

Abstract
The frequency distribution of words has been a key object of study in statistical linguistics for the past 70 years. This distribution approximately follows a simple mathematical form known as Zipf ’ s law. This article first shows that human language has a highly complex, reliable structure in the frequency distribution over and above this classic law, although prior data visualization methods have obscured this fact. A number of empirical phenomena related to word frequencies are then reviewed. These facts are chosen to be informative about the mechanisms giving rise to Zipf’s law and are then used to evaluate many of the theoretical explanations of Zipf’s law in language. No prior account straightforwardly explains all the basic facts or is supported with independent evaluation of its underlying assumptions. To make progress at understanding why language obeys Zipf’s law, studies must seek evidence beyond the law itself, testing assumptions and evaluating novel predictions with new, independent data.
Keywords: Language, Zipf’s law, Statistics
Introduction
One of the most puzzling facts about human language is also one of the most basic: Words occur according to a famously systematic frequency distribution such that there are few very high-frequency words that account for most of the tokens in text (e.g., “a,” “the,” “I,” etc.) and many low-frequency words (e.g., “accordion,” “catamaran,” “ravioli”). What is striking is that the distribution is mathematically simple, roughly obeying a power law known as Zipf ’s law: The rth most frequent word has a frequency f(r) that scales according to
| (1) |
for α≈1 (Zipf, 1936, 1949).1 In this equation, r is called the frequency rank of a word, and f(r) is its frequency in a natural corpus. Since the actual observed frequency will depend on the size of the corpus examined, this law states frequencies proportionally: The most frequent word (r = 1) has a frequency proportional to 1, the second most frequent word (r = 2) has a frequency proportional to , the third most frequent word has a frequency proportional to , and so forth.
Mandelbrot proposed and derived a generalization of this law that more closely fits the frequency distribution in language by “shifting” the rank by an amount β (Mandelbrot, 1953, 1962):
| (2) |
for α≈1 and β≈2.7 (Mandelbrot, 1953, 1962; Zipf, 1936, 1949). This paper will study Eq. 2 as the current incarnation of “Zipf’s law,” although we will use the term near-Zipfian more broadly to mean frequency distributions where this law at least approximately holds. Such distributions are observed universally in languages, even in extinct and yet-untranslated languages like Meroitic (R. D. Smith, 2008).
It is worth reflecting on the peculiarity of this law. It is certainly a nontrivial property of human language that words vary in frequency at all; it might have been reasonable to expect that all words should be about equally frequent. But given that words do vary in frequency, it is unclear why words should follow such a precise mathematical rule—in particular, one that does not reference any aspect of each word’s meaning. Speakers generate speech by needing to communicate a meaning in a given world or social context; their utterances obey much more complex systems of syntactic, lexical, and semantic regularity. How could it be that the intricate processes of normal human language production conspire to result in a frequency distribution that is so mathematically simple—perhaps “unreasonably” so (Wigner, 1960)?
This question has been a central concern of statistical language theories for the past 70 years. Derivations of Zipf’s law from more basic assumptions are numerous, both in language and in the many other areas of science where this law occurs (for overviews, see Farmer & Geanakoplos, 2006; Mitzenmacher, 2004; Newman, 2005; Saichev, Malevergne & Sornette, 2010). Explanations for the distribution across the sciences span many formal ideas, frameworks, and sets of assumptions. To give a brief picture of the range of explanations that have been worked out, such distributions have been argued to arise from random concatenative processes (Conrad & Mitzenmacher, 2004; Li, 1992; Miller, 1957), mixtures of exponential distributions (Farmer & Geanakoplos, 2006), scale-invariance (Chater & Brown, 1999), (bounded) optimization of entropy (Mandelbrot, 1953) or Fisher information (Hernando, Puigdomènech, Villuendas, Vesperinas & Plastino, 2009), the invariance of such power laws under aggregation (see Farmer & Geanakoplos, 2006), multiplicative stochastic processes (see Mitzenmacher, 2004), preferential reuse (Simon, 1955; Yule, 1944), symbolic descriptions of complex stochastic systems (Corominas-Murtra & Solé, 2010), random walks on logarithmic scales (Kawamura & Hatano, 2002), semantic organization (Guiraud, 1968; D. Manin, 2008), communicative optimization (Ferrer i Cancho, 2005a, b; Ferrer i Cancho & Solé, 2003; Mandelbrot, 1962; Salge, Ay, Polani, & Prokopenko, 2013; Zipf, 1936, 1949), random division of elements into groups (Baek, Bernhardsson & Minnhagen 2011), first- and second-order approximation of most common (e.g., normal) distributions (Belevitch, 1959), and optimized memory search (Parker-Rhodes & Joyce, 1956), among many others.
For language in particular, any such account of the Zipf’s law provides a psychological theory about what must be occurring in the minds of language users. Is there a multiplicative stochastic process at play? Communicative optimization? Preferential reuse of certain forms? In the face of such a profusion of theories, the question quickly becomes which—if any—of the proposed mechanisms provides a true psychological account of the law. This means an account that is connected to independently testable phenomena and mechanisms and fits with the psychological processes of word production and language use.
Unfortunately, essentially all of the work in language research has focused solely on deriving the law itself in principle; very little work has attempted to assess the underlying assumptions of the hypothesized explanation, a problem for much work on power laws in science (Stumpf & Porter, 2012).2 It should be clear why this is problematic: The law itself can be derived from many starting points. Therefore, the ability of a theory to derive the law provides very weak evidence for that account’s cognitive validity. Other evidence is needed.
This article reviews a wide range of phenomena any theory of word frequency distributions and Zipf’s law must be able to handle. The hope is that a review of facts about word frequencies will push theorizing about Zipf’s law to address a broader range of empirical phenomena. This review intentionally steers clear from other statistical facts about text (e.g., Heap’s law, etc.) because these are thoroughly reviewed in other work (see Baayen, 2001; Popescu, 2009). Instead, we focus here specifically on facts about word frequencies that are informative about the mechanisms giving rise to Zipf’s law.3
We begin first, however, by pointing out an important feature of the law: It is not as simple as Zipf and other since have suggested. Indeed, some of the simplicity of the relationship between word frequency and frequency rank is the result of a statistical sin that is pervasive in the literature. In particular, the plots that motivate Eq. 2 almost always have unaddressed, correlated errors, leading them to look simpler than they should. When this is corrected, the complexities of the word frequency distribution become more apparent. This point is important because it means that Eq. 2 is, at best, a good approximation to what is demonstrably a much more complicated distribution of word frequencies. This complication means that detailed statistical analysis of what particular form the word frequency distribution takes (e.g. Eq. 1 vs. Eq. 2 vs. lognormal distributions, etc.) will not be fruitful; none is strictly “right.”
Following those results, this article presents and reviews a number of other facts about word frequencies. Each fact about word frequencies is studied because of its relevance to a proposed psychological account of Zipf’s law. Most strikingly, the present paper provides experimental evidence that near-Zipfian word frequency distributions occur for novel words in a language production task. The section Models of Zipf’s law then reviews a number of formal models seeking to explain Zipf’s law in language and relates each proposed account to the empirical phenomena.
The word frequency distribution is complex
Quite reasonably, a large body of work has sought to examine what form most precisely fits the word frequency distribution observed in natural language. Zipf’s original suggestion of Eq. 1 was improved by Mandelbrot to that in Eq. 2, but many other forms have been suggested, including, for instance, a log-normal distribution (Carroll, 1967, 1969), which might be considered a reasonably “null” (e.g., unremarkable) hypothesis.
A superb reference for comparing distributions is Baayen (2001, Chap. 3), who reviewed evidence for and against a log-normal distribution (Carroll, 1967, 1969), a generalized inverse Gauss–Poisson model (Sichel, 1975), and a generalized Z-distribution (Orlov & Chitashvili, 1983) for which many other models (due to, e.g., Herdan, 1960, 1964; Mandelbrot, 1962; Rouault, 1978; Simon, 1955, 1960; Yule, 1924) are a special case (see also Montemurro, 2001; Popescu, 2009). Baayen finds, with a quantitative model comparison, that which model is best depends on which corpus is examined. For instance, the log-normal model is best for the text The Hound of the Baskervilles, but the Yule–Simon model is best for Alice in Wonderland. One plausible explanation for this is that none of these simple models—including the Zipf–Mandelbrot law in Eq. 2—is “right,”4 instead only capturing some aspects of the full distribution of word frequencies.
Indeed, none is right. The apparent simplicity of the distribution is an artifact of how the distribution is plotted. The standard method for visualizing the word frequency distribution is to count how often each word occurs in a corpus and to sort the word frequency counts by decreasing magnitude. The frequency f(r) of the rth most frequent word is then plotted against the frequency rank r, typically yielding a mostly linear curve on a log-log plot (Zipf, 1936), corresponding roughly to a power law distribution.5 This approach—although essentially universal since Zipf—commits a serious error of data visualization. In estimating the frequency-rank relationship this way, the frequency f(r) and frequency rank r of a word are estimated on the same corpus, leading to correlated errors between the x-location r and y-location f(r) of points in the plot.
This is problematic because it may suggest spurious regularity.6 The problem can be best understood by a simple example. Imagine that all words in language were actually equally probable. In any sample (corpus) of words, we will find that some words occur more than others just by chance. When plotted in the standard manner, we will find a strikingly decreasing plot, erroneously suggesting that the true frequency-rank relationship has some interesting structure to be explained. This spurious structure is especially problematic for low-frequency words, whose frequencies are measured least precisely. Additionally, in the standard plot, deviations from the Zipfian curve are difficult to interpret, due to the correlation of measurement errors; it is hard to tell systematic deviations from noise.
Fortunately, the problem is easily fixed: We may use two independent corpora to estimate the frequency and frequency rank. In the above case where all words are equally probable, use of independent corpora will lead to no apparent structure—just a roughly flat frequency-rank relationship. In general, we need not have two independent corpora from the start; we can imagine splitting our initial corpus into two subcorpora before any text processing takes place. This creates two corpora that are independent bodies of text (conditioned on the general properties of the starting corpus) and, so, from which we can independently estimate r and f(r). A convenient technique to perform this split is to perform a binomial split on observed frequency of each word: If we observe a word, say, 100 times, we may sample from a binomial (N = 100, p = .5) and arrive at a frequency of, say, 62 used to estimate its true frequency and a frequency of N – 62 = 38 to estimate its true frequency rank. This exactly mirrors randomly putting tokens of each word into two independent corpora, before any text processing began. The choice of p = .5 is not necessary but yields two corpora of approximately the same size. With this method, the deviations from a fit are interpretable, and our plotting method no longer introduces any erroneous structure.
Figure 1a shows such a plot, giving the frequency/frequency-rank relationship from the American National Corpus (ANC; Reppen & Ide, 2004), a freely available collection of written American English. All figures in this paper follow this plotting procedure unless otherwise noted. The plot shows a two-dimensional histogram of where words fall in frequency/frequency-rank space.7 The shading of the histogram is done logarithmically with the number of words falling into each hexagonal bin and is white for zero-count bins. Because the plot has a logarithmic y-axis, words with zero frequency after the split are not shown. The fit of Eq. 2 using a maximum-likelihood method on the separate frequency and frequency rank portions of the corpus is shown in the red solid line. Additionally, a locally smoothed regression line (LOESS) (Cleveland, Grosse, & Shyu, 1992) is shown in gray. This line corresponds to a local estimate of the mean value of the data and is presented as a comparison point to see how well the fit of Eq. 2 matches the expected value of the points for each frequency rank (x-value). In the corner, several key values are reported: the fit α and β, an R2 measure giving the amount of variance explained by the red line fit, and an adjusted capturing the proportion of explainable variance captured by the fit, taking the smoothed regression as an estimate of the maximum amount of variance explainable. For simplicity, statistics are computed only on the original R2, and its significance is shown with standard star notation (three stars means p < .001).
Fig. 1.
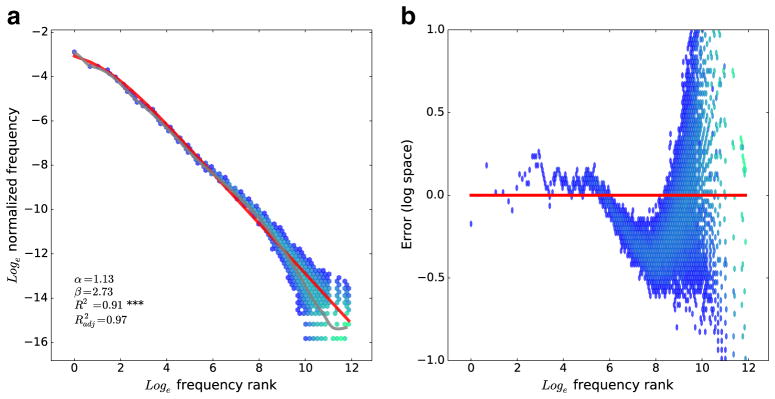
a Relationship between frequency rank (x-axis) and (normalized) frequency (y-axis) for words from the American National Corpus. This is plotted using a two-dimensional hexagonal histogram. Bins are shaded blue to green along a logarithmic scale depending on how many words fall into the bin. The red line shows the fit of Eq. 2 to these data. b Frequency rank versus the difference (in log space) between a word’s frequency and the prediction of Eq. 2. This figure shows only a subset of the full y range, cropping some extreme outliers on the right-hand side of the plot in order to better visualize this error for the high-frequency words
This plot makes explicit several important properties of the distribution. First, it is approximately linear on a log-log plot, meaning that the word frequency distribution is approximately a power law, and moreover, is fit very well by Eq. 2 according to the correlation measures. This plot shows higher variability toward the low-frequency end, (accurately) indicating that we cannot estimate the curve reliably for low-frequency words. While the scatter of points is no longer monotonic, note that the true plot relating frequency to frequency rank must be monotonic by definition. Thus, one might imagine estimating the true curve by drawing any monotonic curve through these data. At the low-frequency end, we have more noise and, so, greater uncertainty about the shape of that curve. This plot also shows that Eq. 2 provides a fairly accurate fit (red) to the overall structure of the frequency-rank relationship across both corpora.
Importantly, because we have estimated r and f(r) in a statistically independent way, deviations from the curve can be interpreted. Figure 1b shows a plot of these deviations, corresponding to the residuals of frequency once Eq. 2 is fit to the data. Note that if the true generating process were something like Eq. 2, the residuals should be only noise, meaning that those that are above and below the fit line (y = 0 in the residual plot) should be determined entirely by chance. There should be no observable structure to the residual plot. Instead, what Fig. 1b reveals is that there is considerable structure to the word frequency distribution beyond the fit of the Zipf–Mandelbrot equation, including numerous minima and maxima in the error of this fit. This is most apparent in the “scoop” on the right-hand size of the plot, corresponding to misestimation of higher ranked (lower-frequency) words. This type of deviation has been observed previously with other plotting methods and modeled as a distinct power law exponent by Ferrer i Cancho and Solé (2001), among others.
However, what is more striking is the systematic deviation observed in the left half of this plot, corresponding to low-rank (high-frequency) words. Even the most frequent words do not exactly follow Zipf’s law. Instead, there is a substantial autocorrelation, corresponding to the many local minima and maxima (“wiggles”) in the left half of this plot. This indicates that there are further statistical regularities—apparently quite complex—that are not captured by Eq. 2. These autocorrelations in the errors are statistically significant using the Ljung–Box Q-test (Ljung & Box, 1978) for residual autocorrelation (Q = 126,810.1, p < .001), even for the most highly ranked 25 (Q = 5.7, p = .02), 50 (Q = 16.7, p < .001), or 100 (Q = 39.8, p < .001) words examined.
Such a complex structure should have been expected: Of course, the numerous influences on language production result in a distribution that is complex and structured. However, the complexity is not apparent in standard ways of plotting power laws. Such complexity is probably incompatible with attempts to characterize the distribution with a simple parametric law, since it is unlikely that a simple equation could fit all of the minima and maxima observed in this plot. At the same time, almost all of the variance in frequencies is fit very well by a simple law like Zipf’s power law or its close relatives. A simple relationship captures a considerable amount about word frequencies but clearly will not explain everything. The distribution in language is only near-Zipfian.
Empirical phenomena in word frequencies
Having established that the distribution of word frequencies is more complex than previously supposed, we now review several basic facts about word frequencies that any theory of the Zipfian or near-Zipfian distribution must account for. The plan of this article is to present these empirical phenomena in this section and then use them to frame specific model-based accounts of Zipf’s law in the section, Models of Zipf’s law. As we will see, the properties of word frequencies reviewed in this section will have much to say about the most plausible accounts of the word frequency distribution in general.
The general method followed in this section is to study relevant subsets of the lexicon and quantify the fit of Eq. 2. This approach contrasts somewhat with the vast literature on statistical model comparison to check for power laws (as compared with, e.g., lognormal distributions, etc.). The reason for this is simple: the previous section provides strong evidence that no simple law can be the full story behind word frequencies because of the complexities of the frequency rank/frequency curve. Therefore, comparisons between simple models will inevitably be between alternatives that are both “wrong.”
In general, it is not so important which simple distributional form is a better approximation to human language. What matters more are the general properties of word frequencies that are informative about the underlying mechanisms behind the observed distribution. This section tries to bring out those general properties. Do the distributions appear near-Zipfian for systematic subsets of words? Are distributions that look similar to power laws common across word types, or are they restricted to words with certain syntactic or semantic features? Any psychologically justified theory of the word frequency distribution will depend on appreciating, connecting to, and explaining these types of high-level features of the lexical frequency distribution.
Semantics strongly influences word frequency
As a language user, it certainly seems like we use words to convey an intended meaning. From this simple point of view, Zipf’s law is really a fact about the “need” distribution for how often we need to communicate each meaning. Surprisingly, many accounts of the law make no reference to meaning and semantics (except see Semantic Accounts section and some work in Communicative Accounts section), deriving it from principles independent of the content of language. But this view is incompatible with the fact that even cross-linguistically, meaning is systematically related to frequency. Calude and Pagel (2011) examined Swadesh lists from 17 languages representing six language families and compared frequencies of words on the list. Swadesh lists provide translations of simple, frequent words like “mother” across many languages; they are often used to do historical reconstruction. Calude and Pagel reported an average interlanguage correlation in log frequency of R2 = .53 (p < .0001) for these common words, indicating that word frequencies are surprisingly robust across languages and predictable from their meanings. Importantly, note that Swadesh words will tend to be high frequency, so the estimated R2 is almost certain to be lower for less frequent words. In any case, if meaning has any influence on frequency, a satisfying account of the frequency distribution will have to address it.
We can also see a systematic frequency-rank relationship across languages, grouping words by their meaning. Figure 2 shows frequency-rank plots of the Swadesh lists compiled in Calude and Pagel (2011),8 plotted, like all other plots in the article, according to the methods. However, unlike other plots in this article, the frequency rank here is fixed across all languages, estimated independently on 25% of the data from each language and then collapsed across languages. Thus, the rank ordering—corresponding to the x-location of each meaning on the Swadesh list—does not vary by language and is determined only by aggregate, cross-linguistic frequency (independently estimated from the y-location). We can then compare the frequencies at each rank to see whether they follow similar distributions. As these plots reveal, the distributions are extremely similar across languages and follow a near-Zipfian distribution for the pooled rank ordering.
Fig. 2.

Cross-linguistic word frequency distributions using words from a Swadesh list (data provided by Calude & Pagel, 2011). Here, the x-location of each point (word) is fixed across languages according to the aggregate frequency rank of the word’s meaning on an independent set of data. The systematicity here means that the word frequency distribution falls off similarly according to word meaning across languages and approximately according to a power law like Eq. 2 (red)
In this plot, because the rank ordering is fixed across all languages, not only do frequencies fall off like Eq. 2, but they do so with roughly the same coefficients cross-linguistically. If frequency was not systematically related to meaning, these plots would reveal no such trends.
Another domain where the meaning dependence of frequency is apparent is that of number words (Dehaene & Mehler 1992; Piantadosi, 2012). Figure 3 shows number word frequencies (e.g., “one,” “two,” “three,” etc.), previously reported in Piantadosi. These plots show cardinality versus frequency in English, Russian, and Italian, using all the data from the Google Books N-gram data set (Lin et al., 2012). This clearly shows that across languages, number words follow a near-Zipfian distribution according to the magnitude (meaning)—in fact, a very particular one with exponent α≈−2 (the inverse square law for number frequency), a finding previously reported by Dehaene and Mehler. Piantadosi shows that these trends also hold for the decade words and across historical time. Thus, the frequency of these words is predictable from what cardinality the words refer to, even across languages.
Fig. 3.
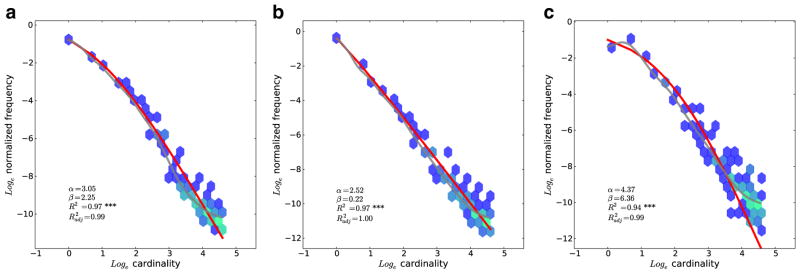
Power law frequencies for number words (“one,” “two,” “three,” etc.) in English (a), Russian (b), and Italian (c), using data from Google (Lin et al., 2012). Note that here the x-axis is ordered by cardinality, not frequency rank, although these two coincide. Additionally, decades (“ten,” “twenty,” “thirty,” etc.) were removed from this analysis due to unusually high frequency from their approximate usage. Here and in all plots, the red line is the fit of Eq. 2, and the gray line is a LOESS
The general point from this section is, therefore, that word meaning is a substantial determinant of frequency, and it is perhaps intuitively the best causal force in shaping frequency. “Happy” is more frequent than “disillusioned” because the meaning of the former occurs more commonly in topics people like to discuss. A psychologically justified explanation of Zipf’s law in language must be compatible with the powerful influence that meaning has on frequency.
Near-Zipfian distributions occur for fixed referential content
Given that meanings in part determine frequencies, it is important to ask whether there are any phenomena that cannot be straightforwardly explained in terms of meaning. One place to look is words that have roughly the same meaning, at least in terms of referential content. Facts like the principle of contrast (Clark, 1987) may mean that true synonyms do not exist in human language. However, taboo words provide a class of words that refer, at least approximately, to the same thing (e.g., “fornicating,” “shagging,” “fucking,” etc.). Figure 4 shows the frequency distribution of several taboo words, gerunds referring to sex (Fig. 4a) and synonyms for feces (Fig. 4b),9 on data from the ANC. Both cases reveal that near-Zipfian word frequency distributions can still be observed for words that have a fixed referential content, meaning that other factors (e.g., formality, social constraints) also play a role in determining word frequency.
Fig. 4.
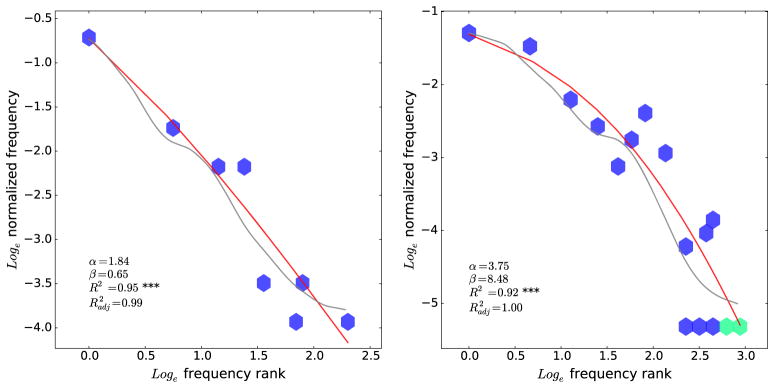
Distributions for taboo words for a sex (gerunds) and b feces
Near-Zipfian distributions occur for naturally constrained meanings
If meanings in part determine word frequencies, it is plausible that the distribution arises from how human languages segment the observable world into labeled categories. For instance, languages are in some sense free to choose the range of referents for each word10: Should “dog” refer to a specific kind of dog, to a broad class, or to animals in general? Perhaps language evolution’s process for choosing the scope of word meanings gives rise to the frequency distribution (for a detailed account, see D. Manin, 2008).
However, the distribution follows a near-Zipfian distribution even in domains where the objects of reference are highly constrained by the natural world. Figure 5a–c shows several of these domains,11 chosen a priori for their semantic fixedness: months, planets, and element names. Intuitively, in each of these cases, it is likely that the lexicon did not have much freedom in how it labeled the terms in these categories, since the referents of these terms are salient, fixed natural kinds. For instance, our division of the world into 12 months comes from phases of the moon and the seasons, not from a totally free choice that language may easily adapt or optimize. These plots all show close fits by Eq. 2, shown in red, and high, reliable correlations.
Fig. 5.
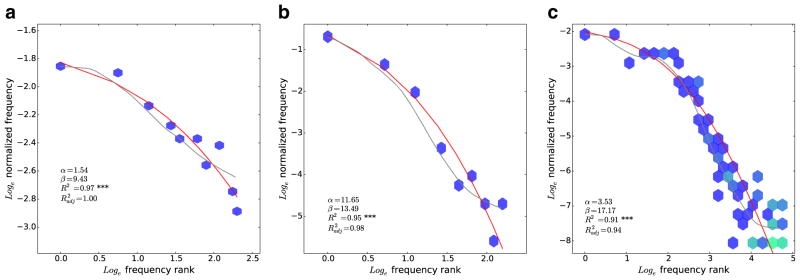
Frequency distribution in the American National Corpus for words whose scope of meaning has been highly constrained by the natural world: a months, b planets, and c elements
The fit of Zipfian distributions vary by category
Zipf’s law is stated as a fact about the distribution of words, but it is important to remember that there may not be anything particularly special about analyzing language at the level of words. Indeed, words may not even be a precisely defined psychological class, with many idiomatic phrases stored together by language-processing mechanisms and some word forms potentially created on the fly by grammatical or morphological mechanisms. It is therefore important to examine the frequency distribution for other levels of analysis.
Figure 6 shows the frequency distribution of various syntactic categories (part of speech tags on individual words) from the Penn Treebank (Marcus, Marcinkiewicz, & Santorini, 1993), using the tagged Brown corpus. This reveals that word categories are also fit nicely by Eq. 2—perhaps even more closely than words—but the shape of the fit (parameters α and β) differs. The quality of fit appears to be off for the lowest frequency tags, although it is not clear how much of this effect is due to data sparsity. The general pattern suggests that a full explanation of the word frequency distribution would ideally call on mechanisms general enough to apply to syntactic categories and possibly even other levels of analysis.12
Fig. 6.

Frequency distribution of syntactic categories from the Penn Treebank
The same corpus can also be used to examine the fit and parameters within syntactic categories. Figure 7a–c shows the distribution of words within each of six categories from the treebank: determiners, prepositions/subordinating conjunctions, modals, singular or mass nouns, past participle verbs, and third-person singular present tense verbs. None of these were predicted to pattern in any specific way by any particular theory but were chosen post hoc as interesting examples of distributions. Determiners, modals, and some verbs appear to have the lowest adjusted correlations when Eq. 2 is fit. These figures illustrate that the word types vary substantially in the best-fitting parameters α and β but show, in general, fairly Zipfian distributions. Additionally, the residual structure (deviation from the red line fit) shows interesting variability between categories. For instance, the verbs (Fig. 7f) show an interesting concavity that is the opposite of that observed in typical Zipfian distributions, bowing to the bottom rather than the top. This concavity is primarily driven by the much larger frequency of the first several words, like “is,” “has,” and “does.” These auxiliary verbs may, in truth, belong in a separate category than other verbs, perhaps changing the shape of this curve. There also appears to be a cluster of low-frequency modals, all of about the same frequency. The determiner plot suggests that the rate at which frequency decreases with rank changes through two scaling regimes—a slow fall-off followed by a fast one—which is often argued for the lexicon in general (Ferrer i Cancho & Solé, 2001) and would be inconsistent with the simple fit of Eq. 2.
Fig. 7.

Frequency distribution of words within several syntactic categories from the Penn Treebank: determiners (DTs), prepositions or subordinating conjunctions (INs), modals (MDs), nouns (NNs), past participle verbs (VBNs), third-person singular present verbs (VBZs). These plots represent a post-hoc selected subset of all syntactic categories
Overall, the variability across part-of-speech categories suggests that some of the fit of Zipfian distribution arises by collapsing together different parts of speech.
The distribution of word frequencies is not stationary
An often overlooked factor in the search for explanations of Zipf’s law is that word frequencies are not stationary, meaning that the probability of uttering each word changes depending on other factors. This phenomenon occurs at, for instance, a long time scale reflecting the topic of discussion. One is more likely to utter “Dallas” in a discussion about Lyndon Johnson than in a discussion about Carl Sagan. The nonstationarity of text is addressed by Baayen (2001, Chap. 5), who notes that the clumpy randomness of real text leads to difficulties estimating vocabulary sizes and distributions. Recently, Altmann, Pierrehumbert, and Motter (2009) showed that word recurrences on a time scale compatible with semantics (not syntax) follow a stretched exponential distribution, with a certain degree of “burstiness.” The variability in frequencies is an important method of classification of documents via topic models (see Blei & Lafferty, 2007, 2009; Blei, Ng, & Jordan, 2003; Steyvers & Griffiths, 2007) or latent semantic analysis (Dumais, 2005; Landauer, Foltz, & Laham, 1998). Such models work by essentially noting that word frequencies within a document are cues to its semantic topic; one can then work backward from the frequencies to the topic or set of possible topics. The variability in word frequencies is also useful in information retrieval (Manning & Schütze, 1999, Chap. 15).
The nonstationarity of word frequencies has an important theoretical implication for explanations of Zipf’s law. The frequencies of words we observe are actually averages over contexts. The probability of uttering a word w is given by
| (3) |
where P(W = w|C = w) is the probability of w in a particular context c. If the observed frequency is an average over contexts, our explanation of Zipf’s law must respect the fact that it is an average, and not explain it with a model that is incompatible with context-dependent frequencies.
Word frequency varies according to many forces
Thanks in large part to the recent availability of gigantic, freely available, longitudinal corpora like Lin et al. (2012), recent studies have also been able to chart changes in word frequencies throughout modern time. These studies generally reveal substantial complexity in the forces that shape word frequencies. Altmann, Pierrehumbert, and Motter (2011) showed that a word’s niche, its characteristic features and the environment in which it is used, strongly influences the word’s change in frequency. More specifically, they argued that some of the nonstationarity of word frequencies results from features of individuals like desires to convey information or identify with a particular social group. Petersen, Tenenbaum, Havlin, and Stanley (2012) showed that word usage varies according to social, technological, and political pressures. In the simplest case, of course people start saying words like “e-mail” once e-mail is invented; but these trends extend to, for instance, measurable differences in word frequencies and word birth and death in periods of drastic social and political change. Pagel, Atkinson, and Meade (2007) showed that word frequency and language change are closely linked, such that low-frequency words tend to evolve the most.
In general, these studies suggest that any theory aiming to explain Zipf’s law must connect to the forces that shape frequencies and with language change in general. How is it that processes affecting how frequencies change and how lexica evolve all yield a relatively conserved distribution across time? How does the nature of—perhaps drastic—language change maintain the distribution? Any theory that is not directly compatible with change must be missing a large part of what determines frequencies.
Power laws arise from (almost) nothing
A wide range of explanations of Zipf’s law make reference to optimization and language change. However, we next show that this cannot be the entire story: A near-Zipfian word frequency distribution occurs even for wholly novel words whose content and use could not have been shaped by any processes of language change.
In a behavioral experiment, 25 subjects were recruited from Amazon’s Mechanical Turk, an online platform that is becoming increasingly popular for experimental psychology (Buhrmester, Kwang, & Gosling, 2011; Gibson, Piantadosi, & Fedorenko, 2011; Mason & Suri, 2012; Paolacci, Chandler, & Ipeirotis, 2010). Participants were given the following prompt: “An alien space ship crashes in the Nevada desert. Eight creatures emerge, a Wug, a Plit, a Blicket, a Flark, a Warit, a Jupe, a Ralex, and a Timon. In at least 2000 words, describe what happens next.” Subjects’ relative frequency distribution of each of these eight novel words was then computed on their produced text. Because different subjects may pick a different creature as their “primary” character in the text, the analysis aggregated statistics by rank across subjects. It used the sampling methods described for Fig. 1a to determine the estimated frequency f(r) of each subject’s rth most frequent word and then collapsed this distribution across subjects by rank. Thus, the frequency we report for the rth most frequent word is the sum (or, scaled, mean) of each individual subject’s rth most frequent word. This aggregation was done to decrease noise, since each subject uses each word only a handful of times.13
The resulting subject-average frequency distribution is shown in Fig. 8. This clearly demonstrates near-Zipfian scaling in frequency, despite the fact that all words are, in some sense, equivalent in the prompt; participants are not told, for instance, that one creature is extra salient or that they should primarily describe one character. The context was chosen to bias them as little as possible as to how much to describe each creature and what role it should play in their novel story. Moreover, subjects show this distribution even though they are told almost nothing about the creatures (other than that they crashed from an alien ship) and are told absolutely nothing about what happens next. Even in this context, words still approximately follow the power law distribution, although larger-scale studies should be used to check that this effect is seen within individuals and is not the result of averaging together subjects.
Fig. 8.

An approximate power law distribution of novel alien names used by subjects in making up a story
In general, these findings suggest that a parsimonious, broad-coverage explanation for near-Zipfian distributions in language—one that can explain this experiment—should be applicable to people speaking about entirely novel, relatively unspecified referents.
Zipf’s law occurs in other human systems
Interestingly, Zipf’s law occurs in very many aspects of human society, including communication other than natural language. For instance, Zipfian (or near-Zipfian) frequency distributions occur in music (see Manaris et al., 2005; Zanette, 2006, among others). They are observed in computer systems in the distribution of hardware instructions for programming languages (see Chen, 1991; Concas, Marchesi, Pinna, & Serra, 2007; Shooman & Laemmel, 1977; Veldhuizen, 2005, among others), across many levels of abstraction in software (Louridas, Spinellis, & Vlachos, 2008), in n-tuples in computer code (Gan, Wang, & Han, 2009), and in many aspects of the Internet (Adamic & Huberman, 2002). These findings complement the general result that Zipfian distributions occur in some form in a striking number of physical and biological systems (Farmer & Geanakoplos, 2006; S. A. Frank, 2009; Li, 2002; Mitzenmacher, 2004; Newman, 2005; Saichev et al., 2010). An important question for future work is to determine how broadly the word frequency distribution should be explained. Should we seek explanations that unify language with music and perhaps other areas like computer software? Or does the profusion of derivations of Zipf’s law mean that we should not place such a strong weight on all-encompassing explanations, since very different mechanisms may give rise to the power law in different domains?
Models of Zipf’s law
Now that we have reviewed a number of empirical phenomena about word frequencies, we next consider several of the attempts to explain Zipf’s law in language and relate these to the empirical phenomena just reviewed. These include explanations based on very simple statistical models (random typing, preferential reuse), the organization of semantic systems, deep optimization properties of communication, and universal properties of computational systems. As was described above, very little of this work has sought independent tests of the key assumptions or addressed the range of empirical phenomena described above. As we will see, none of the accounts is compellingly adequate alone. However, it may be true that there is no unitary explanation for word frequencies and that multiple causal forces are at play.
Random-typing accounts
Given the ubiquity and robustness of Zipf’s law, some have argued that the law is essentially a statistical artifact. This view is even widespread in certain communities and advocated by some prominent linguists such as Chomsky (personal communication). The random-typing account holds that Zipf’s law is uninteresting because it holds even in very trivial statistical systems, like a monkey randomly banging on a typewriter (Conrad & Mitzenmacher, 2004; Li, 1992; Miller, 1957). Such a monkey will occasionally hit the space bar, creating a word boundary, and we can then look at the distribution of “word” frequencies. It turns out that they follow a Zipfian distribution even though words are created entirely at random, one letter at a time. Intuitively, short words will tend to have a high probability, with the probability or frequency of words falling off approximately geometrically in their length. Although this process is clearly not an apt description of how humans generate language (see Howes, 1968; Piantadosi, Tily, & Gibson, 2013), the idea is that it should be treated as a null hypothesis about how language may be in the absence of other forces.
Indeed, the theoretical challenge raised by this model can be illustrated by taking a corpus of text and dividing it on a character other than the space (“ ”) character, treating, for instance, “e” as a word boundary.14 Doing this robustly recovers a near-Zipfian distribution over these artificial “words,” as shown in Fig. 9. This shows some interesting deviations from the shape of the curve for natural language, but the general pattern is unmistakably similar to Fig. 9, with a strong decrease in “word” frequency that falls off like a power law (linear on this plot) with length. So if the distribution occurs for even linguistically nonsensical “word” boundaries (like “e”), perhaps its presence in real language is not in need of explanation.
Fig. 9.

Frequency distribution of the 25,000 most frequent “words” in the ANC, where “e” rather than space (“ ”) was treated as a word boundary. This exhibits a clear near-Zipfian distribution, with the frequency of these words falling off much like Eq. 2
Some work has examined the ways in which the detailed statistics of random-typing models look unlike that observed in real human language (Baayen, 2001; Ferrer i Cancho & Elvevåg 2010; Ferrer i Cancho & Solé, 2002; D. Manin, 2008, 2009; Tripp & Feitelson, 1982). For instance, random-typing models predict that the number of word types of a given length should decay exponentially in length; but in real language, this relationship is not even monotonically decreasing (D. Manin, 2009). Indeed, even the particular frequency distribution does not appear well-approximated by simple random-typing models (Ferrer i Cancho & Elvevåg 2010), although in other work, Ferrer i Cancho is a strong proponent of such models (Ferrer i Cancho & Moscoso del Prado Martin, 2011). Of course, random-typing advocates might point out that tweaking the details of random-typing models (e.g., changing letter frequencies, introducing Nth order Markov dependence) might allow them to fit the details of human language (for Zipf’s law in Markov processes with random transitions, see Kanter & Kessler, 1995).
As such, a stronger argument than the details of the distribution is to recognize that they do not capture anything like the real causal process and, therefore, are poor scientific theories (Howes, 1968; Piantadosi et al., 2013). Indeed, once we appreciate that humans know words in their entirety and generate them intentionally to convey a meaning, it no longer makes sense to consider null hypotheses based on subword processes whose key feature is that a word’s frequency is wholly determined by its components (e.g., letters) (Ferrer i Cancho & Elvevåg 2010; Howes, 1968; Piantadosi et al., 2013). In the real cognitive system, people know whole words and do not emit subword components at random, and so, clearly, such processes cannot explain the cognitive origins of the law; a “deeper” (D. Manin, 2008) explanation is needed.
This counterpoint was articulated early by Howes (1968), but his reply has not been widely appreciated: “If Zipf’s law indeed referred to the writings of ‘random monkeys,’ Miller’s [random-typing] argument would be unassailable, for the assumptions he bases it upon are appropriate to the behavior of those conjectural creatures. But to justify his conclusion that people also obey Zipf’s law for the same reason, Miller must perforce establish that the same assumptions are also appropriate to human language. In fact, as we shall see, they are directly contradicted by well-known and obvious properties of languages.” Those facts are, of course, that language is not generated at random, by accidentally happening to create a word boundary. The following question remains, then: Why is it that real processes of language generation give rise to this word frequency distribution?
Beyond the theoretical arguments against random-typing accounts, such accounts are not compatible with several empirical facts reviewed earlier. The systematicity of word frequencies across meanings (see Semantics strongly influences word frequency) are particularly problematic for random-typing models, since any process that is remotely like random typing will be unable to explain such patterns. One certainly would not be able to explain why cardinal number words also follow a near-Zipfian distribution, ordered precisely by magnitude. Moreover, random-typing accounts cannot explain the variability across syntactic categories (see The fit of Zipfian distributions vary by category). Why would certain word categories appear not to follow the model? Nor can it explain the tendency of subjects to follow the distribution for novel words (see Power laws arise from [almost] nothing), and the simplest forms of random-typing models are incompatible with the nonstationarity word frequencies exhibit (see The distribution of word frequencies is not stationary).
Simple stochastic models
One of the oldest approaches to explaining Zipf’s law is to posit simple stochastic models of how words tend to be reused in text. The idea is that preferential reuse will lead to a very skewed frequency distribution, since frequent words will tend to get reused even more. Intuitively, if, say, you say “pineapple” once, you are more likely to repeat it later in the text, and such reuse can often be shown under certain assumptions to lead to Zipfian or near-Zipfian distributions. For instance, building on work of Yule (1944), Simon (1955) introduced a stochastic model that assumes (1) preferential reuse of previously frequent words and (2) a constant probability of introducing a new word. The stochastic model that Simon described can be imagined to sequentially generate a text according to these assumptions, giving rise to a particular word frequency distribution over word types. Extensive discussion of this type of model and related ones can be found in Mitzenmacher (2004), Baayen (2001), and Farmer and Geanakoplos (2006), and a sophisticated and recent variant can be found in Zanette and Montemurro (2005).
This general class of models occupies an interesting ground between the psychological implausibility of random-typing models and psychologically plausible models that capture, for instance, subjects’ knowledge of whole words. However, like random-typing models, they do not plausibly connect real causal stories of language generation. As D. Manin (2008) write, “Simon’s model seems to imply that the very fact of some words being frequent and others infrequent is a pure game of chance.” Such models show only that if language generation behaved like a certain stochastic model, then it would give rise to Zipf’s law. It fails to establish what exactly it would mean for real human speakers to behave like the model, especially concerning the intentional production of meaningful language.
In this vein, Herdan (1961) wrote of Simon’s (1955) model: “For mathematical models to be of real value it is necessary that (1) the relationship between events of which the mathematical structure is to be a model should be what the mathematician believes it to be; (2) that the assumptions needed for constructing the model should be sensible, i.e. in accordance with how the operations in question take place; and (3) that the formulae derived in this way should fit the observed facts. None of these requirements must be neglected if the model is to fulfill its purpose. It is now a sad fact that model construction in mathematical linguistics seems dogged by the neglect of one or other of these requirements, especially the first, which cannot but have in its wake the neglect of the other two.” Human speech is created with a purpose, and the explanation for the frequency distribution must take into account this intentionality: Why does an intentional process result in the Zipfian distribution? That is the fact that theories should seek to explain.
Furthermore, it is not clear that the randomness of this kind of model can easily be connected to systematic relationships between meaning and frequency (see Semantics strongly influences word frequency). However, in some situations, the simple stochastic model may actually be correct. The near-Zipfian use of novel words (see Power laws arise from [almost] nothing) may be explained by these kinds of processes; perhaps, in deciding how to continue their story, participants essentially sample from past referents with a probability that scales with recent use. It is useful to consider whether this idea might even generalize to all language production: Perhaps language is constrained by other factors like syntax but, on a large scale is characterized by stochastic reuse along the lines of Simon’s model. Indeed, it is likely that given the nonstationarity of word frequencies (see The distribution of word frequencies is not stationary), something like these models must be approximately true. Words really are more likely to be reused later in discourse. However, the underlying cause of this is much deeper than these models assume. Words are reused in language (probably) not because of an intrinsic preference for reuse itself, but instead because there is a latent hidden variable, a topic, that influences word frequencies.
Semantic accounts
If the meanings of words in part determine frequency, it is useful to consider whether semantic organization itself may give rise to the word frequency distribution. Guiraud (1968) argued that the law could result from basic ternary (true/false/undefined) elements of meaning called semes (e.g., animate/inanimate), with each word coding some number of semes. If semes must be communicated in speech, this setup can give rise to a Zipfian word frequency distribution. Another hypothesis along the lines of semantics was put forth by D. Manin (2008), who argued that the law could result from labeling of a semantic hierarchy (e.g., Collins & Quillian, 1969; Fellbaum, 1998), combined with a pressure to avoid synonymy. Intuitively, if words label different levels of semantic space and evolve to avoid too much overlap, the lexicon arrives at coverings of semantic space, which, he shows via simulation, will result in Zipf’s law.
This theory motivated the comparisons in the section near-Zipfian distributions occur for naturally constrained meanings, which examined words whose meanings are strongly constrained by the world. It is unlikely that language had much of a “choice”—or optimizing pressure—in choosing which of the possible ways of labeling months, planets, or elements, since these meanings are highly constrained by the natural world. Yet we see near-Zipfian distributions for even these words. We find similar results for words whose referential content is fixed, like taboo words (see Near-Zipfian distributions occur for fixed referential content). The results on number words (see Semantics strongly influences word frequency) provide another compelling case where choice of semantic referent by the lexicon is not likely to explain word frequencies that are, nonetheless, power laws. The behavioral experiment (see Power laws arise from [almost] nothing) additionally indicates that even for words that are initially, in some sense, on equal ground and whose specific semantics is not given, people still follow a near-Zipfian distribution. All of these results do not indicate that semantic explanations play no role in determining word frequencies, but only that they are likely not the entire story.15
Communicative accounts
Various authors have also explained the Zipfian distribution according to communicative optimization principles. Zipf (1949) himself derived the law by considering a trade-off between speakers’ and listeners’ efforts. Mandelbrot (1953) shows how the Zipfian distribution could arise from minimizing information-theoretic notions of cost (Mandelbrot (1962, 1966), ideas further developed by D. Manin (2009), Ferrer i Cancho and colleagues (Ferrer i Cancho, 2005a, 2005b; Ferrer i Cancho & Solé, 2003) and, more recently, Salge et al. (2013).
In Ferrer i Cancho and Solé (2003), the authors imagine optimizing a matrix A = {Aij}, where Aij is 1 if the ith word can refer to the jth meaning. In their framework, speakers pay a cost proportional to the diversity of signals they must convey, and listeners pay a cost proportional to the (expected) entropy over referents given a word (for variants and elaborations, see Ferrer i Cancho & Díaz-Guilera, 2007). There is a single parameter which trades off the cost between speakers and listeners, and the authors show that for a very particular setting of this parameter, λ = 0.41 they recover a Zipfian distribution.
While mathematically sophisticated, their approach makes several undesirable choices. In the implementation, it assumes that meanings are all equally likely to be conveyed, an assumption that is likely far from true even in constrained semantic domains (Fig. 5). Later versions of this model (Ferrer i Cancho, 2005c) study variants without this assumption, but it is not clear—for any model—what the psychologically relevant distribution should be for how often each meaning is needed and how robust this class of models is to that distribution or how such accounts might incorporate other effects like memory latency, frequency effects, or context-based expectations.16
Second, the assumption that speakers’ difficulty is proportional to the entropy over signals is not justified by data and is not predicted from a priori means; a better a priori choice might have been the entropy over signals conditioned on a meaning, since this captures the uncertainty for the psychological system. In this vein, none of the assumptions of the model are tested or justified on independent psychological grounds.
Third, this work requires a very specific parameter, λ≈0.4, to recover Zipf’s law, and the authors show that it no longer does for λ = 0.5 or λ = 0.3. The required specificity of this parameter is undesirable from the perspective of statistical modeling, the so-called “Spearman’s principle” (Glymour, Scheines, Spirtes, and Kelly 1987), as it suggests non-robustness.
In the context of the corpus analyses provided above, communicative accounts would likely have difficulty explaining near-Zipfian distribution for fixed referential content (see Near-Zipfian distributions occur for fixed referential content) and variability of fits across syntactic categories (see The fit of Zipfian distributions vary by category). Theories based on communicative optimization, like that in Ferrer i Cancho and Solé (2003), are based on choosing which meanings go with which words; when optimized for communication, this process is supposed to give rise to the law. But we still see it in domains where this mapping is highly constrained (see Near-Zipfian distributions occur for naturally constrained meanings) and for number words (see Semantics strongly influences word frequency), where it is hard to imagine what such optimization might mean. Therefore, it is unclear on a conceptual level how these accounts might handle such data. It is also not straightforward to see how communicative accounts could accommodate the behavioral results (see Power law occurs in other human systems), since it is hard to imagine in what sense communication of names might be actively optimized by speakers simply telling a story. The intentionality of storytelling—wanting to convey a sequence of events you have just thought of—seems very different than the language-wide optimization of information-theoretic quantities required by communicative accounts.
This is certainly not to say that there is no way a communicative theory could account for the facts or that communicative influences play no role. An adequate theory has just not been formalized or empirically evaluated yet.17
Explanations based on universality
The models described so far explain Zipf’s law from psychological or statistical processes. But it is also possible that Zipf’s law in language arises from a universal pressure that more generally explains its prevalence throughout the sciences. An analogy is that of the central limit theorem (CLT) and the normal distribution. When a normal distribution is observed in the world (in, e.g., human heights), commonly the CLT is taken to explain why that distribution is found, since the theorem shows that normal distributions should be expected in many places—in particular, where many independent additive processes are at play.18,19 It is reasonable to ask whether there is a such a theorem for power laws: Do they simply arise “naturally” in many domains according to some universal law? Perhaps even the multitude of derivations of Zipf’s law indicate that the presence of the law in language is not so surprising or noteworthy.
There are, in fact, derivations of Zipf’s law from very fundamental principles that, in principle, span fields. Corominas-Murtra and Solé (2010) showed that Zipfian distributions of symbol sequences can be derived in the (maximally general) framework of algorithmic information theory (Li & Vitányi, 2008), considering symbols to be observations of a system growing in size, but which is constrained to have bounded algorithmic complexity. Their account even explains the exponent α≈1 observed in language, providing a compelling explanation of Zipf’s law in general complex systems. Y. I. Manin (2013) provides a related account deriving Zipf’s law from basic facts about Kolmogorov complexity and Levin’s probability distribution (see also Veldhuizen, 2005). S. A. Frank (2009) studied entropy maximizing processes, relating power laws to normal distributions and other common laws in the sciences. In general, these accounts say that we should have expected Zipf’s law to appear in many systems simply due to the intrinsic properties of information, complexity, and computation.
Similarly, there have also been somewhat more deflationary universal explanations. Remarkably, Belevitch (1959), showed how a Zipfian distribution could arise from a first-order approximation to most common distributions; he then showed how the Zipf–Mandelbrot law arose from a second-order approximation. In this kind of account, Zipf’s law could essentially be a kind of statistical artifact of using a frequency/frequency-rank plot, when the real underlying distribution of frequencies is any of a large class of distributions.
All of these accounts based on universal a priori notions are interesting because they would explain the surprising scope of Zipf’s law across the sciences without requiring many domain-specific assumptions. However, one troubling shortcoming of these theories as explanations is that they have not been used to generate novel predictions; it is hard to know what type of data could falsify them or how we would know whether they are really the “right” explanation, as opposed to any of the more psychologically motivated theories. Do the assumptions they require really hold in human psychology, and how would we know? One interesting test might be for these kinds of explanations to derive predictions for the variance beyond Zipf’s law that should be expected in any finite sample and perhaps, in some situations, even predict correlated errors like those seen in Fig. 1b. If Zipf’s law is universal, we would require additional mechanisms to explain domains where Zipf’s law holds less well or for different parameters (see The fit of Zipfian distributions vary by category) or how it could also hold given systematic 1relationships with meaning (see Semantics strongly influences word frequency). It is unclear whether the behavioral experiment (see Power law arises from [almost] nothing) is compatible with these accounts. What might people be doing psychologically in this experiment, and how does it translate into universal derivations of Zipf’s law?
Other models
We note that there are many other accounts of Zipf’s law in language and elsewhere, actually giving rise to a fat tail of theories of the law. For instance, Baek et al. (2011) showed how Zipf’s law can be derived from processes that randomly divide elements into groups. Arapov and Shrejder (1978) argued that Zipf’s law can be derived by simultaneously maximizing two entropies: the number of different texts creatable by a lexicon and the number of different ways the same text can be created by a lexicon. As was argued by D. Manin (2008), this approach compellingly lacks a priori justification and a possible optimizing mechanism. Other optimizations of, for example, Fisher information (Hernando et al., 2009) can also give rise to Zipfian distributions. Popescu (2009, Chap. 9) sketched a simple vocabulary growth model. Parker-Rhodes and Joyce (1956) argued that the distribution arises by a linear search through words in long-term memory ordered by frequency during normal language processing, where the time required to scan a word is proportional to the number of words scanned. To date, there is no evidence for this kind of process in normal language use. In general, it is not clear that any of these kinds of accounts could handle the gamut of empirical phenomena reviewed above, and to our knowledge, none have proposed and evaluated independent tests of their assumptions.
Conclusion and forward directions
Word frequencies are extremely interesting. They are one of the most basic properties of humans’ communicative system and play a critical role in language processing and acquisition.20 It is, in short, remarkable that they can be well-characterized by a simple mathematical law. With good cause, many have attempted to derive this law from more basic principles. Notably, theories of language production or discourse do not explain the law.
This review has highlighted several limitations in this vast literature. First, the method of plotting word frequency distributions has obscured an important fact: Word frequencies are not actually so simple. They show a statistically reliable structure beyond Zipf’s law that likely will not be captured with any simple model. At the same time, the large-scale structure is robustly Zipfian.
Second, essentially all of the prior literature has focused very narrowly on deriving the frequency/frequency-rank power law, while ignoring these types of broader features of word frequencies. This in some sense represents a misapplication of effort toward explaining an effect—the Zipfian distribution—instead of uncovering the causal forces driving word frequencies in the first place. This is what makes so many derivations of Zipf’s law unsatisfying: They do not account for any psychological processes of word production, especially the intentionality of choosing words in order to convey a desired meaning. A focus on explaining what words are needed at each point in a normal conversation would begin to explain why word frequencies look like they do. Until then, a deep mystery remains: Why should language generation mechanisms follow such a precise mathematical law, even in cases of constrained meanings and totally novel words, but apparently not identically for all syntactic categories?
It should be clear that this question will be addressable only by broadly studying properties of word frequencies beyond the frequency distribution itself. The empirical phenomena reviewed here (see Near-Zipfian distributions occur for naturally constrained meanings) have aimed to encourage more comprehensive evaluation of theories of the Zipfian distribution that is observed. This review has revealed that, likely, none of the previous accounts are sufficient alone and that the facts surrounding word frequencies are complex and subtle. A sticking point for many theories will be the behavioral results showing Zipf’s law for novel words. These results likely have to do with properties of human memory, since it is hard to think of other pressures in this experiment that would lead people into power law use of words. Indeed, human memory has independently been characterized as following powers laws (see Wickelgren, 1974, 1977; Wixted, 2004a, 2004b; Wixted & Ebbesen, 1991, 1997). Such scaling relationships are broadly observed elsewhere in cognition (Kello et al. 2010). If these properties of memory are the underlying cause of near-Zipfian laws in language, it could provide a parsimonious and general explanation, able to unify word frequencies with memory, while also explaining the occurrence of related laws in other systems humans use, such as computer software and music (Zipf’s law occurs in other human systems).
Interestingly, if human memory is the underlying cause of Zipf’s law in language, we are left to ask why memory has the form that it does. A plausible hypothesis advocated by Anderson and Schooler (1991) is that memory is well-adapted to environmental stimuli, meaning that Zipfian structures in the real world might ultimately create the observed form of word frequency distributions. Of course, any such theory of word frequencies would require substantial elaboration in order to address the complexities of how well Zipfian distributions fit different types of words, the residual deviations from the distribution observed in language (see Near-Zipfian distributions occur for fixed referential content), and interactions with semantics (see Semantics strongly influences word frequency).
In general, the absence of novel predictions from authors attempting to explain Zipf’s law has led to a very peculiar situation in the cognitive sciences, where we have a profusion of theories to explain an empirical phenomenon, yet very little attempt to distinguish those theories using scientific methods. This is problematic precisely because there are so many ways to derive Zipf’s law that the ability to do so is extremely weak evidence for any theory. An upside of this state of the field is that it is ripe for empirical research. The downside is that because proposals of theories have not been based on incremental empirical discoveries, many can be easily shown to be inadequate using only minimal new data. The key will be for explanations of Zipf’s law to generate novel predictions and to test their underlying assumptions with more data than the law itself. Until then, the prior literature on Zipf’s law has mainly demonstrated that there are many ways to derive Zipf’s law. It has not provided any means to determine which explanation, if any, is on the right track.
Acknowledgments
I’m very grateful to Leon Bergen, Ev Fedorenko, and Kyle Mahowald for providing detailed comments on this paper. Andreea Simona Calude James generously shared the data visualized in Figure 2. I am highly appreciative of Dmitrii Manin, Bob McMurray and an anonymous reviewer for providing extremely helpful comments on this work. Research reported in this publication was supported by the Eunice Kennedy Shriver National Institute Of Child Health & Human Development of the National Institutes of Health under Award Number F32HD070544.
Footnotes
Note that this distribution is phrased over frequency ranks because the support of the distribution is an unordered, discrete set (i.e., words). This contrasts with, for instance, a Gaussian that is defined over a complete, totally ordered field (
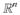 ) and, so, has a more naturally visualized probability mass function.
) and, so, has a more naturally visualized probability mass function.
As they write, “Finally, and perhaps most importantly, even if the statistics of a purported power law have been done correctly, there is a theory that underlies its generative process, and there is ample and uncontroversial empirical support for it, a critical question remains: What genuinely new insights have been gained by having found a robust, mechanistically supported, and in-all-other-ways superb power law? We believe that such insights are very rare.”
Importantly, however, other statistical properties are also likely informative, since a “full” theory of word frequencies would be able to explain a wide range of empirical phenomena.
See Ferrer i Cancho and Servedio (2005) for related arguments based on the range of Zipfian exponents.
Since linearity on a log-log plot means that log f = a log r + b, so f = ebra∝ra.
Such estimation also violates the assumptions of typical algorithms used to fit Zipfian exponents, since most fitting algorithms assume that x is known perfectly and only y is measured with error. This concern applies in principle to maximum-likelihood estimation, least squares (on log-log values), and any other technique that places all of measurement error on frequencies, rather than both frequencies and frequency ranks.
In these plots, tied ranks are not allowed, so words of the same frequency are arbitrarily ordered.
We are extremely grateful to the authors for providing these data.
More common taboo words meaning “penis” and “vagina” were not used, since many of their euphemisms have salient alternative meanings (e.g., “cock” and “box”).
Although there are compelling regularities in at least some semantic domains (see, e.g., Kemp & Regier, 2012; Kay and Regier 2003).
In the elements, “lead” and “iron” were excluded due to their ambiguity and, thus, frequent use as nonelements. In the months, “May” and “March” were removed for their alternative meanings.
It is apparently unclear whether N-grams in text follow Zipf’s law (see Egghe, 1999, 2000; cf. Ha, Hanna, Ming, & Smith, 2009; Ha et al. 2002).
However, because we use separate subsets of the sample to estimate r and f(r), this method does not introduce any spurious effects or nonindependence errors.
Such that the string “I ate a enchilada for easter” would be segmented into “words” I-at, -an-, nchilada-for-, ast, r.
In evaluating theories, one might wonder whether these semantic comparisons are essentially just random subsets of words and whether a random subset of a Zipfian distribution may tend to look Zipfian. Therefore, it may not be very strong evidence against theories based on meaning that we still see Zipfian distributions when we control or constrain meaning. However, note that theories based on meaning explain the distribution starting from semantics. They explain patterns across the entire lexicon by appealing to semantic properties of single words and, so, cannot explain the subsets of words that look Zipfian but do not have the required semantic properties.
A result on a large class of meaning distributions might help that issue.
Moving forward, however, it will be important for communicative accounts to explicitly address the predictability of words. As Shannon (1948) demonstrated, the predictability (negative log probability) of a word is the measure of the information it conveys. This means that a theory based on communication should be intrinsically linked to theories of what human language comprehenders find predictable (e.g. Demberg & Keller, 2008; A. Frank & Jaeger, 2008; Jaeger, 2010; Levy, 2008; Levy & Jaeger, 2007; Piantadosi, Tily, & Gibson, 2011; N. J. Smith & Levy, in press) and how much information is effectively conveyed for such mechanisms.
For generalizations of the CLT that are connected to power laws and similar distributions, see Gnedenko and Kolmogorov (1968) and Roehner and Winiwarter (1985).
In actuality, it may not even be clear for most common situations how the assumptions of the CLT or its generalizations hold (Lyon, in press). The true reason for the ubiquity of normal distribution may be related to its other properties, such as entropy maximization (Lyon, in press), suggesting that maximum-entropy derivations may be most fruitful for explaining Zipf’s law broadly (see, e.g., S. A. Frank, 2009).
While it rarely enters into discussions of the origins of Zipf’s law, it is important to point out that people really do appear to know word frequencies. Evidence for this is apparent in both detailed, controlled (e.g., Dahan, Magnuson, & Tanenhaus, 2001) and broad-coverage (e.g., Demberg & Keller, 2008) analyses of language processing (for a review, see Ellis, 2002). Similarly, frequency effects are observed in language production (Jescheniak & Levelt, 1994; Levelt, 1999; Oldfield & Wingfield, 1965). These effects show that speakers know something about the frequencies with which words occur in their input and that this type of knowledge is used in online processing.
The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
References
- Adamic LA, Huberman BA. Zipf’s law and the Internet. Glottometrics. 2002;3(1):143–150. [Google Scholar]
- Altmann EG, Pierrehumbert JB, Motter AE. Beyond word frequency: Bursts, lulls, and scaling in the temporal distributions of words. PLoS One. 2009;4(11):e7678. doi: 10.1371/journal.pone.0007678. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Altmann EG, Pierrehumbert JB, Motter AE. Niche as a determinant of word fate in online groups. PloS ONE. 2011;6(5):e19009. doi: 10.1371/journal.pone.0019009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson J, Schooler L. Reflections of the environment in memory. Psychological Science. 1991;2(6):396. [Google Scholar]
- Arapov M, Shrejder Y. Zakon cipfa i princip dissimmetrii sistem [Zipf’s law and system dissymmetry principle] Semiotics and Informatics. 1978;10:74–95. [Google Scholar]
- Baayen R. Word frequency distributions. Vol. 1. Kluwer Academic Publishers; 2001. [Google Scholar]
- Baek SK, Bernhardsson S, Minnhagen P. Zipf’s law unzipped. New Journal of Physics. 2011;13(4):043004. [Google Scholar]
- Belevitch V. On the statistical laws of linguistic distributions. Annales de la Societe Scientifique de Bruxelles. 1959;73(3):301–326. [Google Scholar]
- Blei DM, Lafferty JD. A correlated topic model of science. The Annals of Applied Statistics. 2007:17–35. [Google Scholar]
- Blei DM, Lafferty JD. Topic models. Text mining: classification, clustering, and applications. 2009;10:71. [Google Scholar]
- Blei DM, Ng AY, Jordan MI. Latent dirichlet allocation. Journal of Machine Learning Research. 2003;3:993–1022. [Google Scholar]
- Buhrmester M, Kwang T, Gosling SD. Amazon’s mechanical turk a new source of inexpensive, yet high-quality, data? Perspectives on Psychological Science. 2011;6(1):3–5. doi: 10.1177/1745691610393980. [DOI] [PubMed] [Google Scholar]
- Calude AS, Pagel M. How do we use language? shared patterns in the frequency of word use across 17 world languages. Philosophical Transactions of the Royal Society B: Biological Sciences. 2011;366(1567):1101–1107. doi: 10.1098/rstb.2010.0315. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carroll JB. On sampling from a lognormal model of word frequency distribution. Computational analysis of present-day American English. 1967:406–424. [Google Scholar]
- Carroll JB. A rationale for an asymptotic lognormal form of word-frequency distributions. 1969. [Google Scholar]
- Chater N, Brown GD. Scale-invariance as a unifying psychological principle. Cognition. 1999;69(3):B17–B24. doi: 10.1016/s0010-0277(98)00066-3. [DOI] [PubMed] [Google Scholar]
- Chen YS. Zipf’s law in natural languages, programming languages, and command languages: the Simon-Yule approach. International journal of systems science. 1991;22(11):2299–2312. [Google Scholar]
- Clark EV. The principle of contrast: A constraint on language acquisition. Mechanisms of language acquisition. Hillsdale: Erlbaum; 1987. [Google Scholar]
- Cleveland WS, Grosse E, Shyu WM. Local regression models. Statistical models in S. 1992:309–376. [Google Scholar]
- Collins AM, Quillian MR. Retrieval time from semantic memory. Journal of verbal learning and verbal behavior. 1969;8(2):240–247. [Google Scholar]
- Concas G, Marchesi M, Pinna S, Serra N. Power-laws in a large object-oriented software system. Software Engineering, IEEE Transactions on. 2007;33(10):687–708. [Google Scholar]
- Conrad B, Mitzenmacher M. Power laws for monkeys typing randomly: the case of unequal probabilities. Information Theory, IEEE Transactions on. 2004;50(7):1403–1414. [Google Scholar]
- Corominas-Murtra B, Solé RV. Universality of zipf’s law. Physical Review E. 2010;82(1):011102. doi: 10.1103/PhysRevE.82.011102. [DOI] [PubMed] [Google Scholar]
- Dahan D, Magnuson JS, Tanenhaus MK. Time course of frequency effects in spoken-word recognition: Evidence from eye movements. Cognitive psychology. 2001;42(4):317–367. doi: 10.1006/cogp.2001.0750. [DOI] [PubMed] [Google Scholar]
- Dehaene S, Mehler J. Cross-linguistic regularities in the frequency of number words. Cognition. 1992;43(1):1–29. doi: 10.1016/0010-0277(92)90030-l. [DOI] [PubMed] [Google Scholar]
- Demberg V, Keller F. Data from eye-tracking corpora as evidence for theories of syntactic processing complexity. Cognition. 2008;109(2):193–210. doi: 10.1016/j.cognition.2008.07.008. [DOI] [PubMed] [Google Scholar]
- Dumais ST. Latent semantic analysis. Annual Review of Information Science and Technology. 2005;38(1):188–230. [Google Scholar]
- Egghe L. On the law of Zipf-Mandelbrot for multi-world phrases. 1999. [Google Scholar]
- Egghe L. The distribution of N-grams. Scientometrics. 2000;47(2):237–252. [Google Scholar]
- Ellis N. Frequency effects in language processing. Studies in second language acquisition. 2002;24(2):143–188. [Google Scholar]
- Farmer JD, Geanakoplos J. Santa Fe Institute Tech Report. 2006. Power laws in economics and elsewhere (Tech. Rep.) [Google Scholar]
- Fellbaum C. WordNet: An electronic lexical database. Cambridge: MIT Press; 1998. [Google Scholar]
- Ferrer i Cancho R. Decoding least effort and scaling in signal frequency distributions. Physica A: Statistical Mechanics and its Applications. 2005a;345(1):275–284. [Google Scholar]
- Ferrer i Cancho RF. Hidden communication aspects inside the exponent of zipf’s law. 2005b;11:98–119. [Google Scholar]
- Ferrer i Cancho R. Zipf’s law from a communicative phase transition. The European Physical Journal B-Condensed Matter and Complex Systems. 2005c;47(3):449–457. [Google Scholar]
- Ferrer i Cancho R, Díaz-Guilera A. The global minima of the communicative energy of natural communication systems. Journal of Statistical Mechanics: Theory and Experiment. 2007;(06):P06009. [Google Scholar]
- Ferrer i Cancho R, Elvevåg B. Random Texts Do Not Exhibit the Real Zipf’s Law-Like Rank Distribution. PLoS ONE. 2010;5(3) doi: 10.1371/journal.pone.0009411. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferrer i Cancho R, Moscoso del Prado Martín F. Information content versus word length in random typing. Journal of Statistical Mechanics: Theory and Experiment. 2011;2011:L12002. [Google Scholar]
- Ferrer i Cancho R, Servedio VD. Can simple models explain zipf’s law in all cases? Glottometrics. 2005;11:1–8. [Google Scholar]
- Ferrer i Cancho R, Solé R. Zipf’s law and random texts. Advances in Complex Systems. 2002;5(1):1–6. [Google Scholar]
- Ferrer i Cancho R, Solé R. Least effort and the origins of scaling in human language. Proceedings of the National Academy of Sciences of the United States of America. 2003;100(3):788. doi: 10.1073/pnas.0335980100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferrer i Cancho R, Solé RV. Two regimes in the frequency of words and the origins of complex lexicons: Zipf’s law revisited. Journal of Quantitative Linguistics. 2001;8(3):165–173. [Google Scholar]
- Frank A, Jaeger T. Speaking rationally: Uniform information density as an optimal strategy for language production. Proceedings of the Cognitive Science Society.2008. [Google Scholar]
- Frank SA. The common patterns of nature. Journal of evolutionary biology. 2009;22(8):1563–1585. doi: 10.1111/j.1420-9101.2009.01775.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gan X, Wang D, Han Z. N-tuple Zipf Analysis and Modeling for Language, Computer Program and DNA. 2009. arXiv, pre-print arXiv:0908.0500. [Google Scholar]
- Gibson E, Piantadosi S, Fedorenko K. Using Mechanical Turk to Obtain and Analyze English Acceptability Judgments. Language and Linguistics Compass. 2011;5(8):509–524. [Google Scholar]
- Glymour C, Scheines R, Spirtes P, Kelly K. Discovering causal structure: Artificial intelligence, philosophy of science, and statistical modeling. Academic Press; 1987. [Google Scholar]
- Gnedenko BV, Kolmogorov A. Limit distributions for sums of independent random variables. Vol. 233. Addison-Wesley Reading; 1968. [Google Scholar]
- Guiraud P. The semic matrices of meaning. Social Science Information. 1968;7(2):131–139. [Google Scholar]
- Ha LQ, Hanna P, Ming J, Smith F. Extending Zipf’s law to n-grams for large corpora. Artificial Intelligence Review. 2009;32(1):101–113. [Google Scholar]
- Ha LQ, Sicilia-Garcia EI, Ming J, Smith FJ. Extension of Zipf’s law to words and phrases. Proceedings of the 19th international conference on computational linguistics; 2002. pp. 1–6. [Google Scholar]
- Herdan G. Type-token mathematics. Vol. 4. Mouton: 1960. [Google Scholar]
- Herdan G. A critical examination of simon’s model of certain distribution functions in linguistics. Applied Statistics. 1961:65–76. [Google Scholar]
- Herdan G. Quantitative linguistics. Butterworths; London: 1964. [Google Scholar]
- Hernando A, Puigdomènech D, Villuendas D, Vesperinas C, Plastino A. Zipf’s law from a fisher variational-principle. Physics Letters A. 2009;374(1):18–21. [Google Scholar]
- Howes D. Zipf’s law and miller’s random-monkey model. The American Journal of Psychology. 1968;81(2):269–272. [Google Scholar]
- Jaeger F. Redundancy and reduction: Speakers manage syntactic information density. Cognitive Psychology. 2010;61(1):23–62. doi: 10.1016/j.cogpsych.2010.02.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jescheniak JD, Levelt WJ. Word frequency effects in speech production: Retrieval of syntactic information and of phonological form. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1994;20(4):824. [Google Scholar]
- Kanter I, Kessler D. Markov processes: linguistics and zipf’s law. Physical review letters. 1995;74(22):4559–4562. doi: 10.1103/PhysRevLett.74.4559. [DOI] [PubMed] [Google Scholar]
- Kawamura K, Hatano N. Universality of zipf’s law. 2002. arXiv, preprint cond-mat/0203455. [Google Scholar]
- Kay P, Regier T. Resolving the question of color naming universals. Proceedings of the National Academy of Sciences. 2003;100(15):9085–9089. doi: 10.1073/pnas.1532837100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kello CT, Brown GD, Ferrer i Cancho R, Holden JG, Linkenkaer-Hansen K, Rhodes T, Van Orden GC. Scaling laws in cognitive sciences. Trends in cognitive sciences. 2010;14(5):223–232. doi: 10.1016/j.tics.2010.02.005. [DOI] [PubMed] [Google Scholar]
- Kemp C, Regier T. Kinship categories across languages reflect general communicative principles. Science. 2012;336(6084):1049–1054. doi: 10.1126/science.1218811. [DOI] [PubMed] [Google Scholar]
- Landauer TK, Foltz PW, Laham D. An introduction to latent semantic analysis. Discourse processes. 1998;25(2–3):259–284. [Google Scholar]
- Levelt WJ. Models of word production. Trends in cognitive sciences. 1999;3(6):223–232. doi: 10.1016/s1364-6613(99)01319-4. [DOI] [PubMed] [Google Scholar]
- Levy R. Expectation-based syntactic comprehension. Cognition. 2008;106(3):1126–1177. doi: 10.1016/j.cognition.2007.05.006. [DOI] [PubMed] [Google Scholar]
- Levy R, Jaeger T. Speakers optimize information density through syntactic reduction. Advances in neural information processing systems. 2007;19:849–856. [Google Scholar]
- Li M, Vitányi P. An introduction to Kolmogorov complexity and its applications. New York: Springer-Verlag; 2008. [Google Scholar]
- Li W. Random texts exhibit zipf’s-law-like word frequency distribution. Information Theory, IEEE Transactions on. 1992;38(6):1842–1845. [Google Scholar]
- Li W. Zipf’s law everywhere. Glottometrics. 2002;5:14–21. [Google Scholar]
- Lin Y, Michel J, Aiden E, Orwant J, Brockman W, Petrov S. Syntactic Annotations for the Google Books Ngram Corpus. 2012. [Google Scholar]
- Ljung GM, Box GE. On a measure of lack of fit in time series models. Biometrika. 1978;65(2):297–303. [Google Scholar]
- Louridas P, Spinellis D, Vlachos V. Power laws in software. ACM Transactions on Software Engineering and Methodology (TOSEM) 2008;18(1):2. [Google Scholar]
- Lyon A. Why are normal distributions normal? The British Journal for the Philosophy of Science 2014 [Google Scholar]
- Manaris B, Romero J, Machado P, Krehbiel D, Hirzel T, Pharr W, Davis RB. Zipf’s law, music classification, and aesthetics. Computer Music Journal. 2005;29(1):55–69. [Google Scholar]
- Mandelbrot B. An informational theory of the statistical structure of language. Communication theory. 1953:486–502. [Google Scholar]
- Mandelbrot B. On the theory of word frequencies and on related markovian models of discourse. Structure of language and its mathematical aspects. 1962:190–219. [Google Scholar]
- Mandelbrot B. Information theory and psycholinguistics: A theory of word frequencies. In: Lazarsfield P, Henry N, editors. Readings in mathematical social sciences. Cambridge: MIT Press; 1966. [Google Scholar]
- Manin D. Zipf’s law and avoidance of excessive synonymy. Cognitive Science. 2008;32(7):1075–1098. doi: 10.1080/03640210802020003. [DOI] [PubMed] [Google Scholar]
- Manin D. Mandelbrot’s Model for Zipf’s Law: Can Mandelbrot’s Model Explain Zipf’s Law for Language? Journal of Quantitative Linguistics. 2009;16(3):274–285. [Google Scholar]
- Manin YI. Zipf’s law and L. Levin’s probability distributions. 2013. arXiv, preprint arXiv:1301.0427. [Google Scholar]
- Manning C, Schütze H. Foundations of statistical natural language processing. Cambridge: MIT Press; 1999. [Google Scholar]
- Marcus MP, Marcinkiewicz MA, Santorini B. Building a large annotated corpus of english: The penn treebank. Computational linguistics. 1993;19(2):313–330. [Google Scholar]
- Mason W, Suri S. Conducting behavioral research on amazon’s mechanical turk. Behavior research methods. 2012;44(1):1–23. doi: 10.3758/s13428-011-0124-6. [DOI] [PubMed] [Google Scholar]
- Miller G. Some effects of intermittent silence. The American Journal of Psychology. 1957:311–314. [PubMed] [Google Scholar]
- Mitzenmacher M. A brief history of generative models for power law and lognormal distributions. Internet mathematics. 2004;1(2):226–251. [Google Scholar]
- Montemurro M. Beyond the Zipf–Mandelbrot law in quantitative linguistics. Physica A: Statistical Mechanics and its Applications. 2001;300(3):567–578. [Google Scholar]
- Newman M. Power laws, Pareto distributions and Zipf’s law. Contemporary physics. 2005;46(5):323–351. [Google Scholar]
- Oldfield RC, Wingfield A. Response latencies in naming objects. Quarterly Journal of Experimental Psychology. 1965;17(4):273–281. doi: 10.1080/17470216508416445. [DOI] [PubMed] [Google Scholar]
- Orlov J, Chitashvili R. Generalized Z-distribution generating the well-known rank-distributions. Bulletin of the Academy of Sciences, Georgia. 1983;110:269–272. [Google Scholar]
- Pagel M, Atkinson QD, Meade A. Frequency of word-use predicts rates of lexical evolution throughout indo-european history. Nature. 2007;449(7163):717–720. doi: 10.1038/nature06176. [DOI] [PubMed] [Google Scholar]
- Paolacci G, Chandler J, Ipeirotis P. Running experiments on Amazon Mechanical Turk. Judgment and Decision Making. 2010;5(5):411–419. [Google Scholar]
- Parker-Rhodes A, Joyce T. A theory of word-frequency distribution. Nature. 1956;178:1308. [Google Scholar]
- Petersen AM, Tenenbaum J, Havlin S, Stanley HE. Statistical laws governing fluctuations in word use from word birth to word death. Scientific reports. 2012:2. doi: 10.1038/srep00313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Piantadosi S. Approximate number from first principles. 2012. Manuscript under review. [Google Scholar]
- Piantadosi S, Tily H, Gibson E. Word lengths are optimized for efficient communication. Proceedings of the National Academy of Sciences. 2011;108(9):3526–3529. doi: 10.1073/pnas.1012551108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Piantadosi S, Tily H, Gibson E. Information content versus word length in natural language: A reply to Ferrer i Cancho and Moscoso del Prado Martin. 2013. Manuscript under review. [Google Scholar]
- Popescu II. Word frequency studies. Vol. 64. Walter de Gruyter; 2009. [Google Scholar]
- Reppen R, Ide N. The american national corpus overall goals and the first release. Journal of English Linguistics. 2004;32(2):105–113. [Google Scholar]
- Roehner B, Winiwarter P. Aggregation of independent paretian random variables. Advances in applied probability. 1985:465–469. [Google Scholar]
- Rouault A. Annales de l’institut h. poincare. 1978. Lois de Zipf et sources Markoviennes. [Google Scholar]
- Saichev A, Malevergne Y, Sornette D. Theory of Zipf’s law and beyond. Vol. 632. Springer; 2010. [Google Scholar]
- Salge C, Ay N, Polani D, Prokopenko M. Santa Fe Institute Working Paper #13–10–033. 2013. Zipf’s Law: Balancing Signal Usage Cost and Communication Efficiency (Tech. Rep.) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shannon C. The mathematical theory of communication. Urbana: University of Illinois Press; 1948. [Google Scholar]
- Shooman M, Laemmel A. In Compcon fall’77. 1977. Statistical theory of computer programs information content and complexity; pp. 341–347. [Google Scholar]
- Sichel HS. On a distribution law for word frequencies. Journal of the American Statistical Association. 1975;70(351a):542–547. [Google Scholar]
- Simon HA. On a class of skew distribution functions. Biometrika. 1955:425–440. [Google Scholar]
- Simon HA. Some further notes on a class of skew distribution functions. Information and Control. 1960;3(1):80–88. [Google Scholar]
- Smith NJ, Levy R. The effect of word predictability on reading time is logarithmic. Cognition. 2014 doi: 10.1016/j.cognition.2013.02.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith RD. Investigation of the zipf-plot of the extinct meroitic language. 2008. arXiv, preprint arXiv:0808.2904. [Google Scholar]
- Steyvers M, Griffiths T. Probabilistic topic models. Handbook of latent semantic analysis. 2007;427(7):424–440. [Google Scholar]
- Stumpf MP, Porter MA. Critical truths about power laws. Science. 2012;335(6069):665–666. doi: 10.1126/science.1216142. [DOI] [PubMed] [Google Scholar]
- Tripp O, Feitelson D. Studies on Zipf’s law. 1982. Zipf’s law re-visited; pp. 1–28. [Google Scholar]
- Veldhuizen TL. Software libraries and their reuse: Entropy, kolmogorov complexity, and zipf’s law. 2005. arXiv, preprint cs/0508023. [Google Scholar]
- Wickelgren WA. Single-trace fragility theory of memory dynamics. Memory & Cognition. 1974;2(4):775–780. doi: 10.3758/BF03198154. [DOI] [PubMed] [Google Scholar]
- Wickelgren WA. Learning and memory. NJ: Prentice-Hall Englewood Cliffs; 1977. [Google Scholar]
- Wigner EP. The unreasonable effectiveness of mathematics in the natural sciences. Communications on pure and applied mathematics. 1960;13(1):1–14. [Google Scholar]
- Wixted JT. On common ground: Jost’s (1897) law of forgetting and Ribot’s (1881) law of retrograde amnesia. Psychological review. 2004a;111(4):864–879. doi: 10.1037/0033-295X.111.4.864. [DOI] [PubMed] [Google Scholar]
- Wixted JT. The psychology and neuroscience of forgetting. Annu Rev Psychol. 2004b;55:235–269. doi: 10.1146/annurev.psych.55.090902.141555. [DOI] [PubMed] [Google Scholar]
- Wixted JT, Ebbesen EB. On the form of forgetting. Psychological science. 1991;2(6):409–415. [Google Scholar]
- Wixted JT, Ebbesen EB. Genuine power curves in forgetting: A quantitative analysis of individual subject forgetting functions. Memory & Cognition. 1997;25(5):731–739. doi: 10.3758/bf03211316. [DOI] [PubMed] [Google Scholar]
- Yule GU. A mathematical theory of evolution, based on the conclusions of Dr. JC Willis, FRS. Philosophical Transactions of the Royal Society of London Series B, Containing Papers of a Biological Character. 1924;213:21–87. [Google Scholar]
- Yule GU. CUP Archive. 1944. The statistical study of literary vocabulary. [Google Scholar]
- Zanette D, Montemurro M. Dynamics of text generation with realistic zipf’s distribution. Journal of quantitative Linguistics. 2005;12(1):29–40. [Google Scholar]
- Zanette DH. Zipf’s law and the creation of musical context. Musicae Scientiae. 2006;10(1):3–18. [Google Scholar]
- Zipf G. The Psychobiology of Language. London: Routledge; 1936. [Google Scholar]
- Zipf G. Human Behavior and the Principle of Least Effort. New York: Addison-Wesley; 1949. [Google Scholar]