

Abstract
To date, the support vector machine (SVM) has been widely applied to diverse bio-medical fields to address disease subtype identification and pathogenicity of genetic variants. In this paper, I propose the weighted K-means support vector machine (wKM-SVM) and weighted support vector machine (wSVM), for which I allow the SVM to impose weights to the loss term. Besides, I demonstrate the numerical relations between the objective function of the SVM and weights. Motivated by general ensemble techniques, which are known to improve accuracy, I directly adopt the boosting algorithm to the newly proposed weighted KM-SVM (and wSVM). For predictive performance, a range of simulation studies demonstrate that the weighted KM-SVM (and wSVM) with boosting outperforms the standard KM-SVM (and SVM) including but not limited to many popular classification rules. I applied the proposed methods to simulated data and two large-scale real applications in the TCGA pan-cancer methylation data of breast and kidney cancer. In conclusion, the weighted KM-SVM (and wSVM) increases accuracy of the classification model, and will facilitate disease diagnosis and clinical treatment decisions to benefit patients. A software package (wSVM) is publicly available at the R-project webpage (https://www.r-project.org).
Electronic supplementary material
The online version of this article (doi:10.1186/s40064-016-2677-4) contains supplementary material, which is available to authorized users.
Keywords: Support vector machine, K-means clustering, Weighted SVM, TCGA
Introduction
Cutting-edge microarray and sequencing techniques for transcriptome and DNA methylome have received increasing attentions to decipher biological processes and to predict the multi-causes of complex diseases [e.g., cancer diagnosis (Ramaswamy et al. 2001), prognosis (Vijver et al. 2002), and therapeutic outcomes (Ma et al. 2004)]. To this end, the supervised machine learning has considerably contributed to developing tools towards the translational and clinical application. For example, diverse biomarker panels on the basis of transcriptional expressions have been released [e.g. MammaPrint (van ’t Veer 2002), Oncotype DX (Paik et al. 2004), Breast Cancer Index BCI (Zhang et al. 2013) and PAM50 (Parker et al. 2009)] for survival, recurrence, drug response and disease subtypes. It is evident that effective prediction tasks advance clinical diagnosis tools that build on translating models from transcriptomic studies. In this standpoint, rapid and precise classification rules are imperative to support exploring disease-related biomarkers, diagnosis and sub-types identification, and to deliver meaningful information for tailored treatment and precision medicine.
The support vector machine (SVM) was originally introduced by Cortes and Vapnik (1995). Over the decades, the SVM has been applied to a range of study fields, including pattern recognition (Kikuchia and Abeb 2005), disease subtype identification (Gould et al. 2014), pathogenicity of genetic variants (Kircher et al. 2014) and so on. In theory, the forte of the SVM is attributed to its flexibility and outstanding classification accuracy. However, the SVM relies on the quadratic programming (QP), whose computational complexity is commonly costly and subject to size of data. Some methods to circumvent this drawback (Wang and Wu 2005; Lee et al. 2007) were proposed to speed up its computation with minimizing loss of accuracy. Interestingly, Wang and Wu (2005) applied the SVM to centers of K-means clustering alone (KM-SVM). Due to small cluster size K, this method dramatically diminishes the number of observations, and hence can reduces the high-computational cost. The KM-SVM assumes that cluster centers adequately account for original data. This KM-SVM is also called the Global KM-SVM (Lee et al. 2007) in short. Similarly, Lee et al. (2007) also proposed so-called the By-class KM-SVM, where class labels separate samples into two groups at the outset, to which I apply K-means clustering respectively, while the Global KM-SVM, in contrast, employs a majority voting to determine class labels of respective centers. Not surprisingly, it is commonplace that the KM-SVM performs worsen than the standard SVM in most cases. In other words, the KM-SVM pursues computational efficiency at the expense of prediction accuracy.
Yang et al. (2007) and Bang and Jhun (2014) proposed the weighted support vector machine and the weighted KM-SVM to improve accuracy in the context of the outlier sensitivity problem (i.e., WSVM-outlier). The primary idea is to assign weights to each data sample, which manipulates relative importance. It is proved that WSVM-outlier reduces the effect of outliers, and yields higher classification rates. Yet I notice that the WSVM-outlier solely adopts outlier-sensitive algorithms (e.g., a robust fuzzy clustering, kernel-based possibilistic c-means), that are only well-suited to adjusting outlier effects, but not always guarantees to perform best in general cases. It is, therefore, interesting to add other weight schemes applicable to general scenarios.
Boosting is a machine learning ensemble algorithm, making it possible to reduce bias and variance, and to boost predictive power. More specifically, most boosting algorithms (Schapire 1990; Breiman 1998; Freund and Schapire 1997) iteratively glean weak classifiers, and incorporate them to a strong classifier. At each iteration, weak classifiers gain weights in some reasonable ways, and thereby subsequent weak learners focus more on samples that preceding weak learners mis-classified. Over the decades, many have introduced diverse boosting algorithms: Schapire (1990) originally proposed (a recursive majority gate formulation), and Mason et al. (2000) developed boost by majority. Interestingly, Freund and Schapire (1997) then developed AdaBoost.M1, an adaptive algorithm known to be superior to the previous ones.
Taking all things into consideration, I proposed a new algorithm, the weighted KM-SVM (wKM-SVM) and weighted support vector machine (wSVM) to improve the KM-SVM (and SVM) via weights, together with the boosting algorithm. In this paper, I utilize AdaBoost.M1 (Freund and Schapire 1997) in place of the outlier-sensitive algorithms used in WSVM-outlier (Yang et al. 2007). The wKM-SVM (wSVM) adds weights to the hinge loss term, making it straightforward to derive the quadratic programming (QP) objective function, while the WSVM-outlier, to the contrary, directly maneuvers the penalization constant corresponding to each sample. Yang et al. (2007) hardly enables to grasp how each weight is implemented in optimization, whereas my proposed wKM-SVM (wSVM) can demonstrate the numerical relationship between the objective function and weights. The weighted KM-SVM (wKM-SVM) is universally applicable to many different data analysis scenarios, for which comprehensive experiments assess accuracy and provide comparisons with other methods.
In this paper, I applied the proposed method to pan-cancer methylation data (https://tcga-data.nci.nih.gov/tcga/) including breast cancer (breast invasive carcinoma) and kidney cancer (kidney renal clear cell carcinoma). From simulations and real applications, the proposed wKM-SVM (wSVM) is shown to be more efficient in predictive power, as compared to the standard SVM and KM-SVM, including but not limited to many popular classification rules (e.g., decision trees and k-NN and so on). In conclusion, the wKM-SVM (and wSVM) increases accuracy of the classification model that will ultimately improve disease understanding and clinical treatment decisions to benefit patients.
This paper is outlined as follows. In “Backgrounds” section, I review background studies in terms of the SVM and ensemble methods. In “Proposed methods” section, the weighted SVM algorithm is proposed. In “Numerical studies” section, I compare performance of my proposed methods with other methods, and claim biological implications from analysis of the TCGA pan-cancer data. In “Conclusion and discussion” section, conclusions and further studies are discussed.
Backgrounds
Support vector machine
Consider the data of , with and for , where denotes an input space. Let and be an input and class label of the nth sample. and denote the inner product and norm in . Define hyperplane by . A classification rule that builds on f(x) is
Commonly, w and b are called the weight vector and bias. The optimal vector and bias can be obtained by solving the following quadratic optimization problem,
| 1 |
subject to , for , where are slack variables and C is the regularization parameter. Note that (1) can be reformulated with the Wolfe dual form by introducing the Lagrange multipliers.
| 2 |
where is the Lagrange multiplier with respect to for . is then the solution of (2). From the derivatives of the Lagrange equations, I see that the solution of f(x) as below:
Importantly, () is a non-zero solution and its properties are induced by the Karush–Kuhn–Tucker conditions including boundary constraints. Taken together, the decision rule can be formed as
For nonlinear decision rules, a kernel method can be applicable with the inner product replaced by a nonlinear kernel, . For more details, see Cortes and Vapnik (1995).
K-means SVM
The support vector machine using the K-means clustering (KM-SVM) is the SVM algorithm sequentially combined with the K-means clustering. Importantly, it is believed that the K-means clustering is one of the most popular clustering methods. The following describes how to implement KM-SVM. I first divide samples of train data into several clusters by applying the K-means clustering. Given pre-defined K, the K-means clustering produces clusters . Class labels (i.e., or 1) of are assigned via majority voting (). Second, I build up a SVM classifier over derived cluster centers. It is interesting to note that the KM-SVM greatly cut down the number of data and support vectors used to estimate solutions, and so has the forte of computational efficiency. Wang and Wu (2005) originally introduced the prototype KM-SVM (Global KM-SVM). Due to its practical utilities, diverse KM-SVM-type classification rules have been proposed afterward (Gu and Han 2013; Lee et al. 2007). In this paper, I mainly focus on the KM-SVM methods proposed by Lee et al. (2007). Wang and Wu (2005) applies the K-means clustering to whole input data, while Lee et al. (2007) uses the K-means clustering to two sample groups independently separated by each class label (By-class KM-SVM). It is known that the By-class KM-SVM improves error rates, and efficiently circumvents the problem of imbalanced class labels.
Proposed methods
Weighted support vector machine
In this section, I newly introduce the weighted SVM that can accommodate some weights. The previous weighted SVMs (Yang et al. 2007; Bang and Jhun 2014) directly maneuver the penalization constant corresponding to each sample. With these strategies, I hardly grasp how each weight plays a role in optimization, leading to challenges to verify the numerical relationship between the objective function and weights. To the contrary, my proposed method adds weights to the hinge loss term, making it tractable to derive the quadratic programming (QP) objective function, and to impose weights to the hinge loss. In short, I call this the weighted KM-SVM (wKM-SVM) henceforth. In what follows, I formulate the SVM objective function with the penalization form:
| 3 |
where is a weight of the nth sample. This penalization form with is the same as
subject to the constraints . Consider the soft margin SVM. Let
| 4 |
and
| 5 |
where and . Equivalence between (4) and (5) is proved in Lemmas 1 and 2.
Lemma 1
Letforand. Then, I get
subject to and for. The details of the proof are presented in Additional file1.
Lemma 2
Letbe the minimizer ofsubjectto (3.5). I obtain
Hence, (4) is derived by optimizing (5) with respect to. See the details of the proof in Additional file1.
Solutions for weighted SVM
In this section, I derive the solution of the weighted SVM. I adopt the quadratic programming (QP) to solve for some ,
| 6 |
subject to the constraints and for . Consider the Lagrangian
| 7 |
With a little of algebra, I can build the Wolfe dual form to estimate the weight term w and b, and it is enough to solve the dual problem as below:
subject to and for . See the details of the proof in Additional file 1.
Weighted KM-SVM with an ensemble technique
Generally it is known that the KM-SVM boosts computational efficiency at the expense of prediction accuracy. Such low accuracy of KM-SVM can be overcome with importing ensemble methods (e.g., boosting Schapire 1990; Breiman 1998), and these ensemble methods can be applicable to the standard SVM as well. In this paper, I make use of AdaBoost.M1 introduced by Freund and Schapire (1997). In principle, AdaBoost.M1 increases weights to mis-classified samples. At each boosting iteration, weighted weak classifiers are stacked by samples, and produces integrated classification rules by majority voting. Simply put, the weighted KM-SVM (and wSVM) is more of applying boosting to weights in order to add an artificial impact to mis-classified samples. The following is the weighted KM-SVM (and wSVM) objective function (3):
The weight is updated via where and . Table 1 summarizes the algorithm of the weighted KM-SVM (and SVM) with the boosting method. At each iteration , I fit a KM-SVM weak classifier together with the weighted term as in Step 2-(1). The weighted error rate () is then calculated in Step 2-(2). In Step 2-(3), I calculate the weight constant given . It is worthwhile to note that weights of clustering centers misclassified by increases by exp(). In other words, serves to adjust relative importance of misclassified samples. In Step 2-(4), I finalize the classifier G(x) by integrating all weak classifiers via majority voting.
Table 1.
The weighted KM-SVM (or SVM) with the boosting algorithm
| 1. Initialize the weight with . | |
| 2. For to M: | |
| (1) Fit a KM-SVM (or SVM) with weights to clustering centers of train data. | |
| (2) Compute | |
| (3) Compute | |
| (4) Set | |
| 3. Output . |
Numerical studies
Simulated data
In this section, I examine predictive performance of the weighted KM-SVM (and SVM) with boosting. Below I briefly illustrate how I generate simulated data. Let be the binary variable of the sample (; for ), and be a matrix of two predictor variables randomly generated from the bivariate normal distribution, where and for , and . With the simulation scheme above, I generated samples for train data and samples for test data. The regularization parameter C was chosen by 5-fold cross-validation over from train data, and the radial based kernel was applied with (a.k.a. free parameter). The number of clusters (K) is defined by half size of train data. Making use of the weighted KM-SVM (and SVM) fitted by the optimal parameter, I calculated error rates of test data. The experiment to generate test error rates (= error rates of test data) was repeated 1000 times and average values are presented in Fig. 1a, b. The test error rates were benchmarked to compare with other classification rules. In Fig. 1a, I first observe that the SVM (= 0.265) performs better than the KM-SVM (= 0.291) in accuracy. This is consistent with previous experimental knowledge (Lee et al. 2007). In addition, I notice that the weighted KM-SVM (= 0.278) (and SVM = 0.265) considerably improves the non-weighted KM-SVM (= 0.291) (and SVM = 0.26). Generally, the SVM is believed to be superior to many popular prediction rules. In this simulation, I consider CART (Breiman et al. 1984), kNN (Altman et al. 1992) and Random forest (Ho 1998) for comparison with the family of SVM classifiers. In Fig. 1a, the weighted SVM performs best among all of classification rules. Moreover, it is remarkable to see that the weighted KM-SVM performs better than CART and Random forest despite its data reduction. Figure 2a, b illustrate how the proposed methods reduce error rates as iterated. The test error rates dramatically drop after the first few iterations, and hence boosting evidently helps increasing accuracy. In Fig. 1b, the declining pattern of test error rates are presented as r (i.e., a parameter for for ) increases in size ranging from 0.6 to 1.4. It is clear to say that the weighted KM-SVM (and wSVM) is consistently better than the KM-SVM (and SVM).
Fig. 1.
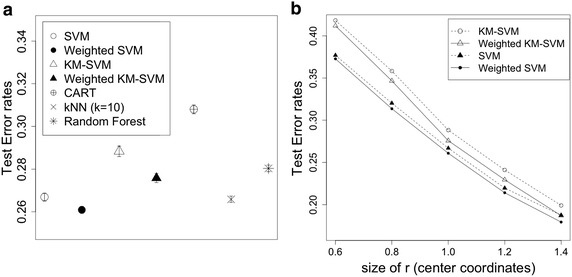
Performance comparisons across different classification rules. Each dot represents the averaged values of repeated simulations, and the bars overlaid with dots represent standard errors. a Prediction errors of six different classification rules, b decreasing patterns of test error rates as r (coordinates of centers) increases in value
Fig. 2.
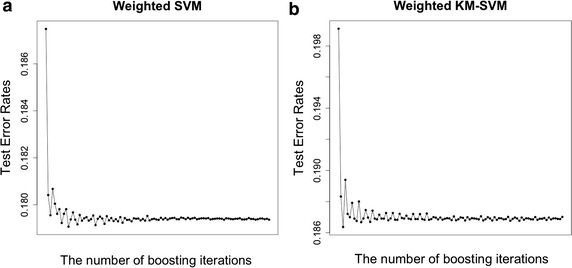
a Test error rates of the weighted SVM as the boosting increases in iteration. b Test error rates of the weighted KM-SVM as the boosting increases in iteration
Application to genomic data
Below I demonstrate applications to two real methylation expression profiles for breast and kedney cancer. TCGA cancers data (Level 3 DNA methylation of beta values targeting on methylated and the unmethylated probes) from the TCGA database (https://tcga-data.nci.nih.gov/tcga/), where I retrieved methylation data of two cancer types (Breast carcinoma (BRCA), Kidney renal clear cell carcinoma (KIRC). I matched up features across all studies and filtered out probes by the rank sum of mean and standard deviation (Wang et al. 2012) (mean <0.7, SD <0.7), which leaves 910 probes. Table 2 describes details of TCGA data. In this application, I pose a hypothetical question if the proposed methods (wKM-SVM and wSVM) can improve accuracy for cancer prediction. To this end, I first randomly split the whole data set into two parts with approximately same size, which I denote as train and test data. The number of clusters (K) is defined by half size of train data. I examined by the test set weighted KM-SVM’s (and wSVM’s) performance using each SVM constructed by the train set. Similar to simulation studies, I observe that the weighted KM-SVM (and wSVM) outperforms the standard KM-SVM (and SVM) in prediction accuracy. It is also notable that the weighted KM-SVM (and wSVM) better performs than CART, kNN and Random Forest, as shown in Fig. 3a, b. Therefore, I conclude that the proposed weighted SVM can facilitate cancer prediction with enhanced accuracy.
Table 2.
Shown are the brief descriptions of the nineteen microarray datasets of disease-related binary phenotypes (e.g., case and control). All datasets are publicly available
| Name | Study | Type | # of samples | Control | Case | # of matched genes | Reference |
|---|---|---|---|---|---|---|---|
| BRCA | Breast cancer | Methylation | 343 | 27 | 316 | 10,121 | The Cancer Genome Atlas (TCGA) |
| KIRC | Kidney cancer | Methylation | 418 | 199 | 219 | 10,121 | The Cancer Genome Atlas (TCGA) |
Fig. 3.
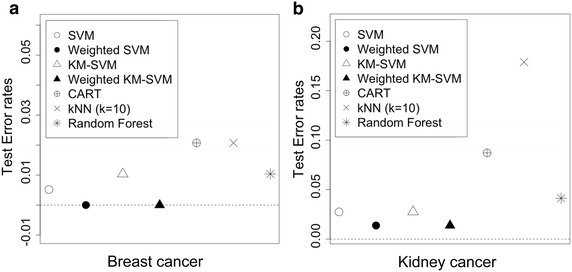
a Performance comparisons of breast cancer data across different classification rules, b performance comparisons of kidney cancer data across different classification rules
Conclusion and discussion
In this paper, I propose the new algorithm for the weighted KM-SVM to improve prediction accuracy. Typically, the KM-SVM has higher error rate than that it appears in the SVM, due to data reduction. To circumvent this issue, I suggest the weighted KM-SVM (and SVM) and evaluated performance of each of classifiers through various experimental scenarios. Putting together, I conclude that the proposed weighted KM-SVM (and SVM) is effective to diminish its error rates. In particular, I applied the weighted KM-SVM (and SVM) to TCGA cancer methylation data, and found its improved performance for disease prediction. Due to high accuracy, the weighted KM-SVM (and wSVM) can be widely used to facilitate predicting the complex diseases and therapeutic outcomes. Looking beyond this scope, this precise classification rule advances the upcoming horizon in pursuit of precision medicine, as it is urgently required in the bio-medical field to identify relations between bio-molecular units and clinical phenotype patterns (e.g., candidate biomarker detection, disease subtypes identification and associated biological pathways). The KM-SVM, however, does not involve size of clusters (i.e., the number of samples that belong to a cluster), and so clustering centers may not suitably represent original data structures. This weakness point may potentially results in poor prediction. For future work, I may suggest a new weighting scheme in proportion to size of clusters to improve more in accuracy. I leave this idea to next study.
Competing interests
The author declares that he has no competing interests.
Additional file
10.1186/s40064-016-2677-4 Numerical verification for the weighted support vector machine.
References
- Ramaswamy S, Tamayo P, Mukherjee R, Yeang C, et al. Multiclass cancer diagnosis using tumor gene expression signatures. Proc Natl Acad Sci. 2001;26:15149–54. doi: 10.1073/pnas.211566398. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van de Vijver M, He Y, Dai H, Hart A, et al. A gene-expression signature as a predictor of survival in breast cancer. New Engl J Med. 2002;347:1999–2009. doi: 10.1056/NEJMoa021967. [DOI] [PubMed] [Google Scholar]
- Ma X, Wang Z, Ryan P, Isakoff S, et al. A two-gene expression ratio predicts clinical outcome in breast cancer patients treated with tamoxifen. Cancer Cell. 2004;5:607–616. doi: 10.1016/j.ccr.2004.05.015. [DOI] [PubMed] [Google Scholar]
- van’t Veer L, Dai H, van de Vijver M, He Y. Gene expression profiling predicts clinical outcome of breast cancer. Nature. 2002;415:530–536. doi: 10.1038/415530a. [DOI] [PubMed] [Google Scholar]
- Paik S, Shak S, Tang G, Kim C, et al. A multigene assay to predict recurrence of tamoxifentreated, node-negative breast cancer. N Engl J Med. 2004;351:2817–2826. doi: 10.1056/NEJMoa041588. [DOI] [PubMed] [Google Scholar]
- Zhang Y, Schnabel C, Schroeder B, Jerevall P, et al. Breast cancer index identifies early-stage estrogen receptor-positive breast cancer patients at risk for early- and late-distant recurrence. Clin Cancer Res. 2013;19:4196–4205. doi: 10.1158/1078-0432.CCR-13-0804. [DOI] [PubMed] [Google Scholar]
- Parker J, Mullins M, Cheang M, Leung S, et al. Supervised risk predictor of breast cancer based on intrinsic subtypes. J Clin Oncol. 2009;27:1160–1167. doi: 10.1200/JCO.2008.18.1370. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cortes C, Vapnik V. Support-vector networks. Mach Learn. 1995;20:273–297. [Google Scholar]
- Kikuchia T, Abeb S. Comparison between error correcting output codes and fuzzy support vector machines. Pattern Recognit Lett. 2005;26:1937–1945. doi: 10.1016/j.patrec.2005.03.014. [DOI] [Google Scholar]
- Gould C, Shepherd A, Laurens K, Cairns M, et al. Multivariate neuroanatomical classification of cognitive subtypes in schizophrenia: a support vector machine learning approach. Neuroimage Clin. 2014;18:229–236. doi: 10.1016/j.nicl.2014.09.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kircher M, Witten D, Jain P, O’Roak B, et al. A general framework for estimating the relative pathogenicity of human genetic variants. Nat Genet. 2014;46:310–315. doi: 10.1038/ng.2892. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang J, Wu X (2005) Support vector machines based on K-means clustering for real-time business intelligence systems. Int J Bus Intell Data Min 1, 1
- Lee S, Park C, Jhun M, Koo J. Support vector machine using K-means clustering. J Korean Stat Soc. 2007;36:175–182. [Google Scholar]
- Yang X, Song Q, Wang Y. Support vector machine using K-means clustering. J Korean Stat Soc. 2007;21:961–976. [Google Scholar]
- Schapire R. The strength of weak learnability. Mach Learn. 1990;21:197–227. [Google Scholar]
- Breiman R. Arcing classifier (with discussion and a rejoinder by the author) Ann Stat. 1998;26:801–849. doi: 10.1214/aos/1024691079. [DOI] [Google Scholar]
- Freund Y, Schapire R. A decision-theoretic generalization of on-line learning and an application to boosting. J Comput Syst Sci. 1997;55:119–139. doi: 10.1006/jcss.1997.1504. [DOI] [Google Scholar]
- Mason L, Baxter J, Bartlett P, Frean M. Boosting algorithms as gradient descent. Adv Neural Inf Process Syst. 2000;12:512–518. [Google Scholar]
- Bang S, Jhun M. Weighted support vector machine using k-means clustering. Commun Stat Simul Comput. 2014;12:2307–2324. doi: 10.1080/03610918.2012.762388. [DOI] [Google Scholar]
- Gu Q, Han J (2013) Clustered support vector machines. In: Proceedings of the 16th international conference on artificial intelligence and statistics (AISTATS) 31
- Breiman L, Friedman J, Olshen R, Stone C. Classification and regression trees. Monterey: Wadsworth & Brooks/Cole Advanced Books & Software; 1984. [Google Scholar]
- Altman N, Friedman J, Olshen R, Stone C. An introduction to kernel and nearest-neighbor nonparametric regression. Am Stat. 1992;46:175–185. [Google Scholar]
- Ho N. The random subspace method for constructing decision forests. IEEE Trans Pattern Anal Mach Intell. 1998;20:832–844. doi: 10.1109/34.709601. [DOI] [Google Scholar]
- Wang X, Lin Y, Song C, Sibille E, et al. Detecting disease-associated genes with confounding variable adjustment and the impact on genomic meta-analysis: with application to major depressive disorder. BMC Bioinform. 2012;13:13–52. doi: 10.1186/1471-2105-13-13. [DOI] [PMC free article] [PubMed] [Google Scholar]