

Summary
For comparison of proportions there are three commonly used measurements: the difference, the relative risk and the odds ratio. Significant effort has been spent on exact confidence intervals for the difference. In this paper, we focus on the relative risk and the odds ratio when data are collected from a matched-pairs design or a two-arm independent binomial experiment. Exact one-sided and two-sided confidence intervals are proposed for each configuration of two measurements and two types of data. The one-sided intervals are constructed using an inductive order, they are the smallest under the order, and are admissible under the set inclusion criterion. The two-sided intervals are the intersection of two one-sided intervals. R codes are developed to implement the intervals. Supplementary materials for this article are available online.
Keywords: Binomial distribution, Coverage probability, Multinomial distribution, Set inclusion
1. INTRODUCTION
In medical research we often need to compare two treatments using binary data, and three parameters are commonly used: the risk difference (the difference of two proportions), the relative risk (the ratio of two proportions) and the odds ratio. The risk difference is an absolute measurement of effect, while the relative risk and the odds ratio are relative measurements for comparing outcomes. In retrospective case-control studies, the odds ratio is used because the other two parameters cannot be estimated. It is also well known that the odds ratio has a direct relationship with the regression coefficient in logistic regression. The relative risk is used in randomized controlled trials and cohort studies especially when the two relevant proportions are both small. In such a case, the risk difference is not as informative as the relative risk (see McCullagh 1980, Goodman 1985, and Agresti 2002, p.44). The relative risk and the odds ratio are comparable when the disease is rare with very low probability. For some common diseases (e.g., hypertension), the value of the odds ratio could be overestimated, and the relative risk should be used instead. It should be noted that the relative risk and the odds ratio are defined differently in Eq (3) and Eq (23) for a matched-pairs design and a two-arm independent binomial experiment. In this paper we focus on interval estimation of the relative risk and the odds ratio using data that are collected in a matched-pairs design or a two-arm independent binomial experiment, and are organized in a 2 × 2 contingency table. Results on the risk difference can be found, for example, in Wang (2010, 2012).
When no pivot quantity can be found for a discrete distribution, the coverage probability of a confidence interval is typically not a constant. Therefore, for a secure capture of the parameter of interest the coverage probability function of a desired confidence interval must be always at least the nominal level 1 − α for all parameter configurations, and we call it an exact confidence interval of level 1 − α (see Casella and Berger, 1990, p. 404). Such an interval guarantees predetermined coverage for a fixed sample size no matter where the true parameter vector is located in the parameter space. The implementation, however, is typically challenging as compared with asymptotic intervals. Some studies have shown that asymptotic intervals for proportions may have an infimum coverage probability lower than the nominal level by a fixed positive amount regardless of sample size, see Huwang (1995), Agresti and Coull (1998), Brown, Cai and DasGupta (2001), and Wang and Zhang (2014). In particular, the Wald interval, the Wilson interval (1927), and the Agresti-Coull interval (1998) for a binomial proportion are proven to have an incorrect infimum coverage even for very large sample sizes. One may turn to bootstrap intervals, especially when the parameter of interest is complicated. Such efforts can be found in, for example, Li, Taylor and Nan (2010), Lin et al. (2009) and Parzen et al. (2002). However, Wang (2013) proved that all bootstrap intervals for any function of proportions, including the relative risk and the odds ratio, always have an infimum coverage probability of zero. Therefore, practitioners are at their own risk to use these intervals, since the intervals may have a very small chance of capturing the parameter of interest, and the usage of exact intervals is justified.
Exact intervals for the relative risk and the odds ratio may be obtained by inverting exact tests in the case of two independent binomials, see for example, Gart (1971), Santner and Snell (1980), and Chan and Zhang (1999). This indirect construction may result in wider intervals. Wang (2010, 2012) proposed optimal intervals for the risk difference based on a direct analysis of coverage probability and an inductive order of the sample space. Shan and Wang (2013) developed an R-package, ExactCIdiff, to implement his intervals. This approach is now adapted to more complicated cases: the relative risk and the odds ratio. In Section 2 we describe preliminary results for the smallest one-sided interval construction. Section 3 discusses how to derive exact intervals for the relative risk and the odds ratio using a matched-pairs design and how to implement the computation. Section 4 deals with the case of a two-arm independent binomial experiment. The proposed intervals tend to be shorter than the ones from SAS (Version 9.3). Section 5 is a summary. The proofs and some figures are given in Supplementary Materials online.
2. PRELIMINARY RESULTS
Following the work by Buehler (1957), Bol’shev (1965), Chen (1993), Lloyd and Kabaila (2003), and Wang (2010) the construction of an exact one-sided confidence interval becomes automatic provided that an order (or equivalently, a rank function on a finite sample space) is specified in advance. We describe this result here, as it will be applied four times in the paper. Suppose a random vector X is observed from a finite sample space S, i.e., . A rank function R(.), assuming positive integer values, is defined on S. The probability mass function of X is given by p(x; ξ), where ξ is the parameter vector belonging to a parameter space H, a subset of Rk. Suppose ξ = (θ, η) and
where θ is the parameter of interest and η is the nuisance parameter vector, [A, B] is a given interval in R1 (A and B may be ±∞, and the interval is open when the corresponding end is infinity) and D(θ) is a subset of Rk−1 depending on θ. We are interested in searching for the smallest exact lower one-sided confidence interval [LS(X), B] among all 1 − α intervals for θ with form [L(X), B] that satisfy
So a sample point x with a smaller rank has a larger confidence limit.
Lemma 1: Assume α ∈ (0, 1). For a given rank function R(.) on S and any x ∈ S, consider
| (1) |
If fx(θ) is a continuous function in θ, define
| (2) |
then
-
i)
[LS(X), B] is of level 1 − α and satisfies 1) and 2);
-
ii)
for any 1 − α interval [L(X), B] satisfying 1) and 2), L(X) ≤ LS(X).
This lemma follows Theorem 4 in Wang (2010). Due to ii), [LS(X), B] is the smallest interval since it is a subset of any other interval. Then it is the best under the given rank function R(.). In order to derive the smallest exact interval for parameters including the relative risk and the odds ratio with A = 0 and B = +∞, we have to resolve the following two problems for implementation:
-
A)
provide a reasonable rank function R(.) for each of four cases;
-
B)
find the infimum in Eq (1) over D(θ) and the smallest solution of Eq (1) efficiently.
For a sample space S with n sample points, there are about 2n possible rank functions on S. Some are clearly bad for interval construction. For example, the rank function Rc(.) that assumes a constant value over S (i.e., all sample points are tied) produces an interval with a constant confidence limit over S. Lemma 1 still shows that it is the smallest under Rc(.). However, such an interval is useless in practice, and can be uniformly improved by simply giving up those ties. Therefore, identifying a reasonable rank function is extremely important and also challenging, but Lemma 1 does not discuss it. One may use, for example, the maximum likelihood estimator for θ as the rank function. This, however, generates too many ties and results in a wide confidence interval. Wang (2010) proposed an inductive construction on rank function that yields an admissible interval. We apply this idea to two interesting parameters: the relative risk and the odds ratio.
Searching for the infimum of a given function is a classic, but difficult problem in numerical computation, especially for a multivariate function. A more challenging issue is that the infimum must be computed a large number of times. Programs exist for optimization, however, none is able to provide a solution precisely and quickly. Our study suggests that a two-stage grid search (explained later) for the infimum on D(θ) is an effective solution.
3. CASE I: A MATCHED-PAIRS DESIGN
In a 2 × 2 table with a matched-pairs design, suppose there are n independent and identical trials, and each trial is inspected by two criteria 1 and 2. By criterion i, each trial is classified as Si or Fi for i = 1, 2. The numbers of trials with outcomes (S1, S2), (S1, F2), (F1, S2) and (F1, F2) are the observations, and are denoted by N11, N12, N21 and N22, respectively. Thus Xp = (N11, N12, N21) follows a multinomial distribution with probabilities p11, p12, and p21, respectively, denoted by Multinomial(n, p11, p12, p21). Let p1* = P (S1) and p*1 = P(S2) be the two paired proportions. The involved items are displayed below.
| S2 | F2 | ||
| S1 | (S1, S2), N11, p11 | (S1, F2), N12, p12 | p1* = p11 + p12 |
| F1 | (F1, S2), N21, p21 | (F1, F2), N22, p22 | |
| p*1 = p11 + p21 | ∑i,j Nij = n,∑i,j pij = 1 |
The relative risk θpr and the odds ratio θpo are given by:
| (3) |
Here, the subscripts p, r and o stand for “paired proportions”, “relative risk” and “odds ratio”, respectively. Two one-sided 1 − α confidence intervals [L(Xp), +∞) and [0, U(Xp)] and a two-sided 1 − α confidence interval [L(Xp), U(Xp)] are to be constructed for θpr and θpo. To the best of our knowledge, no exact confidence intervals have been proposed for these parameters. StatXact 10 (2013) claims to compute an interval for so called “the odds ratio” (see Equations 13.17 and 13.7 in the user manual). It is indeed θpr, but we find that their computed interval is for p12/p21 not θpr. SAS (Version 9.3) does not have any discussion on exact intervals for the parameters. The sample space and the parameter space are
| (4) |
with (n + 1)(n + 2)(n + 3)/6 sample points and
| (5) |
respectively. The random vector Xp has a joint probability mass function
| (6) |
with n22 = n−n11 −n12 −n21 and p22 = 1−(p1* + p*1−p11). We illustrate the setting below.
Example 1. Bentur et al. (2009, p.847) conducted a study on airway hyper-responsiveness (AHR) status before and after stem cell transplantation (SCT) on 21 patients. The AHR status for each patient is assessed by a methacholine challenge test (MCT) twice, before and after SCT. The data summary is given as follows.
| Before SCT | ||||
|---|---|---|---|---|
| AHR yes | AHR no | total | ||
| After SCT | AHR yes | 1(=n11), p11 | 7(=n12), p12 | 8, p1* |
| AHR no | 1(=n21), p21 | 12(=n22), p22 | 13 | |
| total | 2, p*1 | 19 | 21 | |
For example, one (= n11) patient has AHR before and after SCT, and p11 is the probability that a patient has AHR before and after SCT. Exact confidence intervals for θpr and θpo will be derived to study the effect of SCT on AHR status especially in this small sample.
3.1 INTERVALS FOR θpr
Three intervals (lower one-sided, upper one-sided and two-sided) are to be constructed for θpr. The two-sided 1 − α interval can be obtained by using the intersection of the two one-sided 1 − α/2 intervals. The next lemma discusses how to obtain an upper one-sided interval from a lower one-sided interval. Therefore, we focus on the construction of a lower one-sided 1 − α interval. Let [a, b] = [a, +∞) if b = +∞.
Lemma 2: Suppose [L(N11, N12, N21), +∞) is a lower one-sided 1− α confidence interval for θpr. Then
| (7) |
is an upper one-sided 1 − α confidence interval for θpr. Furthermore, [L(N11, N12, N21), U(N11, N12, N21)] is a two-sided 1 − 2α interval for θpr.
The parameter space Hp can be expressed in terms of (θpr, p11, p21) with
| (8) |
as follows: Hpr = {(θpr, p11, p21) : (p11, p21) ∈ Dpr(θpr), ∀ θpr ∈ [0, +∞)}, where
| (9) |
The first line in (9) is a triangle with three vertices, (0, 0), (1/θpr, 0) and (0, 1/(θpr + 1)), in the p11-p21 plane, and the second is the intersection of two triangles, one just mentioned and the other with three vertices, (0, 0), (1, 0) and (0, 1). See both cases in Figure S1 in Supplementary Materials. The joint probability mass function pp is rewritten as
| (10) |
where pp and p12 are given in (6) and (8), respectively.
As in Lemma 1, the construction of a one-sided interval [L(Xp), +∞) depends on a rank function Rpr(.) on Sp. Point xp is large if Rpr(xp) is small. Here are three natural rules on Rpr.
-
a)
Rpr(0, n, 0) = 1. i.e., point (0, n, 0) is the largest.
-
b)
Rpr(n11, n12, n21) ≤ Rpr(n11, n12 − 1, n21) for any n12 ∈ [1, n − n11 − n21].
-
c)
Rpr(n11, n12, n21 − 1) ≤ Rpr(n11, n12, n21) for any n21 ∈ [1, n − n11 − n12].
Rule a) follows the intuition that (0, n, 0) provides the largest estimate for θpr. Rules b) and c) follow the monotonicity of function θpr = (p11 + p12)/(p11 + p21). One would expect a similar rule for the case that n12 and n21 are fixed and n11 varies. Both the numerator and the denominator of θpr include p11, so it is not appropriate to propose a simple rule for n11.
The rank function Rpr(.) is determined by combining Rules a), b), c) and numerical evaluation sequentially on all sample points. Again, Rpr(0, n, 0) = 1. We next describe how to assign a value for the rank function from small to large (i.e., determine sample points from large to small). Suppose that Rpr(.) has been assigned values to sets Epr,1 through Epr,k with values 1 through k (e.g., Epr,1 = {(0, n, 0)}) for some k ≥ 1. i.e., set Epr,i contains the ith largest point(s) for i ≤ k. Let . Now we identify a nonempty set Epr,k+1 in Sp that contains the (k + 1)th largest point(s). If such a set is found, then by induction, the function Rpr(.) is defined on Sp because Spr,k is strictly increasing and Sp is finite.
For each point xp = (n11, n12, n21), we introduce five points: A = (n11 + 1, n12, n21), B = (n11, n12 − 1, n21), C = (n11, n12, n21 + 1), D = (n11 − 1, n12, n21), E = (n11 + 1, n12 − 1, n21), that are next to but less than xp. Let Nxp be the neighbor set that consists up to four points:
| (11) |
See Nxp in Figure S2 in Supplementary Materials for xp = (3, 3, 2).
The neighbor set for Spr,k, denoted by Npr,k, consists of points in Nxp for any xp ∈ Spr,k but not in Spr,k. i.e.,
| (12) |
However, some points in Npr,k are impossible to be the (k + 1)th largest due to Rules b) and c). To eliminate them from the selection, consider a subset of Npr,k, called the candidate set Cpr,k, given by
| (13) |
Set Epr,k+1 is to be selected from Cpr,k, not Npr,k. For each , consider an equation similar to (1)
| (14) |
where ppr is given in (10). Let be the smallest solution to the above equation if a solution exists, and let be 0 otherwise. Then define
| (15) |
| (16) |
Eq (15) assures that the rank function Rpr(.) yields the smallest (best) interval (with the largest lower confidence limit) in each step. Since Epr,k+1 is not empty, and Sp is finite, there always exists a positive integer kpr such that Spr,kpr = Sp. Thus, the rank function Rpr(.) is defined on the entire Sp, and the construction for Rpr(.) is complete. Then the smallest lower one-sided 1 − α confidence interval [Lpr, +∞) for θpr, under the rank function Rpr(.), is derived following Lemma 1, the smallest upper one-sided 1 − α interval [0, Upr] follows Lemma 2, and [Lpr, Upr] is a two-sided 1 − 2α interval. If we use an existing function, e.g., the maximum likelihood estimator of θpr, to define an order, then many sample points, for example, the points (n11, n12, n21) with n11 + n12 = n11 + n21, are tied since they have the same estimate, 1, for θpr. So, the corresponding confidence limits are equal to each other at these sample points following Lemma 1. In particular, the confidence limits at points (n11, n12, n21) = (i, 0, 0), for i = 1, …, n, remain unchanged, indicating that the order by the maximum likelihood estimator is unreasonable.
Three facts are worth mentioning for the computation in (14) and (15). i) Find Epr,k+1 from Cpr,k in (13) instead of Npr,k in (12). ii) Using a two-stage grid search for the infimum in (14). i.e., for each Dpr(θpr) a partition is given first. We pick a point (θpr, p11, p12) in each set of the partition and identify the point that yields the minimum value of the function in (14). Then on the set of the partition that contains this point, we have another finer partition and search for the minimum again. iii) Suppose two points xp1 and xp2 belong to Cpr,k and we already compute L* (xp1). If we find fxp2(L* (xp1)) < 1 − α, then xp2 does not belong to Epr,k+1 and the computation of L*(xp2) is not needed. These three facts make the computation more efficient, and are also used for the other three cases in this paper. Next, we provide a closed form for Lpr(0, n, 0), which is useful for checking the precision of the numerical calculation.
Lemma 3: For any rank function R(.) with R(0, n, 0) = 1, let [L(N11, N12, N21), +∞) be the smallest one-sided 1 − α interval for θpr under R. Then
| (17) |
Example 2. For illustration purpose, we show the construction of the largest four Lpr(xp)’s on four sample points with ranks 1 through 4, when 1 − α = 0.95 and n = 3.
Due to a) Rpr(0, 3, 0) = 1. So Lpr(0, 3, 0) = 0.5832 following (17), or one can obtain the same result by solving a special case of (1):
To find the sample point with rank 2, we have
following (11), (12) and (13). Then solve (14) twice by using x′ = (0, 2, 0) and x′ = (1, 2, 0), respectively, with Spr,1 = {(0, 3, 0)}, and obtain L*(0, 2, 0) = 0.4320 and L*(1, 2, 0) = 0.5504. Since L*(1, 2, 0) is larger than L*(0, 2, 0), set Epr,1 = {(1, 2, 0)} and the rank function Rpr(1, 2, 0) = 2.
To find the sample points with ranks 3 and 4, repeat a similar step to the above paragraph. Then Rpr(1, 1, 0) = 3 and Rpr(2, 1, 0) = 4. The details are given in Table 1. Note that Cpr,3 is a proper subset of Npr,3 and set Epr,3 is found within Cpr,3 instead of Epr,3. This would save a lot of computing time especially when n is large.
Table 1.
The details of the construction of Lpr at the four largest sample points in Example 2.
| k | Epr,k | Npr,k | Cpr,k | xp | Rpr(xp) | Lpr(xp) | ||
|---|---|---|---|---|---|---|---|---|
| (0,3,0) | 1 | 0.5832 | ||||||
| 1 | (0,3,0) | (0,2,0) | (0,2,0) | 0.4320 | ||||
| (1,2,0) | (1,2,0) | 0.5504 | 0.5504 | (1,2,0) | 2 | 0.5504 | ||
| 2 | (1,2,0) | (0,2,0) | (0,2,0) | 0.4320 | ||||
| (1,1,0) | (1,1,0) | 0.5151 | 0.5151 | (1,1,0) | 3 | 0.5151 | ||
| (2,1,0) | (2,1,0) | 0.4750 | ||||||
| 3 | (1,1,0) | (0,2,0) | (0,2,0) | 0.4104 | ||||
| (1,0,0) | (1,0,0) | 0.1127 | ||||||
| (1,1,1) | (1,1,1) | 0.2169 | ||||||
| (0,1,0) | (2,1,0) | 0.4521 | 0.4521 | (2,1,0) | 4 | 0.4521 | ||
| (2,1,0) | ||||||||
| (2,0,0) |
The lower confidence limits on these four points, (0,3,0), (1,2,0), (1,1,0) and (2,1,0), are also given in Table 1 following Lemma 1 with the rank function Rpr(.) at the four points. For example, Lpr(1, 1, 0) = 0.5151 is the smallest solution of the following function of θpr, which is also a special case of (1).
Example 1 (continued). Confidence intervals for θpr are reported in Table 2. For example, the 95% intervals [Lpr, +∞), [0, Upr] and the 90% interval [Lpr, Upr] for θpr are equal to [1.2906, +∞), [0, 15.9291] and [1.2906, 15.9291], respectively. It is clear that SCT increases the chance of having AHR because the lower-sided and two-sided intervals are inside (1, +∞). We obtain Lpr(1, 7, 1) = 1.2906 and Lpr(1, 1, 7) following Lemma 1 under the rank function Rpr(.), then Upr(1, 7, 1) = 1/Lpr(1, 1, 7) = 15.9291 by Lemma 2. The computation takes time as the infimum in (14) is found over a two-dimensional region Dpr(θpr) many times.
Table 2.
Exact one-sided and two-sided intervals for θpr and θpo in Example 1 when n11 = 1, n12 = 7, n21 = 1, n22 = 12.
| Two-sided 90% | Two-sided 95% | |||
|---|---|---|---|---|
| Lower 95% | Upper 95% | Lower 97.5% | Upper 97.5% | |
| θ pr | 1.2906 | 15.9291 | 1.0448 | 23.0365 |
|
| ||||
| θ po | 1.4149 | 26.9615 | 1.1956 | 37.4813 |
3.2 INTERVALS FOR θpo
Similar to Lemma 2, we provide a one-to-one relationship between lower and upper confidence intervals for θpo. Therefore, we only derive a lower confidence interval as upper one-sided and two-sided intervals follow Lemma 4.
Lemma 4: Suppose [L(N11, N12, N21), +∞) is a lower one-sided 1 − α confidence interval for θpo. Then
| (18) |
is an upper one-sided 1 − α confidence interval for θpo. Furthermore, [L(N11, N12, N21), U(N11, N12, N21)] is a two-sided 1 − 2α interval for θpo.
The parameter space Hp is expressed in terms of (θpo, p11, p21) with
| (19) |
as follows: Hpo = {(θpo, p11, p21) : (p11, p21) ∈ Dpo(θpo), ∀ θpo ∈ [0, +∞)}, where
which is a right curved triangle. See Figure S3 in Supplementary Materials for this set with different values of θpo. The joint probability mass function pp in (6) is rewritten as ppo(n11, n12, n21; θpo, p11, p21) = pp(n11, n12, n21; p11, p12, p21), where p12 is in (19).
The construction of an interval [L(Xp), +∞) depends on a rank function Rpo(.) on Sp. Since θpo and θpr have the same monotonicity in p11, p12 and p21, Rules a), b) and c) for Rpr(.) in Section 3.1 are also valid for Rpo(.). However, we add one more rule for Rpo(.): d) Rpo(n11, n12, n21) = Rpo(n22, n12, n21), which follows that θpo is invariant if p11 and p22 are exchanged. This rule in fact makes the sample space simpler. For a point xp = (n11, n12, n21) let be a set in Sp:
| (20) |
By Rule d), the rank function Rpo(.) assumes a constant value on set . Thus Rpo(.) generates ties, and the confidence interval assumes a constant value on that coincides with the nature of θpo. When computing probability, each is one sample point in a new sample space
| (21) |
and the associated probability mass function is
| (22) |
Each (n11, n12, n21) that satisfies (21) is called the representation of . In this section, can be the representation or the set in (20). The advantage of in (21) over Sp in (4) is that the former contains fewer elements. For example, when n = 3, there are twenty points in Sp but only thirteen points in . Each set and its representation are listed below:
| in terms of (20) | the representation of | in terms of (20) | the representation of |
|---|---|---|---|
| {(0,0,0), (3,0,0)} | (0,0,0) | {(0,0,1), (2,0,1)} | (0,0,1) |
| {(0,0,2), (1,0,2)} | (0,0,2) | {(0,0,3)} | (0,0,3) |
| {(0,1,0),(2,1,0)} | (0,1,0) | {(0,1,1),(1,1,1)} | (0,1,1) |
| {(0,1,2)} | (0,1,2) | {(0,2,0),(1,2,0)} | (0,2,0) |
| {(0,2,1)} | (0,2,1) | {(0,3,0)} | (0,3,0) |
| {(1,0,0),(2,0,0)} | (1,0,0) | {(1,0,1)} | (1,0,1) |
| {(1,1,0)} | (1,1,0) |
In the list above, for example, Rpo(0, 3, 0) = 1 and Rpo(0, 0, 0) = Rpo(3, 0, 0).
The construction of the rank function Rpo(.) is the same as Rpr(.) except that xp and Sp in (4) and ppr in (10) are replaced by in (20), in (21) and in (22), respectively. In particular, we need to follow (12) through (16) to build up Rpo(.). Once Rpo(.) is defined on , the smallest lower one-sided 1 − α confidence interval [Lpo, +∞) for θpo under Rpo(.) is derived following Lemma 1, the smallest upper one-sided 1 − α confidence interval [0, Upo] follows Lemma 4, and [Lpo, Upo] is a 1 − 2α interval.
Example 1 (continued). The three intervals above are also reported in Table 2. SCT does increase the odds of having AHR because the lower one-sided and the two-sided confidence intervals are inside (1, +∞). Again, we compute the lower one-sided interval first, then the upper one-sided and two-sided intervals follow Lemma 4.
As a closing remark for this section, the associate editor pointed out that the interval construction just developed can also be applied to the multinomial sampling in a 2 × 2 table to infer another odds ratio
see Agresti (2002, p. 44). However, the technical details are quite different due to the structure of this odds ratio (OR), and will not be discussed in this paper.
4. CASE II: A TWO-ARM INDEPENDENT BINOMIAL EXPERIMENT
We also have a 2 × 2 table, but each row contains a binomial experiment as follows:
| S | F | ||
|---|---|---|---|
| experiment 1 | S1, X, p1 | F1, n1 − X, 1 − p1 | n1 |
| experiment 2 | S2, Y, p2 | F2, n2 − Y, 1 − p2 | n2 |
where X ~ Bin(n1, p1) is a binomial observation with n1 trials and a success probability p1 and Y ~ Bin(n2, p2) is independent of X. The relative risk θir and the odds ratio θio,
| (23) |
are of interest. The subscript i stands for “independent proportions”. Compared with Xp = (N11, N12, N21) that has three parameters p11, p12 and p21 in Section 3, we now observe a simpler random vector Xi = (X, Y) with two parameters p1 and p2. In consequence, the interval construction is easier. The sample space and the parameter space are given below:
| (24) |
and
| (25) |
The joint probability mass function is
| (26) |
Example 3. Consider a study in Essenberg (1952), where a two-arm randomized clinical trial was conducted for testing the effect of tobacco smoking on tumor development in mice. In the treatment (smoking) group, there were 23(= n1) mice, and tumors were observed on 21(= x) mice; in the control group, n2 = 32 and y = 19. Let p1 and p2 be the tumor rates for the treatment and control groups, respectively. A comparison between p1 and p2 using θir and θio will be discussed for the smoking effect on tumor development.
4.1 INTERVALS FOR θir
Similar to Lemmas 2 and 4, there exists a one-to-one relationship between lower and upper one-sided intervals.
Lemma 5: Suppose [Ln2,n1(Y, X), +∞) is a lower one-sided 1 − α confidence interval for 1/θir = p2/p1. Then
| (27) |
is an upper one-sided 1 − α interval for θir. Suppose [Ln1,n2(X, Y ), +∞) is a lower one-sided 1 − α interval for θir, then [Ln1,n2(X, Y), U(X, Y)] is a two-sided 1 − 2α interval for θir.
Following Lemma 5, only the construction of Ln1,n2(X, Y) for all possible n1 and n2 is needed. We drop the subscript and use L(X, Y) for future discussion. The interval construction depends on a rank function Rir(.) on Si. Here Rir(.) should satisfy several rules that are from the monotonicity of θir = p1/p2 as a function of p1 and p2.
-
a)
Rir(n1, 0) = 1. i.e., point (n1, 0) is the largest.
-
b)
Rir(x, y) ≤ Rir(x − 1, y) for any x ∈ [1, n1] and y ∈ [0, n2].
-
c)
Rir(x, y − 1) ≤ Rir(x, y) for any x ∈ [0, n1] and y ∈ [1, n2].
These rules are shown in
where “←” means “larger than or equal to”.
The parameter space Hi is rewritten in terms of (θir, p2) with p1 = θirp2 as follows:
where Dir(θir) is a line segment. See Figure S4 in Supplementary Materials. The joint probability mass function pi for (X, Y) is rewritten as pir(x, y; θir, p2) = pi(x, y; θirp2, p2), where pi is given in (26). The construction for the rank function Rir(.) is similar to Wang (2010). By induction, we start with Rir(n1, 0) = 1. Let Epr,1 = {(n1, 0)}. Suppose Rir has been defined on k(≥ 1) sets Eir,1, , , Eir,k with values 1, 2, …, k. Let
be the neighbor set of . Then, from
a subset of Nir,k, we pick the point(s) (x, y) that has the largest possible lower confidence limit to form a set Eir,k+1 and assign a rank of Rir(x, y) = k + 1 to any point (x, y) ∈ Eir,k+1. This is similar to (15) and (16). Following induction, the construction of the rank function Rir(.) is complete. Then the smallest lower one-sided 1 − α confidence interval [Lir, +∞) under the rank function Rir(.) is derived following Lemma 1, the smallest upper one-sided 1 − α confidence interval [0, Uir] follows Lemma 5, and [Lir, Uir] is a 1 − 2α interval.
Example 3 (continued). We apply the three intervals above to Example 3 and then compare to exact intervals from SAS (Version 9.3). The intervals are reported in Table 3. For example, the 95% intervals [Lir, +∞), [0, Uir] and the 90% interval [Lir, Uir] for θir are equal to [1.1671, +∞), [0, 2.0859] and [1.1671, 2.0859], respectively. The lower one-sided and two-sided intervals are subsets of (1, +∞), so the smoking group has a higher tumor rate than the control group. Regarding interval construction, we first compute Lir = 1.1671 with n1 = 23, n2 = 32, x = 21 and y = 19 (using the rank function Rir(.) and Lemma 1), then compute Lir = 0.4794 using n1 = 32, n2 = 23, x = 19 and y = 21, and then Uir = 1/0.4794 = 2.0859 (use Lemma 5). The calculation takes about 4 minutes on an HP-2760 laptop with Intel(R) Core(TM) i5=2520M CPU@2.50 GHz and 8 GB RAM using an R-code from the authors. SAS (Version 9.3) provides two exact intervals for θir using “proc freq; exact relrisk;”. The first interval (default in SAS, Santner and Snell, 1980) is computed by inverting two separate one-sided exact tests that use the unstandardized relative risk as the test statistic; it is clearly too wide. The second interval (method=fmscore) also inverts tests, but uses the Farrington-Manning relative risk score statistic (Chan and Zhang, 1999), which is a less discrete statistic than the raw relative risk, and produces much sharper confidence limits (Agresti and Min, 2001) than the default. However, our two-sided intervals are shorter. See Section 4.3 for another comparison.
Table 3.
Exact one-sided and two-sided intervals for θir, θio and p1 − p2 in Example 3 when n1 = 23, x = 21, n2 = 32, y = 19.
| Two-sided 90% | Two-sided 95% | ||||
|---|---|---|---|---|---|
| Lower 95% | Upper 95% | Lower 97.5% | Upper 97.5% | ||
| θ ir | Our method | 1.1671 | 2.0859 | 1.1259 | 2.2289 |
| SAS(default) | 0.1919 | 123356 | 0.0960 | 152092 | |
| SAS(fmscore) | 1.1755 | 2.1519 | 1.1204 | 2.2301 | |
|
| |||||
| θ io | Our method | 1.9534 | 33.0987 | 1.5832 | 48.5190 |
| SAS | 1.6022 | 48.2034 | 1.3114 | 71.3653 | |
|
| |||||
| p1 − p2 | Wang (2010) | 0.1330 | 0.4860 | 0.0947 | 0.5126 |
4.2 INTERVALS FOR θio
The construction of intervals [Lio, +∞), [0, Uio] and [Lio, Uio] for θio is similar to that for θir since the monotonicity of θio as a function of p1 and p2 is the same for θir.
First, we have the following and skip the proof.
Lemma 6: Suppose [Ln2,n1(Y, X), +∞) is a lower one-sided 1 − α confidence interval for 1/θio = p2(1 − p1)/[p1(1 − p2)]. Then
| (28) |
is an upper one-sided 1 − α interval for θio. Suppose [Ln1,n2(X, Y), +∞) is a lower one-sided 1 − α interval for θio, then [Ln1,n2(X, Y), U(X, Y)] is a two-sided 1 − 2α interval for θio.
Secondly, the rank function Rio(X, Y) needed for the construction of L(X, Y) satisfies the same three rules for Rir(X, Y). However, there is a new computing issue. The parameter space Hi is rewritten in terms of (θio, p2) with
| (29) |
as follows: , where Dio(θio) is an interval independent of θio. See Figure 1.
Figure 1.
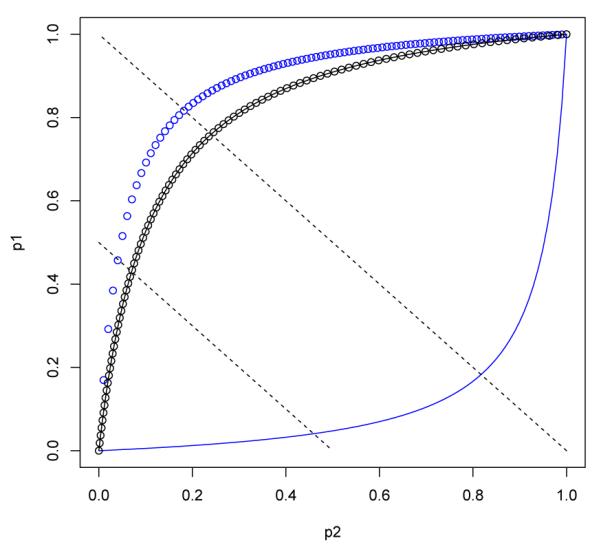
The parameter space Hio (the unit square), the sets of θio = 0.05 (the solid curve), θio = 20 with the equal p2-spacing (the circle curve), θio = 10 with the equal u-spacing (the circle-line curve), two lines p1 + p2 = u for u = 0.5 (the dashed line, short) and u = 1 (the dashed line, long). Note θio ∈ [0, +∞), p2 ∈ [0, 1] and u ∈ [0, 2].
The joint probability mass function pi for (X, Y) is rewritten as pio(x, y; θio, p2) = pi(x, y; p1, p2), where pi and p1 are given in (26) and (29), respectively. We need to compute probabilities on the curve of a fixed value for θio to find the infimum in (1) by a grid search on the curve. However, as shown in the circle curve of θio = 20 (Figure 1) that is obtained by partitioning [0, 1] with equal spacing in p2, the partitioned points are clearly not evenly distributed on the curve. This is very different from Figure S4 (in Supplementary Materials), where the circle points are evenly distributed on the line of θir = constant. Had we used the circle points in Figure 1 for a grid search for the infimum in (1), it would have led to an inaccurate numerical solution. So we introduce a new parameter u so that both p1 and p2 are functions of u ∈ [0, 2] at each fixed value of θio:
| (30) |
where
This makes the selected points on the curve much more evenly distributed, as shown in the circle-line curve of θio = 10. More importantly, these points are symmetric about the line p1+p2 = 1, which does not occur for the circle points. In fact, point (p2, p1) is the intersection of the curve with a fixed value θio and the line p1 + p2 = u for any u ∈ [0, 2]. Therefore, we partition u on interval [0, 2] with an equal spacing instead of p2 on interval [0, 1]. This change is clearly justified by a comparison of the two spacings in Figure 1 (θio = 10 vs θio = 20).
Lastly, we use the rank function Rio(.) to derive the smallest 1 − α interval [Lio, +∞) following Lemma 1, and obtain [0, Uio] of level 1 − α and [Lio, Uio] of level 1 − 2α by Lemma 6.
Example 3 (continued). Three proposed exact intervals and their correspondents from SAS based on Thomas (1971) (see also Gart, 1971) are reported in Table 3. Lower one-sided and two-sided intervals are inside (1, +∞) indicating that the odds of developing a tumor for the smoking group was higher than the control group. The proposed intervals are much smaller subsets of those from SAS. An R code for the proposed intervals is available. Exact intervals for p1 − p2 in Wang (2010) are also included in Table 3.
4.3 A SMALL COMPARISON
The comparison between exact and approximate intervals is not valid since they do not have the same confidence level 1 − α, even though the approximate interval claims to be of level 1 − α. Here we present a limited comparison between the proposed exact 90% confidence intervals [Lij, Uij] for j = r and j = o in Case II and the corresponding exact 90% intervals from SAS using “proc freq; exact relrisk(method=fmscore); exact or;”, denoted by . When n1 = n2 = 10, there are 121 intervals on all sample points. We only compare the interval lengths that are finite, and they are given in Figure 2. Each point in the plot has coordinate (, Uij − Lij) at a sample point (x, y) ∈ Si. Most points are in the lower triangle; also the average of the length ratio, , over these sample points is equal to 0.9490992 and 0.723343, respectively, for j = r and j = o. Both indicate a shorter length for the proposed intervals. Figure 3 gives the coverage probability comparison of these intervals. The left one in Figure 3, for example, is the plot of the infimum coverage probabilities of two intervals, [Lir, Uir] and , over set Dir(θir) versus θir. The coverage probability of proposed intervals is closer to the nominal level than that from SAS. A similar result is expected for other sample sizes.
Figure 2.

The length comparison for the proposed two-sided 90% intervals and the 90% intervals from SAS in Case II when n1 = n2 = 10. The horizontal axis is the length of the SAS interval and the vertical axis is for the proposed interval. Each circle is the length of two intervals at a sample point.
Figure 3.

The coverage comparison for the proposed two-sided 90% intervals and the 90% intervals from SAS in Case II when n1 = n2 = 10.
5. SUMMARY
The relative risk and the odds ratio are commonly used in medical research to compare two treatments. Estimating them both with accuracy and precision is important for practitioners. In this paper, we propose twelve intervals in four sets, each set contains two one-sided intervals and one two-sided interval for each of four parameters θpr, θpo, θir, and θio. They are all of level 1 − α. The one-sided intervals are smallest under the rank functions, and are also admissible by the set inclusion criterion (see Wang, 2006). This indicates that a uniform improvement is impossible. An inductive construction is employed and in each step of the process, the shortest (best) interval is picked as shown, for example, in Eq (15). This, similar to Wang (2010, Proposition 3), indeed justifies the admissibility of the one-sided intervals. The computation time on intervals is affected by the number of nuisance parameters.
Supplementary Material
Acknowledgements
The authors thank Dr. Yi-Hau Chen, an associate editor, and two referees for their valuable comments and suggestions that improved the manuscript significantly. Shan’s research is partially supported by NIH Grant 5U54GM104944.
Footnotes
Proofs of Lemmas 2 through 5 and Figures S1 through S4 referenced in Sections 3 and 4 are available with this paper at the Biometrics website on Wiley Online Library.
References
- Agresti A. Categorical Data Analysis. 2nd ed John Wiley & Sons, Inc; New York: 2002. [Google Scholar]
- Agresti A, Coull BA. Approximate is better than “exact” for interval estimation of binomial proportions. The American Statistician. 1998;52:119–126. [Google Scholar]
- Agresti A, Min Y. On small-sample confidence intervals for parameters in discrete distributions. Biometrics. 2001;57:963–971. doi: 10.1111/j.0006-341x.2001.00963.x. [DOI] [PubMed] [Google Scholar]
- Bentur L, Lapidot M, Livnat G, Hakim F, Lidroneta-Katz C, Porat I, Vilozni D, Elhasid R. Airway reactivity in children before and after stem cell transplantation. Pediatric Pulmonology. 2009;44:845–850. doi: 10.1002/ppul.20964. [DOI] [PubMed] [Google Scholar]
- Bol’shev LN. On the construction of confidence limits. Theory of Probability and its Applications. 1965;10:173–177. (English translation) [Google Scholar]
- Brown LD, Cai TT, DasGupta A. Interval estimation for a binomial proportion. Statistical Sciences. 2001;16:101–133. [Google Scholar]
- Buehler RJ. Confidence intervals for the product of two binomial parameters. Journal of the American Statistical Association. 1957;52:482–493. [Google Scholar]
- Chan ISF, Zhang Z. Test-based exact confidence intervals for the difference of two binomial proportions. Biometrics. 1999;55:1202–1209. doi: 10.1111/j.0006-341x.1999.01202.x. [DOI] [PubMed] [Google Scholar]
- Casella G, Berger RL. Statistical Inference. Duxbury Press; Belmont, CA: 1990. [Google Scholar]
- Chen J. The order relations in the sample spaces and the confidence limits for parameters. Advances in Mathematics. 1993;22:542–552. [Google Scholar]
- Essenberg JM. Cigarette smoke and the incidence of primary neoplasm of the lung in albino mice. Science. 1952;116:561–562. doi: 10.1126/science.116.3021.561. [DOI] [PubMed] [Google Scholar]
- Gart JJ. The comparison of proportions: a review of significance tests, confidence intervals, and adjustments for stratification. Review of the International Statistical Institute. 1971;39(2):148–169. [Google Scholar]
- Goodman LA. The Analysis of Cross-Classified Data Having Ordered and/or Unordered Categories: Association Models, Correlation Models, and Asymmetry Models for Contingency Tables With or Without Missing Entries. The Annals of Statistics. 1985;13:10–69. [Google Scholar]
- Huwang L. A note on the accuracy of an approximate interval for the binomial parameter. Statistics & Probability Letters. 1995;24:177–180. [Google Scholar]
- Li Z, Taylor JMG, Nan B. Construction of confidence intervals and regions for ordered binomial probabilities. The American Statistician. 2010;64:291–298. [Google Scholar]
- Lin Y, Newcombe RG, Lipsitz S, Carter RE. Fully specified bootstrap confidence intervals for the difference of two independent binomial proportions based on the median unbiased estimator. Statistics in Medicine. 2009;28:2876–2890. doi: 10.1002/sim.3670. [DOI] [PubMed] [Google Scholar]
- Lloyd CJ, Kabaila P. On the optimality and limitations of Buehler bounds. Australian and New Zealand Journal of Statistics. 2003;45:167–174. [Google Scholar]
- McCullagh P. Regression Models for Ordinal Data. Journal of the Royal Statistical Society. Series B. 1980;42:109–142. [Google Scholar]
- Parzen M, Lipsitz S, Ibrahim J, Klar N. An estimate of the odds ratio that always exists. Journal of Computational and Graphical Statistics. 2002;11:420–436. [Google Scholar]
- Santner TJ, Snell MK. Small-sample confidence intervals for p1−p2 and p1/p2 in contingency tables. Journal of the American Statistical Association. 1980;75:386–394. [Google Scholar]
- Shan G, Wang W. ExactCIdiff: an R package for computing exact confidence intervals for the difference of two proportions. The R Journal. 2013;5(2):62–70. [Google Scholar]
- StatXact 10th release of the most popular exact statistics analysis software. Cytel Inc. 675 Massachusetts Avenue; Cambridge, MA: 2013. p. 02139. [Google Scholar]
- Thomas DG. Algorithm AS-36: exact confidence limits for the odds ratio in a 2 × 2 table. Applied Statistics. 1971;20:105–110. [Google Scholar]
- Wang W. Smallest confidence intervals for one binomial proportion. Journal of Statistical Planning and Inference. 2006;136:4293–4306. [Google Scholar]
- Wang W. On construction of the smallest one-sided confidence interval for the difference of two proportions. The Annals of Statistics. 2010;38:1227–1243. [Google Scholar]
- Wang W. An inductive order construction for the difference of two dependent proportions. Statistics & Probability Letters. 2012;82:1623–1628. [Google Scholar]
- Wang W. A note on bootstrap confidence intervals for proportions. Statistics & Probability Letters. 2013;83:2699–2702. [Google Scholar]
- Wang W, Zhang Z. Asymptotic infimum coverage probability for interval estimation of proportions. Metrika. 2014;77:635–646. [Google Scholar]
- Wilson EB. Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association. 1927;22:209–212. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.