


Abstract
Somatic mosaicism refers to the existence of somatic mutations in a fraction of somatic cells in a single biological sample. Its importance has mainly been discussed in theory although experimental work has started to emerge linking somatic mosaicism to disease diagnosis. Through novel statistical modeling of paired-end DNA-sequencing data using blood-derived DNA from healthy donors as well as DNA from tumor samples, we present an ultra-fast computational pipeline, LocHap that searches for multiple single nucleotide variants (SNVs) that are scaffolded by the same reads. We refer to scaffolded SNVs as local haplotypes (LH). When an LH exhibits more than two genotypes, we call it a local haplotype variant (LHV). The presence of LHVs is considered evidence of somatic mosaicism because a genetically homogeneous cell population will not harbor LHVs. Applying LocHap to whole-genome and whole-exome sequence data in DNA from normal blood and tumor samples, we find wide-spread LHVs across the genome. Importantly, we find more LHVs in tumor samples than in normal samples, and more in older adults than in younger ones. We confirm the existence of LHVs and somatic mosaicism by validation studies in normal blood samples. LocHap is publicly available at http://www.compgenome.org/lochap.
INTRODUCTION
Many cancers arise from a series of mutational events occurring throughout a person's life span (1,2). Considerable evidence (3,4) has accumulated supporting the presence of genetically heterogeneous cells in a somatic sample, a phenomenon called somatic mosaicism, which may be a precursor to the onset of many cancers (5). However, there are no effective and economical tools that can reliably measure the presence and degree of somatic mosaicism in a biological sample. Single cell sequencing (6) in principle provides the genetic landscape of each individual cells, although in practice only up to hundreds or thousands of cells can be measured due to the formidable cost of money and effort. In contrast, next-generation sequencing (NGS) technologies assemble an average genome sequence of all the cells in a sample, assuming cellular homogeneity. In the presence of somatic mosaicism, the average genome may not be a good representation of the sample. Despite continuous breakthroughs in DNA sequencing since the completion of the human genome project (7), researchers are still unable to precisely dissect individual cellular genomes on large scales.
Somatic mosaicism is often seen in samples derived from patients with cancer. Future targeted and personalized cancer therapy must take into account mosaic tumor cells in order to better customize therapies (8,9). In contrast, somatic mosaicism in samples from healthy individuals has been discussed as a theory over the last decade (10–12), with only a few recently reported examples (5,13–20). Due to the availability of high-throughput DNA sequencing, hundreds of millions of short reads can now be mapped to cover whole genomes or exomes. If somatic mosaicism is present in a biological sample, the DNA sequences of the short reads are expected to reflect the variations of the cellular genomes at the single nucleotide level. Based on this concept, pioneering work in 2014 by Genovese et al. (5) reported the presence of somatic mutations in blood samples as precursor of hematologic cancer and death. They carefully constructed bioinformatics and statistical methods to filter single nucleotide variants (SNVs) based on whole-exome and whole-genome sequencing data and identified clonal somatic blood samples with somatic mutations. Because the somatic mutations were only present in a fraction of the cells, the blood sample was considered mosaic. Their main computational analysis aimed to identify SNVs with variant allele fractions (VAFs) that are far <0.5 and attributed these SNVs to the existence of small cellular subpopulations harboring the SNVs. Computationally it is challenging to differentiate true biological subpopulations from noise and artifact in the NGS data since both would give rise to small VAFs (21).
We propose here a different approach. Instead of using SNVs, we consider ‘local haplotypes’ (LHs) for calling somatic mosaicism. An LH is a scaffold of multiple proximal SNVs (Figure 1). Examining paired-end DNA-sequencing data, we find that sometimes multiple SNVs are simultaneously mapped by the same short reads. The short reads provide linked genotypes for the SNVs. In Figure 1, two SNVs are considered in each example and some short reads cover both SNVs. Treating the scaffold of the two SNVs as an LH, shown in Figure 1, we observe three different genotypes with substantial read counts in each example. We call such an LH a local haplotype variant (LHV). The presence of LHVs across the genome is direct evidence supporting mosaicism and cellular heterogeneity because a homogeneous cell population can only manifest up to two haplotypes. Therefore, the key idea of examining an LH instead of an SNV allows for direct observation of more than two alleles in local genomes, a rare event for single loci but not for haplotypes. Based on this idea, we develop an open-source, ultrafast and powerful computational tool, ‘LocHap’, for identifying LHVs using deep DNA-sequencing data from a single biological sample. We construct rigorous statistics models that provide probability measure for the LHVs. We also introduce bioinformatic filters that account for the usual noise and artifact in NGS data. However, the noise and artifact are partially mitigated due to the use of LHVs instead of SNVs. We elaborate more on these points in the next section. LocHap can be applied to any DNA-sequence data using paired-end reads and only requires a binary alignment and mapping (bam) file, the associated index (bai) file and the corresponding variant call format (vcf) file (‘Materials and Methods’ section). These files are almost always generated from standard variant-calling pipelines. To facilitate downstream analyses and experimental validation, we introduce a new file format, the haplotype call format, or hcf, that contains a list of LHVs inferred by LocHap. An hcf file has a tab-delimited format similar to a vcf file, and can be viewed in popular visualization tools like integrated genome viewer (IGV) (22). The proposed hcf format is derived from the vcf format to facilitate visualization and interpretation. However, unlike vcf which contains SNVs and other genetic variants, hcf only contains information about LHVs, which is a scaffold of multiple local SNVs (each SNV is in the vcf file for the sample). Therefore, a non-empty hcf file presents information supporting genetically heterogeneous samples.
Figure 1.
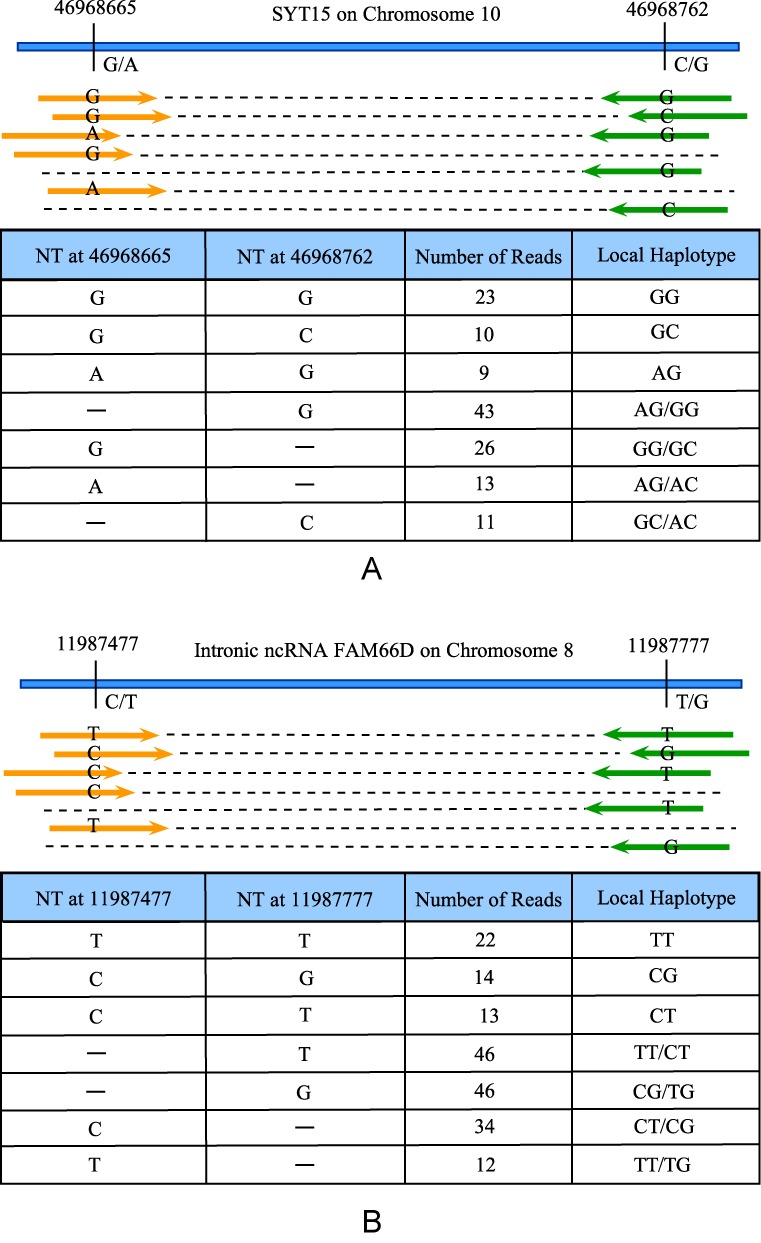
Two examples of LHVs based on direct observations of aligned short reads. The pairs of a single short read are marked with orange and green colored arrow, respectively. Panel (A): an LHV called from WES data of a normal blood sample. The haplotype consists of two SNVs separated by 97 bps in a coding region of gene SYT15. Among all the short reads mapped to this region, 23, 10 and 9 short reads are mapped to both SNVs and exhibit alleles GG, GC and AG, respectively. Due to the large count of the least frequent allele (AG) and the combined information from all other short reads, LocHap calls three local haplotypes (LH) with high statistical confidence, making it a variant (i.e., an LHV). Panel (B): an LHV called from WGS data of a normal blood sample from a normal individual (NA12878 in the CEU TRIO family in the 1000 genome project). The LH consists of two SNVs separated by 300 bps in an intronic region of an ncRNA FAM66D. Again, similar haplotype variants are seen based on the short reads mapped to both SNVs. In both examples, some reads are mapped to only one of the two SNVs. These reads provide partial information on the existence of certain haplotypes. For example, reads with ‘-G’ in panel (A) are only mapped to the second SNV with genotype ‘G’. They support that haplotypes AG or GG might be present in the sample. Hence, reads mapped to both SNVs and reads mapped to at least one SNV are used in the statistical models of LocHap.
MATERIALS AND METHODS
Main idea
The basic idea of LHV calling is to probabilistically model short reads mapped to multiple proximal SNVs and look for multi-allelic loci. In other words, we search for proximal SNVs that are scaffolded by short reads and exhibit more than two alleles with high statistical confidence. For example, Figure 1A shows an LHV consisting of two SNVs, at chromosomal locations separated by only 97 bp. Examining data ‘horizontally’ across both SNVs, many reads scaffold the SNVs as they are mapped to both loci. There are three directly observed haplotypes, GG, GC, and AG, with read frequencies 23, 10, and 9, respectively. In addition, four other types of overlapping short reads cover only one of the two SNVs. Each type of short reads potentially supports the presence of one or two different haplotypes and collectively they provide information on how many and what haplotypes are present in the region. Using all the short reads, LocHap employs a Bayesian hierarchical model, performs statistical inference accounting for the noise in the data and filters dubious LHV calls based on false discovery rates (FDR) (23,24).
Statistical methods
SNV segments
LocHap uses DNA-Seq data and assumes that base calling, reads alignment and variant calling have been completed and bam, bai and vcf files are available for one or more samples. LocHap first constructs non-overlapping segments on the genome, each of which is a set of continuous base pairs (bps) and contains at least two proximal SNVs separated by no more than K bps apart. The segment is formed by starting at a SNV and extended to the next closest SNV as long as it is within K bps from the previous SNV. The segment ends if the next closest SNV is more than K bps away. Therefore, each segment starts and ends at a SNV, with potential multiple SNVs in between. A schematic illustration of DNA segmentation is shown in Figure 2.
Figure 2.
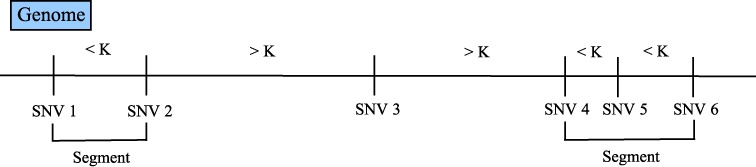
Illustration of DNA segments in LocHap. The first segment consists of two SNVs (SNV 1 and 2) and the second one has three SNVs (SNV 3, 4 and 5). SNV 3 is more than K base pairs from its adjacent SNVs 2 and 5, and therefore is not included in any segment.
Along the genome, we start with the first called SNV, and form as many segments as we can until we reach the last called SNV. LocHap allows any integer K set by users as the maximum distance between two adjacent SNVs. For short-read data, we allow K to vary between 50 and 1000. Changing K values will affect the size and number of segments. Usually the value of K can be set to reflect the insert length of the DNA sequencing experiment.
Probability model for LHV calling
LocHap analyzes each DNA segment separately. The goal of the analysis is to estimate the number and sequences of the haplotypes within the segment. Assume N numbers of short reads are mapped to the segment and each read overlaps with at least one SNV in the segment. Mapped reads that do not overlap with any SNVs are discarded since they do not contribute to the haplotype calling.
For a given segment, let i = 1, …, N be the index of the mapped short reads. Assume that R SNVs are present in the segment. We consider up to L = 2R candidate haplotypes that can be formed by R SNVs. That is, we assume at each SNV, one can observe up to two different alleles (e.g., a reference and a variant allele). More than two alleles are rarely observed from short reads for an SNV and most of them are caused by sequencing error. We use j = 1, …, K to index possible haplotypes. The genotypes (nucleotide sequences) of each candidate haplotype are denoted by 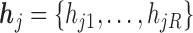 , j = 1, …, L, where hjr takes one of the four nucleotides, i.e., hjr ∈ {A, C, G, T} for r = 1, …, R. For example, in Figure 1, R = 2 and L = 2R = 4. In each example some short reads overlap with both SNVs. Specifically, for each short read i, use
, j = 1, …, L, where hjr takes one of the four nucleotides, i.e., hjr ∈ {A, C, G, T} for r = 1, …, R. For example, in Figure 1, R = 2 and L = 2R = 4. In each example some short reads overlap with both SNVs. Specifically, for each short read i, use 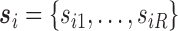 to denote an R-base DNA sequence of interest, where sir ∈ {A, C, G, T, M}; here M denotes a missing base readout when there is no overlap between a short read and an SNV. Let
to denote an R-base DNA sequence of interest, where sir ∈ {A, C, G, T, M}; here M denotes a missing base readout when there is no overlap between a short read and an SNV. Let 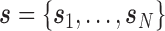 be the set of all short reads. One could define an indicator mir = I(sir = M) to denote the missing base of
be the set of all short reads. One could define an indicator mir = I(sir = M) to denote the missing base of 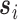 and set up a model f(mir∣θ). We assume missing completely at random (MCAR) (25) , which leads to conditional independence in the posterior inference. That is, conditional on
and set up a model f(mir∣θ). We assume missing completely at random (MCAR) (25) , which leads to conditional independence in the posterior inference. That is, conditional on 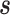 , parameters in the model describing target haplotypes are independent of
, parameters in the model describing target haplotypes are independent of 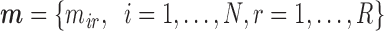 , the vector of missing indicators. This greatly simplifies the inference procedure. The MCAR assumption is proper here since in NGS experiment, typically the missing base in sir is due to that read i is not aligned to base SNV r, which is caused by the limited read length as a technological limitation. Hence the missing mechanism in sir has nothing to do with what sequences are observed or not observed.
, the vector of missing indicators. This greatly simplifies the inference procedure. The MCAR assumption is proper here since in NGS experiment, typically the missing base in sir is due to that read i is not aligned to base SNV r, which is caused by the limited read length as a technological limitation. Hence the missing mechanism in sir has nothing to do with what sequences are observed or not observed.
Using standard missing data notations, let:
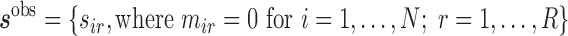 |
and
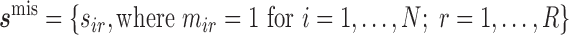 |
denote the observed and missing DNA sequences for reads i at SNV r, respectively, for all i's and r's. Then 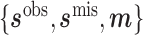 are the complete data, and
are the complete data, and 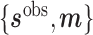 are the observed data. We introduce a few additional notations needed for modeling. Denote {λj = 1} or {λj = 0} the event that haplotype j is present or absent in the sample, respectively. Apparently λj's are key parameters of interest. Intuitively, the sequence similarity between haplotype sequences
are the observed data. We introduce a few additional notations needed for modeling. Denote {λj = 1} or {λj = 0} the event that haplotype j is present or absent in the sample, respectively. Apparently λj's are key parameters of interest. Intuitively, the sequence similarity between haplotype sequences 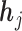 and short read sequences
and short read sequences 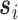 provides information on which haplotype is present. For example, if
provides information on which haplotype is present. For example, if 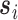 matches
matches 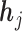 in most of the R bases, it is likely
in most of the R bases, it is likely 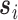 is generated from a DNA segment having haplotype j, thereby supporting the presence of the haplotype. To model the similarity, we denote
is generated from a DNA segment having haplotype j, thereby supporting the presence of the haplotype. To model the similarity, we denote 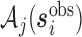 and
and 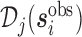 the set of agreeing and disagreeing bases between
the set of agreeing and disagreeing bases between 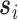 and
and 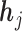 , respectively. Mathematically, they refer to:
, respectively. Mathematically, they refer to:
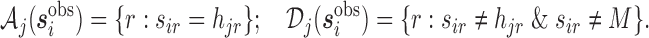 |
Denote I() the indicator function and let
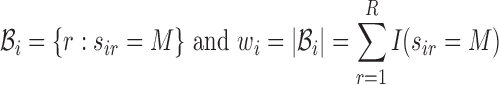 |
be the set of indices and number of missing bases of read i, respectively.
We propose a Bayesian probability model treating 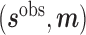 as observed data and
as observed data and 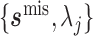 as unknown parameters. The inference is based on posterior probability that a haplotype j is present in the sample,
as unknown parameters. The inference is based on posterior probability that a haplotype j is present in the sample, 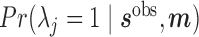 . The higher value the probability takes, the more likely haplotype j is present. We will show next that this posterior probability can be calculated in a closed form.
. The higher value the probability takes, the more likely haplotype j is present. We will show next that this posterior probability can be calculated in a closed form.
Let 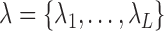 and
and 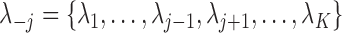 be the vector without the j-th component. The posterior probability
be the vector without the j-th component. The posterior probability 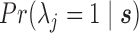 can be calculated as follows:
can be calculated as follows:
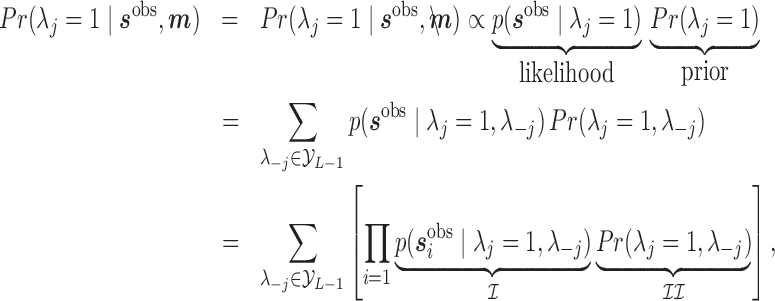 |
(1) |
where 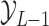 denotes the set of all binary (0 or 1) strings of length (L − 1). The first equation is due to the MCAR assumption. It can be shown (Supplementary Data) that:
denotes the set of all binary (0 or 1) strings of length (L − 1). The first equation is due to the MCAR assumption. It can be shown (Supplementary Data) that:
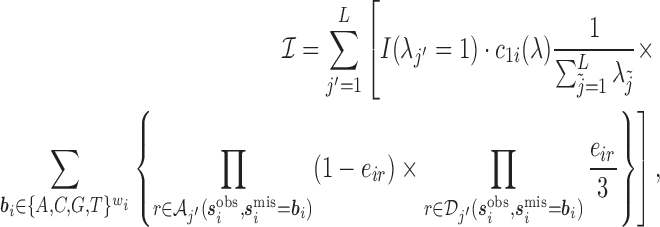 |
where eir is the error probability for the DNA sequence called at base r on short read i. Typically eir is known from upstream analysis, e.g. in the form of Phred quality score. LocHap requires user-assigned values for eir with a default value of 0.001 (corresponding to a Phred score of 30). Alternatively, we recommend setting eir = 10−log(Ph) where Ph is the Phred score at the base r of read i (26).
Next, the second term ( ) of Equation (1) is the product of independent prior term for each λj for all j = 1, ⋅⋅⋅, L,
) of Equation (1) is the product of independent prior term for each λj for all j = 1, ⋅⋅⋅, L,
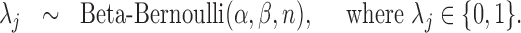 |
The Beta-Bernoulli prior for λ is the marginal density of hierarchical construction in which
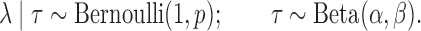 |
Integrating out τ, we get a Beta-Bernoulli prior given by
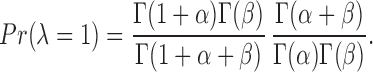 |
(2) |
To reflect the weak prior belief that a random haplotype has a low prior probability to be present in a sample, we set α = 0.05 and β = 1 so that a priori the probability that haplotype j is present is only 5%.
FDR-based inference and calibration of eir
Denoting 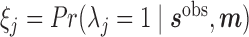 the posterior probability that haplotype j is present in the sample. Posterior inference is based on selecting the haplotypes with the largest ξj subject to an FDR threshold. For example, with a desired FDR threshold of f0, compute
the posterior probability that haplotype j is present in the sample. Posterior inference is based on selecting the haplotypes with the largest ξj subject to an FDR threshold. For example, with a desired FDR threshold of f0, compute
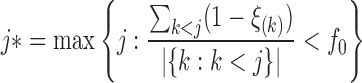 |
(3) |
where ξ(k) is the ordered statistics with decreasing order and |{set}| is the cardinality of the set. Then select all the haplotypes with ξj > ξj*. Such a selection procedure is optimal (23,24) in controlling posterior expected FDR.
All the parameters in the proposed Bayesian model are estimated directly. The models only depend on one calibration parameter, eir, which must be given. The error rate eir captures the quality and Phred quality score from base calling, an upstream analysis. In most cases, a Phred quality score of >30 is considered of high quality for a base, which translates to eir < 0.001 by definition (http://en.wikipedia.org/wiki/Phred_quality_score). Also, shown in Ji et al. (26) a higher error rate leads to more noisy inference, in our case, less confidence on haplotype calls. As an example, Supplementary Data Table S1 provides a simulated dataset in which each row represents a short read and its called bases and a ‘−’ sign represents a missing base. Applying our proposed model with eir = 0.001 for all reads and bases, we infer that three LHs, AA, GA and GG, are present in the sample using an FDR threshold f0 = 0.01. If we increase the eir to 0.2 we obtain only one LH AA with f0 = 0.01. If we use eir = 0.14, we get two significant LHs AA and GG.
In LocHap, we remove reads having a mapping quality score <30; we also consider a base missing if the Phred quality score of base calling is <30. These two steps ensure the high quality of the reads and bases used in the statistical inference. Then we take a conservative value of 0.001 for all the eir's as the default setting. This is a conservative choice since 0.001 is the largest possible eir value after the above read filtering. As a less conservative choice, one could use the provided eir for each base and read from the bam file.
Efficient computational algorithm
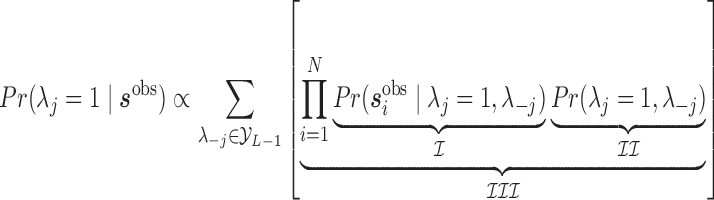
Posterior inference of LHVs centers at the calculation of 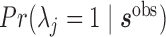 . We re-list Equation (1) again to facilitate the subsequent discussion, given by
. We re-list Equation (1) again to facilitate the subsequent discussion, given by
 |
(4) |
As mentioned before, if the number of SNVs is R, then the number of possible haplotypes L = 2R, assuming up to two alleles can be observed at each SNV. Correspondingly, we have L number of λj's to estimate and the total different configurations of all the λj's is 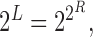 a super exponent of R. Therefore, when R is slightly increased, say from 2 to 4, the number of configurations to be calculated increases from 64 to 65, 536. This super-exponential increment calls for efficient computation.
a super exponent of R. Therefore, when R is slightly increased, say from 2 to 4, the number of configurations to be calculated increases from 64 to 65, 536. This super-exponential increment calls for efficient computation.
A straightforward way to calculate the right hand side of the Equation (4) would follow the derivation in the previous section, resulting in computing multiple loops of summations and products. It would be time consuming. We take a more efficient approach. For each j = 1, 2, …, L, summing over all the binary configurations of 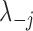 amounts to 2L − 1 many sums. Each term under the outer sum is denoted by
amounts to 2L − 1 many sums. Each term under the outer sum is denoted by  in (4). A straightforward computation of (4) would calculate term
in (4). A straightforward computation of (4) would calculate term  (L*2L − 1) times for all the j. Same amount of computation is also required for calculation of
(L*2L − 1) times for all the j. Same amount of computation is also required for calculation of 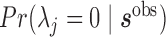 for all j = 1, 2, …, L. But careful examination of the terms to be added reveals that some terms are repeatedly calculated L times. For example, assume L = 4. In calculating the probability for the event
for all j = 1, 2, …, L. But careful examination of the terms to be added reveals that some terms are repeatedly calculated L times. For example, assume L = 4. In calculating the probability for the event 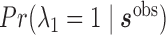 , we have to sum over all the other 2L − 1 = 8 configurations of
, we have to sum over all the other 2L − 1 = 8 configurations of 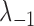 . Let us take one specific configuration from that set of eight configurations,
. Let us take one specific configuration from that set of eight configurations, 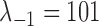 (meaning the three elements in
(meaning the three elements in 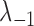 take values 1, 0 and 1, respectively). When λ1 = 1, the full vector
take values 1, 0 and 1, respectively). When λ1 = 1, the full vector 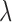 takes 1101. However, the value 1101 will also show up in the computation of
takes 1101. However, the value 1101 will also show up in the computation of 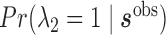 with
with 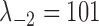 ,
, 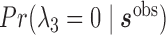 with
with 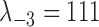 and
and 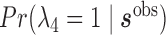 with
with 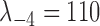 . Therefore, we only need to compute the joint probability of
. Therefore, we only need to compute the joint probability of 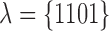 once and re-use it for the other three terms. Similarly, for all other possible configurations of
once and re-use it for the other three terms. Similarly, for all other possible configurations of 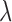 , we only need to compute it once. The straightforward way of computation would calculate each configuration four times.
, we only need to compute it once. The straightforward way of computation would calculate each configuration four times.
Once all 2L configurations are calculated, we add up the probabilities from appropriate configurations in order to calculate the probability 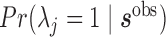 . We first put decimal indices against all the configurations of
. We first put decimal indices against all the configurations of 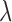 from 0 to (2L − 1) by treating the first position as the most significant bit of a binary string and convert the binary string to its decimal equivalent number. For example, the decimal index of
from 0 to (2L − 1) by treating the first position as the most significant bit of a binary string and convert the binary string to its decimal equivalent number. For example, the decimal index of 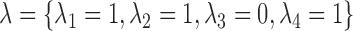 is 13. Denote each configuration by Cl where l = 0, 1, …2L − 1. Once indexing is done, then for each event we sum up the probabilities for a fixed (computed beforehand) set of indices of configurations. For example, for the computation of
is 13. Denote each configuration by Cl where l = 0, 1, …2L − 1. Once indexing is done, then for each event we sum up the probabilities for a fixed (computed beforehand) set of indices of configurations. For example, for the computation of 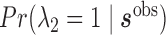 the set of indices is {4, 5, 6, 7, 12, 13, 14, 15}. Similarly for
the set of indices is {4, 5, 6, 7, 12, 13, 14, 15}. Similarly for 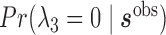 that set is {0, 1, 4, 5, 8, 9, 12, 13}. Denote the set of indices for computing
that set is {0, 1, 4, 5, 8, 9, 12, 13}. Denote the set of indices for computing 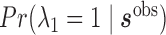 and
and 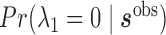 by
by 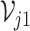 and
and 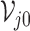 , respectively. Below, we propose Algorithm 1 for computing (4).
, respectively. Below, we propose Algorithm 1 for computing (4).

Calculation of 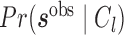 for all l = 0, 1, …, 2L − 1 in Algorithm 1 is carried out with an additional algorithm that takes advantage of the structured probability formulation. The detail is shown in Supplementary Data. Calculation of Pr(Cl) is trivial based on the independent prior of λj's. Because of the closed-form derivation for (4) and efficient computation algorithms, LocHap is ultra-fast in analyzing whole-genome and whole-exome data, taking usually less than a minute for a whole genome.
for all l = 0, 1, …, 2L − 1 in Algorithm 1 is carried out with an additional algorithm that takes advantage of the structured probability formulation. The detail is shown in Supplementary Data. Calculation of Pr(Cl) is trivial based on the independent prior of λj's. Because of the closed-form derivation for (4) and efficient computation algorithms, LocHap is ultra-fast in analyzing whole-genome and whole-exome data, taking usually less than a minute for a whole genome.
LocHap pipeline
A computational pipeline (Figure 3) supports LocHap applications. LocHap analyzes one sample at a time and can be used sequentially or in parallel for the analysis of multiple samples. For a single sample, the input of LocHap includes (i) a bam file with the associated index bai file and (ii) a corresponding vcf file that contains the SNVs in the sample, called by any standard variant calling algorithm, such as GATK's (27–29) UnifiedGenotyper tool. The output of LocHap is a set of LHVs stored in hcf files, one for each sample.
Figure 3.

Overview of the LocHap pipeline.
Haplotype call format (hcf)
Each line in the hcf file contains information about one particular LHV segment. Below is a line in an hcf file from analysis of real-world data.
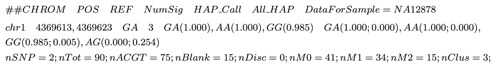
Same as vcf, an hcf file is a tab-delimited text file. After the initial header fields, each line in the hcf file represents a LH (might not be a variant) and has seven column fields. Also, at the end of each hcf file, a summary stating the total number of SNVs in the vcf file, number of segments with zero significant haplotypes, one significant haplotype, two significant haplotypes and so on, are given (see Supplemental Data).
Post processing
The inferred LHVs can be filtered to remove false positives caused by artifact and noise in the sequencing data. The filters are devised to remove dubious reads and SNVs. In NGS data, known artifact and error affect SNV calling (21) by erroneously calling or aligning the bases on short reads. However, they do not artificially create additional LHs which require more sophisticated changes to the bases of short reads across multiple SNVs. The typical artifact and error often changes the base calling or alignment for a single locus and usually affect all the short reads in the region. Therefore, LHV-based inference is less prone to the errors and artifacts for SNV calling. Nonetheless, we apply a set of optional and customizable filters (Supplementary Data) with different stringency levels for post-processing of the LHVs in the output hcf files. Currently, despite the large amount of effort directed by the community (21) the noise and error in NGS experiments and data preprocessing cannot be statistically modeled or quantified. There is no consensus on filtering the variant calls from various analysis pipelines. We present a conservative filtering pipeline that is heavily biased toward reducing FDR, so that reported LHVs are of high confidence. The proposed filtering depends on various parameters that can be modified to enforce different degrees of filter stringency. A more stringent filter results in fewer LHVs at the end.
The proposed filters can remove SNVs that are too close to each other (within, say 50 bps) and SNVs that are close to other types of variants such as indels. It has been noted (30,31) that these variant calls are not trustworthy due to artifacts and base calling errors in the data. In addition, our filters can remove SNVs for which most reads are aligned to the SNV at a base near the end of the reads. The reason is that bases called toward the end of a read are usually of low quality, which then affect the reliability of the alignment. Lastly, SNVs mapped by reads with strand bias (32) are also filtered.
Integrated genome viewer (IGV) compatibility
For better visualization, we provide an additional IGV-compatible format so that LHV segments can be visually examined in the popular genome visualization tool IGV (22). A snapshot of five hcf files in IGV is shown in Figure 4. The details of the corresponding command is given in Quick Manual (http://compgenome.org/lochap/code_release/QuickManual-LocHap-release-v1.0.pdf). Note that the LHVs are shown by red bars and non variants are shown by blue bars.
Figure 4.
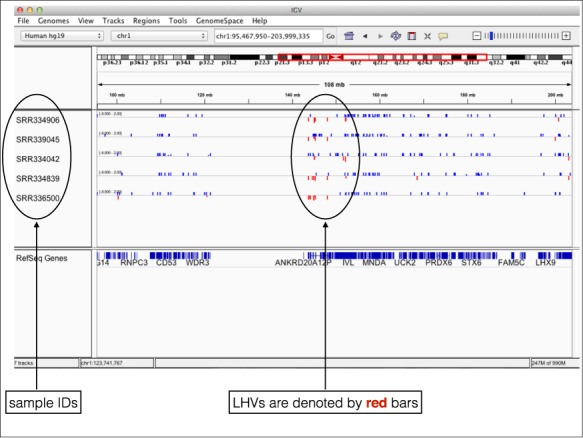
Visualization of hcf files in IGV.
RESULTS AND DISCUSSION
Simulation
We first demonstrate the utility of the proposed statistical model using simulated data. In all of the following examples we used eir = 0.001 as the default value and FDR threshold was set at f0 = 0.01. Also we assumed that the probability of observing more than two different alleles at a particular locus in a genome was considered rare. This is assumed because of the small chance of having a point mutation occurring twice at the same nucleotide (33–35). All of the simulation examples were based on short reads data generated for a single segment. Also, we only show examples with a small number of short reads. When a large number of reads were simulated, the proposed models performed very well, easily recovering the simulation truth. Tabulated posterior probabilities for all the scenarios are provided in the Supplementary Tables S1–S9.
Simulation Scenario 1
We generated eight short reads covering two SNVs. Assuming at each SNV that only two alleles could be observed, there were 22 = 4 possible haplotypes. The simulated short reads had genotypes
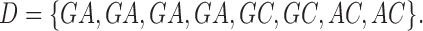 |
Applying LocHap, we inferred three significant haplotypes with the following sequences and posterior probabilities.
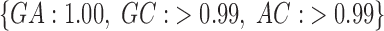 |
Simulation Scenario 2
In this scenario, we generated eight short reads, each of which only covered one of the two SNVs.
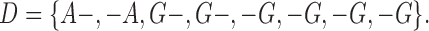 |
Here the read labeled ‘A −’ indicated that the first SNV position had a readout A and the read did not cover the second SNV position. Hence, we used ‘−’ sign to represent a missing genotype. Using LocHap, no haplotypes can be inferred to be present based on the FDR threshold f0 = 0.01.
Simulation Scenario 3
In this scenario, we simulated five short reads covering three SNVs with genotypes given by
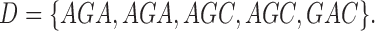 |
LocHap called three significant haplotypes {AGA, AGC, GAC} with posterior probabilities all >0.99.
Simulation Scenario 4
In this scenario, we generated eight short reads covering three SNVs, given by
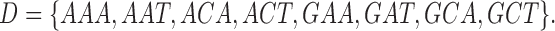 |
LocHap did not identify any significant haplotypes. This is due to the lack of strong evidence for any of the haplotypes as each of them is supported by only one read. The proposed model correctly recognized the uncertainty in the data and did not provide statistical significance for any haplotypes.
Simulation Scenario 5
This scenario is similar to scenario 4 but here we generated five short reads each for the haplotypes AAA, AAT and ACA. The data is given by,
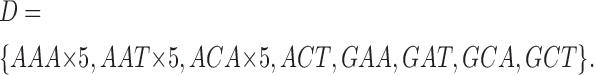 |
Although LocHap did not find any significant haplotypes in the previous scenario, LocHap called three significant haplotypes {AAA, AAT, ACA} with posterior probabilities all equal to 1.00 because of more reads are generated for these three haplotypes. It is easy to see that with more number of reads our inference model would work more accurately.
Simulation Scenario 6
This scenario is similar to scenario 1 but here we generated five times more number of short reads for every categories. The data is given by,
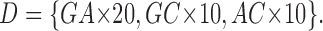 |
Applying LocHap, we again inferred three significant haplotypes with posterior probabilities all equal to 1.00.
Simulation Scenario 7
This scenario is same as the real-life data in Figure 1A. The data is given by
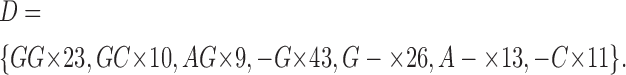 |
Applying LocHap, we inferred three significant haplotypes {GG, GC, AG}with posterior probabilities all equal to1.00.
Simulation Scenario 8
This scenario is same as the real-life data Figure 1B. The data is given by,
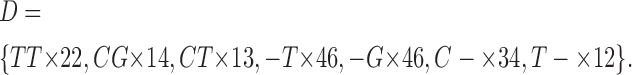 |
Applying LocHap, we again inferred three significant haplotypes {TT, CG, CT} with posterior probabilities all equal to 1.00.
All eight scenarios show that LocHap performs well. When the number of reads increases, the confidence in the statistical inference also increases.
Three DNA-seq datasets
We applied LocHap to three different datasets, among which two were public and one from our own in-house validation experiments. We provide main findings next and put analysis details in the Supplementary Data.
Head and neck cancer (HNC) data
We analyzed whole exome sequencing (WES) data of 30 matched tumor and blood sample pairs (total 60 samples) from patients with head and neck cancer (HNC) (36). Whole exome Sequence Read Archive (SRA) files of matched tumor and normal samples were downloaded from the SRA (http://www.ncbi.nlm.nih.gov/sra). Standard bioinformatics analyses were performed to extract fast-q sequences, map short reads and call SNVs. We generated bam files (one per sample) and a vcf file for all the samples. The bam files contained short read sequences and alignments and the vcf file contained SNV calls of all the samples. The bam files with associated bai and vcf files were provided to the LocHap pipeline, which subsequently generated 60 hcf files, one for each sample.
Figure 5A shows a circos plot (37) of the called LHVs. Most LHVs are located in different genomic regions across patients, suggesting somatic mutations occurred randomly across the genome. Also, the fact that called LHVs are mostly different between patients indirectly shows that LHV calling is not driven by artifact and noise in the NGS data. The reported LHVs all passed the aforementioned noise filtering with stringent criteria. Read depth of one exome of a normal sample is shown in Figure 5B. A few LHVs are mapped with large numbers of reads but overall the read depths between LHVs and non-variant regions are comparable. Most LHs are not LHVs, having no more than two genotypes and most LHVs possess three genotypes (Figure 5C). Tumors in general possess more LHVs than corresponding normal samples (Figure 5D) and chromosomes 9, 14 and 17 are ‘hotspots’ for LHVs exhibiting higher frequencies in tumors than blood samples (Figure 5E). Transitions are more frequent than transversions (Figure 5F), as expected. Finally, overlapping LHVs are present in both tumor and the matched blood samples for each of the 30 patients (Figure 6), while the tumor and blood samples also possess unique LHVs of their own.
Figure 5.
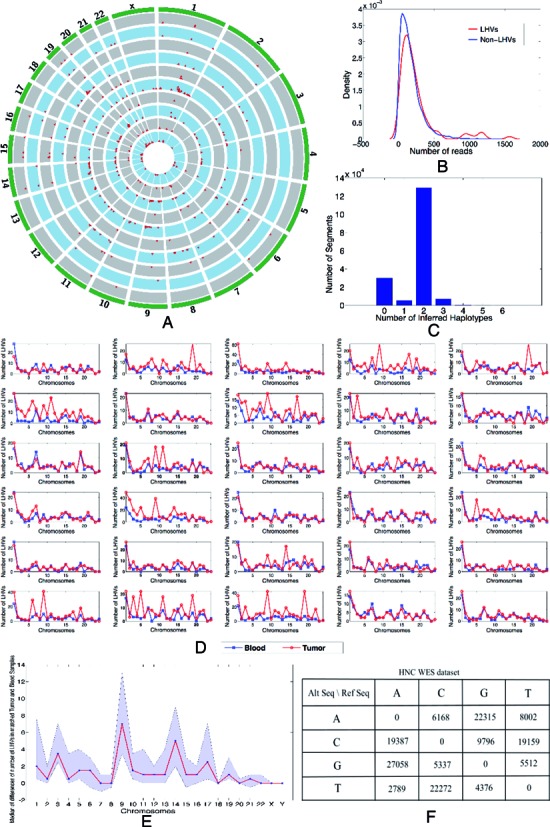
LHV calling for a head and neck cancer (HNC) WES dataset with 30 pairs of matched tumor and normal samples. (A) A circos plot of prevalence of LHVs for five arbitrarily selected sample pairs. Each red dot indicates the existence of at least one LHV in the corresponding exonic region of 1M bps. The height of a red dot indicates the number of LHVs present in the segment of 1M bps long. A pair of matched tumor and normal samples are arranged as adjacent circles with grey and blue color, respectively. (B) Comparison of read depth for genome regions with and without LHVs. No apparent difference is observed. (C) Histogram showing the frequencies of DNA segments (vertical axis) with different numbers of haplotype calls (horizontal axis). Most regions have up to two haplotypes, i.e., no variants. Regions with greater than two haplotypes are variants implying genome mosaicism. (D) A total of 30 line plots, one for each pair of matched tumor (red) and normal (blue) samples from an individual patient. The number of LHVs is shown for each chromosome for each patient. In general, tumors exhibit more LHVs implying more mosaicism. (E) Summary of (D). For each chromosome, a blue dot is the median of the difference in the number of LHVs between tumor and its matched normal sample across 30 patients; point-wise confidence intervals are shown as purple bands. Tumors show much higher frequencies of LHVs on chromosomes 9, 14 and 17, indicating potential disease-related variations on these regions. (F) Summary of sequence mutations for the SNVs within called LHVs. Transitions are much more prevalent than transversions.
Figure 6.
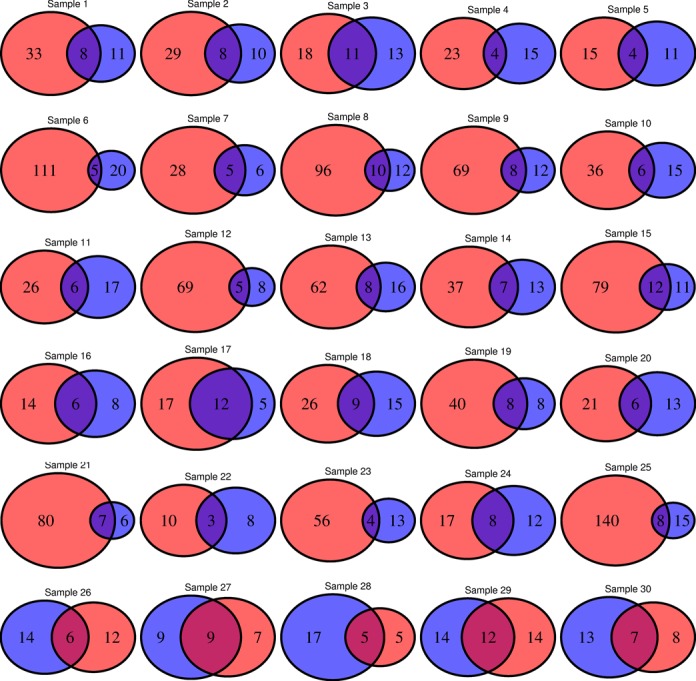
Venn diagrams showing the overlap of LHV calling for a HNC WES dataset with 30 pairs of matched tumor and normal samples. For each pair, LHV counts for tumor and the matched normal sample are shown in red and blue color, respectively. In most of the samples, number of LHVs in tumor is greater than that of the matched normal except for the last five samples where the numbers are comparable or number of LHVs found in the tumor sample is less the corresponding number in the matched normal sample.
Table 1 summarizes the statistics from the unfiltered hcf file from one particular normal blood sample.
Table 1. Statistics from hcf file of a sample from HNC dataset.
| No. of variants | Segments with no. of significant haplotypes | Segments with more than three variants | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (lr)2–10 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | (Not analyzed) |
| 137886 | 460 | 85 | 2070 | 90 | 11 | 0 | 0 | 0 | 0 | 457 |
CEU-TRIO data from 1000-genomes project
We applied LocHap to whole genome sequencing (WGS) data of a CEU TRIO family of father, mother and child from the 1000-Genomes project (http://www.1000genomes.org/). The analysis procedure was identical to the HNC data, except here we have WGS data from three members of a family. Genome-wide LHVs (Figure 7A) are found in all three individuals with father having the largest number of LHVs and daughter the smallest (Figure 7B). This reflects the evolutionary conjecture that somatic mutations emerge over time as a result of accumulating mitotic errors and that the longer an individual lives, the more likely somatic mosaicism is seen on the genome (18). Similar to the results obtained in the previous analysis of cancer WES data, most LHs are not LHVs and most LHVs possess three genotypes (Figure 7C). Most LHVs reside in intergenic and intronic regions with less than 1% in exons (Figure 7D). Here again transitions are more prevalent than transversions (Figure 7E). We called copy number variations (CNVs) using CNVnator (38). Convincingly, CNVs are not observed for most LHVs regions, suggesting that the LHVs are not associated with CNVs, a potential confounder for LHV calling. There are almost no overlapping LHVs across the three family members. This is expected since LHVs are results of somatic mutations, which do not usually re-occur in different individuals. Under the most stringent filter, on average 400–500 LHVs are reported per genome using the WGS data in CEU trio compared with 4–5 per exome using the WES data from the HNC sample.
Figure 7.
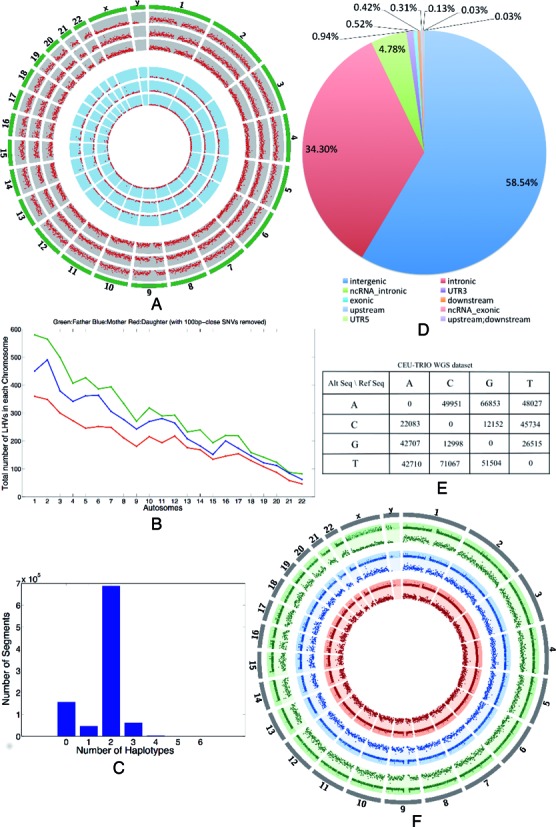
LHV calls for normal samples from a CEU trio of father, mother and daughter in the 1000 genome project based on WGS data. (A) A circos plot of prevalence of LHVs. Outer three arcs and inner three arcs represent results of TRIO samples filtered by type III filter and type I filter, respectively. See ‘Materials and Methods’ section for details of the filters. Each red dot indicates the existence of at least one LHV in the corresponding genomic region of 1M bp. The height of a red dot indicates the number of LHVs present in the region. (B) Comparison of the three family members in the number of LHVs per chromosome. The daughter has the smallest and the father has the largest number of LHVs in all chromosomes (autosome). (C) Histogram showing the frequencies of DNA segments (vertical axis) with different numbers of haplotype calls (horizontal axis). Most segments have up to two haplotypes indicating no variant. Segments with greater than two haplotypes are variants implying genome mosaicism. (D) Functional annotations of the genome regions where LHVs are found. Most are intergenic and intronic, with <1% LHVs in exons. (E) Summary of sequence mutations for the SNVs within called LHVs. Transitions are much more prevalent than transversions. (F) Copy number calls based on CNVnator (38) are directly compared with LHVs for all three family members. In most cases, there are no copy number variations on genome regions where LHVs are found. Copy numbers are represented in the outer arc and LHVs are shown in the adjacent inner arc in the same color for each sample.
Table 2 summarizes the statistics from the unfiltered hcf file from one particular sample (NA12891) in this dataset.
Table 2. Statistics from hcf file of a sample from CEU trio dataset.
| No. of variants | Segments with no. of significant haplotypes | Segments with more than three variants | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (lr)2–10 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | (Not analyzed) |
| 6378548 | 43322 | 17216 | 232750 | 22839 | 1430 | 54 | 2 | 0 | 0 | 196078 |
Validation
In order to validate our results, we sequenced whole blood DNA from three members of a parent–child trio using two different sequencing platforms, Complete Genomics, Inc. (CGI) (http://www.completegenomics.com/documents/DataFileFormats_Standard_Pipeline_2.5.pdf, http://cgatools.sourceforge.net/docs/1.8.0/cgatools-user-guide.pdf) and Illumina whole genome sequencing (ILMN) (http://www.illumina.com/applications/sequencing.html). All members of the trio were healthy. Their blood samples were collected between 2007 and 2012 and sequenced by CGI in 2012 (39). We also sequenced DNA from the same three samples using the ILMN platform in 2014. Because ILMN and CGI utilized different sequencing technologies and the sequencing experiments were performed at separate times by more than 2 years apart, results from the two sequencing experiments serve to validate each other.
NGS data produced by both technologies were analyzed using the LocHap pipeline. At the end, for each of the two datasets we generated a list of LHV. We then overlapped the two lists of LHVs, and identified shared LHVs between both datasets. Nine LHVs overlapped between the two datasets in the child; 10 LHVs overlapped in the mother and 15 LHVs overlapped in the father. We applied highly stringent filtering rules (Supplemental Data) to ensure high quality of the reported LHVs, although such filtering could also remove true LHVs with weak confidence. Also, many LHVs were excluded due to insufficient evidence from the CGI data. Figure 8 shows the locations of LHVs for the CGI and ILMN data. Figure 9 presents two LHV examples that are shared between CGI and ILMN data. For these two LHVs, the short reads provide direct evidence of somatic mosaicism—the reads suggest that at least three LHs must be present.
Figure 8.
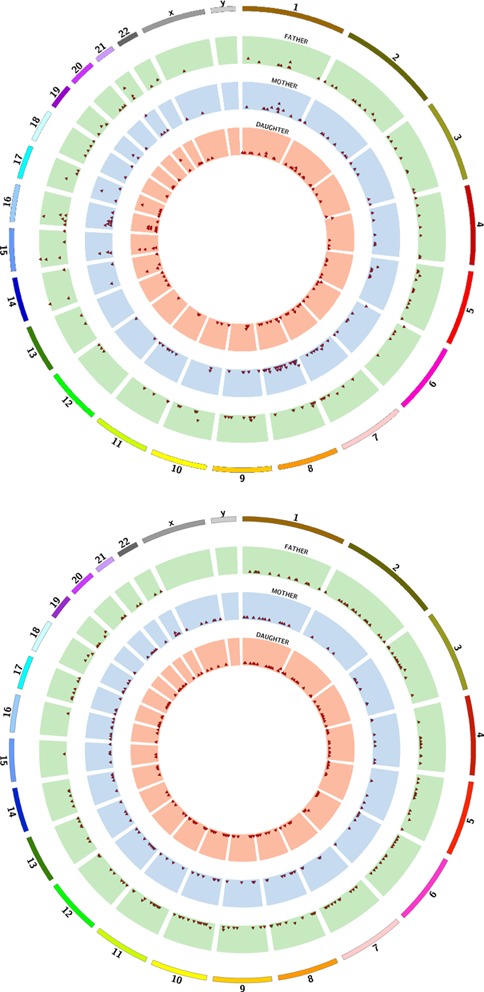
Summary of the LHVs found in the father, mother and daughter of a family based on both Illumina (ILMN) and CGI data. The ages are 57, 47 and 22, respectively. Top panel: A circos plot of prevalence of LHVs for ILMN data. The three colored rings describe the genome-wide prevalence and locations of the LHVs for the three family members. Each red triangle dot indicates the existence of at least one LHV in the corresponding genomic region of 1M bp. The higher a red dot resides, the larger number of LHVs present in the region. Bottom panel: a circos plot of prevalence of LHVs for CGI data. The plot follows the same arrangement as in the top panel.
Figure 9.
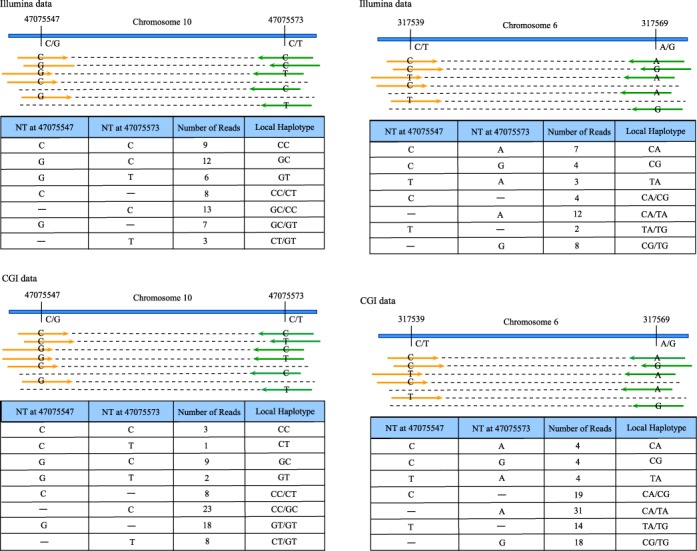
Two examples of LHVs that overlap between CGI and ILMN data. LHV1 consists of two single nucleotide variants (SNVs) separated by 26 bps on Chromosome 10. For the ILMN data (top tables), among all the short reads mapped to this region, 9, 12 and 6 short reads are mapped to both SNVs and exhibit genotypes CC, GC and GT, respectively. For the CGI data (bottom tables), those numbers are 3, 9 and 2 respectively. Also, many other reads are mapped to one of the SNVs for both data, which reinforces the finding. Statistical inference shows high significance supporting more than two haplotypes in the region. LHV 2 consists of two SNVs separated by 30 bp. For the ILMN data, 7, 4 and 3 reads are mapped to both SNVs with genotypes CA, CG and TA, respectively. Those numbers are 4, 4 and 4 for the CGI data.
These analyses provide evidence supporting our hypothesis that normal cells in a healthy person could be genetically heterogeneous and possess distinct populations of somatic cells, a phenomenon also observed in (5). Specifically, in all three individuals there are LHVs that are discovered by independent sequencing platforms from different experimentalists at different times.
DISCUSSION
Through a novel means of analyzing NGS data, LocHap attempts to reveal potential somatic mosaicism in the form of LHVs. We implement Bayesian hierarchical models that borrow strength from the mapped short reads to infer the number and sequences of LHVs genome-wide. In applications of LocHap using deep-sequencing data, we provide evidence that supports the existence of normal somatic mosaicism (NSM) and tumor somatic mosaicism (TSM) at single-nucleotide level. Applying LocHap to 30 matched blood and tumor samples, we find LHVs in exomes of normal blood and tumor samples. The frequencies of LHVs are in general higher in tumor samples (one-sided paired t-test, P-value < 0.0001). Performing the analysis on CEU trio from the 1000-genome project, we confirm the findings of genome-wide LHVs and also identify an increasing trend of LHV occurrences with aging (chi-squared test (40) for trend, P-value < 0.0001). Based on our results, we propose three hypotheses that deserve future investigation.
Similar to cancer cells, non-cancer cells undergo random mutation events that could potentially lead to subclonal cell populations, resulting in genome-wide somatic mosaicism within individuals.
The probability of acquiring NSM increases with the age of an individual, owning to accumulating mutation burden.
In general, TSM is more prevalent than NSM.
LocHap is different from existing subclonal callers (35,41–47) in a fundamentally distinct way. LocHap provides direct evidence (e.g., examples in Figure 1) of genome mosaicism in both non-cancer and cancer cells. The units of analysis under LocHap are haplotypes, each as a scaffold of SNVs. In contrast, most subclone callers in the literature analyze allelic fractions of individual SNVs. We argue that LocHap provides a more direct view on genome mosaicism for somatic samples. The power of detecting LHVs is affected by the length of paired-end reads and coverage. In this context, it is important to note that an unexpected insert size in a paired-end read is handled by either initial choice of the value K (if it is too large) or by using a post-processing filter (if it is too small). In addition, our analysis does not include paired-end reads that are not properly mapped since these reads do not provide reliable information about LHVs.
Naturally, sequencing coverage, quality and read length affect the performance of LocHap. Deeper coverage allows LHVs with small population frequencies in the sample to be detected. Longer read length (and/or insert length) allows SNVs that are farther apart to be phased and therefore improve the chance of detecting LHVs. In our WES data our coverage was about 30× with read length 75 bps and in WGS data we have about 60× coverage with read length 100 bps. We found that our LocHap performed well in reporting LHVs under these conditions. For detail of all the bioinformatics pipelines, filters and parameters, we refer the readers to the Supplemental Data.
Our main purpose is not to identify all the LHVs in the genome. Instead, we aim to utilize existing short-read NGS data and provide a new method for detecting sample heterogeneity and mosaicism based on LHVs. Presence of LHVs itself supports mosaicism since a homogeneous human biological sample cannot harbor LHVs.
LocHap is available at http://www.compgenome.org/lochap/ for free download. A manual is provided along with the software. It is ultrafast in calling LHVs. For one WES sample with about 30× depth of coverage, whole-exome LHV calling by LocHap took about 11 s on a Macbook Pro (2.8GHZ Intel Core i7 and 16GB 1600 MHz DDR3 memory). For each WGS dataset with about 60× depth of coverage the analysis took about 47 s.
Cellular mosaicism based on LHVs would facilitate studies on heterogeneity of cell populations. Availability of NGS data allows for more powerful investigation of somatic cell subpopulations. The resolution of analysis can be at single nucleotide level, as opposed to mega-bases for microarray data. Further validation of somatic mosaicism and its relationship to aging and diseases is needed using much bigger sample sizes. Such effort could help us reveal and quantify heterogeneity in non-cancer and cancer samples, potentially affecting cancer diagnosis and prognosis.
CONCLUSION
Through LocHap we provide a new approach to extract information of LHs from NGS data for a single sample. We found wide-spread LHVs across genome in both tumor and non-tumor samples. These results and software tools can be used for further investigation of somatic mosaicism in human samples, helping investigators to understand the frequency and genome locations of mosaic events. Thanks to the ultrafast speed of LocHap, it can be used to analyze a large number of samples using a single computer or a small cluster. The newly developed hcf files follow the existing format standards for vcf files and can be visualized in the popular tool IGV.
Supplementary Material
Acknowledgments
We thank the anonymous reviewers for their helpful comments and suggestions which helped us to improve the quality of the paper. We also thank Dr. Peter W. Faber who is the technical director of the University of Chicago Genomic Facility for helping us to carry out the sequencing experiment for the parent-child trio needed for validation.
SUPPLEMENTARY DATA
Supplementary Data are available at NAR Online.
FUNDING
Yuan Ji's research is partially supported by NIH [R01 CA132897] and The University BIG Award from the University of Chicago. Carole Ober's research is partially supported by NIH [R01 HD21244] and NIH [R01 HL085197].
Conflict of interest statement. None declared.
REFERENCES
- 1.Gerlinger M., Rowan A., Horswell S., Larkin J., Endesfelder D., Gronroos E., Martinez P., Matthews N., Stewart A., Tarpey P., et al. Intratumor heterogeneity and branched evolution revealed by multiregion sequencing. N. Engl. J. Med. 2012;366:883–892. doi: 10.1056/NEJMoa1113205. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Wang Y., Waters J., Leung M.L., Unruh A., Roh W., Shi X., Chen K., Scheet P., Vattathil S., Liang H., et al. Clonal evolution in breast cancer revealed by single nucleus genome sequencing. Nature. 2014;512:155–160. doi: 10.1038/nature13600. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Lupski J.R. Genome Mosaicism–one human, multiple genomes. Science. 2013;341:358–359. doi: 10.1126/science.1239503. [DOI] [PubMed] [Google Scholar]
- 4.Youssoufian H., Pyeritz R.E. Mechanisms and consequences of somatic mosaicism in humans. Nat. Rev. Genet. 2002;3:748–758. doi: 10.1038/nrg906. [DOI] [PubMed] [Google Scholar]
- 5.Genovese G., Kähler A.K., Handsaker R.E., Lindberg J., Rose S.A., Bakhoum S.F., Chambert K., Mick E., Neale B.M., Fromer M., et al. Clonal hematopoiesis and blood-cancer risk inferred from blood DNA sequence. N. Engl. J. Med. 2014;371:2477–2487. doi: 10.1056/NEJMoa1409405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Shapiro E., Biezuner T., Linnarsson S. Single-cell sequencing-based technologies will revolutionize whole-organism science. Nat. Rev. Genet. 2013;14:618–630. doi: 10.1038/nrg3542. [DOI] [PubMed] [Google Scholar]
- 7.Lander E.S., Linton L.M., Birren B., Nusbaum C., Zody M.C., Baldwin J., Devon K., Dewar K., Doyle M., FitzHugh W., et al. Initial sequencing and analysis of the human genome. Nature. 2001;409:860–921. doi: 10.1038/35057062. [DOI] [PubMed] [Google Scholar]
- 8.Russnes H.G., Navin N., Hicks J., Borresen-Dale A.-L. Insight into the heterogeneity of breast cancer through next-generation sequencing. J Clin. Invest. 2011;121:3810–3818. doi: 10.1172/JCI57088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Navin N., Krasnitz A., Rodgers L., Cook K., Meth J., Kendall J., Riggs M., Eberling Y., Troge J., Grubor V., et al. Inferring tumor progression from genomic heterogeneity. Genome Res. 2010;20:68–80. doi: 10.1101/gr.099622.109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Frank S.A. Somatic mosaicism and cancer: inference based on a conditional Luria–Delbrück distribution. J. Theor. Biol. 2003;223:405–412. doi: 10.1016/s0022-5193(03)00117-6. [DOI] [PubMed] [Google Scholar]
- 11.Frank S.A. Somatic evolutionary genomics: mutations during development cause highly variable genetic mosaicism with risk of cancer and neurodegeneration. Proc. Natl. Acad. Sci. 2010;107(Suppl. 1):1725–1730. doi: 10.1073/pnas.0909343106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Frank S.A. Somatic mosaicism and disease. Curr. Biol. 2014;24:R577–R581. doi: 10.1016/j.cub.2014.05.021. [DOI] [PubMed] [Google Scholar]
- 13.O'Huallachain M., Karczewski K.J., Weissman S.M., Urban A.E., Snyder M.P. Extensive genetic variation in somatic human tissues. Proc. Natl. Acad. Sci. 2012;109:18018–18023. doi: 10.1073/pnas.1213736109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Abyzov A., Mariani J., Palejev D., Zhang Y., Haney M.S., Tomasini L., Ferrandino A.F., Rosenberg Belmaker L.A., Szekely A., Wilson M., et al. Somatic copy number mosaicism in human skin revealed by induced pluripotent stem cells. Nature. 2012;492:438–442. doi: 10.1038/nature11629. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Nagata N., Yamanaka S. Perspectives for induced pluripotent stem cell technology new insights into human physiology involved in somatic mosaicism. Circ. Res. 2014;114:505–510. doi: 10.1161/CIRCRESAHA.114.303043. [DOI] [PubMed] [Google Scholar]
- 16.Forsberg L.A., Rasi C., Razzaghian H.R., Pakalapati G., Waite L., Thilbeault K.S., Ronowicz A., Wineinger N.E., Tiwari H.K., Boomsma D., et al. Age-related somatic structural changes in the nuclear genome of human blood cells. Am. J. Hum. Genet. 2012;90:217–228. doi: 10.1016/j.ajhg.2011.12.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Laurie C.C., Laurie C.A., Rice K., Doheny K.F., Zelnick L.R., McHugh C.P., Ling H., Hetrick K.N., Pugh E.W., Amos C., et al. Detectable clonal mosaicism from birth to old age and its relationship to cancer. Nat. Genet. 2012;44:642–650. doi: 10.1038/ng.2271. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Jacobs K.B., Yeager M., Zhou W., Wacholder S., Wang Z., Rodriguez-Santiago B., Hutchinson A., Deng X., Liu C., Horner M.-J., et al. Detectable clonal mosaicism and its relationship to aging and cancer. Nat. Genet. 2012;44:651–658. doi: 10.1038/ng.2270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Schick U.M., McDavid A., Crane P.K., Weston N., Ehrlich K., Newton K.M., Wallace R., Bookman E., Harrison T., Aragaki A., et al. Confirmation of the reported association of clonal chromosomal mosaicism with an increased risk of incident hematologic cancer. PLoS One. 2013;8:e59823. doi: 10.1371/journal.pone.0059823. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Forsberg L.A., Rasi C., Malmqvist N., Davies H., Pasupulati S., Pakalapati G., Sandgren J., de StÃ¥hl T.D., Zaghlool A., Giedraitis V., et al. Mosaic loss of chromosome Y in peripheral blood is associated with shorter survival and higher risk of cancer. Nat. Genet. 2014;46:624–628. doi: 10.1038/ng.2966. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Li H. Towards better understanding of artifacts in variant calling from high-coverage samples. Bioinformatics. 2014;30:2843–2851. doi: 10.1093/bioinformatics/btu356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Thorvaldsdóttir H., Robinson J.T., Mesirov J.P. Integrative Genomics Viewer (IGV): high-performance genomics data visualization and exploration. Brief. Bioinform. 2013;14:178–192. doi: 10.1093/bib/bbs017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Newton M.A., Noueiry A., Sarkar D., Ahlquist P. Detecting differential gene expression with a semiparametric hierarchical mixture method. Biostatistics. 2004;5:155–176. doi: 10.1093/biostatistics/5.2.155. [DOI] [PubMed] [Google Scholar]
- 24.Müller P., Parmigiani G., Robert C., Rousseau J. Optimal sample size for multiple testing: the case of gene expression microarrays. J. Am. Stat. Assoc. 2004;99:990–1001. [Google Scholar]
- 25.Rubin D.B. Inference and missing data. Biometrika. 1976;63:581–592. [Google Scholar]
- 26.Ji Y., Xu Y., Zhang Q., Tsui K.-W., Yuan Y., Norris C., Jr, Liang S., Liang H. BM-Map: bayesian mapping of multireads for next-generation sequencing data. Biometrics. 2011;67:1215–1224. doi: 10.1111/j.1541-0420.2011.01605.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.McKenna A., Hanna M., Banks E., Sivachenko A., Cibulskis K., Kernytsky A., Garimella K., Altshuler D., Gabriel S., Daly M., et al. The genome analysis toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 2010;20:1297–1303. doi: 10.1101/gr.107524.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.DePristo M.A., Banks E., Poplin R., Garimella K.V., Maguire J.R., Hartl C., Philippakis A.A., del Angel G., Rivas M.A., Hanna M., et al. A framework for variation discovery and genotyping using next-generation DNA sequencing data. Nat. Genet. 2011;43:491–498. doi: 10.1038/ng.806. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Auwera G.A., Carneiro M.O., Hartl C., Poplin R., del Angel G., Levy-Moonshine A., Jordan T., Shakir K., Roazen D., Thibault J., et al. From FastQ data to high-confidence variant calls: the genome analysis toolkit best practices pipeline. Curr. Protoc. Bioinform. 2013;43:11–10. doi: 10.1002/0471250953.bi1110s43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Meacham F., Boffelli D., Dhahbi J., Martin D.I., Singer M., Pachter L. Identification and correction of systematic error in high-throughput sequence data. BMC Bioinformatics. 2011;12:451. doi: 10.1186/1471-2105-12-451. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Dohm J.C., Lottaz C., Borodina T., Himmelbauer H. Substantial biases in ultra-short read data sets from high-throughput DNA sequencing. Nucleic Acids Res. 2008;36:e105. doi: 10.1093/nar/gkn425. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Guo Y., Li J., Li C.-I., Long J., Samuels D.C., Shyr Y. The effect of strand bias in Illumina short-read sequencing data. BMC Genomics. 2012;13:666. doi: 10.1186/1471-2164-13-666. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Kimura M. The number of heterozygous nucleotide sites maintained in a finite population due to steady flux of mutations. Genetics. 1969;61:893–903. doi: 10.1093/genetics/61.4.893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Hudson R.R. Properties of a neutral allele model with intragenic recombination. Theor. Popul. Biol. 1983;23:183–201. doi: 10.1016/0040-5809(83)90013-8. [DOI] [PubMed] [Google Scholar]
- 35.Jiao W., Vembu S., Deshwar A.G., Stein L., Morris Q. Inferring clonal evolution of tumors from single nucleotide somatic mutations. BMC Bioinformatics. 2014;15:35. doi: 10.1186/1471-2105-15-35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Stransky N., Egloff A.M., Tward A.D., Kostic A.D., Cibulskis K., Sivachenko A., Kryukov G.V., Lawrence M.S., Sougnez C., McKenna A., et al. The mutational landscape of head and neck squamous cell carcinoma. Science. 2011;333:1157–1160. doi: 10.1126/science.1208130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Krzywinski M., Schein J., Birol İ., Connors J., Gascoyne R., Horsman D., Jones S.J., Marra M.A. Circos: an information aesthetic for comparative genomics. Genome Res. 2009;19:1639–1645. doi: 10.1101/gr.092759.109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Abyzov A., Urban A.E., Snyder M., Gerstein M. CNVnator: an approach to discover, genotype, and characterize typical and atypical CNVs from family and population genome sequencing. Genome Res. 2011;21:974–984. doi: 10.1101/gr.114876.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Livne O.E., Han L., Alkorta-Aranburu G., Wentworth-Sheilds W., Abney M., Ober C., Nicolae D.L. PRIMAL: fast and accurate pedigree-based imputation from sequence data in a founder population. PLoS Comput. Biol. 2015;11:e1004139. doi: 10.1371/journal.pcbi.1004139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Agresti A. Categorical data analysis. Hoboken: John Wiley & Sons; 2002. [Google Scholar]
- 41.Roth A., Khattra J., Yap D., Wan A., Laks E., Biele J., Ha G., Aparicio S., Bouchard-Côté A., Shah S.P. PyClone: statistical inference of clonal population structure in cancer. Nat. Methods. 2014;11:396–398. doi: 10.1038/nmeth.2883. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Oesper L., Mahmoody A., Raphael B.J. THetA: inferring intra-tumor heterogeneity from high-throughput DNA sequencing data. Genome Biol. 2013;14:R80. doi: 10.1186/gb-2013-14-7-r80. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Strino F., Parisi F., Micsinai M., Kluger Y. TrAp: a tree approach for fingerprinting subclonal tumor composition. Nucleic Acids Res. 2013;41:e165. doi: 10.1093/nar/gkt641. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Chen M., Gunel M., Zhao H. Somatica: Identifying, characterizing and quantifying somatic copy number aberrations from cancer genome sequencing data. PloS One. 2013;8:e78143. doi: 10.1371/journal.pone.0078143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Andor N., Harness J.V., Mueller S., Mewes H.W., Petritsch C. EXPANDS: expanding ploidy and allele frequency on nested subpopulations. Bioinformatics. 2014;30:50–60. doi: 10.1093/bioinformatics/btt622. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Fischer A., Vázquez-García I., Illingworth C.J., Mustonen V. High-definition reconstruction of clonal composition in cancer. Cell Rep. 2014;7:1740–1752. doi: 10.1016/j.celrep.2014.04.055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Deshwar A.G., Vembu S., Yung C.K., Jang G.H., Stein L., Morris Q. PhyloWGS: reconstructing subclonal composition and evolution from whole-genome sequencing of tumors. Genome Biol. 2015;16:35. doi: 10.1186/s13059-015-0602-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.