

Abstract
Objectives
To compare two Bayesian models capable of identifying unusual and unstable temporal patterns in spatiotemporal data.
Setting
Annual counts of mammography screening users from each statistical local area (SLA) in Brisbane, Australia, recorded between 1997 and 2008 inclusive.
Primary outcome measures
Mammography screening counts.
Results
The temporal trends of 91 SLAs (58%) were dissimilar from the overall common temporal trend. SLAs that followed the common temporal trend also tended to have stable temporal trends. SLAs with unstable temporal trends tended to be situated farther from the city and farther from mammography screening facilities.
Conclusions
This paper demonstrates the usefulness of the two models in identifying unusual and unstable temporal trends, and the synergy obtained when both models are applied to the same data set. An analysis of these models has provided interesting insights into the temporal trends of mammography screening counts and has shown several possible avenues for further research, such as extending the models to allow for multiple common temporal trends and accounting for additional spatiotemporal heterogeneity.
Keywords: EPIDEMIOLOGY, PUBLIC HEALTH, STATISTICS & RESEARCH METHODS
Strengths and limitations of this study.
The models presented allow for the joint analysis of space and time, to provide useful insights into trends relating to a major health issue.
The models fit the data well and provide good predictions.
Some aspects of the model specification may be too restrictive.
Additional data such as the screening counts in rural areas were not available.
Introduction
Breast cancer is one of the most common types of cancer encountered by women in Australia, and the second most common cause of cancer-related deaths, accounting for 2914 deaths in 2011 alone.1 Evidence suggests that regular mammography screening to be effective in detecting early breast cancer thereby increasing the chances of survival.2–6 However, recent studies have suggested that mammography screening services may be underutilised due to geographical factors such as the travel distance to a mammography screening facility.6–8
Hyndman et al6 conducted a study to investigate the effects of distance to a mammography screening facility and social disadvantage on service utilisation. This study found that women with a lower socioeconomic status had more difficulty travelling to a mammography screening facility, and suggested that facilities should be located closer to disadvantaged communities to increase utilisation. However, the influence of the location of mammography screening facility was less clear when socioeconomic factors play no significant role in service utilisation. In another work, Legler et al9 modelled how state mammography screening rates depend on service user demographics, county-level socioeconomic factors and previous mammography intervention research projects. The study found that states with one or more published intervention studies and states with higher levels of education tended to have higher rates of mammography screening service utilisation. Zenk et al8 assessed the equitability of spatial accessibility to low-cost or no-fee mammography screening services in Chicago by modelling distance and time to travel to a facility as a function of geographic and sociodemographic variables including race and poverty. The study concluded that travel time and distance were generally less for poorer neighbourhoods, except for neighbourhoods with a higher proportion of African-American residents. It is unclear from this study, however, if these barriers to access translated into lower screening utilisation since mammography screening utilisation rates were not considered.
The methodologies used in the above studies vary greatly. Hyndman et al6 used geographic information system (GIS) techniques and screening data from six mammography screening facilities in Perth, Australia. Legler et al9 opted for a hierarchical model to estimate the effects of education, occupation and demographic group on mammography screening rates for each state. The model was fit to data collected at two time points, 1987 and 1993–1994, which mark a period during which numerous intervention studies were published. Although the model was applied to data at two time points, it only included spatial covariates, thus limiting inferences to differences between the two fitted models for each time point and spatial effects. Zenk et al8 used ordinary least squares regression models to estimate the effects of covariates on the accessibility measures. However, the authors found that the residuals exhibited spatial autocorrelation, even when endogenous spatial lag regression was used. Furthermore, travel times and distances were estimated using GIS and other software rather than observed, and required numerous assumptions, adding to the uncertainty and the potential bias of the estimates.
The literature contains many other studies that analyse low-cost or no-fee mammography screening utilisation rates and related data. The focus of these studies has typically been aimed at estimating the effect of one or more variables on screening rates. These variables are usually spatially dependent and include service user demographics, socioeconomic factors, accessibility factors and variables relating to the spatial units of the study such as the degree of urbanisation.7 10–13 While estimation of the covariate effects on mammography screening utilisation is useful, little attention has been given to identifying the trends in screening utilisation rates, especially trends that vary over both space and time. Analysis of such trends permits a wider variety of statistical inferences, with implications for service management. Moreover, ignoring spatial and temporal correlation when present can lead to errors in prediction and inference.14
This paper aims to build on previous research in this field by presenting two spatiotemporal models, applied to no-fee mammography screening facility attendance data in Brisbane, Australia. In short, these models are designed to identify ‘unusual’ or ‘unstable’ temporal patterns. The use of the terms ‘unusual’ and ‘unstable’ are model specific, and their meanings are discussed in further detail in Methods.
By nature, spatiotemporal data can be clustered and/or autocorrelated, and are sometimes sparse whereby some regions exhibit relatively low numbers of observed and expected counts. Spatial models typically account for these issues by encoding neighbourhood information as part of the wider model. This has the added advantage of reducing estimated risks with high uncertainty towards the mean risk. Bayesian methods naturally incorporate this information using prior distributions and hierarchical model structures, and allow for estimation of a full probability model for the unknown parameters.8 15–18
Both models considered in this paper have in common the specification of spatial and/or temporal random effects, albeit in different forms, and a model indicator as a means of differentiating SLAs that exhibit a common/stable temporal trend as opposed to an unusual/unstable temporal trend. Both models are estimated using Bayesian techniques and overcome the difficulties associated with autocorrelated data by explicitly including the spatial and temporal dependencies in the models.
Methods
Data
The data used in this study consisted of the number of visits made to mammography screening facilities operated by BreastScreen Queensland in the Brisbane region per year, from 1997 to 2008 inclusive. For each year, the number of visits was recorded by statistical local area (SLA), with 158 SLAs included in the Brisbane region. The eligible population was defined as women aged 40 years or over at the time of screening, in line with the BreastScreen Australia Programme eligibility criteria.3
The physical location and opening and closing dates of each mammography screening facility were also recorded. Some of the mammography screening facilities were mobile and therefore only available at a specific location for a shorter time period. Using these data, a covariate 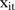 was created, which represents the relative availability of services in a catchment area, defined as
was created, which represents the relative availability of services in a catchment area, defined as
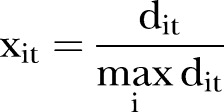 |
1 |
where 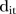 is the cumulative number of days that each mammography screening facility was operating in SLA
is the cumulative number of days that each mammography screening facility was operating in SLA  or any SLA that shares a border with SLA
or any SLA that shares a border with SLA  ,
, 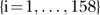 during year
during year  ,
, 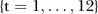 . This catchment area service availability for odd years only is depicted graphically in figure 1.
. This catchment area service availability for odd years only is depicted graphically in figure 1.
Figure 1.

Map of the SLAs in the Brisbane region (Moreton Island not shown) depicting the relative availability of mammography screening services based on the operating duration and location of mammography screening facilities in each SLA and neighbouring SLAs over time (odd years shown only), as defined by equation (1). SLAs, statistical local areas.
Socioeconomic status was also considered as a covariate. However, a preliminary analysis of socioeconomic data did not indicate evidence of an effect. For this reason, it was excluded from the final models.
Model formulation
Two models are proposed for the spatiotemporal analysis of data. Both models are examples of Bayesian spatial generalised linear mixed models (GLMMs) that fall within the wider class of linear models.19–21
Let 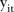 denote the observed count of visits to mammography screening facilities in SLA
denote the observed count of visits to mammography screening facilities in SLA  during year
during year  . Given a population at risk
. Given a population at risk 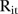 , the corresponding expected number of visits is given by
, the corresponding expected number of visits is given by
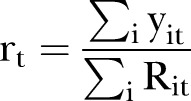 |
where 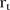 is the reference screening rate in year
is the reference screening rate in year  .22
.22
The first model considered was the BaySTDetect model proposed by Li et al.23 This model consists of two competing models: a common trend model where the temporal trend is the same for each SLA and an area-specific model where the temporal trends are allowed to depart from the common trend. The two competing models are hierarchical in structure and are related to the likelihood via a model selection step, given by equation (2). The BaySTDetect model assumes that the 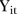 counts are a Poisson random variable, for example,
counts are a Poisson random variable, for example,
where
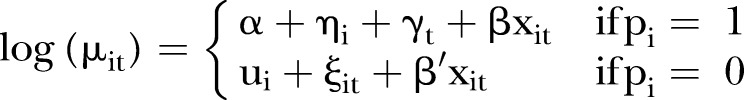 |
2 |
| 3 |
The components of equation (2) are as follows:  is the common intercept;
is the common intercept; 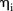 and
and 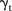 are random effects of space and time respectively;
are random effects of space and time respectively; 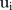 is the area-specific intercept;
is the area-specific intercept; 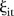 is the area-specific random effect and
is the area-specific random effect and 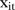 is the covariate defined by equation (1). Regarding the prior for
is the covariate defined by equation (1). Regarding the prior for 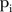 , it is expected that temporal trends are fairly homogeneous for most SLAs, and thus the hyper-parameter δt is chosen to be 0.95. To incorporate spatial and temporal smoothing, intrinsic conditional autoregressive (ICAR) priors24 are assigned under random effects
, it is expected that temporal trends are fairly homogeneous for most SLAs, and thus the hyper-parameter δt is chosen to be 0.95. To incorporate spatial and temporal smoothing, intrinsic conditional autoregressive (ICAR) priors24 are assigned under random effects 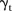 and
and 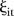 :
:
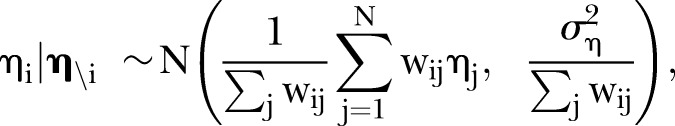 |
4 |
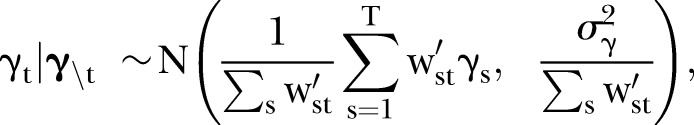 |
5 |
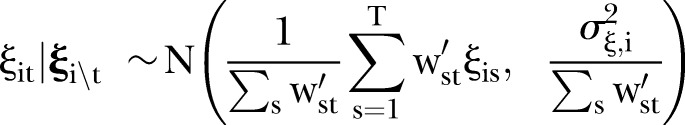 |
6 |
where  denotes all areas excluding
denotes all areas excluding  and
and  is the
is the 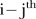 element of a symmetric spatial adjacency weight matrix
element of a symmetric spatial adjacency weight matrix 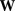 with elements
with elements 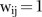 if the
if the 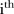 and
and 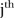 areas are neighbours, and zero otherwise. Similarly, \t denotes all years excluding
areas are neighbours, and zero otherwise. Similarly, \t denotes all years excluding  and
and 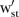 is the
is the 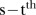 element of a symmetric temporal adjacency weight matrix
element of a symmetric temporal adjacency weight matrix 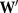 with elements
with elements 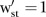 if the
if the 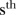 and
and 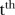 years are neighbours, and zero otherwise. Note that the temporal adjacency information is the same for each of the
years are neighbours, and zero otherwise. Note that the temporal adjacency information is the same for each of the  terms of
terms of 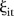 .
.
The parameters  ,
, 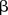 ,
, 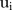 and
and 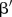 are assumed to be normally distributed with mean 0 and variance 1000. The hyper-parameters
are assumed to be normally distributed with mean 0 and variance 1000. The hyper-parameters 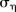 and
and 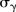 were assigned weakly informative half-normal priors to reflect a lack of prior knowledge about these parameters but restrict their values to be strictly positive and yet not too large.25 The prior for the hyper-parameter
were assigned weakly informative half-normal priors to reflect a lack of prior knowledge about these parameters but restrict their values to be strictly positive and yet not too large.25 The prior for the hyper-parameter 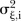 is log-normal,
is log-normal,
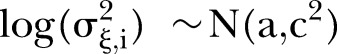 |
where the variance is given an informative prior relative to the data,
to reflect prior expectations about the temporal variability.23
The second model considered was based on the mixture model approach proposed by Abellan et al.26 This model estimates the common spatial and temporal trends based on the data and identifies SLAs the residual temporal patterns of which show volatility, that is, are unstable. In this hierarchical model, the counts 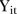 are modelled as Poisson random variables with mean
are modelled as Poisson random variables with mean 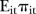 , for example,
, for example,
| 7 |
Here the term  is the common intercept; λi and
is the common intercept; λi and 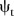 represent the random effects for space and time, respectively and
represent the random effects for space and time, respectively and  represents space–ime interaction. Like the BaySTDetect model, the spatial and temporal random effects are modelled jointly using ICAR priors,
represents space–ime interaction. Like the BaySTDetect model, the spatial and temporal random effects are modelled jointly using ICAR priors,
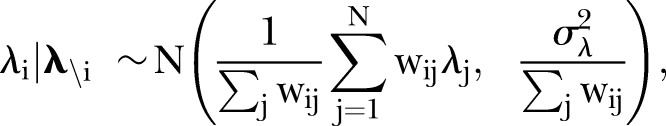 |
8 |
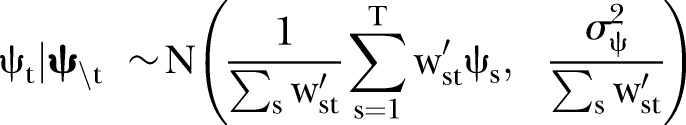 |
9 |
where 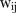 and
and 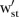 are as defined earlier (see equations 4–6). Normal priors are defined for the intercept and covariate effect terms,
are as defined earlier (see equations 4–6). Normal priors are defined for the intercept and covariate effect terms,
while the prior distribution for 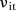 is described by a mixture of two normal distributions with different variances, one representing stable patterns and the other unstable patterns:
is described by a mixture of two normal distributions with different variances, one representing stable patterns and the other unstable patterns:
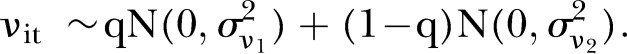 |
The variance is determined by a latent model indicator variable 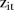 , specified in the model by the multinomial distribution consisting of a single draw,
, specified in the model by the multinomial distribution consisting of a single draw,
where the prior for the mixture weights 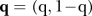 is a Dirichlet distribution:
is a Dirichlet distribution:
The latent indicators take the value 1 if 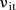 is modelled by
is modelled by 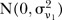 or 2 if
or 2 if 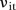 is modelled by
is modelled by 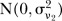 , with
, with 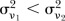 . To avoid the issue of label switching,27
28 and in line with the model specification, the priors for the two variances are specified as
. To avoid the issue of label switching,27
28 and in line with the model specification, the priors for the two variances are specified as
where 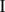 denotes the indicator function
denotes the indicator function 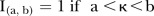 .
.
By analysing the posterior frequencies of the latent indicator variables 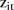 , this mixture model can be used to identify SLAs with unstable temporal trends. For example, let
, this mixture model can be used to identify SLAs with unstable temporal trends. For example, let
| 10 |
represent the posterior probability that 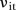 follows
follows 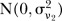 , that is, the posterior probability that the space–time interaction has a large variance. Thus the closer the
, that is, the posterior probability that the space–time interaction has a large variance. Thus the closer the 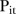 values are to 1, and the more the
values are to 1, and the more the 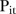 values that are close to 1 for
values that are close to 1 for 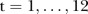 , the more unstable the temporal patterns are for the i-th SLA. Abellan et al26 propose two rules for classifying SLAs as unstable. The first rule considers the
, the more unstable the temporal patterns are for the i-th SLA. Abellan et al26 propose two rules for classifying SLAs as unstable. The first rule considers the 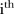 SLA to be unstable if
SLA to be unstable if 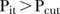 for at least one
for at least one  , where
, where 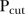 is some specified threshold. The second rule classifies the
is some specified threshold. The second rule classifies the 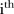 SLA as unstable if the average of the three largest
SLA as unstable if the average of the three largest 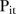 values
values 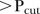 . Rule 2 is slightly more conservative since it averages the
. Rule 2 is slightly more conservative since it averages the 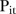 values over three years. Both of these rules were used.
values over three years. Both of these rules were used.
Comparing the two models
While the distinction between unusual and unstable temporal trends may seem trivial, these two models aim to address two very different questions relating to spatiotemporal patterns, and hence each model may provide unique insights.
The BaySTDetect model assumes one common temporal trend, 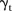 , across all areas and uses a model choice step to fit a competing model with independent random temporal effects for each area if there is considerable departure from the common trend. This allows identification of SLAs that have an unusual temporal trend. For example, assuming a constant mammography screening utilisation rate on average (the common trend), then SLAs that exhibit a high screening rate one year followed by a low rate the next year would be considered to have an unusual temporal trend and would therefore most likely be modelled by the area-specific model.
, across all areas and uses a model choice step to fit a competing model with independent random temporal effects for each area if there is considerable departure from the common trend. This allows identification of SLAs that have an unusual temporal trend. For example, assuming a constant mammography screening utilisation rate on average (the common trend), then SLAs that exhibit a high screening rate one year followed by a low rate the next year would be considered to have an unusual temporal trend and would therefore most likely be modelled by the area-specific model.
In contrast, the space–time mixture tries to estimate the overall spatiotemporal trend. If the annual screening counts for a given SLA are quite different from that which is predicted by the model, then this apparent departure from the overall spatiotemporal trend suggests that the screening rate for this SLA is unstable.
Implementation
Both models were estimated using Markov Chain Monte Carlo (MCMC) techniques, implemented in WinBUGS through R using the R2WinBUGS package (R Core Team. R: A language and environment for statistical computing [Internet]. Vienna: R Foundation for Statistical Computing; 2012 [cited 2014 Dec 1]. http://www.R-project.org/).29 30 The results are based on 25 000 iterations after discarding an initial 100 000 iterations as burn-in. Convergence was assessed informally via visual checks of trace and density plots, as well as formally using the Geweke convergence diagnostic.31
Initially, both models were implemented with the hierarchical structure and priors as specified by the respective authors as described above. These models were then adapted to our scientific problem of interest through a number of modifications. The main changes to the models involved modelling the spatial and temporal random effects 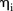 ,
, 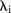 and
and 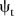 using ICAR priors directly, rather than modelling their respective means, due to a lack of strong autocorrelation between parameters and issues with identifiability of parameters (results not shown). Both models were also extended to include the covariate given by equation (1).
using ICAR priors directly, rather than modelling their respective means, due to a lack of strong autocorrelation between parameters and issues with identifiability of parameters (results not shown). Both models were also extended to include the covariate given by equation (1).
Schematic diagrams of the BaySTDetect and mixture models, after taking into account the changes outlined above, are provided in online supplementary figure S1 and online supplementary figure S2 respectively, available online. The WinBUGS code is also provided, in online supplementary Codes 1 and 2. The posterior distributions of the key model parameters for each model are summarised in figures 2A–L and 3A–O.
bmjopen-2015-010253supp_figures.pdf (412.9KB, pdf)
bmjopen-2015-010253supp_code1.pdf (44.4KB, pdf)
bmjopen-2015-010253supp_code1.pdf (44.4KB, pdf)
Assessment of model fit and predictive performance
Posterior predictive checks (PPCs) were performed to assess the goodness-of-fit and predictive performance of the models given by equations (2) and (7). In brief, PPCs aim to assess the consistency between predictions from the model and the observed data.32–34 If 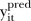 is a prediction of
is a prediction of 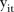 from the specified model, PPCs involve draws from the posterior predictive distribution:
from the specified model, PPCs involve draws from the posterior predictive distribution:
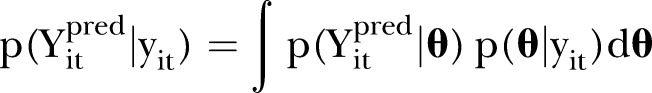 |
where 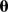 denotes all the parameters in the model.33 These predictions were formed by sampling 200 times from the joint posterior distribution and using each posterior sample to generate
denotes all the parameters in the model.33 These predictions were formed by sampling 200 times from the joint posterior distribution and using each posterior sample to generate 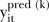 ,
,  . The consistency between the predicted and observed counts for each SLA-year was evaluated using the L-criterion,32 defined as the square root of the mean squared prediction error,
. The consistency between the predicted and observed counts for each SLA-year was evaluated using the L-criterion,32 defined as the square root of the mean squared prediction error,
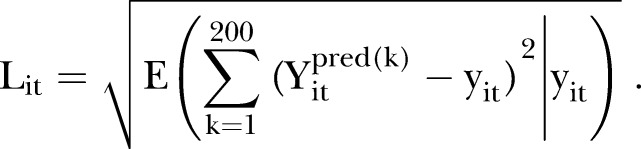 |
11 |
The estimate 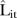 of this quantity is easily computed from the MCMC estimate of the posterior predictive distribution. The results of this PPC are discussed below.
of this quantity is easily computed from the MCMC estimate of the posterior predictive distribution. The results of this PPC are discussed below.
Results
Predictive performance of the models
As a summary of the differences between the predicted and observed counts for each SLA, figure 4 shows the L-criterion estimates 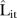 averaged over time for the BaySTDetect model. (The spatial composition of average
averaged over time for the BaySTDetect model. (The spatial composition of average 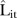 values for the mixture model is almost identical and thus omitted). The
values for the mixture model is almost identical and thus omitted). The 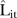 values were about 19.21 and 18.70 counts on average for the BaySTDetect and mixture models, respectively, suggesting acceptable and comparable predictive performance. While there were two regions of SLAs with predominantly larger
values were about 19.21 and 18.70 counts on average for the BaySTDetect and mixture models, respectively, suggesting acceptable and comparable predictive performance. While there were two regions of SLAs with predominantly larger 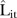 values (the north and south east), there did not appear to be any correlation between SLAs with larger
values (the north and south east), there did not appear to be any correlation between SLAs with larger 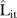 values and service availability (compare figures 1 and 4).
values and service availability (compare figures 1 and 4).
Figure 4.

Map of SLAs in the Brisbane region (Moreton Island not shown) depicting the closeness between yij and 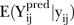 for each SLA for the final (modified) BaySTDetect model, as specified by the L-criterion defined in equation (11). Lighter regions represent SLAs with smaller aggregated L-criterion estimates. SLAs, statistical local areas.
for each SLA for the final (modified) BaySTDetect model, as specified by the L-criterion defined in equation (11). Lighter regions represent SLAs with smaller aggregated L-criterion estimates. SLAs, statistical local areas.
BaySTDetect model
Figure 2A–C show the posterior means of the three spatially indexed parameters, 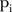 ,
, 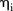 , and
, and 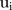 respectively, ordered by the average population at risk,
respectively, ordered by the average population at risk,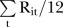 from smallest to largest, left to right.
from smallest to largest, left to right.
Figure 2.

Posterior densities and means of model parameters for 1 chain of the final (modified) BaySTDetect model: (A) posterior mean and 95% CI for pi, (B) posterior mean and 95% CI for ηi, (C) posterior mean and 95% CI for ui, (D) posterior density for β, (E) posterior density for β′, (F) posterior mean and 95% CI for γt, (G) posterior mean and 95% CI for ξ10t, (H) posterior mean and 95% CI for ξ22t, (I) posterior mean and 95% CI for ξ57t, (J) posterior mean and 95% CI for ξ68t, (K) posterior mean and 95% CI for ξ92t and (L) posterior mean and 95% CI for ξ158t.
Figure 2A shows the posterior means for the model indicator parameter 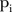 which represent the posterior probabilities of selecting the common trend model for the
which represent the posterior probabilities of selecting the common trend model for the 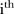 SLA (refer to (3)). For those SLAs whose posterior mean of
SLA (refer to (3)). For those SLAs whose posterior mean of 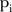 was close to zero, the visits to mammography screening facilities
was close to zero, the visits to mammography screening facilities 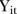 were better modelled by the area-specific model because these SLAs had temporal trends that differed considerably from the common trend
were better modelled by the area-specific model because these SLAs had temporal trends that differed considerably from the common trend 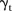 . This was the case for most SLAs, with 91 (58%) SLAs having a posterior mean
. This was the case for most SLAs, with 91 (58%) SLAs having a posterior mean 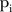 ≤to 0.05, where 61 (39%) SLAs actually had a posterior mean
≤to 0.05, where 61 (39%) SLAs actually had a posterior mean 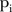 equal to zero. The
equal to zero. The 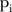 values for SLAs with a larger average population at risk tended to have a smaller posterior mean, indicating that the temporal trend for SLAs with a larger population at risk tended to be less similar to the common temporal trend. The spatial formation of these posterior means is provided in figure 5.
values for SLAs with a larger average population at risk tended to have a smaller posterior mean, indicating that the temporal trend for SLAs with a larger population at risk tended to be less similar to the common temporal trend. The spatial formation of these posterior means is provided in figure 5.
Figure 5.

Map of SLAs in the Brisbane region (Moreton Island not shown) representing the degree to which SLAs follow the common temporal trend (lighter regions) or exhibit unusual temporal trends (darker regions). SLAs, statistical local areas.
Figure 2B, C shows the posterior means of the parameters for the effects of space (on the logarithm scale) for the common-trend and area-specific models, respectively. While the majority of the posterior means of 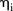 were close to zero, zero was included in only 5 of these 95% credible intervals (CIs) and a small quantity of these means were quite far from zero. In particular, eight SLAs had a posterior mean of <−5 which corresponds to SLAs with zero observed counts. The posterior distributions for
were close to zero, zero was included in only 5 of these 95% credible intervals (CIs) and a small quantity of these means were quite far from zero. In particular, eight SLAs had a posterior mean of <−5 which corresponds to SLAs with zero observed counts. The posterior distributions for 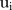 in the area-specific model were similar to those for
in the area-specific model were similar to those for 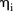 in that the majority of posterior means were close to zero, and it is the same eight SLAs which had a large negative posterior mean. Incidentally, these eight SLAs have the eight smallest aggregated L-criterion estimates, and can easily be identified in figure 4 as the white regions.
in that the majority of posterior means were close to zero, and it is the same eight SLAs which had a large negative posterior mean. Incidentally, these eight SLAs have the eight smallest aggregated L-criterion estimates, and can easily be identified in figure 4 as the white regions.
The posterior densities of the parameters for the effects of the covariate 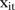 in the two competing models are shown in figure 2D, E. The densities of these parameters indicate a positive marginal effect of the catchment covariate on service utilisation, that is, a tendency for service utilisation to be higher in SLAs that fall within the catchment area of a mammography screening facility, as would be expected.
in the two competing models are shown in figure 2D, E. The densities of these parameters indicate a positive marginal effect of the catchment covariate on service utilisation, that is, a tendency for service utilisation to be higher in SLAs that fall within the catchment area of a mammography screening facility, as would be expected.
Figure 2F shows the posterior means of the parameters for the effects of time for the common-trend model. The posterior means generally decrease with time, indicating a fairly consistent downward trend. The observed counts of visits to mammography screening facilities, however, generally increase over time. While this result is surprising, the temporal effect is very small. More interestingly, there are few SLAs for which their respective temporal trends agree with this common trend, as indicated by the posterior means of 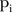 . This is partly explained by the variety of space–time trends in the area-specific model. The posterior means of these space–time trends
. This is partly explained by the variety of space–time trends in the area-specific model. The posterior means of these space–time trends 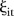 for six selected SLAs are shown in figure 2G–L.
for six selected SLAs are shown in figure 2G–L.
Space–time mixture model
While the BaySTDetect model aims to determine SLAs with unusual temporal trends, the space–time mixture model is designed to identify SLAs whose residual temporal trend exhibits volatility. Figure 3A shows the posterior density of the parameter for the covariate effect, whose estimation and interpretation is comparable to that of 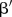 in the BaySTDetect model. Figure 3B shows the posterior means of
in the BaySTDetect model. Figure 3B shows the posterior means of 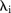 , which are almost identical to those of the spatial effect term in the BaySTDetect model. (The eight smallest values of
, which are almost identical to those of the spatial effect term in the BaySTDetect model. (The eight smallest values of 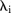 correspond to the SLAs with zero observed counts.)
correspond to the SLAs with zero observed counts.)
Figure 3.

Posterior summary of the main model parameters for 1 chain of the final (modified) space–time mixture model: (A) posterior density for b, (B) posterior mean and 95% CI for λi, (C) posterior mean and 95% CI for ψt, (D) posterior mean and 95% CI for ν10t, (E) posterior mean and 95% CI for ν22t, (F) posterior mean and 95% CI for ν57t, (G) posterior mean and 95% CI for ν68t, (H) posterior mean and 95% CI for ν92t, (I) posterior mean and 95% CI for ν158t, (J) posterior mean and 95% CI for z10t, (K) posterior mean and 95% CI for z22t, (L) posterior mean and 95% CI for z57t, (M) posterior mean and 95% CI for z68t, (N) posterior mean and 95% CI for z92t and (O) posterior mean and 95% CI for z158t.
The temporal effect 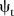 shown in figure 3C indicates a slight, decreasing trend overall. While this differs from the common temporal trend in the BaySTDetect model, the effect size in both cases is small.
shown in figure 3C indicates a slight, decreasing trend overall. While this differs from the common temporal trend in the BaySTDetect model, the effect size in both cases is small.
Figure 3D–I show the posterior means and 95% CIs for the space–time interaction effects 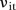 for the same six selected SLAs in figure 2G–L, respectively. They exhibit a variety of SLA-specific temporal trends similar to
for the same six selected SLAs in figure 2G–L, respectively. They exhibit a variety of SLA-specific temporal trends similar to 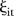 in the BaySTDetect model. Figure 3J–O show the posterior means of the latent indicator variables
in the BaySTDetect model. Figure 3J–O show the posterior means of the latent indicator variables 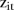 associated with the space–time interaction parameters (equal to
associated with the space–time interaction parameters (equal to 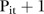 ). By analysing the posterior probabilities
). By analysing the posterior probabilities 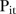 given by equation (10), SLAs with unstable residual temporal trends can be identified. The two rules for classifying unstable SLAs proposed by Abellan et al26 were used using a variety of different values for
given by equation (10), SLAs with unstable residual temporal trends can be identified. The two rules for classifying unstable SLAs proposed by Abellan et al26 were used using a variety of different values for 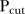 ; the results are summarised graphically in figure 6.
; the results are summarised graphically in figure 6.
Figure 6.

Map of SLAs in the Brisbane region (Moreton Island not shown) with unstable trends (shaded areas) determined by Rule 1 and Rule 2 using different values for the threshold, Pcut. SLAs, statistical local areas.
Discussion
This paper has presented two Bayesian hierarchical spatiotemporal models that were used to analyse the utilisation patterns of no-fee mammography screening services in Brisbane over 12 years. In contrast to previous studies, the models sought to identify SLAs with unusual or unstable temporal patterns as an initial step in improving management of these services. The results from both the BaySTDetect and space–time mixture models provide a useful insight into the spatial and temporal patterns in mammography screening service utilisation.
First, the BaySTDetect model highlighted a large number of SLAs which had unusual temporal trends relative to the common trend. Although a covariate for the relative availability of services was included in the model to account for mobile facility relocations and facility operating times, service utilisation rates for these SLAs changed from year to year in a way that differs from the common trend.
Second, although the BaySTDetect model estimates a common temporal trend 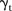 , it is not common in the sense that very few SLAs exhibit this particular temporal trend. To understand why this is the case, consider the space–time trend
, it is not common in the sense that very few SLAs exhibit this particular temporal trend. To understand why this is the case, consider the space–time trend 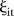 in the area-specific model. Figure 2G–L show the area-specific temporal trend residuals for six selected SLAs. For SLA 10,
in the area-specific model. Figure 2G–L show the area-specific temporal trend residuals for six selected SLAs. For SLA 10, 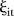 exhibits a fairly stable upward trend; SLA 22 shows a downward trend; SLA 57 has a distinctive oscillating pattern; SLA 68 exhibits an oscillating pattern for the first 7 years followed by a relatively stable upward trend; SLA 92 shows no discernable pattern and SLA 158 has a constant trend. This variety of trends suggests that there is not one but several common temporal trends, and explains why the area-specific model is favoured by the Bayesian model choice. Given the large proportion of SLAs that have a temporal trend which departs from the common trend, departures from this trend should be interpreted with care.
exhibits a fairly stable upward trend; SLA 22 shows a downward trend; SLA 57 has a distinctive oscillating pattern; SLA 68 exhibits an oscillating pattern for the first 7 years followed by a relatively stable upward trend; SLA 92 shows no discernable pattern and SLA 158 has a constant trend. This variety of trends suggests that there is not one but several common temporal trends, and explains why the area-specific model is favoured by the Bayesian model choice. Given the large proportion of SLAs that have a temporal trend which departs from the common trend, departures from this trend should be interpreted with care.
Third, there is an apparent correlation between SLAs which follow the common temporal trends (lighter regions in figure 5) and SLAs with stable temporal trends (white regions in figure 6). This is most noticeable for smaller values of 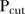 , especially when Rule 1 is used to classify unstable SLAs. This is unsurprising since the common temporal trend is itself fairly flat (only ranges between −0.02 and 0.02 approximately), that is, stable. However, there also exist SLAs the temporal trends of which are unusual but stable, and SLAs the temporal trends of which are usual but unstable.
, especially when Rule 1 is used to classify unstable SLAs. This is unsurprising since the common temporal trend is itself fairly flat (only ranges between −0.02 and 0.02 approximately), that is, stable. However, there also exist SLAs the temporal trends of which are unusual but stable, and SLAs the temporal trends of which are usual but unstable.
Fourth, the analysis of the space–time mixture model identified a number of SLAs as unstable, depending on the value of 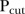 and the classification rule used. Figure 6 indicates that unstable SLAs tend to be situated on the outskirts of the Brisbane region, that is, unstable SLAs tend to be more rural than urban, particularly for larger values of
and the classification rule used. Figure 6 indicates that unstable SLAs tend to be situated on the outskirts of the Brisbane region, that is, unstable SLAs tend to be more rural than urban, particularly for larger values of 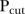 . Comparing figures 1 and 6, these unstable SLAs also tend to be in regions outside of catchment areas. This suggests that the distance to a screening facility has an impact on the consistency of clients accessing mammography screening services.
. Comparing figures 1 and 6, these unstable SLAs also tend to be in regions outside of catchment areas. This suggests that the distance to a screening facility has an impact on the consistency of clients accessing mammography screening services.
Last, the predicted values for eight SLAs with zero observed counts were the most consistent with the data in both the BaySTDetect and mixture models, as evidenced by the smallest L-criterion estimates. This implies that the existing model components and covariates are adequate in accounting for the lack of service utilisation from these SLAs. Figure 1 shows that these SLAs tend to fall outside the catchment areas, which reinforces the notion that service utilisation is influenced by the distance to the nearest screening facility.
The two models presented in this paper are not without limitations. Li et al23 raised a concern about the number of time periods over which the BaySTDetect model detects changes in the temporal trend. The authors advise that a single model indicator 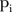 for each SLA may be ‘too restrictive’ when the number of time periods is >10 because the current design assumes only one common temporal trend for the whole period, which is less likely to be the case for longitudinal data collected over many time points. This could be addressed by changing the model indicator to apply to SLAs and years, say
for each SLA may be ‘too restrictive’ when the number of time periods is >10 because the current design assumes only one common temporal trend for the whole period, which is less likely to be the case for longitudinal data collected over many time points. This could be addressed by changing the model indicator to apply to SLAs and years, say 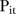 . Another potential issue with the BaySTDetect model is the a priori specification of the prior for the model indicator,
. Another potential issue with the BaySTDetect model is the a priori specification of the prior for the model indicator, 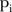 . Li et al23 use 0.95 for the Bernoulli probability in equation (3) to reflect their belief that only a small proportion of areas are actually unusual. This rather informative prior may have been adequate for the chronic disease mortality data analysis performed by Li et al,23 but based on the results that indicate a large proportion of unusual SLAs; it may be more appropriate to specify a hyperprior for the Bernoulli probability, perhaps using additional spatial covariate information if available.
. Li et al23 use 0.95 for the Bernoulli probability in equation (3) to reflect their belief that only a small proportion of areas are actually unusual. This rather informative prior may have been adequate for the chronic disease mortality data analysis performed by Li et al,23 but based on the results that indicate a large proportion of unusual SLAs; it may be more appropriate to specify a hyperprior for the Bernoulli probability, perhaps using additional spatial covariate information if available.
Similarly, the Dirichlet prior for 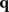 in the mixture model could be extended to include additional effects of space and/or time. The change in the dimensionality of
in the mixture model could be extended to include additional effects of space and/or time. The change in the dimensionality of 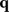 to
to 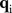 ,
, 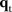 or
or 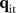 should be straightforward since the space–time effect
should be straightforward since the space–time effect 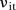 is already indexed by space and time. However, this may increase the computational burden significantly.
is already indexed by space and time. However, this may increase the computational burden significantly.
In both models, there are a large number of parameters to be estimated, some of which have posterior means close to zero (in particular some of the space–time trends 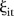 and
and 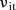 ). It may be beneficial to zero out such parameters using appropriate spike and slab priors.
). It may be beneficial to zero out such parameters using appropriate spike and slab priors.
In this study, the spatial autocorrelation between the observed data for any given year appears to be weak, as indicated by the posterior means of 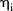 and
and 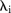 , shown in figures 2B and 3B. However, measures of spatial autocorrelation such as Moran's I and Geary's C indicate the contrary (results not shown). Although Geary's C is more sensitive to local spatial autocorrelation, such statistics imply that spatial autocorrelation in this data set is global rather than local, and thus perhaps not easily captured through ICAR priors. Results may be improved by changing the adjacency weight elements
, shown in figures 2B and 3B. However, measures of spatial autocorrelation such as Moran's I and Geary's C indicate the contrary (results not shown). Although Geary's C is more sensitive to local spatial autocorrelation, such statistics imply that spatial autocorrelation in this data set is global rather than local, and thus perhaps not easily captured through ICAR priors. Results may be improved by changing the adjacency weight elements 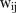 to be non-zero for second-order and third-order neighbours, for example.
to be non-zero for second-order and third-order neighbours, for example.
A possible extension to the work of Abellan et al26 concerns the rules used to classify SLAs as unusual or not. The methodology proposed by Abellan et al26 allows SLAs with unstable temporal trends to be identified, but methods to identify the degree to which an SLA is unstable would undoubtedly be more informative and comparable to the results from the BaySTDetect model. Another avenue for future research is the inclusion of additional covariates that vary in space and/or time, such as accessibility to public transport, which may improve inferences relating to spatial and/or temporal trends.
The L-criterion values also provide insight into the observed trends. It is speculated that larger 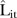 values may be attributed to some unknown factor such as the influence of services offered by private mammography screening facilities. For both models, the predictive performance tended to decrease with time, with the annual average
values may be attributed to some unknown factor such as the influence of services offered by private mammography screening facilities. For both models, the predictive performance tended to decrease with time, with the annual average 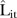 values increasing by about 4 between 1997 and 2008. Inclusion of other temporal factors may improve predictive performance in later years.
values increasing by about 4 between 1997 and 2008. Inclusion of other temporal factors may improve predictive performance in later years.
Overall, this paper has shown that the BaySTDetect and space–time mixture models are useful in analysing mammography screening service utilisation data. In particular, the BaySTDetect model was able to identify SLAs which had temporal trends that differed from the overall temporal trend, and the space–time mixture model identified SLAs with unstable temporal trends. Analysis of these models has shown insight into patterns of the observed trends, and showed potentially important factors not yet considered.
Acknowledgments
The authors thank the two reviewers for their insightful comments and suggestions, which significantly contributed to improving the quality of this manuscript. The authors acknowledge Associate Professor Adrian Barnett, School of Public Health and Social Work, Queensland University of Technology, for his perceptive comments and feedback on an earlier draft of this manuscript.
Footnotes
Contributors: EWD applied the models and analysed the data, prepared an initial draft of the manuscript and collaborated in the the manuscript revision process. NMW and KM made substantial contributions to the methodological design and development of the models, provided critical comments and suggestions on all drafts of the manuscript, and assisted in the analysis and interpretation of the models and data. All authors approved the final draft of the manuscript for publication.
Funding: This work was supported by the Cooperative Research Centre for Spatial Information (CRCSI), the activities of which are funded by the Australian Commonwealth's Cooperative Research Centres Programme. This research was also supported under the Australian Research Council (ARC) Centre of Excellence for Mathematical and Statistical Frontiers (ACEMS) (project number CE140100049) and ARC Discovery project (number DP140103564).
Competing interests: None declared.
Patient consent: Obtained.
Ethics approval: Queensland University of Technology Human Research Ethics Committee.
Provenance and peer review: Not commissioned; externally peer reviewed.
Data sharing statement: No additional data are available.
References
- 1.Australian Institute of Health and Welfare. Australian Cancer Incidence and Mortality (ACIM) books: breast cancer. Canberra: AIHW, 2014. (updated 8 February 2015; cited 1 March 2015). http://www.aihw.gov.au/acim-books [Google Scholar]
- 2.Australian Institute of Health and Welfare. Breast cancer in Australia: an overview. Cancer series no. 71. Cat. no. CAN 67 Canberra: AIHW, 2012. (cited 27 November 2014). http://www.aihw.gov.au/WorkArea/DownloadAsset.aspx?id=10737423006 [Google Scholar]
- 3.Australian Government Department of Health. BreastScreen Australia: About the program. 2015. (updated 5 March 2015; cited 1 July 2015). http://www.cancerscreening.gov.au/internet/screening/publishing.nsf/Content/about-the-program
- 4.Shen Y, Yang Y, Inoue LYT et al. Role of detection method in predicting breast cancer survival: analysis of randomized screening trials. J Natl Cancer Inst 2005;97:1195–203. 10.1093/jnci/dji239 [DOI] [PubMed] [Google Scholar]
- 5.Alexander FE, Anderson TJ, Brown HK et al. 14 years of follow-up from the Edinburgh randomised trial of breast-cancer screening. Lancet 1999;353:1903–8. 10.1016/S0140-6736(98)07413-3 [DOI] [PubMed] [Google Scholar]
- 6.Hyndman JCG, Holman CDJ, Dawes VP. Effect of distance and social disadvantage on the response to invitations to attend mammography screening. J Med Screen 2000;7:141–5. 10.1136/jms.7.3.141 [DOI] [PubMed] [Google Scholar]
- 7.Jackson MC, Davis WW, Waldron W et al. Impact of geography on mammography use in California. Cancer Cause Control 2009;20:1339–53. 10.1007/s10552-009-9355-6 [DOI] [PubMed] [Google Scholar]
- 8.Zenk SN, Tarlov E, Sun J. Spatial equity in facilities providing low- or no-fee screening mammography in Chicago neighborhoods. J Urban Health 2006;83:195–210. 10.1007/s11524-005-9023-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Legler J, Breen N, Meissner H et al. Predicting patterns of mammography use: a geographic perspective on national needs for intervention research. Health Serv Res 2002;37:929–47. 10.1034/j.1600-0560.2002.59.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Maxwell AJ. Relocation of a static breast screening unit: a study of factors affecting attendance. J Med Screen 2000;7:114–15. 10.1136/jms.7.2.114 [DOI] [PubMed] [Google Scholar]
- 11.Engelman KK, Hawley DB, Gazaway R et al. Impact of geographic barriers on the utilization of mammograms by older rural women. J Am Geriatr Soc 2002;50:62–8. 10.1046/j.1532-5415.2002.50009.x [DOI] [PubMed] [Google Scholar]
- 12.Selvin E, Brett KM. Breast and cervical cancer screening: sociodemographic predictors among white, black, and Hispanic women. Am J Public Health 2003;93:618–23. 10.2105/AJPH.93.4.618 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Makuc DM, Breen N, Freid V. Low income, race, and the use of mammography. Health Serv Res 1999;34:229–39. [PMC free article] [PubMed] [Google Scholar]
- 14.Hoeting JA. The importance of accounting for spatial and temporal correlation in analyses of ecological data. Ecol Appl 2009;19:574–7. 10.1890/08-0836.1 [DOI] [PubMed] [Google Scholar]
- 15.Lekdee K, Ingrisawang L. Generalized linear mixed models with spatial random effects for spatio-temporal data: an application to dengue fever mapping. J Math Stat 2013;9:137–43. 10.3844/jmssp.2013.137.143 [DOI] [Google Scholar]
- 16.Zhang H. On estimation and prediction for spatial generalized linear mixed models. Biometrics 2002;58:129–36. 10.1111/j.0006-341X.2002.00129.x [DOI] [PubMed] [Google Scholar]
- 17.Best N, Richardson S, Thomson A. A comparison of Bayesian spatial models for disease mapping. Stat Methods Med Res 2005;14:35–59. 10.1191/0962280205sm388oa [DOI] [PubMed] [Google Scholar]
- 18.Bernardinelli L, Clayton D, Pascutto C et al. Bayesian analysis of space—time variation in disease risk. Stat Med 1995;14:2433–43. 10.1002/sim.4780142112 [DOI] [PubMed] [Google Scholar]
- 19.Schall R. Estimation in generalized linear models with random effects. Biometrika 1991;78:719–27. 10.1093/biomet/78.4.719 [DOI] [Google Scholar]
- 20.Zeger SL, Karim MR. Generalized linear models with random effects; a Gibbs sampling approach. J Am Stat Assoc 1991;86:79–86. 10.1080/01621459.1991.10475006 [DOI] [Google Scholar]
- 21.Waclawiw MA, Liang K. Prediction of random effects in the generalized linear model. J Am Stat Assoc 1993;88:171–8. [Google Scholar]
- 22.Pascutto C, Wakefield JC, Best NG et al. Statistical issues in the analysis of disease mapping data. Stat Med 2000;19:2493–519. 10.1002/1097-0258(20000915/30)19:17/18<2493::AID-SIM584>3.0.CO;2-D [DOI] [PubMed] [Google Scholar]
- 23.Li G, Best N, Hansell AL et al. BaySTDetect: detecting unusual temporal patterns in small area data via Bayesian model choice. Biostatistics 2012;13:695–710. 10.1093/biostatistics/kxs005 [DOI] [PubMed] [Google Scholar]
- 24.Besag J, Kooperberg C. On conditional and intrinsic autoregressions. Biometrika 1995;82:733–46. [Google Scholar]
- 25.Gelman A. Prior distributions for variance parameters in hierarchical models. Bayesian Anal 2006;1:515–33. 10.1214/06-BA117A [DOI] [Google Scholar]
- 26.Abellan JJ, Richardson S, Best N. Use of space-time models to investigate the stability of patterns of disease. Environ Health Perspect 2008;116:1111–19. 10.1289/ehp.10814 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Redner RA, Walker HF. Mixture densities, maximum likelihood and the EM algorithm. SIAM J Appl Math 1984;26:195–239. 10.1137/1026034 [DOI] [Google Scholar]
- 28.Stephens M. Dealing with label switching in mixture models. J R Stat Soc Series B Stat Methodol 2000;62:795–809. 10.1111/1467-9868.00265 [DOI] [Google Scholar]
- 29.Lunn DJ, Thomas A, Best N et al. WinBUGS—a Bayesian modelling framework: concepts, structure, and extensibility. Stat Comput 2000;10:325–37. 10.1023/A:1008929526011 [DOI] [Google Scholar]
- 30.Sturtz S, Ligges U, Gelman A. R2WinBUGS: a package for running WinBUGS from R. J Stat Softw 2005;12:1–16. 10.18637/jss.v012.i03 [DOI] [Google Scholar]
- 31.Geweke J. Evaluating the accuracy of sampling-based approaches to calculating posterior moments. In: Bernardo JM, Berger JO, Dawid AP, Smith AFM, eds. Bayesian statistics. Oxford: Clarendon Press, 1992:169–93. [Google Scholar]
- 32.Ibrahim JG, Laud PW. A predictive approach to the analysis of designed experiments. J Am Stat Assoc 1994;89:309–19. 10.1080/01621459.1994.10476472 [DOI] [Google Scholar]
- 33.Ntzoufras I. Bayesian modeling using WinBUGS. Hoboken: Wiley, 2009. [Google Scholar]
- 34.Gelman A, Carlin JB, Stern HS et al. Bayesian data analysis. 3rd edn Boca Raton: Chapman and Hall, 2013. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
bmjopen-2015-010253supp_figures.pdf (412.9KB, pdf)
bmjopen-2015-010253supp_code1.pdf (44.4KB, pdf)
bmjopen-2015-010253supp_code1.pdf (44.4KB, pdf)