

Abstract
Multiple outcomes multivariate meta-analysis (MOMA) is gaining in popularity as a tool for jointly synthesizing evidence coming from studies that report effect estimates for multiple correlated outcomes. Models for MOMA are available for the case of the pairwise meta-analysis of two treatments for multiple outcomes. Network meta-analysis (NMA) can be used for handling studies that compare more than two treatments; however, there is currently little guidance on how to perform an MOMA for the case of a network of interventions with multiple outcomes. The aim of this paper is to address this issue by proposing two models for synthesizing evidence from multi-arm studies reporting on multiple correlated outcomes for networks of competing treatments. Our models can handle continuous, binary, time-to-event or mixed outcomes, with or without availability of within-study correlations. They are set in a Bayesian framework to allow flexibility in fitting and assigning prior distributions to the parameters of interest while fully accounting for parameter uncertainty. As an illustrative example, we use a network of interventions for acute mania, which contains multi-arm studies reporting on two correlated binary outcomes: response rate and dropout rate. Both multiple-outcomes NMA models produce narrower confidence intervals compared with independent, univariate network meta-analyses for each outcome and have an impact on the relative ranking of the treatments.
Keywords: Correlation, Heterogeneity, Mixed-treatment comparison, Multivariate meta-analysis
1. Introduction
When studies report on multiple outcomes for each patient, a joint, multivariate meta-analysis (multiple outcomes multivariate meta-analysis, MOMA) can be used to incorporate all possible correlations in order to perform a simultaneous synthesis of all data for all outcomes. The effects of disregarding all possible correlations by performing a series of independent, univariate analyses have been explored and may include a loss of precision and an increase of selective reporting bias (Kirkham and others, 2012; Riley, 2009). There are two types of correlations to consider: within-study correlations of the estimated relative treatment effects on the multiple outcomes, reflecting the fact that the same patients report on each of these outcomes and between-study correlations of the true relative treatment effects on the different outcomes, reflecting the way these true effects depend on each other when measured in different setting. Many estimation methods for MOMA models have been suggested in recent years, both in a frequentist and a Bayesian setting (Jackson and others, 2013; Riley and others, 2007a; Wei and Higgins, 2013b; for reviews, see Jackson and others, 2011; Mavridis and Salanti, 2013).
Currently available models for performing an MOMA of randomized trials focus on the case of meta-analysis for studies that compare only two treatments and report on multiple, possibly correlated outcomes. As in practice, many alternative treatments exist for the same condition, network meta-analysis (NMA) is increasingly gaining in popularity as it allows the synthesis of data over a network of treatments compared in studies for a certain outcome (Dias and others, 2013; Lu and Ades, 2004; Salanti, 2012; Salanti and others, 2008). It is therefore desirable to extend MOMA methods for multiple-treatment comparisons. To our knowledge, there is no general model available for performing a joint, multiple-outcome NMA for multi-arm studies, that incorporates both within- and between-studies correlations (multiple outcomes network meta-analysis, MONMA), for binary, continuous and time-to-event outcomes. In this paper, we propose two different modeling approaches to perform such an analysis. The first approach is based on making a set of simplifying assumptions to model both within- and between-studies correlation coefficients. The second approach is a generalization of a bivariate model proposed by Riley and others that allows for a single correlation coefficient to model the overall correlation, an amalgam of the within- and between-study correlations (Riley and others, 2008). We fit the models in a Bayesian framework that offers flexibility in incorporating prior beliefs and allows for a straightforward inclusion of studies that do not report on all outcomes, as well as accounting for uncertainty in parameter estimates.
The paper is structured as follows: in Section 2, we describe the data we used to illustrate our methods. In Section 3, we present the two approaches and discuss the technicalities of fitting the models. In Section 4, we apply the methods to our data to produce estimates for outcome-specific relative treatment effects and evaluate the relative ranking of the treatments for each outcome. In Section 5, we present our conclusions, discuss the limitations of the models and suggest areas for future research.
2. Example: the acute mania dataset
The dataset we used as an example is a network of 68 studies comparing 13 active antimanic drugs and placebo for acute mania (Cipriani and others, 2011). The majority of the studies had two arms (50 studies) and there were 18 three-arm studies. The primary outcomes of interest were efficacy and treatment discontinuation (acceptability) after 3 weeks. Acceptability was estimated as the number of patients leaving the study early for any reason, before or after having a response to the treatment, out of the total number of randomized patients. All-cause discontinuation from allocated treatment may be due to a number of reasons, such as adverse effects, inefficacy, other reasons not related to treatment (e.g. moving away, protocol violation), or a combination of the above. Efficacy was reported either as dichotomous outcome (number of patients who responded to treatment, defining response as a reduction of at least 50% in manic symptoms from baseline to week 3) or as continuous outcome (mean change scores on a standardized rating scale for mania after 3 weeks). Although we recognize that outcome dichotomization may lose some information, in this paper we use data on efficacy as a dichotomous outcome as it may be easier to interpret clinically and allows us to illustrate our methodology for two related binary outcomes, a frequent scenario encountered by researchers. Only a few patients did not provide data for response to treatment and their outcome was coded as treatment failure; an imputation assumption that has been shown to be sensible (Spineli and others, 2013). Among the included studies, only 65 contributed with data for at least one of the outcomes of interest: 18 studies (28%) did not report usable data on response, while only one study did not report information on the number of dropouts (1.5%). Efficacy and acceptability outcomes are generally expected to be negatively correlated; although early full response to the treatment may be a cause for leaving the study prematurely, more often it is reasonable to assume that more efficacious treatments are associated with a lower dropout rate. Within-study correlations were not reported in any of the studies and individual patient data (IPD) which could be used to estimate within-study correlations were not available. The dataset included a total of 69 head-to-head comparisons for response and 100 for dropout. In Section 1 of the supplementary material available at Biostatistics online, we provide a table with all head-to-head comparisons for each outcome, along with the odds ratios and their 95% confidence interval. The initial analysis consisted of two independent network meta-analyses, one for each outcome (Cipriani and others, 2011). As both outcomes are crucially important for clinical decision making, the ranking of the treatments was presented for both efficacy and acceptability in a two-dimensional scatter plot (Figure 6 in Cipriani and others) so that efficacious treatments with high tolerability could be identified. This is a suboptimal approach and the rankings of the treatments for each outcome can be better estimated jointly in a MONMA model to account for the correlation in the outcomes. This is especially important here as 19 studies provide data on only one of the two outcomes, and MONMA can “borrow strength” from these studies even for the missing outcomes.
3. Methods
First, we revise the models used for performing an MOMA when only two treatments are compared. We then generalize these methods for a network of interventions that includes multi-arm studies.
3.1. Pairwise multivariate meta-analysis of multiple outcomes
Suppose we have a total of 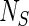 studies comparing two treatments (e.g. a new treatment versus a placebo) with respect to two different but correlated outcomes, denoted with
studies comparing two treatments (e.g. a new treatment versus a placebo) with respect to two different but correlated outcomes, denoted with 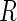 and
and 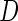 . We denote the observed treatment effects in study for outcomes
. We denote the observed treatment effects in study for outcomes 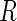 and
and 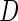 with
with 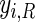 and
and 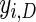 respectively; in our example, these are the log odds ratio estimates comparing the two treatments for
respectively; in our example, these are the log odds ratio estimates comparing the two treatments for 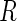 and
and 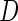 , but in other situations they could be mean difference or log hazard ratio estimates, for example. The bivariate random effects meta-analysis model is:
, but in other situations they could be mean difference or log hazard ratio estimates, for example. The bivariate random effects meta-analysis model is:
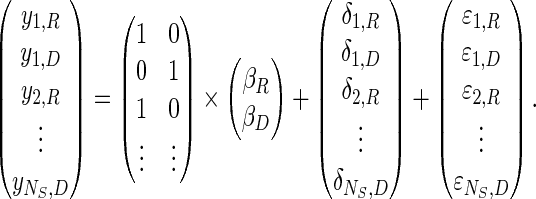 |
(3.1) |
The parameters 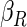 and
and 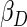 are the true mean relative treatment effects, which summarize how the treatment performs on average across studies for each outcome. We can rewrite (3.1) using matrix notation as
are the true mean relative treatment effects, which summarize how the treatment performs on average across studies for each outcome. We can rewrite (3.1) using matrix notation as 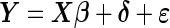 . Assuming all studies report both outcomes,
. Assuming all studies report both outcomes, 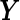 is the 2
is the 2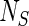 -imensional vector of the observed effects,
-imensional vector of the observed effects, 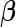 is the vector
is the vector 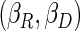 , X is the (
, X is the (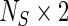 ) design matrix, and
) design matrix, and 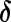 and
and 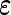 are the vectors of random effects (reflecting between-study variability) and random errors (reflecting within-study sampling variability), respectively. In the meta-analysis model of (3.1), we must incorporate the correlations between the outcomes, both within and between studies. We assume multivariate normal distributions for
are the vectors of random effects (reflecting between-study variability) and random errors (reflecting within-study sampling variability), respectively. In the meta-analysis model of (3.1), we must incorporate the correlations between the outcomes, both within and between studies. We assume multivariate normal distributions for 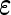 and
and 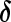 , so that and
, so that and 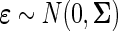 and
and 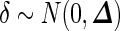 , with
, with 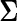 and
and 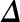 being the within- and between-study variance–covariance matrices. The variance–covariance matrix for the random effects takes a block-diagonal form:
being the within- and between-study variance–covariance matrices. The variance–covariance matrix for the random effects takes a block-diagonal form:
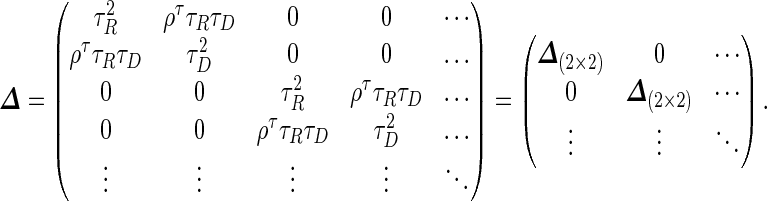 |
(3.2) |
The above 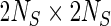 matrix involves the heterogeneity standard deviations for each outcome,
matrix involves the heterogeneity standard deviations for each outcome, 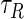 and
and 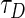 , and the between-studies correlation coefficient,
, and the between-studies correlation coefficient, 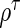 . Note that this between-studies variance–covariance matrix is block-diagonal with identical
. Note that this between-studies variance–covariance matrix is block-diagonal with identical 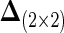 matrices in its diagonal. The parameters
matrices in its diagonal. The parameters 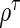 ,
, 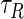 , and
, and 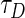 need to be estimated from the model. In a frequentist framework options include restricted maximum likelihood and methods of moments; here, we focus on a Bayesian framework estimated using Markov Chain Monte Carlo (described in Section 4). The random errors variance–covariance matrix is also block diagonal:
need to be estimated from the model. In a frequentist framework options include restricted maximum likelihood and methods of moments; here, we focus on a Bayesian framework estimated using Markov Chain Monte Carlo (described in Section 4). The random errors variance–covariance matrix is also block diagonal:
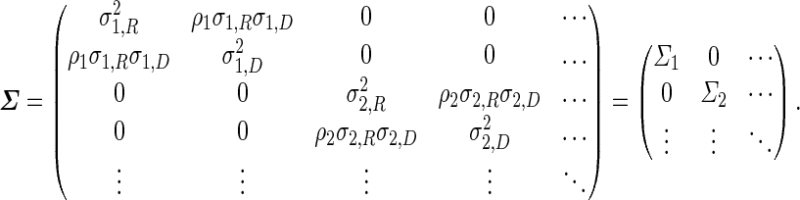 |
(3.3) |
In this matrix, 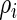 is the within-study correlation coefficient, and
is the within-study correlation coefficient, and 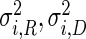 are the variances of the effect sizes in each study
are the variances of the effect sizes in each study 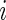 . All entries in
. All entries in 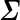 are estimated from the data. Sample estimates for
are estimated from the data. Sample estimates for 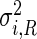 and
and 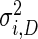 are often available, but few studies, if any, would provide enough information to estimate the within-study correlation coefficient
are often available, but few studies, if any, would provide enough information to estimate the within-study correlation coefficient 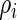 and the majority of meta-analyses do not have access to IPD that would enable its estimation. Within a Bayesian framework, we can give prior distributions to all the correlation coefficients entering (3.3) in order to perform a full multivariate meta-analysis. One can model these coefficients in a variety of ways, e.g. assume all
and the majority of meta-analyses do not have access to IPD that would enable its estimation. Within a Bayesian framework, we can give prior distributions to all the correlation coefficients entering (3.3) in order to perform a full multivariate meta-analysis. One can model these coefficients in a variety of ways, e.g. assume all 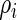 to be equal
to be equal 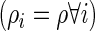 , assume a different coefficient depending on study characteristics, place a vague or informative prior on each
, assume a different coefficient depending on study characteristics, place a vague or informative prior on each 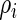 , etc.
, etc.
Following a different approach, Riley and others (2008) proposed an alternative model for bivariate random effects pairwise meta-analysis that allows for a single coefficient to model the overall correlation, an amalgam of the correlations within and between studies. Instead of modeling 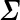 and
and 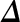 separately, they assume an overall variance–covariance matrix
separately, they assume an overall variance–covariance matrix 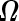 , so that
, so that 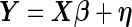 with
with 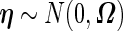 . This matrix
. This matrix 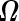 is again block diagonal with each block corresponding to a study, so that
is again block diagonal with each block corresponding to a study, so that 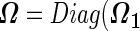 ,
, 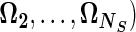 For a study
For a study 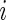 ,
,
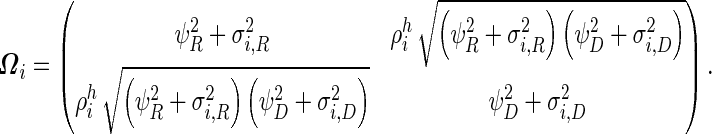 |
(3.4) |
The 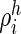 coefficient in (3.4) is the overall correlation in study
coefficient in (3.4) is the overall correlation in study 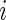 , a hybrid of the within- and between-study correlation coefficients. We can again model the different
, a hybrid of the within- and between-study correlation coefficients. We can again model the different 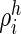 in a variety of ways, depending on the nature of the data, e.g.
in a variety of ways, depending on the nature of the data, e.g. 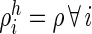 . The
. The 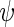 parameters model for the variation additional to the sampling error that enters due to heterogeneity, and they are similar to the
parameters model for the variation additional to the sampling error that enters due to heterogeneity, and they are similar to the 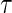 parameters of (3.2), but not directly equivalent unless the within-study variances are small relative to the between-study variances in model (3.2). The clear advantage of model (3.4) is that the within-study correlations are no longer needed.
parameters of (3.2), but not directly equivalent unless the within-study variances are small relative to the between-study variances in model (3.2). The clear advantage of model (3.4) is that the within-study correlations are no longer needed.
3.2. NMA for two correlated outcomes
The two models described in the previous section can be easily extended to perform a meta-analysis for a network of treatments, if all included studies have just two treatments arms. These models, however, cannot handle the case of studies comparing more than two treatments.
In this section, we present two models for performing an NMA of studies with multiple arms reporting on two correlated outcomes, generalizing the models presented in Section 3.1. The outcomes can be binary (and relative treatment effect can be measured as log odds ratios or log risk ratios), continuous (effects measured as mean differences or standardized mean differences) or time to event (effects measured as log hazard ratios). Note that in order to use the standardized mean difference for a continuous outcome a large sample approximation is required. For more details, see Section 3 of supplementary material available at Biostatistics online. In the acute mania example, the outcomes are identified as the binary response to the treatment (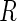 ) and dropout rate (
) and dropout rate ( ). We exemplify the methodology for the case of networks containing studies with a maximum of three arms. We assume a random effects model and that the consistency equations (
). We exemplify the methodology for the case of networks containing studies with a maximum of three arms. We assume a random effects model and that the consistency equations (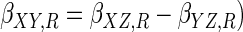 hold for all treatments
hold for all treatments  and
and 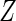 ; similarly for outcome
; similarly for outcome 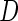 .
.
3.2.1. Model 1: Simplifying the variance–covariance matrices
The first method is based on simplifying the within- and between-study variance–covariance matrices so that the number of parameters needed is minimized, eases computational burden and potential estimation difficulties. Let us start by considering a network of studies reporting on the correlated outcomes 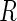 and
and 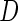 for a network of
for a network of 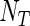 different treatments The model is
different treatments The model is 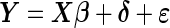 with
with 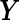 the vector of the observed effects,
the vector of the observed effects, 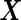 the design matrix,
the design matrix, 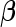 the vector of the basic parameters, i.e. the
the vector of the basic parameters, i.e. the 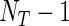 parameters for the comparison of each treatment versus the reference (Lu and Ades, 2004; Salanti and others, 2008),
parameters for the comparison of each treatment versus the reference (Lu and Ades, 2004; Salanti and others, 2008), 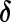 the vector of random effects, and
the vector of random effects, and 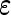 the vector of random errors (Dias and others, 2013; Salanti and others, 2008). The design matrix
the vector of random errors (Dias and others, 2013; Salanti and others, 2008). The design matrix 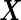 describes the structure of the network and embeds the consistency equations (Salanti and others, 2008); it maps the observed comparisons into the basic parameters. For example, if
describes the structure of the network and embeds the consistency equations (Salanti and others, 2008); it maps the observed comparisons into the basic parameters. For example, if 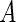 is chosen to be the reference treatment, a study comparing
is chosen to be the reference treatment, a study comparing 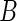 to
to 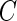 for outcome
for outcome 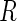 provides information for a linear combination of two basic parameters as
provides information for a linear combination of two basic parameters as 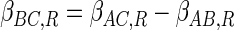 .
.
For a two-arm study 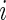 that compares treatments
that compares treatments 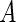 and
and 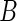 the random errors are assumed to follow a multivariate normal distribution,
the random errors are assumed to follow a multivariate normal distribution, 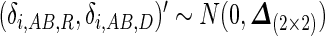 , with
, with 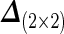 defined in (3.2). Note that this matrix is always positive definite for
defined in (3.2). Note that this matrix is always positive definite for 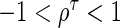 . In NMA, it is often assumed that the heterogeneity is independent of the comparison being made (Salanti and others, 2008); i.e
. In NMA, it is often assumed that the heterogeneity is independent of the comparison being made (Salanti and others, 2008); i.e 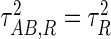 and
and 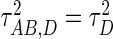 for every pair of treatments
for every pair of treatments  ,
,  , and we also assume this here. For a three-arm study
, and we also assume this here. For a three-arm study 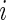 that compares treatments
that compares treatments 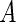 ,
, 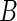 and
and 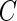 , the random effects are again assumed to follow a multivariate normal distribution
, the random effects are again assumed to follow a multivariate normal distribution 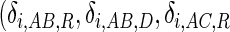 ,
, 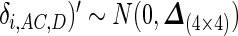 . Assuming equal heterogeneities between treatment comparisons and equal correlations between random effects of different comparisons and different outcomes, i.e. corr
. Assuming equal heterogeneities between treatment comparisons and equal correlations between random effects of different comparisons and different outcomes, i.e. corr 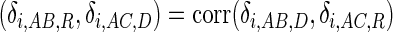 , we show in Section 2 of supplementary material available at Biostatistics online that the
, we show in Section 2 of supplementary material available at Biostatistics online that the 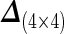 matrix takes the following form:
matrix takes the following form:
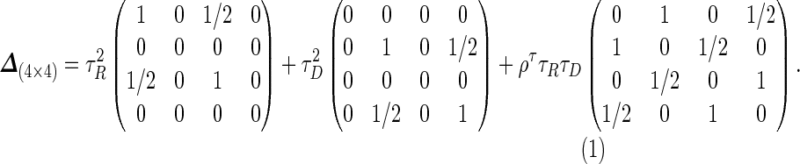 |
(3.5) |
When a considerable amount of data is available and the network is very dense (i.e. many studies connecting pairs of interventions) then the assumptions we used to reduce the number of model parameters might not be necessary, e.g. if there are at least three studies per comparison, then different heterogeneity variances can be used. However, real-life networks of interventions tend to be poorly connected and the median number of studies per comparison has been found to be low, equal to two studies (Nikolakopoulou and others, 2014). In Section 2 of supplementary material available at Biostatistics online, we present how 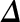 is modeled when correlations between different treatments and different outcomes are not equal. Note that the variance–covariance matrix as defined above is always positive definite. This matrix contains three parameters that need to be estimated: the heterogeneity variance
is modeled when correlations between different treatments and different outcomes are not equal. Note that the variance–covariance matrix as defined above is always positive definite. This matrix contains three parameters that need to be estimated: the heterogeneity variance 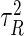 for outcome
for outcome 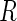 , the heterogeneity variance
, the heterogeneity variance 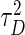 for outcome
for outcome 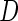 , and the between-studies correlation coefficient
, and the between-studies correlation coefficient 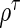 , the same three parameters as in (3.2), assumed the same for each treatment comparison.
, the same three parameters as in (3.2), assumed the same for each treatment comparison.
The random errors are also assumed to follow a multivariate normal distribution. For a three-arm study 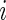 that compares treatments
that compares treatments 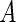 ,
, 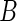 and
and 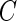 for response (
for response (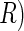 and dropout (
and dropout (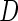 ), we assume
), we assume 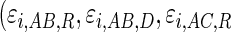 ,
, 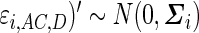 . The variance–covariance matrix
. The variance–covariance matrix 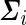 is:
is:
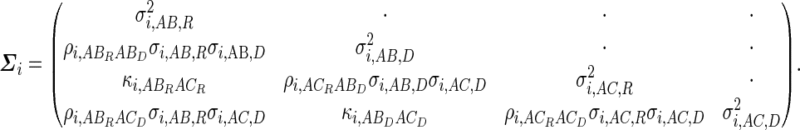 |
(3.6) |
The 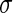 and
and 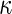 coefficients in
coefficients in 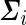 can be readily estimated if arm-level data are available. In the acute mania example, the variance of the
can be readily estimated if arm-level data are available. In the acute mania example, the variance of the 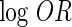 of the
of the 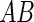 comparison for response (
comparison for response (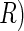 can be estimated as
can be estimated as 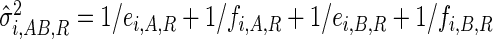 and also
and also 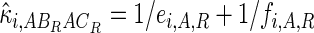 given the number of events (
given the number of events (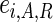 ,
, 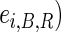 and failures (
and failures (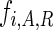 ,
, 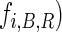 for each arm. In what follows, we present a method for dealing with the remaining correlation terms within
for each arm. In what follows, we present a method for dealing with the remaining correlation terms within 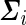 . We start by assuming that there are two different types of within-study correlation coefficient for every study
. We start by assuming that there are two different types of within-study correlation coefficient for every study 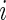 :
: 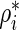 that correlates relative treatment effects of different outcomes for the same treatment comparison and enters the variance–covariance matrices for both two- and three-arm studies, and
that correlates relative treatment effects of different outcomes for the same treatment comparison and enters the variance–covariance matrices for both two- and three-arm studies, and 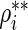 that correlates relative treatment effects for different comparisons and different outcomes within the same study and enters only the
that correlates relative treatment effects for different comparisons and different outcomes within the same study and enters only the 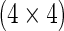 matrices of the three-arm studies. This means that:
matrices of the three-arm studies. This means that:
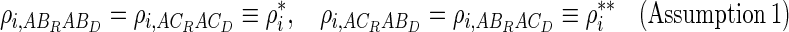 |
The within-study variance–covariance matrix for a two-arm study 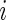 comparing treatments
comparing treatments 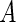 and
and 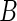 for two outcomes is:
for two outcomes is:
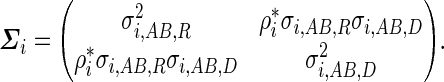 |
(3.7) |
For a three-arm study comparing treatments 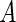 ,
, 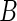 , and
, and 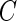 for two outcomes, the matrix of (3.6) becomes:
for two outcomes, the matrix of (3.6) becomes:
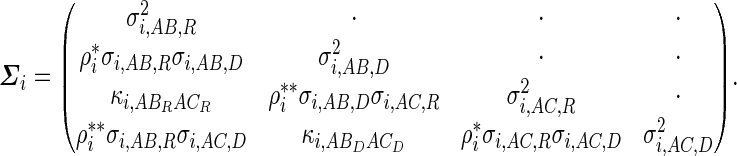 |
It is very often the case that study arms are balanced in numbers of patients randomized. Then, for treatments that are not very different in efficacy and dropout (e.g. drugs from the same class) we can assume that
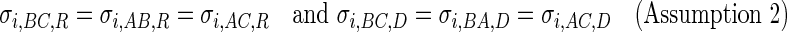 |
This assumption will not be reasonable if trials are imbalanced or compare very different treatments. Insight on the validity of this assumption can be obtained from the data after scanning for important differences among the estimated variances across studies. If we choose to employ this assumption, the model is considerably simplified as it implies that 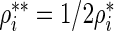 (see Section 3 of supplementary material available at Biostatistics online). Consequently, an estimate of the variance–covariance matrix for the three-arm study
(see Section 3 of supplementary material available at Biostatistics online). Consequently, an estimate of the variance–covariance matrix for the three-arm study 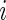 after Assumptions 1 and 2 is as follows:
after Assumptions 1 and 2 is as follows:
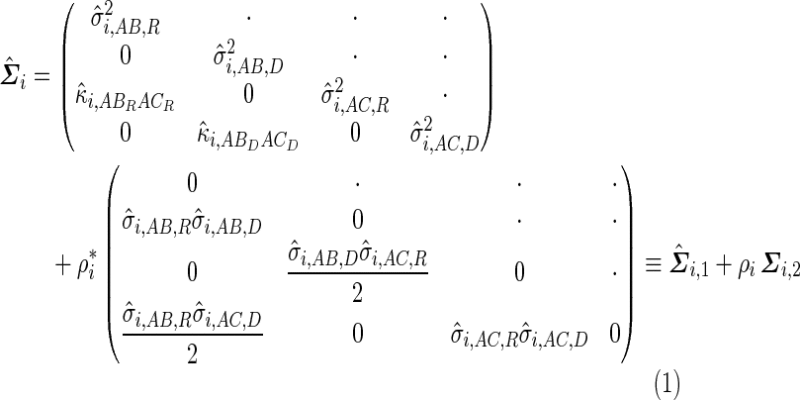 |
(3.8) |
In the last line, we have renamed 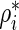 to
to 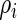 , in order to simplify notation and to highlight that the correlation coefficient is equivalent to the one presented in (3.3). It is important to note that Assumption 2 does not mean that we force all study variances to be equal: the diagonal elements of
, in order to simplify notation and to highlight that the correlation coefficient is equivalent to the one presented in (3.3). It is important to note that Assumption 2 does not mean that we force all study variances to be equal: the diagonal elements of 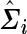 are distinct and are estimated from the studies. We employ this assumption only for the offdiagonal elements of the variance–covariance matrix so that all correlations are functions of a single parameter
are distinct and are estimated from the studies. We employ this assumption only for the offdiagonal elements of the variance–covariance matrix so that all correlations are functions of a single parameter 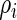 . Consequently, all elements of
. Consequently, all elements of 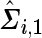 and
and 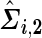 in (3.8) can be estimated when arm-level data are available. The assumption of equal variances within a multi-arm study can be omitted, if it is deemed inappropriate. In Section 3 of supplementary material available at Biostatistics online, we present the most general form of the variance–covariance matrix for different variances and compute general relations between the correlation coefficients it contains. This, however, results in a rather complicated structure for the
in (3.8) can be estimated when arm-level data are available. The assumption of equal variances within a multi-arm study can be omitted, if it is deemed inappropriate. In Section 3 of supplementary material available at Biostatistics online, we present the most general form of the variance–covariance matrix for different variances and compute general relations between the correlation coefficients it contains. This, however, results in a rather complicated structure for the 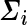 matrix and we will not consider it in this paper.
matrix and we will not consider it in this paper.
To summarize, we have expressed all within-study variance–covariance matrices utilizing a set of correlation coefficients 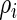 , one for every study
, one for every study 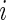 , that measure the correlation between the relative treatment effects of the two outcomes
, that measure the correlation between the relative treatment effects of the two outcomes 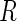 and
and 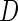 for the same treatment comparison. These coefficients might be available in study reports or can be deducted from empirical evidence and expert opinion (Efthimiou and others, 2014; Riley, 2009). If IPD are available then the correlation coefficient can be estimated (Bujkiewicz and others, 2013). A joint NMA of the two outcomes can be performed within a Bayesian framework after assigning prior distributions to the
for the same treatment comparison. These coefficients might be available in study reports or can be deducted from empirical evidence and expert opinion (Efthimiou and others, 2014; Riley, 2009). If IPD are available then the correlation coefficient can be estimated (Bujkiewicz and others, 2013). A joint NMA of the two outcomes can be performed within a Bayesian framework after assigning prior distributions to the 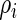 . These priors can be either uninformative or can be defined after consulting with clinicians (Wei and Higgins, 2013b). We have a number of options on how to model these coefficients. The simplest one is to assume
. These priors can be either uninformative or can be defined after consulting with clinicians (Wei and Higgins, 2013b). We have a number of options on how to model these coefficients. The simplest one is to assume  , common correlation for all studies. We could alternatively assume correlation coefficients across studies to share a common distribution. Another choice would be to have different
, common correlation for all studies. We could alternatively assume correlation coefficients across studies to share a common distribution. Another choice would be to have different 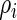 's for different group of studies. For example, we could assume a coefficient
's for different group of studies. For example, we could assume a coefficient 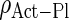 for placebo-controlled studies, and another
for placebo-controlled studies, and another 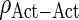 for head-to-head studies that compare only active treatments; this would be based on the assumption that the two relative effect measures are differently correlated when one of the treatments compared is the placebo.
for head-to-head studies that compare only active treatments; this would be based on the assumption that the two relative effect measures are differently correlated when one of the treatments compared is the placebo.
One technical implication that comes up is that the positive definiteness of the within-study variance–covariance matrix is not guaranteed for three-arm studies. The estimated matrix 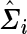 for the random errors in (3.8) is not always positive definite, as it depends on the data and on an arbitrary parameter
for the random errors in (3.8) is not always positive definite, as it depends on the data and on an arbitrary parameter 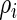 . One way to overcome this problem is to compute the four eigenvalues
. One way to overcome this problem is to compute the four eigenvalues 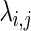 of
of 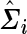 for every study
for every study 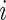 , with
, with 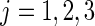 , and 4, and truncate them to zero, replacing
, and 4, and truncate them to zero, replacing 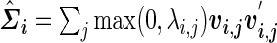 , with
, with 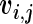 the corresponding eigenvectors as in Jackson and others (2010). This, however, might be difficult to implement, particularly if a Bayesian software is used. Here, we propose a different way of dealing with this problem: we can truncate the correlation coefficient for every study so that the positive definiteness of the variance–covariance matrix is ensured. If for example we assume a uniform
the corresponding eigenvectors as in Jackson and others (2010). This, however, might be difficult to implement, particularly if a Bayesian software is used. Here, we propose a different way of dealing with this problem: we can truncate the correlation coefficient for every study so that the positive definiteness of the variance–covariance matrix is ensured. If for example we assume a uniform 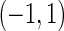 prior distribution for each
prior distribution for each 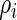 , we must truncate:
, we must truncate: 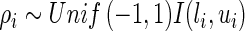 . The limits
. The limits 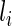 and
and 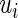 are the lowest and highest values of
are the lowest and highest values of 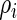 that lead to a positive-definite matrix. That means that we need to compute those values for all three-arm studies: it can be easily achieved by checking the corresponding eigenvalues of the variance–covariance matrix, as a positive-definite matrix has only positive eigenvalues. In Section 4 of supplementary material available at Biostatistics online, we provide a program in R software that computes the limits
that lead to a positive-definite matrix. That means that we need to compute those values for all three-arm studies: it can be easily achieved by checking the corresponding eigenvalues of the variance–covariance matrix, as a positive-definite matrix has only positive eigenvalues. In Section 4 of supplementary material available at Biostatistics online, we provide a program in R software that computes the limits 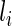 and
and 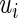 for every three-arm study. Wei and Higgins discuss other approaches to ensure positive-definite matrices including Cholesky paramaterization and spherical decomposition (Wei and Higgins, 2013a).
for every three-arm study. Wei and Higgins discuss other approaches to ensure positive-definite matrices including Cholesky paramaterization and spherical decomposition (Wei and Higgins, 2013a).
3.2.2. Model 2: Extending the alternative MOMA model
In this section, we discuss a second method for performing an MONMA, by extending Riley's and others alternative model (Riley and others, 2008). The model described in Section 3.1 is 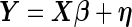 , with
, with 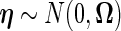 , where, as in the case of pairwise meta-analysis the matrix
, where, as in the case of pairwise meta-analysis the matrix 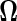 is block diagonal. For a two-arm study, the variance–covariance matrix is as given in (3.4). As we show in Section 5 of supplementary material available at Biostatistics online, if we are willing to employ Assumption 2 for a three-arm study
is block diagonal. For a two-arm study, the variance–covariance matrix is as given in (3.4). As we show in Section 5 of supplementary material available at Biostatistics online, if we are willing to employ Assumption 2 for a three-arm study 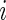 comparing treatments
comparing treatments 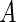 ,
, 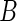 and
and 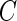 for two outcomes, then its variance–covariance matrix
for two outcomes, then its variance–covariance matrix 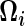 is given by:
is given by:
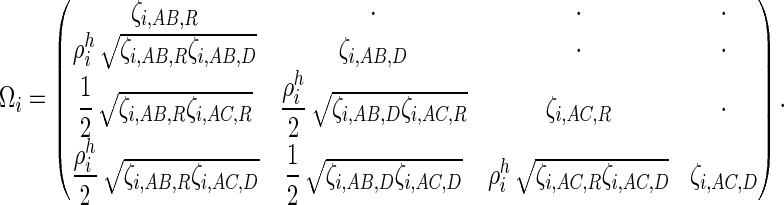 |
(3.9) |
Here we have defined 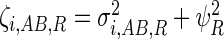 ,
, 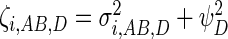 , etc. Equation (3.9) extends the model presented by Riley and others for three-arm studies with two outcomes. The
, etc. Equation (3.9) extends the model presented by Riley and others for three-arm studies with two outcomes. The 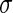 parameters can again be estimated from the data as the standard errors of the effect sizes, and assuming a common correlation coefficient across studies there are three parameters left to estimate:
parameters can again be estimated from the data as the standard errors of the effect sizes, and assuming a common correlation coefficient across studies there are three parameters left to estimate: 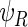 ,
, 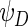 , and
, and 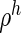 . One of the advantages of this approach is that the variance-covariance matrix is always positive-definite, so a multivariate meta-analysis can be readily performed without further complications. As described in the previous section, the equal variance assumption (Assumption 2) can be omitted if the studies are imbalanced or the treatments have significant differences in the measured effects, leading, however, to a much more complicated
. One of the advantages of this approach is that the variance-covariance matrix is always positive-definite, so a multivariate meta-analysis can be readily performed without further complications. As described in the previous section, the equal variance assumption (Assumption 2) can be omitted if the studies are imbalanced or the treatments have significant differences in the measured effects, leading, however, to a much more complicated 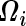 variance-covariance matrix.
variance-covariance matrix.
4. Application to acute mania dataset: NMA for response and dropout
4.1. Model fit and analysis plan
We fit both models in a Bayesian framework using the OpenBUGS software. Prior distributions must be assigned to all model parameters. The parameters 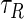 ,
, 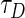 of the first model and
of the first model and 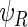 ,
, 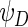 of the second can be assigned minimally informative prior distributions. If there is no prior information on the correlation of the outcomes, an uninformative
of the second can be assigned minimally informative prior distributions. If there is no prior information on the correlation of the outcomes, an uninformative 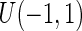 prior can be used on all correlation coefficients. If external information is available on these coefficients, e.g. elicited from experts in the field, it can be used to inform
prior can be used on all correlation coefficients. If external information is available on these coefficients, e.g. elicited from experts in the field, it can be used to inform 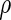 or
or 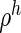 . In our example, the correlation between response and dropout rate is expected to be negative so we assigned appropriate negative priors to parameters
. In our example, the correlation between response and dropout rate is expected to be negative so we assigned appropriate negative priors to parameters 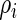 (the within-study correlations between outcomes, assumed equal across studies),
(the within-study correlations between outcomes, assumed equal across studies), 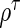 (the between-study correlation in outcomes), and
(the between-study correlation in outcomes), and 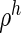 (the overall correlation). However, the robustness of conclusions to this assumption could be checked if desired. In order to rank the treatments with respect to the response and the dropout rate, we computed the surface under the cumulative ranking curve, SUCRA (Salanti and others, 2011), for each treatment and for each outcome. For treatment
(the overall correlation). However, the robustness of conclusions to this assumption could be checked if desired. In order to rank the treatments with respect to the response and the dropout rate, we computed the surface under the cumulative ranking curve, SUCRA (Salanti and others, 2011), for each treatment and for each outcome. For treatment 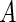 , outcome
, outcome 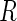 , SUCRA is defined as
, SUCRA is defined as 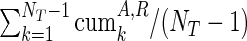 , with
, with 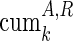 denoting the probability of
denoting the probability of 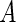 ranking among the best
ranking among the best 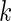 treatments for outcome
treatments for outcome 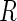 . SUCRA values lie between 0 (when the treatment is certain to be the worst for the outcome) and 1 (when the treatment is certain to be the best for the outcome). It is a transformation of the mean rank which takes uncertainty of estimation into account. All results pertain to 1 000 000 iterations and thinning of 100 after a 5000 burn-in period; the thinning was deemed necessary since a preliminary analysis showed a high auto-correlation in the chains. The code used is provided in Sections 6 and 7 of supplementary material available at Biostatistics online. We explored the following analysis scenarios:
. SUCRA values lie between 0 (when the treatment is certain to be the worst for the outcome) and 1 (when the treatment is certain to be the best for the outcome). It is a transformation of the mean rank which takes uncertainty of estimation into account. All results pertain to 1 000 000 iterations and thinning of 100 after a 5000 burn-in period; the thinning was deemed necessary since a preliminary analysis showed a high auto-correlation in the chains. The code used is provided in Sections 6 and 7 of supplementary material available at Biostatistics online. We explored the following analysis scenarios:
I Univariate (independent) NMA of response and dropout rate separately, assuming
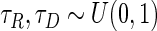 . This corresponds to setting all correlations equal to zero.
. This corresponds to setting all correlations equal to zero.II MONMA following the approach of Section 3.2.1 with minimally informative priors for the heterogeneity parameters:
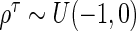 ,
, 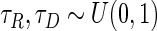 , and (a) assuming a negative common
, and (a) assuming a negative common  with
with 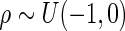 ; (b) assuming a strongly informative, negative, and common
; (b) assuming a strongly informative, negative, and common 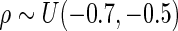 ; (c) assuming a common fixed
; (c) assuming a common fixed  with
with 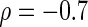 ; and (d) assuming two different within-studies correlation coefficients
; and (d) assuming two different within-studies correlation coefficients 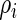 : one for the studies comparing two active treatments, which we denote as
: one for the studies comparing two active treatments, which we denote as 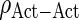 , and another for the studies comparing active treatments to placebo,
, and another for the studies comparing active treatments to placebo, 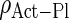 . This distinction could be based on the assumption that the two relative treatment effects are differently correlated when one of the treatments compared is the placebo. For both parameters, we used a uniform negative,
. This distinction could be based on the assumption that the two relative treatment effects are differently correlated when one of the treatments compared is the placebo. For both parameters, we used a uniform negative, 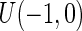 , prior distribution.
, prior distribution.- III MONMA following the approach in Section 3.2.2, assuming a common correlation coefficient and the following prior distributions for the parameters of the model:
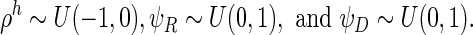
In order to evaluate our assumption of a negative correlation coefficient within and across studies we fitted MONMA model following the approach of Section 3.2.1 with  with
with 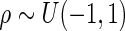 and
and 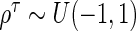 .
.
4.2. Results
The median posterior values for 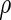 and
and 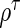 when non-informative
when non-informative 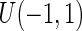 priors are used were
priors are used were  0.33 and
0.33 and  0.84 with 95% credible intervals [
0.84 with 95% credible intervals [ 0.66;0.14] and [
0.66;0.14] and [ 0.99;
0.99; 0.38], respectively. These values corroborate our prior belief of a negative association between dropout and efficacy. In Table 1, we present the mean posterior estimates and 95% credible intervals for the parameters in each model. An interesting observation is that the heterogeneity variances
0.38], respectively. These values corroborate our prior belief of a negative association between dropout and efficacy. In Table 1, we present the mean posterior estimates and 95% credible intervals for the parameters in each model. An interesting observation is that the heterogeneity variances 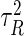 and
and 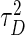 are invariant across the different models. This may be due to the large number of studies available in this meta-analysis. The mean estimates for the correlation coefficients are well below zero (e.g. the between-study correlation ranges from
are invariant across the different models. This may be due to the large number of studies available in this meta-analysis. The mean estimates for the correlation coefficients are well below zero (e.g. the between-study correlation ranges from  0.56 for scenario II.c up to
0.56 for scenario II.c up to  0.82 for scenario II.a). The posterior median value for the overall correlation
0.82 for scenario II.a). The posterior median value for the overall correlation 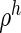 in model III is
in model III is  0.51 (95% credible intervals [
0.51 (95% credible intervals [ 0.68;
0.68; 0.29]), a value lying between the estimates of the two correlation coefficients for the multivariate model II.a (
0.29]), a value lying between the estimates of the two correlation coefficients for the multivariate model II.a ( 0.34 for
0.34 for 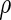 and
and  0.82 for
0.82 for 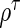 ). This is reasonable since
). This is reasonable since 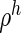 is an overall correlation coefficient that amalgamates the within- and between-studies correlations measured by
is an overall correlation coefficient that amalgamates the within- and between-studies correlations measured by 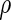 and
and 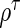 .
.
Table 1.
Median posterior estimates and 95% credible intervals for the heterogeneity variance and correlation parameters in MONMA models.
| Model | 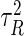 |
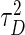 |
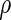 |
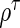 |
|---|---|---|---|---|
| I | 0.08 [0.02; 0.17] | 0.13 [0.06; 0.24] | — | — |
| II.a | 0.07 [0.02; 0.16] | 0.13 [0.06; 0.24] |
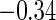 [ [ 0.66; 0.66;  0.04] 0.04] |
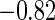 [ [ 0.99; 0.99;  0.38] 0.38] |
| II.b | 0.07 [0.02; 0.15] | 0.13 [0.06; 0.23] |
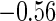 [ [ 0.68; 0.68;  0.50] 0.50] |
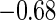 [ [ 0.93; 0.93;  0.23] 0.23] |
| II.c | 0.07 [0.02; 0.16] | 0.13 [0.06; 0.24] | — |
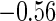 [ [ 0.83; 0.83;  0.12] 0.12] |
| II.d | 0.08 [0.02; 0.16] | 0.13 [0.06; 0.23] |
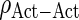 : :  0.31 [ 0.31 [ 0.71; 0.71;  0.02] 0.02] |
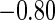 [ [ 0.99; 0.99;  0.33] 0.33] |
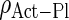 : :  0.39 [ 0.39 [ 0.77; 0.77;  0.04] 0.04] |
||||
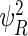 |
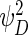 |
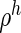 |
||
| III | 0.07 [0.02;0.16] | 0.12 [0.04;0.22] |
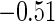 [ [ 0.68; 0.68;  0.29] 0.29] |
|
In Figure 1, we present the summary odds ratios for both outcomes for each treatment versus placebo and for models I, II.b, and III. In Section 8 of supplementary material available at Biostatistics online, we present the results from fitting each model in detail. The multivariate approach has a minimal effect on the summary results for the dropout outcome compared with the univariate. That is expected (Riley and others, 2007a) since this outcome was reported in all studies except one, and thus inferences do not gain much through the joint analysis in terms of the posterior estimates and precision for this outcome. In contrast, the posterior summary ORs for the response to treatment outcome have considerable gain in precision when we use a multivariate rather than univariate model. This gain arises because 28% of the studies did not report on response, and thus the multivariate models additionally borrow strength from the correlated dropout outcome in these studies (Riley and others, 2007a). The gain in precision is larger as within-study correlation coefficient moves away from zero; the decrease in the width of the confidence intervals of the ORs compared with the results from the univariate approach is on average 8.4% for analysis II.a, 12% for II.b, 12.1% for II.c, 8.2% for II.d, and 10.8% for model III. Note that apart from differences in precision gain there are small changes in the point estimates for most odds ratios among the MONMA models (see Section 8 of supplementary material available at Biostatistics online).
Fig. 1.

Summary odds ratios for response and dropout, for active treatment versus placebo. The thick lines correspond to model I (univariate model), the slim lines to model II.b (MONMA model assuming strong correlation coefficient 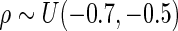 ) and the dashed lines to model III (alternative MONMA model assuming
) and the dashed lines to model III (alternative MONMA model assuming 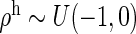 .
.
In Figure 2, we present the relative ranking of treatments for response and dropout, for models I, II.b and III, based on the SUCRA value for each outcome. Treatments near the upper right corner are the best when both acceptability and efficacy outcomes are considered jointly important; those near the bottom left corner (dark areas of the plots) are the worst. Note that Gabapentin is not present in the graph, since it was only reported for dropout. Regardless of the choice of model, OLA has the highest ranking across both outcomes jointly. However, the ranking of some other treatments is affected by the choice of multivariate rather than univariate, especially in regard the response outcome which (through correlation) is able to borrow strength from the more complete acceptability outcome. This use of additional information leads to (small) differences in the multivariate and univariate mean posterior estimates and precision of the summary ORs for response, and this has an impact on the relative ranking of the treatments for this outcome. For example, Carbamazepine ranks as the best treatment in terms of response with the univariate model but it falls to the fourth place when we consider a within-study correlation coefficient 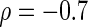 .
.
Fig. 2.
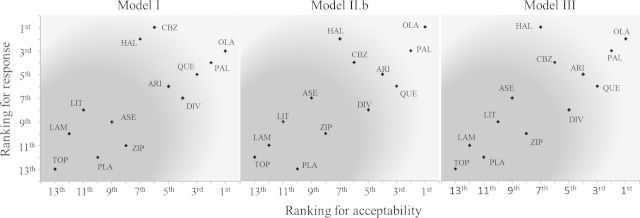
Ranking of antimanic drugs for response and acceptability. Treatments located in the darker (brighter) areas of the plots have the lowest (highest) rankings. ARI, aripiprazole; ASE, asenapine; CBZ, carbamazepine; VAL, divalproex; HAL, haloperidol; LAM, lamotrigine; LIT, lithium; OLZ, olanzapine; PBO, placebo; QTP, quetiapine; PAL, paliperidone; TOP, topiramate; ZIP, ziprasidone.
5. Discussion
We have developed two models for meta-analyzing evidence from multi-arm studies reporting multiple correlated outcomes in a network of interventions. Our models require minimum aggregated-level information, are independent of the mechanism that induces the correlations, and are applicable to any NMA with multiple continuous, dichotomous, or time-to-event outcomes; that is the majority of the NMA applications (Nikolakopoulou and others, 2014).
The set of models we present provides a unified way of handling multiple outcomes in the presence of multi-arm studies using only a handful of parameters. Choice between the two models may be informed by various factors. The first MONMA model accounts for within-study variances (sampling error), between-study variance (heterogeneity) as well as within and between-studies correlation. The second (alternative) model includes both within- and between-study variances, but uses a single correlation parameter 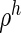 . Thus, the second model can be viewed as an approximation of the first MONMA model, with the latter having a more detailed likelihood structure. The second model can be used in the common situation when within-study covariances (the
. Thus, the second model can be viewed as an approximation of the first MONMA model, with the latter having a more detailed likelihood structure. The second model can be used in the common situation when within-study covariances (the 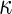 parameters in (3.6)) are not available from all studies or cannot be reliably obtained from external data or expert opinion. Ease of application is another consideration when choosing between the two models. The first model is more difficult to implement as it has a richer structure and investigators need to ensure the positive definiteness of the variance–covariance matrix.
parameters in (3.6)) are not available from all studies or cannot be reliably obtained from external data or expert opinion. Ease of application is another consideration when choosing between the two models. The first model is more difficult to implement as it has a richer structure and investigators need to ensure the positive definiteness of the variance–covariance matrix.
Although NMA is an increasingly popular technique, few attempts have been made so far to combine it with multiple outcomes models. Our models are more general than those currently available in the literature. Welton and others (2008) presented an MONMA model applicable to NMA with two-arm studies only. Hong and others (2013) presented methods for synthesizing multiple outcomes for multiple competing treatments, but their approach completely ignores within-study correlations and we do not recommend it. Madan and others (2014) presented an approach for modeling multiple outcomes reported over multiple follow-up times; their models are applicable only for repeated measurements for a binary outcome and requires arm-level data.
Our models perform better than the univariate one in terms of precision; this gain, however, does not come without a cost. The complexity of the multivariate analysis is an important limitation, and the difficulty in implementing the models rises as the number of outcomes of interest or the number of arms of the studies in the network grows. When only a small number of studies do not report on all outcomes, the gain in precision can be trivial, rendering the use of multivariate methods redundant. The models are also limited by the assumptions we used to simplify the structure of the variance–covariance matrices; in supplementary material available at Biostatistics online, we offer guidance for the case the analyst is unwilling to employ these assumptions. The gain in power by joint modeling of correlated outcomes is sometimes too small to justify the increased modeling complexity (Trikalinos and others, 2013). Multivariate meta-analysis might provide more powerful results when several studies provide only one of the outcomes and in the presence of selective outcome reporting (Copas and others, 2014; Kirkham and others, 2012). We recommend to consider both multivariate and univariate approaches, to ascertain if clinical conclusions about the ranking of treatments for each outcome remain consistent under different model assumptions.
Despite their limitations the two presented models are to our knowledge the first attempts for meta-analyzing data from networks of interventions comprising multi-arm studies that report on multiple correlated outcomes. Efthimiou and others (2014) have developed a framework that utilizes expert clinical opinion about quantities easily understood by clinicians (such as proportions) to impute unreported correlation parameters. Their method is applicable only for binary outcomes measured with odds ratios. In the present approach, we provide two general models for all types of outcomes assuming that the within-study correlations are known or directly informed by external evidence (model 1) or completely unknown (model 2). Finally since MONMA is a new, largely unexplored area, there are still many open areas for research. A possible extension would be to include IPD, either exclusively or in a combination with aggregated data. Furthermore, our models could be implemented in popular statistical software making MONMA more easily accessible to review authors.
Supplementary Material
Supplementary material is available at http://biostatistics.oxfordjournals.org
Funding
This work was supported by the European Research Council (IMMA 260559 to Orestis Efthimiou, Dimitris Mavridis, and Georgia Salanti) and the MRC Methodology Research Programme (MR/J013595/1 to Richard D. Riley).
Supplementary Material
Acknowledgements
Conflict of Interest: None declared.
References
- Bujkiewicz S. Multivariate meta-analysis of mixed outcomes: a Bayesian approach. Statistics in Medicine. 2013;32:3926–3943. doi: 10.1002/sim.5831. and others. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cipriani A. Comparative efficacy and acceptability of antimanic drugs in acute mania: a multiple-treatments meta-analysis. Lancet. 2011;378:1306–1315. doi: 10.1016/S0140-6736(11)60873-8. and others. [DOI] [PubMed] [Google Scholar]
- Copas J. A model-based correction for outcome reporting bias in meta-analysis. Biostatistics. 2014;15:370–383. doi: 10.1093/biostatistics/kxt046. and others. [DOI] [PubMed] [Google Scholar]
- Dias S. Evidence synthesis for decision making 2: a generalized linear modeling framework for pairwise and NMA of randomized controlled trials. Medical Decision Making. 2013;33:607–617. doi: 10.1177/0272989X12458724. and others. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Efthimiou O. An approach for modelling multiple correlated outcomes in a network of interventions using odds ratios. Statistics in Medicine. 2014;33:2275–2287. doi: 10.1002/sim.6117. and others. [DOI] [PubMed] [Google Scholar]
- Hong H. A Bayesian Missing Data Framework for Multiple Continuous Outcome Mixed Treatment Comparisons. Rockville, MD: Agency for Healthcare Research and Quality; 2013. and others. [PubMed] [Google Scholar]
- Jackson D., Riley R., White I. R. Multivariate meta-analysis: potential and promise. Statistics in Medicine. 2011;30:2481–2498. doi: 10.1002/sim.4172. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jackson D., White I. R., Riley R. D. A matrix-based method of moments for fitting the multivariate random effects model for meta-analysis and meta-regression. Biometrical Journal. 2013;55:231–245. doi: 10.1002/bimj.201200152. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jackson D., White I. R., Thompson S. G. Extending DerSimonian and Laird's methodology to perform multivariate random effects meta-analyses. Statistics in Medicine. 2010;29:1282–1297. doi: 10.1002/sim.3602. [DOI] [PubMed] [Google Scholar]
- Kirkham J. J., Riley R. D., Williamson P. R. A multivariate meta-analysis approach for reducing the impact of outcome reporting bias in systematic reviews. Statistics in Medicine. 2012;31:2179–2195. doi: 10.1002/sim.5356. [DOI] [PubMed] [Google Scholar]
- Lu G., Ades A. E. Combination of direct and indirect evidence in mixed treatment comparisons. Statistics in Medicine. 2004;23:3105–3124. doi: 10.1002/sim.1875. [DOI] [PubMed] [Google Scholar]
- Lu G., Ades A. E. Assessing evidence inconsistency in mixed treatment comparisons. Journal of the American Statistical Association. 2006;101:447–459. [Google Scholar]
- Madan J. Synthesis of evidence on heterogeneous interventions with multiple outcomes recorded over multiple follow-up times reported inconsistently: a smoking cessation case-study. Journal of the Royal Statistical Society A. 2014;177:295–314. and others. [Google Scholar]
- Mavridis D., Salanti G. A practical introduction to multivariate meta-analysis. Statistical Methods in Medical Research. 2013;22:133–158. doi: 10.1177/0962280211432219. [DOI] [PubMed] [Google Scholar]
- Nikolakopoulou A. Characteristics of networks of interventions: a description of a database of 186 published networks. PLoS ONE. 2014;9:86754. doi: 10.1371/journal.pone.0086754. and others. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Riley R. D. Multivariate meta-analysis: the effect of ignoring within-study correlation. Journal of the Royal Statistical Society A. 2009;172:789–811. [Google Scholar]
- Riley R. D. An evaluation of bivariate random-effects meta-analysis for the joint synthesis of two correlated outcomes. Statistical Medicine. 2007a;26:78–97. doi: 10.1002/sim.2524. and others. [DOI] [PubMed] [Google Scholar]
- Riley R. D. Bivariate random-effects meta-analysis and the estimation of between-study correlation. BMC Medical Research Methodology. 2007b;7:1–15. doi: 10.1186/1471-2288-7-3. and others. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Riley R. D., Thompson J. R., Abrams K. R. An alternative model for bivariate random-effects meta-analysis when the within-study correlations are unknown. Biostatistics. 2008;9:172–186. doi: 10.1093/biostatistics/kxm023. [DOI] [PubMed] [Google Scholar]
- Salanti G. Indirect and mixed-treatment comparison, network, or multiple-treatments meta-analysis: many names, many benefits, many concerns for the next generation evidence synthesis tool. Research Synthesis Methods. 2012;3:80–97. doi: 10.1002/jrsm.1037. [DOI] [PubMed] [Google Scholar]
- Salanti G., Ades A. E., Ioannidis J. P. Graphical methods and numerical summaries for presenting results from multiple-treatment meta-analysis: an overview and tutorial. Journal of Clinical Epidemiology. 2011;64:163–171. doi: 10.1016/j.jclinepi.2010.03.016. [DOI] [PubMed] [Google Scholar]
- Salanti G. Evaluation of networks of randomized trials. Statistical Methods in Medical Research. 2008;17:279–301. doi: 10.1177/0962280207080643. and others. [DOI] [PubMed] [Google Scholar]
- Spineli L. M. Evaluating the impact of imputations for missing participant outcome data in a network meta-analysis. Clinical Trials. 2013;10:378–388. doi: 10.1177/1740774512470317. and others. [DOI] [PubMed] [Google Scholar]
- Trikalinos T. A., Hoaglin D. C., Schmid C. H. Empirical and Simulation-Based Comparison of Univariate and Multivariate Meta-Analysis for Binary Outcomes. Rockville, MD: Agency for Healthcare Research and Quality; 2013. [PubMed] [Google Scholar]
- Wei Y., Higgins J. P. Bayesian multivariate meta-analysis with multiple outcomes. Statistical Medicine. 2013a;32:2911–2934. doi: 10.1002/sim.5745. [DOI] [PubMed] [Google Scholar]
- Wei Y., Higgins J. P. Estimating within-study covariances in multivariate meta-analysis with multiple outcomes. Statistical Medicine. 2013b;32:1191–1205. doi: 10.1002/sim.5679. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Welton N. J. Mixed treatment comparison with multiple outcomes reported inconsistently across trials: evaluation of antivirals for treatment of influenza A and B. Statistical Medicine. 2008;27:5620–5639. doi: 10.1002/sim.3377. and others. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.