

Abstract
Action selection, planning and execution are continuous processes that evolve over time, responding to perceptual feedback as well as evolving top-down constraints. Existing models of routine sequential action (e.g. coffee- or pancake-making) generally fall into one of two classes: hierarchical models that include hand-built task representations, or heterarchical models that must learn to represent hierarchy via temporal context, but thus far lack goal-orientedness. We present a biologically motivated model of the latter class that, because it is situated in the Leabra neural architecture, affords an opportunity to include both unsupervised and goal-directed learning mechanisms. Moreover, we embed this neurocomputational model in the theoretical framework of the theory of event coding (TEC), which posits that actions and perceptions share a common representation with bidirectional associations between the two. Thus, in this view, not only does perception select actions (along with task context), but actions are also used to generate perceptions (i.e. intended effects). We propose a neural model that implements TEC to carry out sequential action control in hierarchically structured tasks such as coffee-making. Unlike traditional feedforward discrete-time neural network models, which use static percepts to generate static outputs, our biological model accepts continuous-time inputs and likewise generates non-stationary outputs, making short-timescale dynamic predictions.
Keywords: sequential action control, neural model, everyday action
1. Introduction
Action control is essential to the daily routines of life, being an integral part of everyday activities from getting dressed to making pancakes. Yet, in our effort to distill cognitive processes in the laboratory, our controlled experiments often remove many of the interesting aspects of voluntary action. Although arbitrary stimulus–response experiments have in fact granted many insights into basic cognitive mechanisms of perception, learning and decision-making, as engineers endeavour to build humanoid robots to accomplish everyday cooking and cleaning tasks [1], the field of cognitive psychology seemingly has embarrassingly little advice to offer (for a review, see [2]). Despite early interest in how an action precipitates from thinking of its to-be-achieved effects, or goal [3], the more mainstream sensorimotor paradigm investigates the reverse: stimuli-driven perception resulting in action. From the sensorimotor perspective [4,5], the stimulus is seen as the driving force behind the subsequent selection, preparation, planning and execution of an action. However, the sensorimotor approach is difficult to extend to the broader arena of goal-directed action, where desired effects can lead executive function to initiate appropriate actions.
The theory of event coding (TEC; [6]) uses an ideomotor perspective and additional principles to explain a wide variety of action control phenomena [7]. TEC emphasizes that task context is important for selecting which features are emphasized, and which are ignored. Indeed, perceived features such as size and location can sometimes influence actions beyond cognitive control, as seen in stimulus–response compatibility phenomena such as the Simon effect [8]. This implies that a fairly direct route from perception to action is possible—one that may bypass many of the sensorimotor view's steps of planning, selection and preparation. TEC's premise that perception and action plans share a common representation allows percepts—along with task context—to generate and select actions. Because action effects also share this common coding, desired effects (i.e. goals) can activate relevant actions to achieve the effect [9]. It turns out that TEC is underspecified, however, for it was originally conceived as a meta-theoretical framework mainly concerned with simple one-step, ballistic actions. This lack of specificity becomes more obvious when considering the complexities of everyday action, which are thought to require sequential, hierarchically structured goals.
In this paper, we present a computational model of sequential action learning, stemming from the biologically motivated Leabra cognitive architecture [10,11]. We show how this model implements the central principles of TEC and situates it in a biological and ecological context. We address two key questions: (i) How might goals be represented? and (ii) Do multi-step, nested actions require hierarchical representations? Both questions are important because TEC assumes that goals have strong impact but it is not specific as to how the goal is represented. It also seems to suggest that goal representation is implicit (i.e. the goal is represented by the way it affects the system: e.g. weighting features according to their importance for achieving the goal [12]). Leabra fills out this missing information and gives a concrete explanation of how goals can be implicit and yet yield feedback for learning.
We begin by reviewing TEC and previous attempts at modelling everyday action, focusing on ways to integrate theoretical, empirical and biological constraints. We then propose how Leabra can resolve some of the remaining constraints by representing proximal goals as implicit task context in separate neural subpopulations. Because goals and actions share a common coding, error-driven learning can be used to learn associations between subsequent actions. We describe a proof-of-concept neural model that demonstrates how these mechanisms can account for everyday action in a coffee-making task.
2. Theory of event coding
TEC is a theoretical framework that describes how an agent's actions and perceptions are remembered, and how these memories are used to generate future actions (and thus perceptions). TEC assumes that perception and actions are represented using the same feature codes, which encode relevant aspects of the environment (e.g. colour, size, location, shape) and not merely proximal features. Thus, activation of feature codes that represent distal events is an integral part of both perception and action planning. The assumption that feature codes are used to represent both the properties of a response as well as those of a stimulus in the environment is derived from ideomotor theory, which states that actions are represented in terms of their perceivable effects [3,13]. When an action is executed, the motor pattern becomes associated with the perception of the action's effects. Elsner & Hommel [9] explored this in a series of experiments, finding that key presses (i.e. actions) producing particular auditory tones were later primed by hearing the corresponding tone, demonstrating that the learned action–effect association also works when temporally reversed.
The universal representation proposed by TEC, called an event code (or event file), represents features of the environment rather than proximal features of the sensation (e.g. auditory intensity). For example, consider a version of the 1967 Simon & Rudell task [8], in which subjects are asked to respond with a left or right keypress to target colour patches (e.g. green or red), which appear either on the left or right of the screen. Although the spatial location is irrelevant to the response, subjects respond faster and more accurately when the target requires a compatible response (left stimulus and left response, or right stimulus and response), in comparison to incompatible responses (left stimulus and right response or vice versa). TEC accounts for this effect because when a perception (green, left side) activates a feature (e.g. left) that is shared with an action, that action (e.g. left keypress) is primed. That is, the event code is the integrated assembly of distal sensorimotor features (e.g. spatial location, colour) that are relevant for perception and action, integrated with task context. The development of an event file enables low-level action planning, for once an action becomes associated with a distal effect, the desire to achieve an effect activates the action. Further evidence for shared representational resources comes from studies showing that verifying perceptual properties from the same modality (e.g. sight: colour and luminance) results in processing advantages, compared to properties from different modalities—if it is for the same object or different objects [14,15]. This supports the idea that sensorimotor simulations are involved in many, if not all cognitive representations. This is a central tenet of TEC and is consistent with the idea of embodied cognition in general [16].
The core principles of TEC have been instantiated in HiTEC [17], a connectionist model composed of sensory-motor, feature and task levels. While this initial model proved that the basic tenets of TEC are sufficient to account for a wide variety of experimental compatibility effects—as has been predicted by TEC—HiTEC does not provide a fully general account of how feature and task codes can be learned from experience. Moreover, although TEC explains simple goal-directed action in addition to the standard sensorimotor stimulus–response account, it has not yet been extended to sequences of actions, which are typical in everyday tasks, let alone hierarchies of tasks and goals.
3. Modelling everyday action
Learning everyday actions is generally agreed to be complex, for actions are experienced serially, and yet are typically thought of as hierarchical since some subactions (e.g. mixing in eggs) are part of multiple actions (e.g. making pancakes or cookies). Moreover, these shared subactions may precede or follow distinct actions. Lashley [18] pointed out that the bulk of human sequential actions cannot be explained by merely associating perceptual inputs and actions, as the prior action and the current percepts do not sufficiently constrain action selection (for a review, see [19]). Rather, a more elaborate representation of task context is needed that persists through multiple actions and helps select the appropriate next action. For example, when a baker sees a bowl of cake batter, he may need to know whether he is making cupcakes or a cake—the high-level goal—in order to perform the next action: pouring the batter into an appropriate receptacle. Task structure is typically defined by researchers as hierarchical, since everyday tasks such as tea- and coffee-making often contain subtasks such as adding cream or adding sugar that are discrete and interchangeable.
Thus, action selection for everyday tasks requires representing the task context in a way that preserves both the high-level task, as well as appropriate subtasks. In schema-based models, this multi-level task context is built-in via hand-coded hierarchical representation of the task structure [20,21]. The strength of schema-based models could be argued to be their explicit representation of goals and subgoals as nodes in a task hierarchy that is comprehensible to researchers, if perhaps not laymen. Many robotic systems use schema-based architectures: despite the need to hand-code much of the representation, roboticists may find it worth the certainty of knowing how exactly the system will react to any given set of conditions, rather than reacting stochastically and perhaps unpredictably. Given researchers' strong belief in the hierarchical structure of everyday tasks, and that the cognitive representation probably mirrors this compositional structure, we must ask how the structure of complex everyday actions can be learned by the human system: is it necessary to explicitly build hierarchy into the representation?
Ultimately, a realistic model needs to be able to learn the general task structure from a series of exemplars, much like the learning problem that humans face. A model that extracts the semi-hierarchy of a task should allow more natural generalization to new tasks, since subsequences at the appropriate level will be seen to be quite similar, and thus shared. How can a model represent task context during temporally extended task execution, in a way that also supports learning of these structures via experience? Botvinick & Plaut [22] introduced a connectionist model that encodes context at multiple timescales. Essentially, the model is a simple recurrent network (SRN; [23]) consisting of three groups of neurons arranged in a loop: perception, internal and action. The perception group receives input from the simulated environment (e.g. ‘sugar packet’), and the action group outputs simple actions (e.g. ‘pick-up cup’) that modify the environment (and thus, the next percept). The hidden internal neuron group is recurrent, allowing it to come to represent temporal context, possibly representing previous states of the environment. The SRN model performs well at an instant coffee-making task, which consists of four subtasks: adding coffee, adding cream, adding sugar (from a bowl or paper packet) and drinking. Each of these subtasks comprises several simple actions, such as picking up, putting down and pouring. This model was shown to be able to generalize to tea-making—which shares subactions such as adding sugar—without catastrophic forgetting. The SRN model is trained via backpropagation through time [24] and shows many of the same substitution and omission errors that humans commit.
Botvinick & Plaut [22] demonstrates that it is possible to learn hierarchically structured actions from training on sequential actions, and without hierarchy built into the model. Furthermore, Botvinick [25] argues that strictly hierarchical models cannot account for context-sensitivity. For example, you might add different types and amounts of sugar to different beverages (coffee or tea). Do you then need different schema nodes for every type of sugar-adding? If you have multiple nodes, then how do you also encode the similarities between sugar-adding for these different beverages? Recurrent connectionist models, with spreading activation over distributed representations, allow similar sequences to develop similar representations, producing generalization as a natural by-product. However, although the SRN model provides a first proof-of-concept for representing hierarchical everyday action without hierarchy, it lacks both biological foundations and any account of goal-directed behaviour.
TEC got away without a complex representational structure because in single-step actions, a goal is equivalent to the outcome of the action, which is often not the case when several steps are necessary to reach the goal. However, Leabra shows that it is fortunately unnecessary to give representations complex structure in TEC: hierarchically structured actions can be produced without hierarchy in the representations, much like the SRN.
4. Learning sequential actions with leabra
Leabra (Local, Error-driven and Associative, Biologically Realistic Algorithm) is a general model of the neocortex that incorporates many widely accepted biological principles of neural processing and has been used to successfully implement a growing number (50+) of models and tasks [10,26]. Leabra models the brain at scales ranging from individual neurons up to the structural organization of macroscopic areas and makes predictions regarding the neural mechanisms, time course and substrates of cognitive processing. Models consist of a homogeneous set of mechanisms including a biological integrate-and-fire neuron model [27], k-winners-take-all inhibitory competition, and deep architectures with bidirectional excitatory synapses. Most parameter settings are consistent across models and thus, the model described here can be viewed as a specific instantiation of a systematic modelling framework opposed to a model with completely new mechanisms.
Learning in Leabra models is traditionally accomplished by a biphasic algorithm that incorporates self-organizing Hebbian and error-driven components derived from synaptic long-term potentiation/long-term depression mechanisms. For the error-driven component, the network state is said to be in the minus phase when representing a prediction, and the plus phase when an actual outcome occurs. In learning to represent temporally ordered properties such as action sequences, a model must be able to generate the state at time t using the representation from time t − 1. Leabra's error-driven learning makes this difficult, since synaptic weights are updated to minimize the difference in neural activations across the minus and plus phases, which are assumed to occur in sequence. To address this difficulty, we have extended the Leabra learning algorithm to make predictions about time t by explicitly representing information from time t − 1 and integrating errors over these two periods.
We refer to this extension as LeabraTI (Temporal Integration). A full description of the algorithm is presented in O'Reilly et al. [11], although we briefly summarize the computation and biological motivation here (see the electronic supplementary material for implementation details). LeabraTI is closely related to the traditional SRN architecture, which explicitly represents the previous time step's information in a population of ‘context’ neurons. Accomplishing this property in biological neural circuits that are continuously updated requires a mechanism to gate information into a relatively isolated subpopulation of neurons. In LeabraTI, a microcircuit extending vertically through the cortex to the thalamus accomplishes this operation (figure 1a). Specifically, sensory input enters cortex through the thalamus in Layer 4 and is transmitted to superficial layers (Layers 2 and 3). From there, information is both propagated downstream to Layer 4 of the secondary cortical area, as well as to deep layers of the primary area (Layers 5 and 6), which we believe serve as a temporal context representation as they are relatively isolated from interareal inputs.
Figure 1.

Neocortical anatomy supporting LeabraTI. (a) Cortical areas are composed of columns of neurons with canonical circuitry within and between areas. Within a column, information follows the path Layer 4 → Layer 2/3 → Layer 5 → Layer 6. Layer 2/3 sends feedforward projections to the next area and is the primary site of feedback, and thus can be seen as doing bidirectional information processing. (b) Layer 5 neurons integrate contextual information from Layer 2/3 → Layer 5 synapses, and gate this context signal into Layer 6 neurons. These Layer 6 neurons sustain the context via recurrent projections through the thalamus, which also recirculate the context through the local column to support generation of the next prediction during the minus phase. Veridical information from the sensory periphery drives the column in the plus phase. Layer 6 context is not used during the plus phase but is updated through the Layer 2/3 → Layer 5 → Layer 6 intra-columnar circuit at the end of processing (every 100 ms). thal, thalamus. (Online version in colour.)
In LeabraTI, predictions in the minus phase, driven by temporal context from Layer 6 to Layer 4 transthalamic synapses, are interleaved across time with actual information from the sensory periphery transmitted through the thalamus to Layer 4 during the plus phase. Temporal context in deep layers is updated at the end of the plus phase with the current sensory information. The total time across the minus and plus phases in the model is 100 ms, which is sufficient for generation of a reasonable prediction and processing peripheral sensory inputs. The difference between the minus and plus phases is used to update both the interareal synaptic weights as well as the intracolumnar Layer 5 to Layer 6 synaptic weights, allowing the network to jointly learn the current input as well as the mapping between subsequent inputs. The overall LeabraTI computation is depicted in figure 1b. For computational efficiency, we do not explicitly model Layer 4 → Layer 2/3 or Layer 2/3 → Layer 5 intracolumnar synapses and instead assume that they are perfect one-to-one relays. This reduces the complexity of the model to bidirectionally connected superficial (Layer 2/3) layers with corresponding deep (Layer 6) layers that sustain the previous moment's context.
5. Model of coffee-making task
We built a model incorporating the general LeabraTI architecture to perform a coffee-making task that has been targeted by other recent models of sequential action [20,22]. Making instant coffee or tea is a suitable everyday task to study sequential action, for it is composed of a number of subtasks (e.g. adding sugar) that may be performed in varying order and number of repetitions. For training, we used a formalization similar to that used by Botvinick & Plaut [22], using features to describe the currently fixated object, held object and performed actions (e.g. a single step: fixate 1-handled cup with clear liquid, holding nothing, and now fixate the coffee packet). However, instead of using a few fixed training orders like Botvinick & Plaut [22], we wrote a finite state grammar to generate reasonable sequences of actions (see below).
The model architecture is depicted in figure 2. The model contains three sensorimotor layers (visual, manual, action; 25 neurons each) bidirectionally connected to a hidden layer, which is in turn connected bidirectionally to a second hidden layer (24 neurons each). A model with a single 48-unit hidden layer was also investigated. Context layers are composed of the same number of neurons as their superficial counterparts, effectively doubling the number of units in the network. All connections in the model, including those between superficial and deep layers, are all-to-all, connecting each unit in the receiving layer to every unit in the sending layer. Context is stored by filtering the state of superficial layers at the end of the plus phase through the superficial-to-deep weights and applying it as an additional graded input to the receiving area during the minus phase. The electronic supplementary material contains additional details of the LeabraTI algorithm.
Figure 2.
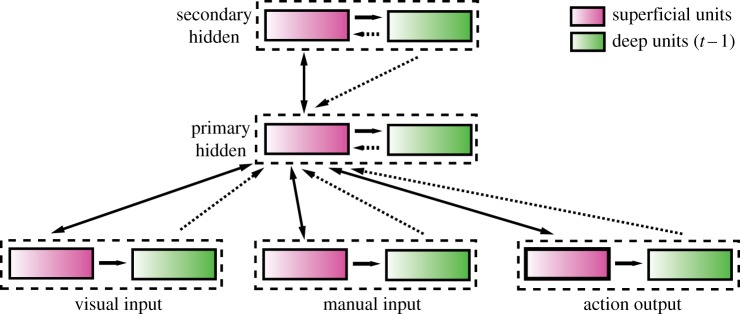
Network architecture for the coffee–tea simulation. Similar to Botvinick & Plaut's [22] SRN model of this task, the input is divided into visual and manual perceptual layers, feeding into a recurrent hidden layer, which in turn drives another hidden layer that is not connected to the sensorimotor layers. Note that each layer in a LeabraTI network has both a superficial layer (purple) and a corresponding deep layer (green). Superficial layers can only project to superficial layers (and their own deep layer), but deep layers can project to any superficial layer. Deep layers receive only projections from their own superficial layer. (Online version in colour.)
Our implementation of the task closely follows that of Botvinick & Plaut [22], using localist representations of the relevant features. The visual layer represents 19 features: the cup, 1-handle, 2-handle, lid, clear liquid, brown liquid, light, carton, open, closed, foil, paper, torn, untorn, spoon, teabag, sugar and empty. The manual layer represents all 19 of the features in the visual layer, with the addition of ‘nothing’ (i.e. an empty hand). The action layer represents 19 actions: pick up, put down, pour, peel open, tear open, pull open, pull off, scoop, sip, stir, dip, say ‘Done’, fixate cup, fixate coffee packet, fixate spoon, fixate carton, fixate sugar packet and fixate sugar bowl. Following Botvinick & Plaut [22], these basic sensorimotor features were used to compose the steps for four different coffee-making sequences and two tea-making sequences, which were randomly selected for training in each epoch. Details of the training are given in the electronic supplementary material. Broadly, coffee-making sequences consist of adding coffee grounds, and then adding cream and sugar in either order. Since sugar can come from either a packet or a bowl, there are thus four possible coffee-making sequences. Finally, the beverage is sipped. For the tea-making task—used to test generalization at test—the teabag is steeped, an amount of sugar may be added from a packet or bowl, and the tea is sipped.
The model was trained using the LeabraTI extension of the Leabra algorithm for 200 epochs of 50 training steps. These steps were generated from the finite state grammar of coffee- and tea-making subactions defined above, and the model iterated over these steps and adjusted connection weights according to LeabraTI. We trained 100 networks with randomly initialized weights for 200 epochs (i.e. 10 000 trials per network). The mean squared error and accuracy per epoch during training for 100 simulated networks is shown in figure 3, along with 100 networks trained with only a single 48-unit hidden layer for comparison. Although the single larger hidden layer improves faster in early training, by the final 50 epochs of training the model architectures perform very similarly (see the electronic supplementary material for details). It seems that the recurrence in the LeabraTI context projections is sufficient to support learning the task; additional recurrence in a deep hidden layer is not necessary. For test manipulations, we investigate the dual hidden layer model to maintain similarity to the SRN model.
Figure 3.

(a) Mean squared error (m.s.e.) and (b) proportion correct per 50-step epoch during training for 100 simulated networks of two hidden layer configurations. Networks with a single 48-unit hidden layer improve faster than two 24-unit layers, but by the end of 200 epochs performance is nearly indistinguishable. (Online version in colour.)
The 100 trained networks were subjected to several test manipulations in order to investigate the relative contributions of LeabraTI, its context projections and the second hidden layer on performance. For the test task, each network was used to generate 37 coffee- or tea-making steps 100 times, and the error in generating the appropriate action was measured. The manipulations were as follows: completely lesioning the second hidden layer (hid2 lesion), running the model without using LeabraTI (i.e. without the deep context projections; non-TI), or reducing the weight of the context projections by a factor of three (weak context). In table 1, the overall resulting error rates demonstrate that while lesioning the second hidden layer harms performance somewhat, weakening the LeabraTI context projections—or removing them entirely in the non-TI version—is much more detrimental. Detailed results concerning the relative error rates for different trials are in the electronic supplementary material.
Table 1.
Normalized error on test trials for various network manipulations.
| condition | normalized error | s.d. |
|---|---|---|
| normal | 0.035 | 0.003 |
| hid2 lesion | 0.087 | 0.028 |
| weak context | 0.413 | 0.042 |
| non-TI | 0.623 | 0.021 |
The model differs from previous SRN models in several ways. First, each layer input modality contains its own implicit context representation opposed to a single shared context representation attached to the hidden layer. This allows the model to learn more quickly and more robustly by learning visual- or manual-specific errors before integrating them into the hidden layer and its corresponding context. The model also has a second hidden layer (though see [25]), which provides minimal structural hierarchy, granting our model greater power in representing nuanced context differences by learning what information to preserve or update over time. The bidirectionality of projections between the hidden layer and the sensorimotor layers sets our model apart from the sensorimotor-loop style of the SRN, bringing it in accord with TEC's ideomotor principle.
The LeabraTI model also makes use of a biologically tractable learning rule compared to the SRN model of Botvinick & Plaut [22], which was trained using backpropagation through time (BPTT; [24]). BPTT requires the entire network to be unfolded through all of the steps in the action sequence before averaging the weights together which is computationally inefficient and relatively implausible as far as the brain is concerned. LeabraTI is capable of learning in a step-wise fashion in real time, synchronized with sensory inputs and action outputs. LeabraTI also appears to learn much faster. Whereas the SRN model required 20 000 epochs—each comprised more than 200 steps of the full task and background tasks (e.g. adding sugar)—to plateau1 the LeabraTI model asymptotes after less than 150 epochs of only 50 training steps: a more than 500-fold decrease in training steps.
Finally, we also performed some of the analyses from Botvinick & Plaut [22], including a PCA (principal component analysis) plot of the second hidden layer's activations across the tea and coffee versions of the task for the sugar packet sequence (when it was the second item in each task). As figure 4 shows, we see that the hidden layer activations traverse a similar trajectory through this sequence, for both the tea and coffee tasks, but a small additional difference reflects the overall task context. The cluster plot from figure 4 shows that the corresponding steps from the tea and coffee tasks are each most similar to each other, but there is also interesting semantic structure on top of that, reflecting both the actions and objects of those actions. Thus, although the second hidden layer is not necessary to learn the task, when a second hidden layer is present it comes to have similar representations for the shared subtasks from different hierarchies.
Figure 4.

(a) PCA projection of the second hidden layer's activation patterns for the sugar packet sequence of actions within the tea and coffee versions of the task (cf. fig. 4 in [22]). (b) The cluster plot of these same data points reveals further semantic structure on top of the basic similarity of each corresponding step across tasks. (Online version in colour.)
6. Discussion
This paper has argued that the TEC, an ideomotor approach to explaining voluntary goal-directed action, is a more useful construct for explaining action control than the sensorimotor approach, which does not account for internally motivated action. Feedforward discrete-time neural networks roughly implement a sensorimotor loop, moving from sensation to recognition, response selection and response execution. Recurrent networks such as the SRN [23] provide feedback from the previous internal state of the network to the hidden layer, allowing this representation to influence the next step's perceptual input, and subsequent action selection. Since actions influence the environment, their effects propagate to perception, and then to the internal state. Thus, the SRN does not directly learn bidirectional action–effect associations, nor the action-selected perception and action-context feedback that TEC states are required to account for compatibility effects and endogenously motivated action.
By contrast, the LeabraTI algorithm offers a biologically motivated biphasic learning model that alternately forms expectations and then uses prediction error as a feedback signal, meanwhile preserving task context. LeabraTI's interleaved prediction (minus) and sensation (plus) phases occur with an overall period of around 100 ms, corresponding to the 10 Hz alpha rhythm widely observed across the cortex [28,29]. Discretizing time at this rate gives the network enough time to compute reasonable expectations and matches the psychologically estimated rate for discretization of perception [30]. Furthermore, this chunking and error-driven learning also meets the requirements for event files [31], which must bidirectionally bind stimulus features, action features and their co-occurrence. LeabraTI is one of several recent models to implement predictive/generative deep learning to great benefit [32]. In LeabraTI, top-down and bottom-up signals mutually inform each other: both are excitatory and combine via mutual constraint satisfaction to reach an interpretation that integrates information from both signals. Thus, both task context—at multiple timescales—and perception inform the agent's next action. Other core principles of TEC are also implemented in the Leabra model. For example, TEC's assumption that action representation is goal-oriented maps to the prediction phase of LeabraTI. This explains the important theoretical issue of how to implicitly handle the intuitively goal-oriented nature of routine actions using biological mechanisms. As we demonstrated, explicit goal representations are not necessary to produce goal-directed behaviour, which is consistent with TECs assumption that action goals are represented implicitly. It is certainly true that people represent action goals explicitly as well, as they can report and reflect upon them. However, there are reasons to assume that it is exactly those post-actional purposes that such explicit representations serve, while their involvement in online action control is rather unlikely [33,34].
We demonstrated how the LeabraTI algorithm can be used for learning and performing routine sequential actions such as coffee-making, which are hierarchical and partially ordered, despite the model's relatively heterarchical structure. This model yields all of the advantages of Botvinick & Plaut's [22] SRN model, but with stronger biological foundations. By maintaining internal state in two (or only one) hidden layers, the model reflects the input and network history, while the predictions and actual output become more fine-tuned as further perceptual input is received and the internal context (i.e. the implicit representation of goals) evolves. Thus, this model can, in principle, show a variety of context effects for goal-directed sequential actions that humans also show. For timescales larger than those encountered in routine actions, Leabra's basal ganglia model could be used to selectively gate the activity of the frontal cortex ‘stripes’ where basic behaviours—similar to those in our model—are learned. In our continuing work, we plan to establish more connections between theory, modelling and empirical results to better explain everyday human action.
Supplementary Material
Endnote
Botvinick & Plaut [22] note that learning takes roughly half as many epochs for correct responses if a winner-take-all criterion is used.
Funding statement
The preparation of this work was supported in part by the European Commission (EU Cognitive Systems project ROBOHOW.COG; FP7-ICT-2011) and ONR grant no. N00014–13–1–0067.
References
- 1.Tenorth M, Beetz M. 2013. Knowrob: a knowledge processing infrastructure for cognition-enabled robots. The knowrob system. Int. J. Robot. Res. 32, 566–590. ( 10.1177/0278364913481635) [DOI] [Google Scholar]
- 2.de Kleijn R, Kachergis G, Hommel B. 2014. Everyday robotic action: lessons from human action control. Front. Neurorobot. 8, 13 ( 10.3389/fnbot.2014.00013) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.James W. 1890. The principles of psychology. New York, NY: Henry Holt. [Google Scholar]
- 4.Donders FC. [1868] 1969. On the speed of mental processes. In Attention and performance ii (ed. Koster WG.), pp. 412–431. Amsterdam: North Holland. [DOI] [PubMed] [Google Scholar]
- 5.Sternberg S. 1969. The discovery of processing stages: extensions of Donders’ method. Acta Psychol. 30, 276–315. ( 10.1016/0001-6918(69)90055-9) [DOI] [Google Scholar]
- 6.Hommel B, Müsseler J, Aschersleben G, Prinz W. 2001. The theory of event coding (TEC): a framework for perception and action planning. Behav. Brain Sci. 24, 849–937. ( 10.1017/S0140525X01000103) [DOI] [PubMed] [Google Scholar]
- 7.Hommel B. 2009. Action control according to TEC (theory of event coding). Psychol. Res. 73, 512–526. ( 10.1007/s00426-009-0234-2) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Simon JR, Rudell AP. 1967. Auditory S-R compatibility: the effect of an irrelevant cue on information processing. J. Appl. Psychol. 51, 300–304. ( 10.1037/h0020586) [DOI] [PubMed] [Google Scholar]
- 9.Elsner B, Hommel B. 2001. Effect anticipation and action control. J. Exp. Psychol. Hum. Percept. Perform. 27, 229–240. ( 10.1037/0096-1523.27.1.229) [DOI] [PubMed] [Google Scholar]
- 10.O'Reilly RC, Munakata Y. 2000. Computational explorations in cognitive neuroscience: understanding the mind by simulating the brain. Cambridge, MA: MIT Press. [Google Scholar]
- 11.O'Reilly RC, Wyatte D, Rohrlich J. Submitted. Learning through time in the thalamocortical loops. (http://arxiv.org/abs/1407.3432. )
- 12.Memelink J, Hommel B. 2013. Intentional weighting: a basic principle in cognitive control. Psychol. Res. 77, 249–259. ( 10.1007/s00426-012-0435-y) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Stock A, Stock C. 2004. A short history of ideo-motor action. Psychol. Res. 68, 176–188. ( 10.1007/s00426-003-0154-5) [DOI] [PubMed] [Google Scholar]
- 14.Pecher D, Zeelenberg R, Barsalou LW. 2003. Verifying properties from different modalities for concepts produces switching costs. Psychol. Sci. 14, 119–124. ( 10.1111/1467-9280.t01-1-01429) [DOI] [PubMed] [Google Scholar]
- 15.Pecher D, Zeelenberg R, Barsalou LW. 2004. Sensorimotor simulations underlie conceptual representations: modality-specific effects of prior activation. Psychon. Bull. Rev. 11, 164–167. ( 10.3758/BF03206477) [DOI] [PubMed] [Google Scholar]
- 16.Barsalou LW. 1999. Perceptual symbol systems. Behav. Brain Sci. 22, 577–660. [DOI] [PubMed] [Google Scholar]
- 17.Haazebroek P, van Dantzig S, Hommel B. 2011. A computational model of perception and action for cognitive robotics. Cogn. Process. 12, 355–365. ( 10.1007/s10339-011-0408-x) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Lashley KS. 1951. The problem of serial order in behavior. In Cerebral mechanisms in behavior (ed. Jeffress LA.), pp. 112–136. New York, NY: Wiley. [Google Scholar]
- 19.Rosenbaum DA, Cohen RG, Jax SA, Van Der Wel R, Weiss DJ. 2007. The problem of serial order in behavior: Lashley's legacy. Hum. Mov. Sci. 26, 525–554. ( 10.1016/j.humov.2007.04.001) [DOI] [PubMed] [Google Scholar]
- 20.Cooper RP, Shallice T. 2000. Contention scheduling and the control of routine activities. Cogn. Neuropsychol. 17, 297–338. [DOI] [PubMed] [Google Scholar]
- 21.Cooper RP, Shallice T. 2006. Hierarchical schemas and goals in the control of sequential behavior. Psychol. Rev. 113, 887–916. ( 10.1037/0033-295X.113.4.887) [DOI] [PubMed] [Google Scholar]
- 22.Botvinick M, Plaut DC. 2004. Doing without schema hierarchies: a recurrent connectionist approach to routine sequential action and its pathologies. Psychol. Rev. 111, 395–429. ( 10.1037/0033-295X.111.2.395) [DOI] [PubMed] [Google Scholar]
- 23.Elman JL. 1990. Finding structure in time. Cogn. Sci. 14, 179–211. ( 10.1207/s15516709cog1402_1) [DOI] [Google Scholar]
- 24.Williams RJ, Zipser D. 1995. Gradient-based learning algorithms for recurrent neural networks and their computational complexity. In Backpropagation: theory, architectures, and applications (eds Chauvin Y, Rumelhart DE.), pp. 433–486. Hillsdale, NJ: Erlbaum. [Google Scholar]
- 25.Botvinick M. 2007. Multilevel structure in behaviour and in the brain: a model of Fuster's hierarchy. Phil. Trans. R. Soc. B 362, 1615–1626. ( 10.1098/rstb.2007.2056) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.O'Reilly RC, Munakata Y, Frank MJ, Hazy TE,, et al. 2013. Computational cognitive neuroscience, 2nd edn Wiki Book; See http://ccnbook.colorado.edu. [Google Scholar]
- 27.Brette R, Gerstner W. 2005. Adaptive exponential integrate-and-fire model as an effective description of neuronal activity. J. Neurophysiol. 94, 3637–3642. ( 10.1152/jn.00686.2005) [DOI] [PubMed] [Google Scholar]
- 28.Lorincz ML, Kekesi KA, Juhasz G, Crunelli V, Hughes SW. 2009. Temporal framing of thalamic relay-mode firing by phasic inhibition during the alpha rhythm. Neuron 63, 683–696. ( 10.1016/j.neuron.2009.08.012) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Buffalo E, Fries P, Landman R, Buschman T, Desimone R. 2011. Laminar differences in gamma and alpha coherence in the ventral stream. Proc. Natl Acad. Sci. USA 108, 11 262–11 267. ( 10.1073/pnas.1011284108) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.VanRullen R, Koch C. 2003. Is perception discrete or continuous? Trends Cogn. Sci. 7, 207–213. ( 10.1016/S1364-6613(03)00095-0) [DOI] [PubMed] [Google Scholar]
- 31.Hommel B. 2004. Event files: feature binding in and across perception and action. Trends Cogn. Sci. 8, 494–500. ( 10.1016/j.tics.2004.08.007) [DOI] [PubMed] [Google Scholar]
- 32.Hinton GE, Salakhutdinov RR. 2006. Reducing the dimensionality of data with neural networks. Science 313, 504–507. ( 10.1126/science.1127647) [DOI] [PubMed] [Google Scholar]
- 33.Hommel B. 2013. Dancing in the dark: no role for consciousness in action control. Front. Psychol. 4, 380. (10.3389/fpsyg.2013.00380) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Masicampo EJ, Baumeister RF. 2013. Conscious thought does not guide moment-to-moment actions—it serves social and cultural functions. Front. Psychol. 4, 478 ( 10.3389/fpsyg.2013.00478) [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.