

Abstract
The most critical attribute of human language is its unbounded combinatorial nature: smaller elements can be combined into larger structures based on a grammatical system, resulting in a hierarchy of linguistic units, e.g., words, phrases, and sentences. Mentally parsing and representing such structures, however, poses challenges for speech comprehension. In speech, hierarchical linguistic structures do not have boundaries clearly defined by acoustic cues and must therefore be internally and incrementally constructed during comprehension. Here we demonstrate that during listening to connected speech, cortical activity of different time scales concurrently tracks the time course of abstract linguistic structures at different hierarchical levels, e.g. words, phrases, and sentences. Critically, the neural tracking of hierarchical linguistic structures is dissociated from the encoding of acoustic cues as well as from the predictability of incoming words. The results demonstrate that a hierarchy of neural processing timescales underlies grammar-based internal construction of hierarchical linguistic structure.
Introduction
To understand connected speech, listeners must construct a hierarchy of linguistic structures of different sizes, including syllables, words, phrases, and sentences1–3. It remains puzzling how the brain simultaneously handles the distinct time scales of the different linguistic structures, e.g., from a few hundred milliseconds for syllables to a few seconds for sentences4–14. Previous studies have suggested that cortical activity is synchronized to acoustic features of speech, approximately at the syllabic rate, providing an initial time scale for speech processing15–19. But how the brain utilizes such syllabic-level phonological representations closely aligned with the physical input to build multiple levels of abstract linguistic structure, and represent these concurrently, is not known. Here we hypothesize that cortical dynamics emerge at all time scales required for the processing of different linguistic levels, including the time scales corresponding to larger linguistic structures such as phrases and sentences, and that the neural representation of each linguistic level corresponds to time scales matching the time scales of the respective linguistic level.
Although linguistic structure building can clearly benefit from prosodic20, 21 or statistical cues22, it can also be achieved purely based on the listeners' grammatical knowledge. To isolate experimentally the neural representation of the internally constructed hierarchical linguistic structure, we developed novel speech materials wherein the linguistic constituent structure was dissociated from prosodic or statistical cues. We manipulated the levels of linguistic abstraction to demonstrate separable neural encoding of each different linguistic level.
Results
Cortical Tracking of Phrasal and Sentential Structures
In the first set of experiments, we sought to determine the neural representation of hierarchical linguistic structure in the absence of prosodic cues. We constructed hierarchical linguistic structures using an isochronous, 4 Hz sequence of syllables that were independently synthesized (Fig. 1ab, Supplementary Fig. 1, Supplementary Table 1). Due to the acoustic independence between syllables (i.e., no coarticulation), the linguistic constituent structure could only be extracted using lexical, syntactic, and semantic knowledge, but not prosodic cues. The materials were first developed in Mandarin Chinese, in which syllables are relatively uniform in duration and are also the basic morphological unit (always morphemes, and in most cases monosyllabic words). Cortical activity was recorded from native listeners of Mandarin Chinese using magnetoencephalography (MEG). Since different linguistic levels, i.e. the monosyllabic morphemes, phrases, and sentences, were presented at unique and constant rates, the hypothesized neural tracking of hierarchical linguistic structure was tagged at distinct frequencies.
Fig. 1.
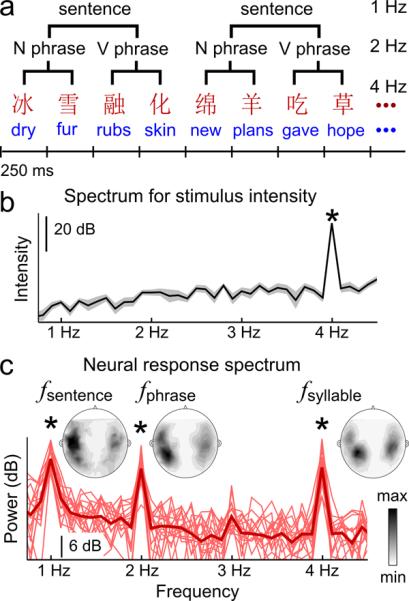
Neural tracking of hierarchical linguistic structures. a, Sequences of Chinese or English monosyllabic words are presented isochronously, forming phrases and sentences. b, Spectrum of stimulus intensity fluctuation reveals syllabic rhythm but no phrasal or sentential modulation. The shaded area covers 2 SEM across stimuli. c, MEG-derived cortical response spectrum for Chinese listeners/materials (bold curve: grand average; thin curves: individual listeners, N = 16; 0.11 Hz frequency resolution).. Neural tracking of syllabic, phrasal, and sentential rhythms is reflected by spectral peaks at corresponding frequencies. Frequency bins with significantly stronger power than neighbors (0.5 Hz range) are marked (* P< 0.001, paired one-sided t-test, FDR corrected). The topographical maps of response power across sensors are shown for the peak frequencies.
The MEG response was analyzed in the frequency domain, and we extracted response power in every frequency bin using an optimal spatial filter (see Methods). In line with our hypothesis, the response spectrum shows 3 peaks: at the syllabic rate (P = 1.4 × 10−5, paired one-sided t-test, FDR-corrected), phrasal rate (P = 1.6 × 10−4, paired one-sided t-test, FDR-corrected), and sentential rate (P = 9.6 × 10−7, paired one-sided t-test, FDR-corrected), respectively, and the response is highly consistent across listeners (Fig. 1c). Since the phrasal- and sentential-rate rhythms are not conveyed by acoustic fluctuations at the corresponding frequencies (Fig. 1b), cortical responses at the phrasal and sentential rates must be a consequence of internal online structure building processes. Cortical activity at all the 3 peak frequencies is seen bilaterally (Fig. 1c, contour plot inserts). The response power averaged over sensors in each hemisphere is significantly stronger in the left hemisphere at the sentential rate (P = 0.014, paired two-sided t-test) but not at the phrasal (P = 0.20, paired two-sided t-test) or syllabic rates (P = 0.40, paired two-sided t-test).
Dependence on Syntactic Structures
Are the responses at the phrasal and sentential rates indeed separate neural indices of processing at distinct linguistic levels, or are they merely sub-harmonics of the syllabic rate response, generated by intrinsic cortical dynamical properties? We address this question by manipulating different levels of linguistic structure in the input. When the stimulus is a sequence of random syllables that preserves the acoustic properties of Chinese sentences (Fig. 1) but eliminates the phrasal/sentential structure, only syllabic (acoustic) level tracking occurs (Fig.2a, Supplementary Fig. 2, P = 1.1 × 10−4 at 4 Hz, paired one-sided t-test, FDR-corrected). Furthermore, this manipulation preserves the position of each syllable within a sentence (see Methods) and therefore further demonstrates that the phrasal- and sentential-rate responses are not due to possible acoustic differences between the syllables within a sentence. When two adjacent syllables/morphemes combine into verb phrases but there is no 4-element sentential structure, phrasal-level tracking emerges at 1/2 of the syllabic rate (Fig. 2b, P = 8.6 × 10−4 at 2 Hz and P = 2.7 × 10−4 at 4 Hz, paired one-sided t-test, FDR-corrected). Similar responses are observed for noun phrases (Supplementary Fig. 3).
Fig. 2.

Tracking of different linguistic structures. Each panel: syntactic structure repeating in the stimulus (left) and the cortical response spectrum (right; shaded area: 2SEM over listeners, N = 8). a, Chinese listeners, Chinese materials: syllables are syntactically independent, cortical activity encodes only acoustic/syllabic rhythm. b, c, Additional tracking emerges with larger linguistic structures. Spectral peaks marked by a star (black: P< 0.001; gray: P< 0.005: paired one-sided t-test, FDR corrected). d, English listeners, Chinese materials from Fig. 1: acoustic tracking only, since no parsable structure e, f, English listeners, English materials: syllabic rate (4/1.28 Hz) and sentential/phrasal rate responses to parsable structure in stimulus.
To test whether the phrase-level responses segregate from the sentence level, longer verb phrases were constructed which were unevenly divided into a monosyllabic verb followed by a 3-syllable noun phrase (Fig. 2c). We expect the neural responses to the long verb phrase to be tagged at 1 Hz while the neural responses to the monosyllabic verb and the 3-syllable noun phrase will present as harmonics of 1 Hz. In line with our hypothesis, cortical dynamics emerges at 1/4 of the syllabic rate while the response at 1/2 of the syllabic rate is no longer detectable (P = 1.9 × 10−4, 1.7 × 10−4, and 9.3 × 10−4 at 1, 3, and 4 Hz respectively, paired one-sided t-test, FDR-corrected).
Dependence on Language Comprehension
When listening to Chinese sentences (Fig. 1a), listeners who did not understand Chinese only showed responses to the syllabic (acoustic) rhythm (Fig. 2d, P = 3.0 × 10−5 at 4 Hz, paired one-sided t-test, FDR-corrected), further supporting the argument that cortical responses to larger, abstract linguistic structures is a direct consequence of language comprehension.
If aligning cortical dynamics to the time course of linguistic constituent structure is a general mechanism required for comprehension, it must apply across languages. Indeed, when native English speakers were tested with English materials (Fig. 1a), their cortical activity also followed the time course of larger linguistic structures, i.e. phrases and sentences (Fig. 2ef, P = 3.9 × 10−3, 4.3 × 10−3, and 6.8 × 10−6 at the sentential, phrasal, and syllabic rates respectively in Fig. 2f and P = 4.1 × 10−5 at the syllabic rate in Fig. 2e, paired one-sided t-test, FDR-corrected).
Neural Tracking of Linguistic Structures Rather than Probability Cues
It is demonstrated that concurrent neural tracking of multiple levels of linguistic structure is not confounded with the encoding of acoustic cues (Figs. 1 and 2). However, is it simply explained by the neural tracking of the predictability of smaller units? As a larger linguistic structure, e.g. a sentence, unfolds in time, its component units become more predictable. Therefore, cortical networks solely tracking transitional probabilities across smaller units could show temporal dynamics matching the time scale of larger structures. To test this alternative hypothesis, we crafted a constant transitional probability Markovian Sentence Set (MSS) wherein the transitional probability of lower-level units was dissociated from the higher-level structures (Fig. 3a, Supplementary Fig. 1ef). The constant transitional probability MSS is contrasted with a varying transitional probability MSS, in which the transitional probability is low across sentential boundaries and high within a sentence (Fig. 3bc). If cortical activity only encodes the transitional probability between lower-level units (e.g. acoustic chunks in the MSS) independent of the underlying syntactic structure, it can show tracking of the sentential structure for the varying probability MSS but not for the constant probability MSS. In contrast to this prediction, indistinguishable neural responses to sentences are observed for both MSS (Fig. 3d), demonstrating that neural tracking of sentences is not confounded by transitional probability. Specifically, for the constant transitional probability MSS, the response is statistically significant at the sentential rate, two times the sentential rate, and the syllable rate (P = 1.8 × 10−4, 2.3 × 10−4, and 2.7 × 10−6 respectively). For the varying transitional probability MSS, the response is statistically significant at the sentential rate, two times the sentential rate, and the syllable rate (P = 7.1 × 10−4, 7.1 × 10−4, and 4.8 × 10−6 respectively).
Fig. 3.

Dissociating sentential structures and transitional probability. Grammar of an artificial Markovian stimulus set with constant (a) or variable (b) transitional probability. Each sentence consists of 3 acoustic chunks, each containing 1–2 English words. The listeners memorize the grammar before experiments. c, Schematic timecourse and spectrum of the transitional probability. d, Neural response spectrum, the shaded area covering 2 SEM over listeners (N = 8). Significant neural responses to sentences seen for both languages. Spectral peaks shown by a star (P< 0.001, paired one-sided t-test, FDR corrected, same color code as the spectrum). Responses are not significantly different between the two languages in any frequency bin (paired two-sided t-test, P> 0.09, uncorrected).
Since the MSS involved real English sentences, listeners had prior knowledge of the transitional probabilities between acoustic chunks. To control for the effect of such prior knowledge, we additionally created a set of Artificial Markovian Sentences (AMS). In the AMS, the transitional probability between syllables was the same within and across sentences (Supplementary Fig. 4a). The AMS was composed of Chinese syllables, but no meaningful Chinese expressions were embedded in the AMS sequences. Since the AMS was not based on the grammar of Chinese, the listeners had to learn the AMS grammar in order to segment sentences. By comparing the neural responses to the AMS sequences before and after the grammar was learned, we could separate the effect of prior knowledge of transitional probability and the effect of grammar learning. Here, the grammar of the AMS indicates the set of rules that governs the sequencing of the AMS, i.e. the rule which syllables can follow which syllables.
The neural responses to the AMS before and after grammar learning were analyzed separately (Supplementary Fig. 4). Before learning, when the listeners were instructed that the stimulus was just a sequence of random syllables, the response showed a statistically significant peak at the syllabic rate (P = 0.0003, bootstrap), but not at the sentential rate. After the AMS grammar was learned, however, a significant response peak emerged at the sentential rate (P = 0.0001, bootstrap). A response peak was also observed at two times the sentential rate, possibly reflecting the 2nd harmonic of the sentential response. This result further confirms that neural tracking of sentences is not confounded by neural tracking of transitional probability.
Neural Tracking of Sentences Varying in Duration and Structure
The above results are based on sequences of sentences that have uniform duration and syntactic structure. Next we address whether cortical tracking of larger linguistic structures generalizes to sentences that are variable in duration (4–8 syllables) and syntactic structures. These sentences were again built on isochronous Chinese syllables, intermixed and sequentially presented without any acoustic gap at the sentence boundaries. Examples translated into English include: “Don't be nervous,” “The book is hard to read,” “Over the street is a museum.”
Since these sentences have irregular durations that are not tagged by frequency, the MEG responses were analyzed in the time domain by averaging sentences of the same duration. To focus on sentential level processing, the response was low-pass filtered at 3.5 Hz. The MEG response (root-mean-square, RMS, over all sensors) rapidly increases after a sentence boundary and continuously changes throughout the duration of a sentence (Fig. 4a). To illustrate the detailed temporal dynamics, we averaged the RMS response over all sentences containing 6 or more syllables after aligning them to the sentence offset (Fig. 4b). During the last 4 syllables of a sentence, the RMS response continuously and significantly decreases for every syllable (shaded squares), demonstrating that the neural response continuously changes during the course of a sentence rather than being a transient response only occurring at the sentence boundary.
Fig. 4.

Neural tracking of sentences of varying structures. a, Neural activity tracks the sentence duration, even when the sentence boundaries (dotted lines) not separated by acoustic gaps. b, Averaged response near a sentential boundary (dotted line). The power continuously changes throughout the duration of a sentence. Shaded area covers 2 SEM over listeners (N = 8). Significance power differences between time bins (shaded squares) marked by stars, significance level P = 0.01 (one-sided t-test, FDR corrected). c, Confusion matrix for neural decoding of the sentence duration. d, Neural activity tracks noun phrase duration (shown in the bottom). Yellow areas: significant differences between curves, significance level P = 0.005 (bootstrap, FDR corrected).
A single-trial decoding analysis was performed to confirm independently that cortical activity tracks the duration of sentences (Fig. 4c). The decoder applies template matching for the response time course (leave-one-out cross-validation, see Methods), and correctly determines the duration of 34.9 ± 0.6% sentences (mean ± SEM over subjects, significantly above chance, P = 1.3 × 10−7, one-sided t-test).
After demonstrating cortical tracking of sentences, we further tested if cortical activity also tracks the phrasal structure inside of a sentence. We constructed sentences that consist of a noun phrase followed by a verb phrase and manipulated the duration of the noun phrase (3-syllable or 4-syllable). The cortical responses closely follow the duration of the noun phrase: The RMS response gradually decreases within the noun phrase, then shows a transient increase after the onset of the verb phrase (Fig. 4d).
Neural Source Localization using Electrocorticography (ECoG)
Large-scale neural activity measured by MEG is shown to concurrently follow the hierarchical linguistic structure of speech, but which neural networks generate such activity? To address this question, we recorded the ECoG responses to English sentences (Fig. 2e) and an acoustic control (Fig. 2f). ECoG signals are mesoscopic neurophysiological signals recorded by intracranial electrodes implanted in epilepsy patients for clinical evaluation (see Supplementary Fig. 5 for the electrode coverage), and they possess better spatial resolution than MEG. We first analyzed the power of the ECoG signal in the high gamma band (70–200 Hz) as it highly correlated with multiunit firing23. The electrodes exhibiting significant sentential, phrasal and syllabic rate fluctuations in high gamma power are shown separately (left panels of Fig. 5). The sentential rate response clusters over the posterior and middle superior temporal gyrus (pSTG), bilaterally, with a second cluster over the left inferior frontal gyrus (IFG). Phrasal rate responses are also observed over the pSTG bilaterally. Importantly, although the sentential and phrasal rate responses are observed in similar cortical areas, electrodes showing phrasal rate responses only partially overlap with electrodes showing sentential rate responses within the pSTG (Fig. 6). For electrodes showing a significant response at either the sentential rate or the phrasal rate, the strength of the sentential rate response is negatively correlated with the strength of the phrasal rate response (R = −0.32, P = 0.004, bootstrap). This phenomenon demonstrates spatially dissociable neural tracking of the sentential and phrasal structures.
Fig. 5.

Localizing cortical sources of the sentential and phrasal rate responses using ECoG (N = 5). The left panel is based on the power envelope of high-gamma activity, and the right panel is based on the waveform of low-frequency activity. Electrodes in the right hemisphere are projected to the left hemisphere and right-hemisphere (left-hemisphere) electrodes are shown by hollow (filled) circles. The figure only shows electrodes that show statistically significant neural responses to sentences in Fig. 2e and no significant response to the acoustic control shown in Fig. 2f. The significance tests in this figure are based on bootstrap (FDR-corrected) and the significance level is 0.05. The response strength, i.e. the response at the target frequency relative to the mean response averaged over a 1-Hz wide neighboring region, is color-coded. Electrodes with response strength less than 10 dB are shown by smaller symbols. The sentential and phrasal rate responses are seen in bilateral pSTG, TPJ, and left IFG.
Fig. 6.

Spatial dissociation between sentential-rate, phrasal-rate, and syllabic-rate responses (N = 5). a, The power spectrum of the power envelope of high-gamma activity. b, The power spectrum of low-frequency ECoG waveform. The top panels (green curves) show the response averaged over all electrodes that show a significant sentential-rate response but not a significant phrasal-rate response. All significance tests in this figure are based on bootstrap (FDR-corrected) and the significance level is 0.05. The shaded area is 1 standard deviation over electrodes on each side. The middle panels (blue curves) show the response averaged over all electrodes that show a significant phrasal-rate response but not a significant sentential-rate response. The bottom panels (red curves) show a significant sentential-rate or a significant phrasal-rate response, but not a significant syllabic response. cd, The topographic distribution of the three groups of electrodes analyzed in panels a and b. As in Fig. 5, electrodes showing a response greater than 10 dB are shown by larger symbols than electrodes showing a response weaker than 10 dB.
Furthermore, some electrodes with a significant sentential or phrasal rate response show no significant syllabic rate response (Fig. 6). In other words, there are cortical circuits specifically encoding larger, abstract linguistic structures without responding to syllabic-level acoustic features of speech. Additionally, although the syllabic responses are not significantly different for English sentences and the acoustic control in the MEG results, they are dissociable spatially in the ECoG results (Fig. 7). Electrodes showing significant syllabic responses to sentences but not the acoustic control are seen in bilateral pSTG, bilateral anterior STG (aSTG), and left IFG.
Fig. 7.

Syllabic-rate ECoG responses to English sentences and the acoustic control (N = 5). The top panel shows electrodes showing statistically significant syllabic-rate ECoG responses to the acoustic control, i.e. shuffled sequences, which has the same acoustic/syllabic rhythm as the English sentences but contains no hierarchical linguistic structures (Fig. 2f). The significance tests in this figure are based on bootstrap (FDR-corrected) and the significance level is 0.05. The responses are most strongly seen in bilateral STG for both high-gamma and low-frequency activity and also in bilateral pre-motor areas for low-frequency activity. The bottom panel shows the syllabic-rate ECoG responses to English sentences. The figure shows electrodes that show statistically significant neural responses to sentences and no significant response to the acoustic control. The syllabic rate responses specific to sentences are strong along bilateral STG for high-gamma activity and are widely distributed in the frontal and temporal lobes for low-frequency activity.
We then analyzed neural tracking of the sentential, phrasal, and syllabic rhythms in the low-frequency ECoG waveform (right panels, Fig. 5), which is a close neural correlate of MEG activity. Here Fourier analysis is directly applied to the ECoG waveform and the Fourier coefficients at 1, 2, and 4 Hz are extracted. Low-frequency ECoG activity is usually viewed as the dendritic input to a cortical area24. The low-frequency responses are more distributed than high-gamma activity, possibly reflecting that the neural representations of different levels of linguistic structures serve as inputs to broad cortical areas. Sentential and phrasal rate responses are strong in STG, IFG, and TPJ. Compared with the acoustic control, the syllabic-rate response to sentences is stronger in broad cortical areas including the temporal and frontal lobes (Fig. 7). Similar to the high-gamma activity, the low-frequency responses to the sentential and phrasal structures are not reflected in the same set of electrodes (Fig. 6). For electrodes showing a significant response at either the sentential rate or the phrasal rate, the strength of the sentential rate response is also negatively correlated with the strength of the phrasal rate response (R = −0.21, significantly greater than 0, P = 0.023, bootstrap).
Discussion
The data show that the multiple time scales that are required for the processing of linguistic structures of different sizes emerge in cortical networks during speech comprehension. The neural sources for sentential, phrasal, and syllabic rate responses are highly distributed and include cortical areas previously found to be critical for prosodic (e.g. right STG), syntactic and semantic (e.g. left pSTG and left IFG) processing9, 25–28. Neural integration on different time scales is likely to underlie the transformation from shorter-lived neural representations of smaller linguistic units to longer-lasting neural representations of larger linguistic structures11–14. These results underscore the undeniable existence of hierarchical structure building operations in language comprehension1, 2, and can be applied to objectively assess language processing in children, difficult-to-test populations, as well as animal preparations to allow for cross-species comparisons.
Relation to Language Comprehension
Concurrent neural tracking of hierarchical linguistic structures provides a plausible functional mechanism for temporally integrating smaller linguistic units into larger structures. In this form of concurrent neural tracking, the neural representation of smaller linguistic units is embedded at different phases of the neural activity tracking a higher-level structure. Therefore, it provides a possible mechanism to transform the hierarchical embedding of linguistic structures into hierarchical embedding of neural dynamics, which may facilitate information integration in time10, 11. Low-frequency neural tracking of linguistic structures may further modulate higher-frequency neural oscillations29–31, proposed to provide additional roles for structure building7. Additionally, multiple resources and computations are needed for syntactic analysis, e.g. access to combinatorial syntactic subroutines, and such operations may correspond to neural computations on distinct frequency scales, which are coordinated by the low-frequency neural tracking of linguistic constituent structures. Furthermore, low-frequency neural activity and oscillations have been hypothesized as critical mechanisms to generate predictions about future events32. For language processing, it is likely that concurrent neural tracking of hierarchical linguistic structures provides mechanisms to generate predictions on multiple linguistic levels and allow interactions across linguistic levels33.
Neural Entrainment to Speech
Recent work has shown that cortex tracks the slow acoustic fluctuations of speech below 10 Hz15–18, 34, 35, and this phenomenon is commonly described as `cortical entrainment' to the syllabic rhythm of speech. It has been controversial whether such syllabic-level cortical entrainment is related to low-level auditory encoding or language processing6. The current study demonstrates processing that goes well beyond stimulus-bound analysis: cortical activity is entrained to larger linguistic structures that are by necessity internally constructed, based on syntax. The emergence of slow cortical dynamics provides time scales suitable for the analysis of larger chunk sizes13, 14.
A long-lasting controversy concerns how the neural responses to sensory stimuli are related to intrinsic, ongoing neural oscillations. This question is heavily debated for the neural response entrained to the syllabic rhythm of speech36 and can also be asked for neural activity entrained to the time courses of larger linguistic structures. The current experiment is not designed to answer this question; however, it clearly demonstrates that cortical speech processing networks have the capacity of generating activity on very long time scales corresponding to larger linguistic structures such as phrases and sentences. In other words, the time scales of larger linguistic structures fall in the time scales, or temporal receptive windows12, 13, that the relevant cortical networks are sensitive to. Whether the capacity of generating low-frequency activity during speech processing is the same as the mechanisms generating low-frequency spontaneous neural oscillations has to be addressed by future studies.
Nature of the Linguistic Representations
Language processing is not monolithic and involves partially segregated cortical networks for the processing of, e.g., phonological, syntactic, and semantic information9. The phonological, syntactic, and semantic representations are all hierarchically organized37 and may rely on the same core structure building operations38. In natural speech, linguistic structure building can be facilitated by prosodic39 and statistical cues22, and some underlying neural signatures have been demonstrated6, 8, 20. Such cues, however, are not always available, and even when available generally not sufficient. Therefore, robust structure building relies on a listeners' tacit syntactic knowledge, and the current study provides unique insights into the neural representation of abstract linguistic structures that are internally constructed based on syntax alone. Although the construction of abstract structures is driven by syntactic analysis, when such structures are built, different aspects of the structure, including semantic information, can be integrated in the neural representation. Indeed, the wide distribution of cortical tracking of hierarchical linguistic structures suggests that it is a general neurophysiological mechanism for combinatorial operations involved in hierarchical linguistic structure building in multiple linguistic processing networks (e.g., phonological, syntactic, and semantic). Furthermore, coherent synchronization to the correlated linguistic structures in different representational networks, e.g. syntactic, semantic, and phonological, provides a way to integrate multi-dimensional linguistic representations into a coherent language percept38, 40, just as temporal synchronization between cortical networks provides a possible solution to the binding problem in sensory processing41.
Relation to Event-related Responses
Whereas many previous neurophysiological studies on structure building have focused on syntactic/semantic violations42–44, fewer address normal structure building: On the lexical-semantic level, the N400/N400m has been identified as a marker of the semantic predictability of words43, 45, and its amplitude continuously reduces within a sentence46, 47. For syntactic processing, when two words combine into a short phrase, increased activity is seen in the temporal and frontal lobes4. The current study builds on and extends these findings by demonstrating structure building at different levels of the linguistic hierarchy, during online comprehension of connected speech materials in which the structural boundaries are neither physically cued nor confounded by the semantic predictability of the individual words (Fig. 3). Note that although the two Markovian languages (compared in Fig. 3) differ in their transitional probability between acoustic chunks, they both have fully predictable syntactic structures. The equivalence in syntactic predictability is likely to result in the very similar responses between the two conditions.
Lastly, the emergence of slow neural dynamics tracking superordinate stimulus structures is reminiscent of what has been observed during decision making48, action planning49, and music perception50, suggesting a plausible common neural computational framework to integrate information over distinct time scales12. These findings invite MEG/EEG research to extend from the classic event-related designs to investigating continuous neural encoding of internally constructed perceptual organization of an information stream.
Online Methods
Participants
Thirty-four native listeners of Mandarin Chinese (19–36 yrs old, mean 25 yrs old; 13 male) and 13 native listeners of American English (22–46 yrs old, mean 26 yrs old; 6 male) participated in the study. All Chinese listeners received high school education in China and 26 of them also received college education in China. None of the English listeners understood Chinese. All participants were right-handed31. Five experiments were run for Chinese listeners and 2 experiments for English listeners. Each experiment included 8 listeners (except that the AMS experiment involved 5 listeners) and each listener participated in at most 2 experiments. The number of listeners per experiment was chosen based on previous MEG experiments on neural tracking of continuous speech. The sample size for previous experiments was typically between three and twelve6,18, and the basic phenomenon reported here was replicated in all the 7 experiments of the study (N = 47 in total). The experimental procedures were approved by the New York University Institutional Review Board, and written informed consent was obtained from each participant prior to the experiment.
Stimuli I: Chinese Materials
All Chinese materials were constructed based on an isochronous sequence of syllables. Even when the syllables were hierarchically grouped into linguistic constituents, no acoustic gaps were inserted between constituents. All syllables were synthesized independently using the Neospeech synthesizer (http://www.neospeech.com, the male voice, Liang). The synthesized syllables were 75 ms to 354 ms in duration (mean duration 224 ms), and were adjusted to 250 ms by truncation or padding silence at the end. The last 25 ms of each syllable were smoothed by a cosine window.
4-syllable sentences
Fifty 4-syllable sentences were constructed, in which the first two syllables formed a noun phrase and the last two syllables formed a verb phrase (Table S1). The noun phrase could be composed of either a single 2-syllable noun or a 1-syllable adjective followed by a 1-syllable noun. The verb phrase could be composed of either a 2-syllable verb or a 1-syllable verb followed by a 1-syllable noun object. In a normal trial, 10 sentences were sequentially played and no acoustic gaps were inserted between sentences (Extended Data Fig. 1A). Due to the lack of phrasal and sentential level prosodic cues, the sound intensity of the stimulus, characterized by the sound envelope, only fluctuates at the syllabic rate but not at the phrasal or sentential rate (Extended Data Fig. 2). An outlier trial was the same as a normal trial except that the verb phrases in two sentences were exchanged, creating two nonsense sentences with incompatible subjects and predicates (an example in English would be “new plans rub skin”).
4-syllable verb phrases
Two types of 4-syllable verb phrases were created. Type I verb phrase contained a 1-syllable verb followed by a 3-syllable noun phrase, which could be a compound noun or an adjective + noun phrase (Extended Data Fig. 1B, Table S1). Type II verb phrase contained a 2-syllable verb followed by a 2-syllable noun (Extended Data Fig. 1C, all phrases listed in Table S1). Fifty instances were created for each type of verb phrases. In a normal trial, 10 phrases of the same type were sequentially presented. An outlier trial was the same as a normal trial except that the verbs in two phrases were exchanged, creating two nonsense verb phrases with incompatible verbs and objects (an example in English would be “drink a long walk”).
2-syllable phrases
The verb phrases (or the noun phrases) in the 4-syllable sentences were presented in a sequence (Extended Data Fig. 1D). In a normal trial, 20 different phrases were played. In an outlier trial, one of the 20 phrases was replaced by two random syllables that did not constitute a sensible phrase.
Random syllabic sequences
The random syllabic sequences were generated based on the 4-syllable sentences. Each 4-syllable sentence was transformed into 4 random syllables using the following rule: The 1st syllable in the sentence was replaced by the 1st syllable of a randomly chosen sentence. The 2nd syllable was replaced by the 2nd syllable of another randomly chosen sentence and the same for the 3rd and the 4th syllables. This way, if there were any consistent acoustic differences between the syllables at different positions in a sentence, those acoustic differences were preserved in the random syllabic sequences. Each normal trial contained 40 syllables. In outlier trials, 4 consecutive syllables were replaced by a Chinese idiom.
Backward syllabic sequences
In normal trials, ten 4-syllable sentences were played but with all syllables being played backward in time. An outlier trial was the same as a normal trial except that 4 consecutive syllables at a random position were replaced by 4 random syllables that were not reversed in time.
4-syllable idioms
Fifty common 4-syllable idioms were selected (Table S1), in which the first two syllables formed a noun phrase and the last two syllables formed a verb phrase. In a normal trial 10 sentences were played. An outlier trial was the same as a normal trial except that the noun phrases in two idioms were exchanged, creating two nonexistent and semantically nonsensical idioms.
Sentences with variable duration and syntactic structures
The sentence duration was varied between 4 and 8 syllables. Forty sentences were constructed for each duration, resulting in a total of 200 sentences (listed in Table S1). All 200 sentences were intermixed. In a normal trial, ten different sentences were sequentially played without inserting any acoustic gap in between sentences. In an outlier trial, one of the 10 sentences was replaced by a syntactically correct but semantically anomalous sentence. Examples of nonsense sentences, translated into English, included “ancient history is drinking tea” and “take part in his portable hard drive”.
Sentences with variable NP durations
All sentences consisted of a noun phrase followed by a verb phrase (Table S1). The noun phrase had 3 syllables for half of the sentences (N = 45) and 4 syllables for the other half. A 3-syllable noun phrase was followed by either a 4-syllable verb phrase (N = 20) or a 5-syllable verb phrase (N = 25). A 4-syllable noun phrase was followed by a 3-syllable verb phrase (N=20) or a 4-syllable verb phrase (N = 25). Sentences with different noun phrase durations and verb phrase durations were intermixed. In a normal trial 10 different sentences were played sequentially, without inserting any acoustic gap between phrases or sentences. In an outlier trial one sentence was replaced by a sentence with the same syntactic structure but that was semantically anomalous.
Artifical Markovian sentences (AMS)
Five sets of artificial Markovian sentences (AMS) were created. Each sentence consisted of 3 components, C1, C2, and C3. Each component (C1, C2, or C3) was independently chosen from 3 candidate syllables with equal probability. The grammar of the AMS is illustrated in Extended Data Fig. 7A. In the experiments, sentences were played sequentially without any gap between sentences. Since all components were chosen independently and each component was chosen from 3 syllables with equal probability, all components were equally predictable regardless of its position in a sequence. In other words, P(C1) = P(C2) = P(C3) = P(C2|C1) = P(C3|C2) = P(C1|C3) = 1/3.
All Chinese syllables were synthesized independently and adjusted to 300 ms by truncation or padding silence at the end. In each trial, 60 sentences were played and no additional gap was inserted between sentences. Therefore, the syllables were played at a constant rate of 3.33 Hz and the sentences were played at a constant rate of 1.11 Hz. To make sure that neural encoding of the AMS was not confounded by acoustic properties of a particular set of syllables, five sets of AMS were created (Table S1). No meaningful Chinese expressions are embedded in the AMS sequences.
Stimuli II: English Materials
All English materials were synthesized using the MacinTalk Synthesizer (male voice Alex, in Mac OS X 10.7.5).
4-syllable English sentences
Sixty 4-syllable English sentences were constructed (Table S1), and each syllable was a monosyllabic word. All sentences had the same syntactic structure: adjective/pronoun + noun + verb + noun. Each syllable was synthesized independently, and all the synthesized syllables (250 – 347 ms in duration) were adjusted to 320 ms by padding silence at the end or truncation. The offset of each syllable was smoothed by a 25 ms cosine window. In each trial, 12 sentences were presented without any acoustic gap between them. In an outlier trial, 3 consecutive words from a random position were replaced by 3 random words so that the corresponding sentence(s) became ungrammatical.
Shuffled sequences
Shuffled sequences were constructed as an unintelligible sound sequence that preserved the acoustic properties of the sentence sequences. All syllables in the 4-syllable English sentences were segmented into five overlapping slices. Each slice was 72 ms in duration and overlapped with neighboring slices for 10 ms. The first 10 ms and the last 10 ms of each slice was smoothed by a linear ramp, except for the onset of the first slice and the offset of the last slice.
A shuffled “sentence” was constructed by shuffling all slices at the same position across the 4-syllable sentences. For example, the 1st slice of the 1st syllable in a given sentence was replaced by the 1st slice of the 1st syllable in a different randomly chosen sentence. For another example, the 3rd slice of the 4th syllable in one sentence was replaced by the 3rd slice of the 4th syllable in another randomly chosen sentence. In a normal trial, 12 different shuffled “sentences” were played sequentially, resulting in a trial that had the same duration as a trial of 4-syllable English sentences. In an outlier trial, 4 consecutive shuffled syllables were replaced by 4 randomly chosen English words that did not construct a sentence.
Markovian sentences
The pronunciation of an English syllable strongly depends on its neighbors. To simulate more natural English, we also synthesized English sentences based on an isochronous multi-syllabic “acoustic chunk”. Every sentence was divided into 3 acoustic chunks that were roughly equal in duration. Each acoustic chunk consisted of 1–2 monosyllabic or bisyllabic words and was synthesized as a whole, independently of neighboring acoustic chunks. All synthesized acoustic chunks (250 ms to 364 ms in duration) were adjusted to 350 ms by truncation or padding silence at the end. The offset of each chunk was smoothed by a 25 ms cosine window.
Two types of Markov chain sentences were generated based on isochronous sequences of acoustic chunks. In one type of Markovian sentences, called the constant predictability sentences, each acoustic chunk was equally predictable based on the preceding chunk, regardless of its position within a sentence. The constant predictability sentences were generated based on the grammar specified in Fig. 3A and Extended Data Fig. 1E. Listeners were familiarized with the grammar and were able to write down the full grammar table before participating in the experiment. In each trial, 10 sentences were separately generated based on the grammar and sequentially presented without any acoustic gap between them.
The other type of Markovian sentences, called the predictable sentences, consisted of a finite number of sentences (N = 25, Table S1) that were extensively repeated (11–12 times) in a ~7 minute block. In these sentences, the 2nd and the 3rd acoustic chunks were uniquely determined by the 1st chunk. In each trial, 10 different sentences were played sequentially without any acoustic gap between them.
Acoustic Analysis
The intensity fluctuation of the sound stimulus is characterized by its temporal envelope. To extract the temporal envelope, the sound signal is first half-wave rectified and then downsampled to 200 Hz. The Discrete Fourier Transform of the temporal envelope (without any windowing) is shown in Fig. 1 and Extended Data Fig. 2.
Experimental Procedures
Seven experiments were run. Experiment 1–4 involved Chinese listeners listening to Chinese materials, experiment 5 involved English listeners listening to Chinese materials, and experiment 6 involved English listeners listening to English materials. Experiment 7 involved Chinese listeners listening to Artificial Markovian Sentences (AMS).
In all experiments except for experiment 5, listeners were instructed to detect outlier trials. At the end of each trial, listeners had to report whether it was a normal trial or an outlier trial via button press. Following the button press, the next trial was played after a delay randomized between 800 and 1400 ms. In experiment 5, listeners performed a syllable counting task described below. Behavioral results are reported in Supplementary Table 2.
Experiment 1
4-syllable Chinese sentences, 4-syllable idioms, random syllabic sequences, and backward syllabic sequences were presented in separate blocks. The order of the blocks was counter balanced across listeners. Listeners took breaks between blocks. In each block, 20 normal trials and 10 outlier trials were intermixed and presented in a random order.
Experiment 2
4-syllable sentences, type I 4-syllable verb phrases, type II 4-syllable verb phrases, 2-syllable noun phrases, and 2-syllable verb phrases were presented in separate blocks. The order of the blocks was counter balanced across listeners. Listeners took breaks between blocks. In each block, 20 normal trials and 5 outlier trials were intermixed and presented in a random order.
Experiment 3
Sentences with variable durations and syntactic structures, as described in the Chinese Materials section above, were played in an intermixed order. Listeners took a break every 25 trials. In total, 80 normal trials and 20 outlier trials were presented.
Experiment 4
Sentences with variable NP durations, as described in the Chinese Materials section above, were presented in a single block, counterbalanced with three other blocks that presented language materials not analyzed here. In that block, 27 normal trials and 7 outlier trials were presented. The other 3 blocks presented other language materials not analyzed here. The order of the blocks was counterbalanced across listeners.
Experiment 5
Trials consisting of 4-syllable sentences, 4-syllable idioms, random syllabic sequences, and backward syllabic sequences were intermixed and presented in a random order. Twenty normal trials for each type of materials were presented. In each trial, the last 1 or 2 syllable was removed, each with 50% probability. Listeners were instructed to count the number of syllables in each trial in a cyclic way: 1, 2, 3, 4, 1, 2, 3, 4, 1, 2… The final count could only be 2 or 3 and the listeners had to report whether it was 2 or 3 at the end of each trial via button press.
Experiment 6
4-syllable English sentences, shuffled sequences, constant predictability Markovian sentences, and predictable Markovian sentences were presented in separate blocks. The order of the blocks was counterbalanced across listeners. Listeners took breaks between blocks. In each block, 22 normal trials and 8 outlier trials were intermixed and presented in a random order.
Experiment 7
The experiment involved the Artificial Markovian Sentences (AMS) and was divided into two sessions. In the first session, 10 trials were presented (2 trials from each AMS set; see the upper row in Extended Data Fig. 7B). In each trial, the last syllable was removed with 50% probability. The listeners were told that the stimulus was only a sequence of random syllables. They were asked to count the number of syllables in a cyclic way: 1, 2, 1, 2, 1, 2… and report whether the final count was 1 or 2 at the end of each trial via button press. Since each trial contained 179 or 180 rapidly presented syllables, the listeners were not able to count accurately (mean performance 52 ± 9.7 %, not significantly above chance, P > 0.8, t-test). However, the listeners were asked to follow the rhythm and keep counting even when they lost count. After the first session of the experiment was finished, the listeners were told about that the general structure of the AMS and examples were given based on real Chinese sentences. In the second session of the experiment, the listeners had to learn the 5 sets of AMS separately (lower row, Extended Data Fig. 7B). For each set of the AMS, during training, the listeners listened to 20 sentences from the AMS set in a sequence, with a 300-ms gap being inserted between sentences to facilitate learning. Then, the listeners listened to two trials of sentences from the same AMS set, which they also listened to in the first session (shown by symbol S in Extended Data Fig. 7B). They had to do the same cyclical counting task. However, they were told that the last count was 1 if the last sentence was incomplete and the last count was 2 if the last sentence was complete (mean performance 82 ± 8.0 %, significantly above chance P < 0.2, t-test). At the end of the two trials, the listeners had to report the grammar of the AMS, i.e. which 3 syllables could be the first syllable of a sentence, which 3 syllables could be the middle one, and which 3 syllables could be the last one. The grammatical roles of 77 ± 7.6 % (mean ± standard error across subjects) syllables were reported correctly.
Neural Recordings
Cortical neuromagnetic activity was recorded using a 157-channel whole-head MEG system (KIT) in a magnetically shielded room. The MEG signals were sampled at 1 kHz, with a 200-Hz low-pass filter and a 60 Hz notch filter applied online and a 0.5-Hz high-pass filter applied offline (time delay compensated). The environmental magnetic field was recorded using 3 reference sensors and regressed out from the MEG signals using time-shifted PCA32. Then, the MEG responses were further denoised using the blind source separation technique, Denoising Source Separation (DSS)33. The MEG responses were decomposed into DSS components using a set of linear spatial filters, and the first 6 DSS components were retained for analysis and transformed back to the sensor space. The DSS decomposes multi-channel MEG recordings to extract neural response components that are consistent over trials and has been demonstrated to be effective in denoising cortical responses to connected speech18,34,35. The DSS was applied to more accurately estimate the strength of neural activity phase-locked to the stimulus. Even when the DSS spatial filtering process was omitted, for the RMS response over all MEG sensors, the sentential, phrasal, and syllabic responses in Fig. 1 were still statistically significant (P < 0.001, bootstrap).
Data Analysis
Only the MEG responses to normal trials were analyzed.
Frequency Domain Analysis
In experiments 1, 2, 5, and 6, the linguistic structures of different hierarchies were presented at unique and constant rates and neural tracking of those linguistic structures was analyzed in the frequency domain. For each trial, to avoid the transient response to the acoustic onset of each trial, the neural recordings were analyzed in a time window between the onset of the 2nd sentence (or the 5th syllable if the stimulus contained no sentential structure) and the end of the trial. The single-trial responses were transformed into the frequency domain using the discrete Fourier transform (DFT). For all Chinese materials and the artificial Markovian language materials, 9 sentences were analyzed in each trial, resulting in a frequency resolution of 1/9 of the sentential rate (~0.11 Hz). For the English sentences and the shuffled sequences, the trials were longer and the duration equivalent to 44 English syllables was analyzed, resulting in a frequency resolution of 1/44 of the syllabic rate, i.e. 0.071 Hz.
The response topography (Fig. 1c) showed the power of the DFT coefficients at a given frequency, and hemispheric lateralization was calculated by averaging the response power over the sensors in each hemisphere (N = 54).
Since the properties of the neural responses to linguistic structures and background neural activity might vary in different frequency bands, to treat each frequency band equally, a separate spatial filter was designed for every frequency bin in the DFT output to optimally estimate the response strength. The linear spatial filter was the DSS filter36. The output of the DSS filter was a weighted summation over all MEG sensors, and the weights were optimized to extract neural activity consistent over trials. In brief, if the DFT of the MEG response averaged over trials is X(f) and the autocorrelation matrix of single-trial MEG recordings is R(f), the spatial filter is w = R−1(f)X(f) (see the appendix of reference 36). The spatial filter w is an 157 × 1 vector (for the 157 sensors), the same size as X(f), and R(f) is a 157 × 157 matrix. The spatial filter could be viewed as a virtual sensor that was optimized to record phase-locked neural activity at each frequency. Power of the scalar output of the spatial filter, |XT(f)R−1(f)X(f)|2, was the power spectral density shown in the figures.
Time Domain Analysis
The response to each sentence was baseline corrected based on the 100 ms period preceding the sentence onset, for each sensor. To remove the neural response to the 4-Hz isochronous syllabic rhythm and focus on the neural tracking of sentential/phrasal structures, we low-pass filtered the neural response waveforms using a 0.5-second duration linear phase FIR filter (cut-off 3.5 Hz). The filter delay was compensated by filtering the neural signals twice, once forward and once backward. When the response power at 4 Hz was extracted separately by a Fourier analysis, it does not significantly change as a function of sentence duration (P > 0.19, 1-way ANOVA). The root-mean-square (RMS) of the MEG responses was calculated as the sum of response power (i.e., square of the MEG response) of all sensors, and the RMS response was further low-pass filtered by a 0.5-second duration linear phase FIR filter (cut-off 3.5 Hz, delay compensated).
A linear decoder was built to decode the duration of sentences. In the decoding analysis, the multi-channel MEG responses were compressed to a single channel, i.e. the first DSS component, and the decoder solely relied on the time course of the neural response. A 2.25-second response epoch was extracted for each sentence, starting from the sentence onset. A leave-one-out cross-validation procedure was employed to evaluate the decoder's performance. Each time, the response to one sentence was used as the testing response, and the responses to all other sentences were treated as the training set. The training signals were averaged for sentences of the same duration, creating a template for the response time course for each sentence duration. The testing response was correlated with all the templates and the category of the most correlated templates was the decoder's output. For example, if the testing response was most correlated with the template for 5-syllable sentences, the decoder's output would be that the testing response was generated by a 5-syllable sentence.
Statistical Analysis and Significance Tests
For spectral peaks (Fig. 1–2), a one-tailed paired t-test was used to test if the neural response in a frequency bin was significantly stronger than the average of the neighboring 4 frequency bins (2 bins on each side). Such a test was applied to all frequency bins below 5 Hz, and a FDR correction for multiple comparisons was applied. Except for the analysis of the spectral peaks, two-tailed t-tests were applied. For all the t-tests applied in this study, data from the two conditions had comparable variance and showed no clear deviation from the normal distribution when checking the histograms. If the t-test was replaced by a bias-corrected and accelerated bootstrap, all results remained significant.
In Fig. 4, the standard error of the mean (SEM) over subjects was calculated using bias-corrected and accelerated bootstrap37. In the bootstrap procedure, all the subjects were resampled with replacement 2000 times. The standard deviation of the resampled results was taken as the SEM. In Fig. 4d, the statistical difference between the two curves, i.e. the 3-syllable NP condition and the 4-syllable NP condition, was also tested using bootstrap. For each subject, the difference between the responses in these two conditions was taken. At each time point, the response difference was resampled with replacement 2000 times across the 8 subjects, and percentage of the resampled differences being larger or smaller than 0 (the smaller value) was taken as the significance level. A FDR correction was applied to the bootstrap results.
Code availability
The computer code used for the MEG analyses is available upon request.
Neural Source Localization Using ECoG
ECoG Participants
Electrocorticographic (ECoG) recordings were obtained from 5 patients (3 female; average 33.6 years old, range 19 – 42 years old,) diagnosed with pharmaco-resistant epilepsy and undergoing clinically motivated subdural electrode recordings at the New York University Langone Medical Center. Patients provided informed consent prior to participating in the study in accordance with the Institutional Review Board at the New York University Langone Medical Center. Three patients were right-handed, two were left-handed. All patients were native English speakers (one of them was a bilingual Spanish/English speaker), and all patients were left-hemisphere dominant for language.
ECoG Recordings
Participants were implanted with 96–179 platinum-iridium clinical subdural grid or strip electrodes (3 patients with a left-hemisphere implant and 2 patients with a right hemisphere implant, additional depth electrodes implanted for some patients but not analyzed). The electrode locations per patient are shown in Extended Data Fig. 4. Electrode localization followed previously described procedures 38. In brief, for each patient we obtained pre-op and post-op T1-weighted MRIs which were co-registered with each other and normalized to a MNI-152 template, allowing the extraction of the electrode location in MNI space.
The ECoG signals were recorded with a Nicolet clinical amplifier at a sampling rate of 512 Hz. The ECoG recordings were re-referenced to the grand average over all electrodes (after removing artifact-laden or noisy channels). Electrodes from different subjects were pooled per hemisphere, resulting in 385/261 electrodes in the left/right hemispheres. High gamma activity was extracted by high-pass filtering the ECoG signal above 70 Hz (with additional notch filters at 120 Hz and 180 Hz). The energy envelope of high gamma activity was extracted by taking the square of high-gamma response waveform.
ECoG Procedures
Participants performed the same task as healthy subjects in the MEG (see Fig. 2ef for MEG results). In brief, they listened to a set of English sentences and control stimuli in the first and second block. The control stimulus, i.e. the shuffled sequences, preserves the syllabic-level acoustic rhythm of English sentences but contain no hierarchical linguistic structure. The procedure was the same as the MEG experiment, except for a familiarization session in which the subjects listened to individual sentences with visual feedback. Sixty trials of sentences and control stimuli were played. The ECoG data from each electrode was analyzed separately and converted to the frequency domain via DFT (frequency resolution 0.071 Hz).
A significant response at the syllabic, phrasal, or sentential rate was reported if the response power at the target frequency was stronger than the response power averaged over neighboring frequency bins (0.5 Hz range above and below the target frequency). The significance level for each electrode was first determined based on a bootstrap procedure that randomly sampled the 60 trials 1000 times and then underwent FDR correction for multiple comparisons across all electrodes within the same hemisphere.
A supplementary methods checklist is available.
Supplementary Material
Acknowledgments
We thank Jeff Walker for MEG technical support, Thomas Thesen, Werner Doyle and Orrin Devinsky for their instrumental help in collecting ECoG data, and György Buzsaki, Gregory Cogan, Stanislas Dehaene, Anna-Lise Giraud, Gregory Hickok, Nobert Hornstein, Ellen Lau, Alec Marantz, Nima Mesgarani, Marcela Peña, Bijan Pesaran, Liina Pylkkänen, Charles Schroeder, Jonathan Simon, and Wolf Singer for their comments on previous versions of the manuscript. Work supported by NIH 2R01DC05660 (DP).
Footnotes
Author Contributions N.D., L.M., and D.P. conceived and designed the experiments; N.D., H.Z., and X.T. performed the MEG experiments; L.M. performed the ECoG experiment; N.D., L.M., and D.P. wrote the paper. All authors discussed the results and edited the manuscript.
References
- 1.Berwick RC, Friederici AD, Chomsky N, Bolhuis JJ. Evolution, brain, and the nature of language. Trends in cognitive sciences. 2013;17:89–98. doi: 10.1016/j.tics.2012.12.002. [DOI] [PubMed] [Google Scholar]
- 2.Chomsky N. Syntactic structures. Mouton de Gruyter; 1957. [Google Scholar]
- 3.Phillips C. Linear order and constituency. Linguistic inquiry. 2003;34:37–90. [Google Scholar]
- 4.Bemis DK, Pylkkänen L. Basic linguistic composition recruits the left anterior temporal lobe and left angular gyrus during both listening and reading. Cerebral Cortex. 2013;23:1859–1873. doi: 10.1093/cercor/bhs170. [DOI] [PubMed] [Google Scholar]
- 5.Giraud A-L, Poeppel D. Cortical oscillations and speech processing: emerging computational principles and operations. Nature Neuroscience. 2012;15:511–517. doi: 10.1038/nn.3063. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Sanders LD, Newport EL, Neville HJ. Segmenting nonsense: an event-related potential index of perceived onsets in continuous speech. Nature neuroscience. 2002;5:700–703. doi: 10.1038/nn873. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Bastiaansen M, Magyari L, Hagoort P. Syntactic unification operations are reflected in oscillatory dynamics during on-line sentence comprehension. Journal of cognitive neuroscience. 2010;22:1333–1347. doi: 10.1162/jocn.2009.21283. [DOI] [PubMed] [Google Scholar]
- 8.Buiatti M, Peña M, Dehaene-Lambertz G. Investigating the neural correlates of continuous speech computation with frequency-tagged neuroelectric responses. Neuroimage. 2009;44:509–551. doi: 10.1016/j.neuroimage.2008.09.015. [DOI] [PubMed] [Google Scholar]
- 9.Pallier C, Devauchelle A-D, Dehaene S. Cortical representation of the constituent structure of sentences. Proceedings of the National Academy of Sciences. 2011;108:2522–2527. doi: 10.1073/pnas.1018711108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Schroeder CE, Lakatos P, Kajikawa Y, Partan S, Puce A. Neuronal oscillations and visual amplification of speech. Trends in Cognitive Sciences. 2008;12:106–113. doi: 10.1016/j.tics.2008.01.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Buzsáki G. Neural syntax: cell assemblies, synapsembles, and readers. Neuron. 2010;68:362–385. doi: 10.1016/j.neuron.2010.09.023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Bernacchia A, Seo H, Lee D, Wang X-J. A reservoir of time constants for memory traces in cortical neurons. Nature neuroscience. 2011;14:366–372. doi: 10.1038/nn.2752. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Lerner Y, Honey CJ, Silbert LJ, Hasson U. Topographic Mapping of a Hierarchy of Temporal Receptive Windows Using a Narrated Story. Journal of Neuroscience. 2011;31:2906–2915. doi: 10.1523/JNEUROSCI.3684-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Kiebel SJ, Daunizeau J, Friston KJ. A hierarchy of time-scales and the brain. PLoS computational biology. 2008;4:e1000209. doi: 10.1371/journal.pcbi.1000209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Luo H, Poeppel D. Phase Patterns of Neuronal Responses Reliably Discriminate Speech in Human Auditory Cortex. Neuron. 2007;54:1001–1010. doi: 10.1016/j.neuron.2007.06.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Ding N, Simon JZ. Emergence of neural encoding of auditory objects while listening to competing speakers. Proceedings of the National Academy of Sciences of the United States of America. 2012;109:11854–11859. doi: 10.1073/pnas.1205381109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Zion Golumbic EM, et al. Mechanisms Underlying Selective Neuronal Tracking of Attended Speech at a “Cocktail Party”. Neuron. 2013;77:980–991. doi: 10.1016/j.neuron.2012.12.037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Peelle JE, Gross J, Davis MH. Phase-Locked Responses to Speech in Human Auditory Cortex are Enhanced During Comprehension. Cerebral Cortex. 2013;23:1378–1387. doi: 10.1093/cercor/bhs118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Pasley BN, et al. Reconstructing Speech from Human Auditory Cortex. PLoS Biology. 2012;10:e1001251. doi: 10.1371/journal.pbio.1001251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Steinhauer K, Alter K, Friederici AD. Brain potentials indicate immediate use of prosodic cues in natural speech processing. Nature neuroscience. 1999;2:191–196. doi: 10.1038/5757. [DOI] [PubMed] [Google Scholar]
- 21.Peña M, Bonatti LL, Nespor M, Mehler J. Signal-driven computations in speech processing. Science. 2002;298:604–607. doi: 10.1126/science.1072901. [DOI] [PubMed] [Google Scholar]
- 22.Saffran JR, Aslin RN, Newport EL. Statistical learning by 8-month-old infants. Science. 1996;274:1926–1928. doi: 10.1126/science.274.5294.1926. [DOI] [PubMed] [Google Scholar]
- 23.Ray S, Maunsell JH. Different origins of gamma rhythm and high-gamma activity in macaque visual cortex. PLoS biology. 2011;9:e1000610. doi: 10.1371/journal.pbio.1000610. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Einevoll GT, Kayser C, Logothetis NK, Panzeri S. Modelling and analysis of local field potentials for studying the function of cortical circuits. Nature Reviews: Neuroscience. 2013;14:770–785. doi: 10.1038/nrn3599. [DOI] [PubMed] [Google Scholar]
- 25.Hagoort P, Indefrey P. The neurobiology of language beyond single words. Annual Review of Neuroscience. 2014;31 doi: 10.1146/annurev-neuro-071013-013847. [DOI] [PubMed] [Google Scholar]
- 26.Grodzinsky Y, Friederici AD. Neuroimaging of syntax and syntactic processing. Current opinion in neurobiology. 2006;16:240–246. doi: 10.1016/j.conb.2006.03.007. [DOI] [PubMed] [Google Scholar]
- 27.Hickok G, Poeppel D. The cortical organization of speech processing. Nature Reviews: Neuroscience. 2007;8:393–402. doi: 10.1038/nrn2113. [DOI] [PubMed] [Google Scholar]
- 28.Friederici AD, Meyer M, Cramon D.Y.v. Auditory language comprehension: an event-related fMRI study on the processing of syntactic and lexical information. Brain and language. 2000;74:289–300. doi: 10.1006/brln.2000.2313. [DOI] [PubMed] [Google Scholar]
- 29.Canolty RT, et al. High Gamma Power Is Phase-Locked to Theta Oscillations in Human Neocortex. Science. 2006;313:1626–1628. doi: 10.1126/science.1128115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Lakatos P, et al. An oscillatory hierarchy controlling neuronal excitability and stimulus processing in the auditory cortex. Journal of Neurophysiology. 2005;94:1904–1911. doi: 10.1152/jn.00263.2005. [DOI] [PubMed] [Google Scholar]
- 31.Sirota A, Csicsvari J, Buhl D, Buzsáki G. Communication between neocortex and hippocampus during sleep in rodents. Proceedings of the National Academy of Sciences. 2003;100:2065–2069. doi: 10.1073/pnas.0437938100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Arnal LH, Giraud A-L. Cortical oscillations and sensory predictions. Trends in cognitive sciences. 2012;16:390–398. doi: 10.1016/j.tics.2012.05.003. [DOI] [PubMed] [Google Scholar]
- 33.Poeppel D, Idsardi WJ, Wassenhove V.v. Speech perception at the interface of neurobiology and linguistics. Philosophical Transactions of the Royal Society B: Biological Sciences. 2008;363:1071–1086. doi: 10.1098/rstb.2007.2160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Peña M, Melloni L. Brain oscillations during spoken sentence processing. Journal of cognitive neuroscience. 2012;24:1149–1164. doi: 10.1162/jocn_a_00144. [DOI] [PubMed] [Google Scholar]
- 35.Gross J, et al. Speech Rhythms and Multiplexed Oscillatory Sensory Coding in the Human Brain. PLoS biology. 2013;11:e1001752. doi: 10.1371/journal.pbio.1001752. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Ding N, Simon JZ. Cortical entrainment to continuous speech: functional roles and interpretations. frontiers in human neuroscience. 2014;8 doi: 10.3389/fnhum.2014.00311. 10.3389/fnhum.2014.00311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Jackendoff R. Foundations of language: Brain, meaning, grammar, evolution. Oxford University Press; 2002. [DOI] [PubMed] [Google Scholar]
- 38.Hagoort P. On Broca, brain, and binding: a new framework. Trends in cognitive sciences. 2005;9:416–423. doi: 10.1016/j.tics.2005.07.004. [DOI] [PubMed] [Google Scholar]
- 39.Cutler A, Dahan D, Donselaar WV. Prosody in the comprehension of spoken language: A literature review. Language and Speech. 1997;40:141–201. doi: 10.1177/002383099704000203. [DOI] [PubMed] [Google Scholar]
- 40.Frazier L, Carlson K, Jr CC. Prosodic phrasing is central to language comprehension. Trends in Cognitive Sciences. 2006;10:244–249. doi: 10.1016/j.tics.2006.04.002. [DOI] [PubMed] [Google Scholar]
- 41.Singer W, Gray CM. Visual feature integration and the temporal correlation hypothesis. Annual review of neuroscience. 1995;18:555–586. doi: 10.1146/annurev.ne.18.030195.003011. [DOI] [PubMed] [Google Scholar]
- 42.Friederici AD. Towards a neural basis of auditory sentence processing. Trends in cognitive sciences. 2002;6:78–84. doi: 10.1016/s1364-6613(00)01839-8. [DOI] [PubMed] [Google Scholar]
- 43.Kutas M, Federmeier KD. Electrophysiology reveals semantic memory use in language comprehension. Trends in cognitive sciences. 2000;4:463–470. doi: 10.1016/s1364-6613(00)01560-6. [DOI] [PubMed] [Google Scholar]
- 44.Neville H, Nicol JL, Barss A, Forster KI, Garrett MF. Syntactically based sentence processing classes: Evidence from event-related brain potentials. Journal of cognitive Neuroscience. 1991;3:151–165. doi: 10.1162/jocn.1991.3.2.151. [DOI] [PubMed] [Google Scholar]
- 45.Lau EF, Phillips C, Poeppel D. A cortical network for semantics: (de)constructing the N400. Nature Reviews: Neuroscience. 2008;9:920–933. doi: 10.1038/nrn2532. [DOI] [PubMed] [Google Scholar]
- 46.Halgren E, et al. N400-like magnetoencephalography responses modulated by semantic context, word frequency, and lexical class in sentences. Neuroimage. 2002;17:1101–1116. doi: 10.1006/nimg.2002.1268. [DOI] [PubMed] [Google Scholar]
- 47.Van Petten C, Kutas M. Interactions between sentence context and word frequencyinevent-related brainpotentials. Memory & Cognition. 1990;18:380–393. doi: 10.3758/bf03197127. [DOI] [PubMed] [Google Scholar]
- 48.O'Connell RG, Dockree PM, Kelly SP. A supramodal accumulation-to-bound signal that determines perceptual decisions in humans. Nature neuroscience. 2012;15:1729–1735. doi: 10.1038/nn.3248. [DOI] [PubMed] [Google Scholar]
- 49.Koechlin E, Ody C, Kouneiher F. The architecture of cognitive control in the human prefrontal cortex. Science. 2003;302:1181–1185. doi: 10.1126/science.1088545. [DOI] [PubMed] [Google Scholar]
- 50.Nozaradan S, Peretz I, Missal M, Mouraux A. Tagging the neuronal entrainment to beat and meter. Journal of Neuroscience. 2011;31:10234–10240. doi: 10.1523/JNEUROSCI.0411-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Oldfield RC. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia. 1971;9:97–113. doi: 10.1016/0028-3932(71)90067-4. [DOI] [PubMed] [Google Scholar]
- 52.de Cheveigné A, Simon JZ. Denoising based on time-shift PCA. J. Neurosci. Methods. 2007;165:297–305. doi: 10.1016/j.jneumeth.2007.06.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.de Cheveigné A, Simon JZ. Denoising based on spatial filtering. J. Neurosci. Methods. 2008;171:331–339. doi: 10.1016/j.jneumeth.2008.03.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Ding N, Simon JZ. Adaptive Temporal Encoding Leads to a Background-Insensitive Cortical Representation of Speech. J. Neurosci. 2013;33:5728–5735. doi: 10.1523/JNEUROSCI.5297-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Ding N, Simon JZ. Neural Coding of Continuous Speech in Auditory Cortex during Monaural and Dichotic Listening. J. Neurophysiol. 2012;107:78–89. doi: 10.1152/jn.00297.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Wang Y, et al. Sensitivity to Temporal Modulation Rate and Spectral Bandwidth in the Human Auditory System: MEG Evidence. J. Neurophysiol. 2012;107:2033–2041. doi: 10.1152/jn.00310.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Efron B, Tibshirani R. An introduction to the bootstrap. CRC press; 1993. [Google Scholar]
- 58.Yang AI, et al. Localization of dense intracranial electrode arrays using magnetic resonance imaging. NeuroImage. 2012;63:157–165. doi: 10.1016/j.neuroimage.2012.06.039. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.