

Abstract
Background
The XRCC2 gene is a key mediator in the homologous recombination repair of DNA double strand breaks. We hypothesised that inherited variants in the XRCC2 gene might also affect susceptibility to, and survival from, breast cancer.
Methods
We genotyped 12 XRCC2 tagging SNPs in 1,131 breast cancer cases and 1,148 controls from the Sheffield Breast Cancer Study (SBCS), and examined their associations with breast cancer risk and survival by estimating odds ratios (ORs) and hazard ratios (HRs), and their corresponding 95% confidence intervals (CIs). Positive findings were further investigated in 860 cases and 869 controls from the Utah Breast Cancer Study (UBCS) and jointly analysed together with available published data for breast cancer risk. The survival findings were further confirmed in studies (8,074 cases) from the Breast Cancer Association Consortium (BCAC).
Results
The most significant association with breast cancer risk in the SBCS dataset was the XRCC2 rs3218408 SNP (recessive model p=2.3×10−4, MAF=0.23). This SNP yielded an ORrec (95% CI) of 1.64 (1.25–2.16) in a two-site analysis of SBCS and UBCS, and a meta-ORrec (95% CI) of 1.33 (1.12–1.57) when all published data were included. This SNP may mark a rare risk haplotype carried by 2 in 1000 of the control population. Furthermore, the XRCC2 coding R188H SNP (rs3218536, MAF=0.08) was significantly associated with poor survival, with an increased per-allele HR (95% CI) of 1.58 (1.01–2.49) in a multivariate analysis. This effect was still evident in a pooled meta-analysis of 8,781 breast cancer patients from the BCAC [HR (95% CI) of 1.19 (1.05–1.36), p=0.01].
Conclusions
Our findings suggest that XRCC2 SNPs may influence breast cancer risk and survival.
Keywords: Single nucleotide polymorphism, XRCC2, breast cancer risk, breast cancer survival
INTRODUCTION
Homologous recombination repair (HRR) of DNA double strand breaks (DSB) is a crucial cellular defence system to maintain genomic integrity. Unrepaired or incorrectly repaired DSB may give rise to chromosome aberrations, such as loss or gain of chromosome segments and chromosome translocations. These changes might lead to carcinogenesis by disruption of tumour suppressor genes and activation of proto-oncogenes.[1, 2] The involvement of the highly penetrant breast cancer genes BRCA1 and BRCA2 in the homologous recombination repair pathway[3–6] highlights the importance of this mechanism in breast cancer aetiology.
X-ray repair cross complementing gene-2 (XRCC2) possesses the ATP binding domains known as Walker motifs A and B, and is one of the RAD51 family of proteins that are implicated in DNA DSB repair.[7, 8] XRCC2-deficient cells show a greater than 100 fold reduction in HRR compared to XRCC2-proficient cells,[9] and demonstrate various forms of chromosomal instability that are often described in breast cancer.[7, 10–12, 8, 13] The restoration of RAD51 nuclear foci in XRCC2-deficient cells irrespective of RAD51 levels,[14, 15] and specific binding of XRCC2 to RAD51 family proteins[16] further suggests a non-redundant role of XRCC2 in normal HRR function. In addition, DNA damage caused by anticancer drugs and radiation has been documented to require XRCC2 for its repair in mammalian cells.[17–21] Several lines of evidence demonstrate that high levels of expression of XRCC3, another member of the RAD51 family of proteins, are associated with radio- and cytotoxic resistance in human tumour cell lines[22–24] suggesting that XRCC2 might also be relevant to the effects of tumour treatment.
It has been widely hypothesised that inherited variations in DNA sequence, such as single nucleotide polymorphisms (SNPs), may modulate DNA repair capacity, thus affecting individual susceptibility to cancer risk or survival. Earlier investigations concentrated on the XRCC2 missense SNP rs3218536 (R188H), for its association with breast cancer risk. An effect of this SNP has been largely ruled out by the Breast Cancer Association Consortium (BCAC) study,[25] although, due to its low minor allele frequency (MAF), small recessive effects could not be excluded. More recently, a few gene-based association studies have been carried out to evaluate XRCC2 SNPs in the context of breast cancer risk.[26–28] However, only one study examined the XRCC2 SNP associations with breast cancer survival.[27] Therefore, we genotyped a comprehensive set of XRCC2 tagging SNPs (tSNPs) selected from resequencing data and tested the hypotheses that the XRCC2 germline variants captured by the tag SNPs affect breast cancer risk or survival.
METHODS
Study populations
The Sheffield Breast Cancer study (SBCS) formed the discovery set for this study. The study characteristics and recruitment have been described in detail previously.[29, 30] Briefly, 1,266 female patients with histologically confirmed breast cancer were recruited from surgical outpatient clinics at the Royal Hallamshire Hospital, Sheffield and Rotherham District General Hospital between November 1998 and June 2002. Control subjects (n=1,270) were drawn from women aged 50–65 years who attended the mammography breast screening programme in Sheffield between October 2000 and August 2002. The eligibility criterion for controls was the absence of any evidence of breast malignancy. Study subjects were all resident in the Sheffield area and of Northern European ancestry. Tumour characteristics, such as histology, grade, lymph node status, estrogen receptor (ER) and progesterone receptor (PR) status and tumour size were retrieved by reviewing medical records and histopathology reports. Follow-up data on vital status was available until September 2009 through hospital records and the Trent Cancer Registry. All subjects gave informed consent for the collection of data and blood specimens, and approval for this study was obtained from South Sheffield Research Ethics Committee.
The Utah breast cancer study (UBCS) was used to replicate the findings in relation to breast cancer risk. Breast cancer cases (n=860) were drawn from high-risk cancer pedigrees, identified using a genealogical database (Utah Population Database, UPDB) linked to the Utah Cancer Registry.[31] Cases known to be due to BRCA1 or BRCA2 mutations were excluded. Controls (n=869) included unaffected family members and unrelated matched cancer-free controls. The latter were matched based on sex, birth year (within 5 years) and birth-place.[32]
Six studies from the BCAC (that had genotype data for XRCC2 R188H, and survival data available), were employed to verify the XRCC2 SNP associations with survival, including the Australian Breast Cancer Family Study (ABCFS, n=1,223), the Spanish National Cancer Centre Breast Cancer study (CNIO-BCS, n=190), the Hannover Breast Cancer Study (HABCS, n=598), the National Cancer Institute Breast Cancer Study in Poland (PBCS, n=1,507), Studies of Epidemiology and Risk Factors in Cancer Heredity (SEARCH, n=4,234) and the US Radiologic Technologist (USRT, n=322) Study.[33, 25] A brief description of the sources of breast cancer patients and the collection of clinical characteristics and vital status is given in the Supplementary Materials. Most breast cancer patients were prevalent cases (supplementary table 1). The majority of tumours were of ductal type, moderately or well differentiated, with low tumour stage (<=2), no lymph node involvement, and positive for ER and PR status (supplementary table 2).
Tagging reference panel and selection of tagging SNPs
The Polymorphism Discovery Resource (PDR90) is a mixed-ethnic population of 24 European, 24 African, 12 Mexican, 6 Native and 24 Asian Americans,[34] and has been used to discover genetic variants by thorough resequencing of all exons, conserved sequences, and over 1 kb of 5’ upstream and 3’ downstream regions of over 300 genes.[35] Using 4025 Yoruba-specific SNPs from HapMap Release 22 (i.e. those SNPs known to be polymorphic in only the Yoruban group), we identified and excluded 22 individuals likely to be of African genetic background. Data from the remaining 68 subjects (PDR68) were used to select tSNPs for the XRCC2 gene. The GERBIL (genotype resolution and block identification using likelihood) software[36] was used to estimate haplotype frequencies of 61 common SNPs (MAF > 5%) across the XRCC2 gene region in PDR68. Two haplotype blocks were identified. A minimum allelic r2 of 0.8 within blocks was employed to select tSNPs using the STATA programme, htSNP2.[37]
Genotyping and quality control
DNA samples were arrayed in 384-well plates, comprising equal numbers of cases and controls, together with duplicates (~10% of samples). Genotyping was carried out using the 5’ nuclease (TaqMan) and SNPlex multiplex assays (Applied Biosystems, Foster city, CA). There was no significant deviation of genotype frequencies in controls from those expected under Hardy-Weinberg equilibrium (HWE) (see supplementary table 3), except for rs3218455 (empirical p=1×10−4). No obvious clustering errors were found for rs3218455 by visual inspection of the cluster plots, and this SNP was included in the analysis to maintain tagging efficiency. Two SNPs were excluded based on a duplicate discordance of over 2.5%. Further to this, any SNP with a call rate of <80%, and any study subjects with > 50% missing genotypes, were also excluded from analyses. A summary of genotyping quality is given in supplementary table 3. Among these SNPs there were no differences in genotype missing rates between cases and controls, except for rs3218534 (p for fisher exact test=0.04, overall call rate of 95.9%).
Statistical analysis
The χ2 goodness-of-fit test with 1 degree freedom was performed to examine the departure of genotype frequency from HWE among control subjects, and the empirical significance value was obtained using Monte Carlo permutation procedures. Associations between the XRCC2 SNPs and breast cancer risk under specified genetic models were evaluated by likelihood ratio tests (LRT), using the SNPassoc 1.6–0 package in R 2.90.[38] SNP associations below the arbitrary Bonferroni threshold for multiple tests of 12 SNPs were selected for replication. P values shown in the tables are uncorrected for multiple testing. Haplotype analyses were performed using the SAS PROC HAPLOTYPE routine. Odds ratios (ORs) and corresponding 95% confidence intervals (CIs) for SNPs and haplotypes were derived from logistic regression models, with the most common genotype or haplotype used as the reference. The Genie software was also used to estimate ORs and 95% CIs, in order to account for the known relatedness amongst Utah subjects.[39, 40] Estimates and CIs were very consistent between the two methods.
Published data based on a Medline search through April 2010 were incorporated into the meta-analysis for rs3218408. We also included data from the Cancer Genetic Markers of Susceptibility (CGEMS, http://cgems.cancer.gov/data/) genome-wide association study (GWAS) of Hunter et al[41], based on postmenopausal women (1,145 cases and 1,142 controls from the Nurses’ Health Study, NHS). Preliminary analysis showed that OR estimates obtained from random and fixed effect models were similar, therefore meta-ORs for tSNPs were estimated and illustrated by forest plots using fixed effect models. The Cochran Q test and I2[42] were used to examine the homogeneity of ORs across different centres. All the meta-analyses were performed using the STATA command metan.[43]
For the analysis of associations with survival following breast cancer diagnosis, time at risk was defined as the interval between date of diagnosis and date of the last follow-up or death. The heterogeneity of the Kaplan-Meier (K-M) survival functions of genotypes for each SNP was assessed by the log-rank test. The Cox proportional hazard model was employed to estimate the hazard ratio (HR) for each tSNP in terms of genotype or alleles, adjusted for age at diagnosis, and taking into account time between study entry and diagnosis (left censoring).[44] Lymph node status (categorical variable), grade (categorical variable) and tumour size (categorical variable; <=2 cm, 2–5 cm, >5 cm) were included as covariates in the Cox models for those SNPs with significant associations. Pooled HR estimates were estimated by including study as a stratification variable. Schoenfeld residuals were used to assess the assumption of proportional hazards. All significance tests were two-sided and were performed using the Intercooled STATA 9.2 (College Station, TX), unless otherwise specified.
RESULTS
XRCC2 SNP associations with breast cancer risk
Twelve XRCC2 tSNPs, including one missense SNP rs3218536 (R188H), were successfully genotyped in 1,131 cases and 1,148 controls from the SBCS. The mean prediction accuracy achieved for ungenotyped SNPs based on these tSNPs was > 90%, as assessed in PDR68. Of the 12 SNPs, 11 were found not to be associated with breast cancer risk under additive, codominant, dominant or recessive models (figure 1), with all ORs close to unity (see supplementary table 4). However, we observed statistical evidence of rs3218408 association with breast cancer risk under the codominant (pLRT=6.7×10−4) and recessive models (pLRT=2.3×10−4), and both of these p values were below a notional Bonferroni threshold of 4.2×10−3 for 12 SNPs (figure 1). The unadjusted OR for the recessive effect of rs3218408 was 1.92 (1.35–2.75), and remained similar after adjusting for age at diagnosis, age at menarche, age at first full term pregnancy and family history; 1.85 (1.25–2.72).
Figure 1.

Negative log10 p values for additive, codominant, dominant and recessive models for the XRCC2 SNPs in the SBCS. For each model the upper dash line represents the Bonferroni threshold of 4.2×10−3 and the lower dash line represents the nominal significant value of 0.05. Chromosome positions are given in Mb and refer to NCBI build36/hg18 of the human genome
Haplotype analyses were performed in the two haplotype blocks as defined in Materials and Methods. All haplotypes with above 1% frequency were tested individually against the most common haplotype in the block, and rare haplotypes (frequency < 1%) were grouped together. In Block 1 (rs3218556, rs3218536, rs3218534, rs3218501, and rs3218499) no haplotypes were associated with breast cancer risk relative to the most common haplotype (table 1). In Block 2 (rs3218455, rs3111465, rs3094406, rs3218408, rs3218400, rs2106776, and rs3218374), the combined group of rare haplotypes were associated with increased risk relative to the most common haplotype with an estimated OR (95% CI) of 1.68 (1.21–2.32) (table 1). On closer inspection, the inflated risk was primarily due to one rare haplotype that included the minor allele of rs3218408, together with the minor allele at rs3218374 (frequency of 0.89% in cases and 0.20% in controls),which was associated with an OR (95% CI) of 6.50 (1.88–22.48). This suggests that this very rare haplotype may harbour one or more susceptibility loci (table 1).
Table 1.
Estimated breast cancer odds ratios (ORs) for haplotypes in the XRCC2 gene in SBCS
| Haplotypes* | Case frequency (%) | Control frequency (%) | OR (95% CI) |
|---|---|---|---|
| Block1† | |||
| 1-1-2-1-1 | 987.98 (43.68) | 1024.45 (44.62) | 1 |
| 1-1-1-1-2 | 524.75 (23.2) | 510.97 (22.25) | 1.07 (0.92–1.24) |
| 1-1-1-1-1 | 393.56 (17.4) | 368.08 (16.03) | 1.12 (0.94–1.33) |
| 1-2-1-1-1 | 178.07 (7.87) | 203.09 (8.85) | 0.9 (0.72–1.13) |
| 2-1-1-1-1 | 85.94 (3.8) | 93.79 (4.09) | 0.94 (0.69–1.3) |
| 1-1-1-2-1 | 80.14 (3.54) | 80.29 (3.5) | 1.03 (0.75–1.42) |
| rare haplotypes | 11.57 (0.51) | 15.33 (0.67) | 0.77 (0.34–1.77) |
| Block2‡ | |||
| 1-1-1-1-1-1-2 | 959.74 (42.43) | 1004.07 (43.73) | 1 |
| 1-1-1-2-1-2-1 | 506.51 (22.39) | 501.74 (21.85) | 1.05 (0.90–1.23) |
| 1-1-1-1-2-2-1 | 230.88 (10.21) | 221.96 (9.67) | 1.10 (0.89–1.35) |
| 2-1-1-1-1-2-1 | 175.95 (7.78) | 197.57 (8.60) | 0.91 (0.73–1.13) |
| 1-2-2-1-1-1-1 | 102.96 (4.55) | 108.17 (4.71) | 0.99 (0.73–1.33) |
| 1-1-2-1-1-1-1 | 95.57 (4.23) | 96.37 (4.20) | 1.06 (0.76-1.47) |
| 1-1-1-1-1-2-1 | 85.98 (3.8) | 99.69 (4.34) | 0.89 (0.64–1.23) |
| rare haplotypes | 104.42 (4.61) | 66.43 (2.89) | 1.68 (1.21–2.32) |
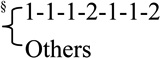 |
20.24 (0.89) | 4.56 (0.20) | 6.50 (1.88–22.48) |
| 84.17 (3.72) | 61.87 (2.69) | 1.37 (0.96–1.97) | |
1 represents the common allele and 2 the minor allele. “Rare haplotypes” indicates those with frequency below 1%.
the order of SNPs in block 1 are rs3218556, rs3218536, rs3218534, rs3218501, and rs3218499.
The order of SNPs in block 2 are rs3218455, rs3111465, rs3094406, rs3218408, rs3218400, rs2106776, and rs3218374.
the bracket indicates the subdivision of the rare haplotypes into 1112112 and the rest.
To confirm the single SNP finding for rs3218408, we genotyped it in 860 cases and 869 controls from the UBCS. The MAF of the G allele in UBCS controls was similar to that seen in the SBCS controls, 0.21 compared to 0.23 (supplementary table 3), and genotype frequencies were consistent with HWE (pHWE=0.98). There was evidence of association between rs3218408 and breast cancer risk in the UBCS, although the inheritance pattern was more consistent with the additive and dominant models, in contrast to the codominant and recessive models that were indicated in the SBCS dataset (figure 2). However, there was no evidence of heterogeneity between studies for any model (phet=0.17–0.45 and I2=0%-46.6%; data not shown). In a joint analysis of the SBCS and UBCS, SNP rs3218408 showed statistically significant association with the susceptibility to breast cancer in the additive, recessive, and codominant models, with ORs (95% CIs) of 1.16 (1.04–1.29) [p=6×10−3] per G allele, 1.64 (1.25–2.16) [p=3.31×10−4] under a recessive model and 1.66 (1.26–2.19)[p=3.18×10−4] for homozygosity of the minor allele. To further validate this finding, we extended the analysis to include publicly available data for rs3218408. These included data from Han et al[28] based on premenopausal women from the NHS and from the CGEMs GWAS of Hunter et al[41] based on postmenopausal women from the NHS. In addition, we included data from the SEARCH study on the SNP rs3218499,[45] which is in high LD with rs3218408 (r2=0.97 in our controls). All five studies consistently demonstrated a risk effect for the rare homozygotes, with meta-OR (95% CI) for the recessive model of 1.33 (1.12–1.57) [p=0.001] (figure 2) in a sample size of 5,518 cases and 5,890 controls.
Figure 2.

Meta-analysis of the association of rs3218408 with breast cancer risk. Due to the lack of rs3218408 genotype data in the SEARCH study, data for the highly correlated SNP, rs3218499, was used. Fixed effect estimates are shown, with p value for homogeneity in parenthesis
XRCC2 SNP associations with survival of breast cancer patients
Vital status post-diagnosis was available for 814 of the 1,131 SBCS breast cancer cases. The median follow-up was 11.12 years (range 0.98–40.59). Many of the cases were prevalent cases, with a mean of 4.05 and a median of 2.85 years between diagnosis and recruitment to the study. Table 2 summarises the survival data by SNP. There were statistically significant differences in the K-M survival functions among genotypes for rs3218536 (p=4×10−6), rs3218534 (p=0.0224), rs3218455 (p=2×10−6) and rs3218374 (p=0.0248), with the p values for rs3218536 and rs3218455 being below a Bonferroni correction threshold of 4.2×10−3 for 12 SNPs. After adjustment for age and accounting for left-censoring time, the adjusted HRs [aHRs (95% CIs)] of the homozygous minor allele genotypes were 4.26 (1.69–10.72) and 3.86 (1.76–8.47) for rs3218536 and rs3218455, respectively, whilst both rs3218534 and rs3218374 heterozygous genotypes had about 40% reduction in aHRs, compared to the homozygous genotypes for the common allele. There were allele-dosage effects for both rs3218536 and rs3218455, with aHRs (95% CIs) of 1.48 (1.04–2.13) [p=0.032] for rs3218536 and 1.51 (1.08–2.10) [p=0.016] for rs3218455 (table 2). The assumption of proportionality of the baseline hazards was valid for both SNPs (p>0.05). These two SNPs are correlated (r2=0.85) and thus are likely to reflect the same underlying effect. The rs3218536 SNP, which causes the amino acid substitution R188H, was included in a model that further adjusted for lymph node status, grade and tumour size. The minor A allele was significantly associated with poor survival, with a aHR (95% CI) of 1.58 (1.01–2.49)[p=0.046].
Table 2.
Associations of XRCC2 SNPs with survival in SBCS breast cancer patients
| SNPs | Genotypes* | No. Total/Death† | Log-rank p value | aHR‡ (95% CI) |
|---|---|---|---|---|
| rs3218556 | CC | 721/178 | 0.1295 | 1 |
| CT | 63/20 | 1.63 (0.97–2.75) | ||
| rs3218536 | GG | 652/165 | 4×10−6 | 1 |
| GA | 110/30 | 1.19 (0.76–1.89) | ||
| AA | 7/5 | 4.26 (1.69–10.72) | ||
| Per A allele | 1.48 (1.04–2.13) | |||
| rs3218534 | CC | 259/71 | 0.0224 | 1 |
| CT | 396/93 | 0.60 (0.42–0.85) | ||
| TT | 150/41 | 0.74 (0.46–1.19) | ||
| Per T allele | 0.79 (0.62–1.01) | |||
| rs3218501 | CC | 721/193 | 0.2316 | 1 |
| CG+GG | 54/8 | 0.60 (0.26–1.35) | ||
| rs3218499 | GG | 445/122 | 0.7159 | 1 |
| GC | 284/68 | 0.87 (0.61–1.24) | ||
| CC | 39/9 | 0.80 (0.35–1.84) | ||
| rs3218455 | TT | 648/165 | 2×10−6 | 1 |
| TC | 113/29 | 1.16 (0.73–1.83) | ||
| CC | 11/7 | 3.86 (1.76–8.47) | ||
| Per C allele | 1.51 (1.08–2.10) | |||
| rs3111465 | GG | 600/155 | 0.7031 | 1 |
| GA+AA | 51/12 | 0.95 (0.48–1.88) | ||
| rs3094406 | CC | 508/130 | 0.1816 | 1 |
| CG+GG | 115/36 | 1.49 (0.97–2.26) | ||
| rs3218408 | TT | 442/121 | 0.8815 | 1 |
| TG | 248/61 | 0.90 (0.62–1.30) | ||
| GG | 66/16 | 0.87 (0.47–1.63) | ||
| rs3218400 | CC | 586/155 | 0.6323 | 1 |
| CA+AA | 190/47 | 1.04 (0.71–1.51) | ||
| rs2106776 | CC | 177/53 | 0.1076 | 1 |
| CT | 313/69 | 0.79 (0.51–1.22) | ||
| TT | 128/38 | 1.26 (0.77–2.06) | ||
| rs3218374 | CC | 235/67 | 0.0248 | 1 |
| CG | 365/89 | 0.59 (0.41–0.86) | ||
| GG | 157/42 | 0.78 (0.49–1.24) | ||
| Per G allele | 0.82 (0.64–1.05) |
genotypes were grouped if the number of deaths were less than 3
total numbers differ between SNPs due to missing genotypes
adjusted for age (continuous variable) and left-censoring at recruitment
We tested for replication of the rs3218536 association with survival in six studies from the BCAC, for which genotype data for rs3218536 and survival data were available. The distribution of age at diagnosis, time from diagnosis to recruitment, follow-up time, and available clinical characteristics for each study are shown in supplementary tables 1 and 2. Table 3 shows a summary of the HR estimates associated with rs3218536 by study. Four of the six replication studies demonstrated an increased hazard for the allelic effect of rs3218536, although individual study hazard ratios were not statistically significant. The pooled analysis of 8,781 breast cancer cases (including 1,414 deaths) showed that overall, each copy of the minor allele for rs3218536 was associated with a hazard ratio of 1.19 (1.05–1.36), p=0.01, after adjustment for age and study (table 3 and supplementary figure 1). Similar results were obtained if the analysis was restricted to European subjects [1,381 deaths out of 8,615; HR: 1.19 (1.04–1.37)]. The HR for the combined replication studies when SBCS data was excluded was 1.15 (1.00–1.33)[p=0.05].
Table 3.
Association of rs3218536 with breast cancer survival by study*
| Study | No. Total | No. Deaths | HR† (95% CI) | p value |
|---|---|---|---|---|
| ABCFS | 1223 | 270 | 1.14 (0.81–1.60) | 0.45 |
| CNIO-BC S |
190 | 6 | 1.03 (0.14–7.67) | 0.97 |
| HABCS | 598 | 86 | 0.80 (0.39–1.62) | 0.53 |
| PBCS | 1507 | 209 | 1.21 (0.83–1.77) | 0.33 |
| SBCS | 707 | 139 | 1.48 (1.04–2.13) | 0.03 |
| SEARCH | 4234 | 700 | 1.16 (0.97–1.39) | 0.11 |
| USRTS | 322 | 4 | 1.72 (0.17–17.86) | 0.65 |
| Pooled | 8781 | 1414 | 1.19 (1.05–1.36) | 0.01 |
the number of cases do not correspond to supplementary table 1 due to some missing genotype data.
adjusted for age and left-censoring at recruitment; pooled estimate stratified by study
Pooley et al (2008) reported that the rs3218536 SNP was specifically associated with receptor-positive tumours.[27] Therefore, we explored the hypothesis of a differential survival effect according to receptor status. However, the effect of rs3218536 on survival in the pooled dataset did not vary significantly according to ER or PR status (pinteraction=0.16 for PR; pinteraction=0.61 for ER; supplementary table 5).
DISCUSSION
In this study we successfully genotyped a total of 12 tSNPs in the XRCC2 gene and examined their associations with breast cancer risk and survival in the SBCS. The SNP rs3218408 was associated with breast cancer susceptibility. A rare haplotype, including the minor allele at rs3218408, was also identified as associated with breast cancer risk, but this result will require very large samples to replicate, given the rarity of the haplotype. SNP rs3218408 was also associated with breast cancer risk in the UBCS data set. The data were most consistent with a recessive mode of inheritance.
Four similar candidate gene case-control studies employing tag-SNP approaches have been published with respect to XRCC2 and breast cancer risk. Han et al. found the OR (95% CI) for the additive effect of rs3218408 was 0.98 (0.76–1.26) for premenopausal breast cancer risk in a sample size of 238 cases and 474 controls drawn from the predominantly Caucasian Nurses Health Study.[28] Using the genotype distributions supplementary to their publication, we estimated the OR (95% CI) for the recessive effect to be 1.26 (0.68–2.31). Pharoah et al genotyped the rs3218499 SNP in 2176 cases and 2274 controls from the SEARCH study.[45] This SNP is correlated with rs3218408 with r2=0.97, and yielded an OR (95% CI) of 1.14 (0.86–1.50) for the recessive model. Both of the above studies, together with GWAS data from the CGEMs NHS study, were incorporated into the meta-analysis shown in figure 2, resulting in an overall recessive OR (95% CI) of 1.33 (1.12–1.57). In another SEARCH study, Pooley et al genotyped a panel of 8 SNPs in XRCC2, in 2,270 cases and 2,280 controls. However, none of these were any more strongly correlated to rs3218408 than the rs3218499 SNP included in our meta-analysis. Pooley et al found a weak protective effect of rs3218536 (R188H), which was most significant in ER and PR positive tumours.[27] This effect was not seen in our SBCS data, nor was it reproduced in the large study done by the BCAC,[25] although we did observe a non-significant protective OR in SBCS receptor positive tumours [OR (95% CI) 0.80 (0.61–1.05); data not shown]. Haiman et al[26] genotyped 24 XRCC2 SNPs, including rs3218408, in a multi-ethnic study of 2,093 cases and 2,303 controls, and none of the XRCC2 SNPs were associated with breast cancer under an additive model, although the genotype distributions were not available to allow assessment of any recessive effects and could therefore not be included in our meta analysis. The available data suggests a recessive mode of inheritance, although we are not able to rule out other models. While further studies are required to resolve this issue, it seems biologically plausible that homozygous deficiency of a protein involved in DNA repair might be associated with increased cancer risk.
We also examined the XRCC2 SNPs for their associations with overall survival in breast cancer patients. We observed that two XRCC2 SNPs (rs3218536 and rs3218455) were statistically associated with survival. These two SNPs are correlated (r2=0.85) and are likely to be reflecting the same underlying effect. The effect of rs3218536 (R188H) remained significant in the multivariate analysis after adjustment for age at diagnosis, grade, lymph node, and tumour size, suggesting it may have an independent role in overall survival.
Our finding of a role for rs3218536 was not in accord with a recently published work, which found no statistically significant effect of the XRCC2 R188H SNP on breast cancer survival in 2,270 cases from the SEARCH study.[27] However, our pooled analysis of 7 datasets from the BCAC, including both the SBCS and a larger set of SEARCH cases (4,234), provided some support for an association. The minor allele of rs3218536 was associated with a 19% increased risk of death in a total of 8,781 case subjects (p=0.01). Further replications are needed to confirm this nominally significant result.
Despite the strength of the use of the large sample sizes, there are some limitations in this study. The risk association reported here was confined to the meta-analysis of the candidate gene studies and one available set of GWAS data; further replication by the incorporation of other relevant genome-wide association data would be beneficial. The use of the UBCS cases could lead to a biased estimate of risk, since they are drawn from high risk pedigrees. However, we see no evidence of this, since the estimate of the odds ratio from the meta-analysis remained the same when the UBCS data was excluded [recessive OR=1.33 (1.11–1.59)]. In addition, the inclusion of prevalent cases may potentially bias our estimates of breast cancer risk and survival if certain genotypes favour long-term survival. However, we found no evidence that the risk SNP rs3218408 was associated with breast cancer survival, thus the risk estimate is unlikely to be biased. The inclusion of prevalent cases in the survival study may lead to bias in HR estimates. To minimise any potential bias, we employed the left-truncated Cox model. The use of this model with prevalent cases yields the same HR estimates as those found when only incident cases are included. [44]
Due to the role of BRCA1 and BRCA2 in DNA repair, a large number of candidate gene studies of DNA repair genes have been carried out, although few have been conclusively replicated. Genome-wide association and sequencing studies have however provided support for a role for DNA repair genes in breast cancer risk. RAD51L1 (RAD51B) is a member of the RAD51 family of DNA double strand break repair proteins and is associated with risk,[46] and a number of proteins that interact with BRCA1 and BRCA2, such as PALB2 and BRIP1, have been shown to be mutated, albeit rarely, in familial breast cancers (reviewed in [47]). More recently a variant near the MERIT40 gene, whose protein is a component of the BRCA1-A complex, has been shown to act as a modifier of risk in BRCA1 mutation carriers,[48] and to affect ovarian cancer risk.[49]
In conclusion, our study provides evidence supporting an association of the XRCC2 rs3218408 SNP with the risk of breast cancer. If further replicated, data for this SNP could be incorporated into risk models with other validated SNPs. Beyond this single SNP result, a significant haplotype association, incorporating the minor allele at this SNP, was also identified. However, much larger studies of multiple SNPs will be required to further investigate this potentially large effect. With respect to overall survival, we observed an association with the XRCC2 rs3218536 (R188H) SNP. An association with survival has also been reported for this SNP in pancreatic cancer patients, especially in those who received both chemotherapy and X-ray therapy.[50] With the observation that rs3218536 variant cells show increased resistance to cisplatin treatments compared to wild-type cells,[51] future studies are needed to evaluate rs3218536 in the context of chemotherapy, to determine whether there may be implications for treating breast cancer.
Supplementary Material
ACKNOWLEDGEMENTS
The work reported in this paper would not have been possible without the contribution of many individuals. In particular we thank Sue Higham, Gordon MacPherson, Helen Cramp, Dan Connley and Ian Brock (SBCS), Fiona Blows, Craig Lucarrini, Don Conroy, the SEARCH team and the Eastern Cancer Registration and Information Centre (SEARCH), Manjeet Humphreys (BCAC), Katrin Gerriets, Maria Schiekel, Aysun Ay, Andreas Meyer, Michael Bremer, Frank Papendorf, Peter Hillemanns and Johann Hinrich Karstens (HABCS), Charo Alonso, Tais Moreno, Guillermo Pita and Anna González-Neira (CNIO-BCS), Drs. Louise Brinton, Stephen Chanock, Neonila Szeszenia- Dabrowska, Beata Peplonska, Witold Zatonski, Pei Chao and Michael Stagner (PBCS), the USRT radiologic technologists, Jerry Reid, Diane Kampa, Allison Iwan, and Laura Bowen (USRT). We also extend our thanks to the many women and their families that generously participated in all the studies. The CGEMS breast cancer GWAS stage 1-NHS data set was provided by the US National Institutes of Health (NIH) database of Genotypes and Phenotypes (dbGAP, accession no. phs000147.v1.p1). We thank the original investigators Hunter DJ, Kraft P, Jacobs KB, Cox DG, Yeager M, Hankinson SE, Wacholder S, Wang Z, Welch R, Hutchinson A, Wang J, Yu K, Chatterjee N, Orr N, Willett WC, Colditz GA, Ziegler RG, Berg CD, Buys SS, McCarty CA, Feigelson HS, Calle EE, Thun MJ, Hayes RB, Tucker M, Gerhard DS, Fraumeni JF Jr, Hoover RN, Thomas G, and Chanock SJ for making these data available, and we acknowledge NIH funding for the NHS study, as detailed in Hunter et al.[41]
FUNDING
The SBCS study was funded by the Breast Cancer Campaign (grant 2004Nov 49), and Yorkshire Cancer Research core funding. The Australian Breast Cancer Family Study was supported by the National Health and Medical Research Council of Australia, the New South Wales Cancer Council, the Victorian Health Promotion Foundation (Australia), and the National Cancer Institute, National Institutes of Health under RFA-CA-06–503 and through cooperative agreements with members of the Breast Cancer Family Registry (CFR) and Principal Investigators. The University of Melbourne (U01 CA69638) contributed data to this study. The content of this manuscript does not necessarily reflect the views or the policies of the National Cancer Institute or any of the collaborating centres in the CFR, nor does mention of trade names, commercial products or organizations imply endorsement by the US Government or the CFR. JLH is a National Health and Medical Research Council Australia Fellow. MCS is a National Health and Medical Research Council Senior Research Fellow. JLH and MCS are both group leaders of the Victoria Breast Cancer Research Consortium. The CNIO-BCS work was partly funded by the Red Temática de Investigación Cooperativa en Cáncer, the Asociación Española Contra Cáncer and grants from the Fondo de Investigación Santiario (PI081583 to R.L.M. and PI081120 to J.B.). SEARCH is funded by Cancer Research UK (C490/A10124) and the Cambridge NIHR Biomedical Research Centre. The PBCS was funded by Intramural Research Funds of the National Cancer Institute, Department of Health and Human Services, USA. The USRT study was funded by the Intramural Research Program of the Division of Cancer Epidemiology and Genetics, National Cancer Institute, National Institutes of Health.
References
- 1.van Gent DC, Hoeijmakers JHJ, Kanaar R. Chromosomal stability and the DNA double-stranded break connection. Nat Rev Genet. 2001;2:196–206. doi: 10.1038/35056049. [DOI] [PubMed] [Google Scholar]
- 2.Khanna KK, Jackson SP. DNA double-strand breaks: signaling, repair and the cancer connection. Nat Genet. 2001;27:247–254. doi: 10.1038/85798. [DOI] [PubMed] [Google Scholar]
- 3.Moynahan ME, Chiu JW, Koller BH, Jasin M. Brca1 controls homology-directed DNA repair. Mol Cell. 1999;4:511–518. doi: 10.1016/s1097-2765(00)80202-6. [DOI] [PubMed] [Google Scholar]
- 4.Moynahan ME, Pierce AJ, Jasin M. BRCA2 is required for homology-directed repair of chromosomal breaks. Mol Cell. 2001;7:263–272. doi: 10.1016/s1097-2765(01)00174-5. [DOI] [PubMed] [Google Scholar]
- 5.Miki Y, Swensen J, ShattuckEidens D, Futreal PA, Harshman K, Tavtigian S, Liu QY, Cochran C, Bennett LM, Ding W, Bell R, Rosenthal J, Hussey C, Tran T, McClure M, Frye C, Hattier T, Phelps R, Haugenstrano A, Katcher H, Yakumo K, Gholami Z, Shaffer D, Stone S, Bayer S, Wray C, Bogden R, Dayananth P, Ward J, Tonin P, Narod S, Bristow PK, Norris FH, Helvering L, Morrison P, Rosteck P, Lai M, Barrett JC, Lewis C, Neuhausen S, CannonAlbright L, Goldgar D, Wiseman R, Kamb A, Skolnick MH. A Strong Candidate for the Breast and Ovarian-Cancer Susceptibility Gene Brca1. Science. 1994;266:66–71. doi: 10.1126/science.7545954. [DOI] [PubMed] [Google Scholar]
- 6.Wooster R, Bignell G, Lancaster J, Swift S, Seal S, Mangion J, Collins N, Gregory S, Gumbs C, Micklem G, Barfoot R, Hamoudi R, Patel S, Rice C, Biggs P, Hashim Y, Smith A, Connor F, Arason A, Gudmundsson J, Ficenec D, Kelsell D, Ford D, Tonin P, Bishop DT, Spurr NK, Ponder BAJ, Eeles R, Peto J, Devilee P, Cornelisse C, Lynch H, Narod S, Lenoir G, Egilsson V, Barkadottir RB, Easton DF, Bentley DR, Futreal PA, Ashworth A, Stratton MR. Identification of the Breast-Cancer Susceptibility Gene Brca2. Nature. 1995;378:789–792. doi: 10.1038/378789a0. [DOI] [PubMed] [Google Scholar]
- 7.Cartwright R, Tambini CE, Simpson PJ, Thacker J. The XRCC2 DNA repair gene from human and mouse encodes a novel member of the recA/RAD51 family. Nucleic Acids Res. 1998;26:3084–3089. doi: 10.1093/nar/26.13.3084. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Liu N, Lamerdin JE, Tebbs RS, Schild D, Tucker JD, Shen MR, Brookman KW, Siciliano MJ, Walter CA, Fan WF, Narayana LS, Zhou ZQ, Adamson AW, Sorensen KJ, Chen DJ, Jones NJ, Thompson LH. XRCC2 and XRCC3, new human Rad51-family members, promote chromosome stability and protect against DNA cross-links and other damages. Mol Cell. 1998;1:783–793. doi: 10.1016/s1097-2765(00)80078-7. [DOI] [PubMed] [Google Scholar]
- 9.Johnson RD, Liu N, Jasin M. Mammalian XRCC2 promotes the repair of DNA double-strand breaks by homologous recombination. Nature. 1999;401:397–399. doi: 10.1038/43932. [DOI] [PubMed] [Google Scholar]
- 10.Cui X, Brenneman M, Meyne J, Oshimura M, Goodwin EH, Chen DJ. The XRCC2 and XRCC3 repair genes are required for chromosome stability in mammalian cells. Mutation Research-DNA Repair. 1999;434:75–88. doi: 10.1016/s0921-8777(99)00010-5. [DOI] [PubMed] [Google Scholar]
- 11.Griffin CS, Simpson PJ, Wilson CR, Thacker J. Mammalian recombination-repair genes XRCC2 and XRCC3 promote correct chromosome segregation. Nat Cell Biol. 2000;2:757–761. doi: 10.1038/35036399. [DOI] [PubMed] [Google Scholar]
- 12.Deans B, Griffin CS, O'Regan P, Jasin M, Thacker J. Homologous recombination deficiency leads to profound genetic instability in cells derived from Xrcc2-knockout mice. Cancer Res. 2003;63:8181–8187. [PubMed] [Google Scholar]
- 13.Huang HM, Fletcher L, Beeharry N, Daniel R, Kao G, Yen TJ, Muschel RJ. Abnormal cytokinesis after X-irradiation in tumor cells that override the G(2) DNA damage checkpoint. Cancer Res. 2008;68:3724–3732. doi: 10.1158/0008-5472.CAN-08-0479. [DOI] [PubMed] [Google Scholar]
- 14.O’Regan P, Wilson C, Townsend S, Thacker J. XRCC2 is a nuclear RAD51-like protein required for damage-dependent RAD51 focus formation without the need for ATP binding. J Biol Chem. 2001;276:22148–22153. doi: 10.1074/jbc.M102396200. [DOI] [PubMed] [Google Scholar]
- 15.Takata M, Sasaki MS, Tachiiri S, Fukushima T, Sonoda E, Schild D, Thompson LH, Takeda S. Chromosome instability and defective recombinational repair in knockout mutants of the five Rad51 paralogs. Mol Cell Biol. 2001;21:2858–2866. doi: 10.1128/MCB.21.8.2858-2866.2001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Liu N, Schild D, Thelen MP, Thompson LH. Involvement of Rad51C in two distinct protein complexes of Rad51 paralogs in human cells. Nucleic Acids Res. 2002;30:1009–1015. doi: 10.1093/nar/30.4.1009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Tsaryk R, Fabian K, Thacker J, Kaina B. Xrcc2 deficiency sensitizes cells to apoptosis by MNNG and the alkylating anticancer drugs temozolomide, fotemustine and mafosfamide. Cancer Lett. 2006;239:305–313. doi: 10.1016/j.canlet.2005.08.036. [DOI] [PubMed] [Google Scholar]
- 18.Roos WP, Nikolova T, Quiros S, Naumann SC, Kiedron O, Zdzienicka MZ, Kaina B. Brca2/Xrcc2 dependent HR, but not NHEJ, is required for protection against O-6-methylguanine triggered apoptosis, DSBs and chromosomal aberrations by a process leading to SCEs. DNA Repair. 2009;8:72–86. doi: 10.1016/j.dnarep.2008.09.003. [DOI] [PubMed] [Google Scholar]
- 19.Sprong D, Janssen HDL, Vens C, Begg AC. Resistance of hypoxic cells to ionizing radiation is influenced by homologous recombination status. Int J Radiat Oncol Biol Phys. 2006;64:562–572. doi: 10.1016/j.ijrobp.2005.09.031. [DOI] [PubMed] [Google Scholar]
- 20.Evans JW, Chernikova SB, Kachnic LA, Banath JP, Sordet O, Delahoussaye YM, Treszezamsky A, Chon BH, Feng Z, Gu Y, Wilson WR, Pommier Y, Olive PL, Powell SN, Brown JM. Homologous recombination is the principal pathway for the repair of DNA damage induced by tirapazamine in mammalian cells. Cancer Res. 2008;68:257–265. doi: 10.1158/0008-5472.CAN-06-4497. [DOI] [PubMed] [Google Scholar]
- 21.De Silva IU, McHugh PJ, Clingen PH, Hartley JA. Defining the roles of nucleotide excision repair and recombination in the repair of DNA interstrand cross-links in mammalian cells. Mol Cell Biol. 2000;20:7980–7990. doi: 10.1128/mcb.20.21.7980-7990.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Yanagisawa T, Urade M, Yamamoto Y, Furuyama J. Increased expression of human DNA repair genes, XRCC1, XRCC3 and RAD51, in radioresistant human KB carcinoma cell line N10. Oral Oncol. 1998;34:524–528. doi: 10.1016/s1368-8375(98)00045-1. [DOI] [PubMed] [Google Scholar]
- 23.Wang ZM, Chen ZP, Xu ZY, Christodoulopoulos G, Bello V, Mohr G, Aloyz R, Panasci LC. In vitro evidence for homologous recombinational repair in resistance to melphalan. J Natl Cancer Inst. 2001;93:1473–1478. doi: 10.1093/jnci/93.19.1473. [DOI] [PubMed] [Google Scholar]
- 24.Bello VE, Aloyz RS, Christodoulopoulos G, Panasci LC. Homologous recombinational repair vis-a-vis chlorambucil resistance in chronic lymphocytic leukemia. Biochem Pharmacol. 2002;63:1585–1588. doi: 10.1016/s0006-2952(02)00954-1. [DOI] [PubMed] [Google Scholar]
- 25.The Breast Cancer Association Consortium. Commonly studied single-nucleotide polymorphisms and breast cancer: Results from the Breast Cancer Association Consortium. J Natl Cancer Inst. 2006;98:1382–1396. doi: 10.1093/jnci/djj374. [DOI] [PubMed] [Google Scholar]
- 26.Haiman CA, Hsu C, de Bakker PIW, Frasco M, Sheng X, Van Den Berg D, Casagrande JT, Kolonel LN, Le Marchand L, Hankinson SE, Han J, Dunning AM, Pooley KA, Freedman ML, Hunter DJ, Wu AH, Stram DO, Henderson BE. Comprehensive association testing of common genetic variation in DNA repair pathway genes in relationship with breast cancer risk in multiple populations. Hum Mol Genet. 2008;17:825–834. doi: 10.1093/hmg/ddm354. [DOI] [PubMed] [Google Scholar]
- 27.Pooley KA, Baynes C, Driver KE, Tyrer J, Azzato EM, Pharoah PDP, Easton DF, Ponder BAJ, Dunning AM. Common Single-Nucleotide Polymorphisms in DNA Double-Strand Break Repair Genes and Breast Cancer Risk. Cancer Epidemiol Biomarkers Prev. 2008;17:3482–3489. doi: 10.1158/1055-9965.EPI-08-0594. [DOI] [PubMed] [Google Scholar]
- 28.Han JL, Haiman C, Niu TH, Guo Q, Cox DG, Willett WC, Hankinson SE, Hunter DJ. Genetic variation in DNA repair pathway genes and premenopausal breast cancer risk. Breast Cancer Res Treat. 2009;115:613–622. doi: 10.1007/s10549-008-0089-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Rafii S, O'Regan P, Xinarianos G, Azmy I, Stephenson T, Reed M, Meuth M, Thacker J, Cox A. A potential role for the XRCC2 R188H polymorphic site in DNA-damage repair and breast cancer. Hum Mol Genet. 2002;11:1433–1438. doi: 10.1093/hmg/11.12.1433. [DOI] [PubMed] [Google Scholar]
- 30.MacPherson G, Healey CS, Teare MD, Balasubramanian SP, Reed MWR, Pharoah PDP, Ponder BAJ, Meath M, Bhattacharyya NP, Cox A. Association of a common variant of the CASP8 gene with reduced risk of breast cancer. J Natl Cancer Inst. 2004;96:1866–1869. doi: 10.1093/jnci/dji001. [DOI] [PubMed] [Google Scholar]
- 31.Cannon-Albright LA. Utah family-based analysis: Past, present and future. Hum Hered. 2008;65:209–220. doi: 10.1159/000112368. [DOI] [PubMed] [Google Scholar]
- 32.Allen-Brady K, Cannon-Albright LA, Neuhausen SL, Camp NJ. A role for XRCC4 in age at diagnosis and breast cancer risk. Cancer Epidemiol Biomarkers Prev. 2006;15:1306–1310. doi: 10.1158/1055-9965.EPI-05-0959. [DOI] [PubMed] [Google Scholar]
- 33.Garcia-Closas M, Hall P, Nevanlinna H, Pooley K, Morrison J, Richesson DA, Bojesen SE, Nordestgaard BG, Axelsson CK, Arias JI, Milne RL, Ribas G, Gonzalez-Neira A, Benitez J, Zamora P, Brauch H, Justenhoven C, Hamann U, Ko YD, Bruening T, Haas S, Dork T, Schurmann P, Hillemanns P, Bogdanova N, Bremer M, Karstens JH, Fagerholm R, Aaltonen K, Aittomaki K, Von Smitten K, Blomqvist C, Mannermaa A, Uusitupa M, Eskelinen M, Tengstrom M, Kosma VM, Kataja V, Chenevix-Trench G, Spurdle AB, Beesley J, Chen X, Devilee P, Van Asperen CJ, Jacobi CE, Tollenaar R, Huijts PEA, Klijn JGM, Chang-Claude J, Kropp S, Slanger T, Flesch-Janys D, Mutschelknauss E, Salazar R, Wang-Gohrke S, Couch F, Goode EL, Olson JE, Vachon C, Fredericksen ZS, Giles GG, Baglietto L, Severi G, Hopper JL, English DR, Southey MC, Haiman CA, Henderson BE, Kolonel LN, Le Marchand L, Stram DO, Hunter DJ, Hankinson SE, Cox DG, Tamimi R, Kraft P, Sherman ME, Chanock SJ, Lissowska J, Brinton LA, Peplonska B, Hooning MJ, Meijers-Heijboer H, Collee JM, Van den Ouweland A, Uitterlinden AG, Liu J, Lin LY, Yuqing L, Humphreys K, Czene K, Cox A, Balasubramanian SP, Cross SS, Reed MWR, Blows F, Driver K, Dunning A, Tyrer J, Ponder BAJ, Sangrajrang S, Brennan P, McKay J, Odefrey F, Gabrieau V, Sigurdson A, Doody M, Struewing JP, Alexander B, Easton DF, Pharoah PD. Heterogeneity of breast cancer associations with five susceptibility loci by clinical and pathological characteristics. Plos Genetics. 2008;4:e1000054. doi: 10.1371/journal.pgen.1000054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Collins FS, Brooks LD, Chakravarti A. A DNA polymorphism discovery resource for research on human genetic variation. Genome Res. 1998;8:1229–1231. doi: 10.1101/gr.8.12.1229. [DOI] [PubMed] [Google Scholar]
- 35.Livingston RJ, von Niederhausern A, Jegga AG, Crawford DC, Carlson CS, Rieder MJ, Gowrisankar S, Aronow BJ, Weiss RB, Nickerson DA. Pattern of sequence variation across 213 environmental response genes. Genome Res. 2004;14:1821–1831. doi: 10.1101/gr.2730004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Kimmel G, Shamir R. GERBIL: Genotype resolution and block identification using likelihood. Proc Natl Acad Sci U S A. 2005;102:158–162. doi: 10.1073/pnas.0404730102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Chapman JM, Cooper JD, Todd JA, Clayton DG. Detecting disease associations due to linkage disequilibrium using haplotype tags: A class of tests and the determinants of statistical power. Hum Hered. 2003;56:18–31. doi: 10.1159/000073729. [DOI] [PubMed] [Google Scholar]
- 38.Gonzalez JR, Armengol L, Sole X, Guino E, Mercader JM, Estivill X, Moreno V. SNPassoc: an R package to perform whole genome association studies. Bioinformatics. 2007;23:644–645. doi: 10.1093/bioinformatics/btm025. [DOI] [PubMed] [Google Scholar]
- 39.Allen-Brady K, Wong J, Camp NJ. PedGenie: an analysis approach for genetic association testing in extended pedigrees and genealogies of arbitrary size. Bmc Bioinformatics. 2006;7:209. doi: 10.1186/1471-2105-7-209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Curtin K, Wong J, Allen-Brady K, Camp NJ. PedGenie: meta genetic association testing in mixed family and case-control designs. Bmc Bioinformatics. 2007;8:448. doi: 10.1186/1471-2105-8-448. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Hunter DJ, Kraft P, Jacobs KB, Cox DG, Yeager M, Hankinson SE, Wacholder S, Wang ZM, Welch R, Hutchinson A, Wang JW, Yu K, Chatterjee N, Orr N, Willett WC, Colditz GA, Ziegler RG, Berg CD, Buys SS, McCarty CA, Feigelson HS, Calle EE, Thun MJ, Hayes RB, Tucker M, Gerhard DS, Fraumeni JF, Hoover RN, Thomas G, Chanock SJ. A genome-wide association study identifies alleles in FGFR2 associated with risk of sporadic postmenopausal breast cancer. Nat Genet. 2007;39:870–874. doi: 10.1038/ng2075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Higgins JPT, Thompson SG, Deeks JJ, Altman DG. Measuring inconsistency in meta-analyses. Br Med J. 2003;327:557–560. doi: 10.1136/bmj.327.7414.557. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Harris RJ, Bradburn MJ, Deeks JJ, Harbord RM, Altman DG, Sterne JAC. metan: fixed- and random-effects meta-analysis. Stata Journal. 2008;8:3–28. [Google Scholar]
- 44.Azzato EM, Greenberg D, Shah M, Blows F, Driver KE, Caporaso NE, Pharoah PDP. Prevalent cases in observational studies of cancer survival: do they bias hazard ratio estimates? Br J Cancer. 2009;100:1806–1811. doi: 10.1038/sj.bjc.6605062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Pharoah PDP, Tyrer J, Dunning AM, Easton DF, Ponder BAJ. Association between common variation in 120 candidate genes and breast cancer risk. Plos Genetics. 2007;3:401–406. doi: 10.1371/journal.pgen.0030042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Thomas G, Jacobs KB, Kraft P, Yeager M, Wacholder S, Cox DG, Hankinson SE, Hutchinson A, Wang Z, Yu K, Chatterjee N, Garcia-Closas M, Gonzalez-Bosquet J, Prokunina-Olsson L, Orr N, Willett WC, Colditz GA, Ziegler RG, Berg CD, Buys SS, McCarty CA, Feigelson HS, Calle EE, Thun MJ, Diver R, Prentice R, Jackson R, Kooperberg C, Chlebowski R, Lissowska J, Peplonska B, Brinton LA, Sigurdson A, Doody M, Bhatti P, Alexander BH, Buring J, Lee IM, Vatten LJ, Hveem K, Kumle M, Hayes RB, Tucker M, Gerhard DS, Fraumeni JF, Hoover RN, Chanock SJ, Hunter DJ. A multistage genome-wide association study in breast cancer identifies two new risk alleles at 1p11.2 and 14q24.1 (RAD51L1) Nat Genet. 2009;41:579–584. doi: 10.1038/ng.353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Stratton MR, Rahman N. The emerging landscape of breast cancer susceptibility. Nat Genet. 2008;40:17–22. doi: 10.1038/ng.2007.53. [DOI] [PubMed] [Google Scholar]
- 48.Antoniou AC, Wang XS, Fredericksen ZS, McGuffog L, Tarrell R, Sinilnikova OM, Healey S, Morrison J, Kartsonaki C, Lesnick T, Ghoussaini M, Barrowdale D, Peock S, Cook M, Oliver C, Frost D, Eccles D, Evans DG, Eeles R, Izatt L, Chu C, Douglas F, Paterson J, Stoppa-Lyonnet D, Houdayer C, Mazoyer S, Giraud S, Lasset C, Remenieras A, Caron O, Hardouin A, Berthet P, Hogervorst FBL, Rookus MA, Jager A, van den Ouweland A, Hoogerbrugge N, van der Luijt RB, Meijers-Heijboer H, Garcia EBG, Devilee P, Vreeswijk MPG, Lubinski J, Jakubowska A, Gronwald J, Huzarski T, Byrski T, Gorski B, Cybulski C, Spurdle AB, Holland H, Goldgar DE, John EM, Hopper JL, Southey M, Buys SS, Daly MB, Terry MB, Schmutzler RK, Wappenschmidt B, Engel C, Meindl A, Preisler-Adams S, Arnold N, Niederacher D, Sutter C, Domchek SM, Nathanson KL, Rebbeck T, Blum JL, Piedmonte M, Rodriguez GC, Wakeley K, Boggess JF, Basil J, Blank SV, Friedman E, Kaufman B, Laitman Y, Milgrom R, Andrulis IL, Glendon G, Ozcelik H, Kirchhoff T, Vijai J, Gaudet MM, Altshuler D, Guiducci C, Loman N, Harbst K, Rantala J, Ehrencrona H, Gerdes AM, Thomassen M, Sunde L, Peterlongo P, Manoukian S, Bonanni B, Viel A, Radice P, Caldes T, de la Hoya M, Singer CF, Fink-Retter A, Greene MH, Mai PL, Loud JT, Guidugli L, Lindor NM, Hansen TVO, Nielsen FC, Blanco I, Lazaro C, Garber J, Ramus SJ, Gayther SA, Phelan C, Narod S, Szabo CI, Benitez J, Osorio A, Nevanlinna H, Heikkinen T, Caligo MA, Beattie MS, Hamann U, Godwin AK, Montagna M, Casella C, Neuhausen SL, Karlan BY, Tung N, Toland AE, Weitzel J, Olopade O, Simard J, Soucy P, Rubinstein WS, Arason A, Rennert G, Martin NG, Montgomery GW, Chang-Claude J, Flesch-Janys D, Brauch H, Severi G, Baglietto L, Cox A, Cross SS, Miron P, Gerty SM, Tapper W, Yannoukakos D, Fountzilas G, Fasching PA, Beckmann MW, Silva IDS, Peto J, Lambrechts D, Paridaens R, Rudiger T, Forsti A, Winqvist R, Pylkaas K, Diasio RB, Lee AM, Eckel-Passow J, Vachon C, Blows F, Driver K, Dunning A, Pharoah PPD, Offit K, Pankratz VS, Hakonarson H, Chenevix-Trench G, Easton DF, Couch FJ. A locus on 19p13 modifies risk of breast cancer in BRCA1 mutation carriers and is associated with hormone receptor-negative breast cancer in the general population. Nat Genet. 2010;42 doi: 10.1038/ng.669. 885-+ [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Bolton EL, Tyrer J, Song H, Ramus SJ, Notaridou M, Jones C, Sher T, Gentry-Maharaj A, Wozniak E, Tsai YY, Weidhaas J, Paik D, Van den Berg DJ, Stram DO, Pearce CL, Wu AH, Brewster W, Anton-Culver H, Ziogas A, Narod SA, Levine DA, Kaye SB, Brown R, Paul J, Flanagan J, Sieh W, McGuire V, Whittemore AS, Campbell I, Gore ME, Lissowska J, Yang HP, Medrek K, Gronwald J, Lubinski J, Jakubowska A, Le ND, Cook LS, Kelemen LE, Brook-Wilson A, Massuger L, Kiemeney LA, Aben KKH, van Altena AM, Houlston R, Tomlinson I, Palmieri RT, Moorman PG, Schildkraut J, Iversen ES, Phelan C, Vierkant RA, Cunningham JM, Goode EL, Fridley BL, Kruger-Kjaer S, Blaeker J, Hogdall E, Hogdall C, Gross J, Karlan BY, Ness RB, Edwards RP, Odunsi K, Moyisch KB, Baker JA, Modugno F, Heikkinenen T, Butzow R, Nevanlinna H, Leminen A, Bogdanova N, Antonenkova N, Doerk T, Hillemanns P, Duurst M, Runnebaum I, Thompson PJ, Carney ME, Goodman MT, Lurie G, Wang-Gohrke S, Hein R, Chang-Claude J, Rossing MA, Cushing-Haugen KL, Doherty J, Chen C, Rafnar T, Besenbacher S, Sulem P, Stefansson K, Birrer MJ, Terry KL, Hernandez D, Cramer DW, Vergote I, Amant F, Lambrechts D, Despierre E, Fasching PA, Beckmann MW, Thiel FC, Ekici AB, Chen XQ, Johnatty SE, Webb PM, Beesley J, Chanock S, Garcia-Closas M, Sellers T, Easton DF, Berchuck A, Chenevix-Trench G, Pharoah PDP, Gayther SA. Common variants at 19p13 are associated with susceptibility to ovarian cancer. Nat Genet. 2010;42:880–884. doi: 10.1038/ng.666. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Li DH, Liu H, Jiao L, Chang DZ, Beinart G, Wolff RA, Evans DB, Hassan MM, Abbruzzese JL. Significant effect of homologous recombination DNA repair gene polymorphisms on pancreatic cancer survival. Cancer Res. 2006;66:3323–3330. doi: 10.1158/0008-5472.CAN-05-3032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Danoy P, Sonoda E, Lathrop M, Takeda S, Matsuda F. A naturally occurring genetic variant of human XRCC2 (R188H) confers increased resistance to cisplatin-induced DNA damage. Biochem Biophys Res Commun. 2007;352:763–768. doi: 10.1016/j.bbrc.2006.11.083. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.