

Abstract
Given the pace at which human-induced environmental changes occur, a pressing challenge is to determine the speed with which selection can drive evolutionary change. A key determinant of adaptive response to multivariate phenotypic selection is the additive genetic variance–covariance matrix (G). Yet knowledge of G in a population experiencing new or altered selection is not sufficient to predict selection response because G itself evolves in ways that are poorly understood. We experimentally evaluated changes in G when closely related behavioural traits experience continuous directional selection. We applied the genetic covariance tensor approach to a large dataset (n = 17 328 individuals) from a replicated, 31-generation artificial selection experiment that bred mice for voluntary wheel running on days 5 and 6 of a 6-day test. Selection on this subset of G induced proportional changes across the matrix for all 6 days of running behaviour within the first four generations. The changes in G induced by selection resulted in a fourfold slower-than-predicted rate of response to selection. Thus, selection exacerbated constraints within G and limited future adaptive response, a phenomenon that could have profound consequences for populations facing rapid environmental change.
Keywords: Bulmer effect, experimental evolution, genetic covariance tensor, G-matrix, selection limit, wheel running
1. Introduction
Given the pace at which human-induced environmental changes occur, a pressing challenge is to determine the speed with which selection can drive evolutionary change and adaptation (as opposed to extinction [1–3]). Prediction of evolutionary change for multiple traits is obtained from the product of the linear selection gradient vector (β), which indicates how selection is acting on individual traits after adjusting for trait correlations, and the additive genetic variance–covariance matrix of those traits (G) [4]. Most typically, G is viewed as affecting the efficacy of selection [5]; crucially, however, G can evolve in response to selection because of changes in allele frequencies and/or the build up of linkage disequilibrium (LD) among important loci [6,7]. Thus, evolutionary processes can shape genetic variation in ways that may either facilitate or constrain future evolutionary changes [5,8].
Simulation-based studies point to the hypothetical conditions under which G will evolve to the greatest extent (e.g. small population, weak correlational selection, low mutational correlation among traits [9,10]). However, general answers from simulations seem unlikely to emerge because it is extremely complex to consider all of the relevant parameters involved across the whole range of relevant parameter values (e.g. population size, number of loci, number of alleles, distribution of allelic effects, dominance, epistasis, mutation rate, strength of selection [11]). Therefore, if and how selection influences G remains largely an empirical question [11–13]. Most empirical studies to date have been modest in scale, biased towards certain taxa (mainly a few insect and plant species) or types of characters (mostly morphological and life-history traits), and varied in both statistical and experimental approaches [11]. As a result, how long the G matrix remains stable under multiple generations of selection (and/or random genetic drift) remains a contentious issue [2].
Replicated artificial selection experiments evaluating the stability of G under selection are rare [14,15], but bring crucial strengths to this key endeavour (e.g. replication, potentially large sample size, known selection, constant environment). Interestingly, selection experiments under laboratory conditions commonly reach an evolutionary limit (i.e. a plateau in the response to selection) even when significant additive genetic variance (VA) remains for the trait under selection [16]. This result is paradoxical from a univariate perspective, in which the response to selection is determined strictly by the product of the directional selection differential and the narrow-sense heritability (h2) of a trait. The paradox can sometimes be resolved by adopting a multivariate perspective on additive genetic variance and selection [5]. Even in the presence of VA in all traits, an absolute genetic constraint can occur if there are one or more directions within G for which no VA exists (i.e. G is semi-positive definite and singular because one or more of its eigenvectors have zero eigenvalues). Thus, an evolutionary limit to selection can result from a multivariate constraint within G, manifested as a lack of VA in the multivariate direction favoured by selection [15]. (Alternatively, genetic covariances between traits can also accelerate evolution if they allow VA in the direction favoured by selection [5].)
Testing the possibility that the evolution of G may result in genetic limits to adaptive evolution is crucial for accurately predicting the phenotypic outcomes of selection because response to selection in wild populations may be more limited than is currently believed [17]. Moreover, in a rapidly changing environment, multivariate constraints could increase risk of local extinctions because populations may not be able to adapt quickly enough to keep pace with environmental change [2]. Here, we experimentally test if and how continuous directional selection induces changes in the form of G in a way that limits future adaptation. We use data from a long-term, fourfold replicated, artificial selection experiment on voluntary wheel-running behaviour in house mice [18]. Considering wheel running expressed over 6 successive days as a series of closely related traits, our objective is to evaluate if and how directional selection on a subset of the daily behaviours induced changes in G overall.
2. Material and methods
(a). Animals, housing and selection protocol
The experiment started from outbred Hsd : ICR mice, the origins of which are described fully elsewhere [18]. A total of 112 males and 112 females, each from a different family, were purchased from Harlan Sprague Dawley (designated generation −2) and paired randomly (details in electronic supplementary material, appendix S1). The resulting offspring, designated generation −1, were assigned to eight closed lines. To establish lines, one male and one female were chosen randomly from each litter. These individuals were then paired randomly except that full-sibling matings were disallowed. Lines were randomly assigned into four non-selected control (C) lines and four selected ‘high-runner’ (HR) lines. Their offspring were designated generation 0 and selection started at this generation in HR lines. Each line was maintained with at least 10 families per generation, routinely housed in same-sex groups of four per cage except during breeding (one pair per cage) and wheel-running measurements (one individual per cage). Mice were maintained on a 12 L : 12 D cycle (lights on 07.00 h), which was also maintained during the wheel-running trials.
Each generation, approximately 600 mice six to eight weeks of age were monitored for wheel revolutions for 6 consecutive days. Voluntary wheel running was measured on stainless steel and Plexiglas, Wahman-type activity wheels (circumference = 112 cm, diameter = 35.7 cm and width = 10 cm; Lafayette Instruments, Lafayette, IN, USA) attached to standard home cages. Three batches of approximately 200 mice each were measured during three successive weeks. Mice from a given batch were weighed and placed on randomly assigned wheels during the morning of the first day; data collection was started at approximately 13.00 h. Data were downloaded every 23.5 h, at which time wheels were checked to remove any food pellets or wood shavings and to ensure freedom of rotation. On the sixth day, mice were removed from the wheels and weighed.
Starting at generation 0, selection was based on the residual average number of wheel revolutions run on days 5 and 6 (transformed as necessary to improve normality of residuals) from a multiple regression model used to control for several biological and nuisance variables, including measurement block (batches 1–3 and rooms 1–2), sex (in interaction with selection history) and family [18]. Within-family selection was used to increase the effective population size, reduce the rate of inbreeding and help to eliminate the possibly confounding influences of some maternal effects. To produce offspring in the next generation for each of the four HR lines, the highest running male and the highest running female from each family were chosen to breed and paired randomly, with the provision of no full-sibling mating. Over 31 generations, the selection differential averaged 0.92 (s.d. = 0.23) phenotypic standard deviations in the HR lines and approximated zero in the C lines [16]. In C lines, a male and female from within each family were chosen randomly to obtain breeders, again with no full-sibling matings allowed.
(b). Data and pedigree
We used the same data and pedigree for wheel running on days 5 and 6 as compiled and checked in a previous study [16]. Here, we added data on days 1–4 and excluded an additional 572 individuals for which wheel running on a given day was obviously abnormal compared with wheel running on the other days (this often resulted from wheel problems that were detected and corrected during the first 4 days). This resulted in a sample of 17 328 individuals with wheel running measured on the 6 days from generation 0–31.
(c). Animal models for quantitative genetic analyses
Falconer [19] and many authors since have recognized that, conceptually, a given element of the phenotype (e.g. body mass) measured in several environments or serially at several ages or life stages can be considered as a set of traits that are expected to be genetically correlated. We adopted such a ‘character-state’ approach and considered wheel running expressed over the 6 successive days as a series of closely related traits. Our choice is supported by previous research showing that the genetic architecture for running distance varies somewhat across successive days [20]. For example, some detected quantitative trait loci have an effect only during the initial 3 days of exposure to wheels, which are believed to be related to anxiety or fear-related behaviours upon initial exposure to a new environment (e.g. individual housing, introduction to a running wheel [20]). Another option would have been to adopt a ‘function-valued’ approach and use random regression to model wheel running as a function of day for each individual. However, in this case, many of the logistical and statistical advantages of using the function-valued approach are not relevant, and the low number of index values at which measures were taken (six) makes it likely that the function-valued and character-state approaches will result in models that are equivalent [21]. A major disadvantage of using the character-state approach here is the increased number of model parameters (i.e. covariances among all traits); however, this is not a practical problem because of the relatively low number of separate traits (i.e. 6) and relatively large sample size.
We quantified G for wheel running on each of the 6 days (referred to below as ‘traits' for simplicity) using Bayesian multivariate animal models in the MCMCglmm package of R [22]. We chose to pool the data for replicate lines within C and HR, and divide the 32 generations into roughly three equal time periods: generations 0–10, 11–20 and 21–31. This offered the best trade-off between having large sample size within each time period (electronic supplementary material, table S1) to allow estimation of G with adequate precision while at the same time examining temporal change in G over periods before (generations 0–10), during (generations 11–20) and mostly after (generations 21–31) the selection plateaus had been reached [16]. For each time period, we ran two separate models (one for C and one for HR mice) restricted to the pedigree and phenotypic data from that time period, yielding a total of six G matrices. We followed a heuristic approach for estimating G for the specific time periods in the selection experiment [23] where the pedigree used for each time period treated animals in the first generation of the period (i.e. 0, 11 or 21) as the descendants of a hypothetical unrelated, non-selected and non-inbred population, and included pedigree information for all individuals in that time period [23]. Thus, the animal model inferred G back to the hypothetical parental population of the time period given the data provided. Obviously, in finite populations (with drift) and especially in populations under selection (the HR lines) in which allele frequencies change [24], some assumptions of the infinitesimal model do not hold. In this case, the animal model may not yield a strict estimate of G in the base parental population, but one that is ‘biased’ towards subsequent generations for which data are included. Further research is required to better understand exactly how animal models perform in such situations [25]. To ensure the differences found were attributable to selection per se and not genetic drift, we also ran MCMC models on a line-by-line basis, which yielded a total of 24 G matrices for comparison (i.e. one for each of the eight lines per generation block).
Each model included the six traits as response variables and a series of fixed effects (age, sex, measurement batch and room, and inbreeding coefficient) fitted separately for each trait. All traits were standardized (mean = 0, variance = 1) for each line in each generation. Choice of scale can have a substantial influence on both univariate and multivariate analyses [26]; we thus wanted to account for the large fluctuations in phenotypic means across generations and the increase in the total phenotypic variance across generations in the HR lines [16] (see also electronic supplementary material, figure S1). Moreover, by standardizing trait variances, we made sure that no individual trait dominates the eigenstructure of individual G matrices [27].
Each model included unstructured (co)variance matrices for random effects of maternal identity (common environmental (co)variances), animal identity linked to the pedigree (additive genetic (co)variance; G) and the residuals. Analyses were run using weakly informative inverse-Wishart priors with the scale parameter defined as a diagonal matrix containing values of one-third of the phenotypic variance and distribution parameters set to 0.001 for the degrees of freedom [22]. Posterior distributions were estimated from 6 500 000 MCMC iterations sampled at 5000 iteration intervals following an initial burn-in period of 1 500 000 iterations. Autocorrelations were less than 0.1 for all (co)variance components (electronic supplementary material, figure S2), which yielded effective samples sizes close to 1000 for all (co)variances and fixed effects. We visually inspected plots of the traces and posterior distributions, and calculated the autocorrelation between samples to make sure that all models properly converged.
(d). Covariance tensor within a Bayesian framework
A genetic covariance tensor analysis [27] captures all of the variation among multiple G matrices and subsequently allows identification of the trait combinations that differ most in VA among the G matrices. The covariance tensor analysis yields matrices of loadings that each represent independent aspects of how the original G matrices differ and can be interpreted in a fashion similar to the original G matrices. The covariance tensor approach has recently been integrated within a Bayesian framework [12], meaning that uncertainty in estimates of each G is subsequently incorporated into the comparisons among G matrices. Consequently, this also provides estimates of confidence to be placed on the estimation of differences among G matrices. Moreover, one can conduct a covariance tensor analysis on G matrices created under a null model (e.g. by randomization), thereby allowing tests of whether the identified differences among observed G are more pronounced than predicted by a particular null hypothesis. Indeed, it is possible to use the posterior predictive distribution of breeding values obtained from a Bayesian animal model to generate a set of G matrices where any differences among these are assumed to be driven by random sampling variation. Thus, applying the covariance tensor analysis to both the observed and randomized sets of G matrices provides a test of the hypothesis that the observed G matrices differ more than expected by random sampling per se (i.e. of individuals from a population for analysis). We briefly describe the implementation below, but refer interested readers to an example in the electronic supplementary material, appendix S2, and recommend Hine et al. [27] and Aguirre et al. [12] for more details about the methods.
Tensors from multilinear algebra extend the notion of vectors (which are first-order tensors) and matrices (second-order tensors) to higher-order structures that can be used to characterize variation in these lower-order variables (i.e. vectors and matrices). The variation among multiple G matrices can be characterized by a fourth-order genetic covariance tensor, Σ. The independent aspects of variation among multiple G matrices are described by second-order eigentensors (E) of Σ, and the amount by which an E contributes to the total variation among G matrices is quantified by the size of the eigenvalue corresponding to an E. The eigentensors of Σ are obtained by first mapping Σ onto the symmetric matrix S [27]. The elements in the eigenvectors of the matrix S are then scaled and arranged to form the second-order eigentensors (E). Therefore, the E matrices (second-order eigentensors) contain information regarding independent directions in which the original G matrices differ and can be read, similar to how one interprets a G matrix. For example, if an E contains large positive values along the diagonal and values near zero on the off-diagonals then the conclusion would follow that the original G matrices differ in the VA of individual traits (with the relative difference among G for each trait reflected by the relative magnitude of the diagonal elements of E; see electronic supplementary material, appendix S2). Further, we can determine the genetically orthogonal linear combinations of traits that describe independent changes among G matrices by obtaining the eigenvectors (e) and eigenvalues of each E. These eigenvectors (e) can be interpreted in a way similar to eigenvectors of a G matrix. For example, if the largest eigenvalue of an e is close to 1, then the detected change in covariance structure, described by the eigentensor, can be attributed to the change in VA for a single combination of traits.
We next applied the covariance tensor method in a Bayesian framework. For the ith MCMC sample of the set of G, we determined the matrix representation of the tensor, Si. We then calculated the elements of 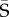 from the corresponding posterior means of the elements of the set of Si (i = 1–1000). We projected the jth eigenvector of
from the corresponding posterior means of the elements of the set of Si (i = 1–1000). We projected the jth eigenvector of 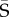 onto Si (equivalent to projecting of
onto Si (equivalent to projecting of 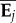 onto Σ) to determine αij, the variance among the ith MCMC sample of the G matrices for the aspect of covariance structure specified by
onto Σ) to determine αij, the variance among the ith MCMC sample of the G matrices for the aspect of covariance structure specified by 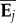 . Projecting an eigentensor onto a tensor is analogous to projecting a vector onto a G matrix to determine how much variance is present in a particular direction. This allowed us to calculate the VA along the axis of greatest variation among the six G of interest by projecting the leading eigenvector of E1 (i.e. e11) onto the observed G matrices. The posterior distribution of αj summarizes the uncertainty in the variance in covariance structure represented by
. Projecting an eigentensor onto a tensor is analogous to projecting a vector onto a G matrix to determine how much variance is present in a particular direction. This allowed us to calculate the VA along the axis of greatest variation among the six G of interest by projecting the leading eigenvector of E1 (i.e. e11) onto the observed G matrices. The posterior distribution of αj summarizes the uncertainty in the variance in covariance structure represented by 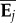 .
.
To test whether the observed differences among G matrices were statistically significant, we used randomizations to generate a null model in which we assumed the differences among G were driven by random sampling variation alone (see electronic supplementary material, appendix S2, for an application of the Bayesian genetic covariance tensor on simulated G matrices to help interpret the results obtained from this approach). Note that for a single trait, the variance in true breeding values is VA and similarly the covariance in true breeding values between two traits is the additive genetic covariance (COVA). Thus, we used the marginal posterior distribution of each estimated G to generate breeding values and assigned them randomly to one of the six combinations of selection group (i.e. C or HR) and generation block (i.e. 0–10, 11–20 or 21–31) under the null hypothesis that sampling variation is the only process explaining the divergence among G [12]. Thus, we calculated posterior predictive breeding values for each trait in every individual by taking draws from a multivariate normal distribution with a mean of zero and covariance according to Kronecker product between the ith MCMC sample of the jth G and the pedigree-derived numerator relationship matrix. We then calculated randomized G matrices as the variances within and covariances between the simulated vectors of breeding values assigned to each hypothetical population. Subsequently, we applied the covariance tensor method to both the observed and randomized sets of G to test the hypothesis that the observed G matrices differ significantly more than by sampling variation alone. Specifically, we compared the distribution of αj obtained from the genetic covariance tensor applied to the observed versus randomized sets of G. Although the expectation of αj for the randomized set of G is approximately 0, the upper bound of its 95% highest posterior density (HPD) interval provides an estimation of the variation among G matrices that can be obtained by chance given the dataset and structure of the pedigrees.
(e). The multivariate breeder's equation
We used the multivariate breeder's equation [4], R = Gβ, to illustrate the extent to which changes in G induced by continuous directional selection influence subsequent response to selection (R). To do this, we used the β estimated in HR mice (see below) to predict R in both C and HR mice for each generation block, which demonstrates how the changes in G induced by selection altered evolutionary responses in units of phenotypic standard deviations. We calculated relative fitness as the number of pups produced by a given HR mouse divided by the average number of pups in HR mice for different blocks of generations (i.e. 0–10, 11–20 and 21–31). This analysis included all HR mice for which we had wheel-running data, including the non-selected individuals (who were attributed a pup production of zero). We then used MCMCglmm and the data for each generation block to run multiple linear regressions of relative fitness as a function of wheel running on days 1–6 (each day standardized to a mean of 0 and a variance of 1) with the same fixed effects as used in the multivariate animal models (see above). The partial regression coefficients from these multiple linear regressions provided the vectors of selection gradients (β), which represents the strength of directional selection on wheel running for each of days 1–6, corrected for correlations with all other traits in the model and adjusting for other fixed effects. Interpretation of partial regression coefficients can in some cases be counterintuitive to univariate examination of mean differences between successful and unsuccessful individuals. In particular, it is not uncommon that a trait that displays a very low selection differential when examined from a univariate perspective appears as very important in the multiple regression by having a large partial regression coefficient, or vice versa.
Very high correlations among independent variables are well known to cause instability in the estimates of partial regression coefficients and their standard errors, which is possible here because the raw phenotypic correlations between wheel running on different days ranged from 0.53 to 0.85 in selected mice. The generalized variance inflation factors were below 5 for all wheel-running variables, however, suggesting problems with multicollinearity were not serious [28]. Most importantly, we incorporated the uncertainty in both G and β to obtain the posterior distribution of R [29]. For a given generation block, we took the ith sample of the posterior distribution of G from the multivariate animal model and post-multiplied it by the ith sample of the posterior distribution of the vector of β from the multiple regression model to obtain the ith sample of the posterior distribution for R. We could then calculate the posterior mode and 95% HPD intervals for the predicted response to selection for wheel running on days 1–6 in each generation block, separately for C and HR mice.
3. Results
(a). Correlated responses to selection
Over 31 generations, we measured 17 328 young adult mice for wheel revolutions on 6 consecutive days, across which wheel running increases monotonically in every generation (figure 1a). Substantial response to selection occurred over the first 20 generations, at which point HR mice were running approximately 2.5-fold more revolutions per day compared with C (figure 1b) and after which no further increase in wheel running has occurred, despite continued directional selection and the presence of VA in the selected trait (see also [16]). Although the first 4 days of wheel running were intended primarily to allow familiarization with the testing apparatus (e.g. reduce or eliminate neophobia) and not part of the selection criterion, substantial correlated responses occurred for each of those days (figure 1a). On an absolute basis, HR mice show a greater daily increase than C mice in wheel running across the 6-day trial (figure 1c), which may require co-adaptational changes in training ability and other subordinate traits that support or cause wheel running [30]. The differential increase in wheel running is less apparent on a relative basis, especially after generation 24 (figure 1b).
Figure 1.
(a) Daily average number of wheel revolutions run (pooled means ± s.d. for four replicate lines in each selection group) over 6 days of wheel access in control (C) and selected (HR) mice, averaged over blocks of four generations (see also electronic supplementary material, figure S1). (b) Relative and (c) absolute difference in wheel running in C versus HR mice. (Online version in colour.)
(b). Additive genetic (co)variances matrices
Throughout the experiment, the six behavioural traits showed higher VA in C mice (range 0.167 to 0.307) than HR mice (range 0.073 to 0.118) (electronic supplementary material, figures S3 and S4). All of the COVA were positive, but they were consistently higher in C (range 0.112 to 0.219) than HR mice (range 0.026 to 0.068), even over the first 10 generations (electronic supplementary material, figures S3 and S4). For sake of completeness, we also calculated scaled individual components of G (i.e. h2 and rA) which yielded similar differences between C and HR mice (see electronic supplementary material, figure S4). That the estimated COVA were all positive is reflected in the correlated increases observed for days 1–4 as a result of selection only on days 5–6 (see above).
(c). Genetic covariance tensor
The eigentensor E1 described 91.9% of the variation among the six observed G matrices (figure 2a and table 1). E1 reveals that the variation across the six G matrices was substantial for all elements (figure 2b). Note that there seems to be more variability among G matrices for elements in the lower right corner of the matrix, which corresponds to VA and COVA for days 4–6 (figure 2b). The leading eigenvector e11 explained 99.8% of the variation captured by E1 (table 1). Thus, almost all of the variation among the six G matrices is captured by a single combination of traits. The loadings of e11 range over a rather restricted range of −0.37 to −0.44 (table 1), suggesting that the six traits contribute roughly equally to the major axis of variation among G matrices. Calculating the VA along this axis of variation shows that the changes captured in e11 were driven by a steady difference in VA between C and HR mice across generation blocks (figure 2c). Note that VA along e11 did not differ statistically within HR mice across the generation blocks (figure 2c).
Figure 2.

(a) Variance (α; ±95% HPD intervals) accounted for by each eigentensor (En) for the observed (black dots) and randomized (grey dots) sets of G. Because the 95% HPD intervals of the observed versus randomized sets of G did not overlap for E1 and E2, these eigentensors described significantly more variation among the observed G than by chance. (b) ‘Heat map’ displaying the pattern of greatest variation among G matrices as captured by E1 (darker shading indicates greater variation among G matrices as measured by elements of E1, which reflect variance of the (co)variances among the six G matrices). Hence, variability among G matrices was distributed throughout the entire matrix, but was slightly more intense for trait combinations involving days 4–6 compared with those earlier in the day sequence. (c) The additive genetic variance (VA) in control (C) and selected (HR) mice along the direction of the first eigenvector of E1 (i.e. e11) across generation blocks. (Online version in colour.)
Table 1.
Summary of the genetic covariance tensor. Shown are the eigenvectors (e) of the two leading eigentensors (E1 and E2), their eigenvalues and the percentage of variation each eigenvector explains within their respective E, and loadings on each trait (wheel running on days 1–6). Only shown are the eigenvectors describing more than 45% of the variance within their respective eigentensor.
| E | eigenvalues of E | variation explained | e | eigenvalues of e | variation explained in E | trait loadings |
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| day 1 | day 2 | day 3 | day 4 | day 5 | day 6 | ||||||
| E1 | 0.1917 | 91.9% | e11 | −0.999 | 99.8% | −0.374 | −0.408 | −0.389 | −0.427 | −0.439 | −0.409 |
| E2 | 0.0076 | 3.7% | e21 | 0.725 | 52.6% | 0.820 | 0.461 | 0.151 | 0.262 | 0.135 | −0.070 |
| e22 | −0.687 | 47.2% | 0.277 | −0.149 | −0.386 | −0.325 | −0.455 | −0.663 | |||
Applying the tensor analysis to the 24 G matrices estimated for each line and generation block yielded results that are consistent with the pooled analysis (electronic supplementary material, figure S5 and table S2). E1 captured a large part (75.6%) of the variance among G matrices and the comparison of observed versus null G indicated that this eigentensor explained significantly more variance than expected by chance (electronic supplementary material, figure S5a,b and table S2). The leading eigenvector e11 explained 99.6% of the variation captured by E1 (electronic supplementary material, table S2), with loadings ranging from −0.35 to −0.45 only (electronic supplementary material, table S2). Compared with C lines, all four HR lines consistently showed lower VA along e11 (electronic supplementary material, figure S5c). These results show that the effect of selection on G was repeatable at the level of replicate lines and that differences among G were not affected by genetic drift among the lines.
(d). Predicted response to selection
Multiple regressions of relative fitness as a function of wheel running on days 1 to 6 revealed that the selection gradients were positive for days 5 and 6, but some were negative and significantly different from zero for days 1–4 (electronic supplementary material, table S3). We used these partial regression coefficients estimated in HR mice as our β in the multivariate breeder's equation to predict the between-generation changes for days 1–6 if selection were to be applied to both C and HR lines separately for each generation block (i.e. using the six separate G-matrices estimated above). For all six behavioural traits, HR mice show an approximately fourfold lower predicted R than do C mice (figure 3; electronic supplementary material, table S4). Because the predicted responses for days 5 and 6 were still positive and statistically significant in generations 21–31, however, we can confidently rule out the possibility that changes in the form of G and/or β caused the selection plateaus that occurred in each of the four HR lines during generations 21–31, which is consistent with the conclusions of Careau et al. [16].
Figure 3.
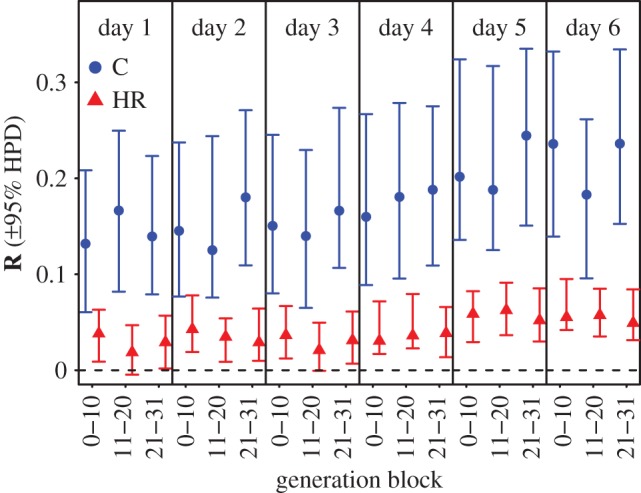
Predicted response to selection (R; in units of standard deviation) for wheel running on days 1–6 in control (C) and selected (HR) mice over different blocks of generations. The posterior modes and 95% HPD intervals incorporate the uncertainty from estimating both G (estimated separately for C and HR lines) and β (as estimated in HR lines). This figure shows the consequences of changes to G induced by directional selection (i.e. a large reduction in R in HR lines). However, for wheel running on days 5 and 6 (the selected traits), values of R were still significantly higher than zero even at the selection plateau (i.e. generations 21–31). (Online version in colour.)
4. Discussion
Our results address two major questions in evolutionary biology. First, does the multivariate quantitative genetic architecture typically cause some trait combinations to have far more VA than others? Second, is VA typically low in the direction of past prevailing selection? These questions are related by the possibility that selection itself can contribute to the generation of semi-positive definite and singular G matrices by eroding VA for the trait combinations that are under strong selection, thus potentially causing selection plateaus [5]. More generally, if and how the elements within G (VA and COVA) change under selection are long-standing questions in evolutionary biology [7,31]. We used a Bayesian framework [12] to directly incorporate the uncertainty associated with estimating G and applied the genetic covariance tensor approach [27], where we identified a single trait combination that captured most of the variation among G matrices from a single selection experiment. These methods enabled us to determine that selection induced statistically significant changes in the quantitative genetic architecture of behavioural traits. Most importantly, we found that directional selection significantly reduced VA present in the dominant direction of variation within G, which resulted in a fourfold slower predicted response to subsequent selection.
Experimental studies evaluating the effect of selection on G in a constant environment are rare [14,15]. In a selection experiment on thorax length in Drosophila melanogaster, the G matrix of the control population did not seem to differ from that of the populations selected for small or large thorax [14]. In D. serrata, Hine et al. [15] showed that an evolutionary limit to selection for an increase in male attractiveness was caused by a lack of VA in the direction favoured by sexual selection. Hine et al.'s study exemplifies a key feature of the multivariate response to selection: VA can exist for all traits within G, yet little or no VA may exist along the direction selection is trying to move the population [5]. This raises the possibility that a change in the orientation of G, induced by selection, could have caused the selection plateaus that occurred in HR mice during generations 21–31 [16]. We can confidently rule out this possibility, as the level of VA captured by the leading eigentensor (E1) did not differ significantly in HR mice before versus after the observed selection plateaus (figure 2c), and the multivariate breeder's equation predicted positive and significant response in the selected traits (days 5 and 6) in generations 21–31 (figure 3). Such discrepancy between the predicted and observed responses to selection may be related to additional constraints on the evolution of locomotor behaviour arising from unmeasured behavioural, neurobiological or physiological traits.
Changes in G under selection were repeatable across the four replicate HR lines (electronic supplementary material, figure S5), suggesting a negligible effect of genetic drift on differences in the estimates of G between C and HR. Yet one could argue that the observed differences among G matrices are attributable to founder effects that were simply maintained throughout the experiment. This scenario is highly improbable for several reasons. First, the possibility for any large difference in VA among lines at generation 0 is very unlikely because all eight lines were established by randomly choosing individuals from a randomly bred population who all shared the same grandparents (see also the paper by Garland et al. [32] regarding the mini-muscle allele). Second, each line was assigned by coin toss to a selection group (i.e. C or HR), meaning there is an extremely low probability of the observed pattern occurring by chance. The probability that four lines with relatively lower G were all randomly assigned to the selection group is p = 0.014 (details in electronic supplementary material, appendix S1). Third, we have good evidence that h2 of the selected trait (average wheel running on days 5 and 6) was very similar in C and HR mice at generation 0, but rapidly decreased in HR mice (electronic supplementary material, figure S6). Finally, a complete reanalysis of the data, based on smaller blocks of four generations, also suggests that C and HR lines did not initially differ in VA along e11 (electronic supplementary material, figure S7). Thus, we are confident that the differences among G matrices in C versus HR mice were caused by selection per se.
Some of our observations could suggest that the changes in G were caused by selection generating negative LD among the loci that affect the six behavioural traits [6]. Indeed, the differences in G between C and HR mice emerged within the first generation block (i.e. 0–10), after which the differences remained relatively stable (see electronic supplementary material, figure S8, for a fine-scale analysis based on smaller generation blocks). However, because the selected trait has relatively low h2 and selection was practised within families, the change attributable to the combined effects of inbreeding and LD should be relatively small (see also [25]). According to calculations based on the infinitesimal model, the predicted reduction in each element of G is only approximately 11% after 10 generations of selection (electronic supplementary material, figure S9). This clearly does not account for the 50–80% reduction we observed throughout the entire matrix.
Under the infinitesimal model, selection is not expected to significantly change allele frequencies at any particular locus, because this (null) model assumes that quantitative traits are determined by an infinite number of genes, each of them with an infinitesimally small effect. However, changes in allele frequency under directional selection have been shown in a few livestock populations [24] and in the current experiment. Specifically, we previously showed, in two of the four HR lines, dramatic changes in the frequency of a Mendelian recessive ‘mini-muscle’ allele that causes a 50% reduction in hind limb muscle mass, as well as many pleiotropic effects that are apparently conducive to supporting high levels of endurance exercise [32]. It is likely that allele frequencies were also altered at many additional loci.
In addition, previous research has shown that wheel running results for days 1–6 generally share some common quantitative trait loci [20], which could explain why changes in G were proportional (i.e. distributed throughout the entire matrix). Unique genomic regions were also identified to specifically affect wheel running during the initial exposure (days 1–3) to wheels [20]. These differences among days may be related to anxiety or fear-related behaviours having an effect on wheel running only during the initial days following exposure to a wheel and altered housing conditions [20]. Previous research failed to detect behavioural differences in C versus HR mice in a novel open-field test [33], suggesting that anxiety or fear-related traits were not indirectly selected in the HR lines. Generally, trait combinations under weak selection should display higher VA than those under strong selection [31,34]. Consistent with this expectation, we observed fewer differences among G matrices for trait combinations involving wheel running on days 1–3 than for elements of G corresponding to later in the sequence of days (figure 2b; see also trait loadings on e11, e21 and e22, table 1), which could be explained by differential alteration of allele frequencies for days 1–3 versus 4–6.
An important feature of this experiment is that selection was applied on behaviour, a type of trait for which we have little information regarding G. Most previous comparisons of G matrices among populations and species have concentrated on relationships among morphological or life-history traits [11]. As this study is the first robust empirical test of the stability of G under selection involving behaviour, it broadens our understanding of the stability of G to a new type of quantitative trait. Compared with morphological traits, behavioural traits generally are more closely associated with Darwinian fitness [35] and generally have lower h2 [5]. Future research is needed to determine whether the evolutionary dynamics of G under selection are generally different among types of characters, and whether the stability of G relates to how closely the character types are related to fitness.
More research is also needed to determine the extent to which our results apply to wild populations experiencing natural rates of immigration and emigration (gene flow) and spatio-temporal variation in selection gradients. To the extent that the evolutionary dynamics of G are similar in laboratory versus wild populations, then our results have important implications for populations facing a consistent and directional rapid environmental change. The sensitivity of a population to global change will be mediated by both its resilience (i.e. ability to withstand and recover from a perturbation) and its adaptive capacity (i.e. both phenotypic plasticity and evolutionary potential) [1]. Locomotor capacity may be a key component of the resilience of a population [3], because it strongly affects the ability of individuals to disperse within and across increasingly fragmented habitats, and hence the ability of the population to expand its range rapidly following disturbance. Moreover, locomotor capacity can itself evolve towards higher levels if global change favours higher dispersal ability or broader daily ranging patterns. For example, individuals with high locomotor capacity might have higher Darwinian fitness if they can successfully disperse to and take advantage of habitats that have become newly available or favourable [2]. Thus, evolution towards higher locomotor capacity may help populations to track the preferred climate space [3]. However, if directional selection further exacerbates constraints on the evolution of locomotor behaviour, as we observed here, then evolution may not occur quickly enough to allow evolutionary adaptation to rapidly shifting environmental conditions [6].
Supplementary Material
Acknowledgements
We thank people who collected the data over the generations, and J. G. Kingsolver, J. Endler, A. Charmantier and three anonymous reviewers for comments on various versions of the manuscript.
Data accessibility
Authors' contributions
T.G. and P.A.C designed and performed the selection experiment. P.A.C. and V.C. compiled the data and pedigree. V.C. and M.E.W. analysed the data. All authors were involved in interpreting the results and contributed to writing the manuscript.
Competing interests
We have no competing interests.
Funding
This project was supported by grants from NSF to T.G. (IOS-1121273) and to P.A.C. (EF-0328594).
References
- 1.Williams SE, Shoo LP, Isaac JL, Hoffmann AA, Langham G. 2008. Towards an integrated framework for assessing the vulnerability of species to climate change. PLoS Biol. 6, 2621–2626. ( 10.1371/journal.pbio.0060325) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Hoffmann AA, Sgro CM. 2011. Climate change and evolutionary adaptation. Nature 470, 479–485. ( 10.1038/nature09670) [DOI] [PubMed] [Google Scholar]
- 3.Feder ME, Garland T Jr, Marden JH, Zera AJ. 2010. Locomotion in response to shifting climate zone: not so fast. Annu. Rev. Physiol. 72, 167–190. ( 10.1146/annurev-physiol-021909-135804) [DOI] [PubMed] [Google Scholar]
- 4.Lande R. 1979. Quantitative genetic analysis of multivariate evolution, applied to brain: body size allometry. Evolution 33, 402–416. ( 10.2307/2407630) [DOI] [PubMed] [Google Scholar]
- 5.Walsh B, Blows MW. 2009. Abundant genetic variation + strong selection = multivariate genetic constraints: a geometric view of adaptation. Annu. Rev. Ecol. Syst. 40, 41–59. ( 10.1146/annurev.ecolsys.110308.120232) [DOI] [Google Scholar]
- 6.Blows MW, Walsh B. 2009. Spherical cows grazing in flatland: constraints to selection and adaptation. In Adaptation and fitness in animal populations (eds van der Werf J, Graser H-U, Frankham R, Gondro C), pp. 83–101. Dordrecht, The Netherlands: Springer. [Google Scholar]
- 7.Barton NH, Turelli M. 1987. Adaptive landscapes, genetic distance and the evolution of quantitative characters. Genet. Res. 49, 157–173. ( 10.1017/S0016672300026951) [DOI] [PubMed] [Google Scholar]
- 8.Etterson JR, Shaw RG. 2001. Constraint to adaptive evolution in response to global warming. Science 294, 151–154. ( 10.1126/science.1063656) [DOI] [PubMed] [Google Scholar]
- 9.Revell LJ. 2007. The G matrix under fluctuating correlational mutation and selection. Evolution 61, 1857–1872. ( 10.1111/j.1558-5646.2007.00161.x) [DOI] [PubMed] [Google Scholar]
- 10.Jones AG, Arnold SJ, Bürger R. 2007. The mutation matrix and the evolution of evolvability. Evolution 61, 727–745. ( 10.1111/j.1558-5646.2007.00071.x) [DOI] [PubMed] [Google Scholar]
- 11.Arnold SJ, Bürger R, Hohenlohe PA, AJie BC, Jones AG. 2008. Understanding the evolution and stability of the G-matrix. Evolution 62, 2451–2461. ( 10.1111/j.1558-5646.2008.00472.x) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Aguirre JD, Hine E, McGuigan K, Blows MW. 2014. Comparing G: multivariate analysis of genetic variation in multiple populations. Heredity 112, 21–29. ( 10.1038/hdy.2013.12) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Turelli M. 1988. Phenotypic evolution, constant covariances, and the maintenance of additive variance. Evolution 42, 1342–1347. ( 10.2307/2409017) [DOI] [PubMed] [Google Scholar]
- 14.Shaw FH, Shaw RG, Wilkinson GS, Turelli M. 1995. Changes in genetic variances and covariances: G whiz! Evolution 49, 1260–1267. ( 10.2307/2410450) [DOI] [PubMed] [Google Scholar]
- 15.Hine E, McGuigan K, Blows MW. 2011. Natural selection stops the evolution of male attractiveness. Proc. Natl Acad. Sci. USA 108, 3659–3664. ( 10.1073/pnas.1011876108) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Careau V, Wolak ME, Carter PA, Garland T Jr. 2013. Limits to behavioral evolution: the quantitative genetics of a complex trait under directional selection. Evolution 67, 3102–3119. ( 10.1111/evo.12200) [DOI] [PubMed] [Google Scholar]
- 17.Blows MW, Hoffmann AA. 2005. A reassessment of genetic limits to evolutionary change. Ecology 86, 1371–1384. ( 10.1890/04-1209) [DOI] [Google Scholar]
- 18.Swallow JG, Carter PA, Garland T Jr. 1998. Artificial selection for increased wheel-running behavior in house mice. Behav. Genet. 28, 227–237. ( 10.1023/A:1021479331779) [DOI] [PubMed] [Google Scholar]
- 19.Falconer DS. 1952. The problem of environment and selection. Am. Nat. 86, 293–298. ( 10.1086/281736) [DOI] [Google Scholar]
- 20.Kelly SA, et al. 2010. Genetic architecture of voluntary exercise in an advanced intercross line of mice. Physiol. Genomics 42, 190–200. ( 10.1152/physiolgenomics.00028.2010) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Roff DA, Wilson AJ. 2014. Quantifying genotype-by-environment interactions in laboratory systems. In Genotype-by-environment interactions and sexual selection (eds Hunt J, Hosken D), pp. 101–136. Chichester, UK: John Wiley and Sons. [Google Scholar]
- 22.Hadfield JD. 2010. MCMC methods for multi-response generalised linear mixed models: the MCMCglmm R package. J. Stat. Softw. 33, 1–22. ( 10.18637/jss.v033.i02)20808728 [DOI] [Google Scholar]
- 23.Sorensen DA, Kennedy BW. 1984. Estimation of genetic variances from unselected and selected populations. J. Anim. Sci. 59, 1213–1223. [Google Scholar]
- 24.Fontanesi L, Schiavo G, Scotti E, Galimberti G, Calò DG, Samorè AB, Gallo M, Russo V, Buttazzoni L. 2015. A retrospective analysis of allele frequency changes of major genes during 20 years of selection in the Italian Large White pig breed. J. Anim. Breed. Genet. 132, 239–246. ( 10.1111/jbg.12127) [DOI] [PubMed] [Google Scholar]
- 25.Meyer K, Hill WG. 1991. Mixed model analysis of a selection experiment for food intake in mice. Genet. Res. 57, 71–81. ( 10.1017/S0016672300029062) [DOI] [PubMed] [Google Scholar]
- 26.Hansen TF, Houle D. 2008. Measuring and comparing evolvability and constraint in multivariate characters. J. Evol. Biol. 21, 1201–1219. ( 10.1111/j.1420-9101.2008.01573.x) [DOI] [PubMed] [Google Scholar]
- 27.Hine E, Chenoweth SF, Rundle HD, Blows MW. 2009. Characterizing the evolution of genetic variance using genetic covariance tensors. Phil. Trans. R. Soc. B 364, 1567–1578. ( 10.1098/rstb.2008.0313) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Zuur A, Ieno EN, Walker N, Saveiliev AA, Smith GM. 2009. Mixed effects models and extensions in ecology with R. New York, NY: Springer. [Google Scholar]
- 29.Stinchcombe JR, Simonsen AK, Blows MW. 2014. Estimating uncertainty in multivariate responses to selection. Evolution 68, 1188–1196. ( 10.1111/evo.12321) [DOI] [PubMed] [Google Scholar]
- 30.Gomes FR, Rezende EL, Malisch JL, Lee SK, Rivas DA, Kelly SA, Lytle C, Yaspelkis BB III, Garland T Jr. 2009. Glycogen storage and muscle glucose transporters (GLUT-4) of mice selectively bred for high voluntary wheel running. J. Exp. Biol. 212, 238–248. ( 10.1242/jeb.025296) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Lande R. 1980. The genetic covariance between characters maintained by pleiotropic mutations. Genetics 94, 203–215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Garland T Jr, Morgan MT, Swallow JG, Rhodes JS, Girard I, Belter JG, Carter PA. 2002. Evolution of a small-muscle polymorphism in lines of house mice selected for high activity levels. Evolution 56, 1267–1275. ( 10.1111/j.0014-3820.2002.tb01437.x) [DOI] [PubMed] [Google Scholar]
- 33.Careau V, Bininda-Emonds ORP, Ordonez G, Garland T Jr. 2012. Are voluntary wheel running and open-field behavior correlated in mice? Different answers from comparative and artificial selection approaches. Behav. Genet. 42, 830–844. ( 10.1007/s10519-012-9543-0) [DOI] [PubMed] [Google Scholar]
- 34.Arnold SJ, Pfrender ME, Jones AG. 2001. The adaptive landscape as a conceptual bridge between micro- and macroevolution. Genetica 112–113, 9–32. ( 10.1023/A:1013373907708) [DOI] [PubMed] [Google Scholar]
- 35.Careau V, Garland T Jr. 2012. Performance, personality, and energetics: correlation, causation, and mechanism. Physiol. Biochem. Zool. 85, 543–571. ( 10.1086/666970) [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.