

Abstract
High-dimensional data common in genomics, proteomics, and chemometrics often contains complicated correlation structures. Recently, partial least squares (PLS) and Sparse PLS methods have gained attention in these areas as dimension reduction techniques in the context of supervised data analysis. We introduce a framework for Regularized PLS by solving a relaxation of the SIMPLS optimization problem with penalties on the PLS loadings vectors. Our approach enjoys many advantages including flexibility, general penalties, easy interpretation of results, and fast computation in high-dimensional settings. We also outline extensions of our methods leading to novel methods for non-negative PLS and generalized PLS, an adoption of PLS for structured data. We demonstrate the utility of our methods through simulations and a case study on proton Nuclear Magnetic Resonance (NMR) spectroscopy data.
Keywords: sparse PLS, sparse PCA, NMR spectroscopy, generalized PCA, non-negative PLS, generalized PLS
1. INTRODUCTION
Technologies to measure high-throughput biomedical data in proteomics, chemometrics, and genomics have led to a proliferation of high-dimensional data that pose many statistical challenges. As genes, proteins, and metabolites, are biologically interconnected, the variables in these data sets are often highly correlated. In this context, several have recently advocated using partial least squares (PLS) for dimension reduction of supervised data, or data with a response or labels [1–4]. First introduced by Wold [5] as a regression method that uses least squares on a set of derived inputs accounting for multicolinearities, others have since proposed alternative methods for PLS with multiple responses [6] and for classification [7,8]. More generally, PLS can be interpreted as a dimension reduction technique that finds projections of the data that maximize the covariance between the data and the response. Recently, several have proposed to encourage sparsity in these projections, or loadings vectors, to select relevant features in high-dimensional data [3,4,9]. In this paper, we seek a more general and flexible framework for regularizing the PLS loadings that is computationally efficient for high-dimensional data.
There are several motivations for regularizing the PLS loadings vectors. Partial least squares is closely related to principal components analysis (PCA); namely, the PLS loadings can be computed by solving a generalized eigenvalue problem [6]. Several have shown that the PCA projection vectors are asymptotically inconsistent in high-dimensional settings [10,11]. This is also the case for the PLS loadings, recently shown in Refs 4 and 12. For PCA, encouraging sparsity in the loadings has been shown to yield consistent projections [10,13,14]. While an analogous result has not yet been shown in the context of PLS, one could surmise that such a result could be attained. In fact, this is the motivation for Chun and Keleş’s [4] recent Sparse PLS method. In addition to consistency motivations, sparsity has many other qualities to recommend it. The PLS loadings vectors can be used as a data compression technique when making future predictions; sparsity further compresses the data. As many variables in high-dimensional data are noisy and irrelevant, sparsity gives a method for automatic feature selection. This leads to results that are easier to interpret and visualize.
While sparsity in PLS is important for high-dimensional data, there is also a need for more general and flexible regularized methods. Consider NMR spectroscopy as a motivating example. This high-throughput data measures the spectrum of chemical resonances of all the latent metabolites, or small molecules, present in a biological sample [15]. Typical experimental data consists of discretized, functional, and non-negative spectra with variables measuring in the thousands for only a small number of samples. Additionally, variables in the spectra have complex dependencies arising from correlation at adjacent chemical shifts, metabolites resonating at more than one chemical shift, and overlapping resonances of latent metabolites [16]. Because of these complex dependencies, there is a long history of using PLS to reduce the NMR spectrum for supervised data [17,18]. Classical PLS or Sparse PLS, however, are not optimal for this data as they do not account for the non-negativity or functional nature of the spectra. In this paper, we seek a more flexible approach to regularizing PLS loadings that will permit (i) general penalties such as to encourage sparsity, group sparsity, or smoothness, (ii) constraints such as non-negativity, and (iii) that directly account for known data structures such as ordered chemical shifts for NMR spectroscopy. Our framework, based on a penalized relaxation of the SIMPLS optimization problem [6], also leads to a more computationally efficient numerical algorithm.
As we have mentioned, there has been previous work on penalizing the PLS loadings. For functional data, Goutis and Fearn [19] and Reiss and Ogden [20] have extended PLS to encourage smoothness by adding smoothing penalties. Our approach is more closely related to the Sparse PLS methods of Lê Cao et al. [3] and Chun and Keleş [4]. In the latter, a generalized eigenvalue problem related to PLS objectives is penalized to achieve sparsity, although they solve an approximation to this problem via the elastic net Sparse PCA approach of Zou et al. [21]. Noting that PLS can be interpreted as performing PCA on the deflated cross-products matrix, Lê Cao et al. [3] replace PCA with Sparse PCA using the approach of Shen and Huang [22]. The core of our algorithm with an ℓ1 penalty is similar to this approach. We show that this algorithm directly solves a penalized generalization of the SVD problem that is a concave relaxation of the SIMPLS criterion. The major novelty of our work is from this optimization approach, developing a flexible regularization scheme that includes general norm penalties, non-negativity constraints, and generalizations for structured data. Our flexible algorithms lead to interpretable results and fast computational approaches for high-dimensional data.
The paper is organized as follows. Our framework for regularized partial least squares (RPLS) is introduced in Section 2. In Section 3, we introduce two novel extensions of PLS and RPLS: non-negative PLS and generalized PLS (GPLS) for structured data. We illustrate the comparative strengths of our approach in Sections 4 and 5 through simulation studies and a case study on NMR spectroscopy data, respectively, and conclude with a discussion in Section 6.
2. REGULARIZED PARTIAL LEAST SQUARES
In this section, we introduce our framework for regularized partial least squares. While most think of PLS as a regression technique, here we separate the steps of the PLS approach into the dimension reduction stage where the PLS loadings and factors are computed and a prediction stage where regression or classification using the PLS factors as predictors is performed. As our contributions lie in our framework for regularizing the PLS loadings in the dimension reduction stage, we predominately focus on this aspect.
2.1. RPLS Optimization Problem
Introducing notation, we observe data (predictors), X ∈ ℜn×p, with p variables measured on n samples and a response Y ∈ ℜn×q. We will assume that the columns of X have been previously standardized. The possibly multivariate response (q > 1) could be continuous as in regression or encoded by dummy variables to indicate classes as in Ref. 8, a consideration which we ignore while developing our methodology. The p × q sample cross-product matrix is denoted as M = XT Y.
Both of the two major algorithms for computing the multivariate PLS factors, NIPALS [5] and SIMPLS [6], can be written as solving a single-factor eigenvalue problem of the following form at each step: maximizev vT M MT v subject to vT v = 1, where v ∈ ℜp are the PLS loadings. Chun and Keleş [4] extend this problem by adding an ℓ1-norm constraint, ||v|| ≤ t, to induce sparsity and solve an approximation to this problem using the Sparse PCA method of Zou et al. [21]. Lê Cao et al. [3] replace this optimization problem with that of the Sparse PCA approach of Shen and Huang [22].
We take a similar algorithmic approach, but seek regularized PLS factors that directly optimize a criterion related to classical PLS. Notice that the single factor PLS problem can be re-written as the following: maximizev,u vT Mu subject to vT v = 1 & uT u = 1, where u ∈ ℜq is a nuisance parameter. The equivalence of these problems was pointed out by de Jong [6] and is a well understood matrix analysis fact. Our single-factor RPLS problem penalizes a direct concave relaxation of this problem:
| (1) |
Here, we assume that P() is a convex penalty function that is a norm or semi-norm; these assumptions are discussed further in the subsequent section. To induce sparsity, for example, we can take P(v) = ||v||1. Notice that we have relaxed the equality constraint for v to an inequality constraint. In doing so, we arrive at an optimization problem that is simple to maximize via an alternating strategy. Fixing u, the problem in v is concave, and fixing v the problem is a quadratically constrained linear program in u with a global solution. Our optimization problem is most closely related to some recent direct biconcave relaxations for two-way penalized matrix factorizations [23,24] and yields similar results to regression based sparse approaches [3,22,25]. Studying the solution to this problem and its properties in the subsequent section will reveal some of the advantages of this optimization approach.
Computing the multifactor PLS solution via the two traditional multivariate approaches, SIMPLS and NIPALS, require solving optimization problems of the same form as the single-factor PLS problem at each step. The SIMPLS method is more direct and has several benefits within our framework; thus, this is the approach we adopt. The algorithm begins by solving the single-factor PLS problem; subsequent factors solve the single-factor problem for a Gram-Schmidt deflated cross-products matrix. If we let the matrix of projection weights Rk ∈ ℜp×k be defined recursively then, where zk = X vk is the kth sample PLS factor. The Gram–Schmidt projection matrix Pk ∈ ℜp×p is given by , which ensures that for j < k. Then, the optimization problem to find the kth SIMPLS loadings vector is the same as the single-factor problem with the cross-products matrix, M, replaced by the deflated matrix, M̂(k) = Pk−1 M̂(k−1) [6]. Thus, our multifactor RPLS replaces M in (1) with M̂(k) to obtain the kth RPLS factor. While our rank-one optimization problem is closely related to the sparse CCA approach of Witten et al. [23], the solutions differ in subsequent factors due to the SIMPLS deflation scheme.
The deflation approach employed via the NIPALS algorithm is not as direct. One typically defines a deflated matrix of predictors and responses, and , with the matrix of projection weights defined as above, and then solves an eigenvalue problem in this deflated space: maximizewk subject to [5]. The PLS loadings in the original space are then recovered by Vk = Wk (Rk Wk)−1. While one can incorporate regularization into the loadings, wk (as suggested by Chun and Keleş [4]), this is not as desirable. If one estimates sparse deflated loadings, w, then much of the sparsity will be lost in the transform to obtain V. In fact, the elements of V will be zero if and only if the corresponding elements of W are zero for all values of k. Then, each of the K PLS loadings will have the exact same sparsity pattern, loosing the flexibility of each set of loadings having adaptively different levels of sparsity. Given this, the more direct deflation approach of SIMPLS is our preferred framework.
2.2. RPLS Solution
A major motivation for our optimization framework for RPLS is that it leads to a simple and direct solution and algorithm. Recall that the single-factor RPLS problem, Eq. (1), is concave in v with u fixed and is a quadratically constrained linear program in u with v fixed. Thus, we propose to solve this problem by alternating maximizing with respect to v and u. Each of these maximizations has a simple analytical solution:
PROPOSITION 1
Assume that P() is convex and homogeneous of order one, that is P() is a norm or semi-norm. Let u be fixed at u′ such that Mu′ ≠ 0 or v fixed at v′ such that MT v′ ≠ 0. Then, the coordinate updates, u* and v*, maximizing the single-factor RPLS problem, (1), are given by the following: Let . Then, v* = v̂/||v̂||2 if ||v̂||2 > 0 and v* = 0 otherwise, and u* = MT v′/|| MT v′||2. When these factors are updated iteratively, they monotonically increase the objective and converge to a local optimum.
While the proof of this result is given in the appendix, we note that this follows closely the Sparse PCA approach of Shen and Huang [22] and the use general penalties within PCA problems of Allen et al. [24]. Our RPLS problem can then be solved by a multiplicative update for u and by a simple re-scaled penalized regression problem for v. The assumption that P() is a norm or semi-norm encompasses many penalties types including the ℓ1-norm or lasso [26], the ℓ1/ℓ2-norm or group lasso [27], the fused lasso [28], and ℓq -balls [29]. For many possible penalty types, there exists a simple solution to the penalized regression problem. With a lasso penalty, P(v) = ||v||1, for example, the solution is given by soft-thresholding: v̂ = S(Mu, λ), where S(x, λ) = sign(x)(|x| − λ)+ is the soft-thresholding operator. Our approach gives a more general framework for incorporating regularization directly in the PLS loadings that yield simple and computationally attractive solutions.
We note that the RPLS solution is guaranteed be at most a local optimum of Eq. (1), a result that is typical of other penalized PCA problems [21–25] and sparse PLS methods [3,4]. For a special case, however, our problem has a global solution:
COROLLARY 1
When q = 1, that is when Y is univariate, then the global solution to the single-factor penalized PLS problem (1) is given by the following: Let . Then, v* = v̂/||v̂||2 if ||v̂||2 > 0 and v* = 0 otherwise.
This, then is an important advantage of our framework over competing methods. We also briefly note that for PLS regression, there is an interesting connection between Krylov sequences and the PLS regression coefficients [30]. As we take the RPLS factors to be a direct projection of the RPLS loadings, this connection to Krylov sequences is broken, although perhaps for prediction purposes, this is immaterial.
2.3. RPLS Algorithm
Given our RPLS optimization framework and solution, we now put these together in the RPLS algorithm, Algorithm 1. Note that this algorithm is a direct extension of the SIMPLS algorithm [6], where the solution to our single-factor RPLS problem, Eq. (1), replaces the typical eigenvalue problem in Step 2(b). Thus, the algorithmic structure is analogous to that of Lê Cao et al. [3]. Since our RPLS problem is nonconcave, there are potentially many local solutions and thus the initializations of u and v are important. Similar to much of the Sparse PCA literature [21,22], we recommend initializing these factors to the global single-factor SVD solution, Step 2(a). Second, notice that choice of the regularization parameter, λ, is particularly important. If λ is large enough that vk = 0, then the kth RPLS factor would be zero and the algorithm would cease. Thus, care is needed when selecting the regularization parameters to ensure they remain within the relevant range. For the special case where q = 1, computing , the value at which v̂k = 0, is a straightforward calculation following from the Karush–Khun–Tucker conditions. With the LASSO penalty, for example, this gives [31]. For general q, however, λmax does not have a closed form. While one could use numerical solvers to find this value, this is a needless computational effort. Instead, we recommend to perform the algorithm over a range of λ values, discarding any values resulting in a degenerate solution from consideration. Finally, unlike deflation-based Sparse PCA methods which can exhibit poor behavior for very sparse solutions, because of orthogonalization with respect to the data, our RPLS loadings and factors are well behaved with large regularization parameters.
Algorithm 1.
K-Factor Regularized PLS
|
Selecting the appropriate regularization parameter, λ, is an important practical consideration. Existing methods that incorporate regularization in PLS have suggested using cross-validation or other model selection methods in the ultimate regression or classification stage of the full PLS procedure [4,20]. While one could certainly implement these approaches within our RPLS framework, we suggest a simpler and more direct approach. We select λ within the dimension reduction stage of RPLS, specifically in Step 2(b) of our RPLS Algorithm. Doing so, has a number of advantages. First, this increases flexibility as it separates selection of λ from deciding how many factors, K, to use in the prediction stage, permitting a separate regularization parameter, λk, to be selected for each RPLS factor. Second, coupling selection of the regularization parameter to the prediction stage requires fixing the supervised modeling method before computing the RPLS factors. With our approach, the RPLS factors can be computed and stored to use as predictors in a variety of modeling procedures. Finally, separating selection of λk and K in the prediction stage is computationally advantageous as a grid search over tuning parameters is avoided. Nesting selection of λ within Step 2(b) is also faster as recent developments such as warm starts and active set learning can be used to efficiently fit the entire path of solutions for many penalty types [31]. Practically, selecting λk within the dimension reduction stage is analogous to selecting the regularization parameters for Sparse PCA methods on M̂(k). Many approaches including cross-validation [22,32] and BIC methods [24,25] have been suggested for this purpose; in results given in this paper, we have implemented the BIC method as described by Allen et al. 24. Selection of the number of RPLS factors, K, will largely be dependent on the supervised method used in the prediction stage, although cross-validation can be used with any method. When choosing K for PLS regression, for example, Huang et al. [33] suggest an automatic approach via regularization.
Computationally, our algorithm is an efficient approach. As discussed in the previous section, the particular computational requirements for computing the RPLS loadings in Step 2(b) are penalty specific, but are minimal for a wide class of commonly used penalties. Beyond Step 2(b), the major computational requirement is inverting the weight matrix, , to compute the projection matrix. As this matrix is found recursively via the Gram-Schmidt scheme, however, employing properties of the Schur complement can reduce the computational effort to that of matrix multiplication O(pk) [34]. Finally, notice that we take the RPLS factors to be the direct projection of the data by the RPLS loadings. Overall, the advantages of our RPLS framework and algorithm include (i) computational efficiency, (ii) flexible modeling, and (iii) direct estimation of the RPLS loadings and factors.
3. EXTENSIONS
As our framework for regularizing PLS is general, there are many possible extensions of our methodology. Many have suggested, for example, to extend PLS and sparse PLS specifically for discriminant analysis [8] and for generalized linear models [7,35]. Such extensions are also possible within our framework. In this section, we specifically focus on two novel extensions of PLS and RPLS that will be useful for applications to spectroscopy data. These include generalizations for PLS and RPLS with structured data and non-negative PLS and RPLS.
3.1. GPLS for Structured Data
Recently, Allen et al. [24] proposed a generalization of PCA (GPCA) that is a appropriate for high-dimensional structured data, or data in which the variables are associated with some known distance metric. As motivation, consider NMR spectroscopy data where variables are ordered on the spectrum and variables at adjacent chemical shifts are known to be highly correlated. Classical multivariate techniques such as PCA and PLS ignore these structures; GPCA encodes structure into a matrix factorization problem through positive semi-definite quadratic operators such as graph Laplacians or smoothing matrices [24,36]. If we assume that the noise in the data follows the data structure and these quadratic operators capture aspects of this structure, then Allen et al. [24] showed that GPCA can be interpreted as finding principal modes of variation that are orthogonal to the structured noise. In the context of NMR spectroscopy, we seek PLS factors that are independent from the known noise correlations at adjacent chemical shifts. Similar to GPCA then, we seek to directly account for known structure in PLS and within our RPLS framework.
Our development of GPLS is motivated by NMR spectroscopy; that is, we seek a quadratic operator that encodes the known structural relationships, the correlations between adjacent variables. Let us define then quadratic operator, Q ∈ ℜp×p: Q ≥ 0 which we assume is fixed and known. For spectroscopy data, for example, Q could be taken as a diagonal tapered matrix thus accounting for the correlations between adjacent variables. By transforming all inner-product spaces to those induced by the Q-norm, we can define our single-factor Generalized RPLS optimization problem in the following manner:
| (2) |
By finding the RPLS factors in the Q-norm, we find factors separate from the noise structure of the data. For the multifactor Generalized RPLS problem, the factors and projection matrices are also changed. The kth factor is given by zk = X Q vk, the weighting matrix, as before, and the projection matrix is with deflated cross-products matrix M̂(k) = Pk−1 M̂(k−1). Note that if λ = 0 and if the inequality constraint is forced to be an equality constraint, then we have the optimization problem for GPLS. Notice also that instead of enforcing orthogonality of the PLS loadings with respect to the data, , the GPLS problem enforces orthogonality in a projected data space, . If we let Q̃ be a matrix square root of Q as defined by Allen et al. [24], then (2) is equivalent to the multifactor RPLS problem for X̃ = X Q̃ and ṽ = Q̃ v. This equivalence is shown in the proof of the solution to Eq. (2).
As with PLS and our RPLS framework, GPLS and Generalized RPLS can be solved by coordinate-wise updates that converge to the global and local optimum respectively:
PROPOSITION 2
GPLS: The GPLS problem, Eq. (2) when λ = 0, is solved by the first set of GPCA factors of M. The global solution to the GPLS problem can be found by iteratively updating the following until convergence: v = Mu/||Mu||Q and u = MT Q v/|| MT Q v||2, where ||x||Q is defined as .
Generalized RPLS: Under the assumptions of Proposition 1, let , then the coordinate-wise updates to Eq. (2) are given by: v* = v̂/||v̂||Q if ||v̂||Q > 0 and v* = 0 otherwise, and with u* defined as above. When updated iteratively, these converge to a local optimum of (2).
Thus, the solution to our Generalized RPLS problem can be solved by a generalized penalized least squares problem. Algorithmically, solving the multi-factor GPLS and Generalized RPLS problems follow the same structure as that of Algorithm 2.2. The solutions outlined above replace Step 2(b), with the altered Generalized RPLS factors and projections matrices replacing Steps 2 (c), (d), and (e). In other words, GPLS or Generalized RPLS is performed by finding the GPCA or Regularized GPCA factors of a deflated cross-products matrix, where the deflation is performed to rotate the cross-products matrix so that it is orthogonal to the data in the Q-norm. Computationally, these algorithms can be performed efficiently using the techniques described by Allen et al. [24] that do not require inversion or taking eigenvalue decompositions of Q. Thus, the GPLS and Generalized RPLS methods are computationally feasible for high-dimensional data sets.
We have shown the most basic extension of GPCA technology to PLS and our RPLS framework, but there are other possible formulations. For two-way data, projections in the ‘sample’ space may be appropriate in addition to projecting variables in the Q-norm. With neuroimaging data, for example, the data matrix may be oriented as brain locations, voxels, by time points. As the time series is most certainly not independent, one may wish to transform these inner product spaces using another quadratic operator, W ∈ ℜn×n, changing M to XT W Y and Rk to , analogous to Allen et al. [24]. Overall, we have outlined a novel extension of PLS and our RPLS methodologies to work with high-dimensional structured data.
3.2. Non-Negative PLS
Many have advocated estimating non-negative matrix factors [37] and non-negative principal component loadings [38] as a way to increase interpret-ability of multivariate methods. For scientific data sets such as NMR spectroscopy in which variables are naturally non-negative, enforcing non-negativity of the loadings vectors can greatly improve interpretability results and the performance of methods [36]. Here, we illustrate how to incorporate non-negative loadings into our RPLS framework. Consider the optimization problem for single-factor non-negative RPLS:
| (3) |
Solving this optimization problem is a simple adaption of Proposition 1; the penalized regression problem is replaced by a penalized non-negative regression problem. For many penalty types, these problems have a simple solution. With the ℓ1-norm penalty, for example, the soft-thresholding operator in the update for v is replaced by the positive soft-thresholding operator: v = P(Mu, λ) = (Mu − λ)+ [36]. Our RPLS framework, then, gives a simple and computationally efficient method for enforcing non-negativity in the PLS loadings. Also, as in Ref. 36, non-negativity and quadratic operators can be used in combination for PLS to create flexible approaches for high-dimensional data sets.
4. SIMULATION STUDIES
We explore the performance of our RPLS methods for regression in a univariate and a multivariate simulation study.
4.1. Univariate Simulation
In this simulation setting, we compare the mean squared prediction error and variable selection performance of RPLS against competing methods in the univariate regression response setting with correlated predictors. Following the approach in Section 5.3 of Chun and Keleş [4], we include scenarios where n is greater than p and where n is less than p with differing levels of noise. For the n > p setting, we use n = 400 and p = 40. For the first n < p setting, we use n = 40 and p = 80. For these cases, 75% of the p predictors are true predictors, while the remaining 25% are spurious predictors that are not used in the generation of the response. We also include an additional n < p setting where the underlying signal is more sparse. In this case, we use n = 40 and p = 200 with 25% of the p predictors as true predictors. For the low and high noise scenarios, we use signal-to-noise ratios (SNR) of 10 and 5.
To create correlated predictors as in Ref. 4, we construct hidden variables H1, …, H3, where Hi ~
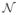 (0, 25In). The columns of the predictor matrix Xi are generated as the sum of a hidden variable and independent random noise as follows. For the cases where 75% of the p predictors are used in the generation of the response, Xi = H1 + εi for 1 ≤ i ≤ 3p/8, Xi = H2 + εi for 3p/8 < i ≤ 3p/4, and Xi = H3 + εi for 3p/4 < i ≤ p, where εi ~
(0, In). When 25% of the p predictors are used in the generation of the response, Xi = H1 + εi for 1 ≤ i ≤ p/8, Xi = H2 + εi for p/8 < i ≤ p/4, and Xi = H3 + εi for p/4 < i ≤ p, where εi ~
(0, In). For all cases, the response vector Y = 3H1 − 4H2 + f, where f ~
(0, 25In/SNR). Training and test sets for all settings of n, p and SNR are created using this approach.
(0, 25In). The columns of the predictor matrix Xi are generated as the sum of a hidden variable and independent random noise as follows. For the cases where 75% of the p predictors are used in the generation of the response, Xi = H1 + εi for 1 ≤ i ≤ 3p/8, Xi = H2 + εi for 3p/8 < i ≤ 3p/4, and Xi = H3 + εi for 3p/4 < i ≤ p, where εi ~
(0, In). When 25% of the p predictors are used in the generation of the response, Xi = H1 + εi for 1 ≤ i ≤ p/8, Xi = H2 + εi for p/8 < i ≤ p/4, and Xi = H3 + εi for p/4 < i ≤ p, where εi ~
(0, In). For all cases, the response vector Y = 3H1 − 4H2 + f, where f ~
(0, 25In/SNR). Training and test sets for all settings of n, p and SNR are created using this approach.
For the comparison of methods, X and Y are standardized, and parameter selection is carried out using 10-fold cross validation on the training data. For the sparse partial least squares (SPLS) method described by Chun and Keleş [4], the spls R package [39] is used with η chosen from the sequence (0.1, 0.2, …, 0.9) and K from 5 to 10. Note that for our methods, we choose to select K automatically via the lasso penalized PLS regression problem as in Ref. 33. Thus for RPLS, lasso penalties were used with λ and γ chosen from 25 equally spaced values between 10−5 and log(max(|X′Y|)) on the log scale. For the lasso and elastic net, the glmnet R package [31] is used with the same choices for λ.
The average mean squared prediction error (MSPE), true positive rate (TPR), and false positive rate (FPR) across 30 simulation runs are given in Table 1. The penalized regression methods clearly outperform traditional PLS in terms of the mean squared prediction error, with RPLS having the best prediction accuracy among all methods. SPLS and RPLS are nearly perfect in correctly identifying the true variables, but SPLS tends to have higher rates of false positives. In contrast, the lasso and elastic net have high specificity, but fail to identify many true predictors.
Table 1.
Comparison of mean squared prediction error (MSPE), true positive rate (TPR) and false positive rate (FPR) with standard errors (SE).
| Simulation 1: n = 400, p = 40, SNR = 10 | Simulation 2: n = 400, p = 40, SNR = 5 | ||||||
|---|---|---|---|---|---|---|---|
| Method | MSPE (SE) | TPR (SE) | FPR (SE) | Method | MSPE (SE) | TPR (SE) | FPR (SE) |
| PLS | 504.2 (293.8) | PLS | 655.2 (212.9) | ||||
| Sparse PLS | 72.6 (4.1) | 1.00 (0.00) | 0.61 (0.27) | Sparse PLS | 143.7 (9.8) | 1.00 (0.00) | 0.66 (0.29) |
| RPLS | 66.4 (3.8) | 1.00 (0.00) | 0.22 (0.35) | RPLS | 131.4 (9.3) | 1.00 (0.00) | 0.19 (0.37) |
| Lasso | 70.9 (4.9) | 0.60 (0.07) | 0.00 (0.02) | Lasso | 139.3 (9.5) | 0.49 (0.07) | 0.00 (0.00) |
| Elastic net | 70.5 (4.5) | 0.61 (0.07) | 0.01 (0.03) | Elastic net | 139.0 (9.5) | 0.50 (0.07) | 0.00 (0.00) |
| Simulation 3: n = 40, p = 80, SNR = 10 | Simulation 4: n = 40, p = 80, SNR = 5 | ||||||
|---|---|---|---|---|---|---|---|
| Method | MSPE (SE) | TPR (SE) | FPR (SE) | Method | MSPE (SE) | TPR (SE) | FPR (SE) |
| PLS | 624.1 (256.5) | PLS | 612.6 (256.8) | ||||
| Sparse PLS | 104.9 (26.3) | 0.99 (0.05) | 0.77 (0.30) | Sparse PLS | 206.4 (53.9) | 0.98 (0.07) | 0.70 (0.31) |
| RPLS | 76.0 (20.8) | 1.00 (0.00) | 0.45 (0.43) | RPLS | 155.1 (59.0) | 1.00 (0.00) | 0.52 (0.43) |
| Lasso | 83.7 (19.7) | 0.17 (0.04) | 0.02 (0.06) | Lasso | 178.3 (49.7) | 0.12 (0.04) | 0.01 (0.02) |
| Elastic net | 82.4 (18.6) | 0.17 (0.03) | 0.02 (0.04) | Elastic net | 172.7 (46.0) | 0.12 (0.04) | 0.01 (0.03) |
| Simulation 5: n = 40, p = 200, SNR = 10 | Simulation 2: n = 40, p = 200, SNR = 5 | ||||||
|---|---|---|---|---|---|---|---|
| Method | MSPE (SE) | TPR (SE) | FPR (SE) | Method | MSPE (SE) | TPR (SE) | FPR (SE) |
| PLS | 649.7 (175.8) | PLS | 691.9 (188.5) | ||||
| Sparse PLS | 85.7 (20.4) | 1.00 (0.02) | 0.76 (0.32) | Sparse PLS | 182.0 (42.0) | 0.98 (0.08) | 0.61 (0.36) |
| RPLS | 84.8 (52.2) | 1.00 (0.00) | 0.53 (0.47) | RPLS | 153.3 (40.9) | 1.00 (0.00) | 0.48 (0.49) |
| Lasso | 83.1 (15.1) | 0.19 (0.04) | 0.01 (0.01) | Lasso | 163.1 (35.7) | 0.15 (0.04) | 0.00 (0.01) |
| Elastic net | 82.2 (14.7) | 0.19 (0.05) | 0.00 (0.01) | Elastic net | 160.6 (33.7) | 0.15 (0.03) | 0.01 (0.02) |
4.2. Multivariate Simulation
In this simulation setting, we compare the mean squared prediction error of regularized PLS against competing methods for multivariate regression. As in the univariate simulation, we include scenarios where n > p and n < p with varying levels of noise, but now our response Y is a matrix of dimension n × q with q = 10. For the n > p scenario, we use n = 400 and p = 40 with 5 true predictors. For the moderate n < p scenario, we use n = 40 and p = 80 with 10 true predictors. We also include a more extreme scenario where we use n = 40 and p = 200 with 25 true predictors. In each case, we test the methods using SNR of 2 and 1.
The simulated data is generated using eight binary hidden variables H1, …, H8 with entries drawn from the Bernoulli (0.5) distribution. The coefficient matrix A contains standard normal random entries for the first ptrue columns, with the remaining columns set to 0. The predictor matrix X = H · A + E, where the entries of E are drawn from the
(0, 0.12) distribution. The coefficient matrix B contains entries drawn from the
(0, SNR · n · q/tr(HH′)) distribution. The response matrix Y = H · B + F, where the entries of F are drawn from the standard normal distribution. Both training and test sets are generated using this procedure, and both X and Y are standardized.
For the penalized methods including sparse PCA (SPCA) and regularized PLS (RPLS) the penalty parameter λ is chosen from 25 equally spaced values between −5 and log(max(|X′Y|)) on the log scale using the BIC criterion. For RPLS, γ, the PLS regression penalty parameter for selecting K, is chosen from the same set of options as λ using the BIC criterion. To obtain the coefficient β = VZ′Ytraining, the columns of V and Z were normalized. The results shown in Table 2 demonstrate that regularized PLS outperforms both sparse PCA and standard PLS.
Table 2.
Comparison of mean squared prediction error (MSPE) with standard errors (SE) for multivariate methods.
| Simulation 1: n = 400, p = 40, SNR = 2 | Simulation 2: n = 400, p = 40, SNR = 1 | ||
|---|---|---|---|
| Method | MSPE (SE) | Method | MSPE (SE) |
| SPCA | 2376.2 (337) | SPCA | 2204.1 (313) |
| PLS | 2567.7 (316) | PLS | 2343.3 (281) |
| RPLS | 404.7 (96) | RPLS | 339.4 (175) |
| Simulation 3: n = 40, p = 80, SNR = 2 | Simulation 4: n = 40, p = 80, SNR = 1 | ||
|---|---|---|---|
| Method | MSPE (SE) | Method | MSPE (SE) |
| SPCA | 711.3 (107) | SPCA | 721.7 (109) |
| PLS | 647.0 (101) | PLS | 659.9 (81) |
| RPLS | 14.2 (3) | RPLS | 13.3 (3) |
| Simulation 5: n = 40, p = 200, SNR = 2 | Simulation 6: n = 40, p = 200, SNR = 1 | ||
|---|---|---|---|
| Method | MSPE (SE) | Method | MSPE (SE) |
| SPCA | 1269.9 (211) | SPCA | 1263.1 (208) |
| PLS | 830.0 (102) | PLS | 843.7 (87) |
| RPLS | 20.3 (8) | RPLS | 19.4 (7) |
5. CASE STUDY: NMR SPECTROSCOPY
We evaluate the utility of our methods through a case study on NMR spectroscopy data, a classic application of PLS methods from the chemometrics literature. We apply our RPLS methods to an in vitro one-dimensional NMR data set consisting of 27 samples from five classes of neural cell types: neurons, neural stem cells, microglia, astrocytes, and ogliodendrocytes [40], analyzed by some of the same authors using PCA methods in Ref. 36. Data are pre-processed in the manner described by Dunn et al. [18]: functional spectra is discretized into bins of size 0.04 ppms yielding a total of 2394 variables, spectra for each sample are baseline corrected and normalized to their integral, and variables are standardized. For all PLS methods, the response, Y is 27 × 5 and coded with indicators inversely proportional to the sample size in each class as described by Barker and Rayens [8]. For each method, five PLS or PCA factors were taken and used as predictors in linear discriminant analysis to classify the NMR samples. To be consistent, the BIC method was used to select any penalty parameters except for the Sparse PLS method of Chun and Keleş [4] where the default in the R package spls was employed [39]. The Sparse GPCA and Sparse GPLS methods were applied with non-negativity constraints as described by Allen & Maletić-Savatić [36] and in Section 3. Finally, for the generalized methods, the quadratic operator was selected by maximizing the variance explained by the first component; a weighted Laplacian matrix with weights inversely proportional to the Epanechnikov kernel with a bandwidth of 0.2 ppms was employed [24].
In Table 3, we give the training and leave-one out cross-validation misclassification errors for our methods and competing methods on the neural cell NMR data. Notice that our Sparse GPLS method yields the best error rates followed by the Sparse PLS [4] and our GPLS methods. Additionally, our Sparse GPLS methods are significantly faster than competing approaches. In Table 4, the time in seconds to compute the entire solution path (51 values of λ) is reported. Timing comparisons were done on a Intel Xeon X5680 3.33 Ghz processor with 16 GB RAM using single-threaded scripts coded in Matlab or C as indicated. (These comparisons should be interpreted keeping in mind that there are possibly minor speed differences between Matlab and R.)
Table 3.
Misclassification errors for methods applied to the neural cell NMR data. Various methods were used to first reduce the dimension with the resulting factors used as predictors in linear discriminant analysis.
Table 4.
Timings comparisons. Time in seconds to compute the entire solution path for the neural cell NMR data.
| Time in seconds | |
|---|---|
| Sparse PLS (via RPLS in C) | 1.01 |
| Sparse PLS (via RPLS in Matlab) | 57.01 |
| Sparse PLS (R package spls) | 1033.86 |
| Sparse Non-negative GPLS (in C) | 28.16 |
In addition to faster computation and better classification rates, our method’s flexibility leads to easily interpretable results. We present the Sparse GPLS loadings superimposed on the scaled spectra from each neural cell type and sample heatmaps in Fig. 1. For comparison, we give the first two PLS loadings in Fig. 2 for PLS and Sparse PLS [4]. The PLS loadings are noisy, and the sample PLS components for PLS and Sparse PLS are difficult to interpret as the loadings are both positive and negative. By constraining the PLS loadings to be non-negative, the chemical shifts the metabolites indicative of each neural cell type are readily apparent with the Sparse non-negative GPLS loadings. Additionally as shown in the sample PLS heatmaps, the neural cell types are well differentiated. For example, chemical resonances at 1.30 and 3.23 ppms characterize Glia (Astrocytes and Ogliodendrocytes) and Neurons (PLS 1), resonances at 1.19 and 3.66 ppms characterize Microglia (PLS 2), resonances at 3.23 and 2.65 ppms characterize Astrocytes (PLS 3), resonances at 1.30, 3.02, and 3.55 ppms characterize Ogliodendrocytes (PLS 4), and resonances at 1.28 and 3.23 ppms characterize Neural stem cells. Note that some of these metabolites were identified by some of the same authors using PCA methods in Refs 36,40. Using our flexible PLS approach for supervised dimension reduction, however, gives a much clear metabolic signature of each neural cell type. Overall, this case study on NMR spectroscopy data has revealed the many strengths of our method as well as identified possible metabolite biomarkers for further biological investigation.
Fig. 1.

Sparse non-negative GPLS loadings and sample PLS heatmaps for the neural cell NMR data. The loadings are superimposed on the mean scaled spectral intensities for each class of neural cells. [Color figure can be viewed in the online issue, which is available at wileyonlinelibrary.com.]
Fig. 2.

The first two PLS and Sparse PLS [4] loadings and sample PLS heatmaps for the neural cell NMR data. The loadings are superimposed on the mean scaled spectral intensities for each class of neural cells. [Color figure can be viewed in the online issue, which is available at wileyonlinelibrary.com.]
6. DISCUSSION
We have presented a framework for regularizing partial least squares with convex and order one penalties. Additionally, we have shown how this approach can be extend for structured data via GPLS and Generalized RPLS and extended to incorporate non-negative PLS or RPLS loadings. Our approaches directly solve penalized relaxations of the SIMPLS optimization criterion. These in turn, have many advantages including computational efficiency, flexible modeling, easy interpretation and visualization, better feature selection, and improved predictive accuracy as demonstrated in our simulations and case study on NMR spectroscopy.
There are many future areas of research related to our methodology. As many have advocated using PCA, or even supervised PCA [41], as a dimension reduction technique prior supervised modeling, RPLS may be a powerful alternative in this context. While we have briefly discussed the use of our methods for general regression or classification procedures, specific investigation of the RPLS factors as predictors in the generalized linear model framework [7,35], the survival analysis framework [42], and others are needed. Additionally, following the close connection of PLS for classification with the classes coded as dummy variables to Fisher’s discriminant analysis [8], our RPLS approach may give an alternative strategy for regularized linear discriminant analysis. Further development of our novel extensions for GPLS and Nonnegative PLS is also needed. Finally, Nadler and Coifman [12] and Chun and Keleş [4] have shown asymptotic inconsistency of PLS regression methods when the number of variables is permitted to grow faster than the sample size. For related PCA methods, a few have shown consistency of Sparse PCA in these settings [10,13]. Proving consistent recovery of the RPLS loadings and the corresponding regression or classification coefficients is an open area of future research.
Finally, we have demonstrated the utility of our methods through a case study on NMR spectroscopy data, but there are many other potential applications of our technology. These include chemometrics, proteomics, metabolomics, high-throughput genomics, imaging, hyperspectral imaging, and neuroimaging. Overall, we have presented a flexible and powerful tool for supervised dimension reduction of high-dimensional data with many advantages and potential areas of future research and application. An R package and a Matlab toolbox named RPLS that implements our methods will be made publicly available.
Acknowledgments
The authors thank the editor and three anonymous referees for helpful comments and suggestions that improved this paper. We also thank Frederick Campbell and Han Yu for assistance with the software development for this paper. G. Allen is partially supported by NSF DMS-1209017. C. Peterson acknowledges support from the Keck Center of the Gulf Coast Consortia, on the NLM Training Program in Biomedical Informatics, National Library of Medicine (NLM) T15LM007093; M. Vannucci and M. Maletić-Savatić are partially supported by the Collaborative Research Fund from the Virgina and L. E. Simmons Family Foundation.
APPENDIX
PROOFS
Proof of Proposition 1
The proof of this result follows from an argument in Ref. 24, but we outline this here for completion. The updates for u are straightforward. We show that the subgradient equations of the penalized regression problem, , for v* as defined in the stated result are equivalent to the KKT conditions of Eq. (1). The subgradient equation of the latter is, Mu − λ∇P(v*) − 2γ* v* = 0, where ∇P() is the subgradient of P() and γ* is the Lagrange multiplier for the inequality constraint with complementary slackness condition, γ*((v*)T v* − 1) = 0. The subgradient of the penalized regression problem is Mu − v̂ − λ∇P(v̂) = 0. Now, since P() is order one, we this subgradient is equivalent to for any c > 0 and for ṽ = cv̂. Then, taking c = 1/||v̂||2 = 1/2γ* for any v̂ ≠ 0, we see that both the complimentary slackness condition is satisfied and the subgradients are equivalent. It is easy to verify that the pair (0, 0) also satisfy the KKT conditions of Eq. (1).
Proof of Corollary 1
The proof of this fact follows in a straightforward manner from that of Proposition 1 as the only feasible solution for u is u* = 1. We are then left with a concave optimization problem, maximizev vT M − λP(v) subject to vT v ≤ 1. From the proof of Proposition 1, we have that this optimization problem is equivalent to the desired result. As we are left with a concave problem, the global optimum is achieved.
Proof of Proposition 2
First, define Q̃ to be a matrix square root of Q as in Ref. 24. In this paper, they showed that Generalized PCA was equivalent to PCA on the matrix X̃ = X Q̃ for projected factors V = Q̃†Ṽ. In other words, if X̃ = ŨD̃Ṽ is the singular value decomposition, then the GPCA solution, V can be defined accordingly. Here, we will prove that the multi-factor RPLS problem for X̃ and ṽk is equivalent to the stated Generalized RPLS problem (2) for λ = 0. The constraint regions are trivially equivalent so we must show that . The PLS factors, z̃k = X̃ṽk = X Q vk = zk, are equivalent. Ignoring the normalizing term in the denominator, the columns of the projection weighting matrix are R̃k = X̃Tz̃k = Q̃T X zk = Q̃T Rk. Thus, the ij th element of as stated. Putting these together, we have which simplifies to the desired result.
Following this, the proof of the first part is a straightforward extension of Theorem 1 and Proposition 1 in Ref. 24. The proof for the second part follows from combining the arguments in Proposition 1 and those in the proof of Theorem 2 in Ref. 24.
References
- 1.Nguyen D, Rocke D. Tumor classification by partial least squares using microarray gene expression data. Bioinformatics. 2002;18(1):39–50. doi: 10.1093/bioinformatics/18.1.39. [DOI] [PubMed] [Google Scholar]
- 2.Boulesteix A, Strimmer K. Partial least squares: a versatile tool for the analysis of high-dimensional genomic data. Brief Bioinform. 2007;8(1):32. doi: 10.1093/bib/bbl016. [DOI] [PubMed] [Google Scholar]
- 3.Cao KLê, Rossouw D, Robert-Granié C, Besse P. A sparse PLS for variable selection when integrating omics data. Stat Appl Genet Mol Biol. 2008;7(1):35. doi: 10.2202/1544-6115.1390. [DOI] [PubMed] [Google Scholar]
- 4.Chun H, Keleş S. Sparse partial least squares regression for simultaneous dimension reduction and variable selection. J Roy Stat Soc Ser B. 2010;72(1):3–25. doi: 10.1111/j.1467-9868.2009.00723.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Wold H. Estimation of principal components and related models by iterative least squares. Multivariate Anal. 1966;1:391–420. [Google Scholar]
- 6.de Jong S. SIMPLS: an alternative approach to partial least squares regression. Chemomet Intell Lab Syst. 1993;18(3):251–263. [Google Scholar]
- 7.Marx B. Iteratively reweighted partial least squares estimation for generalized linear regression. Technometrics. 1996:374–381. [Google Scholar]
- 8.Barker M, Rayens W. Partial least squares for discrimination. J Chemomet. 2003;17(3):166–173. [Google Scholar]
- 9.Cao KLê, Boitard S, Besse P. Sparse PLS discriminant analysis: biologically relevant feature selection and graphical displays for multiclass problems. BMC Bioinform. 2011;12(1):253. doi: 10.1186/1471-2105-12-253. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Johnstone I, Lu A. On consistency and sparsity for principal components analysis in high dimensions. J Am Stat Assoc. 2009;104(486):682–693. doi: 10.1198/jasa.2009.0121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Jung S, Marron J. PCA consistency in high dimension, low sample size context. Ann Stat. 2009;37(6B):4104–4130. [Google Scholar]
- 12.Nadler B, Coifman R. The prediction error in CLS and PLS: the importance of feature selection prior to multivariate calibration. J Chemomet. 2005;19(2):107–118. [Google Scholar]
- 13.Amini A, Wainwright M. High-dimensional analysis of semidefinite relaxations for sparse principal components. Ann Stat. 2009;37(5B):2877–2921. [Google Scholar]
- 14.Shen D. PhD Thesis. University of North Carolina; 2012. Sparse PCA asymptotics and analysis of tree data. [Google Scholar]
- 15.Nicholson J, Lindon J. Systems biology: metabonomics. Nature. 2008;455(7216):1054–1056. doi: 10.1038/4551054a. [DOI] [PubMed] [Google Scholar]
- 16.De Graaf R. In Vivo NMR Spectroscopy: Principles and Techniques. Wiley-Interscience; 2007. [Google Scholar]
- 17.Goodacre R, Vaidyanathan S, Dunn W, Harrigan G, Kell D. Metabolomics by numbers: acquiring and understanding global metabolite data. Trends Biotechnol. 2004;22(5):245–252. doi: 10.1016/j.tibtech.2004.03.007. [DOI] [PubMed] [Google Scholar]
- 18.Dunn W, Bailey N, Johnson H. Measuring the metabolome: current analytical technologies. Analyst. 2005;130(5):606–625. doi: 10.1039/b418288j. [DOI] [PubMed] [Google Scholar]
- 19.Goutis C, Fearn T. Partial least squares regression on smooth factors. J Am Stat Assoc. 1996;91(434):627–632. [Google Scholar]
- 20.Reiss P, Ogden R. Functional principal component regression and functional partial least squares. J Am Stat Assoc. 2007;102(479):984–996. [Google Scholar]
- 21.Zou H, Hastie T, Tibshirani R. Sparse principal component analysis. J Comput Graph Stat. 2006;15(2):265–286. [Google Scholar]
- 22.Shen H, Huang J. Sparse principal component analysis via regularized low rank matrix approximation. J Multivariate Anal. 2008;99(6):1015–1034. [Google Scholar]
- 23.Witten D, Tibshirani R, Hastie T. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics. 2009;10(3):515. doi: 10.1093/biostatistics/kxp008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Allen GI, Grosenick L, Taylor J. A generalized least squares matrix decomposition. Rice University Technical Report No TR2011-03. 2011 [Google Scholar]
- 25.Lee M, Shen H, Huang J, Marron J. Biclustering via sparse singular value decomposition. Biometrics. 2010;66(4):1087–1095. doi: 10.1111/j.1541-0420.2010.01392.x. [DOI] [PubMed] [Google Scholar]
- 26.Tibshirani R. Regression shrinkage and selection via the lasso. J Roy Stat Soc Ser B. 1996;58(1):267–288. [Google Scholar]
- 27.Yuan M, Lin Y. Model selection and estimation in regression with grouped variables. J Roy Stat Soc Ser B. 2006;68(1):49–67. [Google Scholar]
- 28.Tibshirani R, Saunders M, Rosset S, Zhu J, Knight K. Sparsity and smoothness via the fused lasso. J Roy Stat Soc Ser B. 2005;67(1):91–108. [Google Scholar]
- 29.Raskutti G, Wainwright M, Yu B. Minimax rates of convergence for high-dimensional regression under LQ-ball sparsity. 47th Annual Allerton Conference on Communication, Control, and Computing; 2009; Allerton. 2009. pp. 251–257. [Google Scholar]
- 30.Krämer N. An overview on the shrinkage properties of partial least squares regression. Comput Stat. 2007;22(2):249–273. [Google Scholar]
- 31.Friedman J, Hastie T, Tibshirani R. Regularization paths for generalized linear models via coordinate descent. J Stat Softw. 2010;33(1):1. [PMC free article] [PubMed] [Google Scholar]
- 32.Owen A, Perry P. Bi-cross-validation of the SVD and the nonnegative matrix factorization. Annals. 2009;3(2):564–594. [Google Scholar]
- 33.Huang X, Pan W, Park S, Han X, Miller L, Hall J. Modeling the relationship between LVAD support time and gene expression changes in the human heart by penalized partial least squares. Bioinformatics. 2004;20(6):888–894. doi: 10.1093/bioinformatics/btg499. [DOI] [PubMed] [Google Scholar]
- 34.Horn RA, Johnson CR. Matrix Analysis. Cambridge University Press; 1985. [Google Scholar]
- 35.Chung D, Keles S. Sparse partial least squares classification for high dimensional data. Stat Appl Genet Mol Biol. 2010;9(1) doi: 10.2202/1544-6115.1492. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Allen G, Maletić-Savatić M. Sparse non-negative generalized PCA with applications to metabolomics. Bioinformatics. 2011;27(21):3029–3035. doi: 10.1093/bioinformatics/btr522. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Lee D, Seung H. Learning the parts of objects by non-negative matrix factorization. Nature. 1999;401(6755):788–791. doi: 10.1038/44565. [DOI] [PubMed] [Google Scholar]
- 38.Hoyer P. Non-negative matrix factorization with sparseness constraints. J Mach Learn Res. 2004;5:1457–1469. [Google Scholar]
- 39.Chung D, Chun H, Keles S. SPLS: Sparse Partial Least Squares (SPLS) Regression and Classification. R package, version 2.1-1. 2012 [Google Scholar]
- 40.Manganas L, Zhang X, Li Y, Hazel R, Smith S, Wagshul M, Henn F, Benveniste H, Djurić P, Enikolopov G, Maletić-Savatić M. Magnetic resonance spectroscopy identifies neural progenitor cells in the live human brain. Science. 2007;318(5852):980. doi: 10.1126/science.1147851. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Bair E, Hastie T, Paul D, Tibshirani R. Prediction by supervised principal components. J Am Stat Assoc. 2006;101(473):119–137. [Google Scholar]
- 42.Nguyen D, Rocke D. Partial least squares proportional hazard regression for application to DNA microarray survival data. Bioinformatics. 2002;18(12):1625–1632. doi: 10.1093/bioinformatics/18.12.1625. [DOI] [PubMed] [Google Scholar]