

Abstract
The increased availability of time series genetic variation data from experimental evolution studies and ancient DNA samples has created new opportunities to identify genomic regions under selective pressure and to estimate their associated fitness parameters. However, it is a challenging problem to compute the likelihood of non-neutral models for the population allele frequency dynamics, given the observed temporal DNA data. Here, we develop a novel spectral algorithm to analytically and efficiently integrate over all possible frequency trajectories between consecutive time points. This advance circumvents the limitations of existing methods which require fine-tuning the discretization of the population allele frequency space when numerically approximating requisite integrals. Furthermore, our method is flexible enough to handle general diploid models of selection where the heterozygote and homozygote fitness parameters can take any values, while previous methods focused on only a few restricted models of selection. We demonstrate the utility of our method on simulated data and also apply it to analyze ancient DNA data from genetic loci associated with coat coloration in horses. In contrast to previous studies, our exploration of the full fitness parameter space reveals that a heterozygote-advantage form of balancing selection may have been acting on these loci.
Keywords and phrases: population genetics, spectral method, transition density function, hidden Markov model
1. Introduction
Natural selection is a fundamental evolutionary process and finding genomic regions experiencing selective pressure has important applications, including identifying the genetic basis of diseases and understanding the molecular basis of adaptation. There has been a long line of theoretical and experimental research devoted to modeling and detecting selection acting at a given locus. Several earlier works have considered modeling the stationary distribution of allele frequencies in a population undergoing non-neutral evolution (Fearnhead, 2003, 2006; Genz and Joyce, 2003; Stephens and Donnelly, 2003). More recently, there has been growing interest to utilize time series genetic variation data to enhance our ability to infer allele frequency trajectories, thereby enabling better estimates of selection parameters. For example, the sequencing of samples over several generations in experimental evolution of a population (e.g., Bacteria (Wiser, Ribeck and Lenski, 2013), yeast (Lang et al., 2013), and Drosophila (Burke et al., 2010; Orozcoter Wengel et al., 2012)) under controlled laboratory environments, or direct measurements in fast evolving populations such as HIV (Shankarappa et al., 1999), has allowed us to better understand the genetic basis of adaptation to changes in the environment. Also, recent technological advances have given us the unprecedented ability to acquire ancient DNA samples (e.g., for humans (Hummel et al., 2005), ancient hominids (Green et al., 2010; Reich et al., 2010), and horses (Ludwig et al., 2009; Orlando et al., 2013)), providing useful information about allele frequency trajectories over long evolutionary timescales.
Most methods for analyzing times series DNA data model the underlying population-wide allele frequency as an unobserved latent variable in a hidden Markov model (HMM) framework, in which the sample of alleles drawn from the population at a given time is treated as a noisy observation of the hidden population allele frequency. In this framework, computing the probability of observing time series genetic variation data involves integrating over all possible hidden trajectories of the population allele frequency. For short evolutionary timescales, a discrete-time Wright-Fisher model of random mating is often used to describe the dynamics of the population allele frequency in the underlying HMM. This approach has been used to estimate the effective population size from temporal allele frequency variation, assuming a neutral model of evolution (Williamson and Slatkin, 1999). More recently, temporal and spatial variations of advantageous alleles have been investigated through an HMM framework that can incorporate migration between multiple subpopulations (Mathieson and McVean, 2013).
If the evolutionary timescale between consecutive sampling times is large, it can become computationally cumbersome to work with discrete-time models of reproduction. However, by a suitable rescaling of time, population size, and population genetic parameters, one can obtain a continuous-time process (the Wright-Fisher diffusion) which accurately approximates the population allele frequency of the discrete-time Wright-Fisher model. The key quantity needed when applying the diffusion process is the transition density function, which describes the probability density of the allele frequency changing from value x to value y in time t. This transition density function satisfies a certain partial differential equation (PDE) with coefficients that depend on the mutation and selection parameters. Bollback, York and Nielsen (2008) have used a finite-difference numerical method to approximate the solution to the PDE and incorporated the results into the aforementioned HMM framework to infer the strength of selection from time series data. Recently, an alternative approach (Malaspinas et al., 2012) based on a one-step Markov process has been proposed to compute the necessary transition densities. In both of these approaches, the allele frequency space has to be discretized finely enough in order to reliably approximate various numerical integrals that are needed for computing the HMM likelihood. The efficiency and accuracy of these grid-based numerical methods depend critically on the spacing and distribution of the discrete grid points. Furthermore, an appropriate choice of this discretization scheme could be strongly dependent on the underlying population genetic parameters. Another limitation of these previous works is that only a few restricted models of selection have been considered. Feder, Kryazhimskiy and Plotkin (2014) recently developed a likelihood-ratio test for identifying signatures of selection from time series data, in which they combined a deterministic model and a Gaussian noise process. This approximation is less accurate than the diffusion approximation, but it facilitates computation and seems sufficiently accurate provided that the allele frequency does not get too close to the boundaries during the period of observation.
In this paper, we develop a novel algorithm based on the spectral method to circumvent the limitations mentioned above. Specifically, instead of approximating the solution to the PDE numerically, we utilize a method recently developed by Song and Steinrücken (2012) which finds an explicit spectral representation of the transition density as a function of x, y, and t. We show that the probability of observing a given time series dataset can be computed analytically by combining the spectral representation with the forward algorithm for HMMs to efficiently and analytically integrate over all population allele frequency trajectories. The key idea in our work is to represent the intermediate densities in the forward algorithm in the basis of eigenfunctions of the infinitesimal generator of the Wright-Fisher diffusion process. Exploiting the spectral representation of the transition density, we can then efficiently compute the coefficients in this basis representation. Furthermore, since this spectral representation applies to general diploid models of selection, we are able to leverage this representation to consider more complex models of selection than previously possible. We first demonstrate the accuracy of our method on simulated data. We then apply the method to analyze time series ancient DNA data from genetic loci (ASIP and MC1R) that are associated with horse coat coloration. In contrast to the conclusions of previous studies which considered only a few special models of selection (Ludwig et al., 2009; Malaspinas et al., 2012), our exploration of the full parameter space of general diploid selection reveals that a heterozygote-advantage form of balancing selection may have been acting on these loci. We implemented the algorithms described in this paper in a publicly available software package called spectral HMM1.
The remainder of this paper is organized as follows. In Section 2, we formally introduce the HMM framework and describe the details of our spectral algorithm. The proofs of the theoretical results underlying our algorithm are provided in the supplemental article (Steinrücken, Bhaskar and Song, 2014). In Section 3, we use simulated data to investigate the statistical properties of our maximum likelihood estimator and also apply our method to analyze the aforementioned ancient DNA data for the loci associated with horse coat coloration (Ludwig et al., 2009). We conclude in Section 4 with a discussion of future extensions of our model.
2. Method
Here we provide a formal description of the time series data considered in this paper and present our inference method for analyzing such data.
2.1. Time series allele frequency data
The data we analyze consist of genotype samples obtained from individuals at K distinct times t1
<···< tK in the past (given in years). The present time is denoted by tpresent ≥ tK. At each time point tk, a sample of nk ∈
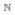 individuals is randomly drawn from the population. We assume that the locus under consideration is biallelic, and that the identities of the ancestral allele A0 and the derived allele A1 are known. We also assume that the allele A1 became selected at some time t0 ≤ t1. We use dk to denote the number of derived alleles in the sample of nk alleles drawn at time tk, where 0 ≤ dk ≤ nk. For notational convenience, we use ok to denote the tuple (tk, nk, dk), and O[i:j] to denote the partial sequence of observations oi, oi+1, …, oj. Figure 1 shows an example of a time series allele frequency dataset with samples drawn at three time points.
individuals is randomly drawn from the population. We assume that the locus under consideration is biallelic, and that the identities of the ancestral allele A0 and the derived allele A1 are known. We also assume that the allele A1 became selected at some time t0 ≤ t1. We use dk to denote the number of derived alleles in the sample of nk alleles drawn at time tk, where 0 ≤ dk ≤ nk. For notational convenience, we use ok to denote the tuple (tk, nk, dk), and O[i:j] to denote the partial sequence of observations oi, oi+1, …, oj. Figure 1 shows an example of a time series allele frequency dataset with samples drawn at three time points.
Fig 1.
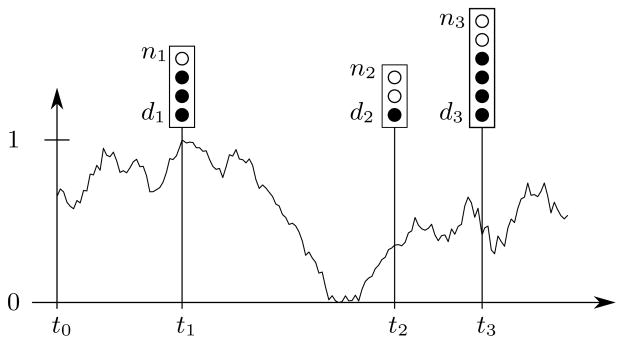
In this example, samples of size n1 = 4, n2 = 3, and n3 = 6 (illustrated by the total number of circles) are taken at times t1, t2, and t3 respectively. The observed number of derived alleles (filled circles) is d1 = 3, d2 = 1, and d3 = 4. The initial time is t0, and the curve indicates a particular trajectory of the underlying population allele frequency Y(t) ∈ [0, 1].
2.2. The diffusion approximation
Consider a locus evolving according to a discrete Wright-Fisher model of random mating with an effective population size of Ne diploids. Let u01 be the per-generation probability of mutation from the ancestral allele A0 to the derived allele A1, and u10 the probability of the reverse mutation. We use si to denote the selection coefficient of an individual with i copies of the derived allele A1, where 0 ≤ i ≤ 2. Without loss of generality, we can assume that s0 = 0. In each generation of reproduction, an offspring randomly chooses a parent having i copies of the derived allele with probability proportional to 1 + si.
Consider the scaling limit where the population size Ne → ∞ while the unit of time is rescaled by Ne and the population-scaled parameters (2Nes1, 2Nes2, 4Neu01, 4Neu10) approach some constants. In this limit, the trajectory of the population frequency of allele A1 follows a Wright-Fisher diffusion process (Ewens, 2004). The unit of time τ in this diffusion approximation is related to the physical unit of time t as
where g is the average number of years per generation of reproduction. Similarly, we let τk denote the population-scaled versions of the physical times tk, where
| (2.1) |
The population-scaled selection and mutation parameters of the Wright-Fisher diffusion process are related to the corresponding parameters in physical units as
| (2.2) |
| (2.3) |
| (2.4) |
From here on, we use the above population-scaled parameters when describing our analysis of the Wright-Fisher diffusion. The initial population frequency of the allele A1 when it became selected at time τ0 is distributed according to the density function ρ(y). In this paper, we are interested in estimating the selection coefficients of the heterozygote and A1-homozygote (s1 and s2, respectively) given the other population genetic parameters and assuming that the allele A1 became selected at time τ0.
2.3. Hidden Markov model framework
To analyze the time series data described earlier, we employ a hidden Markov model (HMM) framework as in Bollback, York and Nielsen (2008). In this approach, the population-wide frequency Y(τ) of the A1 allele at time τ is modeled as an unobserved hidden variable (see Figure 1). We denote a realization of the frequencies at the sampling times τk by yk ≡ Y(τk). The initial frequency at time τ0 is distributed according to the density function ρ, i.e. Y(τ0) ~ ρ. For example, the density function ρ(y) = δ(y − 1/(2Ne)) models the case where the selected allele A1 arose as a de novo mutation in one individual of the population at time τ0.
The probability of transitioning from frequency yk−1 at time tk−1 to frequency yk at time tk is described by the transition density function pΘ(τk − τk−1; yk−1, yk) of the Wright-Fisher diffusion process, where Θ = (σ1, σ2, α, β, τ0, Ne) and τ k are population-scaled parameters as given in equations (2.1)–(2.4). The observations in the HMM are the number of copies dk of the allele A1 among the nk alleles in the sample drawn at time tk. The probability of such an observation at time tk with population allele frequency yk is given by the probability mass function ξ(dk; nk, yk) of a binomial distribution
To compute the probability
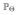 {O[1:K]} of observing the data O[1:K] under the model parameters Θ, we introduce the forward density functions fk, given by
{O[1:K]} of observing the data O[1:K] under the model parameters Θ, we introduce the forward density functions fk, given by
| (2.5) |
The function fk is the joint density of the observed data up to time τk and the hidden population allele frequency at time τk. We also find it convenient to consider a second auxiliary density function, gk, given by
| (2.6) |
This function gk is the joint density of the observed data up to time τk−1 and the hidden frequency at τk. The forward density function f0 is given by the density function for the initial allele frequency as
Since we approximate the time evolution of the hidden population allele frequency by the Wright-Fisher diffusion, we can get a recurrence relation between the density functions gk and fk−1 by integrating over all possible allele frequencies at τk−1:
| (2.7) |
where k ∈ {1, …, K}. Using the binomial distribution for sampling dk derived alleles out of nk individuals at time τk, we get another recurrence relation between the density functions fk and gk as follows:
| (2.8) |
Finally, the probability
{O[1:K]} of observing the data is computed by integrating over all possible hidden frequencies at the last sampling time:
| (2.9) |
Note that the equations above describe a forward-in-time procedure for computing the probability of the data O[1:K], where the intermediate density functions have a natural interpretation.
While (2.7), (2.8) and (2.9) succinctly describe the sampling probability of the data O[1:K], no analytic solutions to the integrals in (2.7) and (2.9) are known. In the previous approaches mentioned in Introduction, these integrals were approximated numerically by discretizing the allele frequency state space. The accuracy of these approximations depends critically on the careful choice of the discretization grid. We present an analytical solution to this problem which obviates the need for such a discretization.
2.4. Spectral representation of the transition density
The biallelic Wright-Fisher diffusion with general diploid selection has the infinitesimal generator
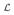 given by
given by
| (2.10) |
where
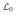 is the infinitesimal generator of the diffusion process without selection, given by
is the infinitesimal generator of the diffusion process without selection, given by
| (2.11) |
We refer the reader to Ewens (2004) for more details about the Wright-Fisher diffusion. Song and Steinrücken (2012) developed an efficient method to compute the eigenvalues and eigenfunctions of
, and we utilize that method here. A brief summary of their approach is provided below.
To approximate the spectral decomposition of the operator
, consider the functions
| (2.12) |
where σ̄(x) := 4σ1x(1 − x) + 2σ2x2 is the mean fitness of the population and
are a rescaled version of the classical orthogonal Jacobi polynomials and are defined in Section B of the supplemental article (Steinrücken, Bhaskar and Song, 2014). The α and β parameters in (2.12) are the population-scaled mutation rates given in (2.3) and (2.4). The set
forms a basis for the Hilbert space L2([0, 1], π) of real-valued functions on [0, 1] that are square integrable with respect to the stationary density π of the diffusion generator
. Specifically,
| (2.13) |
The basis elements are orthogonal with respect to the inner product 〈·, ·〉π defined by .
In the basis
, the operator
is given by the matrix
| (2.14) |
where
is a diagonal matrix containing the eigenvalues of the neutral diffusion generator
,
is the matrix of coefficients from the three-term recurrence relation for the Jacobi polynomials
, and
are constant coefficients defined in Section C of the supplemental article (Steinrücken, Bhaskar and Song, 2014). Explicit expressions for the entries of Λ(α,β) and G are provided in equations (B.3) and (B.5), respectively, in Section B of the supplemental article.
The eigenvalues λn of the full diffusion generator
are given by the eigenvalues of M, and the coefficients of the eigenfunctions of
in the basis
are given by the eigenvectors of M. In particular, the eigenfunction Bn of
is given by
| (2.15) |
where wn = (wn,0, wn,1, …) is the eigenvector of M corresponding to eigen-value λn. We use Λ = diag (λ0, λ1, …) to denote the diagonal matrix of eigenvalues of M, and W to denote the matrix with rows given by the eigenvectors wn. As can be seen from (2.15), W is the change-of-basis matrix between the basis of eigenfunctions Bn of
and the basis
.
The leading eigenvalues and the associated eigenvectors of the infinite matrix M can be approximated by the eigenvalues and eigenvectors of sufficiently large submatrices of M. We refer the reader to Song and Steinrücken (2012) for a more detailed empirical discussion on how the approximation accuracy varies for different submatrix sizes and different parameter regimes. The transition density function pΘ(τ; x, y) for the probability density of the allele changing frequency from x to y in time τ is given by the following spectral decomposition,
| (2.16) |
2.5. Incorporating the spectral representation into the HMM
Using the spectral decomposition of the transition density function in (2.16), we devise a dynamic programming algorithm to compute the likelihood
{O[1:K]}. This algorithm recursively computes the density functions fk and gk given in (2.5) and (2.6), respectively. To update these density functions efficiently, we represent them in the basis of scaled eigenfunctions
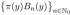 of the diffusion generator
. More precisely, we express fk and gk as
of the diffusion generator
. More precisely, we express fk and gk as
| (2.17) |
| (2.18) |
where we employ the vector notation
| (2.19) |
| (2.20) |
| (2.21) |
We now describe how the coefficient vectors ak,
bk and the probability
{O[1:K]} can be computed efficiently. All proofs can be found in Section A of the supplemental article (Steinrücken, Bhaskar and Song, 2014). First, the following proposition determines the vector b0 of coefficients for the initial forward density function f0:
Proposition 1
If the allele frequency at τ0 is distributed according to the density function ρ(y) = δ(y−x), then the initial forward density function f0 in the basis
has the vector of coefficients
where Bn(x) is given by (2.15), and cn are the squared norms of Bn given by
| (2.22) |
where denote the squared norms of the Jacobi polynomials given in equation (B.2) in Section B of the supplemental article (Steinrücken, Bhaskar and Song, 2014).
In the case where the selected allele A1 arises from de novo mutation at t0 in one of the individuals in the population, we set x = 1/(2Ne) in Proposition 1. We note that our framework allows us to easily model other distributions for the frequency of the mutant allele A1 when it became selected. For example, the initial distribution of mutation-drift balance can be used to model selection arising from standing genetic variation. Some of these initial distributions are described in Section D of the supplemental article (Steinrücken, Bhaskar and Song, 2014).
The following theorem establishes how the representations of the densities fk and gk, for k > 0, can be computed algebraically in a recursive fashion:
Theorem 2
Let and D := diag (c0, c1, …) denote diagonal matrices with entries and cn defined as in Proposition 1. Then, for each k ∈ {1,…, K}, the coefficients in the representation of the densities gk(y) and fk(y) in (2.17) and (2.18) can be computed recursively as
| (2.23) |
| (2.24) |
where W−1 is given by
| (2.25) |
Combining Proposition 1 and Theorem 2, we obtain a dynamic programming algorithm for calculating the coefficients bk and ak in the representations for fk and gk given in (2.17) and (2.18), respectively. The vectors and matrices appearing in the above results are infinite dimensional. As in previous works (Song and Steinrücken, 2012; Steinrücken, Wang and Song, 2013) on the spectral representation of the transition density, when applying the above results we truncate the infinite vectors and matrices by choosing cutoffs for the dimensions. We provide more practical details in Section 3.3.
Finally, the probability of observing the full data O[1:K] can be computed using the following proposition:
Proposition 3
The probability
{O[1:K]} of observing the data O[1:K] given the population genetic parameters Θ is
| (2.26) |
where B0(0) is given by
3. Results
In this section, we perform parametric inference via the maximum likelihood framework, using a finite grid in the parameter space. We first test the accuracy on simulated data and then apply it to analyze an ancient DNA dataset related to coat coloration in domesticated horses (Ludwig et al., 2009).
Since ancient DNA data are often collected from only those loci which are segregating at the present time, in our empirical study we condition on observing at least one copy of the derived allele at the last sampling time τK. In particular, the likelihood of the parameters is given by L(Θ) :=
{O[1:K] | dK > 0}. We chose to maximize this function on a grid, since the algorithm described in the previous section can be parallelized, thus allowing to efficiently evaluate the likelihood under given parameters for several datasets at once.
3.1. Performance on simulated data
We simulated data under a discrete-time Wright-Fisher model with several values for the effective population size and selection coefficients. We chose the mutation probabilities to be u01 = u10 = 10−6, and the number of years per generation to be five years. These parameters are similar to those considered by previous works that analyzed time series allelic samples from the ASIP and MC1R loci in horses (Ludwig et al., 2009; Malaspinas et al., 2012). In our simulations, 5% of the population carried the mutant allele when it first became positively selected. We sampled 40 individuals at each of 10 time points over the course of 32,000 years.
We investigated the performance of our maximum likelihood estimator in various scenarios of selection. Here, we present the results for the following four particular selection schemes:
Genic selection, in which the selective fitness of the heterozygote is the arithmetic mean of the fitness of the two homozygotes, i.e. s1 = s/2 and s2 = s.
Heterozygote advantage selection, in which s1 = s and s2 = 0.
Recessive selection, in which s1 = 0, s2 = s.
Dominant selection, in which s1 = s, s2 = s.
For each scenario, we considered s ∈ {0, 0.001, 0.0025, 0.005, 0.01} and simulated 200 datasets for each value of s.
Figure 2 shows the performance of the maximum likelihood estimator under a model of genic selection with an effective population size of Ne = 2,500 and Ne = 10,000. It illustrates empirical boxplots of the maximum likelihood estimates, where the tips of the whiskers denote the 2.5%-quantile and the 97.5%-quantile, and the boxes represent the upper and lower quartile. As the figure shows, our maximum likelihood estimates are unbiased. The uncertainty of the estimate tends to increase with increasing values of s, while the uncertainty decreases as the population size increases, illustrating the fact that for larger population sizes, selection acts more efficiently and is easier to detect. In the case of Ne = 10,000, if the true selection coefficient is 0.0025 or more, all our maximum likelihood estimates are higher than the 97.5%-quantile of the empirical distribution of the maximum likelihood estimates for s = 0. Hence, there is high power to reject neutrality in these scenarios.
Fig 2.

Empirical distribution of the maximum likelihood estimates for 200 datasets simulated under a model of genic selection, with heterozygote fitness s1 = s/2 and derived allele homozygote fitness s2 = s, for each of several different values of selection strength s. The dashed lines indicate the true values. (a) The effective population size Ne is 2,500 individuals. (b) Ne = 10,000 individuals.
The performance of our maximum likelihood estimator for several additional selection schemes and parameter regimes can be found in Figure 3, where we also consider a scenario with fewer sampling time points. The figure shows that our maximum likelihood estimates are unbiased across the different parameter ranges and scenarios. In general, the low variance of the empirical distribution of the maximum likelihood estimates shows that our method can be used to accurately infer the selection parameters of interest in a wide range of scenarios.
Fig 3.

Empirical distribution of the maximum likelihood estimates of 200 simulated datasets each under different modes of selection of differing strength with Ne = 10,000. The dashed lines indicate the true values of s. (a) Genic selection (s1 = s/2, s2 = s) with only five sampling time points. (b) Heterozygote advantage model of selection (s1 = s, s2 = 0) with ten sampling time points. (c) Recessive selection (s1 = 0, s2 = s) with ten sampling time points. (d) Dominant selection (s1 = s, s2 = s) with ten sampling time points.
3.2. Analysis of ancient DNA data: coat coloration in domesticated horses
Ludwig et al. (2009) extracted genotype data at several loci from ancient horse DNA obtained from various sites in Eurasia. In particular, they extracted temporal allele frequency data at eight loci that are known to play a role in coat color determination in contemporary horses. Only the locus encoding for the Agouti signaling peptide (ASIP) and the locus for the melanocortin 1 receptor (MC1R) showed strong fluctuations in the sample allele counts. Table 1 shows the time series data for the ASIP and the MC1R loci in the curated form of the original work (Ludwig et al., 2009).
Table 1.
The temporal allele frequency datasets for the ASIP and MC1R loci associated with coat coloration in domesticated horses (Ludwig et al., 2009, Figure S.3). For each sampling time tk (given in years BCE), the table lists the number dk of derived alleles among the sampled nk alleles.
| time of sampling [tk] (BCE) | 20,000 | 13,100 | 3,700 | 2,800 | 1,100 | 500 |
|---|---|---|---|---|---|---|
| # of samples [nk] | 10 | 22 | 20 | 20 | 36 | 38 |
| ASIP (# der. alleles) [dk] | 0 | 1 | 15 | 12 | 15 | 18 |
| MC1R (# der. alleles) [dk] | 0 | 0 | 1 | 6 | 13 | 24 |
Using the method of Bollback, York and Nielsen (2008) for the model of genic selection (s1 = s/2, s2 = s), Ludwig et al. (2009) established that selection acted significantly on only the ASIP and the MC1R loci. However, another recent analysis (Malaspinas et al., 2012) of the same dataset considered the model of recessive selection (s1 = 0, s2 = s) and did not find a significant signal of selection at the ASIP locus.
To investigate the dependence of the previous conclusions on the assumed selection scheme, we applied our method to reanalyze the ASIP and the MC1R data under a general selection scheme with arbitrary selection coefficients s1 and s2. We set the mutation probability to u01 = u10 = 10−6 and the average length of a generation to 5 years. Table 1 shows that the derived allele is absent in both datasets at time 20,000 BCE. Thus, we set the initial frequency of the derived allele as 1/2Ne, corresponding to the case where the selected allele arises as a de novo mutation at time t0. We tried a range of values for Ne and t0.
Figure 4(a) shows the likelihood surface for the temporal allele frequency data from the ASIP locus, for Ne = 2,500 and t0 = 17,000 BCE. The empirical maximum of the likelihood surface is located at (s1, s2) = (0.0025, 0), indicated by the ‘x’ in Figure 4(a). This maximum suggests that a selective scheme of heterozygote advantage best explains the data, where both the ancestral and derived allele homozygotes are of equal fitness, while the heterozygous genotype confers a selective advantage over the homozygotes. To establish the significance of this finding, we performed the following bootstrap procedure: We resampled the ASIP dataset 100 times to obtain sub-sampled datasets . For each bootstrapped dataset 1 ≤ j ≤ 100, we resampled alleles at each time . The number of derived alleles for dataset j was obtained by binomial sampling from the empirical frequency of derived alleles in the original ASIP dataset, i.e.,
Fig 4.

Analysis of the ASIP locus. (a) Empirical values of the likelihood L(Θ) for temporal samples from the ASIP locus where the likelihood is computed over a 21 × 21 grid. The maximum is attained at (s1, s2) = (0.0025, 0), indicated by the ‘x’. (b) A joint density plot and marginal histograms of the maximum likelihood estimates for 100 bootstrap resampled datasets of the temporal data at the ASIP locus. The circles are centered on the grid points at which the likelihood function is evaluated, and the sizes of the circles indicate the proportion of maximum likelihood estimates that occupy the same grid point. The marginal empirical 2.5% and 97.5%-quantiles are [0.0025, 0.0235] for the heterozygote fitness s1, and [0, 0.0045] for the derived allele homozygote fitness s2, as indicated by the dashed box.
We then reported the empirical maximum of the likelihood surface for each of these resampled datasets. Figure 4(b) shows the empirical maximum likelihood estimates and marginal histograms of the maxima for the 100 re-sampled datasets. The marginal 2.5% and 97.5% quantiles of the empirical distribution are [0.0025, 0.0235] for the heterozygote fitness s1 and [0, 0.0045] for the derived allele homozygote fitness s2, thus providing further evidence that the data are significantly better explained by a selection model where a heterozygous individual is selectively advantageous over the homozygous individuals. As Figure 5 shows, changing Ne from 1,000 to 10,000, or changing t0 from 19,000 BCE to 15,000 BCE has only a minimal effect on the shape of the likelihood surface and maximum likelihood estimate, again supporting that a selective scheme of heterozygote advantage best explains the data.
Fig 5.

Likelihood surfaces for the ASIP dataset under various combinations of Ne ∈ {1 000, 2 500, 10 000} and t0 ∈ {15 000 BCE, 17 000 BCE, 19 000 BCE}. The respective maxima are indicated by an ‘x’.
A similar analysis of the MC1R locus can be found in Figures 6 and 7. For this dataset, the maximum of the likelihood surface is attained at (s1, s2) = (0.004, 0.0015), and the empirical marginal 2.5% and 97.5%-quantiles are [0.001, 0.025] for the heterozygote fitness and [−0.009, 0.0135] for the derived allele homozygote fitness. Together with the results shown in Figure 7, this suggests that the data at the MC1R locus is also best explained by a selection model of heterozygote advantage. However, although the marginal quantiles for the homozygote fitness cover s2 = 0, they are rather far apart, so the evidence of heterozygote advantage for the MC1R locus is weaker than that for the ASIP locus.
Fig 6.

Analysis of the MC1R locus using the parameters Ne = 2,500 and t0 = 7,000 BCE. (a) Likelihood surface for the MC1R locus. The maximum likelihood estimate is at (s1, s2) = (0.004, 0.0015) and is indicated by the ‘x’. (b) A joint density plot and marginal histograms of the maximum likelihood estimates for 100 bootstrap resampled datasets obtained from the MC1R data as described in Section 3.2. The marginal 2.5% and 97.5%-quantiles are [0.001, 0.025] for the heterozygote fitness s1 and [−0.009, 0.0135] for the derived allele homozygote fitness s2, as indicated by the dashed box.
Fig 7.

Likelihood surfaces for the MC1R dataset under various combinations of Ne ∈ {1 000, 2 500, 10 000} and t0 ∈ {5 000 BCE, 7 000 BCE, 9 000 BCE}. The respective maxima are indicated by an ‘x’.
3.3. Computational performance
The running time of our algorithm for computing the likelihood of a given set of population-scaled parameters is dependent on the dimensions of the truncation M̃ of the infinite matrix M given in (2.14). In particular, the time complexity of computing a single likelihood is the cost of computing the eigenvalues and eigenvectors of M̃ plus the cost of computing the coefficients bk in Theorem 2, where k ∈ {1, …, K}. To compute the eigenvalues and eigenvectors of M̃ to high precision, we first used LAPACK2 to compute them to double precision, and then refine them by using inverse iteration (Press et al., 2007, Chapter 11.8). Each step of the inverse iteration involves solving a linear system with matrix M̃ − μI, where μ is an estimate for an eigenvalue of M̃. Since this matrix has bandwidth at most 9, this linear system can be solved in O(D) time, where D is the dimension of M̃. By using the repeated squaring algorithm for taking powers of the matrices G and 1 − G and exploiting the fact that G and 1 − G are tridiagonal matrices, each coefficient bk can be computed in O(D2 + D min(D, nk)2 log nk) time, where the first O(D2) term comes from the matrix-vector multiplications in (2.24).
For the analysis of the ASIP and MC1R datasets reported in Figures 4 and 6, we approximated the eigenvalues and eigenvectors of M defined in (2.14) using a 600 × 600 submatrix. Furthermore, we used the first 590 terms in (2.15) to approximate the eigenfunctions, and the dimensions of the vectors of coefficients in (2.19) and (2.20) were set to 580. We empirically verified that these cutoffs produced a stable approximation of the likelihood. Using these values the computation time for a single point of the grid in Figure 4(a) was approximately 95 seconds. We adjusted the cutoffs appropriately for the other analyses reported in Section 3.
4. Discussion
In this paper, we have developed a novel, efficient spectral algorithm to analyze time series allele frequency data under a general diploid selection model. We have demonstrated that our method can be used to accurately estimate selection parameters on simulated data.
We have also applied our method to investigate loci involved in horse coat coloration. Our inferred selection coefficients show that the data are best explained by a heterozygote advantage model of balancing selection. As mentioned earlier, Ludwig et al. (2009) provided evidence for slightly positive selection at the ASIP locus, assuming a model of genic selection (where s1 = s2/2). More precisely, they obtained a point estimate of s2 = 0.0007 and a 95% confidence interval of [0.0001, 0.0015]. However, using a model of selection where the derived allele homozygote is recessive (i.e., s1 = 0), a subsequent re-analysis (Malaspinas et al., 2012) of the same data found that s2 has a point estimate of −0.001 with a 95% confidence interval of [−0.02, 0.051], thus not rejecting neutrality at the ASIP locus. In our work, we have allowed our method to explore the two-dimensional parameter space of general diploid selection models and presented evidence for a selection mode where heterozygous individuals are advantageous over homozygous individuals. It is possible that previous analyses have only been able to infer very weak selection acting at the ASIP locus because they have restricted the model of selection to certain one-dimensional models. Indeed, if we restrict our analysis to a model of genic selection, we get results similar to those reported by Ludwig et al. (2009). Our analysis does not conclusively prove that individuals that were heterozygous at the ASIP locus had a constant evolutionary advantage since 17,000 BCE, because we have ignored the interaction of selection and demographic history, epistatic interactions between loci, time-varying models of selection, and other factors. However, our results suggest the possibility that some mode of heterozygote advantage balancing selection has maintained polymorphism at the ASIP locus that is involved in horse coat coloration.
Although we have focused on time series samples taken at a biallelic locus, the mathematical framework presented here could be readily extended to handle an arbitrary number of alleles using the spectral representation derived by Steinrücken, Wang and Song (2013). Further, changes in the population size and selection coefficients could be modeled by suitably combining the spectral representations for different population genetic parameters at the change points. It is also possible to extend the method to multiple populations and to incorporate samples taken from extinct ancestral populations. In light of emerging ancient DNA sequence data for ancient hominids (Green et al., 2010; Reich et al., 2010), such temporal sequence data and inference methods present novel opportunities to gain insight into adaptation in humans. For a more adequate modeling of biologically relevant scenarios, it is also necessary to incorporate the exchange of migrants into the model (Gutenkunst et al., 2009; Lukić, Hey and Chen, 2011), and extend the framework to incorporate variation at linked loci. By taking advantage of genetic hitchhiking at closely linked sites during the course of selective sweeps, one might be able to further improve the inference of selection coefficients.
Supplementary Material
Acknowledgments
We thank Rasmus Nielsen, Joshua Schraiber, and Montgomery Slatkin for helpful comments and discussions. We also thank Karen Kafadar and two anonymous referees for suggestions that improved the exposition of this paper. Moreover, we thank Richard J. Mathar (Mathar, 2009) for making his sourcecode available to us.
Footnotes
Available from http://spectralhmm.sf.net
Available from http://www.netlib.org/lapack/
A novel spectral method for inferring general diploid selection from time series genetic data
(doi: TBD;.pdf). We provide proofs of the results stated in Section 2. The modified Jacobi polynomials appearing in this paper are defined and some of their key properties are listed. Also, the coefficients in the definition of the matrix M in equation (2.14) are provided. Lastly, we describe some alternate density functions for the allele frequency at the time when selection arises.
References
- Bollback JP, York TL, Nielsen R. Estimation of 2Nes From Temporal Allele Frequency Data. Genetics. 2008;179:497–502. doi: 10.1534/genetics.107.085019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burke MK, Dunham JP, Shahrestani P, Thornton KR, Rose MR, Long AD. Genome-wide analysis of a long-term evolution experiment with Drosophila. Nature. 2010;467:587–590. doi: 10.1038/nature09352. [DOI] [PubMed] [Google Scholar]
- Ewens W. Mathematical Population Genetics: I. Theoretical Introduction. 2. Springer; 2004. [Google Scholar]
- Fearnhead P. Ancestral processes for non-neutral models of complex diseases. Theoretical Population Biology. 2003;63:115–130. doi: 10.1016/s0040-5809(02)00049-7. [DOI] [PubMed] [Google Scholar]
- Fearnhead P. The stationary distribution of allele frequencies when selection acts at unlinked loci. Theoretical Population Biology. 2006;70:376–386. doi: 10.1016/j.tpb.2006.02.001. [DOI] [PubMed] [Google Scholar]
- Feder AF, Kryazhimskiy S, Plotkin JB. Identifying Signatures of Selection in Genetic Time Series. Genetics. 2014;196:509–522. doi: 10.1534/genetics.113.158220. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Genz A, Joyce P. Computation of the normalizing constant for exponentially weighted Dirichlet distribution integrals. Computing Science and Statistics. 2003;35:181–212. [Google Scholar]
- Green RE, Krause J, Briggs AW, Maricic T, Stenzel U, Kircher M, Patterson N, Li H, Zhai W, Fritz MH-Y, et al. A draft sequence of the Neandertal genome. Science. 2010;328:710–722. doi: 10.1126/science.1188021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gutenkunst RN, Hernandez RD, Williamson SH, Bustamante CD. Inferring the Joint Demographic History of Multiple Populations from Multidimensional SNP Frequency Data. PLoS Genetics. 2009;5:e1000695. doi: 10.1371/journal.pgen.1000695. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hummel S, Schmidt D, Kremeyer B, Herrmann B, Oppermann M. Detection of the CCR5-Delta32 HIV resistance gene in Bronze Age skeletons. Genes and Immunity. 2005;6:371–374. doi: 10.1038/sj.gene.6364172. [DOI] [PubMed] [Google Scholar]
- Lang GI, Rice DP, Hickman MJ, Sodergren E, Weinstock GM, Botstein D, Desai MM. Pervasive genetic hitchhiking and clonal interference in forty evolving yeast populations. Nature. 2013;500:571–574. doi: 10.1038/nature12344. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ludwig A, Pruvost M, Reissmann M, Benecke N, Brockmann GA, Castaños P, Cieslak M, Lippold S, Llorente L, Malaspinas A-S, Slatkin M, Hofreiter M. Coat Color Variation at the Beginning of Horse Domestication. Science. 2009;324:485. doi: 10.1126/science.1172750. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lukić S, Hey J, Chen K. Non-equilibrium allele frequency spectra via spectral methods. Theoretical Population Biology. 2011;79:203–219. doi: 10.1016/j.tpb.2011.02.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Malaspinas AS, Malaspinas O, Evans SN, Slatkin M. Estimating allele age and selection coefficient from time-serial data. Genetics. 2012;192:599–607. doi: 10.1534/genetics.112.140939. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mathar RJ. A Java Math.BigDecimal Implementation of Core Mathematical Functions. ArXiv e-prints. 2009 http://arxiv.org/abs/0908.3030v1.
- Mathieson I, McVean G. Estimating selection coefficients in spatially structured populations from time series data of allele frequencies. Genetics. 2013;193:973–984. doi: 10.1534/genetics.112.147611. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Orlando L, Ginolhac A, Zhang G, Froese D, Albrechtsen A, Stiller M, Schubert M, Cappellini E, Petersen B, Moltke I, et al. Recalibrating Equus evolution using the genome sequence of an early Middle Pleistocene horse. Nature. 2013;499:74–78. doi: 10.1038/nature12323. [DOI] [PubMed] [Google Scholar]
- Orozcoter Wengel P, Kapun M, Nolte V, Kofler R, Flatt T, Schlötterer C. Adaptation of Drosophila to a novel laboratory environment reveals temporally heterogeneous trajectories of selected alleles. Molecular Ecology. 2012;21:4931–4941. doi: 10.1111/j.1365-294X.2012.05673.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Press W, Teukolsky S, Vetterling WT, Flannery BP. Numerical Recipes: The Art of Scientific Computing. 3. Cambridge University Press; 2007. [Google Scholar]
- Reich D, Green RE, Kircher M, Krause J, Patterson N, Durand EY, Viola B, Briggs AW, Stenzel U, Johnson PLF, Maricic T, Good JM, Marques-Bonet T, Alkan C, Fu Q, Mallick S, Li H, Meyer M, Eichler EE, Stoneking M, Richards M, Talamo S, Shunkov MV, Derevianko AP, Hublin J-J, Kelso J, Slatkin M, Pääbo S. Genetic history of an archaic hominin group from Denisova Cave in Siberia. Nature. 2010;468:1053–1060. doi: 10.1038/nature09710. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shankarappa R, Margolick JB, Gange SJ, Rodrigo AG, Upchurch D, Farzadegan H, Gupta P, Rinaldo CR, Learn GH, He X, Huang XL, Mullins JI. Consistent viral evolutionary changes associated with the progression of human immunodeficiency virus type 1 infection. Journal of Virology. 1999;73:10489–10502. doi: 10.1128/jvi.73.12.10489-10502.1999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song YS, Steinrücken M. A Simple Method for Finding Explicit Analytic Transition Densities of Diffusion Processes with General Diploid Selection. Genetics. 2012;190:1117–1129. doi: 10.1534/genetics.111.136929. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steinrücken M, Bhaskar A, Song YS. Supplement to “A novel spectral method for inferring general diploid selection from time series genetic data”. 2014 doi: 10.1214/14-aoas764. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steinrücken M, Wang YXR, Song YS. An explicit transition density expansion for a multi-allelic Wright-Fisher diffusion with general diploid selection. Theoretical Population Biology. 2013;83:1–14. doi: 10.1016/j.tpb.2012.10.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stephens M, Donnelly P. Ancestral inference in population genetics models with selection. Australian & New Zealand Journal of Statistics. 2003;45:395–423. [Google Scholar]
- Williamson EG, Slatkin M. Using maximum likelihood to estimate population size from temporal changes in allele frequencies. Genetics. 1999;152:755–761. doi: 10.1093/genetics/152.2.755. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wiser MJ, Ribeck N, Lenski RE. Long-term dynamics of adaptation in asexual populations. Science. 2013;342:1364–1367. doi: 10.1126/science.1243357. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.