ), then (2) becomes
| (3) |
which also yields a consistent estimator.
Remark 3. To ensure the consistency of the estimation of β, only one of the two expectations E{g(Y, xTβ) | xTβ} and E{α(x) | xTβ} can be misspecified. The other expectation needs to be calculated consistently, this typically requires specifying a correct parametric model or performing nonparametric regression.
Remark 4. In contrast to the existing literature on sufficient dimension reduction (Cook 1998), when using (2) or its misspecified versions to identify SY|x, no additional assumptions are made on the covariate vector. This means that (i) we do not need to assume a specific joint distribution for x; (ii) we do not need to assume the linearity condition or the constant variance condition; and (iii) we do not need to assume x to be continuously distributed. Although Cook and Li (2005) also considered noncontinuous covariates, they had to assume a parametric model for the distribution of the covariate vector x conditional on the response Y.
Remark 5. If we are willing to make additional parametric assumptions on E{α(x) | xTβ} in (3), for example, E{α(x) | xTβ} = Cx or E{α(x) | xTβ} = C for a quantity C that may or may not depend on β, then we will no longer need to perform a nonparametric estimation of E{α(x) | xTβ} when using (3). Such assumptions greatly simplify the computation. We suspect this is the implicit motivation behind the linearity condition and the constant variance condition, which are widely used in the sufficient dimension reduction literature. We will explore this issue in detail in the next two sections.
The double robustness property further allows us to obtain a -consistent estimator without any undersmoothing requirement even when d ≥ 3 through nonparametrically estimating both E{g(Y, xTβ) | xTβ} and E{α(x) | xTβ}. We state this result in Theorem 1 and provide the proof in the online supplementary document.
Theorem 1. Under conditions (C1)–(C4) given in Appendix 4, the estimator obtained from the estimating equation
satisfies
in distribution, where
Here vec(M) denotes the vector formed by concatenating the columns of M.
3. CONNECTION WITH EXISTING METHODS
In this section, we will examine several popular existing sufficient dimension-reduction methods, and illustrate why they are special cases of the semiparametric estimation family. We will show that all these methods take advantage of the double robustness property. In addition, we will point out that the linearity condition and/or the constant variance condition are used in these methods to simplify the computation. To be specific, the linearity condition characterizes the mean of x conditional on xTβ by assuming
| (4) |
and the constant variance condition characterizes the variance-covariance matrix of x conditional on (xTβ) by assuming
| (5) |
where P = β(βTβ)−1βT = ββT, Q = Ip − P. Note that here the two conditions are given in the context where E(x) = 0 and cov(x) = Ip. Here, both P and Q are symmetric matrices.
Before presenting the specific analysis on these methods, We first highlight two simple linear algebra results that will be used frequently in the remaining context. These are simple linear algebra results; hence, we only sketch the proofs in the online supplementary document.
Lemma 1. Assume Λ is a p × p symmetric matrix of rank d. If and only if β satisfies
then the span of the columns in β is the eigenspace of Λ corresponding to the d nonzero eigenvalues.
Lemma 2. Assume Λ is a p × p symmetric nonnegative definite matrix of rank d. If and only if β satisfies
then the span of the columns in β is the eigenspace of Λ corresponding to the d nonzero eigenvalues.
3.1 Sliced Inverse Regression
The classic SIR (Li 1991) requires x to satisfy the linearity condition (4). It uses the eigenvectors associated with the d nonzero eigenvalues of the matrix to span SY|x. For ease of illustration, we assume that ΛSIR has rank d hence excluding some degenerated cases.
To obtain SIR as a semiparametric estimator, we set g(Y, xTβ) = E(x | Y) and α(x) = xT in (2). The linearity condition promises a parametric form E{α(x) | xTβ} = xTP, hence we can use the misspecified version (3) while selecting h(xTβ) = 0. This choice of g, α, and h in (3) yields E{E(x | Y)xT}(Ip − P) = 0, or equivalently, ΛSIRQ = 0. Because ΛSIR is nonnegative definite and has rank d, hence ΛSIRQ = 0 is equivalent to QΛSIRQ = 0. Lemma 2 indicates that this is equivalent to obtaining the eigenspace of ΛSIR to span SY|x.
The above semiparametric derivation of SIR indicates clearly that the linearity condition is not structurally necessary for constructing SIR. When the linearity condition (4) does not hold, we simply lose the convenience of replacing E{α(x) | xTβ} by xTP, everything else remains unchanged. Specifically, in this case, SIR becomes
where E(· | xTβ) and E(· | Y) need to be estimated nonparametrically. This is what we propose as the semiparametric generalization of SIR in the absence of the linearity condition.
3.2 Sliced Average Variance Estimation
The SAVE (Cook and Weisberg 1991) assumes both the linearity condition (4) and the constant variance condition (5). Similar to SIR, SAVE uses the eigenvectors associated with the d nonzero eigenvalues of a matrix ΛSAVE to span SY|x, where .
To obtain SAVE from the semiparametric approach, we define g1(Y, xTβ) = Ip − cov(x | Y), g2(Y, xTβ) = g1(Y, xTβ)E(x | Y) and α1(x) = −x{x − E(x | xTβ)}T, α2(x) = xT. As we have pointed out in Remark 1, is an element in Λ⊥, hence it yields a valid semiparametric estimating equation. In this construction, taking advantage of the double robustness, we are allowed to misspecify E(g1 | xTβ) = 0 and E(g2 | xTβ) = 0. Some algebra then yields
| (6) |
The linearity condition (4) and the constant variance condition (5) further allow us to replace E(x | xTβ) and cov(x | xTβ) with Px and Q, which directly simplifies (6) to
Because ΛSAVE is nonnegative definite, solving ΛSAVEQ = 0 is equivalent to solving QΛSAVEQ = 0, which is equivalent to SAVE because of Lemma 2.
Relaxing the linearity condition and the constant variance condition is now obvious. Because (6) is obtained without using these two conditions, we can simply use (6) as the condition-free semiparametric generalization of SAVE, while in implementation, we need to estimate E(x | xTβ) and cov(x | xTβ) nonparametrically.
3.3 Directional Regression
Like SAVE, the DR (Li and Wang 2007) also assumes both the linearity condition (4) and the constant variance condition (5). It uses the eigenvectors associated with the d nonzero eigenvalues of the matrix ΛDR to span SY|x. Here, , and is an independent copy of (x, Y).
To obtain DR from the semiparametric approach, we choose g1(Y, xTβ) = Ip − E(xxT | Y), g2(Y, xTβ) = E{E(x | Y)E(xT | Y)}E(x | Y), g3(Y, xTβ) = E{E(xT | Y)E(x | Y)}E(x | Y), α1(x) = −x{x − E(x | xTβ)}T and α2(x) = α3(x) = xT. Remark 1 indicates that is an element in Λ⊥. Taking advantage of the double robustness property, we misspecify E(gj | xTβ) = 0, for j = 1, 2, 3. The subsequent estimating equation is therefore the sample version of
| (7) |
When both the linearity condition (4) and the constant variance condition (5) hold, we can insert E(x | xTβ) = Px and cov(x | xTβ) = Q in (7). Some algebra then leads to the equivalence between (7) and
where the last equality is due to Li and Wang (2007). Because ΛDR is nonnegative definite, solving ΛDRQ = 0 is equivalent to solving QΛDRQ = 0, which is equivalent to DR because of Lemma 2.
Similar to SAVE, as (7) is obtained without any of the linearity or constant variance condition, it can thus be used as a semiparametric generalization of DR.
Li and Dong (2009) and Dong and Li (2010) extended SIR, SAVE, and DR to the case when the linearity condition (4) is violated while the constant variance condition (5) is true. Similar analysis shows that these are also special cases of the semiparametric approach. These results are available in the supplementary document.
4. SEMIPARAMETRIC ESTIMATION OF THE CENTRAL MEAN SUBSPACE
In situations when one only concerns about the conditional mean of the response given the predictors, Cook and Li (2002) introduced the notion of the central mean subspace. They defined the column space of β as a mean dimension-reduction subspace if β satisfies
The intersection of all mean dimension-reduction subspaces is defined as the central mean subspace, denoted by SE(Y|x), if the intersection itself is also a mean dimension-reduction subspace. The conditional mean model assumes the mean of Y conditional on x relies on xTβ only. In other words, x contributes to the conditional mean of Y only through xTβ. Our main interest is to estimate SE(Y|x), or equivalently, a basis matrix β which spans SE(Y|x).
To facilitate the semiparametric analysis, we write the conditional mean model as
| (8) |
where is an unspecified smooth function and E(ε | x) = 0. We emphasize that because we make no assumptions on ε other than conditional mean zero, (8) is equivalent to the central mean subspace model. For the conditional mean model (8), the likelihood of one random observation (x, Y) is
where η1 has the same meaning as in Section 2, ℓ(xTβ) is the mean function of Y conditional on x (or equivalently, on xTβ), and η2 is the conditional pmf/pdf of the residual ε = Y − E(Y | xTβ) on x. Here, η2 satisfies E(ε | x) = 0, and is otherwise unconstrained. Similarly, treating η1, η2, and ℓ as nuisance parameters while β as the parameter of interest, following the semiparametric analysis in Appendix 3, we obtain the nuisance tangent space orthogonal complement to be the class of the form
Similar to (1), the form of Λ⊥ allows us to take any α(x) to obtain
as a valid element in Λ⊥. Hence, a general class of estimating equations can be obtained using the sample version of
| (9) |
Similar to Appendix 2, we can easily show that (9) has a double robustness property, in that we can misspecify either E(Y | xTβ) or E{α(x) | xTβ}, the resulting estimator from (9) will still yield a consistent estimating equation.
4.1 Ordinary Least Squares
We first inspect the OLS (Li and Duan 1989) method, where the linearity condition (4) is assumed to hold. The OLS method uses cov(x, Y) to infer a subspace of the column space of β in (8).
From the semiparametric approach, we let α(x) = x in (9). Taking advantage of the double robustness, we misspecify E(Y | xTβ) = 0. Then (9) reduces to
Note that (βTβ)−1βTE(xY) is a d × 1 vector. This directly yields cov(x, Y) as a one-dimensional subspace of SE(Y|x), which is exactly the OLS estimation.
When the linearity condition (4) does not hold, (9) has the form
and can still be used to estimate β. A simple treatment is to set E(x | xTβ) = 0 and solve the sample version of the above display to obtain β.
4.2 Principal Hessian Directions
The principal Hessian directions (PHD) method (Li 1992) assumes both the linearity condition (4) and the constant variance condition (5). It uses the eigenvectors associated with d nonzero eigenvalues of ΛPHD to form a basis of SE(Y|x). Here, . To obtain PHD from the semiparametric approach, we let α(x) = xxT in (9). Taking advantage of the double robustness, we misspecify E(Y | xTβ) = E(Y). The linearity condition (4) and the constant variance condition (5) yield a simplification α(x) − E{α(x) | xTβ} = xxT − Q − PxxTP, hence (9) reduces to
Lemma 1 indicates that this is equivalent to the PHD method. When either (4) or (5) is not true, we can use
to estimate β, where we calculate E(Y | xTβ) and E(xxT | xTβ) nonparametrically. We can opt to misspecify E(Y | xTβ) = 0 or preferably E(xxT | xTβ) = 0 to simplify the computation. The second simplification
will be considered as the semiparametric generalization of the PHD method without extra conditions.
5. IMPLEMENTATION
To focus on delivering the main message, we have avoided detailing the implementation details in practice, which we explain now.
The proposed semiparametric counterparts of SIR, SAVE, DR, PHD, and so on, which were respectively denoted by semi-SIR, semi-SAVE, semi-DR, and semi-PHD for ease of subsequent illustration, all have the similar components of estimating conditional expectation and solving estimating equations. Because the number of the estimating equations sometimes is larger than the number of parameters, the implementation is through minimizing their Frobenius norm. We use the familiar Newton-Raphson procedure to numerically obtain the minimizer. This essentially means that at the jth iteration β(j), we perform nonparametric conditional estimation using, say, a kernel regression method to evaluate an estimating equation at β(j), and use numerical difference to obtain the derivative of the estimating equation with respect to β evaluated at β(j). We then update β(j). This process iterates until the difference between two consecutive candidates are sufficiently small.
Because semi-DR has the most complicated form, we now outline an algorithm for semi-DR as a concrete illustration. We use β(j) to denote the value of at the jth iteration, and use K(·) to denote a kernel function. Let Kh(·) = K(·/h)/h for any bandwidth h. We use the Epanechnikov kernel function in the implementation. Assume the observations are (xi, Yi) for i = 1, …, n.
- Nonparametrically estimate E(xxT | Y) and E(x | Y) using
The bandwidth can be selected using the classic cross-validation procedure. We evaluate the above estimations at Yi, for i = 1, …, n. Form , and .
Pick an arbitrary starting value β(1), for example, the classical DR estimate.
At the jth iteration, form for i = 1, …, n.
-
Nonparametrically estimate E(x | xTβ(j)) and cov(x | xTβ(j)) using
andWe use a same bandwidth to estimate the above two quantities to ensure that is positive definite. The bandwidth can be selected using the cross-validation procedure. Evaluate the above estimations at xTβ(j) = t1, …, tn.
-
Form the sample version of the left-hand side of (7):
Update β(j) using the following Newton-Raphson steps.
-
Form the derivative of ∂{∥r(β)∥2}/∂{vec(β)} evaluated at β(j) through numerical difference. Specifically, let δ be a small number and decide an order for the elements in β(j). Let and . Here ek has the same size as β but has 1 in the kth entry and zero elsewhere. Repeat the procedure in Step 5 to obtain and . Set the kth row of ∂{∥r(β)∥2}/∂{vec(β)} to be . Repeat this for all the entries in β(j) For simplicity, we denote the resulting first derivative ∂{∥r(β(j))∥2}/∂{vec(β)}. Following similar procedures, we obtain the second derivative ∂2{∥r(β)∥2}/∂{vec(β)}∂{vec(β)}T.
Practically, δ = 0.001 is sufficiently small to obtain a close approximation of the derivatives. If more precision is desired, one can simply opt for smaller δ.
- Update to obtain
Repeat Steps 4 to 8 until convergence.
For identification, x must contain at least one continuous variable (Ichimura 1993; Horowitz and Hardle 1996). The above algorithm is applicable if the support of xTβ is connected. When the support consists of several disjoint regions, we need to carry out the kernel estimation in Step 5 in each region.
Another important component in dimension reduction is to decide the dimension d of SY|x or SE(Y|x). To this end, the bootstrap procedure described by Dong and Li (2010) adapts the idea of Ye and Weiss (2003) by taking into account the variation of the covariates, and is very flexible. This is what we recommend for use in our context. Specifically, we can decide d through the following procedure. Let λ1, …, λk be the nonzero eigenvalues of
where u and v are two generic random vectors. In addition, we let
For any working dimension k = 1, …, p − 1, we let be the estimate based on the original sample, and be the estimate based on the bth bootstrap sample, for b = 1, …, B. We then estimate the structural dimension d by maximizing over k = 1, …, p − 1
| (10) |
Interested readers are referred to Dong and Li (2010) for more details.
6. SIMULATION STUDY
In this section, we conduct simulation studies to evaluate the performance of different estimation procedures. Unless otherwise stated, we repeat the experiments 500 times each with sample size n = 200 and reduced space dimension d = 2. Throughout the simulations, we used the Epanechnikov kernel and fixed as bandwidth, where is the robust estimation of the standard deviation of xTβ, which is the default bandwidth selector implemented in Matlab routine ksdensity. We choose the predictor dimension p to be 6 and 12, and consider the following two cases for the covariate vector x = (X1, …, Xp)T.
Case 1: We generate (X1, X2)T (corresponding to the case p = 6) and X1, X2, X7, …, Xp)T (corresponding to the case p = 12) from normal population with mean zero and variance-covariance matrix (σij)(p − 4) × (p − 4) where σij = 0.5|i − j|. We generate X3 and X4 from nonlinear models: X3 = |X1 + X2| + |X1| ε1, and X4 = |X1 + X2|2 + |X2| ε2, where εi’s are independently generated from the standard normal population, X5 from a Bernoulli distribution with success probability exp (X2)/{1 + exp (X2)}, and X6 from another Bernoulli distribution with success probability Φ (X2), where Φ(·) denotes the cumulative distribution function of standard normal population. Note that in this case, both the linearity condition (4) and the constant variance condition (5) are violated.
Case 2: We generate x from normal population with mean zero and variance-covariance matrix (σij)p × p where σij = 0.5|i − j|. Note that in this case, the covariates satisfy both the linearity condition (4) and the constant variance condition (5).
Let β be a basis matrix of SY|x and be its estimate. To assess the estimation accuracy of , we use the Euclidean distance between and β, defined as the Frobenius norm of the matrix . In both cases, the distance ranges from zero to two, and a smaller distance indicates a better estimate.
6.1 Example 1
We generate the response variable using the following four different models:
where β1 and β2 are p × 1 vectors with their first six components being and , respectively. When p = 12, the rest components of β1 and β2 are identically zero. The error term ε has a standard normal distribution. Models (I)–(IV) are chosen to compare, respectively, SIR, SAVE, DR, and PHD with their semiparametric counterparts. We also include dMAVE (Xia 2007) and MAVE (Xia et al. 2002) into our comparison as they are often used as a benchmark. To make a fair comparison on the core methodologies of these proposals, we estimate the kernel matrices of the classical SIR, SAVE, DR by using kernel smoothing rather than the usual slicing estimation. This allows us to avoid selecting the number of slices which usually adversely affects the performance. Thus, SIR, SAVE, and DR are implemented in their improved form.
The boxplots of the Euclidean distances are reported in Figure 1. The results under Case 1 are presented in panels (A) and (C), where we show the boxplots of Euclidean distances for different estimation procedures when both the linearity condition (4) and the constant variance condition (5) are violated. In this case, we can see that the semiparametric estimates are substantially more accurate than their classical dimension-reduction counterparts across all four models, indicating the significant improvement when the violation of these conditions is taken into account. Note that dMAVE has very large variability in these settings and sometimes even perform worse than the classical dimension-reduction methods. This is because some covariates are discrete which violates the continuity requirement of dMAVE. Because the semiparametric estimation procedures do not require continuous covariates, and they do not rely on any conditional moment or distributional assumptions, their performance dominates the competitors in all scenarios. The results for Case 2 are in panels (B) and (D), which contain the boxplots of Euclidean distances when both the linearity condition (4) and the constant variance condition (5) are satisfied. We can see that, surprisingly, our semiparametric proposals are still superior to their classical counterparts in these particular examples. This reminds us of a quite interesting phenomenon where sometimes, estimating a quantity even if it is known brings gain (Henmi and Eguchi 2004). However, whether this gain is real, in general, or just in these specific examples deserves further theoretical investigation. On the other hand, our estimators seem to perform comparably with dMAVE, which usually produces very accurate estimates when all the covariates are continuous, such as the case here. Following the request of a referee, we also experimented the simulations with p = 50, which corresponds to 96 free parameters with the sample size n = 200. Unfortunately, none of the methods examined above can provide any reasonable results in this case. We believe that to handle p very large in comparison with n, additional assumptions such as sparsity is needed. The sparsity assumption assumes many rows of β are zeros, hence the corresponding variables in x simply have no effect on the response variable Y. Many existing methods are available to take advantage of the sparsity assumption (see, e.g., Li 2007; Wang and Wang 2010). Combining the sparsity techniques and the dimension reduction methods are promising future work.
Figure 1.
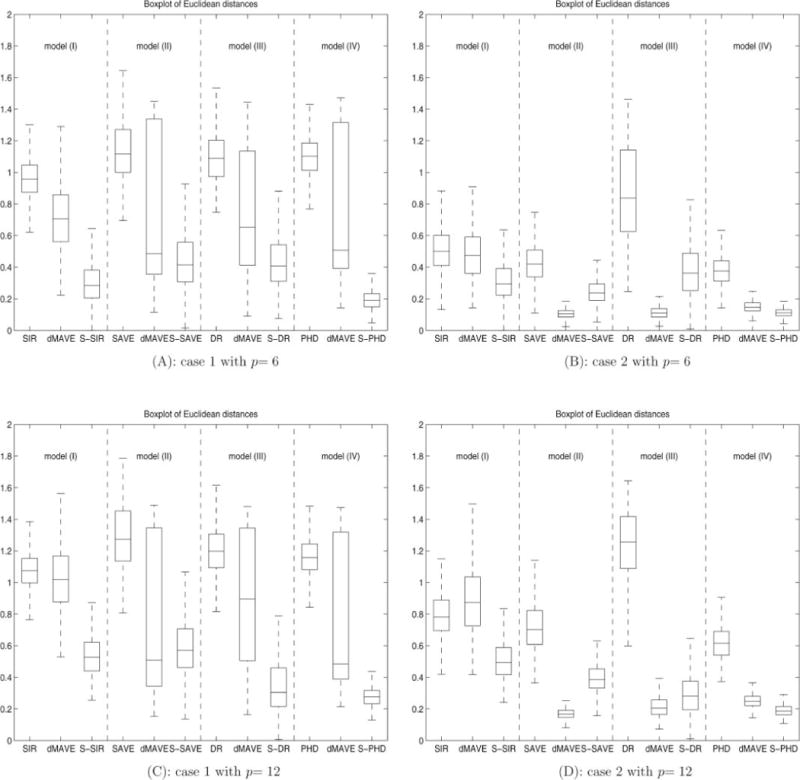
Boxplots of Euclidean distances for models (I)–(IV) with p = 6 and p = 12 in Example 1. Semi-SIR, Semi-SAVE, Semi-DR, and Semi-PHD are shorten to S-SIR, S-SAVE, S-DR, and S-PHD, respectively, in the labels.
6.2 Example 2
Next, we perform simulations to demonstrate the performance of the bootstrap procedure conjuncted with the semiparametric methods in estimating the structural dimension d. We continue to use models (I)–(IV) in Example 1, and generate the predictors x from case 1 when p = 6. We generated 100 datasets of sample size n = 200, with bootstrap size B = 100.
We report the relative frequency of the bootstrap selected dimensions for models (I)–(IV) in Table 1. It can be easily seen that with at least 95% accuracy the bootstrap method correctly chose the dimension, which we consider quite satisfactory.
Table 1.
Relative frequency of the estimated dimension
| Model | Method |
|
|
|
|
||||
|---|---|---|---|---|---|---|---|---|---|
| (I) | Semi-SIR | 1% | 99% | 0% | 0% | ||||
| (II) | Semi-SAVE | 1% | 97% | 0% | 2% | ||||
| (III) | Semi-DR | 3% | 97% | 0% | 0% | ||||
| (IV) | Semi-PHD | 5% | 95% | 0% | 0% |
7. REAL DATA APPLICATION
We illustrate further our semiparametric proposals through a dataset concerning the employees’ salary in the Fifth National Bank of Springfield (Albright, Winston, and Zappe 1999). The aim of this study is to understand how an employee’s salary associates with his/her personal characteristics. To this end, an employee’s annual salary is the response variable Y, and six covariates are possibly associated with the salary: the employee’s current job level, where a larger number indicates a higher rank (X1); the employee’s working experience at current bank, which is measured by the number of years of the employment (X2); the employee’s age (X3); the experience of an employee at another bank prior to working at the Fifth National, which is measured by the number of years at other banks (X4); the employee’s gender (X5); and a binary variable indicating whether the employee’s job is computer related (X6). We removed an obvious outlier in this dataset, leaving 207 observations in the subsequent analysis.
Under various working dimensions k = 1, …, 5, we implement the proposed semi-DR method given in (7) in association with the bootstrap method described in Section 5, with bootstrap size B = 1000. The results are presented as boxplots in Figure 2. It is clear that bootstrap method favors d = 1, which indicates that the six covariates affect the salary through one single linear combination direction. We present the estimation of this direction in Table 2. For comparison, we also implement the dMAVE and the classical DR with kernel smoothing. We emphasize here that dMAVE requires the covariates to be continuous, which is not the case for gender (X5), and DR requires linearity condition and constant variance condition, which are not satisfied in this example (see Figure 3). Hence, both results should not be fully trusted.
Figure 2.
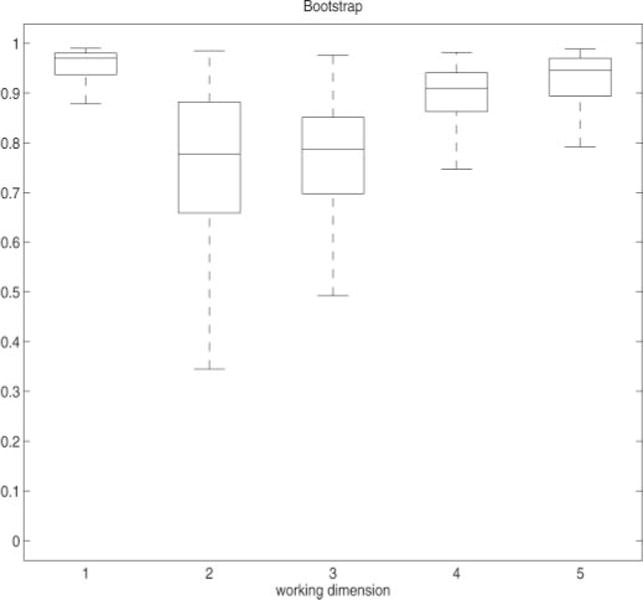
Boxplot of the values defined in (10) from 1000 bootstrapped Semi-DR.
Table 2.
Estimated coefficients of x
| Method | X1 | X2 | X3 | X4 | X5 | X6 |
|---|---|---|---|---|---|---|
| Semi-DR | 0.7330 | 0.5794 | 0.2523 | 0.0147 | 0.1830 | 0.1723 |
| dMAVE | 0.8388 | 0.4404 | 0.2295 | 0.0417 | 0.1373 | 0.1711 |
| DR | 0.2673 | 0.8596 | 0.2829 | −0.1023 | 0.3050 | 0.0782 |
Figure 3.
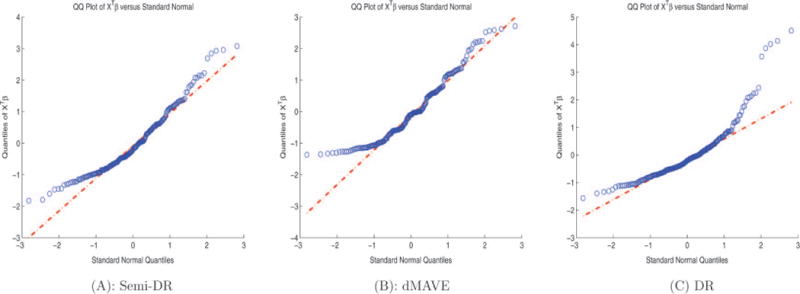
The Q–Q plot of , with estimated from Semi-DR, dMAVE, and DR. (The online version of this figure is in color.)
To see the dimension-reduction effect from a different perspective, in Figure 4, we present the scatterplots of Y versus , where denotes the estimate obtained from Semi-DR, dMAVE, and DR. We can see that the estimates obtained from Semi-DR and dMAVE exhibit a more obvious pattern than DR in that the data cloud appears more compact. We also include in Figure 4 three curves (the dashed lines) fitted from a quadratic function on . These fit the data cloud rather well and illustrate a homoscedastic error pattern. Thus, we further used the fitted curves to perform a cross-validation procedure to calculate the prediction error. The resulting prediction errors from Semi-DR, dMAVE and DR are, respectively, 21.3191, 23.4481, and 47.0288, which further illustrate the advantage of the Semi-DR method. All these evidences support the conclusion that Semi-DR has successfully reduced the dimension from p = 6 to d = 1 and has found the right linear combination of the covariates in terms of establishing the association between salary and an employee’s characteristic.
Figure 4.
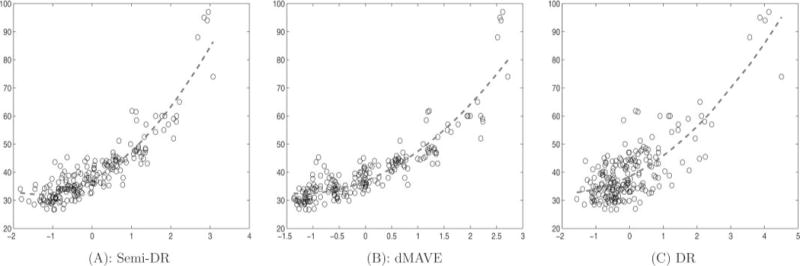
Scatterplot of Y versus , with estimated from Semi-DR, dMAVE, and DR. The dash lines are fitted curves based on quadratic regression modeling.
8. DISCUSSION
It is worth mentioning that (2) and (9) only differ in the first component. For (2), this component can be constructed from any function of Y and xTβ, namely, any g(Y, xTβ), while for (9), the only valid choice is g(Y, xTβ) = Y. Thus, the family of estimators provided by (2) is much richer than the one provided by (9). In fact, it includes the family of (9) as a subfamily of estimators. This is easy to understand intuitively as model (1) assumes more structures than model (8), consequently one can have more ways to construct estimators for (1) and, therefore, model (1) has a larger subspace Λ⊥. Because of this relation, any estimator for model (8) is necessarily also an estimator for (1). This also agrees with the dimension-reduction result that the conditional mean subspace SE(Y|x) is a subspace of the conditional subspace SY|x, because if (1) holds for β, then (8) also holds for β or a submatrix of β.
For illustration, we have chosen to derive SIR, SAVE, and DR as examples for the central subspace problem and OLS and PHD as examples for the central mean subspace from the semiparametric approach, mainly due to their popularity in the dimension-reduction literature. Because Λ⊥ contains all the influence functions, hence every root-n consistent method must correspond to a special choice of the functions in Λ⊥. In this sense, the families given in Sections 2 and 4 are complete.
Finally, we acknowledge here that the linearity condition and the constant variance condition, when assumed to hold only at the true value of β, can be mild and often hold approximately, especially when p is large (Hall and Li 1993). However, our simulations in Case 1 have shown that this approximation may not be sufficient to justify making and using these assumptions. In other words, if we assume the linearity condition and/or constant variance condition to hold exactly at the true β while, in fact, they are only approximately true, the subsequent estimation of the central subspace or central mean subspace can be quite different. In addition, even if the linearity and constant variance conditions do hold exactly, our limited numerical results seem to indicate that it might be still beneficial not to use them if one is concerned more about the estimation quality than the computational cost. Investigation on whether this is indeed a general phenomenon or some special isolated instances is a worthy endeavor.
Supplementary Material
Acknowledgments
Yanyuan Ma’s work was supported by the National Science Foundation (DMS-0906341) and the National Institute of Neurological Disorders and Stroke (R01-NS073671). Liping Zhu’s work was supported by the Natural Science Foundation of China (11071077).
APPENDIX: SOME TECHNICAL DERIVATIONS
A.1. General Introduction to Semiparametrics
Consider the Hilbert space H consisting of all the mean zero, finite variances, length m vector functions of x, Y, where the inner product between two functions h, g is defined as E(hTg). Here and in the following definitions, all the expectations are calculated under the true distribution. The nuisance tangent space Λ is a subspace of H defined as the mean squared closure of all the elements of the form B S, where S is an arbitrary nuisance score vector function, and B is any conformable matrix with m rows. Here the nuisance score vector functions are calculated conventionally in every possible valid parameterization of the infinite-dimensional nuisance parameter, where a “valid parameterization” means that there exists one parameter value which yields the truth. Furthermore, Λ⊥ is defined to be the orthogonal complement of Λ in H.
Semiparametric theory ensures that every regular, asymptotic linear, root n consistent (RAL) estimator corresponds to an influence function, and every influence function is a normalized element in Λ⊥, where the normalization is to ensure . Here, Sβ is the usual score vector with respect to the parameter of interest β, and we use ϕ to denote an influence function and Im to denote the size m identity matrix. This link between the complete family of RAL estimators and the space Λ⊥ allows one to derive estimators through characterizing Λ⊥ and identifying members in Λ⊥. Every explicit identification of one function in Λ⊥ ensures the discovery of one estimator. This is the semiparametric approach that drives all our derivations.
A.2. The Derivation of Λ⊥ in Model (1)
Denote the nuisance tangent space corresponding to η1 and η2, respectively, Λ1 and Λ2. We have
Obviously, Λ1 ⊥ Λ2, hence Λ = Λ1 ⊕ Λ2. It is easy to see that . We now show that . Obviously, functions having the required conditional expectation property are certainly elements in . To show that elements in have to satisfy the conditional expectation requirement, consider any . We let g = E(f | βTx, Y) − E(f | βTx). Obviously, g ∈ Λ2 hence E(gTf) = 0. On the other hand,
Hence g itself should be zero. This means f indeed satisfies the conditional expectation requirement.
We now show that
To see this, note that its form simply says for any element in Λ⊥, it should satisfy the condition E(g | βTx, Y) = 0. Let us denote the set A = {f(Y, x) − E(f | βTx, Y) : E(f | x) = E(f | βTx) ∀ f}. Obviously, . Because
hence as well. Hence, A ⊂ Λ⊥. On the other hand, for any f ∈ Λ⊥, because , we have E(f | βTx, Y) = a(βTx) for some a. Writing this out, we obtain
Now, we have
because E(f | x) = 0 due to . Thus, elements in Λ⊥ indeed have the form f(Y, x) − E(f | Y, βTx). The requirement of these elements belonging to generates the second requirement of A, and we obtain Λ⊥ ⊂ A. This completes the derivation of Λ⊥.
A.3. The Double Robustness of (2)
Denote E*(g | xTβ) the misspecified function of E(g | xTβ). We have
Denote E*(a | xTβ) the misspecified function of E(a | xTβ). We have
A.4. The Derivation Λ⊥ in Model (8)
Denote the nuisance tangent space corresponding to η1, η2, and m, respectively, Λ1, Λ2, and Λm. Straightforward derivation yields
Consequently, we have
To further derive Λ⊥ ⊂ (Λ1 + Λ2)⊥, we first inspect an α(x)ε ∈ Λ⊥. For any h(xTβ), α(x) satisfies
This implies E{α(x) | xTβ} = 0. Therefore,
A.5. Regularity Conditions for Theorem 1
(C1) The univariate kernel function K(·) is Lipschitz, has compact support. It satisfies
The d-dimensional kernel function is a product of d univariate kernel functions, that is, for u = (u1, …, ud)T. Here, we abuse the notation and use the same K regardless of the dimension of its argument.
(C2) Let r1(xTβ) = E{α(x) | xTβ}f(xTβ) and r2(xTβ) = E{g(Y, xTβ) | xTβ}f(xTβ). The mth derivatives of r1(xTβ), r2(xTβ) and f(xTβ) are locally Lipschitz-continuous.
(C3) The density functions of x and xTβ, denoted, respectively, by fx(x) and f(xTβ), are bounded from below and above. Each entry in the matrices E{α(x)αT(x) | xTβ} and E{g(Y, xTβ)gT(Y, xTβ) | xTβ} is locally Lipschitz-continuous and bounded from above as a function of xTβ.
(C4) The bandwidth h = O(n−κ) for 1/(4m) < κ < 1/(2d).
Footnotes
Supplementary materials for this article are available online. Please go to www.tandfonline.com/r/JASA
Contributor Information
Yanyuan Ma, Department of Statistics, Texas A&M University, 3143 TAMU, College Station, TX 77843-3143 (ma@stat.tamu.edu).
Liping Zhu, School of Statistics and Management, Shanghai University of Finance and Economics, Shanghai 200433, China (zhu.liping@mail.shufe.edu.cn).
References
- Albright SC, Winston WL, Zappe CJ. Data Analysis and Decision Making with Microsoft Excel. Pacific Grove, CA: Duxbury Press; 1999. [176] [Google Scholar]
- Bickel PJ, Klaassen CAJ, Ritov Y, Wellner JA. Efficient and Adaptive Estimation for Semiparametric Models. Baltimore, MD: The Johns Hopkins University Press; 1993. [169] [Google Scholar]
- Box GEP, Cox DR. An Analysis of Transformations (with discussion) (Series B).Journal of the Royal Statistical Society. 1964;26:211–252. [168] [Google Scholar]
- Cook RD. Regression Graphics: Ideas for Studying Regressions through Graphics. New York: Wiley; 1998. [168, 169, 170] [Google Scholar]
- Cook RD, Forzani L. Likelihood-Based Sufficient Dimension Reduction. Journal of the American Statistical Association. 2009;104:197–208. [168] [Google Scholar]
- Cook RD, Li B. Dimension Reduction for Conditional mean in regression. The Annals of Statistics. 2002;30:455–474. [168, 172] [Google Scholar]
- Cook RD, Li L. Dimension Reduction in Regressions with Exponential Family Predictors. Journal of Computational and Graphical Statistics. 2005;18:774–791. [170] [Google Scholar]
- Cook RD, Nachtsheim CJ. Reweighting to Achieve Elliptically Contoured Covariates in Regression. Journal of the American Statistical Association. 1994;89:592–599. [168] [Google Scholar]
- Cook RD, Weisberg S. Discussion of Sliced Inverse Regression for Dimension Reduction. Journal of the American Statistical Association. 1991;86:28–33. [168, 171] [Google Scholar]
- Dong Y, Li B. Dimension Reduction for Non-Elliptically Distributed Predictors: Second-Order Moments. Biometrika. 2010;97:279–294. [168, 172, 174] [Google Scholar]
- Fung WK, He X, Liu L, Shi P. Dimension Reduction Based on Canonical Correlation. Statistica Sinica. 2002;12:1093–1113. [168] [Google Scholar]
- Hall P, Li KC. On Almost Linearity of Low Dimensional Projections from High Dimensional Data. The Annals of Statistics. 1993;21:867–889. [176] [Google Scholar]
- Härdle W, Hall P, Ichimura H. Optimal Smoothing in SingleIndex Models. The Annals of Statistics. 1993;21:157–178. [168] [Google Scholar]
- Härdle W, Stoker TM. Investigating Smooth Multiple Regression by the Method of Average Derivatives. Journal of the American Statistical Association. 1989;84:986–995. [168] [Google Scholar]
- Hernández A, Velilla S. Dimension Reduction in Nonparametric Kernel Discriminant Analysis. Journal of Computational and Graphical Statistics. 2005;14:847–866. [168] [Google Scholar]
- Henmi M, Eguchi S. AParadox Concerning Nuisance Parameters and Projected Estimating Functions. Biometrika. 2004;91:929–941. [174] [Google Scholar]
- Horowitz JL, Härdle W. Direct Semiparametric Estimation of Single-Index Models with Discrete Covariates. Journal of the American Statistical Association. 1996;91:1632–1639. [168, 173] [Google Scholar]
- Ichimura H. Semiparametric Least Squares (SLS) and Weighted SLS Estimation of Single-Index Models. Journal of Econometrics. 1993;58:71–120. [168, 173] [Google Scholar]
- Li KC. Sliced Inverse Regression for Dimension Reduction (with discussion) Journal of the American Statistical Association. 1991;86:316–342. [168, 171] [Google Scholar]
- Li KC. On Principal Hessian Directions for Data Visualization and Dimension Reduction: Another Application of Stein’s Lemma. Journal of the American Statistical Association. 1992;87:1025–1039. [168, 172] [Google Scholar]
- Li L. Sparse Sufficient Dimension Reduction. Biometrika. 2007;94:603–613. [174] [Google Scholar]
- Li B, Dong Y. Dimension Reduction for Non-Elliptically Distributed Predictors. The Annals of Statistics. 2009;37:1272–1298. [168, 172] [Google Scholar]
- Li KC, Duan N. Regression Analysis Under Link Violation. The Annals of Statistics. 1989;17:1009–1052. [168, 172] [Google Scholar]
- Li B, Wang S. On Directional Regression for Dimension Reduction. Journal of the American Statistical Association. 2007;102:997–1008. [168, 171, 172] [Google Scholar]
- Newey WK. Semiparametric Efficiency Bounds. Journal of Applied Econometrics. 1990;5:99–135. [170] [Google Scholar]
- Park JH, Sriram TN, Yin X. Dimension Reduction in Time Series. Statistica Sinica. 2010;20:747–770. [168] [Google Scholar]
- Power JL, Stock JH, Stoker TM. Semiparametric Estimation of Index Coefficients. Econometrika. 1989;51:1403–1430. [168] [Google Scholar]
- Tsiatis AA. Semiparametric Theory and Missing Data. New York: Springer; 2006. [169] [Google Scholar]
- Wang J, Wang L. Sparse Supervised Dimension Reduction in High Dimensional Classification. Electronic Journal of Statistics. 2010;4:914–931. [174] [Google Scholar]
- Wang H, Xia Y. Sliced Regression for Dimension Reduction. Journal of the American Statistical Association. 2008;103:811–821. [168] [Google Scholar]
- Xia Y. A Constructive Approach to the Estimation of Dimension Reduction Directions. The Annals of Statistics. 2007;35:2654–2690. [168, 174] [Google Scholar]
- Xia Y, Tong H, Li WK, Zhu LX. An Adaptive Estimation of Dimension Reduction Space (with discussion) (Series B).Journal of the Royal Statistical Society. 2002;64:363–410. [168, 174] [Google Scholar]
- Ye Z, Weiss RE. Using the Bootstrap to Select one of a New Class of Dimension Reduction Methods. Journal of the American Statistical Association. 2003;98:968–979. [174] [Google Scholar]
- Yin X, Cook RD. Direction Estimation in Single-Index Regressions. Biometrika. 2005;92:371–384. [168] [Google Scholar]
- Yin X, Li B, Cook RD. Successive Direction Extraction for Estimating the Central Subspace in a Multiple-Index Regression. Journal of Multivariate Analysis. 2008;99:1733–1757. [168] [Google Scholar]
- Zhu LX, Fang KT. Asymptotics for Kernel Estimation of Sliced Inverse Regression. The Annals of Statistics. 1996;3:1053–1068. [168] [Google Scholar]
- Zhu Y, Zeng P. Fourier Methods for Estimating the Central Subspace and the Central Mean Subspace in Regression. Journal of the American Statistical Association. 2006;101:1638–1651. [168] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.