

Abstract
Prior effective sample size (ESS) of a Bayesian parametric model was defined by Morita, et al. (2008, Biometrics, 64, 595–602). Starting with an ε-information prior defined to have the same means and correlations as the prior but to be vague in a suitable sense, the ESS is the required sample size to obtain a hypothetical posterior very close to the prior. In this paper, we present two alternative definitions for the prior ESS that are suitable for a conditionally independent hierarchical model. The two definitions focus on either the first level prior or second level prior. The proposed methods are applied to important examples to verify that each of the two types of prior ESS matches the intuitively obvious answer where it exists. We illustrate the method with applications to several motivating examples, including a single-arm clinical trial to evaluate treatment response probabilities across different disease subtypes, a dose-finding trial based on toxicity in this setting, and a multicenter randomized trial of treatments for affective disorders.
Keywords: Bayesian hierarchical model, Conditionally independent hierarchical model, Computationally intensive methods, Effective sample size, Epsilon-information prior
1 Introduction
Recently, a definition for the effective sample size (ESS) of a given prior π(θ) with respect to a sampling model p(Y | θ) was proposed by Morita, Thall, and Müller (2008) (MTM). The ESS provides an easily interpretable index of the informativeness of a prior with respect to a given likelihood. The approach is to first define an ε-information prior π0(θ) having the same means and correlations as π(θ) but being vague in a suitable sense, and then define the ESS to be the sample size n of hypothetical outcomes Yn = (Y1, ···Yn) that, starting with π0(θ), yields a hypothetical posterior πn(θ | Yn) very close to π(θ). MTM define the distance between π(θ) and πn(θ | Yn) in terms of the trace of the negative second derivative matrices of log{π(θ)} and log{πn(θ | Yn)}. The ESS is defined as the interpolated value of n that minimizes this “prior-to-posterior” distance. While this definition is suitable for a wide range of models and applications, it fails for hierarchical models.
In this paper, we propose two extensions of the definition for prior ESS that are applicable to two-stage conditionally independent hierarchical models (CIHMs) (Kass and Steffey, 1989). Our approach is pragmatic in that the ESS can always be evaluated either analytically or by using a simulation-based approach. We validate the definitions by verifying that they match the intuitively obvious answers in important special cases where such answers exist. We focus on the class of CIHMs due to their practical importance in settings where data are collected from exchangeable subgroups, such as study centers, schools, cities, etc. Important areas of application include meta-analysis (cf. Berry and Stangl, 1996; Berlin and Colditz, 1999), and clinical trial design (cf. Thall et al., 2003).
Moreover, we restrict attention to CIHMs as the most commonly used versions of hierarchical models. For more complex hierarchical models, one might report prior ESS values for appropriate sub-models, although it might become less meaningful to report an overall ESS.
A two-level CIHM for K sub groups is defined as follows. Let Yk = (Yk,1, …, Yk,nk) denote the vector of outcomes for sub-group k and let
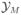 = (Y1,…,
YK), with the K vectors assumed to be distributed independently conditional on hyperparameters. We use f(·) generically to indicate the sampling model of observable data, which may be a single variable Yk,j, a vector Yk, or the vector
of all n1 +···+nK observations. The nature of the argument will clarify the specific meaning of f(·). In the first level, Yk follows distribution f(Yk | θk). In the second level, the subgroup-specific parameters θ=(θ1, ···, θK) are assumed to be i.i.d. with prior π1(θk | θ̃), where the hyperparameter θ̃ has a hyperprior π2(θ̃ | φ) with known φ. The model is summarized in equation (1).
= (Y1,…,
YK), with the K vectors assumed to be distributed independently conditional on hyperparameters. We use f(·) generically to indicate the sampling model of observable data, which may be a single variable Yk,j, a vector Yk, or the vector
of all n1 +···+nK observations. The nature of the argument will clarify the specific meaning of f(·). In the first level, Yk follows distribution f(Yk | θk). In the second level, the subgroup-specific parameters θ=(θ1, ···, θK) are assumed to be i.i.d. with prior π1(θk | θ̃), where the hyperparameter θ̃ has a hyperprior π2(θ̃ | φ) with known φ. The model is summarized in equation (1).
| (1) |
A common example of a CIHM (1) is a conjugate normal/inverse χ2-normal-normal model. Let Inv-χ2(ν, S) denote a scaled inverse χ2 distribution with ν degrees of freedom, mean for ν > 2, and variance for ν > 4. This model has a normal sampling distribution Yk,i | θk ~ N(θk,σ2) with known σ2, where N(μ, σ2) denotes a normal distribution with mean μ, and variance σ2. Independent conjugate normal priors θk | μ̃, γ̃2 ~ N(μ̃, γ̃2) on the location parameters θ1, ···, θK are assumed, with a normal/inverse χ2 hyperprior μ̃ | μφ, and γ̃2 | νφ, Sφ ~ Inv-χ2(νφ, Sφ). Once the methodology is established, we will explain how to compute ESS when σ2 is not assumed to be known but rather is random with its own prior.
To compute an ESS under a CIHM, we will consider the following two cases, which address different inferential objectives. In case 1, the target is the marginalized prior,
| (2) |
An example is a setting where θ1,…,θK are treatment effects in K different disease subtypes and they are the parameters of primary interest. In case 2, the target prior is
| (3) |
For example, this would arise if an overall treatment effect θ̃ obtained by averaging over K clinical centers in a multi-center clinical trial is the parameter of primary interest. We propose two definitions for the ESS under a CIHM, one for each case, allowing the possibility that both types of ESS may be of interest in a given analysis. For later reference we define the marginal likelihood
| (4) |
by integrating with respect to the level I prior.
Section 2 presents motivating examples. We briefly summarize the MTM formulation in Section 3. The two definitions of ESS in CIHMs and accompanying computational methods are given in Section 3. In Section 4 we compute the ESS for the three motivating examples. In Section 5 we discuss some standard CIHMs, and we close with a brief discussion in Section 6.
2 Motivating examples
2.1 A Single-Arm Sarcoma Trial
Thall et al. (2003) present a design for a single-arm phase II trial to examine the efficacy of the targeted drug imatinib for sarcoma, a disease with many subtypes. Since sarcomas are uncommon, the goal was to construct a design that allowed the efficacy of imatinib to be evaluated in K = 10 sarcoma subtypes. This was achieved by assuming the following CIHM, where the treatment effects differ across subtypes. The parameters of primary interest were the subtype-specific tumor response probabilities, ξ1, ···, ξ10. Let Ga(aφ, bφ) denote a gamma distribution with mean aφ/bφ and variance . Denoting θk = log{ξk/(1 − ξk)}, it was assumed that θ1, …, θ10 were i.i.d. N(μ̃, γ̃−1) and that μ̃, and the precision parameter γ̃ followed independent normal and gamma hyperpriors, respectively. Elicitation of prior probabilities characterizing association between pairs of ξk’s yielded the hyperpriors μ̃~ N(−1.386,10) and γ̃ ~ Ga(2, 20), so that E(γ̃) = .10 and var(γ̃) = .005. In summary, the trial design assumed the following model:
| (5) |
Thall et al. (2003) used the marginal posterior probability Pr(ξk > 0.30 |
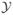 ) to define an early stopping criterion in disease subtype k, which was computed based on the posterior π(θ |
) under (5). Thus, 10 stopping rules were applied, one for each subtype. Note that
included the data from all ten subtypes in order to exploit the association among the θk’s induced by the hierarchical model. This rule was first applied after observing a minimum of eight patients in each disease subtype, and subsequently at sample sizes of 17, 23, and 30 patients. Thus, an overly informative prior, for example, with a prior ESS ≥ 40 might be considered inappropriate since the prior, rather than patient response data, would dominate early termination decisions. Because both a prior and hyperprior were specified, the methods in MTM are not applicable, and it is not obvious how to determine the ESS of this model. We will show below that the ESS can be determined for this model using an approach that is coherent in the sense that it gives the intuitively obvious answer in cases where the ESS exists.
) to define an early stopping criterion in disease subtype k, which was computed based on the posterior π(θ |
) under (5). Thus, 10 stopping rules were applied, one for each subtype. Note that
included the data from all ten subtypes in order to exploit the association among the θk’s induced by the hierarchical model. This rule was first applied after observing a minimum of eight patients in each disease subtype, and subsequently at sample sizes of 17, 23, and 30 patients. Thus, an overly informative prior, for example, with a prior ESS ≥ 40 might be considered inappropriate since the prior, rather than patient response data, would dominate early termination decisions. Because both a prior and hyperprior were specified, the methods in MTM are not applicable, and it is not obvious how to determine the ESS of this model. We will show below that the ESS can be determined for this model using an approach that is coherent in the sense that it gives the intuitively obvious answer in cases where the ESS exists.
2.2 A CRM Dose-finding Trial for Multiple Patient Subgroups
As an extension of the HM in (5) we consider a phase I dose-finding trial with multiple patient subgroups using a model-based design. We assume an implementation that generalizes the continual reassessment method (O’Quigley et al, 1990). Suppose that there are K = 4 subgroups (k = 1,…, 4) with population proportions (.40, .30, .20, .10). Each patient in each subgroup receives one of six doses, 100, 200, 300, 400, 500, 600, denoted by d1,…,d6, with standardized doses . The outcome variable is the indicator Yk,i = 1 if the ith patient in subgroup k suffers toxicity, 0 if not. The probability of toxicity in subgroup k under dose xi is denoted by πk(xi,αk,βk) = Pr(Yk,i = 1 | xi,αk,/βk) with logit (πk(xi, αk,/βk)} = αk + βkxi, for k = 1,2,3,4. We have a CRM-type goal of finding the “optimal” dose in each subgroup k. Optimal is defined as the posterior mean of being closest to some fixed target π*. The maximum sample size is 36, with the cohort size of 1, starting at the lowest dose d1, and not skipping a dose level when escalating, with target toxicity probability π* = .30. The parameters of primary interest are θk = (αk, βk), k = 1,2, 3, 4. It is assumed that α1, …, α4 and β1,…, β4 are i.i.d. and , respectively, and that (μ̃α and μ̃β follow independent normal hyperpriors. For the variance hyperparameters and , following Gelman (2006, Section 4.3) we assume that σ̃α and σ̃β are uniform on [0, Uφ]. Denoting the dose assigned to the ith patient by x[i], in summary we assume
| (6) |
We will later, in Section 3.4, discuss how the ESS in this example depends not only on the assumed probability model and hyperparameters, but also on design choices like the adaptive dose-finding algorithm, the population proportions, etc. Note that we assume that (μ̃α, ) and (μ̃β, ) are independent, in order to have a reasonably parsimonious model. We can use elicited information to solve for the hyperprior means μα,φ and μβ,φ, as follows. Given the standardized doses, those hyperprior means are calculated based on the elicited values E{πk (x2 = −.403)} = .25 at the second lowest dose and E{πk(x5 = .513)} = .75 at the second highest dose for all the subgroups. These give μα,φ= −0.131 and μβ,φ= 2.398. We will evaluate the ESS under several combinations of ( , Uφ) in a sensitivity analysis.
2.3 A Multicenter Randomized Trial
When analyzing data from a multicenter trial, it often is important to examine the inter-center variability of treatment effects, i.e., treatment-by-center interaction (Gray, 1994), since substantial variation among treatment effects across centers may cause a regulatory agency to question the generalizability of results obtained from such a trial before giving approval for a new therapy. As a third example, we consider a multicenter randomized clinical trial reported by Stangl (1996). The trial was carried out to examine the inter-center variability of the effect of imipramine hydrochloride for preventing the recurrence of depression. The primary outcome was time to the first recurrence of a depressive episode, denoted by Tjk,1, …,Tjk,njk for njk patients receiving treatment j at the kth center, for j = 1,2 and k = 1,…, K. A total of 150 patients were enrolled in K = 5 centers. For each (j, k), the recurrence times Tjk,1, …, Tjk,njk were assumed to be i.i.d. exponentially distributed with recurrence rate θjk. Working with the transformed parameters ζk = log(θ1k/θ2k) and ηk = log(θ2k)> the priors were assumed to be and . The hyperparameter of the inter-center heterogeneity of the treatment effect log ratios is of primary interest in this example, while represents the inter-center heterogeneity in the effect of the control treatment arm. Lognormal hyperpriors were assumed with , and ση ~ LN(−0.22,1), where LN(μ, σ2) denotes the lognormal distribution of eX for X ~ N(μ, σ2). The model is summarized as follows:
| (7) |
Stangl assumed two alternative sets of hyperparameters (mφ, ), to represent two types of prior belief on in a Bayesian sensitivity analysis. The first choice was , which places substantial prior belief on smaller , and the second was , which places prior weight on larger . We will evaluate the ESS of each prior on under case 2 of our proposed methods.
Event time data, like the recurrence time, often includes extensive censoring. In the presence of censoring, the amount of information, and thus the ESS, depends on the number of observed events in addition to the sample size. The ESS computation in this example, therefore, needs to account for censoring cases which can occur depending on study duration. We will discuss details of the ESS computation in the presence of censoring and other relevant design details in Section 3.4.
In any CIHM, the prior choice is subject to two competing desiderata. On one hand, an informative hyperprior that expresses a belief of strong association among the θk’s is needed to borrow strength across subpopulations. In some settings, it is appropriate to use an informative prior that reflects accurate and comprehensive prior knowledge. If the hyperprior is elicited from an area expert, then the ESS provides an easily understood numerical value that the expert may use, if desired, to modify his/her original elicited values. On the other hand, in some settings it is necessary to avoid excessively informative priors that may compromise the objectivity of one’s conclusions. In practice, many arbitrary choices are made for technical convenience while formulating a model. A skeptical reviewer may like to quantify the prior information as being equivalent to a certain number of hypothetical observations, i.e., a prior ESS. Such a summary immediately allows a reader to judge the relative contributions of the prior and the data to the final conclusion.
3 Effective sample size in CIHMs
3.1 Prior Effective Sample Size in Non-hierarchical Models
In this subsection, we review and formalize the heuristic definition of ESS for non-hierarchical models given by MTM. We give formal definitions of the ε-information prior and a prior-to-posterior distance. The intuitive motivation for MTM’s method is to mimic the rationale for why the ESS of a beta distribution, Be(a,b), equals a + b. A binomial variable Y with binomial sample size n and success probability θ following a Be(a, b) prior implies a Be(a + Y, b + n − Y) posterior. Thus, saying that a given Be(a, b) prior has ESS m = a + b requires the implicit reasoning that the Be(a, b) may be identified with a Be(c + Y, d + m − Y) posterior arising from a previous Be(c, d) prior having a very small amount of information. A simple way to formalize this is to set c + d, = ε for an arbitrarily small value ε > 0 and solve for m = a + b − (c + d) = a + b − ε.
In a generic, non-hierarchical model, let f(Y | θ) denote the distribution of a random, possibly vector-valued outcome Y and π(θ | θ̃) the prior on the parameter vector θ = (θ1, …, θd), with hyperparameters θ̃. The definition of the ESS of π(θ | θ̃) given f(Y | θ) requires the notions of an ε-information prior and the distance between the prior and a hypothetical posterior corresponding to a sample of a given size used to update an ε-information prior. The following definition formalizes the heuristic definition given by MTM. Denote .
Definition of epsilon-information prior
Let π(θ | θ̃) be a prior with , where V̄j(θ̃) is a fixed bound, for all j = 1,…, d. Given arbitrarily small ε > 0. the prior π0(θ | θ̃0) defined on the same domain and in the same parametric family as π(θ | θ̃) is an ε-information prior if Eπ0(θ) = Eπ(θ), Corrπ0(θj, θj′) = Corrπ(θj, θj′) for all j ≠ j′ and
| (8) |
In the case V̄j(θ̃) = ∞, condition (8) reduces to . Thus, in this case one may simply choose θ̃0, subject to the constraints on the means and correlations, so that is large enough to ensure that this inequality holds. When V̄j(θ̃) < ∞, note that (8) can be written in the form . Thus, in this case one should choose θ̃0 so that is sufficiently close to V̄j(θ̃) from below to ensure this inequality For example, if π(θ | θ̃) is a beta distribution, Be(α̃,β̃), then and V̄(θ̃) = μ(1 − μ), where μ = α̃/(α̃ + β̃). One may construct π0(θ | θ̃0)as a Be(α̃/c, β̃/c) by choosing c > 0 large enough so that 1/c < ε, since this implies that the above inequality holds.
Alternatively, a proper non-informative prior could be considered for π0(θ | θ̃0). However, this might not be appropriate for defining ESS. For example, the Jeffreys prior for a binomial success probability is , which gives ESS values that are too large by an additive factor of 1 due to the implied sample size of 1.
To see how the definition works for θ of dimension > 1, consider a bivariate normal distribution with mean μ̃ = (μ̃1, μ̃2)′, variances and covariance σ̃12. An ε-information prior is specified by using the same means μ̃ but variances and and covariance c1c2<σ̃12 for arbitrarily large c1 > 0 and c2 > 0. As a practical guideline, we suggest choosing c large enough so that a further increase would not change the ESS by more than 0.1.
Given the likelihood of a i.i.d. sample Yn = (Y1, …, Yn) and ε-information prior π0(θ | θ̃0), the posterior is
MTM define a distance between the prior π(θ | θ̃) and πn(θ | θ̃0, Yn) obtained from a hypothetical sample Yn of size n starting with π0. To do this, MTM use the prior variance and the average posterior variance under the ε-information prior. The average is with respect to the prior predictive distribution f(Yn | θ̃) = ∫ f(Yn | θ) π(θ | θ̃)dθ. Let denote the posterior variance of θj conditional on Yn, under the ε-information prior π0. Then . In cases where these variances cannot be computed analytically, we use approximations, denoted by and . For example, one could use the negative second derivatives of the log distributions, as in MTM. We define the distance between π and π0,n to be
| (9) |
When interest focuses on only one of the parameters, say θj, then we use to define a distance between the marginal prior on θj versus the marginal posterior on θj under the ε-information prior and a sample of size n.
Definition of ESS in the non-CIHM case
The effective sample size (ESS) of a parametric prior π(θ | θ̃) for which for all j = 1, …, d, with respect to the likelihood f(Yn | θ) is the interpolated integer n that minimizes the distance Δ(n, π, π0).
Computation of Δ(n, π, π0) is carried out either analytically or using a simulation-based numerical approximation.
3.2 Conditionally independent hierarchical models
We extend the definition of ESS to accommodate two-level CIHMs in a balanced study design with K subgroups each having sample size m, i.e., Yk = (Yk,1, ···, Yk,m) for each k = 1, ···, K and the total sample size of
= (Y1, …, YK) is M = m × K. To accommodate the hierarchial structure, we propose the following two alternative definitions of ESS for CIHMs. Recall the discussion following (1). Under a CIHM interest may focus on θ1, …, θK (case 1) or on θ̃ (case 2).
Case 1
When θ = (θ1, …, θK) are the parameters of primary interest, the ESS is a function of the target marginal prior π12(θ | φ) and the sampling model f(·). In this case, we constructively define an ε-information prior, π12,0(θ | φ), as follows. First, specify an ε-information prior π1,0(θ | θ̃) of π1(θ | θ̃), as described in Section 3.1, and use this to define π12,0(θ | φ) = ∫ π1,0(θ | θ̃) π2(θ̃ | φ)dθ̃. A proof that π12,0 defined in this way is in fact an ε-information prior is given in the appendix.
An alternative way to define an ε-information prior for case 1 could be to first specify π12(θ | φ) and then compute π12,0. However, this approach is tractable only if π12(θ | φ) can be specified analytically. Consequently, we do not use this alternative approach.
Given the likelihood
and π12,0(θ | φ), we denote the hypothetical posterior by π12,M(θ | φ,
) ∝ π12,0(θ | φ)f(
| θ). Denote θ̄12 = Eπ12(θ | φ), the prior mean of θ under π12(θ | φ) and let
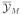 = E(
| θ̄12) denote the prior mean of
under θ̄12. We will later discuss how to proceed in problems where
is not meaningfully defined, due to censoring, the use of covariates, and other reasons. Let Σπ12 denote the marginal variance-covariance matrix of θ under π12, and similarly for Σπ12,M (
) under π12,M(θ | φ,
). Often exact evaluation is not possible and approximations Σ̂π12 and Σ̂π12,M must be used. For example, one could use the negative inverse Hessian matrices of log(π12) and log(π12,M) evaluated at θ̄12. Similarly to Δ(·) in equation (9) for a non-hierarchical model, in case 1 of a CIHM we define the distance between π12(θ | φ) and π12,M(θ | φ,
) to be
= E(
| θ̄12) denote the prior mean of
under θ̄12. We will later discuss how to proceed in problems where
is not meaningfully defined, due to censoring, the use of covariates, and other reasons. Let Σπ12 denote the marginal variance-covariance matrix of θ under π12, and similarly for Σπ12,M (
) under π12,M(θ | φ,
). Often exact evaluation is not possible and approximations Σ̂π12 and Σ̂π12,M must be used. For example, one could use the negative inverse Hessian matrices of log(π12) and log(π12,M) evaluated at θ̄12. Similarly to Δ(·) in equation (9) for a non-hierarchical model, in case 1 of a CIHM we define the distance between π12(θ | φ) and π12,M(θ | φ,
) to be
| (10) |
Definition of ESS for Case 1
The ESS of π12(θ | φ) with respect to f(·), denoted by ESS12(θ | φ), is the interpolated value of the sample size M minimizing Δ1(M, π1, π2, π1,0).
We use determinants in the definition of Δ1 to incorporate the off-diagonal elements of the variance/covariance matrices and thereby account for association induced by the hyperprior among the parameters, θ1, …, θK, which is a key aspect of a CIHM. The determinants quantify the total amounts of variability of the prior π12 and the hypothetical posterior π12,M. The same definition of distance could be used for non-hierarchical models in place of (9). However, the trace used in (9) is easier to evaluate and leads to exactly the same ESS in all cases that we considered. Although our choice seems to make sense intuitively, it still is arbitrary. We validate the definition by investigating important cases of CIHMs, given in Section 5 and the supplementary materials.
Case 2
When the hyperparameters θ̃ are of primary interest, the ESS is a function of the target prior π2(θ̃ | φ) and the marginal likelihood (4). We define an ε-information prior, π2,0(θ̃ | φ0), and use the marginal likelihood f1(
| θ̃) to update π2,0(θ̃ | φ0) to obtain the hypothetical posterior π2,M(θ̃ | φ0,
). Let
denote the prior mean of θ̃ under π2(θ̃ | φ), and let
. We define a distance between π2(θ̃ | φ) and π2,M(θ̃ | φ0,
) for sample size M as in the definition in (11), using the variance/covariance matrices Σπ2 under the prior π2(θ̃ | φ) and Σπ2,M(
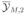 ) under π2,M(θ̃ | φ0,
). When the variance/covariance matrices are not available in closed form, one can again use a numerical approximation.
) under π2,M(θ̃ | φ0,
). When the variance/covariance matrices are not available in closed form, one can again use a numerical approximation.
Definition of ESS for Case 2
The ESS of π2(θ̃ | φ) with respect to fM(
| θ̃), denoted by ESS2(θ̃ | φ), is the interpolated value of M minimizing
| (11) |
Definition (11) is equivalent to the non-hierarchical ESS definition, simply because after marginalizing with respect to the group specific parameters θk the hierarchical model (1) reduces to a non-hierarchical model. If interest is focused on a subvector θ̃s of θ̃, the ESS can be determined similarly in terms of the marginal hyperprior π2(θ̃s | φ).
An important aspect of the definition is that the ESS could be infinite when it is not possible to achieve a comparably informative posterior with any finite sample size. For example, recall the stylized normal/normal CIHM introduced after (1). Assume we fix γ̃2 = 1, μ̃ ~ N(0, 0.01) and K = 10. In particular, we keep the number K of subpopulations fixed and consider an increasing number of samples per group. No matter how many observations, it is impossible to match the prior variance Var(μ̃) = 0.01 as the posterior variance under π0,n. Formally, the minimization (11) has no solution. This is desireable. The informative prior μ̃ ~ N(0, 0.01) cannot be interpreted as the posterior under any hypothetical sample having finite sample size, because, in this example, the number of groups is fixed at K = 10. However, while no sample size of a hypothetical prior study under the same experimental design, i.e., fixed K, can justify the employed prior, it still is possible to report a meaningful finite ESS under an alternative experimental design. For example, one could report the required sample size of a hypothetical prior study with fixed m = 20, σ2 = 1, and increasing K. In this example we find ESS = 2100 with K = 105.
3.3 Algorithm for ESS Computation
Let θ̄12 denote the prior mean vector of θ under π12(θ | φ), and let denote the prior mean vector of θ̃ under π2(θ̃ | φ). Let Mmax = mmax × K be a positive integer multiple of K chosen so that it is reasonable to assume that ESS ≤ Mmax.
Algorithm 1, ESS for Case 1
-
Step 1
Evaluate the target marginal prior π12(θ | φ)
-
Step 2
Evaluate ε-information prior π12,0(θ | φ)
-
Step 3
For each M = 0, K, 2K, …, Mmax, compute Δ1(M, π1, π2, π1,0).
-
Step 4
ESS12(θ | φ) is the interpolated value of M minimizing Δ1(M, π1, π2, π1,0).
When
cannot be evaluated analytically, then one can use the negative Hessian of the log prior as approximation
. The Hessian Hπ12 is the matrix of second derivatives of the log(π12) with respective to θj. The Hessian is evaluated at θ̄12. When π12(θ | φ) itself is not available in closed form, then we use the following simulation-based approximation. First, simulate a Monte Carlo sample θ̃(1), …, θ̃(T) from π2(θ̃ | φ) for large T, e.g. T = 100,000. Use the Monte Carlo average
in place of
, and similarly for the second order partial derivatives. When θ̄12 = Eπ12(θ | φ) cannot be computed analytically, first simulate a Monte Carlo sample θ(1), …, θ(T) from π12(θ | φ) = ∫ π1(θ | θ̃) π2(θ̃ | φ)dθ̃ for large T, and compute the mean
. Similarly, when
is not available in closed form one can use the negative Hessian of log π12,M(θ̄12 |
, φ) the as a convenient approximation,
. The posterior π12,M is evaluated conditional on
and the Hessian is evaluated at θ̄12.
Algorithm 2, ESS for Case 2
-
Step 1
Specify π2,0(θ̃ | φ0).
-
Step 2
For each M = 0, K, 2K, …, Mmax, compute Δ2(M, π2, π2,0).
-
Step 3
ESS2(θ̃ | φ) is the interpolated value of M minimizing Δ2(M, π2, π2,0).
When
or
are not available in closed form we proceed similarly as before, using the negative Hessians to approximate
and
. The posterior π2,M is evaluated conditional on
. The Hessian is evaluated at
. In many cases, steps 2 and 3 may be repeated to compute ESS2(θ̃ | φ) for subvectors of θ̃ that are of interest.
3.4 Numerical Evaluation of ESS
Equations (10) and (11) define a distance between prior and posterior as a difference of determinants of a prior precision matrix versus a posterior precision matrix. The posterior precision matrix is evaluated using the plug-in values
in Δ1 and
in Δ2, respectively. In some studies, however, the definition of
or
as an expectation is simply not meaningful. This is explained most easily by the following examples. Many phase I studies involve choosing doses for future patients as a function of the outcomes of earlier patients. In such settings, it is not meaningful to represent a sample of size M by a mean
or
. More generally, outcome adaptive designs for clinical studies make it difficult to meaningfully define
. Similar difficulties arise when studies involve censored outcomes or regression on covariates.
In these cases, we use an extended definition of Δ1 that replaces the plug in of
by full prior predictive marginalization. Specifically, we replace
by an expectation of
, averaging over possible study realizations
with M patients. The sampling scheme might include additional variables, like assigned dose, patient-specific covariates, or censoring times. Let xi denote these additional variables for the ith patient. Let g(xi | Y1, …, Yi−1, x1, …, xi−1, θ̄12) denote a probability model for xi. When xi is a deterministic function of the conditioning variables, we interpret g(·) as a degenerate distribution with a single point mass. For example, in the case of an adaptive dose escalation design, the dose for the ith patient is a function of the earlier outcomes. Thus, the outcomes are not independent, making the interpretation of
tricky. We replace use of the plug in
by the expectation of
with respect to the marginal model,
| (12) |
In words, fM(·) is the marginal distribution of possible study outcomes when we carry out the study under a given design, and the prior mean θ̄12. The predictive model (12) highlights the fact that ESS is defined in the context of an assumed experimental design. This includes details like the expected extent of censoring, distribution of covariates xi, and more. Recall the stylized normal/normal CIHM stated below (1). One could consider two alternative experiments, either increasing the number of observations within each subpopulation, k = 1, …, K for fixed K, or alternatively one could consider increasing the number of groups K with a fixed number of observations per group. The two experiments naturally report different ESS values for the same prior, simply because the information that is being accrued with hypothetical future patients differs.
In the definition of the ESS, Case 1, for such studies we replace in definition of Δ1 by
| (13) |
where Σ−1(YM) = Var(θ |
) is the posterior variance under data
and prior π12. Similarly, we replace
in the definition of Δ2 in Case 2 by
| (14) |
where
| (15) |
For the standard CIHMs discussed later, in §5, the definitions using (13) instead of
and (14) in place of
in the definitions of Δ1 and Δ2, respectively, give the same ESS as the original definitions. That is why we recommend using the simplified definitions (10) and (11) when possible. We recommend using the extended definitions only for problems where the definition of
or
is not meaningful.
Algorithms 1 and 2 remain unchanged. The only additional detail is the evaluation of Δ1 and Δ2. For Δ1, we use numerical evaluation of the integral (13).
Algorithm 3, Numerical Evaluation of Δ1
Evaluation of (13) as a Monte Carlo integral.
| Repeat L iterations of Steps 1–6: | ||
| Step 1: Generate Y1 ~ f(Y1 | x1, θ̄12) | ||
| Repeat for i = 2, …, M: | ||
| Step 2: Evaluate g(xi | Y1, …, Yi−1, xi, …, xi−1, θ̄12). If g(·) is a deterministic function (as in dose allocation), record the value as xi. If g(·) is a non-degenerate distribution generate xi accordingly. | ||
| Step 3: Generate Yi ~ f(Yi | Y1, …, Yi−1, xi, θ̄12), using xi from Step 2. | ||
| Step 4: The vector
= (Y1, …, YM) is a simulated outcome vector. | ||
| Step 5: Evaluate the posterior variance covariance matrix Σ(θ |
). This evaluation might require Markov chain Monte Carlo integration when the model is not conjugate. | ||
| Step 6: Evaluate det(Σ−1(
)). | ||
| Step 7: The average over all L iterations of steps 1 through 6. | ||
| ||
| approximates the desired integral. The sum is over the L repeat simulations of Steps 1 through 6, plugging in the vector
that is generated in each step of the simulation. |
With a minor variation, the same algorithm can be used to evaluate (14). Step 1 is replaced by
Step 1′: Generate and generate Y1 ~ f(Y1 | x1, θ).
The rest of the algorithm for computing ESS remains unchanged, with θ replacing θ̄12. It is important that a new value θ is generated for each of the L repetitions of steps 1 through 6. This approximates the outer integral with respect to θ.
4 Application to the motivating examples
4.1 ESS for the sarcoma trial
The goal of the sarcoma trial was to estimate the efficacy of a molecularly targeted drug within each disease subtype. Recall that ξk was the response probability in subtype k, and θk = log{ξk/(1 − ξk)}. The likelihood for M patients with m patients in each subtype having response indicators Yk,m = (Yk1, …, Ykm) is
| (17) |
For this example, based on the normal-gamma hierarchical prior described in Section 2, a closed form of the target prior in case 1 can be found analytically, as we will show in Section 5. Based on this prior and the likelihood (17), applying Algorithm 1 of subsection 3.3 gives ESS12(θ | φμ̃ = (−1.386, 10), φγ̃ = (2, 20)) = 2.6. This ESS value is reasonable, since a separate early stopping rule was applied for each subtype in this study. For comparison, if one assumes instead that φμ̃ = (−1.386, 1) and φγ̃= (20, 1), then ESS12(θ | φμ̃) = 702.2. This illustrates the important practical point that a seemingly reasonable choice of and φγ̃ = (aφ, bφ) may give an excessively informative prior. Figure 1 gives plots of the ESS12 values as a function of for each of the four pairs φγ̃ = (2, 20), (5, 20), (10, 20), and (10, 10), when μφ = −1.386. Figure 1 shows that, as the variance parameter in the hyperprior of μ̃ gets larger, the ESS12 values decrease, which is intuitively correct. Similarly, ESS12 increases with the prior mean of the precision parameter γ̃ under π2(γ̃ | φγ̃).
Figure 1.
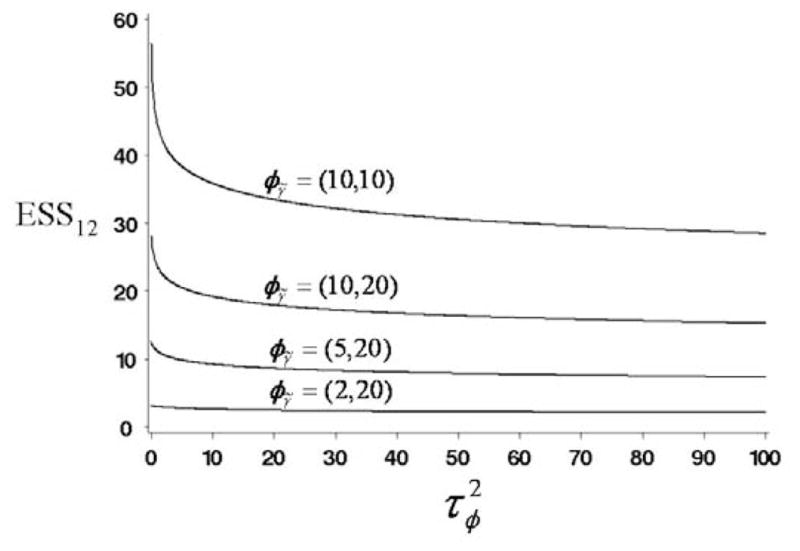
Plots of ESS12 as a function of variance parameter in the hyperprior of μ̃ for the four sets of φγ̃ = (2, 20), (5, 20), (10, 20), and (10, 10), when μφ = −1.386.
If one wishes to focus, instead, on the overall mean treatment effect across all disease subtypes, (case 2), it leads to consideration of the hyperprior π2(μ̃ | φμ̃). The ESS in this case may be computed using Algorithm 2 of subsection 3.3, which gives ESS2(μ̃ | φ) = 3.7. We conclude that the hierarchical prior used by Thall et al. (2003) is reasonable under both points of view, either when one is concerned with inference on success probabilities for the sarcoma subtypes, or when one is interested in the average response probability for all sarcomas.
4.2 A CRM Dose-finding Trial for Multiple Patient Subgroups
In the second example, the goal of the CRM-type dose-finding study is to find the optimal dose in each subgroup. Recall that the probability of toxicity in each subgroup is modeled by πk(xi, θk) with logit{πk(xi, θk)} = αk + βkxi, where θk = (αk, βk). Let m1, m2, m3, m4 denote the number of patients in the four subgroups, let xk,[i] denote the dose assignment for the ith patient in subgroup k, and let Dmk = {Yk,1, xk,[1], …, Yk,mk, xk,[mk]} denote the dose assignments and the responses observed in subgroup k. The likelihood for all patients is
| (18) |
Following the extended ESS definition given in Section 3.4, we compute ESS values under several combinations of ( , Uφ) for using Algorithm 3. Dose levels are determined on the basis of the observed data. As mentioned before, ESS is always defined in the context of an assumed experimental design. In the case of this study, the assumed relative accrual rates (0.4, 0.3, 0.2, 0.1) are part of the design, and are used in the evaluation of ESS.
Posterior summaries are evaluated using Markov chain Monte Carlo posterior simulation (with three parallel chains of length 5,000 with a burn-in of 500). The posterior means at the six dose levels in each subgroup are required in the dose-escalation/de-escalation algorithm for the respective new cohort. Table 1 summarizes the results of the computations, including the subgroup ESS values based on the assumed relative accrual rates (0.4, 0.3, 0.2, 0.1). Those computations suggest that, considering the maximum sample size of 36, the prior choices that are summarized in the first two rows of the table are defensible. The implied ESS is reasonably small compared to the sample size, since in these cases the per-subgroup sample size is less than 2. The prior in the third row may or may not be considered suitably non-informative for a dose-finding trial, but the prior in row 4 clearly is far too informative. Without computing ESS, it would be very difficult to make such determinations.
Table 1.
ESS values computed for several sets of level 2 prior parameters ( , Uφ). The per-subgroup ESS values are based on assumed relative accrual rates .40, .30, .20, .10 for k = 1, 2, 3, 4.
|
|
Uφ | ESS | Per-subgroup ESS
|
||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | ||||
| 100 | 5 | 6.6 | 2.6 | 2.0 | 1.3 | 0.7 | |
| 25 | 5 | 7.1 | 2.8 | 2.1 | 1.4 | 0.7 | |
| 4 | 5 | 9.1 | 3.6 | 2.7 | 1.8 | 0.9 | |
| 25 | 2 | 25.8 | 10.3 | 7.7 | 5.2 | 2.6 | |
Computation of frequentist operating characteristics (OCs) by computer simulation, and calibration of prior hyperparameters as well as design parameters on that basis, has become standard practice in Bayesian clinical trial design. An important question is how computing the prior’s ESS can improve this process. This is especially important logistically because obtaining both prior ESS and the design’s OCs are computationally intensive. However, computing an ESS takes even less time than the time required for OCs under only one scenario. This is the case because in contrast to OC simulation, the evaluation of ESS does not require the simulation of complete trial histories. Also, in practice, after establishing hyperparameters that determine prior mean values, one guesses numerical values of second order hyperparameters, including variances and correlations, simulates the trial using that prior, and examines the resulting OCs. Since the numerical values of prior hyper-variances have no meaning per se, in the absence of ESS, one must rely on the OCs alone to determine whether the prior is acceptable and reasonable. This process often is repeated many times, until satisfactory choices are found, and is quite time-consuming and tedious. When the ESS of each prior is computed, however, it may be used to calibrate the hyper-variances so that they give a reasonable ESS, before running any simulations of complete trial histories. This saves a great deal of time because, as noted above, computing an ESS is far less time-consuming than running simulations.
Aside from obtaining a design’s OCs, because the ESS is readily interpretable, it is a useful tool for deciding whether a prior is reasonable per se. Recall that the ESS is a property of the prior, likelihood, and experimental design. In contrast, obtaining the OCs of a given design also requires the specification of particular scenarios (fixed outcome probabilities) under which the design is evaluated. In the absence of ESS, it is possible to obtain OCs that look reasonable when in fact the prior is undesirably informative. That is, one may unknowingly be misled by simulation results. This is especially worrying when the clinical outcome is a complex function of treatment, as in a dose-response setting. As an example, consider the CRM dose-finding trial with heterogeneous subgroups under the prior with level 2 prior parameters and Uφ = 2 in the last row of Table 1. Recall that the ESS = 25.8 for that prior. A simulation of the trial assuming these level 2 hyper-prior parameters is summarized in Table 2, which shows that, despite the overly informative prior in terms of ESS, the subgroup-specific CRM design is most likely to choose the right doses in subgroups 1, 2, and 3. In contrast, the dose selection is clearly wrong in subgroup 4, since the highest dose level would be most desirable in that subgroup. In the assumed scenario, the dose-toxicity curve in subgroup 4 is qualitatively different from the other subgroups, with true π4(xi) = .10 or .20 for all doses, well below the target of .30. Since subgroup 4 has the lowest accrual rate of 10% and thus accrues on average .10 × 36 = 3.6 patients, the data from the trial cannot overcome the overly informative prior (ESS = 2.7) in this subgroup. Based on the ESS, however, one would never assume the prior with and Uφ = 2. This example shows how use of the prior ESS complements the evaluation of OCs. In summary, in the context of Bayesian clinical trial design, prior ESS is both a tool for calibrating hyper-variances and thus speeding up the process of simulation to obtain the design’s OCs, and also a simple summary statistic that helps investigators decide whether a prior is acceptable.
Table 2.
Simulation study of the CRM dose-finding trial with heterogeneous subgroups assuming the prior with level 2 prior parameters and Uφ = 2. The percentage of times that the method selected each dose level as the final MTD in each subgroup (%recommendation) and the numbers of patients who were treated at each dose level (No. of patients) out of 36 patients are summarized. Correct selections are marked in bold-face.
| Subgroup | Dose level | d1 | d2 | d3 | d4 | d5 | d6 |
|---|---|---|---|---|---|---|---|
| 1 | True prob. tox | .05 | .10 | .15 | .30 | .50 | .65 |
| %recommendation | .05 | .16 | .30 | .36 | .07 | .04 | |
| No. of patients | 2.1 | 3.1 | 4.5 | 3.6 | 1.1 | .4 | |
| 2 | True prob. tox | .10 | .20 | .30 | .45 | .60 | .70 |
| %recommendation | .08 | .26 | .39 | .24 | .02 | .01 | |
| No. of patients | 1.8 | 2.9 | 3.3 | 2.0 | .6 | .1 | |
| 3 | True prob. tox | .15 | .30 | .45 | .55 | .65 | .75 |
| %recommendation | .12 | .34 | .32 | .16 | .02 | .01 | |
| No. of patients | 1.2 | 2.2 | 1.9 | 1.0 | .3 | .1 | |
| 4 | True prob. tox | .10 | .10 | .10 | .20 | .20 | .20 |
| %recommendation | .05 | .20 | .32 | .31 | .09 | .02 | |
| No. of patients | .5 | .9 | 1.0 | .8 | .2 | .1 |
4.3 ESS for a Multicenter Randomized Trial
In the third example, recall that θ1k and θ2k denote the affective disorder recurrence rates in the two treatments arms for trial center k, and these are reparameterized as ζk = log(θ1k/θ2k) and ηk = log(θ2k). Recall that Tjk,i is the time to the event for patient i receiving treatment j at center k. Denote the observed time to an event at T or right-censoring by To and δ = I[To = T]. Let and δm denote the vectors of all event observation times and indicators in the sample of M = m × K patients. The likelihood under the exponential model is
| (19) |
where θ1k = exp(ζk + ηk) and θ2k = exp(ηk). Recall that the hyperparameter characterizing inter-center variability is of primary interest (Case 2). Based on the hierarchical model described in Section 2 and the likelihood (19), we use Algorithm 2 to compute , which are and . The two ESS values indicate that the first prior may be too informative, since the total sample size of the trial is 150. One may obtain a less informative hyperprior for by specifying larger . For example, , 1.02, and 1.252 give , 1.4, and 0.4. Table 3 summarizes the values computed for several sets of (mφ, ) pairs.
Table 3.
values computed for several sets of (mφ, ), where represents the inter-center heterogeneity of the treatment effect, and mφ and respectively denote the mean and variance parameters of the lognormal hyperprior of σ̃ζ.
| mφ |
|
ESS2 | |
|---|---|---|---|
| −1.61 | 0.52 | 27.6 | |
| −1.61 | 0.752 | 12.1 | |
| −1.61 | 1.02 | 8.4 | |
| −1.61 | 1.252 | 6.6 | |
| −0.5 | 0.52 | 15.5 | |
| −0.5 | 0.752 | 8.0 | |
| −0.5 | 1.02 | 5.7 | |
| −0.5 | 1.252 | 2.1 | |
| 0.0 | 0.52 | 9.1 | |
| 0.0 | 0.752 | 5.0 | |
| 0.0 | 1.02 | 1.4 | |
| 0.0 | 1.252 | 0.4 |
As we mentioned in Section 2.3, the ESS computation in this example accounts for censoring in the process of numerical computation of the distance between the prior and posterior. For the above computations, we set-up the study duration at 2 years, as it was done in Stangl’s study design. That is, patients are followed for 2 years, or until they experience the event. If patients do not experience the event by the end of the study, they are treated as censored cases. Given the event rates in the two treatment groups, the proportion of censored cases goes up as the study duration becomes shorter. When the study duration is 2 years, the ESS is computed to be 27.6, as shown in the first row of Table 3. When the study duration is 10 years, the ESS value is computed to be 24.5, while the ESS is 36.3 in case the duration is 0.5 years. That is, as the proportion of censored cases rises up, the ESS goes up, and vice-versa.
From Figure 7 of Stangl (1996), it can readily be seen by inspection that prior 1 is too informative by comparing the posterior and prior of the 3rd stage variances. The ESS formalizes this judgment by quantifying the informativeness of prior 1. Moreover, the ESS validates prior 2 as being reasonable, whereas this in not obvious using only a graphical evaluation.
5 Validation in Some Standard CIHMs
The aim of the proposed ESS definitions is to provide an easily interpretable way to quantify the prior informativeness of commonly used CIHMs. The definition of ESS obtained by matching a given prior with a posterior distribution under an ε-information prior could be argued to be a natural choice. In order to formalize this, however, many detailed technical choices must be made. The definitions that we have proposed here are two of many possible formalizations. We arrived at the definitions after considering many alternatives, and evaluating the performance of each for several widely used CIHMs. The examples (one is in this section and two are in the supplementary materials) report the implied ESS for these models. As standard CIHMs, we use hierarchical extensions of standard models listed in Chapter 5 of Congdon (2005). In this section, we show how to compute the ESSs in cases 1 and 2 analytically in the normal CIHM with known sampling variance, and we argue that the obtained ESSs are sensible. In the supplementary materials, we provide computational details for a hierarchical model for binary responses recorded over different subpopulations as in the sarcoma trial of Section 2.1, and also for an alternative hierarchical model for the multicenter randomized trial analysis given in Section 2.3, assuming an exponential sampling model for the observed recurrence times.
Perhaps the most widely used CIHM is a hierarchical model with normal sampling model and conjugate prior and hyperprior. A typical example of such a CIHM is discussed in Gelman et al. (1995, Section 5.5), for a study of special coaching programs to prepare students for the scholastic aptitude test (SAT). The observed outcomes are SAT scores, where Yki denotes score of the i-th student in school k. The scores are assumed to be normally distributed with school specific means θ1, …, θk and known variance σ2. The model is completed with conjugate hyperpriors, as follows:
Thus, for K schools, μ̃ represents an overall effect and γ̃2 represents inter-school variability. The fixed hyperparameters are and φγ̃2 = (νφ, Sφ). Let denote the intra-class correlation. In this model the ESS in both cases 1 and 2 can be found analytically, because both the marginal prior π12 and the posterior π12,M are multivariate normal, thus the information matrices of the prior and posterior can be obtained analytically as the inverses of their variance-covariance matrices. Details are given in the supplementary materials.
Case 1
When the main goal is inference on the school-specific SAT scores θ1, …, θK, assuming fixed prior variance γ̃2,
| (20) |
This formula confirms what one would expect intuitively. The precision 1/γ̃2 of the conjugate normal prior for each school is equivalent to σ2/γ̃2 observations (SAT scores). Thus K independent priors for θ1, …, θK, corresponding to r = 0, would be equivalent to Kσ2/γ̃2 observations. The second factor in (20) is obtained analytically from the determinant of the information matrix of π12 for the normal CIHM with conjugate priors (computational details are given in the supplementary materials). This factor accounts for the dependence among θ1, …, θK in the two-level prior. Given K, as the correlation among θ1, …, θK increases, this factor reduces the ESS12. That is, as r → 1, the ESS12 → 0. In particular, for K = 2 schools, . Figure 2 shows a plot of ESS12(θ | φμ̃) as a function of r and γ̃2 for K = 5 and σ2 = 1.0.
Figure 2.
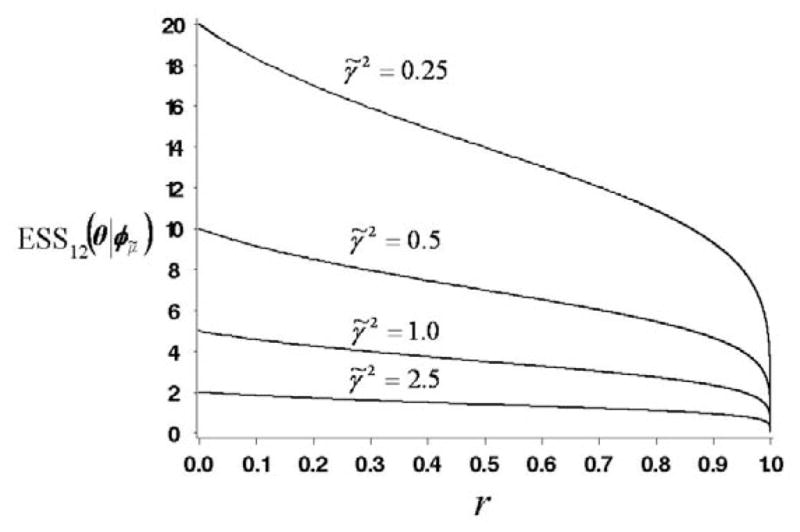
Plots of ESS12(θ | φμ̃) as a function of prior variance γ̃2 and r for the normal/inverse χ2-normal-normal model, when K = 5 and σ2 = 1.0.
To validate the plausibility of (20), we consider three limiting cases, each of which leads to a non-hierarchical model having an obvious prior ESS. (i) Given γ̃2, as r → 0, i.e. as , which is the limiting case with K independent schools, ESS12 → K × σ2/γ̃2 and σ2/γ̃2 is the ratio of the data variance to the prior variance, which is the prior ESS of a non-hierarchical model (Spiegelhalter et al. 1994, Section 3.1.2; MTM, Section 5, Example 3). (ii) In contrast, given γ̃2, as , and consequently r → 1, and there is one common effect θ = θ1 = … = θk, i.e. this limiting case is a non-hierarchical model where schools are ignored. The marginal prior variance
for the common effect diverges, however, which is reflected by the fact that ESS12 → 0, as desired, (iii) On the other hand, consider the case where is fixed and γ̃2 → 0. Again, the model reduces to one common effect θ = θ1 = … = θK, but now with finite marginal prior variance . In this case, to learn with certainty that all effects are equal would require extremely reliable data, i.e., a very large number of students in each school, which is (correctly) reflected by the fact that ESS12(θ | φμ̃) → +∞. If we allow γ̃2 to be random, ESS12(θ | φ) takes the same form as expression (20), but with γ̃2 replaced by its prior mean μγ̃2. (see Supplementary Materials, section 1).
Case 2
If the primary focus is the population parameter μ̃, averaging across all schools,
| (21) |
under the restriction that . An explanation of this restriction is given in the supplementary materials, Section 1 (Normal/Inverse χ2-Normal-Normal Model).
6 Discussion
We have proposed two practical definitions for the prior ESS of a conditionally independent hierarchical model. The main limitations are the need for numerical evaluations in many cases and the use of several arbitrary choices in the definitions. The arbitrary choices in the definition include the construction of an ε-information prior, evaluation of the posterior variance/covariance matrices conditional on
and
, and evaluation of the distances Δ1 and Δ2 at the prior means θ̄12 and
. The definitions of the two distances, based on the determinants of the information matrices, are reasonable but arbitrary. Alternative choices could be investigated. For example, one could use L2 distance after a transformation of the variance-covariance matrix to some suitable standard form. E.g. the Cayley transformation maps the variance-covariance matrix Σ to the orthogonal matrix (I − Σ)(I + Σ)−1. The main strengths of the method are the constructive nature of the definitions, and validation by matching prior ESS values obtained by the method with intuitively correct prior ESS values in special but important cases.
One of the reasons for the big success of hierarchical models, in particular, in inference for biomedical studies is the following feature. The hierarchical model constructs an informative prior for any given subgroup by borrowing strength from other subgroups and using the information contained in the data. If this feature is important, then the investigator might wish assurance that the hyperprior should not be excessively informative. The proposed ESS facilitates such judgements.
An important area of practical application for the proposed prior ESS summaries is design and inference for early phase clinical trials with small to moderate sample sizes. A concern about inappropriately influential prior information is one of the main impediments to a more widespread use of Bayesian methods in clinical trials. With the ever growing pressure for efficient use of resources and higher ethical standards, clinical trial designs are becoming increasingly more complex. Trial designs now routinely include the use of multiple outcomes, borrowing strength across different disease sub-types or patient subpopulations, the use of biomarkers, adaptive allocation, sequential stopping, etc. Such complexity may lead naturally to the use of a CIHM. The ability to compute prior ESS in such models provides a natural basis for calibrating priors as well as explaining the model to non-statisticians. Prior ESS values provide a similar tool when using a CIHM in a meta-analysis, which is an area of extensive activity. The two case studies in Section 2 are typical examples. It may be argued that, without an understanding of the prior ESS, it is impossible to carry out a fair regulatory review of a clinical trial protocol using a method based on a Bayesian CIHM. The proposed methodology may be used to mitigate this concern.
Overall, we believe that reporting ESS is most useful in judging the relative role of the prior, either informative or non-informative, in a clinical trial design, and as a tool to greatly facilitate the process of design simulation to calibrate the prior and obtain OCs. In this setting, both investigators and regulators may be very concerned that the trial conduct should not be overly biased by (sometimes inappropriately) optimistic priors. The ESS also is helpful to report and interpret the results of a data analysis, since comparing the ESS to the data sample size allows one to judge the prior’s relative informativeness.
Supplementary Material
Acknowledgments
Satoshi Morita’s work was supported in part by Grant H20-CLINRES-G-009 from the Ministry of Health, Labour, and Welfare in Japan and a non-profit organization Epidemiological and Clinical Research Information Network (ECRIN). Peter Müller’s work was partially supported by Grant NIH/NCI R01 CA 75981. Peter Thall’s work was partially supported by Grant NIH/NCI R01 CA 083932. We thank the associate editor and the referees for their thoughtful and constructive comments and suggestions.
Appendix
In Case 1 of a CIHM, the fact that constructing an ε-information prior π1,0(θ | θ̃) for π1(θ | θ̃) ensures that π12,0(θ | φ) = ∫ π1,0(θ | θ̃)π2(θ̃ | φ)dθ̃ is an ε-information prior for π12(θ | φ) can be proved as follows:
Assume for simplicity that V̄j = ∞; the proof in the case V̄j < ∞ is similar. Accounting for the variability at both levels of the CIHM, the variance of each θj can be written in the expanded form . Similarly, using π1,0 in place of π1, . Since the definition of ε-information prior ensures that Eπ1,0(θj|θ̃0) = Eπ1(θj|θ̃), the second terms of the two expansions are identical. Denoting this common term by cj, and also denoting and , the ratio of variances may be written as
| (22) |
Given θ̃, under the assumption V̄j = ∞ one can choose θ̃0 so that and . Writing these inequalities as and , taking the expectations with respect to π2 and reversing the algebra in each inequality, it follows that and . Writing the right-hand side of (22) as (aj/bj + cj/bj)/(1 + cj/bj), since cj/bj > 0 this is bounded above by aj/bj + cj/bj, which by the foregoing is bounded above by ε/2 + ε/2 = ε.
References
- Berlin JA, Colditz GA. The role of meta-analysis in the regulatory process for foods, drugs, and devices. Journal of the American Medical Association. 1999;281:830–834. doi: 10.1001/jama.281.9.830. [DOI] [PubMed] [Google Scholar]
- Berry DA, Stangl DK. Bayesian Biostatistics. New York: Marcel Dekker; 1996. [Google Scholar]
- Congdon P. Bayesian Statistical Modelling. 2. Chichester: John Wiley and Sons; 2005. [Google Scholar]
- Gelman A, Carlin JB, Stern HS, Rubin DB. Bayesian Data Analysis. 2. New York: Chapman and Hall/CRC; 2004. [Google Scholar]
- Gelman A. Prior distributions for variance parameters in hierarchical models. Bayesian Analysis. 2006;1:515–533. [Google Scholar]
- Gray RJ. A Bayesian analysis of institutional effects in a multicenter cancer clinical trial. Biometrics. 1994;50:244–253. [PubMed] [Google Scholar]
- Kass RE, Steffey D. Approximate Bayesian Inference in Conditionally Independent Hierarchical Models. Journal of the American Statistical Association. 1989;84:717–726. [Google Scholar]
- Morita S, Thall PF, Müller P. Determining the effective sample size of a parametric prior. Biometrics. 2008;64:595–602. doi: 10.1111/j.1541-0420.2007.00888.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O’Quigley J, Pepe M, Fisher L. Continual reassessment method: a practical design for phase I clinical trials in cancer. Biometrics. 1990;46:33–48. [PubMed] [Google Scholar]
- Spiegelhalter DJ, Freedman LS, Parmar MKB. Bayesian approaches to randomized trials. Journal of the Royal Statistical Society, Series A. 1994;157:357–416. [Google Scholar]
- Stangl DK. Hierarchical Analysis of Continuous-Time Survival Models. In: Berry DA, Stangl DK, editors. Bayesian Biostatistics. 1996. pp. 429–450. [Google Scholar]
- Thall PF, Wathen K, 1, Bekele BN, Champlin RE, Baker LH, Benjamin RS. Hierarchical Bayesian approaches to phase II trials in diseases with multiple subtypes. Statistics in Medicine. 2003;22:763–780. doi: 10.1002/sim.1399. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.