

Abstract
Individuals with developmental language impairment can show deficits into adulthood. This suggests that neural networks related to their language do not normalize with time. We examined the ability of 16 adults with and without impaired language to learn individual words in an unfamiliar language. Adults with impaired language were able to segment individual words from running speech, but needed more time to do so than their normal-language peers. ICA analysis of fMRI data indicated that adults with language impairment activate a neural network that is comparable to that of adults with normal language. However, a regional analysis indicated relative hyperactivation of a collection of regions associated with language processing. These results are discussed with reference to the Statistical Learning Framework and the sub-skills thought to relate to word segmentation.
Abbreviations: LI, Language impaired; NL, Normal language
Keywords: Statistical learning, Language, Learning, Specific language impairment, fMRI, Brain
Highlights
-
•
Adults with developmental language impairment were imaged during a word segmentation task in an unfamiliar natural language.
-
•
Impaired adults learned to identify individual words, although it took them longer than their typical language peers.
-
•
The impaired group used the same learning network as the typical group, arguing against recruitment of additional regions.
-
•
Hyper-activation in language regions characterized the impaired group, unless performance was equated between groups.
-
•
This suggests that hyper-activation for the impaired group reflects greater effort by learners at earlier stages of learning.
1. Introduction
Developmental language impairment has traditionally been considered a childhood disorder. Indeed, the disorder is typically diagnosed in early childhood, often on the basis of morphosyntactic errors and/or limited vocabulary skills. However longitudinal studies have consistently shown that poor language skills, originally diagnosed during childhood, persist into the adolescent and adult years (Aram et al., 1984, Conti-Ramsden et al., 2008, Elbro et al., 2011, Johnson et al., 2010, Stothard et al., 1998). Persistent impairments can have a significant functional impact into adulthood. Adults with a history of language impairment tend to lag behind their age-peers in terms of educational achievement (Conti-Ramsden and Durkin, 2012, Conti-Ramsden et al., 2009, Elbro et al., 2011). These individuals are also more likely to pursue vocational rather than academic education after the compulsory school years (Conti-Ramsden et al., 2009, Elbro et al., 2011). If working, these adults are more likely than peers to hold jobs that correspond to lower socio-economic outcomes (Conti-Ramsden and Durkin, 2012, Elbro et al., 2011, Johnson et al., 2010).
Despite these outcomes, relatively little is known about the nature of language impairment during the adult years. In this paper, we consider the adult presentation of this disorder from a neurological perspective. Specifically, we are interested in whether and how the neural resources recruited during new learning by young adults with language impairment differ from those of their normal language peers. We employed a task that requires implicit learning of syllable sequences that represent word forms in an unfamiliar language.
The language network of normal adults is well described as involving left-lateralized activation of an inferior frontal and superior temporal network with additional activation typically seen in dorsolateral prefrontal cortex, the lateral precentral gyrus, and the temporoparietal junction (see Hickok, 2012, Price, 2010, Price, 2012, Vigneau et al., 2006 for reviews). Individuals with language impairment also activate this network during language processing, although task related regional differences in activation can occur, when compared with their normal language peers (Ellis Weismer et al., 2005, Plante et al., 2006). These same regions also engage during periods of active language learning by adults with normal language (e.g., Bahlmann et al., 2008, Cunillera et al., 2009, McNealy et al., 2006, Plante et al., 2015a, Plante et al., 2014). However, no information is yet available concerning whether those with developmental language impairment recruit the same neural resources as they attempt to learn from language input. In the present study, we examine the learning of word forms embedded into running speech in a novel language.
1.1. The statistical learning framework
The Statistical Learning Framework is a theory that posits that individuals acquire information about the distributional characteristics of the sensory input they receive and extract information about structure from the input (see Erickson and Theissen, 2015, Gerken and Aslin, 2005, Karmiloff-Smith et al., 1998, Saffran, 2003 for overviews). Learning under the Statistical Learning Framework is unguided, in that learners do not require feedback to learn. Statistical learning relies on general cognitive processes that serve learning in multiple domains. Recent thinking holds that the cognitive skills needed may differ depending on the nature of the statistical learning task. Erickson and Theissen (2015) have proposed that extracting elements from input and linking them may be more important for some types of statistical learning and integration of information across stored units may be more important for others. This perspective implies that encoding of informational units into memory is also critical to the learning process, and Erickson and Theissen (2015) acknowledge a role for both attention to input and working memory as processes basic to statistical learning.
There is evidence implicating poor statistical learning by children and adults with language impairment. Children with SLI are slower to recognize co-occurring syllables as word units compared with their age-mates in an artificial language paradigm (Evans et al., 2009). Likewise, adults and children with impaired language have difficulty recognizing legal combinations of words in an artificial grammar (Plante et al., 2002, Plante et al., 2013). Multiple studies of adolescents and adults show poor learning of dependencies between non-adjacent elements in the input (Hsu et al., 2014, Grunow et al., 2006) and recognizing relations among classes of elements (Torkildsen et al., 2013, Richardson et al., 2006). However, there is evidence that learning can improve if those with language impairment are given more time to learn (Evans et al., 2009) or if input is optimized in ways known to facilitate statistical learning (Torkildsen et al., 2013, Grunow et al., 2006). Therefore, the proposed deficit in statistical learning appears to be one of degree rather than an all-or-nothing phenomenon.
Although the Statistical Learning Framework does not make specific neurological predictions, there have been multiple studies that have examined the neural basis of statistical learning in the verbal domain. The statistical learning network for verbal material overlaps substantially with the network used to process language form (e.g., Bahlmann et al., 2008, Cunillera et al., 2009, Karuza et al., 2013, McNealy et al., 2006, McNealy et al., 2010, Plante et al., 2015a, Plante et al., 2015b, Plante et al., 2014, Newman-Norlund et al., 2006, Optiz and Kotz, 2012). Most relevant to the present study are studies that have used artificial languages in which spoken syllable triplets co-occur as word units. These have consistently reported left-lateralized activation in the superior temporal gyrus (Cunillera et al., 2009, Karuza et al., 2013, McNealy et al., 2006, McNealy et al., 2010). Activation in inferior parietal (Karuza et al., 2013, McNealy et al., 2010) and ventral premotor regions (Cunillera et al., 2009) has also been reported. Activation levels in other regions, including the inferior frontal gyrus and basal ganglia have been reported to correlate with post-scan test performance (Karuza et al., 2013, McNealy et al., 2010), but this region is not significantly activated during the learning period itself.
Natural language studies of word segmentation are less common. In the one available study (Plante et al., 2015b), two groups of listeners were scanned while listening to Norwegian sentences that either provided or did not provide statistical cues to embedded words. Input that permitted statistical learning of the embedded words not only prompted rapid learning, but recruited a much more widely-distributed neural network than did input that lacked distributional cues. In addition to the superior temporal gyrus activation consistently reported in artificial language studies, activation included the inferior and middle frontal gyrus, superior and inferior parietal lobule, and posterior temporal-occipital junction, as well as regions in the thalamus and basal ganglia.
Given that the Statistical Learning Framework is intended to account for how language is acquired, it is not surprising that imaging studies most consistently report activation in areas classically associated with language processing. Considered within the context of the Statistical Learning Framework, the overall pattern of activation during learning should reflect the key cognitive processes involved. At least two processes are required to segment words from an unfamiliar language. First, information about syllable order must be extracted from the input. In studies involving encoding the serial position of individual words within word lists, stronger activation in the left superior temporal gyrus, left inferior frontal gyrus (BA44), and left supramarginal gyrus have been documented (Clark and Wagner, 2003, Cassanto et al., 2002, Kalm and Norris, 2014, Optiz and Kotz, 2012). This suggests that the basic language network may be directly involved in tracking order dependencies. Second, syllables showing strong order dependencies must be encoded as individual words in memory. Activation in the left superior temporal gyrus, left inferior frontal gyrus, left dorsolateral prefrontal cortex, and bilateral superior parietal lobule has been associated with successful encoding of words into memory (Blumfeld and Ranganath, 2006, Clark and Wagner, 2003, Cassanto et al., 2002, Davachi et al., 2001, Kalm and Norris, 2014). These findings suggest that a broad network reported in statistical word learning studies to date may actually relate to at least two distinct processes predicted by the Statistical Learning Framework.
1.2. The present study
For the present study, we have adopted the natural language learning task from Plante et al. (2015b) in which adults were able to identify words in an unfamiliar language (Norwegian) rapidly when statistical cues to word units were present. In that study, adults with typical language skills were asked to segment real bi-syllabic words from spoken Norwegian sentences. This task shares conceptual similarities with artificial language tasks in which syllable-level dependencies allow learning of word units. In the present study, the natural language task provides a learning context that has ecological validity for the central issue of natural language processing.
There are three logical possibilities for how adults with impaired language may compare to their normal-language counterparts. The first is that adults with language impairment fail to recognize distributional cues in the input, preventing them from using these cues to segment words. If this is the case, adults with language impairment should perform very poorly and consequently activate a very restricted network. This outcome would be similar to typical adults who were provided with input that lacked distributional cues to word boundaries (cf. Plante et al., 2015b). A second possibility is that performance is strong and the neural networks will be fundamentally similar for both groups. However, the participants with language impairment may have to expend more effort than the typical language group to obtain performance parity. A third outcome represents an intermediate and more likely outcome. Adults with impaired language will learn from distributional information, but it will take them longer than their normal langue peers to achieve above-chance performance (cf. Evans et al., 2009). Under this scenario, it is likely that their neural response will differ most from their peers when learning is weakest, although activation may normalize as learning strengthens. We will focus exploration on regions predicted to relate to unguided language learning likely to be activated by the specific demands for this task (order information: superior temporal gyrus, inferior frontal gyrus, supramarginal gyrus; memory encoding: superior temporal gyrus, inferior frontal gyrus, middle frontal gyrus, superior parietal lobule).
2. Materials and methods
2.1. Participants
The participants were 32 college-enrolled adults. Half were identified as having impaired language skills (the LI group) and were receiving academic support services for their disability. This group included 7 males and 9 females whose average age was 20 years (SD = 2.2 years). Two of the females were left-handed and the remaining participants were right-handed. The participants in the LI group were matched with 16 individuals comprising a normal language (NL) group for age (mean = 20 years, SD = 3.5 years), gender (7 m, 9f), and handedness (2 left-handed females). All participants in both groups showed left-hemisphere lateralization on the language task employed here.
All participants passed a pure-tone hearing screening at 20 dB HL at 1000, 2000, & 4000 Hz and < 25 dB HL at 500 Hz. No participant had a history of neurological conditions that would alter brain function (e.g., seizures, concussion), psychotropic medications, or contra-indicators for MRI scanning. All provided informed consent under procedures approved by the University of Arizona Institutional Review Board.
Language status was assessed using a battery of tests designed to detect developmental language impairments in adulthood (Fidler et al., 2011). This method uses a composite of three test scores and identifies individuals with a childhood history of specific language impairment with 80% sensitivity and 87% specificity (Fidler et al., 2011). Individual participant scores were entered into a regression equation that was used to indicate language status (impaired/typical). Therefore, rather than treating scores separately, a weighted composite of all three measures was used to determine group membership. All language scores were significantly different between groups (p < 0.05). In contrast, there was no group difference on a test of nonverbal skills (Test of Nonverbal Intelligence-III, Brown et al., 1997). All test scores are reported in Table 1.
Table 1.
Test scores for the Normal Language (NL) and Language Impaired (LI) groups.
| CELF-4 WDa | Written spellingb | Modified token testc | TONI-3d | |
|---|---|---|---|---|
| Mean (SD) | Mean (SD) | Mean (SD) | Mean (SD) | |
| Normal language group | 14.00 (4.18) | 13.13 (2.13) | 40.13 (2.66) | 106.33 (16.73) |
| Language impaired group | 9.13 (2.20) | 6.47 (2.83) | 32.67 (5.54) | 110.13 (18.47) |
Word Definitions subtest of the Clinical Evaluation of Language Fundamentals - Fourth Edition (CELF-4; Semel et al., 2003). Scores are subtest standard scores with a normative sample mean of 10 and SD of 3. Note that for participants over the age of 21, standard scores are anchored to the CELF norms for 21 year olds.
The Written Spelling test from Fidler et al. (2011). Scores provided are raw scores out of 15 possible items.
The Modified Token Test (Morice and McNicol, 1985). Scores provided are raw scores out of 15 possible items.
Test of Nonverbal Intelligence-III, (Brown et al., 1997). Scores are standard scores with a normative sample mean of 100 and SD of 15.
2.2. Materials
The stimuli used were those originally used in a behavioral study by Kittleson et al. (2010) and later used in an fMRI study by Plante et al., (2015b). Stimuli consisted of a set of 54 sentences and 54 complex tones that participants heard during the scanning phase of the study, and 18 test items that were presented after each scan to test learning.
2.2.1. Sentence stimuli
Sentence stimuli were spoken by a male native-speaker of Norwegian, who spoke the Bergen dialect following the Bokmål orthography. Each sentence contained one of nine two-syllable words that were the intended targets of learning during the study (Target words). The nine Target words each appeared in six different sentences of 4–11 words in length. With the exception of the Target words, no other content words appeared in more than one sentence. Other grammatical elements (e.g., articles, gender marking) did repeat across sentences, consistent with their presence in natural language stimuli. Although Target words appeared in sentence initial, sentence final, and sentence medial positions, for the majority of the sentences (43 sentences) the Target word was neither the first nor the last word of the sentence. This is consistent with general characteristics of natural language stimuli, which allow content words to appear in multiple sentence positions. Sentence stimuli were spoken with an intonation pattern appropriate to the syntax and meaning of the sentence. However, the sentences were edited to produce approximately equal overall loudness between sentences.
The six sentences containing the same Target word were presented within an 18.2 s block during the scan. There were nine sentence blocks containing nine target words to be learned. Sentences were separated by a brief silent period, which sounded to the participant like a brief pause between sentences. The length of this varied randomly between sentences and was dictated by the time remaining in the 18.2 s block after accounting for the time taken up by the set of six sentences. To orient the participants to the sentence stimuli, each sentence block was preceded by a cue period of 5.2 s in which a female native English speaker instructed the participant to listen to the sentences.
2.2.2. Complex tone stimuli
Complex tones were used as a contrasting condition to the blocks of sentence stimuli. Fifty-four complex tones were created from pure tones between 250 and 2500 Hz, with durations approximately equal to each of the sentence stimuli. Tones were then frequency and amplitude modulated in a variety of ways so that different tone stimuli were perceptually unique. We then combined pairs of these modulated tones such that one with an original pure tone frequency of 1000 Hz was blended with another with an original pure tone frequency of 1000 Hz. Both blended tones had the same duration. Complex tones were edited to produce approximately equal loudness across tone stimuli and with the sentence stimuli. These complex tones were then arranged in 18.2 s blocks of six tones each, with brief pauses between. To alert the participants that an upcoming block did not contain Norwegian sentences, each tone block was preceded by a cue period of 5.2 s in which a female native English speaker instructed the participant to relax.
2.2.3. Test stimuli
Test stimuli were identical to those in Kittleson et al. (2010) and Plante et al. (2015b). Test stimuli consisted of the nine Target words and nine nonword foils. A single exemplar of each Target word (e.g., vandrer, lever) was clipped from the sentence stimuli it was embedded in for use as a test item. Nonwords consisted of adjacent syllables clipped from the sentence stimuli. For five nonwords, the second syllable of a Target word was selected along with the immediately following syllable (e.g., drerman). For four nonwords, the first syllable of a Target word was combined with the immediately preceding syllable (e.g., somlev). Therefore, all nonwords consisted entirely of syllables heard in the original sentences, and in the order they were heard in those sentences.
Critical to this study, Kittleson et al. (2010) established that listeners who heard only the test items, without the sentence stimuli, were not able to differentiate between the actual Norwegian words and the nonwords. Therefore, there was nothing that signaled that Target words were real words and the nonwords were not. However, embedded in the sentence stimuli, Target words had a two-way syllable dependency of 0.90 and a forward transitional probability of 0.884. In contrast, nonwords had a two-way syllable dependency of 0.184 and a forward transitional probability of 0.127. In prior studies (Kittleson et al., 2010, Plante et al., 2015b), the higher dependency syllable combinations are significantly more likely to be identified as words after exposure to the sentences that contain them.
We note that a limitation of the test stimuli is that relatively few correct and incorrect test items were used. Presentation of larger numbers of test items can interfere with the original implicit representation acquired during learning. Performance can erode with testing as the presentation of incorrect test items operate as counter-examples to the correct pattern (cf., Gómez and Lakusta, 2004), lowering performance as testing proceeds. This limits the ability to compare test performance, as the outcome of learning, to imaging data in several ways. Measurement error associated with individual test items can be sizeable compared with error that is averaged across a large number of items, as described by classical test theory (e.g., Kline, 2005; Wilson, Allen, & Li, 2006). The inherent item error, particularly with small item sets, can undermine an individual differences approach to data analysis. More problematic is the use of difference scores to gage changes in learning (e.g., from one scan to the next), because such scores reflect differences among a subset of an already small test pool. Furthermore, the limited range of possible scores restricts the power to detect associations between activation during learning and outcome testing because the limited score range lowers the upper bound of the possible correlation. These are general statistical limitations inherent to measuring the outcome of learning in implicit paradigms, which also apply to this study. However, item error tends to average out across test takers, making group data much more stable than individual participant data. Moreover, these factors affect test data only, and do not impact the ability to image learning as it occurs, independent of post-scan test data.
2.2.4. Scanner instrumentation
Participants were scanned with a 32-channel head coil on a 2.9 T Siemens Skyra running software version syngo MR D13. Stimuli were delivered with noise attenuating MR compatible Sensimetrics S14 insert earphones.
2.3. Procedures
2.3.1. Behavioral procedures
Just prior to scanning, participants were given a brief training session during which they heard an auditory file similar to that used during scanning. This included the cue phrases and alternating blocks of complex tone and Norwegian sentences. However, the sentences presented during practice did not contain any of the Target words or nonword syllable combinations contained in the scanner stimuli. Instead, these stimuli were intended only to familiarize the listener with the general experimental conditions they would experience in the scanner. Participants were informed that they would hear similar stimuli during the scans and would be tested on what they learned after each scan.
During the scan, the nine cue + tone blocks were interleaved with the nine cue + sentence blocks, beginning with a tone block. This arrangement ensured that participants were acclimated to the scanner before the first block of sentences occurred. Blocks occurred in the same fixed order for all participants and all scans. The total time for each scan was 6 min, 26.4 s with 2 min, 43.8 s of exposure to the Norwegian stimuli during that time.
During each functional scan, participants listened to the complex tone and sentence stimuli, without making responses. Immediately after each functional scan, and while still in the scanner, participants heard the 18 test words presented in computer-generated random order. They were asked to indicate, via button press, whether each test item was a real Norwegian word or not. They did not receive feedback on their responses.
2.3.2. Scanning procedures
Both structural and functional scans were acquired as part of this study. An MPRAGE, acquired in sagittal orientation, provided a high-resolution volume to aid in registering the functional scans into standard space. This GRAPPA2 volume was collected left to right (TR 2300, TE 2.95, Flip angle 9, FOV 176 × 240, Matrix 176 × 240 × 256).
Three consecutive scan and test phases were collected with the participant in the scanner throughout this period. Functional scans were acquired with GRAPPA2, an interleaved inferior to superior echo planar free induction decay acquisition and an axial orientation (TR 2600, TE 25, Flip angle 90, FOV 224 × 200 × 135 mm, Matrix 74 × 66 × 45 mm). Each of the three scans was 172 volumes. This included 8 pre-stimulus volumes that were collected to insure the scanner had reached equilibrium and the participant was settled into the scan prior to the onset of the stimuli. There were also 2 post-stimulus volumes collected to allow the signal from the final block to begin to fall off prior to the end of the scan. Field maps were collected to facilitate boundary based registration (Greve and Fischl, 2009) of the fMRI data. The field maps each included a phase image and two magnitude images (TR 434, TE 4.92 [magnitude image 1], 7.38 [magnitude image 2, and phase image], Flip angle 60, FOV 224, Matrix 68 × 68 × 41).
Each functional scan was 7 min, 2.7 s. All participants had acceptably low movement for the duration of the scan. Movement in the two groups was quite similar (LI mean = 0.504 mm, SD = 0.337; NL mean = 0.583 mm, SD = 0.401). There were two potential participants (both with normal language) whose scans were withdrawn from the study due to excessive movement (> 2 mm movement). They were replaced so that the participant groups were matched as reported above.
2.3.3. Image preprocessing
Images were preprocessed using numerous software tools. The eight pre-stimulus volumes were trimmed from each functional scan. We then identified the most representative volume in the remaining scan for later realignment and registration into standard space. We used a combined 3D volume registration and within-volume slice-wise motion correction algorithm (SLOMOCO; Beall and Lowe, 2014) for re-alignment, which reduced the number of outlier spikes by approximately 12 fold as compared to standard volume registration in AFNI (http://afni.nimh.nih.gov/). However, we modified the SLOMOCO algorithm to use the representative volume that we identified earlier for realignment rather than the first volume. This procedure reduced the amount of movement required for realignment by about 50%. De-spiking was applied after realignment. To register each participant's scans into standard space, we first applied FSL's Brain Extraction Tool (BET, Smith, 2002) to the MPRAGE and fieldmap images, manually editing any poor results using iMango (http://ric.uthscsa.edu/mango/imango.html; Lancaster et al., 2012). We then used FSL's boundary-based registration to register each functional scan to the participant's MPRAGE and then to standard space. Boundary based registration takes advantage of the grey-white matter boundaries, because these tend to be more reliable than the external grey matter boundaries (Greve and Fischl, 2009). Each normalized scan was then smoothed with a 5 mm filter.
2.3.4. ICA analysis
We used ICA analysis for two main reasons. First, this provides comparability with our previous study that used the same stimuli (Plante et al., 2015b), which also used an ICA approach. The earlier study serves as a baseline for understanding whether results from the LI group reflect lack of ability to recognize or use these cues vs. other logical possibilities. Second, ICA maximizes signal-to-noise because it segregates the complex fMRI signal into multiple component signals that are statistically independent. ICA will identify signal sources associated with physiologic noise (e.g., task-correlated participant movement, pulsatility, fluid drainage), and residual participant movement, and segregate these from task-based signal. Other analysis techniques (e.g., General Linear Model [GLM] approaches) aggregate these different signal sources, regardless of whether they are truly task related or associated with other sources of noise in the signal. Because of this, ICA tends to be more sensitive than GLM for identifying cognitively-driven signal in fMRI data (e.g., McKeown et al., 1998, Thorton et al., 2010). The results of a simple GLM analysis are presented as Supplemental Fig. 1.
The LI and NL participants were run in a single independent component analysis (ICA) using the GIFT 3.0a toolbox (Rachakonda et al., 2007, http://mialab.mrn.org/software/#gica) for MATLAB. The ICA uses principle component analysis (PCA) as an initial data-reduction step. We used multi power iteration (MPOWIT) to run the PCA because it extracts the dominant components in fewer iterations than the traditional PCA analysis.
For the ICA itself, we expected important individual differences not only between groups (LI vs typical) but also from scan to scan as participants tried new strategies to learn the material. We therefore used the Entropy Rate Based Minimization (ERBM) (Li and Adali, 2010) ICA algorithm in GIFT because it preserves individual differences better than the standard Infomax algorithm. Following current best practices, we used a relatively high model order (50 ICs) to help refine the components to better match known functional and structural divisions (Allen et al., 2014). The analysis accounted for 82.63% of the variance in the dataset. We scaled the components in z-scores and ran the ICASSO Fast ICA procedure 10 times to evaluate component overlap and stability.
We expected that not all of the 50 independent components generated by this analysis would actually represent cognitive contributions to the task. However, we also were cognizant that components may differentially activate over the course of learning (cf. Plante et al., 2014). For example, one IC could be recruited early in the learning process and become less necessary as learning progressed and another IC may strengthen and only become significant as the learning begins to reflect consistent application of successful strategy. Therefore, we considered all ICs that were positively correlated with blocks in which sentences, rather than tones, were presented for any or all of the three scans. This eliminated 11 ICs from further consideration. We then considered the stability of the IC estimate. We evaluated the strength of the Iq metric (an IC stability index in which 0 is completely unstable and 1 is completely stable). We considered only ICs for which the Iq value was above 0.75. This somewhat liberal criterion allowed for the possibility that the mix of NL and LI participants may increase the variability of a combined IC estimate relative to what studies of only NL individuals have found (e.g., Iq > 0.80). This criterion eliminated an additional 21 ICs from further consideration. We also eliminated from further consideration any IC that was not identified in all 10 of the ICASSO iterations. One additional IC failed this criterion. Finally, we examined the visual displays for the remaining ICs to determine whether the spatial distribution appeared to represent signal from cortical or subcortical grey matter or was artifactual in nature. We eliminated 11 ICs in which the peak signal was primarily in areas of cerebral spinal fluid (e.g., ventricles, tentorium, superior longitudinal fissure) and one IC that was indicative of residual participant movement (i.e. a thin rim around each of the brain slices). This left six ICs that were subjected to further analyses. The average Iq value for these six ICs was 0.89 with a range of 0.77 to 0.97. As a final check, we ran separate ICAs for the NL and LI groups to insure that there were not stable components that were unique to one group and not the other. This was not the case, so we retained the six ICs identified by the combined group ICA for analysis. For the six remaining ICs, we used back reconstruction to estimate the signal on a participant-by-participant basis. The beta values representing the degree of association between signal change and the periods of exposure to Norwegian were tested for significance (p < 0.01) on a region-by-region basis within a Weave visualization environment (Patterson et al., 2015). This procedure produces results that are comparable to brain-wide analyses that are corrected for multiple comparisons (Patterson et al., 2015). The corresponding regions of significant activation within each of the six ICs are reported for each scan in Supplemental Table 1. The ICs were visually displayed by first thresholding each IC at p < 0.01 family-wise error (FWE) correction. The ICs were then superimposed on an anatomical image for display.
3. Results
3.1. Behavioral results
The behavioral results collected after each scan are presented in Fig. 1. Performance levels are expressed as d-prime (d’), which indicates the extent to which participants differentially responded to correct and incorrect test items. Higher d’ values indicate proportionately greater acceptance of correct items than incorrect items. We performed an initial analysis to determine the scan after which participants in each group performed at above chance levels. For the NL group, this was after Scan 1 (t = 4.38, p = 0.001, d = 1.10), indicating that learning had occurred with just under 3 min of exposure to the Norwegian stimuli. For the LI group, performance did not exceed chance until after Scan 2 (t = 3.34, p = 0.005, d = 1.14), indicating that they needed as much as twice the input for learning to occur. However, it should be noted that learning for both groups was relatively rapid, occurring with less than 6 min of Norwegian input.
Fig. 1.
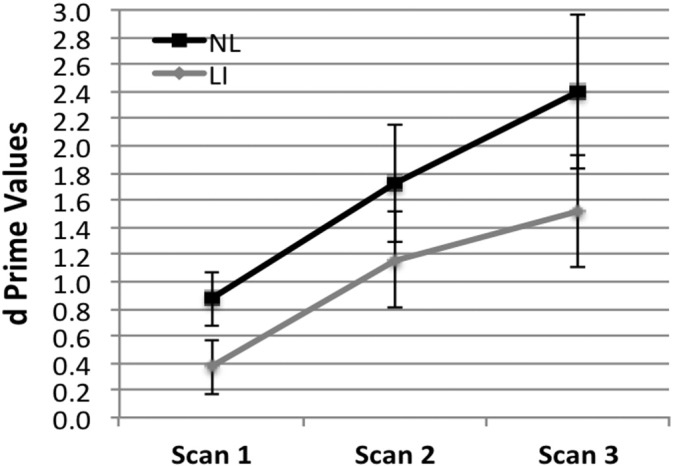
Average behavioral performance for the normal language and language impairment groups after each consecutive scan. Error bars indicate the standard error of measure.
Differences between groups and across time were tested using a mixed ANOVA. The main effect for group was not significant (F(1,20) = 2.77, p = 0.107, ƞ2 = 0.08), nor was the group × time interaction (F(2,60) = 0.20, p = 0.882, ƞ2p = 0.01). There was a main effect for time (F(2,60) = 8.42, p = 0.001, ƞ2p = 0.22). Follow-up testing indicated d’ values obtained immediately after Scan 1 were significantly lower than after both Scan 2 (t = 2.84, p = 0.007, d = 0.52) and Scan 3 (t = 3.99, p = 0.0004, d = 1.34). However, d’ values after Scan 2 did not differ significantly from Scan 3 (t = 1.50, p = 0.144, d = 0.26).
3.2. Imaging results
3.2.1. ICA results
The six ICs for the NL and LI groups are displayed in Fig. 2. A full list of cortical and subcortical regions with significant activation or de-activation for each IC in each scan is provided in Supplemental Table 1. As this figure suggests, the spatial distribution of the ICs was remarkably similar across the two groups. As is typical of ICA, the activity returned is more extensive than that seen for a typical GLM analysis (see Supplemental Fig. 1) in part because of ICA's superior noise reduction and ability to segregate signals that would be lost in a GLM analysis.
Fig. 2.

Spatial distribution of six independent components found for the Normal Language and Language Impairment groups. Colors represent each independent signal time course (IC). Spatial overlap between ICs is represented in blue. All regions are corrected for multiple comparisons at p < 0.01 FWE.
The first IC (IC 1) most strongly reflected temporal lobe contributions, with peak activations centered over Heschl's gyrus and the planum temporale bilaterally. IC 2 primarily represented activation of central operculum and precentral gyrus bilaterally. IC 3 and IC 4 represented strong activation in inferior and middle frontal cortex as well as the temporal-parietal junction. IC 3 showed leftward lateralization; IC 4 showed strong right hemisphere lateralization, with deactivation of left hemisphere regions. IC 5 included strong activation of the supramarginal gyrus as well as the insula and opercular cortices bilaterally. IC 6 included left-lateralized activation within the inferior frontal gyrus (BA44 and BA45) and angular gyrus.
3.2.2. Region of interest analysis
Overall, the spatial distribution of the ICs was remarkably similar across the Language Impaired and Normal Language groups. However, we were primarily interested in the strength of activation for regions predicted by the Statistical Learning Framework and whether these regions showed significant differences between groups. To conduct this analysis, we extracted the mean activation from regions predicted by this framework using regional masks based on the Harvard-Oxford cortical and subcortical atlases as implemented by FSL. We selected only those regions that showed a statistically significant and visible activation peak within the predicted region. This avoided tests for regions that showed either nonsignificant (chance) activation overall and regions for which activation represented the spread around a peak that was actually centered in a neighboring region. The z-scores for activation data within each region were then tested for differences between groups, regions, and scans.
Note that some regions showed significant activation in more than one IC. This is not unexpected, given that the brain involves both feed-forward and feedback networks that are likely to operate on different time courses. In addition, the multiple cognitive processes assumed by the Statistical Learning Framework would predict involvement of multiple and perhaps overlapping networks (e.g., inferior frontal gyrus is implicated both for tracking positional order and for successful memory encoding). However, there is no a priori means of determining which IC time course might be most closely related to one particular cognitive function or another. Therefore, when a single region was active in more than one IC, the region of activation was analyzed for each of the time courses (ICs) for which it occurred.
Activation within a priori regions of interest is displayed in Fig. 3a and b. Two separate cognitive processes are predicted under this model: tracking of positional order information (2a) and encoding syllable sequences constituting words into memory (2b). As discussed in the introduction, the former is likely to involve the inferior frontal gyrus, superior temporal gyrus, and supramarginal gyrus in the left hemisphere. Regions unique to the latter involve the middle frontal gyrus and superior parietal lobule.
Fig. 3.

Regions predicted to differ across groups for a) positional order encoding and b) additional regions associated with item encoding. Only regions containing statistically significant activation (p < 0.05, uncorrected) and an activation peak within the region are plotted. A significant group effect was found for regions associated with Order Encoding. * indicates individual regions with significant group differences (Fisher's LSD posthoc testing following a significant group effect). Abbreviations: LI = Language Impairment Group; NL = Normal Language Group; L = left; R = right; BA44 = Inferior Frontal Gyrus-pars opercularis, MFG = Middle Frontal Gyrus; SMG = Supramarginal Gyrus-posterior; SPL = Superior Parietal Lobule; STG = Superior Temporal Gyrus-Posterior. The IC in which each region was found is also indicated in parentheses.
These regions were tested with mixed ANOVAs with group (LI vs. NL) as a between-group effect and the regions and scan number as within-group factors. For regions associated with order encoding, there was a significant main effect for group (F(1,30) = 7.37, p = 0.011) with the LI group showing higher activation overall compared with the NL group. This was followed by Fisher LSD post-hoc testing to determine individual regions that showed significant group differences. These included BA44 (IC3, in Scan 2 only) and the superior temporal gyrus in Scans 2 and 3. The anterior division of the supramarginal gyrus was significantly different for all three scans and the posterior division was significant in Scan 1 only. None of the interaction effects involving group were significant, nor were effects involving scan number significant.
We analyzed those regions unique to memory encoding processes (middle frontal gyrus and superior parietal lobule) with a mixed ANOVA with group, region, and scan number as factors. As might be expected, the main effect for region was significant (F(2,60) = 164.99, p < 0.0001), but no effects involving group or scan number were significant.
We considered whether the group difference found here was a function of differences in the stage of learning for the NL and LI groups. To test this, we compared activation for all regions in Scan 1 for the NL group (when they achieved above-chance performance) to activation for the LI group during scan 2 (when they achieved above-chance performance). The group differences found in the original analysis for encoding order information were no longer statistically significant and there were no significant interactions involving the group factor. The region effect remained significant (F(3,90) = 104.54, p < 0.0001). For memory encoding, the group and group interaction effects remained nonsignificant, and, as expected, the region effect was still significant (F(6,180) = 143.64, p < 0.0001).
4. Discussion
The adults in this study were successfully able to identify target words embedded in sentences in an unfamiliar language. Adults with normal language showed evidence of above-chance learning after just under 3 min of exposure to Norwegian input and adults with impaired language lagged just behind with above chance performance occurring after approximately five and a half minutes. Group differences in behavioral accuracy were not statistically significant and reflected relatively rapid learning by both groups. This outcome contrasts with an earlier report of relatively slow learning of individual words in an artificial language by children (Evans et al., 2009). In that study, typical children (ages 6–14 years) achieved above-chance learning after a 21-minute exposure. Children with language impairment showed word learning after 42 min of exposure, but not after 21 min.
The relatively rapid learning by our adult participants may be partially related to age. Typical adults exposed to artificial language stimuli that were highly similar to that of Evans et al. (2009) showed evidence of learning after the first minute of exposure (Cunillera et al., 2009). Our use of natural language stimuli may also have facilitated rapid learning. Word segmentation tasks depend on detecting co-occurrence patterns between adjacent elements within serially presented stimulus streams. Compared to artificial languages, our natural language stimuli contained few co-occurring elements with the remaining sentence elements. In other words, syllables other than those comprising Target words had very low statistical dependency. This likely made the few consistent between-syllables dependencies more salient. Natural languages also contain multiple cues to the presence of individual words in addition to transitional probabilities. For example, words can be characterized by phonotactic and stress patterns as well as transitional probabilities, each of which can be used by learners to assist learning (e.g., Cunillera et al., 2006, Mattys et al., 1999). Therefore, it is possible that both age-related and stimulus-related characteristics account for better performance than has been reported previously, particularly for language-impaired learners.
The networks activated by the normal language and language impairment groups were roughly similar in that the same set of ICs characterized the learning network for both groups. Therefore, it is not apparent that the learners with impaired language were using a fundamentally different or compensatory mechanism to learn from the input. However, our a priori region of interest analyses did reveal some group differences. These differences did not occur across the board, but rather conformed to a particular cognitive process consistent with encoding syllable order information. We proposed that the cognitive processes critical to word segmentation involved tracking positional syllable order cues that define word-level syllable dependencies as an initial processing step. The language impairment group showed significantly higher activation in regions previously associated with tracking word order information (Clark and Wagner, 2003, Cassanto et al., 2002, Kalm and Norris, 2014, Optiz and Kotz, 2012). Regions attributed to tracking positional word order also constitute the basic language network. This is consistent with the Statistical Learning Framework account, given that this theory posits that language is acquired by using more basic processing skills, which would be expected to overlap with the language network. Accordingly, group differences in this particular set of regions reported here may reflect difficulty with handling order information in particular, language input as more broadly defined, or both.
Those with language impairment showed higher activation levels than their normal language peers in this theoretically-defined sub-network. This activation difference occurred in the context of relatively rapid learning by the impairment group. This suggests that more robust recruitment of these regions was needed to support learning in the face of a language impairment. This is consistent with findings of hyperactivtaion in dyslexia, a closely related and frequently comorbid disorder. Hoeft and colleagues found hyperactivation occurred during a rhyme judgment task, a task in which their adolescent participants with and without dyslexia were able to perform relatively comparably (Hoeft et al., 2007). Interestingly, when scans for our normal language and impaired groups were most closely equated for post-scan test performance, group activation differences were no longer present. This suggests that relative activation levels may also have been a side effect of the relative stage in the learning process for the two groups. This is similar to the Hoeft et al. (2007) finding that hyperactivtion in their dyslexia group disappeared when this group was compared with a younger group of children who were matched for reading level.
The analysis of regions uniquely associated with successful encoding of items into memory (Blumfeld and Ranganath, 2006, Clark and Wagner, 2003, Cassanto et al., 2002, Davachi et al., 2001, Kalm and Norris, 2014) failed to reveal any group differences. This is somewhat surprising as a previous imaging study of memory with language-impaired adolescents showed significant hypoactivation in these same regions during memory encoding, particularly in the area of the superior parietal lobule (Ellis Weismer et al., 2005). However, that study utilized a task that had a substantial working memory load compared to that required in the present task (recognition memory for bisyllabic words). Other behavioral work has suggested that memory deficits emerge in the context of language impairment when working memory loads are high (e.g., Leonard et al., 2013, Isaki et al., 2008, Montgomery and Evans, 2009). Therefore, the similar activation in these areas may reflect relatively low memory demands during our task.
4.1. Conclusion
The present data indicate that adults with language impairment are capable of identifying words within running speech within a relatively brief amount of time. Their ability to achieve above chance performance within the context of a natural language was only slightly behind that of their typical language peers. However, it appears that they required greater activation of core language regions than their normal peers in order to accomplish the same task. Regions showing hyper-activation are consistent with both classic language cortex and the theoretical perspective of statistically-based language learning.
The following are the supplementary data related to this article.
GLM analysis results. Images are thresholded at a FWE rate of p < 0.05.
Regions of significant activation (p < 0.01) for each task-related independent component (IC) during each scan. XYZ coordinates indicate the location of the peak activation within each region, using the Harvard-Oxford cortical and subcortical atlases in FSL (http://www.cma.mgh.harvard.edu/fsl_atlas.html; Desikan et al., 2006)1. Regions were extracted from the ICA data using a process developed byPatterson et al., 2015.2
Acknowledgement
This work was funded through National Institute on Deafness and Other Communication Disorders grant R01DC011276.
References
- Allen E.A., Damaraju E., Plis S.M., Erhardt E.B., Eichele T., Calhoun V.D. Tracking whole-brain connectivity dynamics in the resting state. Cereb. Cortex. 2014;24(3):663–676. doi: 10.1093/cercor/bhs352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aram D.M., Ekelman B., Nation J.E. Preschoolers with language disorders, 10 years later. J. Speech Lang. Hear. Res. 1984;27:232–244. doi: 10.1044/jshr.2702.244. [DOI] [PubMed] [Google Scholar]
- Beall E.B., Lowe M.J. SimPACE: generating simulated motion corrupted BOLD data with synthetic-navigated acquisition for the development and evaluation of SLOMOCO: a new, highly effective slicewise motion correction. Neuroimage. 2014:10121–10134. doi: 10.1016/j.neuroimage.2014.06.038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bahlmann J., Schubotz R.I., Friederichi A.D. Hierarchical artificial grammar processing engages Broca's area. NeuroImage. 2008;42:525–534. doi: 10.1016/j.neuroimage.2008.04.249. [DOI] [PubMed] [Google Scholar]
- Blumfeld R.S., Ranganath C. Dorsolateral prefrontal cortex promotes long-term memory formation through its role in working memory organization. J. Neurosci. 2006;26:916–925. doi: 10.1523/JNEUROSCI.2353-05.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown L., Sherbenou R., Johnsen S. Pearson; Bloomington, MN: 1997. Test of Nonverbal Intelligence-3. [Google Scholar]
- Cassanto D.J., Kilgore W.D.S., Maldjian J.A., Glosser G., Alsop D.C., Cooke A.M. Neural correlates of successful and unsuccessful verbal memory encoding. Brain Lang. 2002;80:287–295. doi: 10.1006/brln.2001.2584. [DOI] [PubMed] [Google Scholar]
- Clark D., Wagner A.D. Assembling and encoding word representations: fMRI subsequent memory effects implicate a role for phonological control. Neuropsychologia. 2003;41:304–317. doi: 10.1016/s0028-3932(02)00163-x. [DOI] [PubMed] [Google Scholar]
- Conti-Ramsden G., Botting N., Durkin K. Parental perspectives during the transition to adulthood of adolescents with a history of specific language impairment (SLI) J. Speech Lang. Hear. Res. 2008;51:84–96. doi: 10.1044/1092-4388(2008/006). [DOI] [PubMed] [Google Scholar]
- Conti-Ramsden G., Durkin K. Postschool educational and employment experiences of young people with specific language impairment. Lang. Speech Hear. Serv. Sch. 2012;43:507–520. doi: 10.1044/0161-1461(2012/11-0067). [DOI] [PubMed] [Google Scholar]
- Conti-Ramsden G., Durkin K., Simkin Z., Knox E. Specific language impairment and school outcomes. I: identifying and explaining variability at the end of compulsory education. Int. J. Lang. Commun. Disord. 2009;44:15–35. doi: 10.1080/13682820801921601. [DOI] [PubMed] [Google Scholar]
- Cunillera T., Càmara E., Toro J.M., Marco-Pallares J., Sebastián-Galles, Ortiz H., Pujol J., Rodríguez-Fornells A. Time course and functional neuroanatomy of speech segmentation in adult. NeuroImage. 2009;48:541–553. doi: 10.1016/j.neuroimage.2009.06.069. [DOI] [PubMed] [Google Scholar]
- Cunillera T., Toro J.M., Sebastián-Galles N., Rodríguez-Fornells A. The effects of stress and statistical cues on continuous speech segmentation: an event-related brain potential study. Brain Res. 2006;1123:168–178. doi: 10.1016/j.brainres.2006.09.046. [DOI] [PubMed] [Google Scholar]
- Davachi L., Maril A., Wagner A.D. When keeping in mind supports later bringing to mind: neural markers of phonological rehearsal predict subsequent remembering. J. Cogn. Neurosci. 2001;13:1059–1070. doi: 10.1162/089892901753294356. [DOI] [PubMed] [Google Scholar]
- Elbro C., Dalby M., Maarbjerg S. Language-learning impairments: a 30-year follow-up of language-impaired children with and without psychiatric, neurological and cognitive difficulties. Int. J. Lang. Commun. Disord. 2011;46:437–448. doi: 10.1111/j.1460-6984.2011.00004.x. [DOI] [PubMed] [Google Scholar]
- Ellis Weismer S., Plante E., Jones M., Tomblin J.B. A functional magnetic resonance imaging investigation of verbal working memory in adolescents with specific language impairment. J. Speech Lang. Hear. Res. 2005;48:405–425. doi: 10.1044/1092-4388(2005/028). [DOI] [PubMed] [Google Scholar]
- Erickson L.C., Theissen E.D. Statistical learning of language: theory, validity, and predictions of a statistical learning account of language acquisition. Dev. Rev. 2015;37:66–108. [Google Scholar]
- Evans J.L., Saffran J.R., Robe-Torres K. Statistical learning in children with specific language impairment. J. Speech Lang. Hear. Res. 2009;52:321–335. doi: 10.1044/1092-4388(2009/07-0189). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fidler L.J., Plante E., Vance R. Identification of adults with developmental language impairments. Am. J. Speech Lang. Pathol. 2011;20:2–13. doi: 10.1044/1058-0360(2010/09-0096). [DOI] [PubMed] [Google Scholar]
- Gerken L., Aslin R.N. Thirty years of research on infant speech perception: the legacy of Peter W. Jusczyk. Language Learning and Development. 2005;1:5–21. [Google Scholar]
- Gómez R.L., Lakusta L. A first step in form-based category abstractions by 12 month-old infants. Dev. Sci. 2004;7:567–580. doi: 10.1111/j.1467-7687.2004.00381.x. [DOI] [PubMed] [Google Scholar]
- Greve D.N., Fischl B. Accurate and robust brain image alignment using boundary-based registration. NeuroImage. 2009;48(1):63–72. doi: 10.1016/j.neuroimage.2009.06.060. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grunow H., Spaulding T.J., Gómez R.L., Plante E. The effects of variation on learning word order rules by adults with and without language-based learning disabilities. J. Commun. Disord. 2006;39:158–170. doi: 10.1016/j.jcomdis.2005.11.004. [DOI] [PubMed] [Google Scholar]
- Hoeft F., Meyler A., Hernandez A., Juel C., Taylor-Hill H., Martindale J.L. Functional and morphometric brain dissociation between dyslexia and reading disability. Proc. Natl. Acad. Sci. U. S. A. 2007;104:4234–4239. doi: 10.1073/pnas.0609399104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hickok G. The cortical organization of speech processing: feedback control and predictive coding the context of a dual-stream model. J. Commun. Disord. 2012;45:393–402. doi: 10.1016/j.jcomdis.2012.06.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hsu H.J., Tomblin J.B., Christiansen M.H. Impaired statistical learning of nonadjacent dependencies in adolescents with specific language impairment. Front. Psychol. 2014;5:1–10. doi: 10.3389/fpsyg.2014.00175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Isaki E., Spaulding T.J., Plante E. Contributions of verbal and memory demands to verbal memory performance in language-learning disabilities. J. Commun. Disord. 2008;41:512–530. doi: 10.1016/j.jcomdis.2008.03.006. [DOI] [PubMed] [Google Scholar]
- Johnson C.J., Beitchman J.H., Brownlie E.B. Twenty-year follow-up of children with and without speech-language impairments: family, educational, occupational, & quality of life outcomes. Am. J. Speech Lang. Pathol. 2010;19:51–65. doi: 10.1044/1058-0360(2009/08-0083). [DOI] [PubMed] [Google Scholar]
- Kalm K., Norris D. The representation of order information in auditory-verbal short-term memory. J. Neurosci. 2014;34:6879–6886. doi: 10.1523/JNEUROSCI.4104-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karmiloff-Smith A., Plunket K., Johnson M., Elman J., Bates E. What does it mean to claim that something is ‘innate’? Response to Clark, Harris, Lightfoot and Samuels. Mind Lang. 1998;13(4):588–604. [Google Scholar]
- Karuza E.A., Newport E.L., Aslin R.N., Starling S.J., Tivarus M.E., Bavelier D. The neural correlates of statistical learning in a word segmentation task: an fMRI study. Brain Lang. 2013;127:46–54. doi: 10.1016/j.bandl.2012.11.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kittleson M., Aguilar J.M., Tokerud G.L., Plante E., Asbjørnsen A.E. Implicit language learning: adult's ability to segment words in Norwegian. Biling. Lang. Congn. 2010;13:513–523. doi: 10.1017/S1366728910000039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kline T.J.B. Psychological Testing: a Practical Approach to Design and Evaluation. Sage Publications; Thousand Oaks, CA: 2005. Classical test theory: Assumptions, equations, limitations, and item analyses; pp. 91–107. [Google Scholar]
- Lancaster J.L., Laird A.R., Eickhoff S., Martinez M.J., Fox P.M., Fox P.T. Automated regional behavioral analysis for human brain images. Front. Neuroinform. 2012;6:23. doi: 10.3389/fninf.2012.00023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leonard L.B., Deevy P., Fey M.E., Brendin-Oja S.L. Sentence comprehension in specific language impairment: a task designed to distinguish between cognitive capacity and syntactic complexity. J. Speech Lang. Hear. Res. 2013;56:577–589. doi: 10.1044/1092-4388(2012/11-0254). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li X.-L., Adali T. IEEE International Conference on Acoustics, Speech and Signal Processing. Proceedings. 2010. Blind spatiotemporal separation of second and/or higher-order correlated sources by entropy rate minimization; pp. 1934–1937. [Google Scholar]
- Mattys S.L., Jusczyk P.W., Luce P.A., Morgan J.L. Phonotactic and prosodic effects on word segmentation in infants. Cogn. Psychol. 1999;38:465–494. doi: 10.1006/cogp.1999.0721. [DOI] [PubMed] [Google Scholar]
- McKeown M.J., Makeig S., Brown G.G., Jung T., Kinderman S.S., Bell A.J., Sejnowski T.J. Analysis of fMRI data by blind separation into independent spatial components. Hum. Brain Mapp. 1998;6:160–188. doi: 10.1002/(SICI)1097-0193(1998)6:3<160::AID-HBM5>3.0.CO;2-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McNealy K., Mazziotta J.C., Dapretto M. Cracking the language code: neural mechanisms underlying speech parsing. J. Neurosci. 2006;26:7629–7639. doi: 10.1523/JNEUROSCI.5501-05.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McNealy K., Mazziotta J.C., Dapretto M. The neural basis of speech parsing in children and adults. Dev. Sci. 2010;13:385–406. doi: 10.1111/j.1467-7687.2009.00895.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morice R., McNicol D. The comprehension and production of complex syntax in schizophrenia. Cortex. 1985;21:567–580. doi: 10.1016/s0010-9452(58)80005-2. [DOI] [PubMed] [Google Scholar]
- Montgomery J.M., Evans J.L. Complex sentence comprehension and working memory in children with specific language impairment. J. Speech Lang. Hear. Res. 2009;52:269–288. doi: 10.1044/1092-4388(2008/07-0116). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Newman-Norlund R.D., Frey, Petitto L.-A., Grafton S.T. Anatomic substrates of visual and auditory miniature second-language learning. J. Cogn. Neurosci. 2006;18:1984–1997. doi: 10.1162/jocn.2006.18.12.1984. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Optiz B., Kotz S.A. Ventral premotor lesions disrupt learning of sequential grammatical structures. Cortex. 2012;48:664–673. doi: 10.1016/j.cortex.2011.02.013. [DOI] [PubMed] [Google Scholar]
- Patterson D., Hicks T., Dufilie A., Grinstein G., Plante E. Dynamic data visualization with weave and brain choropleths. PLoS One. 2015:1–17. doi: 10.1371/journal.pone.0139453. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Plante E., Almryde K., Patterson D.K., Vance C.J., Asbjønsen A.E. Language lateralization shifts with learning by adults. Laterality: Asymmetries of Body, Brain, & Cognition. 2015;20:306–324. doi: 10.1080/1357650X.2014.963597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Plante E., Vance R., Moody A., Gerken L.A. What influences children's conceptualization of language input? J. Speech Lang. Hear. Res. 2013;56:1613–1624. doi: 10.1044/1092-4388(2013/12-0129). [DOI] [PubMed] [Google Scholar]
- Plante E., Patterson D., Dailey N.S., Almryde K.R., Fridriksson J. Dynamic changes in network activations characterize early learning of a natural language. Neuropsychologia. 2014;62:77–86. doi: 10.1016/j.neuropsychologia.2014.07.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Plante E., Patterson D.K., Gómez R., Almryde K.R., White M.G., Asbjørnsen A.E. The nature of the language input affects brain activation during learning from a natural language. Neurolinguistics. 2015;36:17–34. doi: 10.1016/j.jneuroling.2015.04.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Plante E., Gómez R., Gerken L.A. Sensitivity to word order cues by normal and language/learning disabled adults. J. Commun. Disord. 2002;35:453–462. doi: 10.1016/s0021-9924(02)00094-1. [DOI] [PubMed] [Google Scholar]
- Plante E., Ramage A., Maglöire J. Processing narratives for verbatim and gist information by adults with language learning disabilities: a functional neuroimaging study. Learn. Disabil. Res. Pract. 2006;21:61–76. [Google Scholar]
- Price C.J. The anatomy of language: a review of 100 fMRI studies published in 2009. Ann. N. Y. Acad. Sci. 2010;1191:62–88. doi: 10.1111/j.1749-6632.2010.05444.x. [DOI] [PubMed] [Google Scholar]
- Price C.J. A review and synthesis of the first 20 years of PET and fMRI studies of heard speech, spoken language, and reading. NeuroImage. 2012;62:816–847. doi: 10.1016/j.neuroimage.2012.04.062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Richardson J., Harris L., Plante E., Gerken L.A. Subcategory learning in normal and language learning-disabled adults: how much information do they need? J. Speech Lang. Hear. Res. 2006;49:1257–1266. doi: 10.1044/1092-4388(2006/090). [DOI] [PubMed] [Google Scholar]
- Rachakonda S., Egolf E., Correa N., Calhoun V. Group ICA of fMRI Toolbox (GIFT) Manual. 2007. http://mialab.mrn.org/software/#gica Available at. (Downloaded 14.12.12)
- Saffran J.R. Statistical language learning: mechanisms and constraints. Curr. Dir. Psychol. Sci. 2003;12:110–114. [Google Scholar]
- Semel E., Wiig E.H., Secord W. fourth ed. PsychCorp; San Antonio, TX: 2003. The Clinical Evaluation of Language Fundamentals. [Google Scholar]
- Stothard S.E., Snowling M.J., Bishop D.M.V., Chipchase B.B., Kaplan C.A. Language-impaired preschoolers: a follow-up into adolescence. J. Speech Lang. Hear. Res. 1998;41:407–418. doi: 10.1044/jslhr.4102.407. [DOI] [PubMed] [Google Scholar]
- Smith S.M. Fast robust automated brain extraction. Hum. Brain Mapp. 2002;17:143155. doi: 10.1002/hbm.10062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thorton R.C., Rodionov R., Laufs H., Vulliemoz S., Vaudano A., Carmichael D., Cannadathu S., Guye M., McEvoy A., Lhatoo S., Bartolomei F., Chauvel P., Diehl B., De Martino F., Elwes R.C.D., Walker M.C., Duncan J.S., Lemieux L. Imaging haemodynamic changes related to seizures: comparison of EEG-based general linear model, independent component analysis of fMRI and intractranial EEG. NeuroImage. 2010;53:196205. doi: 10.1016/j.neuroimage.2010.05.064. [DOI] [PubMed] [Google Scholar]
- Torkildsen J., Dailey N., Aguilar J.M., Gómez R., Plante E. Exemplar variability facilitates rapid learning of an otherwise unlearnable grammar by individuals with language impairment. J. Speech Lang. Hear. Res. 2013;56:618–629. doi: 10.1044/1092-4388(2012/11-0125). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vigneau M., Beaucousin V., Hervé P.Y., Duffau H., Crivello F., Houdé O., Mazoyer B., Tzourio-Mazoyer N. Meta-analyzing left hemisphere language areas: phonology, semantics, and sentence processing. NeuroImage. 2006;30:1414–1432. doi: 10.1016/j.neuroimage.2005.11.002. [DOI] [PubMed] [Google Scholar]
- Wilson M., Allen D.D., Li J.C. Improving measurement in health education and health behavioral research using item response modeling: comparison with the classical test theory approach. Health Educ. Res. 2006;21:i19–i32. doi: 10.1093/her/cyl053. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
GLM analysis results. Images are thresholded at a FWE rate of p < 0.05.
Regions of significant activation (p < 0.01) for each task-related independent component (IC) during each scan. XYZ coordinates indicate the location of the peak activation within each region, using the Harvard-Oxford cortical and subcortical atlases in FSL (http://www.cma.mgh.harvard.edu/fsl_atlas.html; Desikan et al., 2006)1. Regions were extracted from the ICA data using a process developed byPatterson et al., 2015.2