

Summary
Individualized treatment rules recommend treatments based on individual patient characteristics in order to maximize clinical benefit. When the clinical outcome of interest is survival time, estimation is often complicated by censoring. We develop nonparametric methods for estimating an optimal individualized treatment rule in the presence of censored data. To adjust for censoring, we propose a doubly robust estimator which requires correct specification of either the censoring model or survival model, but not both; the method is shown to be Fisher consistent when either model is correct. Furthermore, we establish the convergence rate of the expected survival under the estimated optimal individualized treatment rule to the expected survival under the optimal individualized treatment rule. We illustrate the proposed methods using simulation study and data from a Phase III clinical trial on non-small cell lung cancer.
Keywords: Censored data, Doubly robust estimator, Individualized treatment rule, Risk bound, Support vector machine
1. Introduction
Clinicians routinely tailor treatment to the individual characteristics of each patient. Individualized treatment rules formalize this practice by mapping patient characteristics to a recommended treatment. There is a large body work on estimation of optimal individualized treatment rules, using data from clinical trials or observational studies (Murphy, 2003; Robins, 2004; Zhao et al., 2009, 2011; Qian & Murphy, 2011; Zhang et al., 2012b). Regression-based approaches model the regression of outcome on patient covariates and treatment and infer the optimal individualized treatment rule from the modeled regression. The performance of regression-based methods depends critically on the predictive performance of the estimated regression model. In addition, because regression-based approaches require the modeling of treatment-covariate interactions, the number of terms can be large with high-dimensional covariates. An alternative class of procedures, known as classification-based methods, maximize an estimator of the marginal mean outcome over a pre-specified class of individualized treatment rules. These methods typically rely on fewer modeling assumptions about the conditional distribution of the outcome given covariates and treatment and so are potentially more robust to model misspecification; furthermore, they avoid inversion of a predictive model, which can be computationally expensive in some settings. Zhao et al. (2012) and Zhang et al. (2012a) showed that maximization of the estimated marginal mean outcome is equivalent to minimizing a weighted misclassification error with weights that are proportional to the observed clinical outcomes. Classification-based approaches have been shown to work well in settings without censoring (Zhao et al., 2012; Zhang et al., 2012a; Kang et al., 2014; Zhao et al., 2014). However, heretofore both regression-based and classification-based methods were restricted to use with non-censored data.
When the primary outcome of interest is survival time, the observations are commonly subject to right censoring because of subject dropout or administrative censoring. One approach is to fit a parametric or semiparametric survival model, including patient covariates and treatments to infer the optimal decision rule from the fitted survival model. Goldberg & Kosorok (2012) model the completely observed survival time and adjust for censoring by inverse probability of censoring weighting. These methods are intended to form high-quality predictions but may not be consistent for the optimal treatment rule (Qian & Murphy, 2011). Furthermore, parametric or semiparametric models can be sensitive to model misspecification and inverse-weighting may suffer from numerical instability when the censoring rate is high.
We extend the outcome weighted learning approach of Zhao et al. (2012) to accommodate censored data. The extension involves maximizing an estimator of the mean survival time under right censoring. The method avoids inversion of a predictive model by recasting the estimated mean survival time as a weighted misclassification rate where the weights involve both the observed outcome and inverse probability of censoring weights. We also introduce a doubly robust version of outcome weighted learning to account for potential bias introduced by a misspecified censoring model. The method is doubly robust in the sense that the obtained individualized treatment rule is consistent for the optimal rule when the model for either survival or censoring times is correct, but not necessarily both. We use a convex relaxation idea from support vector machines (Cortes & Vapnik, 1995) to construct a computationally efficient algorithm.
2. Methodology
2·1. Value function and optimal treatment rule
Let T̃ denote survival time, X = (X1,…, Xd)T ∈
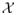 denote subject covariates, and A ∈ {−1, 1} denote the binary treatment assigned. Define τ to be the end of the study; because there is no information about survival beyond τ we use T = min(τ, T̃) as the outcome of interest. When we are interested in survival time on the log scale, we can use log(T) as the outcome. We assume that data are collected in a randomized trial so that treatment A is randomly assigned with a randomization probability that is completely determined by X. Thus, there are no unmeasured confounders (Rubin, 1974, 1978; Splawa-Neyman et al., 1990). Furthermore, we assume that π(a; X) = pr(A = a |X) is strictly bounded away from zero with probability 1 for each a. A treatment rule, say
denote subject covariates, and A ∈ {−1, 1} denote the binary treatment assigned. Define τ to be the end of the study; because there is no information about survival beyond τ we use T = min(τ, T̃) as the outcome of interest. When we are interested in survival time on the log scale, we can use log(T) as the outcome. We assume that data are collected in a randomized trial so that treatment A is randomly assigned with a randomization probability that is completely determined by X. Thus, there are no unmeasured confounders (Rubin, 1974, 1978; Splawa-Neyman et al., 1990). Furthermore, we assume that π(a; X) = pr(A = a |X) is strictly bounded away from zero with probability 1 for each a. A treatment rule, say
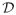 , is a function from
into the space of treatments {−1, 1}; under
, a patient with covariates X = x is assigned treatment
(x). The value of a regime
, denoted V(
), is the expected outcome under
. Let E denote expectation with respect to the distribution of (T, A, X) in the observed data, and
, is a function from
into the space of treatments {−1, 1}; under
, a patient with covariates X = x is assigned treatment
(x). The value of a regime
, denoted V(
), is the expected outcome under
. Let E denote expectation with respect to the distribution of (T, A, X) in the observed data, and
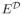 denote expectation under the restriction that A =
(X), then it can be shown (Qian and Murphy, 2011) that
denote expectation under the restriction that A =
(X), then it can be shown (Qian and Murphy, 2011) that
| (1) |
where I(·) is an indicator function. A treatment rule, say
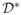 , is said to be optimal if V (
) ≥ V(
) for all rules
. To characterize
, write the last term in (1) as E {[I{
(X) = 1}E(T | A = 1, X) + I{
(X) = −1}E(T | A = −1, X)]} which implies
, is said to be optimal if V (
) ≥ V(
) for all rules
. To characterize
, write the last term in (1) as E {[I{
(X) = 1}E(T | A = 1, X) + I{
(X) = −1}E(T | A = −1, X)]} which implies
| (2) |
Thus,
(x) is the maximizer of E(T|X = x, A = a) with respect to a.
2·2. Outcome weighted learning with censored data
Censoring due to patient dropout is commonly seen in studies of survival time. Let C denote the potential censoring time, which could exceed τ, and assume that C and T are independent given (A, X). We observe data comprising n independent identically distributed subjects, {Yi = Ti ∧ Ci, Δi = I(Ti ≤ Ci), Xi, Ai}, i = 1, …, n, where Δ = I(T ≤ C) denotes the censoring indicator. Our goal is to estimate the optimal treatment rule
using the censored data.
Maximizing V (
) is equivalent to minimizing E [TI{A ≠
(X)}/π(A; X)] according to (1). This is a weighted classification problem, where misclassification corresponds to A ≠
(X), and the weights are T/π(A; X). This point of view motivated the development of outcome weighted learning for noncensored outcomes (Zhao et al., 2012). We generalize this approach to censored outcomes. Hereafter, we assume that event times and censoring times are continuous. Let
be the conditional treatment specific survival function for the censoring time given covariates x. Recall that T = min(T̃, τ). Then,
where we have used the conditional independence of T and C given X, A. Therefore,
| (3) |
To obtain an estimator of
one could attempt to maximize an empirical estimate of the right-hand-side of (3). This is equivalent to minimizing
| (4) |
where ŜC is a consistent estimator for
. However, direct optimization is intractable because of the discontinuous indicator functions; instead, we minimize a convex relaxation of (4). Because the objective function can be viewed as a weighted misclassification rate, we base our relaxation on support vector machines (Cortes & Vapnik, 1995). We replace I{A ≠
(x)} with a convex surrogate ϕ{Af(x)}, where
(x) = sign{f(x)} and ϕ(t) = max(1 − t, 0) denotes the hinge loss. Details for estimating
are at the end of this section.
In the above formulation, a misspecified model for C given (A, X) can lead to biased estimation. Thus, we also propose a doubly robust estimator which protects against such misspecification. Let denote a working model for the conditional mean residual life-time given (A, X) derived from a working survival model for ST̃ (t | A, X), and let denote a working model for SC(t | A, X). Then, using the construction given in Section 2.3.2 of van der Laan & Robins (2003), we define the augmented value function,
where NC(t) = (1 − Δ)I(Y ≤ t). In addition to the inverse probability of censoring weighting, there is an augmentation term in the weights for I{A =
(X)}. The following lemma shows that Vm(
) is equivalent to V(
) when either working model is correct; the proof is deferred to the Supplementary Material.
Lemma 1
If either
or
, then Vm(
) = V(
).
Define
| (5) |
Lemma 1 shows that if either working model is correct then . Thus, we can apply the weighted classification approach to estimate the optimal treatment rule using weights .
To distinguish the two learning approaches, we call the first approach inverse censoring weighted outcome weighted learning and the second approach doubly robust outcome weighted learning. Estimation is implemented as follows:
- Step 1. Fit a model for T̃ given (A, X) to construct estimate ŜT̃ (T | A, X) of ST̃ (T |, A, X). Estimate ET̃ (T | T > t, A, X) for t ∈ [0, τ) by
Step 2. Fit a model for C given (A, X) to form estimate ŜC(t | A, X) of SC(t | A, X).
Step 3. Calculate Wi = ΔiYi/ŜC(Yi | Ai, Xi) for the first approach and Wi = R(Yi, Δi, ŜC, ÊT̃) for the second approach. If negative weights occur with the doubly robust methods we can subtract mini Wi from all the weights.
- Step 4. Use the algorithm outlined below to obtain f̂(x) by minimizing
(6) Step 5. The decision rule is
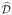 (x) = sign{f̂(x)}.
(x) = sign{f̂(x)}.
We have added a regularization term λn||f||2 to avoid overfitting in Step 4. Here, ||f|| is a norm defined on the space that f belongs to, and λn is a tuning parameter that controls the severity of penalization. We use a linear decision function f(x) = θ0 + θT x, to illustrate the algorithm utilized in this step. In this case, ||f|| is the Euclidean norm of θ. Let W denote a generic weight constructed in Step 3 using one of the proposed methods. The optimization problem in Step 4 can be written as subject to ξ ≥ 0 and Ai(θT Xi + θ0) ≥ (1− ξi). By introducing Lagrange multipliers, we obtain the Lagrangian
By taking derivatives with respect to θ, θ0 and ξi, we have and αi = γWi − μi. It follows that the dual problem is
| (7) |
subject to 0 ≤ αi ≤ γWi and
. The dual problem can be solved using quadratic programming. Estimates θ̂ = Σα̂i0α̂iAiXi and θ̂0 follow from the Karush–Kuhn–Tucker conditions. When a linear decision rule is not sufficient, the procedure can be generalized using nonlinear kernel functions. For every positive definite kernel k :
×
→ ℝ, there is a unique reproducing kernel Hilbert space
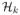 , which is the completion of the linear span of all functions {k(·, x), x ∈
}. The norm in
, denoted by ||·||k, is induced by the inner product,
, for
and
. A general nonlinear function f(x) can be used instead of a linear function. By the representer theorem (Kimeldorf & Wahba, 1971), the minimizer must admit a representation of the form
. In addition, to solve the optimization problem, we only need to compute the kernel matrix, where the inner product
in the dual objective function (7) is replaced by k(Xi, Xj). Quadratic programming can still be applied to obtain α̂i (i = 1,…, n). The resulting decision rule is
(X) = sign{Σα̂i0α̂ik(Xi, X) + θ̂0}.
, which is the completion of the linear span of all functions {k(·, x), x ∈
}. The norm in
, denoted by ||·||k, is induced by the inner product,
, for
and
. A general nonlinear function f(x) can be used instead of a linear function. By the representer theorem (Kimeldorf & Wahba, 1971), the minimizer must admit a representation of the form
. In addition, to solve the optimization problem, we only need to compute the kernel matrix, where the inner product
in the dual objective function (7) is replaced by k(Xi, Xj). Quadratic programming can still be applied to obtain α̂i (i = 1,…, n). The resulting decision rule is
(X) = sign{Σα̂i0α̂ik(Xi, X) + θ̂0}.
2·3. Working models for estimating SC(t | A, X) and ET̃ (T | T > t, A, X)
In our simulated experiments we used the Cox proportional hazards model for the requisite survival functions (Cox, 1972). Let ZT and ZC denote regressors constructed from X and A used in the Cox proportional hazards models for T and C respectively. Let λCi(t) and λTi(t) denote the hazard functions of censoring and failure times for subject i respectively. Under the Cox model, and , where λC0(t) and λT0(t) are baseline hazard functions for censoring and failure times, respectively. The estimator for βC, say β̂C, maximizes the partial likelihood
We use the Breslow estimator
for the cumulative baseline hazard function ΛC0(t). An estimator of ΛC(t|Ai, Xi), the cumulative hazard function of censoring time for subject i, is . An estimator for SC(t|Ai, Xi) is . Estimates β̂T and Λ̂T̃0(t) are obtained similarly. Details for estimating ET̃(T|T > t, A, X) are in the Supplementary Material.
3. Theoretical Results
Let f(x) be the decision function with the decision rule given by
(x) = sign{f(x)}, and write V (f) to denote the value function V (
). We define the pseudo value as
Therefore, Lemma 1 can be restated as , where is the true conditional survival function of C given (A, X), and is the true conditional mean residual lifetime given (A, X). Define convex surrogate loss function
| (8) |
where ϕ(t) = max(1 − t, 0). Define
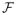 to be the set of all measurable functions from
into ℝ. Our first result states that the decision function obtained by minimizing the expectation of this surrogate loss over
maximizes VR for any SC and ET̃. Furthermore, we quantify the differences using the hinge loss versus zero-one loss. The proofs are essentially the same as Theorems 3.1 and 3.2 in Zhao et al. (2012) and are thus omitted.
to be the set of all measurable functions from
into ℝ. Our first result states that the decision function obtained by minimizing the expectation of this surrogate loss over
maximizes VR for any SC and ET̃. Furthermore, we quantify the differences using the hinge loss versus zero-one loss. The proofs are essentially the same as Theorems 3.1 and 3.2 in Zhao et al. (2012) and are thus omitted.
Lemma 2
If f̃ minimizes E{Lϕ(f, SC, ET̃)) over
with any models for SC and ET̃, then
VR(f̃, SC, ET̃) =
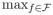 VR(f, SC, ET̃), that is, f̃ yields the maximum value of VR;
VR(f, SC, ET̃), that is, f̃ yields the maximum value of VR;-
for any f ∈,
that is, the value lost due to using a suboptimal decision function f is bounded by the expected surrogate loss.
Our main result establishes the convergence rates for value of the estimated decision rule f̂. As described in Section 2, we use weights that depend on the estimated survival functions, and hinge loss as a surrogate loss function. To bound the difference between the true and the empirical expectation of the surrogate, which involves random quantities, that is, estimates for survival and censoring times, we use the following assumptions:
Assumption 1
Both ÊT̃(T|A = a, X = x) and ŜC(t|A = a, X = x) converge in probability to and uniformly in t ∈ (0, τ] for every (x, a). Moreover, for some constant γ > 0,
| (9) |
Assumption 2
For some η > 0, with probability 1.
Assumption 1 implies that ÊT̃(T|A, X) and ŜC(t|A, X) converge to fixed functions, even if the imposed working models are wrong. Moreover, it imposes an assumption on the variance of the survival function estimators. The constant γ depends on the working models used for estimating SC and ET̃. If we assume parametric or semiparametric models, including the Cox proportional hazards model and transformation models, then γ = 1/2 in (9). Assumption 2 ensures that some subjects do not fail at the end of the study and thus have observation time τ.
In addition, we restrict the choice of reproducing kernel Hilbert space to the space associated with Gaussian radial basis function kernels,
, x, x′ ∈
, where σn > 0 is the kernel bandwidth parameter varying with n controlling the spread of the kernel. We can determine the complexity of
in terms of capacity bounds with respect to the empirical L2-norm, defined as
, f, g ∈
for functional class
. For any ε > 0, the covering number of
with respect to L2(Pn), N{
, ε, L2(Pn)}, is the smallest number of L2(Pn) ε-balls needed to cover
, where an L2(Pn) ε-ball around a function g ∈
is the set {f ∈
:||f − g||L2(Pn) < ε}. It has been shown in Theorem 2.1 of Steinwart & Scovel (2007) that for any ε > 0,
| (10) |
where
,
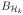 is the closed unit ball of
, p and δ are any numbers satisfying 0 < p ≤ 2 and δ > 0, cp,δ,d is a constant depending only on p, δ and d, and the supremum is taken over finitely discrete probability measures Pn.
is the closed unit ball of
, p and δ are any numbers satisfying 0 < p ≤ 2 and δ > 0, cp,δ,d is a constant depending only on p, δ and d, and the supremum is taken over finitely discrete probability measures Pn.
Let . According to Lemma 2, fm also maximizes , and for any function f. Hence, the convergence rate of the value using the estimated rule under the hinge loss will dominate the rate under the 0–1 loss. Define the approximation error function
The following theorem bounds the excess value optimal treatment rule relative to the doubly robust estimator of the optimal treatment rule. Its proof can be found in the Appendix.
Theorem 1
Assume Assumptions 1 and 2 hold and that λn → 0 and λnnmin(2γ,1) → ∞ as n → ∞. If we estimate f̂ within a reproducing kernel Hilbert space
associated with Gaussian radial basis function kernels, then with probability greater than 1 − 2e−b,
| (11) |
where Mp is a constant depending on p and K is a sufficiently large positive constant.
In this theorem, f*(x) = E(T|A = 1, X = x) − E(T|A = −1, X = x) gives the optimal treatment rule. On the right-hand-side of (11), the first term reflects the estimation bias from the working models for T and C. The second term is the approximation error due to using the
space. The last term is the stochastic variability of estimating
and
. The rest of the terms contain the empirical loss function for estimation of the optimal treatment rule. In particular, the convergence rate γ depends on the estimating procedure applied to the two working models.
A corollary is that when either the model for survival time or the model for censoring time is correctly specified, with probability greater than 1 − 2e−b, we have
Remark 1
With the hinge loss, it has been shown that if the reproducing kernel Hilbert space is rich enough, the optimizer within the reproducing kernel Hilbert space approaches the optimal treatment decision rule as the sample size goes to ∞ for appropriately chosen tuning parameters. The Gaussian kernel is one such kernel, which can induce a reproducing kernel Hilbert space that is flexible enough to approximate the optimal decision rule. While the approximation error term usually goes to zero as λn → 0, the other term controlling the stochastic error will increase. The optimal bandwidth λn can be obtained by setting the orders of a(λn) and equal to each other. The approximation error function a(λn) is usually related to the data-generating distribution, especially the behavior close to the decision boundary, which is the true optimal decision rule if either working model is correct. Intuitively, we should be able to learn the treatment rule more rapidly for well-separated optimal treatment classes, that is, distributions that have low density near the boundary.
This behavior can be characterized in terms of the size of the set of points that are close to boundary f*(x) = 0 (Tsybakov, 2004; Steinwart & Scovel, 2007). There exist a constant c1 such that , when using a Gaussian kernel with its kernel band-width σn varying with λn as and . Here, q > 0 is the noise exponent that characterizes the distribution close to the boundary (Steinwart & Scovel, 2007), and a larger q indicates a better separation between two treatment classes. More details on q are provided in the Appendix. An optimal choice of λn that balances bias and variance is λn = max{n−2(q+1)/{(4+p)q+2+(2−p)(2+δ)}, n−2(q+1)γ/(2q+1)}. The achieved convergence rate of the value due to the estimated rule versus the optimal value is thus max[n−2q/{(4+p)q+2+(2−p)(2+δ)}, n−2qγ/(2q+1)].
The rate consists of two parts: the first part reflects the rate of convergence in estimating the optimal decision rule, which is consistent with the results without censoring (Zhao et al., 2012); the second part is related to survival function estimation. When q is sufficiently large and δ and p are close to zero, the convergence rate is close to n−γ, where γ is determined by the survival function estimator. A Cox model for the survival function estimates leads to γ = 1/2. Other working models can also be applied, such as transformation models (Zeng & Lin, 2007), nonparametric methods based on kernel type estimators (Dabrowska, 1989), or machine learning techniques (Zhu & Kosorok, 2012). However, the rate n−γ can be slower than Op(n−1/2) for certain estimators.
Remark 2
Although the theoretical results are derived only for doubly robust estimators, inverse censoring weighted estimators enjoy the property stated in Theorem 1, as it is a special case obtained by setting the augmentation term to zero. However, the first term on the right-hand-side of (11) will change unless the censoring model is correctly specified.
4. Simulation Studies
4·1. Preliminaries
We aim to maximize the value function in terms of the survival time on the log scale. We compare the inverse censoring weighted and the doubly robust methods for selecting optimal individualized treatment with Cox regression and Q-learning adjusted with censoring weights (Goldberg & Kosorok, 2012). For Cox regression, we fit a proportional hazards model with treatment-by-covariate interactions, and identify the optimal individualized treatment based on the predicted outcomes. To apply Q-learning, we fit Q(X, A) = Φ(X, A)θ, where Φ(X, A) = (1, X, A, XA), to the log of the failure time. We also apply a regularized version of Q-learning, called L2 Q-learning, where an L2 penalty is used for regularization. The estimator is obtained as
where λn is a tuning parameter to be selected using cross-validation, and ŜC(Y|A, X) is the estimated conditional survival function of C given (A, X) that can be obtained using Cox regression. The estimated optimal decision rule is
(x) = argmaxa∈{−1,1}Φ(x, a)θ̂.
4·2. Simulation study
Ten independent covariates, X1, …, X10, were generated from the uniform distribution on [0, 1]. Treatments were generated from {−1, 1} with equal probabilities 0·5. Four different scenarios are presented, corresponding to different combinations of correct or incorrect survival time and censoring time models. Specifically, we generated T̃ or C from the accelerated failure time or Cox models in different scenarios, while we always used a proportional hazards model as a working model for both T̃ and C given (A, X). Regarding the specification of the model basis, we include treatment covariate interaction terms in the survival function modeling since we are interested in whether certain characteristics moderate treatment effects. Conversely, we do not model the censoring time with interaction terms unless we have full knowledge of the data, because it is not typical to posit a complex model for the censoring mechanism in practice. Details for calculating the doubly robust weights using Cox working models are given in the Supplementary Material.
For each scenario, a test data set of size 10,000 is generated to evaluate the estimated rules. The decision rules are estimated from training data using the proposed methods as described in Section 2 and the competitors. The sample sizes for the training data sets were taken to equal to 100, 200 and 400, and the simulations were repeated 1000 runs for each sample size. A linear basis is applied for model fitting in Q-learning. Linear kernels were used for both the implementation of inverse censoring weighted and doubly robust outcome weighted learning. We also explored the use of Gaussian kernels, and found that the performances were comparable to the linear kernel. The learning procedure was implemented using a Library for Support Vector Machines developed in Chang & Lin (2011). The tuning parameter λn in (6) was chosen using 5-fold cross validation over a pre-specified grid, with the criterion being the empirical pseudo value function. Specifically, for each tuning parameter, we partitioned the training data into 5 parts, each of which serves as the validation set once while the other 4 parts of the data are utilized for estimation. We sum up the empirical pseudo values calculated across the validation sets from the corresponding trained decision rules, and choose the optimal tuning parameter as the one maximizing the summed value.
In the following, we consider four generative models.
Case 1: The true models are Cox models for both T̃ and C. The survival time T is the minimum of τ = 1.5 and T̃, where T̃ is generated with hazard rate function
and λT̃0(t) = 2t. The censoring time C is generated with hazard rate function
where λC0(t) = 2t. The censoring percentage is around 56%. The optimal decision boundary is linear with
(X) = −sign(0·6 − 0·4X1 − 0·2X2 − 0·4X3). We use the Cox regression model with covariates (X1, X2, X3, A, X1A, X2A, X3A) to model survival and censoring times respectively. Therefore, both models are correctly specified.
Case 2: The true model for T̃ is a Cox model, and the true model for C is an accelerated failure time model. The survival time T is the minimum of τ = 2 and T̃, where
We let censoring time C be generated from an accelerated failure time model with
where ε is generated from N(0, 1). The censoring percentage is around 34%. The optimal decision boundary is
(X) = −sign(0·5 − 0·1X1 − 0·6X2). We use the Cox model as the working model for both T̃ and C given (A, X). Specifically, we use (X1, X2, A, X1A, X2A) as covariates to model survival time, and (X1, X2, X3) to model censoring time. Therefore, the working model is correctly specified for T but incorrect for C.
Case 3: The true model for T̃ is an accelerated failure time model, and the true model for C is a Cox model. The survival time T is the minimum of τ = 2 and T̃, which is generated with
The censoring time C is generated from the Cox proportional hazards model, where
and λC0(t) = 2t. The censoring percentage is around 45%. The optimal decision boundary is linear with
(X) = sign(0·6 − 0·4X1 − 0·1X2 − 0·4X3). We use the Cox model for both T̃ and C given (A, X). Specifically, we use (X, A, XA) to model survival time, and (X1, X2, X3, A, X1A, X2A, X3A) to model censoring time. Therefore, the working model is correctly specified for C but incorrect for T.
Case 4: The true models are accelerated failure time models for both T and C. The survival time T is the minimum of τ = 2.5 and T̃, where
The censoring time C is generated from an accelerated failure time model with
and ε is generated from N(0, 1). The censoring percentage is around 31%. The optimal decision boundary is linear with
(X) = sign(0·5 − 0·1X1 − 0·6X2 + 0·1X3). We use (X, A, XA) to model survival time, and X to model censoring time. Therefore, both working models are incorrectly specified.
Since we know the true data generating mechanism under every scenario, for each of 1000 replicates, we calculate the values based on the logarithm of the survival time using the constructed rule from different methods. Figure 1 shows these values when n = 100, where larger values indicate longer survival. Additional results using other sample sizes are provided in the Supplementary Material.
Fig. 1.

Boxplots of values of estimated rules using different methods, representing the logarithm of the survival time with higher values being more preferable. Cox, Cox model; Q, inverse censoring weighted Q-learning; L2Q, inverse censoring weighted L2 Q-learning; ICO, inverse censoring weighted outcome weighted learning with linear kernel; DRO, doubly robust outcome weighted learning with linear kernel.
In general, inverse censoring weighted and doubly robust outcome weighted learning have satisfactory performances. Inverse censoring weighted outcome weighted learning performs better when the censoring model is correctly specified, see Fig. 1(a) and 1(c). Indeed, doubly robust outcome weighted learning requires estimating both censoring and survival probabilities, which yield a higher variability compared with that of the inverse censoring weighted outcome weighted learning. The strength of doubly robust approach can be seen when the censoring model is mis-specified but the survival model is correct, since it can correct the bias from using only inverse censoring weighting, see Fig. 1(b). When the survival data are truly generated from the Cox model, Cox regression with correct basis results in the best performances, see Fig. 1(a) and 1(b). However, the strength is lost when the survival time is generated from an accelerated failure time model. Although Q-learning is improved by L2-regularization, possibly by reducing overfitting, Q-learning based methods can have suboptimal performances even when the censoring model is correctly specified but survival time is generated from a Cox model, see Fig. 1(a). This is due to model misspecification when inverse censoring weighted Q-learning models the logarithm of the survival time.
We also consider a nonlinear example of possible model misspecification in the Supplementary Material. The number of covariates is increased to 30, and T̃ and C are generated from Cox models with complex effects. When the censoring or survival model is correctly specified, we use the true sets of covariates for model fitting. If the model is incorrect for survival time or censoring time, we use a linear basis. In addition to a linear kernel, we apply both methods with a Gaussian kernel. We can see that the gain from using a Gaussian kernel is pronounced, since it may better approximate the nonlinear treatment decision rules.
5. Application
We illustrate the proposed methods using advanced non-small-cell lung cancer data (Socinski et al., 2002), which is collected in a two-arm randomized trial with survival time as the primary endpoint. Non-small-cell lung cancer is the leading cause of cancer-related mortality, and approximately 30% to 40% of all new cases present with stage IV or stage IIIB disease. To investigate the optimal duration of therapy that maximizes survival, a prospective randomized phase III trial was initiated in 1998. Patients with advanced non-small-cell lung cancer were recruited and randomized to either four cycles of carboplatin/paclitaxel or continuous therapy with carboplatin/pactaxel until disease progression. The study enrolled 230 subjects; however, we restrict our analysis to the 224 subjects with complete information. In the analysis sample, 112 subjects were assigned to each treatment. The censoring rate was 32%. The baseline covariates include age ranging from 32 to 82 with median 63, sex with 138 male and 86 female, race with 162 white, 54 black and 8 other, performance status with 117 Karnofsky performance status 90% to 100% and 97 70% to 80%, and stage with 30 Stage IIIB and 194 Stage IV.
In addition to the proposed methods, we apply Cox regression, inverse censoring weighted Q-learning and L2 Q-learning with a linear basis. We consider two sets of working models: we first use Cox regression with basis (X, A, XA) for both survival time and censoring time, and then use the Kaplan–Meier estimator for censoring time as an alternative. A treatment decision rule
is evaluated based on its empirical value adjusted for censoring. The empirical value is calculated by
, with R̃ equal to
where ŜC(t | A, X) and ÊT̃ (T | T > t, A, X) are the estimated censoring probability and residual life conditional on patients characteristics. To avoid overfitting, we employ a cross-validated analysis. At each run, we partition the whole data set into 5 pieces, where 4 parts of the data are used as training data to estimate the individualized treatment rules, and the remaining part is the validation set for implementing the estimated rules, with empirical values stored for each method respectively. The cross-validated values are obtained by averaging the empirical values on all 5 validation subsets. The procedure is repeated 100 times. The averages and standard errors of these values are reported in Table 1, where larger values correspond to longer survival time.
Table 1.
Mean (s.e.) cross-validated days on log sale using different working models for C, with working model for T being a Cox regression model with basis (X, A, XA)
| Working model for C | Mean (s.e.) Cross-validated Values | ||||
|---|---|---|---|---|---|
| Cox | Q | L2Q | ICO | DRO | |
| Cox model, basis (X, A, XA) | 5·061 (0·381) | 5·234 (0·578) | 5·258 (0·575) | 5·339 (0·404) | 5·257 (0·526) |
| Kaplan–Meier | 5·061 (0·381) | 5·002 (0·621) | 5·000 (0·632) | 5·473 (0·166) | 5·446 (0·273) |
s.e., standard errors; Cox, Cox model; Q: inverse censoring weighted Q-learning; L2Q, inverse censoring weighted L2 Q-learning; ICO, inverse censoring weighted outcome weighted learning with linear kernel; DRO, doubly robust outcome weighted learning with linear kernel.
Both inverse censoring weighted and doubly robust outcome weighted learning methods lead to higher values more frequently. We see a comparable performance between the two proposed approaches, which is reasonable if the censoring distribution is correctly specified, although doubly robust outcome weighted learning may have a larger variance. Since the number of covariates is not large, the performances of inverse censoring weighted Q-learning and L2 Q-learning are similar. They could have difficulties in identifying the optimal treatment rules if the model for survival time does not fit well, even if the censoring weight is correctly specified. Also, when we apply Cox regression to model the censoring time, none of the covariates has a significant effect. Thus, working models with either Kaplan–Meier estimators or Cox regression estimators yield similar results. We then apply the proposed methods to the whole data set using Cox regression working models for both T and C. The treatment recommendations from inverse censoring weighted outcome weighted learning recommends that 119 patients be assigned to continuous therapy with carboplatin/pactaxel, while by using doubly robust outcome weighted learning, 122 out of 224 patients should be given the continuous therapy. By checking the empirical value, we find that both strategies yield close values: 5·301 for inverse censoring weighted outcome weighted learning and 5·567 for doubly robust outcome weighted learning. In fact, sometimes we may have equivalent treatment strategies if there are no differential treatment effects on a subset of the patients. The treatment decision rule produced by inverse censoring weighted Q-learning and L2 Q-learning however, only leads to an empirical value of 4·756, and an empirical value of 4·744 by using Cox regression.
6. Discussion
As one reviewer pointed out, the proposed method is only one possible reduction of optimizing treatment rules to a weighted classification problem. Alternative choices have been proposed for continuous outcomes (Zhang et al., 2012b; Rubin & van der Lann, 2012), which can be generalized to the censoring data setup.
There may exist multiple treatments for comparison. One approach for extending the proposed framework to handle this case is to incorporate techniques developed in multicategory classification (Lee et al., 2004; Liu & Yuan, 2011). Another important extension is to settings in which there are a large number of variables. In this setting, penalized methods in classification by using sparse penalties could be adapted (Zhu et al., 2004).
Effective management of a chronic illness requires individualized treatment recommendations that are responsive to a patient’s changing health status. Dynamic treatment regimens formalize a dynamic treatment plan as a sequence of treatment rules, one per stage of clinical intervention, that map current patient information to a recommended treatment. Longer life expectancy and an aging population have created a surge in the rate of chronic illness related death. Thus, there is increasing interest in dynamic treatment regimens (Thall et al., 2002; Murphy, 2003; Robins, 2004; Moodie et al., 2007; Zhao et al., 2011; Goldberg & Kosorok, 2012; Huang et al., 2014). Extension of the proposed approach for survival data to the dynamic setting is of great interest.
Supplementary Material
Acknowledgments
This research was supported by the U.S. National Institutes of Health. We are grateful to the editors and the reviewers for their insightful comments which have led to important improvements in this paper.
Appendix
Proof of Theorem 1
First, it can be established that
According to Lemma 2(a), , where . Hence, it suffices to derive the convergence rate of .
Let . Then,
To bound (II) and (III), we consider the class of functions
where δ0 is a small constant, and are the limits of β̂T, β̂C, Λ̂C0 and Λ̂T0 based on the Cox models. Then |R{Y, Δ, SC(βC, ΛC0), ET̃ (βC, ΛC0)}|/π(A, X) can be bounded from above by a constant, say M.
Trivial bounds for ||f̂||k and are obtained as and . For every . Thus,
We use empirical process theory to bound (I). Define the functional class
and
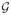 = {E(l) − l : E(l) = ε, l ∈
= {E(l) − l : E(l) = ε, l ∈
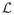 }. Let
. Since E(g) = 0, g ∈
, it follows from Lemma S.1 in the Supplementary Material, by setting ρ = 1, that pr{Z ≥ 2E(Z) + σ(Kb)1/2n−1/2 + 2KBbn−1} ≤ e−b, where
. Furthermore,
following the arguments for proving Theorem 3.4 in Zhao et al. (2012), given that
, where
. In addition, for
,
}. Let
. Since E(g) = 0, g ∈
, it follows from Lemma S.1 in the Supplementary Material, by setting ρ = 1, that pr{Z ≥ 2E(Z) + σ(Kb)1/2n−1/2 + 2KBbn−1} ≤ e−b, where
. Furthermore,
following the arguments for proving Theorem 3.4 in Zhao et al. (2012), given that
, where
. In addition, for
,
Since |
| and |
| are bounded by δ0, they lie in a hypercube of ℝ2d. Moreover, {
} is a class of monotone functions, so is {
}. The function in
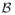 is Lipschitz continuous with respect to all these parameters and the Lipschitz constant is less than a constant W. There exists a constant K, depending on d, such that the bracketing number for
satisfies N[·]{
, εW, L2(P)} ≤ K(δ0/ε)2d+2. According to (10), supPn log N {
, ε, L2(Pn)} ≤ cnε−p, and therefore
is Lipschitz continuous with respect to all these parameters and the Lipschitz constant is less than a constant W. There exists a constant K, depending on d, such that the bracketing number for
satisfies N[·]{
, εW, L2(P)} ≤ K(δ0/ε)2d+2. According to (10), supPn log N {
, ε, L2(Pn)} ≤ cnε−p, and therefore
where cp is a constant depending on p. See Proposition 5.5 in Steinwart & Scovel (2007) and references therein. Consequently,
Given that
is convex, if l ∈
satisfies
and E{l(X)} ≥ ε, there exists l′ ∈
such that
and E{l′(X)} = ε. Thus, with probability at least 1 − e−b, every l ∈
with
satisfies El ∈ ε (Bartlett et al., 2006; Steinwart & Scovel, 2007). Since
with probability at least 1 − e−b,
It follows that,
with and . Using Mp as a new constant depending on p, we subsequently obtain the desired results.
Geometric noise exponent
The approximation error depends on the noise component q, called the geometric noise exponent (Steinwart & Scovel, 2007). Let
Hence, 2η(x) − 1 is the decision boundary for the optimal treatment decision rules when we use the pseudo-outcomes. We further define
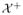 = {x ∈
: 2η(x) − 1 > 0}, and
= {x ∈
: 2η(x) − 1 > 0}, and
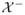 = {x ∈
: 2η(x) − 1 < 0}. A distance function to the boundary between
and
is Δ(x) = d̃(x,
) if x ∈
, Δ(x) = d̃(x,
) if x ∈
and Δ(x) = 0 otherwise, where d̃(x,
= {x ∈
: 2η(x) − 1 < 0}. A distance function to the boundary between
and
is Δ(x) = d̃(x,
) if x ∈
, Δ(x) = d̃(x,
) if x ∈
and Δ(x) = 0 otherwise, where d̃(x,
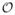 ) denotes the distance of x to a set
with respect to the Euclidean norm. Then the distribution P is said to have geometric noise exponent 0 < q < ∞, if there exists a constant C > 0 such that
) denotes the distance of x to a set
with respect to the Euclidean norm. Then the distribution P is said to have geometric noise exponent 0 < q < ∞, if there exists a constant C > 0 such that
Δ(X) actually measures the size of the set of points that are close to the opposite class. Indeed, if the data are distinctly separable, that is, when |2η(x) − 1| > δ > 0, for some constant δ, and η is continuous, q can be very large. If either model for the survival time or the censoring time is correctly specified, 2η(x) − 1 is the optimal treatment decision rule, where sign{2η(x) − 1} = sign{f*(X)}.
Footnotes
Supplementary material available at Biometrika online includes extended proofs of technical results, calculation of pseudo-outcome using Cox proportional hazards models, and additional simulation results.
Contributor Information
Y. Q. Zhao, Email: yqzhao@biostat.wisc.edu, Department of Biostatistics and Medical Informatics, University of Wisconsin-Madison, Madison, Wisconsin, 53792, U.S.A
D. Zeng, Email: dzeng@bios.unc.edu, Department of Biostatistics, University of North Carolina at Chapel Hill, Chapel Hill, North Carolina, 27599, U.S.A
E. B. Laber, Email: eblaber@ncsu.edu, Department of Statistics, North Carolina State University, Raleigh, North Carolina, 27695, U.S.A
R. Song, Email: rsong@ncsu.edu, Department of Statistics, North Carolina State University, Raleigh, North Carolina, 27695, U.S.A
M. Yuan, Email: myuan@stat.wisc.edu, Department of Statistics, University of Wisconsin-Madison, Madison, Wisconsin, 53792, U.S.A
M. R. Kosorok, Email: kosorok@unc.edu, Department of Biostatistics, University of North Carolina at Chapel Hill, Chapel Hill, North Carolina, 27599, U.S.A
References
- Bartlett PL, Jordan MI, McAuliffe JD. Convexity, classification, and risk bounds. J Am Statist Assoc. 2006;101:138–156. [Google Scholar]
- Chang CC, Lin CJ. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology. 2011;2:27:1–27:27. Software available at http://www.csie.ntu.edu.tw/cjlin/libsvm. [Google Scholar]
- Cortes C, Vapnik V. Support-vector networks. Mach Learn. 1995;20:273–297. [Google Scholar]
- Cox DR. Regression models and life-tables (with discussion) J R Statist Soc B. 1972;34:187–220. [Google Scholar]
- Dabrowska DM. Uniform consistency of the kernel conditional Kaplan–Meier estimate. Ann Statist. 1989;17:1157–1167. [Google Scholar]
- Goldberg Y, Kosorok MR. Q-learning with censored data. Ann Statist. 2012;40:529–560. doi: 10.1214/12-AOS968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang X, Ning J, Wahed AS. Optimization of individualized dynamic treatment regimes for recurrent diseases. Statist Med. 2014 doi: 10.1002/sim.6104. In press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kang C, Janes H, Huang Y. Combining biomarkers to optimize patient treatment recommendations. Biometrics. 2014 doi: 10.1111/biom.12191. In Press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kimeldorf G, Wahba G. Some results on Tchebycheffian spline functions. J Math Anal Appl. 1971;33:82–95. [Google Scholar]
- Lee Y, Lin Y, Wahba G. Multicategory support vector machines, theory, and application to the classification of microarray data and satellite radiance data. J Am Statist Assoc. 2004;99:67–81. [Google Scholar]
- Liu Y, Yuan M. Reinforced multicategory support vector machines. J Comput Graph Statist. 2011;20:909–919. doi: 10.1080/10618600.2015.1043010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moodie EEM, Richardson TS, Stephens DA. Demystifying optimal dynamic treatment regimes. Biometrics. 2007;63:447–455. doi: 10.1111/j.1541-0420.2006.00686.x. [DOI] [PubMed] [Google Scholar]
- Murphy SA. Optimal dynamic treatment regimes (with discussion) J R Statist Soc B. 2003;65:331–366. [Google Scholar]
- Qian M, Murphy SA. Performance guarantees for individualized treatment rules. Ann Statist. 2011;39:1180–1210. doi: 10.1214/10-AOS864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins JM. Optimal structural nested models for optimal sequential decisions. In: Lin DY, Heagerty PJ, editors. Proc 2nd Seattle Symp Biostatist. New York: Springer; 2004. [Google Scholar]
- Rubin DB. Estimating causal effects of treatments in randomized and nonrandomized studies. J Educ Psychol. 1974;66:688–701. [Google Scholar]
- Rubin DB. Bayesian inference for causal effects: The role of randomization. Ann Statist. 1978;6:34–58. [Google Scholar]
- Rubin DB, van der Lann MJ. Statistical issues and limitations in personalized medicine research with clinical trials. J Educ Psychol. 2012;8 doi: 10.1515/1557-4679.1423. Article 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Socinski MA, Schell MJ, Peterman A, Bakri K, Yates S, Gitten R, Unger P, Lee J, Lee JH, Tynan M, Moore M, Kies MS. Phase III trial comparing a defined duration of therapy versus continuous therapy followed by second-line therapy in advanced-stage IIIB/IV nonsmall-cell lung cancer. J Clin Oncol. 2002;20:1335–1343. doi: 10.1200/JCO.2002.20.5.1335. [DOI] [PubMed] [Google Scholar]
- Splawa-Neyman J, Dabrowska DM, Speed TP. On the application of probability theory to agricultural experiments (engl. transl by D M Dabrowska and T P Speed) Statist Sci. 1990;5:465–472. [Google Scholar]
- Steinwart I, Scovel C. Fast rates for support vector machines using Gaussian kernels. Ann Statist. 2007;35:575–607. [Google Scholar]
- Thall PF, Sung HG, Estey EH. Selecting therapeutic strategies based on efficacy and death in multicourse clinical trials. J Am Statist Assoc. 2002;97:29–39. [Google Scholar]
- Tsybakov AB. Optimal aggregation of classifiers in statistical learning. Ann Statist. 2004;32:135–166. [Google Scholar]
- van der Laan MJ, Robins JM. Unified Methods for Censored Longitudinal Data and Causality. New York: Springer-Verlag; 2003. [Google Scholar]
- Zeng D, Lin D. Maximum likelihood estimation in semiparametric regression models with censored data (with discussion) J R Statist Soc B. 2007;69:507–564. [Google Scholar]
- Zhang B, Tsiatis AA, Davidian M, Zhang M, Laber E. Estimating optimal treatment regimes from a classification perspective. Stat. 2012a;1:103–114. doi: 10.1002/sta.411. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B, Tsiatis AA, Laber EB, Davidian M. A robust method for estimating optimal treatment regimes. Biometrics. 2012b;68:1010–1018. doi: 10.1111/j.1541-0420.2012.01763.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Kosorok MR, Zeng D. Reinforcement learning design for cancer clinical trials. Statist Med. 2009;28:3294–3315. doi: 10.1002/sim.3720. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Zeng D, Socinski MA, Kosorok MR. Reinforcement learning strategies for clinical trials in nonsmall cell lung cancer. Biometrics. 2011;67:1422–1433. doi: 10.1111/j.1541-0420.2011.01572.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao YQ, Zeng D, Laber EB, Kosorok MR. New statistical learning methods for estimating optimal dynamic treatment regimes. J Am Statist Assoc. 2014 doi: 10.1080/01621459.2014.937488. In Press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao YQ, Zeng D, Rush AJ, Kosorok MR. Estimating individualized treatment rules using outcome weighted learning. J Am Statist Assoc. 2012;107:1106–1118. doi: 10.1080/01621459.2012.695674. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu J, Rosset S, Hastie TJ, Tibshirani RJ. 1-norm support vector machines. Adv Neural Inf Process Syst. 2004;16:49–56. [Google Scholar]
- Zhu R, Kosorok MR. Recursively imputed survival trees. J Am Statist Assoc. 2012;107:331–340. doi: 10.1080/01621459.2011.637468. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.