

Summary
We propose an adaptive nuclear norm penalization approach for low-rank matrix approximation, and use it to develop a new reduced rank estimation method for high-dimensional multivariate regression. The adaptive nuclear norm is defined as the weighted sum of the singular values of the matrix, and it is generally non-convex under the natural restriction that the weight decreases with the singular value. However, we show that the proposed non-convex penalized regression method has a global optimal solution obtained from an adaptively soft-thresholded singular value decomposition. The method is computationally efficient, and the resulting solution path is continuous. The rank consistency of and prediction/estimation performance bounds for the estimator are established for a high-dimensional asymptotic regime. Simulation studies and an application in genetics demonstrate its efficacy.
Keywords: Low-rank approximation, Nuclear norm penalization, Reduced rank regression, Singular value decomposition
1. Introduction
Given n observations of the response yi ∈ ℜq and predictor xi ∈ ℜp, we consider the multi-variate linear regression model
| (1) |
where Y = (y1, …, yn)T, X = (x1, …, xn)T, C0 is an p × q coefficient matrix, and E = (e1, …, en)T is an n × q matrix of independently and identically distributed random errors with mean zero and variance σ2. Throughout, we write p ∧ q = min(p, q), n ∧ q = min(n, q), r* = r(C0) and rx = r(X), where r(·) denotes the rank of a matrix.
We consider the scenario in which both the predictor dimension p and response dimension q may depend on and even exceed the sample size n. Such high-dimensional regression problems are increasingly encountered. Ordinary least squares estimation is equivalent to separately regressing each response on the set of predictors, but this ignores the dependence structure of the multivariate response and may be infeasible in high-dimensional settings. The curse of dimensionality can be mitigated by assuming that the true coefficient matrix C0 has some low-dimensional structure and employing regularization/penalization approaches for model estimation. For Gaussian data, it is appropriate to estimate C0 by minimizing the penalized least squares criterion
| (2) |
with respect to C ∈ ℜp×q, where
is the sum of squared errors, with ||·||F denoting the Frobenius norm,
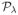 (·) is some penalty function measuring the complexity of the enclosed matrix, and λ is a non-negative tuning parameter controlling the penalty.
(·) is some penalty function measuring the complexity of the enclosed matrix, and λ is a non-negative tuning parameter controlling the penalty.
Within this general framework, an important model is reduced rank regression (Anderson, 1951, 1999, 2002; Izenman, 1975; Reinsel & Velu, 1998), in which dimension reduction is achieved by constraining the coefficient matrix to have low rank. The classical small-p case and maximum likelihood inference for the rank-constrained approach have been extensively investigated. Recently, Bunea et al. (2011) proposed a rank selection criterion that is valid for high dimensional settings, revealing that rank-constrained estimation can be viewed as a penalized regression method (2) with a penalty proportional to the rank of C. The penalty can also be cast as an l0 penalty in terms of the number of non-zero singular values of C, i.e., , where I(·) is the indicator function, and di(·) represents the ith largest singular value of a matrix. This results in an estimator obtained by hard-thresholded singular value decomposition; see Section 2. Yuan et al. (2007) proposed a nuclear norm penalized least squares criterion, in which the penalty is defined as , where ||·||* denotes the nuclear norm. This l1 penalty encourages sparsity among the singular values and achieves simultaneous rank reduction and shrinkage estimation (Negahban & Wainwright, 2011; Bunea et al., 2011; Lu et al., 2012). Rohde & Tsybakov (2011) investigated the theoretical properties of the Schatten-b quasi-norm penalty, which is defined as for 0 < b ≤ 1, and obtained non-asymptotic bounds for prediction risk. Several other extensions and theoretical developments related to reduced rank estimation exist; see, e.g., Aldrin (2000), Negahban & Wainwright (2011), Mukherjee & Zhu (2011), and Chen et al. (2012). Reduced rank methodology has connections with many popular tools including principal component analysis and canonical correlation analysis, and has been extensively studied in matrix completion problems (Candès & Recht, 2009; Candès et al., 2011; Koltchinskii et al., 2011).
The aforementioned reduced rank approaches are closely related to the singular value decomposition (Eckart & Young, 1936; Reinsel & Velu, 1998). It is intriguing that the rank and nuclear norm penalization approaches can be viewed as l0 and l1 singular value penalization methods, respectively. Moreover, the squared l2 singular value penalty is in fact a ridge penalty, because . Motivated by these connections and with a desire to close the gap between the l0 and l1 penalization schemes, we propose the adaptive nuclear norm regularization method. The adaptive nuclear norm of a matrix C ∈ ℜp×q is defined as a weighted sum of its singular values:
| (3) |
where wis are the non-negative weights; a similar idea can be found in an unpublished 2009 University of Illinois manuscript by Jiaming Xu. We show that the adaptive nuclear norm is non-convex when the weight of the singular value decreases with the singular value, a condition needed for a meaningful regularization; see Section 2. Despite the non-convexity, we show below that the adaptive nuclear norm penalized estimator has a closed-form solution in matrix approximation problems.
Based on the proposed adaptive nuclear norm, we develop a new method for conducting simultaneous dimension reduction and coefficient estimation in high-dimensional multivariate regression. Our proposal combines two main ideas. Firstly, the proposed method builds a bridge between the l0 and l1 singular value penalization methods, and it can be viewed as analogous to the adaptive lasso (Tibshirani, 1996; Zou, 2006; Huang et al., 2008) developed for univariate regression. Secondly, we penalize XC rather than C, which allows the reduced rank estimation problem to be solved explicitly and efficiently. This setup was used by Klopp (2011) and Koltchinskii et al. (2011) in trace regression problems. Compared to the computationally intensive l1 method (Yuan et al., 2007) which tends to overestimate the rank, the proposed method with the aid of some well-chosen adaptive weights may improve rank determination. Compared to the discontinuous l0 method (Bunea et al., 2011), the proposed method results in a continuous solution path and allows a more flexible bias-variance tradeoff in model fitting.
2. Adaptive nuclear norm penalty
The adaptive nuclear norm ||C||*w forms a rich class of penalty functions indexed by the weights. Clearly, it includes the nuclear norm as a special case with unit weights. Since the nuclear norm is convex and is a matrix norm, an immediate question arises as to whether or not its weighted extension (3) preserves the convexity, which is the case for the entrywise lasso and adaptive lasso penalties (Zou, 2006). However, the following theorem shows that the convexity of (3) depends on the ordering of the non-negative weights.
Theorem 1
For any matrix C ∈ ℜp×q, let f(C) = ||C||*w be defined in (3). Then f(·) is convex in C if and only if w1 ≥ ··· ≥ wp∧q ≥ 0.
Hence, for the adaptive nuclear norm (3) to be a convex function, the weights must be nondecreasing with the singular value. However, for penalized estimation, the opposite is desirable, i.e., we would and shall henceforth impose the order constraint
| (4) |
which ensures that a larger singular value receives a lighter penalty to help reduce the bias and a smaller singular value receives a heavier penalty to help promote sparsity. The non-convexity of f(·) arises from the constraint (4), so f(·) is no longer a matrix norm. Here is an example showing that (3) is neither convex nor concave under constraint (4). Consider p = q = 2, and
Let w1 = 1 and w2 = 2. It can be verified that f(C1) = f(C2) = f (−C2) = 4, while f{(C1 + C2)/2} = 4·5 > {f(C1) + f(C2)}/2; also, f{(C1 − C2)/2} = 1·5 < {f(C1) + f(−C2)}/2.
Consider the low-rank matrix approximation problem, Y = C0 + E, a special case of model (1) where X is an identity matrix and C0 is n × q. This model provides a framework for denoising the data matrix Y. Certain low-rank estimators of C0 can be derived from the singular value decomposition of Y ∈ ℜn×q,
| (5) |
where U and V are respectively n × (n ∧ q) and q × (n ∧ q) orthonormal matrices, d(Y) = {d1(Y), …, dn∧q(Y)}T consists of the singular values of Y in descending order, and diag(·) denotes a diagonal matrix with the enclosed vector on its diagonal. Consider the following two kinds of estimators of C0,
| (6) |
| (7) |
where λ ≥ 0 and x+ = max(0, x). The following proposition shows that the hard-thresholding estimator in (6) yields the l0 rank penalized estimator (Eckart & Young, 1936), and the soft-thresholding estimator in (7) yields the l1 nuclear norm penalized estimator (Cai et al., 2010).
Proposition 1
For any λ ≥ 0 and Y ∈ ℜn×q,
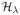 (Y) defined by (6) can be characterized as
, and
(Y) defined by (6) can be characterized as
, and
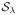 (Y) in (7) can be characterized as
.
(Y) in (7) can be characterized as
.
The estimator
(Y) eliminates any singular values below a threshold λ, while
(Y) shrinks all the singular values by λ towards zero. These operations are natural extensions of the hard/soft-thresholding rules for scalars and vectors (Donoho & Johnstone, 1995; Cai et al., 2010). In general, a soft-thresholding estimator has smaller variance but larger bias than its hard-thresholding counterpart. Soft-thresholding may, however, be preferable when data are noisy and highly correlated (Donoho & Johnstone, 1995).
The preceding discussion on the connections between different thresholding rules and penalty terms motivates us to consider the use of the adaptive nuclear norm in bridging the gap between the l0 and l1 singular value penalties and fine-tuning the bias-variance tradeoff. In the context of low-rank matrix approximation, we are able to obtain, with complete characterization, an explicit global minimizer of the least squares criterion penalized by a non-convex adaptive nuclear norm.
Theorem 2
For any λ ≥ 0, 0 ≤ w1 ≤ ··· ≤ wn∧q, and Y ∈ ℜn×q with a singular value decomposition Y = UDVT, a global optimal solution to the optimization problem
| (8) |
is
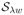 (Y), where
(Y), where
| (9) |
Further, if all the nonzero singular values of Y are distinct, then
(Y) is the unique optimal solution.
The fact that a closed-form global minimizer can be found for the non-convex problem (8) is rather surprising. The result stems from the von Neumann’s trace inequality (Mirsky, 1975); see the Appendix. Following Zou (2006), the weights can be set to be , for i = 1, …, n ∧ q, where γ ≥ 0 is a pre-specified constant. In this way, the order constraint (4) is automatically satisfied. We discuss a general way to construct the weights in Section 7.
3. Adaptive nuclear norm penalization in multivariate regression
3·1. Rank and nuclear norm penalized regression methods
We now consider estimating the coefficient matrix C0, which is possibly of low rank, in the multivariate regression model (1) with an arbitrary design matrix X. Below, let P = X(XTX)−XT be the projection matrix onto the column space of X and ĈL = (XT X)−XT Y the least squares estimator of C0, where (·)− denotes a Moore–Penrose inverse.
The results in Section 2 can be readily applied to derive certain low-rank estimator of C0 in the general regression setting. First, consider the rank selection criterion (Bunea et al., 2011),
| (10) |
Minimizing (10) is the same as minimizing , owing to Pythagoras’ theorem. We now demonstrate that this is also equivalent to minimizing , which can be cast as a constrained matrix approximation problem,
| (11) |
However, the constrained minimizer of (11) turns out to be the same as its unconstrained counterpart. To see this, let V̂D̂2V̂T be the eigenvalue decomposition of YTPY = (XĈL)TXĈL. The singular value decomposition of XĈL is then given by ÛD̂V̂T, where Û = PYV̂D̂− = XĈLV̂D̂−. It follows from Proposition 1 that the unconstrained minimizer equals
| (12) |
where . Therefore, is the desired constrained minimizer of (11). Moreover, , i.e., . Consequently, , for any C ∈ ℜp×q, i.e., minimizes (10). It can also be shown that the set of rank-constrained estimators, obtained by minimizing subject to r(C) ≤ r, for r = 1, …, p ∧ q, spans the solution path of (10) (Reinsel & Velu, 1998).
The nuclear norm penalized least squares criterion (Yuan et al., 2007) is
| (13) |
We denote the minimizer of (13) by , which generally does not have an explicit form. Extensive research has been devoted to this minimization problem (Cai et al., 2010; Toh & Yun, 2010). One popular algorithm is to alternate between a majorization step of the objective function and a minimization step by singular value soft-thresholding operation until convergence, but it is computationally intensive for large-scale data (Cai et al., 2010).
3·2. Adaptive nuclear norm penalized regression method
Predictive accuracy and computational efficiency are both important in high dimensional regression problems. Motivated by criteria (10) and (13), we propose to estimate C0 by minimizing
| (14) |
where the weights {wi} are required to be non-negative and non-decreasing. In practice, a fore-most task of using (14) is setting proper adaptive weights. Following Zou (2006), this can be based on the least squares solution,
| (15) |
where PY = XĈL is the projection of Y onto the column space of X and γ is a non-negative constant.
The proposed method (14) is built on two main ideas. Firstly, the criterion focuses on the fitted values XC, and encourages sparsity among the singular values of XC rather than those of C. This may yield a low-rank estimator for XC0 and hence for C0 (Koltchinskii et al., 2011). A prominent advantage of this setup is that the problem can then be solved explicitly and efficiently. Secondly, the adaptive penalization of the singular values allows a flexible bias-variance tradeoff: a large singular value receives a small penalty to control possible bias, and a small singular value receives a large penalty to induce sparsity and hence reduce the rank. The following corollary shows that this criterion admits an explicit minimizer.
Corollary 1
A minimizer of (14), denoted by , is given by
| (16) |
where ĈL is the least squares estimator of C0, ÛD̂V̂T is the singular value decomposition of XĈL, and
(·) is defined in (9).
By Pythagoras’ theorem, minimizing criterion (14) is equivalent to minimizing with respect to C. The above result then follows directly from Theorem 2. The proposed method first projects Y onto the column space of X, i.e., PY = XĈL; the estimator is then obtained as a low-rank approximation of PY by adaptively soft-thresholding the singular values. The thresholding level is data-driven: the smaller an initially estimated singular value, the larger its thresholding level. Therefore, the estimated rank corresponds to the smallest singular value of PY that exceeds its thresholding level, i.e., r̂ = max{r : dr(PY) > λwr}. For the choice of the weights in (15), the estimated rank is
| (17) |
for and r̂ = 0 for . Therefore, the plausible range of the tuning parameter is , with λ = 0 corresponding to the least squares solution and to the null solution.
The proposed estimator and the l0 estimator in (12) differ only in their estimated singular values for XC0, but the difference can be consequential. While the solution path of the l0 method is discontinuous and the number of possible solutions equals the maximum rank, the proposed criterion offers more flexibility in that the resulting solution path is continuous and guided by the data-driven weights. The two methods can both be efficiently computed, in contrast to the computationally intensive l1 method in (13).
For any fixed λ ≥ 0, can be computed by (16). To choose an optimal λ and hence an optimal solution, K-fold cross validation method can be used, based on predictive performance of the models (Stone, 1974). In our numerical studies, we first compute the solutions over a grid of 100 λ values equally spaced on the log scale and select the best λ value; subsequently we refine the selection process around the chosen λ value with a finer grid of 100 λ values.
4. Rank consistency and error bounds
We study the rank estimation and prediction properties of the proposed adaptive nuclear norm penalized regression method. Our theoretical analysis is built on the framework developed by Bunea et al. (2011). We mainly focus on the random weights constructed in (15), in line with the adaptive lasso method (Zou, 2006) developed for univariate regression. Similar results are obtained for any pre-specified sequence of non-random weights satisfying certain order restriction and boundedness requirements. All the proofs are given in the Appendix.
The rank of the coefficient matrix C0, denoted as r*, can be viewed as the number of effective linear combinations of the predictors linked to the responses. Rank determination is always a foremost task of reduced rank estimation. The quality of the rank estimator, given in (17), clearly depends on the signal to noise ratio. Following Bunea et al. (2011), we shall use the r*th largest singular value of XC0, i.e., dr*(XC0), to measure the signal strength, and use the largest singular value of the projected noise matrix PE, i.e., d1(PE), to measure the noise level. Intuitively, if d1(PE) is much larger than the size of the signal, some of the signal could be masked by the noise and lost during the thresholding procedure; as such, r̂ may be much smaller than the true rank. The lemma below characterizes the limit or the true target of r̂ and its relationship with the signal and noise levels, as well as the adaptive weights.
Lemma 1
Suppose that there exists an index s ≤ r* such that ds(XC0) > (1 + δ)λ1/(γ+1) and ds+1(XC0) ≤ (1 − δ)λ1/(γ+1) for some δ ∈ (0, 1]. Then pr(r̂ = s) ≥ 1 − pr{d1(PE) ≥ δλ1/(γ+1)}, where r* is the rank of C0, r̂ the estimated rank given in (17), P the projection matrix onto the column space of X, E the error matrix in model (1), and γ the power parameter in the adaptive weights (15).
To achieve consistent rank estimation, we consider the following assumptions:
Assumption 1. The error matrix E has independent N(0, σ2) entries.
Assumption 2. For any θ > 0, λ = {(1 + θ)σ(√rx + √q)/δ}γ+1 with δ defined in Lemma 1, and dr*(XC0) > 2λ1/(γ+1).
Assumption 1 ensures that the noise level d1(PE) is of order √rx + √q; see Lemma 2 in the Appendix (Bunea et al., 2011). Assumption 2 concerns the signal strength relative to the noise level and the appropriate rate of the tuning parameter.
Theorem 3
Suppose Assumptions 1–2 hold. Let r̂ be the estimated rank given in (17), and rx = r(X) the rank of X. Then pr(r̂ = r*) → 1 as rx + q → ∞.
Theorem 3 shows that the proposed estimator is able to identify the correct rank with probability tending to 1 as rx + q goes to infinity. As in Bunea et al. (2011), the consistency results can be extended to the case of sub-Gaussian errors and can also be easily adapted to the case when rx + q is bounded and the sample size n goes to infinity. The rank consistency of the proposed estimator is thus valid for both classical and high-dimensional asymptotic regimes.
Our main results about the prediction performance of the proposed estimator are presented in Theorem 4. For simplicity, we write ĈS for .
Theorem 4
Suppose Assumptions 1–2 hold. Let c = d1(XC0)/dr*(XC0) ≥ 1. Then
with probability greater than 1 − exp{−θ2(rx + q)/2}, for any 0 < a < 1 and any p × q matrix B with r(B) ≤ r*. Moreover, taking B = C0 and a = 1/2 yields
| (18) |
with probability greater than 1 − exp{−θ2(rx + q)/2}.
The established bound in (18) shows that the prediction error is bounded by up to some multiplicative constant, with probability 1 − exp{−θ2(rx + q)/2}, i.e., the smaller the noise level or the true rank, the smaller the prediction error. The bound is valid for any X and C0. The estimation error bound of ĈS can also be readily derived from Theorem 4, e.g., if drx(X) ≥ ρ > 0 for some constant ρ, then under Assumptions 1–2, .
So far, we have considered random weights based on the least squares solution, as given in (15). We now briefly outline the results for any pre-specified sequence of non-negative and nondecreasing, non-random weights {wi; i = 1, …, n ∧ q}.
Corollary 2
Suppose Assumption 1 holds, and that (i) 0 ≤ w1 ≤ ··· ≤ wn∧q, and there exists 0 < m < ∞ such that wr* ≤ m ≤ wr*+1, (ii) the tuning parameter λ = (1 + θ)σ(√rx + √q)/m and (iii) dr*(XC0) > 2λm. Then
pr(r̂ = r*) → 1 as rx + q → ∞; and
with probability greater than 1 − exp{−θ2(rx + q)/2}.
The proof is similar to that of Theorems 3 and 4 and hence is omitted.
The error bounds of the proposed estimator established in Theorem 4 and Corollary 2 are comparable to those of the l0 rank penalized estimator and the l1 nuclear norm penalized estimator (Bunea et al., 2011; Rohde & Tsybakov, 2011). The rate of convergence is (rx + q)r* because (√rx + √q)2 ≤ 2(rx + q), which is the optimal minimax rate for rank sparsity under suitable regularity conditions (Rohde & Tsybakov, 2011; Bunea et al., 2012). However, the bounds for the nuclear norm penalized estimator were obtained with extra restrictions on the design matrix, and a tuning sequence for achieving the smallest mean squared error usually does not lead to correct rank recovery (Bunea et al., 2011). While both the rank selection criterion and the proposed method are able to achieve correct rank recovery and minimal mean squared error simultaneously, the latter possesses a continuous solution path produced by data-driven adaptive penalization, which may lead to improved empirical performance.
5. Robustification of reduced rank estimation
As suggested by a referee and motivated by Mukherjee & Zhu (2011), we discuss the robustification of the reduced rank methods by adding a ridge penalty. Mukherjee & Zhu (2011) proposed a reduced rank ridge regression method; see also Bunea et al. (2011) and She (2012). The shrinkage estimation induced by a ridge penalty makes the reduced rank estimation robust and hence is especially suitable when the predictors are highly correlated. The method can be viewed as minimizing the following criterion
| (19) |
where , and λ1 and λ2 are tuning parameters. We denote the resulting robustified estimator by , which can be obtained by data augmentation. Specifically, letting
(19) can be written as a rank selection criterion , whose solution is given in (12); see Mukherjee & Zhu (2011).
The adaptive nuclear norm penalization method can also be robustified by incorporating a ridge penalty term. Similar to (14), for efficient computation, we impose a ridge penalty on XC rather than C,
| (20) |
Interestingly, criterion (20) is analogous to the adaptive elastic net criterion (Zou & Zhang, 2009) in univariate regression. We denote the minimizer of (20) by . It can be verified that
| (21) |
where , defined in (16), denotes the proposed estimator in the absence of the ridge penalty.
For each fixed λ2, solving (19) requires inverting an p × p matrix (XTX + λ2I) and performing a singular value decomposition of an q × q matrix. When p is much greater than n, the Woodbury matrix identity is useful in speeding up computation (Hager, 1989), i.e., . Following Mukherjee & Zhu (2011), in practice we use K-fold cross validation to determine the optimal rank and select the optimal λ2 from a sequence of 100 values. On the other hand, obtaining the whole solution path of (20) only requires a one-time matrix inversion and singular value decomposition. We perform a 100 × 100 grid search of (λ1, λ2) to obtain the final estimator.
6. Empirical studies
6·1. Simulation
We compare the prediction, estimation and rank determination of various reduced rank estimators including the nuclear norm penalized estimator (Yuan et al., 2007), the rank penalized estimator (Bunea et al., 2011), and our proposed adaptive nuclear norm penalized estimator with several choices of the weight parameter γ. The robustified versions, namely, and , are also considered. For simplicity, we suppress the superscripts from the notations of the various estimators. We used the accelerated proximal gradient algorithm implemented in Matlab by Toh & Yun (2010) for computing ĈN. R code for computing ĈHR was provided by the original authors (Mukherjee & Zhu, 2011), and we modified their code to make use of the Woodbury matrix identity. We implemented all the other methods in R (R Development Core Team, 2013). All computation was done on computers with 3.4 GHz CPU, 8 GB RAM and the Linux operating system.
We consider the same simulation models as in Bunea et al. (2011). The coefficient matrix C0 is constructed as , where b > 0, C1 ∈ ℜp×r*, C2 ∈ ℜq×r* and all entries in C1 and C2 are random samples from N(0, 1). Two scenarios of model dimensions are considered, with p, q < n and p, q > n. In Model I, we set n = 100, p = q = 25 and r* = 10. The matrix X is constructed by generating its n rows as random samples from N(0, Γ), where Γ = (Γij)p×p and Γij = ρ|i−j| with some 0 < ρ < 1. In Model II, we set n = 20, p = q = 25, r* = 5 and rx = 10. The matrix X is generated as X = X0Γ1/2, where Γ is defined as above, X0 = X1X2, X1 ∈ ℜn×rx, X2 ∈ ℜrx×p, and all entries of X1, X2 are N(0, 1) random samples.
The data matrix Y is then generated by Y = XC0 + E, where the elements of E are N(0, 1) random samples. Each simulated model is characterized by the sample size n, the number of predictors p, the number of responses q, the true model rank r*, the rank of the design matrix rx, the correlation ρ ∈ {0·1, 0·5, 0·9}, and the signal strength b ∈ {0·05, 0·1, 0·3}. The experiment was replicated 500 times for each parametric setting.
One way to alleviate inaccuracy in the empirical tuning parameter selection and to reveal the true potential of each method for fair comparison is to tune each method based on its predictive accuracy evaluated with a very large independently generated validation data set; this yields optimally tuned estimators. We have also tried ten-fold cross validation for selecting the tuning parameters but the results are omitted for brevity, as they are similar to or slightly worse than those of the optimal tuning procedure; see the Supplementary Material. For each method, the model accuracy is measured by the average of the scaled mean squared errors from all 500 runs, i.e., for estimation, and for prediction. To evaluate the rank determination performance, we report the average of the estimated ranks from all runs and the percentage of correct rank identification. Tables 1 and 2 summarize the simulation results and list the average computation time per simulation run for Models I and II.
Table 1.
Comparison of optimally tuned reduced rank estimators using Model I. The estimation and prediction errors are reported, with their standard errors in parentheses.
| b | ĈN | ĈH | ĈS(2) | ĈS(0) | ĈHR | ĈSR(2) | |
|---|---|---|---|---|---|---|---|
| ρ = 0·9 | |||||||
|
| |||||||
| 0·05 | Est | 1·6 (0·2) | 3·2 (0·6) | 2·6 (0·4) | 2·5 (0·3) | 1·6 (0·2) | 2·5 (0·4) |
| Pred | 7·8 (0·8) | 12·2 (1·3) | 9·9 (1·0) | 10·5 (1·0) | 8·1 (0·8) | 9·8 (1·0) | |
| Rank | 7·7, 3% | 3·3, 0% | 5·5, 0% | 10·9, 26% | 7·6, 4% | 6·0, 0% | |
| 0·1 | Est | 3·5 (0·4) | 5·6 (0·7) | 4·5 (0·5) | 4·3 (0·5) | 3·6 (0·4) | 4·4 (0·5) |
| Pred | 12·1 (1·0) | 16·1 (1·4) | 13·5 (1·2) | 14·4 (1·1) | 12·5 (1·0) | 13·4 (1·1) | |
| Rank | 11·2, 19% | 6·2, 0% | 8·1, 5% | 14·1, 0% | 7·9, 5% | 8·4, 9% | |
| 0·3 | Est | 6·4 (0·7) | 6·8 (0·8) | 6·2 (0·7) | 6·8 (0·7) | 6·1 (0·7) | 6·2 (0·7) |
| Pred | 16·4 (1·2) | 16·9 (1·2) | 16·0 (1·2) | 18·5 (1·2) | 15·9 (1·2) | 15·9 (1·2) | |
| Rank | 10·7, 30% | 9·8, 81% | 10·3, 64% | 17·0, 0% | 9·9, 86% | 10·4, 59% | |
|
| |||||||
| ρ = 0·5 | |||||||
|
| |||||||
| 0·05 | Est | 0·8 (0·1) | 1·2 (0·1) | 0·9 (0·1) | 0·9 (0.1) | 0·8 (0·1) | 0·9 (0·1) |
| Pred | 12·4 (1·0) | 16·8 (1·5) | 13·6 (1·2) | 13·3 (1·1) | 13·0 (1·1) | 13·0 (1·1) | |
| Rank | 12·8, 1% | 6·0, 0% | 8·0, 5% | 13·3, 0% | 7·9, 6% | 9·1, 27% | |
| 0·1 | Est | 1·2 (0·1) | 1·4 (0·1) | 1·2 (0·1) | 1·2 (0·1) | 1·2 (0·1) | 1·1 (0·1) |
| Pred | 16·2 (1·2) | 17·4 (1·2) | 15·7 (1·1) | 16·8 (1·1) | 15·7 (1·1) | 15·4 (1·1) | |
| Rank | 15·2, 0% | 9·2, 32% | 10·0, 58% | 15·8, 0% | 9·4, 47% | 10·4, 52% | |
| 0·3 | Est | 1·3 (0·1) | 1·3 (0·1) | 1·2 (0·1) | 1·5 (0·1) | 1·2 (0·1) | 1·2 (0·1) |
| Pred | 17·1 (1·3) | 16·2 (1·2) | 16·0 (1·2) | 19·5 (1·3) | 16·0 (1·2) | 15·9 (1·2) | |
| Rank | 10·9, 14% | 10·0, 100% | 10·2, 80% | 17·8, 0% | 10·0, 100% | 10·3, 74% | |
|
| |||||||
| ρ = 0·1 | |||||||
|
| |||||||
| 0·05 | Est | 0·6 (0·1) | 0·9 (0·1) | 0·7 (0·1) | 0·7 (0·1) | 0·7 (0·1) | 0·7 (0·1) |
| Pred | 13·3 (1·0) | 17·4 (1·4) | 14·1 (1·2) | 13·7 (1·1) | 14·0 (1·2) | 13·5 (1·1) | |
| Rank | 14·3, 0% | 6·6, 1% | 8·5, 12% | 13·6, 0% | 8·1, 10% | 9·6, 35% | |
| 0·1 | Est | 0·9 (0·1) | 0·9 (0·1) | 0·8 (0·1) | 0·9 (0·1) | 0·8 (0·1) | 0·8 (0·1) |
| Pred | 16·8 (1·2) | 17·3 (1·3) | 15·9 (1·2) | 17·2 (1·2) | 16·1 (1·2) | 15·5 (1·2) | |
| Rank | 16·5, 0% | 9·5, 52% | 10·2, 64% | 16·1, 0% | 9·6, 63% | 10·6, 44% | |
| 0·3 | Est | 0·9 (0·1) | 0·8 (0·1) | 0·8 (0·1) | 1·0 (0·1) | 0·8 (0·1) | 0·8 (0·1) |
| Pred | 17·7 (1·5) | 16·2 (1·2) | 16·0 (1·2) | 19·6 (1·3) | 16·0 (1·2) | 16·0 (1·2) | |
| Rank | 11·3, 3% | 10·0, 100% | 10·2, 83% | 17·9, 0% | 10·0, 100% | 10·3, 76% | |
|
| |||||||
| Time | 17·5 | 0·0 | 0·2 | 0·2 | 3·9 | 2·1 | |
ĈN, nuclear norm penalized estimator (Yuan et al., 2007); ĈH, rank penalized estimator (Bunea et al., 2011); ĈS(γ): adaptive nuclear norm penalized estimator with weight parameter γ; ĈHR, robustified rank penalized estimator; ĈSR(γ), robustified adaptive nuclear norm penalized estimator with weight parameter γ; Est, estimation error; Pred, prediction error; Rank, average of estimated rank and percentage of correct rank identification; Time, average computation time in seconds per simulation run.
Table 2.
Comparison of optimally tuned reduced rank estimators using Model II. The layout of the table is the same as in Table 1.
| b | ĈN | ĈH | ĈS(2) | ĈS(0) | ĈHR | ĈSR(2) | |
|---|---|---|---|---|---|---|---|
| ρ = 0·9 | |||||||
|
| |||||||
| 0·05 | Est | 1·1 (0·2) | 1·2 (0·2) | 1·2 (0·2) | 1·2 (0·2) | 1·2 (0·2) | 1·2 (0·2) |
| Pred | 34·1 (4·1) | 31·5 (4) | 29·1 (3·5) | 35·3 (4·2) | 29·8 (3·5) | 28·9 (3·5) | |
| Rank | 7·4, 2% | 4·7, 73% | 5·2, 71% | 8·3, 0% | 4·8, 83% | 5·3, 66% | |
| 0·1 | Est | 4·5 (0·7) | 4·5 (0·7) | 4·5 (0·7) | 4·5 (0·7) | 4·5 (0·7) | 4·5 (0·7) |
| Pred | 37·0 (4·4) | 30·8 (3·6) | 30·0 (3·6) | 38·9 (4·8) | 30·3 (3·6) | 29·9 (3·6) | |
| Rank | 7·6, 3% | 5·0, 99% | 5·2, 79% | 8·8, 0% | 5·0, 99% | 5·3, 75% | |
| 0·3 | Est | 40·4 (5·6) | 40·6 (5·9) | 40·6 (5·9) | 40·6 (5·9) | 40·6 (5·9) | 40·6 (5·9) |
| Pred | 32·3 (5·5) | 30·2 (3·5) | 30·1 (3·5) | 41·3 (5·0) | 30·0 (3·5) | 30·0 (3·5) | |
| Rank | 5·5, 75% | 5·0, 100% | 5·2, 82% | 9·1, 0% | 5·0, 100% | 5·3, 75% | |
|
| |||||||
| ρ = 0·5 | |||||||
|
| |||||||
| 0·05 | Est | 1·1 (0·2) | 1·1 (0·2) | 1·1 (0·2) | 1·1 (0·2) | 1·1 (0·2) | 1·1 (0·2) |
| Pred | 35·0 (4·2) | 31·0 (3·9) | 29·1 (3·6) | 35·9 (4·7) | 29·7 (3·6) | 29·0 (3·6) | |
| Rank | 8·0, 0% | 4·9, 90% | 5·2, 77% | 8·4, 0% | 4·9, 93% | 5·3, 68% | |
| 0·1 | Est | 4·5 (0·6) | 4·5 (0·6) | 4·5 (0·6) | 4·5 (0·6) | 4·5 (0·6) | 4·5 (0·6) |
| Pred | 37·8 (4·6) | 30·2 (3·5) | 29·6 (3·3) | 39·0 (4·2) | 29·8 (3·4) | 29·5 (3·4) | |
| Rank | 7·8, 7% | 5·0, 99% | 5·2, 81% | 8·9, 0% | 5·0, 99% | 5·3, 74% | |
| 0·3 | Est | 40·4 (6·1) | 40·1 (6·0) | 40·1 (6·0) | 40·1 (6·0) | 40·1 (6·0) | 40·1 (6·0) |
| Pred | 31·6 (4·9) | 30·3 (3·1) | 30·2 (3·1) | 41·3 (4·0) | 30·2 (3·1) | 30·2 (3·1) | |
| Rank | 5·3, 86% | 5·0, 100% | 5·2, 78% | 9·2, 0% | 5·0, 100% | 5·3, 70% | |
|
| |||||||
| ρ = 0·1 | |||||||
|
| |||||||
| 0·05 | Est | 1·1 (0·2) | 1·1 (0·2) | 1·1 (0·2) | 1·1 (0·2) | 1·1 (0·2) | 1·1 (0·2) |
| Pred | 35·2 (4·2) | 31·0 (3·8) | 29·3 (3·5) | 36·0 (4·3) | 29·9 (3·5) | 29·1 (3·6) | |
| Rank | 8·1, 0% | 4·9, 88% | 5·2, 76% | 8·4, 0% | 4·9, 91% | 5·3, 65% | |
| 0·1 | Est | 4·6 (0·7) | 4·5 (0·7) | 4·5 (0·7) | 4·5 (0·7) | 4·5 (0·7) | 4·5 (0·7) |
| Pred | 37·7 (4·6) | 30·2 (3·5) | 29·7 (3·5) | 38·9 (4·4) | 29·8 (3·5) | 29·6 (3·4) | |
| Rank | 7·9, 5% | 5·0, 100% | 5·2, 79% | 8·8, 0% | 5·0, 100% | 5·3, 73% | |
| 0·3 | Est | 40·5 (6·2) | 40·5 (5·6) | 40·5 (5·6) | 40·5 (5·6) | 40·5 (5·6) | 40·5 (5·6) |
| Pred | 31·3 (5·1) | 30·1 (3·4) | 30·0 (3·4) | 41·2 (4·6) | 29·9 (3·4) | 29·9 (3·4) | |
| Rank | 5·3, 86% | 5·0, 100% | 5·2, 76% | 9·1, 0% | 5·0, 100% | 5·3, 68% | |
|
| |||||||
| Time | 20·2 | 0·0 | 0·2 | 0·2 | 4·0 | 2·5 | |
We first examine the effects of the adaptive weights on the proposed estimator ĈS. For the case of equal weights, i.e., γ = 0, ĈS tends to overestimate the rank and does not have good predictive performance in most cases. The performance of ĈS is substantially better when γ = 2, which implements data-driven weights, than when γ = 0. We have also experimented with other γ values, and our results show that γ = 2 is generally a good choice; see the Supplementary Material. Henceforth we refer to the case of γ = 2 in the following comparisons.
A sharper comparison between the various estimators can be obtained by contrasting their performance on each simulated dataset. For instance, for each experimental setting, we compare ĈH with ĈS by computing the percentage reduction in the mean squared prediction error of ĈS relative to ĈH for each of the 500 simulated datasets:
where Pred(·) denotes the scaled mean squared prediction error of a method. Figure 1 displays the notched boxplots of the percentage reduction in the mean squared prediction error of ĈS relative to ĈH across all experimental settings, whereas Figure 2 displays those of ĈS relative to ĈN. The notches in each boxplot extend 1·58/√500 times its inter-quartile range from the median (McGill et al., 1978).
Fig. 1.


Notched boxplots of the percentage reduction in the mean squared prediction error of ĈS relative to ĈH. The boxplots are shaded in dark grey for ρ = 0.9, in light grey for ρ = 0.5, and in white for ρ = 0.1.
Fig. 2.


Notched boxplots of the percentage reduction in the mean squared prediction error of ĈS relative to ĈN. All other settings are same as in Figure 1.
The proposed estimator ĈS generally outperforms the rank penalized estimator ĈH, especially in Model I. Figure 1 shows that the improvement in prediction can be substantial, when the signal is weak or moderate and the correlation among the predictors is high. For rank determination, both estimators perform well when the signal is moderate to strong and the correlation among the predictors is weak to moderate. The proposed estimator ĈS, however, tends to slightly overestimate the rank.
The proposed method often outperforms nuclear norm penalized regression (Yuan et al., 2007), and is more parsimonious than the latter in both rank reduction and computation. Table 1 and Figure 2 show that in Model I, when the signal is weak and/or the correlation among the predictors is high, the nuclear norm penalized estimator ĈN performs better than ĈS in estimation and prediction. However, this gain has a price, for ĈN often overestimates the rank and is much harder to compute. In the high dimensional setting of Model II, ĈS generally enjoys similar or better predictive performance than ĈN. Our findings agree with those of Bunea et al. (2011).
Table 1 shows that shrinkage estimation due to the additional ridge penalty generally enhances an estimator, especially in the presence of highly correlated predictors. However, ĈS benefits much less from the additional ridge penalty than does ĈH, because, unlike the latter, ĈS is already an adaptive shrinkage estimator, owing to the soft-thresholding operation. In general, it is worthwhile to incorporate ridge penalization in order to further improve prediction, if the increased computational cost is affordable.
6·2. Application
We consider a breast cancer data set (Witten et al., 2009), consisting of gene expression measurements and comparative genomic hybridization measurements for n = 89 subjects. The data were used to demonstrate the effectiveness of the rank selection criterion in a preprint of Bunea et al. (2011) posted at the website http://arxiv.org. The data set is available in the R package PMA (Witten et al., 2009), and a detailed description can be found in Chin et al. (2006).
Prior studies have demonstrated that certain types of cancer are characterized by abnormal DNA copy-number changes (Pollack et al., 2002; Peng et al., 2010). It is thus of interest to examine the relationship between DNA copy-number variations and gene expression profiles, for which multivariate regression methods can be useful. Biologically, it makes sense to regress gene expression profiles on copy-number variations because the amplification or deletion of the portion of DNA corresponding to a given gene may result in a corresponding increase or decrease in expression of that gene. The reverse approach is also meaningful, in that the resulting predictive model may identify functionally relevant copy-number variations. This approach has been shown to be promising in enhancing the limited comparative genomic hybridization data analysis with the wealth of gene expression data (Geng et al., 2011; Zhou et al., 2012). We have tried both approaches, i.e., setting 1: designating the copy-number variations of a chromosome as predictors and the gene expression profiles of the same chromosome as responses, and setting 2: reversing the roles of the predictors and the responses. We find that in setting 1, none of the methods provides an adequate fit to the data, and the rank selection criterion may even fail to pick up any signals. The reduced rank models give much better results under setting 2. We thus report only the results for setting 2.
We focus the analysis on chromosome 21, for which p = 227 and q = 44. Both the responses and predictors are standardized. We compare the various reduced rank methods by the following cross-validation procedure. The data were randomly split into a training set of size ntrain = 79 and a test set of size ntest = 10. All model estimation was carried out using the training data, with the tuning parameters selected by ten-fold cross validation. We used the test data to calibrate the predictive performance of each estimator Ĉ, specifically, by its mean squared prediction error , where (Ytest, Xtest) denotes the test set. The random-splitting process was repeated 100 times to yield the average mean squared prediction error and the average rank estimate for each method; see the upper panel of Table 3.
Table 3.
Comparison of the model fits to the chromosome 21 data for various reduced rank methods. The mean squared prediction errors and the estimated ranks are reported, with their standard errors in parentheses.
| ĈN | ĈH | ĈHR | ĈS(2) | ĈSR(2) | |
|---|---|---|---|---|---|
| Full data | |||||
|
| |||||
| MSPE | 0·71 (0·2) | 0·.69 (0·1) | 0·68 (0·1) | 0·68 (0·1) | 0·68 (0.·1) |
| Rank | 6·2 (0·8) | 1·0 (0·0) | 1·0 (0·0) | 1·0 (0·2) | 1·8 (0·4) |
|
| |||||
| Selected predictors | |||||
|
| |||||
| MSPE | 0·85 (0·2) | 0·90 (0·2) | 0·82 (0·1) | 0·85 (0·1) | 0·84 (0·1) |
| Rank | 4·6 (0·7) | 1·3 (0·5) | 1·9 (0·3) | 2·1 (0·2) | 2·4 (0·5) |
MSPE, average of mean squared prediction errors based on 100 replications of 79/10 splits of the data; Rank: corresponding average of the rank estimates. The notations of the estimators are the same as in Table 1.
As the number of predictors is much greater than the sample size, it is reasonable to assume that only a subset of predictors is important. Therefore, a perhaps better modeling strategy is subset multivariate regression with a selected subset of predictors. Recently, several variable selection methods have been proposed in the context of reduced rank regression (Chen et al., 2012; Chen & Huang, 2012; Bunea et al., 2012). We modified the preceding cross-validation procedure for comparing the reduced rank subset regression methods. The only modification was that for each random split, we first applied the method of Chen et al. (2012) using the training set to select a set of predictors, with which the reduced rank methods were subsequently carried out using the training set and calibrated using the test set. Since our main goal is to compare the various reduced rank methods, we omit the description of the predictor selection procedure but refer the interested reader to Chen et al. (2012) for details. The results are summarized in the lower panel of Table 3.
Table 3 shows that the proposed estimator ĈS enjoys slightly better predictive performance than both ĈH and ĈN. The numbers of selected predictors in the 100 splits range from 71 to 102, hence incorporating variable selection greatly reduces the number of predictors and may potentially improve model interpretation. However, in this example, reduced rank estimation using a subset of predictors results in higher mean squared prediction error than using all predictors, uniformly for all methods, but more so for ĈH than for other methods. The nuclear norm penalized estimator ĈN generally yields a higher rank estimate than the other methods. Incorporating ridge penalization improves the predictive performance of the reduced rank methods. Particularly, ĈHR may substantially outperform its non-robust counterpart ĈH. We find that both ĈN and ĈHR can be computationally intensive for large datasets, while other methods are much faster to compute. These results are consistent with the simulation findings in Section 6·1.
7. Discussion
Adaptive nuclear norm penalization can serve as a building block to study a family of singular value penalties. This is based on the connection between an adaptive l1 penalty and many concave penalty functions (Knight & Fu, 2000; Fan & Li, 2001; Huang et al., 2008). Consider the regression problem (2) with a general singular value penalty , where pλ(·) is a penalty function, e.g., for some 0 < b ≤ 1 (Huang et al., 2008; Rohde & Tsybakov, 2011). In this setup the optimization of (2) can be challenging. A promising approach is to adopt a local linear approximation (Zou & Li, 2008), , for di(C) ≈ d̃i, where d̃i is some initial estimator of di(C). It can be seen that for fixed d̃i, up to a constant, the first-order approximation yields exactly an adaptive nuclear norm penalty. This suggests that these problems may be solved by an iteratively reweighted adaptive nuclear norm penalization approach.
Incorporating an extra ridge penalty can improve reduced rank estimation (Mukherjee & Zhu, 2011; She, 2012). When combined with the adaptive nuclear norm penalty, such a criterion bears resemblance to the adaptive elastic-net criterion (Zou & Hastie, 2005; Zou & Zhang, 2009) in univariate regression. It would be interesting to investigate the theoretical properties of this approach and compare it with the nonlinear fusion of nuclear norm and ridge penalties in Owen (2007) and She (2012). Another pressing problem is to extend regularized reduced rank regression methods to generalized linear and nonparametric regression models (Yee & Hastie, 2003; Li & Chan, 2007; She, 2012). On the optimization aspect, it is interesting to study the use of adaptive nuclear norm in some classical sparse optimization areas, such as matrix completion (Candès et al., 2011).
Supplementary Material
Acknowledgments
We thank Howell Tong, and are grateful to an associate editor and two referees for constructive comments that helped improve the paper significantly. The work was partially supported by the U.S. National Institutes of Health and National Science Foundation.
Appendix. Technical details
Proof of Theorem 1
First we show by a counter-example that if we have an index k such that wk < wk+1, then f (·) is non-convex. Let C and Z be diagonal p × p matrices such that cii = i, for i = 1, …, p, while Z equals C but with entries switched at positions p − k + 1 and p − k for some 1 ≤ k ≤ p − 1 on the diagonal. It is then easy to verify that
, where f(·) is defined in (3). Therefore f(·) is non-convex.
Next we prove that f(C) = ||C||w* is a convex function of C ∈ ℜp×q for w1 ≥ ··· ≥ wp∧q ≥ 0. Without loss of generality, assume p ≤ q so that we can simply write p = p ∧ q. First consider the case that wp > 0, and define the following function on ℜp:
| (A1) |
where δ is a permutation of {1,…, p} determined by x such that |x|δ(1) ≥ ··· ≥ |x|δ(p). We claim that w(·) in (A1) is a symmetric gauge function (Horn & Johnson, 1985, Definition 7.4.23), i.e., it satisfies the following six conditions: (a) w(x) ≥ 0, for any x ∈ ℜ; (b) w(x) = 0 if and only if x = 0; (c) w(αx) = |α|w(x), for any α ∈ ℜ; (d) w(x + y) ≤ w(x) + w(y); (e) w(x) = w(|x|); (f) w(x) = w{τ (x)} for any τ that is a permutation of indices {1,…, p}.
All conditions except (d) are trivial to verify. To prove (d), let δ, σ and τ be permutations such that |x + y|δ(i), |x|σ(i) and |y|τ(i) are placed in non-increasing order respectively.
where the second inequality is due to the Hardy–Littlewood–Pólya inequality (Hardy et al., 1967). By a straightforward application of Horn & Johnson (1985, Theorem 7.4.24), since ||C||w* = w{d(C)} where d(C) = {d1(C),…, dp(C)}T, the function f(·) = ||·||w* defines a matrix norm and hence is convex.
For the case that wp = 0, let s be the largest index such that ws > 0. For 0 < ε < ws, consider the perturbed w̃ that w̃i = wi, for i = 1,…, s, and w̃i = ε, for i = s + 1,…, p. Then for any C,Z ∈ ℜp×q, ||C + Z||w̃*/2 ≤ ||C||w̃*/2 + ||Z||w̃*/2. By taking ε → 0, ||C + Z||w*/2 ≤ ||C||w*/2 + ||Z||w*/2. Therefore ||·||w* is convex.
Proof of Theorem 2
We first prove that
(Y) is indeed a global optimal solution to (8). Below, we write h for n ∧ q. Let
, which implies the entries of g are in non-increasing order. Since the penalty term only depends on the singular values of C, (8) can be equivalently written as:
For the inner minimization, we have the inequality
The last inequality is due to von Neumann’s trace inequality (von Neumann, 1937; Mirsky, 1975). Equality holds when C admits the singular value decomposition C = Udiag(g)VT, where U and V are defined in (5) as the left and right singular matrices of Y. Then the optimization reduces to
| (A2) |
The objective function is completely separable and is minimized only when gi = {di(Y) − λwi}+. This is a feasible solution because {di(Y)} is in non-increasing order, while {wi} is in non-decreasing order. Therefore
(Y) = Udiag[{d(Y) − λw}+]VT is a global optimal solution to (8). The uniqueness follows by the equality condition for the von Neumann’s trace inequality when Y has distinct nonzero singular values, and the uniqueness of the strictly convex optimization (A2). This concludes the proof.
Proof of Lemma 1
By (17), r̂ > s holds if and only if ds+1(PY) > λ1/(γ+1) and r̂ < s holds if and only if ds(PY) ≤ λ1/(γ+1). Then
Based on Weyl’s inequalities on singular values (Franklin, 2000) and observing that PY = XC0 + PE, we have d1(PE) ≥ ds+1(PY) − ds+1(XC0) and d1(PE) ≥ ds(XC0) − ds(PY). Hence ds+1(PY) > λ1/(γ+1) implies d1(PE) ≥ λ1/(γ+1) − ds+1(XC0), and ds(PY) ≤ λ1/(γ+1) implies d1(PE) ≥ ds(XC0) − λ1/(γ+1). It then follows that
Note that min{λ1/(γ+1) − ds+1(XC0), ds(XC0) − λ1/(γ+1)} ≥ δλ1/(γ+1). This completes the proof.
Lemma 2 (Bunea et al., 2011)
Let rx denote the rank of X and suppose Assumption 1 holds. Then for any t > 0, E{d1(PE)} ≤ σ(√rx + √q), and pr[d1(PE) ≥ E{d1(PE)} + σt] ≤ exp(−t2/2).
Proof of Theorem 3
When dr* (XC0) > 2λ1/(γ+1), we have dr* (XC0) > 2λ1/(γ+1) ≥ (1 + δ)λ1/(γ+1) and dr*+1(XC0) = 0 ≤ (1 − δ)λ1/(γ+1), for some 0 < δ ≤ 1. The effective rank s defined in Lemma 1 equals the true rank, i.e., s = r*, and min{λ1/(γ+1) − dr*+1(XC0), dr* (XC0) − λ1/(γ+1) } ≥ δλ1/(γ+1). It then follows from Lemma 2 that
as rx + q → ∞. This completes the proof.
Proof of Theorem 4
We write h for n ∧ q. By the definition of ĈS in (16),
for any p × q matrix B. Note that
Then we have
| (A3) |
Now consider any B with r(B) ≤ r̂,
Recall that , so wr̂ − w1 ≥ ··· ≥ wr̂ − wr̂−1 ≥ 0. Therefore, both and satisfy the triangle inequality; see the proof of Theorem 1. Moreover, Weyl’s inequalities (Franklin, 2000) and the equality PY = XC0 + PE imply that dr̂ (PY) ≥ dr̂(XC0) − d1(PE) and d1(PY) ≤ d1(XC0) + d1(PE). Hence,
The last inequality is due to the Cauchy–Schwarz inequality. Using (A3), r(XĈS − XB) ≤ r(ĈS − B) ≤ 2r̂ and the inequality 2xy ≤ x2/a + ay2, we have
Since , consequently, for any 0 < a < 1,
As shown in Theorem 3, on the event {d1(PE) < δλ1/(γ+1)}, the estimated rank r̂ equals the true rank r*, i.e., r̂ = r*, and pr{d1(PE) ≥ δλ1/(γ+1)}≤ exp{−θ2(rx + q)/2}. Also, dr* (XC0) > 2λ1/(γ+1) and c = d1(XC0)/dr* (XC0) ≥ 1. Therefore, with probability at least 1 − exp{−θ2(rx + q)/2},
Since B is an arbitrary matrix with r(B) ≤ r*, the second part of the theorem is obtained by taking B = C0 and a = 1/2. This completes the proof.
Footnotes
Supplementary material available at Biometrika online includes additional simulation results.
Contributor Information
Kun Chen, Email: kun.chen@uconn.edu, Department of Statistics, University of Connecticut, 215 Glenbrook Road, Storrs, Connecticut 06269, U.S.A.
Hongbo Dong, Email: hdong6@wisc.edu, Wisconsin Institutes for Discovery, University of Wisconsin, 330 N. Orchard St., Madison, Wisconsin 53715, U.S.A.
Kung-Sik Chan, Email: kung-sik-chan@uiowa.edu, Department of Statistics and Actuarial Science, University of Iowa, Iowa City, Iowa 52242, U.S.A.
References
- Aldrin M. Multivariate prediction using softly shrunk reduced-rank regression. The American Statistician. 2000;54:29–34. [Google Scholar]
- Anderson TW. Estimating linear restrictions on regression coefficients for multivariate normal distributions. Annals of Mathematical Statistics. 1951;22:327–351. [Google Scholar]
- Anderson TW. Asymptotic distribution of the reduced rank regression estimator under general conditions. Annals of Statistics. 1999;27:1141–1154. [Google Scholar]
- Anderson TW. Specification and misspecification in reduced rank regression. Sankhyâ. 2002;64:193–205. [Google Scholar]
- Bunea F, She Y, Wegkamp M. Optimal selection of reduced rank estimators of high-dimensional matrices. Annals of Statistics. 2011;39:1282–1309. [Google Scholar]
- Bunea F, She Y, Wegkamp M. Joint variable and rank selection for parsimonious estimation of high dimensional matrices. Annals of Statistics. 2012;40:2359–2388. [Google Scholar]
- Cai JF, Candès EJ, Shen Z. A singular value thresholding algorithm for matrix completion. SIAM Journal on Optimization. 2010;20:1956–1982. [Google Scholar]
- Candès EJ, Li X, Ma Y, Wright J. Robust principal component analysis? Journal of the ACM. 2011;58:1–37. [Google Scholar]
- Candès EJ, Recht B. Exact matrix completion via convex optimization. Found Comput Math. 2009;9:717–772. [Google Scholar]
- Chen K, Chan KS, Stenseth NC. Reduced rank stochastic regression with a sparse singular value decomposition. Journal of the Royal Statistical Society Series B. 2012;74:203–221. [Google Scholar]
- Chen L, Huang JZ. Sparse reduced-rank regression for simultaneous dimension reduction and variable selection. Journal of the American Statistical Association. 2012;107:1533–1545. [Google Scholar]
- Chin K, DeVries S, Fridlyand J, Spellman PT, Roydasgupta R, Kuo WL, Lapuk A, Neve RM, Qian Z, Ryder T. Genomic and transcriptional aberrations linked to breast cancer pathophysiologies. Cancer Cell. 2006;10:529–541. doi: 10.1016/j.ccr.2006.10.009. [DOI] [PubMed] [Google Scholar]
- Donoho DL, Johnstone IM. Adapting to unknown smoothness via wavelet shrinkage. Journal of the American Statistical Association. 1995;90:1200–1224. [Google Scholar]
- Eckart C, Young G. The approximation of one matrix by another of lower rank. Psychometrika. 1936;1:211–218. [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association. 2001;96:1348–1360. [Google Scholar]
- Franklin J. Matrix Theory. Toronto: Dover Publications; 2000. [Google Scholar]
- Geng H, Iqbal J, Chan WC, Ali HH. Virtual CGH: an integrative approach to predict genetic abnormalities from gene expression microarray data applied in lymphoma. BMC Medical Genomics. 2011;4:32. doi: 10.1186/1755-8794-4-32. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hager WW. Updating the inverse of a matrix. SIAM Review. 1989;31:221–239. [Google Scholar]
- Hardy GH, Littlewood JE, Pólya G. Inequalities. Cambridge University Press; 1967. [Google Scholar]
- Horn RA, Johnson CR. Matrix Analysis. Cambridge University Press; 1985. [Google Scholar]
- Huang J, Horowitz JL, Ma S. Asymptotic properties of bridge estimators in sparse high-dimensional regression models. Annals of Statistics. 2008;36:587–613. [Google Scholar]
- Izenman AJ. Reduced-rank regression for the multivariate linear model. Journal of Multivariate Analysis. 1975;5:248–264. [Google Scholar]
- Klopp O. Rank penalized estimators for high-dimensional matrices. Electron J Statist. 2011;5:1161–1183. [Google Scholar]
- Knight K, Fu W. Asymptotics for lasso-type estimators. Annals of Statistics. 2000;28:1356–1378. [Google Scholar]
- Koltchinskii V, Lounici K, Tsybakov A. Nuclear norm penalization and optimal rates for noisy low rank matrix completion. Annals of Statistics. 2011;39:2302–2329. [Google Scholar]
- Li MC, Chan KS. Multivaraite reduced-rank nonlinear time series modeling. Statistica Sinica. 2007;17:139–159. [Google Scholar]
- Lu Z, Monteiro RDC, Yuan M. Convex optimization methods for dimension reduction and coefficient estimation in multivariate linear regression. Math Program. 2012;131:163–194. [Google Scholar]
- McGill R, Tukey JW, Larsen WA. Variations of box plots. The American Statistician. 1978;32:12–16. [Google Scholar]
- Mirsky L. A trace inequality of John von Neumann. Monatschefte fur Mathematik. 1975;79:303–306. [Google Scholar]
- Mukherjee A, Zhu J. Reduced rank ridge regression and its kernel extensions. Statistical Analysis and Data Mining. 2011;4:612–622. doi: 10.1002/sam.10138. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Negahban S, Wainwright MJ. Estimation of (near) low-rank matrices with noise and high-dimensional scaling. Annals of Statistics. 2011;39:1069–1097. [Google Scholar]
- Owen AB. A robust hybrid of lasso and ridge regression. Contemporary Mathematics. 2007;443:59–71. [Google Scholar]
- Peng J, Zhu J, Bergamaschi A, Han W, Noh D-Y, Pollack JR, Wang P. Regularized multivariate regression for identifying master predictors with application to integrative genomics study of breast cancer. Ann Appl Stat. 2010;4:53–77. doi: 10.1214/09-AOAS271SUPP. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pollack JR, Sørlie T, Perou CM, Rees CA, Jeffrey SS, Lonning PE, Tibshirani RJ, Botstein D, Børresen-Dale ALL, Brown PO. Microarray analysis reveals a major direct role of DNA copy number alteration in the transcriptional program of human breast tumors. Proceedings of the National Academy of Sciences of the United States of America. 2002;99:12963–12968. doi: 10.1073/pnas.162471999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing; Vienna, Austria: 2013. [Google Scholar]
- Reinsel GC, Velu P. Multivariate Reduced-rank Regression: Theory and Applications. New York: Springer; 1998. [Google Scholar]
- Rohde A, Tsybakov A. Estimation of High-Dimensional Low-rank Matrices. Annals of Statistics. 2011;39:887–930. [Google Scholar]
- She Y. Reduced Rank Vector Generalized Linear Models for Feature Extraction. Statistics and Its Interface. 2012 To appear. [Google Scholar]
- Stone M. Cross-validation and multinomial prediction. Biometrika. 1974;61:509–515. [Google Scholar]
- Tibshirani RJ. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B. 1996;58:267–288. [Google Scholar]
- Toh K-C, Yun S. An accelerated proximal gradient algorithm for nuclear norm regularized least squares problems. Pacific J Optim. 2010;6:615–640. [Google Scholar]
- von Neumann J. Some matrix inequalities and metrization of matric-space. Tomsk University Review. 1937;1:286–300. [Google Scholar]
- Witten DM, Tibshirani RJ, Hastie TJ. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics. 2009;10:515–534. doi: 10.1093/biostatistics/kxp008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yee T, Hastie TJ. Reduced rank vector generalized linear models. Statistical Modeling. 2003:367–378. [Google Scholar]
- Yuan M, Ekici A, Lu Z, Monteiro R. Dimension reduction and coefficient estimation in multivariate linear regression. Journal of the Royal Statistical Society Series B. 2007;69:329–346. [Google Scholar]
- Zhou Y, Zhang Q, Stephens O, Heuck CJ, Tian E, Sawyer JR, Cartron-Mizeracki MA, Qu P, Keller J, Epstein J, Barlogie B, Shaughnessy JD. Prediction of cytogenetic abnormalities with gene expression profiles. Blood. 2012;119:148–150. doi: 10.1182/blood-2011-10-388702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou H. The adaptive lasso and its oracle properties. Journal of the American Statistical Association. 2006;101:1418–1429. [Google Scholar]
- Zou H, Hastie TJ. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society Series B. 2005;67:301–320. [Google Scholar]
- Zou H, Li R. One-step sparse estimates in nonconcave penalized likelihood models. Annals of Statistics. 2008;36:1509–1533. doi: 10.1214/009053607000000802. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou H, Zhang HH. On the adaptive elastic-net with a diverging number of parameters. Annals of Statistics. 2009;37:1733–1751. doi: 10.1214/08-AOS625. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.