

Abstract
All of our perceptual experiences arise from the activity of neural populations. Here we study the formation of such percepts under the assumption that they emerge from a linear readout, i.e., a weighted sum of the neurons’ firing rates. We show that this assumption constrains the trial-to-trial covariance structure of neural activities and animal behavior. The predicted covariance structure depends on the readout parameters, and in particular on the temporal integration window w and typical number of neurons K used in the formation of the percept. Using these predictions, we show how to infer the readout parameters from joint measurements of a subject’s behavior and neural activities. We consider three such scenarios: (1) recordings from the complete neural population, (2) recordings of neuronal sub-ensembles whose size exceeds K, and (3) recordings of neuronal sub-ensembles that are smaller than K. Using theoretical arguments and artificially generated data, we show that the first two scenarios allow us to recover the typical spatial and temporal scales of the readout. In the third scenario, we show that the readout parameters can only be recovered by making additional assumptions about the structure of the full population activity. Our work provides the first thorough interpretation of (feed-forward) percept formation from a population of sensory neurons. We discuss applications to experimental recordings in classic sensory decision-making tasks, which will hopefully provide new insights into the nature of perceptual integration.
Author Summary
This article deals with the interpretation of neural activities during perceptual decision-making tasks, where animals must assess the value of a sensory stimulus and take a decision on the basis of their percept. A “standard model” for these tasks has progressively emerged, whence the animal’s percept and subsequent choice on each trial are obtained from a linear integration of the activity of sensory neurons. However, up to date, there has been no principled method to estimate the parameters of this model: mainly, the typical number of neurons K from the population involved in conveying the percept, and the typical time scale w during which these neurons’ activities are integrated. In this article, we propose a novel method to estimate these quantities from experimental data, and thus assess the validity of the standard model of percept formation. In the process, we clarify the predictions of the standard model regarding two classic experimental measures in these tasks: sensitivity, which is the animal’s ability to distinguish nearby stimulus values, and choice signals, which assess the amount of correlation between the activity of single neurons and the animal’s ultimate choice on each trial.
Introduction
Most cortical neurons are noisy, or at least appear so in experiments. When we record the responses of sensory neurons to well-controlled stimuli, their spike patterns vary from trial to trial. Does this variability reflect the uncertainties of the measurement process, or does it have a direct impact on behavior? These questions are central to our understanding of percept formation and decision-making in the brain and have been the focus of much previous work [1]. Many studies have sought to address these problems by studying animals that perform simple, perceptual decision-making tasks [2, 3]. In such tasks, an animal is typically presented with different stimuli s and trained to categorize them through a simple behavioral report. When this perceptual report is monitored simultaneously with the animal’s neural activity, one can try to find a causal link between the two.
One particular hypothesis about this link—which we refer to as the “sensory noise” hypothesis—postulates that the accuracy of the animal’s perceptual judgments is primarily limited by noise at the level of sensory neurons [4, 5]. In terms of signal detection theory, the hypothesis predicts a quantitative match between (1) the animal’s ability to discriminate nearby stimulus values—known as psychometric sensitivity, and (2) an ideal observer’s ability to discriminate nearby stimulus values based on the activities of the underlying neural population—known as neurometric sensitivity. Both types of sensitivities can be quantified as signal-to-noise ratios (SNR). With this idea in mind, several studies have compared the neurometric and psychometric sensitivities in various sensory systems and behavioral tasks (see [6, 7] for reference).
However, as was soon realized, any extrapolation from a few recorded cells to the entire population is fraught with implicit assumptions. For example, if neurons in a population behave independently one from another, then the SNR of the population is simply the sum of the individual SNRs. Consequently, any estimate of neurometric sensitivity will grow linearly with the number of recorded neurons K. However, if neurons in a population do not behave independently, the precise growth of neural sensitivity with K is determined by the correlation structure of noise in the population [8–10]. In addition, the neurometric sensitivities also depend on the time scale w that is used to integrate each neuron’s spike train in a given trial [3, 11–13]. Indeed, the more spikes are incorporated in the readout, the more accurate that readout will be. Adding extra neurons by increasing K, or adding extra spikes by increasing w, are two dual ways of increasing the readout’s overall SNR.
As there is no unique way of reading out information from a population of sensory neurons, the sensory noise hypothesis can only be tested if we understand how the organism itself “reads out” the relevant information. In other words, how many sensory neurons K, and what integration time scale w, provide a relevant description of the animal’s percept formation? Given the “K-w” duality mentioned above, we cannot answer that question based solely on sensitivity (SNR). Another experimental measure should also be included in the analysis.
A good candidate for such a measure are choice signals, i.e., measures of the trial-to-trial correlation between the activity of each recorded neuron and the animal’s ultimate choice on each trial. These signals, weak but often significant, arise from the unknown process by which each neuron’s activity influences—or is influenced by—the animal’s perceptual decision. In two-alternative forced choice (2AFC) discrimination tasks, they have generally been computed in the form of choice probabilities (CP) [14, 15]. The temporal evolution of CPs has been used to find the instants in time when a given population covaries with the animal’s percept [13, 16]. In a seminal study, Shadlen et al. (1996) proposed to jointly use sensitivity and choice signals, as two independent constraints characterizing the underlying neural code [17]. They derived a feed-forward model of perceptual integration in visual area MT, and studied numerically how the population’s sensitivity and CPs vary as a function of various model parameters. They acknowledged the existence of a link between CPs and pairwise noise correlations—both measures being (partial) reflections of how information is embedded in the neural population as a whole (see also [12, 18]). However, the quantitative nature of this link was only revealed recently, when Haefner et al. (2013) derived the analytical expression of CPs in the standard model of perceptual integration [19] (see Methods).
In this article, we show that the standard feed-forward model of percept formation gives rise to three characteristic equations that describe analytically the trial-to-trial covariance between neural activities and animal percept. These equations depend on the brain’s readout policy across neurons and time, and hold for any noise correlation structure in the neural population. In accordance with the intuition of Shadlen et al. (1996), we show that sensitivity and choice signals correspond to two distinct, characteristic properties of the readout. The equation describing choice signals is equivalent to the one derived by Haefner et al. (2013), but stripped from the non-linear complications inherent to the CP formulation. We use a linear formulation instead, which gives us a particularly simple prediction of choice signals at every instant in time.
We then show how these equations can be used in order to recover the time window and the number of neurons used in the formation of a percept. A quantitative analysis of choice signals allows us to overcome the “K–w trade-off” inherent to neurometric sensitivity. We specifically focus on situations in which only a finite sample of neurons has been measured from a large, unknown population. We show how to recover the typical number of neurons K, provided that the experimenter could record at least K neurons simultaneously. Finally, we discuss the scope and the limitations of our method, and how it can be applied to real experimental data.
Results
Experimental measures of behavior and neural activities
We will study the formation of percepts in the context of perceptual decision-making experiments (Fig. 1, see Methods or Tables 1–3 for the corresponding formulas). In these experiments, an animal is typically confronted with a stimulus, s, and must then make a behavioral choice, c, according to the rules of the task. A specific example is the classic discrimination task in which the animal’s choice c is binary, and the animal must report whether it perceived s to be higher (c = 1) or lower (c = 0) than a fixed reference s 0 (Fig. 1A, top and middle panels). While the animal is performing the task, the neural activity in a given brain area can be monitored (Fig. 1A, bottom panel). Typical examples from the literature include area MT in the context of a motion discrimination task [3], area MT or V2 in the context of a depth discrimination task [11, 20], or area S1 in the context of a tactile discrimination task [21]. For concreteness, we will mostly focus on these discrimination tasks, although the general framework can be applied to arbitrary perceptual decision-making tasks.
Fig 1. Framework and main experimental measures.

(A) Experimental setup. Top: A set of stimulus values s (color-coded as blue, yellow, red) are repeatedly presented to an animal. Middle: The animal’s choice c on each trial (green) indicates whether the animal judged s to be larger or smaller than the fixed central value, s 0. Bottom: In each session, several task-relevant sensory neurons are recorded simultaneously with the behavior. (B) The psychometric curve ψ(s) quantifies the animal’s sensory accuracy. Its inverse slope in s 0 provides the just-noticeable-difference (JND), Z. (C) The noise covariance structure can be assessed in each pair of simultaneously recorded neurons, as their joint peri-stimulus histogram (JPSTH) C ij(t, u). (D) Responses of a particular neuron. Each thin line is the schematic (smoothed) representation of the spike train on one trial. Segregating trials according to stimulus (top), we access the neuron’s peri-stimulus histogram (PSTH, thick lines) and its tuning signal b i(t)—shown in panel (E). Fixing a stimulus value and segregating trials according to the animal’s choice c (bottom), we access the neuron’s choice covariance (CC) curve d i(t)—shown in panel (F).
Table 1. Variables and notations: typography.
| Notation | Description | Examples |
|---|---|---|
| Bold | Lower case: vector notation, across neurons Upper case: matrix notation, across neurons |
r(t), b(t) C(t, u), |
| Overline | Temporal integration, using readout parameters (w, t R) | , , |
| Starred | Pertaining to the animal’s true behavior (as opposed to model-based predictions) |
Z ⋆, , |
| E[⋅] | Expectation across trials (can also be conditional) | E[s], E[r i(t)∣s], E[sr i(t)] |
| Cov[⋅] | Covariance across trials (can also be conditional) | Cov[r i(t), c ⋆∣s] |
| x r | Vector (or matrix) x restricted to neurons in readout ensemble 𝓔 | a r, , , |
Table 3. Variables and notations: model and methods.
| Linear readout and decision model | Ref in text | ||
| w | Readout window—duration of the temporal integration | ||
| t R | extraction time—time at which the percept is formed | ||
| a i | Readout weight—contribution of neuron i to the percept | ||
| σ d | Decision noise—added to the percept at decision time | ||
| Readout—computed on every trial | eq. 2 | ||
| c | Choice—computed on every trial | eq. 3 | |
| Model predictions (characteristic equations) | |||
| Z | Just-noticeable difference | eq. 8 | |
| d(t) | Choice covariance for every neuron | eq. 9 | |
| κ(Z) | Conversion factor from Percept Covariance to Choice Covariance | eq. 46 | |
| Restricted optimality hypothesis | |||
| 𝓔 | Readout ensemble—neurons used for the readout | ||
| K | Readout size—number of neurons in 𝓔 | ||
| H | Restriction matrix on 𝓔 (of size K × N tot) | eq. 54 | |
| a r | Optimal readout vector (over 𝓔) | eq. 12 | |
| Population-wide indicators for choice signals | |||
| q(u, t) | Population-wide link between tuning and CC | q(u, t)≔⟨b i(u)d i(t)⟩i | eq. 14 |
| V | Deviation from linearity between tuning and CC | eq. 15 | |
| Rescaled indicators (used in the SVD analysis) | |||
| A | Total covariance matrix | eq. 50 | |
| Y | Sensitivity to stimulus | eq. 47 | |
| e | Total percept covariance | e ≔ A a | eq. 76 |
| Q | Rescaled version of | eq. 18, 79 | |
| η | Tuning vector in the space of modes | eq. 68 | |
Table 2. Variables and notations: experimental data.
| Raw experimental data | Ref in text | ||
| s | Stimulus—a varying scalar value on each trial | ||
| s 0 | Threshold stimulus value in the 2AFC task | ||
| c ⋆ | Animal choice—binary report on each trial | ||
| r i(t) | Spike train from neuron i in a given trial | ||
| Stimulus variance across trials | after eq. 18 | ||
| Animal psychometry | |||
| ψ ⋆(s) | Psychometric curve | ψ ⋆(s)≔E[c ⋆∣s] | eq. 23 |
|
Z
⋆
|
Just-noticeable difference Decision bias |
Best fit to | eq. 27 |
| Individual statistics for the neurons | |||
| m i(t; s) | PSTH for neuron i with stimulus s | m i(t; s)≔E[r i(t)∣s] | eq. 24 |
| b i(t) | Tuning signal for neuron i
(variation of the PSTH wrt. stimulus) |
eq. 30, 31 | |
| C ij(t, u) | JPSTH for neurons i and j
(pairwise noise correlations) |
eq. 25, 32 | |
| Noise covariance matrix (time average of C, with parameters (w, t R)) |
eq. 40 | ||
| Choice Covariance for neuron i
(linear equivalent of choice probabilities) |
eq. 26, 33 | ||
The animal’s behavior in a discrimination task can be quantified through the psychometric curve ψ(s). This curve measures the animal’s repartition of responses at each stimulus value s (Fig. 1B). If the animal is unbiased, it will choose randomly whenever the stimulus s is equal to the threshold value s 0, so that ψ(s 0) = 1/2. The slope of the psychometric curve at s = s 0 determines the animal’s ability to distinguish near-threshold values of the stimulus, i.e., its psychometric sensitivity. We assess this sensitivity through the just noticeable difference (JND) or difference limen, noted Z. The more sensitive the animal, the smaller Z, and the steeper its psychometric curve.
We assume that the neural activity within the recorded brain area conveys the stimulus information that the animal uses to make its choice (Fig. 1A, bottom). We describe the activity of this neural population on every trial as a multivariate point process r(t) = {r i(t)}i = 1…Ntot, where each r i(t) is the spike train for neuron i, and N tot denotes the full population size, a very large and unknown number. (The number of neurons actually recorded is generally much smaller.) As is common in electrophysiological recordings, we will quantify the raw spike trains by their first and second order statistics. First, neuron i’s trial-averaged activity in response to each tested stimulus s is given by the peri-stimulus time histogram (PSTH) or time-varying firing rate, m i(t; s) (Fig. 1D). In so-called “fine” discrimination tasks, the stimuli s display only moderate variations around the central value s 0, so that the PSTH at each instant in time can often be approximated by a linear function of s: . The slope b i(t), defined at every instant in time, summarizes neuron i’s tuning properties (Fig. 1E). Second, we assume that several neurons can be recorded simultaneously, so that we can access samples from the trial-to-trial covariance structure of the population activity (Fig. 1C). For every pair of neurons (i, j) and instants in time (t, u), the joint peri-stimulus time histogram (JPSTH, [22]) C ij(t, u) summarizes the pairwise noise correlations between the two neurons (eq. 25). For simplicity, we furthermore assume that the JPSTHs do not depend on the exact stimulus value s.
Finally, we can measure a choice signal for each neuron, which captures the trial-to-trial covariation of neuron activity r i(t) with the animal’s choice (Fig. 1F). Traditionally, this signal is measured in the form of choice probability (CP) curves. We consider here a simpler linear equivalent, that we term choice covariance (CC) curves [3]. The CC curve for neuron i, denoted by d i(t), measures the difference in firing rate (at each instant in time) between trials where the animal chose c = 1 and trials where it chose c = 0—all experimental features (including stimulus value) being fixed.
Unlike many characterizations of neural activity that rely only on spike counts, our framework requires an explicit temporal description of neural activity through PSTHs, JPSTHs, and CC curves. Exact formulas for these statistical measures are provided in the Methods. By keeping track of time, we will be able to predict when, and how long, perceptual integration takes place in an organism.
From the neural activities to the animal’s choice
Linear readout model
Our goal is to quantify the mapping from the neural activities, r(t), to the animal’s choice, c. This can be done if we assume (1) how the stimulus information is extracted from the neural activities and (2) how the animal’s decision is formed. For (1) we assume the common linear readout model (Fig. 2A). Here, each neuron’s spike train r i(t) is first integrated into a single number describing the neuron’s activity over the trial. We write,
| (1) |
where the kernel h(⋅) defines the shape of the integration window (e.g., square window, decreasing exponential, etc.), the parameter w controls the length of temporal integration, and the parameter t R specifies the time at which the percept is built or read out. Second, the actual percept is given by a weighted sum over the neurons’ activities,
| (2) |
where a = (a 1, …, a Ntot) is a specific readout vector, or “perceptual policy”. This classic linear readout has sometimes been referred to as the “standard” model of perceptual integration [17, 19].
Fig 2. Linear readout and its interpretation.
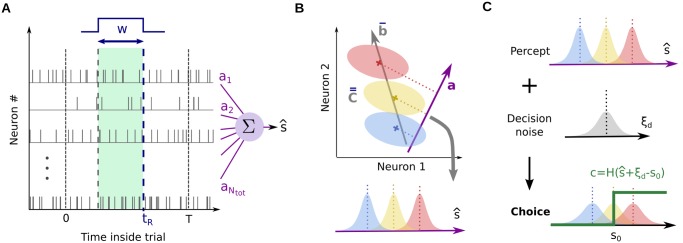
(A) We study a “standard” model of percept formation, with two parameters w and t R defining integration in time, and a readout vector a defining integration across neurons. (B) Geometric interpretation of the model. The temporal parameters w and t R define the tuning vector and noise covariance matrix in the population. Colored ellipses represent the distribution of neural activities from trial to trial, for the three possible stimulus values. The readout can be viewed as an orthogonal projection of neural activities in the direction given by a. (C) Behavioral part of the model. The percept can be corrupted by decision noise ξ d. Then it is thresholded to produce a binary choice c.
Previous studies have generally made ad hoc choices for the various constituents of this model. Most often, is taken to be the total spike count for neuron i, in which case t R = w coincides with the end of the stimulation period, and h(⋅) in eq. 1 is a square kernel. However, this readout is likely incorrect: the length of the integration window w influences the neurometric sensitivity, and experiments suggest that animals do not always use the full stimulation period to build their judgment [23]. Similarly, vector a is often defined over an arbitrary set of neurons, typically those recorded by the experimenter. Again, this choice is arbitrary, and it has a direct influence on the predicted sensitivities.
Instead, we view the readout window w and extraction time t R as free parameters, and we generically define a over the full, unknown population of neurons. If a neuron does not contribute to the percept, it simply corresponds to a zero entry in a. For conceptual and implementation simplicity, we take h(⋅) to be a simple square window (see Discussion for a generalization). Our goal is now to understand whether the readout can be a good model for the animal’s true percept formation and if yes, for what set of parameters.
Decision policy
The linear model builds a continuous-valued, internal percept of stimulus value by the animal on each trial. To emulate the discrimination tasks, we also need to model the animal’s decision policy, which converts the continuous percept into a binary choice c. While the linear model is rather universal, the decision model will depend on the specifics of each experimental task. To ground our argumentation, we model here the required decision in a classic random dot motion discrimination task [3]. However, the ideas herein could also be transposed to other types of behavioral tasks (see Discussion).
On each trial, we assume that an extraneous source of noise ξ d is added to the animal’s percept (Fig. 2C). Known in the literature as ‘decision noise’ or ‘pooling noise’, ξ d encompasses all extra-sensory sources of variation which may influence the animal’s decision. We assume that ξ d is a Gaussian variable with variance , which we take as an additional model parameter. Then, the animal’s choice on each trial is built deterministically, by comparing to the threshold value s 0 (Fig. 2C), so that
| (3) |
where H(⋅) is the Heaviside function. We note that the decision noise is negligible in the classic “sensory noise hypothesis”, in which case σ d → 0.
The characteristic equations of the standard model
The linear readout model and the animal’s decision policy specify both how the animal’s percepts are formed from its neural activities and how its choices are generated from these percepts. If we had recorded the activities of the entire neural population together with the animal’s behavior, then the parameters of this model could be estimated from the data using any standard regression method. However, this is generally not a realistic experimental situation. Instead, we take here a statistical approach to the problem, which (1) allows us to deal with incomplete recordings and (2) relates the estimation problem to the standard experimental measures described above.
Characteristic equations of the linear readout
Thanks to its linear structure, the readout defined in eq. 2 induces a simple covariance between the neural activities, r(t), and the resulting percept, (Fig. 2B). Since the linear readout relies on the integrated spike trains, eq. 1, we need similarly integrated versions of the neural tuning and noise covariances in order to express the respective covariance relations. In general, we will denote these time-integrated quantities by an overhead bar, and alert the reader that the respective quantities depend implicitly on the readout window w and the extraction time t R. We will write for the integrated version of the neural tuning, b i(t), we will write for the once integrated noise covariances, and for the doubly integrated noise covariance. This latter quantity, known in the literature as the ‘noise covariance matrix’, measures how the spike counts of two neurons, and , covary due to shared random fluctuations across trials (stimulus s being held fixed). We can then summarize the covariances between neural activities and the resulting percepts by three characteristic equations (see Methods):
| (4) |
| (5) |
| (6) |
On the left-hand sides of eq. 4–6, we find statistical quantities related to the percept . On the right-hand sides of these equations, we find the model’s predictions, which are based on the neurons’ (measurable) response statistics, b and C. More specifically, the first line describes the average dependency of on stimulus s, the second line expresses the resulting variance for the percept, and the third line expresses the linear covariance between each neuron’s spike train, and the animal’s percept on the trial.
Characteristic equations of the decision policy
To produce a binary choice, the continuous percept is fed into the decision model (Fig. 2C). From the output of this decision model, we obtain a second set of characteristic equations (see Methods),
Here the first equation simply expresses that both percept and decision are assumed to be unbiased. The second equation relates the JND, Z, extracted from the psychometric curve, to the variance in the percept, . The third equation restates the definition of choice covariance, except for the scaling factor, κ(Z), which will be constant for most practical purposes, and is described in detail in the Methods (eq. 46). Hence, in our full model of the task, we are able to predict both the psychometric sensitivity and the individual neurons’ choice signals from the first and second-order statistics of the neural responses. Specifically, by combining the characteristic equations for the linear readout and the decision policy, we obtain
| (7) |
| (8) |
| (9) |
Importantly, since these equations deal with integrated versions of the raw neural signals, they depend on both the readout time window, w, and the extraction time, t R.
We note that the choice covariance equation (eq. 9) can also be derived in a simpler, time-averaged form. Let be the time-integrated version of d i(t), using the readout’s temporal parameters (w, t R). Then, eq. 9 becomes
| (10) |
which provides the linear covariance between each neuron’s spike count on the trial, and the animal’s choice. This is essentially the relationship already revealed by Haefner et al. (2013) [19], that choice probabilities are related to readout weights through the noise covariance matrix. The simpler linear measure of choice covariance, used in this article, allows us (1) to get rid of some non-linearities inherent to the choice probability formulation, and (2) to easily extend the interpretation of choice signals in the time domain, with eq. 9.
Estimating the parameters of sensory integration
Equations 7–9 describe the analytical link between measures of neural response to the stimulus (b i and C ij) and measures related to the animal’s percept (Z and d i), based on the model’s readout parameters (a, w, t R, and σ d). This naturally raises the reverse question: can we estimate the parameters of the standard model (a, w, t R, and σ d) from actual measurements? From here on, we will denote the true (and unknown) values of these parameters, i.e., the values used in the animal’s actual percept formation, with a star (a ⋆, w ⋆, , and ).
As mentioned in the introduction, our primary interest concerns the trade-off between the time scale w ⋆ of integration, and the size K ⋆ of the functional population which conveys the animal’s percept to downstream areas. Thus, we assume that the animal’s percept is constructed from a specific sub-ensemble 𝓔⋆ of neurons, of size K ⋆ (Fig. 3A). Neurons inside 𝓔⋆ correspond to nonzero entries in the readout vector a ⋆, while neurons outside 𝓔⋆ have zero entries. Since only a subset of neurons within a cortical area will project to a downstream area, we can generally assume that K ⋆ < N tot.
Fig 3. Statistical recovery of readout parameters: method.

(A) The full population (of size N
tot) and the true readout ensemble  ⋆ (of size K
⋆), are not fully measured. Only subsets of N neurons are recorded simultaneously from the population. (B) True measures for the three statistical indicators: the animal’s psychometric JND Z
⋆, plus indicators q
⋆(u, t) and V
⋆ that summarize the distribution of the recorded neurons’ CC curves . (C) A large number of neural ensembles
⋆ (of size K
⋆), are not fully measured. Only subsets of N neurons are recorded simultaneously from the population. (B) True measures for the three statistical indicators: the animal’s psychometric JND Z
⋆, plus indicators q
⋆(u, t) and V
⋆ that summarize the distribution of the recorded neurons’ CC curves . (C) A large number of neural ensembles  of size K are randomly selected from the experimental pool and proposed as the candidate readout ensemble. This yields model-based predictions for the indicators as a function of the proposed readout parameters (K, σ
d, w, t
R). (D-F) The three statistical indicators considered (see text for details).
of size K are randomly selected from the experimental pool and proposed as the candidate readout ensemble. This yields model-based predictions for the indicators as a function of the proposed readout parameters (K, σ
d, w, t
R). (D-F) The three statistical indicators considered (see text for details).
Naturally, all those parameters are not measurable experimentally. For any candidate set of parameters, a, w, t R, and σ d, the characteristic equations 7–9 lead to predictions for Z and d i(t) (note the absence of star when referring to predictions). In turn, the experimenter can measure the animal’s actual choice c ⋆ on each trial, from which they can estimate the JND Z ⋆, and the CC curves for all recorded neurons. In the next three sections, we study whether this information is sufficient to retrieve the true readout parameters, depending on the amount of data available.
In the ideal scenario where all neurons in the population are recorded simultaneously, N = N tot, all parameters can be retrieved exactly (Case 1). In most experimental recordings, however, we only measure the activities of a small subset of that population (Fig. 3A). If this subset is representative of the full population, we may want to retrieve the readout parameters through extrapolation. Unfortunately, any such extrapolation is fraught with additional assumptions—whether implicit or explicit—as it requires to replace the missing data with some form of (generative) model. In Case 2, we impose a generative model for the readout vector a. Coupled with a statistical principle, it allows us to estimate the true size K ⋆ of the readout ensemble, provided that the number of neurons recorded simultaneously, N, is larger: N > K ⋆. In Case 3, we study the scenario in which N ≤ K ⋆. Here, we need to assume a generative model for the neural activities themselves. Since the noise covariance structure assumed by that model exerts a strong influence on the predicted JND and CC curves, a direct inference of the readout scales becomes impossible.
Case 1: all cells recorded
If all neurons in the population have been recorded, with a sufficient amount of trials to estimate the complete covariance structure of the population, then the only unknown quantities in eq. 7–9 are the readout parameters w, t R and a, and the decision noise σ d. For fixed parameters w and t R, eq. 7 and 9 impose linear constraints on vector a. These constraints are generally over-complete, since a is N tot-dimensional, while each time t in eq. 9 provides N tot additional linear constraints. Thus, in general, a solution a will only exist if one has targeted the true parameters w ⋆ and , and it will then be unique. (If no choice of the readout parameters approximately fulfills the characteristic equations, we would have to conclude that the linear readout model is fundamentally wrong.) In practice, we can find the best solution to the characteristic equations by simply combining them and then minimizing the following mean-square error:
| (11) |
where the parameters λ and μ trade off the importance of the errors in the different characteristic equations. Note that the loss function L depends not only on the readout weights a and the decision noise σ d, but also on the parameters w and t R, both of which enter all the time integrations that are denoted by an overhead bar. Once vector a ⋆ is estimated, the readout ensemble 𝓔⋆ will correspond to the set of neurons with nonzero readout weights.
Case 2: more than K ⋆ cells recorded
Unfortunately, measuring the neural activity of a full population is essentially impossible, although optogenetic techniques are coming ever closer to this goal [24–26]. Nevertheless, if the activity patterns of the recorded cells are statistically similar to those of the readout ensemble, and if the number of simultaneously recorded cells exceeds the number of cells in the readout ensemble, we can still retrieve the readout parameters by making specific assumptions about the true readout vector a ⋆.
A statistical approach
Our central assumption will be that the system uses the principle of restricted optimality: we assume that the readout vector a ⋆ extracts as much information as possible from the neurons within the readout ensemble, 𝓔⋆, and no information from all other neurons. Since most of the neurons contributing to the readout were probably not recorded, we cannot directly estimate the true readout vector, a ⋆. However, we can form candidate ensembles from the recorded pool of neurons, 𝓔, compute their optimal readout vector, a r(𝓔), and then test to what extent these candidate ensembles can predict the JND or the CC curves (Fig. 3C). By changing the size of the candidate ensembles, K, we can in turn infer the number of neurons involved in the readout.
For an arbitrary candidate ensemble 𝓔, we can express its optimal readout vector, a r(𝓔) ≔ {a i}i ∈ 𝓔, on the basis of the neurons’ tuning and noise covariance, through a formula known as Fisher’s linear discriminant [27]:
| (12) |
Here, the subscript r indicates that all quantities are only evaluated for the neurons within the ensemble 𝓔. The remaining neurons in the population do not participate in the readout. The resulting readout vector verifies eq. 7, and minimizes the just noticeable difference Z under the given constraints. Specifically, by entering the optimal readout into eq. 8, we obtain a prediction for the JND (Fig. 3D),
| (13) |
As for CC signals, the statistical description eliminates any reference to neuron identities, so we can no longer work directly with eq. 9. Instead, we re-express this equation in terms of two population-wide indicators, that summarize the CC signals of the individual neurons. The first indicator assesses the population-wide link between a neuron’s tuning at each time u, and its choice covariance at each time t. The second indicator measures the average deviation from this link (see also Methods):
| (14) |
| (15) |
Here, the angular brackets ⟨⋅⟩i denote averaging over the full neural population—or, in practice, over a representative ensemble of neurons (see Methods on how to construct this from actual data).
Experimentally, q(u, t) is expected to be globally positive, because the tuning of a neuron is often found to be somewhat correlated with its choice signal [11, 15] (Fig. 3E)—likely due to the fact that positively-tuned neurons contribute positively to stimulus estimation, and negatively-tuned neurons negatively. This correlation can be quantified under the assumption of restricted optimality (see Methods). The indicator q(u, t) has a simple interpretation which we will illustrate by focusing on its doubly time-integrated version, . When we seek to predict a neuron’s choice covariance from its tuning , then is the best regression coefficient (Fig. 3F), so that
The deviations from this prediction are indicated by ξ i, whose variance in turn is measured by the indicator V (Fig. 3F). A similar relation holds for the time-dependent indicator q(u, t).
We now seek readout parameters which provide the best fit to the indicators introduced above. We set a number of potential values for parameters K, w, t R, σ d, and we explore routinely all their possible combinations. For each tested value of the readout ensemble size, K, we repeatedly pick a random neural ensemble 𝓔 of size K from the pool of neurons recorded by the experimenter, and propose it as the source of the animal’s percept (Fig. 3C). Then, we compute the average indicators across ensembles of similar size (see Methods), which we will denote by , , and . Note that all of these indicators depend on the parameters w, t R, K, and σ d. Finally, we replace the loss function of Case 1 (eq. 11) by the following “statistical” loss function:
| (16) |
The minimum of the loss function then indicates what values of the readout parameters agree best with the recorded data.
Network simulations and retrieval of readout parameters
To validate these claims, we have tested our method on synthetic data—which are the only way to control the true parameters of integration, and thus to test our predictions. We implemented a recurrent neural network with N = 5000 integrate-and-fire neurons that encodes some input stimulus s in the spiking activity of its neurons, and we built a perceptual readout from that network according to our model, with parameters K ⋆ = 80 neurons, w ⋆ = 50 ms, ms, and stimulus units (see Methods for a description of the network, and supporting S1 Text).
Then, as experimenters, we observed on every trial the perceptual report c ⋆ and samples of network activity, from which we computed neural response statistics b i(t) and C ij(t, u), the psychometric curve ψ ⋆(s), and the neuron CC curves (Fig. 4). From these (partial) measures, we extracted the three population-wide indicators Z ⋆, q ⋆(u, t) and V ⋆, and investigated whether the loss function from eq. 16 allows us to recover the system’s true scales of perceptual integration .
Fig 4. Simulated neural network used for testing the method.

(A) Spike count statistics amongst the population of 5000 neurons (spike counts over 400 msec, on 3 × 180 stimulus repetitions). Note the weak, but significant, correlation between tuning (b i) and choice covariance (d i). (B) Sample PSTHs: the model neurons display varied firing rates, and tunings of different polarities. (C) Sample choice covariance curves for the same neurons as panel B (thin lines: bootstrap-based error bars). (D) Sample JPSTHs (noise correlations) for pairs of model neurons. Inset: corresponding cross-correlograms, obtained by projection along the diagonal. For better visibility, the curves in panels B-D were computed from a larger number of trials (3 × 3000) than used for the study itself (3 × 180), and time-averaged with a 10 msec Gaussian kernel.
The results, summarized in Fig. 5, show that the recovery is indeed possible. Each indicator plays a specific role in recovering some of the parameters. First, indicator q(u, t) allows us to recover the temporal parameters of integration (w, t R). Indeed, it characterizes the time interval during which the population—as a whole—shows the strongest choice covariance (Fig. 5A), and the bounds of this interval are essentially governed by parameters (w, t R) (Fig. 5B). As a result, the match between true measure and prediction—second term in eq. 16—shows a clear optimum near the true values (Fig. 5C). The bi-temporal structure of q(u, t) in eq. 14, with time index u corresponding to the neurons’ tuning b i(u), stabilizes the results by insuring that q(u, t) is globally positive.
Fig 5. Statistical recovery of readout parameters: structure of the results.

(A) Experimental indicator q
⋆(u, t). Note the noisiness due to limited amounts of data. (B) Prediction  for a given set of readout parameters (w, t
R, K, σ
d). The temporal location of the CC signal is mostly governed by parameters w and t
R. (C) (Normalized) mean square error between measured and predicted q(u, t), as a function of readout parameters (w, t
R). The true values are indicated by a white square. (D) Predicted JND
for a given set of readout parameters (w, t
R, K, σ
d). The temporal location of the CC signal is mostly governed by parameters w and t
R. (C) (Normalized) mean square error between measured and predicted q(u, t), as a function of readout parameters (w, t
R). The true values are indicated by a white square. (D) Predicted JND  as a function of K and w. (E) Predicted JND
as a function of K and w. (E) Predicted JND  as a function of K and σ
d. (F) Predicted deviation
as a function of K and σ
d. (F) Predicted deviation  as a function of K and σ
d. In panels C-F, the white square indicates the true (starred) value for the parameters being represented. The parameters not represented are always fixed at their true (starred) value. In panels D-F, the red curve marks the intersection of the predicted indicator with its measured value. All indicators have units derived from Hz, owing to stimulus s being itself a frequency (see Methods).
as a function of K and σ
d. In panels C-F, the white square indicates the true (starred) value for the parameters being represented. The parameters not represented are always fixed at their true (starred) value. In panels D-F, the red curve marks the intersection of the predicted indicator with its measured value. All indicators have units derived from Hz, owing to stimulus s being itself a frequency (see Methods).
Second, indicator Z allows us to target readouts with the correct ‘overall amount’ of integration, resulting in a JND compatible with the data. Fig. 5D depicts the predicted value for Z as a function of w and K. The mark of the ‘K-w trade-off’ is visible: higher sensitivity to stimulus can be achieved either through longer temporal integration (w), or through larger readout ensembles (K). Analytically, the JND Z depends on w because the covariance matrix will generally scale with w −1 (under mild assumptions, supporting S1 Text). The red curve marks the pairs (K, w) for which the prediction matches the measured JND Z ⋆—thereby minimizing the first loss term in eq. 16. The true parameters (K ⋆, w ⋆) lie along that curve (white square in Fig. 5D). Since w ⋆ is recovered independently thanks to indicator q(u, t), this in turn allows us to recover parameter K ⋆.
If sensory noise is the main source of error in the animal’s judgments (meaning σ d ≃ 0 in the model), the two indicators q(u, t) and Z suffice to characterize the readout parameters. But in the general case, the observed JND Z ⋆ can also be influenced by extraneous sources of noise in the animal’s decision, and bias the comparison between Z ⋆ and its prediction. To account for this potential effect, our model includes the decision-noise term σ d. For a fixed value of w, the JND Z is influenced both by parameters K and σ d (eq. 13, Fig. 5E). However, both parameters can be disentangled thanks to the third indicator V, which depends mostly on K (Fig. 5F).
The signification of V hinges on the following result, that was first shown in [19]: when the readout is truly optimal over the full population (K = N tot), then each neuron’s choice covariance is simply proportional to its tuning (see Methods). Since the indicator V quantifies the deviations from perfect proportionality between and (eq. 15, Fig. 3F), it becomes a marker of the readout’s global optimality, and decreases to zero as K grows to large populations. At the same time, the dependency of V on parameter σ d is minimal, and limited to the influence of the scaling factor κ(Z) in eq. 9 (see Methods).
When minimizing the loss function in eq. 16, we impose the joint fit of the three indicators Z, q(u, t) and V. Following the explanations above, this will be obtained for parameters close to the true values . In our simulation, the minimum was achieved for the following values: w = 50 msec, t R = 100 msec, K = 60 neurons, σ d = 0.25 stimulus units (with the following levels of discretization: 10 neurons for K, 0.25 stimulus units for σ d, 10 msec for w and t R).
The best fit parameters are represented in Fig. 6, along with bootstrap confidence intervals derived from 14 resamplings of our original data. The temporal parameters (w, t R) are recovered with good precision (panel A). Conversely, parameters K and σ d are somewhat underestimated (panels B and C) compared to their true values (black square). Indeed, the values of K and σ d are disentangled thanks to indicator V which, of the three indicators introduced, is the most subject to measurement noise. As a result, the match between V ⋆ and its prediction V is not as precise as the other two: see Fig. 5F. Nevertheless, the true values are rather close to the final estimates, lying within the 1-standard deviation confidence region (Fig. 6C).
Fig 6. Statistical recovery of readout parameters: best fit parameters.
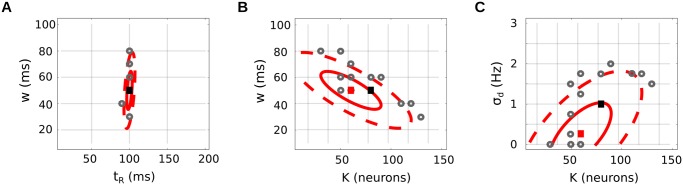
Efficiency of the inference method, applied to our simulated LIF network. The three panels show different 2d projections of the underlying 4d parameter space: (t R, w) plane (A), (K, w) plane (B), (K, σ d) plane (C). Black square: true parameters used to produce the data. Red square: best fit parameters (K, w, t R, σ d), achieving the minimum of the loss function in eq. 16. Gray points: best fit parameters for 14 (bootstrap) resamplings of the original trials (some points are superimposed, due to the finite grid of tested parameters). Red ellipses: corresponding confidence intervals, as the 1- and 2- standard deviation of the bootstrap resamplings.
Importantly, only a reasonable amount of data is required to produce these estimates. Network activity was monitored on 15 independent runs, each run consisting of 180 repetitions for each of the 3 stimuli. On each run, a different set of N = 170 random neurons were simultaneously recorded—out of a total population of N tot = 5000. As a result, (i) individual neuron statistics such as C ij(t, u) or display an important amount of measurement noise, (ii) population statistics such as indicator V are computed from relatively few neurons i. Numerically, this noisiness introduces a number of biases in the above indicators, such as overfitting, which require counteracting with specific corrections (see Methods and supplementary material for details). Naturally, the width of the confidence intervals in Fig. 6 is directly related to the amount of data available.
In conclusion, if the data conform to a number of hypotheses (optimal linear readout from a neural ensemble typical of the full population, and smaller than the recording pool size), then it is possible to estimate the underlying readout’s parameters, from a plausible amount of experimental samples.
Case 3: less than K ⋆ cells recorded
By construction, the method presented in Case 2 can only test ensemble sizes K smaller than N, the number of neurons recorded simultaneously by the experimenter. If N is smaller than the true size K ⋆, the method will provide biased estimates. In current-day experiments, N can range from a few tens to a few hundred neurons. While it is not excluded that typical readout sizes K ⋆ be of that magnitude in real neural populations (as suggested, e.g., by [8]), it is also possible that they are larger. In this case, the only way to estimate the readout parameters is to make specific assumptions about the nature of the full population activity. In turn, the extrapolated results will depend on these assumptions.
Singular value analysis of the linear readout
To investigate the underlying issues, and to explain why there is no “natural” extrapolation, we will study how the indicators Z, , and V defined above evolve as a function of the number of neurons K used for the readout. For simplicity, we assume a fixed choice of (w, t R) and focus on the time-integrated neural activities (eq. 1). We also suppose that the decision noise σ d ≃ 0 is negligible. Finally, we consider alternative definitions for the indicators Z and that simplify the following analysis. We define
| (17) |
| (18) |
where is the variance of the tested stimuli, i.e., . The sensitivity Y is simply an inverse reparametrization of the JND, Z. More specifically, Y is the ratio between the signal-related variance and the total variance (see Methods), which grows from zero (if Z = ∞) to one (if Z = 0) as the readout’s sensitivity to the stimulus increases. As for Q, it is simply a convenient linear rescaling of .
Then, we re-express the population activity through a singular value decomposition (SVD) (see Methods for details). Specifically, we write the time-averaged activity of neuron i for the q-th presentation of stimulus s as
| (19) |
where is the trial-averaged activity of each neuron. This decomposition is best interpreted as a change of variables, which re-expresses the neural activities in terms of a new set of variables, {v m}m = 1…M, which we will call the activations of the population’s modes. These modes can be viewed as the underlying “patterns of activity” that shape the population on each trial. Each mode m has a strength λ m > 0 which describes the mode’s overall impact on population activity. We assume λ 1 ≥ … ≥ λ M, so we progressively include modes with lower strengths (Fig. 7A). The vector u m is the “shape” of mode m and describes how the mode affects the individual neurons. Finally, is the mode’s activation variable, which takes a different (random) value on every trial q for a given stimulus s. The number of modes M is the intrinsic dimensionality of the neural population’s activity. In real populations we may expect M < N tot, because neural activities are largely correlated.
Fig 7. Readout properties as a function of ensemble size K.

(A) The SVD decomposes population activity into a number of modes m with decreasing powers . (B) Each mode m has a sensitivity to stimulus, y m. Red bars: individual sensitivities, black dots: cumulative distribution. (C) The fractions ϵ m(K) describe the “proportion” of each mode which can be observed, on average, in random neural ensembles of size K. They are a function of the SVD decomposition, but bear no analytical expression in general. (D) Mean sensitivity from neural ensembles of size K, empirically measured (blue) and predicted with eq. 21 (green). The dashed black line indicates the optimal sensitivity, for a readout from the full population. (E) Same for the CC indicator Q (eq. 22). All panels computed from the spike counts of the 5000 simulated neurons, over the first 10 msec after stimulus presentation, on 3 × 3000 recording trials (without correcting for measurement errors owing to the large dimensionality and limited number of trials).
Since the singular value decomposition is simply a linear coordinate transform, we can redefine all quantities with respect to the activity modes. Of particular interest is the sensitivity of each mode, which is the square of its respective tuning parameter, or (see Methods)
| (20) |
If the readout vector a is chosen optimally over the full population, the resulting percept’s sensitivity will be a simple sum over the modes: Y tot = ∑m y m.
The mode sensitivities and their cumulative sum for the simulated network above are shown in Fig. 7B. Note the presence of a “dominant” mode for the sensitivity. This seems to be a rather systematic effect, which arises because the definition of total covariance (Methods, eq. 50) favors the appearance of a mode almost collinear with . Even so, this dominant mode accounted only for 71% of the population’s total sensitivity, so the residual sensitivity in the other modes is generally not negligible.
Sensitivity and choice covariance as a function of the size K of the readout ensemble
However, we wish to study the more general case where the readout is built from sub-ensembles of size K. In such a case, not all modes are equally observable, and we rather need to introduce a set of fractions, {ϵ m(K)}m = 1…M, that express to what extent each mode m is “observed”, on average, in sub-ensembles 𝓔 of size K (see Methods for a precise definition). Modes with larger power λ m tend to be observed more, so ϵ m(K) globally decreases with m. Conversely, ϵ m(K) naturally increases with K. For the full population, ϵ m(N tot) = 1 for all modes m, meaning that all modes are fully observed (see Fig. 7C; here, the mode observation fractions were empirically computed by averaging over random neural sub-ensembles). Using these fractions, we can analytically approximate the values of Y and Q which are expected, on average, if the readout is based on ensembles of size K:
| (21) |
| (22) |
Thus, the sensitivity ⟨Y⟩𝓔 grows with K as mode sensitivities y m are progressively revealed by the fractions ϵ m(K). The sensitivity reaches its maximum value, Y(N tot) = Y tot, when ϵ m(K) = 1 for all modes m with a nonzero y m (Fig. 7D). Conversely, ⟨Q⟩𝓔 decreases with K. Indeed, it can be viewed as an average of the squared powers , each mode m contributing with a weight ϵ m(K)y m. As ϵ m(K) progressively reveals modes with lower power λ m, this average power is expected to decrease with K. Again, the minimum value is reached when all nonzero y m are revealed (Fig. 7E).
The results for the simulated network in Fig. 7D-E illustrate that the approximations leading to eq. 21–22 are well justified in practice. As for the third indicator used in Case 2, V, it can also be expressed in the SVD basis (see Methods). However, being a second-order variance term, its approximation based solely on the average fractions {ϵ m(K)}, as in eq. 21–22, is generally poor.
The extrapolation problem revisited
What do these results imply in terms of extrapolation to larger neural ensembles than those recorded by the experimenter? Arguably, eq. 21–22 constitute an interesting basis for principled extrapolations to larger sizes K. These equations show that the evolution of Y and Q in growing ensembles of size K is mostly related to the interplay between the modes’ sensitivity spectrum {y m} and their power spectrum {λ m}. (Empirically, the observation fractions {ϵ m(K)} seem primarily governed by the decay rate of {λ m}, although the analytical link between the two remains elusive.) However, note that the spectra {y m}, {λ m} and {ϵ m(K)} are generally not accessible to the experimenter—this would precisely require to have recorded at least N > M neurons, and potentially the whole neural population if M = N tot.
To extrapolate sensitivity ⟨Y⟩𝓔(K) in ensembles of size K larger than those monitored, one must (implicitly or explicitly) assume a model for {λ m} and {y m}—which amounts to characterizing the relative embedding of signal and noise in the full population [28]. A number of reasonable heuristics could be used to produce such a model. For example, one may assume a simple distribution for {λ m}, such as a power law, and estimate its parameters from recorded data. Alternatively, it is often assumed that the noise covariance matrix is “smooth” with respect to the signal covariance matrix, so that the former can be predicted on the basis of the latter [19, 29]. Finally, the extrapolation could rely on more specific assumptions about how neural activities evolve, e.g., through linear dynamics with additive noise [30]. In all cases, the additional assumptions impose (implicit) constraints on the structure of the spectra {λ m} and {y m}.
However, most likely, any chosen model will be (1) difficult to fit rigorously on the basis of experimental data, (2) subject to pathological situations when extrapolations fail to produce the correct predictions. For example, one can imagine scenarios in which the most sensitive modes (those with highest y m) correspond to very local circuits of neurons, independent from the rest of the population, and thus invisible to the experimenter (see also [19]). Another pathological situation could be a neural network specifically designed to dispatch information non-redundantly across the full population [31, 32], resulting in a few ‘global’ modes of activity with very large SNR—meaning high y m and low λ m. As a result, extrapolation to neural populations larger than those recorded is never trivial, and always subject to some a priori assumptions. The most judicious assumptions, and the extent to which they are justified, will depend on each specific context.
Discussion
We have proposed a framework to interpret sensitivity and choice signals in a standard model of perceptual decision-making. Our study describes percept formation within a full sensory population, and proposes novel methods to estimate its characteristic readout scales on the basis of realistic samples of experimental data. Here, we briefly discuss the underlying assumptions and their restrictions, the possibility of further extensions, and the applicability to real data.
The linear readout assumption
The readout model (eq. 2) used to analyze sensitivity and choice signals is an installment of the “standard”, feed-forward model of percept formation [17, 19]. As such it makes a number of hypotheses which should be understood when applying our methods to real experimental data. First, it assumes that the percept is built linearly from the activities of the neurons—a common assumption which greatly simplifies the overall formalism (but see, e.g., [33] for a recent example of nonlinear decoding). Even if the real percept formation departs from linearity, fitting a linear model will most likely retain meaningful estimates for the coarse information (temporal scales, number of neurons involved) that we seek to estimate in our work.
More precisely, the model in eq. 1–2 assumes that spikes are integrated using a kernel that is separable across neurons and time, that is A i(t) = a i h(t/w)/w. Theory does not prevent us from studying a more general integration, where each neuron i contributes with a different time course A i(t). The readout’s characteristic equations are derived equally well in that case. Rather, assuming a separable form reflects our intuition that the time scale of integration is somewhat uniform across the population. This time scale, w, is then the one crucial parameter of the integration kernel. Although the shape h(t) of the kernel could also be fit from data in theory, it seems more fruitful to assume a simple shape from the start. We assumed a classic square kernel in our applications. Other shapes may be more plausible biologically, such as a decreasing exponential mimicking synaptic integration by downstream neurons. However, given that our goal is to estimate the (coarse) time scale of percept formation, our method will likely be robust to various simple choices for h. As a simple example, we tested our method, assuming a square kernel, on data produced by an exponential readout kernel, and still recovered the correct parameters w, t R and K (data not shown).
Through the process of integration across time and neurons, each instant in time could be associated to an “ongoing percept”, i.e., the animal’s estimate of stimulus value at current time. In our model, the animal’s estimate at time t R serves as the basis for its behavioral report (Fig. 2A), and we designate this single number as the “percept”. A second strong assumption of our model is that this perceptual readout occurs at the same time t R on every stimulus presentation. In reality, there is indirect evidence that t R could vary from trial to trial, as suggested by the subjects’ varying reaction times (RT) when they are allowed to react freely [34, 35]. In such tasks, we expect the variations in t R to be moderate—because subjects generally react as fast as they can—and we may even try to correct for fluctuations across trials by measuring RTs. On the other hand, when subjects are forced to wait for a long period of time before responding, there is room for ample variations in t R from trial to trial, and the model presented above may become insufficient.
As a first step towards addressing this question, we derived a more general version of the characteristic equations 4–6 assuming that t R in eq. 1 is itself a random variable, drawn on each trial following some probability distribution g(t) (supporting S1 Text). The main impact of this modification is on CC curves, which become broader and flatter; essentially, the resulting curve resembles a convolution of the deterministic CC curve by g(t) (Fig. 8A). This means that if a behavioral task is built such that t R can display strong variations from trial to trial, the methods introduced above will produce biased estimates. In theory, this issue could be resolved by adding an additional parameter in the analysis, to describe g(t) (see supporting S1 Text).
Fig 8. Discussion.
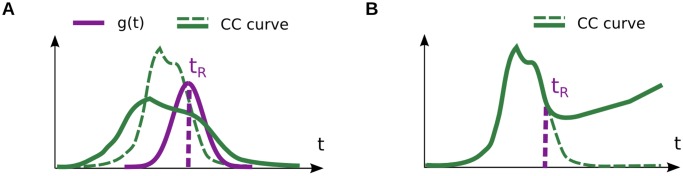
(A) If the extraction time t R varies strongly from trial to trial (with density g(t)), it leads to a flattening of CC signals (thick green curve) compared to the case with deterministic t R (dashed green curve). (B) If a choice-related signal feedbacks into sensory areas, it leads to an increase of CC signals (thick green curve) after the extraction time t R, compared to the case without feedback (dashed green curve).
The decision model
The linear readout provides a percept on every trial. In principle, behavioral experiments could be set up such that the subject directly reports this percept, so that . Such experiments could be treated completely without a decision model. However, almost all experiments that have been studied in the past involve a more indirect report of the animal’s percept. In these cases, some assumptions about how the percept is transformed into the behavioral report c need to be made.
In the choice of a decision model, we have followed the logic of the classic random dot motion discrimination task [3], in which a monkey observes a set of randomly moving dots whose overall motion is slightly biased towards the left (s < 0 in our notations) or towards the right (s > 0). The monkey must then press either of two buttons depending on its judgment of the overall movement direction. The simplest decision model assumes a fixed integration time window, additive noise on the percept, , and an optimal binary decision. A slightly more sophisticated model, the “integration-to-bound” model, assumes that the integration time is not fixed, but rather limited by a desired behavioral accuracy. This model requires variable readout windows, rather than the fixed readout window assumed here, and will require further investigation in the future.
In another classic task [2], the monkey must discriminate the frequencies s 1 and s 2 of two successive vibrating stimuli on their fingertip. They must press either of two buttons depending on whether they consider that s 1 > s 2 or not. In this task, the optimal behavioral model would be . In reality, however, the monkey needs to memorize s 1 for a few seconds before s 2 is presented, so potential effects of memory loss may also come into play (see e.g. [36] for a study of these problems).
More generally, behaving animals can display biases, lapses of attention, various exploratory and reward-maximization policies that lead to deviations from the optimal behavioral model. Choosing a relevant behavioral model is a connected problem that cannot be addressed here, and that will vary depending on the task and individual considered. For most tractable behavioral models, the predicted sensitivities and choice signals will ultimately rely on the quantities introduced in this article.
The feedforward assumption
Finally, the standard model assumes that percept formation is exclusively feed-forward. The activities r i(t) of the sensory neurons are integrated to give rise to the percept and the animal’s choice c, yet the formation of this decision does not affect sensory neurons in return. Recent evidence suggests that reality is more complex. By looking at the temporal evolution of CP signals in V2 neurons during a depth discrimination task, Nienborg and Cumming (2009) evidenced dynamics which are best explained by a top-down signal, biasing the activity of the neurons on each trial after the choice is formed [20]. In our notations, the population spikes r i(t) would thus display a choice-dependent signal which kicks in on every trial after time t R, resulting in CC signals that deviate from their prediction in the absence of feedback (Fig. 8B).
What descriptive power does our model retain, if such top-down effects are strong? The answer depends on the nature of the putative feedback. If the feedback depends linearly on percept (and thus, on the spike trains), its effects are fully encompassed in our model. Indeed, this feedback signal will then be totally captured by the neurons’ linear covariance structure C ij(t, u), so that our predictions will naturally take it into account. On the other hand, if the feedback depends directly on the choice c—which displays a nonlinear, “all-or-none” dependency on —then it will not be captured by our model, and lead to possible biases. Even so, our model would still apply if percept and decision were essentially uncoupled before the putative extraction time t R, in which case one could simply compare true and predicted CC signals up to (candidate) time t R (see Fig. 8B).
Undersampled neural populations
In most real-life situations, experimenters only have access to samples from a large, unknown population, so they must resort to a statistical description of readout vector a. Our solution relies on an assumption of restricted optimality, based on Fisher’s linear discriminant formula (eq. 12). By assuming that readout is made optimally from some unknown neural ensemble 𝓔, we reformulated the problem of characterizing a in that of characterizing 𝓔, and could in turn exploit the characteristic equations 4–6 statistically.
In real experiments, the true readout profile a may not match this description: most vectors a do not implement optimal readout from a sub-ensemble. This potential discrepancy from the true readout is inescapable, once we start representing a through a statistical model. However, note that our model uses two distinct sources of non-optimality: (1) the size K of the readout ensemble, which can be much smaller than the full population, and (2) the decision noise σ d, which adds a ‘global’ non-optimality to the readout. Arguably, by combining both factors, our chosen model for a will be flexible enough to provide meaningful estimates when fit to real data.
At present, the main limitation is likely to be the size of ensembles of neurons that have been recorded simultaneously. Past work has often shown that small ensembles of neurons are completely sufficient to account for an animal’s behavior [3, 37]. However, there is an inherent trade-off between the number of neurons and the time scale of integration. One simple explanation for the small sizes of previous readout ensembles is that the true readout time scales used by subjects are much shorter. Unfortunately, as detailed above (Case 3), extrapolations from a finite-size recording onto the whole population always come at the price of strong additional assumptions.
However, as experimental techniques advance, and as the number of simultaneously recorded neurons reaches the number of neurons implied in the readout, we will eventually be able to directly infer the readout parameters from the data. In this case, our method can readily be tested on real data, and hopefully provide new insights into the nature of percept formation from populations of sensory neurons.
Methods
The methods are organized as follows. First, we set our basic notations and definitions. Second, we derive the characteristic equations of the model, both for the linear part and decision part. Third, we detail the predictions in case of an optimal readout from some neural sub-ensemble 𝓔. Fourth, we re-express these predictions in the basis of the population’s SVD modes. Finally, we detail our methodology to empirically estimate the quantities used in this article, from limited amounts of experimental data. Tables 1–3 summarize the main variables and notations used in the article.
Statistical notation
In the following, we generally deal with variables x that assume different values on different trials. An example is the spike count of a single neuron. Trials in turn can be grouped by stimulus s or choice c. We can make this explicit by writing x scq to denote the q-th trial in which the stimulus was s and the subject’s choice was c. Given such a variable, we will write E[x] for its expectation value, i.e., for the hypothetical value this quantity would take if it could be averaged over infinitely many trials. We will write E[x∣s] for the expectation value conditioned on stimulus s, i.e., for the expectation value computed over all trials in which the stimulus was s. A similar notation holds when conditioning on choices c. We note that for quantities that are already conditional expectations, for instance, y(s) = E[x∣s], their expectation value E[y(s)] will average out the stimuli according to their relative probabilities, i.e., E[y(s)] = ∑s p(s)y(s). Thereby, each stimulus s contributes to the expectation in proportion to the number of trials associated to it. Then the notations are coherent, since we have . Covariances are generically defined as Cov[x, y] = E[xy] − E[x]E[y], and variances as Var[x] = Cov[x, x]. For vectorial quantities, we assume Cov[x, y] = E[x y ⊤] − E[x]E[y ⊤], and introduce the shorthand Cov[x] ≔ Cov[x, x].
Experimental statistics of neural activity and choice
Classic measures in decision-making experiments can be interpreted as estimates of the first- and second-order statistics of choice c and recorded spike trains r i(t), across all trials with a fixed stimulus value s:
| (23) |
| (24) |
| (25) |
| (26) |
Here, ψ(s) is the psychometric curve, m i(t; s) is known as the PSTH, and C ij(t, u; s) as the JPSTH. The choice covariance (CC) curve d i(t; s) is our proposal for measuring each neuron’s “choice signal”. Theoretically, the temporal signals in eq. 24–26 are well-defined quantities in the framework of continuous-time point processes [38]. In practice, they are estimated by binning spike trains r i(t) with a finite temporal precision, depending on the amount of data available.
From the psychometric curve, we also derive two simpler quantities: the animal’s just-noticeable difference (JND), Z, and decision bias μ d. We obtain them as the best (MSE) fit to the following formula:
| (27) |
where Φ is the standard cumulative normal distribution. Z measures the inverse slope of the psychometric curve (up to a scaling factor ). The decision bias μ d, when non-zero, represents a bias towards one button when s = s 0. This formula for the psychometric curve arises naturally when we model the decision task (see below).
Choice covariance and choice probability
Throughout the article, we consider the special case of a binary choice c = {0, 1}. In this case, the variance of the choice conditioned on s is given by
| (28) |
and a straightforward computation shows that
| (29) |
(These formulas, and all those below, assume that the choice takes values 0 and 1. Any other binary parametrization should first be reparametrized to {0, 1}.)
The term in brackets is the difference between the two conditional PSTHs, computed only from trials where the animal took one decision vs. the other (stimulus s keeping a fixed value). This measure is sometimes used as a simpler alternative to choice probabilities [3]. In fact, CC curves and CP curves can be analytically related if one assumes Gaussian statistics: see [19] or supporting S1 Text.
Simplified dependencies on the stimulus
The neural statistics in eq. 24–26 are defined conditionally for each stimulus s used in the task. To ease the subsequent analysis, we assume that the activity of each neuron is well approximated by a time-varying, linear dependency on the stimulus s, and that C ij(t, u; s) is independent of s. Consequently,
Since we are modeling a discrimination task, in which stimuli s display only small variations around the central value s 0, the linearity assumption seems reasonable. In turn, we can write
| (30) |
We will refer to b i(t) as the neural tuning. More precisely, it is the slope of the neuron’s tuning curve at each time point.
Naturally, actual data (even from a synthetic simulation) always somewhat deviate from this idealized situation. In practice, we obtain the best fits for b i(t) and C ij(t, u) using linear regression, so that
| (31) |
| (32) |
Similarly, it is convenient to integrate the various CC curves d i(t; s) (eq. 26) into a single CC curve for each neuron, say d i(t). There is no obvious choice for this simplification, because d i(t; s) has to change with s. For example, the CC signal is non-zero only if stimulus s and threshold s 0 are close enough for the animal to make occasional mistakes (this is reflected in eq. 29, since tends to zero when the animal makes no mistakes). In the experimental literature, a common choice is to focus only on the CC curve at threshold, that is d i(t) = d i(t; s 0). In experiments with a limited number of trials, this has the inconvenience of losing the statistical power from nearby stimulus values s that were also tested. We thus propose an alternative definition:
| (33) |
which exploits each stimulus s in proportion to the number of associated trials. In our model, this averaging also limits the influence of the JND Z on the magnitude of CC signals: see eq. 45–46.
Derivation of the linear characteristic equations
The readout defined in eq. 1–2 is linear with respect to the underlying spike trains {r i(t)}. To clarify the equations, let us introduce the temporal averaging kernel
| (34) |
where parameters w and t R are generally implicit. Then, the integrated spike counts from eq. 1 are simply .
Using this notation, eq. 2 becomes . Thanks to the linear structure, the two first moments of can easily be developed:
Given our various definitions (eq. 24–25), and after differentiating the first line with respect to s, see eq. 30, we obtain:
| (35) |
| (36) |
| (37) |
These are exactly the characteristic equations 4–6 from the main text, after introducing the following vectors and matrices:
| (38) |
| (39) |
| (40) |
| (41) |
which simply correspond to the statistics of activity for the integrated spike counts (eq. 1). Indeed, (tuning vector), (noise covariance matrix), and (choice covariance vector). Given our assumptions above, the resulting quantities are all independent of the stimulus s. Note though, that all quantities depend on the readout parameters w and t R. Importantly, one can show that the noise covariance matrix scales as w −1, under mild assumptions (supporting S1 Text, section 2).
The decision model of a fine-discrimination task
To produce a binary choice, the (continuous) percept is fed into the decision model , where H is the Heaviside function, s 0 is the (task-imposed) decision threshold, and ξ d ∼ 𝒩(μ d, σ d) is a Gaussian variable representing additional noise and biases. The mean μ d implements a possible bias towards one button when s = s 0. The standard deviation σ d implements additional sources of noise in the animal’s decision process.
Using this decision model, and mild additional assumptions, we can relate the left-hand sides of eq. 35–37 to experimental data. First, we assume that , meaning that follows s on average. (In statistical terminology, is an unbiased estimator of s.) Then, the left-hand side of eq. 35 is simply equal to
| (42) |
Second, we assume that the distribution of r(t) (given s) is Gaussian. (In theory, this assumption is violated at small time scales due to the binary nature of r i(t). But in practice this is not an issue, as the spike trains always undergo some form of temporal integration afterwards.) Then, (given s) is normally distributed, and eq. 36 ensures that its variance is independent of s (see Fig. 2B). In these conditions, the predicted formula for the psychometric curve is exactly that of eq. 27, namely,
and the JND, Z, is given by the following expression:
| (43) |
Furthermore, under the same assumptions, we can predict the CC curve for each neuron. We use the following general result: for any bivariate normal variables (X, Y) and threshold t, Cov[X, H(Y − t)] = Cov[X, Y]𝒢(t; μ Y, σ Y), where 𝒢(⋅; μ, σ) is the normal density function. Here, we take X = r i(t), and t = s 0, to obtain:
| (44) |
With d i(t) defined as an average CC curve over tested stimuli (eq. 33), we finally obtain
| (45) |
| (46) |
The final equation for CC signals (eq. 9) is obtained by combining eq. 37 and 45.
In many experimental setups, the averaging over stimuli s will ensure that κ(Z) has only a mild dependency on its argument Z. Indeed, note the rough approximation κ(Z) ∝ ∫sds𝒢(s; s 0−μ d, Z) = 1, valid whenever the tested stimuli s are uniformly distributed over a range of values comparable to Z. This is another practical argument for considering the stimulus-averaged CC signal d i(t), from eq. 33.
Signal, noise, and sensitivity
The just-noticeable difference (JND) and the sensitivity can be related to the variances of signal and noise in the population. Here, we briefly review these relations. The variance of any scalar variable x that changes from trial to trial can be decomposed in a signal term and a noise term . Then, note that .
The noise term Z x defines the minimal level past which fluctuations in x can be attributed to s rather than intrinsic noise—hence the term JND. When a decision is taken on the basis of variable x, the JND governs the inverse slope of the corresponding psychometric curve (see eq. 27). We also define the sensitivity of variable x as
| (47) |
which is simply the ratio of the signal to the total variance. The sensitivity Y x takes values between 0 and 1. It thus avoids singularities which may occur when Z x tends to 0 or +∞.
We can also distinguish between signal-related and noise-related variance for the (time-averaged) neural activities . The signal covariance matrix, Σ, noise covariance matrix, , and total covariance matrix, A, are given by the following relations:
| (48) |
| (49) |
| (50) |
The last equality is the classic decomposition of total covariance into noise and signal terms. Note that Σ is a rank-1 matrix, owing to the system’s assumed linearity wrt. stimulus s.
In turn, these matrices allow to compute the signal- and noise- variances for any weighted sum of the neural activities. For our linear readout (with added decision noise ξ d), we have , and thus:
| (51) |
| (52) |
| (53) |
Optimal readout from a neural ensemble 𝓔
We now assume that the readout vector a has support only on some neural ensemble 𝓔. Formally, we introduce the K × N tot projection matrix H(𝓔), such that for i ∈ 𝓔 and every neuron j, H ij(𝓔) = δ ij. Then, the restrictions of vectors and matrices in neuron space, such as and , to ensemble 𝓔 will be denoted by a subscript r (for restriction), so that
| (54) |
| (55) |
Our principle of (restricted) optimality selects the readout vector a which maximizes the signal-to-noise ratio of the resulting percept . Since (unbiased percept, eq. 35 and 42), the signal variance is imposed to be (eq. 51). Under this constraint, optimality is achieved by minimizing the noise variance (eq. 52)—or equivalently, the total variance a ⊤ A a (eq. 53). The solution, known as Fisher’s Linear Discriminant, is easily found with Lagrange multipliers (either based on or A):
| (56) |
The second formulation of a r, based on the total covariance matrix A r, will prove more useful when we turn to the SVD analysis. It also has the advantage of avoiding the singularity which may occur when vector lies outside the span of matrix . In that case one simply replaces (A r)−1 by the (Moore-Penrose) pseudoinverse (A r)+.
When combining the optimal readout in eq. 56 with the equation for the JND (eq. 52), we obtain the JND predicted by the model:
| (57) |
Equivalently, using the formulations based on total variance (eq. 47, 53, 56) we obtain the model’s prediction for sensitivity:
| (58) |
CC signals for the optimal readout
When combining the optimal readout in eq. 56 with the characteristic equation for the CC curves (eq. 9), we obtain the CC curves predicted by the model,
| (59) |
Here, d i(t) is the resulting, predicted CC curve for every neuron i in the population (not only in ensemble 𝓔). Note that is the restriction of vector (eq. 39) to neurons j ∈ 𝓔, but that i = 1…N tot still runs over all neurons. Equation 59 can also be expressed in its temporally-integrated form, using the definition :
| (60) |
If neuron i belongs to the readout ensemble 𝓔, matrix simplifies away from eq. 60, yielding:
| (61) |
This equation, first shown in [19], means that choice signals within the readout ensemble are simply proportional to tuning. This is not true, however, for neurons outside the readout ensemble.
This has two important implications. First, it proves that choice signals are markedly different for neurons inside or outside the readout ensemble (an observation made empirically by [12]). Second, as we consider readout ensembles 𝓔 larger and larger, eq. 61 will become true for more and more neurons. As a result the statistical indicator V (eq. 15), which measures the population-wide deviation from linearity between and , is expected to decrease with the readout ensemble’s size K.
Finally, under the assumption of (restricted) optimality, the time-averaged statistical indicator is always positive. Indeed, averaging over all neurons i in the population is akin to a scalar product: . Using this relation and eq. 60, we get
| (62) |
which is always positive because both matrices and are symmetric semi-definite positive.
Singular value decomposition
We denote the time-averaged activities of neuron i in the q-th presentation of stimulus s as . We interpret these activities as a very large N tot × Ω matrix, where N tot refers to the number of neurons and Ω to an idealized, and essentially infinitely large number of trials.
Next, we consider the singular value decomposition (SVD) of the neural activities. The (compact) SVD is a standard decomposition which can be applied to any rectangular matrix R. It is given by R = U Λ V ⊤, where Λ is an M × M diagonal matrix with strictly positive entries λ m (the singular values), U is an N tot × M matrix of orthogonal columns (meaning U ⊤ U = Id M), and V is an Ω × M matrix of orthogonal columns (meaning V ⊤ V = Id M).
Using the indices defined above, the SVD decomposition for the neural activities becomes
| (63) |
where is the average activity of each cell over all trials and stimuli. The orthogonality of U implies that for all indices m and n, we have , while the orthogonality of V similarly implies .
Statistics of activity, in the space of modes
The SVD decomposition (eq. 63) is best interpreted as a change of variables re-expressing neural activities in terms of mode appearance variables . As a result, we can define the respective equivalents of all statistical quantities in the space of activity modes. Specifically, we can reinterpret sums over trials in the SVD as expectations, thus emphasizing the statistical interpretation of the SVD. First we note that for all neurons i, so that the data for the actual SVD has been “centered”. This centering implies for all modes m that
| (64) |
| (65) |
where η m is the tuning parameter of the m-th mode, just as was the tuning parameter for the i-th neuron. Grouping all mode appearance variables in a vector v, we obtain the signal covariance and total covariance matrices in mode space as
| (66) |
| (67) |
where the last relation follows from the orthogonality of V explained in the previous section. The singular values λ m and distribution vectors u m then allow us to relate the statistics at the levels of neurons and modes. Using the SVD formula (eq. 63) yields (in matrix form):
| (68) |
| (69) |
Sensitivity of sub-ensembles, in the space of modes
We now wish to understand which factors govern the sensitivity embedded in a neural sub-ensemble 𝓔 of cardinality K. For simplicity, we will consider the case for which the decision noise is negligible, i.e., σ d → 0. Then, from eq. 58, we have
| (70) |
Here we use explicitly the most general formula, based on the pseudo-inverse of matrix A r. To re-express this sensitivity of finite sub-ensembles 𝓔 into mode space, we need to find the equivalent, restricted expressions of eq. 68–69. For that purpose, we introduce the design matrix associated to ensemble 𝓔 in mode space:
| (71) |
where H is the restriction operator from eq. 54. X is an M × K matrix with elements . Using this matrix, we obtain from eq. 68–69 that and A r = X ⊤ X, so that eq. 70 becomes
| (72) |
where we have defined the M × M matrix
| (73) |
Note that P is simply the orthogonal projector on , since P = P 2 = P ⊤, and Im(P) = Im(X).
The projector P = P(𝓔) spans more and more space as the size K of ensemble 𝓔 increases. In the limiting case, when K is larger than the number of modes M, then necessarily P = Id M, and we obtain
| (74) |
In other words, all modes are available experimentally, and sensitivity estimates saturate to their maximum value, independently of ensemble 𝓔. We can explicitly denote the sensitivity of each mode’s activation variable v m by defining
| (75) |
By solving eq. 68 for η, we obtain , which in turn yields eq. 20 from the main text.
CC signals, in the space of modes
Similarly, we can express CC signals in mode space. First, we re-express the CC equation (eq. 10) as a function of the total covariance A (eq. 50) to obtain
We further recall that (unbiased percept, see eq. 35 and 42). Hence, up to a scaling and shift, the CC vector can be replaced by the total percept covariance vector
| (76) |
In the case of an optimal readout, vector a is given by eq. 56, so that we obtain
| (77) |
Second, using the corresponding sensitivity Y (eq. 70), and the SVD expressions for A and (eq. 68–69), and for A r and as a function of matrix X (eq. 71), we write:
| (78) |
Here also, the final result can be expressed as a function of P, the projection matrix associated to ensemble 𝓔 in the space of modes (eq. 73). Note again that e provides the CC signal for every neuron i in the population (not only in ensemble 𝓔). As 𝓔 tends to the full population, P = P(𝓔) tends to Id M and we recover , the prediction for choice signals in the case of a (globally) optimal readout [19].
Using eq. 78, we can finally compute the analytical predictions for the two CC statistical indicators, and V. Precisely, we compute the following population-wide regression coefficient between e and :
| (79) |
Again, we made use of the SVD expressions for (eq. 68) and e (eq. 78). Note that, since e is a linear rescaling of , Q is a similar rescaling of indicator , as pointed in the main text (eq. 18). Finally, a very similar computation leads to the expression of indicator V (eq. 15) in the space of modes:
| (80) |
Sensitivity and CC signals as a function of K
We are now better armed to understand how sensitivity and CC indicators vary as a function of the readout ensemble 𝓔. We are mostly interested in averages of these quantities over very large numbers of randomly chosen ensembles 𝓔 of size K; we thus use the generic notation E[x∣K]≔E[x(𝓔)∣Card(𝓔) = K] to denote the expected value of a variable x when averaging over ensembles of size K. Note that this notation is equivalent to the more explicit notation used in the main text, so that E[x∣K] = ⟨x⟩𝓔(K). From eq. 72 we find: .
To understand the properties of the (M × M) matrix E[P∣K], we view the (M × K) design matrix X(𝓔) (eq. 71) as a collection of K random vectors x i in mode space, viewing neuron identities i as the random variable. Thus, P(𝓔) is the orthogonal projector on the linear span of the K sample vectors {x i}i ∈ 𝓔. As a projector, its trace is equal to its rank, so we have . Furthermore, since K+1 samples span on average more space than K samples, we are ensured that E[P∣K+1] ≽ E[P∣K], in the sense of positive semidefinite matrices.
Finally, intuition and numerical simulations suggest that E[P∣K] is almost diagonal. Indeed, as the various modes are linearly independent, there is no linear interplay between the different dimensions of x i across samples i. More precisely, the expectation value over neurons is . This leads to the matrix expression:
Let us consider the (compact) SVD decomposition X X ⊤≔ W D W ⊤, with W ⊤ W = Id, and D an invertible diagonal matrix. Then, the projection matrix P is simply equal to W W ⊤. As for the previous equation, it rewrites
Here, both matrices D and Λ are diagonal. So, if we assume a form of independence between W and D, it is reasonable to suppose that E[W W ⊤∣K] = E[P∣K] is close to diagonal as well. (Actually, we postulate that E[P∣K] is exactly diagonal when the random vectors x i follow a normal distribution. In the general case, small or moderate deviations from diagonality can be observed.) We denote these diagonal terms as
| (81) |
The properties of E[P∣K] stated above imply that ∑m ϵ m(K) = K (trace property), and ϵ m(K+1) ≥ ϵ m(K) (growth property). Finally, we can consider the resulting approximations of sensitivity (eq. 72) and CC indicator (eq. 79):
| (82) |
| (83) |
In this expression, we recognize the individual mode sensitivities . For CC signals, we also make the approximation E[YQ∣K] ≃ E[Y∣K]E[Q∣K], and recover eq. 21–22 from the main text. Unfortunately, there is no such simple approximation for indicator V, that would lead from eq. 80 to E[V∣K].
Validation on a simulated neural network
In this final part of the Methods, we provide additional information for applying our inference method (Case 2) to experimental data. The neural network used to test our methods is described in detail in supporting S1 Text (section 3). Briefly, on each trial, 2000 input Poisson neurons fire with rate s, taking one of three possible values 25, 30 and 35 Hz (so in our simulation, stimulus units are Hz). The encoding population per se consists of 5000 leaky integrate-and-fire (LIF) neurons. 1000 of these neurons receive sparse excitatory projections from the input Poisson neurons, which naturally endows them with a positive tuning to stimulus s. Another 1000 neurons receive sparse inhibitory projections from the Poisson neurons, which naturally endows them with negative tuning. The remaining 3000 neurons receive no direct projections from the input. Instead, all neurons in the encoding population are coupled through a sparse connectivity with random delays up to 5 msec. Synaptic weights are random and balanced, leading to a mean firing rate of 21.8 Hz in the population. We implemented and simulated the network using Brian, a spiking neural network simulator in Python [39].
The “true” perceptual readout from this network was built from a fixed random set of K ⋆ = 80 neurons, with temporal parameters w ⋆ = 50 msec and msec, and decision noise stimulus units (Hz). The readout vector a ⋆ was built optimally given these constraints (eq. 12). The trials used to learn a ⋆ were not used in the subsequent analysis. The resulting JND for the “animal” was Z ⋆ ≈ 3 stimulus units (Hz).
Then, “experimentally”, neural activity was observed through 15 pools of 170 simultaneously recorded neurons, each pool being recorded on 3 × 180 trials. For the statistical inference method, we assumed a square integration kernel h. We tested all combinations of the following readout parameters (in matrix notation): K = 10:10:150 neurons, w = 10:10:100 msec, t R = 10:10:200 msec, σ d = 0:0.25:3 stimulus units (Hz). For each tested size K, we picked 2000 random candidate ensembles 𝓔 (always within one of the 15 simultaneous pools) to build the predictions. For each ensemble 𝓔, another ensemble ℐ of 20 neurons, segregated from 𝓔, were used to predict CC signals outside the readout ensemble (this was always possible since recording pools had size 170, and K ≤ 150). The details of these predictions are explained in the following paragraph. Finally, the three terms in the “statistical” loss function (eq. 16) were weighted according to the power of the respective, true measures. That is:
Experimental predictions for CC indicators
Here, we detail how to compute the CC indicators q(u, t) and V (eq. 14–15) from actual data. For the measured versions q ⋆(u, t) and V ⋆(w, t R), this is straightforward. One considers the true, measured CC signals , and computes the population averages in eq. 14–15 over as many neurons i as were recorded. Note however that the final indicators can be corrupted by noise, whenever each measure comes from too few recording trials (this problem is addressed in the next section). Also note that, since the definition of V requires a temporal integration, we actually have to produce a different “true” V ⋆ for each tested set of temporal parameters w and t R.
Conversely, special care must be taken when it comes to predicted CC indicators. Whenever a candidate ensemble 𝓔 is proposed as the source of the readout, eq. 59 predicts the resulting CC signal d i(t∣𝓔) for every neuron i in the population. However, in practice, the noise covariance term is required in the computation, so neuron i and ensemble 𝓔 must have been recorded simultaneously during the same run. This limits the number of neurons i which can participate in the population averages.
Furthermore, choice covariances will generally differ between neurons that are part of the readout ensemble and neurons that are not (see eq. 61 and the associated discussion). As a result, the two following averages must be predicted separately:
| (84) |
| (85) |
before one can recombine them in the correct proportions:
| (86) |
| (87) |
and similarly for V(𝓔). To compute experimentally, each tested candidate ensemble 𝓔 (of size K) is associated to a complimentary set of neurons ℐ (of size I), which we use to approximate the average in eq. 85:
| (88) |
All neurons in ensembles 𝓔 and ℐ must have been recorded during the same run, which imposes that I+K ≤ N. Hence in our simulations, we chose a size I = 170−150 = 20 neurons.
Clearly, 20 neurons is not sufficient for q ℐ to be a reliable population average. So in practice, we cannot estimate reliably each prediction q(u, t ∣𝓔) from eq. 87. Luckily, we are not interested in their value for each individual readout ensemble 𝓔. We simply need to estimate their means across all tested ensembles 𝓔 of similar size:
| (89) |
| (90) |
which will be reliable as soon as we test a sufficient amount of candidate ensembles 𝓔.
Note that in the final inference (eq. 16), a match is sought between the true indicators q ⋆ and V ⋆—which arise from a single readout ensemble 𝓔⋆, and the predictions and —which are average values across all readout ensembles 𝓔 of size K. Thus, a prediction error can occur whenever the true readout ensemble 𝓔⋆ is not a “typical” representative of its size K ⋆. To quantify these potential errors, one should also estimate the indicators’ variance across ensembles 𝓔 of same size.
Correcting for the finite amounts of data
The computations of Z, q and V, as described above, can produce imprecise results when the data are overly limited. Generically, for any quantity X estimated from the data, we can write
where ξ represents the measurement error on X due to the finite amounts of data. If we could recompute X from a different set of neurons and/or a different set of trials, variable ξ would take a different value—meaning that Var(ξ) > 0. This is an inescapable phenomenon for experimental measures.
More problematically, variable ξ can display a systematic bias, meaning that E(ξ) ≠ 0. Since the bias is generally different for the ‘true’ and ‘predicted’ versions, the comparison between the two (eq. 16) will be systematically flawed. To counteract this effect, we applied a number of correction procedures when computing indicators Z, q and V, to ensure that they are globally unbiased. We only provide an overview here, and refer to supporting S1 Text for a detailed description.
First, when the optimal vector a is computed with Fisher’s linear discriminant, it systematically underestimates the JND Z (overestimates the sensitivity Y). Essentially, vector a r computed through eq. 12 finds artificial “holes” in matrix which are only due to its imprecise measurement—a phenomenon known as statistical overfitting. The less recording trials, the more overfitting there will be [40, 41]. We addressed this problem with a regularization technique, inspired by Bayesian linear regression [42]. We replaced eq. 12 by the following:
where the strength of parameter λ imposes the degree of regularization. We chose λ according to an ‘empirical Bayes’ principle, to maximize the likelihood of the data under a given statistical model (supporting S1 Text, section 4). It largely mitigated the effects of overfitting, without totally suppressing them—as can be seen in Fig. 5D-E.
Second, indicator V (eq. 15) can also display substantial biases (E(ξ) ≠ 0 in the above discussion). Indeed, its computation relies on squared quantities—such as or —that systematically transform measurement errors into positive biases. The required corrections are very similar to the classic “N/(N−1)” correction for the naive variance estimator, with the additional difficulty that V is affected by two sources of noise: the finite number of recording trials, and the finite number of recorded neurons. The exact corrections to ensure an unbiased estimation of V are detailed in supporting S1 Text, section 5.
Third, indicator q(u, t) displays little or no measurement bias—because its computation is essentially linear. Yet, it can display an important level of measurement noise (Var(ξ) ≫ 0 in the above discussion) that may deteriorate the subsequent inference procedure. We mitigated this measurement noise by applying a bi-temporal Gaussian smoothing to q ⋆(u, t) and predictions q(u, t), with time constant 10 msec.
To estimate the measurement errors due to the finite number of trials, we produced 14 sets of surrogate data by sampling our original trials with replacement (bootstrap procedure). These resamplings were used to derive some of the correction terms for V, and also to derive confidence intervals on our final estimators, as shown in Fig. 6. This departure from the statistical canon was imposed by the length of the whole inference procedure (see supporting S1 Text, section 5, for details).
Reproduction of our results and implementation
In the Supporting Information, we provide a generic implementation of the inference method (“Case 2” above) in MATLAB, which can be applied to any data from a 2AFC discrimination task. We also provide the Python code for the network simulation, and MATLAB scripts for the reproduction of the experimental Figures in this article (Fig. 4–7).
Supporting Information
Contains additional information about Choice Probabilities (section 1), the influence of parameter w on stimulus sensitivity (section 2), the encoding neural network used for testing the method (section 3), the Bayesian regularization procedure on Fisher’s linear discriminant (section 4), unbiased computation of CC indicators in the presence of measurement noise (section 5), and an extended readout model with variable extraction time t R (section 6).
(PDF)
(GZ)
Funding Statement
The authors acknowledge support from an “Emmy-Noether Grant” of the Deutsche Forschungsgemeinschaft (Germany) and a “Chaire d’excellence” of the Agence Nationale de la Recherche (France). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Renart A, Machens CK (2014) Variability in neural activity and behavior. Current Opinion in Neurobiology 25: 211–220. 10.1016/j.conb.2014.02.013 [DOI] [PubMed] [Google Scholar]
- 2. Mountcastle V, Steinmetz MA, Romo R (1990) Frequency discrimination in the sense of flutter: psychophysical measurements correlated with postcentral events in behaving monkeys. Journal of Neuroscience 10: 3032–3044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Britten KH, Shadlen MN, Newsome WT, Movshon JA (1992) The analysis of visual motion: a comparison of neuronal and psychophysical performance. Journal of Neuroscience 12: 4745–4765. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Werner G, Mountcastle V (1965) Neural activity in mechanoreceptive cutaneous afferents: Stimulus-response relations, weber functions, and information transmission. Journal of Neurophysiology 28 [DOI] [PubMed] [Google Scholar]
- 5. Talbot W, Darian-Smith I, Kornhuber H, Mountcastle V (1968) The sense of flutter-vibration: comparison of the human capacity with response patterns of mechanoreceptive afferents from the monkey hand. Journal of Neurophysiology 31 [DOI] [PubMed] [Google Scholar]
- 6. Romo R, Salinas E (2003) Flutter discrimination: neural codes, perception, memory and decision making. Nature Reviews Neuroscience 4: 203–18. 10.1038/nrn1058 [DOI] [PubMed] [Google Scholar]
- 7. Gold JI, Shadlen MN (2007) The neural basis of decision making. Annual Review of Neuroscience 30: 535–74. 10.1146/annurev.neuro.29.051605.113038 [DOI] [PubMed] [Google Scholar]
- 8. Shadlen MN, Newsome WT (1998) The variable discharge of cortical neurons: implications for connectivity, computation, and information coding. Journal of Neuroscience 18: 3870–3896. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Abbott LF, Dayan P (1999) The effect of correlated variability on the accuracy of a population code. Neural computation 11: 91–101. 10.1162/089976699300016827 [DOI] [PubMed] [Google Scholar]
- 10. Averbeck BB, Latham PE, Pouget A (2006) Neural correlations, population coding and computation. Nature Reviews Neuroscience 7: 358–66. 10.1038/nrn1888 [DOI] [PubMed] [Google Scholar]
- 11. Uka T, DeAngelis GC (2003) Contribution of middle temporal area to coarse depth discrimination: comparison of neuronal and psychophysical sensitivity. Journal of Neuroscience 23: 3515–30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Cohen MR, Newsome WT (2009) Estimates of the contribution of single neurons to perception depend on timescale and noise correlation. Journal of Neuroscience 29: 6635–48. 10.1523/JNEUROSCI.5179-08.2009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Price NSC, Born RT (2010) Timescales of sensory- and decision-related activity in the middle temporal and medial superior temporal areas. Journal of Neuroscience 30: 14036–45. 10.1523/JNEUROSCI.2336-10.2010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Green D, Swets J (1966) Signal detection theory and psychophysics, volume 1974 Wiley, New York, USA. [Google Scholar]
- 15. Britten KH, Newsome WT, Shadlen MN, Celebrini S, Movshon AJ (1996) A relationship between behavioral choice and the visual response of neurons in macaque MT. Visual Neuroscience 13: 87–100. 10.1017/S095252380000715X [DOI] [PubMed] [Google Scholar]
- 16. de Lafuente V, Romo R (2006) Neural correlate of subjective sensory experience gradually builds up across cortical areas. Proceedings of the National Academy of Sciences of the United States of America 103: 14266–71. 10.1073/pnas.0605826103 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Shadlen MN, Britten KH, Newsome WT, Movshon AJ (1996) A computational analysis of the relationship between neuronal and behavioral responses to visual motion. Journal of Neuroscience 76: 1486–1510. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Nienborg H, Cumming BG (2010) Correlations between the activity of sensory neurons and behavior: how much do they tell us about a neuron’s causality? Current opinion in neurobiology 20: 376–381. 10.1016/j.conb.2010.05.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Haefner RM, Gerwinn S, Macke JH, Bethge M (2013) Inferring decoding strategies from choice probabilities in the presence of correlated variability. Nature Neuroscience 16: 235–242. 10.1038/nn.3309 [DOI] [PubMed] [Google Scholar]
- 20. Nienborg H, Cumming BG (2009) Decision-related activity in sensory neurons reflects more than a neuron’s causal effect. Nature 459: 89–92. 10.1038/nature07821 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Hernández A, Zainos A, Romo R (2000) Neuronal correlates of sensory discrimination in the somatosensory cortex. Proceedings of the National Academy of Sciences of the United States of America 97: 6191–6. 10.1073/pnas.120018597 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Aertsen AM, Gerstein GL, Habib MK, Palm G (1989) Dynamics of neuronal firing correlation: modulation of “effective connectivity”. Journal of neurophysiology 61: 900–17. [DOI] [PubMed] [Google Scholar]
- 23. Luna R, Hernández A, Brody CD, Romo R (2005) Neural codes for perceptual discrimination in primary somatosensory cortex. Nature Neuroscience 8: 1210–9. 10.1038/nn1513 [DOI] [PubMed] [Google Scholar]
- 24. Ahrens MB, Orger MB, Robson DN, Li JM, Keller PJ (2013) Whole-brain functional imaging at cellular resolution using light-sheet microscopy. Nature methods 10: 413–420. 10.1038/nmeth.2434 [DOI] [PubMed] [Google Scholar]
- 25. Panier T, Romano SA, Olive R, Pietri T, Sumbre G, et al. (2013) Fast functional imaging of multiple brain regions in intact zebrafish larvae using selective plane illumination microscopy. Frontiers in neural circuits 7 10.3389/fncir.2013.00065 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Portugues R, Feierstein CE, Engert F, Orger MB (2014) Whole-brain activity maps reveal stereotyped, distributed networks for visuomotor behavior. Neuron 81: 1328–1343. 10.1016/j.neuron.2014.01.019 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Hastie T, Tibshirani R, Friedman J (2009) The elements of statistical learning. Springer Verlag, New York, USA. [Google Scholar]
- 28. Wohrer A, Humphries MD, Machens CK (2013) Population-wide distributions of neural activity during perceptual decision-making. Progress in Neurobiology 103: 156–193. 10.1016/j.pneurobio.2012.09.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Wohrer A, Romo R, Machens CK (2010) Linear readout from a neural population with partial correlation data. In: Advances in Neural Information Processing. volume 23, pp. 2469–2477. [Google Scholar]
- 30. Turaga S, Buesing L, Packer AM, Dalgleish H, Pettit N, et al. (2013) Inferring neural population dynamics from multiple partial recordings of the same neural circuit. In: Advances in Neural Information Processing Systems. pp. 539–547. [Google Scholar]
- 31. Boerlin M, Machens CK, Denève S (2013) Predictive coding of dynamical variables in balanced spiking networks. PLoS computational biology 9: e1003258 10.1371/journal.pcbi.1003258 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Boerlin M, Denève S (2011) Spike-based population coding and working memory. PLoS computational biology 7 10.1371/journal.pcbi.1001080 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Schaub M, Schultz S (2012) The ising decoder: reading out the activity of large neural ensembles. Journal of Computational Neuroscience 32: 101–118. 10.1007/s10827-011-0342-z [DOI] [PubMed] [Google Scholar]
- 34. Cook EP, Maunsell JHR (2002) Dynamics of neuronal responses in macaque mt and vip during motion detection. Nature neuroscience 5: 985–994. 10.1038/nn924 [DOI] [PubMed] [Google Scholar]
- 35. Stanford TR, Shankar S, Massoglia DP, Costello MG, Salinas E (2010) Perceptual decision making in less than 30 milliseconds. Nature Neuroscience 13: 379–385. 10.1038/nn.2485 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Ashourian P, Loewenstein Y (2011) Bayesian inference underlies the contraction bias in delayed comparison tasks. PloS one 6: e19551 10.1371/journal.pone.0019551 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Miura K, Mainen ZF, Uchida N (2012) Odor representations in olfactory cortex: distributed rate coding and decorrelated population activity. Neuron 74: 1087–1098. 10.1016/j.neuron.2012.04.021 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Daley D, Vere-Jones D (2007) An introduction to the theory of point processes, volume 1 Springer Verlag, New York, USA. [Google Scholar]
- 39. Goodman D, Brette R (2008) Brian: a simulator for spiking neural networks in python. Frontiers in neuroinformatics 2 10.3389/neuro.11.005.2008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Raudys S, Duin R (1998) Expected classification error of the fisher linear classifier with pseudoinverse covariance matrix. Pattern Recognition Letters 19: 385–392. 10.1016/S0167-8655(98)00016-6 [DOI] [Google Scholar]
- 41. Hoyle DC (2011) Accuracy of pseudo-inverse covariance learning–a random matrix theory analysis. Pattern Analysis and Machine Intelligence, IEEE Transactions on 33: 1470–1481. 10.1109/TPAMI.2010.186 [DOI] [PubMed] [Google Scholar]
- 42. Bishop CM (2006) Pattern recognition and machine learning. Springer Verlag, New York, USA. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Contains additional information about Choice Probabilities (section 1), the influence of parameter w on stimulus sensitivity (section 2), the encoding neural network used for testing the method (section 3), the Bayesian regularization procedure on Fisher’s linear discriminant (section 4), unbiased computation of CC indicators in the presence of measurement noise (section 5), and an extended readout model with variable extraction time t R (section 6).
(PDF)
(GZ)