

Abstract
We discuss a novel diagnostic method for predicting the early recurrence of liver cancer with high accuracy for personalized medicine. The difficulty with cancer treatment is that even if the types of cancer are the same, the cancers vary depending on the patient. Thus, remarkable attention has been paid to personalized medicine. Unfortunately, although the Tokyo Score, the Modified JIS, and the TNM classification have been proposed as liver scoring systems, none of these scoring systems have met the needs of clinical practice. In this paper, we convert continuous and discrete data to categorical data and keep the natively categorical data as is. Then, we propose a discrete Bayes decision rule that can deal with the categorical data. This may lead to its use with various types of laboratory data. Experimental results show that the proposed method produced a sensitivity of 0.86 and a specificity of 0.49 for the test samples. This suggests that our method may be superior to the well-known Tokyo Score, the Modified JIS, and the TNM classification in terms of sensitivity. Additional comparative study shows that if the numbers of test samples in two classes are the same, this method works well in terms of the F1 measure compared to the existing scoring methods.
1. Introduction
Liver cancer is one of the refractory cancers, and overcoming it is of national concern. Despite complete surgical resection, the problem with refractoriness lies in the high percentage of recurrences of liver cancer [1]. If recurrence can be accurately predicted for each patient, effective treatment can be administered, and recurrence-free patients may not need to be given unnecessary anticancer agents or undergo computed tomography (CT) scans. As a result, health care costs can also be controlled. Therefore, personalized medicine that provides the best cancer treatment to each patient is needed.
The difficulty with cancer treatment is that even if the types of cancer are the same, the cancers vary depending on the patient. Even a wide variety of tests such as blood tests or CT scans reveal only certain aspects of cancer, and there is no test that can perfectly detect cancer. Nevertheless, by using various combinations of laboratory data (also called markers), the Tokyo Score [2], the Modified JIS [3], and the TNM classification [4, 5] have been proposed as representative liver scoring systems. However, none of these scoring systems have met the needs of clinical practice. The reason is that as noted above, each marker has not played a decisive role in the prediction of recurrence, and further, the combination of markers used in these scoring systems has been experimentally obtained from the results of physician trial and error, indicating no assurance of optimal prediction.
The diagnosis of leukemia was made possible using levels of gene expression, and this triggered the diagnosis of cancer by machine learning [6]. As a result, full-scale deployment of microarray techniques has begun in the field of cancer diagnosis. Furthermore, thanks to the latest progress in machine learning such as artificial neural networks [7] and support vector machines (SVM) [8], various cancer diagnostic methods have been developed [9–14]. Other than these techniques involving levels of gene expression, reports have been published on the diagnosis of liver cancer by blood tests that characteristically use methylation volume [15] and on the diagnosis of lung cancer through artificial neural networks that characteristically use clinical data and which are based on SVM [16]. However, all of these methods use quantitative data that consequentially limit the available data.
Generally, with laboratory data, quantitative data (metric data or continuous data), which are represented by numerical numbers, intermingle with qualitative data (nonmetric data or categorical data). Unfortunately, as with the machine learning described above, the conventional Bayes classifier, which is particularly popular in statistical pattern recognition [17], cannot also be applied to qualitative data. To overcome this practical limitation, we propose a discrete Bayes decision rule that deals with qualitative data. For the quantitative data, they are first converted to qualitative data by thresholding, and as a result, all laboratory data become discretized data (qualitative data). Then, a patient is represented as a pattern vector that consists of the discretized laboratory data. Next, the problem of predicting recurrence is defined as a two-class problem that distinguishes between a pattern of recurrence class and a pattern of nonrecurrence class in a patient. For this two-class problem, a classifier is designed according to our own discrete Bayes decision rule that can handle discrete data, and the resulting classifier distinguishes between the presence and absence of recurrence with a high degree of accuracy. Moreover, to handle the high dimensionality of pattern vectors, the optimal combination of markers is selected by feature selection, which is based on the resampling technique using virtual samples.
2. Decision Rule and Feature Selection
2.1. Classifier Design by Discrete Bayes Decision Rule
As previously mentioned, the discrete Bayes classifier is characterized by the fact that it can handle discrete data. Given M markers as candidates, the range of each marker is divided into divisions so that they become mutually exclusive events. Suppose that x 1, x 2,…, x d are selected as d targeted markers from among M markers and then the discretized laboratory data of a patient in marker x j belongs to the division x j(rj), j = 1,2, …, d. Here, x j(rj) denotes the r jth division of marker x j. The subscript j is a discrimination number representing a marker. Then, the patient is described as the pattern vector x = [x 1(r1), x 2(r2),…, x d(rd)]. The class-conditional probability P(x j(rj)∣ω i) of the division x j(rj) for class ω i is defined as
| (1) |
where n j(rj) i represents the number of patients who belong to the division x j(rj) among n i patients from class ω i.
Assuming that, in general, the events in which the discretized laboratory data belong to any of the divisions are mutually independent, the class-conditional probability P(x∣ω i) is described as follows:
| (2) |
The posterior probability P(ω i∣x ) in the two-class problem is provided by Bayes' theorem as follows:
| (3) |
where P(ω i) is the prior probability for class ω i. To equally deal with the recurrence class and nonrecurrence class, we assume that the prior probability P(ω i) is an equal probability of 0.5. Then, the posterior probability is simplified as follows:
| (4) |
By substituting (2) into this formula, the posterior probability can be calculated as follows:
| (5) |
By the discrete Bayes decision rule, a pattern x is classified into a class ω i where the posterior probability P(ω i∣x) is maximum.
Cases of the relationship between the divisions and the number of patients are shown in Table 1. Table 1 shows that the range of marker x 2 is divided into three divisions of x 2(1), x 2(2), and x 2(3), and among these divisions the division x 2(2) includes n 2(2) i patients from class ω i. Here, the total sum of the number of the patients in each division is the following: n 2(1) i + n 2(2) i + n 2(3) i = n i. As previously mentioned, n i is the number of all patients from class ω i.
Table 1.
Divisions and numbers of patients with each marker.
| Division of markers | ω 1 | ω 2 |
|---|---|---|
| x 1(1) | n 1(1) 1 | n 1(1) 2 |
| x 1(2) | n 1(2) 1 | n 1(2) 2 |
|
| ||
| x 2(1) | n 2(1) 1 | n 2(1) 2 |
| x 2(2) | n 2(2) 1 | n 2(2) 2 |
| x 2(3) | n 2(3) 1 | n 2(3) 2 |
|
| ||
| ⋮ | ⋮ | ⋮ |
|
| ||
| x j(rj) | n j(rj) 1 | n j(rj) 2 |
|
| ||
| ⋮ | ⋮ | ⋮ |
|
| ||
| x d(rd) | n d(rd) 1 | n d(rd) 2 |
|
| ||
| ⋮ | ⋮ | ⋮ |
We explain the discrete Bayes decision rule by using concrete cases. Assume that in the case of d = 2 markers x 1 and x 2 are used and the discretized laboratory data of a patient belong to x 1(1) in marker x 1 and x 2(3) in marker x 2. Figure 1 illustrates this with the use of data from Table 2 and shows that the number of recurrence patients belonging to x 1(1) and x 2(3) is 7. Then, the equations are the following:
| (6) |
and the class-conditional probability P(x 1(1), x 2(3)∣ω 1) is as follows:
| (7) |
Similarly, P(x 1(1), x 2(2)∣ω 2) is obtained and from (5) and the posterior probabilities of classes ω 1 and ω 2 are each obtained, and then the patient is classified into the class in which the posterior probability is maximum.
Figure 1.
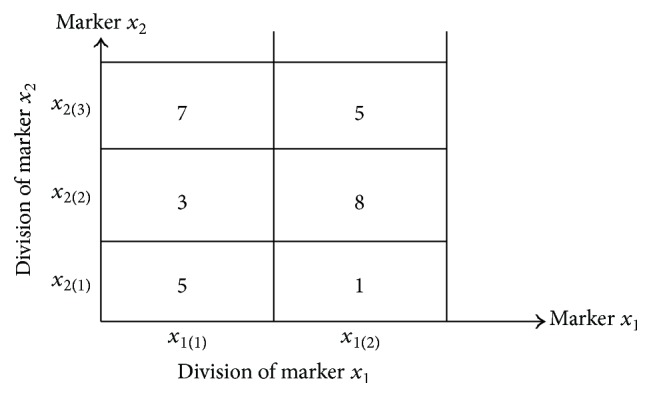
Arrangement of training samples of the recurrence class for markers x 1 and x 2.
Table 2.
Division and number of training samples in each class.
| Division of markers | Number of samples | |
|---|---|---|
| 29 | 89 | |
| Recurrence within 1 year | Nonrecurrence within 1 year | |
| x 1(1) ALB > 3.5 | 15 | 60 |
| x 1(2) ALB ≤ 3.5 | 14 | 29 |
|
| ||
| x 2(1) Tumor number × tumor size < 4 | 6 | 47 |
| x 2(2) Tumor number × tumor size 4~9 | 11 | 29 |
| x 2(3) Tumor number × tumor size > 9 | 12 | 13 |
|
| ||
| x 3(1) vp+ | 10 | 18 |
| x 3(2) vp− | 19 | 71 |
|
| ||
| x 4(1) ICG < 15 | 14 | 44 |
| x 4(2) ICG ≥ 15 | 15 | 45 |
|
| ||
| x 5(1) vv+ | 9 | 16 |
| x 5(2) vv− | 20 | 73 |
|
| ||
| x 6(1) Number of platelets ≥ 10 | 16 | 70 |
| x 6(2) Number of platelets < 10 | 13 | 19 |
|
| ||
| x 7(1) PT ≥ 80 | 18 | 67 |
| x 7(2) PT < 80 | 11 | 22 |
|
| ||
| x 8(1) Bilirubin < 1 | 17 | 61 |
| x 8(2) Bilirubin ≥ 1 | 12 | 28 |
|
| ||
| x 9(1) Degree of differentiation non-por | 25 | 79 |
| x 9(2) Degree of differentiation por | 4 | 10 |
|
| ||
| x 10(1) Liver damage A | 15 | 60 |
| x 10(2) Liver damage B | 14 | 29 |
Now, let us compare the discrete Bayes classifier to the conventional Bayes classifier, both of which classify patterns based on the posterior probability. In the conventional Bayes classifier, a pattern is represented as a multidimensional vector that consists of quantitative data, and the statistical information of the pattern distribution is in the mean vector and covariance matrix. In general, the number of patients is small and the number of dimensions is large. In small sample size situations, the discrete Bayes decision rule is also influenced by the number of samples, as with the conventional Bayes decision rule, and the discrimination ability deteriorates. In the conventional Bayes decision rule, an inverse of a covariance matrix may not exist. At this time, although the conventional Bayes classifier cannot be designed, the discrete Bayes classifier can be designed, irrespective of an inverse matrix. The first advantage of the discrete Bayes decision rule is that it does not need the inverse of a covariance matrix. Second, from the viewpoint of computational cost, in the conventional Bayes classifier, which deals with quantitative data alone, the computational cost increases sharply with an increasing number of dimensions (number of markers). Meanwhile, in any of the discrete Bayes classifiers, which deal with discrete data alone, computation is only scalar computation. Even if a dimension is high, the discrete Bayes classifier can be easily calculated, indicating that the classifier is practical. To simplify the discussion, we have so far dealt with a two-class problem, but this decision rule can easily be extended to multiclass problems.
2.2. Selection of Optimal Markers
Knowing which markers are used for the discrete Bayes classifier is essential in discrimination. This is a problem of feature selection in the statistical pattern recognition fields [17]. Here, we explain a method to solve a feature-selection problem in which a combination of d markers useful for discrimination is selected from among M candidate markers. The small number of training samples in marker selection often causes the overfitting problem [18] that while a classifier with use of selected markers may allow perfect classification of the training samples, it is unlikely to perform well on new patterns. To avoid the overfitting problem, by using virtual samples, which are produced by the resampling technique from available training samples, an optimal combination of markers is obtained. This idea comes from a Bootstrap technique [19]. The flow is shown in Figure 2.
Figure 2.

Selection of optimal markers.
First, training samples are randomly divided into virtual training samples and virtual test samples. Then, the number of markers at the start of searching is determined, and one combination of markers of interest is used. Second, based on the discrete Bayes decision rule with the markers of interest, the class-conditional probability P(x∣ω i) is calculated from the discretized laboratory data of the virtual training samples, and a virtual test sample is classified based on the posterior probability P(ω i∣x) calculated by using the class-conditional probability. In discrimination, we investigate which divisions the discretized laboratory data of a virtual test sample belong to according to the markers of interest. Next, using the class-conditional probability corresponding to the divisions to which the data belong, the posterior probability is obtained from (5), and the virtual test sample is classified into a class in which the posterior probability is maximum. The procedures described above are repeated independently N times. The means of the sensitivity and specificity against the virtual test samples are estimated from N trials. Then, using the same number of markers, the whole of another combination of markers is evaluated. Because we consider that the prediction of recurrence is important, high sensitivity is required. Now, in the number of markers involved, under the constrained conditions of a specificity of 0.5 against the virtual test samples, a combination of markers that maximizes the mean sensitivity is selected as a candidate of the optimized solution for the number of markers involved. Next, the number of markers is increased by one, and this similar procedure is repeated until the number of markers M − 1 is reached. Thus, from among the candidates obtained, an optimal combination of markers is selected and is used for the design of the classifier.
3. Experiment
3.1. Data
Data were obtained from patients whose liver cancers were entirely excised during surgery at Yamaguchi University School of Medicine. Of these patients, 57 experienced a recurrence of liver cancer within one year and 177 experienced no recurrence. Liver cancer is classified as type C liver cancer, type B liver cancer, and others depending on the infecting virus type. The virus types of liver cancer used are shown in Table 3 according to the training samples and the test samples. Additionally, similar to the Tokyo Score, Modified JIS, and TNM classification, the proposed method is also not reliant on virus type.
Table 3.
Classification of samples by virus type.
(a) Breakdown of training samples
| Virus type | Recurrence within 1 year | Nonrecurrence within 1 year |
|---|---|---|
| B | 6 | 16 |
| C | 18 | 56 |
| Samples that are neither B type nor C type | 5 | 17 |
|
| ||
| Total number of samples | 29 | 89 |
(b) Breakdown of test samples
| Virus type | Recurrence within 1 year | Nonrecurrence within 1 year |
|---|---|---|
| B | 6 | 16 |
| C | 17 | 55 |
| Samples that are neither B type nor C type | 5 | 17 |
|
| ||
| Total number of samples | 28 | 88 |
Among candidate markers such as ALB, tumor number × tumor size [20], ICG, vp, vv, platelets, PT, bilirubin, degree of differentiation, and liver damage, an optimal combination of markers was obtained. This optimal combination was used for the discrete Bayes classifier.
We explain the details of Table 2, in which the cutoff value for each marker was determined by a physician in advance, as follows. As an example, for ALB, patients are divided into patients with recurrence and patients without recurrence based on whether the value of the marker exceeds 3.5. Among 29 of the patients with recurrence, 15 have an ALB of greater than 3.5, and 14 have an ALB of not more than 3.5. For any marker, the total number of divided recurrence patients is 29 within the marker.
3.2. Experimental Method
The holdout method [21] splits the available data into two mutually exclusive sets, referred to as the training and test sets. The classifier is designed using the training set, and performance is evaluated on the independent test set. The holdout method preserves the independence of the training samples and test samples, which are used for estimation of discrimination performance. The recurrence samples (n = 57) and nonrecurrence samples (n = 177) are each randomly divided into halves, and one-half is assigned to training samples and the other half to test samples. Consequently, the number of recurrence training samples is 29 and that of nonrecurrence training samples is 89, whereas the number of recurrence test samples is 28 and that of nonrecurrence test samples is 88. The flow of classifier design and evaluation is shown in Figure 3. An optimal combination of markers was determined initially.
Figure 3.
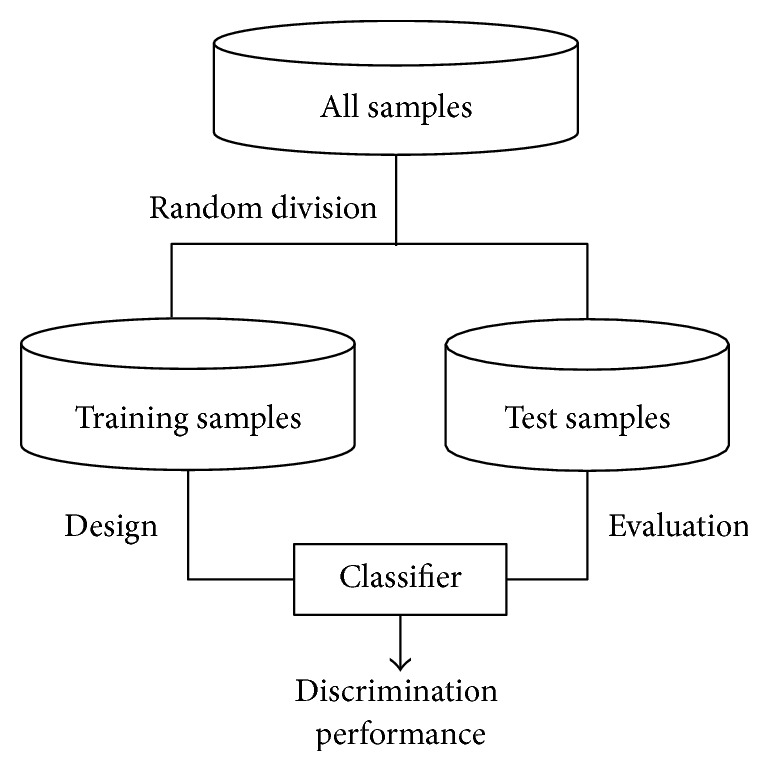
Flow of classifier design and evaluation.
Next, the optimal combination of markers was fixed, and the number of training samples is discussed. Generally, an increase in the number of training samples results in an improvement of the discrimination ability of the classifier. Therefore, a designer is interested in how many training samples are needed for classifier design. Then, as a subset of the increased number of training samples, we assume that a series of 6 training subsets, as shown in Figure 4, holds the following relation:
| (8) |
Here, a subset takes a structure of nested subsets. The first subset S 1 consists of 5 recurrence training samples and 15 nonrecurrence training samples. The next subset S 2 contains 23 training samples by adding one true recurrence training sample and two nonrecurrence training samples. In this manner, a discrete Bayes classifier is designed for each subset with increased true training samples, and the discrimination abilities of 6 discrete Bayes classifiers for the same test samples are obtained. This trial was independently repeated 30 times, and the influence of an increase in training samples on discrimination ability was investigated.
Figure 4.

Relationships between the training sample subsets.
Then, a comparison of the performance of the classifiers with the existing scoring formulae was conducted. For comparison, we adopted accuracy, sensitivity, specificity, the Youden index [22] (= sensitivity + specificity − 1.0), F1 measure, and diagnostic odds ratio [23, 24] for the test samples as evaluation values of the discrimination performance of a classifier. The higher the values are, the higher the discrimination performance of a classifier is. Here, sensitivity means the rate of correctly classifying patients as patients with recurrence among all patients with recurrence, and specificity means the rate of correctly classifying patients as patients without recurrence among all patients without recurrence. To predict early recurrence, our primary interest is in the sensitivity, under the constrained condition of a specificity of 0.5. ROC analysis [18] was also performed.
Here, we explain the score formulae as targets for comparison. For the Tokyo Score [2], the Modified JIS [3], and the TNM classification [4, 5], a score value is assigned to each marker used according to cutoff value determined by a physician. Then, a total score is assigned as a summation of all individual score values. Patients are diagnosed by the cutoff value against this summary score. For example, in the Tokyo Score, 4 markers, albumin, bilirubin, tumor size, and the number of tumors, are used. If a patient has an albumin value of 3.0 g/dL, bilirubin value of 1.5 g/dL, tumor size of 1.0 cm, and the number of tumors of 4, the score values of each marker are 1 point, 1 point, 0 points, and 2 points, respectively, resulting in a total score of 4 points. If the cutoff value is 2, then the patient is diagnosed as having possible recurrence.
Finally, as described previously, the discrete Bayes classifier uses scalar function alone for discrimination, and, thus, it has a computational advantage. To clarify this advantage, we prepared 1,160,000 artificial test samples that were obtained from 116 actual test samples copied 10000 times. Then, using combinations of the markers shown in Table 4, the discrimination time of the artificial test samples was measured by changing the number of markers one by one from 3 to 6. The discrimination time was defined as the time from the start to the end of the discrimination process, and the time was measured using the clock function.
Table 4.
Optimal combinations of markers per number of markers and their discrimination performances obtained using training samples.
| Number of markers | Sensitivity | Specificity | Youden index | Combination of markers | |||||
|---|---|---|---|---|---|---|---|---|---|
| 3 | 0.79 | 0.50 | 0.29 | Tumor number × tumor size | vp | Liver damage | |||
|
| |||||||||
| 4 | 0.80 | 0.50 | 0.30 | Tumor number × tumor size | vp | ICG | Liver damage | ||
|
| |||||||||
| 5 | 0.75 | 0.50 | 0.25 | ALB | Tumor number × tumor size | vv | Degree of differentiation | Liver damage | |
|
| |||||||||
| 6 | 0.74 | 0.51 | 0.24 | ALB | Tumor number × tumor size | vp | ICG | Degree of differentiation | Liver damage |
|
| |||||||||
| 7 | — | — | — | ||||||
| 8 | — | — | — | ||||||
| 9 | — | — | — | ||||||
3.3. Results
3.3.1. Optimal Combinations of Markers
Table 4 shows the candidate combinations of the markers that were obtained from 100 times of resampling per number of markers and their discrimination performances. A dash symbol in the table indicates that no combinations meeting the constrained conditions of sensitivity and specificity existed. Based on sensitivity under the constrained condition of a specificity of 0.5, a combination of the four markers of tumor number × tumor size, vp, ICG, and liver damage was considered to be optimal, among the four candidates.
3.3.2. Influence of the Number of Training Samples on Discrimination Performance
The relationship between the number of training samples and sensitivity is shown in Figure 5. The horizontal lines indicate the 95% confidence intervals of the sensitivity values.
Figure 5.
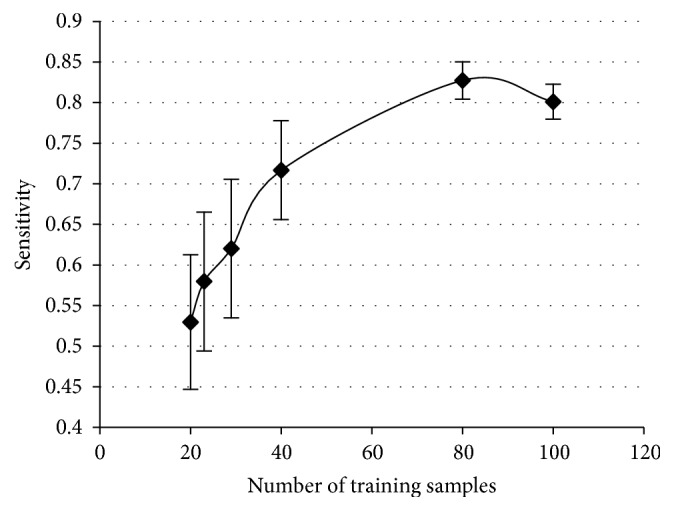
Relationship between the number of training samples and sensitivity.
3.3.3. Performance Comparison between the Classifier and Existing Liver Scoring Systems
Discrimination performances were compared between the discrete Bayes classifier and existing liver scoring systems. The classifier was evaluated by well-known indices such as F1 and the diagnostic odds ratio [23, 24], and the results are shown in Table 5. Furthermore, the results of the ROC analysis are shown in Figure 6. The discrete Bayes classifier does not use a cutoff value but instead constructs ROC curves to determine sensitivity and specificity by changing the markers one by one from 3 to 6. Additionally, between the marker numbers of 3 and 4, the sensitivity and specificity were the same at 0.86 and 0.49, respectively.
Table 5.
Results from the proposed method and existing liver scoring systems.
(a) Results using 28 recurrence test samples and 88 nonrecurrence test samples
| Index | Proposed method | Modified JIS with 3 | TNM classification with 2 | Tokyo score with 2 |
|---|---|---|---|---|
| Accuracy | 0.58 | 0.77 | 0.34 | 0.49 |
| Sensitivity, recall | 0.86 | 0.57 | 0.96 | 0.71 |
| Specificity | 0.49 | 0.83 | 0.14 | 0.42 |
| F1 measure | 0.49 | 0.54 | 0.41 | 0.40 |
| Youden index | 0.35 | 0.40 | 0.10 | 0.13 |
| Diagnostic odds ratio | 5.73 | 6.49 | 4.26 | 1.81 |
(b) Results using 28 test samples/class obtained by resampling
| Index | Proposed method | Modified JIS with 3 | TNM classification with 2 | Tokyo score with 2 |
|---|---|---|---|---|
| Accuracy | 0.67 [0.66, 0.69] | 0.70 [0.69, 0.71] | 0.55 [0.54, 0.56] | 0.57 [0.55, 0.58] |
| Sensitivity, recall | 0.86 | 0.57 | 0.96 | 0.71 |
| Specificity | 0.49 [0.46, 0.52] | 0.83 [0.81, 0.85] | 0.14 [0.12, 0.16] | 0.42 [0.39, 0.44] |
| F1 measure | 0.73 [0.72, 0.73] | 0.66 [0.65, 0.67] | 0.68 [0.68, 0.69] | 0.62 [0.62, 0.63] |
| Youden index | 0.35 [0.32, 0.37] | 0.40 [0.38, 0.42] | 0.10 [0.08, 0.12] | 0.13 [0.11, 0.16] |
| Diagnostic odds ratio | 6.03 [5.39, 6.67] | 7.88 [6.22, 9.53] | 4.62 [3.86, 5.38] | 1.95 [1.74, 2.15] |
Figure 6.
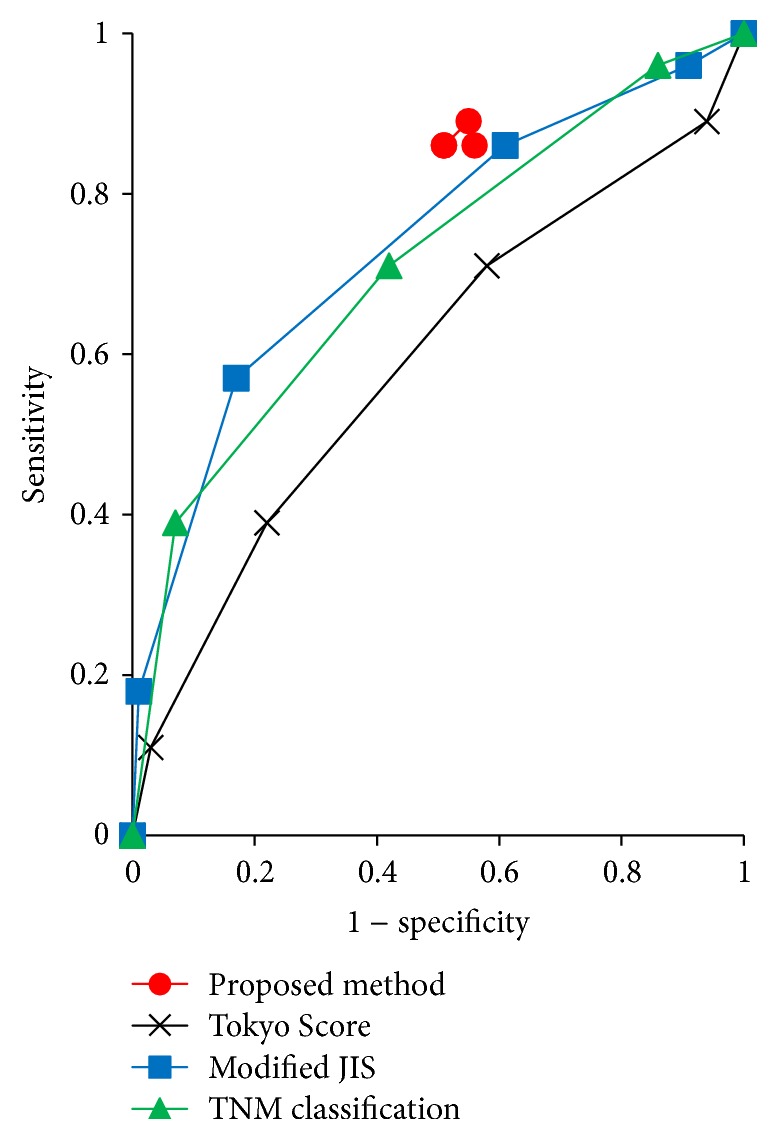
ROC curve.
3.3.4. Computational Complexity
The relationship between the number of markers and CPU time as the number of markers is changed one by one from 3 to 6 is shown in Figure 7, suggesting that linear computational complexity was observed.
Figure 7.
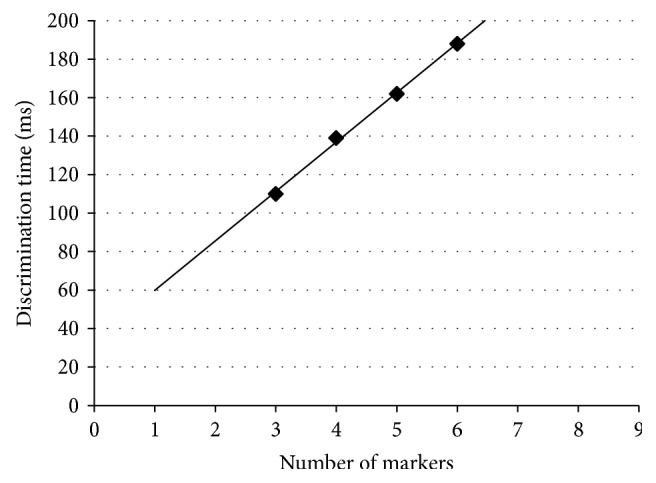
Relation between the number of markers and discrimination time.
3.4. Discussion
Based on the results of this experiment, it was revealed that a combination of 4 markers (tumor number × tumor size, vp, ICG, and liver damage) selected from among the 10 candidates was optimal. Next, when the influence of the training sample size on discrimination performance was investigated, as shown in Figure 5, the number of training samples almost converged to 100 from the viewpoint of the sensitivity. The discrimination performance was compared with that of three existing representative liver scoring systems. Discrimination performance of the discrete Bayes decision rule using the optimal combination of markers against test samples showed a sensitivity of 0.86 and a specificity of 0.49, as shown in Table 5(a). The discrete Bayes classifier achieved high sensitivity, which is an important indicator of the prediction of early recurrence, and the decrease in specificity was smaller than that of the existing scoring systems. Because we tried not to miss cancer recurrence, we adopted an evaluation standard in which sensitivity is maximum by maintaining the specificity at a certain level.
Meanwhile, in terms of accuracy and the F1 measure, we assumed that the numbers of recurrence test samples and nonrecurrence test samples were the same. Then, using 28 recurrence test samples and 28 nonrecurrence test samples that were derived by the resampling method, we independently reevaluated them 100 times. The results are shown in Table 5(b). From Table 5(b), we see that if the numbers of test samples in two classes are the same, this method is superior to the existing scoring methods in terms of the F1 measure. Next, as shown in Figure 6, an ROC curve was constructed using the data shown in Table 5(a), which shows that the curve for the proposed method is located above the curves of the existing scoring methods, suggesting that the proposed method is better than the existing scoring methods. In addition, when the number of markers was greatly changed, the specificity and sensitivity did not change significantly. Finally, we performed calculation experiments showing that as the number of markers is increased, the discrimination time also increases in linear order, which indicates that this method has an advantage in computational cost for big data such as methylation or genes that have several hundreds of thousands and several tens of thousands of candidate markers, respectively.
In addition, we point out an advantage of the discrete Bayes classifier over the existing scoring systems. Because the existing scoring systems require the use of specific markers, they cannot be used when the data of the markers are insufficient. However, the proposed technique can be used by selecting an optimal combination of markers from the laboratory data that a patient already has. Moreover, the physician is presented with the markers that should be added to improve discrimination performance for each patient. In this way, on the basis of the technique proposed here, the best personalized medicine can be expected.
4. Conclusion
In this paper, a discrete Bayes decision rule that predicts early recurrence of highly refractory liver cancer with a high degree of accuracy was proposed. This discrete Bayes decision rule can deal not only with qualitative data but also with quantitative data by discretization. Discrimination experiments enabled us to predict early recurrence of liver cancer with higher sensitivity than that of the Tokyo Score, the Modified JIS, and the TNM classification, which are existing representative scoring systems. Realization of personalized medicine via this discrete Bayes decision rule may be expected.
One of the main limitations of this paper was the use of a small amount of sample data from a single institution. This limited the evaluation of the performance. Further study is needed to evaluate the proposed method using data collected from other institutions. In addition, this method uses the hypothesis of independence without discussion to simplify the calculations. Although verification of independence is difficult, a study on independence such as the adoption of Bayesian networks will be a future challenge. Also, because the discrimination ability of this method depends on the cutoff value used when marker values are discretized, optimization will also be an interesting challenge.
Acknowledgments
This work was supported by JSPS KAKENHI Grant no. JP15K00238.
Competing Interests
The authors declare that there are no competing interests regarding the publication of this paper.
References
- 1.Iizuka N., Hamamoto Y., Tsunedomi R., Oka M. Translational microarray systems for outcome prediction of hepatocellular carcinoma. Cancer Science. 2008;99(4):659–665. doi: 10.1111/j.1349-7006.2008.00751.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Tateishi R., Yoshida H., Shiina S., et al. Proposal of a new prognostic model for hepatocellular carcinoma: an analysis of 403 patients. Gut. 2005;54(3):419–425. doi: 10.1136/gut.2003.035055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Ikai I., Takayasu K., Omata M., et al. A modified Japan integrated stage score for prognostic assessment in patients with hepatocellular carcinoma. Journal of Gastroenterology. 2006;41(9):884–892. doi: 10.1007/s00535-006-1878-y. [DOI] [PubMed] [Google Scholar]
- 4.Minagawa M., Ikai I., Matsuyama Y., Yamaoka Y., Makuuchi M. Staging of hepatocellular carcinoma: assessment of the Japanese TNM and AJCC/UICC TNM systems in a cohort of 13,772 patients in Japan. Annals of Surgery. 2007;245(6):909–922. doi: 10.1097/01.sla.0000254368.65878.da. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Henderson J. M., Sherman M., Tavill A., Abecassis M., Chejfec G., Gramlich T. AHPBA/AJCC consensus conference on staging of hepatocellular carcinoma: consensus statement. HPB. 2003;5(4):243–250. doi: 10.1080/13651820310015833. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Golub T. R., Slonim D. K., Tamayo P., et al. Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science. 1999;286(5439):531–527. doi: 10.1126/science.286.5439.531. [DOI] [PubMed] [Google Scholar]
- 7.Khan J., Wei J. S., Ringnér M., et al. Classification and diagnostic prediction of cancers using gene expression profiling and artificial neural networks. Nature Medicine. 2001;7(6):673–679. doi: 10.1038/89044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Furey T. S., Cristianini N., Duffy N., Bednarski D. W., Schummer M., Haussler D. Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics. 2000;16(10):906–914. doi: 10.1093/bioinformatics/16.10.906. [DOI] [PubMed] [Google Scholar]
- 9.Iizuka N., Oka M., Hamamoto Y., et al. Oligonucleotide microarray for prediction of early intrahepatic recurrence of hepatocellular carcinoma after curative resection. The Lancet. 2003;361(9361):923–929. doi: 10.1016/s0140-6736(03)12775-4. [DOI] [PubMed] [Google Scholar]
- 10.Tibshirani R., Hastie T., Narasimhan B., Chu G. Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proceedings of the National Academy of Sciences of the United States of America. 2002;99(10):6567–6572. doi: 10.1073/pnas.082099299. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lee K. E., Sha N., Dougherty E. R., Vannucci M., Mallick B. K. Gene selection: a Bayesian variable selection approach. Bioinformatics. 2003;19(1):90–97. doi: 10.1093/bioinformatics/19.1.90. [DOI] [PubMed] [Google Scholar]
- 12.Xiong M., Li W., Zhao J., Jin L., Boerwinkle E. Feature (gene) selection in gene expression-based tumor classification. Molecular Genetics and Metabolism. 2001;73(3):239–247. doi: 10.1006/mgme.2001.3193. [DOI] [PubMed] [Google Scholar]
- 13.Guyon I., Weston J., Barnhill S., Vapnik V. Gene selection for cancer classification using support vector machines. Machine Learning. 2002;46(1–3):389–422. doi: 10.1023/a:1012487302797. [DOI] [Google Scholar]
- 14.Kourou K., Exarchos T. P., Exarchos K. P., Karamouzis M. V., Fotiadis D. I. Machine learning applications in cancer prognosis and prediction. Computational and Structural Biotechnology Journal. 2015;13:8–17. doi: 10.1016/j.csbj.2014.11.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Iizuka N., Oka M., Sakaida I., et al. Efficient detection of hepatocellular carcinoma by a hybrid blood test of epigenetic and classical protein markers. Clinica Chimica Acta. 2011;412(1-2):152–158. doi: 10.1016/j.cca.2010.09.028. [DOI] [PubMed] [Google Scholar]
- 16.Parthiban L., Subramanian R. CANFIS—a computer aided diagnostic tool for cancer detection. Journal of Biomedical Science and Engineering. 2009;2(5):323–335. doi: 10.4236/jbise.2009.25048. [DOI] [Google Scholar]
- 17.Jain A. K., Duin R. P. W., Mao J. Statistical pattern recognition: a review. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2000;22(1):4–37. doi: 10.1109/34.824819. [DOI] [Google Scholar]
- 18.Duda R. O., Hart P. E., Stork D. G. Pattern Classification. 2nd. John Wiley & Sons; 2001. [Google Scholar]
- 19.Jain A. K., Dubes R. C., Chen C. Bootstrap techniques for error estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1987;9(5):628–633. doi: 10.1109/tpami.1987.4767957. [DOI] [PubMed] [Google Scholar]
- 20.Tokumitsu Y., Tamesa T., Matsukuma S., et al. An accurate prognostic staging system for hepatocellular carcinoma patients after curative hepatectomy. International Journal of Oncology. 2015;46(3):944–952. doi: 10.3892/ijo.2014.2798. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Webb A. R. Statistical Pattern Recognition. 2nd. John Wiley & Sons; 2002. [DOI] [Google Scholar]
- 22.Youden W. J. Index for rating diagnostic tests. Cancer. 1950;3(1):32–35. doi: 10.1002/1097-0142(1950)3:160;32::aid-cncr282003010662;3.0.co;2-3. [DOI] [PubMed] [Google Scholar]
- 23.van Rijsbergen C. J. Foundation of evaluation. Journal of Documentation. 1974;30(4):365–373. doi: 10.1108/eb026584. [DOI] [Google Scholar]
- 24.Powers D. M. W. Evaluation: from precision, recall and F-measure to ROC, informedness, markedness & correlation. Journal of Machine Learning Technologies. 2011;2(1):37–63. [Google Scholar]