

Abstract
Classical regression methods treat covariates as a vector and estimate a corresponding vector of regression coefficients. Modern applications in medical imaging generate covariates of more complex form such as multidimensional arrays (tensors). Traditional statistical and computational methods are proving insufficient for analysis of these high-throughput data due to their ultrahigh dimensionality as well as complex structure. In this article, we propose a new family of tensor regression models that efficiently exploit the special structure of tensor covariates. Under this framework, ultrahigh dimensionality is reduced to a manageable level, resulting in efficient estimation and prediction. A fast and highly scalable estimation algorithm is proposed for maximum likelihood estimation and its associated asymptotic properties are studied. Effectiveness of the new methods is demonstrated on both synthetic and real MRI imaging data.
Keywords: Brain imaging, dimension reduction, generalized linear model (GLM), magnetic resonance imaging (MRI), multidimensional array, tensor regression
1 Introduction
Understanding the inner workings of the human brains and their connection with neuropsychiatric and neurodegenerative disorders is one of the most intriguing scientific questions. Studies in neuroscience are greatly facilitated by a variety of neuroimaging technologies, including anatomical magnetic resonance imaging (MRI), functional magnetic resonance imaging (fMRI), electroencephalography (EEG), diffusion tensor imaging (DTI), and positron emission tomography (PET), among others. The sheer size and complexity of medical imaging data, however, pose unprecedented challenge to many classical statistical methods and have received increasing interest in recent years (Lindquist, 2008; Lazar, 2008; Martino et al., 2008; Friston, 2009; Ryali et al., 2010; Hinrichs et al., 2009; Kang et al., 2012).
In the literature, there have been roughly three categories of statistical methods for establishing association between brain images and clinical traits. The first is the voxel-based methods, which take each voxel as responses and clinical variables such as age and gender as predictors. They generate a statistical parametric map of test statistics or p-values across all voxels (Lazar, 2008; Worsley et al., 2004). A major drawback is that all voxels are treated as independent units and important spatially correlation is ignored (Li et al., 2011; Yue et al., 2010; Polzehl et al., 2010). The second type of solutions adopts the functional data analysis approach. Reiss and Ogden (2010) notably extended functional regression model to incorporate two-dimensional images as predictors. Generalizations to 3D and higher dimensional images, however, is far from trivial and requires substantial research. The third category employs a two-stage strategy. These methods first carry out a dimension reduction step, often by principal component analysis (PCA), and then fit a regression model based on the top principal components (Caffo et al., 2010). This strategy is intuitive and easy to implement. However, it is well known that PCA is an unsupervised dimension reduction technique and the extracted principal components can be irrelevant to the response.
In this article, we formulate a regression framework that treats clinical outcome as response, and images, in the form of multi-dimensional array, as covariates. Most classical regression methods take vectors as covariates. Naively turning an image array into a vector yields an unsatisfactory solution. For instance, typical anatomical MRI images of size 256-by-256-by-256 implicitly require 2563 = 16, 777, 216 regression parameters. Both computability and theoretical guarantee of the classical regression analysis are compromised by this ultra-high dimensionality. More seriously, vectorizing an array destroys the inherent spatial structure of the image that possesses wealth of information.
Exploiting the array structure in imaging data, our new regression method substantially reduces the dimensionality of imaging data, leading to efficient estimation and prediction. The method works for general array-valued covariates and/or any combination of them, and thus it is applicable to a variety of imaging modalities, e.g., EEG, MRI and fMRI. It is embedded in the generalized linear model (GLM) framework, so it works for both continuous and discrete responses. We develop a highly scalable algorithm for maximum likelihood estimation, as well as statistical inferential tools. Regularized tensor regression is also investigated to identify regions of interest in brains that are relevant to a particular response. This region selection problem corresponds to variable selection in the usual vector-valued regression.
The contributions of this article are two-fold. First, from a brain imaging analysis point of view, our proposal timely responds to a number of growing needs of neuroimaging analysis. In the review article, Lindquist (2008) noted the increasing trend and demands of using brain images for disease diagnosis and prediction, for characterization of subjective human experience, and for understanding association between brain regions and cognitive outcomes. Our tensor regression framework offers a systematic solution to this family of problems. Moreover, the framework warrants potential solutions to address questions such as multi-modality imaging analysis, multi-phenotype analysis and imaging genetics (Friston, 2009; Casey et al., 2010), which largely remain as open challenges. Second, from a statistical methodology point of view, our proposal develops a general statistical framework for regression with array covariates. A large number of models and extensions, e.g., quasi-likelihood models (McCullagh and Nelder, 1983), are potential outcomes within this framework. It can also be viewed as a logic extension from the classical vector-valued covariate regression to functional covariate regression and then to array-valued covariate regression.
The rest of the article is organized as follows. Section 2 begins with a review of matrix/array properties, and then develops the tensor regression models. Section 3 presents an effcient algorithm for maximum likelihood estimation. Section 4 provides theoretical results such as identifiability, consistency, and asymptotic normality. Section 5 discusses regularization including region selection. Section 6 presents numerical results. Section 7 concludes with a discussion of future extensions. Technical proofs are delegated to the Appendix.
2 Model
2.1 Preliminaries
Multidimensional array, also called tensor, plays a central role in our approach and we start with a brief summary of notation and a few results for matrix/array operations. Extensive references can be found in the survey paper (Kolda and Bader, 2009). In this article we use the terms multidimensional array and tensor interchangeably.
Given two matrices and , the Kronecker product is the mp-by-nq matrix A ⊗ B = [a1 ⊗ Ba1 ⊗ B … an ⊗ B]. If A and B have the same number of columns n = q, then the Khatri-Rao product (Rao and Mitra, 1971) is defined as the mp-by-n columnwise Kronecker product A ⊙ B = a1 ⊗ b1 a2 ⊗ b2 … an ⊗ bn]. If n = q = 1, then A ⊙ B = A ⊗ B. Some useful operations transform a tensor into a matrix/vector. The vec(B) operator stacks the entries of a D-dimensional tensor into a column vector. Specifically, an entry bi1…iD maps to the j-th entry of vec B, in which . For instance, when D = 2, the matrix entry xi1i2 maps to position j = 1 + i1 − 1 + (i2 − 1)p1 = i1 + (i2 − 1)p1, which is consistent with the more familiar vec operation on a matrix. The mode-d matricization, B(d), maps a tensor B into a pd × Πd′≠dpd′ matrix such that the (i1, …, iD) element of the array B maps to the (id, j) element of the matrix B(d), where j = 1 + Σd′≠;d(id′ − 1) Πd″<d′,d″≠dpd″. With d = 1, we observe that vec B is the same as vectorizing the mode-1 matricization B(1). The mode-(d, d′) matricization is defined in a similar fashion (Kolda, 2006). We also introduce an operator that turns vectors into an array. Specifically, an outer product, b1 ο b2 ο ⋯ ο bD, of D vectors is a p1 × ⋯ × pD array with entries .
Tensor decomposition plays a central role in our proposed tensor regression in Section 2.3. An array admits a rank-R decomposition if
| (1) |
where , d = 1, …, D, r = 1, …, R, are all column vectors, and B cannot be written as a sum of less than R outer products. For convenience, the decomposition is often represented by a shorthand, B = ⟦B1, …, BD⟧, where (Kolda, 2006; Kolda and Bader, 2009). The following well-known result relates the mode-d matricization and the vec operator of an array to its rank-R decomposition.
Lemma 1. If a tensor admits a rank-R decomposition (1), then
Throughout the article, we adopt the following notations. Y is a univariate response variable, denotes a p0-dimensional vector of covariates, such as age and sex, and is a D-dimensional array-valued predictor. For instance, for MRI, D = 3, representing the 3D structure of an image, whereas for fMRI, D = 4, with an additional time dimension. The lower-case triplets (yi, xi, zi), i = 1, …, n, denote the independent, observed sample instances of (Y, X, Z).
2.2 Motivation and Basic Model
To motivate our model, we first start with a vector-valued X and absorb Z into X. In the classical GLM (McCullagh and Nelder, 1983) setting, Y belongs to an exponential family with probability mass function or density
| (2) |
where θ and ϕ > 0 denote the natural and dispersion parameters. The classical GLM relates a vector-valued to the mean μ = E(Y|X) via g(μ) = η = α + β⊺X, where g(·) is a strictly increasing link function, and η denotes the linear systematic part with intercept α and the coefficient vector .
Next, for a matrix-valued covariate (D = 2), it is intuitive to consider a GLM model with the systematic part given by
where and , respectively. The bilinear form is a natural extension of the linear term β⊺X in the classical GLM with a vector covariate X. It is interesting to note that, this bilinear form was first proposed by Li et al. (2010) in the context of dimension reduction, and then employed by Hung and Wang (2011) in the logistic regression with matrix-valued covariates (D = 2). Moreover, note that .
Now for a conventional vector-valued covariate Z and a general array-valued , we propose a GLM with the systematic part given by
| (3) |
where and for d = 1, …, D. This is our basic model for regression with array covariates. The key advantage of model (3) is that it dramatically reduces the dimensionality of the tensor component, from the order of Πd pd to the order of Σd pd. Take MRI imaging as an example, the size of a typical image is 2563 = 16, 777, 216. PIf we simply turn X into a vector and fit a GLM, this brutal force solution is over 16 million-dimensional, and the computation is practically infeasible. In contrast, the multilinear model (3) is only 256 + 256 + 256 = 768-dimensional. The reduction in dimension, and consequently in computational cost, is substantial.
A critical question then is whether such a massive reduction in the number of parameters would limit the capacity of model (3) to capture regions of interest with specific shapes. The illustrative example in Figure 1 provides some clues. In Figure 1, we present several two-dimensional images (shown in the first column), along with the estimated images by model (3) (in the second column labeled by TR(1)). Specifically, we simulated 1,000 univariate responses yi according to a normal model with mean μi = γ⊺zi + 〈B, xi〉, where γ = 15. The inner product between two arrays is defined as 〈B, X〉 = 〈vecB, vecX〉 = Σi1,…,iD βi1…iDxi1…iD. The coefficient array B is binary, with the true signal region equal to one and the rest zero. The regular covariate zi and image covariate xi are randomly generated with all elements being independent standard normals. Our goal is to see if model (3) can identify the true signal region in B using data (yi, zi, xi). Before examining the outcome, we make two remarks about this illustration. First, our problem differs from the usual edge detection or object recognition in imaging processing (Qiu, 2005, 2007). In our setup, all elements of the image X follow the same distribution. The signal region is defined through the coefficient image B and needs to be inferred from the association between Y and X after adjusting for Z. Second, the classical GLM is difficult to apply in this example if we simply treat vec(X) as a covariate vector, since the sample size n = 1, 000 is much less than the number of parameters p = 5 + 64 × 64 = 4, 101. Back to Figure 1, the second column clearly demonstrates the ability of model (3) in identifying the rectangular (square) type region (parallel to the image edges). On the other hand, since the parameter vector βd in a rank-1 model is only able to capture the accumulative signal along the d-th dimension of the array variate X, it is unsurprising that it does not perform well for signals that are far away from rectangle, such as triangle, disk, T-shape and butterfly. This motivates us to develop a more flexible tensor regression model in the next section.
Figure 1.
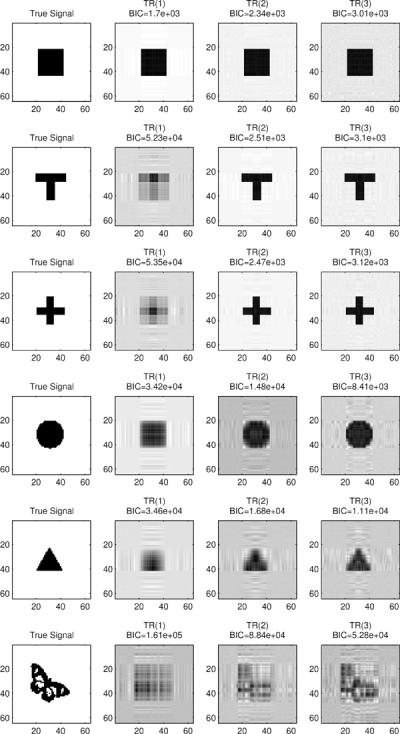
True and recovered image signals by tensor regression. The matrix variate has size 64 by 64 with entries generated as independent standard normals. The regression coefficient for each entry is either 0 (white) or 1 (black). The sample size is 1000. TR(R) means estimate from the rank-R tensor regression.
2.3 Tensor Regression Model
We start with an alternative view of the basic model (3), which will lead to its generalization. Consider a D-dimensional array variate , and a full coefficient array B of same size that captures the effects of each array element. Then the most flexible GLM suggests a linear systematic part
The issue with this model is that B has the same number of parameters, , as X, which is ultrahigh dimensional and far exceeds the usual sample size. Then a natural idea is to approximate B with less parameters. If B admits a rank-1 decomposition (1), i.e., B = β1 ο β2 ο ⋯ ο βD, where , then by Lemma 1, we have
In other words, model (3) is indeed a data-driven model with a rank-1 approximation to the general signal array B. This observation motivates us to consider a more flexible tensor regression model.
Specifically, we propose a family of rank-Rgeneralized linear tensor regression models, in which the systematic part of GLM is of the form
| (4) |
where , is the Khatri-Rao product and 1R is the vector of R ones.. Equivalently we assume that the tensor regression parameter admits a rank-R decomposition B = ⟦B1, …, BD⟧. When R = 1, it reduces to model (3). A few remarks on (4) are in order. First, since our formulation only deals with the linear predictor part of the model, it easily extends to the quasi-likelihood models (McCullagh and Nelder, 1983) where more general mean-variance relation is assumed. Second, for simplicity, we only discuss exponential family with a univariate response. Extension to multivariate exponential family, such as multinomial logit model, is straightforward. Third, due to the GLM setup (2), we call (4) a generalized linear tensor regression model. However, we should bear in mind that the systematic component η is a polynomial rather than linear in the parameters Bd. Finally, the rank-R tensor decomposition (1) is called canonical decomposition or parallel factors (CANDECOMP/PARAFAC, or CP) in psychometrics (Kolda and Bader, 2009). In that sense, model (4) can be viewed as a supervised version of the classical CP decomposition for multi-dimensional arrays.
The number of parameters in model (4) is p0 + R Σd pd, which is still substantially smaller than p0 + Πd pd. With such a massive reduction in dimensionality, however, it provides a reasonable approximation to many low rank signals. Returning to the previous illustration, in Figure 1, images TR(R) are the recovered signals by the rank-R tensor regression (in third and fourth columns). The square signal can be perfectly recovered by a rank-1 model, whereas rank-2 and 3 regressions show signs of overfitting. The T-shape and cross signals can be perfectly recovered by a rank-2 regression. Triangle, disk, and butterfly shapes cannot be exactly recovered by any low rank approximations; however, a rank 3 tensor regression already yields a fairly informative recovery. Clearly, the general tensor regression model (4) is able to capture significantly more tensor signals than the basic model (3).
3 Estimation
We pursue the maximum likelihood (ML) route for parameter estimation in model (4). Given n i.i.d. data {(yi, xi, zi), i = 1, …, n}, the log-likelihood function for (2) is
| (5) |
where θi is related to regression parameters (α, γ, B1, …, BD) through (4). We propose an efficient algorithm for maximizing ℓ(α, γ, B1, …, BD). A key observation is that although g(μ) in (4) is not linear in (B1, …, BD) jointly, it is linear in Bd individually. This suggests alternately updating (α,γ) and Bd, d = 1, …, D, while keeping other components fixed. It yields a so-called block relaxation algorithm (de Leeuw, 1994; Lange, 2010). An appealing feature of this algorithm is that at each iteration, updating a block Bd is simply a classical GLM problem. To see this, when updating , we rewrite the array inner product in (4) as
Consequently the problem turns into a traditional GLM regression with Rpd parameters, and the estimation procedure breaks into a sequence of low dimensional GLM optimizations and is extremely easy to implement using ready statistical softwares such as R, S+, SAS, and Matlab. The full estimation procedure is summarized in Algorithm 1. For the Gaussian models, it reduces to the alternating least squares (ALS) procedure (de Leeuw et al., 1976).
|
|
| Algorithm 1 Block relaxation algorithm for maximizing (5). |
|
|
Initialize: (α(0), γ(0)) = argmaxα,γ ℓ(α, γ, 0, …, 0),  a random matrix for d = 1, …, D. a random matrix for d = 1, …, D. |
| repeat |
| for d = 1, …, D do |
| end for |
| until ℓ(θ(t+1)) − ℓ(θ(t)) < ∊ |
|
|
As the block relaxation algorithm monotonically increases the objective function, it is numerically stable and the convergence of objective values ℓ(θ(t)) is guaranteed whenever ℓ(θ) is bounded from above. Therefore the stopping rule of Algorithm 1 is well-defined. We denote the algorithmic map by M, i.e., M(θ(t)) = θ(t+1), with θ = (α, γ, B1, …, BD) collecting all parameters. Convergence properties of Algorithm 1 are summarized in Proposition 1.
Proposition 1. Assume (i) the log-likelihood function ℓ(θ) is continuous, coercive, i.e., the set {θ : ℓ(θ) ≥ ℓ(θ(0))} is compact, and bounded above, (ii) the objective function in each block update of Algorithm 1 is strictly concave, and (iii) the set of stationary points (modulo scaling and permutation indeterminancy) of ℓ(θ) are isolated. We have the following results.
(Global Convergence) The sequence generated by Algorithm 1 converges to a stationary point of ℓ(θ).
(Local Convergence) Let be a strict local maximum of ℓ(θ). The iterates generated by Algorithm 1 are locally attracted to θ∞ for θ(0) sufficiently close to θ∞.
We make a few quick remarks. First, although a stationary point is not guaranteed to be even a local maximum (it can be a saddle point), in practice the block relaxation algorithm almost always converges to at least a local maximum. In general, the algorithm should be run from multiple initializations to locate an excellent local maximum, especially for higher rank models with limited sample size. Second, ℓ(θ) is not required to be jointly concave in θ. Only the concavity in the blocks of variables is needed. This condition holds for all GLM with canonical link such as linear model, logistic model and Poisson log-linear model.
The above algorithm assumes a known rank when estimating B. Estimating an appropriate rank for our tensor model (4) is of practical importance. It can be formulated as a model selection problem, and we adopt the usual model section criterion, e.g., Bayesian information criterion (BIC), −2ℓ(θ)+log(n)pe, where pe is the effective number of parameters for model (4): pe = R(p1 + p2) − R2 for D = 2, and pe = R(Σdpd−D+1) for D > 2. Returning to the illustrative example in Section 2.2, we fitted a rank-1, 2 and 3 tensor models, respectively, to various signal shapes. The corresponding BIC values are shown in Figure 1. The criterion is seen correctly estimating the rank for square as 1, and the rank for T and cross as 2. The true ranks for disk, triangle and butterfly are above 3, and their BIC values at rank 3 are smallest compared to those at 1 and 2.
4 Theory
We study the statistical properties of maximum likelihood estimate (MLE) for the tensor regression model defined by (2) and (4). For simplicity, we omit the intercept α and the classical covariate part γ⊺Z, though the conclusions generalize to an arbitrary combination of covariates. We adopt the usual asymptotic setup with a fixed number of parameters p and a diverging sample size n, because this is an important first step toward a comprehensive understanding of the theoretical properties of the proposed model. The asymptotics with a diverging p is our future work and is pursued elsewhere.
4.1 Score and Information
We first derive the score and information for the tensor regression model, which are essential for statistical estimation and inference. The following standard calculus notations are used. For a scalar function f, ∇f is the (column) gradient vector, df = [∇f]⊺ is the di erential, and d2f is the Hessian matrix. For a multivariate function , denotes the Jacobian matrix holding partial derivatives ∂gi/∂xj.
We start from the Jacobian and Hessian of the systematic part η ≡ g(μ) in (4). The proof is given in the Appendix.
Lemma 2.
- The gradient is
where is the Jacobian
and Πd is the permutation matrix that reorders vecB(d) to obtain vecB, i.e., vecB = Πd vecB(d).(6) - The Hessian has entries
and can be partitioned in D2 blocks as
The block has pdpd′R nonzero elements which can be retrieved from the matrix X(dd′)(BD ⊙⋯⊙Bd+1 ⊙ Bd−1 ⊙⋯⊙Bd′+1 ⊙ Bd′−1 ⊙⋯⊙ B1) where X(dd′) is the mode-(d, d′) matricization of X.
Remark 1: The Hessian d2η is highly sparse and structured. An entry in d2η(B1,…,BD) is nonzero only if it belongs to different directions d but the same outer product r.
Let ℓ(B1,…,BD|y, x) = ln p(y|x, B1,…,BD) be the log-density. Next result derives the score function, Hessian, and Fisher information of the tensor regression model.
Proposition 2. Consider the tensor regression model defined by (2) and (4).
- The score function (or score vector) is
with Jd, d = 1,…,D, defined by (6).(7) - The Hessian of the log-density ℓ is
with d2η defined in Lemma 2.(8) - The Fisher information matrix is
(9)
Remark 2: For canonical link, θ = η, θ′(η) = 1, θ″(η) = 0, and the second term of Hessian vanishes. For the classical GLM with linear systematic part (D = 1), d2η(B1,…,BD) is zero and thus the third term of Hessian vanishes. For the classical GLM (D = 1) with canonical link, both the second and third terms of the Hessian vanish and thus the Hessian is non-stochastic, coinciding with the information matrix.
4.2 Identifiability
Before studying asymptotic property, we need to deal with the identifiability issue. The parameterization in the tensor model is nonidentifiable due to two complications. Consider a rank-R decomposition of an array, . The first complication is the indeterminacy of B due to scaling and permutation:
-
–
scaling: for any diagonal matrices Λd = diag(λd1,…,λdR), d = 1,…,D, such that ∐dλdr = 1 for r = 1,…,R.
-
–
permutation: for any R-by-R permutation matrix ∐. For the matrix case (D = 2), a further complication is the nonsingular transformation indeterminancy: for any R-by-R nonsingular matrix O. Note the scaling and permutation indeterminancy is subsumed in the nonsingular transformation indeterminancy. The singular value decomposition (SVD) of a matrix is unique because it imposes orthonormality constraint on the columns of the factor matrices.
To deal with this complication, it is necessary to adopt a specific constrained parameterization to fix the scaling and permutation indeterminacy. For D > 2, we need to put (D − 1)R restrictions on the parameters B and apparently there is an infinite number of ways to do this. In this paper we adopt the following convention. B1,…, BD−1 are scaled such that , i.e., the first rows are ones. This in turn determines entries in the first row of BD and fixes scaling indeterminacy. To fix the permutation indeterminancy, we assume that the first row entries of BD are distinct and arranged in descending order . The resulting parameter space is
which is open and convex. The formulae for score, Hessian and information in Proposition 2 require changes accordingly, i.e., the entries in the first rows of Bd, d = 1, …, D−1, are fixed at ones and their corresponding entries, rows and columns in score, Hessian and information need to be deleted. Treatment for the D = 2 case is similar and omitted for brevity. We emphasize that our choice of the restricted space is arbitrary and exclude many arrays that might be of interest, e.g., arrays with any entries in the first rows of Bd, d = 1, …, D − 1, equal to zeros or with ties in the first row of BD. However the set of such exceptional arrays has Lebesgue measure zero. In specific applications, subject knowledge may suggest alternative constraints on the parameters.
The second complication comes from possible non-uniqueness of decomposition when D > 2 even after adjusting scaling and permutation indeterminacy. The next proposition collects some recent results that give easy-to-check conditions for the uniqueness (up to scaling and permutation) of decomposition. The first two are useful for checking uniqueness of a given tensor, while the latter two give general conditions for uniqueness almost everywhere in the D = 3 or 4 case.
Proposition 3. Suppose that a D-dimensional array has rank R.
(Sufficiency)(Sidiropoulos and Bro, 2000) The decomposition (1) is unique up to scaling and permutation if , where kA is the k-rank of a matrix A, i.e., the maximum value k such that any k columns are linearly independent.
(Necessity)(Liu and Sidiropoulos, 2001) If the decomposition (1) is unique up to scaling and permutation, then mind=1,…,D rank(B1⊙⋯⊙Bd−1⊙Bd+1⊙⋯⊙BD) = R, which in turn implies that mind=1,…,D (Πd′≠d rank(Bd′)) ≥ R.
(de Lathauwer, 2006) When D = 3, R ≤ p3 and R(R−1) ≤ p1(p1−1)p2(p2−1)/2, the decomposition (1) is unique for almost all such tensors except on a set of Lebesgue measure zero.
(de Lathauwer, 2006) When D = 4, R ≤ p4 and R(R − 1) ≤ p1p2p3(3p1p2p3 − p1p2 − p1p3 − p2p3 − p1 − p2 − p3 + 3)/4, the decomposition (1) is unique for almost all such tensors except on a set of Lebesgue measure zero.
Next we give a sufficient and necessary condition for local identifiability. The proof follows from a classical result (Rothenberg, 1971) that relates local identifiability to the Fisher information matrix.
Proposition 4 (Identifiability). Given iid data points {(yi, xi), i = 1, …, n} from the tensor regression model. Let be a parameter point and assume there exists an open neighborhood of B0 in which the information matrix has a constant rank. Then B0 is locally identifiable up to permutation if and only if
is nonsingular.
Remark 3.1: Proposition 4 explains the merit of tensor regression from another angle. For identifiability, the classical linear regression requires vec , i = 1, …, n, to be linearly independent in order to estimate all parameters, which requires a sample size n ≥ Πd pd. The more parsimonious tensor regression only requires linearly independence of the “collapsed” vectors , i = 1, …, n. The requirement on sample size is greatly lessened by imposing structure on the arrays.
Remark 3.2: Although global identifiability is hard to check for a finite sample, a parameter point is asymptotically and globally identifiable as far as it admits a unique decomposition up to scaling and permutation and has full rank for n ≥ n0, or, when considered stochastically, E[(vec X)(vec X)T] has full rank. To see this, whenever has full rank, the full coefficient array is globally identifiable and thus the decomposition is identifiable whenever it is unique.
Generalizing the concept of estimable functions for linear models, we call any linear combination of , i = 1, …, n, an estimable function. We can estimate estimable or collection of estimable functions even when the parameters are not identifiable.
4.3 Asymptotics
The asymptotics for tensor regression follow from those for MLE or M-estimation. The key observation is that the nonlinear part of tensor model (4) is a degree-D polynomial of parameters and the collection of polynomials form a Vapnik-C̆ervonenkis (VC) class. Then standard uniform convergence theory for M-estimation (van der Vaart, 1998) applies.
Theorem 1 (Consistency). Assume is (globally) identifiable up to permutation and the array covariates Xi are iid from a bounded distribution. The MLE is consistent, i.e., converges to B0 (modulo permutation) in probability, in the following models: (1) normal tensor regression with a compact parameter space ; (2) binary tensor regression; and (3) poisson tensor regression with a compact parameter space .
Remark 4: (Misspecified Rank) In practice it is rare that the true regression coefficient is exactly a low rank tensor. However the MLE of the rank-R tensor model converges to the maximizer of function ln pB or equivalently ln(pB/pBtrue). In other words, the MLE is consistently estimating the best rank-R approximation of Btrue in the sense of Kullback-Leibler distance.
To establish the asymptotic normality of , we note that the log-likelihood function of tensor regression model is quadratic mean differentiable (q.m.d).
Lemma 3. Tensor regression model is quadratic mean differentiable (q.m.d.).
Theorem 2 (Asymptotic Normality). For an interior point with nonsingular information matrix I(B01, …, B0D) (9) and is consistent,
converges in distribution to a normal with mean zero and covariance I−1(B01, …, B0D).
5 Regularized Estimation
The sample size in typical neuroimaging studies is quite small, and thus even for a rank-1 tensor regression (3), it is likely that the number of parameters exceeds the sample size. Therefore the p ≫ n challenge is a rule rather than an exception in neuroimaging analysis, and regularization becomes essential. Even when the sample size exceeds the number of parameters, regularization is still useful for stabilizing the estimates and improving their risk property. We emphasize that there are a large number of regularization techniques for different purposes. Here we illustrate with using sparsity regularization for identifying sub-regions that are associated with the response traits. This problem can be viewed as an analogue of variable selection in the traditional vector-valued covariates. Toward that end, we maximize a regularized log-likelihood function
where Pλ(|β|, ρ) is a scalar penalty function, ρ is the penalty tuning parameter, and λ is an index for the penalty family. Some widely used penalties include: power family (Frank and Friedman, 1993), in which Pλ(|β|, ρ) = ρ|β|λ, λ ∈ (0, 2], and in particular lasso (Tibshirani, 1996) (λ = 1) and ridge (λ = 2); elastic net (Zou and Hastie, 2005), in which Pλ(|β|, ρ) = ρ[(λ−1)β2/2 + (2−λ)|β|], λ ∈ [1, 2]; and SCAD (Fan and Li, 2001), in which ∂/∂|β|Pλ(|β|, ρ) = ρ{1{|β|≤ρ} + (λρ − |β|)+/(λ − 1)ρ1{|β|>ρ}}, λ > 2, among many others. Choice of penalty function and tuning parameters ρ and λ depends on particular purposes: prediction, unbiased estimation, or region selection.
Regularized estimation for tensor models incurs slight changes in Algorithm 1. When updating Bd, we simply fit a penalized GLM regression problem,
for which many software packages exist. Same paradigm certainly applies to regularizations other than sparsity. The fitting procedure boils down to alternating regularized GLM regression. The monotone ascent property of Algorithm 1 is retained under the modified algorithm. Convex penalties, such as elastic net and power family with λ ≥ 1, tend to convexify the objective function and alleviate the local maximum problem. On the other hand, concave penalty such as power family with λ < 1 and SCAD produces more unbiased estimates but the regularized objective function is more ruggy and in practice the algorithm should be initialized from multiple start points to increase the chance of finding a global maximum. Many methods are available to guide the choice of the tuning parameter ρ and/or λ for regularized GLM, notably AIC, BIC and cross validation. For instance the recent work (Zhou et al., 2011) derives BIC type criterion for GLM with possibly non-concave penalties such as power family, which can be applied to regularized tensor regression models in a straightforward way.
Two remarks are in order. First, it is conceptually possible to apply these regularization techniques directly to the full coefficient array without considering any structured decomposition as in our models. That is, one simply treats vecX as the predictor vector as employed in the classical total variation regularization in image denoising and recovery. However, for the brain imaging data, we should bear in mind the dimensionality of the imaging arrays. For instance, to the best of our knowledge, no software is able to deal with fused lasso or even simple lasso on 643 = 262, 144 or 2563 = 16, 777, 216 variables. This ultrahigh dimensionality certainly corrupts the statistical properties of the regularized estimates too. Second, penalization is only one form of regularization. In specific applications, prior knowledge often suggests various constraints among parameters, which may be exploited to regularize parameter estimate. For instance, for MRI imaging data, sometimes it may be reasonable to impose symmetry on the parameters along the coronal plane, which effectively reduces the dimensionality by pdR/2. In many applications, nonnegativity of parameter values is also enforced.
6 Numerical Analysis
We have carried out an extensive numerical study to investigate the finite sample performance of the proposed methods. In this section, we report selected results from synthetic examples and an analysis of a real brain imaging data.
6.1 2D Shape Examples
We first elaborate on the illustrative example given in Section 2.2 with a collection of 2D shapes. We examine the performance of the tensor model under a variety of sample sizes and signal strengths, and compare the estimates with and without regularization. More specifically, the tensor model in Section 2.2 is employed, where the response is normally distributed with mean, η = γTZ + 〈B, X〉, and standard deviation σ. X is a 64 × 64 2D matrix, Z is a 5-dimensional covariate vector, both of which have standard normal entries, γ = (1, 1, 1, 1, 1)T, and B is binary with the true signal region equal to one and the rest zero. We fit both a rank-3 tensor model without regularization, and one with a lasso regularization. For sample size, we examine n = 200, 300, 400, 500 and 750. Note that, for this example, the number of parameters of a rank-3 model is 380 = 5 + 3 × (64 + 64) − 32. As such, there are multiple solutions when n = 200 or 300, and we arbitrarily choose one estimate. For signal strength, we vary the noise level σ = 50%, 20%, 10%, 5% and 1% of the standard deviation of the mean η, respectively.
We summarize the results in three plots: the snapshots of estimates with varying sample size, the snapshots with varying signal strength, and the line plot of the average root mean squared error (RMSE) for estimation of B. For space consideration, only the first plot is presented in Figure 2 (with 10% noise level), and the rest in the supplementary appendix. We make the following observations. First, estimation accuracy steadily increases with the sample size, demonstrating consistency of the proposed method. This can be seen from both the snapshots with improved quality and the decreasing RMSE. Similar patterns are observed with increasing signal strength. Second, regularization clearly improves estimation, especially when the sample size is limited. In practice, when the number of imaging subjects is moderate, regularized tensor regression is recommended.
Figure 2.

Snapshots of tensor estimation with varying sample size. The matrix variate has size 64 by 64 with entries generated as independent standard normals. The regression coefficient for each entry is either 0 (white) or 1 (black).
For this example, we also examined the recovered signals by regularized tensor regression with a fixed sample size n = 500 and varying penalty parameter. The results are reported in the appendix A.2.
6.2 Attention Deficit Hyperactivity Disorder Data Analysis
We applied our methods to the attention deficit hyperactivity disorder (ADHD) data from the ADHD-200 Sample Initiative (http://fcon_1000.projects.nitrc.org/indi/adhd200/). ADHD is a common childhood disorder and can continue through adolescence and adulthood. Symptoms include difficulty in staying focused and paying attention, difficulty in controlling behavior, and over-activity. The data set that we used is part of the ADHD-200 Global Competition data sets. It consists of 776 subjects, with 491 normal controls and 285 combined ADHD subjects. Among them, there are 442 males with mean age 12.0 years and standard deviation 3.1 years, and 287 females with mean age 11.9 years and standard deviation 3.5 years. We removed 47 subjects due to the missing observations or poor image quality. Resting state fMRIs and T1-weighted images were acquired for each subject. The T1-weighted images were preprocessed by standard steps including AC (anterior commissure) and PC (posterior commissure) correction, N2 bias field correction, skull-stripping, intensity inhomogeneity correction, cerebellum removal, segmentation, and registration. After segmentation, the brains were segmented into four different tissues: grey matter (GM), white matter (WM), ventricle (VN), and cerebrospinal fluid (CSF). We quantified the local volumetric group differences by generating RAVENS maps (Davatzikos et al., 2001) for the whole brain and each of the segmented tissue type (GM, WM, VN, and CSF) respectively, using the deformation field we obtained during registration. RAVENS methodology is based on a volume-preserving spatial transformation, which ensures that no volumetric information is lost during the process of spatial normalization, since this process changes an individual's brain morphology to conform it to the morphology of a template. In addition to image covariates, we include the subjects' age, gender, and whole brain volume as regular covariates. One scientific question of interest is to understand association between the disease outcome and the brain image patterns after adjustment for the clinical and demographical variables. We first examined the case with real image covariates and simulated responses. The goal is to study the empirical performance of our methods under various response models. We then showed the performance of the regularized estimation in terms of region selection. Finally, we applied the method to the data with the true observed binary response.
6.2.1 Real Image Covariates and Simulated Response
We first consider a number of GLMs with the real brain image covariates, where η = γTZ + 〈B, X〉, the signal tensor B admits a certain structure, η = (1, 1, 1)T, X denotes the 3D MRI image with dimension 256 × 256 × 198, and Z denotes the vector of age, gender and whole brain volume. We consider two structures for B. The first admits a rank one decomposition, with , , and , and all of whose (90 + j)th element equal to sin(jπ/14) for j = 0, 1, …, 14. This corresponds to a single-ball signal in a 3D space. The second admits a rank two decomposition, with , , and . All the first columns of Bd have their (90 + j)th element equal to sin(jπ/14), and the second columns of Bd have their (140 + j)th element equal to sin(jπ/14) for j = 0, 1, …, 14. This mimics a two-ball signal in the 3D space. We then generate the response through the GLM models: for the normal model, Y ~ Normal(μ, 1), where μ = η; for the binomial model, Y ~ Bernoulli(p), with p = 1/[1 + exp(−0.1η)]; and for the poisson model, Y ~ Poission(μ), with μ = exp(0.01η). Table 1 summarizes the average RMSE and its standard deviation out of 100 data replications. We see that the normal and poisson responses both have competitive performance, whereas the binomial case is relatively more challenging. The two-ball signal is more challenging than a one-ball signal, and overall the tensor models work well across different response types and different signals.
Table 1.
Tensor regression estimation for the ADHD data. Reported are mean RMSE and its standard deviation (in parenthesis) of evaluation criteria based on 100 data replications.
| Signal | Param. | Normal | Binomial | Poisson |
|---|---|---|---|---|
| one-ball | γ | 0.0639 (0.0290) | 0.2116 (0.0959) | 0.0577 (0.0305) |
| B | 0.0039 (0.0002) | 0.0065 (0.0002) | 0.0064 (0.0002) | |
| two-ball | γ | 0.0711 (0.0310) | 0.3119 (0.1586) | 0.0711 (0.0307) |
| B | 0.0058 (0.0002) | 0.0082 (0.0003) | 0.0083 (0.0003) |
6.2.2 Regularized Estimation
Next we focus on the ability of the regularized tensor regression model to identify relevant regions in brain associated with the response. This is analogous to the variable selection problem in the traditional regression with vector-valued covariates. We employ the two-ball signal and the normal model in Section 6.2.1. Figure 3 shows images with the true signal, the un-regularized tensor regression estimate, and the regularized tensor regression estimates with a lasso penalty, respectively, overlaid on an image of an arbitrarily chosen subject, or on a 3D rendering of a template. The plots clearly show that the true sparse signal regions can be well recovered through regularization.
Figure 3.

Region selection. The true signal regions are colored in red, the estimated signal regions are in green, and the overlapped regions are in yellow. The left panel is the true or estimated signal overlaid on a randomly selected subject, and the right panel is a 3D rendering of the true or estimated signal overlaid on the template
6.2.3 Real Data Analysis
Finally, we analyze the ADHD data with the observed binary diagnosis status as the response. We fitted a rank-3 tensor logistic regression model, since in practice it is rare that the true signal would follow an exact reduced rank formulation. We also applied the regularized estimation using a lasso penalty. Figure 4 shows the results. Inspecting Figure 4 reveals two regions of interest: left temporal lobe white matter and the splenium that connects parietal and occipital cortices across the midline in the corpus callosum. The anatomical disturbance in the temporal lobe has been consistently revealed and its interpretation would be consistent with a finer-grained analysis of the morphological features of the cortical surface, which reported prominent volume reductions in the temporal and frontal cortices in children with ADHD compared with matched controls (Sowell et al., 2003). Moreover, a reduced size of the splenium is the most reliable finding in the corpus callosum (Valera et al., 2007).
Figure 4.
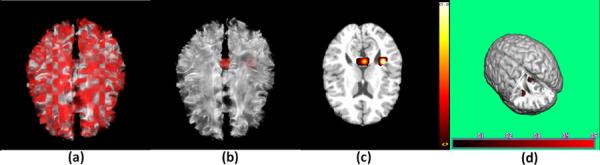
Application to the ADHD data. Panel (a) is the unpenalized estimate overlaid on a randomly selected subject; (b) is the regularized estimate overlaid on a randomly selected subject; (c) is a selected slice of the regularized estimate overlaid on the template; and (d) is a 3D rendering of the regularized estimate overlaid on the template.
7 Discussion
We have proposed a tensor decomposition based approach for regression modeling with array covariates. The curse of dimensionality is lessened by imposing a low rank approximation to the extremely high-dimensional full coefficient array. This allows development of a fast estimation algorithm and regularization. Numerical analysis demonstrates that, despite its massive reduction, the method works well in recovering various geometric as well as natural shape images. Although there has been imaging studies utilizing tensor structure (Li et al., 2005; Park and Savvides, 2007), our proposal, to the best of our knowledge, is the first that integrates tensor decomposition within a statistical regression (supervised learning) paradigm.
A motivation of our work is the recent emergence of large-scale neuroimaging data. Early imaging studies usually have only a handful of subjects. More recently, however, a number of large-scale brain imaging studies are accumulating imaging data from a much larger number of subjects. For instance, the Attention Deficit Hyperactivity Disorder Sample Initiative (ADHD, 2012) consists of 776 participants from eight imaging centers with both MRI and fMRI images, as well as their clinical information. Another example is the Alzheimer's Disease Neuroimaging Initiative (ADNI, 2012) database, which includes 818 participants with MRI, fMRI and genomics data. The proposed tensor regression model aims to address the computational and modeling challenges of such large-scale imaging data. Meanwhile, our approach is equally applicable to smaller scale imaging data, e.g., images acquired from a single lab with a moderate number of subjects. In this scenario, the regularization strategy outlined in Section 5 is expected to play a central role for scientific discovery.
The classical large n asymptotics in Section 4 may seem irrelevant for imaging data with a limited sample size. However, it outlines some basic properties of the proposed tensor regression model and has practical relevance in several aspects. For instance, by choosing a small rank such that the model size pe is effectively smaller than n, we know that, under the specified conditions, the tensor regression model is consistently estimating the best rank-R approximation to the full model in the sense of Kullback-Liebler distance. A low rank estimate often provides a reasonable approximation to the true tensor regression parameter, even when the truth is of a high rank. This can be seen from our various numerical experiments, where a rank-3 model yields a good recovery of a butterfly shape in Figure 1 and a two-ball structure in Figure 3. Moreover, the regular asymptotics is useful for testing significance of a low rank sparse model in a replication study. Classical hypothesis testes such as likelihood ratio test can be formulated based on the asymptotic normality of the tensor estimates established in Section 4. The explicit formula for score and information in Section 4.1 and the identifiability issue discussed in Section 4.2 are not only useful for asymptotic theory but also for computation.
As the challenge of p ≫ n being a rule rather than exception in brain imaging analysis, regularization is to play a crucial role in practical applications. We consider the tensor regression, with or without regularization, presented in this paper an analog of the hard thresholding in classical regression, where the rank of the model is fixed. Respecting the array structure, the regularized tensor regression yields significantly better estimates than the classical regularization applied to the vectorized tensor covariates. Appendix A.3 presents a numerical comparison with the classical lasso. Currently, we are also investigating another line of regularization through “soft thresholding”. That is, we estimate the tensor regression model without fixing the rank but instead subject to a convex regularization of the rank of the tensor parameter. Results along this line will be reported elsewhere.
The scale and complexity of neuroimaging data require the estimation algorithm to be highly scalable, efficient and stable. The methods in this paper are implemented in an efficient Matlab toolbox. For instance, the median run time of fitting a rank-3 model to the 2D triangle shape in Figure 1 was about 5 seconds. Fitting a rank-3 logistic model to the 3D ADHD data in Section 6.2.3 took about 285 seconds for 10 runs from 10 random starting points, averaging < 30 seconds per run. Appendix A.4 contains more numerical results to study the algorithm stability with respect to starting values as well as computing time. All results were obtained on a standard laptop computer with a 2.6 GHz Intel i7 CPU.
We view the method of this article as a first step toward a more general area of array regression analysis, and the idea can be extended to a wide range of problems. We describe a few potential future directions here. First, although we only present results for models with a conventional covariate vector and an array covariate, the framework applies to arbitrary combination of array covariates. This provides a promising approach to the analysis of multi-modality data which becomes increasingly available in modern neuroimaging and medical studies. Second, we remark that our modeling approach and algorithm equally apply to many general loss functions occurring in classification and prediction. For example, for a binary response Y ∈ {0, 1}, the hinge loss takes the form
and should play an important role in support vector machines with array variates. Third, in this article rotation has not been explicitly considered in the modeling. When prior knowledge indicates, sometimes it is prudent to work in polar coordinates. For example, the `disk' signal in Figure 1 can be effectively captured by a rank-1 outer product if the image is coded in polar coordinates. A diagonal signal array has full rank and cannot be approximated by any lower rank array, but if changed to polar coordinates, the rank reduces to one. Some of these extensions are currently under investigation. In summary, we believe that the proposed methodology timely answers calls in modern neuroimaging data analysis, whereas the general methodology of tensor regression is to play a useful role and also deserves more attention in statistical analysis of high-dimensional complex imaging data.
Supplementary Material
References
- ADHD [[Online; accessed 22-Jan-2012]];The ADHD-200 sample. 2012 http://fcon_1000.projects.nitrc.org/indi/adhd200/,
- ADNI [[Online; accessed 22-Jan-2012]];Alzheimers Disease Neuroimaging Initiative. 2012 http://adni.loni.ucla.edu,
- Caffo B, Crainiceanu C, Verduzco G, Joel S, S.H. M, Bassett S, Pekar J. Two-stage decompositions for the analysis of functional connectivity for fMRI with application to Alzheimer's disease risk. Neuroimage. 2010;51:1140–1149. doi: 10.1016/j.neuroimage.2010.02.081. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Casey B, Soliman F, Bath KG, Glatt CE. Imaging genetics and development: Challenges and promises. Human Brain Mapping. 2010;31:838–851. doi: 10.1002/hbm.21047. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davatzikos C, Genc A, Xu D, Resnick S. Voxel-based morphometry using the RAVENS maps: methods and validation using simulated longitudinal atrophy. NeuroImage. 2001;14:1361–1369. doi: 10.1006/nimg.2001.0937. [DOI] [PubMed] [Google Scholar]
- de Lathauwer L. A link between the canonical decomposition in multilinear algebra and simultaneous matrix diagonalization. SIAM J. Matrix Analysis Applications. 2006;28:642–666. [Google Scholar]
- de Leeuw J. Information Systems and Data Analysis. Springer; Berlin: 1994. Block-relaxation algorithms in statistics; pp. 308–325. [Google Scholar]
- de Leeuw J, Young F, Takane Y. Additive structure in qualitative data: an alternating least squares method with optimal scaling features. Psychometrika. 1976;41:471–503. [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Amer. Statist. Assoc. 2001;96:1348–1360. [Google Scholar]
- Frank IE, Friedman JH. A statistical view of some chemometrics regression tools. Technometrics. 1993;35:109–135. [Google Scholar]
- Friston KJ. Modalities, modes, and models in functional neuroimaging. Science. 2009;326:399–403. doi: 10.1126/science.1174521. [DOI] [PubMed] [Google Scholar]
- Hinrichs C, Singh V, Mukherjee L, Xu G, Chung MK, Johnson SC, ADNI Spatially augmented LPboosting for AD classification with evaluations on the ADNI dataset. NeuroImage. 2009;48:138–149. doi: 10.1016/j.neuroimage.2009.05.056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hung H, Wang C-C. Matrix variate logistic regression analysis. 2011 arXiv:1105.2150v1. [Google Scholar]
- Kang H, Ombao H, Linkletter C, Long N, Badre D. Spatio-spectral mixed effects model for functional magnetic resonance imaging data. Journal of American Statistical Association. 2012 doi: 10.1080/01621459.2012.664503. in press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kolda TG. Tech. rep. Sandia National Laboratories; 2006. Multilinear operators for higher-order decompositions. [Google Scholar]
- Kolda TG, Bader BW. Tensor decompositions and applications. SIAM Rev. 2009;51:455–500. [Google Scholar]
- Lange K. Optimization. Springer Texts in Statistics; Springer-Verlag; New York: 2004. [Google Scholar]
- Lange K. Numerical Analysis for Statisticians. 2nd ed Statistics and Computing; Springer; New York: 2010. [Google Scholar]
- Lazar NA. The Statistical Analysis of Functional MRI Data. Springer; New York: 2008. [Google Scholar]
- Lehmann EL, Romano JP. Testing Statistical Hypotheses. 3rd ed Springer Texts in Statistics; Springer; New York: 2005. [Google Scholar]
- Li B, Kim MK, Altman N. On dimension folding of matrix- or array-valued statistical objects. The Annals of Statistics. 2010;38:1094–1121. [Google Scholar]
- Li Y, Du Y, Lin X. Kernel-Based Multifactor Analysis for Image Synthesis and Recognition. ICCV. 2005:114–119. [Google Scholar]
- Li Y, Zhu H, Shen D, Lin W, Gilmore JH, Ibrahim JG. Multiscale adaptive regression models for neuroimaging data. Journal of the Royal Statistical Society: Series B. 2011;73:559–578. doi: 10.1111/j.1467-9868.2010.00767.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lindquist M. The statistical analysis of fMRI data. Statistical Science. 2008;23:439–464. [Google Scholar]
- Liu X, Sidiropoulos ND. Cramér-Rao lower bounds for low-rank decomposition of multidimensional arrays. IEEE Trans. on Signal Processing. 2001;49:2074–2086. [Google Scholar]
- Martino FD, Valente G, Staeren N, Ashburner J, Goebel R, Formisano E. Combining multivariate voxel selection and support vector machines for mapping and classification of fMRI spatial patterns. NeuroImage. 2008;43:44–58. doi: 10.1016/j.neuroimage.2008.06.037. [DOI] [PubMed] [Google Scholar]
- McCullagh P, Nelder JA. Monographs on Statistics and Applied Probability. Chapman & Hall; London: 1983. Generalized Linear Models. [Google Scholar]
- Ostrowski AM. Pure and Applied Mathematics. Vol. IX. Academic Press; New York-London: 1960. Solution of Equations and Systems of Equations. [Google Scholar]
- Park SW, Savvides M. Individual Kernel Tensor-Subspaces for Robust Face Recognition: A Computationally Efficient Tensor Framework Without Requiring Mode Factorization. IEEE Transactions on Systems, Man, and Cybernetics, Part B. 2007;37:1156–1166. doi: 10.1109/tsmcb.2007.904575. [DOI] [PubMed] [Google Scholar]
- Pollard D. Convergence of Stochastic Processes. Springer Series in Statistics; Springer-Verlag; New York: 1984. [Google Scholar]
- Polzehl J, Voss HU, Tabelow K. Structural adaptive segmentation for statistical parametric mapping. NeuroImage. 2010;52:515–523. doi: 10.1016/j.neuroimage.2010.04.241. [DOI] [PubMed] [Google Scholar]
- Qiu P. Image processing and jump regression analysis. Wiley series in probability and statistics, John Wiley; 2005. [Google Scholar]
- Qiu P. Jump surface estimation, edge detection, and image restoration. Journal of the American Statistical Association. 2007;102:745–756. [Google Scholar]
- Rao CR, Mitra SK. Generalized Inverse of Matrices and its Applications. John Wiley & Sons, Inc.; New York-London-Sydney: 1971. [Google Scholar]
- Reiss P, Ogden R. Functional generalized linear models with images as predictors. Biometrics. 2010;66:61–69. doi: 10.1111/j.1541-0420.2009.01233.x. [DOI] [PubMed] [Google Scholar]
- Rothenberg TJ. Identification in parametric models. Econometrica. 1971;39:577–91. [Google Scholar]
- Ryali S, Supekar K, Abrams DA, Menon V. Sparse logistic regression for whole-brain classification of fMRI data. NeuroImage. 2010;51:752–764. doi: 10.1016/j.neuroimage.2010.02.040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sidiropoulos ND, Bro R. On the uniqueness of multilinear decomposition of N-way arrays. Journal of Chemometrics. 2000;14:229–239. [Google Scholar]
- Sowell ER, Thompson PM, Welcome SE, Henkenius AL, Toga AW, Peterson BS. Cortical abnormalities in children and adolescents with attention-deficit hyperactivity disorder. Lancet. 2003;362:1699–1707. doi: 10.1016/S0140-6736(03)14842-8. [DOI] [PubMed] [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the lasso. J. Roy. Statist. Soc. Ser. B. 1996;58:267–288. [Google Scholar]
- Valera EM, Faraone SV, Murray KE, Seidman LJ. Meta-analysis of structural imaging findings in attention-deficit/hyperactivity disorder. Biol Psychiatry. 2007;61:1361–1369. doi: 10.1016/j.biopsych.2006.06.011. [DOI] [PubMed] [Google Scholar]
- van der Vaart A, Wellner J. Weak Convergence and Empirical Processes: With Applications to Statistics. Springer; 2000. corrected ed. [Google Scholar]
- van der Vaart AW. Asymptotic Statistics, vol. 3 of Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press; Cambridge: 1998. [Google Scholar]
- Worsley KJ, Taylor JE, Tomaiuolo F, Lerch J. Unified univariate and multivariate random field theory. NeuroImage. 2004;23:189–195. doi: 10.1016/j.neuroimage.2004.07.026. [DOI] [PubMed] [Google Scholar]
- Yue Y, Loh JM, Lindquist MA. Adaptive spatial smoothing of fMRI images. Statistics and its Interface. 2010;3 [Google Scholar]
- Zhou H, Armagan A, Dunson D. Path following and empirical Bayes model selection for sparse regressions. 2011 manuscript in preparation. [Google Scholar]
- Zou H, Hastie T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005;67:301–320. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.