

Summary
The amount and complexity of patient-level data being collected in randomized controlled trials offers both opportunities and challenges for developing personalized rules for assigning treatment for a given disease or ailment. For example, trials examining treatments for major depressive disorder are not only collecting typical baseline data such as age, gender, or scores on various tests, but also data that measure the structure and function of the brain such as images from magnetic resonance imaging (MRI), functional MRI (fMRI), or electroencephalography (EEG). These latter types of data have an inherent structure and may be considered as functional data. We propose an approach that uses baseline covariates, both scalars and functions, to aid in the selection of an optimal treatment. In addition to providing information on which treatment should be selected for a new patient, the estimated regime has the potential to provide insight into the relationship between treatment response and the set of baseline covariates. Our approach can be viewed as an extension of “advantage learning” to include both scalar and functional covariates. We describe our method and how to implement it using existing software. Empirical performance of our method is evaluated with simulated data in a variety of settings and also applied to real data arising from the study of patients suffering from major depressive disorder from which baseline scalar covariates as well as functional data from EEG are available.
Keywords: Advantage learning, Depression, Electroencephalography data, Functional data, Personalized medicine, Treatment regime
1. Introduction
Personalized medicine aims to provide a sound approach for making treatment decisions based on each individual’s clinical characteristics. These characteristics may include demographic information such as age, gender, or race, as well as more complex clinical information such as brain structure or function. The latter type of information may be viewed as functional data (Ramsay and Silverman, 2005). Developments in medical technology have begun to allow for the collection of such data on a scale that has never been seen before and there is growing interest in how best to use these data to guide clinicians in selecting targeted therapies that have the greatest chance to successfully combat a given disease or ailment.
One area of medical research that may substantially benefit from advances in personalized medicine is the development and assignment of treatment for major depressive disorder (MDD). It has been reported that fewer than 40% of patients find success (i.e., achieve remission) in using the first-line treatment that they are prescribed (Gaynes et al., 2009; Holtzheimer and Mayberg, 2011) even though a wide array of first-line treatments is available for patients suffering from MDD. This is especially troubling since selection of the “wrong” initial treatment may not only allow for MDD symptoms to persist but may also result in the worsening of those symptoms, additional suffering from treatment-related side effects, or heightened risk of suicide.
Considering the consequences of using an improper or ineffective first-line treatment for MDD, investigators have suggested that focus should shift to identifying baseline biological markers that can guide clinicians in treatment selection (McGrath et al., 2013). More specifically, it has been suggested that the search for these biomarkers should be among measures derived from neuroimaging modalities such as magnetic resonance imaging (MRI), functional MRI (fMRI), and electroencephalography (EEG), among others. Large clinical trials are now underway, EMBARC (NCT01407094) and iSPOT-D (NCT00693849), that have been designed to discover baseline clinical characteristics that modify the effect of treatment in MDD patients. In these studies, investigators are collecting large amounts of baseline information consisting of hundreds or thousands of scalar quantities as well as hundreds of 1-, 2-, and 3-dimensional brain images that can be regarded as functional data.
The statistical literature indicates that there is a growing interest in developing methods for using data from clinical settings to estimate strategies for providing treatment. While some investigators have focused on methods for making a treatment decision at one time point (Qian and Murphy, 2011; Zhao et al., 2012; Zhang et al., 2012; Lu et al., 2013), others have considered strategies consisting of a sequence of decisions often referred to as dynamic treatment regimes (Murphy, 2003; Robins, 2004; Zhao et al., 2009; Chakraborty et al., 2009; Moodie and Richardson, 2010; Laber et al., 2014).
Whether the focus has been on developing rules for one or multiple time points, the majority of the research has concentrated on using scalar covariates to guide treatment selection while decisions based on functional covariates or combinations of scalars and functions which account for the smooth nature of the functional covariates have remained unexplored. Oftentimes, when functional data are collected in clinical trials that involve an imaging component, these data are reduced to “expert-derived” scalar covariates which are used to develop treatment assignment strategies. Such large scale reduction in the data may explain why there has been relatively little success in identifying biomarkers for MDD treatment response based on imaging studies. Here we propose a method that overcomes the need to reduce functional data to scalar summaries but rather allows for functions and scalars to be used together to estimate a treatment decision rule and better understand heterogeneity in treatment response. Moreover, our approach can help investigators discover features of functional data that are most strongly associated with treatment response.
To our knowledge McKeague and Qian (2014) are the only ones to date who have taken a functional data approach to constructing treatment policies. They propose methods for estimating and evaluating treatment regimes based on one baseline functional covariate. With respect to estimation of a treatment policy, they discuss several approaches including (1) the FAME model of James and Silvermam (2005), (2) models based on a single component of the functional covariate (i.e., models that use only one value of the functional covariate at a specified time, location, etc.), and (3) an “area impact” model in which treatment selection is based on a localized region of the functional covariate.
We are interested in considering situations in which multiple functional covariates or combinations of scalar and functional covariates are available and can be used to estimate a treatment regime. We propose a method in which the task of estimating the optimal regime using scalar and functional predictors is cast as a loss-minimizing procedure where the loss function corresponds to a form of A-learning (Murphy, 2003; Robins, 2004; Blatt et al., 2004). Accordingly, we expect that the estimated regime is robust to certain types of mis-specification of the posited model for the response provided that the part of the model involving interactions between treatment and baseline covariates is correctly specified. We provide evidence of this via numerical investigations. Furthermore, our approach produces an estimated regime that can be used to better understand how the scalar and functional baseline covariates interact with treatment. This may provide important information about which patient-level characteristics are particularly important in guiding treatment selection and may also aid in understanding the etiology of the disease being treated. In contrast to McKeague and Qian (2014) our method (i) allows for both multiple scalars and multiple functions to be used in estimating a treatment regime and (ii) employs penalized functional regression (PFR) (Goldsmith et al., 2011) to incorporate the functional predictors.
The remainder of the paper is organized as follows. In Section 2 we discuss the framework of potential outcomes and treatment regimes in the setting where both scalar and functional baseline covariates are available. We follow this with a description of our approach for estimating a treatment decision rule. Our proposed approach is assessed via simulations in Section 3. In Section 4 we apply our method to a data set arising from a study of subjects with MDD from which baseline scalar covariates and baseline functional covariates derived from EEG measures were collected. We conclude with a discussion in Section 5. Additional information including a derivation, additional simulation results, and R code is available in the online appendix.
2. Framework and Methodology
2.1 Formal Framework
In what follows, we essentially restrict our discussion to data arising from a randomized controlled trial (RCT) where treatment is randomly assigned. However, we note that data from observational studies, where treatment is not randomly assigned, can be cast in the same framework and analyzed using the subsequently described methodology.
Suppose we have n subjects sampled from a patient population of interest. Each subject is randomly given one of two possible treatments. These treatments are assigned based on some pre-specified probabilities that are the same for all subjects. Let the variable A, corresponding to treatment assignment, take on the value of either 0 or 1. For each subject we observe a collection of baseline covariates consisting of scalar values and functions. Denote the set of baseline scalar covariates by a p-dimensional vector Z = (Z1, …, Zp)⊤ and denote the set of baseline functional covariates by the q-element set of functions X = {X1, …, Xq}. Here we assume that X1, …, Xq are one-dimensional functional random variables (Xℓ : Dℓ ⊂ ℝ → ℝ, ℓ = 1, …, q) that are each square integrable on a compact support I ⊂ ℝ (i.e, , ℓ = 1, …, q). Although we present only one-dimensional functional predictors here, it is possible to extend our approach to higher dimensional functional random variables such as images. Lastly, let Y be the observed outcome of interest. Without loss of generality, we assume that larger values of Y are preferred. The observed data are given by (Yi, Ai, Zi, Xi), i = 1, …, n, which are independent and identically distributed with Zi = (Z1i, …, Zpi), Xi = {X1i, …, Xqi}, and Xℓi(s) is the value of ith subject’s ℓth functional covariate at argument s.
We wish to use these data to construct a rule for assigning treatment, often referred to as a “treatment regime” (Zhang et al., 2012; Murphy, 2003), to future subjects in such a way that the selected treatment yields higher outcome values than the alternative treatment for these subjects. As in Zhang et al. (2012), we formalize the notion of an optimal treatment regime by defining the potential outcomes Y*(0) and Y*(1) to be the values of the outcome that would be observed if a subject was assigned treatment 0 or 1 respectively. We assume that Y = Y*(1)A + Y*(0)(1 − A) (i.e., for the treatment that is actually received, the observed and potential outcomes are the same (Rubin, 1978)), which is known as the consistency assumption. Furthermore, we assume that subjects do not interfere with one another and that an individual’s treatment assignment is independent of the potential outcomes conditional on the baseline covariates. This final assumption is satisfied in the context of a RCT where treatment is randomly assigned.
A treatment regime is a function, g, that maps the baseline covariates (Z, X) to {0, 1} such that a patient with baseline covariates (Z = z, X = x) will receive treatment 1 if g(z, x) = 1 and will receive treatment 0 if g(z, x) = 0. The “optimal treatment regime”, gopt, is the function that maximizes the expected value of the response among some class of functions 𝒢, i.e., gopt(Z, X) = argmaxg∈𝒢 E[Y*{g(Z, X)}].
With the framework and assumptions discussed above, we have that
where E(Z,X) (·) denotes expectation with respect to the joint distribution of (Z, X) and the optimal treatment regime is given by
| (1) |
In the case where E(Y|Z, X, A = 1) = E(Y|Z, X, A = 0), one might employ a randomization procedure to select the treatment or use whichever treatment corresponds to the current standard of care if such a treatment is being considered.
A typical approach for deriving an optimal treatment regime is to assume some structure on E(Y|Z, X, A) and employ a regression model. Here we consider a semi-parametric model. Specifically, we propose to model the expected value as
| (2) |
where h0 is some “baseline” function that corresponds to the effects of the baseline covariates on the response for A = 0, Z̃ = (1, Z⊤)⊤, β = (β0, …, βp)⊤, and {ω1, …, ωq} are smooth square integrable weight functions. In (2), f(Z, X) corresponds to the effect of the treatment A = 1 on the response, which is a function of the baseline covariates and is typically referred to as the “contrast.”When the conditional expectation of the response is modeled in this way, we see that f(Z, X) = E(Y|Z, X, A = 1)−E(Y|Z, X, A = 0) and so the optimal treatment regime corresponding to the model in (2) is given by gopt(Z, X) = I{f(Z, X) > 0}. Since the optimal treatment regime depends only on the contrast, primary interest lies in obtaining estimates for the corresponding contrast parameters (i.e., β and ω = {ω1, …, ωq}).
2.2 Methodology
In order to develop an optimal treatment decision rule, we propose to take an approach that views the estimation of the contrast parameters as a loss-minimizing procedure in the framework of advantage learning (A-learning) (Murphy, 2003; Robins, 2004; Blatt et al., 2004). This approach parallels that taken in Lu et al. (2013) which considered only scalar baseline covariates in a high-dimensional setting. Given the observed data, (Yi, Ai, Zi, Xi), i = 1, …, n, we seek to minimize the loss function
| (3) |
where ϕ(Zi, Xi) is an arbitrary function of the baseline covariates which may or may not approximate h0 from (2) well and π(Zi, Xi) = P(Ai = 1|Zi, Xi) is the propensity score which gives the probability that a subject with a specific covariate profile will receive treatment A = 1. For our purposes, we treat the propensity score as a known constant that is determined by trial protocols. In an observational study setting, one may posit a model for π (e.g., logistic model) that depends on all of or a subset of the baseline covariates and substitute the predicted propensity scores in (3).
In the case where there are only scalar baseline covariates, the estimating equations corresponding to (3) have been shown to provide consistent and asymptotically normal estimates for the contrast parameters of interest (Robins, 2004; Lu et al., 2013). This is advantageous in that even if h0(Z, X) is mis-specified, the estimates of the contrast parameters can be consistently estimated, so long as the contrast is correctly specified and the propensity scores are known or can be estimated consistently.
Our setting is more complex since we have functional baseline covariates in addition to scalar ones. However, if we represent the functional covariates and their corresponding coefficient functions in terms of some suitably chosen set(s) of basis functions then we can view the loss function in (3) as wholly consisting of scalar quantities. This puts us back in a setting where we might expect the same benefit of consistent estimates for the contrast parameters.
There is a wide variety of basis functions from which to choose for representing the functional covariates and/or their corresponding coefficient functions including functional principal components, splines, and wavelets. We choose to employ the same representation used in Goldsmith et al. (2011) so that we can take advantage of existing software for obtaining estimates of the contrast parameters and ultimately of the treatment regime. We review this representation here. For ℓ ∈ {1, …, q} let where ψℓ(·) = {ψℓk(·) : 1 ≤ k ≤ Kℓ} are the first Kℓ eigenfunctions of the smoothed estimated covariance operator ΣXℓ(s1, s2) = cov{Xℓ(s1), Xℓ(s2)}. Each coefficient function can be expressed in terms of a truncated power series spline basis given by θℓ = {θ1, …, θMℓ} such that where we have θ1(s) = 1, θ2(s) = s, θm(s) = (s−κm)+ for m = 3, …, Mℓ, and are knots. Using these representations, the contrast can be written as where the functional principal component (FPC) scores for the ℓth functional predictor from the ith observation are given by cℓi = (cℓi1, …, cℓiKℓ)⊤, the unknown spline coefficients for the ℓth coefficient function are bℓ = (bℓ1, …, bℓMℓ)⊤, and Jℓ is a Kℓ × Mℓ dimensional matrix with entry (u, υ) given by ∫ ψℓu(s)θυ(s)ds. Letting we have that (3) can be expressed as
| (4) |
which provides a loss function in the framework of A-learning. In Web Appendix A we show this loss function yields estimating equations corresponding to those associated with A-learning.
As noted above, a desirable consequence of using A-learning in our setting is that we expect the estimates of the contrast parameters to be robust to mis-specification of the h0 function. Thus our approach is flexible in that it allows us to use any functional form for ϕ. Simulation studies conducted by Lu et al. (2013) and Schulte et al. (2014) show that if one happens to properly model the h0 function, then one can expect good estimation accuracy and treatment selection performance with smaller sample sizes than if h0 is mis-specified. Although it is not necessary to specify ϕ(z, x), it is common practice to employ some simple parametric form. One option is to use a linear model , which, in practice, would require using similar representations for the functional components of ϕ as those involved in the contrast. As for each ωℓ, each αℓ, corresponds to a vector of unknown basis coefficients which we will denote by aℓ = (aℓ1, …, aℓVℓ)⊤. As an alternative to using a function that is linear in the baseline predictors, one might choose to use a constant function for ϕ (i.e., ϕ2(z, x) = γ).
For ϕ taking any parametric form, estimates of β and b1, …, bq (and therefore ω1, …, ωq) can be obtained using penalized functional regression (PFR) (Goldsmith et al., 2011). PFR allows for the functional covariates to be sparsely or densely sampled and also allows for them to be measured with or without error. Furthermore, PFR can be performed using existing software, pfr, contained in the R package refund (Crainiceanu et al., 2014). PFR takes account of the functional nature of ω1, …, ωq in order to provide smooth estimates. Smoothing is induced by assuming that for ℓ = 1, …, q, where 0bℓ is a vector of zeros of length (Mℓ − 2) and Ibℓ is an (Mℓ − 2) × (Mℓ − 2) identity matrix. If ϕ1 is used for ϕ then we also have that for ℓ = 1, …, q, where 0aℓ is a vector of zeros of length (Vℓ − 2) and Iaℓ is a (Vℓ − 2) × (Vℓ − 2) identity matrix. (We note that if ϕ2 is used for ϕ then there are no basis coefficients that need to be estimated in addition to those corresponding to the coefficient functions in the contrast.)
The basis coefficients are viewed as random effects in a mixed effects model. The variance components, (and if applicable), can be viewed as smoothing parameters and can be estimated via restricted maximum likelihood estimation (REML). The corresponding model for the response is
| (5) |
which is a mixed model with random effects in the case where ϕ = ϕ1 or in the case where ϕ = ϕ2. As noted in Goldsmith et al. (2011), maximizing the likelihood over the unknown parameters β, b1, …, bq, and any parameters related to ϕ, based on the data, is equivalent to minimizing
| (6) |
where if ϕ = ϕ1 and Pa = 0 if ϕ = ϕ2,
Furthermore, minimizing (6) is equivalent to minimizing
As noted above, the smoothing parameters can be automatically selected using REML. The tuning parameters that need to be selected by the user consist of the numbers of leading functional principal components used for representing each of the functional predictors and the numbers of spline basis functions used to represent each of the coefficient functions. Goldsmith et al. (2011) note that as long as the values of these tuning parameters are chosen “large enough,” then their specific values will have little impact on estimation. Alternatively, one can employ an objective data-driven procedure for selecting these tuning parameters such as cross-validation with the objective being to minimize (6). In practice, the sample size, n, sets upper limits on the values {M1, …, Mq} (and {V1, …, Vq} if applicable) as well as on the number of parameters corresponding to the scalar covariates that can be estimated. Specifically, if we choose to employ ϕ = ϕ1 then there are parameters to estimate whereas if we employ ϕ = ϕ2 then there are parameters to estimate.
3. Numerical Investigations
3.1 Numerical Investigation Setup
We assess the performance of our method with respect to estimation accuracy and selection of the optimal treatment regime on simulated data in various settings. We consider six scenarios that differ in the the number of baseline covariates available and in the true form of the baseline h0 function. Each simulated observation consists of a treatment assignment indicator, a set of p scalar covariates (p = 2 in Scenarios 1 – 3, p = 15 in Scenarios 4 – 6), a set of q functional covariates (q = 2 in Scenarios 1 – 3, q = 15 in Scenarios 4 – 6), and a response.
The treatment assignment indicator, A, is generated such that π(Z, X) = 0.5. The vector of baseline scalar covariates, Z = (Z1, …, Zp)⊤, is generated from a multivariate normal distribution with each component having mean 0 and variance 1. Correlation between the components is given by corr(Zj, Zk) = 0.5|j−k|.
The functional baseline covariates, {X1, …, Xq}, are generated to be similar to the EEG curves observed in the motivating data set discussed in Section 4. To simulate the baseline functional covariates, we take an approach similar to that used in Swihart et al. (2013). Specifically, to generate a new functional covariate, Xℓ, we compute the first 5 observed (O) principal component basis functions , corresponding score variances, , and mean function, , from a FPC decomposition of the collection of curves from the data set corresponding to the ℓth electrode from the cap worn during an EEG recording. To produce the ℓth simulated (S) full (F) functional covariate for the ith observation, we generate subject-specific PC loadings, , from , let , and evaluate this function at 300 equally spaced values of s yielding, , a vector of 300 values. The first value corresponds to the current source density (CSD) value, a measure derived from EEG, at the 0.25 Hz frequency and the 300th value corresponds to the CSD value at the 75 Hz frequency. To mirror the analysis that we perform in Section 4, we trim the full functional covariates to argument values roughly corresponding to the theta and alpha bands (4 – 13 Hz) of the EEG CSD curves, to form which is a vector of 37 values. Figure 1 shows 25 simulated functional covariates for each of 2 different electrodes.
Figure 1.

Simulated functional predictors: (left) 25 and (right) 25 functional predictors from one simulated data set.
Responses are generated such that . The error term, ε, follows a distribution where σε is chosen such that R2 = 0.85.
In Scenarios 1 – 3, in which p = q = 2, we have β = (β0, β1, β2)⊤ = (−0.65, 0.65,−0.65)⊤, ω1(s) = [1/{135 · 152 · Γ(3)}](s/36)2e−10(s/36), and ω2(s) = −[1/{135 · 152 · Γ(3)}]{(s − 36)/36}2e10{(s−36)/36}. In Scenarios 4 – 6, in which p = q = 15, we have β = (β0, …, β15)⊤ = (−0.65, 0.65,−0.65, 013)⊤ (0d is a zero-vector of length d), ω1 and ω2 are the same as in Scenarios 1 – 3, and ω3 = …= ω15 ≡ 0.
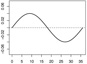
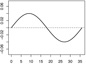
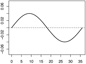
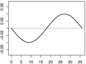
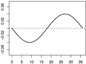
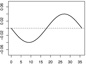
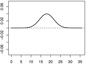
We consider three forms for h0 that are composed of the functions h01 and h02. Let and . In Scenarios 1 – 3 we have γ1 = (γ1,1, γ1,2)⊤ = (0.65, −0.65)⊤, γ2 = (γ2,1, γ2,2)⊤ = (−0.65, 0.65)⊤, α1,1(s) = 0.04sin(2πs/36), α1,2(s) = −0.04sin(2πs/36), , and . In Scenarios 4 – 6 we have γ1 = (γ1,1, …, γ1,15)⊤ = (0.65, −0.65, 013)⊤, γ2 = (γ2,1, …, γ2,15)⊤ = (−0.65, 0.65, 013)⊤, {α1,1, α1,2, α2,1, α2,2} are the same as in Scenarios 1 – 3 and α1,3 = … = α1,15 = α2,3 = …= α2,15 ≡ 0. In Scenarios 1 and 4 we have h0 = 1 + h01, a linear function of the baseline covariates. In Scenarios 2 and 5 we have h0 = 1 + 0.5h01h02, involving interactions among the baseline covariates. In Scenarios 3 and 6 we have , involving nonlinear functions of the baseline covariates. Table 1 shows the form of h0 and all parameter values, including plots of the functional coefficients, used in each of the six scenarios. Note that scenario pairs 1 and 4, 2 and 5, and 3 and 6 are exactly the same except that Scenarios 4 – 6 include more baseline variables that are unrelated to the response.
Table 1.
Parameters for models generating responses in simulation Scenarios 1 – 6 and average treatment responses under these scenarios.
| Parameter | Scenario 1 | Scenario 2 | Scenario 3 | Scenario 4 | Scenario 5 | Scenario 6 | ||
|---|---|---|---|---|---|---|---|---|
| Baseline Function | ||||||||
| h0 | 1 + h01 | 1 + 0.5h01h02 |
|
1 + h01 | 1 + 0.5h01h02 |
|
||
| γ1,1 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | ||
| γ1,2 | −0.65 | −0.65 | −0.65 | −0.65 | −0.65 | −0.65 | ||
| γ1,3 − γ1,15 | - | - | - | 0 | 0 | 0 | ||
| γ2,1 | - | −0.65 | −0.65 | - | −0.65 | −0.65 | ||
| γ2,2 | - | 0.65 | 0.65 | - | 0.65 | 0.65 | ||
| γ2,3 − γ2,15 | - | - | - | - | 0 | 0 | ||
| α1,1 | 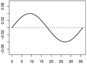 |
 |
 |
 |
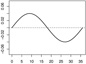 |
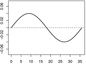 |
||
| α1,2 | 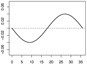 |
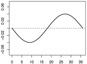 |
 |
 |
 |
 |
||
| α1,3 − α1,15 | - | - | - | 0 | 0 | 0 | ||
| α2,1 | - |  |
 |
- |  |
 |
||
| α2,2 | - |  |
 |
- |  |
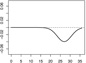 |
||
| α2,3 − α2,15 | - | - | - | - | 0 | 0 | ||
| Contrast Function | ||||||||
| β0 | −0.65 | −0.65 | −0.65 | −0.65 | −0.65 | −0.65 | ||
| β1 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | ||
| β2 | −0.65 | −0.65 | −0.65 | −0.65 | −0.65 | −0.65 | ||
| β3 − β15 | - | - | - | 0 | 0 | 0 | ||
| ω1 | 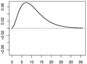 |
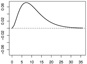 |
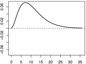 |
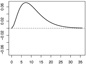 |
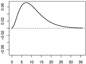 |
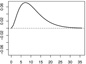 |
||
| ω2 |  |
 |
 |
 |
 |
 |
||
| β3 − β15 | - | - | - | 0 | 0 | 0 | ||
| Average Treatment Response | ||||||||
| E{Y*(0)} | 0.93 | 0.77 | 1.09 | 0.93 | 0.77 | 1.09 | ||
| E{Y*(1)} | 0.82 | 0.66 | 0.97 | 0.82 | 0.66 | 0.97 | ||
| E{Y*(gopt)} | 1.31 | 1.16 | 1.47 | 1.31 | 1.16 | 1.47 | ||
A “-” indicates that the parameter is not applicable in the scenario.
We compare two different commonly employed working models for and ϕ2(Z, X) = γ.We consider four different sample sizes n = 75, 150, 300, and 600 for Scenarios 1 – 3 and two sample sizes n = 300 and 600 for Scenarios 4 – 6. (We do not fit models for Scenarios 4 – 6 with the smaller sample sizes because the number of parameters is too large in each case.) For each scenario and sample size combination, we generate 250 data sets and estimate a treatment regime for each. For each scenario we also generate a test set with N = 150, 000 independent observations that are used for evaluating treatment selection performance. Based on previous analyses, not discussed here, we chose to employ PFR using 8 B-spline basis functions since this provided a small but rich-enough set of functions to estimate the contrast coefficients well in all settings. We also used the first 10 observed functional principal components as we found that they accounted for over 99% of the variation in each of the functional predictors.
Estimation performance is evaluated separately for the scalar and functional parts of the models. For the scalar coefficients, we compute the mean squared error (MSE), ‖β̂ − β0‖2 where β0 is the vector of true values for β, from each of the 250 estimated regimes and report the mean and corresponding standard error. For the functional coefficients, we compute the mean integrated mean squared error (MIMSE) for the estimated coefficient functions corresponding to the first two functional predictors, where L is the length of the interval over which the baseline covariate functions are observed, from each of the 250 estimated regimes and report the mean and corresponding standard error. We consider estimation error in only the first two coefficient functions in order to draw performance comparisons between the scenarios with no spurious covariates and the corresponding scenarios with spurious covariates.
We evaluate treatment assignment accuracy for each estimated regime on a test data set that is independent of the data used to fit the model. The model estimates are used to compute the treatment assignment for the ith test observation. For the entire set of test observations we compute the percent correct decision (PCD) given by
and take the average of these accuracies over the 250 replications. We also evaluate the treatment selection performance by computing the the expected value of the response under the selected treatment in a test data set. When we constructed the test set for each scenario, we generated the response under each treatment so that we are able to calculate an approximation to the average treatment response under treatment 0 (E{Y*(0)}), under treatment 1 (E{Y*(1)}), and under the optimal treatment (E{Y*(gopt)}). These values are provided in the bottom three rows of Table 1 for each scenario. We point out that in all scenarios, assigning treatment 0 to all subjects is favored over assigning treatment 1 since the average value of the response is larger, but assigning the optimal treatment results in even better (larger) average response. We use the baseline covariates from the test data to estimate treatment assignment from the estimated regimes in the 250 replications and compute the mean response on the selected treatment and then average over the 250 replicates. These values are denoted by 8 E{Y*(ĝ)}.
3.2 Numerical Investigation Results
Tables 2 and 3 summarize the estimation and treatment selection accuracy of our method based on the data generated under Scenarios 1 – 3 and Scenarios 4 – 6 respectively using either ϕ1 or ϕ2 as a working model for h0 and based on varying sample sizes. In general we see that increased sample size yields improved estimation accuracy for both the scalar and functional parameter estimates. The results also suggest that using a richer linear working model for ϕ yields better estimation accuracy when compared with the simpler constant working model, even when h0 is not truly linear in the baseline covariates. We further note that settings in which there are no spurious variables (Scenarios 1 – 3) generally show better estimation performance than the corresponding settings with spurious variables (Scenarios 4 – 6). A closer inspection of estimation performance with respect to the scalar and functional parts of the contrast is provided in Web Appendix C.
Table 2.
Estimation performance (se) and treatment selection performance for Scenarios 1, 2, and 3 for different working functions for h0 (ϕ = ϕ1 or ϕ2) and for various sample sizes.
| Scenario | ϕ | n | Scalar MSE | Functional MIMSE | PCD | Ê{Y*(ĝ)} |
|---|---|---|---|---|---|---|
| 1 | ϕ1 | 600 | 0.030 (0.042) | 3.748 (1.408) | 0.97 | 1.312 (0.001) |
| 300 | 0.062 (0.092) | 4.891 (2.437) | 0.95 | 1.310 (0.002) | ||
| 150 | 0.117 (0.135) | 6.884 (6.401) | 0.94 | 1.306 (0.005) | ||
| 75 | 0.242 (0.291) | 11.498 (15.711) | 0.91 | 1.297 (0.011) | ||
| ϕ2 | 600 | 0.128 (0.150) | 7.289 (6.133) | 0.93 | 1.304 (0.006) | |
| 300 | 0.271 (0.302) | 10.104 (11.895) | 0.91 | 1.295 (0.012) | ||
| 150 | 0.550 (0.666) | 15.945 (19.385) | 0.87 | 1.275 (0.028) | ||
| 75 | 1.195 (1.525) | 40.839 (84.929) | 0.82 | 1.243 (0.055) | ||
| 2 | ϕ1 | 600 | 0.031 (0.036) | 3.633 (1.335) | 0.97 | 1.154 (0.001) |
| 300 | 0.060 (0.071) | 4.804 (2.393) | 0.95 | 1.152 (0.003) | ||
| 150 | 0.115 (0.138) | 6.845 (5.531) | 0.93 | 1.146 (0.006) | ||
| 75 | 0.212 (0.258) | 9.457 (9.847) | 0.91 | 1.138 (0.013) | ||
| ϕ2 | 600 | 0.067 (0.077) | 5.256 (3.407) | 0.95 | 1.151 (0.003) | |
| 300 | 0.123 (0.130) | 6.539 (4.570) | 0.93 | 1.147 (0.006) | ||
| 150 | 0.232 (0.273) | 9.132 (8.516) | 0.91 | 1.139 (0.011) | ||
| 75 | 0.465 (0.565) | 14.722 (20.344) | 0.88 | 1.124 (0.023) | ||
| 3 | ϕ1 | 600 | 0.021 (0.029) | 3.335 (1.242) | 0.97 | 1.467 (0.001) |
| 300 | 0.043 (0.056) | 4.218 (2.130) | 0.96 | 1.465 (0.002) | ||
| 150 | 0.083 (0.091) | 5.867 (4.874) | 0.94 | 1.462 (0.004) | ||
| 75 | 0.160 (0.182) | 8.420 (9.496) | 0.92 | 1.455 (0.007) | ||
| ϕ2 | 600 | 0.070 (0.085) | 5.459 (2.942) | 0.95 | 1.463 (0.003) | |
| 300 | 0.143 (0.157) | 7.545 (6.940) | 0.93 | 1.458 (0.006) | ||
| 150 | 0.274 (0.340) | 9.937 (9.884) | 0.91 | 1.449 (0.013) | ||
| 75 | 0.570 (0.678) | 19.008 (31.063) | 0.87 | 1.431 (0.026) | ||
Note that MIMSE values (se) are ×10−4.
Table 3.
Estimation performance (se) and treatment selection performance for Scenarios 4, 5, and 6 for different working functions for h0 (ϕ = ϕ1 or ϕ2) and for various sample sizes.
| Scenario | ϕ | n | Scalar MSE | Functional MIMSE | PCD | Ê{Y*(ĝ)} |
|---|---|---|---|---|---|---|
| 4 | ϕ1 | 600 | 0.037 (0.052) | 0.922 (0.498) | 0.92 | 1.302 (0.003) |
| 300 | 0.081 (0.112) | 1.833 (2.756) | 0.88 | 1.286 (0.007) | ||
| ϕ2 | 600 | 0.175 (0.226) | 3.484 (6.332) | 0.84 | 1.258 (0.015) | |
| 300 | 0.375 (0.458) | 6.330 (5.365) | 0.78 | 1.212 (0.029) | ||
| 5 | ϕ1 | 600 | 0.037 (0.053) | 0.943 (0.898) | 0.92 | 1.144 (0.003) |
| 300 | 0.074 (0.103) | 1.784 (2.261) | 0.89 | 1.128 (0.008) | ||
| ϕ2 | 600 | 0.075 (0.112) | 1.593 (0.968) | 0.89 | 1.129 (0.007) | |
| 300 | 0.168 (0.216) | 2.842 (2.624) | 0.84 | 1.105 (0.014) | ||
| 6 | ϕ1 | 600 | 0.024 (0.033) | 0.779 (0.597) | 0.93 | 1.459 (0.002) |
| 300 | 0.055 (0.086) | 1.469 (2.903) | 0.90 | 1.448 (0.005) | ||
| ϕ2 | 600 | 0.083 (0.110) | 1.778 (1.296) | 0.88 | 1.438 (0.008) | |
| 300 | 0.173 (0.221) | 3.389 (2.688) | 0.83 | 1.410 (0.016) | ||
Note that MIMSE values (se) are ×10−4.
With respect to treatment selection accuracy as measured by PCD, we observe that larger sample sizes, fewer spurious variables, and a richer working model for ϕ result in higher accuracy in treatment selection in the independent test sets. Furthermore, the results show that our approach can provide treatment selection strategies that can come close to achieving the mean value of the response in the population under the optimal treatment.
In Web Appendix B, we give a brief discussion concerning inference for the difference in the expected values of the response under competing regimes. We also outline and comment on a simple bootstrap procedure for constructing confidence intervals for this difference. In Web Appendix C we show the results of applying this bootstrap procedure for constructing confidence intervals on the simulated data generated under Scenarios 1 – 3.
4. Application to MDD Treatment Data
To illustrate our proposed approach for developing a treatment decision rule using available baseline scalar and functional covariates, we consider data from a study that investigated the use of two treatments for MDD. In addition to standard clinical measures (e.g., age, gender, Hamilton Depression Rating Scale (HAM-D) score, etc.) the study also collected EEG measurements under a controlled resting condition in which subjects had their eyes open or closed. After these baseline data were collected, the participant was randomized to either an antidepressant (a selective serotonin reuptake inhibitor (SSRI)), or placebo. The participant was monitored via assessments at 1, 2, 3, 4, 6, and 8 weeks after initiation of treatment.
There are 92 subjects in the study. We consider a restricted set of baseline scalar covariates consisting of gender, age, and baseline HAM-D score. We also consider two baseline functional covariates derived from resting EEG using a 72-electrode montage. More specifically, these two functional covariates correspond to the curves giving the difference between current source density (CSD) amplitude spectrum values (μV/m2) when the participant’s eyes are closed and when they are open (closed - open) over a frequency range of 3 to 16 Hz for the P5 and P9 electrodes. This frequency range roughly corresponds to what are known as the theta and alpha frequency bands and these two electrodes are located in the posterior region of the 72-electrode montage. Prior studies have suggested that posterior theta and alpha rhythm of the EEG may be useful in differentiating patients who do or do not respond to SSRIs or other treatments for MDD (Bruder et al., 2008; Tenke et al., 2011). A detailed discussion of CSD measures in EEG is provided in Tenke et al. (2011). The top left and right panels of Figure 2 show the CSD difference curves corresponding to the P5 (X1) and P9 (X2) electrodes for the 92 subjects in our data set.
Figure 2.

Top Panels: CSD differences (eyes closed - eyes open) from the P5 channel (left) and P9 channel (right). Bottom Panels: Estimated contrast coefficient functions corresponding to the P5 channel (left) and P9 channel (right)
Of the 92 subjects that we use to develop a treatment decision rule, 48% were randomized to SSRI, 65% are female, the mean age is 39.05, and the mean baseline HAM-D score is 18.34. For the response, we consider HAM-D score at end of the treatment period. Thus lower values of the response variable are desirable. Three of the 92 subjects were missing their HAM-D score at week 8 so we chose to use their score at week 6 for the response.
Let Z = (Z1, Z2, Z3)⊤ be the vector of baseline scalar covariates where Z1 = 1 if the patient is female and 0 otherwise, Z2 = age, and Z3 = HAM-D score at baseline. These scalar covariates are centered and scaled by their respective sample means and standard deviations before fitting the model. Furthermore, let X = {X1, X2} where X1 and X2 are the CSD difference curves corresponding to the P5 and P9 channels respectively. To estimate the decision rule, we assumed equal probability of receiving the SSRI or placebo and used a working baseline function given by . We used 10 functional principal components to represent each of the functional covariates and a B-spline basis with 8 basis functions to represent each of the coefficient functions.
The estimated treatment decision rule is given by
where ω̂1 and ω̂2 are shown in the bottom panels of Figure 2. If ĝ(Z, X) = 1 then the SSRI is selected, otherwise placebo is selected. Although complex, the estimated decision rule may provide some insight into how individual patient characteristics can be used to select treatment. First consider the scalar covariates. Adjusting for all other covariates, being female, being older than the average age in the sample, and having baseline HAM-D that is higher than the average in the sample all increase the value of the contrast and so might suggest the use of the SSRI over placebo. Next consider the functional covariates and their corresponding contrast coefficient estimates shown in Figure 2. Based on ĝ, adjusting for all other covariates, large positive CSD differences across the theta and alpha frequency bands corresponding to the P5 electrode suggest the use of the SSRI over placebo. The estimated contrast coefficient function corresponding to the P9 electrode shows that large positive CSD differences in the theta band, especially at lower frequencies, suggest the use of placebo over the SSRI and large positive CSD differences in the alpha band, especially at higher frequencies, suggest the use of the SSRI over placebo.
To assess treatment selection among the patients used to develop the decision rule, we compared the average value of the response among the following subgroups: (1) those who received placebo, (2) those who received the SSRI, and (3) those who received the treatment that would have been assigned if ĝ were used to assign treatment. There were 52 patients whose actual treatment assignment matched what would have been assigned based on ĝ (22 on placebo, 30 on the SSRI). Figure 3 shows the distributions of the HAM-D score at the end of treatment for each of these three subgroups. The mean HAM-D scores at the end of treatment are 11.42 for those on placebo, 10.93 for those on the SSRI, and 9.38 for those who received their estimated optimal treatment. We used the bootstrap procedure discussed in Web Appendix B (see note on issues related to using a bootstrap procedure) to construct 95% confidence intervals for the mean improvements in HAM-D score at the end of treatment comparing our treatment assignment model (denoted by g) to either (1) assigning the SSRI to all patients (denoted by 1) or (2) assigning placebo to all patients (denoted by 0). The 95% confidence interval for E{Y*(g)} − E{Y*(1)} is (−4.07, −0.06) and for E{Y*(g)}−E{Y*(0)} is (−4.65, −0.17). Both intervals suggest that the treatment regime based on the baseline scalar and functional predictors is preferable, perhaps only slightly, to assigning everyone either SSRI or placebo as it appears to lead to lower HAM-D score at the end of the treatment period.
Figure 3.

Boxplots comparing HAM-D scores at end of treatment for those on placebo, SSRI, or for those whose treatment matched the optimal treatment according to ĝ.
5. Discussion
We have proposed a method for constructing a treatment decision rule based on scalar and functional baseline covariates that casts estimation as a loss-minimizing procedure in the framework of A-learning. In the case of all scalar baseline covariates, A-learning has been shown to provide protection against mis-specification of part of the response model provided that the contrast is correctly specified. Our numerical investigations provide evidence that this property carries over to the case where the baseline covariates consist of both scalars and functions. Furthermore, it has been argued that A-learning is appealing because it may be reasonable to expect that there is a complex relationship between the baseline covariates and the response, but that the optimal treatment rule should depend on those baseline covariates in a simple manner (Schulte et al., 2014). Although the part of the model corresponding to the response among those on the “reference treatment” may be mis-specified, we recommend using a richer working model as we have evidence that a richer model leads to better estimation and treatment selection.
Regarding our application to the MDD data, one reason why the treatment assignment model that we consider did not lead to “substantially” better response may be that we are not considering baseline covariates that are most prescriptive of treatment. In practice, there may be relatively little clinical guidance on which baseline covariates are prescriptive of a particular treatment and so it may be desirable to incorporate a variable selection procedure into our approach that can identify such variables. Furthermore, our numerical investigations demonstrated that the inclusion of spurious variables in the response model can lead to poorer estimates of the contrast parameters and poorer performance with respect to treatment selection. Development of approaches that can both estimate treatment decision rules and select important prescriptive scalar and functional baseline covariates is crucial and could lead to better outcomes for patients suffering from MDD.
Supplementary Material
Acknowledgements
We thank the reviewers, Associate Editor, and Editor of this journal who reviewed a previous version of this article. This article has benefitted substantially from their comments. This work was supported by MH099003-01 from the National Institutes of Health.
Footnotes
The R code that was used to perform the simulations in Section 3 is available with this paper at the Biometrics website on Wiley Online Library. The web-based supplementary materials also include Web Appendies A, B and C, referenced in Sections 2 and 3 as well as Appendix D which addresses aspects of computation.
References
- Blatt D, Murphy S, Zhu J. Technical Report 04-63. The Methodology Center, Pennsylvania State University; 2004. A-learning for approximate planning. [Google Scholar]
- Bruder G, Sedoruk J, Stewart J, McGrath P, Quitkin F, Tenke C. Electroencepholographic alpha measures predict theraputic response to selective serotonin reuptake inhibitor antidepressent: Pre and post-treatment findings. Biological Psychiatry. 2008;63:1171–1177. doi: 10.1016/j.biopsych.2007.10.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chakraborty B, Murphy S, Strecher V. Inference for non-regular parameters in optimal dynamic treatment regimes. Statistical Methods in Medical Research. 2009;19:317–343. doi: 10.1177/0962280209105013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Crainiceanu C, Reiss P, Goldsmith J, Huang L, Huo L, Scheipl F, Swihart B, Greven S, Harezlak J, Kundu M, Zhao Y, McLean M, Xiao L. refund: Regression with functional data. R Package version 0.1-11. 2014 [Google Scholar]
- Gaynes B, Warden D, Trivedi M, Wisniewski S, Fava M, Rush A. What did STAR*D teach us? results from a large-scale, practical, clinical trial for patients with depression. Psychiatric Services. 2009;60:1439–1445. doi: 10.1176/ps.2009.60.11.1439. [DOI] [PubMed] [Google Scholar]
- Goldsmith J, Bobb J, Crainiceanu C, Reich D. Penalized functional regression. Journal of Computational and Graphical Statistics. 2011;20:830–851. doi: 10.1198/jcgs.2010.10007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holtzheimer P, Mayberg H. Stuckinarut: rethinking depression and its treatment. Trends in Neurosciences. 2011;34:1–9. doi: 10.1016/j.tins.2010.10.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- James G, Silvermam B. Functional adaptive model estimation. Journal of the American Statistical Association. 2005;100:565–576. [Google Scholar]
- Laber E, Lizotte D, Qian M, Pelham W, Murphy S. Dynamic treatment regimes: Technical challenges and applications. Electronic Journal of Statistics. 2014;8:1225–1272. doi: 10.1214/14-ejs920. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lu W, Zhang H, Zeng D. Variable selection for optimal treatment decision. Statistical Methods in Medical Research. 2013;22:493–504. doi: 10.1177/0962280211428383. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McGrath C, Kelley M, Holtzheimer P, III, Dunlop B, Craighead W, Franco A, Craddock R, Mayberg H. Toward a neuroimaging treatment selection biomarker for major depressive disorder. JAMA Psychiatry. 2013;70:821–829. doi: 10.1001/jamapsychiatry.2013.143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McKeague I, Qian M. Estimation of treatment policies based on functional predictors. Statistica Sinica. 2014;24:1461–1485. doi: 10.5705/ss.2012.196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moodie E, Richardson T. Estimating optimal dynamic regimes: Correcting bias under the null. The Scandinavian Journal of Statistics. 2010;37 doi: 10.1111/j.1467-9469.2009.00661.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murphy S. Optimal dynamic treatment regimes (with discussion) Journal of the Royal Statistical Society, Series B. 2003;65:331–336. [Google Scholar]
- Qian M, Murphy S. Performance guarantees for individualized treatment rules. Annals of Statistics. 2011;39:1180–1210. doi: 10.1214/10-AOS864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramsay JO, Silverman BW. Functional Data Analysis. Second Edition. New York: Springer; 2005. [Google Scholar]
- Robins J. Optimal structured nested models for optimal sequential decisions. In: Lin D, Heagerty P, editors. Proceedings of the Second Seattle Symposium on Biostatistics. New York: Springer; 2004. pp. 189–326. [Google Scholar]
- Rubin D. Bayesian inference for causal effects: The role of randomization. Annals of Statistics. 1978;6:34–58. [Google Scholar]
- Schulte P, Tsiatis A, Laber E, Davidian M. Q- and A-learning methods for estimating optimal dynamic treatment regimes. Statistical Science. 2014;29:640–661. doi: 10.1214/13-STS450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Swihart B, Goldsmith J, Crainiceanu C. Restricted likelihood ratio tests for functional effects in the functional linear model. Technometrics. 2013 [Google Scholar]
- Tenke C, Kayser J, Manna C, Fekri S, Kroppmann C, Schaller J, Alschuler D, Stewart J, McGrath P, Bruder G. Current source density measures of electroencepholographic alpha predict antidepressant treatment response. Biological Psychiatry. 2011;70:388–394. doi: 10.1016/j.biopsych.2011.02.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B, Tsiatis A, Laber E, Davidian M. A robust method for estimating optimal treatment regimes. Biometrics. 2012;68:1010–1018. doi: 10.1111/j.1541-0420.2012.01763.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Kosorok M, Zeng D. Reinforcement learning design for cancer clinical trials. Statistics in Medicine. 2009;28:3294–3315. doi: 10.1002/sim.3720. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Zeng D, Rush A, Kosorok M. Estimating individualized treatment rules using outcome weighted learning. Journal of the American Statistical Association. 2012;107:1106–1118. doi: 10.1080/01621459.2012.695674. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.