

Abstract
We quantify the VDJ recombination and somatic hypermutation processes in human B cells using probabilistic inference methods on high-throughput DNA sequence repertoires of human B-cell receptor heavy chains. Our analysis captures the statistical properties of the naive repertoire, first after its initial generation via VDJ recombination and then after selection for functionality. We also infer statistical properties of the somatic hypermutation machinery (exclusive of subsequent effects of selection). Our main results are the following: the B-cell repertoire is substantially more diverse than T-cell repertoires, owing to longer junctional insertions; sequences that pass initial selection are distinguished by having a higher probability of being generated in a VDJ recombination event; somatic hypermutations have a non-uniform distribution along the V gene that is well explained by an independent site model for the sequence context around the hypermutation site.
Keywords: somatic hypermutations, VDJ recombination, statistical inference, immune repertoire, B cell, IgH
1. Background
Along with T cells, B cells contribute to the large diversity of immune cells that specifically recognize antigens. The diversity of the B-cell repertoire is encoded in the different amino acid composition of B-cell receptors (BCRs) expressed on the surface of these cells. These receptors are formed during the VDJ recombination process in the bone marrow. Before these cells leave for the periphery, they are initially selected for functionality. Later, they undergo further selection depending on their ability to recognize foreign antigen. Additionally, unlike T cells, BCR sequences are subject to point hypermutations during the proliferation that follows successful recognition of an antigen [1]. These hypermutations are selected for antigen binding through the process of affinity maturation. Apart from the possibility of hypermutations, the generation and selection processes are very similar in B and T cells, and involve common enzymes and pathways [2]. Recent advances in sequencing technologies [3,4] make it possible to obtain copious data on immune cell receptor sequences. We work with large samples of human BCR heavy chain DNA sequence1 and apply advanced statistical techniques to accurately quantify the processes that shape B-cell repertoire diversity—generation, selection and hypermutations. Some of these techniques were developed in [5,6] to describe T-cell repertoires. Here, we also introduce a new probabilistic model to describe hypermutations (specific to B cells), as well as new tools to automatically detect and assign new V, D and J alleles in individuals from their repertoire data, and to infer the distribution of these alleles among their two chromosomes.
Many characteristics of B-cell repertoires have previously been described using a variety of methods. Gene usage was studied by both immunoscope techniques [7,8] and single-cell PCR [9], and the variable length distributions of the complementarity-determining region 3 (CDR3) were reported [10,11]. A number of studies have characterized the effects of B-cell selection, reporting length reduction and selection against hydrophobicity as dominant features [12–18]. Considerable attention has also been given to quantifying hypermutations and disentangling them from site specific selection, either by comparing synonymous and non-synonymous mutations, or functional and non-functional rearrangements [19–26]. Other studies used lineage trees to describe this mutation–selection process [24,27]. Recently, high-throughput sequencing data combined with sophisticated inference techniques have been used to study selection in the affinity maturation process [19] and the statistics of synonymous hypermutation profiles [20].
Yet a comprehensive quantitative description of the entire generation, selection and hypermutation process of the heavy chain repertoire is still lacking. Here, we self-consistently model all parts of these interlinked processes. VDJ recombination is based on a combinatoric process in which V, D and J genes are chosen from a number of genomic templates and joined together, with additional base pair insertions and deletions at the VD and DJ junctions leading to further randomness in the final sequence [2]. In the case of antigen-experienced cells, receptor sequences further undergo random somatic hypermutations. A difficulty that arises in analysing receptor sequences is that a given sequence can be produced in many ways. This complication makes it impossible to unambiguously retrace the steps (V, D, J gene choices, deletions and insertions at the junctions, hypermutations) that have led to its generation. Our method circumvents this difficulty by employing a probabilistic framework that exploits large sequence datasets to accurately infer the statistical properties of the three processes that are central to the generation and evolution of BCRs—VDJ recombination, functional selection and hypermutations. This analysis allows us to quantify the theoretical diversity of these sequences. Our results suggest that, as in the case of T-cell receptors, the VDJ recombination process is biased towards sequences that are likely to pass functional selection. We also show that the diversity of the human B-cell repertoire is significantly reduced during the initial functional selection step. Our probabilistic framework also allows us to account for the statistics of hypermutations, which are well described by an additive DNA context-dependent binding model.
2. Analysis approach
We analysed Illumina reads of BCR DNA sequences from human blood samples taken from two individuals (labelled A and B) [16]. Cells from each sample were sorted into naive and memory subsamples. The variable region of the BCR gene was amplified using sequence specific PCR primers resulting in 130 bp DNA sequence reads anchored on a conserved sequence within the J gene (data from H. Robins, whom we thank for sharing it with us).
The VDJ recombination process is not guaranteed to produce in-frame sequences or, even when sequences are in frame, functional proteins. If the receptor gene from the initially rearranged chromosome is not functional, the second chromosome may be rearranged. If this second recombination event leads to a functional receptor, the cell has two rearranged chromosomes—one functional and expressed, and the other one silenced by allelic exclusion. As a result, the DNA sequence dataset we analysed contains a large fraction of non-productive sequences, which are either out-of-frame or contain a stop codon. These sequences experienced no selection and owe their survival to the receptor expressed by the other chromosome. For this reason, they provide us with the raw, unselected product of the generation process. We used such out-of-frame sequences from the naive subsample to infer the statistics of the VDJ recombination process, and the out-of-frame sequences from the memory subsample to learn the statistics of hypermutations. McCoy et al. [19] previously exploited these differences between in- and out-of-frame sequences in human BCR memory repertoire analysis. The naive productive sequences (in frame and with no stop codon) are expected to have passed a selection process before being admitted to the periphery (henceforth called initial selection, to distinguish it from selection following a recognition event). We used this subsample to learn the selective forces acting on amino acids by comparing how their statistics differ from the raw product of VDJ recombination learned from the naive out-of-frame sequences. Figure 1a summarizes the analysis workflow and emphasizes how the three main processes underlying sequence diversity—VDJ recombination, initial selection, hypermutations—are inferred using three subsamples of the sequences. A typical subsample used in our analysis had approximately 200 000 unique sequences.
Figure 1.
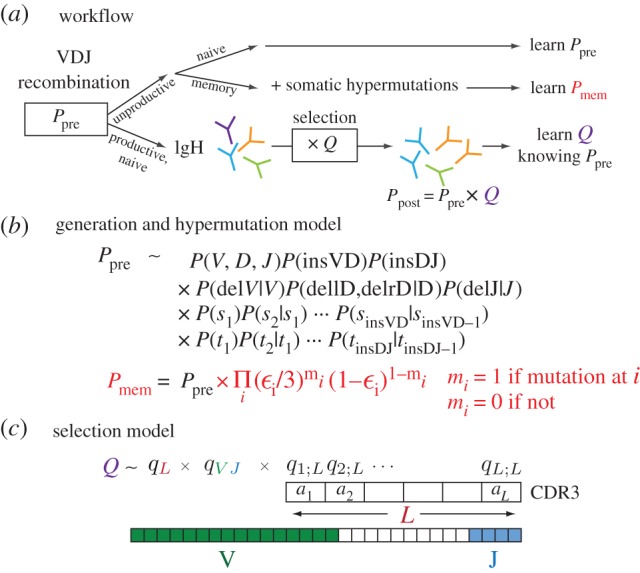
(a) BCR heavy chain sequences are formed during VDJ recombination according to a probability distribution Ppre that we infer from the unproductive naive sequence repertoire. The unproductive memory repertoire is used to infer the rate and sequence dependence of somatic hypermutation. Productive sequences are selected for entry into the naive peripheral repertoire with a sequence-dependent factor Q, resulting in the observed distribution of receptor sequences Ppost. (b) Recombined sequences arise via a scenario involving independent choices of which gene segments to recombine as well as of numbers of deletions and insertions. The probability distribution of these choices is not known unambiguously from the observed sequences and is estimated probabilistically in an iterative procedure. (c) The selection factor Q is assumed to be a product of factors for V and J gene choice together with factors qi;L(a) for the choice of the specific amino acid a at each position i in a CDR3 of length L. These factors are determined from the naive productive sequence repertoire by an iterative procedure.
As we stressed above, one sequence can be the result of a number of scenarios that include different initial gene choices, followed by variable numbers of deleted and inserted base pairs. This problem requires a probabilistic description of the generation process that sums over all the different possible scenarios for producing a given sequence, weighting each scenario by its probability. Each scenario's probability Ppre is calculated using a generation model of the form shown in figure 1b. In brief, the various factors account for the probabilities of uncorrelated events leading to a specific VDJ rearrangement: choice of which gene segments to recombine P(V, D, J), choice of number of nucleotides to insert in a VD or DJ joint P(insVD) and P(insDJ), probability of number of deletions from all four ends of the V, D and J genes at the junctions P(delV|V), P(dellD,delrD|D) and P(delJ|J), as well as factors to account for unequal nucleotide preference in the inserted sequences. Since the recombination machinery is the same for B and T cells, and this model structure captured all the correlations present in T-cell data [5], we expect that it should also capture all correlations present in the B-cell sequence data; we will see below that this is the case. In [5], we described an expectation–maximization method to self-consistently solve for the component probability distributions in Ppre by maximizing the likelihood of the set of observed sequences and we apply the same method here. This method is applied to the naive unproductive sequence repertoires that result from the raw generation process. The expectation–maximization algorithm converges after only a few steps (electronic supplementary material, figure S1). The results of the inference obtained from two disjoint sequence datasets (from the same individual) are almost identical (electronic supplementary material, figure S2), indicating that our results are robust to statistical noise. We validated a posteriori the factorized structure of the model distribution in figure 1b, by checking that correlations between its constitutive elements were consistent with the hypothesized model structure (electronic supplementary material, figure S3).
During proliferation, BCR sequences also acquire point hypermutations that occur with probability εi at position i on the sequence. We use the non-productive memory sequences to learn Pmem, which is the product of Ppre and the probability of a given combination of mutations (given in red in figure 1b). As in the case of non-productive naive sequences, we reasoned that these sequences were not selected at any point (either before or after hypermutations), and that their statistics should reflect the raw product of VDJ recombination followed by random mutations.
Using the (hypermutation-free) generation model as a starting point, we infer selection factors Q acting on each sequence in the naive repertoire, where Q is defined as the fold increase of the probability to see a particular sequence in the functional repertoire (naive, productive) compared with the previously learned generation probability: Q = Ppost/Ppre. To infer those factors, we use a factorized model (figure 1c), where we assume that selection acts independently on the V and J gene choice (through factor qVJ), the length L of the CDR3 sequence (through factor qL), and on each of the amino acids ai at positions 1 ≤ i ≤ L between the conserved cysteine near the end of the V gene and the conserved tryptophan within the J gene (through factors qi;L(ai)). We use an expectation–maximization procedure to update the selection factors until convergence, as previously described by Elhanati et al. [6]. The convergence of log likelihood as a function of iteration number is shown in electronic supplementary material, figure S4, and the reproducibility of the inferred factors across two disjoint datasets in electronic supplementary material, figure S5.
Our inference of recombination scenarios for individual reads requires accurate knowledge of the germline sequence of all the V, D and J genes. These genes have several alleles, and an accurate accounting of sequencing errors and somatic hypermutation events requires knowing which alleles are present on the two chromosomes of each individual. The existing databases do not provide such information, but list all alleles that have been detected, together with an estimate of the population frequency of these alleles [28]. To address this problem, we have developed a method for identifying allelic variation directly from the sequence data for each individual. Working with naive out-of-frame sequence reads (so that hypermutation is not an issue), we accumulate patterns of mismatches between reads and reference genome gene sequences that occur too often to be attributed to chance errors. This procedure usually identifies at most two significant alleles needed to account for a given individual's reads. While the majority of genes are homozygous, a significant number are not (we find that heterozygous V alleles account for 32% of all sequences in individual A). We are of course sensitive only to allelic variation in the region of a gene that can show up within the 130 bp sequence read (while the V gene is almost 300 bp in length). Thus, our ‘alleles’ may not capture the full extent of allelic variation, although they do capture all the information we need for our analysis. In summary, we infer specific alleles for each individual, and then use that individual's specific alleles when inferring generative models or selection models. This refinement of the genetic information yields a much improved accounting of sequencing errors and hypermutation events. A more detailed description of the method can be found in the electronic supplementary material, and a list of inferred heterozygous alleles is given in electronic supplementary material, tables SI and SII.
Given a generative model inferred using this allelic data, we are further able to make a probabilistic assignment of alleles to two chromosomes for each individual. The model includes a joint usage probability distribution P(V, D, J) of the three sets of genes/alleles (in effect treating alleles as separate genes). Since VDJ rearrangement happens on a single chromosome, the probability of recombining a heterozygous V allele with a heterozygous D allele on different chromosomes should be zero, up to assignment errors (figure 2). To reconstruct the two chromosomes, we consider all possible associations of a chromosome to each heterozygous allele. We then compute the likelihood of each chromosomal association as the sum of the joint probability P(V, D, J) over all V, D, J combinations that are associated with the same chromosome, and simply choose the chromosomal association that maximizes this likelihood (see the electronic supplementary material for details). In this way, we found a chromosomal organization for the two individuals that accounted for about 90% of all sequences. We can also evaluate the usage probability of the two chromosomes identified using this procedure. For both individuals, it was consistent with equal usage probability between the two chromosomes, within errors.
Figure 2.
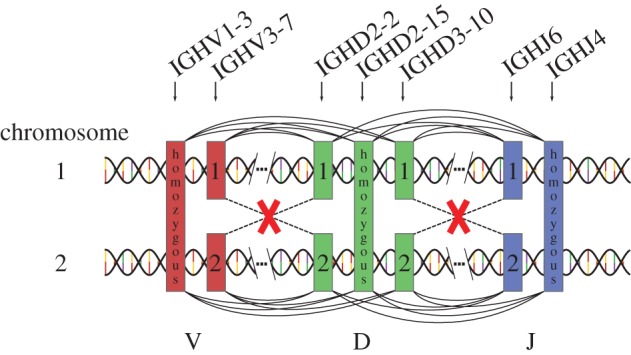
The organization of heterozygous genes into chromosomes can be probabilistically determined. Every recombination event ties together a V, a D, and a J gene, as indicated by the arcs drawn above and below the two chromosomes. Links that recombine alleles on different chromosomes are forbidden (red crosses). Our method gives the probability P(V, D, J) of all possible linkages between three genes (distinguishing between alleles of the same gene), but does not address how the various alleles are grouped on chromosomes. We find the best chromosomal segregation by minimizing the sum of all terms in P(V, D, J) that contain forbidden links (red crosses).
3. Results
(a). Distribution of recombination events
The raw distribution of recombination events Ppre before any selection takes place was inferred from the naive, non-productive sequence dataset, as explained above (figure 1). This inference procedure yielded the VDJ gene usage distribution, as well as the distributions of insertions and deletions, and the frequency of inserted nucleotides. It is notable that V and D gene usage (electronic supplementary material, figures S6–S7) is strongly non-uniform (to simplify displays of gene-specific information here and elsewhere, we agglomerate alleles into their associated genes).
Figure 3 shows the distributions of the number of inserted nucleotides between the V and D genes (figure 3a), or D and J genes (figure 3b), averaged over both individuals. The figure shows both the distributions after generation, i.e. before any selection, as inferred from the non-productive sequences and, for comparison, the same distributions for the productive sequences in the naive repertoire, i.e. after the initial selection process. They have similar forms—wide distributions with exponential tails. The effect of selection is to favour sequences with fewer insertions, thus reducing CDR3 length.
Figure 3.

Distributions of insertions and deletions for the pre- and post-selection repertoires. (a,b) The distribution of numbers of nucleotide insertions in the DJ and VD joints. These distributions are independent of the identities of the genes on either side of the junction, and the VD and DJ insertions are very similar. The selection process that acts on going from the primitively generated to the naive repertoire causes the mean number of insertions to decrease significantly. (c,d) The distribution of deletions from the V and J genes (negative deletions account for palindromic insertions). Deletions are gene-dependent and the plots show the deletion profile averaged over all genes (gene-dependent profiles are shown in electronic supplementary material, figure S8). Selection has little effect on deletion profiles.
The identities of the nucleotides inserted during the generation process are well described by a dinucleotide Markov model (electronic supplementary material, figures S9–S11). As was observed for T-cell receptors [5], the profile for the VD insertions on the sense strand correlates very well with the JD insertions on the antisense strand.
Although the deletion profiles are in fact gene dependent, and we infer a separate deletion profile for each gene (electronic supplementary material, figure S8), for convenience we present here only the weighted mean over all genes of the V and J gene deletion distributions (figure 3c,d). These distributions seem little affected by selection, as evidenced by the similarity between the pre- and post-selection (naive) distributions.
(b). Selection
Armed with the raw recombination model Ppre, we can estimate the effect of selection in the naive repertoire by comparing the statistics of the naive, productive sequences, with those predicted by the generation model. The effect of selection is already evident from the CDR3 length distribution [16], as illustrated in figure 4. The pre-selection sequences are longer and have a wider length distribution than the selected ones. This effect of selection on length is in agreement with previous studies [12,16], and in close parallel with recent observations on T-cell receptors [6].
Figure 4.
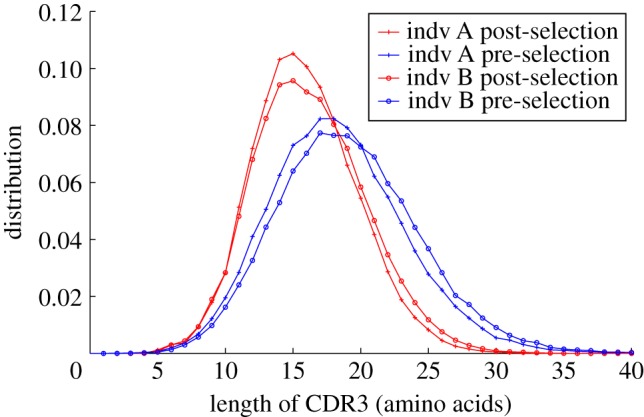
Length distributions (in amino acids) of the CDR3 for different repertoires. The post-selection distributions are derived from the productive sequences in the naive repertoires. The pre-selection distribution is derived from a synthetic repertoire of productive sequences drawn from the generative model Ppre that has been inferred from naive unproductive data sequences. Notable features include the progressive shortening and narrowing of the distribution as selective pressure is applied, and the close similarity, but not identity, between the two individuals.
Selection acting on the rearranged sequences is quantified by position-dependent selection factors qi;L(a) that capture the positive or negative effect that each amino acid at each position has on the functionality of the entire sequence, and in addition by gene-dependent selection factors qVJ (figure 1b). We show the amino acid selection factors averaged over both individuals in figure 5 and show the gene-dependent selection factors in electronic supplementary material, figure S12. The qi;L factors are reasonably consistent between the two individuals (figure 6a), even though their sequence repertoires show slightly different CDR3 length distributions (figure 4). Residue selection patterns show a dependence on the position and length of the CDR3—some patterns are related to either the V or J side of the junction, while other effects are localized in the bulk. This is related to the conserved motifs just outside of the CDR3, which function as anchors for the variable area. Thus, the role of an amino acid is different whether it is close to the V gene conserved motif, the J conserved motif, or far from both.
Figure 5.
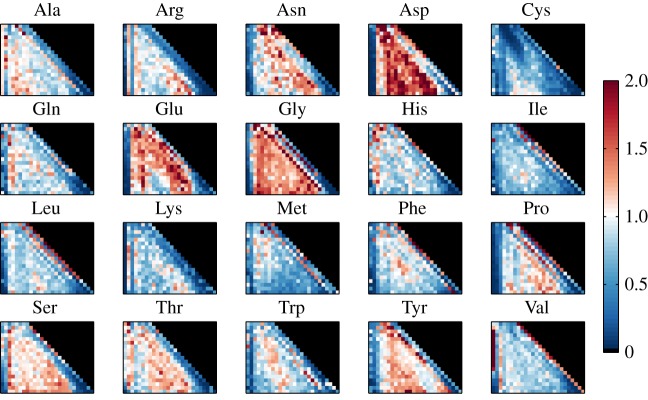
Heat plot of the inferred amino acid selection factors qi;L for each amino acid, ordered by length L of the CDR3 region (ordinate) and position i within that region (abscissa). The CDR3 region is bounded on the left by a Cys residue and by a Trp residue on the right. There is a clear pattern of amino acid preference (or anti-preference) within a few positions of these boundaries, independent of overall CDR3 length L.
Figure 6.

(a) Scatter plot of the logarithms of the amino acid selection factors qi;L(a) between individuals A and B. The selection factors for the two individuals are strongly, if not perfectly, correlated. This justifies a joint analysis of the properties of those factors, as done in the following panels (b–l), showing correlation of the selection factors with several biochemical properties. Each panel shows the histogram, over all positions and lengths of both individuals, of Spearman's correlation coefficient between the selection factors for a given amino acid and the biochemical properties of that amino acid. The following biochemical properties are considered (from left to right, top to bottom): preference to appear in α-helices (b), β-sheets (c), turns (d) (source for (b–d): electronic supplementary material, table 3.3 [29]). Residues that are exposed to solvent in protein–protein complexes (following definitions and data from [30]) are divided into three groups: surface (interface) residues that have unchanged accessibility area when the interaction partner is present (e), rim (interface) residues that have changed accessibility area, but no atoms with zero accessibility in the complex (f) and core (interface) residues that have changed accessibility area and at least one atom with zero accessibility in the complex (g). Finally, we plot the basic biochemical amino acid properties (http://en.wikipedia.org/wiki/Amino_acid; http://en.wikipedia.org/wiki/Proteinogenic_amino_acid): charge (h), pH (i), polarity (j), hydrophobicity (k) and volume (l). For all properties, the actual numerical values used to calculate the correlations are listed in the inset tables.
We also looked at correlation between our selection factors and various biochemical properties of the amino acids. We used quantified numeric properties for every amino acid, such as hydrophobicity or polarity, to look at the Spearman's correlation between these properties and selection factors of the 20 amino acids, for a specific position and CDR3 length. This can be done for every position and length, yielding many correlation coefficients. Figure 6b–l shows the distributions of those correlation coefficients. Selection is not determined by a single property of the amino acid. However, some properties do correlate with selection, namely the tendency of an amino acid to participate in a turn of the protein (figure 6d) and its tendency to be found in the core of the interaction complex (figure 6g). A few other properties, namely amino acid volume (figure 6l), charge (figure 6h), pH (figure 6i) or hydrophobicity (figure 6k) all have a negative influence on the overall amino acid selection probability. This last negative correlation is consistent with the observation that hydrophobic D segments are selected against after rearrangement [16]. Most of these results are similar to what was observed in the case of T cells [6].
(c). Correlation between generation and selection
What kind of sequences are likely to pass initial selection? Each sequence, no matter in what repertoire we observe it, can be assigned a probability of being generated in the initial VDJ recombination event. Figure 7a shows the distribution of this quantity for sequences in the pre- and post-selection repertoires. Remarkably, we note that most sequences have a very low generation probability (typically less than 10−10). The similarity of the naive productive (green) and post-selection model prediction (red) curve is a validation of the model, while the difference from the pre-selection (blue) curve highlights the effect of selection. Sequences that had higher probability to be generated are also more likely to be selected, resulting in a shift towards higher generation probabilities after selection. This correlation between generation probability and selection is made more evident by figure 7b, which shows a two-dimensional density plot of the generation probability and the overall selection factor Ppre versus Q, evaluated over a large set of generated sequences. There is a clear correlation between generation and selection—higher values of generation probability imply also higher values of selection and vice versa. To put it differently, the generation process anticipates the subsequent somatic selection process.
Figure 7.
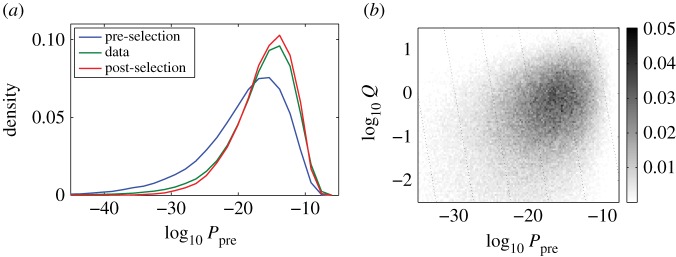
(a) The distribution of generation probabilities (as inferred from the pre-selection model Ppre) for the pre-selection model itself (blue), the post-selection model Ppost (red) and the naive functional sequence repertoire itself (green). The key feature is that sequences in the selected repertoire have systematically higher generation probability. Panel (b) makes the same point via a scatter plot of the primitive generation probability versus the selection factor Q for a synthetic repertoire of sequences generated according to Ppre.
(d). Repertoire entropy
The diversity of the immune repertoire is one of its key characteristics. The rearrangement and selection models enable us to precisely quantify this diversity and identify its sources. Repertoire diversity is an inherently dynamic property. Upon random rearrangement, the initial diversity is established, but initial selection will modify it. Those changes can be demonstrated by looking at the entropy of the different distributions, calculated from the models we infer. Entropy gives a measure of the number of different sequences we can expect to find at different stages of B-cell development (figure 8). The generation entropy can be broken down into contributions from the different events that make up the recombination scenario. Most of the diversity comes from insertions. Note that the entropy of rearranged sequences is smaller than the entropy of recombination events. This is due to convergent recombination—the fact that a given sequence can be produced by different recombination scenarios. Individual B has larger generation entropy than individual A, primarily because it has more insertions. The entropy of productive sequences is further reduced (by two bits) by keeping only the in-frame sequences. Subsequent action of selection reduces the diversity of the repertoire by about 10 bits. This reduction is true for both individuals, regardless of their different generation entropy, and follows from the correlation between Ppre and Q (figure 7b), which concentrates the distribution towards the most probable rearrangements, thus reducing diversity in the selected repertoire.
Figure 8.

Total sequence entropy partitioned into its various elementary contributions for the two individuals. The bottom three horizontal bars in each stack display the partitioning of the entropy of the probability distribution of recombination scenarios. Because multiple scenarios can generate the same sequence, the nucleotide sequence entropy of the sequences directly produced by recombination is smaller than the recombination scenario entropy. Out of those, productivity of the sequence further restricts the diversity by constraining frame and forbidding stop codons appearing, as depicted in the smaller bar above. Finally, as seen in the topmost bar, the initial selection process itself significantly reduces the diversity of those productive sequences. It is worth noticing that while the initial diversity of both individuals is different, consistent with their different CDR3 length distributions, the reduction effect of the selection is quite similar, keeping the same difference in entropy.
The numbers that can be associated with these entropies are extremely large: 271 ∼ 2 × 1020 for the productive sequences and 260 = 1018 for the naive repertoire—much larger than the number of B cells in the body. These numbers are not estimates of the total number of possible sequences—this is set by the maximum number of insertions and is much larger—but rather the equivalent number of outcomes in a uniform probability distribution.
(e). Hypermutations
Upon recognition of an antigen, BCRs undergo an affinity maturation process, by which their binding strength to the antigen is increased through the combination of random somatic hypermutations and selection. Thus, receptor sequences from antigen-experienced cells, such as memory cells, are expected to show the effect of somatic hypermutations, and we can use these sequences from our dataset to learn their statistics.
Hypermutations appear in our sequence reads as mismatches with the genomic sequence. However, because the survival of a sequence in the memory repertoire depends on its affinity for a particular antigen, the statistics of its hypermutations should reflect factors other than just the hypermutation process itself. To overcome this issue, we make the assumption (as in [19]) that when the hypermutation machinery is activated in a cell, it acts on both chromosomes indifferently. This assumption is backed by the comparable number of mismatches seen in the out-of-frame and in-frame memory data (the number of mismatches found in the naive out-of-frame data is smaller by two orders of magnitude). If this assumption is true, out-of-frame sequences will also display the effects of somatic hypermutations, with statistical properties unaffected by any further selection effect. For this reason, we restrict to out-of-frame memory sequences to infer the statistical properties of the somatic hypermutation process.
First, we used the out-of-frame memory sequence reads to infer a model of rearrangement with random hypermutations in the germ line part of the sequence (figure 1b). Such a model allows us to assign a set of likelihood-weighted recombination and hypermutation scenarios to any specific sequence. We thus identified and probabilistically weighted somatic hypermutation events and recorded them, together with their sequence context within a seven-nucleotide window centred on the mutation. We restricted our analysis to V gene-derived segments: D and J gene-derived sequences are much shorter and may not have provided enough statistics for our analysis. We then use statistics of the sequence context of hypermutations to construct a simple additive scoring model for the probability of mutation at any position within a V gene context. Specifically, the probability of observing a somatic hypermutation was assumed to be of the form pSHM(σ) ∝ pbg(σ) exp[∑i=−3,3 ei(σi)], where σ = (σ−3, σ−2, …, σ+3) is the nucleotide sequence in a seven-nucleotide window around the mutated nucleotide σ0; pbg(σ) is the background probability of the heptamer σ occurring in the genomic V gene sequences; and the ei(σi) are contributions of each position to the motif, which play the same role as binding energies [31]. The values of ei are adjusted so as to maximize the likelihood of the data under the model. The ei factors so inferred are displayed in figure 9a. Since they are defined up to a constant, we impose ∑σ ei(σ) = 0 at each position i relative to the mutation site. A positive value of ei(σ) means that nucleotide σ is enriched at position i relative to a mutation site.
Figure 9.

Sequence dependence of somatic hypermutations. (a) The model mutation probability depends on the central base (position 0) and on the sequence context, three base pairs on each side. The log relative probability of a mutation is the sum of contributions (positive and negative) read off from the sequence motif according to the sequence at each of the seven positions. (b) Comparison of the predictions of this model with the observed hypermutation rate at different positions within the V gene. Mutation ‘hotspots’ are well predicted, and the scatter plot (inset) between data and prediction shows strong correlation. The location of the Cys anchor of the CDR3 is indicated, and we note that the hypermutation rate (in data and model) is low within this special codon. (c) Substitution probabilities to the different bases as stacked columns versus the local trimer context, grouped by the central base. Substitution is not uniform, depending primarily on the base being mutated, but varying with the context.
By running pSHM(σ) over the genomic V gene sequences, we get a predicted probability of observing a somatic hypermutation at different positions within the V gene. The prediction of this model averaged over all gene profiles (aligned with respect to the conserved Cys), and its comparison with observed hypermutations is displayed in figure 9b (the profiles for individual genes were found to be similar to the average profile). The scatter plot of model predictions versus data (correlation = 0.8) shows that the model gives a good account of the data, and the plot of their position dependence shows that the model accounts well for the presence of hypermutation hotspots. Note that the hypermutation rate displayed in figure 9b is very large: 5–10% per position. For comparison, the rate of mismatches in the naive out-of-frame sequences (attributable to sequencing errors or a leak of memory cells into the naive set) was approximately 0.1%. Finally, we also looked at the dependence of the substituted nucleotides on the immediate context of the mutation. Figure 9c represents the probabilities of substituted nucleotides as a function of the trimer context. We note a clear dependence on the identity of the mutated base, with additional context-dependent variability from the local trimer sequence.
4. Discussion
Our statistical algorithms allowed us to characterize in detail the generation, initial selection and hypermutation processes that lead to the observed BCR repertoires. Two key ingredients underlie our approach. First, we exploited out-of-frame sequences, assumed to be free of selective pressure, to reconstruct the statistics of the DNA editing processes: VDJ recombination and hypermutations. Out-of-frame sequences have similarly been used as a baseline to study the properties of BCR naive repertoires [16], or to estimate selective pressures related to affinity maturation in memory B cells [19]. Second, our approach overcomes the degeneracy of the recombination problem (whereby the same sequence may be generated by many different recombination events) by using a fully probabilistic approach.
The generation of BCR and T-cell receptor results from similar processes, involving common enzymes and pathways. Thus, perhaps not surprisingly, many of the results we obtain here are similar to what was reported for T-cell receptors using similar methods [6]: statistical independence between the insertion and deletion processes, as well as between gene choice and insertions; the identity of inserted nucleotides following a Markovian probability law. Another similarity with T-cell receptors is that the generation process anticipates the action of selection: sequences that are more likely to be produced are more likely to be retained by selection. This suggests evolutionary adaptation of the generation machinery.
We also noted some differences with T-cell receptors. Because BCRs have more insertions than TCRs, we find that B-cell repertoires are much more diverse than T-cell repertoires, as measured by entropy, even before hypermutations occur. In addition, the selection factors acting on the CDR3 amino acid sequence of BCRs are quite different from those reported for T-cell receptors, consistent with the fact that their cognate epitopes are very different in nature.
Although there is a difference in diversity between our two individuals, this difference is restricted to the generation process and is caused by a slight excess of insertions in individual B. Selection factors on the other hand seem to be well-conserved across individuals, pointing to general biophysical and biochemical properties that are subject to selection. The selection factors correlate with some biochemical properties, including a negative correlation with hydrophobicity (in agreement with a previous report that hydrophobic D segments are selected against [16] after rearrangement).
This study also provides a couple of methodological advances. Thanks to our stochastic framework, we were able to identify heterozygous genes as well as their alleles, even when these were not present in existing databases. We could then reconstruct the partition of these alleles into two chromosomes. We found no significant bias in chromosome usage.
Perhaps the most important difference between BCR and T-cell receptors is the existence of hypermutations accumulated during affinity maturation. Hypermutations are expected to add an enormous amount of sequence diversity. With a hypermutation rate estimated to be of the order of 5–10%, hypermutations are expected to contribute an additional ≈0.4 bit per nucleotide—a huge number if we consider that hypermutations can happen over a region a few hundred nucleotides in length. A common difficulty in studying hypermutations is to disentangle the biases that are inherent to the hypermutation process from the biases that result from affinity-driven selection [32]. While previous efforts have been devoted to the inference of selective pressures in the B-cell memory repertoire [19], here we focused our attention on the raw substitution process. We used out-of-frame memory sequences to learn about the statistics of substitutions unperturbed by the effect of selection, as was suggested in [26]. For this purpose, we adapted our probabilistic framework to infer the hypermutation profile across all genes. The hypermutation rate was found to be very variable along the V-gene sequence but similar across genes. We showed that a simple additive model could correctly predict the hypermutation rate from the immediate sequence context (heptamer) around the mutation site. These results confirm earlier reports that hypermutations are context-dependent both in localization and substitutions [23,26,33,34], as well as recent observations from high-throughput sequencing data restricted to synonymous mutations [20]. Our additive model is consistent with an independent site binding energy model for the hypermutation-inducing enzyme activation-induced cytidine deaminase (AID), where each flanking nucleotide contributes independently to its binding energy, as in the case of transcription factor binding sites [31].
The hypermutation rates and substitution matrices inferred by our model could serve as a baseline or a control for future efforts to infer selective pressures from functional sequences, and could be useful in the inference of mutational phylogenic trees in the study of affinity maturation.
Supplementary Material
Acknowledgements
We thank Harlan Robins for the BCR data without which this work would not be possible. We also thank Mr Shai Chester for assistance in developing our allele-finding algorithms.
Endnote
Data from Harlan Robins group, available at http://adaptivebiotech.com/papers/callan2015.
Authors' contributions
Y.E., Z.S., Q.M., C.G.C., T.M. and A.M.W. designed and performed the research, wrote the paper and approved the final version.
Competing interests
We declare we have no competing interests.
Funding
The work of Y.E., Q.M., T.M. and A.M.W. was supported in part by grant ERCStG no. 306312. The work of Z.S. and C.G.C. was supported in part by NSF grant nos. PHY-0957573 and PHY-1305525.
References
- 1.Teng G, Papavasiliou FN. 2007. Immunoglobulin somatic hypermutation. Annu. Rev. Genet. 41, 107–120. ( 10.1146/annurev.genet.41.110306.130340) [DOI] [PubMed] [Google Scholar]
- 2.Janeway C, Murphy KP, Travers P, Walport M. 2008. Janeway‘s immunobiology. New York, NY: Garland Science. [Google Scholar]
- 3.Six A, et al. 2013. The past, present and future of immune repertoire biology—the rise of next-generation repertoire analysis. Front. Immunol. 4, 413 ( 10.3389/fimmu.2013.00413) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Robins H. 2013. Immunosequencing: applications of immune repertoire deep sequencing. Curr. Opin. Immunol. 25, 646–652. ( 10.1016/j.coi.2013.09.017) [DOI] [PubMed] [Google Scholar]
- 5.Murugan A, Mora T, Walczak AM, Callan CG. 2012. Statistical inference of the generation probability of T-cell receptors from sequence repertoires. Proc. Natl Acad. Sci. USA 109, 16 161–16 166. ( 10.1073/pnas.1212755109) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Elhanati Y, Murugan A, Callan CG, Mora T, Walczak AM. 2014. Quantifying selection in immune receptor repertoires. Proc. Natl Acad. Sci. USA 111, 9875–9880. ( 10.1073/pnas.1409572111) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Lim A, Lemercier B, Wertz X, Pottier SL, Huetz F, Kourilsky P. 2008. Many human peripheral VH5-expressing IgM+ B cells display a unique heavy-chain rearrangement. Int. Immunol. 20, 105–116. ( 10.1093/intimm/dxm125) [DOI] [PubMed] [Google Scholar]
- 8.Foreman AL, et al. 2008. VH gene usage and CDR3 analysis of B cell receptor in the peripheral blood of patients with PBC. Autoimmunity 41, 80–86. ( 10.1080/08916930701619656) [DOI] [PubMed] [Google Scholar]
- 9.Brezinschek HP, Foster SJ, Brezinschek RI, Dörner T, Domiati-Saad R, Lipsky PE. 1997. Analysis of the human VH gene repertoire. differential effects of selection and somatic hypermutation on human peripheral CD5(+)/IgM+ and CD5(−)/IgM+ B cells. J. Clin. Investig. 99, 2488–2501. ( 10.1172/JCI119433) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Rock EP, Sibbald PR, Davis MM, Chien YH. 1994. CDR3 length in antigen-specific immune receptors. J. Exp. Med. 179, 323–328. ( 10.1084/jem.179.1.323) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Wu TT, Johnson G, Kabat EA. 1993. Length distribution of CDRH3 in antibodies. Proteins Struct. Funct. Bioinform. 16, 1–7. ( 10.1002/prot.340160102) [DOI] [PubMed] [Google Scholar]
- 12.Shiokawa S, Mortari F, Lima JO, Nuñez C, Bertrand FE, III, Kirkham PM, Zhu S, Dasanayake AP, Schroeder HW., Jr 1999. IgM heavy chain complementarity-determining region 3 diversity is constrained by genetic and somatic mechanisms until two months after birth. J. Immunol. 162, 6060–6070. [PubMed] [Google Scholar]
- 13.Ivanov II, Schelonka RL, Zhuang Y, Gartland GL, Zemlin M, Schroeder HW. 2005. Development of the expressed Ig CDR-H3 repertoire is marked by focusing of constraints in length, amino acid use, and charge that are first established in early B cell progenitors. J. Immunol. 174, 7773–7780. ( 10.4049/jimmunol.174.12.7773) [DOI] [PubMed] [Google Scholar]
- 14.Wardemann H, Yurasov S, Schaefer A, Young JW, Meffre E, Nussenzweig MC. 2003. Predominant autoantibody production by early human B cell precursors. Science 301, 1374–1377. ( 10.1126/science.1086907) [DOI] [PubMed] [Google Scholar]
- 15.Uduman M, Yaari G, Hershberg U, Stern JA, Shlomchik MJ, Kleinstein SH. 2011. Detecting selection in immunoglobulin sequences. Nucleic Acids Res. 39, W499–W504. ( 10.1093/nar/gkr413) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Larimore K, McCormick MW, Robins HS, Greenberg PD. 2012. Shaping of human germline IgH repertoires revealed by deep sequencing. J. Immunol. 189, 3221–3230. ( 10.4049/jimmunol.1201303) [DOI] [PubMed] [Google Scholar]
- 17.Raaphorst FM, Raman CS, Tami J, Fischbach M, Sanz I. 1997. Human Ig heavy chain CDR3 regions in adult bone marrow pre-B cells display an adult phenotype of diversity: evidence for structural selection of DH amino acid sequences. Int. Immunol. 9, 1503–1515. ( 10.1093/intimm/9.10.1503) [DOI] [PubMed] [Google Scholar]
- 18.Meffre E, Milili M, Blanco-Betancourt C, Antunes H, Nussenzweig MC, Schiff C. 2001. Immunoglobulin heavy chain expression shapes the B cell receptor repertoire in human B cell development. J. Clin. Investig. 108, 879–886. ( 10.1172/JCI13051) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.McCoy CO, Bedford T, Minin VN, Bradley P, Robins H, Matsen FA. 2014. Quantifying evolutionary constraints on B cell affinity maturation. arXiv 1403.3066v3 [q-bio.PE]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Yaari G, et al. 2013. Models of somatic hypermutation targeting and substitution based on synonymous mutations from high-throughput immunoglobulin sequencing data. Front. Immunol. 4, 358 ( 10.3389/fimmu.2013.00358) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Shapiro GS, Aviszus K, Ikle D, Wysocki LJ. 1999. Predicting regional mutability in antibody V genes based solely on di- and trinucleotide sequence composition. J. Immunol. 163, 259–268. [PubMed] [Google Scholar]
- 22.Betz AG, Rada C, Pannell R, Milstein C, Neuberger MS. 1993. Passenger transgenes reveal intrinsic specificity of the antibody hypermutation mechanism: clustering, polarity, and specific hot spots. Proc. Natl Acad. Sci. USA 90, 2385–2388. ( 10.1073/pnas.90.6.2385) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Cowell LG, Kepler TB. 2000. The nucleotide-replacement spectrum under somatic hypermutation exhibits microsequence dependence that is strand-symmetric and distinct from that under germline mutation. J. Immunol. 164, 1971–1976. ( 10.4049/jimmunol.164.4.1971) [DOI] [PubMed] [Google Scholar]
- 24.Kepler TB, et al. 2014. Reconstructing a B-cell clonal lineage. II. Mutation, selection, and affinity maturation. Front. Immunol. 5, 170 ( 10.3389/fimmu.2014.00170) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Lossos IS, Tibshirani R, Narasimhan B, Levy R. 2000. The inference of antigen selection on Ig genes. J. Immunol. 165, 5122–5126. ( 10.4049/jimmunol.165.9.5122) [DOI] [PubMed] [Google Scholar]
- 26.Dunn-Walters DK, Dogan A, Boursier L, MacDonald CM, Spencer J. 1998. Base-specific sequences that bias somatic hypermutation deduced by analysis of out-of-frame human IgVH genes. J. Immunol. 160, 2360–2364. [PubMed] [Google Scholar]
- 27.Steiman-Shimony A, et al. 2006. Lineage tree analysis of immunoglobulin variable-region gene mutations in autoimmune diseases: chronic activation, normal selection. Cell. Immunol. 244, 130–136. ( 10.1016/j.cellimm.2007.01.009) [DOI] [PubMed] [Google Scholar]
- 28.Giudicelli V, Chaume D, Lefranc MP. 2005. IMGT/GENE-DB: a comprehensive database for human and mouse immunoglobulin and T cell receptor genes. Nucleic Acids Res. 33, D256–D261. ( 10.1093/nar/gki010) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Stryer L, Berg JM, Tymoczko JL. 2002. Biochemistry, 5th edn New York, NY: W.H. Freeman & Co Ltd. [Google Scholar]
- 30.Martin J, Lavery R. 2012. Arbitrary protein–protein docking targets biologically relevant interfaces. BMC Biophys. 1, 7 ( 10.1186/2046-1682-5-7) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Berg OG, von Hippel PH. 1987. Selection of DNA binding sites by regulatory proteins: statistical–mechanical theory and application to operators and promoters. J. Mol. Biol. 193, 723–743. ( 10.1016/0022-2836(87)90354-8) [DOI] [PubMed] [Google Scholar]
- 32.Dunn-Walters DK, Spencer J. 1998. Strong intrinsic biases towards mutation and conservation of bases in human IgVH genes during somatic hypermutation prevent statistical analysis of antigen selection. Immunology 95, 339–345. ( 10.1046/j.1365-2567.1998.00607.x) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Oprea M, Cowell LG, Kepler TB. 2001. The targeting of somatic hypermutation closely resembles that of meiotic mutation. J. Immunol. 166, 892–899. ( 10.4049/jimmunol.166.2.892) [DOI] [PubMed] [Google Scholar]
- 34.Spencer J, Dunn-Walters DK. 2005. Hypermutation at A-T base pairs: the A nucleotide replacement spectrum is affected by adjacent nucleotides and there is no reverse complementarity of sequences flanking mutated A and T nucleotides. J. Immunol. 175, 5170–5177. ( 10.4049/jimmunol.175.8.5170) [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.