

Summary
The log-rank test has been widely used to test treatment effects under the Cox model for censored time-to-event outcomes, though it may lose power substantially when the model’s proportional hazards assumption does not hold. In this paper, we consider an extended Cox model that uses B-splines or smoothing splines to model a time-varying treatment effect and propose score test statistics for the treatment effect. Our proposed new tests combine statistical evidence from both the magnitude and the shape of the time-varying hazard ratio function, and thus are omnibus and powerful against various types of alternatives. In addition, the new testing framework is applicable to any choice of spline basis functions, including B-splines and smoothing splines. Simulation studies confirm that the proposed tests performed well in finite samples and were frequently more powerful than conventional tests alone in many settings. The new methods were applied to the HIVNET 012 Study, a randomized clinical trial to assess the efficacy of single-dose Nevirapine against mother-to-child HIV transmission conducted by the HIV Prevention Trial Network.
Keywords: Censoring, Clinical trials, HIV/AIDS, Log-rank test, Score test
1. Introduction
The HIVNET 012 Study is a randomized clinical trial conducted by the HIV Prevention Trial Network (HPTN) between 1997 and 2001 (The HIVNET/HPTN Group, 2003). It showed an astounding prevention benefit for a short course of nevirapine (NVP) versus zidovudine (AZT) among HIV infected pregnant women in Uganda: NVP was associated with a 41% reduction in relative risk of mother-to-child transmission (MTCT) of HIV-1 through to the age of 18 months (Jackson et al., 2003).
Besides the prevention benefit, it was also important for this study to assess whether or not the NVP would eventually improve the newborn’s 18-month survival. As shown in Figure 1(a), Kaplan-Meier curves indicate that the NVP group appears to have better infant survival. However, the log-rank test does not show statistical significance (p-value: 0.147). Although the lack of significance could be due to insufficient sample size, the power of the log-rank test may also be compromised if the proportional hazards assumption does not hold. We plot the log-log-transformed estimated cumulative hazard functions in Figure 1(b), which demonstrates that the two Kaplan-Meier curves indeed appear to get closer as time progresses. This suggests that the hazard ratio is not constant over time.
Figure 1.

The HIVNET 012 Study: estimated Kaplan-Meier curves for two treatment arms and their transformation by log negative log.
In the HIVNET 012 Study, NVP was only given once to the mothers at labor onset and once to the babies within 72 hours of birth, while AZT was given to the mothers from labor onset to delivery and to the babies twice daily for 7 days after birth. It was not expected that the NVP effect would sustain throughout the 18 months of follow-up. In addition, even if the babies were born uninfected, they could be infected after birth via breastmilk because the ratio of HIV-susceptible cells to total breastmilk cells increases over time. Therefore, one would predict the risk reduction of 18-month infant mortality to vary over time. If so, it is important to develop appropriate statistics to test whether there is any infant survival benefit from NVP while allowing for nonproportional hazards.
As alluded to above, the power of log-rank test, or the score test based on the partial likelihood for the Cox proportional hazards model (Cox, 1972), depends on the alternative assumption of proportional hazards. They may lose power if the assumption does not hold, as in the HIVNET 012 Study example. This paper aims to develop flexible testing procedures for potentially time-varying treatment effects for censored time-to-event data.
To be specific, we consider an extended Cox proportional hazards model as follows:
| (1) |
Here, λ(·|X, Z) is the hazard function for the p-dimensional covariate vector X ∈
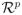 and the treatment indicator Z ∈
and the treatment indicator Z ∈
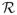 , and λ0(·) is the baseline hazard function. The superscript T is for vector (matrix) transpose. Moreover, β is the time-independent regression parameter of the same p-dimension for X, and θ(·) is the time-varying coefficient for Z that is assumed to be a smooth function of time. When θ(t) is constant, model (1) reduces to the usual Cox model. Under model (1), we are interested in testing the null hypothesis that Z has effect at any time while adjusting for X, i.e., H0: θ(t) = 0 for any t ≥ 0.
, and λ0(·) is the baseline hazard function. The superscript T is for vector (matrix) transpose. Moreover, β is the time-independent regression parameter of the same p-dimension for X, and θ(·) is the time-varying coefficient for Z that is assumed to be a smooth function of time. When θ(t) is constant, model (1) reduces to the usual Cox model. Under model (1), we are interested in testing the null hypothesis that Z has effect at any time while adjusting for X, i.e., H0: θ(t) = 0 for any t ≥ 0.
There have been several approaches in the statistical literature for hypothesis testing involving θ(·) in (1). For example, Self (1991) and Wu and Gilbert (2002) considered adaptively weighted log-rank tests, assuming parametric forms of θ(·) to be polynomial functions. For nonparametric or semiparametric approaches, Gray (1994) applied B-spline bases to approximate θ(·) with a careful manual choice of tuning parameters, such as degrees of freedom and number of knots. Nevertheless, the choice of tuning parameters would depend on the functional shape of true θ(·) and was generally unknown; different choices of tuning parameters could affect power considerably and lead to different p-values. Other approaches may resort to direct nonparametric estimation of θ(·), as seen in O’Sullivan (1988), Hastie and Tibshirani (1990), Zucker and Karr (1990), Sleeper and Harrington (1990), Kooperberg et al. (1995), Brown et al. (2007), and references therein. This work is useful in understanding the overall shape of θ(·). Although asymptotic properties are developed for an estimated θ̂(t) at a specific time t, they are usually not intended for testing the global null H0: θ(t) = 0 for any t ≥ 0.
The null hypothesis of interest is related to but fundamentally different from H0,PH: θ(t) = c for some constant c ∈
. In fact, H0,PH is exactly equivalent to the proportional hazards assumption, with testing procedures including Pettitt and Bin Daud (1990), Gray (1994) and Lin et al. (2006). Specifically in Lin et al. (2006), θ(·) was approximated by smoothing spline bases, and the authors proposed a score test for H0,PH that does not involve tuning parameters. Nevertheless, we would like to emphasize that these approaches test a different null hypothesis from the proposed test, and are thus not comparable with our work. The differences between our work and other previous literature are further clarified in Section 3.5.
In this article, we aim to develop proper testing methods specifically for the null hypothesis H0: θ(t) = 0 for any t ≥ 0 under model (1), based on spline representation of the hazard ratio θ(t). The rest of the paper is organized as follows. In Section 3, we study the extended Cox model and derive the proposed statistics. Extensive Monte-Carlo simulations studies are presented in Section 4 with various choices of θ(t) to evaluate a finite sample performance of our score statistics. We also apply our proposed statistics to compare the 18-month infant survival rates of the HIVNET 012 Study. We conclude in Section 5 by summarizing our results and discussing relevant issues and future directions.
2. The extended Cox model
Throughout this paper, we assume the extended Cox model as in (1). Our aim is to develop powerful and omnibus hypothesis testing procedures for H0: θ(t) = 0 for any t ≥ 0. When θ(·) is constant, model (1) reduces to the usual Cox proportional hazards model. Nevertheless, θ(t) can be quite flexible. It allows the hazard ratio between two treatment groups to change over time for any given X. Some properties regarding this model are summarized as follows:
Property
Denote the cumulative hazard function by . Let θ(0) = θ0 and assume that limt→∞ θ(t) = θ1 < ∞. Then
limt→0 log{Λ(t | X, Z)/Λ0(t)} = XTβ + Zθ0, and
limt→∞ log{Λ(t | X, Z)/Λ0(t)} = XTβ + Zθ1.
Proof of this property is straightforward. Based on this, when θ(·) is monotone, θ0 and θ1 define the lower and upper boundaries of the relative risk in cumulative hazard functions adjusted for X. For example, when θ(t) = 0.7 exp(−t), the hazard ratio for Z is 0.7 at t = 0, but gradually reduces to zero as time progresses. More examples of θ(·) are shown in Figure 2. Self (1991) and Wu and Gilbert (2002) considered special parametric submodels, where the shape θ(·) is represented by a family of polynomial functions indexed by a few parameters to account for early or late effects.
Figure 2.

Functional shapes of hazard ratio θ(t) that were used in simulations. We considered nine hazard functions, including linear (L), quadratic (Q), exponential (E1, E2), inverse-logistic (Expit), logarithm (Log1, Log2), step (S) and cosine (C) functions. Their specific functional forms are specified in Table 1.
2.1 Spline representations of θ(t)
We assume that the collected data consist of n independent and identically distributed (iid) copies of (Y, Δ, X, Z), where Y is the minimum of time to event T and censoring time C, i.e., Y = min(T, C), Δ = I(T ≤ C) is the event indicator, X is the vector of covariates other than the treatment indicator Z, namely {(Yi, Δi, Xi, Zi), i = 1, 2, …, n}. Let denote the ordered observed failure times, i.e., ordered statistics of {Yi: i = 1, 2, ···, n, and Δi = 1}, where is the number of observed failure time points.
To model the time-varying treatment effect flexibly, we consider representing θ(t) by fixed knots B-splines or smoothing splines, i.e.,
| (2) |
where Bk(t) forms a set of basis functions. Note that the methods development below works for both B-spline or smoothing spline approaches, and our experience is that the performance of the two approaches are comparable as long as the number of knots are reasonably dense. If one is using fixed knots B-splines, the number of basis function K is fixed and depends on the number of knots and the order of polynomials. For the smoothing spline approach, on the other hand, the number of basis functions depends on the sample size and the order of polynomials, i.e., K = r + m − 1.
Since the partial likelihood involves θ(t) evaluated at the observed failure time only, we define , where 1 ∈ ℝr is a vector whose elements are all 1, θ = (θ1, …, θK)T ∈ Θ ⊂ ℝr and B is a r × K matrix whose (i, j) element is .
2.2 Penalized likelihood
The spline representation introduces K parameters (θ1, ···, θK) for the hazard ratio function to allow flexibility. However, with a large degree of freedom, the model could overfit and the power to detect deviations from the null may be low. One strategy to avoid overfitting is to introduce a penalized partial likelihood function by penalizing the roughness of θ(t), e.g., in the form of ∫ {θ′(t)}2dt. It can be shown that the penalty term is a quadratic function of θ,
where Σ is a K × K matrix whose (i, j) element is , which is fully determined by the choice of splines. Thus, the penalized partial log likelihood function is defined by
| (3) |
where τ is a tuning parameter that controls smoothness of θ(t), and ℓP is the partial likelihood corresponding to hazard ratio function θ(t),
Note that τ controls the level of smoothness of θ(t) and thus the effective degree of freedom. When τ is small, the penalized partial likelihood encourages solutions that are close to the Cox proportional model with df = 1 for treatment effect. When τ is large, the effect of penalty is negligible and the model involves K + 1 parameters for the treatment effect, e.g., df = K + 1. Under this model, the null hypothesis can be represented as H0: θk = 0, , k ∈ {0, 1, ···, K}. Gray (1994) used B-splines and studied asymptotic properties of Wald, score and likelihood ratio tests for fixed tuning parameter τ. For the choice of tuning parameter, they suggested choosing a suitable degree of freedom (henceforth denoted df) and finding τ to achieve the desired df. However, in practice, the choice of suitable df is subjective, and the power performance depends on the tuning parameter.
To construct tests that do not depend on tuning parameters, one can exploit the connection between the penalized splines and random effects models (Ruppert et al., 2003). Note that the second term of (3) is proportional to the logarithm of a multivariate normal density with mean zero and the covariance matrix τΣ−1. Hence, one can treat θ as “random effects,” and integrate θ out with respect to the multivariate normal density to obtain the marginal partial log likelihood
| (4) |
We use this marginal likelihood as our objective function to derive the score statistics. In fact, since τ is the variance component for the random effects, setting τ = 0 shall lead to θ = 0. As a result, testing H0 is equivalent to H0: θ0 = 0, τ = 0. Note that this mixed effect model representation holds for both B-splines and smoothing splines.
Remark 1
Lin et al. (2006) considered a smoothing splines approach, where the log hazard ratio θ(t) can be represented by
where δj and θk are spline coefficients, {1, t, ···, tm−1} is a set of basis functions for (m − 1)th order polynomials, and , where x+ = x ∨ 0 = max{x, 0}. The choice of m in (2) depends on a pre-specified level of smoothness. If one chooses m = 1, the time-varying coefficient (2) is simplified as , where R(t, s) = min{t, s}. It can be shown that matrix B is exactly the same as Σ in this case.
Remark 2
There are several key differences between Lin et al. (2006) and our work. First, they are interested in testing the proportional hazards assumption, , which is a different null hypothesis. Thus, our approach and theirs are not directly comparable. Second, their null hypothesis involves the variance component parameter only, where ours involves an additional fixed effects parameter θ0. Statistically, as will be seen later, our work involves addressing challenges to combine score tests for both θ0 and τ, due to some non-standard properties for the variance component τ. Third, our approach here is not limited to the smoothing splines approach, and it works for other choices of basis functions such as B-splines.
3. Proposed test statistics
The aim of this paper is to propose “omnibus” testing procedures for potentially time-varying treatment effects, without making parametric assumptions on the shape of the hazard ratio. The idea is to combine evidence from both the average magnitude and shape of the hazard ratio function and construct test statistics that are powerful under both proportional hazards (henceforth denoted PH) and various non-PH alternatives.
3.1 A two-stage test
In the literature, there were developments on hypothesis testing procedures for the proportional hazards assumption, e.g., Lin et al. (2006), denoted by TLZD. If one aims to test treatment effect H0 while accounting for potential non-proportionality, a natural strategy is to construct a two-stage procedure as follows (henceforth denoted T2stg),
-
S1
apply the test TLZD for the PH assumption. Reject H0, if the p-value is less than a pre-determined significance level α1; otherwise, go to the second stage;
-
S2
apply the standard log-rank test for treatment effect. Reject H0 if the p-value is less than another pre-determined significance level α2.
This procedure is a straightforward extension of the log-rank test and TLZD. Note that S1 tests the proportional hazards assumption, while S2 tests treatment effect given the proportional hazards assumption is plausible. The overall null hypothesis is rejected if either stage rejects the null. The overall type I error rate of this two-stage procedure depends on the correlation of two tests, but is bounded by α1 + α2 from above according to the Bonferroni inequality. The parameters α1 and α2 control how much type I error was assigned to the two tests. In practice, one can choose α1 = α2 = α/2 without prior information on the plausibility of proportional hazards, where α is the targeted overall significance level. The performance of this simple two-stage procedure will be compared with the standard log-rank test as well as other proposed methods discussed below.
3.2 Score statistics
Next, we construct a few test statistics based on combining score statistics for θ0 and τ. Taking the derivatives of (4) with respect to θ0 and τ, one obtains
and
| (5) |
where β̂ is the maximum partial likelihood estimate of the Cox model without treatment effect, i.e., the maximizer of the partial likelihood ℓP (β, θ0 = 0, θ = 0). First, we look at the derivative with respect to θ0. Denote S(β, θ0, θ) = (∂/∂γ)ℓP (β, θ0, θ), the kth element of S(β̂, 0, 0) is then . It can be shown that the covariance matrix of S(β, θ0, θ) is given by , where the Fisher information matrices are evaluated under the true parameter values. Thus, 1TS(β̂, 0, 0) is in fact the usual partial likelihood score function evaluated under the null. The standard score test statistic for θ0 can be written as
which is a quadratic form of S(β̂, 0, 0) and converges to due to rank(11T) = 1. Note here I0 = var{1TS(β̂, 0, 0)} = 1TV 1 is exactly the efficient Fisher information for θ0 under the Cox model. Thus, the standardized score test statistic TLR converges to a distribution under the null hypothesis. Next, we look at the derivative with respect to τ. It has been shown that the variation of second term of (5) is negligible relative to the first term (Lin et al., 2006). The first term of (5) is a quadratic form of S(β̂, 0, 0). According to quadratic form theory, its limiting distribution is weighted sum of χ2’s, with weights determined by the eigenvalues of Σ. This suggests that the asymptotic behavior of the score function for τ is non-standard.
Remark 3
For the smoothing splines approach with first-order polynomials (Lin et al., 2006), the term BΣ−1BT simplifies to Σ as B = Σ = BT in this case. They evaluated the score for τ at (β = β̃, θ0 = θ̃0, θ = 0) instead, where β̃ and θ̃0 are their maximum likelihood estimates under the Cox model, because they are testing a different null hypothesis .
3.3 Combine scores for θ0 and τ
To test H0: θ0 = 0, τ = 0, since the null hypothesis involves both θ0 and τ, one needs to combine score functions with respect to θ0 and τ (denoted as Uθ0 and Uτ, respectively), which reflect information from the average magnitude and shape of the hazard ratio function, respectively. Under regularity conditions, score functions for multiple parameters follow multivariate normal distribution asymptotically, and the standard approach is constructing linear combination of Uθ0 and Uτ weighted by the square root of the joint Fisher information matrix. However, this procedure does not work here, due to non-standard properties in testing variance components.
As discussed above, the parameter τ = 0 is on the boundary of its parameter space under the null. The dominating term of the score function with respect to τ converges to a weighted sum of ’s, instead of a Gaussian distribution. To overcome these challenges, we propose methods of combing two score functions to construct test statistics. Note that Uθ0 and Uτ are linear and quadratic forms of S(β̂, 0, 0), respectively. We propose combinations of them that are quadratic forms of S(β̂, 0, 0), whose asymptotic distribution can be derived conveniently.
The first test statistic T1 is constructed by taking the sum of Uτ and ,
| (6) |
where Î0 is an estimate of the efficient information for θ0 in the usual Cox model. Note that T1 is also a quadratic form of S(β̂, 0, 0), and thus its limiting distribution can be easily calculated. It converges to a weighted sum of ’s, with weights determined by eigenvalues of the matrix M1=BΣ−1BT + (Î0)−111T. Using the Satterthwaite approximation, the limiting distribution can be further simplified. Our score statistic rejects the null hypothesis H0 at the nominal level α if where is a 100(1 − α) percentile of the random variable with degree of freedom v. Here, k1 = tr(M1V M1V)/tr(M1V), and v1 = {tr(M1V)}2/tr(M1V M1V), where V = ∂2ℓP {β̂, (θ0, θT) = 0}/∂γ∂γT. The details on deriving the limiting distribution and its approximations are discussed in Appendix A.
The test statistic T1 is a sum of two quadratic forms. However, these two parts are not independent, and taking the sum directly may not be optimal in terms of power, with potential power loss depending their correlation. We propose to remove the projection of Sτ on Sθ0, so that the modified score statistics for τ (denoted by subscript “mPH”, i.e., modified test for PH) is asymptotically independent to the score statistics for θ0. Let
| (7) |
where W = Ir×r−V 11T/{1TV 1}. The matrix W is constructed so that WS(β̂, 0, 0) and 1TS(β̂, 0, 0) are asymptotically independent (see Appendix C). Note that TmPH is also a quadratic form of S(β̂, 0, 0) that reflects evidence on proportionality, on the direction that is orthogonal to the average magnitude of hazard ratio. The degree of freedom of TmPH depends on realizations of the data, and can be calculated by tr(V−1WTBΣ−1BTW).
We now construct the second test statistic by taking the sum of TLR and TmPH,
| (8) |
The test statistic T2 is also a quadratic form, and we can obtain the approximate asymptotic distribution according to Appendix A. Our score statistic T2 rejects the null hypothesis H0 at the nominal level α if where k2 = tr(M2V M2V)/tr(M2V), v2 = {tr(M2V)}2/tr(M2V M2V), and M2 = WTBΣ− 1BTW + (Î0)−111T.
Remark 4
More generally, one can consider the family of linear combinations of TLR and TmPH, e.g., using test statistics
| (9) |
where ρ determines the weights from two parts. The test statistic T(ρ) becomes the standard log-rank test when ρ = 0, and the modified test for proportionality when ρ = 1. The proposed test T2 corresponds to ρ = 0.5. The optimal choice of tuning parameter ρ is not clear and we plan to investigate this family of test statistics in the future. Our simulation studies suggest that T2 performs well in terms of power in finite samples.
3.4 Combination procedures based on p-values
We also explored a few other methods to combine information, e.g., Koziol and Perlman (1978), taking advantage of the fact that TLR and TmPH are asymptotically independent. For example, two commonly used procedures for combining independent tests are based on p-values, Fisher’s and Tippett’s procedures. Specifically, let PLR and PmPH denote p-values from TLR and TmPH respectively. The test statistics for Fisher’s procedure is
Under H0, it can be shown that T3 follows , and thus p-values can be calculated by , where is the cumulative distribution function of . We reject the null when at significance level α. On the other hand, Tippett’s procedure rejects the null when either PLR or PmPH is small, i.e., the test statistic is the minimum of two p-values
Under (asymptotic) independence of two tests, one can show that the formula for p-values for the combined test is P4 = 1 − (1 − T4)2. At significance level α, the rejection region is given by T4 < 1 − (1 − α)1/2.
Note that the two-stage test T2stg described in Section 3.1 can also be viewed as a combination procedure based on p-values. However, the proposed T3 and T4 combines two test statistics that are asymptotically independent, while the two statistics of T2stg are possibly correlated. The finite sample performance of these procedures will be evaluated in simulation studies.
3.5 Connection with previous literature
In the literature, there are two existing approaches most relevant to our proposed methods: Gray (1994) and Lin et al. (2006). However, there are substantial differences between their work and our proposed tests.
First, Gray (1994) used B-splines to model θ(t) and proposed Wald, score and likelihood ratio statistics based on penalized partial likelihood for fixed values of tuning parameter. Their approach is applicable to several hypothesis testing problems, including testing time-varying treatment effect H0 (see Section 4 of their paper). However, it depends on a tuning parameter that controls the effective degree of freedom of splines. The tuning parameter affects the power of these tests substantially and is often difficult to choose in practice. If we use the same B-spline approach, our work can be viewed as extensions of Gray (1994) through a mixed effects model framework. In contrast, our proposed tests are automatic procedures that do not depend on tuning parameters, and are shown to be as or more powerful in finite samples (see the next section).
Second, Lin et al. (2006) proposed smoothing spline based score tests in extended Cox models. They discussed several hypothesis testing problems, including testing the proportional hazards null H0,PH : θ(t) = θ0 versus an alternative model with a time-varying hazard function. From a random effects model perspective, their null hypothesis can be represented via the variance component, i.e., H0,PH : τ = 0. Although our development adapts some technical arguments from Lin et al. (2006), we target a different null hypothesis H0 : θ(t) = 0, or equivalently H0 : θ0 = 0, τ = 0. Their approach is applicable only when the null hypothesis is represented via the variance component τ only, thus excluding the problem of testing H0. Other than the fundamental differences in the null hypotheses of interest, the primary challenge of extending their approach to our problem is how to combine information from θ0 and τ, and this is not straightforward given the non-standard nature of variance components. We proposed a few approaches to combine score statistics for θ0 and τ, and this is one of the main contributions of this paper from a methodological perspective.
4. Numerical Studies
4.1 Simulations
To study the finite sample performance of the proposed tests, survival data of sample sizes n = 100 and n = 500 were generated from the extended Cox model (1) with a binary treatment indicator and no additional covariates. The baseline hazard function was a constant function, i.e., λ0(t) = 1. The censoring distribution was the uniform distribution on [0, c] where c was chosen to yield censoring probability 30% for each scenario. We conducted extensive simulation studies with various choices of θ(t), corresponding to different shapes of hazard ratio functions. The shapes of θ(t) are shown in Figure 2, most of which were considered by Gray (1994) and Lin et al. (2006) up to scale changes.
For each simulated dataset, we compared our methods with the log-rank test (denoted TLR), the two stage procedure with α1 = α2 = 0.025% as described in Section 3.1 (denoted T2stg), and the score statistic of Gray (1994) with pre-selected degree of freedom (denoted with K knots and degree of freedom df). For the score statistic of Gray (1994), we considered four choices, with the number of knots K = 10 and 20, and degrees of freedom df = 1.5 and 5. The performances of the likelihood ratio and Wald statistics of Gray (1994) are similar to the score statistic, and thus we only reported results for their score statistics. We also reported power from the modified test for proportionality, TmPH, since it is a valid test for H0 with a correct type I error. However, we do not mean to compare its performance with other tests directly, as TmPH summarizes evidence from non-constant shape of the hazard ratio only; rather our intention is to gain insights of how each method combines information from the magnitude and shape of the hazard ratio. We implemented the proposed test statistics T1, T2, T3, T4 using both B-splines with K = 20 knots and smoothing splines. The results were similar, and we only report the latter.
Table 1 summarizes results from our simulations. In terms of type I error, all test statistics maintained the nominal level of size (α = 0.05) approximately under the null hypothesis H0. In terms of power, none of the test statistics is optimal in detecting all types of alternatives. It is well known that the log-rank test is most powerful for treatment effect under the PH assumption, but may lose power otherwise. The aim of our work is to propose new “omnibus” tests that do not lose much power compared to log-rank under the PH assumption and also have decent power to detect non-PH alternatives.
Table 1.
Type I error rates and power for the proposed tests versus alternatives in simulations. The testing procedures include standard log-rank test (TLR), modified test for proportionality (TmPH), the two-stage test (T2stg), Gray’s score tests ( with K knots and degree of freedom df) and the proposed test statistics (T1, T2, T3 and T4).
| θ(t) | n | TLR | TmPH | T2stg |
|
|
|
|
T1 | T2 | T3 | T4 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| H0: 0 | 100 | 0.058 | 0.049 | 0.059 | 0.056 | 0.051 | 0.057 | 0.061 | 0.056 | 0.052 | 0.055 | 0.059 | ||||
| 500 | 0.042 | 0.063 | 0.060 | 0.056 | 0.058 | 0.059 | 0.053 | 0.054 | 0.062 | 0.059 | 0.060 | |||||
|
| ||||||||||||||||
| H0,PH: log 1.5 | 100 | 0.363 | 0.042 | 0.292 | 0.369 | 0.258 | 0.418 | 0.271 | 0.329 | 0.323 | 0.278 | 0.298 | ||||
| 500 | 0.971 | 0.053 | 0.933 | 0.966 | 0.905 | 0.964 | 0.912 | 0.943 | 0.946 | 0.932 | 0.934 | |||||
|
| ||||||||||||||||
| L: 0.8t | 100 | 0.350 | 0.221 | 0.369 | 0.421 | 0.373 | 0.444 | 0.424 | 0.491 | 0.428 | 0.407 | 0.373 | ||||
| 500 | 0.968 | 0.843 | 0.986 | 0.994 | 0.988 | 0.990 | 0.994 | 0.998 | 0.995 | 0.992 | 0.986 | |||||
|
| ||||||||||||||||
| Q: −0. 5t(t − 2.6) | 100 | 0.423 | 0.163 | 0.409 | 0.499 | 0.390 | 0.494 | 0.446 | 0.534 | 0.466 | 0.429 | 0.414 | ||||
| 500 | 0.990 | 0.636 | 0.987 | 0.995 | 0.991 | 0.993 | 0.991 | 0.996 | 0.993 | 0.992 | 0.987 | |||||
|
| ||||||||||||||||
| E1: 0.25 exp(0.8t) | 100 | 0.352 | 0.082 | 0.296 | 0.382 | 0.279 | 0.401 | 0.306 | 0.393 | 0.334 | 0.293 | 0.305 | ||||
| 500 | 0.968 | 0.316 | 0.954 | 0.980 | 0.950 | 0.971 | 0.954 | 0.981 | 0.971 | 0.969 | 0.956 | |||||
|
| ||||||||||||||||
| E2: 0.7 exp(−t) | 100 | 0.493 | 0.095 | 0.414 | 0.508 | 0.368 | 0.530 | 0.380 | 0.368 | 0.468 | 0.444 | 0.420 | ||||
| 500 | 0.990 | 0.285 | 0.991 | 0.997 | 0.988 | 0.994 | 0.981 | 0.975 | 0.995 | 0.993 | 0.991 | |||||
|
| ||||||||||||||||
|
|
100 | 0.503 | 0.064 | 0.413 | 0.520 | 0.398 | 0.528 | 0.432 | 0.505 | 0.457 | 0.406 | 0.422 | ||||
| 500 | 0.995 | 0.151 | 0.993 | 1.000 | 0.983 | 0.991 | 0.987 | 0.995 | 0.993 | 0.991 | 0.993 | |||||
|
| ||||||||||||||||
| Log1: 0.5 log(.75t) | 100 | 0.449 | 0.393 | 0.557 | 0.525 | 0.549 | 0.518 | 0.550 | 0.231 | 0.614 | 0.619 | 0.561 | ||||
| 500 | 0.978 | 0.976 | 0.999 | 0.997 | 0.999 | 0.997 | 1.000 | 0.835 | 1.000 | 1.000 | 0.999 | |||||
|
| ||||||||||||||||
| Log2: | 100 | 0.165 | 0.263 | 0.275 | 0.234 | 0.255 | 0.223 | 0.279 | 0.348 | 0.314 | 0.300 | 0.283 | ||||
| 500 | 0.652 | 0.862 | 0.911 | 0.882 | 0.922 | 0.871 | 0.946 | 0.952 | 0.941 | 0.940 | 0.912 | |||||
|
| ||||||||||||||||
| S: 1.5I (t < 1.0) | 100 | 0.187 | 0.439 | 0.413 | 0.297 | 0.494 | 0.307 | 0.514 | 0.372 | 0.441 | 0.449 | 0.417 | ||||
| 500 | 0.760 | 0.996 | 0.997 | 0.996 | 0.998 | 0.987 | 0.999 | 0.990 | 0.998 | 0.998 | 0.997 | |||||
|
| ||||||||||||||||
| C: 0.8 cos(2πt=2.7) | 100 | 0.354 | 0.440 | 0.545 | 0.475 | 0.501 | 0.484 | 0.499 | 0.245 | 0.576 | 0.606 | 0.549 | ||||
| 500 | 0.949 | 0.981 | 0.999 | 0.998 | 0.999 | 0.994 | 0.997 | 0.933 | 0.999 | 0.999 | 0.999 | |||||
We now compare power of various test statistics under both PH alternatives and a wide variety of non-PH alternatives. When the PH assumption holds and the true model is the Cox model (H0,PH), the log-rank test was the most powerful as expected. Gray’s score tests performed well, particularly with low degree of freedom (df = 1.5), but lost power substantially with higher degree of freedom (df = 5). The proposed linear combination statistics T1 and T2 have slightly lower power compared to the log-rank test, but the differences are small. The proposed p-value based statistics T3 and T4 are less powerful than the linear combination tests from simulations.
Under non-PH alternatives, there is no universally best test according to Table 1. First, we compare power performance between two proposed statistics T1 and T2. Under several scenarios (L, Q, E1, Expit, Log2), T1 has slightly higher power than T2 by around 2% and 6%. On the other hand, T2 outperforms T1 in other settings (E2, Log1, S, C), but generally with a more substantial power gain that varies between 7% to as high as 38% (Log1). Thus, the statistic T2 is considered “omnibus” in the sense that it has decent power against all types of alternatives and is our preferred choice, while T1 is prone to very low power to detect certain types of alternatives. The substantial power gain of T2 is likely due to the fact that the latter exploits orthogonality between information on the magnitude and shape of the hazard ratio function.
Next, we compare the proposed score statistic T2 versus the log-rank test (TLR), the modified PH test (TmPH) and the two-stage procedure (T2stg) under non-PH alternatives. Under many settings, T2 outperforms both TLR and Ttwo−stg. For example, under alternative curve Log2 and a sample size of 500, the power for T2 is 61.4%, much higher than both TLR (44.9%) and T2stg (55.7%). Under some alternatives (E1, E2, Expit), the power of T2 is lower than the log-rank test TLR but only by very slight margins. Thus, the proposed test T2 is generally comparable to or more powerful than TLR, since it combines information from the shape of hazard functions. The proposed test can potentially pick up evidence of treatment effects even if both TLR and TwoStg fail to suggest so. We also compared T2 versus Gray’s score tests. The power of Gray’s score tests varies with tuning parameters, especially with the degree of freedom, which needs to be prespecified and can affect power performance considerably. Their score tests with low df ( and ) perform well when the hazard function is close to a constant or linear function but poorly otherwise, while the opposite holds for the tests with high df ( and ). The proposed test T2 is often comparable or close to Gray’s statistics with the “better” choice of df in terms of power, and sometimes outperform all of them under certain alternatives (Log1 and C).
To summarize, the proposed test statistics, especially the preferred T2, demonstrate decent power performances under various alternative hypotheses in simulations. Other testing procedures, such as the log-rank test, the two-stage procedure and Gray (1994)’s score tests, are often powerful against certain alternatives but may lose power substantially against others. In addition, T2 does not depend on tuning parameters, making it an omnibus and desirable testing procedure to use in practice.
4.2 Application to HIVNET 012 Study
We demonstrate our proposed methods by analyzing our motivating example of infant survival in the HIVNET 012 Study mentioned in Section 1. In our data set, 310 women were assigned to the NVP group and 306 women to the AZT group. We exclude the second twins or more and stillbirth babies from the analysis. Mean CD4+ counts at the baseline for mothers in both groups were 482 and 465 (p = .41); mean log RNA viral copies with base 10 at visit 101 were 4.35 and 4.39 (p = .59); mean birth weights were 3080 kg and 3197 kg (p = 0.001), respectively. The total follow-up time is 18 months. The HIV-1 transmission risk and risk of death at the end of the study is 14.9 % and 23.5% (p = 0.007), and 9.3% and 12.7% (p = .18).
As we discussed in Section 1, the log-rank test does not show significance (p = 0.145), with estimated hazard ratio 0.701 (95 % CI: 0.43–1.13). However, the lack of statistical significance may be due to the fact that the log-rank test is not powerful when the PH assumption does not hold, which seemed to be the case in this application (Figure 6).
Next, we applied alternative tests, including weighted log-rank test, Gray’s test and the proposed tests. For weighted log-rank tests, we used weights corresponding to the Peto-Peto modification of the Wilcoxon statistic (Peto and Peto, 1972) considering the drug effect gradually disappeared over time, but the result is not significant (p = 0.125). We also tried weights from the Gρ family (Harrington and Fleming, 1982) with different ρ’s, but the usual choice of ρ between 0 and 1 did not yield a significant result. Gray’s score tests yielded different results depending on tuning parameters such as degrees of freedom and numbers of knots. Specifically, p-values corresponding to df = 1.5, 3 and 5 are 0.073, 0.032 and 0.057, respectively, with K = 10 knots, and are 0.069, 0.032 and 0.053, respectively, with K = 20 knots. These results may be confusing to practitioners since different df led to different p-values, and it is not clear which df one should choose for this specific application. The proposed test T2 suggested significant treatment effects (p = 0.015). To confirm the proportionality of the hazard ratio, we also applied the test and obtained p-value (p = 0.013), which suggested that the hazard ratio is time-varying and that the log-rank test is not optimal in this setting.
5. Discussion
We developed spline based score tests for time-varying treatment effects in an extended Cox model. The proposed approach is designed to test treatment effects when the proportional hazards assumption may not hold. These test statistics do not depend on tuning parameters and are easy to compute since they only require fitting the null model (Cox model). Simulation studies suggested that our methods gained power substantially compared to the log-rank test when the proportional hazards assumption does not hold.
There are some connections between the proposed tests and the widely used weighted log-rank test. As shown in Appendix B, the family of quadratic form tests Q = STUS, which include the weighted log-rank test, Lin et al.’s proportionality test and the proposed tests, are equivalent to a linear combination of several weighted log-rank tests with weights determined by the eigenvectors of the matrix U. The weighted log-rank test (when U has rank 1) is powerful when the chosen weights are close to the true hazard ratio functions, but may lose power substantially otherwise. In contrast, the proposed tests combine several plausible weighted log-rank tests, some of which reflect information on the smoothness of the hazard ratio function, and thus provide omnibus testing procedures that are powerful to detect a variety of alternatives.
There are a few areas for future research. As discussed in Section 2.2, one main challenge is how to combine scores for parameters θ0 and τ, given the non-standard nature of variance components testing. While the two proposed statistics are natural choices, they are not necessarily optimal in terms of power. There may be other ways to combine the score statistics. For example, one may explore the family of linear combinations and find an optimal weight within this family, or even identify the optimal statistics among nonlinear combinations if possible. The proposed methods can also be applied to other models and setting to detect a nonlinear trend. Although we focused on an extended Cox model, our method can be extended to other models such as an additive hazards models. Finally, one could also consider generalized Wald or partial likelihood ratio type approaches, as suggested by the reviewers. These approaches require first obtaining an estimate θ̂(t), which depends on the choice of the smoothing parameter τ. The tuning parameters are often chosen by adaptive approaches such as cross validation, and it is challenging to account for the uncertainty of choosing τ in the inference for θ(t). The (generalized) likelihood ratio test has been developed for linear mixed models (Fan et al., 2001; Crainiceanu and Ruppert, 2004), but not on generalized linear mixed models for discrete outcomes and mixed models for censored time-to-event data. Actually this is one of the main reasons that score tests are more popular in hypothesis testing for nonlinear mixed models.
One reviewer raised an interesting question of deriving a method to differentiate three hypotheses: the null, constant or truly time-varying effect of treatment. Two step procedures will be needed to accomplish this, as standard hypothesis testing is designed to distinguish two hypotheses only. For example, one can first apply the test of Lin et al. (2006), which differentiates “null or constant effect” vs. time-varying effect. If the null was not rejected in the first step, then apply the log-rank test to further differentiate null vs. constant effect. Alternatively, one can first apply the proposed test statistics, which differentiates null vs. “constant or time-varying effect.” If the null was rejected, then apply the test of Lin et al. (2006) to further differentiate constant vs. time-varying effect.
Supplementary Material
Acknowledgments
Takumi Saegusa, Chongzhi Di and Ying Qing Chen were partially supported by NIH grants R01AI089341 and P01CA53996. Chongzhi Di was also supported by NIH grants R21ES022332, R01AG014358 and R01HG006124. We thank Professor Taylor, the AE and reviewers for their helpful comments.
Footnotes
Appendices A, B and C referenced in the paper, as well as R codes for the proposed tests, are available with this paper at the Biometrics website on Wiley Online Library.
Contributor Information
Takumi Saegusa, Department of Biostatistics, University of Washington, Seattle, WA 98195, USA.
Chongzhi Di, Public Health Sciences Division, Fred Hutchinson Cancer Research Center, Seattle, WA 98109, USA.
Ying Qing Chen, Vaccine and Infectious Disease & Public Health Sciences Divisions, Fred Hutchinson Cancer Research Center, Seattle, WA 98109, USA.
References
- Brown D, Kauermann G, Ford I. A partial likelihood approach to smooth estimation of dynamic covariate effects using penalised splines. Biometrical Journal. 2007;49:441–452. doi: 10.1002/bimj.200510325. [DOI] [PubMed] [Google Scholar]
- Cox DR. Regression models and life-tables. Journal of the Royal Statistical Society: Series B (Methodological) 1972;34:187–220. [Google Scholar]
- Crainiceanu CM, Ruppert D. Likelihood ratio tests in linear mixed models with one variance component. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2004;66:165–185. [Google Scholar]
- Fan J, Zhang C, Zhang J. Generalized likelihood ratio statistics and wilks phenomenon. Annals of Statistics. 2001;29:153–193. [Google Scholar]
- Gray RJ. Spline-based tests in survival analysis. Biometrics. 1994;50:640–652. [PubMed] [Google Scholar]
- Harrington DP, Fleming TR. A class of rank test procedures for censored survival data. Biometrika. 1982;69:553–566. [Google Scholar]
- Hastie T, Tibshirani R. Exploring the nature of covariate effects in the proportional hazards model. Biometrics. 1990;46:1005–1016. [PubMed] [Google Scholar]
- Jackson JB, Musoke P, Fleming T, Guay LA, Bagenda D, Allen M, Nakabiito C, Sherman J, Bakaki P, Owor M, Ducar C, Deseyve M, Mwatha A, Emel L, Duefield C, Mirochnick M, Fowler MG, Mofenson L, Miotti P, Gigliotti M, Bray D, Mmiro F. Intrapartum and neonatal single-dose nevirapine compared with zidovudine for prevention of mother-to-child transmission of HIV-1 in Kampala, Uganda: 18-month follow-up of the HIVNET 012 randomised trial. Lancet. 2003;362:859–868. doi: 10.1016/S0140-6736(03)14341-3. [DOI] [PubMed] [Google Scholar]
- Kooperberg C, Stone CJ, Truong YK. Hazard regression. Journal of the American Statistical Association. 1995;90:78–94. [Google Scholar]
- Koziol JA, Perlman MD. Combining independent chi-squared tests. Journal of the American Statistical Association. 1978;73:753–763. [Google Scholar]
- Lin J, Zhang D, Davidian M. Smoothing spline-based score tests for proportional hazards models. Biometrics. 2006;62:803–812. doi: 10.1111/j.1541-0420.2005.00521.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O’Sullivan F. Nonparametric estimation of relative risk using splines and cross-validation. SIAM Journal on Scientific Statistical Computing. 1988;9:531–542. [Google Scholar]
- Peto R, Peto J. Asymptotically efficient rank invariant test procedures. Journal of the Royal Statistical Society: Series A (General) 1972;135:185–207. [Google Scholar]
- Pettitt AN, Bin Daud I. Investigating time dependence in Cox’s proportional hazards model. Journal of the Royal Statistical Society: Series C (Applied Statistics) 1990;39:313–329. [Google Scholar]
- Ruppert D, Wand MP, Carroll RJ. Semiparametric regression. Vol. 12. Cambridge University Press; 2003. [Google Scholar]
- Self SG. An adaptive weighted log-rank test with application to cancer prevention and screening trials. Biometrics. 1991;47:975–986. [PubMed] [Google Scholar]
- Sleeper LA, Harrington DP. Regression splines in the cox model with application to covariate effects in liver disease. Journal of the American Statistical Association. 1990;85:941–949. [Google Scholar]
- The HIVNET/HPTN Group. The HIVNET 012 Protocol: Phase IIB Trial to Evaluate the Efficacy of Oral Nevirapine and The Efficacy of Oral AZT in Infants Born to HIV-Infected Mothers in Uganda for Prevention of Vertical HIV Transmission. The HIV Prevention Trials Network. 2003 http://www.hptn.org.
- Wu L, Gilbert PB. Flexible weighted log-rank tests optimal for detecting early and/or late survival differences. Biometrics. 2002;58:997–1004. doi: 10.1111/j.0006-341x.2002.00997.x. [DOI] [PubMed] [Google Scholar]
- Zucker DM, Karr AF. Nonparametric survival analysis with time-dependent covariate effects: a penalized partial likelihood approach. Annals of Statistics. 1990;18:329–353. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.