

Abstract
Comprehensive, quantitative information on abundances of proteins and their posttranslational modifications (PTMs) can potentially provide novel biological insights into diseases pathogenesis and therapeutic intervention. Herein, we introduce a quantitative strategy utilizing isobaric stable isotope-labeling techniques combined with two-dimensional liquid chromatography–tandem mass spectrometry (2D-LC–MS/MS) for large-scale, deep quantitative proteome profiling of biological samples or clinical specimens such as tumor tissues. The workflow includes isobaric labeling of tryptic peptides for multiplexed and accurate quantitative analysis, basic reversed-phase LC fractionation and concatenation for reduced sample complexity, and nano-LC coupled to high resolution and high mass accuracy MS analysis for high confidence identification and quantification of proteins. This proteomic analysis strategy has been successfully applied for in-depth quantitative proteomic analysis of tumor samples and can also be used for integrated proteome and PTM characterization, as well as comprehensive quantitative proteomic analysis across samples from large clinical cohorts.
Keywords: Quantitative proteomics, Isobaric labeling, iTRAQ, Two-dimensional liquid chromatography, Mass spectrometry
1 Introduction
Large-scale and deep characterization of the proteome and protein posttranslational modifications (PTMs) from clinical specimens holds great promise for better understanding of diseases pathogenesis and providing novel insights into therapeutic interventions [1, 2]. With modern mass spectrometry (MS) instrumentation, it is now feasible to routinely identify thousands of proteins from a biological sample [3]. The ability to utilize such proteomic datasets for improving the diagnosis, treatment, and prevention of diseases such as cancer, however, typically requires that in-depth proteomic analysis be carried out quantitatively across large clinical cohorts [4]. Therefore, a robust, efficient and high-throughput quantitative proteomics strategy is needed to address the challenges in typical clinical applications, such as high sample throughput, consistent quantitation for the entire sample cohort, extensive proteome coverage, and potential extension to characterization of PTMs.
In this chapter, we introduce a quantitative proteomics pipeline using multiplexed, isobaric labeling, and two dimensional reversed phase liquid chromatography coupled to tandem mass spectrometry (2D-LC–MS/MS), which is amenable to large-scale clinical proteomic applications. The workflow includes isobaric labeling of tryptically digested peptides using 4-plexed isobaric tags for relative and absolute quantitation (iTRAQ) [5], basic reverse-phase liquid chromatography (bRPLC) separation with fraction concatenation [6], and nanoelectrospray ionization LC– MS/MS analysis of the fractions. Peptides and proteins are identified through protein sequence database search, and quantified using the iTRAQ reporter ion intensities.
Compared to conventional label-free proteomic approaches, the 4-plex iTRAQ labeling method provides not only higher sample throughput, but also robust protein quantitation across large sample cohort when a “universal reference” strategy [7] is used, i.e., a common reference sample (typically a sample pooled from all samples involved in the comparison) is included in each 4-plex iTRAQ analysis to serve as a “bridge” for cohort-wide comparison. The bRPLC separation with fraction concatenation provides further enhanced proteome coverage and more streamlined sample processing (e.g., no need for sample clean up) compared to conventional strong cation exchange chromatography based fractionation [6]. This workflow is also amenable to integrated proteome and PTM (e.g., phosphorylation) characterization [8, 9], and use with other labeling and multiplexing approaches. For the scope of this chapter, we only describe details of the in-depth quantitative global proteome analysis of tissue sample as a demonstration of this quantitative proteome profiling strategy.
2 Materials
The materials required for this experimental workflow are listed by activity. Prepare all reagents in appropriate containers, preserving sterility when necessary. Ensure that all solvents are LC–MS grade, all chemicals are of high purity, and ultrapure water (prepared by purifying deionized water to attain a sensitivity of 18 MΩ cm at 25 °C) is used for preparation of solutions.
2.1 Materials and Equipment Needed During Each Step
BCA Protein Assay Kit (Thermo Fisher Scientific, Waltham, MA).
Infinite M200 plate reader (Tecan, Morrisville, NC).
Vortex Gene 2 (Scientific Industries, Bohemia, NY).
5417R Refrigerated Microcentrifuge (Eppendorf, Westbury, NY).
Speed-Vac SC250 Express (Thermo Fisher Scientific, Waltham, MA).
Thermomixer R thermal mixer (Eppendorf, Westbury, NY).
2.2 Equipment Used for Partial Automation of Sample Processing (See Note 1)
epMotion 5075 Liquid Handler (Eppendorf, Westbury, NY).
GX-274 Aspec Automated SPE System with 406 Dual Syringe Pumps (Gilson, Middleton, WI).
2.3 Tissue Preparation, Protein Extraction, and Digestion
Kontes™ Pellet Pestle™ Cordless Motor and disposable pestles (Kimble Chase, Rochester, NY).
Sample Lysis/Denaturing buffer: 8 M urea, 50 mM NH4HCO3, pH ~8.0, cOmplete Protease Inhibitor Cocktail, EDTA-free (Roche, Indianapolis, IN).
Sequencing Grade Modified Porcine Trypsin (Promega, Madison, WI).
Branson Sonicator 1510 (Branson, Danbury, CT).
2.4 C18 SPE Clean-Up
1 mL/100 mg SPE Discovery-C18 columns (SUPELCO, Bellefonte, PA).
Vacuum manifold with vacuum for SPE tubes (VisiPrep SUPELCO, Bellefonte, PA).
Washing buffer: 5 % acetonitrile (ACN) with 0.1 % trifluoroacetic acid (TFA).
Conditioning buffer: 0.1 % TFA.
Elution buffer: 80 % CAN.
2.5 iTRAQ Labeling
iTRAQ Reagent Multiplex Kit (Contains iTRAQ® reagents 114, 115, 116, 117, the appropriate buffers, and reagents for five 4-plex assays. Each individual reagent capable of labeling up to 100 μg of protein.) (AB SCIEX, Framingham, MA).
Dissolution Buffer: 500 mM triethylammonium Bicarbonate (TEAB); for dehydrating peptides samples.
2.6 bRPLC Fractionation and Concatenation
Agilent 1200 HPLC System equipped with a quaternary pump, degasser, diode array detector, peltier-cooled autosampler, and fraction collector (set at 4 °C) (Agilent, Santa Clara, CA).
XBridge C18 HPLC column, 250 mm × 4.6 mm column containing 5-μm particles, and a 4.6 mm × 20 mm guard column (Waters, Milford, MA).
Solvent A: 10 mM TEAB, pH 7.5.
Solvent B: 90 % ACN with 10 mM TEAB, pH 7.5.
31-mm deep 96-well plates for collecting fractions.
Rehydrating solution: 50 % methanol (MeOH) with 0.05 % TFA.
2.7 LC–MS/MS Analysis
nanoACQUITY UPLC system (Waters Corporation, Milford, MA).
LTQ Orbitrap Velos mass spectrometer (Thermo Fisher Scientific, Waltham, MA).
3-μm Jupiter C18 bonded particles (Phenomenex, Torrence, CA).
35 cm × 360 μm o.d. × 75 μm i.d. fused silica (Polymicro Technologies, Phoenix, AZ).
Mobile phase A: water with 0.1 % formic acid.
Mobile phase B: ACN with 0.1 % formic acid.
3 Methods
An overview of the quantitative proteomics strategy is illustrated in Fig. 1. Briefly, proteins from the tissue samples are first extracted, tryptically digested, and cleaned up. The resulted peptide samples are then labeled by the four different iTRAQ reagents separately, after which they are combined into one sample and separated using bRPLC with further fraction concatenation. The resulting fractionations (e.g., 24 fractions) are analyzed by capillary LC–MS/MS using the high resolution and high mass accuracy hybrid LTQ Orbitrap Velos mass spectrometer. Peptides and proteins are identified through protein sequence database search, and quantified using the iTRAQ reporter ion intensities. Typical performance of this quantitative proteomics strategy is simultaneous quantification of approximately 7000 proteins using the Orbitrap Velos instrument, or more than 10,000 proteins using the Q Exactive mass spectrometer [8].
Fig. 1.
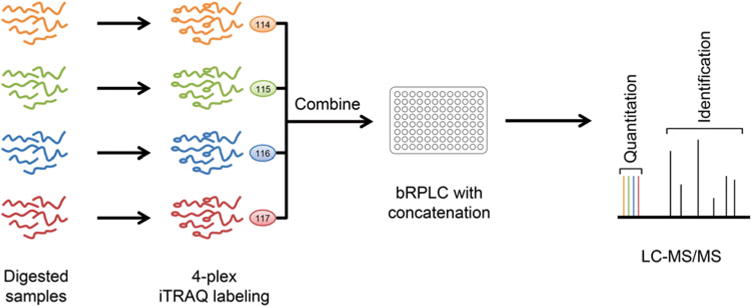
Overview of the quantitative proteomics workflow. The samples were first converted into tryptic peptides and then each labeled by different iTRAQ reagents, combined, and fractionated (with concatenation) for quantitative proteome analysis using tandem mass spectrometry on the high resolution and high accuracy Orbitrap mass analyzer
3.1 Preparation of Tissue Sample for Protein Digestion
Place frozen tissue sample in 1.5-mL microcentrifuge tubes (see Note 2); spatula or tweezers may need to be used for tissue sample transfer (see Note 3).
Add appropriate amount of lysis buffer to the collection tube containing tissue sample (see Note 4).
Homogenize tissue sample in lysis solution by using Kontes™ Pellet Pestle™ Cordless Motor with disposable pestles (see Note 5). Keep microcentrifuge tube containing sample in lysis buffer on the ice or chill rack while performing homogenization.
In general, 15–30 s of the processing time is enough to satisfactorily homogenize ~150 mg of soft tissue sample (e.g., brain or liver) (see Note 6).
Keep collection tube containing homogenized tissue sample on ice or chill rack at all time (see Note 7).
3.2 Protein Extraction and Tryptic Digestion
Shake sample at 1200 rpm for 3 min at room temperature in Thermomixer and sonicate sample in sonication bath with ice for 3 min to homogenize sample further.
Centrifuge sample at 16,000 × g for 10 min to clarify digest from residual tissue matter. Transfer supernatant into new microcentrifuge tube (or into 96-well plate) for the digestion.
Set aside small sample aliquots and run BCA protein assay to determine initial protein concentration of the sample before digestion (see Note 8).
In a mean time, to reduce proteins, add appropriate amount of 500 mM dithiothreitol (DTT) to reach 5 mM in sample and incubate sample at 37 °C for 1 h with 1200 rpm constant shaking in Thermomixer (see Notes 8 and 9).
To alkylate reduced proteins, add sufficient 500 mM iodoacetamide to reach 10 mM final concentration and incubate sample at room temperature in the dark with 1200 rpm constant shaking in Thermomixer for 1 h (see Note 8).
After sample is reduced and alkylated, dilute it eightfold with 50 mM NH4HCO3, pH ~8.0 containing 1 mM CaCl2 (see Notes 8 and 10).
Add sequencing grade-modified trypsin to diluted sample at 1:50 (w/w) trypsin-to-protein ratio, vortex sample to mix, and incubate to digest for 3 h at 37 °C with 700 rpm constant shaking in Thermomixer (see Note 8).
After the 3-h incubation, stop the digestion by acidifying sample to 0.1 % TFA (~pH 3.0) with 10 % TFA. Centrifuge sample at 16,000 × g for 20 min to clarify the digest. Transfer supernatant into a fresh vial without disturbing a debris pellet (see Note 7).
Proceed to manual (using vacuum manifold) or automated (using GILSON GX-274 Aspec Automated SPE System) SPE C18 to obtain purified peptides for iTRAQ isobaric tag labeling.
First, rinse and condition 1-mL SPE C18 column by slowly passing 3 mL of HPLC-grade methanol through the column follow by 2 mL of conditioning buffer.
Load digested sample onto preconditioned SPE C18 column and slowly pass it through.
Wash SPE C18 column with 4 mL of washing buffer.
Finally, elute purified peptides from SPE C18 column with 1 mL of elution buffer into clean low-retention tube.
Concentrate sample down to approximately 100 μL in Speed-Vac and perform BCA protein assay (see Notes 7 and 8).
3.3 iTRAQ Labeling
Postdigestion iTRAQ labeling is performed according to manufacturer’s instructions (AB Sciex, Framingham, MA) [8].
To prepare samples for iTRAQ labeling, equal amount of four different desalted peptide samples was lyophilized in Speed-Vac.
Reconstitute the lyophilized samples in Dissolution Buffer (100 μg of peptides in 30.0 μL of Dissolution Buffer) by vigorously vortexing the samples (see Note 11).
Mix an appropriate amount of room temperature iTRAQ reagent (1 unit dissolved in 70 μL of ethanol) with the peptide sample (add 1 unit of iTRAQ reagent to 100 μg of peptide sample) according to the experiment labeling scheme (e.g., sample 1 to be labeled by reagent 114, sample 2 to be labeled by reagent 117; labeling scheme does not change the final quantitation results). For quantitative analysis of a large sample cohort using the “universal reference” strategy, the pooled reference sample is included in each iTRAQ experiment and labeled using the same iTRAQ reagent (e.g., 117) (see Note 12).
After 1 h incubation at room temperature, the labeling reaction is stopped by adding water (3× the volume) and 30 min incubation at room temperature.
Combine the content of each of the four iTRAQ-labeled samples (i.e., 114, 115, 116, and 117) into a fresh microcentrifuge tube and concentrate it in Speed-Vac to remove ethanol and reduce sample volume (see Note 7).
Perform SPE C18 to clean up the concentrated labeled peptide sample follow the same procedure and using the same type of the SPE C18 columns as described in Subheading 3.2 above (see Note 7).
3.4 Peptide Fractionation by bRPLC
iTRAQ-labeled sample is separated on a Waters reversed-phase XBridge C18 column (250 mm × 4.6 mm column containing 5-μm particles, and a 4.6 mm × 20 mm guard column) using Agilent 1200 HPLC System.
Reconstitute the sample in 900 μL of Solvent A and inject onto the column at a flow rate of 0.5 mL/min.
After sample loading, the C18 column is washed for 35 min with solvent A, before applying a 90-min LC gradient with solvent B. The LC gradient starts with a linear increase of solvent B to 10 % in 10 min, then a linear increase to 20 % B in 15 min, and 30 min to 30 % B, 15 min to 35 % B, 10 min to 45 % B, and another 10 min to 100 % solvent B. The flow rate is 0.5 mL/min.
A total of 96 fractions are collected into a 96-well plate throughout the LC gradient in equal time intervals (see Note 7).
These 96 fractions are concatenated into 24 fractions by combining 4 fractions that are 24 fractions apart (i.e., combining fractions #1, #25, #49, and #73; #2, #26, #50, and #74; and so on) (see Note 8 and 13).
Concentrate the resulting 24 fractions in Speed-Vac and perform BCA protein assay for each fraction to determine peptide concentration. Each fraction is analyzed using LC–MS/MS (see Notes 7 and 8).
3.5 LC–MS/MS Analysis of iTRAQ-Labeled Fractions
Peptide samples are analyzed using a Waters nanoACQUITY UPLC system coupled online to a LTQ Orbitrap Velos mass spectrometer outfitted with a custom electrospray ionization interface.
The capillary column is prepared in-house by slurry packing 3-μm Jupiter C18 bonded particles into 35-cm × 360 μm o.d. × 75 μm i.d. fused silica using a 1-cm sol-gel frit for media retention.
Electrospray emitters are custom built using 150 μm o.d. × 20 μm i.d. chemically etched fused silica.
Mobile phase flow rate is 300 nL/min and consisted of 0.1 % formic acid in water (A) and 0.1 % formic acid in ACN (B) with a gradient profile as follows (min:%B): 0:5, 2:7, 120:25, 125:68, 129:80, 130:5.
The LTQ Orbitrap Velos mass spectrometer is operated under the following conditions: the ion transfer tube temperature and spray voltage are 300 °C and 1.8 kV, respectively; Orbitrap spectra (automatic gain control (AGC): 3 × 106) are collected from 300 to 1800 m/z at a resolution of 30,000 followed by data-dependent higher energy collisional dissociation (HCD) MS/MS (centroid mode, at a resolution of 7500, collision energy 45 %, activation time 0.1 ms, AGC 5 × 104) of the 10 most abundant ions using an isolation width of 2.5 Da; charge state screening is enabled to reject unassigned and singly charged ions; A dynamic exclusion time of 30 s is used to discriminate against previously selected ions (within −0.55 to 2.55 Da).
3.6 Data Analysis
Peptides and proteins are first identified using MS-GF+ [10] which considers static mods of carbamidomethylation (+57.0215 Da) on Cys residues, 4-plex iTRAQ modification (+144.1021 Da) on the peptide N-terminus and Lys residues, and dynamic oxidation (+15.9949 Da) on Met residues when searching against a human protein sequence database (e.g., UniProt; trypsin and keratin contaminant sequences are often included as well). Other settings for MS-GF+ database search include ±10 ppm tolerance for parent ion mass error and, 0.5 m/z tolerance for fragment ion mass error, partially tryptic search, and target decoy database searching strategy [11, 12] for estimation of false discovery rate (FDR).
Spectral identification files from step 1 above are converted to IDPicker3 index files (idpXML) and then used for protein assembly using IDPicker3 [13]. Peptide identification stringency is set at a maximum of 1 % peptide-to-spectrum matches (PSMs) FDR and a minimum of two unique peptides to identify a given protein within the full data set.
The intensities of all four iTRAQ reporter ions are extracted using MASIC software [14]. The PSMs which pass the confidence threshold as described above are linked to the extracted reporter ion intensities by scan number. The reporter ion intensities from different PSMs resulting in the same peptide identification (i.e., different scans in the same and different bRPLC fractions) are summed to represent arbitrary abundance measurement for that peptide; the reporter ion intensities are further summed across all the peptides derived from the same protein to represent arbitrary protein abundance measurement.
The relative protein abundances are then log2 transformed and accessed for the errors during tryptic peptide concentration measurement and pipetting steps (prior to combining the four samples labeled by different iTRAQ reagents), and sample-to- sample normalization coefficients (shifts in log2 scale) are calculated. For a given sample, the log2 normalization coefficient is derived as average log2 for a subset of proteins that are quantified across all samples.
Changes in protein abundance across the four different samples can be accessed by comparing the normalized and log2 transformed reporter ion intensity values.
The same data analysis workflow can also be applied for comprehensive quantitative proteomic analysis across a large sample cohort (see Note 14).
Acknowledgments
Portions of this work were supported by the grant U24CA160019, from the National Cancer Institute Clinical Proteomic Tumor Analysis Consortium (CPTAC) and National Institutes of Health grant P41GM103493. The experimental work described herein was performed in the Environmental Molecular Sciences Laboratory, a national scientific user facility sponsored by the DOE and located at Pacific Northwest National Laboratory, which is operated by Battelle Memorial Institute for the DOE under Contract DE-AC05-76RL0 1830.
Footnotes
Incorporating the automated solutions in proteomics high throughput sample preparation needs to be tailored to the specific workflow and has to be determined by the number of samples, the size and type of these samples, experimental protocols applied, and instruments available in the laboratory [15]. It is problematic to establish a fully automated protocol in extensive and elaborate proteomics workflows due to all the variables in the multiple often disjointed sample preparation steps.
One way to address this challenge is to identify and automate the most redundant and time consuming steps of the experimental workflow. For example, different liquid handling systems are the most commonly used automation systems in the high-throughput sample preparation labs. In our case, the types of liquid handling systems used are Eppendorf epMotion 5075 and GILSON GX-274 Aspec Automated SPE System. For example, making the sample serial dilutions and loading them onto 96-well plates for the BCA assays, can be performed in automated manner using Eppendorf epMotion throughout the process to ensure accuracy and reproducibility of the assay measurements.
1.5-mL microcentrifuge tubes are most preferable at this step; smaller microcentrifuge tubes are not sufficiently large to handle the sample resulted from this step.
It is very important to keep tissue sample and tools (spatulas, tweezers) chilled on dry ice (or in liquid nitrogen) until beginning of the processing. Warming sample up or use warmed tools to handle sample may introduce unnecessary changes in biological properties.
During homogenization, do not exceed volume of 500 μL if using 1.5-mL microcentrifuge tubes to avoid lysis buffer splashing and subsequent sample loss.
QIAGEN TissueRuptor with disposable probes will work as well for low-throughput in-solution tissue homogenization as Kontes™ Pellet Pestle™ Cordless Motor. QIAGEN TissueLyser is well suited for disruption of the tissue samples for high-throughput, 96-well format and automated workflows.
Prior to protein extraction, hard and fibrous tissue (e.g., muscle, skin, and heart) could be cryo-powderized in liquid nitrogen and stored at −80 °C until further processing.
At this point of time sample may be snap frozen in liquid nitrogen and store in −80 °C until further processing.
This step can be automated using Eppendorf epMotion 5075 Liquid Handler.
500 mM stock solutions of DTT and Iodoacetamide are to be made freshly for the digestion.
Before adding activated trypsin to the sample confirm and adjust sample solution to pH 7–9.
It is important to make sure sample solution pH to be ~8 after adding the Dissolution Buffer.
The pooled reference sample does not have to be always labeled using the same iTRAQ reagent (e.g., 117); however, doing so would eliminate any potential bias resulted from the different iTRAQ reagents (e.g., due to reagent quality issues).
Fist, fractions are dried all way down in Speed-Vac. Then, each fraction is reconstituted in 100 μL of 50 % MeOH, 0.05 % TFA for concatenation of 96 fractions into 24 samples. Fractions are concatenated into the same plate or into fresh vials, concentrated down to remove MeOH in the samples. Protein BCA assay may be performed on each concatenated sample if accurate peptide concentration is needed (e.g., for appropriate sample loading in the final LC–MS/MS analysis).
For comparing protein abundances across the entire sample cohort, the quantification relies on the common pooled reference sample that is labeled with a particular iTRAQ reagent (e.g., 117). Therefore to convert arbitrary reporter ion intensities to relative abundances that can be compared across the different 4-plex iTRAQ experiments, the 117 reporter ion cannot be a missing value. After discarding spectra with a missing 117 reporter ion, the sample channels (114, 115, and 116) for the remaining spectra are divided by the intensity of the reference channel (117). Relative protein or abundances from the individual iTRAQ experiments are then simply linked together and form a crosstab pivot table. Prior to further data manipulations the relative abundances are log2 transformed.
References
- 1.Baker ES, Liu T, Petyuk VA, et al. Mass spectrometry for translational proteomics: progress and clinical implications. Genome Med. 2012;4:63. doi: 10.1186/gm364. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Rifai N, Gillette MA, Carr SA. Protein biomarker discovery and validation: the long and uncertain path to clinical utility. Nat Biotechnol. 2006;24:971–983. doi: 10.1038/nbt1235. [DOI] [PubMed] [Google Scholar]
- 3.Domon B, Aebersold R. Mass spectrometry and protein analysis. Science. 2006;312:212–217. doi: 10.1126/science.1124619. [DOI] [PubMed] [Google Scholar]
- 4.Zhang B, Wang J, Wang X, et al. Proteogenomic characterization of human colon and rectal cancer. Nature. 2014;513:382–387. doi: 10.1038/nature13438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Ross PL, Huang YN, Marchese JN, et al. Multiplexed protein quantitation in Saccharomyces cerevisiae using amine-reactive isobaric tagging reagents. Mol Cell Proteomics. 2004;3:1154–1169. doi: 10.1074/mcp.M400129-MCP200. [DOI] [PubMed] [Google Scholar]
- 6.Wang Y, Yang F, Gritsenko MA, et al. Reversed-phase chromatography with multiple fraction concatenation strategy for proteome profiling of human MCF10A cells. Proteomics. 2011;11:2019–2026. doi: 10.1002/pmic.201000722. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Qian WJ, Liu T, Petyuk VA, et al. Large-scale multiplexed quantitative discovery proteomics enabled by the use of an (18)O-labeled “universal” reference sample. J Proteome Res. 2009;8:290–299. doi: 10.1021/pr800467r. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Mertins P, Yang F, Liu T, et al. Ischemia in tumors induces early and sustained phosphorylation changes in stress kinase pathways but does not affect global protein levels. Mol Cell Proteomics. 2014;13:1690–1704. doi: 10.1074/mcp.M113.036392. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Mertins P, Qiao JW, Patel J, et al. Integrated proteomic analysis of post-translational modifications by serial enrichment. Nat Methods. 2013;10:634–637. doi: 10.1038/nmeth.2518. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Kim S, Gupta N, Pevzner PA. Spectral probabilities and generating functions of tandem mass spectra: a strike against decoy databases. J Proteome Res. 2008;7:3354–3363. doi: 10.1021/pr8001244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Elias JE, Gygi SP. Target-decoy search strategy for increased confidence in large-scale protein identifications by mass spectrometry. Nat Methods. 2007;4:207–214. doi: 10.1038/nmeth1019. [DOI] [PubMed] [Google Scholar]
- 12.Qian WJ, Liu T, Monroe ME, et al. Probability-based evaluation of peptide and protein identifications from tandem mass spectrometry and SEQUEST analysis: the human proteome. J Proteome Res. 2005;4:53–62. doi: 10.1021/pr0498638. [DOI] [PubMed] [Google Scholar]
- 13.Zhang B, Chambers MC, Tabb DL. Proteomic parsimony through bipartite graph analysis improves accuracy and transparency. J Proteome Res. 2007;6:3549–3557. doi: 10.1021/pr070230d. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Monroe ME, Shaw JL, Daly DS, et al. MASIC: a software program for fast quantitation and flexible visualization of chromatographic profiles from detected LC-MS(/MS) features. Comput Biol Chem. 2008;32:215–217. doi: 10.1016/j.compbiolchem.2008.02.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Dayon L, Nunez Galindo A, Corthesy J, et al. Comprehensive and scalable highly automated MS-based proteomic workflow for clinical biomarker discovery in human plasma. J Proteome Res. 2014;13:3837–3845. doi: 10.1021/pr500635f. [DOI] [PubMed] [Google Scholar]