

Abstract
Data recordings often include high-frequency noise and baseline fluctuations that are not generated by the system under investigation, which need to be removed before analyzing the signal for the system’s behavior. In the absence of an automated method, experimentalists fall back on manual procedures for removing these fluctuations, which can be laborious and prone to subjective bias. We introduce a maximum likelihood formalism for separating signal from a drifting baseline plus noise, when the signal takes on integer multiples of some value, as in ion channel patch-clamp current traces. Parameters such as the quantal step size (e.g., current passing through a single channel), noise amplitude, and baseline drift rate can all be optimized automatically using the expectation-maximization algorithm, taking the number of open channels (or molecules in the on-state) at each time point as a hidden variable. Our goal here is to reconstruct the signal, not model the (possibly highly complex) underlying system dynamics. Thus, our likelihood function is independent of those dynamics. This may be thought of as restricting to the simplest possible hidden Markov model for the underlying channel current, in which successive measurements of the state of the channel(s) are independent. The resulting method is comparable to an experienced human in terms of results, but much faster. FORTRAN 90, C, R, and JAVA codes that implement the algorithm are available for download from our website.
Introduction
During analysis of experimental data, it is often necessary to first remove from data records any baseline fluctuations (1–6) that are not generated by the phenomenon under study. If nothing is known about the signal beyond its power spectrum, then the best solution is a Wiener filter. But when the idealized signal takes on only certain values, such as in patch-clamp recordings of ion channels, maximum likelihood can be used to estimate the state of the channel(s) given some model for the noise. Experienced experimentalists are able to follow the quantal jumps by eye and subtract the drifting baseline by manually tracing out the baseline before processing by other automated methods.
In the studies of the gating behaviors of single protein ion channels using the powerful patch-clamp technique (7), instabilities in the gigaohm seals formed between isolated biological membrane patches and patch-clamp microelectrodes often result in substantial fluctuations in the magnitude of the observed current. Such baseline fluctuations are usually significantly slower than the abrupt changes in current magnitude caused by opening and closing of the protein channel, and have to be removed before the current traces can be analyzed by standardized algorithms such as QUB (8) and HJCFit (9) that model the channel gating characteristics based on idealized data. Existing baseline subtraction algorithms can require substantial time and/or user interaction as the program requires the user to laboriously check each individual fit by eye and/or to input nodes by hand. When this happens, the front-end to sophisticated time-series analysis algorithms (e.g., Milescu et al. (8), Qin et al. (9), and Colquhoun (10)) devolves to eyeballing and mouse clicking to indicate the baseline trajectory, which is susceptible to subjective bias. Here we develop a minimally parameterized maximum likelihood (11) approach for separating a quantal signal from a noisy and varying baseline, which gives results that largely agree with the mouse-based method and is much faster.
QUB has a set of techniques for baseline removal: linear interpolation between a set of user-defined nodes, and a combined Markov-Kalman process where QUB models the baseline as a continuous process with Markov channels superimposed. The Kalman filter tracks the baseline and the Markov idealization algorithm filters the channel kinetics from the baseline data. Qin et al. (9) use time-course fitting in which the response of the recording system to a step change in input is measured. The step response curve can then be used to estimate the response to arbitrary patterns of channel transitions. Time-course fitting requires checking the baseline before and after each opening, which is time-consuming. Burzomato et al. (12) report having obtained rate constants of ∼130,000/s, faster than the 30-kHz sampling rate (and 3 kHz filter frequency), with time-course fitting. The ability of time-course fitting to fit such fast rates was tested by repeated fits of simulated data (12,13).
Colquhoun notes:
“The most obvious danger of time-course fitting is that of over-ambitiousness. The risk of false events arising from an attempt to fit events that are too short is just the same as described above for the threshold crossing method, but the temptation to fit them may be greater. Not only genuine channel transitions, but any disturbance (artifactual or random noise), if sufficiently brief, will produce a signal that can plausibly be fitted by the time-course method” (1).
In time-course fitting, false events that arise from over-ambitiousness are subsequently removed upon imposing a maximum time resolution.
In addition, the time-course fitting approach requires an estimate of the impulse response function (the IRF or Green's function) of the recording apparatus. Whereas for patch-clamp recordings an estimate of the IRF is readily available, for other single molecule signals it might not be. An increasing variety of fluorescence techniques are being used to provide information on single or few molecule kinetics (14–22). It is not clear that IRF estimates can be obtained in all cases. Although patch-clamp recordings use a well-characterized filter, other single molecule systems may involve filtering intrinsic to the experimental methods used. In most single-molecule studies, the molecules of interest are immersed in a solution containing fluorescent indicators. Such signals involve various chemical reactions, which can themselves be considered as not particularly well-characterized filters.
Our method and the QUB Markov-Kalman method both yield a ranking: the likelihood. When these methods are run repeatedly with different initializations, one need only compare the likelihood scores to ascertain which output is best. There is virtually no subjectivity involved in this scenario. Moreover, maximum likelihood is asymptotically efficient. In the contemporary state of the art of patch-clamp data analysis, the use and application of these methods is not standardized. The method proposed here and some of the QUB methods are objective in the sense that they return a model-based maximum likelihood estimate for the data (by “model” we mean a decomposition of the data into baseline, signal, and noise), but as Box wrote: “all models are wrong” (23).
How does the innate incorrectness of the models weigh against the dangers involved in time-course fitting? We do not address the comparison of various methods in this article. Given the variety of single molecule signals researchers are obtaining, we believe that there is merit in new methods for solving this old problem, particularly ones as conceptually simple and fast as the method we put forth here.
Our technique treats the observed data as comprising three components:
-
1.
A quantal current passing through ion channels;
-
2.
A slowly varying baseline current that we model as a random walk; and
-
3.
A white noise that represents noise within the patch-clamp amplifier and measurement apparatus.
We show in Results that the method can work equally well when the background signal is contaminated by nonwhite noise. The QUB Markov-Kalman method requires the user to provide estimates for baseline and channel properties and generates a Markov model for the channel gating kinetics. Our method does not generate a Markov model. In the case of a single channel, our method returns a conditional posterior probability that the channel is open at each time point. Thus, if the channel PO (equilibrium open probability) changes abruptly for whatever reason, it does not pose difficulties for our method. Our method requires an initial guess for the baseline, which can be quite crude, plus an initial guess for each of three parameters corresponding to the three components of our model (as explained in Methods). These parameter initializations are automatically improved as the method runs.
The current passing through channels is given by the product of the single channel current and the number of open channels at each time point. We use the estimation/maximization (also known as the expectation maximization (EM) algorithm) to estimate the number of open channels, which is treated as missing data. The EM algorithm (24–27) was originally developed by Baum and Petrie (24) in the 1960s and formalized by Dempster et al. (27). We integrate out the baseline, which is equivalent to replacing it with a maximum likelihood estimate. In Methods, we lay out the basic theory for such a system, which yields a likelihood function for the baseline and the data that is similar to the path integral representation of the harmonic oscillator (28,29) or a Gaussian process (30). The Results section is broken down into two subsections corresponding to weak and strong filtering. We present applications of the technique to both synthetic (numerically generated) data and to ion-channel data obtained with the Axon Axopatch 200B patch-clamp amplifier (Molecular Devices, Sunnyvale, CA). We find that the algorithm works well on both weakly and strongly filtered data. The algorithm has a higher probability of error and can fail to converge on strongly filtered data.
Methods
We will describe the basic idea using the language for ion channels that are either open or closed, but the method can be used for any signal that can be reasonably approximated as consisting of some number of equally spaced steps. Both QUB and time-course fitting have methods for traces for which the channel has multiple step sizes. We have not yet developed code for unequal step sizes, but the generalization is straightforward. In this article we treat equal step sizes only. We first sketch the general theory, then signal/noise issues. This section closes with a brief explanation of the experiments that were undertaken to provide the data that the method was tested on. We remark here that one need not understand the mathematics of the general theory that underlies the technique to be able to apply the method or to use the code. For those who are interested more in using the technique than in the mathematics, we recommend reading the opening paragraph of Theory and then skipping to Signal/Noise.
Theory
We imagine an experiment producing a continuous time signal that we sample discretely at sampling frequency ν. The discrete sampling yields a data record d = (d1,d2,…dT). We shall denote a generic time point in the record by dt, where t ∈ (1,2,…,T). We assume that an open channel passes a current and that a closed channel passes no current. In our model, if nt channels are open at time t, the observed signal (the data: dt) is given by dt = bt + nt + σξξt, where dt is the baseline current flowing through the circuit although not necessarily through the ion channel, and ξt is discrete-time Gaussian white noise that has moments 〈ξt〉 = 0, 〈ξtξt′〉 = δtt′. Here δtt′ is the Kronecker delta and σξ is the noise strength. We further assume that the baseline is undergoing a discrete time random walk, , where is discrete-time white noise like ξt. Under these assumptions, it follows immediately that dt − bt − nt and bt+1 − bt are zero mean Gaussian distributed random variables with variances and , respectively. We remark that if the continuous time baseline is undergoing a continuous random walk, as modeled by a Wiener process (31), that the baseline variance should scale inversely with sampling frequency, ∝ 1/ν. Analogous to the definition of d, we also define b and n: b = (b1,b2,…,bT), n = (n1,n2,…nT). Our primary goal is to obtain estimates of the nt, but in doing so we will also obtain estimates of b, , σ2b, and as well. It turns out that it is simpler to parameterize the system in terms of and R2, where
| (1) |
is the ratio of the baseline walk variance to the white-noise variance. We treat both n and b as missing data, although b is integrated out directly without the need of EM.
Our model implies that the joint distribution function for d, b, and n is given by
| (2) |
where is an energy functional given by
| (3) |
and where θ represents the parameters , , and . The value is the normalization factor
| (4) |
where
and Nch is an upper bound on the number of channels contained in the patch. The values dd and db represent the differentials of all the variables being integrated over, e.g.,
In principle, we would like to maximize the likelihood of the data given the model, L(d;θ),
| (5) |
but this is unwieldy. Although the integral over T dimensions can be dealt with, the sum is over at least 2T values and cannot be maximized in one step. Thus we employ the iterative estimation/maximization (EM) procedure. We made use of Fraser’s accessible discussion of the algorithm (32). The EM algorithm attempts to find the maximum likelihood estimate of L by first making an initial guess for , and then iterating the steps
| (6) |
In the above, denotes the expectation of with respect to the distribution . The EM iteration is known to converge to, at worst, a local maximum likelihood estimate for L(d|θ).
Because of the simple dependence that the likelihood function has on b, we can integrate b out and then employ a slightly modified version of the EM algorithm to solve the remaining maximum likelihood problem,
| (7) |
where b∗ is the maximum likelihood estimate of b (or equivalently, the saddle-point) found by minimizing the energy ,
and Δ is the finite difference Laplacian,
Thus
| (8) |
The Laplacian and associated boundary conditions are discussed in the Appendix. The normalization constant is given by
| (9) |
The steps leading from Eq. 7 to Eq. 9 are discussed in the Appendix. As written, the b∗ in the argument of p(d,n;θ,b∗) in Eq. 7 is redundant because b∗ is a known function of d, n, and θ. The reason we have employed this seemingly redundant notation is just to make clear in the algorithm which value of b∗ (old or updated) we used to compute the expected values of n.
We discuss the precise form that our implementation of the EM algorithm takes in the Appendix. The distribution , needed for Q in Eq. 6, becomes after integrating out b. To find , we note that, in general, p(x|y) = p(x,y)/p(y). Thus,
| (10) |
The quantity is the conditional probability that there are nt channels open at the single time point t. To simplify the notation, we write to indicate the conditional probability that there are j channels open at time t,
| (11) |
where
We will use angle brackets without subscripts to denote expectations with respect to so that
For a single channel or single molecule recording, Nch = 1 and Eq. 11 results in
For a single ion channel (or molecule) with multiple equally spaced conductance states, Nch + 1 represents the total number of conducting states that the system can take.
At this point, we can write Q explicitly as
| (12) |
The dependence on is only through b∗ and the angle brackets. The end result of this calculation is that we replace the dependence in on powers of nt with the expected value of those powers: nt → 〈nt〉 and n2t → 〈n2t〉. We maximize by updating θ iteratively in the following steps:
Step 0 (Initialization)
Make initial guess for , and : .
Step I (Estimate or expectation)
Update the expected values of nt and nt2 with respect to p(j|dt,θ,t), which we will denote 〈nt〉 and 〈nt2〉,
| (13) |
At the end of this step, nt and nt2 in will be replaced by 〈nt〉 and 〈nt2〉, respectively.
Step II (Maximize)
A. Update baseline signal:
We obtain b∗ with a standard tridiagonal matrix solver, which is very fast. Note the dependence in b∗ is on rather than on θ. In substeps B, C, and D we update the parameters , σ2ξ, and R2 while keeping b∗ fixed.
B. Update :
The derivative of Q with respect to is
To maximize Q with respect to , we set the above equation to zero, which yields
C. Update .:
The derivative of Q with respect to 1/ is
To maximize Q with respect to , we set the above equation to zero, which yields
| (14) |
D. Update R2:
The derivative of Q with respect to R2 is
where . The updated R2 is the single real positive root of ∂Q/∂R2 = 0. At this point, .
E. Return to Step I:
To summarize, we iterate the steps described above in the order Step 0 Step I Step II Step I. So, in the E step, we compute the Nch expectation values of nt for each t and in the M step, we update the parameters based on maximizing Q in Eq. 27. FORTRAN 90, C, R, and JAVA programs that perform these calculations are available at our website.
Signal/noise
There are two noise sources in our model ξt and , where ξt is the noise in the data (dt = bt + nt + σξξt) and is the noise in the baseline ,
| (15) |
| (16) |
| (17) |
where NO and NC are the mean number of sampling intervals for open and closed events, respectively. SNRξ is a standard signal/noise ratio. SNRb indicates how much the baseline drifts relative to the current during the average open or closed event. SNR is the combined signal/noise ratio:
SNR must be several times larger than unity for the reconstruction to be reliable.
Idealization
Technically the algorithm presented thus far does not yield an idealized record. In the case Nch = 1, the output is simply the posterior probability that the channel is open at each time point. Thus to obtain the most probable record we need only take the value of j for which is maximal, so that we have
| (18) |
which requires only the Nch function evaluations at each time point.
Experiment
Experimental records of current passing through single inositol 1,4,5-trisphosphate (IP3) receptor (IP3R) channels, which are ubiquitous intracellular Ca2+-release protein channels localized mainly to the endoplasmic reticulum and outer nuclear membranes (33), were acquired by nuclear patch-clamp electrophysiology as described in Mak et al. (34,35). Currents passing through outer nuclear membrane patches isolated at the tips of micropipettes were amplified using an Axopatch 200B patch-clamp amplifier (Molecular Devices); filtered either at 1 kHz using a tunable low-pass four-pole Bessel filter (Frequency Devices, Ottawa, IL) or at 5 or 10 KHz using the internal tunable low-pass four-pole Bessel filter of the Axopatch amplifier (Molecular Devices). The current signals were digitized at 5 kHz using an ITC16 interface (HEKA Instruments, Bellmore, NY) and recorded directly onto a data acquisition computer using the Pulse + PulseFit software (HEKA Instruments).
Results
To illustrate the use of the technique we apply it to both simulated and experimental patch-clamp data. We found that the algorithm works best on data that is unfiltered/lightly filtered but that it works with a slight modification on heavily filtered data. The difficulty with heavily filtered data is that the filtering generates correlations in the noise ξ, which becomes harder to distinguish from a random walk. Larger R2 values can give higher likelihoods but worse reconstructions on heavily filtered data because the model assumes no filtering. We found that for the heavily filtered data the algorithm performed better if we held R2 fixed. Choosing a good value of R2 takes some experience or repeated comparisons of the output (n) to the input data.
Synthetic data
To generate the synthetic data we need to simulate both signal and noise. The signal is simulated by first choosing the desired number of open/closed pairs and then choosing a desired equilibrium open probability (PO) and mean open time with the open time specified in units of the sampling interval, NO. Then the length of each open event is chosen randomly to give the selected mean. Closed event lengths with a mean closed interval NC are determined in the same way. In the simulation presented here, we added two twists to make the simulated data more challenging by having it violate the model in a few plausible ways:
First, we chose the PO for the first-half of the record to be 0.1 and to be 0.2 for the second-half of the record. This was done to simulate nonstationarity of the channel behavior.
Second, in addition to the noise ξ, we also treated as a random variable with a well defined mean, , and variance σ2ξ. This was done because ion channel signals are usually noisier when the channel is open than when it is closed. Thus the effective σξ, σξeff, is because of the extra noise when the channel is open. (The variance doubles so the standard deviation goes up by .)
We then chose to use a total of 10,000 open/closed pairs. For the simulation discussed here, this gave us nt for ∼T = 151,000 time points. Next we construct a random walk for the baseline according to , where is a unit norm, zero mean normal deviate. We construct simulated data according to
where ξt is a unit norm, zero mean normal deviate. We chose = 40, σξ = 5, and σb = 2. We used NO = 2 for the entire record, and the mean closed interval, NC, switched from 18 to 8 half-way through the simulation (so that the PO switched from 0.1 to 0.2 half-way through the record). In this case, R2 = /σ2eff ≈ 0.08 and /σξeff = 7.07 so that
This was meant to be challenging for the algorithm. For most runs we were able to find an estimate of n that was accurate to >. In Fig. 1, a and b, the thin lines show a snippet of the time series we generate by this process. The thick line in Fig. 1 a is the algorithm’s estimate of 〈nt〉. The thick line in Fig. 1 b is the algorithm’s estimate of b. With these challenging parameters we occasionally have to play with the starting guesses for the parameters, particularly the initial single channel current, , before the algorithm returns a reasonably accurate estimate of n. Whether an estimate of n is reasonably accurate or not is determined by visual comparison between the estimated n and the raw data.
Figure 1.
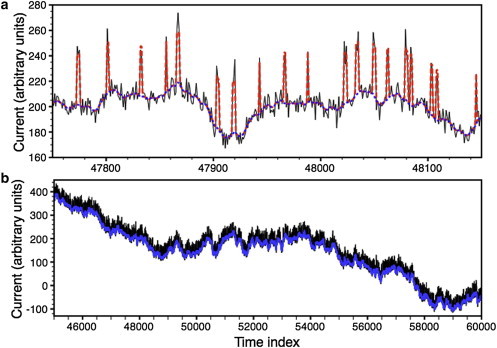
Simulated data. (a) (Thin line) Simulated signal d. (Dashed line) Algorithm’s estimate of bt + 〈nt〉. (Dotted line) Estimated baseline, bt. (b) (Thin line) Simulated signal d. (Thick line) Estimate for b that the algorithm found.
Unfiltered synthetic data
For this case we took the data as described above and applied our algorithm to it. We found that we sometimes need to alter the initial guess for the baseline to reach a better solution. For the results presented here we chose bt = 0.95 dt for the initial guess for the baseline. There is nothing fundamental about the choice of initial baseline. It is probably wise to try several different guesses, particularly if one is having difficulty generating a visually satisfactory estimate of n. The initial guesses for the other parameters were R2 = 0.1, = 20, = 505, and Nch = 1. With these guesses the algorithm converged in 38 iterations (which took a few seconds) and gave estimates for the current of est = 39.9558, POest = 0.131128, σest2ξ = 28.1459, and R2 = 0.141. The true . We found the total error
was ∼100, which means > correct despite the SNR of 3.6. Snippets of the data are shown in Fig. 1. The upper graph shows 500 time points. The thin line is the raw synthetic data. The dashed line is the reconstruction btest + estntest. The dotted line is btest. As general rule we recommend comparing dt, best, and btest + estntest. The lower graph is a larger sample of the data. The thin line is the raw data and the thick one is the estimate of the baseline that the algorithm returned.
Filtered synthetic data
We generated filtered data, , beginning with unfiltered data, (d), from the previous subsection. We filtered diffusively through
with for six steps where . This produced the time series shown as the dark line in Fig. 2. The thin line in that figure is the unfiltered data (d) for the same snippet shown in the top panel of Fig. 1. In this case we made initial guesses of R2 = 1, = 20, = 65.6, and bt = 0.95 dt. We held R2 fixed because updating R2 on this data results in an R2 that appears to increase without bound. This appears to be an essential aspect of filtering that, in our view, is a significant corruption of the data. Filtering generates unwanted correlations in the noise. Consequently the algorithm has trouble distinguishing between the drifting baseline and the white noise. It tends to conclude that all the noise is baseline, thus R2 → ∞ if we update R2. Fig. 3 shows the best reconstruction we were able to produce in a few minutes of playing around with various initial parameters. The heavily filtered data used in Fig. 3 came from the same time series as the lightly filtered data used in Fig. 1. Fig. 1 a and Fig. 3 can be directly compared. The algorithm converged in 86 iterations (which took a few seconds) and generated the following estimates of est,filtered = 12, POest,filtered = 0.171, and (σξest,filtered) = 5. The true POtrue = 0.1316. The total error was ∼8800, which represents a fractional error of 8800/151,000 = 0.05. Note though that whereas the PO is off by 0.04, the fractional error in PO is ∼25%. Clearly we cannot compare the output likelihood scores for different R2 values when using the algorithm with fixed R2 on heavily filtered data. If the likelihood score cannot be trusted for filtered data then the only way to compare different candidate solutions is by visually comparing them to the input data and ranking them. This is arduous and time-consuming. Ultimately we recommend that the data not be filtered except for frequencies above the sampling rate.
Figure 2.
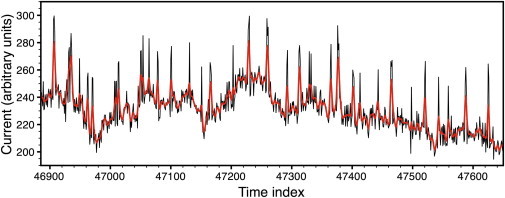
Simulated data. (Thin line) The same unfiltered synthetic data shown in Fig. 1a. (Thick line) Diffusively filtered data.
Figure 3.
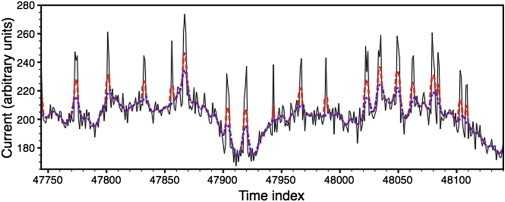
Synthetic filtered data. (Thin line) Unfiltered synthetic data. (Dashed line) Algorithm’s estimate of bt + 〈nt〉. (Dotted line) Estimated baseline, bt. This is the same segment as shown in Figs. 1 and 2. The algorithm had a fairly low error rate on this segment. The total summed error for the filtered data is 8801.
Synthetic data with nonwhite noise
Our method worked equally well on data contaminated by nonwhite noise. We filtered the white noise so that its power spectrum increases with frequency similar to the observed noise (Fig. 4) (see Fig. 1B of Shapovalov and Lester (36) for comparison) and contaminated the background signal with the resulting nonwhite noise. The unfiltered time-trace was generated as described above. We processed 1000 such time-series traces, each having more than 100,000 points and 10,000 events. The mean error was computed by averaging the total error for each run
over the 1000 runs. The total error averaged over the 1000 runs with white and nonwhite noise was 65.235 and 65.127, respectively, meaning that only 65 time points out of 100,000 were classified incorrectly in either case.
Figure 4.
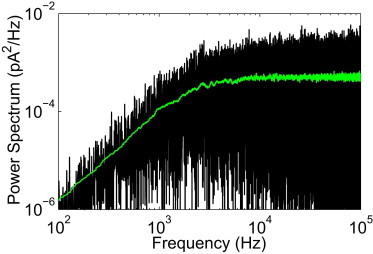
Power spectrum of unfiltered synthetic data with non-white noise. (Shaded line; green online) Averaged power spectrum using a moving box average with a window of 200 points.
Real data
The records shown in Figs. 5 and 6 are two segments from one of the nuclear patch-clamp experiments that studied homotetrameric recombinant rat type 3 IP3R channels expressed in mutant chicken B cells deficient in the expression of all three of the endogenous IP3R isoforms (37). Solution on the cytoplasmic side of the channel contained saturating [IP3] (10 μM), optimal free [Ca2+] (2 μM), with physiological [K+] (140 mM) and free [ATP4−] (0.5 mM). Applied voltage used was 30 mV. The experiment was performed at room temperature. Two records of the same current trace but filtered with different corner frequencies of 1 and 5 kHz were acquired simultaneously. For this data we used an initial baseline guess b[j] = 18, which was an eyeball estimate of the baseline toward the end of the data. For the strongly filtered data (1 kHz corner frequency) we kept R2 fixed at R2 = 0.01. The other parameters were initialized to = 0.1 and = 15. This took ∼5 min of playing around with different initial parameters before a visually reasonable solution was found. The algorithm stopped after 137 iterations and returned values for the current of 13.37 pA and of 3.13, and PO of 0.856.
Figure 5.
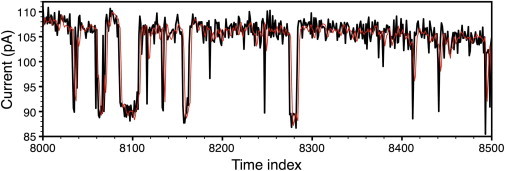
Experimental data. Sampling frequency: 5 kHz. (Thick line) Filter frequency 5 kHz. (Thin line) Filter frequency = 1 kHz.
Figure 6.
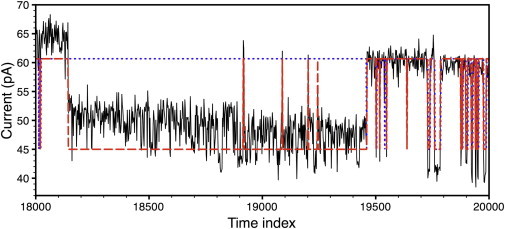
(Thin line) Raw data sampled at 5 kHz with a 5 kHz filter frequency. (Thick dashed line) The algorithm’s estimate of 〈nt〉 using the lightly filtered data as input. (Thick dotted line) The algorithm’s estimate of 〈nt〉 using the data filtered with the 1 kHz filter as input. This snippet was found by plotting running averages of the two estimates and looking for the regions where there were large differences.
The algorithm was then applied to the less filtered version of the same current trace with initial parameters R2 = 0.000001, = 0.1, and = 15. In this case, we could update R2. The algorithm converged in 105 iterations, which took a few seconds on the 88,000 time points. The final value for R2 was 0.02 and was 3.3. The current that was returned was 15.68 pA and PO = 0.813. After idealization we found a mean open time of 25.4 sampling intervals. Thus the algorithm gives an estimate of the signal/noise ratios, SNRξ = /σξ ≈ 8.6 and SNR ≈ 7. The fact that we obtained different values for PO on the filtered and unfiltered data raises the question: which PO value was more accurate?
One cannot directly compare the output for the two files because the input files are slightly shifted from each other because of the difference in filtering. Simply differencing the two data sets generates a large number of differences. Thus we computed 500-point running averages for the two output files and compared those. The running averages were largely indistinguishable, except for brief windows that stood out. In Fig. 6, we plot the raw data (thin line) with 5-kHz filtering overlain with the algorithms output for n for the 1-kHz filter frequency (thick dotted line) and the 5-kHz filter frequency (thick dashed line). In this region the channel was in a rare extended closed period. The output from the heavily filtered data missed it and estimated that the channel was open during this time, which accounts for the fact that the more heavily filtered data yielded a slightly higher PO. Visual comparison between the output and the input is the only standard that we have for gauging the validity of a reconstruction. Thus we concluded that the signal obtained from the less filtered data is more accurate.
We also applied the method outlined to IP3R Ca2+ channels from insect Sf9 cells observed in [IP3] = 300 nM and free [Ca2+] = 70 μM (34,35). The top panel of Fig. 7 (black) shows 1 s of raw data (5000 sampling intervals) filtered at 5 kHz. (The raw data is available on our website in file N1_it.txt.) The middle panel of Fig. 7 (green) shows the same data after the baseline was removed by hand using spline fits. We did the spline fits for only half the file. This process took about two days for Mak, who considered this a particularly challenging data set. The bottom panel of Fig. 7 (red) shows 〈nt〉 for the same data. This takes seconds for the algorithm to process with a few additional minutes required to find good initial guesses for the parameters and baseline.
Figure 7.
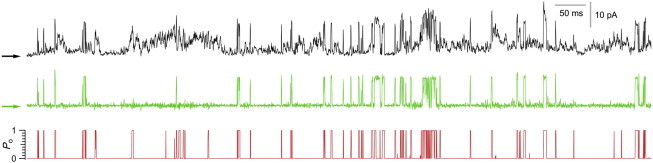
Comparison. (Top panel) Raw data. (Middle panel) Data with baseline subtracted by hand. (Bottom panel) Output of our EM algorithm.
The method works equally well on patch-clamp data from multiple ion channels. Raw data (sampled at 5 kHz and filtered at 1 kHz) from a patch-clamp experiment on IP3R from Sf9 cells ([IP3] = 10 μM, free [Ca2+] = 70 μM) is shown by the thin line in Fig. 8 a, where up to three channels open simultaneously. The baseline extracted by the method is shown by the thick line in Fig. 8 a, whereas the idealized signal generated is shown in Fig. 8 b. An expanded view of a 1000 time-point segment of the raw and idealized time series from Fig. 8, a and b, is shown in Fig. 8, c and d, respectively. Nt = 0, 1, 2, and 3 in Fig. 8, b and d, represent zero, one, two, and three channels open simultaneously.
Figure 8.
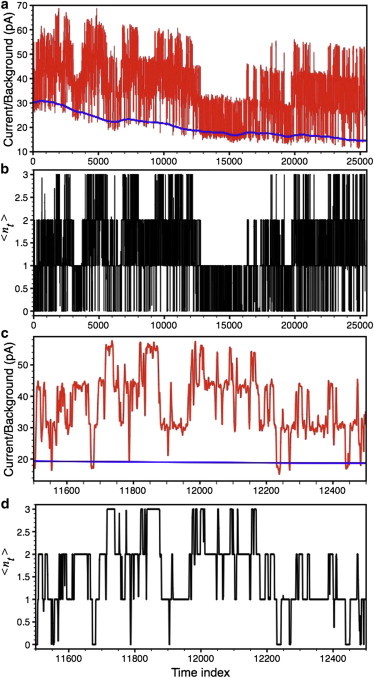
Patch-clamp data from multiple channel. (a) Raw time-series data from three simultaneously patch-clamped IP3Rs in Sf9 cells (thin line) and the baseline extracted from the noisy data (thick line). (b) Processed signal generated by the method. (c and d) Expanded views of the traces in panels a and b, respectively.
Obtaining the codes and data
All files used in the creation of this article are available at ftp://ftp-t10.lanl.gov/pub/pearson/baseline.tar.gz. This archive includes working C and FORTRAN implementations of the baseline subtraction algorithm described in this article. It also includes R and JAVA versions that are currently under development. All other code and data used in generating this article is contained in this archive as well.
Conclusions
Baseline removal and idealization algorithms have been employed for decades(8,10). Despite that fact, many experimentalists still resort to performing this arduous task by hand. The discovery of green fluorescent protein (38) and its subsequent development by Shimomura et al. (38) has enabled experimentalists to obtain signals from a rapidly growing number of single molecules. Single molecule data is necessarily noisy. Algorithms are needed to extract signal out of the noise.
For lack of a simple automated method, experimentalists resort to the eye and mouse-based approach for processing noisy quantized signals such as the patch-clamp data representing the current through an ion channel in various conducting states. This laborious manual procedure sometimes costs experimentalists more time for processing the data than the actual experiment. Here we have developed a minimally parameterized likelihood method to process the noisy quantal data with a varying and drifting baseline. The underlying model we use assumes the data is the sum of three components: the current passing through open channels, a slowly varying baseline that we model as a random walk, and white noise.
We demonstrate the accuracy of our method by applying it to both real and synthetic time-series data. On unfiltered synthetic data we demonstrated that we could accurately reconstruct the underlying signal for a signal/noise ratio of SNRξ = 3.6 and SNRξ = 7. On heavily filtered synthetic data we were forced to hold R2 fixed and the method overestimated the PO.
When applied to experimental patch-clamp data we found SNRξ ≈ 8.6 and SNRξ ≈ 7. We had previously estimated that SNRξ in our patch-clamp system was between 10 and 20. We also applied the algorithm to a current trace that was recorded with two different filter frequencies. Based on visual comparison between the input data and the output data we found that the lightly filtered data yielded a more accurate solution. As expected, based on our simulations, we were forced to hold R2 fixed on the more heavily filtered data but not on the lightly filtered data.
On another data set of heavily filtered experimental data, our method proved comparable to a mouse-based method in accuracy, but much faster. The method can easily be adopted for noisy quantized signals from other systems. For unfiltered/lightly filtered data, we found that we did not need to make visual comparisons between different candidate solutions. The one with the best likelihood score was always the one that gave the best visual comparison to the input data. Thus one can explore how different initial parameter values affect the outcome without needing to visually compare the different solutions. There is, however, one caveat to the likelihood score. The algorithm would occasionally return estimates of the single channel current, , that were near zero (femtoamps and smaller). For a single channel these solutions would always give PO = 0.5 and they would tend to have the best likelihood scores for the data set. Ruling these bad solutions out did not require any effort because one needed only to read off the output current to know that the solution was bad. In a subsequent article, we will show that our approach can also be used on optical data.
Acknowledgments
J.E.P. acknowledges useful conversations with Andy Fraser, David Sigeti, Chris Brislawn, Charlie Doering, Werner Horsthemke, Lorin Milescu, and Fred Sachs. We also thank an anonymous reviewer for many helpful comments.
This material is based upon work supported by the National Institutes of Health under grant No. 5RO1GM065830-08.
Footnotes
William J. Bruno’s current address is Gyrasol Technologies, 2029 Becker Dr., Lawrence, KS 66047.
Appendix
Normalization
Note that the energy functional has the same form as that for a driven discrete time-harmonic oscillator. Thus integrals over b are essentially path integrals for the harmonic oscillator process. Normalization requires that
| (19) |
thus
where db = db1db2…dbT. The d differentials, dd, are defined similarly save for a minor technical point that we must discuss first.
It will prove convenient to rewrite the energy using Dirac’s notation as
| (20) |
where is the differencing operator (with transpose †),
and Δ is the discrete Laplacian, for i and j ≠ 1 or T and and .
If we could do all of the d integrals right now, we would then need to evaluate
A general result for Gaussian integrals of the above form is
but Δ is a singular operator; we cannot blithely do the d integrals. This is the technical difficulty that we alluded to above. We avoid this difficulty by choosing not to integrate over d1, which is equivalent to choosing a reference current by which all others are measured.
We can rearrange the energy to single out the terms involving d1 so that
| (21) |
where . The operator is identical to −Δ except . Now the Gaussian integrals can be done by inspection. (First, do the d integrals over (d2,d3,…dT), then all of b integrals.) This yields
| (22) |
where is the determinant of . It is straightforward to show by induction that . We have nearly determined in Eq. 4:
The summation over n gave the factor of (1 + Nch)T. At this point we have managed to find the normalization factor for the full distribution function but we plan to integrate out b.
We need the marginal distribution p(d,n;θ), so we still have some work to do. Note that the energy functional has the same form as that for a discrete-time driven harmonic oscillator. Thus integrals over b are essentially path integrals for the harmonic oscillator process.
In what follows, we integrate out the bt so that we can use maximum likelihood to find the other parameters. For the marginal likelihood we have
| (23) |
where b∗ is the maximum likelihood estimate of b, I is the T × T identity matrix, and
To calculate the determinant of −Δ + IR2 we take advantage of the relationship to the path integral for the harmonic oscillator and find (29) that in the large T limit
so that
| (24) |
and then
| (25) |
where K is constant with respect to σξ, R2, and .
Our Implementation of the EM algorithm
Thus the form the EM algorithm takes for our model is to initialize and , which is the starting guess for the baseline. Then we iterate the following steps:
| (26) |
| (27) |
| (28) |
| (29) |
| (30) |
Note that b∗ is fully specified by Eq. 8 because n is summed over in the expectation and d is given. Thus, in Eq. 27, b∗ is simply a vector of constants, so that is simply a function of σ2ξ, R2, and .
References
- 1.Colquhoun D. Practical analysis of single channel records. In: Standen N.B., Gray P.T.A., Whitaker M.J., editors. Microelectrode Techniques: The Plymouth Workshop Handbook. Company of Biologists; Cambridge, UK: 1987. pp. 101–139. [Google Scholar]
- 2.Witkoskie J.B., Cao J. Analysis of the entire sequence of a single photon experiment on a flavin protein. J. Phys. Chem. B. 2008;112:5988–5996. doi: 10.1021/jp075980p. [DOI] [PubMed] [Google Scholar]
- 3.Sachs F. Single-Channel Recording. Springer; New York: 2009. Automated analysis of single-channel records. [Google Scholar]
- 4.Colquhoun D., Sigworth F. Single-Channel Recording. Springer; New York: 2009. Fitting and statistical analysis of single-channel data. [Google Scholar]
- 5.Milescu L.S., Yildiz A., Sachs F. Extracting dwell time sequences from processive molecular motor data. Biophys. J. 2006;91:3135–3150. doi: 10.1529/biophysj.105.079517. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Milescu, L. 2003. Applications of hidden Markov models to single molecule and ensemble data analysis. PhD thesis, SUNY, Buffalo, NY.
- 7.Hamill O., Marty A., Sigworth F. Improved patch-clamp techniques for high-resolution current recording from cells and cell-free membrane patches. Pflügers Archiv. Eur. J. Phys. 1981;391:85–100. doi: 10.1007/BF00656997. [DOI] [PubMed] [Google Scholar]
- 8.Milescu, L. S., C. Nicolai, and J. Bannen. 2000–2013. QUB software. http://www.qub.buffalo.edu.
- 9.Qin F., Auerbach A., Sachs F. Estimating single-channel kinetic parameters from idealized patch-clamp data containing missed events. Biophys. J. 1996;70:264–280. doi: 10.1016/S0006-3495(96)79568-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Colquhoun, D. 2007. HJCFit software. http://www.onemol.org.uk/?page_id=8.
- 11.Fisher R. Theory of statistical estimation. Math. Proc. Cambridge Phil. Soc. 1925;22:700–725. [Google Scholar]
- 12.Burzomato V., Beato M., Sivilotti L.G. Single-channel behavior of heteromeric α1β glycine receptors: an attempt to detect a conformational change before the channel opens. J. Neurosci. 2004;24:10924–10940. doi: 10.1523/JNEUROSCI.3424-04.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Colquhoun D., Hatton C.J., Hawkes A.G. The quality of maximum likelihood estimates of ion channel rate constants. J. Physiol. 2003;547:699–728. doi: 10.1113/jphysiol.2002.034165. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Komatsuzaki, T., M. Kawakami, …, R. J. Silbey, editors. 2011. Advances in Chemical Physics, Vol. 146, Single Molecule Biophysics: Experiments and Theory. John Wiley, Hoboken, NJ.
- 15.Cao J. Michaelis-Menten equation and detailed balance in enzymatic networks. J. Phys. Chem. B. 2011;115:5493–5498. doi: 10.1021/jp110924w. [DOI] [PubMed] [Google Scholar]
- 16.Wu J., Cao J. John Wiley; New York: 2011. Generalized Michaelis-Menten Equation for Conformation-Modulated Monomeric Enzymes. [Google Scholar]
- 17.Morimatsu M., Takagi H., Sako Y. Multiple-state reactions between the epidermal growth factor receptor and Grb2 as observed by using single-molecule analysis. Proc. Natl. Acad. Sci. USA. 2007;104:18013–18018. doi: 10.1073/pnas.0701330104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.van Oijen A.M. Single-molecule approaches to characterizing kinetics of biomolecular interactions. Curr. Opin. Biotechnol. 2011;22:75–80. doi: 10.1016/j.copbio.2010.10.002. [DOI] [PubMed] [Google Scholar]
- 19.Qian H. Phosphorylation energy hypothesis: open chemical systems and their biological functions. Annu. Rev. Phys. Chem. 2007;58:113–142. doi: 10.1146/annurev.physchem.58.032806.104550. [DOI] [PubMed] [Google Scholar]
- 20.Elenko M.P., Szostak J.W., van Oijen A.M. Single-molecule imaging of an in vitro-evolved RNA aptamer reveals homogeneous ligand binding kinetics. J. Am. Chem. Soc. 2009;131:9866–9867. doi: 10.1021/ja901880v. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Batzer A.G., Rotin D., Schlessinger J. Hierarchy of binding sites for Grb2 and Shc on the epidermal growth factor receptor. Mol. Cell. Biol. 1994;14:5192–5201. doi: 10.1128/mcb.14.8.5192. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Parker I., Smith I.F. Recording single-channel activity of inositol trisphosphate receptors in intact cells with a microscope, not a patch clamp. J. Gen. Physiol. 2010;136:119–127. doi: 10.1085/jgp.200910390. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Box G. Academic Press; New York: 1979. Robustness in the strategy of scientific model building. In Robustness in Statistics. [Google Scholar]
- 24.Baum L., Petrie T. Statistical inference for probabilistic functions of finite state Markov chains. Ann. Math. Stat. 1966;37:1554–1563. [Google Scholar]
- 25.Baum L., Petrie T., Weiss N. A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains. Ann. Math. Stat. 1970;41:164–171. [Google Scholar]
- 26.Welch, L. R. 2003. Hidden Markov models and the Baum-Welch algorithm. IEEE Info. Theory Soc. Newslet. 53. http://www.itsoc.org/publications/nltr/it_dec_03final.pdf.
- 27.Dempster A., Laird N., Rubin D. Maximum likelihood from incomplete data via the EM algorithm. J. Roy. Stat. Soc. Series B. 1977;39:1–38. [Google Scholar]
- 28.Feynman R., Hibbs A., Styer D. Dover Publications; Mineola, NY: 2010. Quantum Mechanics and Path Integrals: Amended Edition. [Google Scholar]
- 29.Roepstorff G. Springer-Verlag; Berlin, Germany: 1994. Path Integral Approach to Quantum Physics: An Introduction, Vol. 59. [Google Scholar]
- 30.Holmes, I., and W. Bruno. 2000. Finding regulatory elements using joint likelihoods for sequence and expression profile data. In Proceedings of the 8th Annual International Conference on Intelligent Systems for Molecular Biology. AAAI Press, La Jolla, CA, 202–210. [PubMed]
- 31.Horsthemke W., Lefever R. Springer; New York: 2007. Noise-Induced Transitions: Theory and Applications in Physics, Chemistry, and Biology, Vol. 15. [Google Scholar]
- 32.Fraser A. Society for Industrial Mathematics; Philadelphia, PA: 2008. Hidden Markov Models and Dynamical Systems. [Google Scholar]
- 33.Foskett J.K., White C., Mak D.O. Inositol trisphosphate receptor Ca2+ release channels. Physiol. Rev. 2007;87:593–658. doi: 10.1152/physrev.00035.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Mak D., McBride S., Foskett J. Inositol 1,4,5-trisphosphate activation of inositol trisphosphate receptor Ca2+ channel by ligand tuning of Ca2+ inhibition. Proc. Natl. Acad. Sci. USA. 1998;95:15821–15825. doi: 10.1073/pnas.95.26.15821. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Mak D.-O., White C., Foskett J. Calcium Signaling. CRC; Boca Raton, FL: 2005. Nuclear patch clamp electrophysiology of inositol trisphosphate receptor Ca2+ release channels. [Google Scholar]
- 36.Shapovalov G., Lester H.A. Gating transitions in bacterial ion channels measured at 3 microns resolution. J. Gen. Physiol. 2004;124:151–161. doi: 10.1085/jgp.200409087. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Li C., Wang X., White C. Apoptosis regulation by Bcl-x(L) modulation of mammalian inositol 1,4,5-trisphosphate receptor channel isoform gating. Proc. Natl. Acad. Sci. USA. 2007;104:12565–12570. doi: 10.1073/pnas.0702489104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Shimomura, O., M. Chalfie, and R. Tsien. 2008. Nobel Prize in Chemistry. http://www.nobelprize.org/nobel_prizes/chemistry/laureates/2008.