

Abstract
It is well accepted that adoption of innovations are described by S-curves (slow start, accelerating period and slow end). In this paper, we analyse how much information on the dynamics of innovation spreading can be obtained from a quantitative description of S-curves. We focus on the adoption of linguistic innovations for which detailed databases of written texts from the last 200 years allow for an unprecedented statistical precision. Combining data analysis with simulations of simple models (e.g. the Bass dynamics on complex networks), we identify signatures of endogenous and exogenous factors in the S-curves of adoption. We propose a measure to quantify the strength of these factors and three different methods to estimate it from S-curves. We obtain cases in which the exogenous factors are dominant (in the adoption of German orthographic reforms and of one irregular verb) and cases in which endogenous factors are dominant (in the adoption of conventions for romanization of Russian names and in the regularization of most studied verbs). These results show that the shape of S-curve is not universal and contains information on the adoption mechanism.
Keywords: S-curves, language change, endogenous and exogenous factors
1. Introduction
The term S-curve often amounts to the qualitative observation that the change starts slowly, accelerates and ends slowly. Linguists generally accept that ‘the progress of language change through a community follows a lawful course, an S-curve from minority to majority to totality’ [1, p. 133] (see [2] for a recent survey of examples in different linguistic domains). Quantitative analysis is rare and extremely limited by the quality of the linguistic data, which in the best cases have ‘up to a dozen points for a single change’ [2]. Going beyond qualitative observation is essential to address questions like
(i) Are all changes following S-curves?
(ii) Are all S-curves the same (e.g. universal after proper re-scaling)?
(iii) How much information on the process of change can be extracted from S-curves?
(iv) Based on S-curves, can we identify signatures of endogenous and exogenous factors responsible for the change?
Large records of written text available for investigation provide a new opportunity to quantitatively study these questions in language change [3,4]. In figure 1, we show the adoption curves of three linguistic innovations for which words competing for the same meaning can be identified. Our methodology is not restricted to such simple examples of vocabulary replacement and can be applied to other examples of language change and S-curves more generally. Here, we restrict ourselves to data of aggregated (macroscopic) S-curves because only very rarely one has access to detailed data at the individual (microscopic) level (see [5] for an exception).
Figure 1.
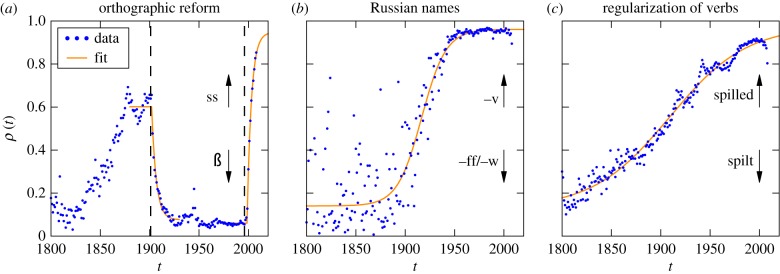
Examples of linguistic changes showing different adoption curves. We estimate the fraction of adopters ρ(t) by the relative frequency as 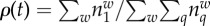 , where
, where 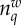 is the total number of occurrences (tokens) of variant q for the word w at year t. (a) The orthography of German words that changed to ‘ss' (q = 1) from ‘ß’ (q = 2) in the orthographic reform of 1996 (many words changed from ‘ss' to ‘ß’ in the 1901 reform). (b) The transliteration of Russian names ending with the letter ‘в’ when written in English (Latin alphabet), changed to an ending in ‘v’ (q = 1) from endings in ‘ff’ (q = 2) or ‘w’ (q = 3) (e.g. w = ‘Capatob’ is nowadays almost unanimously written as ‘Saratov’, but it used to be written also as ‘Saratoff’ or ‘Saratow’). (c) The past form of the verb spill changed to its regular form ‘spilled’ (q = 1) from the irregular form ‘spilt’ (q = 2). The light curve shows the fit of equation (1.2). The estimated parameters a and b are (a)
is the total number of occurrences (tokens) of variant q for the word w at year t. (a) The orthography of German words that changed to ‘ss' (q = 1) from ‘ß’ (q = 2) in the orthographic reform of 1996 (many words changed from ‘ss' to ‘ß’ in the 1901 reform). (b) The transliteration of Russian names ending with the letter ‘в’ when written in English (Latin alphabet), changed to an ending in ‘v’ (q = 1) from endings in ‘ff’ (q = 2) or ‘w’ (q = 3) (e.g. w = ‘Capatob’ is nowadays almost unanimously written as ‘Saratov’, but it used to be written also as ‘Saratoff’ or ‘Saratow’). (c) The past form of the verb spill changed to its regular form ‘spilled’ (q = 1) from the irregular form ‘spilt’ (q = 2). The light curve shows the fit of equation (1.2). The estimated parameters a and b are (a) 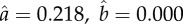 in 1901, and
in 1901, and 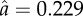 ,
, 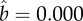 in 1996; (b)
in 1996; (b) 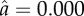 ,
, 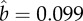 ; and (c)
; and (c) 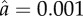 ,
, 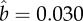 . The corpus is the Google-ngram [3,4] plotted in the minimum (yearly) resolution, see the electronic supplementary material, section I, for details on the data and section IIIB for details on the fit. (Online version in colour.)
. The corpus is the Google-ngram [3,4] plotted in the minimum (yearly) resolution, see the electronic supplementary material, section I, for details on the data and section IIIB for details on the fit. (Online version in colour.)
Data alone is not enough to address the questions listed above, it is also essential to consider mechanistic models responsible for the change [2,6–9]. Dynamical processes in language can also be described from the more general perspectives of evolutionary processes [2,6,10] and complex systems [11–13]. In this framework, the adoption of new words can be seen as the adoption of innovations [9,14–18]. One of the most general and popular models of innovation adoption showing S-curves is the Bass model [16,17]. In its simplest case, it considers a homogeneous population and prescribes that the fraction of adopters (ρ) increases because those that have not adopted yet (1 − ρ) meet adopters (at a rate b) and are subject to an external force (at a rate a). The adoption is thus described by
| 1.1 |
The solution (considering 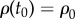 and
and 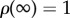 ) is
) is
| 1.2 |
It contains as limiting cases a symmetric S-curve (for a = 0) and an exponential relaxation (for b = 0). The fitting of equation (1.2) to the data in figure 1 leads to very different a and b in the three different examples, strongly suggesting that the S-curves are not universal and contain information on the adoption process. For instance, orthographic reforms are known to be exogenously driven (by language academies) in agreement with b = 0 obtained from the fit in panel (a).
In this paper, we investigate the shape and significance of S-curves in models of adoption of innovations and in data of language change. In particular, we estimate the contribution of endogenous and exogenous factors in S-curves, a popular question which has been addressed in complex systems more generally [19–22]. The different values of a and b in equation (1.1) are an insufficient quantification, e.g. because they fail to indicate which factor is stronger. Here, we introduce a definition for the relevance of different factors in a change. We then show how this quantity can be exactly computed in different models and propose three different methods to estimate it from the time series of ρ(t). We compare the accuracy of the methods using simulations of different network models and we apply the methods to linguistic changes. We obtain that the exogenous factors are responsible for the change in the German orthographic reforms, but it plays a minor role in the case of romanized Russian names and in most of the studied English verbs which are moving towards regularization.
2. Theoretical framework
Consider that i = 1, … , N → ∞ identical agents (assumption 1) adopt an innovation. The central quantity of interest for us here is 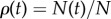 , the fraction of adopters at time t. We assume that ρ(t) is monotonically increasing from
, the fraction of adopters at time t. We assume that ρ(t) is monotonically increasing from 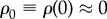 to ρ(∞) = 1 and agents after adopting the innovation do not change back to non-adopted status (assumption 2).
to ρ(∞) = 1 and agents after adopting the innovation do not change back to non-adopted status (assumption 2).
2.1. Endogenous and exogenous factors
In theories of language and cultural change, the importance of different factors is a topic of major relevance, e.g. Labov's internal and external factors [1] and Boyd and Richerson's different types of biases in cultural transmission [10]. The first question we address is how to measure the contribution of different factors to the change. To the best of our knowledge, no general answer to this question has been proposed and computed in adoption models. As a representative case, we divide factors as endogenous and exogenous to the population. Mass media and decisions from language academies count as exogenous factors while grassroots spreading as an endogenous factor. In our simplified classification, Labov's internal (external) factors (to properties of the language [1]) are counted by us as exogenous (endogenous), while Boyd & Richerson's [10] direct bias count as exogenous, whereas the indirect bias and frequency-dependent bias count as endogenous.
Our proposal is to quantify the importance of a factor j as the number of agents that adopted the innovation because of j. More formally, let gi(t) be the adoption probability at time t for agent i (who is in the non-adopted status). We assume that gi can be decomposed in contributions of the different factors j as 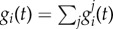 , where
, where 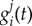 is the adoption probability of agent i at time t because of factor j. If
is the adoption probability of agent i at time t because of factor j. If 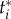 denotes the time agent i adopts the innovation,
denotes the time agent i adopts the innovation, 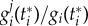 quantifies the contribution of factor j to the adoption of agent i (the adoption does not explicitly depends on t < t* and therefore values of
quantifies the contribution of factor j to the adoption of agent i (the adoption does not explicitly depends on t < t* and therefore values of 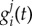 for t < t* are only relevant in the extent that they influence
for t < t* are only relevant in the extent that they influence 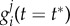 . In principle, the factor
. In principle, the factor 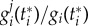 can be obtained empirically by asking recent adopters for their reasons for changing, e.g. for j = exogenous (endogenous) one could ask: How much advertisement (peer pressure) affected your decision? We define the normalized quantification of the change in the whole population due to factor j as an average over all agents
can be obtained empirically by asking recent adopters for their reasons for changing, e.g. for j = exogenous (endogenous) one could ask: How much advertisement (peer pressure) affected your decision? We define the normalized quantification of the change in the whole population due to factor j as an average over all agents
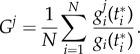 |
2.1 |
In order to show the significance of definition (2.1), and how it can be applied in practice, we discuss how 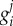 and Gj can be considered in different models. Endogenous (endo) factors happen due to the interaction of an agent with other agents (internal to the population). They are therefore expected to become more relevant as the adoption progress (for increasing ρ). Exogenous factors (exo), on the other hand, are related to a source of information (external to the population) which has no dependence on ρ or time (assumption 3). For simplicity, we report
and Gj can be considered in different models. Endogenous (endo) factors happen due to the interaction of an agent with other agents (internal to the population). They are therefore expected to become more relevant as the adoption progress (for increasing ρ). Exogenous factors (exo), on the other hand, are related to a source of information (external to the population) which has no dependence on ρ or time (assumption 3). For simplicity, we report 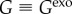 (as
(as 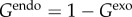 ).
).
2.2. Population dynamics models
Consider as a more general form of equation (1.1)
| 2.2 |
where g(ρ(t)) is the probability that the population of non-adopters (1 − ρ(t)) switches from non-adopted status (0) to adopted status (1) at a given density of ρ. In epidemiology, g(ρ) is known as force of infection [23]. As agents are identical (assumption 1) and ρ(t) is invertible (assumption 2), we can associate 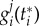 with
with 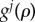 and
and 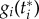 with g(ρ). Introducing g(ρ(t)) from equation (2.2) in the continuous time extension of definition (2.1), we obtain
with g(ρ). Introducing g(ρ(t)) from equation (2.2) in the continuous time extension of definition (2.1), we obtain
| 2.3 |
This equation shows that the strength of factor j is obtained by averaging its normalized strength 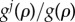 over the whole population or, equivalently, over time (considering the rate of adoption
over the whole population or, equivalently, over time (considering the rate of adoption 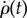 ).
).
When only exogenous and endogenous factors are taken into consideration, g(ρ) = gexo + gendo in equation (2.2). Here, assumption 3 mentioned above corresponds to consider that the adoption happens much faster than the changes in the exogenous factors so that it can be considered independent of time. Therefore, gexo = g(ρ = 0). Any change of g with ρ is an endogenous factor and gendo(ρ) increases with ρ because the pressure for adoption increases with the number of adopters.
For the case of the Bass model defined in equation (1.1), 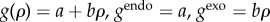 and from equation (2.3) we obtain
and from equation (2.3) we obtain
| 2.4 |
The correspondence of a and bρ to exogenous (innovators) and endogenous (imitators) is a basic ingredient of the Bass model [16] (In our simple model, all agents are identical. The first adopters (innovators) are determined stochastically by the exogenous factor a, while agents adopting at the end of the S-curve (imitators) are more susceptible to the endogenous factor bρ). However, it is only through equation (2.4) that the importance of these factors to the change can be properly quantified. For instance, the case a = b suggests equal contribution of the factors, but equation (2.4) leads to 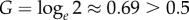 and therefore shows that the exogenous factors dominate (are responsible for a larger number of adoptions than the endogenous factors). This new insight on the interpretation of the classical Bass model illustrates the significance of equation (2.1) and our general approach to quantify the contribution of factors.
and therefore shows that the exogenous factors dominate (are responsible for a larger number of adoptions than the endogenous factors). This new insight on the interpretation of the classical Bass model illustrates the significance of equation (2.1) and our general approach to quantify the contribution of factors.
2.3. Binary-state models on networks
Another well-studied class of models inside our framework considers agents characterized by a binary variable s = {0, 1} connected to each other through a network. We focus on models with a monotone dynamics (assumption 2), such as the Bass, Voter and Susceptible Infected models, which are defined by the probability Fk,m of switching from 0 to 1 given that the agent has k neighbours and m neighbours in state 1 [24]. The one-dimensional population dynamics model in equation (2.2) can be retrieved for simple networks (e.g. fully connected or fixed degree). In the general case, we use the framework of approximate master equations (AME) [25,26] (see the electronic supplementary material, section II), which describes the stochastic binary dynamics in a random network with a given degree distribution Pk. Assuming as before (assumption 3) that the exogenous contribution is given by transitions that occur when no neighbour is infected, i.e. 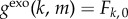 , we obtain the exogenous contribution as (see the electronic supplementary material, section IIB)
, we obtain the exogenous contribution as (see the electronic supplementary material, section IIB)
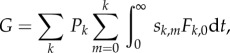 |
2.5 |
where sk,m = sk,m(t) is the fraction of agents of the k,m class in state 0.
3. Time-series estimators
In reality, one usually has no access to information on individual agents and only the aggregated curve ρ(t) is available. This means that G cannot be estimated by equations (2.1) or (2.5). Here, we propose and critically discuss the accuracy of three different methods to estimate G from the S-curve ρ(t) obtained from either empirical or surrogate data. All methods are inspired by the simple population model discussed above, but can be expected to hold also in more general cases. Below we summarize the main idea of the three methods, details on the implementation appear in the electronic supplementary material, section III.
Method 1, fit of S- and exponential curves: We fit equation (1.2) by minimizing the least-square error with respect to the observed time series in the two limiting cases: (i) a = 0, symmetric S-curve (endogenous factors only) and (ii) b = 0, exponential curve (exogenous factors only). Assuming normally distributed errors (which generically vary in time), we calculate the likelihood of the data given each model [27]. The normalized likelihood ratio L of the two models indicates which curve provides a better description of the data [28]. The critical assumption in this method (to be tested below) is to consider the value of L as an indication of the predominance of the corresponding factor, i.e. L > 0.5 indicates stronger exogenous factors (G > 0.5) and L < 0.5 stronger endogenous factors (G < 0.5). This method does not allow for an estimation of G, but it provides an answer to the question of the most relevant factors. The two simple one-parameter curves are unlikely to precisely describe many real adoption curves ρ(t). However, we expect that they will distinguish between cases showing a rather fast/abrupt start at t0 (as in the exponential/exogenous case) from the ones showing a slow/smooth start (as in the S-curve/endogenous case). For this distinction, the 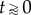 is the crucial part of the ρ(t) curve because for t → ∞ the symmetric S-curve approaches ρ = 1 also exponentially.
is the crucial part of the ρ(t) curve because for t → ∞ the symmetric S-curve approaches ρ = 1 also exponentially.
Method 2, fit of generalized S-curve: We fit equation (1.2) by minimizing the least-square error with respect to the time series and obtain the estimated parameters 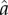 and
and 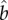 . By inserting these parameters in equation (2.4), we compute
. By inserting these parameters in equation (2.4), we compute 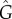 as an estimation of G.
as an estimation of G.
Method 3, estimation of
g(ρ): We estimate g(ρ) from equation (2.2) by calculating a (discrete) time derivative 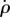 at every point ρ(t). From a (smoothed) curve of g(ρ), we consider g(0) to be the exogenous factors, write gendo = g(ρ) − g(0) and obtain an estimation
at every point ρ(t). From a (smoothed) curve of g(ρ), we consider g(0) to be the exogenous factors, write gendo = g(ρ) − g(0) and obtain an estimation 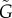 of G from equation (2.3). The advantage of this non-parametric method is that it is not a priory attached to a specific g(ρ) and therefore it is expected to work whenever a population dynamics equation (2.2) provides a good approximation of the data.
of G from equation (2.3). The advantage of this non-parametric method is that it is not a priory attached to a specific g(ρ) and therefore it is expected to work whenever a population dynamics equation (2.2) provides a good approximation of the data.
4. Application to network models
Here, we investigate time-series ρ(t) obtained from simulations of models in which we have access to the microscopic dynamics of agents. Our goal is to measure G on different models and to test the estimators 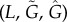 defined in the previous section. We consider two specific network models in the framework described in §2.3, which are defined fixing the network topology (in our case random scale-free) and the function Fk,m (the adoption rate of an agent having m out of k neighbours that already adopted) as [24,25]
defined in the previous section. We consider two specific network models in the framework described in §2.3, which are defined fixing the network topology (in our case random scale-free) and the function Fk,m (the adoption rate of an agent having m out of k neighbours that already adopted) as [24,25]
| 4.1 |
and
| 4.2 |
In both cases, when no infected neighbour is present (m = 0), the rate is Fk,0 = a and therefore the parameter a controls the strength of exogenous factors. Analogously, b controls the increase of Fk,m with m and therefore the strength of endogenous factors. Given a network and values of a and b, we obtain numerically both the time-series ρ(t) (using the AME formalism [25,26]; electronic supplementary material, section IIC), and the strength of exogenous factors G from equation (2.5). Typically, these models cannot be reduced to a one-dimensional population dynamics model and therefore the estimators 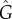 and
and 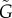 (based on ρ(t)) differ from the actual G. As a test of our methods, we compare the exact G to L,
(based on ρ(t)) differ from the actual G. As a test of our methods, we compare the exact G to L, 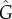 and
and 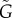 .
.
In figure 2, we apply our time-series analysis to the two models defined above with parameters a = 0.1 and b = 0.5. Method 1 provides L > 0.5 in both cases, incorrectly identifying that the exogenous factor is stronger. Furthermore, 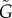 (Method 3) provides a better estimation of G than
(Method 3) provides a better estimation of G than 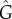 (Method 2). This is expected since the estimation
(Method 2). This is expected since the estimation 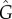 is based on a straight line estimation of g(ρ),
is based on a straight line estimation of g(ρ), 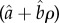 , while
, while 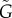 admits more general function (see figure 2b,d). The estimations are better for the Bass model than for the threshold dynamics, consistent with the better agreement between ρ(t) and the fit of equation (1.2) in panel (a) than in panel (c).
admits more general function (see figure 2b,d). The estimations are better for the Bass model than for the threshold dynamics, consistent with the better agreement between ρ(t) and the fit of equation (1.2) in panel (a) than in panel (c).
Figure 2.

Application of time-series estimations to surrogate data. The Bass (a,b) and threshold (c,d) dynamics with parameters a = 0.1 and b = 0.5 were numerically solved in the AME framework for scale-free networks (with degree distribution 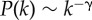 with
with 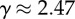 for
for 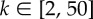 such that
such that 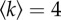 ). (a,c) Adoption curve ρ(t) (fraction of adopted agents over time). (b,d) Numerical estimate of g(ρ), obtained from ρ(t) by inverting equation (2.2). Dashed curves correspond to the fit of equation (1.2) to ρ(t). Estimations of G correspond to the area between the horizontal grey line (
). (a,c) Adoption curve ρ(t) (fraction of adopted agents over time). (b,d) Numerical estimate of g(ρ), obtained from ρ(t) by inverting equation (2.2). Dashed curves correspond to the fit of equation (1.2) to ρ(t). Estimations of G correspond to the area between the horizontal grey line (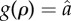 ) and the solid (
) and the solid (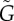 ) or dashed (
) or dashed (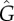 ) curves in (b,d). Results: Bass
) curves in (b,d). Results: Bass 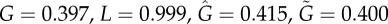 ; threshold
; threshold 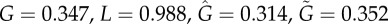 .
.
In figure 3, we repeat the analysis of figure 2 varying the parameters a,b in equation (4.1) and (4.2), while equation (2.5) gives the true value of G. The parameter space a,b is divided into two regions: one for which the exogenous factors dominate G > 0.5 (below the red dashed line G = 0.5) and one for which the endogenous factors dominate G < 0.5 (above the red dashed line G = 0.5). In the Bass dynamics, the division between these regions corresponds to a smooth (roughly straight) line. In the threshold model, a more intricate curve is obtained, with plateaus on rational values of b reflecting the discretization of the threshold dynamics in equation (4.2) (particularly strong for the large number of agents with few neighbours). A strong indication of the limitations of the L and 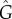 estimators is that the L = 0.5 (panel (d)) and
estimators is that the L = 0.5 (panel (d)) and 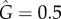 (panel (e)) lines show non-monotonic growth in the a,b space. This artefact disappears using the
(panel (e)) lines show non-monotonic growth in the a,b space. This artefact disappears using the 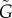 estimator. Regarding the relative errors of the methods 2 and 3 (colour code), the results confirm that
estimator. Regarding the relative errors of the methods 2 and 3 (colour code), the results confirm that 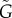 is the best method and provides a surprisingly accurate estimation of G. Comparing the different models, the estimations for Bass are better than for the threshold dynamics (for the same parameters (a,b)). The minimum errors are obtained for b ≈ 0, while for a ≈ 0 maximum errors for both methods are observed.
is the best method and provides a surprisingly accurate estimation of G. Comparing the different models, the estimations for Bass are better than for the threshold dynamics (for the same parameters (a,b)). The minimum errors are obtained for b ≈ 0, while for a ≈ 0 maximum errors for both methods are observed.
Figure 3.

Strength of endogenous factors G in the Bass [equation (4.1), panels (a,b,c)] and threshold [equation (4.2), panels (d,e,f)] models for different parameters a and b. The dashed lines correspond to values of a,b for which G = 1/2 (centre, red), G = 1/3 (black below red) and G = 2/3 (black above red), computed from equation (2.5). The different panels show the estimations based on L (a,d), 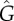 (b,e) and
(b,e) and 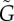 (c,f). Solid lines indicate values of a,b for which values 1/2, 1/3 and 2/3 were obtained and should be compared to the corresponding dashed lines. The colour code indicates the relative errors between the true value G and the estimated values
(c,f). Solid lines indicate values of a,b for which values 1/2, 1/3 and 2/3 were obtained and should be compared to the corresponding dashed lines. The colour code indicates the relative errors between the true value G and the estimated values 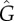 (b,e) and
(b,e) and 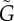 (c,f). The model dynamics was simulated for scale-free networks with the same parameters as in figure 2. (Online version in colour.)
(c,f). The model dynamics was simulated for scale-free networks with the same parameters as in figure 2. (Online version in colour.)
5. Application to data
We now turn to the analysis of empirical data taken from the Google-ngram corpus [3,4], see [29] and the electronic supplementary material, section I. We focus on the three cases reported in figure 1.
(a) German orthographic reforms: The 1996, orthography reform aimed to simplify the spelling of the German language based on phonetic unification. According to this reform, after a short vocal one should write ‘ss' instead of ‘ß’, which predominated since the previous reform in 1901. This rule makes up over 90% of the words changed by the reform [30]. We combine all words affected by this rule to estimate the strength of adoption of the orthographic reform, i.e. ρ(t) is the fraction of word tokens in the list of affected words written with ‘ss'.
Although following the reform was obligatory at schools, strong resistance against it led to debates even in the Federal Constitutional Court of Germany [31]. For example, ‘6 years after the reform, 77% of Germans consider the spelling reform not to be sensible’ [30]. These debates show that besides the exogenous pressure of language academies, endogenous factors can be important in this case also, either for or against the change.
(b) Russian names: Since the nineteenth century, there have been different systems for the romanization of Russian names, i.e. for mapping names from the Cyrillic to the Latin alphabet [32]. These systems can be seen as exogenous factors. Alternatively, imitation from other authors can be considered as endogenous factors. All of the systems suggest a unique mapping from letter ‘в’ to ‘v’ (e.g. Колмогоров to Kolmogorov). Variants to this official romanization system are ‘ff’ or ‘w’ (e.g. Kolmogorow and Kolmogoroff) which were used in different languages such as German and English. Here, we study an ensemble of 50 Russian names ending in either ‘-ов’ or ‘-eв’ that were used often in English (en) and German (de). For each of these two languages, we combine all words (tokens) in order to obtain a single curve ρ(t) measuring the adoption of the ‘v’ convention.
(c) Regularization verbs in English: A classical studied case of grammatical changes is regularization of English verbs [33,34]. From 177 irregular verbs in Old English, 145 cases survived in Middle English and only 98 are still alive [33]. Irregular verbs coexist with their regular (past tense written by -ed) competitors, even if dictionaries may only present irregular forms [3]. Having an easier grammar rule or a rule aligned with a larger grammatical class are good motivations to use more often regular forms. Other potential exogenous factors which favour works against regularization can be dictionaries and grammars. However, there are also cases of verbs that become irregular [3,35]. We analyse 10 verbs that exhibit the largest relative change. In eight cases, regularization is observed.
Besides the linguistic and historical interest in these three cases, there are also two practical reasons for choosing these three simple spelling changes: (i) they provide data with high resolution and frequency and (ii) they allow for an unambiguous identification of ‘competing variants', a difficult problem in language change [36]. The last point allows us to concentrate on the relative word frequency (as defined in figure 1) which we identify with the relative number of adopters ρ(t) in the models of previous sections. The advantage of investigating relative frequencies, instead of the absolute frequency of usage of one specific variation, is that they are not affected by absolute changes in the usage of the word.
Figure 4 shows estimations of the strength of exogenous factors G (using the methods of §3) in the three examples of linguistic change described above. In line with the definition proposed in §2, G is interpreted as the fraction of adoptions because of exogenous factors. Besides the most likely estimation obtained for the complete datasets (red ×), we have performed a careful statistical analysis (based on bootstrapping) in order to determine the confidence of our estimations (grey box plots). We first discuss the performance of the three methods
Figure 4.

Estimation of the strength of exogenous factors in empirical data. The red × indicates the estimated value obtained using the complete database. The box plots (grey box and black bars) were computed using bootstrapping and quantify the uncertainty of the estimated value (from left to right, the horizontal bars in the boxplot indicate the 2.5, 25, 50, 75 and 97.5% percentile). Panels (a–c) show the estimations based on the three methods proposed in §3. (a) Method 1: the likelihood ratio L of the exponential fit (exogenous factors) in relation to the symmetric S-curve fit (endogenous factors). (b) Method 2: estimation 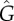 based on the fit of equation (1.2) and on equation (2.4). Method 3: estimation
based on the fit of equation (1.2) and on equation (2.4). Method 3: estimation 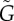 based on the general population dynamics model 4 (see the electronic supplementary material, section III, for details on the implementation of the three methods and for figures of individual adoption curves). (Online version in colour.)
based on the general population dynamics model 4 (see the electronic supplementary material, section III, for details on the implementation of the three methods and for figures of individual adoption curves). (Online version in colour.)
Method 1: The estimation of the likelihood L that the exponential fit (exogenous factors) is better than the symmetric S-curve fit (endogenous factors) resulted almost always in a categorical decision (i.e. L = 0 or L = 1). This is explained by the large amount of data that makes any small advantage for one of the fits to be statistically significant. Naively, one could interpret this as a clear selection of the best model. However, our bootstrap analysis shows that in most cases the decision is not robust against small fluctuations in the data (grey boxes fill the interval 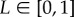 ). In these cases, our conclusion is that the method is unable to determine the dominant factors (endogenous or exogenous).
). In these cases, our conclusion is that the method is unable to determine the dominant factors (endogenous or exogenous).
Method 2: It generated the most tightly constrained estimates of G. The precision of the estimations of the strength of the exogenous factors G varied from case to case but remained typically much smaller than 1 (with the exception of the verb cleave). In all cases for which Method 1 provided a definite result, Method 2 was consistent with it. This is not completely surprising considering that the fit of the curve used in Method 2 has as limiting cases the curves used in the fit by Method 1. The advantage of Method 2 is that it works in additional cases (e.g. the Russian names), it provides an estimation of G (not only a decision whether G > 0.5), and it distinguishes cases in which both factors contribute equally (verb smell) from those that data is unable to decide (verb cleave).
Method 3: The results show large uncertainties and are shifted towards large values of G (in comparison to the two previous methods). In the few cases showing narrower uncertainties, an agreement with Method 2 is obtained in the estimated G (verbs wake and burn) or in the tendency G < 0.5 (Russian names in German). However, for most of the cases the uncertainty is too large to allow for any conclusion. The reason of this disappointing result is that Method 3 is very sensitive against fluctuations. For instance, it requires the computation of the temporal derivative of ρ. In simulations, this can be done exactly and the method provided the best results in §4. However in empirical data, discretization is unavoidable (in our case we have yearly resolution). Furthermore, fluctuations in the time series become magnified when discrete time differences are computed (see the electronic supplementary material, section IIIC for a description of the careful combination of data selection and smoothing used in our data analysis). In order to test these hypotheses, in figure 5 we test the robustness of Methods 2 and 3 against discretization in time—panels (a,b)—and population—panels (c,d)—for the model systems treated in §4. We observe that Method 3 is less robust than Method 2, showing a bias towards larger G for temporal discretizations and broad fluctuations for population discretizations. These findings can be expected to hold for other types of noise and are consistent with our observations in the data.
Figure 5.

Method 2 is more robust against perturbations than Method 3. Estimation of G in undersampled versions of the time series used in figure 2 for Bass (left) and threshold (right) dynamics. The true G [equation (2.5)] is shown as a dashed line and Methods 2 and 3 are shown by symbols. (a,b) Undersampling in time: achieved by varying the time-resolution Δt of the time series, i.e. we sample ρ(t) at times 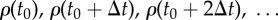 . Resolution increases for Δt → 0. (c,d) Undersampling of the population N. The surrogate time-series ρ(t) in figure 2 assume N → ∞. We consider time series for which only a finite population N is observed. The observed fraction of adopters is determined from N independent Bernoulli trials with probability ρ(t). This corresponds to adding noise to each data point ρ(t). Resolution increases for N → ∞. For each N, we plot the average and standard deviation of G computed over 1000 trials. (Online version in colour.)
. Resolution increases for Δt → 0. (c,d) Undersampling of the population N. The surrogate time-series ρ(t) in figure 2 assume N → ∞. We consider time series for which only a finite population N is observed. The observed fraction of adopters is determined from N independent Bernoulli trials with probability ρ(t). This corresponds to adding noise to each data point ρ(t). Resolution increases for N → ∞. For each N, we plot the average and standard deviation of G computed over 1000 trials. (Online version in colour.)
We now interpret the results of figure 4 for our three examples (see the electronic supplementary material, figures S1–S4, for the adoption curves of individual words)
(a) Results for the German orthographic reform indicate a stronger presence of exogenous factors, consistent with the interpretation of the (exogenous) role of language academies in language change being dominant.
(b) The romanization of Russian names indicates a prevalence of endogenous factors. Most systems that aim at making the romanization uniform have been implemented when the process of change was already taking place (The change starts around 1900 and first agreement is from 1950). Moreover, the implementation of these international agreements is expected to be less efficient than the legally binding decisions of language academies (such as in orthographic reforms).
(c) The regularization of English verbs shows a much richer behaviour. Besides some unresolved cases (e.g. the verb cleave), the general tendency is for a predominance of endogenous factors (e.g. the verbs spill and light), with some exceptions (e.g. the verb wake).
6. Discussions and conclusion
In summary, in this paper we combined data analysis and simple models to quantitatively investigate S-curves of vocabulary replacement. Our data analysis shows that linguistic changes do not follow universal S-curves (e.g. some curves are better described by an exponential than by a symmetric S-curve and fittings of equation (1.2) leads to different values of 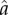 and
and 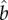 ). These conclusions are independent of theoretical models and should be taken into account in future quantitative investigations of language change.
). These conclusions are independent of theoretical models and should be taken into account in future quantitative investigations of language change.
Non-universal features in S-curves suggest that information on the mechanism underlying the change can be obtained from these curves. To address this point, we considered simple mechanistic models of innovation adoption and three simplifying assumptions (identical agents, monotonic change and constant strength of exogenous factors). We introduced a measure (equation (2.1)) of the strength of exogenous factors in the change and we discussed three methods to estimate it from S-curves. Our results show a connection between the shape of the S-curves and the strength of the factors (figure 3). Exogenous factors typically break symmetries of the microscopic dynamics and lead to asymmetric S-curves. Thus the crucial point in all methods is to quantify how abrupt (exogenous) or smooth (endogenous) the curve is at the beginning of the change. We verified that both our proposed measure and methods correctly quantify the role of exogenous factors in binary-state network models. In empirical data, the finite temporal resolution and other fluctuations have to be taken into account in order to ensure the results of the methods are reliable. These findings and the methods introduced in this paper—data analysis and measure of exogenous factors—can be directly applied also to other problems in which S-curves are observed [14–17].
S-curves provide only a very coarse-grained description of the spreading of linguistic innovations in a population. For those interested in understanding the spreading mechanism, the relevance of our work is to show that S-curves can be used to discriminate between different mechanistic descriptions and to quantify the importance of different factors known to act on language change. In view of the proliferation of competing models and factors, it is essential to compare them to empirical studies, which are often limited to aggregated data such as S-curves. Furthermore, quantitative descriptions of S-curves quantify the speed of change and predict future developments. These features are particularly important whenever one is interested in favouring convergence (e.g. the agreement on scientific terms can be crucial for scientific progress [37] and dissemination [38]).
Supplementary Material
Acknowledgements
We thank J. C. Leitão for the careful reading of the manuscript.
References
- 1.Weinreich U, Labov W, Herzog M. 1968. Empirical foundations for a theory of language change. Austin, TX: University of Texas Press. [Google Scholar]
- 2.Blythe R, Croft W. 2012. S-curves and the mechanisms of propagation in language change. Language 88, 269–304. ( 10.1353/lan.2012.0027) [DOI] [Google Scholar]
- 3.Michel J-B, et al. 2011. Quantitative analysis of culture using millions of digitized books. Science 331, 176–182. ( 10.1126/science.1199644) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Lin Y, Michel J-B, Aiden E, Orwant J, Brockman W, Petrov S. 2012. In Proc. ACL 2012 System Demonstrations, Jeju Island, Korea, July, pp. 169–174. Stroudsburg, PA: Association for Computational Linguistics. [Google Scholar]
- 5.Myers S, Zhu C, Leskovec J. 2012. In Proc. 18th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August, pp. 33–41. New York, NY: ACM. [Google Scholar]
- 6.Niyogi P. 2006. The computational nature of language learning and evolution. Cambridge, MA: MIT Press. [Google Scholar]
- 7.Baxter G, Blythe R, Croft W, McKane A. 2006. Utterance selection model of language change. Phys. Rev. E 73, 046118 ( 10.1103/PhysRevE.73.046118) [DOI] [PubMed] [Google Scholar]
- 8.Ke J, Gong T, Wang W. 2008. Language change and social networks. Commun. Comput. Phys. 3, 935–949. [Google Scholar]
- 9.Pierrehumbert JB, Stonedahl F, Daland R. 2014. A model of grassroots changes in linguistic systems (http://arxiv.org/abs/1408.1985)
- 10.Boyd R, Richerson PJ. 1985. Culture and the evolutionary process. Chicago, IL: University of Chicago Press. [Google Scholar]
- 11.Castellano C, Fortunato S, Loreto V. 2009. Statistical physics of social dynamics. Rev. Mod. Phys. 81, 591–646. ( 10.1103/RevModPhys.81.591) [DOI] [Google Scholar]
- 12.Baronchelli A, Loreto V, Tria F. 2012. Language dynamics. Adv. Complex Syst. 15, 1203002 ( 10.1142/S0219525912030026) [DOI] [Google Scholar]
- 13.Solé RV, Corominas-Murtra B, Fortuny J. 2010. Diversity, competition, extinction: the ecophysics of language change. J. R. Soc. Interface 7, 1647–1664. ( 10.1098/rsif.2010.0110) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Rogers E. 2010. Diffusion of innovations. New York, NY: Simon and Schuster. [Google Scholar]
- 15.Vitanov N, Ausloos M. 2012. Models of science dynamics, pp. 69–125. New York, NY: Springer. [Google Scholar]
- 16.Bass FM. 1969. A new product growth for model consumer durables. Manag. Sci. 15, 215–227. ( 10.1287/mnsc.15.5.215) [DOI] [Google Scholar]
- 17.Bass F. 2004. Comments on “A new product growth for model consumer durables the bass model”. Manag. Sci. 50, 1833–1840. ( 10.1287/mnsc.1040.0300) [DOI] [Google Scholar]
- 18.Bettencourt L, Cintron-Arias A, Kaiser D, Castillo-Chavez C. 2006. The power of a good idea: quantitative modeling of the spread of ideas from epidemiological models. Phys. A Stat. Mech. Appl. 364, 513–536. ( 10.1016/j.physa.2005.08.083) [DOI] [Google Scholar]
- 19.Sornette D, Deschâtres F, Gilbert T, Ageon Y. 2004. Endogenous versus exogenous shocks in complex networks: an empirical test using book sale rankings. Phys. Rev. Lett. 93, 228701 ( 10.1103/PhysRevLett.93.228701) [DOI] [PubMed] [Google Scholar]
- 20.Crane R, Sornette D. 2008. Robust dynamic classes revealed by measuring the response function of a social system. Proc. Natl Acad. Sci. USA 105, 15 649–15 653. ( 10.1073/pnas.0803685105) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Argollo de Menezes M, Barabasi A-L. 2004. Separating internal and external dynamics of complex systems. Phys. Rev. Lett. 93, 068701 ( 10.1103/PhysRevLett.93.068701) [DOI] [PubMed] [Google Scholar]
- 22.Mathiesen J, Angheluta L, Ahlgren P, Jensen M. 2013. Excitable human dynamics driven by extrinsic events in massive communities. Proc. Natl Acad. Sci. USA 110, 17 259–17 262. ( 10.1073/pnas.1304179110) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Hens N, Aerts M, Faes C, Shkedy Z, Lejeune O, Van Damme P, Beutels P. 2010. Seventy-five years of estimating the force of infection from current status data. Epidemiol. Infect. 138, 802–812. ( 10.1017/S0950268809990781) [DOI] [PubMed] [Google Scholar]
- 24.Newman M. 2010. Networks: an introduction. Oxford, UK: Oxford University Press. [Google Scholar]
- 25.Gleeson J. 2013. Binary-state dynamics on complex networks: pair approximation and beyond Phys. Rev. 3, 021004 ( 10.1103/PhysRevX.3.021004) [DOI] [Google Scholar]
- 26.Gleeson J. 2011. High-accuracy approximation of binary-state dynamics on networks. Phys. Rev. Lett. 107, 068701 ( 10.1103/PhysRevLett.107.068701) [DOI] [PubMed] [Google Scholar]
- 27.Hastie T, Tibshirani R, Friedman J. 2009. The elements of statistical learning, 2nd edn New York, NY: Springer. [Google Scholar]
- 28.Burnham KP, Anderson DR. 2002. Model selection and multimodel inference: a practical information-theoretic approach, 2nd edn New York, NY: Springer. [Google Scholar]
- 29.Fakhteh Ghanbarnejad and Martin Gerlach and José María Miotto and Eduardo Altmann. 2014. Timeseries for examples of language change obtained from the Googlengram-corpus. See http//dx..org/10.6084/m9.figshare.1172265.
- 30.Wikipedia. 2014. German orthography reform of 1996—Wikipedia, the free encyclopedia (Online; accessed 13 June 2014).
- 31.Johnson S. 2005. Spelling trouble? Language, ideology and the reform of German orthography. Clevedon, UK: Multilingual Matters. [Google Scholar]
- 32.Wikipedia. 2014. Romanization of Russian— Wikipedia, the free encyclopedia. (Online; accessed 13 June 2014).
- 33.Lieberman E, Michel J-B, Jackson J, Tang T, Nowak M. 2007. Quantifying the evolutionary dynamics of language. Nature 449, 713–716. ( 10.1038/nature06137) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Pinker S. 1999. Words and rules: the ingredients of language. New York, NY: Basic Books. [Google Scholar]
- 35.Cuskley CF, Pugliese M, Castellano C, Colaiori F, Loreto V, Tria F. 2014. Internal and external dynamics in language: evidence from verb regularity in a historical corpus of English. PLoS ONE 9, e102882 ( 10.1371/journal.pone.0102882) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Hruschka D, Christiansen M, Blythe R, Croft W, Heggarty P, Mufwene S, Pierrehumbert J, Poplach S. 2009. Building social cognitive models of language change. Trends Cogn. Sci. 13, 464–469. ( 10.1016/j.tics.2009.08.008) [DOI] [PubMed] [Google Scholar]
- 37.Knapp S, Polaszek A, Watson M. 2007. Spreading the word. Nature 446, 261 ( 10.1038/446261a) [DOI] [PubMed] [Google Scholar]
- 38.Bentley R, Garnett P, O'Brien M, Brock W. 2012. Word diffusion and climate science. PLoS ONE 7, e47966 ( 10.1371/journal.pone.0047966) [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.