


Abstract
Genomes undergo changes in organization as a result of gene duplications, chromosomal rearrangements and local mutations, among other mechanisms. In contrast to prokaryotes, in which genes of a common function are often organized in operons and reside contiguously along the genome, most eukaryotes show much weaker clustering of genes by function, except for few concrete functional groups. We set out to check systematically if there is a relation between gene function and gene organization in the human genome. We test this question for three types of functional groups: pairs of interacting proteins, complexes and pathways. We find a significant concentration of functional groups both in terms of their distance within the same chromosome and in terms of their dispersal over several chromosomes. Moreover, using Hi-C contact map of the tendency of chromosomal segments to appear close in the 3D space of the nucleus, we show that members of the same functional group that reside on distinct chromosomes tend to co-localize in space. The result holds for all three types of functional groups that we tested. Hence, the human genome shows substantial concentration of functional groups within chromosomes and across chromosomes in space.
INTRODUCTION
Cellular processes involve multiple types of functional relations between genes, including protein–protein interactions, regulatory relations and co-expression. Substantial research has been carried out regarding the interplay between functionally related genes and their arrangement on the genome. The most dramatic evidence for non-random organization of co-functioning genes is found in prokaryotes, where genes, usually from the same functional family, are often arranged in operons (1,2). Genes in an operon reside consecutively along the genome and are governed by a common promoter. In contrast, most studied eukaryotes lack operons, with few exceptions, including nematodes (3) and drosophila, where operons tend to be dicistronic (4) (see (3) for a review).
Various computational studies utilized the availability of whole genome sequences to show that eukaryotic functionally related genes do tend to cluster. Hershberg et al. used network analysis methods to show that adjacent genes are often co-regulated by the same transcription factor (TF) (5). In the same spirit, Janga et al. discovered that the majority of TFs exhibit a strong preference to regulate genes on specific chromosomes (6). Moreover genome-wide studies of expression data in several organisms revealed that genes from the same genomic neighborhood tend to have similar expression (7–9). Tendency of interacting proteins to aggregate on chromosomes was observed in yeast (10,11). The clustering trend was observed also in pathways, where Lee and Sonnhammer investigated the levels of clustering within pathways in five eukaryotic species, and found that a large fraction of the pathways exhibits significantly higher clustering levels than expected by chance (12). The aforementioned studies along with a handful of others indicate that there is a link between the relative genomic position of genes and their functional relations, though the eukaryotic clusters are usually much less compact than their prokaryotic counterparts (13). This relatively weaker clustering effect may imply that a more complex mechanism underlies gene arrangement in eukaryotes, incorporating a diversity of influences from multiple types of functional relations.
Furthermore, throughout the past decade it has become clear that the spatial arrangement of genes within the nucleus is also non-random (14). Folding and intermingling of chromosomes may result in high proximity between genes located at distant positions along the genome, including genes from different chromosomes. It was observed that while gene-rich chromosomes in human tend to occupy interior positions in the nucleus, their gene-poor counterparts tend to be peripherally located (15). Several studies have shown that transcription occurs within discrete regions known as transcription factories (16,17) and nuclear speckles (18). Moreover, evidence for co-expression of spatially proximal genes has been accumulating (19–21).
In this study, we develop a general methodology for analyzing the connection between functional gene groups and the linear and spatial arrangement of genes in the human genome. We focus on three types of functional groups: Protein–protein interactions (PPIs), complexes and pathways. We analyze three different facets of gene arrangement: the tendency of genes from the same group to concentrate on few chromosomes, the intra-chromosomal proximity of genes from the same group, and the degree to which genes from the same group tend to lie close to each other in the three dimensional (3D) space within the nucleus. Our findings show that functionally related genes tend to co-localize and manifest clustered organization within and across the chromosomes on all three levels.
MATERIALS AND METHODS
Throughout the paper, we shall use the general term group to denote a single functional unit from any type, i.e. a PPI, a complex or a pathway. Note that each type reflects a relation of a different nature: The two members of a PPI are in direct physical contact under some conditions, while complex members are simultaneously involved as building blocks in the same physical unit. In contrast, pathways summarize sequences of multiple chemical or signaling reactions, and hence some of their members may not physically interact, co-localize or even simultaneously exist.
Human Data
The Human PPIs, complexes and pathways analyzed in this study were taken from IntAct (22), Corum (23) and KEGG (24) respectively. Basic information about the three types of datasets that were used in the analysis is summarized in Table 1.
Table 1. Statistics on the group types used.
| Database | Functionality relation | Number of groups | Group sizes | Total number of genes involved | ||
|---|---|---|---|---|---|---|
| Min | Median | Max | ||||
| IntAct | PPIs | 27 947 | 2 | 2 | 2 | 7669 |
| Corum | Complexes | 1512 | 2 | 3 | 142 | 2421 |
| KEGG | Pathways | 206 | 2 | 49 | 1079 | 4852 |
Chromosomal locations of genes were extracted from NCBI MapView, where only protein coding genes with a unique position were kept. This preliminary filtering resulted in 19 287 genes.
Spatial distances between genes were based on the Hi-C experimental data of human lymphoblastoid cell line GM06990 (25). The 3D similarity matrices normalized by (26) were used.
Removal of Tandem Duplicate Genes
Duplicate genes are expected to have similar functionality by ancestry. Such genes, if generated by tandem duplication, are often located in physical proximity to one other. To avoid clustering effects resulting from tandemly duplicated genes, we eliminated them as done in previous studies (8,9,27), in the following way. First, to identify proteins belonging to the same gene family, an all-against-all BlastP search was performed on all proteins in the genome, and families were defined using the MCL software (28) with default parameters. We then merged consecutive genes of the same gene family. The location of a merged gene was set to the interval spanning the consecutive genes that it replaced. The resulting set contained 18 029 genes.
Statistical Methodology
In order to investigate whether genes from the same group tend to preferentially lie in proximity to each other, we created several tests, each examining a different form of co-localization. The P-value calculation for each of the tests is performed as follows:
Formulate a test statistic that measures the proximity between functionally related genes.
Calculate the value of this statistic, v0, for the real genome.
- Estimate the probability to observe this value or higher (alternatively, smaller) for random gene order.
- Randomly permute the locations of genes to create a genome with random gene order (functional groups are unchanged).
- Calculate the statistic value, v, for the resultant genome.
- Repeat steps (iii)(a) and (iii)(b) n times.
- Calculate the number of times k in which v ≥ v0.
- P-value = (k + 1)/(n + 1).
The random permutations used to create the null model ensure that the genes in the resultant genomes lie only in loci occupied by genes in the real genome, and that the number of genes in each chromosome remains unchanged. Moreover, the gene composition of the functional groups is unaltered. In this way we exclude from our null hypothesis effects that are not related to the gene order itself. We used the Bonferroni correction whenever multiple tests were performed.
Our tests collect information regarding the distribution of values we are interested in, e.g. how many groups are concentrated in k chromosomes, or what is the distribution of distances along the chromosomes—or in 3D space—between genes from the same group. The most natural test statistics are the moments of the distribution. However, sometimes we need a more sensitive test that focuses on the concentration at the tail of the distribution. In the distribution tail test, values are measured and partitioned into bins 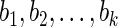 where the frequency fi of values in bin bi is calculated. The test measures the extent of concentration in the first few bins. We seek the minimal number j for which the cumulative frequency
where the frequency fi of values in bin bi is calculated. The test measures the extent of concentration in the first few bins. We seek the minimal number j for which the cumulative frequency 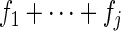 is significantly higher than expected at random (see more details in the Supplementary Information). The P-value was calculated by comparing the real-genome cumulative histogram as in step 3 above, and Bonferroni corrected via multiplying by j.
is significantly higher than expected at random (see more details in the Supplementary Information). The P-value was calculated by comparing the real-genome cumulative histogram as in step 3 above, and Bonferroni corrected via multiplying by j.
RESULTS
We set out to test the tendency of genes with a common function to cluster in the genome using three complementary measures (Figure 1a): inter-chromosomally, by measuring the number of chromosomes co-functioning genes are distributed on; intra-chromosomally, using the genomic distances between co-functioning genes, and in 3D space, by measuring the proximity in the nucleus between co-functioning genes. These three approaches are complementary and each addresses a different aspect of the concentration.
Figure 1.
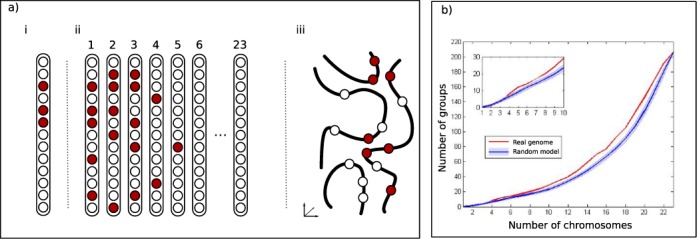
Proximity criteria and pathway concentration. (a) Criteria for chromosome concentration of co-functioning genes. Circles correspond to genes and the red circles are all the members of a group with a common function. (i): concentration within a chromosome (intra-chromosomal). Here clustering/concentration is gauged based on pairwise linear distance (in base pairs or in the number of intervening genes) between co-functioning genes. (ii): dispersal across chromosomes (inter-chromosomal). Out of the 23 pairs of chromosomes, 18 do not contain the group's genes, so this group is concentrated in few chromosomes. This measure takes into account only the chromosomes on which the co-functioning genes reside and ignores the relative locations within each chromosome. (iii): concentration in the 3D space. Curved lines show positions of chromosomal segments in space, with the genes on them. The group is concentrated in space. By identifying the chromosome each segment belongs to, one can distinguish between proximity of inter- and intra-chromosomal gene pairs, and analyze them separately. (b) Pathway concentration in few chromosomes. For each number j of chromosomes, the plots show the number of pathways whose genes reside in at most j chromosomes. Plots for the real genome (red curve) and for an average over 106 random genomes (blue curve) are shown. The shaded area around the blue curve shows ±1 standard deviation. Inset: Zoom in on the region of a small number of chromosomes.
Inter-chromosomal dispersal of genes with a common function
We first investigated the tendency of genes from the same group to concentrate on a small number of chromosomes. Abstractly, each functional type (PPI, complex of pathway) is a collection of groups of genes, where each group shares a common function. For each group, we defined the number of chromosomes involved in the group as the number of different chromosomes containing genes from that group. Our first test function was defined to be the average of this number over all groups of the same type. We generated 106 random genomes by randomly permuting the locations of the genes, and calculated a P-value for each of the group types using the procedure described in ‘Statistical Methodology’ section. The results show that for both PPIs and pathways, the groups tend to concentrate on a small number of chromosomes with P-values 0.001 and 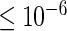 respectively. This test yielded no significant results for complexes (P-value 0.08).
respectively. This test yielded no significant results for complexes (P-value 0.08).
In light of these positive findings, we proceeded with a higher resolution examination of gene arrangement into chromosomes, and applied the distribution tail test. Here fi is defined as the number of groups involving i chromosomes, in order to measure the extent to which genes from the same group tend to concentrate on few chromosomes. The P-value was calculated by comparing the real-genome frequencies to those in 106 random genomes. The results show that there is an enrichment of PPIs and complexes involving a single chromosome (P-value = 0.001 and 0.01, respectively), i.e. the number of PPIs and complexes all of whose genes reside on a single chromosome is significantly higher than randomly expected.
In the case of pathways we reveal a similar trend. The number of pathways that are represented on at most c chromosomes is exhibited in Figure 1b. For c ≥ 5, this number is significantly higher than expected at random (P-value = 0.03 after Bonferroni correction). Hence we observe a tendency of pathways to concentrate on fewer chromosomes than expected by chance.
Intra-chromosomal distances of co-functioning genes
In the previous section, we checked whether genes from the same functional group tend to concentrate on fewer chromosomes than expected by chance. In this section, we would like to check whether genes from the same group that belong to the same chromosome tend to be closer than expected. In order to measure this clustering tendency, we calculated for each group i the average distance (in bases), di, between pairs of genes in group i that reside on the same chromosome. We defined our test statistic to be the mean value of di over all groups in the dataset (see Supplementary Information for more details). We used 106 random genomes to calculate the P-values based on our statistical methodology, where this time we randomly permuted the locations of genes within each chromosome separately. In this way we accounted for clustering effects due to concentration of genes from the same group on few chromosomes. The results show that the average intra-chromosomal distance between genes from the same complex and pathway is significantly smaller than expected by chance, obtaining P-values of 0.001 and 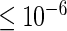 respectively. No significant result was obtained for PPIs (P-value = 0.15).
respectively. No significant result was obtained for PPIs (P-value = 0.15).
Next, we conducted the more sensitive distribution tail test, focusing on groups with short average distances between members. We partitioned the gene groups into 20 bins based on the distances di defined above, as follows. The distances were sorted, and thresholds 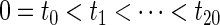 were set such that 5% of the distances were between
were set such that 5% of the distances were between 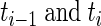 (see Supplementary Information for more details). We then used these thresholds to bin distances for each of 105 random genomes defined as above. We used a lexicographic order of bin frequencies to refine the results (see Supplementary Information). We discovered that for all group types, a statistically significant number of groups tend to cluster within smaller distances than expected at random (all three with P-values
(see Supplementary Information for more details). We then used these thresholds to bin distances for each of 105 random genomes defined as above. We used a lexicographic order of bin frequencies to refine the results (see Supplementary Information). We discovered that for all group types, a statistically significant number of groups tend to cluster within smaller distances than expected at random (all three with P-values 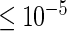 , Bonferroni corrected). This tendency is illustrated in Figure 2. The cumulative distributions of the true genome are plotted along with their random counterparts obtained by averaging over the 105 random histograms. The figure shows the enrichment of short distances for each of the three functional group types.
, Bonferroni corrected). This tendency is illustrated in Figure 2. The cumulative distributions of the true genome are plotted along with their random counterparts obtained by averaging over the 105 random histograms. The figure shows the enrichment of short distances for each of the three functional group types.
Figure 2.
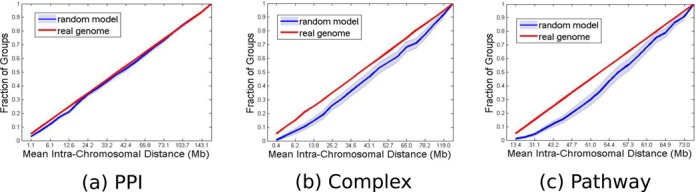
Intra-chromosomal distances. The plot shows the average intra-chromosomal distance between genes from the same group in the real (red) and randomized (blue) genomes. (a) PPIs; (b) Complexes; (c) Pathways. Bins were selected so that the occupancy of pairs from the real genome is uniform (hence the straight red line). The clustering effect is reflected by the larger cumulative fraction in the real genome histograms compared to the random model in the smaller distance bins. The light blue shaded region around the blue curve stands for ±1 standard deviation.
Spatial arrangement of co-functioning genes
In this section we analyze the spatial proximity of functionally related genes in the nucleus. The spatial distances that we used were based on contact map data generated by Lieberman-Aiden et al. using the Hi-C technology (25) and renormalized by Yaffe and Tanay (26) (see Supplementary Information for details). The contact map gives the frequency of observing each two genomic segments next to each other in the experiment. Segment sizes were 1 Mb. As in (25), correlation between the frequency vectors of segments was used to measure proximity, and we use 1-correlation as a measure akin to 3D distance.
We first applied the distribution tail test as follows. For each group we computed the average distance between pairs of genes in the group, irrespectively of whether they reside on the same chromosome or on different chromosomes. The results show that for all three types of groups, functional gene groups exhibit more spatial concentration than expected at random (P-value = 10−4, calculated from 104 simulations). However, the high correlation between linear intra-chromosomal distances (as measured in base pairs) and the corresponding 3D distances (see Supplementary Figure S1 in Supplementary Information) raises the question whether the apparent 3D concentration is merely a result of the linear intra-chromosomal concentration observed earlier. In order to test for spatial concentration effects that are not related to linear gene proximity, we considered only inter-chromosomal gene pairs, excluding all intra-chromosomal distances. To respect the chromosomal organization of each group, we again randomly permuted the locations of genes within each chromosome separately. So, for each group the number of pairs of genes along different chromosomes stays the same in simulated genomes. The results show that the average inter-chromosomal 3D distances between genes from the same pathway are significantly smaller than expected by chance (P-value = 0.009; complexes P-value = 0.09, PPIs P-value = 0.7). Applying the distribution tail test with 20 bins resulted in significant over-population of the first bin for PPIs only (P-value = 0.004). For complexes and pathways, P-values were 0.06 and 0.33 respectively.
The distribution tail test used above checks whether the average inter-chromosomal distances between gene pairs within a group is significantly smaller than expected at random. However, if proximity tendency exists only between specific genes within a group, it may be undetected after averaging all pairs in the group. This could explain the fact that the test was significant for PPIs but not for the other types, which have larger groups. To examine whether such tendency exists, we applied the distribution tail test again, but this time we used the individual distances between gene pairs instead of the average over these distances. We computed the distance between each pair of genes from the same group that reside on different chromosomes, binned the values obtained from the entire set of such pairs into 20 bins, and tested the concentration at the distribution tail. We found that for all three group types, namely PPIs, pathways and complexes, gene pairs from the same group tend to cluster within a small spatial region even when they lie on different chromosomes. For the three resultant distributions, the first bin in the real genome (5% of pairs with highest spatial inter-chromosomal proximity) was significantly more populated than the same bin in the random genomes, with P-values 0.004, 10−4 and 0.02 for PPIs, complexes and pathways respectively. This result reflects the clustering tendency of genes from the same group. For PPIs and complexes, the cumulative distribution of the histogram tail remained statistically significant also beyond the first bin. For PPIs, more than 25% of the pairs displayed strong clustering tendency (e.g. for the sum of frequencies in bins 1–6, the obtained P-value was ≤0.03). An even more pronounced effect was found for complexes, where about 90% of the pairs, populating bins 1–18 in the cumulative histogram, had all P-values below 0.02. These results, normalized by dividing by the real genome values for the sake of better visibility, are illustrated in Figure 3.
Figure 3.
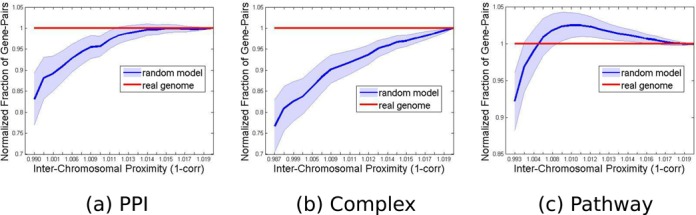
Spatial proximity between inter-chromosomal gene pairs from the same functional group. The cumulative distribution function (cdf) of inter-chromosomal proximity between genes from the same group was computed for real and randomized genomes. The plot shows each cdf divided by the cdf of the real genome. As a result the real genome curve has a constant y-value of 1. Red: real genome, blue: average over 105 random genomes. The light blue bands show ±1 standard deviation. (a) PPIs; (b) Complexes; (c) Pathways. The x-axis units are 1 minus the correlation between the normalized Hi-C contact profiles of the regions containing the gene pairs, so that smaller values reflect higher correlation and shorter distances.
All the tests that we conducted aimed to deduce concentration by looking together at the signal from all groups of co-functioning genes of the same types. As such, they provide answers regarding the general phenomenon of concentration. In addition, our analysis can also be applied to study the concentration of individual groups, which may be of independent interest. Supplementary file 1 contains the full results of each PPI, complex and pathway in each of our three tests. We also tested functional categories of complexes for concentration but obtained no significant results (see Supplementary Information).
DISCUSSION
We have observed that co-functioning genes manifest significant concentration in terms of their organization in the human genome. This holds separately for three types of sets of co-functioning genes (Table 1): gene pairs corresponding to interacting proteins, genes whose proteins belong to the same complex, and genes whose proteins take part in the same pathway. The concentration of co-functioning genes is established in three independent ways (Figure 1a). Co-functioning genes tend to reside on fewer chromosomes than expected by chance. When they are on the same chromosome, they are positioned more closely to each other than randomly selected genes. Moreover, co-functioning genes on different chromosomes tend to be closer to each other in the 3D nuclear space, based on chromosome conformation capture (3C (29) or Hi-C) data.
These tendencies are statistically significant, based on a cumulative signal collected from many groups of co-functioning genes. The distribution of the test statistic (e.g. the spatial distance or the number of involved chromosomes) in the known functional groups is compared to randomly permuted genes (within and/or across chromosomes, where appropriate). In some cases a simple test statistic, like the distribution mean, suffices to determine significance. In others, we tailored a test statistic to focus on the tail of the distribution, corresponding to the closest pairs.
Why are co-functioning genes concentrated? The broadly accepted explanation has to do with co-transcription. Co-location of genes of common function can facilitate direct cis-regulation of several genes simultaneously, at the level of transcription factors and co-factors, and on the nucleosome and other epigenetic levels. Caron et al. observed clustering of highly expressed genes on intervals along the chromosomes in a variety of human tissues (30). Lercher et al. later observed the same phenomenon for housekeeping genes, and in fact argued that the findings of Caron et al. are due primarily to housekeeping genes (9). In lower eukaryotes, by focusing on two or at most three consecutive genes, the co-regulation of adjacent divergent transcriptional units was shown to be prevalent in yeast (5). Taking an evolutionary perspective, Veron et al. analyzed chromosomal rearrangements between mouse and human and showed significant correlation between intra-chromosomal 3D proximity in the human genome and breakpoint pairs, suggesting the functional relevance of the structure (31). Another evolutionary analysis was recently provided by Dai et al., using gene orders in 17 yeast species (32). The authors showed that gene pairs that are adjacent in other yeast species but reside on different chromosomes in Saccharomyces cerevisiae tend to show stronger nuclear co-localization, as measured in (33). Moreover, these co-localized pairs tend to be regulated by the same transcription factors and by the same histone modifications. Hence co-localization is correlated with co-regulation even after separation due to recombination.
The connection between spatial organization within chromosomes and gene expression was attributed to active chromatin hubs (34), nuclear speckles (18) and more generally to transcription factories. These are discrete nuclear regions in which multiple RNA polymerases are active (35). However, evidence for and against the existence of transcription factories is still debated (36). Li et al. recently studied extensively chromatin interactions in human cell lines and observed promoter–promoter interactions, to the extent that they proposed a chromatin-based operon-like mechanism (‘chroperon’) for gene regulation in eukaryotic cells (37). Co-expression and proximity in space were shown to be associated both in studies focusing on a few genes using FISH and microscopy, and, more recently, in genome-wide studies of promoter-enhancer associations (38,39). One novel perspective that we add to this area is the inter-chromosomal dispersion: we show that genes of a common complex or pathway tend to be dispersed on fewer chromosomes than expected by chance. With such clustering, co-regulation of the co-functioning genes is conceivably better than when the dispersal is completely random.
Is it possible that we see co-clustering of members of the same functional gene groups only because they have similar expression levels? Put differently, is the primary phenomenon co-expression of genes of the same functional group, and the co-localization is only its secondary effect? While it is hard to say which effect is primary, co-expression and common function clearly both affect co-localization. There are, however, several advantages to analysis based on common function over analysis based on co-expression: (i) Sharing the same functional group is a ‘cleaner’ and more universal property than co-expression, which is measured on condition-dependent datasets. (ii) Co-expression quantification is based on measurements of expression, which are noisy. (In fact, co-expression may even be the result of biological noise, cf. (40)). Moreover, gene transcription, the main source of co-expression measurements today, is only moderately correlated with protein transcription, where the function is manifest (41,42). (iii) Different pathways or complexes may show co-expression under some conditions even if they have completely different functions. (iv) Since many pathways summarize a temporal sequence of events and interactions, different segments of the pathway may be active at different times and in that case will not show co-expression, even though they belong to the same functional unit. (v) The definition of a group of co-expressed genes can vary depending on the correlation function, the correlation threshold, the normalization methods etc. On the other hand, functional groups are defined based on a holistic understanding of the underlying biology. (vi) Our analysis enables us to examine different types of co-functioning groups, and discern differences among them, which is impossible using co-expression. Further study is required to show which effect is more primary, or that perhaps both co-expression and co-localization are artifacts of yet another more basic, global effect.
The study of nuclear organization has undergone a revolution over the last decade, with the combined contribution of microscopy techniques, chromosome conformation and epigenomics. Seminal studies have established chromatin proximity maps in human (25), baker's yeast (33), fission yeast (43), drosophila (44) and mouse (45), among others. Very recently, an interesting paper by Ben-Elazar et al. (46) studied localization of co-regulated genes in S. cerevisiae using 4C data (33). Focusing on the set of targets of each transcription factor, the authors showed that for about half the transcription factors, the concentration of these targets in space exceeds their linear clustering along the chromosomes. This adds support to the transcription factories paradigm. Note, however, that the statistical test for 3D concentration does not distinguish between targets that are on the same chromosome and those on different chromosomes. In fact, the intra-chromosome contact level observed in 3C maps exceeds the inter-chromosomal level by orders of magnitude (25,33), and therefore it is highly likely that the effect observed by Ben-Elazar et al. is based overwhelmingly on intra-chromosomal contacts. In contrast, our test (Figure 3) separates completely the inter- and intra-chromosomal signals, and shows directly inter-chromosomal spatial proximity among co-functioning genes. Another recent paper (47) analyzed the same yeast contact map data (33) together with gene expression data. Using a large panel of expression profiles, and focusing on inter-chromosomal gene pairs only, Homouz and Kudlicki showed that the measured expression levels of nearby genes are significantly correlated. Moreover, they showed that many of the high level gene ontology groups (GO-slim groups) show significantly more 3D contacts between gene pairs than random gene groups of the same sizes. This test is similar in spirit to the one we have performed here. Note, however, that we took care to create gene sets by randomly permuting genes within each chromosome independently, thereby avoiding possible bias due to uneven distribution of group genes across chromosomes. Another salient difference between our study and these two reports is that our test was conducted on human DNA, for which the contact map resolution is much lower than for yeast, and hence detecting the concentration signal is more challenging. To the best of our knowledge, this is the first study of this kind on the human chromosomal conformation data.
In Figure 3, the normalized cumulative distributions for randomized genomes remain below the real genome plot for PPIs and complexes, showing spatial concentration of co-functioning genes. For short distances this is the case for pathways as well, but for longer distances the real genome apparently has fewer pairs than the randomized genomes. A possible tempting explanation may be due to the different nature of the functional groups. PPIs and complexes consist of proteins that are simultaneously interacting, and thus their co-location (and consequently co-expression) may be an advantage. In contrast, for pathways a time dimension is involved (e.g. when a sequence of metabolic or signaling reactions is performed), and therefore not all the building blocks of the pathway may be active simultaneously. In a large pathway it may be favorable for subunits that act together to be closer in space, and subgroups that act at different times to be well separated in space. Since many of the pathways that we have analyzed are rather large (median size 49), they may contain such non-simultaneous blocks that may give rise to their distinct distribution. This hypothesis requires further analysis and testing.
Gene clusters and tandem gene duplications can affect our intra-chromosomal statistics. In order to remove such effects, we removed known gene clusters and also filtered tandem duplicated genes as done previously (8,9,27). It is possible though that part of the effect that we observe is a result of unknown clusters or remaining duplicated genes that do not appear in tandem. However, this would not explain the inter-chromosomal spatial concentration.
Finally, the test methodology that we developed here can be useful for studying other questions as well. It provides a unified approach for comparison of true and random distributions for a broad variety of test statistics.
SUPPLEMENTARY DATA
Supplementary Data are available at NAR Online.
Acknowledgments
We thank Eitan Yaffe, Amos Tanay, Shai Izraeli, Omer Schwartzman, Manolo Gouy and Osnat Penn for helpful discussions on the manuscript. We thank Laurence Hurst for important comments and references.
Footnotes
The authors wish it to be known that, in their opinion,the first two authors should be regarded as Joint First Authors.
FUNDING
IBM Research Open Collaborative Research; Israel Science Foundation [317/13]; I-CORE Program of the Planning and Budgeting Committee and the Israel Science Foundation [41/11]; Raymond and Beverly Sackler chair in bioinformatics [to R.S.]. Post-doctoral fellowships from the Edmond J. Safra Center for Bioinformatics at Tel Aviv University and from the Alexander von Humboldt Foundation at Bielefeld University [to A.T.]. Funding for open access charge: Israel Science Foundation [317/13]; I-CORE Program of the Planning and Budgeting Committee and the Israel Science Foundation [41/11] [to R.S.].
Conflict of interest statement. None declared.
REFERENCES
- 1.Jacob F., Monod J. Genetic regulatory mechanisms in the synthesis of proteins. J. Mol. Biol. 1961;3:318–356. doi: 10.1016/s0022-2836(61)80072-7. [DOI] [PubMed] [Google Scholar]
- 2.Miller JH, Reznikoff WS, editors. The Operon. 2nd edn. New York: 1980. Cold Spring Harbor Laboratory. [Google Scholar]
- 3.Blumenthal T., Evans D., Link C.D., Guffanti A., Lawson D., Thierry-Mieg J., Thierry-Mieg D., Chiu W.L., Duke K., Kiraly M., et al. A global analysis of Caenorhabditis elegans operons. Nature. 2002;417:851–854. doi: 10.1038/nature00831. [DOI] [PubMed] [Google Scholar]
- 4.Misra S., Crosby M.A., Mungall C.J., Matthews B.B., Campbell K.S., Hradecky P., Huang Y., Kaminker J.S., Millburn G.H., Prochnik S.E. Annotation of the Drosophila melanogaster euchromatic genome: a systematic review. Genome Biol. 2002;3 doi: 10.1186/gb-2002-3-12-research0083. RESEARCH0083. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Hershberg R., Yeger-Lotem E., Margalit H. Chromosomal organization is shaped by the transcription regulatory network. Trends Genet. 2005;21:138–142. doi: 10.1016/j.tig.2005.01.003. [DOI] [PubMed] [Google Scholar]
- 6.Janga S.C., Collado-Vides J., Babu M.M. Transcriptional regulation constrains the organization of genes on eukaryotic chromosomes. Proc. Natl. Acad. Sci. U.S.A. 2008;105:15761–15766. doi: 10.1073/pnas.0806317105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Woo Y.H., Walker M., Churchill G.A. Coordinated expression domains in mammalian genomes. PLoS One. 2010;5:e12158. doi: 10.1371/journal.pone.0012158. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Williams E.J.B., Bowles D.J. Coexpression of neighboring genes in the genome of Arabidopsis thaliana. Genome Res. 2004;14:1060–1067. doi: 10.1101/gr.2131104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Lercher M.J., Urrutia A.O., Hurst L.D. Clustering of housekeeping genes provides a unified model of gene order in the human genome. Nat. Genet. 2002;31:180–183. doi: 10.1038/ng887. [DOI] [PubMed] [Google Scholar]
- 10.Teichmann S.A., Veitia R.A. Genes encoding subunits of stable complexes are clustered on the yeast chromosomes: an interpretation from a dosage balance perspective. Genetics. 2004;167:2121–2125. doi: 10.1534/genetics.103.024505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Poyatos J.F., Hurst L.D. Is optimal gene order impossible. Trends Genet. 2006;22:420–423. doi: 10.1016/j.tig.2006.06.003. [DOI] [PubMed] [Google Scholar]
- 12.Lee J.M., Sonnhammer E.L.L. Genomic gene clustering analysis of pathways in eukaryotes. Genome Res. 2004;14:2510. doi: 10.1101/gr.737703. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Hurst L.D., Pál C., Lercher M.J. The evolutionary dynamics of eukaryotic gene order. Nat. Rev. Genet. 2004;5:299–310. doi: 10.1038/nrg1319. [DOI] [PubMed] [Google Scholar]
- 14.Rajapakse I., Groudine M. On emerging nuclear order. J. Cell Biol. 2011;192:711–721. doi: 10.1083/jcb.201010129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Reddy T.E., Pauli F., Sprouse R.O., Neff N.F., Newberry K.M., Garabedian M.J., Myers R.M. Genomic determination of the glucocorticoid response reveals unexpected mechanisms of gene regulation. Genome Res. 2009;19:2163–2171. doi: 10.1101/gr.097022.109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Wansink D.G., Schul W., van der Kraan I., van Steensel B., van Driel R., de Jong L. Fluorescent labeling of nascent RNA reveals transcription by RNA polymerase II in domains scattered throughout the nucleus. J. Cell Biol. 1993;122:283–293. doi: 10.1083/jcb.122.2.283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Jackson D.A., Hassan A.B., Errington R.J., Cook P.R. Visualization of focal sites of transcription within human nuclei. EMBO J. 1993;12:1059–1065. doi: 10.1002/j.1460-2075.1993.tb05747.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Spector D.L., Lamond A.I. Nuclear speckles. Cold Spring Harb. Perspect. Biol. 2011;3 doi: 10.1101/cshperspect.a000646. a000646. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Schoenfelder S., Sexton T., Chakalova L., Cope N.F., Horton A., Andrews S., Kurukuti S., Mitchell J.A., Umlauf D., Dimitrova D.S., et al. Preferential associations between co-regulated genes reveal a transcriptional interactome in erythroid cells. Nat. Genet. 2010;42:53–61. doi: 10.1038/ng.496. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Fanucchi S., Shibayama Y., Burd S., Weinberg M.S., Mhlanga M.M. Chromosomal contact permits transcription between coregulated genes. Cell. 2013;155:606–620. doi: 10.1016/j.cell.2013.09.051. [DOI] [PubMed] [Google Scholar]
- 21.Rieder D., Ploner C., Krogsdam A.M., Stocker G., Fischer M., Scheideler M., Dani C., Amri E.-Z., Müller W.G., McNally J.G., et al. Co-expressed genes prepositioned in spatial neighborhoods stochastically associate with SC35 speckles and RNA polymerase II factories. Cell. Mol. Life Sci. 2014;71:1741–1759. doi: 10.1007/s00018-013-1465-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Aranda B., Achuthan P., Alam-Faruque Y., Armean I., Bridge A., Derow C., Feuermann M., Ghanbarian A.T., Kerrien S., Khadake J., et al. The IntAct molecular interaction database in 2010. Nucleic Acids Res. 2010;38:D525–D531. doi: 10.1093/nar/gkp878. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Ruepp A., Waegele B., Lechner M., Brauner B., Dunger-Kaltenbach I., Fobo G., Frishman G., Montrone C., Mewes H.-W. CORUM: the comprehensive resource of mammalian protein complexes–2009. Nucleic Acids Res. 2010;38:D497–D501. doi: 10.1093/nar/gkp914. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Kanehisa M., Goto S. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28:27–30. doi: 10.1093/nar/28.1.27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Lieberman-Aiden E., Berkum N.L., van Williams L., Imakaev M., Ragoczy T., Telling A., Amit I., Lajoie B.R., Sabo P.J., Dorschner M.O., et al. Comprehensive mapping of long-range interactions reveals folding principles of the human genome. Science. 2009;326:289–293. doi: 10.1126/science.1181369. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Yaffe E., Tanay A. Probabilistic modeling of Hi-C contact maps eliminates systematic biases to characterize global chromosomal architecture. Nat. Genet. 2011;43:1059–1065. doi: 10.1038/ng.947. [DOI] [PubMed] [Google Scholar]
- 27.Singer G.A.C., Lloyd A.T., Huminiecki L.B., Wolfe K.H. Clusters of co-expressed genes in mammalian genomes are conserved by natural selection. Mol. Biol. Evol. 2005;22:767–775. doi: 10.1093/molbev/msi062. [DOI] [PubMed] [Google Scholar]
- 28.Van Dongen S. PhD thesis. University of Utrecht; 2000. Graph Clustering by Flow Simulation. [Google Scholar]
- 29.Dekker J., Rippe K., Dekker M., Kleckner N. Capturing chromosome conformation. Science. 2002;295:1306–1311. doi: 10.1126/science.1067799. [DOI] [PubMed] [Google Scholar]
- 30.Caron H., van Schaik B., van der Mee M., Baas F., Riggins G., van Sluis P., Hermus M.C., van Asperen R., Boon K., Voûte P.A., et al. The human transcriptome map: clustering of highly expressed genes in chromosomal domains. Science. 2001;291:1289–1292. doi: 10.1126/science.1056794. [DOI] [PubMed] [Google Scholar]
- 31.Véron A.S., Lemaitre C., Gautier C., Lacroix V., Sagot M.-F. Close 3D proximity of evolutionary breakpoints argues for the notion of spatial synteny. BMC Genomics. 2011;12:303. doi: 10.1186/1471-2164-12-303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Dai Z., Xiong Y., Dai X. Neighboring genes show inter-chromosomal colocalization after their separation. Mol. Biol. Evol. 2014;31:1166–1172. doi: 10.1093/molbev/msu065. [DOI] [PubMed] [Google Scholar]
- 33.Duan Z., Andronescu M., Schutz K., McIlwain S., Kim Y.J., Lee C., Shendure J., Fields S., Blau C.A., Noble W.S. A three-dimensional model of the yeast genome. Nature. 2010;465:363–367. doi: 10.1038/nature08973. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.De Laat W., Grosveld F. Spatial organization of gene expression: the active chromatin hub. Chromosome Res. 2003;11:447–459. doi: 10.1023/a:1024922626726. [DOI] [PubMed] [Google Scholar]
- 35.Iborra F.J., Pombo A., Jackson D.A., Cook P.R. Active RNA polymerases are localized within discrete transcription ‘factories’ in human nuclei. J. Cell Sci. 1996;109:1427–1436. doi: 10.1242/jcs.109.6.1427. [DOI] [PubMed] [Google Scholar]
- 36.Sutherland H., Bickmore W.A. Transcription factories: gene expression in unions. Nat. Rev. Genet. 2009;10:457–466. doi: 10.1038/nrg2592. [DOI] [PubMed] [Google Scholar]
- 37.Li G., Ruan X., Auerbach R.K., Sandhu K.S., Zheng M., Wang P., Poh H.M., Goh Y., Lim J., Zhang J., et al. Extensive promoter-centered chromatin interactions provide a topological basis for transcription regulation. Cell. 2012;148:84–98. doi: 10.1016/j.cell.2011.12.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Chepelev I., Wei G., Wangsa D., Tang Q., Zhao K. Characterization of genome-wide enhancer-promoter interactions reveals co-expression of interacting genes and modes of higher order chromatin organization. Cell Res. 2012;22:490–503. doi: 10.1038/cr.2012.15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Zhang Y., Wong C.-H., Birnbaum R.Y., Li G., Favaro R., Ngan C.Y., Lim J., Tai E., Poh H.M., Wong E., et al. Chromatin connectivity maps reveal dynamic promoter-enhancer long-range associations. Nature. 2013;504:306–310. doi: 10.1038/nature12716. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Wang G.-Z., Lercher M.J., Hurst L.D. Transcriptional coupling of neighboring genes and gene expression noise: evidence that gene orientation and noncoding transcripts are modulators of noise. Genome Biol. Evol. 2011;3:320–331. doi: 10.1093/gbe/evr025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.De Sousa Abreu R., Penalva L.O., Marcotte E.M., Vogel C. Global signatures of protein and mRNA expression levels. Mol. Biosyst. 2009;5:1512–1526. doi: 10.1039/b908315d. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Schwanhäusser B., Busse D., Li N., Dittmar G., Schuchhardt J., Wolf J., Chen W., Selbach M. Global quantification of mammalian gene expression control. Nature. 2011;473:337–342. doi: 10.1038/nature10098. [DOI] [PubMed] [Google Scholar]
- 43.Tanizawa H., Iwasaki O., Tanaka A., Capizzi J.R., Wickramasinghe P., Lee M., Fu Z., Noma K. Mapping of long-range associations throughout the fission yeast genome reveals global genome organization linked to transcriptional regulation. Nucleic Acids Res. 2010;38:8164–8177. doi: 10.1093/nar/gkq955. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Sexton T., Yaffe E., Kenigsberg E., Bantignies F., Leblanc B., Hoichman M., Parrinello H., Tanay A., Cavalli G. Three-dimensional folding and functional organization principles of the Drosophila genome. Cell. 2012;148:458–472. doi: 10.1016/j.cell.2012.01.010. [DOI] [PubMed] [Google Scholar]
- 45.Nagano T., Lubling Y., Stevens T.J., Schoenfelder S., Yaffe E., Dean W., Laue E.D., Tanay A., Fraser P. Single-cell Hi-C reveals cell-to-cell variability in chromosome structure. Nature. 2013;502:59–64. doi: 10.1038/nature12593. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Ben-Elazar S., Yakhini Z., Yanai I. Spatial localization of co-regulated genes exceeds genomic gene clustering in the Saccharomyces cerevisiae genome. Nucleic Acids Res. 2013;41:2191–2201. doi: 10.1093/nar/gks1360. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Homouz D., Kudlicki A.S. The 3D organization of the yeast genome correlates with co-expression and reflects functional relations between genes. PLoS One. 2013;8:e54699. doi: 10.1371/journal.pone.0054699. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.