

Abstract
Background
Multi-assembly problems have gathered much attention in the last years, as Next-Generation Sequencing technologies have started being applied to mixed settings, such as reads from the transcriptome (RNA-Seq), or from viral quasi-species. One classical model that has resurfaced in many multi-assembly methods (e.g. in Cufflinks, ShoRAH, BRANCH, CLASS) is the Minimum Path Cover (MPC) Problem, which asks for the minimum number of directed paths that cover all the nodes of a directed acyclic graph. The MPC Problem is highly popular because the acyclicity of the graph ensures its polynomial-time solvability.
Results
In this paper, we consider two generalizations of it dealing with integrating constraints arising from long reads or paired-end reads; these extensions have also been considered by two recent methods, but not fully solved. More specifically, we study the two problems where also a set of subpaths, or pairs of subpaths, of the graph have to be entirely covered by some path in the MPC. We show that in the case of long reads (subpaths), the generalized problem can be solved in polynomial-time by a reduction to the classical MPC Problem. We also consider the weighted case, and show that it can be solved in polynomial-time by a reduction to a min-cost circulation problem. As a side result, we also improve the time complexity of the classical minimum weight MPC Problem. In the case of paired-end reads (pairs of subpaths), the generalized problem becomes NP-hard, but we show that it is fixed-parameter tractable (FPT) in the total number of constraints. This computational dichotomy between long reads and paired-end reads is also a general insight into multi-assembly problems.
Keywords: multi-assembly, RNA-Seq, minimum path cover, directed acyclic graph, network flow, min-cost circulation
Introduction
Background
The last years have witnessed Next-Generation Sequencing technologies applied to mixed settings in which the input sample consists of different, but highly related, genomic sequences. A major problem in this setting is to assemble the NGS reads produced from these different sequences, problem called multi-assembly [1].
An emblematic example is the multi-assembly of the expressed transcripts of a gene from RNA-Seq reads [2,3]. The RNA transcripts of a gene are concatenations of exons, which can be shared among them, and whose length is typically much longer than the short read length. The RNA-Seq technology has proved essential in characterizing gene regulation and function, understanding development, disease, and disorders, including cancer [4-7]. The most popular tool for multi-assembly of RNA-Seq reads is Cufflinks [8], but the great interest in the community has led to a recent proliferation of methods and tools, such as [9-20]. Another example is the multi-assembly of NGS reads from viral quasi-species [21]. Since many viruses, such as HIV or HCV, encode their genomes in RNA rather than DNA, they lack DNA polymerase and are unable to repair mistakes in their genomes as they reproduce. Over the course of infection, the mistakes made in the replication of the virus are passed down to descendants, producing a family of related variants of the original viral genome, referred to as quasi-species. Among all of the new quasi-species produced, some may be more virulent than others, and it is of great epidemiological interest to identify them. Methods for this problem include [22-27].
The vast majority of the multi-assembly tools are genome-guided, in the sense that they have access to one reference genome. Consequently, the analysis proceeds by aligning the reads to this reference, and constructing one of two major graph models. In the first, called an overlap graph, the nodes stand for reads and the edges stand for overlaps between reads. This model is employed both for RNA-Seq reads (by Cufflinks [8]), and for pyrosequencing reads from a viral population (ShoRAH [25,26]). In the second model, called a splicing graph and used mainly for RNA-Seq reads, the nodes stand for contiguous stretches of DNA present entirely in some transcript (pseudo-exons); its edges stand for reads spanning two pseudo-exons and indicate that they are consecutive in some transcript. This model is employed by most of the other methods for the multi-assembly of RNA-Seq reads [9-20]. Since both graph models arise from alignments to a reference sequence, they are also directed and acyclic (DAGs). Moreover, the nodes and the edges of the graph are weighted according to the observed coverage, and different strategies exist for integrating them into the formulation of the multi-assembly problem. For example, in Cufflinks [8], the weight of an edge reflects the belief that its two endpoints originate from different transcripts, and is computed using the percent-spliced-in metric proposed in [28].
Motivation
Given an overlap or a splicing DAG, many methods [8,19,20,25-27] model the multi-assembly problem as a Minimum Path Cover Problem; these include the well-known tool for RNA-Seq reads Cufflinks [8]. A path cover in a directed graph G is a set of paths which cover all the nodes of G. A minimum path cover (MPC) is a path cover of minimum cardinality. Often, the edges of the DAG are weighted, and one is then interested in a minimum weight MPC. Even though this problem is in general NP-complete (a path cover has cardinality 1 if and only if the directed graph has a Hamiltonian path), it is solvable in polynomial time on DAGs [29]. This fact is one of the main reasons why the MPC Problem has attracted so much interest. Therefore, it makes sense to extend it with other biological information, while maintaining its polynomial-time solvability.
In this paper we consider additional information arising from paired-end reads or long reads. Observe that, currently, both graph models and the associated MPC Problem include constraints only on pairs of nodes which must be consecutive in the (same) genomic sequence. However, on the one hand, most sequencers produce paired-end reads; these two reads correspond to nodes that must be in the same genomic sequence, but they are no longer consecutive in it. On the other hand, Third-Generation Sequencing technologies, like Pacific Biosciences [30], produce long reads whose length is in the range of thousands of base-pairs. If properly error-corrected, they introduce additional constraints on the sequences of nodes which must appear as consecutive in the same assembled genomic sequences. In the case of a splicing graph, such additional constraints can be introduced even from short reads completely overlapping a short middle pseudo-exon (such as in the case of alternative donor/acceptor sites [31]).
Two different problem formulations have been recently proposed to better guide the multi-assembly using paired-end or long reads. In the first [20], a partial assembly of the RNA transcripts is assumed (transfrags), and the following problem, which we call Minimum Path Cover with Subpath Constraints (MPC-SC), is proposed. Given a DAG G and a set of subpaths in G (the transfrags, or the long reads), we are asked to find a MPC such that each given subpath is contained completely in some path of the path cover. In [20], the authors consider in fact the weighted version of the problem, and propose a polynomial-time reduction to the classical weighted MPC Problem. However, their reduction is incomplete as it does not deal with the case when two subpaths P1 and P2 are such that a suffix of P1 is a prefix of P2. In the second formulation [19], given a DAG G and a set of paired-end RNA-Seq read alignments to the nodes of G, we are asked to find a minimum path cover whose paths contain all given paired-end reads. We call this problem Minimum Path Cover with Paired Subpaths Constraints (MPC-PSC). In [19], the authors tackle the MPC-PSC Problem by modeling it as the NP-complete set cover problem.
Results and discussion
In this paper, we solve both the MPC-SC and the MPC-PSC Problem. Namely, we state the MPC-SC Problem more generally than in [20], and give a correct and robust polynomial-time reduction of it to the classical MPC Problem on a DAG. Denote by n the number of nodes of the input DAG, by m its number of edges, by c the total number of subpath constraints, and by N the sum of their lengths. Constructing this reduction to the classical MPC Problem requires a pre-processing step, which, if implemented trivially, takes O(c2n2) time; however, we can reduce that to O(N + c2) by use of a suffix tree construction suitable for large alphabets [32], and of an optimal-time algorithm for computing all pairs longest suffix-prefix overlaps [33,34]. The complexity of solving Problem MPC-SC thus becomes .
We also consider the weighted version of Problem MPC-SC, and show that it can be solved in time O(N + (n + c)2 log(n + c) + (n + c)(m + c)) by a reduction to a min-cost circulation problem on a network with flow lower bounds only [35]. Moreover, we prove that the MPC-PSC Problem itself is NP-complete, but we show that it is fixed-parameter tractable (FPT) in the total number of constraints on the DAG.
As a side result of this paper, we obtain a simple algorithm for the classical minimum weight MPC Problem running in time O(n2log n + nm), based on a recent reduction to a network flow problem [36]. This improves the current best bound O(n2 log n + nt(G)), where is the number of edges in the transitive closure of G, arising from the reduction in [29].
In view of this computational dichotomy between paired-end reads and long reads/transfrags, an alternative title of this paper could have been "Long reads are better than paired-end reads in multi-asssembly problems". In fact, in the experiments we conducted for our own tool for RNA-Seq multi-assembly Traph [37,38], we fed Cufflinks [8], IsoLasso [10], SLIDE [12] and Traph both with single-end and paired-end reads, but did not notice any significant change in the multi-assembly accuracy. Nevertheless, an immediate solution to the negative result concerning the complexity of the MPC-PSC Problem could be to simply transform paired-end reads into long reads by a local assembly method which fills the gap between them, such as [39,40].
As a preliminary experiment, in the Supplementary Material we show the solutions of Problem MPC-SC on simulated RNA-Seq data from six cancer-related genes. These results are compared to the ground truth, and to Cufflinks' solutions (given that Cufflinks uses the classical MPC model). These preliminary results indicate that, thanks to the additional long read constraints to the MPC problem, Problem MPC-SC reports more transcripts than Cufflinks, and they are generally more accurate.
Both MPC-SC and MPC-PSC Problems are natural extensions of the classical MPC problem, and can be applied to any graph model for multi-assembly, such as an overlap graph or a splicing graph. The MCP Problem has received great interest in the multi-assembly community, and pair-end reads, long reads, or transfrags are either already, or expected to be easily available in the near future. Our positive result concerning the MPC-SC Problem, and the two proposed solutions for the MPC-PSC Problem, give efficient ways to incorporate additional information that an NGS pipeline can provide. Moreover, all of our solutions are based on easy to implement reductions, and resort to well-known problems in combinatorial optimization, for which there are many existing solvers.
Independently and parallel to this work, [41] gave analogs of our Thm. 4 and Lemma 2 for Problem MPC-PSC.
Methods
A faster algorithm for the weighted Minimum Path Cover (MPC) Problem
Given a directed graph G, we say that a family of paths in G is a path cover of G if every v ∈ V (G) belongs to some Pi. Throughout this paper, we let n stand for the number of vertices of G and m stand for the number of edges of G. A minimum path cover (MPC) of G is a path cover of G of minimum cardinality. If each edge e of G has a non-negative weight w(e), then a minimum weight minimum path cover is a minimum path cover which minimizes the sum of the weights of the edges of the paths of , that is, Σe∈Pw(e).
A well-known result on path covers in directed acyclic graphs (DAGs) is Dilworth's theorem [42], which equates the minimum number of paths in a path cover to the maximum cardinality of an anti-chain (this cardinality is sometimes called width); an anti-chain is a set of nodes with no directed path between any two of them. A constructive proof of this theorem, due to Fulkerson [29], shows that the MPC problem can be reduced to a maximum matching problem in a bipartite graph, as follows. Given a directed graph G, let T(G) denote the transitive closure of G, that is, the digraph obtained from G by repeatedly adding, until no longer possible, an edge (u, v) whenever (u, v) ∉ E(G) but there exist w ∈ V (G) such that (u, w), (w, v) ϵ E(G); we let t(G) denote the number of edges of T(G). Note that if G is a DAG, then T(G) can be computed in time O(t(G)). Fulkerson showed that a MPC can be obtained by computing a maximum matching in a bipartite graph associated to G, having two copies of V (G) as nodes and the edges of T(G) as edges (see Figures 1(a) and 1(b)). Therefore, using the Hopcroft-Karp maximum matching algorithm, a MPC can be computed in time [43]. To compute a minimum weight MPC, the same bipartite graph can be constructed, having edge weights induced from path weights in G. A minimum weight MPC corresponds to a minimum weight maximum matching on this graph, which can be computed in time O(n2 log n + nt(G)) [44].
Figure 1.
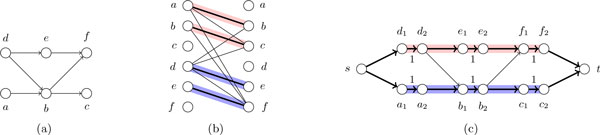
In Fig. 1(a), an input DAG G. In Fig. 1(b), the reduction to the maximum matching problem: a bipartite graph B(G) having as vertices two copies of V(G) and an edge between the first copy of v1 ∈ V(G) and the second copy of v2 ∈ V(G) iff there is a directed path in G from v1 to v2. The edges of a maximum matching of B(G) are highlighted, and a MPC for G is obtained by putting v1 and v2 in the same path there is an edge between v1 and v2 and is selected by the maximum matching. In Fig. 1(c), a network flow N(G) corresponding to G; the labels '1' on some edges are the lower bounds on that edges; all other edges have lower bound 0. The min-flow on N(G) has value 2; the edges with flow value 1 are highlighted; any decomposition of this flow into paths gives a MPC.
A recent solution for the MPC Problem reduces it instead to a min-flow problem [36], as follows. Each node of G is replaced by an arc with lower bound 1 (all other edges of G have lower bound 0), and a new global source s and sink t are added to G and connected to all sources and sinks of G, respectively (see Figures 1(a) and 1(c)). A min-flow on this digraph is a flow of minimum value satisfying all lower bounds. The value of the min-flow on this network equals the maximum size of an anti-chain of G, and any decomposition of it into paths gives a MPC [36]. A decomposition of a flow on a DAG into paths can be computed in time linear in the number of edges, by traversing the edges used by the flow [45]. A min-flow problem can be solved by two applications of a max-flow algorithm [45]. Therefore, using the recent result on max-flows [46], this approach finds a MPC in time O(nm).
If in the unweighted case, the complexity of the method of [36] is incomparable with the complexity of solving the MPC Problem by a maximum matching problem, in the weighted case, the method of [36] leads to one of improved complexity. This is obtained by an algorithm for the following restricted variant of the min-cost circulation problem [45,47]: given a directed graph, and a flow lower bound for each edge and a cost per flow unit for each edge, the task is to find a circulation of minimum total cost satisfying all lower bounds. A circulation is a function assigning a flow value to each edge such that the flow conservation property is satisfied for all nodes; consequently, the flow network cannot have sources or sinks.
To solve the minimum weight MPC Problem, we extend the reduction in [36] by associating to the edges either cost 0, if they correspond to the nodes of G or are incident to s or t; or their weight in G, if they correspond to edges of G. Moreover, we add a new edge from t to s with lower bound 0 and having as cost the sum of all edge weights (plus a positive constant if all are 0). This implies that all min-cost circulations induce a min-flow (removing the edge from t to s), and thus, by [36], induce also a MPC that is of minimum weight; obviously, vice versa, a minimum weight MPC induces a min-cost circulation on the constructed flow network.
There are many algorithms and solvers for the min-cost circulation problem, with various time complexity upper bounds [47], for example O(nm log log C log(nK)) [48], where C is the maximum edge bound, and K is the maximum cost. If edges have only lower bounds, as in our case, the min-cost circulation problem can be solved in time O(n log C(m + n log n)) [35]; since we have C = 1, this reduces to O(n2 log n + nm). Therefore, we have the following theorem.
Theorem 1 A minimum weight MPC of a DAG with n nodes and m edges can be computed in time O(n2log n + nm), by a reduction to a min-cost circulation problem.
The new problem formulations
We first consider the problem arising from long reads, or from transfrags. We introduce a slight generalization of a path cover of a DAG G, namely a set of paths which cover only a given subset of the nodes. We are also given a subset of the edges of G, and a family of subpaths in G that all have to be entirely covered by some path of the path cover. We could have modeled each edge constraint in as a path of length 1 in , but for clarity, we keep these separate. Formally, we have:
Minimum Path Cover with Subpath Constraints (MPC-SC) Problem INPUT: A DAG G and
1 A subset of V (G)
2 A subset of E(G)
3 A family of directed paths in G
TASK: Find a minimum number k of directed paths in G such that
1 Every node in occurs in some
2 Every edge in occurs in some
3 Every path Pin ϵ is entirely contained in some
We call the elements of the sets ,, constraints, and we say that the k paths in a solution satisfy these constraints.
Let us briefly argue that the solution in [20, Sec. 2.4.1. and 2.4.2] for MPC-SC Problem (without the generalization at points 1 and 2) is not complete. (Actually, [20] tackles the Minimum Weight MPC with Subpath Constraints Problem--see below--, but the weights are not relevant for this discussion.) The idea of [20] is to reduce this problem to the classical MPC problem. Consequently, each subpath constraint P is modeled by a single edge having the same endpoints as P , which is subdivided by introducing a node vP in the middle (which must be covered by the MPC). The connections between the first or last node of P and the other nodes of the DAG are maintained, but since the internal nodes of P can no longer be required to be covered by the path cover, they are removed. Moreover, for all nodes v1 and v2 such that there is a path between v1 and v2 in the DAG using a proper subpath of P , a new transitive edge (v1, v2) is added. However, this reduction is missing the case in which two subpath constraints P1 and P2 are such that a suffix of P1 is a prefix of P2. As a matter of fact, our proof will show that the most problematic case is when also a suffix of different length of P1 is a prefix of some other subpath constraint P3 (see Figure 2 and the proof of Lemma 1).
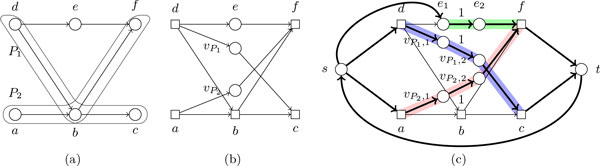
Figure 2.

In Fig. 2(a), subpath constraint P , in Fig. 2(b) the reduction of [20] which replaces path P by node vP connected to the end points of P , removes all internal nodes of P , and adds all transitive edges from and to v1 and v2. In Fig. 2(c), a case not covered by the reduction in [20].
In the second problem, we consider the weighted case, with one further generalization, as follows. As also noted by [20], in practice the paths in the path cover should start only in source nodes or in a specific subset of other nodes of G; similarly for their ending nodes. For example, in our method for the multi-assembly of RNA-transcripts [37,38], these nodes are identified when there is a sharp increase/decrease in read coverage in the middle of an exon, indicating the start/end of a transcript.
Minimum Weight Minimum Path Cover with Subpath Constraints (MW-MPC-SC) Problem
INPUT: A DAG G and
1 A subset of V (G)
2 A subset of E(G)
3 A family of directed paths in G
4 A superset S of the sources of G, and a superset T of the sinks of G
5 A weight w(e) for each e ∈ E(G)
TASK: Find a minimum number k of directed paths in G such that
1 Every node in occurs in some
2 Every edge in occurs in some
3 Every path P in ∈ is entirely contained in some
4 Every path starts in a node of S and ends in a node of T
5 is minimum among all tuples of k paths satisfying properties 1-4
When only paired-end reads are available, each such pair of reads corresponds to a pair of subpaths that must both be covered by the same path in the path cover. Formally, we have:
Minimum Path Cover with Paired Subpath Constraints (MPC-PSC) Problem
INPUT: A DAG G and
1 A subset of V (G)
2 A subset of E(G)
3 A family of pairs of directed paths in G
TASK: Find a minimum number k of directed paths in G such that
1 Every node in occurs in some
2 Every edge in occurs in some
3 For every pair , there exists such that both and are entirely contained in
The MPC with Subpath Constraints (MPC-SC) Problem
The unweighted case
In this section, we reduce the MPC-SC Problem to the classical MPC Problem. We describe our reduction as a sequence of commented algorithmic steps.
Step 1. for every do: ;
If the MPC has a path P covering the arc (u, v), then P also covers both u and v. Therefore, the constraints u, v can be dropped from (if present).
Step 2. for every path and for every edge do:
Similarly to Step 1, if the MPC has a path P covering a subpath , then P also covers every node and edge of , thus these constraints can be dropped from and (if present).
Step 3. while there exist two paths and in such that is contained in do:
After this step, no subpath constraint is completely included into another; this is key for the correctness of Step 4 below.
Step 4. while there exist two paths , such that a suffix of is a prefix of do:
let , be as above and with the common part (i.e., the suffix of which is a prefix of ) the longest possible;
let := the path which starts as and ends as ;
In this step, we merge paths sharing a suffix/prefix. We do this iteratively, at each step merging that pair of paths for which the shared suffix/prefix is longest possible. The correctness of this step is guaranteed by Lemma 1 below.
Lemma 1 If the MPC-SC Problem on an instance admits a solution with k paths, then also the problem instance transformed by applying Steps 1-4 admits a solution with k paths, and this solution also satisfies the original constraints , , .
Proof The correctness of Steps 1-3 was argued next to their introduction. Assume that have been transformed by these first three steps, and let be such that their common part (i.e., the suffix of which is a prefix of ) is longest possible. Suppose that the original problem admits a solution such that are covered by different solution paths say and , respectively. We show that the transformed problem admits a solution , having the same cardinality as, in which are covered by the same path , and also satisfies the original constraints .
Suppose that starts with node ui and ends with node vi, and that starts with node uj and ends with node vj . Let (cf. Figures 3(a) and 3(b)):
Figure 3.

A visual proof of Lemma 1.
• be the path obtained as the concatenation of the path taken from its starting node until vi with the path taken from vi until its end node (so that covers both and ).
• be the path obtained as the concatenation of the path taken from its starting node until vi with the path taken from vi until its end node.
We have to show that the path cover satisfies the original constraints . Since and use exactly the same edges as and , then and are satisfied. Moreover, the only two problematic cases are when there is a subpath constraint which has vi as internal node and is satisfied only by , or it is satisfied only by . Denote, analogously, by uk and vk the endpoints of . From the fact that the input was transformed at Step 3, and are not completely included in .
Case 1. is satisfied only by (Figures 3(a) and 3(b)). Since is not completely included in , uk is an internal node of ; thus, a suffix of is prefix also of . From the fact that the common part between and is longest possible, we have that vertices uj , uk , vi appear in this order in . Thus, is also satisfied by , since uk appears after uj on Pi.
Case 2. is satisfied only by , and it is not satisfied by (Figure 3(c)). This means that starts on before uj and, since it contains vi, it ends on after vi. From the fact that in not completely included in , vk is an internal node of , and thus a suffix of equals a prefix of . This common part is now longer than the common suffix/prefix between and , which contradicts maximality of the suffix/prefix between and . This proves the lemma.
The remaining steps can be seen as analogous to the reduction in [20].
Step 5. for every path do:
say starts in node s and ends in node t;
In this step, we represent each subpath constraint by an edge constraint. Its correctness is guaranteed by the fact that by now, no two subpath constraints are such that a suffix of the first is a prefix of the second. We should stress out that if there are more paths with the same endpoints, we may add parallel edges to the DAG. However, in Step 6 below these parallel edges will be transformed into parallel paths of length 2, rendering the DAG simple again.
Step 6. for every edge do:
subdivide the edge e by introducing a node ve in the middle of it;
At this point, we have transformed all subpath constraints into edge constraints. The edge constraints can be modeled as node constraints by simply subdividing each edge and introducing a new node in the middle of it; this node is then added to .
Step 7. G:= T(G)
We replace G by its transitive closure, since in Step 8 below we are going to remove from G all vertices not in .
Step 8. Remove from G all nodes not in ;
Since only the nodes in have to be covered by the paths in the path cover, we remove all other nodes. This is correct, since, at Step 7 above, we introduced all edges between nodes v and such that was reachable from v through some nodes not in .
Step 9. Compute a MPC for the resulting graph G;
This can be done by any method discussed previously.
Step 10. Postprocess the paths obtained at Step 9 above by reverting the transformations executed at Steps 1-8, in reverse order.
Theorem 2 Problem MPC-SC on a graph with n nodes, m edges, c subpath or edge constraints, and with N being the sum of subpath constraint lengths, can be solved by solving the classical MPC Problem in a graph with O(n + c) nodes and O(n2 + c) edges. This graph can be computed in time O(N + c2 + n2), thus the complexity of Problem MPC-SC is .
Proof The complexity of the pre-processing phase is dominated by Steps 3 and 4. Step 3 can be solved by first building a (generalized) suffix tree on the concatenation of subpath constraints with a distinct symbol #i added after each constraint sequence . This can be done in O(N) time even on our alphabet of size O(n) [32].
Then one can do as follows during depth-first traversal of the tree: If a leaf corresponding to the suffix starting at the beginning of subpath constraint has an incoming edge labeled by only #i and its parent has still other children, then the constraint is a substring of another constraint and must be removed (together with the leaf).
For Step 4, we compute all pairs longest suffix-prefix overlaps between the subpath constraints using an O(N + c2) time algorithm in [33, Theorem 7.10.1, page 137], [45] with [32] as a subroutine for the sake of large alphabet. The output can be casted to a double-linked list L containing elements of the form (i, j, len, previ, nexti, prevj , nextj ) in decreasing order of the overlap length, len, between constraints and . Pointers previ, nexti, prevj, and nextj tell the previous/next occurrences of the tuple having i as the first element and j as the second element, respectively. Then popping the first tuple from L tells us the first constraints to merge, and following prev∗ and next∗ pointers we can remove all overlaps no longer relevant for next mergings; when removing, we need to make sure the nested double-linked lists formed by the prev∗ and next∗ pointers are also updated. Continuing like this until the list L is empty gives all the overlaps in total O(c2) time. Notice that the new merged constraints do not need to be separately taken into account in overlap computation; no completely new overlaps can be created due to Step 3.
Merging itself requires a similar linked list structure being a special case of unionfind: All the constraints are represented as double-linked lists with node numbers as elements. Merging can be done by linking the double-linked lists together, removing the extra overlapping part from the latter list and redirecting its start pointer to point inside the newly formed merged list. When finished with merging, the new constraints are exactly those old constraints whose start pointers still point to the beginning of a node list. The complexity of merging is thus O(N).
The weighted case
To solve the MW-MPC-SC Problem, we build on the reduction in [36] to a network flow problem. This reduction will allow the addition of edge weights and of constraints on the starting/ending nodes of the solution paths. Note that these constraints S and T cannot be included in the reduction of the MPC Problem to a bipartite matching problem. Moreover, the heuristic in [20, Sec. 2.4.2] of arbitrarily extending the paths in a minimum weight MPC towards sources/sinks cannot be proved to be correct.
Given an input for the MW-MPC-SC Problem, we pre-process the graph G by Steps 1-6 of the unweighted case (shown in the previous section). After this pre-processing, we have correctly modeled all subpath constraints by node constraints. On the transformed graph G, we then do a similar reduction as for Thm. 1 (see Figure 4):
Figure 4.
In Fig. 4(a), an input DAG G with two subpath constraints P1 and P2; we take. , , S = {a, d, e} and T = {f, c}; weights are not drawn. In Fig. 4(b), the graph transformed by Steps 1-6; the vertices still in are drawn as circles, other vertices as squares. In Fig. 4(c), the reduction to a min-cost circulation problem; the edges with flow lower bound 1 are labeled as '1'; other edges have flow lower bound 0. In a min-cost circulation of value 3, all highlighted edges have flow value 1, except for (f, t) with flow value 2, and (t, s) with value 3. Any decomposition of the min-cost circulation into 3 paths gives the solution for Problem MW-MPC-SC.
1 We replace each node by an edge (v1, v2) such that all in-neighbors of v are now in-neighbors of v1, and all out-neighbors of v are now out-neighbors of v2. If node v was introduced at Step 6 to model an edge coming from a subpath constraint P , then the cost per unit of flow of (v1, v2) is the sum of the weights of the edges of P ; otherwise, it is 0.
2. For each edge e of G, if e is an original edge of G, we set its flow lower bound to 0 and its cost per unit of flow to w(e); otherwise we set both to 0.
3. The global source s has out-going edges precisely to the nodes in the set S, and the global sink t has in-coming edges precisely from the nodes in T ; we also add the edge (t, s). All edges incident to s or t have flow flower bound 0 and cost 0, except for the edge (t, s) having as cost the sum of all edge weights (plus a positive constant if all are 0). This guarantees, like before, that any min-cost circulation is also a min-flow.
Note that, by reducing to a flow problem, we do not have to perform Steps 7 and 8 anymore, since the coverage constraints are now modeled as flow lower bound constraints. As in the case of Thm. 1, we compute a min-cost circulation on this transformed input G, that is, a function f : E(G) → ℕ which satisfies all the flow conservation property for all nodes, satisfies all edge lower bounds, and minimizes . We then decompose the circulation (from which we remove the edge (t, s)) into paths, and covert these paths into paths of the original input graph. This is done by reverting the transformations executed at Steps 1-6, in reverse order (as done for the MPC-SC Problem). As before, these paths form a MPC satisfying all constraints, and they also start and end in vertices of S and T , respectively (because of the way s and t were connected to the other nodes of the graph). Since these paths arise from a min-cost circulation, then they also form a minimum weight MPC satisfying the input constraints. The flow network has only flow lower bounds, thus we can again apply the algorithm of [49], to get the following:
Theorem 3 Problem MW-MPC-SC on a graph with n nodes, m edges, c subpath or edge constraints, and with N being the sum of subpath constraint lengths, can be solved by reducing it to a min-cost circulation problem on a network with O(n + c) nodes and O(m + c) edges, and with flow lower bounds only. This network can be computed in time O(N + c2 + m), and the complexity of Problem MW-MPC-SC becomes O(N + (n + c)2 log(n + c) + (n + c)(m + c)).
The MPC with Paired Subpaths Constraints (MPC-PSC) Problem
The NP-completeness proof
In this section we show that the MPC-PSC Problem is NP-complete. Our reduction is from the NP-complete problem of deciding whether the chromatic number of a graph G, χ(G), is 3 [50]. We will show that it is actually NP-complete to determine if the MPC-PSC Problem admits a solution with just 3 paths, even on planar DAGs, of width 2, series-parallel, when only paired subpath constraints are imposed, and all subpaths are just edges.
Let G = (V, E) with V = {v1,..., vn} and E = {e1,..., em} be any non-bipartite graph; our question is whether χ(G) = 3. We reformulate this question by building up the DAG P(G) drawn in Figure 5. P(G) consists of a first stage of n blocks corresponding to the n vertices of G, and a second stage of m blocks corresponding to each edge of G, k ∈ {1, ..., m}. Only some of the nodes and edges of P (G) have been labeled; when an edge is labeled [L], we mean that in the family of paired subpath constraints we have the constraint (L, [L]).
Figure 5.

A reduction from chromatic number 3 to the MPC-PSC Problem.
Theorem 4 Problem MPC-PSC is NP-complete.
Proof We show that the graph G = (V, E) has χ(G) = 3 if and only if the DAG P(G) drawn in Figure 5 admits a solution to Problem MPC-PSC with 3 paths.
(⇒) Suppose that χ(G) = 3. Definitely, we need at least three paths to solve P(G), since the three edges v1, X1, Y1 exiting from node 0 cannot be covered by the same path, and each of them is mentioned in some constraint. By definition, G is 3 colorable if and only if V can be partitioned into three sets VA, VB , VC such that no edge of G is contained in any of them. We use these three sets to build up the three solution paths for Problem MPC-PSC as follows: for all X ∈ {A, B, C}, in the first stage (until node n) path PX picks up all edges labeled with a node in VX and no edge labeled with a node in V\VX ; next, in the second stage (from node n until node n + m), PX picks up those edges such that belongs to PX . This is possible, since no edge is contained in the same color class, and consequently the two of edges of P (G) labeled and do not belong to the same path among {PA, PB , PC }. Thus, and do not have to be both covered by the same solution path. Therefore, the three paths PA, PB , PC satisfy all paired subpath constraints, and are a solution to Problem MPC-PSC.
(⇐) Suppose the DAG P(G) drawn in Figure 5 admits a solution to Problem MPC-PSC with 3 paths PA, PB , PC . Then, we partition V into three color classes A, B, C by setting vi∈ × if and only if the edge of P(G) labeled by vi (in the first stage from node 0 to node n) belongs to PX , for all X ∈ {A, B, C}. To see that {A, B, C} is indeed a partition of V , observe that in each block k of the first stage of P(G), no two paths in {PA, PB , PC } can share an edge, since all three edges vk , Xk , Yk appear in some constraint. Therefore, each edge vk appears in exactly one of {PA, PB , PC }. The proof that the partition {A, B, C} is also a proper coloring of G encounters no difficulty, as the rationale behind the reduction was illustrated in the forward implication.
Corollary 1 For no ε > 0 there exists a -approximation algorithm for Problem MPC-PSC unless P=NP. Moreover, the problem is not FPT when parameterized on OPT (the minimum number of paths in a solution).
The FPT algorithm
In the previous section, we obtained the NP-completeness for the decision problem OPT = 3; this rules out a Dynamic Programming approach for Problem MPC-PSC. In this section, we show that if OPT = 2, then the problem can be solved in polynomial time. This also leads to an FPT algorithm on the total number of constraints.
For any constraint of the input DAG G that is made up of a pair (P1, P2) of subpaths of G, we may assume that there exists a directed path of G completely containing both P1 and P2, otherwise, the input instance is infeasible. Given any two constraints X and Y (X and Y can be nodes, edges, or pairs of subpaths), we say that X and Y are compatible if there is a directed path of G completely containing both X and Y . We exploit the following structural property:
Lemma 2 Let C be a set of constraints on a DAG G. There exists a directed path P in G which satisfies all constraints in C if and only if any two constraints in C are compatible.
Proof The forward implication is clear from the definition. For the backward implication, recall that the width of a DAG denotes the maximum size of an anti-chain of it. We claim that the union of the constraints in C is a DAG of width 1. Indeed, if it were of width 2 it would contain two nodes v1 and v2 which are pairwise not reachable by a directed path, thus forming an anti-chain of size 2. Since we assumed that for all pairs (P1, P2) of subpaths constraints of G, there exists a directed path of G completely containing both P1 and P2, this implies that v1 and v2 belong to two different constraints X and Y in C. Thus, X and Y are not compatible, a contradiction.
Theorem 5 Given an instance for Problem MPC-PSC, we can decide in polynomial time if OPT = 2, and if so, find the two solution paths. Moreover, Problem MPC-PSC is fixed-parameter tractable (FPT) in the total number C of input constraints.
Proof We build an incompatibility graph from the input constraints: every constraint is represented by a node, and we add an edge between two constraints iff they are incompatible. Then, OPT = 2 iff this incompatibility graph is bipartite, and the two classes of the bipartition give the two solution paths; this can be done in time O(C2). If OPT > 2, then we try all possible ways of partitioning the set of all input constraints (the number of these possibilities is a function only on C), and check that each class of the partition consists of pairwise compatible constraints.
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
AT conceived the problems and wrote the manuscript. RR, AT and VM contributed to the solutions. All authors read and approved the final manuscript.
Acknowledgements
We thank Anna Kuosmanen and Ahmed Sobih for their prompt help with the preliminary experiments on RNA-Seq data, which we included as Supplementary Material. This work was partially supported by the Academy of Finland under grant 250345 (CoECGR) and by the Finnish Cultural Foundation.
Declarations
Publication of this article was supported by the Academy of Finland under grant 250345 (CoECGR).
This article has been published as part of BMC Bioinformatics Volume 15 Supplement 9, 2014: Proceedings of the Fourth Annual RECOMB Satellite Workshop on Massively Parallel Sequencing (RECOMB-Seq 2014). The full contents of the supplement are available online at http://www.biomedcentral.com/bmcbioinformatics/supplements/15/S9.
References
- Xing Y. et al. The multiassembly problem: reconstructing multiple transcript isoforms from EST fragment mixtures. Genome Research. 2004;14(3):426–441. doi: 10.1101/gr.1304504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mortazavi A. et al. Mapping and quantifying mammalian transcriptomes by RNA-Seq. Nature Methods. 2008;5:621–628. doi: 10.1038/nmeth.1226. [DOI] [PubMed] [Google Scholar]
- Pepke S, Wold B, Mortazavi A. Computation for ChIP-seq and RNA-seq studies. Nature methods. 2009;6(11):22–32. doi: 10.1038/nmeth.1371. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim E, Goren A, Ast G. Insights into the connection between cancer and alternative splicing. Trends in genetics: TIG. 2008;24(1):7–10. doi: 10.1016/j.tig.2007.10.001. [DOI] [PubMed] [Google Scholar]
- Lopez-Bigas N, Audit B, Ouzounis C, Parra G, Guigo R. Are splicing mutations the most frequent cause of hereditary disease? FEBS Letters. 2005;579(9):1900–1903. doi: 10.1016/j.febslet.2005.02.047. [DOI] [PubMed] [Google Scholar]
- Wang Z, Gerstein M, Snyder M. RNA-Seq: a revolutionary tool for transcriptomics. Nature Reviews Genetics. 2009;10(1):57–63. doi: 10.1038/nrg2484. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shah S. et al. The clonal and mutational evolution spectrum of primary triple-negative breast cancers. Nature. 2012;486(7403):395–399. doi: 10.1038/nature10933. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trapnell C. et al. Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation. Nature Biotechnology. 2010;28:511–515. doi: 10.1038/nbt.1621. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Feng J, In: RECOMB - Research in Computational Molecular Biology. Berger, B, editor. Vol. 6044. LNCS; 2010. Inference of isoforms from short sequence reads; pp. 138–157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li W. et al. IsoLasso: a LASSO regression approach to RNA-Seq based transcriptome assembly. Journal of Computational Biology. 2011;18(11):1693–1707. doi: 10.1089/cmb.2011.0171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin YY, WABI - 12th Workshop on Algorithms for Bioinformatics. Vol. 7534. LNCS; 2012. CLIIQ: Accurate Comparative Detection and Quantification of Expressed Isoforms in a Population; pp. 178–189. [DOI] [Google Scholar]
- Li JJ. et al. Sparse linear modeling of next-generation mRNA sequencing (RNA-Seq) data for isoform discovery and abundance estimation. Proceedings National Academy of Sciences. 2011;108(50):19867–19872. doi: 10.1073/pnas.1113972108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guttman M. et al. Ab initio reconstruction of cell type-specific transcriptomes in mouse reveals the conserved multi-exonic structure of lincRNAs. Nature Biotechnology. 2010;28(5):503–510. doi: 10.1038/nbt.1633. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mezlini AM. et al. iReckon: Simultaneous isoform discovery and abundance estimation from RNA-seq data. Genome Research. 2012;23(3):519–529. doi: 10.1101/gr.142232.112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mangul S, In: ACM Conference on Bioinformatics, Computational Biology and Biomedical Informatics. Ranka, S, editor. ACM, New York, NY, USA; 2012. An integer programming approach to novel transcript reconstruction from paired-end RNA-Seq reads; pp. 369–376. [Google Scholar]
- Xia Z. et al. NSMAP: A method for spliced isoforms identification and quantification from RNA-Seq. BMC Bioinformatics. 2011;12(1):162. doi: 10.1186/1471-2105-12-162. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bernard E, Efficient RNA Isoform Identification and Quantification from RNA-Seq Data with Network Flows. preprint: SU2C-AACR-DT0409; SES-0835531; CCF-0939370. [DOI] [PMC free article] [PubMed]
- Hiller D. et al. Simultaneous Isoform Discovery and Quantification from RNA-Seq. Statistics in Biosciences. 2013;5(1):1–19. doi: 10.1007/s12561-013-9088-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song L, Florea L. CLASS: constrained transcript assembly of RNA-seq reads. BMC Bioinformatics. 2013;14(S-5):14. doi: 10.1186/1471-2105-14-S5-S14. Proceedings paper from RECOMB-seq: Third Annual Recomb Satellite Workshop on Massively Parallel Sequencing Beijing, China. 11-12 April 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bao E, Jiang T, Girke T. Branch: boosting rna-seq assemblies with partial or related genomic sequences. Bioinformatics. 2013;29(10):1250–1259. doi: 10.1093/bioinformatics/btt127. [DOI] [PubMed] [Google Scholar]
- Beerenwinkel N, Gu¨nthard HF, Roth V, Metzner KJ. Challenges and opportunities in estimating viral genetic diversity from next-generation sequencing data. Frontiers in Microbiology. 2012;3:329. doi: 10.3389/fmicb.2012.00329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mancuso N, Tork B, Skums P, Mandoiu II, Zelikovsky A. Bioinformatics and Biomedicine Workshops. IEEE, Atlanta, GA, USA; 2011. Viral quasispecies reconstruction from amplicon 454 pyrosequencing reads; pp. 94–101. [Google Scholar]
- O'Neil S, Emrich S. Haplotype and minimum-chimerism consensus determination using short sequence data. BMC Genomics. 2012;13(Suppl 2):4. doi: 10.1186/1471-2164-13-S2-S4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang A, Kantor R, DeLong A, Schreier L, Istrail S. Bioinformatics and Biomedicine Workshops. IEEE, Atlanta, GA, USA; 2011. Qcolors: An algorithm for conservative viral quasispecies reconstruction from short and non-contiguous next generation sequencing reads; pp. 130–136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eriksson N, Pachter L, Mitsuya Y, Rhee SY, Wang C, Gharizadeh B, Ronaghi M, Shafer RW, Beerenwinkel N. Viral population estimation using pyrosequencing. PLoS Computational Biology. 2008;4(5) doi: 10.1371/journal.pcbi.1000074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zagordi O, Bhattacharya A, Eriksson N, Beerenwinkel N. ShoRAH: estimating the genetic diversity of a mixed sample from next-generation sequencing data. BMC Bioinformatics. 2011;12(1):119. doi: 10.1186/1471-2105-12-119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Westbrooks K, Astrovskaya I, Campo DS, Khudyakov Y, Berman P, Zelikovsky A. In: ISBRA Lecture Notes in Computer Science. Mandoiu, I.I., Sunderraman, R., Zelikovsky, A, editor. Vol. 4983. Springer, Berlin; 2008. HCV Quasispecies Assembly Using Network Flows; pp. 159–170. [DOI] [Google Scholar]
- Wang ET, Sandberg R, Luo S, Khrebtukova I, Zhang L, Mayr C, Kingsmore SF, Schroth GP, Burge CB. Alternative isoform regulation in human tissue transcriptomes. Nature. 2008;456(7221):470–476. doi: 10.1038/nature07509. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fulkerson DR. Note on dilworth's decomposition theorem for partially ordered sets. Proceedings of the American Mathematical Society. 1956;7(4):701–702. [Google Scholar]
- Schadt EE, Turner S, Kasarskis A. A window into third-generation sequencing. Human molecular genetics. 2010;19(R2):227–240. doi: 10.1093/hmg/ddq416. [DOI] [PubMed] [Google Scholar]
- Sammeth M, Foissac S, Guig´o R. A General Definition and Nomenclature for Alternative Splicing Events. PLoS Computational Biology. 2008;4(8):1000147. doi: 10.1371/journal.pcbi.1000147. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Farach M. 38th Annual Symposium on Foundations of Computer Science (FOCS'97) IEEE Computer Society, Washington, DC, USA; 1997. Optimal suffix tree construction with large alphabets; pp. 137–143. [Google Scholar]
- Gusfield D. Algorithms on Strings, Trees, and Sequences - Computer Science and Computational Biology. Cambridge University Press, Cambridge UK; 1997. [Google Scholar]
- Gusfield D, Landau GM, Schieber B. An efficient algorithm for the all pairs suffix-prefix problem. Inf Process Lett. 1992;41(4):181–185. doi: 10.1016/0020-0190(92)90176-V. [DOI] [Google Scholar]
- Gabow HN, Tarjan RE. Faster scaling algorithms for network problems. SIAM J Comput. 1989;18(5):1013–1036. doi: 10.1137/0218069. [DOI] [Google Scholar]
- Pijls W, Potharst R. Another note on dilworth's decomposition theorem. Journal of Discrete Mathematics. 2013;2013:692645. [Google Scholar]
- Tomescu AI, Kuosmanen A, Rizzi R, M¨akinen V. WABI 2013 - 13th Workshop on Algorithms for Bioinformatics. Vol. 8126. LNBI; 2013. A Novel Combinatorial Method for Estimating Transcript Expression with RNA-Seq: Bounding the Number of Paths; pp. 440–451. [Google Scholar]
- Tomescu AI, Kuosmanen A, Rizzi R, M¨akinen V. A Novel Min-Cost Flow Method for Estimating Transcript Expression with RNA-Seq. BMC Bioinformatics. 2013;14(Suppl 5):15. doi: 10.1186/1471-2105-14-S5-S15. Proceedings paper from RECOMB-seq: Third Annual Recomb Satellite Workshop on Massively Parallel Sequencing Beijing, China. 11-12 April 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nadalin F, Vezzi F, Policriti A. GapFiller: a de novo assembly approach to fill the gap within paired reads. BMC Bioinformatics. 2012;13(S-14):8. doi: 10.1186/1471-2105-13-S14-S8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boetzer M, Pirovano W. Toward almost closed genomes with gapfiller. Genome Biology. 2012;13(6):56. doi: 10.1186/gb-2012-13-6-r56. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beerenwinkel N, Beretta S, Bonizzoni P, Dondi R, Pirola Y. Lecture Notes in Computer Science. Vol. 8370. Springer, Berlin; 2014. Covering pairs in directed acyclic graphs. In: Language and Automata Theory and Applications; pp. 126–137. [DOI] [Google Scholar]
- Dilworth RP. A Decomposition Theorem for Partially Ordered Sets. The Annals of Mathematics. 1950;51(1) [Google Scholar]
- Hopcroft JE, Karp RM. An n5/2 algorithm for maximum matchings in bipartite graphs. SIAM J Comput. 1973;2(4):225–231. doi: 10.1137/0202019. [DOI] [Google Scholar]
- Fredman ML, Tarjan RE. Fibonacci heaps and their uses in improved network optimization algorithms. J ACM. 1987;34(3):596–615. doi: 10.1145/28869.28874. [DOI] [Google Scholar]
- Ahuja RK, Magnanti TL, Orlin JB. Network Flows: Theory, Algorithms, and Applications. Prentice-Hall, Inc., Upper Saddle River, NJ, USA; 1993. [Google Scholar]
- Orlin JB. STOC '13. ACM, New York, NY, USA; 2013. Max flows in O(nm) time, or better. In: Proceedings of the 45th Annual ACM Symposium on the Theory of Computing; pp. 765–774. [Google Scholar]
- Schrijver A. Combinatorial Optimization - Polyhedra and Efficiency. Springer, Berlin; 2003. [Google Scholar]
- Ahuja RK, Goldberg AV, Orlin JB, Tarjan RE. Finding minimum-cost flows by double scaling. Mathematical Programming. 1992;53:243–266. doi: 10.1007/BF01585705. [DOI] [Google Scholar]
- Gabow HN, Tarjan RE. Faster scaling algorithms for general graph matching problems. J ACM. 1991;38(4):815–853. doi: 10.1145/115234.115366. [DOI] [Google Scholar]
- Garey MR, Johnson DS. Computers and Intractability: A Guide to the Theory of NP-Completeness. W. H. Freeman & Co., New York, NY, USA; 1979. [Google Scholar]