

Abstract
We study a marginal empirical likelihood approach in scenarios when the number of variables grows exponentially with the sample size. The marginal empirical likelihood ratios as functions of the parameters of interest are systematically examined, and we find that the marginal empirical likelihood ratio evaluated at zero can be used to differentiate whether an explanatory variable is contributing to a response variable or not. Based on this finding, we propose a unified feature screening procedure for linear models and the generalized linear models. Different from most existing feature screening approaches that rely on the magnitudes of some marginal estimators to identify true signals, the proposed screening approach is capable of further incorporating the level of uncertainties of such estimators. Such a merit inherits the self-studentization property of the empirical likelihood approach, and extends the insights of existing feature screening methods. Moreover, we show that our screening approach is less restrictive to distributional assumptions, and can be conveniently adapted to be applied in a broad range of scenarios such as models specified using general moment conditions. Our theoretical results and extensive numerical examples by simulations and data analysis demonstrate the merits of the marginal empirical likelihood approach.
Key words and phrases: Empirical likelihood, high-dimensional data analysis, sure independence screening, large deviation
1. Introduction
High-dimensional data are more frequently encountered in current practical problems of finance, biomedical sciences, geological studies and many more areas. Statistical methods for high-dimensional data analysis have received increasing interests to deal with large volume of data containing considerably many features; see Bühlmann and van de Geer (2011), Hastie, Tibshirani and Friedman (2009) and Fan and Lv (2010) for overviews. A fundamental objective of statistical analysis with high-dimensional data is to identify relevant features, so that effective models can be subsequently constructed and applied to solve practical problems.
Recently, independence feature screening methods have been considered, see, for example, Fan and Lv (2008), Fan and Song (2010) and Fan, Feng and Song (2011) for linear models, generalized linear models and nonparametric additive models, respectively. Fan and Lv (2008) and Fan and Song (2010) performed screening by ranking the absolute values of marginal estimates of model coefficients, and Fan, Feng and Song (2011) carried out screening by ranking integrated squared marginal nonparametric curve estimates. Fan and Song (2010) also discussed independence screening by examining the magnitudes of the likelihood ratios. More recently, Wang (2012) considered a sure independence screening by a factor profiling approach; Xue and Zou (2011) studied sure independence screening and sparse signal recovery; see also Zhu et al. (2011) and Li, Zhong and Zhu (2012) for recent development using model-free approaches for feature screening, Li et al. (2012) for a robust rank correcation based approach, and Zhao and Li (2012) for an estimating equation based feature screening approach.
The empirical likelihood approach [Owen (1988, 2001)] is demonstrated effective in scenarios with less restrictive distributional assumptions for statistical inferences; see Qin and Lawless (1994), Newey and Smith (2004) and reference therein. We refer to Chen and Van Keilegom (2009) as a review and discussion of recent development in the empirical likelihood approach. The scope of the empirical likelihood approach recently has also been extended to deal with high-dimensional data; see Hjort, McKeague and Van Keilegom (2009), Chen, Peng and Qin (2009), Tang and Leng (2010), Leng and Tang (2012), and Chang, Chen and Chen (2013). Though demonstrated effective in statistical inferences, the empirical likelihood approach encounters substantial difficulty when data dimensionality is high. More specifically, the data dimensionality p cannot exceed the sample size n in the conventional empirical likelihood construction. In addition, p can be at most o(n1/2) or even slower under which asymptotic properties are established [Chang, Chen and Chen (2013), Chen, Peng and Qin (2009), Hjort, McKeague and Van Keilegom (2009), Leng and Tang (2012), Tang and Leng (2010)]. Therefore, to practically more effectively apply the empirical likelihood approach, a pre-screening procedure is necessary to reduce the candidates of target features.
In this study, we systematically examine the properties of a marginal empirical likelihood approach where the available features are assessed one at a time individually. The marginal empirical likelihood approach only involves univariate optimizations, so that it provides a convenient device for both theoretical analysis and practical implementation. Our analysis reveals the probabilistic behavior of the marginal empirical likelihood ratios as functions of the parameters of interest that can be evaluated at arbitrary values, which itself is a problem of individual interest because existing studies of the empirical likelihood approach generally focus on its properties when evaluated at the truth, or at values in a small neighborhood of the truth. Based on our finding, we propose to conduct feature screening by using the marginal empirical likelihood ratio evaluated at zero. We find that a unified screening procedure can be applied in both linear models and generalized linear models. We also demonstrate how the marginal empirical likelihood approach can be conveniently adapted to solve a broad range of problems for models specified by general moment conditions. Hence, the marginal empirical likelihood approach provides a general and adaptive procedure for solving a broad class of practical problems for feature screening. Our theoretical analyses show that the proposed screening procedure based on the marginal empirical likelihood approach is selection consistent—that is, being able to identify the features that contribute to the response variable when the number of explanatory variables p grows exponentially with sample size n.
Our study contributes to the sure independence feature screening for high-dimensional data analysis from the following two substantial aspects. First of all, a fundamental difference of our approach to all existing approaches is that the marginal empirical likelihood ratio statistic is a self-studentized quantity [Owen (2001)] while other existing screening methods generally rely on the ranking of features based on magnitudes of some marginal estimators. Therefore, our approach is able to incorporate additionally the level of uncertainties associated with the estimators to conduct feature screening. This clearly extends the scope of existing feature screening approaches by considering more aspects of marginal statistical approaches. We show in our simulation studies that when heterogeneity exists in the conditional variance, our approach performs much better than a least-squares based approach. Second, our screening procedure inherits the non-parametric merits of the empirical likelihood approach. Specifically, our approach requires no strict distributional assumptions such as normally distributed errors in the linear models, or exponential family distributed response in the generalized linear models. This generalizes the scope and applicability of our approach. As a result, we show that the marginal empirical likelihood approach provides a unified framework for feature screening in linear regression models and generalized linear models, and can be conveniently applied for solving a broad class of general problems.
The rest of this paper is organized as follows. We elaborate the method of the marginal empirical likelihood approach in Section 2. Properties of the proposed approach are given in Section 3. Section 4 extends the marginal empirical likelihood approach to a broad framework including models specified by general moment conditions, and presents an iterative sure screening procedure using profile empirical likelihood. Numerical examples are given in Section 5. We conclude with some discussions in Section 6. All technical details are contained in the supplementary material of this paper [Chang, Tang and Wu (2013)].
2. Methodology
2.1. Marginal empirical likelihood for linear models
Let us motivate the marginal empirical likelihood approach by first considering the multiple linear regression model
| (2.1) |
where X = (X1, …, Xp)T is the vector of explanatory variables, ε is the random error with zero mean, and β = (β1,…, βp)T is the vector of unknown parameters. Hereinafter, we also use β to denote the truth of the parameter whenever no confusion arises. Without loss of generality, we assume hereinafter that the explanatory variables are standardized such that
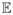 (Xj) = 0 and
(j = 1,…, p). For effective and interpretable practical applications, one may reasonably expect that among the large number of explanatory variables, only a small fraction of them contribute to the response variable. We therefore denote by
(Xj) = 0 and
(j = 1,…, p). For effective and interpretable practical applications, one may reasonably expect that among the large number of explanatory variables, only a small fraction of them contribute to the response variable. We therefore denote by
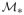 = {1 ≤ j ≤ p :βj ≠ 0} the collection of the effective explanatory variables in the true sparse model whose size is characterized by its cardinality s = |
|. Here we assume that s is much smaller than p, reflecting the case in many practical applications like in finance, biology and clinical studies.
= {1 ≤ j ≤ p :βj ≠ 0} the collection of the effective explanatory variables in the true sparse model whose size is characterized by its cardinality s = |
|. Here we assume that s is much smaller than p, reflecting the case in many practical applications like in finance, biology and clinical studies.
In the recent literature of high-dimensional data analysis, various marginal approaches have been applied for locating the true model
; see, for example, Fan and Lv (2008), Fan and Song (2010) and Fan, Feng and Song (2011). Among those approaches, a popular way is to assess the marginal contribution from a given explanatory variable Xj. Commonly applied criteria for measuring the marginal contribution are the magnitudes of some marginal estimators [Fan, Feng and Song (2011), Fan and Lv (2008), Fan and Song (2010)]. Subsequently, the candidate models are chosen from the top ranked explanatory variables.
To apply a marginal empirical likelihood approach for the linear regression model (2.1), let us consider the marginal moment condition of the least squares estimator:
| (2.2) |
where
is interpreted as the marginal contribution of covariate Xj to Y. From (2.2), we can see that
is the covariance between Xj and Y so that
is equivalent to that Y and Xj are marginally uncorrelated. Here we note the remarkable difference between
and βj where the latter is the truth of the parameter in (2.1). In general,
unless
(XiXj) = 0 for all i ≠ j. In addition to that from βj in the model (2.1),
also contains aggregated contribution from other components that may be correlated with Xj. Thus, the correlation level among covariates has significant impact on the performance of a screening procedure based on (2.2); more discussions on this are given in a later section containing the main results.
A marginal empirical likelihood for linear models can be constructed as follows. Note that , therefore (2.2) is equivalent to
| (2.3) |
Let be collected independent data, gij(β) = XijYi−β (j = 1,…, p) and Xij means the j th component of the ith observation Xi. Based on (2.3), we define the following marginal empirical likelihood:
| (2.4) |
for j = 1,…, p. For any given β in the convex hull of , the marginal empirical likelihood ratio is defined as
| (2.5) |
where λ is the Lagrange multiplier satisfying
| (2.6) |
2.2. Extended coverage to generalized linear models
A merit of the marginal empirical likelihood approach is that the formulation by (2.4) and (2.5) only requires the moment condition (2.3), rather than specific distributional assumption of ε in model (2.1). This entitles our approach robustness against the violation of distributional model assumptions, and thus it can be extended and adapted to a broader framework. Now we elaborate how the above marginal empirical likelihood approach can be equally applied when the response variable Y is in the exponential family with the density function taking the canonical form [McCullagh and Nelder (1989)]:
| (2.7) |
for some suitable known functions b(·), c(·) and canonical parameter θ. Further extensions of the marginal empirical likelihood approach are discussed in a later section. We refer to Kolaczyk (1994) and Chen and Cui (2003) for conventional applications of the empirical likelihood to generalized linear models. Following the convention of generalized linear models, we denote the mean function by μ =
(Y |X) = b′(θ) where θ is modeled by a linear function β0 + XTβ with β = (β1,…, βp)T, and use V(μ) to denote the variance of Y expressed as a function of μ.
For any j = 1,…, p, the moment condition based on the marginal likelihood approach in Fan and Song (2010) for βj is
| (2.8) |
where is the implied mean function that is modeled marginally only using Xj. Here the is again interpreted as the marginal contribution of Xj to the response variable Y ; see also Fan and Song (2010). By the property of the exponential family distribution, and V(μ) = b″(θ). Then (2.8) becomes
| (2.9) |
For linear models, , then b′ (θ) = θ, so that (2.9) becomes by noting that β0 = 0 in the linear model case, which is exactly (2.2). Hence, (2.9) is a natural extension of (2.2) in the generalized linear models.
One way to apply the marginal approach can be generalizing the definition in (2.4) to be gij (β) = Xij{Yi − b′(β0 + βXij)} (j = 1,…, p). However, such a modification is actually not necessary. To see this, we note that when the marginal contribution
, then the marginal moment condition (2.9) becomes
[Xj {Y − b′(β0)}] = 0. Hence, it implies that the covariance between Xj and Y is 0, which exactly shares the same implication of (2.3) as in the linear models. From this perspective, (2.9) and (2.3) are essentially equivalent. Additionally, the response variable in practice can always be centered to have zero mean. This fact eliminates the concern on the intercept β0 in the generalized linear models when considering a marginal empirical likelihood approach. As a result, we conclude that a unified marginal empirical likelihood construction (2.4) with the same gij (β) = XijYi −β can be equally applied for both linear models and generalized linear models with centered response variable Y. The implication of this unified construction is also intuitively very clear by interpreting β as the covariance between a covariate and the response variable.
Furthermore, we note that the distributional assumption (2.7) is actually not required in our marginal empirical likelihood approach. Therefore our approach is not restricted to the exponential family (2.7). Since we only require the marginal moment condition (2.9), our approach can be applied with the quasi-likelihood approach and it also works with misspecified variance functions [McCullagh and Nelder (1989)].
The marginal empirical likelihood ratio (2.5) with gij(β) = XijYi −β evaluated at β = 0—that is, ℓj (0)—has a very clear practical interpretation by noting that it can be used to test the null hypothesis . By noting additionally the intuitively clear fact that ℓj (0) should not be large if , we can see that ℓj (0) can be used as a device for feature screening. More specifically, we have the following procedure:
Step 1: Evaluating ℓj (0) for all j = 1,…, p, where ℓj (·) is defined in (2.5) with gij (β) = XijYi − β. If 0 is not in the convex hull of , we define ℓj (0)=∞ as a strong evidence of significance in predicting Y using Xj.
Step 2: Given a threshold level γn, select a set of variables by
We specify in the next section the requirement for γn so that the screening procedure is consistent. On the other hand, however, explicitly identifying γn in practice is generally difficult because it involves unknown constants. Thus, a screening procedure can be practically implemented in a way such that
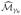 recruits candidate features until certain size such as n1/2 is achieved.
recruits candidate features until certain size such as n1/2 is achieved.
We remark that the evaluation of ℓj (β) in (2.5) in practice is actually very easy by noting that all optimizations involved are univariate, which is very convenient for practical applications. On the other hand, our procedure only needs to evaluate the marginal empirical likelihood ratio (2.5) at β = 0 and avoids the estimation of when conducting the feature screening.
3. Main results
Now we present main results for the marginal empirical likelihood ratio in (2.5) with the unified specification gij (β) = XijYi − β that are generally applicable for both linear models and generalized linear models. In our discussion hereinafter, let ρj =
(XjY). If ρj = 0, it is well known that ℓj (0) is asymptotically chi-square distributed with 1 degree of freedom [Owen (1988, 2001)]. If ρj ≠ 0, however, the properties of ℓj (0) is generally less clear, which is also a question of independent interest. Specifically, if β = ρj +τσn−1/2 where σ2 = var(XjY), it can be shown following the same argument of Owen (1988) that
as n→∞ under some regularity conditions where τ2 is a noncentrality parameter. But if β − ρj converges to zero at a rate slower than n−1/2, the exact diverging rate of ℓj(β) is less clear in existing literature.
We first present a general result that shows that the empirical likelihood ratio ℓj(β) is no longer Op(1) when β −ρj converges to 0 but n1/2(β −ρj) diverges.
Proposition 1
Suppose that U1,…, Un are independent and identically distributed random variables with
(|Ui |ν) <∞ for some ν ≥ 3. Replacing gij (β) in (2.5) and (2.6) by Ui − μ for all i = 1,…, n, we obtain ℓ(μ). If |μ − μ0| = O(n−w) for some
, then
where μ0 =
(Ui) and σ2 =
{(Ui −μ0)2}.
We note that Chen, Gao and Tang (2008) contains a related result showing that the empirical likelihood ratio is diverging when evaluated at values far enough from the truth. Our Proposition 1 contains the specific diverging rate of the empirical likelihood ratio. Proposition 1 implies that if β − ρj converges to zero at a rate slower than n−1/2, ℓj (β) = Op{n(β − ρj)2}. On the other hand, if β − ρj does not weaken to zero, our Theorem 1 presented later shows that ℓj(β) has high probability to take large value. On the other hand, as clearly shown in our proof of Proposition 1 given in Chang, Tang and Wu (2013), the statistics ℓj (0) is self-studentized, and hence it incorporates the level of uncertainties from using the finite sample moment conditions. Such a feature is desirable because in practice levels of uncertainties corresponding to different covariates can be different when contributing to the response variable of interest. This may confound the ranking for feature screening based on marginal estimators themselves without considering their standard errors, not mentioning incorporating the level of uncertainties is difficult especially when handling high-dimensional statistical problems.
An effective marginal screening procedure requires two conditions: (i) if j ∈
, then ρj takes nonnegligible value; and (ii) if j ∉
, then ρj takes negligible value. Actually, the first requirement is closely related to recruiting the true signals that contribute to the response, and the second one affects the size of selected variable set that may contain false signals. Fan and Lv (2008) shows that under the identification condition minj∈
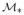 |ρj| ≥ fn > 0 for some function fn, the first requirement is fulfilled. A common assumption for fn is fn = O(n−κ) for some
.
|ρj| ≥ fn > 0 for some function fn, the first requirement is fulfilled. A common assumption for fn is fn = O(n−κ) for some
.
Our next theoretical analysis imposes the following two assumptions:
-
A.1: The random variable Y has bounded variance and there exists a positive constant c1 such that
for some .
- A.2: There are positive constants K1, K2, γ1 and γ2 such that
Assumption A.1 can be viewed as a requirement for the minimal signal strength, and we call it the identification condition for j ∈
. For linear models, the assumption A.1 is same as condition 3 in Fan and Lv (2008) that is commonly assumed in sure independence feature screening. For generalized linear models, Fan and Song (2010) imposes the identification condition as minj∈
|cov(b′(XTβ), Xj)| ≥ c1n−κ. By noticing that cov(b′(XTβ), Xj) =
(XjY), their identification condition for j ∈
is also same as A.1. Since we impose no distributional assumptions, A.2 is assumed to ensure the large deviation results that are used to get the exponential convergence rate. The first part of A.2 is same as the first part of condition D in Fan and Song (2010). For linear regression model, the second part of condition D in Fan and Song (2010) is equivalent to that XTβ satisfies the Cramér condition such that there exists a positive constant H such that
{exp(tXTβ)} <∞ for any |t |<H. If the error ε is independent of covariates and satisfies the Cramér condition, then we can obtain that the variable Y also satisfies the Cramér condition. From Lemma 2.2 in Petrov (1995), a random variable W satisfies Cramér condition is equivalent to that there are positive constants b1 and b2 such that ℙ{|W| ≥ u} ≤ b1 exp(−b2u) for any u > 0. Therefore, our assumption here is actually weaker than that in Fan and Song (2010). On the other hand, A.2 is also a general technical assumption in the literature of large derivations. For example, γ1 = 2 if Xj’s follow normal distribution or sub-Gaussian distribution, and γ1=∞ if Xj’s have compact support.
We now establish the following general result for the distribution of empirical likelihood ratio which is the foundation for our future theoretical results.
Theorem 1
Suppose that U1,…, Un are independent and identically distributed random variables. Assume that there exist three positive constants K̃1, K̃2 and γ such that ℙ{|Ui|>u} ≤ K̃1 exp(−K̃2uγ) for all u>0. Define μ0 =
(Ui),
, H = 21+δ and
, where σ2 =
{(Ui − μ0)2} and K >σ is a sufficiently large positive constant depending only on K̃1, K̃2, γ and μ0, then for L → ∞, there exists a positive constant C only depending on K̃1, K̃2 and γ such that
where ℓ(μ) is defined in Proposition 1.
The proof of Theorem 1 is given in Chang, Tang and Wu (2013), where the main idea is applying large deviation theory [Petrov (1995), Saulis and Statulevičius (1991)].
Theorem 1 reveals the magnitude of the empirical likelihood ratio statistic evaluated at arbitrary values. When μ −μ0 does not diminish to 0, Theorem 1 implies that the empirical likelihood ratio statistic diverges with large probability where the diverging rate synthetically depends on the sample size n, some diverging L and the deviation of μ from the truth. Here L is a general technical device whose diverging rate is arbitrary. As a direct result of Theorem 1, we have the following proposition for ℓj (0).
Proposition 2
Under assumptions A.1 and A.2, there exists a positive constant C1 depending only on K1, K2, γ1 and γ2 appeared in assumption A.2 such that for any j ∈
and L→∞,
where and .
Proposition 2 is a uniform result for all features contributing in the true model. Specifically, with large probability and uniformly for all j ∈
, the diverging rate of ℓj (0) is not slower than n1−2κL−2. From Proposition 1, if |
(XjY)| = O(n−w) for some
and some j ∈
, then
. This can be viewed as a requirement such that the signal strength cannot diminish to 0 at a too fast rate. Therefore, n1/2−κL−1→∞ as n→∞ is required for sure independence screening. By choosing L = n1/2−κ−τ for some
, we obtain the following corollary more specifically summarizing that the set
can be distinguished by examining the marginal empirical likelihood ratio ℓj (0) (j = 1,…, p).
Corollary 1
Under assumptions A.1 and A.2, there exists a positive constant C1 depending only on K1, K2, γ1 and γ2 appeared in assumption A.2 such that, for any ,
where and .
Summarizing above results, we formally establish the screening properties of the marginal empirical likelihood approach.
Theorem 2
Under assumptions A.1 and A.2, there exists a positive constant C1 depending only on K1, K2, γ1 and γ2 appeared in assumption A.2 such that, for any and ,
where and .
Theorem 2 implies the sure screening property for our procedure with nonpolynomial dimensionality:
When the covariates and error are normal, γ1 = 2 and γ2 = 2. Then γ = 1, δ = 1 and log p = o(n1/2−κ) which is weaker than that in Fan and Lv (2008) where log p = o(n1−2κ) is allowed. This can be viewed as a price paid for allowing nonnormal covariate and more general error distribution. Furthermore, we compare our result and that in Fan and Song (2010). The Lemma 1 in Fan and Song (2010) means that γ2 = 1. The corresponding parameters under their this setting are and , respectively. Then, we can handle the nonpolynomial dimensionality
in this setting, which is actually a stronger result than that in Fan and Song (2010) where log p = o(n(1−2κ)γ1/A) and A = max{γ1 + 4, 3γ1 +2}.
Now we investigate how large the set
is. This question is closely related to the asymptotic property of ℓj (0) for j ∉
. Essentially, we need to know the magnitudes of ℓj (0) for j ∉
. We first consider the simple case ρj = 0 for any j ∉
and have the following result.
Proposition 3
Under assumptions A.1 and A.2, if ρj = 0, there is a positive constant C2 depending only on K1, K2, γ1 and γ2 appeared in assumption A.2 such that, for any ,
where .
The assumption ρj = 0 for any j ∉
can be guaranteed by the partial orthogonality condition, that is, {Xj :j ∉
} is independent of {Xj : j ∈
}. The orthogonality condition is essentially the assumption made in Huang, Horowitz and Ma (2008) who showed the model selection consistency in the case with the ordinary linear model and bridge regression. This proposition gives the property of ℓj (0) for any j ∉
which can be used to establish the theoretical result for the size of
where
. Note that
then
By Proposition 3, we obtain the following theorem.
Theorem 3
Under assumptions A.1 and A.2, if ρj = 0 for any j ∉
, then there exists a positive constant C2 depending only on K1, K2, γ1 and γ2 appeared in assumption A.2 such that, for any
and
,
where .
From Theorem 3, we have ℙ{|
| > s} ≤ p exp{−C2n(2τ)^(γ/6)^(γ/(γ+2))} which means that the event {|
| ≤ s} occurs with probability approaching to 1 if log p = o(n(2τ)^(γ/6)^(γ/(γ+2))). On the other hand, following Theorem 2, we have ℙ{
⊂
} → 1 provided log p = o(n((1−2κ−2τ)γ/2)^(1−2κ)). Combining these two results together, we can obtain that
and
This property shows the selection consistency of our procedure. In a more general case without partial orthogonality condition, we could consider the size of the set
under the setting
which is an assumption imposed in Fan and Song (2010).
Proposition 4
Under assumptions A.1 and A.2, if maxj∉
|ρj| = O(n−η) where η > κ and
for some c2 > 0, there exists a positive constant C3 depending only on K1, K2, γ1 and γ2 appeared in assumption A.2 and c2 such that, for any j ∉
and
,
where .
If ρj = 0 for any j ∉
, then η = ∞. Hence, this proposition reduces to Proposition 3. Following the same argument between Proposition 3 and Theorem 3, we can obtain the following theorem related to the size of
.
Theorem 4
Under assumptions A.1 and A.2, if maxj
∉
|ρj| = O(n−η) where η > κ and
for some c2 > 0, then there exists a positive constant C3 only depending on K1, K2, γ1 and γ2 appeared in assumption A.2 and c2 such that, for any
and
,
where .
In summary, our results show that the marginal empirical likelihood approach has a very good control of the size of the recruited variables. With large probability, the set of the recruited variables is not larger than the true contributing explanatory variables. As shown later in our simulation results, the marginal empirical likelihood approach perform very well in terms of the set of false selected variables by the marginal empirical likelihood approach.
4. Extensions
4.1. A broad framework
The marginal empirical likelihood can be applied in a general framework besides the linear models and generalized linear models. Based on general estimating equations approach [Hansen (1982), Qin and Lawless (1994)], we can also apply the screening procedure based on the marginal empirical likelihood. We will demonstrate that the marginal empirical likelihood approach provides an effective device to combine information that can be used to enhance the performance of a screening procedure.
Let Zi ∈ ℝd (i = 1, …, n) be generic observations, β = (β1, …, βp)T ∈ ℝp be parameter of interest and g(Z; β) = (g1(Z; β), …, gr(Z; β))T be the r-dimensional estimating function such that
{g(Z; β)} = 0. Let
= {1 ≤ j ≤ p : βj ≠ 0} be the true model with size |
| = s. We are interested in how to construct a sure feature screening procedure to recover
in the general estimating equation setting. To motivate the marginal empirical likelihood approach, let us consider the estimating function evaluated at
In practice, many components in g(Z; β(j)) do not involve the unknown parameter; see, for example, the estimating function constructed from the least-squares method and our example given later. Therefore, we denote by
an rj (rj ≥ 1)-dimensional estimating function collecting the components in g(Z; β(j)) that depend on the unknown parameter. Usually rj > 1 is small and not all components of Z are involved in g(j)(Z; β). A remarkable advantage of this broad framework is that it provides a device for feature screening using more flexibly constructed conditions so that additional data information can be more effectively incorporated.
Correspondingly, we define the marginal empirical likelihood for β as
| (4.1) |
Then screening can be done based on the ranking of ELj(0) or equivalently using the corresponding marginal empirical likelihood ratio evaluated at 0—that is, ℓj(0). The steps of the procedure are the same as those described earlier. A concrete example of this scenario is given as follows.
Example (Quadratic inference function (QIF) approach [Qu, Lindsay and Li (2000)])
Longitudinal data arise commonly in biomedical research with repeated measurements from the same subject or within the same cluster. Let Yit and Xit(i = 1, …, n, t = 1, …, mi) be the response and covariates of the ith subject measured at time t. Let where β ∈ ℝp is the parameter of interest. Incorporating the dependence among the repeated measurements is essential for efficient inference. Liang and Zeger (1986) proposed to estimate β by solving . Here for the ith subject, Yi = (Yi1, …, Yimi)T, μi = (μi1, …, μimi)T, and , where vi is a diagonal matrix of the conditional variances of subject i and R is a working correlation matrix that may depend on some unknown parameter. This approach uses estimating function , where and r = p. More recently, Qu, Lindsay and Li (2000) proposed to model R−1 by , where M1, …, Mm are known matrices and a1, …, am are unknown constants. Then β can be estimated by the quadratic inference functions approach [Qu, Lindsay and Li (2000)] that uses
| (4.2) |
This falls into our framework with r > p when m > 1, and with r = p if m = 1. When applying the marginal approach, we note that g(j)(Z; β) is an m-dimensional estimating function. The marginal screening by empirical likelihood can be conveniently applied to this scenario, and we note that the existing independence screening methods cannot be directly applied when m > 1.
In a concurrent and independent work, Zhao and Li (2012) considered feature screening using estimating functions when r = p. By using our notations, their approach are based on g(j)(Z; 0)—the marginal estimating function evaluated at 0. Their screening procedure are based on ranking the absolute value of g(j)(Z; 0) for j = 1, …, p. Our approach is different as seen from the above marginal empirical likelihood construction. In addition, analogous to that in linear models and generalized linear models, the marginal empirical likelihood constructed from using the marginal estimating function is also capable of incorporating the level of uncertainties associated with finite sample estimating functions.
We now characterize the properties of the screening procedure in the framework of models specified by estimating equations. For any vector a =(a1, …, aq)T ∈ ℝq, we use ||a||∞ = maxi=1, …, q |aq| and to denote its L∞ and L2 norms, respectively. Aiming to establish the theoretical results, we need the following two assumptions.
-
A.3: There exists a positive constant c3 such that
for some .
-
A.4: There are positive constants K3, K4 and γ3 such that
for each j = 1, …, p and any u > 0.
Assumption A.3 is a general identification condition for the set
when considering the broad framework of models specified by general estimating equations. It means that the weakest signals reflected by ||
{g(j)(Z; 0)}||∞ (j ∈
) cannot vanish at a rate faster than n−1/2. Assumption A.3 is not stringent, and it reduces to A.1 in special cases of linear models and generalized linear models. A similar assumption is also made in Zhao and Li (2012). Assumption A.4, which is a counterpart of A.2 in general cases, is required for establishing exponential inequality when analyzing large deviations. Zhao and Li (2012) assumed boundness of all components in g(j)(Z; 0), which implies A.4.
Theorem 5
Under assumptions A.3–A.4, there exists a positive constant C4 depending only on K3, K4 and γ3 appeared in assumption A.4 such that, for any and ,
where .
This theorem is a natural extension of Theorem 2 in the broad framework for models specified by general estimating equations. In special cases, we have considered for linear models and generalized linear models, g(j)(Z; 0) = Xj Y(j = 1, …, p), and γ3 in assumption A.4 is equal to where γ1 and γ2 are specified in A.2.
Let
We now consider the size of
in the setting
This specification also reduces to those considered in special cases of linear models and generalized linear models. The counterpart of Theorem 4 for establishing the selection consistency is given as follows.
Theorem 6
Under assumptions A.3 and A.4, if maxj
∉
||uj||∞ = O(n−η) where η > κ and minj
∉
λmin(
{g(j)(Z; 0)g(j)(Z; 0)T}) ≥ c4 for some c4 > 0, where λmin(A) means the smallest eigenvalue of A, then there exists a positive constant C5 depending only on K3, K4 and γ3 appeared in assumption A.4 and c4 such that, for any
and, γn=c3,n2τ
Combining the Theorems 5 and 6, we can see that the screening procedure using the marginal empirical likelihood ratio is valid in a broad framework for identifying the set of the effective features.
4.2. Iterative screening procedure
As we can see from the main results, the proposed marginal empirical likelihood screening procedure works ideally for the case with explanatory variables that are independent of each other. To deal with challenging situations with correlated explanatory variables, we propose to use the following iterative sure independence screening procedure.
Step 1: Rank explanatory variables according to ℓj(0) by (2.5) and select top ranked explanatory variables with largest values of ℓj(0)’s until some desirable number of features are included. Denote the set of select explanatory variables by
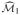 .
.Step 1′: Apply penalized empirical likelihood [Leng and Tang (2012), Tang and Leng (2010)] to explanatory variables in
and denote the final model by
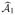 .
.-
Step 2: Let
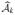 ⊂{1, …, p} be the selected model at the kth step. At the kth iteration, for each j ∉
, denote by
the empirical likelihood for the combined covariates, and denote by
⊂{1, …, p} be the selected model at the kth step. At the kth iteration, for each j ∉
, denote by
the empirical likelihood for the combined covariates, and denote bythe profile empirical likelihood evaluated at μ. Rank explanatory variable j in according to and select the top ranked until some desirable number of features are included. Denote the selected set by
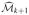 .
. Step 2′: Apply penalized empirical likelihood to explanatory variables in
∪
and denote the final model by
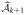 .
.Step 3: Repeat steps 2 and 2′ when either
=
or the size of
reaches a pre-specified number.
The above iterative screening procedure incorporates the profile empirical likelihood. The rationale behind it is to capture the joint impact that may be invisible using the marginal screening procedure if correlations exist among those covariates. Our iterative screening procedure shares some similar features of the analogous ones in Fan and Lv (2008) and Fan and Song (2010). However, on the other hand, the iterative procedure using the profile empirical likelihood ratio shares the feature of the marginal empirical likelihood approach by incorporating the level of uncertainties. In addition, we note that the above iterative procedure is generally applicable in a broad framework.
5. Numerical examples
In this section, we use five simulation examples and a real data example to demonstrate the performance of the proposed empirical likelihood-based screening procedure (denoted by EL-SIS) and corresponding iterative procedure (denoted by EL-ISIS). Depending on the example setting, we compare it with the screening methods proposed in Fan and Lv (2008) (denoted by LS-SIS and LS-ISIS) and Fan and Song (2010) (denoted by GLM-SIS and GLM-ISIS) for linear regression models and generalized linear models, respectively. Whenever appropriate, we compare to the robust rank correlation based screening (RRC-SIS and RRC-ISIS) studied by Li et al. (2012). For all simulation examples, we begin with p = 1000 explanatory variables and screen to a much smaller number d of explanatory variables. The respective SCAD penalized variable selection is further applied to these selected explanatory variables to get the corresponding final model. Results over 200 repetitions are reported. For each case, we report the number of repetitions that each important explanatory variable is selected in the final model and also the average number of unimportant explanatory variables being selected.
Example 1
This example has a very standard setting with three important explanatory variables and is taken from Fan and Lv (2008). Covariates are generated as Xj ~ N(0, 1) and cov(Xj, Xj′) = 1 if j = j′ and 0.3 otherwise. The response is generated as Y = 5X1 + 5X2 + 5X3 + ε with error being independent of the explanatory variables. We consider three different error distribution N(0, 1), N(0, 22), and t4 for ε. Random samples of size n = 100 are used and we set d = ⌊n/(2 log n)⌋ = 10, where ⌊a⌋ denotes the largest integer that is less than or equal to a. Results over 200 repetitions are reported in Table 1, where we report the number of repetitions that each of the important explanatory variables X1, X2 and X3 is selected. For unimportant explanatory variables, Table 1 reports their average number of repetitions for each being selected. It shows that the proposed empirical likelihood-based screening methods perform very competitively when compared to the least squares-based screening or the robust rank correlation-based screening.
Table 1.
Simulation result for Example 1
| ε | Method | X1 | X2 | X3 | Unimportant explanatory variables |
|---|---|---|---|---|---|
| N(0, 1) | LS-SIS | 199 | 199 | 200 | 1.406219 |
| RRC-SIS | 199 | 199 | 199 | 1.407222 | |
| EL-SIS | 194 | 183 | 185 | 1.442327 | |
| LS-ISIS | 200 | 200 | 200 | 0.965898 | |
| RRC-ISIS | 200 | 200 | 200 | 0.800401 | |
| EL-ISIS | 200 | 200 | 200 | 0.659980 | |
| N(0, 22) | LS-SIS | 199 | 199 | 200 | 1.406219 |
| RRC-SIS | 198 | 198 | 199 | 1.409228 | |
| EL-SIS | 192 | 182 | 183 | 1.447342 | |
| LS-ISIS | 200 | 200 | 200 | 1.404213 | |
| RRC-ISIS | 200 | 200 | 200 | 1.403210 | |
| EL-ISIS | 200 | 200 | 200 | 0.980943 | |
| t4 | LS-SIS | 199 | 199 | 200 | 1.406219 |
| RRC-SIS | 198 | 199 | 199 | 1.408225 | |
| EL-SIS | 193 | 186 | 187 | 1.438315 | |
| LS-ISIS | 200 | 200 | 200 | 1.383149 | |
| RRC-ISIS | 200 | 200 | 200 | 1.362086 | |
| EL-ISIS | 200 | 199 | 200 | 0.635908 |
Example 2
The second example is also from Fan and Lv (2008) and has a hidden important explanatory variable, which is important but marginally uncorrelated with the response. This example is to illustrate that the proposed iterative empirical likelihood-based screening works effectively in such challenging cases. Covariates are generated as Xj ~ N(0, 1) and cov(Xj, Xj′) = 1 if j = j′ and 0.3 otherwise except for j ≠ 4. The response is generated as with ε being independent of explanatory variables. We consider three different error distribution N(0, 1), N(0, 22), and t4. Results over 200 repetitions with n = 100 and d = ⌊n/(2 log n)⌋ = 10 are reported in Table 2. It shows that the empirical likelihood-based screening is challenged by the hidden important explanatory variable X4 but the corresponding iterative screening can easily pick it up. Overall the performance of the empirical likelihood-based screening methods is very similar to that of the least squares-based screening methods and is better than the robust rank correlation-based screening. Note that iterative version of the robust rank correlation-based screening is residual-based. This explains the improvement of the robust rank correlation-based screening.
Table 2.
Simulation result for Example 2 with a hidden important explanatory variable X4
| ε | Method | X1 | X2 | X3 | X4 (hidden) | Unimportant explanatory variables |
|---|---|---|---|---|---|---|
| N(0, 1) | LS-SIS | 198 | 197 | 195 | 0 | 1.415663 |
| RRC-SIS | 196 | 197 | 194 | 0 | 1.418675 | |
| EL-SIS | 198 | 198 | 197 | 0 | 1.412651 | |
| LS-ISIS | 200 | 200 | 199 | 196 | 1.125502 | |
| RRC-ISIS | 200 | 199 | 200 | 111 | 1.157631 | |
| EL-ISIS | 199 | 199 | 200 | 193 | 0.853414 | |
| N(0, 22) | LS-SIS | 198 | 197 | 194 | 0 | 1.416667 |
| RRC-SIS | 196 | 196 | 194 | 0 | 1.419679 | |
| EL-SIS | 198 | 196 | 194 | 0 | 1.417671 | |
| LS-ISIS | 199 | 200 | 199 | 196 | 1.210843 | |
| RRC-ISIS | 199 | 199 | 200 | 96 | 1.311245 | |
| EL-ISIS | 200 | 200 | 198 | 188 | 0.912651 | |
| t4 | LS-SIS | 197 | 197 | 197 | 0 | 1.414659 |
| RRC-SIS | 195 | 198 | 196 | 0 | 1.416667 | |
| EL-SIS | 197 | 198 | 196 | 0 | 1.414659 | |
| LS-ISIS | 199 | 200 | 200 | 196 | 1.209839 | |
| RRC-ISIS | 200 | 200 | 199 | 100 | 1.305221 | |
| EL-ISIS | 200 | 198 | 200 | 185 | 0.824297 |
Example 3
The performances of the empirical likelihood-based screening and the least squares-based screening methods are very similar in the previous two examples. It is known that the empirical likelihood approach requires a less restrictive distributional assumption. We next use a heteroscedastic example to show the advantage of the empirical likelihood-based screening. Explanatory variables are generated as Xj ~ N(0, 1) with cov(Xj, Xj′) = 0 for j ≠ j′. The response is generated as with independent ε ~ N(0, 1) and c > 0 controls the signal level. Results over 200 repetitions with n = 70 and d = ⌊n/(2 log n)⌋ = 8 are reported in Table 3 for three different values of c. It shows that the performance of the least squares-based screening is severely affected by the heteroscedasticity especially when the signal level is low. On the other hand, the proposed empirical likelihood-based screening works much better and similarly as the robust rank correlation-based screening.
Table 3.
Simulation result for Example 3
| c | Method | X1 | X2 | X3 | Unimportant explanatory variables |
|---|---|---|---|---|---|
| 1 | LS-SIS | 149 | 147 | 156 | 1.151454 |
| RRC-SIS | 191 | 185 | 190 | 1.037111 | |
| EL-SIS | 190 | 184 | 191 | 1.038114 | |
| 1.5 | LS-SIS | 173 | 171 | 174 | 1.085256 |
| RRC-SIS | 194 | 191 | 193 | 1.025075 | |
| EL-SIS | 196 | 192 | 194 | 1.021063 | |
| 2 | LS-SIS | 182 | 182 | 180 | 1.059178 |
| RRC-SIS | 194 | 194 | 195 | 1.020060 | |
| EL-SIS | 199 | 195 | 194 | 1.015045 |
Example 4
We now consider an example with the extended scope. In this example, we generate data from the longitudinal data example as in Section 4.2 with m = 4 means 4 repeated measurements generated. In particular, the following model is generated:
Here Xil is generated from multivariate normal N(0, Σ) with Σ = (σjk)j,k=1, …, p and σjk = 0.5|j−k|. The error vector εi = (εi1, …, εim)T is generated from multivariate normal distribution with unit variance. The correlation structure of ε is specified as AR(1) with parameter 0.8; see Diggle et al. (2002) for reference for the correlation structure. The first five components of the true β is set to be c · (2.0, −2.0, 0, 0, 2.0)T where c is used to control the signal strength, and all other components of β are zero. We use two sets of basis matrices in (4.2). We take M1 = I as the identity matrix. The second basis matrix M2 is a matrix with two main off-diagonals being 1 and 0 elsewhere corresponding to the AR(1) working correlation [Qu, Lindsay and Li (2000)]. We then apply the marginal empirical likelihood procedure as in Section 4 using the marginal estimating function of (4.2). Here we note that the marginal estimating function is 4-dimensional. By ignoring the correlation structure of the longitudinal data, the least squares-based screening and robust rank correlation-based screening procedures can be applied. Results over 200 repetitions with n = 60 and d = 15 are reported in Table 4. From Table 4, we clearly see that the marginal empirical likelihood approach works much better than the alternative ones, especially when signal is relatively weak. The improvement can be seen as the results of incorporating additional data structural information. Hence, we demonstrate an advantage of the marginal empirical likelihood approach of being adaptive and flexible.
Table 4.
Simulation result for the longitudinal data estimation function example with c controlling the signal strength
| c | Method | X1 | X2 | X5 | Unimportant explanatory variables |
|---|---|---|---|---|---|
| 1 | LS-SIS | 90 | 73 | 153 | 2.692076 |
| GEE-SIS | 111 | 111 | 168 | 2.617854 | |
| RRC-SIS | 84 | 66 | 136 | 2.722166 | |
| EL-SIS | 135 | 128 | 191 | 2.553661 | |
| 1.5 | LS-SIS | 153 | 153 | 195 | 2.506520 |
| GEE-SIS | 165 | 160 | 196 | 2.486459 | |
| RRC-SIS | 142 | 136 | 193 | 2.536610 | |
| EL-SIS | 176 | 187 | 199 | 2.445336 | |
| 2 | LS-SIS | 183 | 183 | 200 | 2.441324 |
| GEE-SIS | 183 | 184 | 200 | 2.440321 | |
| RRC-SIS | 179 | 176 | 200 | 2.452357 | |
| EL-SIS | 192 | 196 | 200 | 2.419258 | |
| 2.5 | LS-SIS | 195 | 195 | 200 | 2.417252 |
| GEE-SIS | 196 | 195 | 200 | 2.416249 | |
| RRC-SIS | 192 | 190 | 200 | 2.425276 | |
| EL-SIS | 198 | 197 | 200 | 2.412237 | |
| 3 | LS-SIS | 199 | 198 | 200 | 2.410231 |
| GEE-SIS | 198 | 197 | 200 | 2.412237 | |
| RRC-SIS | 199 | 198 | 200 | 2.410231 | |
| EL-SIS | 200 | 198 | 200 | 2.409228 |
In the review process, one referee pointed out that our comparison to the LS-SIS is not fair as it is based on the ordinary least squares. It is more reasonable to compare to a weighted least squares-based screening by adjusting to correlation among longitudinal observations. To address this issue, we implement this weighted least squares-based screening by using the R package “geepack,” which can estimate both the correlation structure and regression parameter once a parametric form of the correlation structure is specified. Table 4 is updated accordingly with GEE-SIS denoting this weighted least squares-based screening method. It shows that our newly proposed EL-SIS still does better than the GEE-SIS even though a correct parametric correlation structure, AR(1), is specified.
Example 5
This is an extension of Example 2 to the case with a binary response using logistic regression. Covariates are generated as Xj ~ N(0, 1) and cov(Xj, Xj′) = 1 if j = j′ and 0.3 otherwise except for j ≠ 4. The binary response is generated from Bernoulli distribution with success probability given by . Results over 200 repetitions with n = 400 and d = 10 are reported in Table 5. A similar performance pattern is observed. For this example, the result for the iterative version of the robust rank correlation-based screening is not presented since it is not clear how to define a residual-based iterative procedure.
Table 5.
Simulation result for Example 5
| Method | X1 | X2 | X3 | X4 (hidden) | Unimportant explanatory variables |
|---|---|---|---|---|---|
| GLM-SIS | 200 | 200 | 200 | 0 | 1.405623 |
| RRC-SIS | 200 | 200 | 200 | 0 | 1.405623 |
| EL-SIS | 200 | 200 | 200 | 0 | 1.405623 |
| GLM-ISIS | 200 | 200 | 200 | 200 | 0.324297 |
| EL-ISIS | 199 | 200 | 200 | 199 | 0.764056 |
A real data example
Glioblastoma is the most common primary malignant brain tumor of adults and one of the most lethal of all cancers [Horvath et al. (2006)]. The median survival of glioblastoma patients is 15 months from the time of diagnosis. We next apply our proposed methods to a microarray gene expression dataset of glioblastoma patients reported in Horvath et al. (2006). The dataset has been analyzed by Pan, Xie and Shen (2010) and Li and Li (2008) among many others. Drawn from two different studies, the data consist of two independent sets. We use the set with 50 samples. We use the log survival time, measured in years, as the response. The second sample with a outlier response is excluded and the other 49 samples are used in our analysis. Explanatory variables are gene expression profiles of 1523 genes measured on Affymetrix HG-U133A arrays.
We apply the least squares-based and empirical likelihood-based screening methods with d = 6. LS-SIS selects “GSN”, “FOS”, “COL11A1”, “AVPR1A”, “SELE”, and “TBL1X” as important gene explanatory variables while EL-SIS selects “GSN”, “JAK2”, “COL11A1”, “CDK6”, “ADCYAP1R1”, and “TBL1X”. Note that they select some common genes (“GSN” and “COL11A1”) and some different genes. LS-ISIS selects “GSN”, “COL11A1”, “THBS1”, “SELE”, “TBL1X”, and “GCGR”. EL-ISIS selects “DUSP7”, “COL11A1”, “BST1”, “ADCYAP1R1”, “TBL1X”, and “GCGR”. Similarly two genes (“TBL1X” and “GCGR”) are recruited by the iterative screening methods based on both the least squares and empirical likelihood. The robust rank correlation-based screening performs similarly with 2–3 overlapping genes.
6. Discussion
Screening based on marginal model fitting has enjoyed great popularity in the recent literature. However, most, if not all, of the marginal screening methods studied thus far are based on some restrictive distributional assumptions. Yet these assumptions may not be realistic in applications. Thus motivated we propose a new screening method based on marginal empirical likelihood, which is known to be less restrictive. It has been demonstrated to be effective using both theoretical sure screening property and numerical evidences. Further extensions using empirical likelihood are being investigated.
Supplementary Material
Acknowledgments
We thank the Editor, the Associate Editor and two referees for very constructive comments and suggestions which have improved the presentation of the paper. We are very grateful to Drs. Gaorong Li, Yi Li, Heng Peng and Sihai Dave Zhao for sharing with us programs for implementing their methods and Drs. Hongzhe Li and Wei Pan for sharing the real data.
Footnotes
Supplement to “Marginal empirical likelihood and sure independence feature screening” (DOI: 10.1214/13-AOS1139SUPP; .pdf). This supplement contains all technical proofs.
References
- Bühlmann P, van de Geer S. Theory and Applications. Springer; Heidelberg: 2011. Statistics for High-dimensional Data: Methods. [Google Scholar]
- Chang J, Chen SX, Chen X. High dimensional generalized empirical likelihood for moment restrictions with dependent data. 2013 Available at arXiv:1308.5732. [Google Scholar]
- Chang J, Tang CY, Wu Y. Supplement to “Marginal empirical likelihood and sure independence feature screening”. 2013 doi: 10.1214/13-AOS1139SUPP. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen SX, Cui H. An extended empirical likelihood for generalized linear models. Statist Sinica. 2003;13:69–81. [Google Scholar]
- Chen SX, Gao J, Tang CY. A test for model specification of diffusion processes. Ann Statist. 2008;36:167–198. [Google Scholar]
- Chen SX, Peng L, Qin Y-L. Effects of data dimension on empirical likelihood. Biometrika. 2009;96:711–722. [Google Scholar]
- Chen SX, Van Keilegom I. A review on empirical likelihood methods for regression. TEST. 2009;18:415–447. doi: 10.1007/s11749-009-0165-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Diggle PJ, Heagerty PJ, Liang K-Y, Zeger SL. Oxford Statistical Science Series. 2. Oxford Univ. Press; Oxford: 2002. Analysis of Longitudinal Data; p. 25. [Google Scholar]
- Fan J, Feng Y, Song R. Nonparametric independence screening in sparse ultra-high-dimensional additive models. J Amer Statist Assoc. 2011;106:544–557. doi: 10.1198/jasa.2011.tm09779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Lv J. Sure independence screening for ultrahigh dimensional feature space. J R Stat Soc Ser B Stat Methodol. 2008;70:849–911. doi: 10.1111/j.1467-9868.2008.00674.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Lv J. A selective overview of variable selection in high dimensional feature space. Statist Sinica. 2010;20:101–148. [PMC free article] [PubMed] [Google Scholar]
- Fan J, Song R. Sure independence screening in generalized linear models with NP-dimensionality. Ann Statist. 2010;38:3567–3604. [Google Scholar]
- Hansen LP. Large sample properties of generalized method of moments estimators. Econometrica. 1982;50:1029–1054. [Google Scholar]
- Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2. Springer; New York: 2009. [Google Scholar]
- Hjort NL, McKeague IW, Van Keilegom I. Extending the scope of empirical likelihood. Ann Statist. 2009;37:1079–1111. [Google Scholar]
- Horvath S, Zhang B, Carlson M, Lu KV, Zhu S, Felciano RM, Laurance MF, Zhao W, Shu Q, Lee Y, Scheck AC, Liau LM, Wu H, Geschwind DH, Febbo PG, Kornblum HI, Cloughesy TF, Nelson SF, Mischel PS. Analysis of oncogenic signaling networks in glioblastoma identifies ASPM as a molecular target. Proc Natl Acad Sci USA. 2006;103:17402–17407. doi: 10.1073/pnas.0608396103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang J, Horowitz JL, Ma S. Asymptotic properties of bridge estimators in sparse high-dimensional regression models. Ann Statist. 2008;36:587–613. [Google Scholar]
- Kolaczyk ED. Empirical likelihood for generalized linear models. Statist Sinica. 1994;4:199–218. [Google Scholar]
- Leng C, Tang CY. Penalized empirical likelihood and growing dimensional general estimating equations. Biometrika. 2012;99:703–716. [Google Scholar]
- Li C, Li H. Network-constrained regularization and variable selection for analysis of genomic data. Bioinformatics. 2008;24:1175–1182. doi: 10.1093/bioinformatics/btn081. [DOI] [PubMed] [Google Scholar]
- Li R, Zhong W, Zhu L. Feature screening via distance correlation learning. J Amer Statist Assoc. 2012;107:1129–1139. doi: 10.1080/01621459.2012.695654. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li G, Peng H, Zhang J, Zhu L. Robust rank correlation based screening. Ann Statist. 2012;40:1846–1877. [Google Scholar]
- Liang KY, Zeger SL. Longitudinal data analysis using generalized linear models. Biometrika. 1986;73:13–22. [Google Scholar]
- McCullagh P, Nelder JA. Generalized Linear Models. Chapman & Hall/CRC; New York: 1989. [Google Scholar]
- Newey WK, Smith RJ. Higher order properties of GMM and generalized empirical likelihood estimators. Econometrica. 2004;72:219–255. [Google Scholar]
- Owen AB. Empirical likelihood ratio confidence intervals for a single functional. Biometrika. 1988;75:237–249. [Google Scholar]
- Owen AB. Empirical Likelihood. Chapman & Hall/CRC; New York: 2001. [Google Scholar]
- Pan W, Xie B, Shen X. Incorporating predictor network in penalized regression with application to microarray data. Biometrics. 2010;66:474–484. doi: 10.1111/j.1541-0420.2009.01296.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Petrov VV. Oxford Studies in Probability. Vol. 4. Oxford Univ. Press; New York: 1995. Limit Theorems of Probability Theory: Sequences of Independent Random Variables. [Google Scholar]
- Qin J, Lawless J. Empirical likelihood and general estimating equations. Ann Statist. 1994;22:300–325. [Google Scholar]
- Qu A, Lindsay BG, Li B. Improving generalised estimating equations using quadratic inference functions. Biometrika. 2000;87:823–836. [Google Scholar]
- Saulis L, Statulevičius VA. Limit Theorems for Large Deviations Mathematics and Its Applications (Soviet Series) Kluwer Academic; Dordrecht: 1991. p. 73. Translated and revised from the 1989 Russian original. [Google Scholar]
- Tang CY, Leng C. Penalized high-dimensional empirical likelihood. Biometrika. 2010;97:905–919. [Google Scholar]
- Wang H. Factor profiled sure independence screening. Biometrika. 2012;99:15–28. [Google Scholar]
- Xue L, Zou H. Sure independence screening and compressed random sensing. Biometrika. 2011;98:371–380. [Google Scholar]
- Zhao SD, Li Y. Sure screening for estimating equations in ultra-high dimensions. 2012 Unpublished manuscript. [Google Scholar]
- Zhu L-P, Li L, Li R, Zhu L-X. Model-free feature screening for ultrahigh-dimensional data. J Amer Statist Assoc. 2011;106:1464–1475. doi: 10.1198/jasa.2011.tm10563. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.