

Summary
We introduce a new Empirical Bayes approach for large-scale hypothesis testing, including estimating false discovery rates (FDRs), and effect sizes. This approach has two key differences from existing approaches to FDR analysis. First, it assumes that the distribution of the actual (unobserved) effects is unimodal, with a mode at 0. This “unimodal assumption” (UA), although natural in many contexts, is not usually incorporated into standard FDR analysis, and we demonstrate how incorporating it brings many benefits. Specifically, the UA facilitates efficient and robust computation—estimating the unimodal distribution involves solving a simple convex optimization problem—and enables more accurate inferences provided that it holds. Second, the method takes as its input two numbers for each test (an effect size estimate and corresponding standard error), rather than the one number usually used (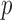 value or
value or 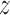 score). When available, using two numbers instead of one helps account for variation in measurement precision across tests. It also facilitates estimation of effects, and unlike standard FDR methods, our approach provides interval estimates (credible regions) for each effect in addition to measures of significance. To provide a bridge between interval estimates and significance measures, we introduce the term “local false sign rate” to refer to the probability of getting the sign of an effect wrong and argue that it is a superior measure of significance than the local FDR because it is both more generally applicable and can be more robustly estimated. Our methods are implemented in an R package ashr available from http://github.com/stephens999/ashr.
score). When available, using two numbers instead of one helps account for variation in measurement precision across tests. It also facilitates estimation of effects, and unlike standard FDR methods, our approach provides interval estimates (credible regions) for each effect in addition to measures of significance. To provide a bridge between interval estimates and significance measures, we introduce the term “local false sign rate” to refer to the probability of getting the sign of an effect wrong and argue that it is a superior measure of significance than the local FDR because it is both more generally applicable and can be more robustly estimated. Our methods are implemented in an R package ashr available from http://github.com/stephens999/ashr.
Keywords: Empirical Bayes, False discovery rates, Multiple testing, Shrinkage, Unimodal
1. INTRODUCTION
Since its introduction in in Benjamini and Hochberg (1995), the “False Discovery Rate” (FDR) has quickly established itself as a key concept in modern statistics, and the primary tool by which most practitioners handle large-scale multiple testing in which the goal is to identify the non-zero “effects” among a large number of imprecisely measured effects.
Here we consider an Empirical Bayes (EB) approach to FDR. This idea is, of course, far from new: indeed, the notion that EB approaches could be helpful in handling multiple comparisons predates introduction of the FDR (e.g. Greenland and Robins, 1991). More recently, EB approaches to the FDR have been extensively studied by several authors, especially Efron and co-workers (Efron and others, 2001; Efron and Tibshirani, 2002; Efron and others, 2003; Efron, 2008, 2010); see also Kendziorski and others (2003), Newton and others (2004), Datta and Datta (2005), and Muralidharan (2010), for example.
So what is the “New Deal” here? We introduce two simple ideas that are new (at least compared with existing widely used FDR pipelines) and can substantially affect inference. The first idea is to assume that the distribution of effects is unimodal. We provide a simple, fast, and stable computer implementation for performing EB inference under this assumption, and illustrate how it can improve inferences when the unimodal assumption (UA) is correct. The second idea is to use two numbers—effect sizes and their standard errors—rather than just one—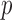 values or
values or 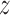 scores—to summarize each measurement. Here we use this idea to allow variation in measurement precision to be better accounted for, avoiding a problem with standard pipelines that poor-precision measurements can inflate estimated FDR. (Ploner and others (2006) also suggest using more than one number in FDR analyses, taking a rather different approach to the one used here.)
scores—to summarize each measurement. Here we use this idea to allow variation in measurement precision to be better accounted for, avoiding a problem with standard pipelines that poor-precision measurements can inflate estimated FDR. (Ploner and others (2006) also suggest using more than one number in FDR analyses, taking a rather different approach to the one used here.)
In addition to these two new ideas, we highlight a third idea that is old but which remains under-used in practice: the idea that it may be preferable to focus on estimation rather than on testing. In principle, Bayesian approaches can naturally unify testing and estimation into a single framework—testing is simply estimation with some positive prior probability that the effect is exactly zero. However, despite ongoing interest in this area from both frequentist (Benjamini and Yekutieli, 2005) and Bayesian (Zhao and Gene Hwang, 2012; Gelman and others, 2012) perspectives, in practice large-scale studies that assess many effects almost invariably focus on testing significance and controlling the FDR, and not on estimation. To help provide a bridge between FDR and estimation we introduce the term “local false sign rate” (lfsr), which is analogous to the “local false discovery rate” (lfdr) (Efron, 2008), but which measures confidence in the sign of each effect rather than confidence in each effect being non-zero. We show that in some settings, particularly those with many discoveries, the 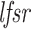 and
and 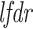 can be quite different and emphasize benefits of the
can be quite different and emphasize benefits of the 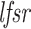 , particularly its increased robustness to modeling assumptions.
, particularly its increased robustness to modeling assumptions.
Although we focus here on FDR applications, the idea of performing EB inference using a flexible unimodal prior distribution is useful more generally. For example, the methods described here can be applied directly to perform shrinkage estimation for wavelet denoising (Donoho and Johnstone, 1995), an idea explored in a companion paper (Xing and Stephens, 2016). And analogous ideas can be used to perform EB inference for variances (Lu and Stephens, 2016). Importantly, and perhaps surprisingly, our work demonstrates how EB inference under a general UA is, if anything, computationally simpler than commonly used more restrictive assumptions—such as a spike and slab or Laplace prior distribution (Johnstone and Silverman, 2004)—as well as being more flexible.
We refer to our EB method as adaptive shrinkage, or ash, to emphasize its key points: using a unimodal prior naturally results in shrinkage estimation, and the shrinkage is adaptive to both the amount of signal in the data and the measurement precision of each observation. We provide implementations in an R package, ashr, available at http://github.com/stephens999/ashr. Code and instructions for reproducing analyses and figures in this paper are at https://github.com/stephenslab/ash.
2. METHODS
2.1. Model outline
Here we describe the simplest version of the method, before briefly discussing embellishments we have also implemented. Implementation details are given in Supplementary Information, see supplementary material available at Biostatistics online.
Let 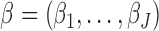 denote
denote 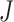 “effects” of interest. For example, in a genomics application
“effects” of interest. For example, in a genomics application 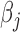 might be the difference in the mean (log) expression of gene
might be the difference in the mean (log) expression of gene 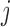 in two conditions. We tackle both the problem of testing the null hypotheses
in two conditions. We tackle both the problem of testing the null hypotheses 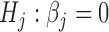 , and the more general problem of estimating, and assessing uncertainty in,
, and the more general problem of estimating, and assessing uncertainty in, 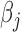 .
.
Assume that the available data are estimates 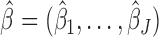 of the effects, and corresponding (estimated) standard errors
of the effects, and corresponding (estimated) standard errors 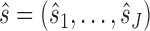 . Our goal is to compute a posterior distribution for
. Our goal is to compute a posterior distribution for 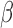 given
given 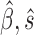 , which by Bayes theorem is
, which by Bayes theorem is
| (2.1) |
For 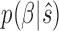 we assume that the
we assume that the 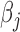 are independent from a unimodal distribution
are independent from a unimodal distribution 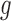 . This UA is a key assumption that distinguishes our approach from previous EB approaches to FDR analysis. A simple way to implement the UA is to assume that
. This UA is a key assumption that distinguishes our approach from previous EB approaches to FDR analysis. A simple way to implement the UA is to assume that 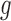 is a mixture of a point mass at 0 and a mixture of zero-mean normal distributions:
is a mixture of a point mass at 0 and a mixture of zero-mean normal distributions:
| (2.2) |
| (2.3) |
where 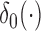 denotes a point mass on 0, and
denotes a point mass on 0, and 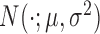 denotes the density of the normal distribution with mean
denotes the density of the normal distribution with mean 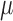 and variance
and variance 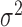 . Here we take
. Here we take 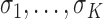 to be a large and dense grid of fixed positive numbers spanning a range from very small to very big (so
to be a large and dense grid of fixed positive numbers spanning a range from very small to very big (so 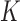 is fixed and large). We encourage the reader to think of this grid as becoming infinitely large and dense, as a non-parametric limit, although of course in practice we use a finite grid—see Implementation Details. The mixture proportions
is fixed and large). We encourage the reader to think of this grid as becoming infinitely large and dense, as a non-parametric limit, although of course in practice we use a finite grid—see Implementation Details. The mixture proportions 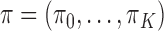 , which are non-negative and sum to one, are hyper-parameters to be estimated.
, which are non-negative and sum to one, are hyper-parameters to be estimated.
For the likelihood 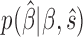 we assume a normal approximation:
we assume a normal approximation:
| (2.4) |
This simple model features both the key ideas we want to emphasize in this paper: the UA is encapsulated in (2.3) while the different measurement precision of different observations is encapsulated in the likelihood (2.4)—specifically, observations with larger standard error will have a flatter likelihood, and therefore have less impact on inference. However, the model also has several additional assumptions that can be relaxed. Specifically,
1. The form (2.3) implies that
 is symmetric about 0. More flexibility can be obtained using mixtures of uniforms (Supplementary Information, equation S.1.1); indeed this allows
is symmetric about 0. More flexibility can be obtained using mixtures of uniforms (Supplementary Information, equation S.1.1); indeed this allows  to approximate any unimodal distribution.
to approximate any unimodal distribution.2. The model (2.2) assumes that the effects are identically distributed, independent of their standard errors
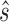 . This can be relaxed [see (3.2)].
. This can be relaxed [see (3.2)].3. The normal likelihood (2.4) can be generalized to a
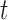 likelihood [see (Supplementary Information, equation S.1.2)].
likelihood [see (Supplementary Information, equation S.1.2)].4. We can allow for the mode of
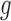 to be non-zero, estimated from the data by maximum likelihood.
to be non-zero, estimated from the data by maximum likelihood.
These embellishments, detailed in supplementary material available at Biostatistics online, are implemented in our software. Other limitations are harder to relax, most notably the independence and conditional independence assumptions (which are also made by most existing approaches). Correlations among tests certainly arise in practice, either due to genuine correlations or due to unmeasured confounders, and their potential impact on estimated FDRs is important to consider whatever analysis methods are used (Efron, 2007; Leek and Storey, 2007).
2.2. Fitting the model
Together, (2.2)–(2.4) imply that 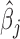 are independent with
are independent with
| (2.5) |
where we define 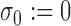 .
.
The usual EB approach to fitting this model would involve two steps:
1. Estimate the hyper-parameters
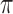 by maximizing the likelihood
by maximizing the likelihood 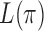 , given by (2.5), yielding
, given by (2.5), yielding 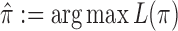 .
.2. Compute quantities of interest from the conditional distributions
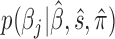 . For example, the evidence against the null hypothesis
. For example, the evidence against the null hypothesis 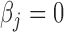 can be summarized by
can be summarized by 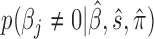 .
.
Both steps are straightforward. Step 1 is a convex optimization problem, and can be solved quickly and reliably using interior point methods (Boyd and Vandenberghe, 2004; Koenker and Mizera, 2013). (Alternatively a simple EM algorithm can also work well, particularly for modest 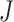 ; see http:://stephenslab.github.io/ash/analysis/IPvsEM.html.) And the conditional distributions
; see http:://stephenslab.github.io/ash/analysis/IPvsEM.html.) And the conditional distributions 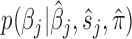 in Step 2 are analytically available, each a mixture of a point mass on zero and
in Step 2 are analytically available, each a mixture of a point mass on zero and 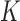 normal distributions. The simplicity of Step 1 is due to our use of a fixed grid for
normal distributions. The simplicity of Step 1 is due to our use of a fixed grid for 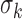 in (2.3), instead of estimating
in (2.3), instead of estimating 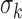 . This simple device may be useful in other applications.
. This simple device may be useful in other applications.
Here we slightly modify this usual procedure: instead of obtaining 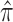 by maximizing the likelihood, we maximize a penalized likelihood [see (Supplementary Information, equation S.2.5)], where the penalty encourages
by maximizing the likelihood, we maximize a penalized likelihood [see (Supplementary Information, equation S.2.5)], where the penalty encourages 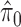 to be as big as possible whilst remaining consistent with the observed data. We introduce this penalty because in FDR applications it is considered desirable to avoid underestimating
to be as big as possible whilst remaining consistent with the observed data. We introduce this penalty because in FDR applications it is considered desirable to avoid underestimating 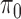 so as to avoid underestimating the FDR.
so as to avoid underestimating the FDR.
Our R package implementation typically takes 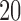 s on a modern laptop for
s on a modern laptop for 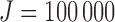 , and scales linearly with
, and scales linearly with 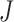 .
.
2.3. The local FDR and local false sign rate
As noted above, the posterior distributions 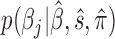 have a simple analytic form. In practice it is common, and desirable, to summarize these distributions to convey the “significance” of each observation
have a simple analytic form. In practice it is common, and desirable, to summarize these distributions to convey the “significance” of each observation 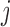 . One natural measure of the significance of observation
. One natural measure of the significance of observation 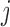 is its “local FDR” (Efron, 2008)
is its “local FDR” (Efron, 2008)
| (2.6) |
In words, 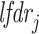 is the probability, given the observed data, that effect
is the probability, given the observed data, that effect 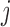 would be a false discovery, if we were to declare it a discovery.
would be a false discovery, if we were to declare it a discovery.
The 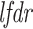 , like most measures of significance, is rooted in the hypothesis testing paradigm which focuses on whether or not an effect is exactly zero. This paradigm is popular, despite the fact that many statistical practitioners have argued that it is often inappropriate because the null hypothesis
, like most measures of significance, is rooted in the hypothesis testing paradigm which focuses on whether or not an effect is exactly zero. This paradigm is popular, despite the fact that many statistical practitioners have argued that it is often inappropriate because the null hypothesis 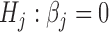 is often implausible. For example, Tukey (1991) argued that “All we know about the world teaches us that the effects of
is often implausible. For example, Tukey (1991) argued that “All we know about the world teaches us that the effects of 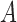 and
and 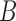 are always different—in some decimal place—for any
are always different—in some decimal place—for any 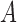 and
and 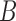 . Thus asking `Are the effects different?’ is foolish.” Instead, Tukey (Tukey, 1962, page 32) suggested that one should address
. Thus asking `Are the effects different?’ is foolish.” Instead, Tukey (Tukey, 1962, page 32) suggested that one should address
... the more meaningful question: “is the evidence strong enough to support a belief that the observed difference has the correct sign?”
Along the same lines, Gelman and co-workers (Gelman and Tuerlinckx, 2000; Gelman and others, 2012) suggest focusing on “type S errors,” meaning errors in sign, rather than the more traditional type I errors.
Motivated by these suggestions, we define the “local False Sign Rate” for effect 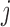 ,
, 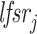 , to be the probability that we would make an error in the sign of effect
, to be the probability that we would make an error in the sign of effect 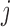 if we were forced to declare it either positive or negative. Specifically,
if we were forced to declare it either positive or negative. Specifically,
| (2.7) |
To illustrate, suppose that
Then from (2.7) 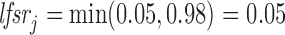 (and, from (2.6),
(and, from (2.6), 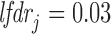 ). This
). This 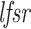 corresponds to the fact that, given these results, we would guess that
corresponds to the fact that, given these results, we would guess that 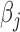 is negative, with probability
is negative, with probability 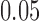 of being wrong.
of being wrong.
As our notation suggests, 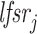 is analogous to
is analogous to 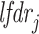 : whereas small values of
: whereas small values of 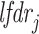 indicate that we can be confident that
indicate that we can be confident that 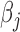 is non-zero, small values of
is non-zero, small values of 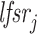 indicate that we can be confident in the sign of
indicate that we can be confident in the sign of 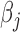 . Of course, being confident in the sign of an effect logically implies that we are confident it is non-zero, and this is reflected in the fact that
. Of course, being confident in the sign of an effect logically implies that we are confident it is non-zero, and this is reflected in the fact that 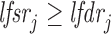 [this follows from the definition because both the events
[this follows from the definition because both the events 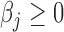 and
and 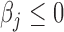 in (2.7) include the event
in (2.7) include the event 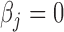 ]. In this sense
]. In this sense 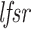 is a more conservative measure of significance than
is a more conservative measure of significance than 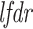 . More importantly,
. More importantly, 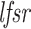 is more robust to modeling assumptions (see Results).
is more robust to modeling assumptions (see Results).
From these “local” measures of significance, we can also compute average error rates over subsets of observations 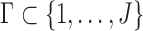 . For example,
. For example,
| (2.8) |
is an estimate of the total proportion of errors made if we were to estimate the sign of all effects in 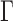 [an error measure analogous to the usual (tail) FDR]. And, we can define the “
[an error measure analogous to the usual (tail) FDR]. And, we can define the “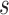 -value”
-value”
| (2.9) |
as a measure of significance analogous to Storey’s 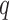 -value (Storey, 2003). [Replacing
-value (Storey, 2003). [Replacing 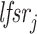 with
with 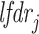 in (2.8) and (2.9) gives estimates for the usual
in (2.8) and (2.9) gives estimates for the usual 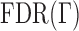 , and the
, and the 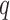 -values respectively.]
-values respectively.]
2.4. Related work
2.4.1. Previous approaches focused on FDR
Among previous methods that explicitly consider FDR, our work seems naturally compared with the EB methods of of Efron (2008) and Muralidharan (2010) (implemented in the R packages locfdr and mixfdr, respectively) and with the widely used methods from Storey (2003) (implemented in the R package qvalue), which although not formally an EB approach, shares some elements in common.
There are two key differences between our approach and these existing methods. First, whereas these existing methods take as input a single number—either a 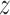 score (locfdr and mixfdr), or a
score (locfdr and mixfdr), or a 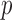 value (qvalue)—for each effect, we instead work with two numbers (
value (qvalue)—for each effect, we instead work with two numbers (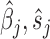 ). Here we are building on Wake-field (2009), which develops Bayes Factors testing individual null hypotheses in a similar way; see also Efron (1993). Using two numbers instead of one clearly has the potential to be more informative, as illustrated in Results (Figure 4).
). Here we are building on Wake-field (2009), which develops Bayes Factors testing individual null hypotheses in a similar way; see also Efron (1993). Using two numbers instead of one clearly has the potential to be more informative, as illustrated in Results (Figure 4).
Fig. 4.

Simulations showing how, with existing methods, but not ash, poor-precision observations can contaminate signal from good-precision observations. (a) Density histograms of 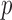 values for good-precision, poor-precision, and combined observations. The combined data show less signal than the good-precision data, due to the contamination effect of the poor-precision measurements. (b) Results of different methods applied to good-precision observations only (
values for good-precision, poor-precision, and combined observations. The combined data show less signal than the good-precision data, due to the contamination effect of the poor-precision measurements. (b) Results of different methods applied to good-precision observations only (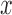 -axis) and combined data (
-axis) and combined data (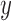 -axis). Each point shows the “significance” (
-axis). Each point shows the “significance” (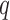 values from qvalue;
values from qvalue; 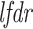 for locfdr;
for locfdr; 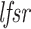 for ash) of a good-precision observation under the two different analyses. For existing methods including the poor-precision observations reduces significance of good-precision observations, whereas for ash the poor-precision observations have little effect (because they have a very flat likelihood). (c) The relationship between
for ash) of a good-precision observation under the two different analyses. For existing methods including the poor-precision observations reduces significance of good-precision observations, whereas for ash the poor-precision observations have little effect (because they have a very flat likelihood). (c) The relationship between 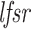 and
and 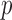 -value is different for good-precision (
-value is different for good-precision (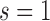 ) and low-precision (
) and low-precision (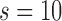 ) measurements: ash assigns the low-precision measurements a higher
) measurements: ash assigns the low-precision measurements a higher 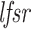 , effectively downweighting them. (d) Trade-off between true positives (
, effectively downweighting them. (d) Trade-off between true positives (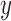 ) vs false positives (
) vs false positives (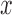 ) as the significance threshold (
) as the significance threshold (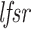 or
or 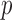 value) is varied. By downweighting the low-precision observations ash re-orders the significance of observations, producing more true positives at a given number of false positives. It is important to note that this behaviour of ash depends on choice of
value) is varied. By downweighting the low-precision observations ash re-orders the significance of observations, producing more true positives at a given number of false positives. It is important to note that this behaviour of ash depends on choice of 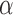 . See Section 3.2.1 for discussion.
. See Section 3.2.1 for discussion.
Second, our UA that the effects are unimodal about zero, is an assumption not made by existing methods, and one that we argue to be both plausible and beneficial in many contexts. Although the UA will not hold in all settings, it will often be reasonable, especially in FDR-related contexts that focus on rejecting the null hypotheses 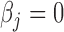 . This is because if “
. This is because if “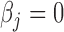 ” is a plausible null hypothesis then “
” is a plausible null hypothesis then “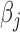 very near 0” should also be plausible. Further, it seems reasonable to expect that larger effects become decreasingly plausible, and so the distribution of the effects will be unimodal about 0. To paraphrase Tukey, “All we know about the world teaches us that large effects are rare, whereas small effects abound.” We emphasize that the UA relates to the distribution of all effects, and not only the detectable effects (i.e. those that are significantly different from zero). It is very likely that the distribution of detectable non-zero effects will be multimodal, with one mode for detectable positive effects and another for detectable negative effects, and the UA does not contradict this.
very near 0” should also be plausible. Further, it seems reasonable to expect that larger effects become decreasingly plausible, and so the distribution of the effects will be unimodal about 0. To paraphrase Tukey, “All we know about the world teaches us that large effects are rare, whereas small effects abound.” We emphasize that the UA relates to the distribution of all effects, and not only the detectable effects (i.e. those that are significantly different from zero). It is very likely that the distribution of detectable non-zero effects will be multimodal, with one mode for detectable positive effects and another for detectable negative effects, and the UA does not contradict this.
In further support of the UA, note that large-scale regression methods almost always make the UA for the regression coefficients, which are analogous to the “effects” we estimate here. Common choices of unimodal distribution for regression coefficients include the spike and slab, Laplace, 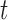 , normal-gamma, normal-inverse-gamma, or horseshoe priors (Carvalho and others, 2010). These are all less flexible than our approach, which provides for general unimodal distributions, and it may be fruitful to apply our methods to the regression context; indeed see Erbe and others (2012) for work in this vein. Additionally, the UA can be motivated by its effect on point estimates, which is to “shrink” the estimates towards the mode—such shrinkage is desirable from several standpoints for improving estimation accuracy. Indeed most model-based approaches to shrinkage make parametric assumptions that obey theUA(e.g. Johnstone and Silverman, 2004).
, normal-gamma, normal-inverse-gamma, or horseshoe priors (Carvalho and others, 2010). These are all less flexible than our approach, which provides for general unimodal distributions, and it may be fruitful to apply our methods to the regression context; indeed see Erbe and others (2012) for work in this vein. Additionally, the UA can be motivated by its effect on point estimates, which is to “shrink” the estimates towards the mode—such shrinkage is desirable from several standpoints for improving estimation accuracy. Indeed most model-based approaches to shrinkage make parametric assumptions that obey theUA(e.g. Johnstone and Silverman, 2004).
Besides its plausibility, the UA has two important practical benefits: it facilitates more accurate estimates of FDR-related quantities, and it yields simple algorithms that are both computationally and statistically stable (see Results).
2.4.2. Other work
There is also a very considerable literature that does not directly focus on the FDR problem, but which involves similar ideas and methods. Among these, a paper about deconvolution (Cordy and Thomas, 1997) is most similar, methodologically, to our work here: indeed, this paper includes all the elements of our approach outlined above, except for the point mass on 0 and corresponding penalty term. However, the focus is very different: Cordy and Thomas (1997) focuses entirely on estimating 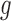 , whereas our primary focus is on estimating
, whereas our primary focus is on estimating 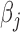 . Also, they provide no software implementation.
. Also, they provide no software implementation.
More generally, the related literature is too large to review comprehensively, but relevant key-words include “empirical Bayes,” “shrinkage,” “deconvolution,” “semi-parametric,” “shape-constrained,” and “heteroskedastic.” Some pointers to recent papers in which other relevant citations can be found include. Xie and others (2012), Sarkar and others (2014), Koenker and Mizera (2014), and Efron (2016). Much of the literature focusses on the homoskedastic case (i.e. 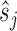 all equal) whereas we allow for heteroskedasticity. And much of the recent shrinkage-oriented literature focuses only on point estimation of
all equal) whereas we allow for heteroskedasticity. And much of the recent shrinkage-oriented literature focuses only on point estimation of 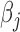 , whereas for FDR-related applications measures of uncertainty are essential. Several recent papers consider more flexible non-parametric assumptions on
, whereas for FDR-related applications measures of uncertainty are essential. Several recent papers consider more flexible non-parametric assumptions on 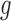 than the UA assumption we make here. In particular, Jiang and Zhang (2009) and Koenker and Mizera (2014) consider the unconstrained non-parametric maximum likelihood estimate (NPMLE) for
than the UA assumption we make here. In particular, Jiang and Zhang (2009) and Koenker and Mizera (2014) consider the unconstrained non-parametric maximum likelihood estimate (NPMLE) for 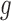 . These methods may be useful in settings where the UA assumption is considered too restrictive. However, the NPMLE for
. These methods may be useful in settings where the UA assumption is considered too restrictive. However, the NPMLE for 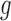 is a discrete distribution, which will induce a discrete posterior distribution on
is a discrete distribution, which will induce a discrete posterior distribution on 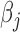 , and so although the NPMLE may perform well for point estimation, it may not adequately reflect uncertainty in
, and so although the NPMLE may perform well for point estimation, it may not adequately reflect uncertainty in 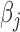 . To address this some regularization on
. To address this some regularization on 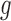 (e.g. as in Efron, 2016) may be necessary. Indeed, one way of thinking about the UA is as a way to regularize
(e.g. as in Efron, 2016) may be necessary. Indeed, one way of thinking about the UA is as a way to regularize 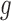 .
.
3. RESULTS
We compare results of ash with existing FDR-based methods implemented in the R packages qvalue (v2.1.1!), locfdr (v1.1-8!), and mixfdr (v1.0, from https://cran.r-project.org/src/contrib/Archive/mixfdr/). In all our simulations we assume that the test statistics follow the expected theoretical distribution under the null, and we indicate this to locfdr using nulltype=0 and to mixfdr using theonull=TRUE. Otherwise all packages were used with default options.
3.1. Effects of the UA
Here we consider the effects of making the UA. To isolate these effects we consider the simplest case, where every observation has the same standard error, 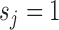 . That is,
. That is, 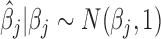 and
and 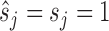 . In this case the
. In this case the 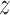 scores
scores 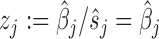 , so modelling the
, so modelling the 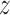 scores is the same as modelling the
scores is the same as modelling the 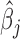 . Thus the primary difference among methods in this setting is that ash makes the UA and other methods do not.
. Thus the primary difference among methods in this setting is that ash makes the UA and other methods do not.
To briefly summarize the results in this section:
1. The UA can produce quite different results from existing methods.
2. The UA can yield conservative estimates of the proportion of true nulls,
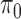 , and hence conservative estimates of
, and hence conservative estimates of 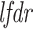 and
and 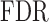 .
.3. The UA yields a procedure that is numerically and statistically stable, and is somewhat robust to deviations from unimodality.
3.1.1. The UA can produce quite different results from existing methods.
We illustrate the effects of the UA with a simple simulation, with effects 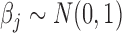 [so with
[so with 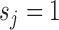 ,
, 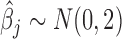 ]. Though no effects are null, there are many
]. Though no effects are null, there are many 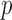 values near 1 and
values near 1 and 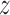 scores near 0 (Figure 1). We used qvalue, locfdr, mixfdr, and ash to decompose the
scores near 0 (Figure 1). We used qvalue, locfdr, mixfdr, and ash to decompose the 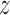 scores (
scores (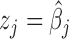 ), or their corresponding
), or their corresponding 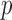 values, into null and alternative components. Here we are using the fact that these methods all provide an estimated
values, into null and alternative components. Here we are using the fact that these methods all provide an estimated 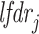 for each observation
for each observation 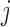 , which implies such a decomposition; specifically the average
, which implies such a decomposition; specifically the average 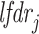 within each histogram bin estimates the fraction of observations in that bin that come from the null vs the alternative component. The results (Figure 1) illustrate a clear difference between ash and existing methods: the existing methods have a “hole” in the alternative
within each histogram bin estimates the fraction of observations in that bin that come from the null vs the alternative component. The results (Figure 1) illustrate a clear difference between ash and existing methods: the existing methods have a “hole” in the alternative 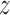 score distribution near 0, whereas ash, due to the UA, has a mode near 0. (Of course the null distribution also has a peak at 0, and the lfdr under the UA is still smallest for
score distribution near 0, whereas ash, due to the UA, has a mode near 0. (Of course the null distribution also has a peak at 0, and the lfdr under the UA is still smallest for 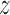 scores that are far from zero—i.e. large
scores that are far from zero—i.e. large 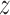 scores remain the “most significant.”)
scores remain the “most significant.”)
Fig. 1.

Illustration that the UA in ash can produce very different results from existing methods. The figure shows, for a single simulated dataset, the way different methods decompose 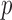 values (left) and
values (left) and 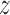 scores (right) into a null component (dark blue) and an alternative component (cyan). In the
scores (right) into a null component (dark blue) and an alternative component (cyan). In the 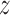 score space the alternative distribution is placed on the bottom to highlight the differences in its shape among methods. The three existing methods (qvalue, locfdr, mixfdr) all produce a “hole” in the alternative
score space the alternative distribution is placed on the bottom to highlight the differences in its shape among methods. The three existing methods (qvalue, locfdr, mixfdr) all produce a “hole” in the alternative 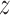 score distribution around 0. In contrast ash makes the UA—that the effect sizes, and thus the
score distribution around 0. In contrast ash makes the UA—that the effect sizes, and thus the 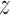 scores, have a unimodal distribution about 0—which yields a very different decomposition. (In this case the ash decomposition is closer to the truth: the data were simulated under a model where all of the effects are non-zero, so the “true” decomposition would make everything cyan.)
scores, have a unimodal distribution about 0—which yields a very different decomposition. (In this case the ash decomposition is closer to the truth: the data were simulated under a model where all of the effects are non-zero, so the “true” decomposition would make everything cyan.)
This qualitative difference among methods is quite general, and also occurs in simulations where most effects are null (e.g. http://stephenslab.github.io/ash/analysis/referee_uaza.html). To understand why the alternative distribution of 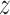 scores from locfdr and qvalue has a hole at zero, note that neither of these methods explicitly models the alternative distribution: instead they simply subtract a null distribution (of
scores from locfdr and qvalue has a hole at zero, note that neither of these methods explicitly models the alternative distribution: instead they simply subtract a null distribution (of 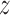 scores or
scores or 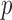 values) from the observed empirical distribution, letting the alternative distribution be defined implicitly, by what remains. In deciding how much null distribution to subtract—that is, in estimating the null proportion,
values) from the observed empirical distribution, letting the alternative distribution be defined implicitly, by what remains. In deciding how much null distribution to subtract—that is, in estimating the null proportion, 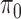 —both methods assume that all
—both methods assume that all 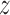 scores near zero (or, equivalently, all
scores near zero (or, equivalently, all 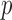 values near 1) are null. The consequence of this is that their (implicitly defined) distribution for the alternative
values near 1) are null. The consequence of this is that their (implicitly defined) distribution for the alternative 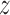 scores has a “hole” at 0—quite different from our assumption of a mode at zero. (Why mixfdr exhibits similar behavior is less clear, since it does explicitly model the alternative distribution; however we believe it may be due to the default choice of penalty term
scores has a “hole” at 0—quite different from our assumption of a mode at zero. (Why mixfdr exhibits similar behavior is less clear, since it does explicitly model the alternative distribution; however we believe it may be due to the default choice of penalty term 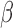 described in Muralidharan (2010).)
described in Muralidharan (2010).)
Figure 1 is also helpful in understanding the interacting role of the UA and the penalty term (Supplementary Information, equation S.2.5) that attempts to make 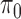 as “large as possible” while remaining consistent with the UA. Specifically, consider the panel that shows ash’s decomposition of
as “large as possible” while remaining consistent with the UA. Specifically, consider the panel that shows ash’s decomposition of 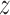 scores, and imagine increasing
scores, and imagine increasing 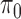 further. This would increase the null component (dark blue) at the expense of the alternative component (light blue). Because the null component is
further. This would increase the null component (dark blue) at the expense of the alternative component (light blue). Because the null component is 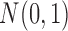 , and so is biggest at 0, this would eventually create a “dip” in the light-blue histogram at 0. The role of the penalty term is to push the dark blue component as far as possible, right up to (or, to be conservative, just past) the point where this dip appears. In contrast the existing methods effectively push the dark blue component until the light-blue component disappears at 0. See https://stephens999.shinyapps.io/unimodal/unimodal.Rmd for an interactive demonstration.
, and so is biggest at 0, this would eventually create a “dip” in the light-blue histogram at 0. The role of the penalty term is to push the dark blue component as far as possible, right up to (or, to be conservative, just past) the point where this dip appears. In contrast the existing methods effectively push the dark blue component until the light-blue component disappears at 0. See https://stephens999.shinyapps.io/unimodal/unimodal.Rmd for an interactive demonstration.
3.1.2. The UA can produce conservative estimates of 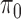
Figure 1 suggests that the UA will produce smaller estimates of 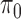 than existing methods. Consequently ash will estimate smaller
than existing methods. Consequently ash will estimate smaller 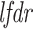 s and FDRs, and so identify more significant discoveries at a given threshold. This is desirable, provided that these estimates remain conservative: that is, provided that
s and FDRs, and so identify more significant discoveries at a given threshold. This is desirable, provided that these estimates remain conservative: that is, provided that 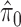 does not underestimate the true
does not underestimate the true 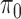 and
and 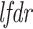 does not underestimate the true
does not underestimate the true 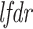 . The penalty term (Supplementary Information, equation S.2.5) aims to ensure this conservative behavior. To check its effectiveness we performed simulations under various alternative scenarios (i.e. various distributions for the non-zero effects, which we denote
. The penalty term (Supplementary Information, equation S.2.5) aims to ensure this conservative behavior. To check its effectiveness we performed simulations under various alternative scenarios (i.e. various distributions for the non-zero effects, which we denote 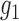 ), and values for
), and values for 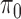 . The alternative distributions are shown in Figure 2(a), with details in supplementary Table 1 available at Biostatistics online. They range from a “spiky” distribution—where many non-zero
. The alternative distributions are shown in Figure 2(a), with details in supplementary Table 1 available at Biostatistics online. They range from a “spiky” distribution—where many non-zero 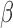 are too close to zero to be reliably detected, making reliable estimation of
are too close to zero to be reliably detected, making reliable estimation of 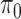 essentially impossible—to a much flatter distribution, which is a normal distribution with large variance (“big-normal”)—where most non-zero
essentially impossible—to a much flatter distribution, which is a normal distribution with large variance (“big-normal”)—where most non-zero 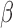 are easily detected making reliable estimation of
are easily detected making reliable estimation of 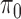 easier. We also include one asymmetric distribution (“skew”), and one clearly bimodal distribution (“bimodal”), which, although we view as generally unrealistic, we include to assess robustness of ash to deviations from the UA.
easier. We also include one asymmetric distribution (“skew”), and one clearly bimodal distribution (“bimodal”), which, although we view as generally unrealistic, we include to assess robustness of ash to deviations from the UA.
Fig. 2.

Results of simulation studies (constant precision 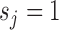 ). (a) Densities of non-zero effects,
). (a) Densities of non-zero effects, 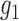 , used in simulations. (b) Comparison of true and estimated values of
, used in simulations. (b) Comparison of true and estimated values of 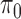 . When the UA holds all methods typically yield conservative (over-)estimates for
. When the UA holds all methods typically yield conservative (over-)estimates for 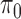 , with ash being least conservative, and hence most accurate. qvalue is sometimes anti-conservative when
, with ash being least conservative, and hence most accurate. qvalue is sometimes anti-conservative when 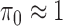 . When the UA does not hold (“bimodal” scenario) the ash estimates are slightly anti-conservative. (c) Comparison of true and estimated
. When the UA does not hold (“bimodal” scenario) the ash estimates are slightly anti-conservative. (c) Comparison of true and estimated 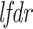 from ash (ash.n). Black line is
from ash (ash.n). Black line is 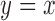 and red line is
and red line is 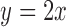 . Estimates of
. Estimates of 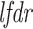 are conservative when UA holds, due to conservative estimates of
are conservative when UA holds, due to conservative estimates of 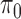 . (d) As in (c), but for
. (d) As in (c), but for 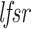 instead of
instead of 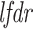 . Estimates of
. Estimates of 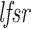 are consistently less conservative than
are consistently less conservative than 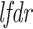 when UA holds, and also less anti-conservative in bimodal scenario.
when UA holds, and also less anti-conservative in bimodal scenario.
For each simulation scenario we simulated 100 independent data sets, each with 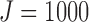 observations. For each data set we simulated data as follows:
observations. For each data set we simulated data as follows:
1. Simulate
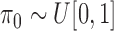 .
.2. For
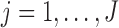 , simulate
, simulate 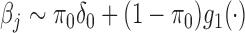 .
.3. For
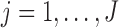 , simulate
, simulate 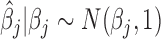 .
.
Figure 2(b) compares estimates of 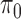 from qvalue, locfdr, mixfdr, and ash (
from qvalue, locfdr, mixfdr, and ash ( -axis) with the true values (
-axis) with the true values ( -axis). For ash we show results for
-axis). For ash we show results for 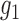 modelled as a mixture of normal components (“ash.n”) and as a mixture of symmetric uniform components (“ash.u”). (Results using the asymmetric uniforms, which we refer to as “half-uniforms,” and denote “ash.hu” in subsequent sections, are here generally similar to ash.u and omitted to avoid over-cluttering figures.) The results show that ash provides the smallest, most accurate, estimates for
modelled as a mixture of normal components (“ash.n”) and as a mixture of symmetric uniform components (“ash.u”). (Results using the asymmetric uniforms, which we refer to as “half-uniforms,” and denote “ash.hu” in subsequent sections, are here generally similar to ash.u and omitted to avoid over-cluttering figures.) The results show that ash provides the smallest, most accurate, estimates for 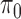 , while remaining conservative in all scenarios where the UA holds. When the UA does not hold (“bimodal” scenario) the ash estimates can be slightly anti-conservative. We view this as a minor concern in practice, since we view such a strong bimodal scenario as unlikely in most applications where FDR methods are used. (In addition, the effects on
, while remaining conservative in all scenarios where the UA holds. When the UA does not hold (“bimodal” scenario) the ash estimates can be slightly anti-conservative. We view this as a minor concern in practice, since we view such a strong bimodal scenario as unlikely in most applications where FDR methods are used. (In addition, the effects on 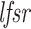 estimates turn out to be relatively modest; see below.)
estimates turn out to be relatively modest; see below.)
3.1.3. The 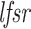 is more robust than
is more robust than 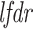
The results above show that ash can improve on existing methods in producing smaller, more accurate, estimates of 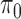 , which will lead to more accurate estimates of FDR. Nonetheless, in many scenarios ash continues to substantially over-estimate
, which will lead to more accurate estimates of FDR. Nonetheless, in many scenarios ash continues to substantially over-estimate 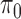 (see the “spiky” scenario, for example). This is because these scenarios include an appreciable fraction of “small non-null effects” that are essentially indistinguishable from 0, making accurate estimation of
(see the “spiky” scenario, for example). This is because these scenarios include an appreciable fraction of “small non-null effects” that are essentially indistinguishable from 0, making accurate estimation of 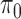 impossible. Put another way, and as is well known,
impossible. Put another way, and as is well known, 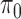 is not identifiable: the data can effectively provide an upper bound on plausible values of
is not identifiable: the data can effectively provide an upper bound on plausible values of 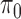 , but not a lower bound (because the data cannot rule out that everything is non-null, but with minuscule effects). To obtain conservative behavior we must estimate
, but not a lower bound (because the data cannot rule out that everything is non-null, but with minuscule effects). To obtain conservative behavior we must estimate 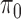 by this upper bound, which can be substantially larger than the true value.
by this upper bound, which can be substantially larger than the true value.
Table 2.
Empirical coverage for nominal 95% lower credible bounds (significant negative discoveries)
| Spiky | Near-normal | Flat-top | Skew | Big-normal | Bimodal | |
|---|---|---|---|---|---|---|
| ash.n | 0.94 | 0.94 | 0.94 | 0.86 | 0.95 | 0.96 |
| ash.u | 0.93 | 0.93 | 0.93 | 0.84 | 0.95 | 0.95 |
| ash.hu | 0.92 | 0.92 | 0.93 | 0.92 | 0.95 | 0.95 |
Coverage rates are generally satisfactory, except for the uniform-based methods in the spiky and near-normal scenarios, and the normal-based method in the flat-top scenario. These results likely reflect inaccurate estimates of the tails of 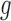 due to a disconnect between the tail of
due to a disconnect between the tail of 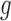 and the component distributions in these cases. For example, the uniform methods sometimes substantially underestimate the length of the tail of
and the component distributions in these cases. For example, the uniform methods sometimes substantially underestimate the length of the tail of 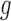 in these long-tailed scenarios, causing over-shrinkage of the tail toward 0
in these long-tailed scenarios, causing over-shrinkage of the tail toward 0
Since FDR-related quantities depend quite sensitively on 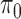 , the consequence of this overestimation of
, the consequence of this overestimation of 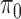 is corresponding overestimation of FDR (and
is corresponding overestimation of FDR (and 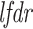 , and
, and 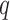 values). To illustrate, Figure 2(c) compares the estimated
values). To illustrate, Figure 2(c) compares the estimated 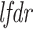 from ash.n with the true value (computed using Bayes rule from the true
from ash.n with the true value (computed using Bayes rule from the true 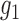 and
and 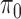 ). As predicted,
). As predicted, 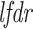 is overestimated, especially in scenarios which involve many non-zero effects that are very near 0 (e.g. the spiky scenario with
is overestimated, especially in scenarios which involve many non-zero effects that are very near 0 (e.g. the spiky scenario with 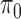 small) where
small) where 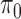 can be grossly overestimated. Of course other methods will be similarly affected by this: those that more grossly overestimate
can be grossly overestimated. Of course other methods will be similarly affected by this: those that more grossly overestimate 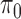 , will more grossly overestimate
, will more grossly overestimate 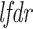 and FDR/
and FDR/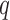 -values.
-values.
The key point we want to make here is that estimation of 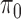 , and the accompanying identifiability issues, become substantially less troublesome if we use the local false sign rate
, and the accompanying identifiability issues, become substantially less troublesome if we use the local false sign rate 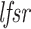 (2.7), rather than
(2.7), rather than 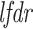 , to measure significance. This is because
, to measure significance. This is because 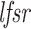 is less sensitive to the estimate of
is less sensitive to the estimate of 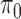 . To illustrate, Figure 2(d) compares the estimated
. To illustrate, Figure 2(d) compares the estimated 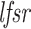 from ash.n with the true value: although the estimated
from ash.n with the true value: although the estimated 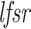 continue to be conservative, overestimating the truth, the overestimation is substantially less pronounced than for the
continue to be conservative, overestimating the truth, the overestimation is substantially less pronounced than for the 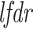 , especially for the “spiky” scenario. Further, in the bi-modal scenario, the anti-conservative behavior is less pronounced in
, especially for the “spiky” scenario. Further, in the bi-modal scenario, the anti-conservative behavior is less pronounced in 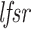 than
than 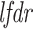 .
.
Compared with previous debates, this section advances an additional reason for focusing on the sign of the effect, rather than just testing whether it is 0. In previous debates authors have argued against testing whether an effect is 0 because it is implausible that effects are exactly 0. Here we add that even if one believes that some effects may be exactly zero, it is still better to focus on the sign, because generally the data are more informative about that question and so inferences are more robust to, say, the inevitable mis-estimation of 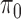 . To provide some intuition, consider an observation with a
. To provide some intuition, consider an observation with a 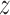 score of 0. The
score of 0. The 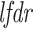 of this observation can range from 0 (if
of this observation can range from 0 (if 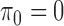 ) to 1 (if
) to 1 (if 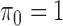 ). But, assuming a symmetric
). But, assuming a symmetric 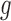 , the
, the 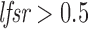 whatever the value of
whatever the value of 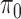 , because the observation
, because the observation 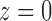 says nothing about the sign of the effect. Thus, there are two reasons to use the
says nothing about the sign of the effect. Thus, there are two reasons to use the 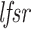 instead of the
instead of the 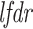 : it answers a question that is more generally meaningful (e.g. it applies whether or not zero effects truly exist), and estimation of
: it answers a question that is more generally meaningful (e.g. it applies whether or not zero effects truly exist), and estimation of 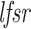 is more robust.
is more robust.
Given that we argue for using 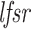 rather than
rather than 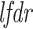 , one might ask whether we even need a point mass on zero in our analysis. Indeed, one advantage of the
, one might ask whether we even need a point mass on zero in our analysis. Indeed, one advantage of the 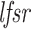 is that it makes sense even if no effect is exactly zero. And, if we are prepared to assume that no effects are exactly zero, then removing the point mass yields smaller and more accurate estimates of
is that it makes sense even if no effect is exactly zero. And, if we are prepared to assume that no effects are exactly zero, then removing the point mass yields smaller and more accurate estimates of 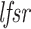 when that assumption is true (supplementary Figure 2a available at Biostatistics online). However, there is “no free lunch”: if in fact some effects are exactly zero then the analysis with no point mass will tend to be anti-conservative, underestimating
when that assumption is true (supplementary Figure 2a available at Biostatistics online). However, there is “no free lunch”: if in fact some effects are exactly zero then the analysis with no point mass will tend to be anti-conservative, underestimating 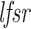 (supplementary Figure 2b available at Biostatistics online). We conclude that if ensuring a “conservative” analysis is important then one should allow for a point mass at 0.
(supplementary Figure 2b available at Biostatistics online). We conclude that if ensuring a “conservative” analysis is important then one should allow for a point mass at 0.
3.1.4. The UA helps provide reliable estimates of 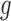
An important advantage of our EB approach based on modelling the effects 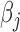 , rather than
, rather than 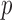 values or
values or 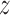 scores, is that it can estimate the effects
scores, is that it can estimate the effects 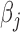 . Specifically, it provides a posterior distribution for each
. Specifically, it provides a posterior distribution for each 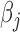 , which can be used to construct interval estimates, etc. Further, because the posterior distribution is, by definition, conditional on the observed data, interval estimates based on posterior distributions are also valid Bayesian inferences for any subset of the effects that have been selected based on the observed data. This kind of “post-selection” validity is much harder to achieve in the frequentist paradigm. In particular the posterior distribution solves the (Bayesian analogue of the) “False Coverage Rate” problem posed by Benjamini and Yekutieli (2005) which Efron (2008) summarizes as follows: “having applied FDR methods to select a set of non-null cases, how can confidence intervals be assigned to the true effect size for each selected case”? Efron (2008) notes the potential for EB approaches to tackle this problem, and Zhao and Gene Hwang (2012) considers in detail the case where the non-null effects are normally distributed.
, which can be used to construct interval estimates, etc. Further, because the posterior distribution is, by definition, conditional on the observed data, interval estimates based on posterior distributions are also valid Bayesian inferences for any subset of the effects that have been selected based on the observed data. This kind of “post-selection” validity is much harder to achieve in the frequentist paradigm. In particular the posterior distribution solves the (Bayesian analogue of the) “False Coverage Rate” problem posed by Benjamini and Yekutieli (2005) which Efron (2008) summarizes as follows: “having applied FDR methods to select a set of non-null cases, how can confidence intervals be assigned to the true effect size for each selected case”? Efron (2008) notes the potential for EB approaches to tackle this problem, and Zhao and Gene Hwang (2012) considers in detail the case where the non-null effects are normally distributed.
The ability of the EB approach to provide valid “post-selection” interval estimates is extremely attractive in principle. But its usefulness in practice depends on reliably estimating the distribution 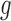 . Estimating
. Estimating 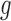 is a “deconvolution problem,” which are notoriously difficult in general. Indeed, Efron emphasizes the difficulties of implementing a stable general algorithm, noting in his rejoinder “the effort foundered on practical difficulties involving the perils of deconvolution ... Maybe I am trying to be overly non-parametric ... but it is hard to imagine a generally satisfactory parametric formulation ...” (Efron (2008) rejoinder, page 46). We argue here that the UA can greatly simplify the deconvolution problem, producing both computationally and statistically stable estimates of
is a “deconvolution problem,” which are notoriously difficult in general. Indeed, Efron emphasizes the difficulties of implementing a stable general algorithm, noting in his rejoinder “the effort foundered on practical difficulties involving the perils of deconvolution ... Maybe I am trying to be overly non-parametric ... but it is hard to imagine a generally satisfactory parametric formulation ...” (Efron (2008) rejoinder, page 46). We argue here that the UA can greatly simplify the deconvolution problem, producing both computationally and statistically stable estimates of 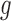 .
.
To illustrate, we compare the estimated 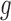 from ash (under the UA) with the non-parametric maximum likelihood estimate (NPMLE) for
from ash (under the UA) with the non-parametric maximum likelihood estimate (NPMLE) for 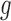 (i.e. estimated entirely non-parametrically without the unimodal constraint). The NPMLE is straightforward to compute in R using the REBayes::GLmix function (Koenker and Mizera, 2014). Figure 3 shows results under six different scenarios. The estimated cdf from ash is generally closer to the truth, even in the bi-modal scenario. [ash tends to systematically overestimate the mass of
(i.e. estimated entirely non-parametrically without the unimodal constraint). The NPMLE is straightforward to compute in R using the REBayes::GLmix function (Koenker and Mizera, 2014). Figure 3 shows results under six different scenarios. The estimated cdf from ash is generally closer to the truth, even in the bi-modal scenario. [ash tends to systematically overestimate the mass of 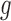 near zero; this can be avoided by removing the penalty term (Supplementary Information, equation S.2.5); supplementary Figure 1 available at Biostatistics online.] Furthermore, the estimate from ash is also substantially more “regular” than the NPMLE, which has several almost-vertical segments indicative of a concentration of density in the estimated
near zero; this can be avoided by removing the penalty term (Supplementary Information, equation S.2.5); supplementary Figure 1 available at Biostatistics online.] Furthermore, the estimate from ash is also substantially more “regular” than the NPMLE, which has several almost-vertical segments indicative of a concentration of density in the estimated 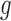 at those locations. Indeed the NPMLE is a discrete distribution (Koenker and Mizera, 2014), so this kind of concentration will always occur. The UA prevents this concentration, effectively regularizing the estimated
at those locations. Indeed the NPMLE is a discrete distribution (Koenker and Mizera, 2014), so this kind of concentration will always occur. The UA prevents this concentration, effectively regularizing the estimated 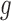 . While the UA is not the only way to achieve this (e.g. Efron, 2016), we view it as attractive and widely applicable.
. While the UA is not the only way to achieve this (e.g. Efron, 2016), we view it as attractive and widely applicable.
Fig. 3.

Comparison of estimated cdfs from ash and the NPMLE. Different ash methods perform similarly, so only ash.hu is shown for clarity. Each panel shows results for a single example data set, one for each scenario in Figure 2(a). The results illustrate how the UA made by ash regularizes the estimated cdfs compared with the NPMLE.
3.1.5. Calibration of posterior intervals
To quantify the effects of errors in estimates of 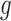 we examine the calibration of the resulting posterior distributions (averaged over 100 simulations in each Scenario). Specifically we examine the empirical coverage of nominal lower 95% credible bounds for (i) all observations; (ii) significant negative discoveries; (iii) significant positive discoveries. We examine only lower bounds because the results for upper bounds follow by symmetry (except for the one asymmetric scenario). We separately examine positive and negative discoveries because the lower bound plays a different role in each case: for negative discoveries the lower bound is typically large and negative and limits how big (in absolute value) the effect could be; for positive discoveries the lower bound is positive, and limits how small (in absolute value) the effect could be. Intuitively, the lower bound for negative discoveries depends on the accuracy of
we examine the calibration of the resulting posterior distributions (averaged over 100 simulations in each Scenario). Specifically we examine the empirical coverage of nominal lower 95% credible bounds for (i) all observations; (ii) significant negative discoveries; (iii) significant positive discoveries. We examine only lower bounds because the results for upper bounds follow by symmetry (except for the one asymmetric scenario). We separately examine positive and negative discoveries because the lower bound plays a different role in each case: for negative discoveries the lower bound is typically large and negative and limits how big (in absolute value) the effect could be; for positive discoveries the lower bound is positive, and limits how small (in absolute value) the effect could be. Intuitively, the lower bound for negative discoveries depends on the accuracy of 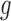 in its tail, whereas for positive discoveries it is more dependent on the accuracy of
in its tail, whereas for positive discoveries it is more dependent on the accuracy of 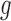 in the center.
in the center.
The results are shown in Table 1–Table 3. Most of the empirical coverage rates are in the range 0.92–0.96 for nominal coverage of 0.95, which we view as adequate for practical applications. The strongest deviations from nominal rates are noted and discussed in the table captions. One general issue is that the methods based on mixtures of uniform distributions often slightly curtail the tail of 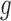 , causing the probability of very large outlying effects to be understated; see also http://stephenslab.github.io/ash/analysis/efron.fcr.html.
, causing the probability of very large outlying effects to be understated; see also http://stephenslab.github.io/ash/analysis/efron.fcr.html.
Table 1.
Empirical coverage for nominal 95% lower credible bounds (all observations)
| Spiky | Near-normal | Flat-top | Skew | Big-normal | Bimodal | |
|---|---|---|---|---|---|---|
| ash.n | 0.90 | 0.94 | 0.95 | 0.94 | 0.96 | 0.96 |
| ash.u | 0.87 | 0.93 | 0.94 | 0.93 | 0.96 | 0.96 |
| ash.hu | 0.88 | 0.93 | 0.94 | 0.94 | 0.96 | 0.96 |
Coverage rates are generally satisfactory, except for the extreme “spiky” scenario. This is due to the penalty term (Supplementary Information, equation S.2.5) which tends to cause over-shrinking towards zero. Removing this penalty term produces coverage rates closer to the nominal levels for uniform and normal methods (Table 2). Removing the penalty in the half-uniform case is not recommended (see online Supplementary Information for discussion)
Table 3.
Empirical coverage for nominal 95% lower credible bounds (significant positive discoveries)
| Spiky | Near-normal | Flat-top | Skew | Big-normal | Bimodal | |
|---|---|---|---|---|---|---|
| ash.n | 0.94 | 0.94 | 0.94 | 0.86 | 0.95 | 0.96 |
| ash.u | 0.93 | 0.93 | 0.93 | 0.84 | 0.95 | 0.95 |
| ash.hu | 0.92 | 0.92 | 0.93 | 0.92 | 0.95 | 0.95 |
Coverage rates are generally satisfactory, except for the symmetric methods under the asymmetric (“skew”) scenario
3.2. Differing measurement precision across units
We turn now to the second important component of our work: allowing for varying measurement precision across units. The key to this is the use of a likelihood, (2.4) (or, more generally, in Supplementary Information, equation (S.1.2)), that explicitly incorporates the measurement precision (standard error) of each 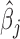 .
.
To illustrate, we conduct a simulation where half the measurements are quite precise (standard error 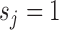 ), and the other half are very poor (
), and the other half are very poor (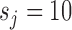 ). In both cases, we assume that half the effects are null and the other half are normally distributed with standard deviation 1:
). In both cases, we assume that half the effects are null and the other half are normally distributed with standard deviation 1:
| (3.1) |
In this setting, the poor-precision measurements 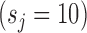 tell us very little, and any sane analysis should effectively ignore them. However, this is not the case in standard FDR-type analyses (Figure 4). This is because the poor measurements produce
tell us very little, and any sane analysis should effectively ignore them. However, this is not the case in standard FDR-type analyses (Figure 4). This is because the poor measurements produce 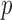 values that are approximately uniform [Figure 4(a)], which, when combined with the good-precision measurements, dilute the overall signal (e.g. they reduce the density of
values that are approximately uniform [Figure 4(a)], which, when combined with the good-precision measurements, dilute the overall signal (e.g. they reduce the density of 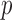 values near 0). This is reflected in the results of FDR methods like qvalue and locfdr: the estimated error rates (
values near 0). This is reflected in the results of FDR methods like qvalue and locfdr: the estimated error rates (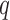 -values, or
-values, or 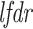 values) for the good-precision observations increase when the low-precision observations are included in the analysis [Figure 4(b)]. In contrast, the results from ash for the good-precision observations are unaffected by including the low-precision observations in the analysis [Figure 4(b)].
values) for the good-precision observations increase when the low-precision observations are included in the analysis [Figure 4(b)]. In contrast, the results from ash for the good-precision observations are unaffected by including the low-precision observations in the analysis [Figure 4(b)].
Another consequence of incorporating measurement precision into the likelihood is that ash can re-order the significance of observations compared with the original 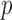 values or
values or 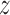 scores. Effectively ash downweights the poor-precision observations by assigning them a higher
scores. Effectively ash downweights the poor-precision observations by assigning them a higher 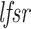 than good precision measurements that have the same
than good precision measurements that have the same 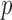 value [Figure 4(c)]. The intuition is that, due to their poor precision, these measurements contain very little information about the sign of the effects (or indeed any other aspect of the effects), and so the
value [Figure 4(c)]. The intuition is that, due to their poor precision, these measurements contain very little information about the sign of the effects (or indeed any other aspect of the effects), and so the 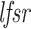 for these poor-precision measurements is always high; see Guan and Stephens (2008) for related discussion. Here this re-ordering results in improved performance: ash identifies more true positive effects at a given level of false positives [Figure 4(d)].
for these poor-precision measurements is always high; see Guan and Stephens (2008) for related discussion. Here this re-ordering results in improved performance: ash identifies more true positive effects at a given level of false positives [Figure 4(d)].
3.2.1. Dependence of 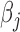 on
on 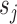
Although downweighting low-precision observations may seem intuitive, we must now confess that the issues are more subtle than our treatment above suggests. Specifically, it turns out that the downweighting behavior depends on an assumption that we have made up to now, that 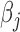 is independent of
is independent of 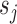 (2.2). In practice this assumption may not hold. For example, in gene expression studies, genes with higher biological variance may tend to exhibit larger effects
(2.2). In practice this assumption may not hold. For example, in gene expression studies, genes with higher biological variance may tend to exhibit larger effects 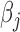 (because they are less constrained). These genes will also tend to have larger
(because they are less constrained). These genes will also tend to have larger 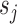 , inducing a dependence between
, inducing a dependence between 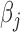 and
and 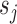 .
.
Motivated by this, we generalize the prior (2.2) to
| (3.2) |
where 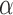 is to be estimated or specified. Setting
is to be estimated or specified. Setting 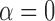 yields (2.2). Setting
yields (2.2). Setting 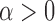 implies that the effects with larger standard error tend to be larger (in absolute value). Fitting this model for any
implies that the effects with larger standard error tend to be larger (in absolute value). Fitting this model for any 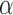 is straightforward using the same methods as for
is straightforward using the same methods as for 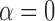 (see supplementary material available at Biostatistics online).
(see supplementary material available at Biostatistics online).
The case 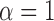 in (3.2) is of special interest because it corresponds most closely to existing methods. Specifically, it can be shown that with
in (3.2) is of special interest because it corresponds most closely to existing methods. Specifically, it can be shown that with 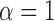 the
the 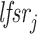 values from ash.n are monotonic in the
values from ash.n are monotonic in the 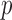 values: effects with smaller
values: effects with smaller 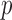 values have smaller
values have smaller 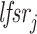 . This result generalizes a result in Wakefield (2009), who referred to a prior that produces the same ranking as the
. This result generalizes a result in Wakefield (2009), who referred to a prior that produces the same ranking as the 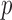 values as a “
values as a “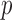 value prior.” Of course, if the
value prior.” Of course, if the 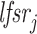 are monotonic in the
are monotonic in the 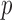 values then the downweighting and reordering of significance illustrated in Figure 4 will not occur. The intuition is that under
values then the downweighting and reordering of significance illustrated in Figure 4 will not occur. The intuition is that under 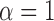 the poor precision observations have larger effects sizes, and consequently the same power as the high-precision observations—under these conditions the poor precision observations are not “contaminating” the high precision observations, and so downweighting them is unnecessary. Thus running ash with
the poor precision observations have larger effects sizes, and consequently the same power as the high-precision observations—under these conditions the poor precision observations are not “contaminating” the high precision observations, and so downweighting them is unnecessary. Thus running ash with 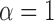 will produce the same significance ranking as existing methods. Nonetheless, it is not equivalent to them, and indeed still has the benefits outlined previously: due to the UA ash can produce less conservative estimates of
will produce the same significance ranking as existing methods. Nonetheless, it is not equivalent to them, and indeed still has the benefits outlined previously: due to the UA ash can produce less conservative estimates of 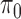 and
and 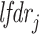 ; and because ash models the
; and because ash models the 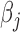 it can produce interval estimates.
it can produce interval estimates.
As an aside, we note that with 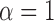 the ash estimates of both
the ash estimates of both 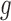 and
and 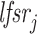 depend on the pairs
depend on the pairs 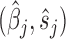 only through the
only through the 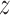 scores
scores 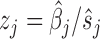 [though interval estimates for
[though interval estimates for 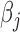 still depend on
still depend on 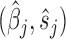 ]. This means that ash can be run (with
]. This means that ash can be run (with 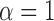 ) in settings where the
) in settings where the 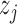 are available but the
are available but the 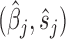 are not. It also opens the intriguing possibility of running ash on
are not. It also opens the intriguing possibility of running ash on 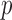 values obtained from any test (e.g. a permutation test), by first converting each
values obtained from any test (e.g. a permutation test), by first converting each 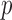 value to a corresponding
value to a corresponding 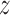 score. However, the meaning of and motivation for the UA may be unclear in such settings, and caution seems warranted before proceeding along these lines.
score. However, the meaning of and motivation for the UA may be unclear in such settings, and caution seems warranted before proceeding along these lines.
In practice, appropriate choice of 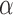 will depend on the actual relationship between
will depend on the actual relationship between 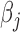 and
and 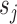 , which will be dataset-specific. Further, although we have focused on the special cases
, which will be dataset-specific. Further, although we have focused on the special cases 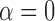 and
and 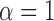 , there seems no strong reason to expect that either will necessarily be optimal in practice. Following the logic of the EB approach we suggest selecting
, there seems no strong reason to expect that either will necessarily be optimal in practice. Following the logic of the EB approach we suggest selecting 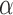 by maximum likelihood, which is implemented in our software using a simple 1-d grid search (implementation due to C. Dai).
by maximum likelihood, which is implemented in our software using a simple 1-d grid search (implementation due to C. Dai).
4. DISCUSSION
We have presented an Empirical Bayes approach to large-scale multiple testing that emphasizes two ideas. First, we emphasize the potential benefits of using two numbers (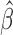 , and its standard error) rather than just one number (a
, and its standard error) rather than just one number (a 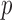 value or
value or 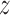 score) to summarize the information on each test. While requiring two numbers is slightly more onerous than requiring one, in many settings these numbers are easily available and if so we argue it makes sense to use them. Second, we note the potential benefits—both statistical and computational—of assuming that the effects come from a unimodal distribution, and provide flexible implementations for performing inference under this assumption. We also introduce the “false sign rate” as an alternative measure of error to the FDR, and illustrate its improved robustness to errors in model fit, particularly mis-estimation of the proportion of null tests,
score) to summarize the information on each test. While requiring two numbers is slightly more onerous than requiring one, in many settings these numbers are easily available and if so we argue it makes sense to use them. Second, we note the potential benefits—both statistical and computational—of assuming that the effects come from a unimodal distribution, and provide flexible implementations for performing inference under this assumption. We also introduce the “false sign rate” as an alternative measure of error to the FDR, and illustrate its improved robustness to errors in model fit, particularly mis-estimation of the proportion of null tests, 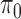 .
.
Multiple testing is often referred to as a “problem” or a “burden.” In our opinion, EB approaches turn this idea on its head, treating multiple testing as an opportunity: specifically, an opportunity to learn about the prior distributions, and other modelling assumptions, to improve inference and make informed decisions about significance (see also Greenland and Robins, 1991). This view also emphasizes that, what matters in multiple testing settings is not the number of tests, but the results of the tests. Indeed, the FDR at a given fixed threshold does not depend on the number of tests: as the number of tests increases, both the true positives and false positives increase linearly, and the FDR remains the same. [If this intuitive argument does not convince, see Storey (2003), and note that the FDR at a given 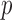 value threshold does not depend on the number of tests
value threshold does not depend on the number of tests 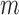 .] Conversely, the FDR does depend on the overall distribution of effects, and particularly on
.] Conversely, the FDR does depend on the overall distribution of effects, and particularly on 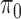 , for example. The EB approach captures this dependence in an intuitive way: if there are lots of strong signals then we infer
, for example. The EB approach captures this dependence in an intuitive way: if there are lots of strong signals then we infer  to be small, and the estimated FDR (or
to be small, and the estimated FDR (or 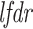 , or
, or 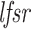 ) at a given threshold may be low, even if a large number of tests were performed; and conversely if there are no strong signals then we infer
) at a given threshold may be low, even if a large number of tests were performed; and conversely if there are no strong signals then we infer  to be large and the FDR at the same threshold may be high, even if relatively few tests were performed. More generally, overall signal strength is reflected in the estimated
to be large and the FDR at the same threshold may be high, even if relatively few tests were performed. More generally, overall signal strength is reflected in the estimated 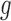 , which in turn influences the estimated FDR.
, which in turn influences the estimated FDR.
Two important practical issues that we have not addressed here are correlations among tests, and the potential for deviations from the theoretical null distributions of test statistics. These two issues are connected: specifically, unmeasured confounding factors can cause both correlations among tests and deviations from the theoretical null (Efron, 2007; Leek and Storey, 2007). And although there are certainly other factors that could cause dependence among tests, unmeasured confounders are perhaps the most worrisome in practice because they can induce strong correlations among large numbers of tests and profoundly impact results, ultimately resulting in too many hypotheses being rejected and a failure to control FDR. We are acutely aware that, because our method is less conservative than existing methods, it may unwittingly exacerbate these issues if they are not adequately dealt with. Approaches to deal with unmeasured confounders can be largely divided into two types: those that simply attempt to correct for the resulting inflation of test statistics (Devlin and Roeder, 1999; Efron, 2004), and those that attempt to infer confounders using clustering, principal components analysis, or factor models (Pritchard and others, 2000; Price and others, 2006; Leek and Storey, 2007; Gagnon-Bartsch and Speed, 2012), and then correct for them in computation of the test statistics (in our case, 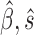 ). When these latter approaches are viable they provide perhaps the most satisfactory solution, and are certainly a good fit for our framework. Alternatively, our methods could be modified to allow for test statistic inflation, an idea that may be worth pursuing in future work.
). When these latter approaches are viable they provide perhaps the most satisfactory solution, and are certainly a good fit for our framework. Alternatively, our methods could be modified to allow for test statistic inflation, an idea that may be worth pursuing in future work.
Another important practical issue is the challenge of small sample sizes. For example, in genomics applications researchers sometimes attempt to identify differences between two conditions based on only a handful of samples in each. In such settings the normal likelihood approximation (2.4) will be inadequate. And, although the 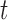 likelihood (Supplementary Information, equation (S.1.2)) partially addresses this issue, it is also, it turns out, not entirely satisfactory. The root of the problem is that, with small sample sizes, raw estimated standard errors
likelihood (Supplementary Information, equation (S.1.2)) partially addresses this issue, it is also, it turns out, not entirely satisfactory. The root of the problem is that, with small sample sizes, raw estimated standard errors 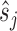 can be horribly variable. In genomics it is routine to address this issue by applying EB methods (Smyth, 2004) to “moderate” (i.e. shrink) variance estimates, before computing
can be horribly variable. In genomics it is routine to address this issue by applying EB methods (Smyth, 2004) to “moderate” (i.e. shrink) variance estimates, before computing 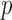 values from “moderated” test statistics. We are currently investigating how our methods should incorporate such “moderated” variance estimates to make it applicable to small sample settings.
values from “moderated” test statistics. We are currently investigating how our methods should incorporate such “moderated” variance estimates to make it applicable to small sample settings.
Our approach involves compromises between flexibility, generality, and simplicity on the one hand, and statistical efficiency and principle on the other. For example, in using an EB approach that uses a point estimate for 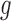 , rather than a fully Bayes approach that accounts for uncertainty in
, rather than a fully Bayes approach that accounts for uncertainty in 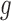 , we have opted for simplicity over statistical principle. And in summarizing every test by two numbers and making a normal or
, we have opted for simplicity over statistical principle. And in summarizing every test by two numbers and making a normal or 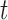 approximation to the likelihood, we have aimed to produce generic methods that can be applied whenever such summary data are available—just as qvalue can be applied to any set of
approximation to the likelihood, we have aimed to produce generic methods that can be applied whenever such summary data are available—just as qvalue can be applied to any set of 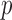 values, for example—although possibly at the expense of statistical efficiency compared with developing multiple tailored approaches based on context-specific likelihoods. Any attempt to produce generic methods will involve compromise between generality and efficiency. In genomics, many analyses—not only FDR-based analyses—involve first computing a series of
values, for example—although possibly at the expense of statistical efficiency compared with developing multiple tailored approaches based on context-specific likelihoods. Any attempt to produce generic methods will involve compromise between generality and efficiency. In genomics, many analyses—not only FDR-based analyses—involve first computing a series of 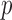 values before subjecting them to some further downstream analysis. An important message here is that working with two numbers (
values before subjecting them to some further downstream analysis. An important message here is that working with two numbers (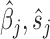 ), rather than one (
), rather than one (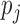 or
or 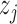 ), can yield substantial gains in functionality (e.g. estimating effect sizes, as well as testing; accounting for variations in measurement precision across units) while losing only a little in generality. We hope that our work will encourage development of methods that exploit this idea in other contexts.
), can yield substantial gains in functionality (e.g. estimating effect sizes, as well as testing; accounting for variations in measurement precision across units) while losing only a little in generality. We hope that our work will encourage development of methods that exploit this idea in other contexts.
Supplementary Material
ACKNOWLEDGMENTS
I thank J. Lafferty for pointing out the convexity of the likelihood function, which lead to an improved implementation with interior point methods. Statistical analyses were conducted in the R programming language (R Core Team, 2012), Figures produced using the ggplot2 package (Wickham, 2009), and text prepared using LaTeX. Development of the methods in this paper was greatly enhanced by the use of the knitr package (Xie, 2013) within the RStudio GUI, and git and github. The ashr R package is available from http://github.com/stephens999/ashr and includes contributions from Chaoxing (Rick) Dai, Mengyin Lu, Nan Xiao, and Tian Sen. Conflict of Interest: None declared.
SUPPLEMENTARY MATERIAL
Supplementary material is available at http://biostatistics.oxfordjournals.org.
FUNDING
National Institutes of Health (HG02585) and a grant from the Gordon and Betty Moore Foundation (GBMF #4559).
REFERENCES
- Benjamini Y. and Hochberg Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society. Series B (Methodological) 57, 289–300. [Google Scholar]
- Benjamini Y. and Yekutieli D. (2005). False discovery rate--adjusted multiple confidence intervals for selected parameters. Journal of the American Statistical Association 100, 71–81. [Google Scholar]
- Boyd S. and Vandenberghe L. (2004). Convex Optimization. Cambridge, UK: Cambridge University Press. [Google Scholar]
- Carvalho C. M. Polson N. G. and Scott J. G. (2010). The horseshoe estimator for sparse signals. Biometrika 97, asq017. [Google Scholar]
- Cordy C. B. and Thomas D. R. (1997). Deconvolution of a distribution function. Journal of the American Statistical Association 92, 1459–1465. [Google Scholar]
- Datta S. and Datta S. (2005). Empirical Bayes screening of many p-values with applications to microarray studies. Bioinformatics 21, 1987–1994. [DOI] [PubMed] [Google Scholar]
- Devlin B. and Roeder K. (1999). Genomic control for association studies. Biometrics 55, 997–1004. [DOI] [PubMed] [Google Scholar]
- Donoho D. and Johnstone I. (1995). Adapting to unknown smoothness via wavelet shrinkage. Journal of the American Statistical Association 90, 1200–1224. [Google Scholar]
- Efron B. (1993). Bayes and likelihood calculations from confidence intervals. Biometrika 80, 3–26. [Google Scholar]
- Efron B. (2004). Large-scale simultaneous hypothesis testing: the choice of a null hypothesis. Journal of the American Statistical Association 99, 96–104. [Google Scholar]
- Efron B. (2007). Correlation and large-scale simultaneous significance testing. Journal of the American Statistical Association 102, 93–107. [Google Scholar]
- Efron B. (2008). Microarrays, empirical Bayes and the two-groups model. Statistical Science 23, 1–22. [Google Scholar]
- Efron B. (2010). Large-scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction, Volume 1 Cambridge, UK: Cambridge University Press; (http://statweb.stanford.edu/${\sim}$ckirby/brad/LSI/monograph_CUP.pdf). [Google Scholar]
- Efron B. (2016). Empirical Bayes deconvolution estimates. Biometrika 103, 1–20. [Google Scholar]
- Efron B. (2003). Robbins, empirical Bayes and microarrays. The Annals of Statistics 31, 366–378. [Google Scholar]
- Efron B. and Tibshirani R. (2002). Empirical Bayes methods and false discovery rates for microarrays. Genetic Epidemiology 23, 70–86. [DOI] [PubMed] [Google Scholar]
- Efron B. Tibshirani R. Storey J. D. and Tusher V. (2001). Empirical Bayes analysis of a microarray experiment. Journal of the American Statistical Association 96, 1151–1160. [Google Scholar]
- Erbe M. Hayes B. J. Matukumalli L. K. Goswami S., Bowman P. J. Reich C. M. Mason B. A. and Goddard M. E. (2012). Improving accuracy of genomic predictions within and between dairy cattle breeds with imputed high-density single nucleotide polymorphism panels. Journal of Dairy Science 95, 4114–29. [DOI] [PubMed] [Google Scholar]
- Gagnon-Bartsch J. A. and Speed T. P. (2012). Using control genes to correct for unwanted variation in microarray data. Biostatistics 13, 539–552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gelman A. and Tuerlinckx F. (2000). Type s error rates for classical and Bayesian single and multiple comparison procedures. Computational Statistics 15, 373–390. [Google Scholar]
- Gelman A. Hill J. and Yajima M. (2012). Why we (usually) don’t have to worry about multiple comparisons. Journal of Research on Educational Effectiveness 5, 189–211. [Google Scholar]
- Greenland S. and Robins J. M. (1991). Empirical-Bayes adjustments for multiple comparisons are sometimes useful. Epidemiology 2, 244–251. [DOI] [PubMed] [Google Scholar]
- Guan Y. and Stephens M. (2008). Practical issues in imputation-based association mapping. PLoS Genetics 4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jiang W. and Zhang C.-H. (2009). General maximum likelihood empirical Bayes estimation of normal means. The Annals of Statistics 37, 1647–1684. [Google Scholar]
- Johnstone I. M. and Silverman B. W. (2004). Needles and straw in haystacks: empirical Bayes estimates of possibly sparse sequences. Annals of Statistics 32, 1594–1649. [Google Scholar]
- Kendziorski C. M. Newton M. A. Lan H. and Gould M. N. (2003). On parametric empirical Bayes methods for comparing multiple groups using replicated gene expression profiles. Statistics in Medicine 22, 3899–3914. [DOI] [PubMed] [Google Scholar]
- Koenker R. and Mizera I. (2013). Convex optimization in R. Journal of Statistical Software 60, 1–23. [Google Scholar]
- Koenker R. and Mizera I. (2014). Convex optimization, shape constraints, compound decisions, and empirical Bayes rules. Journal of the American Statistical Association 109, 674–685. [Google Scholar]
- Leek J. T. and Storey J. D. (2007). Capturing heterogeneity in gene expression studies by surrogate variable analysis. PLoS Genetics 3, 1724–35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lu M. and Stephens M. (2016). Variance adaptive shrinkage (vash): flexible empirical Bayes estimation of variances. bioRxiv, 048660, In press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Muralidharan O. (2010). An empirical Bayes mixture method for effect size and false discovery rate estimation. The Annals of Applied Statistics 4, 422–438. [Google Scholar]
- Newton M. A. Noueiry A., Sarkar D. and Ahlquist P. (2004). Detecting differential gene expression with a semiparametric hierarchical mixture method. Biostatistics 5, 155–176. [DOI] [PubMed] [Google Scholar]
- Ploner A., Calza S., Gusnanto A. and Pawitan Y. (2006). Multidimensional local false discovery rate for microarray studies. Bioinformatics 22, 556–565. [DOI] [PubMed] [Google Scholar]
- Price A. L. Patterson N. J. Plenge R. M. Weinblatt M. E. Shadick N. A. and Reich D. (2006). Principal components analysis corrects for stratification in genome-wide association studies. Nature Genetics 38, 904–9. [DOI] [PubMed] [Google Scholar]
- Pritchard J. K. Stephens M., Rosenberg N. A. and Donnelly P. (2000). Association mapping in structured populations. American Journal of Human Genetics 67, 170–181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- R Core Team. (2012). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria: http://www.R-project.org, Accessed June 3, 2013. [Google Scholar]
- Sarkar A., Mallick B. K. Staudenmayer J., Pati D. and Carroll R. J. (2014). Bayesian semiparametric density deconvolution in the presence of conditionally heteroscedastic measurement errors. Journal of Computational and Graphical Statistics 23, 1101–1125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smyth G. K. (2004). Linear models and empirical Bayes methods for assessing differential expression in microarray experiments. Statistical Applications in Genetics and Molecular Biology 3, Article3. [DOI] [PubMed] [Google Scholar]
- Storey J. D. (2003). The positive false discovery rate: a Bayesian interpretation and the q-value. The Annals of Statistics 31, 2013–2035. [Google Scholar]
- Tukey J. W. (1962). The future of data analysis. The Annals of Mathematical Statistics 33, 1–67. [Google Scholar]
- Tukey J. W. (1991). The philosophy of multiple comparisons. Statistical Science 6, 100–116. [Google Scholar]
- Wakefield J. (2009). Bayes factors for genome-wide association studies: comparison with p-values. Genetic Epidemiology 33, 79–86. [DOI] [PubMed] [Google Scholar]
- Wickham H. (2009). ggplot2: Elegant Graphics for Data Analysis. New York: Springer. [Google Scholar]
- Xie Y. (2013). Dynamic Documents with R and Knitr, Volume 29 Boca Raton, FL: CRC Press. [Google Scholar]
- Xie X., Kou S. C. and Brown L. D. (2012). Sure estimates for a heteroscedastic hierarchical model. Journal of the American Statistical Association 107(500), 1465–1479. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xing Z. and Stephens M. (2016). Smoothing via adaptive shrinkage (smash): denoising poisson and heteroskedastic Gaussian signals. arXiv preprint arXiv:1605.07787. [Google Scholar]
- Zhao Z. and Gene Hwang J. T. (2012). Empirical Bayes false coverage rate controlling confidence intervals. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 74, 871–891. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.