

Abstract
Context dependence is central to the description of complexity. Keying on the pairwise definition of “set complexity,” we use an information theory approach to formulate general measures of systems complexity. We examine the properties of multivariable dependency starting with the concept of interaction information. We then present a new measure for unbiased detection of multivariable dependency, “differential interaction information.” This quantity for two variables reduces to the pairwise “set complexity” previously proposed as a context-dependent measure of information in biological systems. We generalize it here to an arbitrary number of variables. Critical limiting properties of the “differential interaction information” are key to the generalization. This measure extends previous ideas about biological information and provides a more sophisticated basis for the study of complexity. The properties of “differential interaction information” also suggest new approaches to data analysis. Given a data set of system measurements, differential interaction information can provide a measure of collective dependence, which can be represented in hypergraphs describing complex system interaction patterns. We investigate this kind of analysis using simulated data sets. The conjoining of a generalized set complexity measure, multivariable dependency analysis, and hypergraphs is our central result. While our focus is on complex biological systems, our results are applicable to any complex system.
Key words: : complexity, entropy, gene network discovery, interaction information, multivariate dependency
1. Introduction
A living system, while invariably complex, is arguably distinguished from its nonliving counterparts by the way it stores and transmits information. It is just this information that is at the heart of the biological functions and structures. It is also at the center of the conceptual basis of what we call systems biology and is characterized by complexity that is both high in degree, involving a large number of components, variables, and attributes, and difficult to characterize. The definition, and the conceptual context of what we call complexity, is an ongoing discussion, but here we eschew the philosophical issues and focus on as simple, but precise, a description as we can. The conceptual structure of systems biology, we argue here, can be built around the fundamental ideas concerning the storage, transmission, and use of biological information, and descriptions of their collective complexity. Bioinformation resides, of course, in digital sequences in molecules like DNA and RNA, but it is also in three-dimensional structures, chemical modifications, chemical activities, both of small molecules and enzymes, and in other components and arrangements of components and properties of biological systems at many levels. The information depends simply on how each unit interacts with, and is related to, other components of the system. Biological information is therefore inherently context dependent, which raises significant issues concerning its quantitative measure and representation. An important and immediate issue for the effective theoretical treatment of biological systems then is: How can context-dependent information be usefully represented and measured? This is important both to the understanding of the storage and flow of information that occurs in the functioning of biological systems and in evolution. It is also at the heart of the analysis of data extracted from complex systems of all kinds, including biological systems.
In a system with a number of variables, attributes, and characters, one statement of the fundamental problem of definition and discovery of bioinformation revolves around the question: How can we fully describe the joint probability density of the n variables that define the system (as a function of time as well)? Characterization of the joint probability distribution is at the heart of describing the mathematical dependency among the variables. For many reasons, including important applications, this problem has received a lot of attention over past decades, primarily focusing on binary relationships, and in drawing conclusions about multiple variable dependencies from these, as in copula theory, for example, and its central result, Sklar's theorem (Arbenz, 2013; Sklar, 1959). Here we provide a general formulation of the problem and a solution that deals directly with the dependency issue based on multivariable information theory. We do not, in this work, address in any detail the significant problems of implementation of the computations implicated, their efficiency, and their properties. Rather, we lay out the formulation of the approach, the theoretical structures, and with a few simulated examples, illustrate their utility. We thereby provide a number of tools that are useful in the quest for the description of complex biological systems and complexity in general.
2. Results
2.1. Describing a complex system
It is often assumed that the networks that are at the heart of biological systems can be fully described by graphs, and most often by undirected graphs. The representations of relationships that graphs provide are rich indeed, but the complexity of biological systems (and many others) can go well beyond the ability of graphs to represent their full complexity. Even directions, weights, and other attributes assigned to edges can fall short of what is required. Graphs, made up of nodes, and edges connecting these nodes two at a time, are potentially complex mathematical objects but are limited primarily in one way. A full description of a complex system often requires that a relationship among several components at once be described. For example, multiple external parameters like ionic strength and temperature, and many other variables, can together affect biological states. Biochemical reactions that involve more than two participating molecular partners are most common: A + B ⇔ C involves three, and more complex reactions, like A + B ⇔ C + D, are common. Multiple interacting transcription factors affecting the expression of genes, and multiple proteins interacting closely together in protein complexes with a wide range of functions, are other examples in biology.
Hypergraphs are sufficiently complex mathematical structures to describe the level of complexity required for a full description of the dependencies among the components, attributes, or variables in a biological system (Klamt et al., 2009) as has been effectively argued. Undirected hypergraphs, which we will use here (generalization to directed hypergraphs is also possible), consist of nodes or vertices and edges, like a simple graph. Note that there remain significant attributes and parameters that cannot be represented as simple hypergraphs. The edges (we will term these hyperedges), however, may connect any number of vertices at once. Formally, a hypergraph, HG = (V, E), consists of a set of vertices, 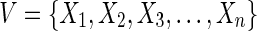 , and a set of subsets of V, we call hyperedges,
, and a set of subsets of V, we call hyperedges, 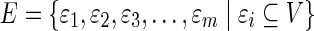 . A simple graph, then, is a hypergraph with all of the hyperedges having a cardinality of 2. To illustrate, the connected hypergraph of nine vertices in Figure 1A has hyperedges of cardinality 2, 3, and 4.
. A simple graph, then, is a hypergraph with all of the hyperedges having a cardinality of 2. To illustrate, the connected hypergraph of nine vertices in Figure 1A has hyperedges of cardinality 2, 3, and 4.
FIG. 1A.
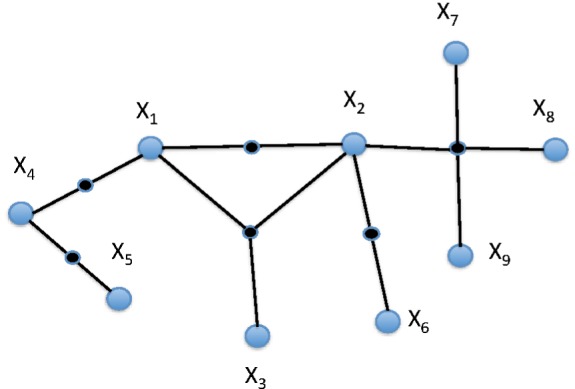
An example of a hypergraph: A hypergraph of nine variables with hyperedges of order 2, 3, and 4.
The hyperedges consist of the subsets {X2, X7, X8, X9}, {X1, X2, X3}, {X2, X6}, {X1, X2}, {X1, X4}, and {X4, X5}. If we use hypergraphs to describe a system, we simply need to define the nature of the hyperedge, including the subset of nodes connected, weight, and other edge attributes. If the vertices in a biological system were proteins, the hyperedge may describe, for example, that the relation “forms a complex” or “regulates.” A specific hyperedge could also connect a subset of another hyperedge of the hypergraph: as with {X1, X2, X3} and {X1, X2} above. Note the similarity of a weighted hypergraph to a Markov random field.
There are, of course, many properties that need description to fully characterize a system, but one property essential with respect to quantitative variables could be described simply as “depends on,” and its inverse “is independent of.” We will focus here on dependence. We define the collective dependence of a subset of variables in the strict sense here that a variable, or attribute, can be predicted only if all the other members of the subset are known. The notion of “independent of” is defined mathematically as the factorability of the joint density distribution. The notion that there is a dependence, or pattern, present only in the entire subset of variable values, but not in any of its proper subsets, is fundamental and is delineated well by hypergraphs. A node can, of course, be part of more than one hyperedge. Consider this simple example in which the nodes have numerical values.
The two relationships in Figure 1B apply to B, a member of both edges, simultaneously. The number of ways that a set of variables can depend on one another is large, and the classification of these dependencies needs detailed consideration. Looking at the two extremes, for example, what we might call “full dependency” among n variables permits knowledge of all variables when only one is known, while the “collective dependency,” defined above, is quite different and requires knowledge of all others to predict one.
FIG. 1B.
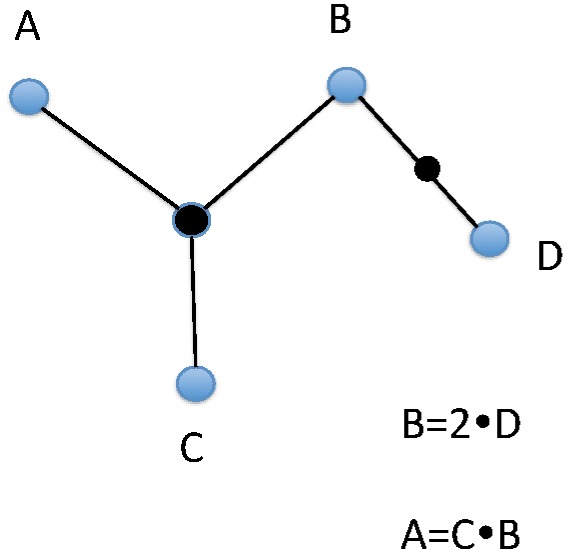
Representing functional dependencies: A hypergraph with “overlapping” edges and the functional dependencies among the variables corresponding to the nodes.
In practice, when trying to decipher the complexity of a system, we are often presented with a data set—values of a set of variables—and we wish to determine and then describe the dependencies among them. In the reality of experimental measurements, this is usually viewed statistically, and most often as a set of pairwise correlations. We are presented with the problem of estimating most accurately, given a data set with values of variables or attributes, the dependencies of the system, no matter how complex they may be. As we demonstrate in a later section, correlation functions, like Pearson and Spearman, because they are inherently pairwise and have other limitations, like the assumption of relatively simple functional dependencies, are often inadequate. If a data set was provided corresponding to the hypergraph depicted in Figure 1A, how could we test or infer the given structure? More simply, given a data set of variables, is there a systematic way of inferring the hypergraph that represents that system? This is the same as the challenge of discovering the structure of variable interdependence and representing it in a hypergraph. To give this a quantitative context, let us add a “weight” to each edge that describes the “strength” or reliability of the dependency. We say that a weight of zero means there is no hyperedge, the variables are not dependent, and a weight near zero indicates a very weak one. At the heart of this challenge is the realization that each variable acquires its meaning and relations from the context of the whole system, and the discovery of representation of this is hard. In order to state the problem clearly we will revert here to a statistical definition of dependency (next section), which is well-matched to the data analysis aspects of our concerns. Jakulin and Bratko (2003) advocate the concept of interaction among attributes as a characterization of regularities or patterns among variables that includes the multiple possibilities of conditional independence, which is similar to our approach. In any case, a key representation of the dependency description is a hypergraph with marginal probability densities associated with vertices and the hyperedges describing dependencies.
It is important to recognize the separation of the two fundamental problems of dependency, the problem of detection of dependency among variables and the problem of determining the nature of the dependency. Simply stated, this is the difference between detecting existence and estimating a function. These are very distinct problems, and while we address only the first of these in this article, the significance of their separation is paramount. Note as well that both problems are completely distinct from the question of causality.
2.2. Context-dependent measures: set complexity
Before grappling with full multivariable dependency we consider pairwise dependence only. We deal here with the problem of the information about one variable represented in another. The information perspective here is a useful one. The basic idea is illustrated by considering a set of bit strings, {xi}. We can ask: What is the information in a given string in the context of the rest of the set of strings (for simplicity we assume the digital strings here are the same length). Two useful concepts here are the mutual information between two strings and the normalized information distance between these strings [this universal distance was defined by Li et al. (2004) and Gacs et al. (2001) and shown to be a metric that does not require the lengths of the strings to be the same). The distance between two strings x and y, d(x, y), is
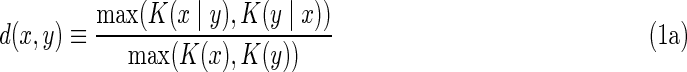 |
where K(x ∣ y) is the conditional complexity or conditional information between the strings. The values of d lie in the interval [0, 1]. We used the above quantities in Galas et al. (2010) as defined either in the context of Kolmogorov complexity or using the Shannon information formalism. While they are different ideas and are applied differently, the concepts are conceptually interchangeable for our purposes, even though they are not quantitatively identical as has been carefully detailed previously (Galas et al., 2010). The use of the Kolmogorov complexity has advantages, like obviating the need to define a state space fully for each variable but has the major disadvantage of being incomputable yet estimatable using compression algorithms. In this article, we use identical alphabets and the same numbers of data points for all variables considered together. We leave the discussion of the difference between these approaches to quantitating information elsewhere.
We rewrite (1a) using information or entropies rather than Kolmogorov complexities, using the relation among the variable information, H(X1 ∣ X2) = H(X1, X2) − H(X2).
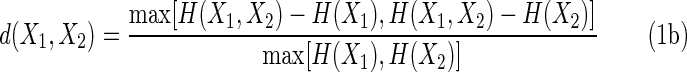 |
The value of d when the two variables are entirely dependent (they are functions of each other) is zero since the joint entropy is equal to any of the two marginal entropies. At the opposite extreme, when the two variables are entirely independent (are independent random variables, for example), the value of d is also easy to determine. In this case, the single variable entropies are the same (since the length of the strings or the range of the variables is the same), and the joint entropy is the sum of the two, thus for complete independence of these two variables we have
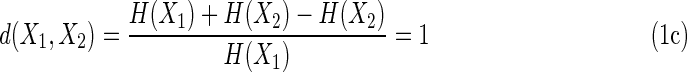 |
As we have proposed (Galas et al., 2010), the key to defining a real context-dependent measure for a member of the set is to impose constraints that have the effect of minimizing the contributions of both redundancy and randomness. We seek a heuristic compromise that for two variables at a time represents the following two constraints (notation: we use lowercase to indicate a string or data and upper case to indicate a variable): 1) If the set already contains a string x identical to the one being considered, y, so that d(x, y) = 0, then y adds no new knowledge to the set (Galas et al., 2010); 2) if y is random (defined strictly only when the length of the string increases without bound), then y also adds nothing to the complexity of the set (Galas et al., 2010). These criteria are fulfilled approximately if we define the information contribution of an element xj to the set  , k(xj ∣ S), in terms of the pair-wise information distance d(x, y) in (1a):
, k(xj ∣ S), in terms of the pair-wise information distance d(x, y) in (1a):
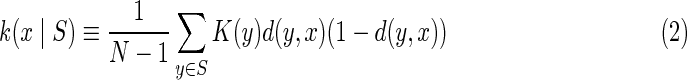 |
in which K(y) is the information measure of an individual element 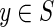 (Galas et al., 2010). We then defined the complexity of the entire set of strings, the “set complexity,” Ψ (Galas et al., 2010) as
(Galas et al., 2010). We then defined the complexity of the entire set of strings, the “set complexity,” Ψ (Galas et al., 2010) as
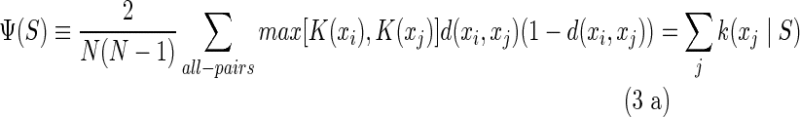 |
and if we order the variables {xi} by the increasing magnitude of K(xi) then
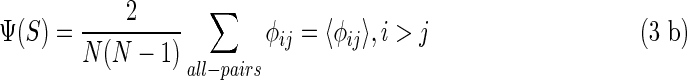 |
where φij = K(xi)d(xi, xj)(1 − d(xi, xj)). If we use the entropy of the probability distribution density as the information measure, as we will in the rest of this article, we indicate this as K(x) = H(x).
2.3. Describing multivariable dependence
The description of a complex system would be severely limited if we restricted ourselves to considering only pairs of variables or functions. It is therefore easily argued that we must define measures for multiple variables considered together rather than by pairs.
The concept of “interaction information” (Sakhanenko and Galas, 2011b; Tsujishita, 1995) was proposed long ago and was used previously by us to optimize a binning process so as to minimize bias and lose a minimum of information in the process (Carter et al., 2009). Interaction information is essentially a multivariable generalization of mutual information (McGill, 1954). For two variables the interaction information is equal to the mutual information and to the Kullback-Leibler divergence of the joint to single probability densities of these two variables. Interaction information [essentially the same as co-information as defined by Ignac et al. (2012a,b)] expresses a measure of the information shared by all random variables from a given set (McGill, 1954; Jakulin and Bratko, 2003; Bell, 2003). For more than two variables it has properties distinct from mutual information, however includes potentially negative values, but it remains symmetric under permutation of variables and has been used in several applications to date.
We first extend the interaction information from two to three variables. The three-variable interaction information, I(X1, X2, Y), can be thought of as being based on two predictor variables, X1 and X2, and a target variable, Y (there is actually nothing special about the choice of target variable since I is symmetric under permutation of variables, but this will be important in later considerations.) The three-variable interaction information can be written as the difference between the two-variable interaction information, with knowledge of the third variable, and the two-variable quantity without that knowledge:
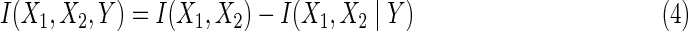 |
where I(X1, X2) is mutual information, and I(X1, X2 ∣ Y) is conditional mutual information, given Y. Note that if the additional variable is independent of the others the interaction information is zero. When expressed entirely in terms of marginal entropies we have the expression:
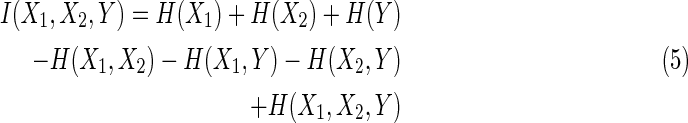 |
H(Xi) is an entropy of a random variable Xi, and 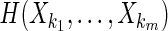 , m ≥ 2, is a joint entropy on a set of m random variables. The symmetry under variable permutation we mentioned above is apparent from Equation (5) and illustrated in Figure 2.
, m ≥ 2, is a joint entropy on a set of m random variables. The symmetry under variable permutation we mentioned above is apparent from Equation (5) and illustrated in Figure 2.
FIG. 2.

Relationships between entropies: An illustration of the relationships between the terms in Equation (5), where the external outline encompasses the area represented by I123.
We can write the interaction information in terms of sums of marginal entropies according to the inclusion–exclusion formula (Jakulin and Bratko, 2003; Bell, 2003), which is the sum of the joint entropies of the sublattice of 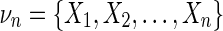 as described by Bell (2003). We have,
as described by Bell (2003). We have,
 |
where the exponent, |τ|, is the cardinality of the the subset τ. Note that there is also a symmetrical formula (a form of Möbius inversion) defining the joint entropy in terms of the interaction information of the subsets:
 |
Simplifying the notation further, we note the first two interaction information expressions (the subscripts refer to the index of variables):
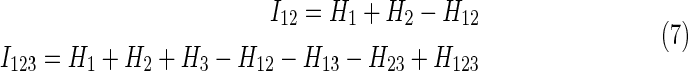 |
Note that the number of terms grows as a power of the number of variables.
Using Equation (1b) we can write
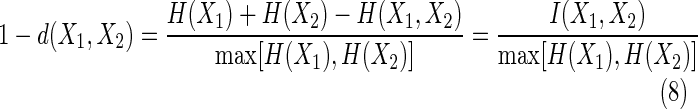 |
Thus, we have proven the following theorem.
Theorem 1
The pairwise set complexity, as defined in (3b), is simply related to the pairwise interaction information in a set of variables as a normalized expectation value of the larger of two terms over all pairs of variables:
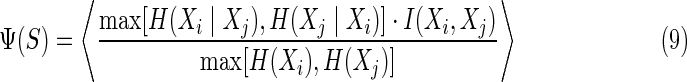 |
The key property of this measure, Ψ, is that at the two extremes—when either all variables are identical (or fully pair-wise dependent), or all variables are independent (or random with respect to one another)—the set complexity is zero. Since “set complexity” can be viewed as an average over all pairs of strings, variables, or functions, every well-defined subset of a larger set will also have a well defined Ψ. The original motivation for the requirement of zeros at the extremes was the resolution of two problems with the idea of biological information, and the product was chosen to force the measure to have zeros at these extremes (Galas et al., 2010). While we know that there are many other ways to get zeros at the extremes, the direct relationship of this simple form with the interaction information suggests that our original heuristic form was actually a natural and fortunate choice.
We begin the construction of our measure with the “interaction information” for multiple variables as defined in Equations (4) and (5). Using this concept for a set of n variables, 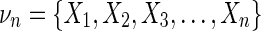 , we define the “differential interaction information” for this set of variables, Δ, as the change in the interaction information between sets that differ only by the addition of one variable. Thus, if νn is obtained from νn−1 by the addition of Xn, we have
, we define the “differential interaction information” for this set of variables, Δ, as the change in the interaction information between sets that differ only by the addition of one variable. Thus, if νn is obtained from νn−1 by the addition of Xn, we have
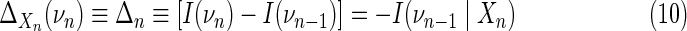 |
The last equality comes from the recursion relation for the interaction information (4). The added variable, Xn, we will call the “target variable,” with respect to the variable set νn−1. The differential interaction information is equivalent to the conditional interaction information, which for the three-variable case is equivalent to the conditional mutual information. It is easy to see that the differential interaction information is zero if Xn, the target variable is independent of any of the variables in the set νn−1, which are independent of one another. We show that if there is collective dependency of the variable set, the differential measure in (10) will be nonzero.
We can write the differential interaction information in terms of the marginal entropies. If 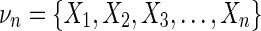 , and {τn} are all the subsets of νn that contain Xn (not all subsets) then
, and {τn} are all the subsets of νn that contain Xn (not all subsets) then
 |
The notation is simplified here so that Δn means an n-variable measure where the nth variable is the “target variable.” Where this may be ambiguous, we will indicate more parameters.
For three and four variables we can write out (11) as (indicating the number variables by the subscript of delta)
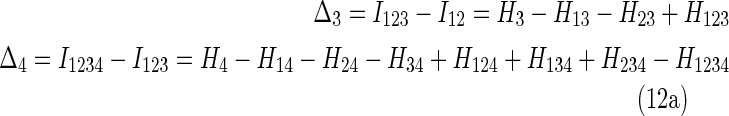 |
where the subscripts of the marginal entropies on the right indicate the variable indices. Note that we can show with a little algebra that the three-variable measure in (12a) is simply the conditional mutual information.
The mutual information, and its conditional for X1, X2 and X3, are
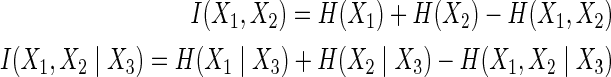 |
By writing out the conditional entropies in terms of marginal entropies, and adopting our previous simplified notation, we see that the conditional mutual information and the differential interaction information for three variables are the same.
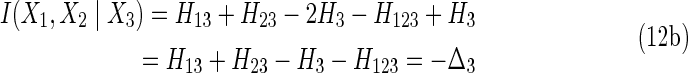 |
Since there is no definition of interaction information for one variable, the definition of the differential for two variables, Δ2, cannot be directly defined by extension from (11). This extension has an unexpected significance, which we will return to consider shortly. Note that the number of terms grows as a power of the number of variables minus one.
We now use the differential interaction information, Δn, to define a generalized form of the set complexity, Ψ, for an arbitrary number of variables. The information distance measure (two variables) has the property that as the two strings converge to identity the normalized mutual information increases to 1, and as they become entirely independent (random) it goes to zero. The distance goes from zero (identity) to one (independence.) In the case of three variables, where we will use Δ3, it is significantly more subtle. When Δ3 is positive it indicates “redundancy”—moving toward identity, while when it is negative it indicates “synergy” or some functional dependency of the three variables that is not identity. This difference in sign is significant. Specific examples help illustrate this difference.
Example 1. Consider three random variables, X1, X2, and X3. Let us evaluate Δ3 for the case when the variables are all independent. Denote this 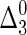 :
:
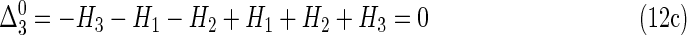 |
It is easy to show that Δi is zero for all numbers of variables, i, if all variables are independent since the joint marginal entropies become additive single entropies.
Example 2. Let us now evaluate Δ3 when X3 depends on X1 and X2 together, but on neither singly. The expression then becomes
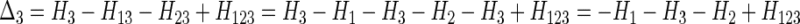 |
and because of the assumed dependency,
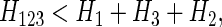 |
so Δ3 < 0. Thus, since X3 is the “target variable” (the asymmetric variable in the definition of Δ3), in this case Δ3 works as an indicator of three-variable dependence. Notice that the symmetry of the interaction information does not carry over to the differential interaction information. Since we are searching for a measure that reliably distinguishes between two-variable and three-variable dependence of all kinds we need our measure to vanish in the presence of only two-variable dependencies. Note that the arguments to follow are exactly true only in the limit of the number of values of the variables (data) increasing without bound. The differential interaction information above actually becomes zero only in some cases, as we can see from two more examples.
Example 3. Suppose X1 and X3 are independent of each other, as are X1 and X2, but X2 and X3 are dependent. In this case H123 = H1 + H23 (in the limit), so we have
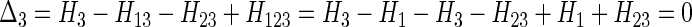 |
Examples 2 and 3 show that if the pair-wise dependency includes X3 then three-variable dependency is needed to get a nonzero Δ3. This is the behavior we want from our measure, which parallels the two-variable measure properties, so it works in these cases.
Example 4. Now suppose X1 and X3 are independent of each other as are X2 and X3, but X1 and X2 are dependent. In other words, the target variable X3 is no longer dependent on the other two variables. The same arguments apply as in example 3, however Δ3 is seen to be nonzero. Example 4 then shows that this measure, Δ3, fails to be three-variable-specific.
It is clear then that we need something else. The measure we want is a nonzero quantity for a subset, τ, of m variables, only if there is mutual dependency among the elements of the subset τ.
The differential interaction information, Δ, that we have described thus far in Equation (11) is based on the specification of a variable we called the “target variable” within the set of variables. The differential is defined as the change that results from addition of this target variable and is therefore asymmetric under permutation of the variables. Since we are asking to detect fully cooperative dependence among the variable set, we require a useful measure to be symmetric for that set. A more general measure emerges by a simple construct that restores symmetry. If we multiply Δ's for a given variable subset with all possible choices of a target variable, the resulting measure will be symmetric for all the variables in the set. It provides a general definition that is functional and straightforward. To be specific, we define the symmetric measure (with normalization) as
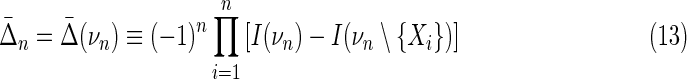 |
where the product is over the choice, i, of a target variable relative to νn, n > 2, a simple permutation. The difference terms in the brackets of Equation (13) are between the interaction information for the full set νn (first term) minus the interaction information for the same set missing a single element (the target variable—second term.) We define this measure only for n > 2 because the differential interaction information for n = 2 is as yet undefined.
For three variables this expression is (simplifying the notation again)
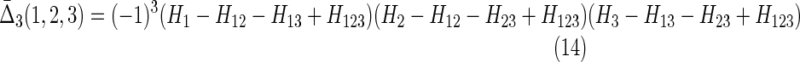 |
Figure 3 illustrates 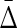 3 and
3 and 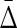 4.
4.
FIG. 3.
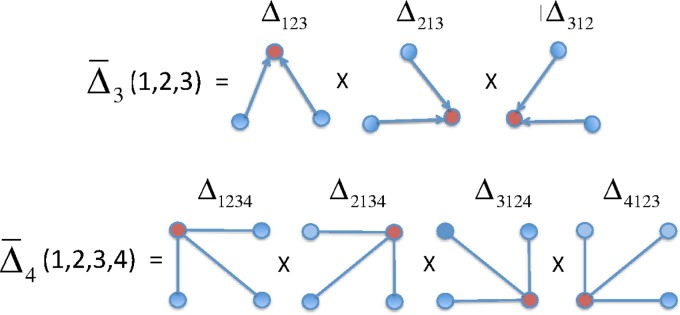
Symmetrization of the differential interaction information: A diagram illustrating the factors in the symmetrized product for the three- and four-variable cases. The Δ's in this diagram signify the factors in the symmetrized product. The upper one, for example, signifies the terms in (13). The first subscript index of each Δ is the target variable.
The advantage of this measure is that  is nonzero only if there is a “collective” dependency, with all three variables involved. In other words, this measure has the extremely useful property that it always vanishes unless all variables in the subset are interdependent. This can be used to allow us to discover and represent exact variable dependencies and to define complexity in interesting ways.
is nonzero only if there is a “collective” dependency, with all three variables involved. In other words, this measure has the extremely useful property that it always vanishes unless all variables in the subset are interdependent. This can be used to allow us to discover and represent exact variable dependencies and to define complexity in interesting ways.
To illustrate these differences among the interaction information, I; the asymmetric differential interaction information, Δi; and the symmetric product form, 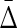 , we have formalized the definitions and calculated the values for some extreme dependencies for three variables, as shown in Table 1. In a later section, we will discuss dependency in terms of “well-behaved functions,” and show some examples.
, we have formalized the definitions and calculated the values for some extreme dependencies for three variables, as shown in Table 1. In a later section, we will discuss dependency in terms of “well-behaved functions,” and show some examples.
Table 1.
Expressions (in Simplified Notation) and Specific Values of These Quantities for Various Cases of Dependence
| I3 = H1 + H2 + H3−H12−H13− H23 + H123 | Δ3 = H3−H13− H23 + H123 |
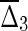 = (H3 − H13 − H23 + H123) × (H2−H12−H23 + H123) × (H1−H12−H13 + H123) = (H3 − H13 − H23 + H123) × (H2−H12−H23 + H123) × (H1−H12−H13 + H123) |
||
|---|---|---|---|---|
| FI | 0 | 0 | 0 | |
| FD | H123 = H1 | 0 | 0 | |
| 2vD | (X1,X2) | 0 | −H1 = −H2 | 0 |
| (X1,X3) | 0 | 0 | 0 | |
| (X2,X3) | 0 | 0 | 0 | |
| CD | (X2&X3) ⇒ X1 | −H1 = −H2 − H3 | −H1 = −H2 − H3 | (−H1)3 |
| (X1&X3) ⇒ X2 | −H2 = −H1 − H3 | −H2 = −H1 − H3 | (−H2)3 | |
| (X1&X2) ⇒ X3 | −H3 = −H1 − H2 | −H3 = −H1 − H2 | (−H3)3 |
Consider variables X1, X2, and X3.
Definition 1
Full independence (FI)
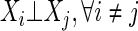 |
Definition 2
Full dependence (FD)
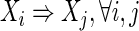 |
Definition 3
Two-variable dependence (2vD(i, j))
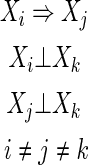 |
Definition 4
Collective dependence (CD(i))
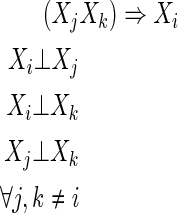 |
Note that the statements of independence in Definition 4 include the cases where Xi is independent of the other single variables but dependent on two of them together.
Table 1 illustrates why 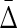 is needed: this measure goes to zero for the first three cases above, but is nonzero when there is a collective, three-variable dependency (fourth case.)
is needed: this measure goes to zero for the first three cases above, but is nonzero when there is a collective, three-variable dependency (fourth case.)
We can complete the theory now by providing a consistent definition for 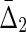 , which connects this measure to the two-variable set complexity (3b, 9). Since we cannot express it as a differential interaction information we define
, which connects this measure to the two-variable set complexity (3b, 9). Since we cannot express it as a differential interaction information we define 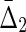 , referring back to the key limiting values of set complexity, simply as
, referring back to the key limiting values of set complexity, simply as
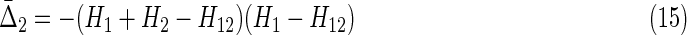 |
Note that this expression has the property of going to zero for either complete independence (first factor goes to zero) or full dependence (second factor goes to zero) of the two variables, consistent with the properties of the expressions for more variables. It is symmetric under exchange of the two variables. Compare this with 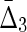 shown in Equation (14). Now since φij = H(Xi)d(Xi, Xj)(1 − d(Xi, Xj)) from Equation (3b), and referring to the definition of d(X1, X2) in (1b), we see the following easily by substitution.
shown in Equation (14). Now since φij = H(Xi)d(Xi, Xj)(1 − d(Xi, Xj)) from Equation (3b), and referring to the definition of d(X1, X2) in (1b), we see the following easily by substitution.
Theorem 2
For two variables X1 and X2, if H1 < H2, and with the definition in (15), we have
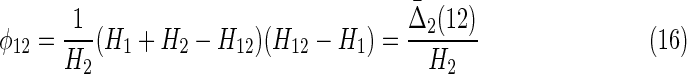 |
Thus, the “set complexity” of a set of N variables ν = {Xi} in terms of 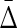 is
is
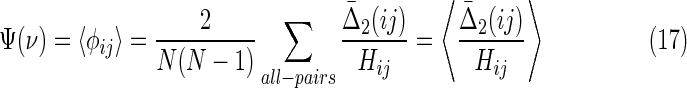 |
2.4. Multivariable complexity measures: generalizing set complexity
The remaining question is how we can use the multivariable dependencies derived from any set of variables or attributes to describe the complexity of the full system they define. By analogy with the previous, two variable “set complexity” measure, Ψ, we can use Equations (8–10) to define a new, multivariable class of set complexity measures. A complexity measure is an expectation value over the full system of a quantity defined on subsets of variables (in the case of the original set complexity these subsets are pairs.) When we examine the range of values of 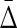 from complete independence of all variables to complete dependence, we discover an interesting property of the class of
from complete independence of all variables to complete dependence, we discover an interesting property of the class of 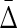 measures. From Table 1 (column 5), illustrating the values of
measures. From Table 1 (column 5), illustrating the values of 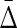 for different types of dependence, we see that
for different types of dependence, we see that 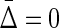 . Full dependence here means knowledge of one variable gives us knowledge of all variables. For full dependence among three variables we have H12 = H1 = H2 and H123 = H1 = H2 = H3. By calculating the product it can easily be seen that all terms cancel and
. Full dependence here means knowledge of one variable gives us knowledge of all variables. For full dependence among three variables we have H12 = H1 = H2 and H123 = H1 = H2 = H3. By calculating the product it can easily be seen that all terms cancel and 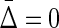 . The interesting property of this measure for three variables is that it has zeros at both extremes (complete independence and full dependence.) That this property holds for an arbitrary number of variables provides a powerful result that we now present as a theorem.
. The interesting property of this measure for three variables is that it has zeros at both extremes (complete independence and full dependence.) That this property holds for an arbitrary number of variables provides a powerful result that we now present as a theorem.
Theorem 3
Given a set of variables 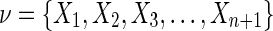 consider three cases: a) the variables are independent, b) the variables are fully dependent, and c) the variable Xn+1 is independent of all the other variables. The value of
consider three cases: a) the variables are independent, b) the variables are fully dependent, and c) the variable Xn+1 is independent of all the other variables. The value of 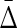 in all three cases, a), b), and c) is zero.
in all three cases, a), b), and c) is zero.
Proof. Choose one variable from the set of n + 1 variables and call it Xk. Let 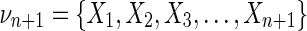 , and {τk} is all the subsets of νn+1 that contain Xk. Consider the corresponding
, and {τk} is all the subsets of νn+1 that contain Xk. Consider the corresponding 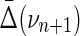 , which has a factor Δk where Xk is a target variable. From equation (11)
, which has a factor Δk where Xk is a target variable. From equation (11)
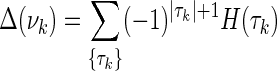 |
Case a: For complete independence the marginal entropies of m variables (|τk| = m),
 |
By summing the coefficients of H(Xi) for all 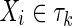 we see that the alternating signs of the contributing tuples for the marginal entropies leads simply to
we see that the alternating signs of the contributing tuples for the marginal entropies leads simply to
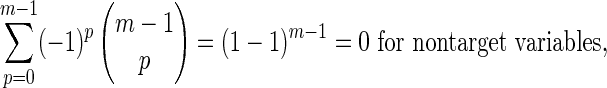 |
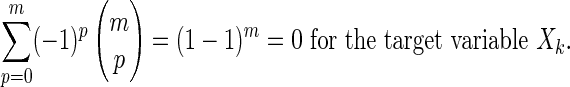 |
So the theorem holds for case a.
Case b: For complete dependence it is even simpler, because we have
 |
and we are able to reduce the entire expression to a sum of coefficients of H(Xk). The sum adds to zero as in case a.
Case c: In this case we split the set {τk} into two non-overlapping subsets, 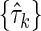 containing the independent variable Xn+1 and
containing the independent variable Xn+1 and 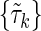 without Xn+1. The marginal entropy of each subset
without Xn+1. The marginal entropy of each subset 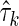 is simply
is simply 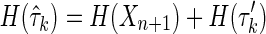 , where
, where 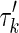 is the subset of all variables in
is the subset of all variables in 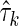 except Xn+1. Then, applying this to the expression of Δk, it is easy to see that entropies
except Xn+1. Then, applying this to the expression of Δk, it is easy to see that entropies 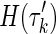 cancel out with entropies
cancel out with entropies 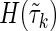 , and the coefficients of H(Xn+1) sum to zero, therefore,
, and the coefficients of H(Xn+1) sum to zero, therefore, 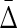 is zero.
is zero.
This proves the theorem.
Thus, as the equivalent of the pair-based “set complexity” we previously defined and used (Galas et al., 2010), we now define a general, multivariable set complexity, Φ, for the set of variables, ν
Definition:
 |
where the expected value is over all possible subsets, τ, of the variable set, and H(τ − 1) is the maximum marginal entropy across all proper subsets of τ obtained by removing one variable. Writing it in detail, where M is the number of subsets in ν,
 |
The above formula can be used to characterize the complexity of any subset of variables as well, of course, and therefore the components of the sum represent the hypergraph form of the set complexity represented by Ψ for ordinary graphs. For two variables this expression reduces to the previous definition of Ψ in Galas et al. (2010). Since the complexity is generally not well represented by a single number, we can better characterize the complexity as the set of components of (19b), {φ(τ) ∣ τ ⊆ ν}, for all subsets of ν where
 |
This completes the generalization of the set complexity concept for an arbitrarily large set of variables and provides a means of defining the “weights” of dependency in the hypergraph describing this system. Note that Theorem 3 provides a much more complete solution to the problems of biological information presented in Galas et al. (2010) since it accounts for full dependence in a much more complete fashion.
2.5. Describing dependency
We have discussed and formalized several limiting cases of dependency: collective dependency, full dependency, and full independence (see Definitions 1–4). We can add to the nuance of dependency by defining a more intuitive and rigorous dependency spectrum using functions that relate the variables in νn, which will help us understand the relationships between the variables, entropies, and the structure of the induced hypergraphs.
We begin with a definition. A function, f, of a set of variables, τ, is called “well behaved” if and only if the equation f (τ) = 0 can be solved for any
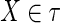 , to yield a function g, such that x = g(τ′), where τ′ is the set missing x. For this to hold, and if we are to have a single solution, X, then clearly f (τ) must be monotonic in each variable. The dependency among the variables of the set τ can then be described by the set of all nonzero functions on all subsets of τ: {f : f (σ) = 0, σ ⊆ τ}. For a well-behaved, monotonic function we need to specify all but one variable value to determine the value of the last one. Keep in mind, however, that for many functions, we expect to encounter the solutions, X, will not be unique. The number of solutions is a key factor.
, to yield a function g, such that x = g(τ′), where τ′ is the set missing x. For this to hold, and if we are to have a single solution, X, then clearly f (τ) must be monotonic in each variable. The dependency among the variables of the set τ can then be described by the set of all nonzero functions on all subsets of τ: {f : f (σ) = 0, σ ⊆ τ}. For a well-behaved, monotonic function we need to specify all but one variable value to determine the value of the last one. Keep in mind, however, that for many functions, we expect to encounter the solutions, X, will not be unique. The number of solutions is a key factor.
For the moment consider only functions with unique solutions so that the dependencies among the variables in the set τ = {Xi} are fully described by the set of all of the well behaved, monotonic functions F = {fi(ηi) = 0, ∀ηi ⊆ τ}.
Let us look at some examples of functions that define dependencies. Consider only pair-wise functions; that is, assume that there are only nonzero functions for the set that relates two variables at a time. Then the functions {xi = gij(xj)} define the edges of a graph of the set in which all nonzero functions correspond to an edge. In this case, if the edges in a graph connect several nodes into a connected path, specifying one value determines the values of all the variables in the path since the functions allow successive solutions across the entire path. We see that the dependence of this set of variables is full dependence if and only if the graph is connected. This means that knowledge of one variable value defines the values of all the rest. This can be seen to hold because all the variables are connected by a chain of solvable equations with unique solutions. Since this property allows us to derive a functional relationship between any two variables on the path, we infer the following result.
Theorem 4
If a dependence graph for a set of well-behaved, monotonic functions with pairwise defined edges is connected, it is always a complete graph.
We can define this completeness as full dependence (as in Definition 2 of Table 1). The connected components of any dependence graph of this kind are always complete. This is not particularly complex in most cases, although it does allow us to divide a set of variables into dependent subsets. A more interesting and realistic situation arises if we are able to infer a dependency from data and also attach a statistical measure to each dependence, a probability associated with each solution. In the general case when there are multiple solutions to the inverted functions, we might ascribe equal probabilities to each or, in the presence of noise or uncertainty, probabilities that reflect this lack of certainty. Suppose that there is a linear connectivity pattern (a path) with identified functions and probabilities. If the connected variables are serially indexed, then the probability of each function connecting two variables is pj−1, j. Then, if we have a good value for variable X1, the functions can be used to find values of all the other variables, but the probability associated with the final variable Xn will be given by
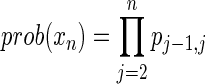 |
If, for example, there were two solutions for each function, a reasonable, unbiased assumption would be to assign a probability of one half to each. Thus, the above product would be (1/2)n. In the case of pairwise functions, we can see that the propagation of values along a path, as described above, will be associated with decreasing probabilities of accuracy, and therefore the completeness described in Theorem 4 becomes a more subtle property for these functions.
For non-pairwise functional dependencies, the situation is more complex and interesting. For any subset of variables, if there is a single well-behaved function describing the relationship among the variables, then the hyperedge is defined by this function. While the determined or known segments of a hypergraph are defined by these dependencies, we usually do not know these functions exactly if we know them at all. The challenge is to determine the weight of an edge (including the level of confidence in the existence of such a function). To our knowledge there is no simple equivalent of Theorem 4 for hypergraphs. If a function is not monotonic in each variable the dispersion of probabilities will grow with the number of solutions.
This raises the issue of how the weights of the edges in a dependence hypergraph are related. It is easy to find examples of dependency that are consistent with only a certain configuration of edges. Another form of this question or issue might be addressed by a topic called the “interaction of dependency hypergraph edges.” There are a number of relationships that can be derived that represent the complexity that results from relaxation of the premise of Theorem 4. This topic is beyond the scope of this article and will be addressed elsewhere.
3. Examples of Data Analysis
To illustrate the practical uses of the theory, we analyze sets of simulated data generated by prescribed dependencies. We have generated multiple datasets of five variables with different degrees of variable dependence: no dependence (all are independent random variables), two dependent variables (one variable is dependent on one of the other independently generated random variables), and three dependent variables. The details of the generation of these datasets are provided in the Appendix. In addition, we have generated other sets of six variables including four-variable dependence. In each of these cases, 1000 multivariable points were generated, and we have calculated the usual pairwise correlations between variables (Pearson correlation and Spearman rank correlation). Details are provided in the Appendix. Example results are presented in the next set of figures.
The values of the measures indicated in Figure 4 illustrate the use of interaction information, and the power of the symmetrized differential interaction information 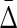 to detect the three-way dependence of variables over the pairwise effects. In these examples, while the differential interaction information is suggestive of some kind of dependence, it is only the
to detect the three-way dependence of variables over the pairwise effects. In these examples, while the differential interaction information is suggestive of some kind of dependence, it is only the 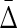 that definitively indicates the three-way dependence, which it does strongly, as shown in Figure 4B.
that definitively indicates the three-way dependence, which it does strongly, as shown in Figure 4B.
FIG. 4.

Applying Δ and 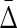 to the simulated data: Information theory–based measures for three variables are shown for the simulated data (1000 points, 5 variables—see Appendix), as indicated. (A)
Differential interaction information in which the first variable indicated in the X-axis label is the target variable, and (B) the symmetrized differential interaction information,
to the simulated data: Information theory–based measures for three variables are shown for the simulated data (1000 points, 5 variables—see Appendix), as indicated. (A)
Differential interaction information in which the first variable indicated in the X-axis label is the target variable, and (B) the symmetrized differential interaction information, 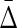 . The functions W(X) and W(X, Y) are complicated functions designed specifically to yield statistical correlations that are comparable to those of independent random variables (they are defined and illustrated in the Appendix and the correlations shown.) W(independent) represents that case where all variables are independent.
. The functions W(X) and W(X, Y) are complicated functions designed specifically to yield statistical correlations that are comparable to those of independent random variables (they are defined and illustrated in the Appendix and the correlations shown.) W(independent) represents that case where all variables are independent.
To illustrate the power of 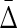 , we further tested it by looking for four different variable dependencies in four datasets of six variables. We calculated the four variable
, we further tested it by looking for four different variable dependencies in four datasets of six variables. We calculated the four variable 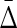 for all these datasets and the results, illustrated in Figure 5, show that the four-variable
for all these datasets and the results, illustrated in Figure 5, show that the four-variable 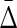 clearly picks out the four-variable dependency. In this case, W is determined entirely by the values of X, Y, and Z, but not by V or U, where all five of these latter variables are independent random variables. Note that, since all variables take on integer values 0 to 3, there are 64 distinct sets of values for the triplet of variables X, Y, and Z, while the function W(X, Y, Z) takes on only four integer values 0 to 3. The function is therefore far from monotonic, because many values of {X, Y, Z} map into the same value of W. Nonetheless, the dependency is clearly indicated by the symmetric measure (the purple bar in Figure 5). This mapping of variables onto W is illustrated in the Appendix (Fig. 9).
clearly picks out the four-variable dependency. In this case, W is determined entirely by the values of X, Y, and Z, but not by V or U, where all five of these latter variables are independent random variables. Note that, since all variables take on integer values 0 to 3, there are 64 distinct sets of values for the triplet of variables X, Y, and Z, while the function W(X, Y, Z) takes on only four integer values 0 to 3. The function is therefore far from monotonic, because many values of {X, Y, Z} map into the same value of W. Nonetheless, the dependency is clearly indicated by the symmetric measure (the purple bar in Figure 5). This mapping of variables onto W is illustrated in the Appendix (Fig. 9).
FIG. 5.

Applying 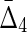 to the simulated data with various dependencies: The four-variable measure
to the simulated data with various dependencies: The four-variable measure 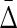 for two datasets (1000 points, 6 variables). The dependencies are as indicated in the legend (further details in the Appendix).
for two datasets (1000 points, 6 variables). The dependencies are as indicated in the legend (further details in the Appendix).
FIG. 9.

Definition of dependencies: The functions defining the dependent variable W: W(X), W(X, Y), and W(X, Y, Z). The variables X, Y, and Z are the digits of a mod4 number N (depicted as a mod10 number here.) (A) W(X) and (B) W(X, Y) is shown as a function of N = X + 4Y. (C) W(X, Y, Z) is shown as a function of N = X + 4Y + 16Z.
Again, the Pearson and Spearman correlations among all pairs of variables are small (mostly <0.11, but all <0.2), but 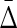 clearly indicates the four related variables nonetheless, since it is more than two orders of magnitude greater than all others. The sensitivity to the four-way dependency is indeed striking and is not confounded by the two or three-way dependency.
clearly indicates the four related variables nonetheless, since it is more than two orders of magnitude greater than all others. The sensitivity to the four-way dependency is indeed striking and is not confounded by the two or three-way dependency.
4. Discussion
A useful representation and mathematical description of the degrees of complexity of complex systems like machines, economies, biological cells, and organisms are a significant challenge. It is a challenge that is at the heart of the realization of systems biology into a systematic, quantitative approach to biology. We previously approached this problem focused on biological information by defining a context-dependent measure based on pairwise relationships (Galas et al., 2010). In this article we present a broad generalization for an arbitrary number of variables, which is the basis for a self-consistent, general, descriptive theory of the complexity of systems that are described by the dependencies among many variables. Our approach to multivariable systems revolves around the question of how we can describe the joint probability density of the n variables that define the system. The characterization of the joint probability density distribution is at the heart of describing the mathematical dependency among the variables, but the use of information theory measures is more forgiving of sampling limitations than direct estimates of probability densities, since many probability densities yield similar or the same information measures. A major property of our generalization is that the multivariable symmetric measure is non zero only if the multiple variables are truly collectively dependent. It is not confounded by dependence among subsets. but it can sometimes be zero in the presence of collective dependence (sometimes termed “conditional independence”).
This theory can represent a very broad scope of systems, but our focus has been on biological complexity. The pairwise measure presented previously (Galas et al., 2010) is the two-variable limit of our general measure. We reviewed the information approach to multivariable dependency that relies on the concept of interaction information (McGill, 1954; Jakulin and Bratko, 2003; Bell, 2003; Sakhanenko and Galas, 2011b; Tsujishita, 1995), and defined a new measure, which we call differential interaction information, that has a number of useful properties. At the three-variable level it is equivalent to the conditional mutual information. We were able to make the connection between the “set complexity” of a set of variables, as previously defined for two variables in (Galas et al., 2010) and differential interaction information, by focusing on the limiting constraints we previously defined. Set complexity, originally devised as a measure of biological information, has been used as a tool to analyze genetic data (Carter et al., 2009) and to examine and describe the complexity of graphs (Sakhanenko and Galas, 2011a; Ignac et al., 2012c), but is limited in its capacity for more complex systems descriptions.
We propose that our general complexity measure, or series of measures, provides a deeper and more sophisticated definition of “biological information” and is also applicable to any complex system. The differential interaction information is the central quantity in this theory, and it has a number of interesting properties, particularly its limiting values at extremes, that makes it both a useful data analysis tool as well as being a natural connection with set complexity.
We propose that the description of complex systems properties with hypergraphs can represent a great deal of the important internal dependencies that generate the complexity of the system. The multivariable differential interaction information provides a tool that can be used to calculate the weights of the hypergraph edges given a dataset describing the system (Klamt et al., 2009). We outline here a general scheme for this analysis, which is applicable in principle to any data set (Fig. 6.)
FIG. 6.

Discovery of dependencies: A general flow diagram illustrating the analysis of datasets to the level of weighted hypergraph generation.
If we limit the number of variables to be included in the subsets, the number of marginal entropies that need to be calculated is not too large, but it is this combinatorial explosion of quantities to be calculated that will ultimately be limiting for very large datasets. This is a well-recognized practical problem in information measure calculations. Various heuristics can be used, however, to limit the range of computed quantities, and this problem has been examined in some detail in entropy calculation. The symmetrized form of this differential measure is remarkably sensitive to multivariable dependencies as demonstrated above. While the calculations are difficult, the extreme sensitivity suggests that approximating heuristics may retain sufficient sensitivity to allow significant computational shortcuts. This will be explored in future work.
Note, however, that this sensitivity does not imply that the form or character of the dependency, the function itself, can be determined by these methods. The two problems of sensitive detection of dependence and the characterization of the dependence function itself are quite distinct problems and can be separated to good effect. For the complex functions like those used in our simulations (see Appendix), their characterization is a very difficult problem requiring much more data than we have provided, but the detection of dependence can be accomplished with this amount of data. This separation of problems also suggests that some of the approximating algorithms for marginal entropies may retain significant sensitivity while reducing computational complexity. We will consider the dependence function problem in future work.
The previous sections provide the means to infer the structure of a hypergraph description of a system represented by a dataset and its dependencies. If we are given a dataset consisting of a set of values of n variables, we can then carry out the steps defined in the flowchart of Figure 6. This diagram provides a general approach to the calculation of the complexities of systems represented by complex datasets and to the inference of a hypergraph representation. Such a complex set of dependencies is indicated in Figure 7 (only nonzero 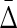 's are shown) illustrating the complexity that can be represented in this way.
's are shown) illustrating the complexity that can be represented in this way.
FIG. 7.

Weighted hypergraph: The complex of dependencies among a set of nine variables (nodes) is illustrated in a hypergraph. This is the same structure as in Figure 1A showing the nonzero 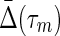 's associated with the hyperedges (in this case the subscripts indicate the nodes connected, the dependency variables.)
's associated with the hyperedges (in this case the subscripts indicate the nodes connected, the dependency variables.)
Equation (14) provides a general formulation of the measure for dependence. In the product we unbias the choice of the additional variables since the product is invariant under permutation of the variables. The expression provides for the calculation of all of the differential interaction information measures from the marginal entropies.
There are some cases where the choice of a target variable is clear and the product form of the measure (14) is unnecessary. Genetic analysis is a case in point. In this case, we have a large number of genetic markers as variables, with a limited number of alternative values (usually two) and usually a single-target variable that is the phenotype. We classify the dependence, and the measure, in this case, as “asymmetric.” In the case where we look for pairwise synthetic genetic effects, for example, we examine all instances of pairs of markers (X1, X2) determining the phenotype (Y).
In addition to the calculation of the hypergraph edge weights, described above, we can consider the necessary self-consistency of the edge weights. These relations will allow the minimal hypergraph description of the dependencies implied by the data in question. This topic will be an important component of the effort to discover the causal models that are consistent with the data, but the analysis of self-consistency relations is beyond the scope of the current article. It will be dealt with in a future publication.
In examining dependencies among variables we will, of course, want to know the nature of the dependencies, which is not addressed here. Our approach provides a theoretical context and a method to discover the existence of dependencies, consistent with the data, that can be further investigated to create sets of hypotheses. We emphasize again the distinction between detection of dependency and discovering information about the nature of the dependency. The latter can be thought of as hypothesis testing. Related to the question of consistent hypotheses, it is also natural to ask about specific causality among real variables. While the characterization of the joint probability distribution is insufficient to address the issue of causality, the changes in associations among variables as indicated by 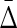 with different subsets of variables and different datasets may be able to contribute to causality indicators. We suggest that while the present theory is limited to the probability calculus, it can be useful in providing some language to extend the theory into the realm of causal tests (Pearl, 2009, 2010). The central idea here is that with the appropriate assumptions, the effect on the symmetric measure of dropping a specific variable from consideration should be able to be used in a calculus of causality of that variable. The introduction of directionality in the hypergraphs could be used to extend the present theory into the realm of representation of causality models as discussed by Pearl (2009, 2010).
with different subsets of variables and different datasets may be able to contribute to causality indicators. We suggest that while the present theory is limited to the probability calculus, it can be useful in providing some language to extend the theory into the realm of causal tests (Pearl, 2009, 2010). The central idea here is that with the appropriate assumptions, the effect on the symmetric measure of dropping a specific variable from consideration should be able to be used in a calculus of causality of that variable. The introduction of directionality in the hypergraphs could be used to extend the present theory into the realm of representation of causality models as discussed by Pearl (2009, 2010).
Finally, it is important to note, as we showed in Equation (12b), that the Δ specific to three variables is equivalent to conditional mutual information. Conditional mutual information has been used previously by other researchers in analyzing biological systems. Califano and colleagues have applied this measure in the analysis of gene regulatory systems (Sumazin et al., 2011; Zhao et al., 2009; Wang et al., 2006a, 2009b). Our work generalizes this measure for an arbitrary number of variables and makes the connection to measures of complexity and biological information.
In summary, we have woven together three important concepts in dealing with dependency in real complex systems: measures of complexity based on information theory ideas that are applicable to biology and similarly complex systems generalizing our previous work, multivariable dependency, and the representation of systems by hypergraphs. We expect that the methods described here can be extended further, but are already powerful in extracting patterns and dependencies from large datasets of all kinds and in understanding the complexity of the systems reflected by datasets.
5. Appendix
5.1. Simulated data
We generated sets of data (1000 points each) with different dependencies among the variables, from complete independence to four-variable dependence.
The data were generated with all variables but W random (X,Y,Z,U,V). In Figure 8a, W is also an independent random variable, whereas in Figure b–d the dependence of W on X, Y, and Z was specified according to Table 2.
FIG. 8.

Correlation: The Pearson and Spearman correlation calculated for several pairs of variables in the 1000-point simulated set. The functions used to generate the dependencies for (b) and (c) are shown.
Table 2.
Dependency Tables of the Variable W on Other Variables as Shown: W(X), W(X,Y) and W(X,Y,Z)
| X | W(X) |
|---|---|
| 0 | 1 |
| 1 | 3 |
| 2 | 0 |
| 3 | 2 |
| X/Y | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0 | 1 | 3 | 2 | 1 |
| 1 | 3 | 0 | 0 | 3 |
| 2 | 2 | 0 | 1 | 2 |
| 3 | 1 | 0 | 3 | 2 |
| X | Y | Z | W | X | Y | Z | W |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 3 | 2 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 2 | 0 | 1 | 0 |
| 0 | 0 | 2 | 0 | 2 | 0 | 2 | 0 |
| 0 | 0 | 3 | 3 | 2 | 0 | 3 | 1 |
| 0 | 1 | 0 | 0 | 2 | 1 | 0 | 0 |
| 0 | 1 | 1 | 3 | 2 | 1 | 1 | 0 |
| 0 | 1 | 2 | 0 | 2 | 1 | 2 | 1 |
| 0 | 1 | 3 | 1 | 2 | 1 | 3 | 1 |
| 0 | 2 | 0 | 0 | 2 | 2 | 0 | 0 |
| 0 | 2 | 1 | 0 | 2 | 2 | 1 | 1 |
| 0 | 2 | 2 | 0 | 2 | 2 | 2 | 1 |
| 0 | 2 | 3 | 1 | 2 | 2 | 3 | 1 |
| 0 | 3 | 0 | 3 | 2 | 3 | 0 | 1 |
| 0 | 3 | 1 | 1 | 2 | 3 | 1 | 1 |
| 0 | 3 | 2 | 1 | 2 | 3 | 2 | 1 |
| 0 | 3 | 3 | 3 | 2 | 3 | 3 | 1 |
| 1 | 0 | 0 | 0 | 3 | 0 | 0 | 3 |
| 1 | 0 | 1 | 3 | 3 | 0 | 1 | 1 |
| 1 | 0 | 2 | 0 | 3 | 0 | 2 | 1 |
| 1 | 0 | 3 | 1 | 3 | 0 | 3 | 3 |
| 1 | 1 | 0 | 3 | 3 | 1 | 0 | 1 |
| 1 | 1 | 1 | 2 | 3 | 1 | 1 | 2 |
| 1 | 1 | 2 | 0 | 3 | 1 | 2 | 1 |
| 1 | 1 | 3 | 2 | 3 | 1 | 3 | 2 |
| 1 | 2 | 0 | 0 | 3 | 2 | 0 | 1 |
| 1 | 2 | 1 | 0 | 3 | 2 | 1 | 1 |
| 1 | 2 | 2 | 1 | 3 | 2 | 2 | 1 |
| 1 | 2 | 3 | 1 | 3 | 2 | 3 | 1 |
| 1 | 3 | 0 | 1 | 3 | 3 | 0 | 3 |
| 1 | 3 | 1 | 2 | 3 | 3 | 1 | 2 |
| 1 | 3 | 2 | 1 | 3 | 3 | 2 | 1 |
| 1 | 3 | 3 | 2 | 3 | 3 | 3 | 2 |
To illustrate the function W(X, Y, Z), we treat the three variables as the digits of a mod4 number, in order to show the function as a two-dimensional plot. The function is shown in Figure 9.
While the complex and apparently arbitrary functions are such that several combinations of variables yield the same value of W [for W(X, Y) and W(X, Y, Z)], the important point is that the other variables determine the value of W and the dependence of W on the other variables is complete.
5.2. The effects of sample size and noise on the dependence measure
We now consider the set of six variables, {X, Y, Z, W, U, V}, where variable W is a function of X and Y (three-variable dependency), while all the rest of the variables are independent. We generated a large set D of 5000 samples and used this dataset to examine the effects of sample size and noise on the symmetric delta measure. The following examples are studied in the context of the general problem of finding a triplet of interdependent variables in the presence of other independent variables. In this case, we have 20 variable triplets, and we expect only one, XY W, to have a large nonzero delta value.
We first examine the fluctuations as a function of data sampling. We consider a partition of D into M equal subsets, Di ⊂ D, ∪iDi = D, Di ∩ Dj = Ø. We considered two cases: 50 subsets with 100 samples each, and 10 subsets with 500 samples each. For each subset, 20 symmetric delta values were computed corresponding to the 20 triplets. We then computed two means/standard deviations: one of delta for XYW across all M subsets and the other one of delta across all M subsets and all remaining 19 triplets. Table 3 shows the results. In both cases (when the subset size equals 100 or 500) the symmetric delta of XY W is considerably lower than the average value of symmetric delta of other triplets. As expected, the results are better when the sample size is larger (500). While random resampling has a small effect on the values of symmetric delta at this sample size range, we are able to clearly distinguish XY W from the other triplets.
Table 3.
The Behavior of 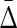 on Samples of Equal-Size Datasets
on Samples of Equal-Size Datasets
| Size |
Mean (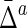 ) ) |
Std (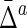 ) ) |
Mean (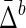 ) ) |
Std (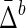 ) ) |
|---|---|---|---|---|
| 100 | −1.8429 | 0.2757 | −0.0367 | 0.0196 |
| 500 | −2.0554 | 0.1107 | −0.0003 | 0.0002 |
Mean and standard deviation of symmetric delta for XY W (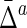 ) averaged across all subsets, as well as mean and standard deviation of symmetric delta averaged across all other 19 triplets and all subsets (
) averaged across all subsets, as well as mean and standard deviation of symmetric delta averaged across all other 19 triplets and all subsets (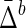 ).
).
How does the number of samples affect the value of symmetric delta? We consider an initial subset, D0 ⊂ D, of 100 samples, and then incrementally construct 49 more subsets by adding 100 more samples each time, such that D49 = D. We then computed the symmetric delta for all 20 triplets in each subset. Figure 10 shows that 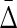 of XY W is considerably different from
of XY W is considerably different from 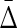 of other triplets. On the other hand, this difference increases as the size of an underlying subset increases to 300 and more. It is clear that in the absence of noise the dependence in our example is detected very well with 200 to 300 samples.
of other triplets. On the other hand, this difference increases as the size of an underlying subset increases to 300 and more. It is clear that in the absence of noise the dependence in our example is detected very well with 200 to 300 samples.
FIG. 10.

Behavior of 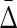 on increasing size of datasets: (top) Average
on increasing size of datasets: (top) Average 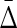 across 19 triplets other than XYW. The error bars correspond to standard deviation. (Bottom)
across 19 triplets other than XYW. The error bars correspond to standard deviation. (Bottom) 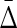 of XYW. The x-axis corresponds to the index i of the subset Di, such that its size is |Di| = 100(i + 1).
of XYW. The x-axis corresponds to the index i of the subset Di, such that its size is |Di| = 100(i + 1).
Finally, we investigate how the amount of noise affects the value of symmetric delta. In this example we only use a dataset of 500 samples. We define a noise level parameter of a random variable as a number of samples chosen at random that are flipped to a different value for that variable. We consider 20 noise levels, starting from 25 flipped values (5% noise) and ending with 500 flipped values (100% noise), each time increasing the number of flipped samples by 25. For each noise level we construct 10 datasets with random positions and values of the flips.
Both the average difference and the ratio between 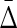 of XYW and other triplets is illustrated in Figure 11. The difference was computed between
of XYW and other triplets is illustrated in Figure 11. The difference was computed between 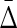 of XYW and
of XYW and 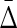 of every other triplet for every set of 10 (1900 combinations for each noise level), and the mean and standard deviation computed. The ratio was computed between
of every other triplet for every set of 10 (1900 combinations for each noise level), and the mean and standard deviation computed. The ratio was computed between 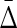 of XYW averaged across 10 sets and
of XYW averaged across 10 sets and 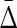 of all other triplets averaged across all triplets and 10 sets. The dependence on the noise level is approximately exponential.
of all other triplets averaged across all triplets and 10 sets. The dependence on the noise level is approximately exponential.
FIG. 11.

Behavior of 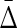 on datasets with increasing noise level: (top) Average difference between
on datasets with increasing noise level: (top) Average difference between 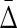 of XYW and all other 19 triplets across 19 triplets. The error bars correspond to standard deviation. (bottom) Ratio of average
of XYW and all other 19 triplets across 19 triplets. The error bars correspond to standard deviation. (bottom) Ratio of average 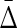 of XYW and average
of XYW and average 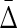 of other 19 triplets. The x-axis corresponds to the index i of the subset noise level, such that the number of flipped samples in a set is 25(i + 1). The maximum at 20 corresponds to 100% of the 500 being subjected to random flips.
of other 19 triplets. The x-axis corresponds to the index i of the subset noise level, such that the number of flipped samples in a set is 25(i + 1). The maximum at 20 corresponds to 100% of the 500 being subjected to random flips.
Acknowledgments
We thank Hong Qian, Joseph Nadeau, and Stuart Kauffman for comments on an earlier version of the manuscript as well as anonymous referees for useful suggestions. We are grateful for funding provided by the Luxembourg Centre for Systems Biomedicine (LCSB) of the University of Luxembourg and the U.S. National Science Foundation, IIS-134619, with additional support provided by the Pacific Northwest Diabetes Research Institute.
Author Disclosure Statement
No competing financial interests exist.
References
- Arbenz P.2013. Bayesian copulae distributions, with application to operational risk management - some comments. Methodology and Computing in Applied Probability 15, 105–108 [Google Scholar]
- Bell A.J.2003. The co-information lattice. In Proc. of 4th International Symposium on Independent Component Analysis and Blind Source Separation (ICA2003), 921–926 [Google Scholar]
- Carter G.W., Galitski T., and Galas D.J.2009. Maximal extraction of biological Information from genetic interaction data. PLoS Comp. Biol. 5, e1000347. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gacs P., Tromp J.T., and Vitanyi P.M.B.2001. Algorithmic statistics. IEEE Transactions on Information Theory 47, 2443–2463 [Google Scholar]
- Galas D.J., Nykter M., Carter G.W., et al. . 2010. Biological information as set based complexity. IEEE Transactions on Information Theory 56, 667–677 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ignac T., Sakhanenko N.A., Skupin A., and Galas D.J.2012a. New methods for finding associations in large data sets: generalizing the maximal information coefficient (MIC). In Proc. of the 9th International Workshop on Computational Systems Biology (WCSB2012), 39–42 [Google Scholar]
- Ignac T., Sakhanenko N.A., Skupin A., and Galas D.J.2012b. Relations between the set-complexity and the structure of graphs and their sub-graphs. EURASIP Journal on Bioinformatics and Systems Biology 13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ignac T.M., Sakhanenko N.A., and Galas D.J.2012c. Complexity of networks II: The set-complexity of a class of edge-colored graphs. Complexity 17, 23–36 [Google Scholar]
- Jakulin A., and Bratko I.2003. Quantifying and visualizing attribute interactions: An approach based on entropy. Computing Research Repository cs.AI/0308002. Available at http://arxiv.org/abs/cs.AI/0308002
- Klamt S., Haus U.-U., and Theis F.2009. Hypergraphs and cellular Networks. PLoS Comp. Biol. 5, e1000385. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li M., Chin L., Bin M., and Vitanyi P.M.B.2004. The similarity metric. IEEE Transactions on Information Theory 50, 3250–3264 [Google Scholar]
- McGill W.J.1954. Multivariate information transmission. Psychometrika 19, 97–116 [Google Scholar]
- Pearl J.2009. Causal inference in statistics: An overview. Statistics Surveys 3, 96–146 [Google Scholar]
- Pearl J.2010. The Mathematics of Causal Relations. Technical Report R-338. UCLA, Los Angeles, CA [Google Scholar]
- Sakhanenko N.A., and Galas D.J.2011a. Complexity of networks I: The set-complexity of binary graphs. Complexity 17, 51–64 [Google Scholar]
- Sakhanenko N.A., and Galas D.J.2011b. Interaction information in the discretization of quantitive phenotype data. In Proc. of the 8th International Workshop on Computational Systems Biology, 161–164 [Google Scholar]
- Sklar A.1959. Fonctions de répartition à n dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris 8, 229–231 [Google Scholar]
- Sumazin P., Yang X., Chiu H.S., et al. . 2011. An extensive microRNA-mediated network of RNA–RNA Interactions regulates established oncogenic pathways in glioblastoma. Cell 147, 370–381 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tsujishita T.1995. On triple mutual information. Advances in Applied Mathematics 16, 269–274 [Google Scholar]
- Wang K., Alvarez M.J., Bisikirska B.C., et al. . 2009a. Dissecting the interface between signaling and transcriptional regulation in human B cells. Pac. Symp. Biocomput. 2009, 264–275 [PMC free article] [PubMed] [Google Scholar]
- Wang K., Banerjee N., Margolin A.A., et al. . 2006. Genome-wide discovery of modulators of transcriptional interactions in human B lymphocytes. In Proc. of the 10th International Conference on Research in Computational Molecular Biology (RECOMB2006), 348–362 [Google Scholar]
- Wang K., Saito M., Bisikirska B.C., et al. . 2009b. Genome-wide identification of post-translational modulators of transcription factor activity in human B cells. Nat. Biotechnol. 27, 829–839 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao X., D'Arca D., Lim W.K., et al. . 2009. The N-Myc-DLL3 cascade is suppressed by the ubiquitin ligase Huwe1 to inhibit proliferation and promote neurogenesis in the developing brain. Dev. Cell. 17, 210–221 [DOI] [PMC free article] [PubMed] [Google Scholar]