

Abstract
Convex and continuous energy formulations for low level vision problems enable efficient search procedures for the corresponding globally optimal solutions. In this work we extend the well-established continuous, isotropic capacity-based maximal flow framework to the anisotropic setting. By using powerful results from convex analysis, a very simple and efficient minimization procedure is derived. Further, we show that many important properties carry over to the new anisotropic framework, e.g. globally optimal binary results can be achieved simply by thresholding the continuous solution. In addition, we unify the anisotropic continuous maximal flow approach with a recently proposed convex and continuous formulation for Markov random fields, thereby allowing more general smoothness priors to be incorporated. Dense stereo results are included to illustrate the capabilities of the proposed approach.
1. Introduction
Convex and continuous approaches to low level vision tasks are appealing for two reasons: (i) the convexity of the formulation ensures global optimality of the obtained solutions; and (ii) setting the problem in a continuous (i.e. non-combinatorial) domain often results in intrinsically data-parallel algorithms, that can be significantly accelerated e.g. by modern graphics processing units. Typically, the main challenge is to find a convex (and optionally continuous) formulation of an apparently non-convex problem. For instance, solving a pairwise Markov random field with multiple labels and linear or convex discontinuity costs requires an embedding of the original formulation into a higher dimensional space (see [6, 13, 11, 12] for combinatorial approaches and [20] for a continuous formulation).
Finding global optimizers for Markov random fields with pairwise and non-convex priors is generally NP-hard, and only approximation algorithms are known. Well-established approaches for MRF optimization in computer vision include belief propagation [26], graph cut methods [7, 15], message passing approaches [14, 16], and sequential fusion of labeling proposals [17, 25].
One major inspiration for this work is the continuous maximal flow framework proposed in [2], which provides globally optimal and efficient solutions to minimal surface problems for image segmentation (e.g. [9]) and stereo [21]. The original framework for continuous maximal flows uses isotropic, i.e. non-direction dependent, capacity constraints. The flow between neighboring nodes (as induced by the ℝN topology) is uniformly limited in all directions. The utilization of anisotropic capacities allows the flow to prefer certain, spatially varying directions.
It turns out, that the flow field with capacity constraints directly corresponds to the dual vector field employed in efficient minimization of total variation energies [10]. The spatially varying isotropic capacity constraint in [2] recurs as weighted total variation [8]. Anisotropic total variation for image denoising was theoretically analyzed in [19], and joint image smoothing and estimation of local anisotropy orientation was proposed in [3].
This work is outlined as follows: Section 2 introduces anisotropic capacity constraints and analyzes the relationship with continuous minimal surface and maximal flow formulations. An iterative optimization procedure maintaining primal and dual variables is presented as well. Section 3 uses strong duality results from non-smooth convex optimization to deduce the corresponding dual energy, that provides further theoretical insights, and is a useful indicator to stop the iterations. In Section 4 the results obtained in the previous sections are used to derive novel procedures for certain classes of Markov random fields, thus providing an extension and unification of [2] and [20]. Section 5 concludes this work.
2. Anisotropic Continuous Maximal Flows
This section presents an extension of continuous maximal flows with isotropic capacity constraints as proposed in [2] to anisotropic node capacities. Fortunately, the approach used in [2] to prove the correctness and stability of the underlying partial differential equations for isotropic capacity constraints can be easily generalized to the anisotropic setting as shown in the next sections.
2.1. Wulff Shapes
The aim of this section is to introduce a technique allowing to rewrite non-differentiable terms like ‖ · ‖ as better manageable expressions: unconstrained optimization of certain non-differentiable objective functions can be formulated as nested optimization of a scalar product term subject to a feasibility constraint induced by the respective Wulff shape (e.g. [19]):
Definition 1
Let ϕ : ℝN → ℝ be a convex, positively 1-homogeneous function (i.e. ϕ(λx) = λϕ(x) for λ > 0). The Wulff shape Wϕ is the set
| (1) |
where we denote the inner product in ℝN by 〈·, ·〉.
The Wulff shape Wϕ is a convex, bounded and closed set. Further 0 ∈ Wϕ. Given a Wulff shape Wϕ the generating function ϕ(·) can be recovered by
| (2) |
For consistency with [2] and with the dual energy formulation (Section 3), we will use Eq. 2 in a slightly modified form with negated dual variables, i.e.
| (3) |
where we introduce the negated Wulff shape,
An important set of functions ϕ satisfying the convexity and positive 1-homogeneity constraint are norms. The Wulff shape for the Euclidean norm, ‖ · ‖2 is the unit ball with respect to ‖ · ‖2. In general, the Wulff shape for the lp norm is the unit ball of the dual norm, ‖ · ‖q, with 1/p + 1/q = 1.
One useful observation about Wulff shapes in the context of this work is the geometry of the Wulff shape for linear combinations of convex and positively 1-homogeneous functions. It is easy to see that the following holds:
Observation 1
Let ϕ and ψ be two convex, positively 1-homogeneous functions, and k ∈ ℝ > 0. Then, the following relations hold:
| (4) |
where A ⊕ B denotes the Minkowski sum of two sets A and B. Further,
| (5) |
This observation allows us to derive the geometry of Wulff shapes for positive linear combinations of given functions from their respective individual Wulff shapes in a straightforward manner.
In [19] is it shown, that we have ϕ (x) = 〈y, x〉 for non-zero x and y ∈ Wϕ if and only if
| (6) |
where ∂Wϕ denotes the boundary of the Wulff shape and NWϕ(y) is the set of outward pointing normals at y ∈ ∂Wϕ. Note that this observation is equivalent to the Fenchel-Young equation (see Section 3), but expressed directly in geometric terms.
2.2. Minimal Surfaces and Continuous Maximal Flows
Appleton and Talbot [2] formulated the task of computing a globally minimal surface separating a known source location from the sink location as a continuous maximal flow problem. Instead of directly optimizing the shape of the separating surface ∂A, the indicator function of the respective region A enclosing the source is determined.
In this section we derive the main result of [2] for anisotropic capacity constraints. Let Ω ⊂ ℝN be the domain of interest, and S ⊂ Ω and T ⊂ Ω the source and sink regions, respectively. Further, let ϕx be a family of convex and positively 1-homogeneous functions for every x ∈ Ω. Then the task is to compute a binary valued function u : Ω → {0, 1}, that is the minimizer of
| (7) |
such that u(x) = 1 for all x ∈ S and u(x) = 0 for all x ∈ T. Note that we have replaced the usually employed weighted Euclidean norm by the general, spatially varying weighting function ϕx. In the following we will drop the explicit dependence of ϕx on x and will only use ϕ. Since ϕ is convex and positively 1-homogeneous, we can substitute ϕ(∇u) by maxy∈Wϕ 〈−y, ∇u〉 (recall Eq. 3) and obtain:
| (8) |
We will collect all dual variables y ∈ −Wϕ into a vector field p : Ω → −Wϕ. Hence, we arrive at the following optimization problem:
| (9) |
together with the source/sink conditions on u and the generalized capacity constraints on p,
| (10) |
In many applications the Wulff shape Wϕ is centrally symmetric, and the constraint −p(x) ∈ Wϕx is then equivalent to p(x) ∈ Wϕx.
The functional derivatives of Eq. 9 with respect to u and p are
| (11) |
subject to Eq. 10 and the source and sink constraints on u. Since we minimize with respect to u, but maximize with respect to p, the gradient descent/ascent updates are
| (12) |
subject to −p ∈ Wϕ. These equations are exactly the ones presented in [2], the only difference lies in the generalized capacity constraint on p. The basic setup is illustrated in Fig. 1.
Figure 1.
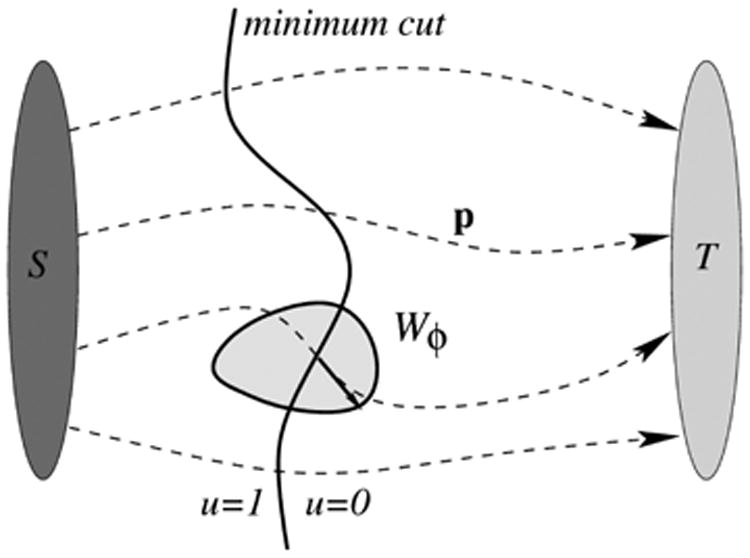
Basic illustration of the anisotropic continuous maximal flow approach. The minimum cut separating the source S and the sink T, the flow field p, and one anisotropic capacity constraint Wϕ (convex shape) are depicted.
Correctness at Convergence
The first order optimality conditions are (recall Eq. 11):
| (13) |
| (14) |
| (15) |
The first equations implies that there are no additional sources or sinks in the vector field p and flow lines connect the source and the sink. If the generalized capacity constraint Eq. 10 is active (i.e. p ∈ −Wϕx), we have ∇u ∈ NWϕ(−P) by Eq. 6. Further, we have 〈 −p, ∇u 〉 = ϕ(∇u) ≥ 0 whenever the capacity is saturated, since ϕ is a non-negative function. Consequently, u is a non-decreasing function along the flow lines of − p (or equivalently, u is non-increasing along the flow lines of p), which is the key observation to prove the essentially binary nature of u. The proof for the optimality after thresholding u by an arbitrary value θ ∈ (0,1) is an extended version of the one given in [2]. Since the proof relies on duality results derived later in Section 3, we postpone the proof to the appendix.
2.3. Numerical Considerations
Discretization
For finite lattices the gradient operator ∇ and the divergence operator div need to be dual. We do not employ the staggered grid approach proposed in [2], but use the same underlying grids for u and p in our implementation. ∇u is evaluated using forward differences, whereas div p is computed by backward differences. In order to ensure that the negated gradient and the divergence are adjoint linear operators, in the finite setting, suitable boundary conditions are required [10, 8].
The gradient descent equations in Eq. 12 are applied using an explicit Euler scheme with a uniform time step τ. Since these equations are the same discrete wave equations as in [2], the same upper bound on the time step holds, i.e. τ < 1/√N. The update of p is followed by a reprojection step to enforce p ∈ −Wϕ.
Complex Wulff Shapes
In many cases this reprojection step is just a clamping operation (e.g. if ϕ is the L1 norm) or a renormalization step (if ϕ is the Euclidean norm). Determining the closest point in the respective Wulff shape can be more complicated for other choices of ϕ. In particular, if the penalty function is of the form (ϕ + ψ), then it is easy to show that maintaining separate dual variables for ϕ and ψ yields to the same optimal solution – with the drawback of increased memory consumption.
Terminating the Iterations
A common issue with iterative optimization methods is a suitable criterion when to stop the iterations. An often employed, but questionable stopping criterion is based on the length of the gradients or update vector. In [2] a stopping criterion was proposed, that tests whether u is sufficiently binary. This criterion is problematic in several cases, e.g. if a reasonable binary initialization is already provided. A common technique in optimization to obtain true quality estimates for the current solutions is to utilize strong duality. The current primal energy (which is minimized) yields a upper bound on the true minimum, whereas the corresponding dual energy provides a lower bound. If the gap is sufficiently small, the iterations can be terminated with guaranteed optimality bounds. Since the formulation and discussion of duality in the context of anisotropic continuous maximal flows provides interesting connections, we devote the next section to this topic.
3. Dual Energy
Many results on the strong duality of convex optimization problems are well-known, e.g. primal and dual formulations for linear programs and Lagrange duality for constrained optimization problems. The primal energy Eq. 7 is generally non-smooth and has constraints for the source and sink regions. Thus, we employ the main result on strong duality from convex optimization to obtain the corresponding dual energy (e.g. [5]).
3.1. Fenchel Conjugates and Duality
The notion of dual programs in convex optimization is heavily based on subgradients and conjugates:
Definition 2
Let f : ℝN → ℝ be a convex and continuous function. y is a subgradient at x0 if
The subdifferential ∂f(x) is the set of subgradients of f at x, i.e. ∂f(x) = {y : y is a subgradient of f at x}.
Intuitively, for functions f : ℝ → ℝ, subgradients of f at x0 are slopes of lines containing (x0, f(x0)) such that the graph f is not below the line.
Definition 3
Let f : ℝN → ℝ be a convex and semi-continuous function. The Fenchel conjugate of f, denoted by f* : ℝN → ℝ is defined by
| (16) |
f** = f if and only if f is convex and semi-continuous. From the definition of f*, we obtain
| (17) |
i.e. the graph of f is above the hyperplane [y, 〈z, y〉 − f*(z)] (Fenchel-Young inequality). Equality holds for given y, z if and only if z is a subgradient of f (or equivalently, y is a subgradient of f*, Fenchel-Young equation).
Let A ∈ ℝM × N be a matrix (or a linear operator in general). Consider the following convex optimization problem for convex and continuous f and g:
| (18) |
The corresponding dual program is [5]:
| (19) |
Fenchel's duality theorem states, that strong duality holds (under some technical condition), i.e. p = d. Further, since the primal program is a minimization problem and the dual program is maximized,
| (20) |
is always true for any y ∈ ℝN and z ∈ ℝM. This inequality allows to provide an upper bound on the optimality gap (i.e. the distance to the true optimal energy) in iterative algorithms maintaining primal and dual variables.
3.2. Dual Energy for Continuous Maximal Flows
Now we consider again the basic energy to minimize (recall Eq. 7)
Without loss of generality, we assume Ω to be 3-dimensional, since our applications are in such a setting. Let A denote the gradient operator, i.e. A(u) = ∇u. In the finite setting, A will be represented by a sparse 3|Ω| × |Ω| matrix with ±1 values at the appropriate positions.
The function g represents the primal energy,
| (21) |
(A ∘ u)(x) denotes ∇u(x) Since A is a linear operator and ϕx is convex, g is Convex with respect to u.
The second function in the primal program, f, encodes the restrictions on u. The value attained by u(x) should be 1 for source locations x ∈ S, and 0 for sink regions, u(x) = 0 for x ∈ T. W.l.o.g. we can assume u(x) ∈ [0,1] for all x ∈Ω. Without this assumption it turns out that the dual energy is unbounded (−∞) if div p(x) ≠ 0 for some x ∈ Ω not in the source or the sink region (see below). We choose f as
| (22) |
We denote the space of functions satisfying the constraints (equivalently, with finite f(u)) by
 .
.
The dual variable is a vectorial function (vector field) p : Ω → ℝ3. Since g(∇u) is a sum (integral) of ϕx acting on independent components of ∇u, we have for the conjugate function g*:
| (23) |
Since all ϕx share the same properties, we drop the index and derive the Fenchel conjugate for any convex, positively 1-homogeneous function ϕ(y). First, note that the Wulff shape Wϕ is nothing else than the subdifferential of ϕ at 0, i.e. Wϕ = ∂ϕ(0):
where we made use of ϕ(0 · y) = 0 · ϕ(y) = 0. Hence, we obtain for every z ∈Wϕ (by the Fenchel-Young equation)
| (24) |
If z ∉ Wϕ, then there exists a y such that 〈z, y〉 > ϕ(y). Further, 〈z, λy〉 > ϕ(λy) = λϕ(y) for any λ > 0, and therefore ϕ*(z) = supy [〈z,y〉 − ϕ(y)] is unbounded. In summary, we obtain
| (25) |
i.e. the conjugate of ϕ is the indicator function of the respective Wulff shape.
The conjugate of f, f*, can be computed directly. The argument of f* is a mapping from Ω to negated divergences, q : Ω → ℝ with
where A* is the adjoint operator to A (recall that ∇* = − div). Further, let Ω̊ denote the domain without the source and sink sets, i.e. Ω̊ = Ω \ (S ∪ T), then
| (26) |
| (27) |
| (28) |
| (29) |
since u is fixed to 1 x ∈ S, u (x) = 0 for x ∈ T, and between 0 and 1 for locations neither at the source nor the sink.
In summary, the primal energy to evaluate is given in Eq. 7, and the dual energy (recall Eq. 19) is given by
| (30) |
| (31) |
subject to p(x) ∈ − Wϕx. The two terms in the dual energy have direct interpretations: the first term,
| (32) |
measures the total outgoing flow from the source, while the second term, ∫Ω̊ min(0, div p) dx, penalizes additional sinks in the interior of Ω. Thus, it corresponds directly to the well-known min-cut/max-flow theorem.
If we do not add a bounds constraint on u, here u(x) ∈ [0,1], then it is easy see show that a strict penalizer on the divergence outside S and T is obtained. The dual energy contains just the source term,
| (33) |
subject to p ∈ −Wϕx and div p = 0 in Ω̊. For p not satisfying these constraints the dual energy is −∞. Algorithms as the gradient descent updates in Eq. 12 achieve div(p) = 0 only in the limit, hence the strict penalty on div(p) ≠ 0 is not beneficial. Nevertheless, Eq. 33 is useful for analysis after convergence.
The bounds constraint u(x) ∈ [0,1] is redundant for the primal energy, since u(x) ∈ [0,1] is always true for minima of Eq. 7 subject to the source and sink constraints. In the dual setting this range constraints has the consequence, that any capacity-constrained flow p is feasible. Any additional flow generated by p at the source S, but vanishing in the interior is subtracted from the total flow in Eq. 31, hence the overall dual energy remains the same, and bounded and unbounded formulations are equivalent. In practice, we observed substantially faster convergence if u is clamped to [0,1] after each update step, and a meaningful value for the duality gap is thus obtained.
3.3. Equivalence of the Dual Variables
It remains to show, that the dual vector field p introduced in Section 2 (Eq. 9) in facts corresponds to the dual vectorial function p introduced in the dual energy formulation (Eq. 31). This is easy to see: after convergence of the primal-dual method, the primal-dual energy is
since u is one in S and zero in T, and div p = 0 in Ω̊. Consequently, the primal-dual energy in terms of p after convergence is identical to the total flow emerging from the source, i.e. equal to the dual energy. Thus, p as maintained in the primal-dual formulation is equivalent to the argument of the pure dual one.
4. Application to Markov Random Fields
In this section we address the task of globally optimizing a Markov random field energy, where every pixel in the image domain can attain a label from a discrete and totally ordered set of labels ℒ. Without loss of generality, we assume that the labels are represented by non-negative integers, i.e. ℒ = {0,…, L − 1}. Similar to [22, 21, 2, 20], we formulate the label assignment problem with linearly ordered label sets as a segmentation task in higher dimensions.
4.1. From Markov Random Fields to Anisotropic Continuous Maximal Flows
We denote the (usually rectangular) image domain by ℐ and particular pixels in bold font, e.g. x ∈ ℐ. We will restrict ourselves to the case of two-dimensional image domains. A labeling function Λ : ℐ → ℒ, x ↦ Λ(x) maps pixels to labels. The task is to find a labeling function that minimizes an energy functional comprised of a label cost and a regularization term, i.e. to find the minimizer of
| (34) |
where c(x, Λ(x)) denotes the cost of selecting label Λ(x) at pixel x and V(·)is the regularization term. Even for convex regularizers V(·)is optimization problem is generally difficult to solve exactly, since the data costs are typically highly non-convex. By embedding the labeling assignment into higher dimensions, and by appropriately restating the energy in Eq. 34, a convex formulation can be obtained. Let Ω be the product space of ℐ and ℒ i.e. Ω = ℐ × ℒ.
In the following, we introduce the level function u,
| (35) |
Since one label must be assigned to every pixel, we require that u(x, L) = 1 for all x ∈ ℐ. Further, u(x, 0) = 0 by construction. In particular, the gradients of these function in spatial direction (∇x) and in the label direction (∇l) play an important role, i.e.
Finally, ∇u specifies the full gradient of u in spatial and label directions, ∇u = (∂u/∂x, ∂u/∂y, ∂u/∂l)T.
We assume, that the regularization energy in Eq. 34 can be written in terms of the gradient of the level function, i.e. V(·) can be formulated as
| (36) |
where ψx,l is a family of convex and 1-positively homogeneous functions, that shapes the regularization term. The same technique as proposed in [20] can be applied to rewrite the data term:
| (37) |
| (38) |
where |∇lu| ensures that costs stay positive even for general choices of u, that attain any real value and are not monotonically increasing in their label argument.
By combining the data fidelity and regularization terms, we can rewrite the original energy Eq. 34 purely in terms of u (where we omit the explicit dependence of x and l),
| (39) |
Since ψx,l and c| · | are convex and 1-positively homogeneous, their sum ϕx,l(·) : = ψx,l(·) + cx,l |·| shares this property. Finally, we can rewrite Eq. 39 as
| (40) |
Since ϕx,l is again a family of positively 1-homogeneous functions, the anisotropic continuous maximal flow approach described in Section 2 can be applied. Specifically, the solution u after convergence is essentially binary and monotone in the label direction, thus the optimal labeling function Λ can be easily recovered from u.
4.2. Choices for ψ
In [20] a different approach is taken to analyze the particular choice ψx(∇u) = ‖∇xu‖2 (resulting in a special case of the updates in Eq. 12). By the co-area formula it can be shown, that this choice for ψx corresponds to the total variation regularization of the underlying labeling function Λ,
| (41) |
As such, using ψx for the smoothness term results in the preference of piecewise constant assigned labels. The corresponding Wulff shape Wϕx,l of ϕx,l = ‖ ∇xu‖2 + αc|∇lu| is a cylinder with its height proportional to the label cost c(x, l). Since the regularization term is isotropic in the image domain, i.e. the smoothness term does not depend on the actual image content, we denote this particular regularization as homogeneous total variation. Note that it is easy to “squeeze” this cylinder depending on the strength and orientation of edges in the reference image in the stereo pair (Figure 2). In order to use only relevant image edges, the structure tensor of the denoised reference image can be utilized to shape the resulting Wulff shape. We use the phase field approach [1] for the Mumford-Shah functional [18] to obtain piecewise smooth images. The positive impact on the resulting depth maps (with the sampling insensitive Birchfield-Tomasi matching cost [4]) is illustrated in Figure 3.
Figure 2.
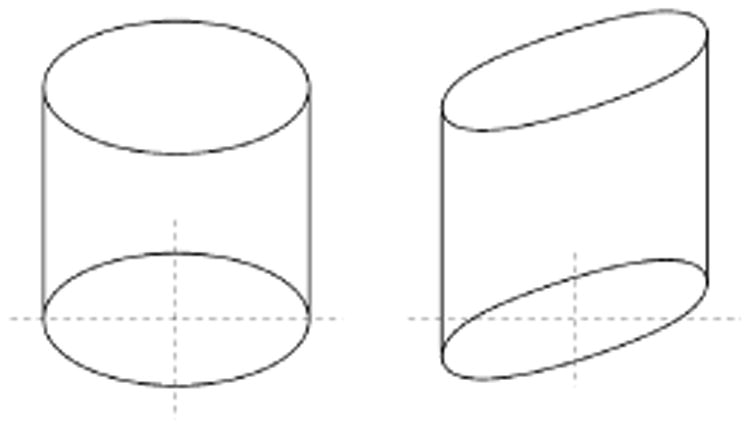
The Wulff shape for homogeneous (left) and edge driven (right) total variation regularizers.
Figure 3.

Depth maps with and without edge driven regularization. (a) is based on homogeneous total variation regularization, and (b) utilizes edge driven regularization. Observe that in (a) the low data fidelity weight yields to substantial loss of detail in the depth map, which is clearly better preserved in (b).
The total variation regularization on the depth map is rather inappropriate if the labels directly correspond to metric depth values in 3D space instead of pure image disparities. A more suitable choice is ψ = ‖∇u‖, if we assume that labels represent equidistantly sampled depth values. This particular choice penalizes the 3D surface area and yields smoother 3D models largely suppressing staircasing artifacts. This specific choice for regularization complies with smoothing the depth map based on an induced surface metric [24]. It can be readily verified that the respective Wulff shape is a capsule-like shape (i.e. a cylinder with half-spheres attached to its base and top face). Figure 4(a–b) visually compares the 3D meshes for the “Dino ring” dataset [23] obtained using total variation regularization ‖∇xu‖ (Fig. 4(a)) and 3D regularization ‖∇u‖ (Fig. 4(b)). Figure 4(c) and (d) display the 3D models obtained for a brick wall, for which a laser scanned reference range image is available. The RMS for (c) is 5.1cm, and 3.2cm for (d) with respect to the known range image.
Figure 4.

3D meshed obtained for ψ = ‖∇xu‖ (a, c) and ψ = ‖∇u‖ (b, d). Clearly, ‖∇xu‖ favors piece-wise constant results. In (d) the strong matching term causes a visible step structure especially in the foreground. Using a lower value of λ in (c) removes the floor (bottom part of the mesh).
The underlying update equations Eq. 12 are very suitable to be accelerated by a modern GPU. Our current CUDA-based implementation executed on a Geforce 8800 Ultra is able to achieve two frames per second for 320 × 240 images and 32 disparity levels (aiming for a 2% duality gap at maximum).
5. Conclusion
This work analyzes the relationship between continuous maximal flows, Wulff shapes, convex analysis and Markov random fields with convex and homogeneous pairwise priors. It is shown that strong results from isotropic continuous maximal flow carry over to flows with anisotropic capacity constraints. The underlying theory yields extensions to a recently proposed continuous and convex formulation for Markov random fields with total variation-based smoothness priors. The numerical simplicity and the data-parallel nature of the minimization method allows an efficient implementation on highly parallel devices like modern graphics processing units.
Future work will address the extension of this work to more general classes of MRFs by investigating other linear operators than ∇, e.g. using ‖∇x ∇lu‖ in the regularization term corresponds to the LP-relaxation of MRFs with a Potts discontinuity prior.
A. The Potential u is Essentially Binary
This section shows, that thresholding of a not necessarily binary primal solution u* of the anisotropic geodesic energy Eq. 7 yields to a equally globally optimal solution. Let u* and p* be a pair of primal and dual globally optimal solutions for the continuous maximal flow energy Eq. 9. Recall that the optimal dual energy is the total flow leaving the source S (Eq. 33):
| (42) |
and that v* is equal to the primal energy E(u*) = ∫ ϕ(∇u*). The thresholded result of u*, uθ, is given by
Further, define Aθ := {x ∈ Ω : u*(x) ≥ θ}. Note that for x ∈ Ω with ∇uθ(x) ≠ 0 (or equivalently x ∈ ∂Aθ) we have ∇u*(x) ≠ 0 by construction. Even a stronger relation holds: ∇uθ(x) = k(x) ∇u*(x) for a positive scalar k(x), since both gradients point in the same direction. Further, the capacity constraint is active at x ∈ Aθ: −p*(x) ∈ ∂Wϕx. Thus, for all x ∈ Aθ (omitting the explicit dependence on x)
Overall we have:
since div p* = 0 in Ω̊ and uθ is 1 in S and 0 in T. This means, that the binary function uθ has the same energy as u* and is likewise optimal.
Contributor Information
Christopher Zach, Email: cmzach@cs.unc.edu.
Marc Niethammer, Email: mn@cs.unc.edu.
Jan-Michael Frahm, Email: jmf@cs.unc.edu.
References
- 1.Ambrosio L, Tortorelli V. Approximation of functionals depending on jumps by elliptic functionals via Γ-convergence. Comm Pure Appl Math. 1990;43:999–1036. [Google Scholar]
- 2.Appleton B, Talbot H. Globally minimal surfaces by continuous maximal flows. IEEE Trans Pattern Anal Mach Intell. 2006;28(1):106–118. doi: 10.1109/TPAMI.2006.12. [DOI] [PubMed] [Google Scholar]
- 3.Berkels B, Burger M, Droske M, Nemitz O, Rumpf M. Cartoon extraction based on anisotropic image classification. Vision, Modeling, and Visualization Proceedings. 2006:293–300. [Google Scholar]
- 4.Birchfield S, Tomasi C. A pixel dissimilarity measure that is insensitive to image sampling. IEEE Trans Pattern Anal Mach Intell. 1998;20(4):401–406. [Google Scholar]
- 5.Borwein J, Lewis AS. Convex Analysis and Nonlinear Optimization: Theory and Examples. Springer; 2000. [Google Scholar]
- 6.Boykov Y, Veksler O, Zabih R. Markov random fields with efficient approximations. Proc CVPR. 1998:648–655. [Google Scholar]
- 7.Boykov Y, Veksler O, Zabih R. Fast approximate energy minimization via graph cuts. IEEE Trans Pattern Anal Mach Intell. 2001;23(11):1222–1239. [Google Scholar]
- 8.Bresson X, Esedoglu S, Vandergheynst P, Thiran J, Osher S. Fast Global Minimization of the Active Contour/Snake Model. J Math Imag Vision. 2007 [Google Scholar]
- 9.Caselles V, Kimmel R, Sapiro G. Geodesic active contours. IJCV. 1997;22(1):61–79. [Google Scholar]
- 10.Chambolle A. An algorithm for total variation minimization and applications. J Math Imag Vision. 2004;20(1–2):89–97. [Google Scholar]
- 11.Chambolle A. Total variation minimization and a class of binary MRF models. Energy Minimization Methods in Computer Vision and Pattern Recognition. 2006:136–152. [Google Scholar]
- 12.Darbon J, Sigelle M. Image restoration with discrete constrained total variation part II: Levelable functions, convex priors and non-convex cases. J Math Imag Vision. 2006;26(3):277–291. [Google Scholar]
- 13.Ishikawa H. Exact optimization for Markov random fields with convex priors. IEEE Trans Pattern Anal Mach Intell. 2003;25(10):1333–1336. [Google Scholar]
- 14.Kolmogorov V. Convergent tree-reweighted message passing for energy minimization. IEEE Trans Pattern Anal Mach Intell. 2006;28(10):1568–1583. doi: 10.1109/TPAMI.2006.200. [DOI] [PubMed] [Google Scholar]
- 15.Kolmogorov V, Zabih R. What energy functions can be minimized via graph cuts? IEEE Trans Pattern Anal Mach Intell. 2004;26(2):147–159. doi: 10.1109/TPAMI.2004.1262177. [DOI] [PubMed] [Google Scholar]
- 16.Komodakis N, Paragios N, Tziritas G. MRF optimization via dual decomposition: Message-passing revisited. Proc ICCV. 2007 [Google Scholar]
- 17.Lempitsky V, Roth S, Rother C. Fusion Flow: Discrete-continuous optimization for optical flow estimation. Proc CVPR. 2008 [Google Scholar]
- 18.Mumford D, Shah J. Optimal approximation by piece-wise smooth functions and associated variational problems. Comm Pure Appl Math. 1989;42:577–685. [Google Scholar]
- 19.Osher S, Esedoglu S. Decomposition of images by the anisotropic Rudin-Osher-Fatemi model. Comm Pure Appl Math. 2004;57:1609–1626. [Google Scholar]
- 20.Pock T, Schoenemann T, Cremers D, Bischof H. A convex formulation of continuous multi-label problems. Proc ECCV. 2008 [Google Scholar]
- 21.Roy S. Stereo without epipolar lines: A maximum flow formulation. IJCV. 1999;34(2/3):147–161. [Google Scholar]
- 22.Roy S, Cox IJ. A maximum flow formulation of the N-camera stereo correspondence problem. Proc ICCV. 1998:492–499. [Google Scholar]
- 23.Seitz S, Curless B, Diebel J, Scharstein D, Szeliski R. A comparison and evaluation of multi-view stereo reconstruction algorithms. Proc CVPR. 2006:519–526. [Google Scholar]
- 24.Sochen N, Kimmel R, Malladi R. A general framework for low level vision. IEEE Trans in Image Processing. 7:310–318. doi: 10.1109/83.661181. [DOI] [PubMed] [Google Scholar]
- 25.Trobin W, Pock T, Cremers D, Bischof H. Continuous energy minimization via repeated binary fusion. Proc ECCV. 2008 [Google Scholar]
- 26.Yedidia J, Freeman WT, Weiss Y. Understanding belief propagation and its generalizations. International Joint Conference on Artificial Intelligence (IJCAI) 2001 [Google Scholar]