

Abstract
Multi-task learning (MTL) learns multiple related tasks simultaneously to improve generalization performance. Alternating structure optimization (ASO) is a popular MTL method that learns a shared low-dimensional predictive structure on hypothesis spaces from multiple related tasks. It has been applied successfully in many real world applications. As an alternative MTL approach, clustered multi-task learning (CMTL) assumes that multiple tasks follow a clustered structure, i.e., tasks are partitioned into a set of groups where tasks in the same group are similar to each other, and that such a clustered structure is unknown a priori. The objectives in ASO and CMTL differ in how multiple tasks are related. Interestingly, we show in this paper the equivalence relationship between ASO and CMTL, providing significant new insights into ASO and CMTL as well as their inherent relationship. The CMTL formulation is non-convex, and we adopt a convex relaxation to the CMTL formulation. We further establish the equivalence relationship between the proposed convex relaxation of CMTL and an existing convex relaxation of ASO, and show that the proposed convex CMTL formulation is significantly more efficient especially for high-dimensional data. In addition, we present three algorithms for solving the convex CMTL formulation. We report experimental results on benchmark datasets to demonstrate the efficiency of the proposed algorithms.
1 Introduction
Many real-world problems involve multiple related classificatrion/regression tasks. A naive approach is to apply single task learning (STL) where each task is solved independently and thus the task relatedness is not exploited. Recently, there is a growing interest in multi-task learning (MTL), where we learn multiple related tasks simultaneously by extracting appropriate shared information across tasks. In MTL, multiple tasks are expected to benefit from each other, resulting in improved generalization performance. The effectiveness of MTL has been demonstrated empirically [1, 2, 3] and theoretically [4, 5, 6]. MTL has been applied in many applications including biomedical informatics [7], marketing [1], natural language processing [2], and computer vision [3].
Many different MTL approaches have been proposed in the past; they differ in how the relatedness among different tasks is modeled. Evgeniou et al. [8] proposed the regularized MTL which constrained the models of all tasks to be close to each other. The task relatedness can also be modeled by constraining multiple tasks to share a common underlying structure [4, 6, 9, 10]. Ando and Zhang [5] proposed a structural learning formulation, which assumed multiple predictors for different tasks shared a common structure on the underlying predictor space. For linear predictors, they proposed the alternating structure optimization (ASO) that simultaneously performed inference on multiple tasks and discovered the shared low-dimensional predictive structure. ASO has been shown to be effective in many practical applications [2, 11, 12]. One limitation of the original ASO formulation is that it involves a non-convex optimization problem and a globally optimal solution is not guaranteed. A convex relaxation of ASO called CASO was proposed and analyzed in [13].
Many existing MTL formulations are based on the assumption that all tasks are related. In practical applications, the tasks may exhibit a more sophisticated group structure where the models of tasks from the same group are closer to each other than those from a different group. There have been many prior work along this line of research, known as clustered multi-task learning (CMTL). In [14], the mutual relatedness of tasks was estimated and knowledge of one task could be transferred to other tasks in the same cluster. Bakker and Heskes [15] used clustered multi-task learning in a Bayesian setting by considering a mixture of Gaussians instead of single Gaussian priors. Evgeniou et al. [8] proposed the task clustering regularization and showed how cluster information could be encoded in MTL, and however the group structure was required to be known a priori. Xue et al. [16] introduced the Dirichlet process prior which automatically identified subgroups of related tasks. In [17], a clustered MTL framework was proposed that simultaneously identified clusters and performed multi-task inference. Because the formulation is non-convex, they also proposed a convex relaxation to obtain a global optimum [17]. Wang et al. [18] used a similar idea to consider clustered tasks by introducing an inter-task regularization.
The objective in CMTL differs from many MTL formulations (e.g., ASO which aims to identify a shared low-dimensional predictive structure for all tasks) which are based on the standard assumption that each task can learn equally well from any other task. In this paper, we study the inherent relationship between these two seemingly different MTL formulations. Specifically, we establish the equivalence relationship between ASO and a specific formulation of CMTL, which performs simultaneous multi-task learning and task clustering: First, we show that CMTL performs clustering on the tasks, while ASO performs projection on the features to find a shared low-rank structure. Next, we show that the spectral relaxation of the clustering (on tasks) in CMTL and the projection (on the features) in ASO lead to an identical regularization, related to the negative Ky Fan k-norm of the weight matrix involving all task models, thus establishing their equivalence relationship. The presented analysis provides significant new insights into ASO and CMTL as well as their inherent relationship. To our best knowledge, the clustering view of ASO has not been explored before.
One major limitation of the ASO/CMTL formulation is that it involves a non-convex optimization, as the negative Ky Fan k-norm is concave. We propose a convex relaxation of CMTL, and establish the equivalence relationship between the proposed convex relaxation of CMTL and the convex ASO formulation proposed in [13]. We show that the proposed convex CMTL formulation is significantly more efficient especially for high-dimensional data. We further develop three algorithms for solving the convex CMTL formulation based on the block coordinate descent, accelerated projected gradient, and gradient descent, respectively. We have conducted experiments on benchmark datasets including School and Sarcos; our results demonstrate the efficiency of the proposed algorithms.
Notation
Throughout this paper, ℝd denotes the d-dimensional Euclidean space. I denotes the identity matrix of a proper size. ℕ denotes the set of natural numbers. denotes the set of symmetric positive semi-definite matrices of size m by m. A ≼ B means that B - A is positie semi-definite. tr (X) is the trace of X.
2 Multi-Task Learning: ASO and CMTL
Assume we are given a multi-task learning problem with m tasks; each task i ∈ ℕm is associated with a set of training data , and a linear predictive function , where wi is the weight vector of the i-th task, d is the data dimensionality, and ni is the number of samples of the i-th task. We denote W = [w1, …, wm] ∈ ℝd×m as the weight matrix to be estimated. Given a loss function ℓ(·, ·), the empirical risk is given by:
We study the following multi-task learning formulation: minW
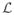 (W) + Ω(W), where Ω encodes our prior knowledge about the m tasks. Next, we review ASO and CMTL and explore their inherent relationship.
(W) + Ω(W), where Ω encodes our prior knowledge about the m tasks. Next, we review ASO and CMTL and explore their inherent relationship.
2.1 Alternating structure optimization
In ASO [5], all tasks are assumed to share a common feature space Θ ∈ ℝh×d, where h ≤ min(m, d) is the dimensionality of the shared feature space and Θ has orthonormal columns, i.e., ΘΘT = Ih. The predictive function of ASO is: , where the weight wi = ui + ΘTvi consists of two components including the weight ui for the high-dimensional feature space and the weight vi for the low-dimensional space based on Θ. ASO minimizes the following objective function: , subject to: ΘΘT = Ih, where α is the regularization parameter for task relatedness. We can further improve the formulation by including a penalty, , to improve the generalization performance as in traditional supervised learning. Since ui = wi - ΘTvi, we obtain the following ASO formulation:
| (1) |
2.2 Clustered multi-task learning
In CMTL, we assume that the tasks are clustered into k < m clusters, and the index set of the j-th cluster is defined as
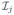 = {v|v ∈ cluster j}. We denote the mean of the jth cluster to be
. For a given W = [w1, ···, wm], the sum-of-square error (SSE) function in K-means clustering is given by [19, 20]:
= {v|v ∈ cluster j}. We denote the mean of the jth cluster to be
. For a given W = [w1, ···, wm], the sum-of-square error (SSE) function in K-means clustering is given by [19, 20]:
| (2) |
where the matrix F ∈ ℝm×k is an orthogonal cluster indicator matrix with
if i ∈
and Fi,j = 0 otherwise. If we ignore the special structure of F and keep the orthogonality requirement only, the relaxed SSE minimization problem is:
| (3) |
resulting in the following penalty function for CMTL:
| (4) |
where the first term is derived from the K-means clustering objective and the second term is to improve the generalization performance. Combing Eq. (4) with the empirical error term
(W), we obtain the following CMTL formulation:
| (5) |
2.3 Equivalence of ASO and CMTL
In the ASO formulation in Eq. (1), it is clear that the optimal vi is given by . Thus, the penalty in ASO has the following equivalent form:
| (6) |
resulting in the following equivalent ASO formulation:
| (7) |
The penalty of the ASO formulation in Eq. (7) looks very similar to the penalty of the CMTL formulation in Eq. (5), however the operations involved are fundamentally different. In the CMTL formulation in Eq. (5), the matrix F is operated on the task dimension, as it is derived from the K-means clustering on the tasks; while in the ASO formulation in Eq. (7), the matrix Θ is operated on the feature dimension, as it aims to identify a shared low-dimensional predictive structure for all tasks. Although different in the mathematical formulation, we show in the following theorem that the objectives of CMTL and ASO are equivalent.
Theorem 2.1
The objectives of CMTL in Eq. (5) and ASO in Eq. (7) are equivalent if the cluster number, k, in K-means equals to the size, h, of the shared low-dimensional feature space.
Proof
Denote
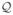 (W) =
(W) + (α+ β) tr WTW, with α, β > 0. Then, CMTL and ASO solve the following optimization problems:
(W) =
(W) + (α+ β) tr WTW, with α, β > 0. Then, CMTL and ASO solve the following optimization problems:
respectively. Note that in both CMTL and ASO, the first term
is independent of F or Θ, for a given W. Thus, the optimal F and Θ for these two optimization problems are given by solving:
Since WWT and WTW share the same set of nonzero eigenvalues, by the Ky-Fan Theorem [21], both problems above achieve exactly the same maximum objective value:
, where λi(W TW) denotes the i-th largest eigenvalue of WTW and ||WTW||(k) is known as the Ky Fan k-norm of matrix WTW. Plugging the results back to the original objective, the optimization problem for both CMTL and ASO becomes minW
(W ) - α||W TW||(k). This completes the proof of this theorem.
3 Convex Relaxation of CMTL
The formulation in Eq. (5) is non-convex. A natural approach is to perform a convex relaxation on CMTL. We first reformulate the penalty in Eq. (5) as follows:
| (8) |
where η is defined as η = β/α > 0. Since FTF = Ik, the following holds:
Thus, we can reformulate ΩCMTL0 in Eq. (8) as the following equivalent form:
| (9) |
resulting in the following equivalent CMTL formulation:
| (10) |
Following [13, 17], we obtain the following convex relaxation of Eq. (10), called cCMTL:
| (11) |
where ΩcCMTL(W, M ) is defined as:
| (12) |
The optimization problem in Eq. (11) is jointly convex with respect to W and M [9].
3.1 Equivalence of cASO and cCMTL
A convex relaxation (cASO) of the ASO formulation in Eq. (7) has been proposed in [13]:
| (13) |
where ΩcASO is defined as:
| (14) |
The cASO formulation in Eq. (13) and the cCMTL formulation in Eq. (11) are different in the regularization components: the respective Hessian of the regularization with respect to W are different. Similar to Theorem 2.1, our analysis shows that cASO and cCMTL are equivalent.
Theorem 3.1
The objectives of the cCMTL formulation in Eq. (11) and the cASO formulation in Eq. (13) are equivalent if the cluster number, k, in K-means equals to the size, h, of the shared low-dimensional feature space.
Proof
Define the following two convex functions of W:
| (15) |
and
| (16) |
The cCMTL and cASO formulations can be expressed as unconstrained optimization w.r.t. W:
where c = αη (1 + η). Let h = k ≤ min(d, m). Next, we show that for a given W, gCMTL(W ) = gASO(W) holds.
Let W = Q1ΣQ2, , and , be the SVD of W, M, and S (M and S are symmetric positive semi-definite), respectively, where Σ = diag{σ1, σ2, …, σm}, , and . Let q < k be the rank of Σ. It follows from the basic properties of the trace that:
The problem in Eq. (15) is thus equivalent to:
| (17) |
It can be shown that the optimal is given by and the optimal is given by solving the following simple (convex) optimization problem [13]:
| (18) |
It follows that . Similarly, we can show that , where
It is clear that when h = k, holds. Therefore, we have gcCMTL(W ) = gcASO(W). This completes the proof.
Remark 3.2
In the functional of cASO in Eq. (16) the variable to be optimized is , while in the functional of cCMTL in Eq. (15) the optimization variable is . In many practical MTL problems the data dimensionality d is much larger than the task number m, and in such cases cCMTL is significantly more efficient in terms of both time and space. Our equivalence relationship established in Theorem 3.1 provides an (equivalent) efficient implementation of cASO especially for high-dimensional problems.
4 Optimization Algorithms
In this section, we propose to employ three different methods, i.e., Alternating Optimization Method (altCMTL), Accelerated Projected Gradient Method (apgCMTL), and Direct Gradient Descent Method (graCMTL), respectively, for solving the convex relaxation in Eq. (11). Note that we focus on smooth loss functions in this paper.
4.1 Alternating Optimization Method
The Alternating Optimization Method (altCMTL) is similar to the Block Coordinate Descent (BCD) method [22], in which the variable is optimized alternatively with the other variables fixed. The pseudo-code of altCMTL is provided in the supplemental material. Note that using similar techniques as the ones from [23], we can show that altCMTL finds the globally optimal solution to Eq. (11). The altCMTL algorithm involves the following two steps in each iteration:
Optimization of W
For a fixed M, the optimal W can be obtained via solving:
| (19) |
The problem above is smooth and convex. It can be solved using gradient-type methods [22]. In the special case of a least square loss function, the problem in Eq. (19) admits an analytic solution.
Optimization of M
For a fixed W, the optimal M can be obtained via solving:
| (20) |
From Theorem 3.1, the optimal M to Eq. (20) is given by M = QΛ*QT, where Λ* is obtained from Eq. (18). The problem in Eq. (18) can be efficiently solved using similar techniques in [17].
4.2 Accelerated Projected Gradient Method
The accelerated projected gradient method (APG) has been applied to solve many machine learning formulations [24]. We apply APG to solve the cCMTL formulation in Eq. (11). The algorithm is called apgCMTL. The key component of apgCMTL is to compute a proximal operator as follows:
| (21) |
where the details about the construction of ŴS and M̂S can be found in [24]. The optimization problem in Eq. (21) is involved in each iteration of apgCMTL, and hence its computation is critical for the practical efficiency of apgCMTL. We show below that the optimal WZ and MZ to Eq. (21) can be computed efficiently.
Computation of Wz
The optimal WZ to Eq. (21) can be obtained by solving:
| (22) |
Clearly the optimal WZ to Eq. (22) is equal to ŴS.
Computation of Mz
The optimal MZ to Eq. (21) can be obtained by solving:
| (23) |
where M̂S is not guaranteed to be positive semidefinite. Our analysis shows that the optimization problem in Eq. (23) admits an analytical solution via solving a simple convex projection problem. The main result and the pseudo-code of apgCMTL are provided in the supplemental material.
4.3 Direct Gradient Descent Method
In Direct Gradient Descent Method (graCMTL) as used in [17], the cCMTL problem in Eq. (11) is reformulated as an optimization problem with one single variable W, given by:
| (24) |
where gCMTL(W ) is a functional of W defined in Eq. (15).
Given the intermediate solution Wk−1 from the (k − 1)-th iteration of graCMTL, we compute the gradient of gCMTL(W ) and then apply the general gradient descent scheme [25] to obtain Wk. Note that at each iterative step in line search, we need to solve the optimization problem in the form of Eq. (20). The gradient of gCMTL(·) at Wk−1 is given by [26, 27]: , where M̂ is obtained by solving Eq. (20) at W = Wk−1. The pseudo-code of graCMTL is provided in the supplemental material.
5 Experiments
In this section, we empirically evaluate the effectiveness and the efficiency of the proposed algorithms on synthetic and real-world data sets. The normalized mean square error (nMSE) and the averaged mean square error (aMSE) are used as the performance measure [23]. Note that in this paper we have not developed new MTL formulations; instead our main focus is on the theoretical understanding of the inherent relationship between ASO and CMTL. Thus, an extensive comparative study of various MTL algorithms is out of the scope of this paper. As an illustration, in the following experiments we only compare cCMTL with two baseline techniques: ridge regression STL (RidgeSTL) and regularized MTL (RegMTL) [28].
Simulation Study
We apply the proposed cCMTL formulation in Eq. (11) on a synthetic data set (with a pre-defined cluster structure). We use 5-fold cross-validation to determine the regularization parameters for all methods. We construct the synthetic data set following a procedure similar to the one in [17]: the constructed synthetic data set consists of 5 clusters, where each cluster includes 20 (regression) tasks and each task is represented by a weight vector of length d = 300. Details of the construction is provided in the supplemental material. We apply RidgeSTL, RegMTL, and cCMTL on the constructed synthetic data. The correlation coefficient matrices of the obtained weight vectors are presented in Figure 1. From the result we can observe (1) cCMTL is able to capture the cluster structure among tasks and achieves a small test error; (2) RegMTL is better than RidgeSTL in terms of test error. It however introduces unnecessary correlation among tasks possibly due to the assumption that all tasks are related; (3) In cCMTL we also notice some ‘noisy’ correlation, which may because of the spectral relaxation.
Figure 1.
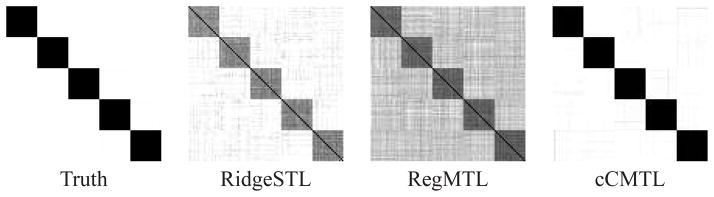
The correlation matrices of the ground truth model, and the models learnt from RidgeSTL, RegMTL, and cCMTL. Darker color indicates higher correlation. In the ground truth there are 100 tasks clustered into 5 groups. Each task has 200 dimensions. 95 training samples and 5 testing samples are used in each task. The test errors (in terms of nMSE) for RidgeSTL, RegMTL, and cCMTL are 0.8077, 0.6830, 0.0354, respectively.
Effectiveness Comparison
Next, we empirically evaluate the effectiveness of the cCMTL formulation in comparison with RidgeSTL and RegMTL using real world benchmark datasets including the School data1 and the Sarcos data2. The regularization parameters for all algorithms are determined via 5-fold cross validation; the reported experimental results are averaged over 10 random repetitions. The School data consists of the exam scores of 15362 students from 139 secondary schools, where each student is described by 27 attributes. We vary the training ratio in the set 5 × {1, 2, ···, 6}% and record the respective performance. The experimental results are presented in Table 1. We can observe that cCMTL performs the best among all settings. Experimental results on the Sarcos dataset is available in the supplemental material.
Table 1.
Performance comparison on the School data in terms of nMSE and aMSE. Smaller nMSE and aMSE indicate better performance. All regularization parameters are tuned using 5-fold cross validation. The mean and standard deviation are calculated based on 10 random repetitions.
| Measure | Ratio | RidgeSTL | RegMTL | cCMTL |
|---|---|---|---|---|
| nMSE | 10% | 1.3954 ± 0.0596 | 1.0988 ± 0.0178 | 1.0850 ± 0.0206 |
| 15% | 1.1370 ± 0.0146 | 1.0636 ± 0.0170 | 0.9708 ± 0.0145 | |
| 20% | 1.0290 ± 0.0309 | 1.0349 ± 0.0091 | 0.8864 ± 0.0094 | |
| 25% | 0.8649 ± 0.0123 | 1.0139 ± 0.0057 | 0.8243 ± 0.0031 | |
| 30% | 0.8367 ± 0.0102 | 1.0042 ± 0.0066 | 0.8006 ± 0.0081 | |
|
| ||||
| aMSE | 10% | 0.3664 ± 0.0160 | 0.2865 ± 0.0054 | 0.2831 ± 0.0050 |
| 15% | 0.2972 ± 0.0034 | 0.2771 ± 0.0045 | 0.2525 ± 0.0048 | |
| 20% | 0.2717 ± 0.0083 | 0.2709 ± 0.0027 | 0.2322 ± 0.0022 | |
| 25% | 0.2261 ± 0.0033 | 0.2650 ± 0.0027 | 0.2154 ± 0.0020 | |
| 30% | 0.2196 ± 0.0035 | 0.2632 ± 0.0028 | 0.2101 ± 0.0016 | |
Efficiency Comparison
We compare the efficiency of the three algorithms including altCMTL, apgCMTLand graCMTL for solving the cCMTL formulation in Eq. (11). For the following experiments, we set α = 1, β = 1, and k = 2 in cCMTL. We observe a similar trend in other settings. Specifically, we study how the feature dimensionality, the sample size, and the task number affect the required computation cost (in seconds) for convergence. The experimental setup is as follows: we terminate apgCMTL when the change of objective values in two successive steps is smaller than 10−5 and record the obtained objective value; we then use such a value as the stopping criterion in graCMTL and altCMTL, that is, we stop graCMTL or altCMTL when graCMTL or altCMTL attains an objective value equal to or smaller than the one attained by apgCMTL. We use Yahoo Arts data for the first two experiments. Because in Yahoo data the task number is very small, we construct a synthetic data for the third experiment.
In the first experiment, we vary the feature dimensionality in the set [500: 500: 2500] with the sample size fixed at 4000 and the task numbers fixed at 17. The experimental result is presented in the left plot of Figure 2. In the second experiment, we vary the sample size in the set [3000: 1000: 9000] with the dimensionality fixed at 500 and the task number fixed at 17. The experimental result is presented in the middle plot of Figure 2. From the first two experiments, we observe that larger feature dimensionality or larger sample size will lead to higher computation cost. In the third experiment, we vary the task number in the set [10: 10: 190] with the feature dimensionality fixed at 600 and the sample size fixed at 2000. The employed synthetic data set is constructed as follows: for each task, we generate the entries of the data matrix Xi from
 (0, 1), and generate the entries of the weight vector from
(0, 1), the response vector yi is computed as yi = Xiwi + ξ, where ξ ~
(0, 0.01) represents the noise vector. The experimental result is presented in the right plot of Figure 2. We can observe that altCMTL is more efficient than the other two algorithms.
(0, 1), and generate the entries of the weight vector from
(0, 1), the response vector yi is computed as yi = Xiwi + ξ, where ξ ~
(0, 0.01) represents the noise vector. The experimental result is presented in the right plot of Figure 2. We can observe that altCMTL is more efficient than the other two algorithms.
Figure 2.
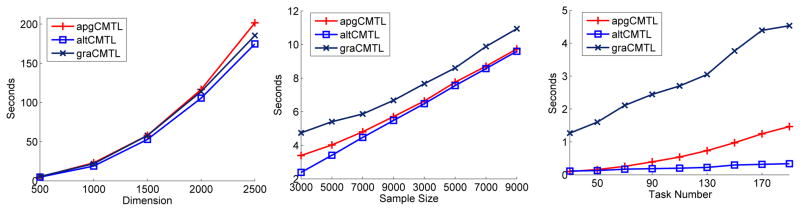
Sensitivity study of altCMTL, apgCMTL, graCMTL in terms of the computation cost (in seconds) with respect to feature dimensionality (left), sample size (middle), and task number (right).
6 Conclusion
In this paper we establish the equivalence relationship between two multi-task learning techniques: alternating structure optimization (ASO) and clustered multi-task learning (CMTL). We further establish the equivalence relationship between our proposed convex relaxation of CMTL and an existing convex relaxation of ASO. In addition, we propose three algorithms for solving the convex CMTL formulation and demonstrate their effectiveness and efficiency on benchmark datasets. The proposed algorithms involve the computation of SVD. In the case of a very large task number, the SVD computation will be expensive. We seek to further improve the efficiency of the algorithms by employing approximation methods. In addition, we plan to apply the proposed algorithms to other real world applications involving multiple (clustered) tasks.
Supplementary Material
Acknowledgments
This work was supported in part by NSF IIS-0812551, IIS-0953662, MCB-1026710, CCF-1025177, and NIH R01 LM010730.
Footnotes
Contributor Information
Jiayu Zhou, Email: jiayu.zhou@asu.edu.
Jianhui Chen, Email: jianhui.chen@asu.edu.
Jieping Ye, Email: jieping.ye@asu.edu.
References
- 1.Evgeniou T, Pontil M, Toubia O. A convex optimization approach to modeling consumer heterogeneity in conjoint estimation. Marketing Science. 2007;26(6):805–818. [Google Scholar]
- 2.Ando RK. Applying alternating structure optimization to word sense disambiguation. Proceedings of the Tenth Conference on Computational Natural Language Learning. 2006:77–84. [Google Scholar]
- 3.Torralba A, Murphy KP, Freeman WT. Sharing features: efficient boosting procedures for multi-class object detection. Computer Vision and Pattern Recognition, 2004, IEEE Conference. 2004;2:762–769. [Google Scholar]
- 4.Baxter J. A model of inductive bias learning. J Artif Intell Res. 2000;12:149–198. [Google Scholar]
- 5.Ando RK, Zhang T. A framework for learning predictive structures from multiple tasks and unlabeled data. The Journal of Machine Learning Research. 2005;6:1817–1853. [Google Scholar]
- 6.Ben-David S, Schuller R. Exploiting task relatedness for multiple task learning. Lecture notes in computer science. 2003:567–580. [Google Scholar]
- 7.Bickel S, Bogojeska J, Lengauer T, Scheffer T. Proceedings of the 25th International Conference on Machine Learning. ACM; 2008. Multi-task learning for hiv therapy screening; pp. 56–63. [Google Scholar]
- 8.Evgeniou T, Micchelli CA, Pontil M. Learning multiple tasks with kernel methods. Journal of Machine Learning Research. 2006;6(1):615. [Google Scholar]
- 9.Argyriou A, Micchelli CA, Pontil M, Ying Y. A spectral regularization framework for multi-task structure learning. Advances in Neural Information Processing Systems. 2008;20:25–32. [Google Scholar]
- 10.Caruana R. Multitask learning. Machine Learning. 1997;28(1):41–75. [Google Scholar]
- 11.Blitzer J, McDonald R, Pereira F. Domain adaptation with structural correspondence learning. Proceedings of the 2006 Conference on EMNLP. 2006:120–128. [Google Scholar]
- 12.Quattoni A, Collins M, Darrell T. Learning visual representations using images with captions. Computer Vision and Pattern Recognition, 2007. IEEE Conference on; IEEE; 2007. pp. 1–8. [Google Scholar]
- 13.Chen J, Tang L, Liu J, Ye J. Proceedings of the 26th Annual International Conference on Machine Learning. ACM; 2009. A convex formulation for learning shared structures from multiple tasks; pp. 137–144. [Google Scholar]
- 14.Thrun S, O’Sullivan J. Clustering learning tasks and the selective cross-task transfer of knowledge. Learning to learn. 1998:181–209. [Google Scholar]
- 15.Bakker B, Heskes T. Task clustering and gating for bayesian multitask learning. The Journal of Machine Learning Research. 2003;4:83–99. [Google Scholar]
- 16.Xue Y, Liao X, Carin L, Krishnapuram B. Multi-task learning for classification with dirichlet process priors. The Journal of Machine Learning Research. 2007;8:35–63. [Google Scholar]
- 17.Jacob L, Bach F, Vert JP. Clustered multi-task learning: A convex formulation. Arxiv preprint arXiv:0809.2085. 2008 [Google Scholar]
- 18.Wang F, Wang X, Li T. Data Mining, 2009. ICDM’09. Ninth IEEE International Conference. IEEE; 2009. Semi-supervised multi-task learning with task regularizations; pp. 562–568. [Google Scholar]
- 19.Ding C, He X. Proceedings of the twenty-first International Conference on Machine learning. ACM; 2004. K-means clustering via principal component analysis; p. 29. [Google Scholar]
- 20.Zha H, He X, Ding C, Gu M, Simon H. Spectral relaxation for k-means clustering. Advances in Neural Information Processing Systems. 2002;2:1057–1064. [Google Scholar]
- 21.Fan K. On a theorem of Weyl concerning eigenvalues of linear transformations I. Proceedings of the National Academy of Sciences of the United States of America. 1949;35(11):652. doi: 10.1073/pnas.35.11.652. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Nocedal J, Wright SJ. Numerical optimization. Springer verlag; 1999. [Google Scholar]
- 23.Argyriou A, Evgeniou T, Pontil M. Convex multi-task feature learning. Machine Learning. 2008;73(3):243–272. [Google Scholar]
- 24.Nesterov Y. Gradient methods for minimizing composite objective function. ReCALL. 2007;76(2007076) [Google Scholar]
- 25.Boyd SP, Vandenberghe L. Convex optimization. Cambridge University Press; 2004. [Google Scholar]
- 26.Gauvin J, Dubeau F. Differential properties of the marginal function in mathematical programming. Optimality and Stability in Mathematical Programming. 1982:101–119. [Google Scholar]
- 27.Wu M, Schölkopf B, Bakır G. A direct method for building sparse kernel learning algorithms. The Journal of Machine Learning Research. 2006;7:603–624. [Google Scholar]
- 28.Evgeniou T, Pontil M. Proceedings of the tenth ACM SIGKDD International Conference on Knowledge discovery and data mining. ACM; 2004. Regularized multi–task learning; pp. 109–117. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.