

Abstract
Background
Cancer is an evolutionary process characterized by the accumulation of somatic mutations in a population of cells that form a tumor. One frequent type of mutations is copy number aberrations, which alter the number of copies of genomic regions. The number of copies of each position along a chromosome constitutes the chromosome’s copy-number profile. Understanding how such profiles evolve in cancer can assist in both diagnosis and prognosis.
Results
We model the evolution of a tumor by segmental deletions and amplifications, and gauge distance from profile to by the minimum number of events needed to transform into . Given two profiles, our first problem aims to find a parental profile that minimizes the sum of distances to its children. Given k profiles, the second, more general problem, seeks a phylogenetic tree, whose k leaves are labeled by the k given profiles and whose internal vertices are labeled by ancestral profiles such that the sum of edge distances is minimum.
Conclusions
For the former problem we give a pseudo-polynomial dynamic programming algorithm that is linear in the profile length, and an integer linear program formulation. For the latter problem we show it is NP-hard and give an integer linear program formulation that scales to practical problem instance sizes. We assess the efficiency and quality of our algorithms on simulated instances.
Availability
Electronic supplementary material
The online version of this article (doi:10.1186/s13015-017-0103-2) contains supplementary material, which is available to authorized users.
Keywords: Cancer, Maximum parsimony, Phylogeny, Somatic mutation, Copy-number variant
Background
The clonal theory of cancer posits that cancer results from an evolutionary process where somatic mutations that arise during the lifetime of an individual accumulate in a population of cells that form a tumor [1]. Consequently, a tumor consists of clones, which are subpopulations of cells sharing a unique combination of somatic mutations. The evolutionary history of the clones can be described by a phylogenetic tree whose leaves correspond to extant clones and whose edges are labeled by mutations. Computational inference of phylogenetic trees is a fundamental problem in species evolution [2], and has recently been studied extensively for tumor evolution in the case where mutations are single-nucleotide variants [3–7]. Here, we study the problem of constructing a phylogenetic tree of a tumor in the case where mutations are copy number aberrations.
Copy number aberrations include segmental deletions and amplifications that affect large genomic regions, and are common in many cancer types [8]. As a result of these events, the number of copies of genomic regions (positions) along a chromosome can deviate from the diploid, two-copy state of each position in a normal chromosome. Understanding these events and the underlying evolutionary tree that relates them is important in predicting disease progression and the outcome of medical interventions [9].
Several methods have been introduced to infer trees from copy number aberrations in cancer. In [10, 11] the authors use fluorescent in situ hybridisation data to analyze gain and loss of whole chromosomes and single genes. However, due to technical limitations, this technology does not scale to a large number of positions. In addition, common deletions and amplifications that affect only a subset of the positions of a chromosome are not supported by the model. In another work, Schwartz et al. [12] introduced MEDICC, an algorithm that analyzes amplifications and deletions of contiguous segments. The input to MEDICC is a set of copy-number profiles, vectors of integers defining the copy-number state of each position. These profiles are measured for multiple samples from a tumor using DNA microarrays or DNA sequencing. The edit distance from profile to was defined as the minimum number of amplifications and deletions of segments required to transform into . Note that this distance is not symmetric. Using this distance measure, the authors applied heuristics to reconstruct phylogenetic trees. However, the complexity of their methods was not analyzed. Recently, Shamir et al. [13] analyzed some combinatorial aspects of this amplification/deletion distance model and proved that the distance from one profile to another can be computed in linear time.
In this work, we consider two problems in the evolutionary analysis of copy-number profiles: the copy-number triplet (CN3) and copy-number tree (CNT) problems. Given two profiles, the CN3 problem aims to find a parental profile that minimizes the sum of distances to its children. The CNT problem asks to construct a phylogenetic tree whose k leaves are labeled by the k given profiles, and to assign profiles to the internal vertices so that the sum of distances over all edges is minimum; such a tree describes the evolutionary history under a maximum parsimony assumption (Fig. 1). For the CN3 problem we give a pseudo-polynomial time algorithm that is linear in n, the number of positions in the profiles, along with an integer linear program (ILP) formulation whose number of variables and constraints is linear in n. We show that the CNT problem is NP-hard and present an ILP formulation that scales to practical problem instance sizes. Finally, we use simulations to test our algorithms.
Fig. 1.
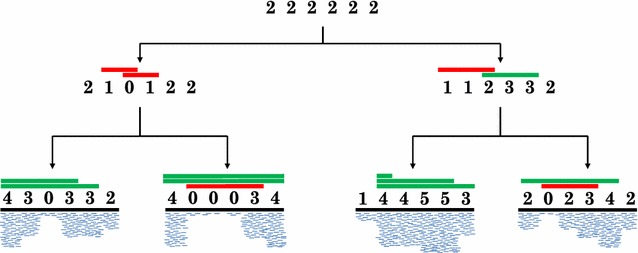
Copy-number tree problem. As input we are given the copy-number profiles of four leaves, each profile is an integer vector that is inferred from data; e.g. the coverage of mapped reads (blue segments). The tree topology and profiles at internal vertices are found to minimize the total number of amplifications (green bars) and deletions (red bars). The displayed scenario has 14 total events.
A preliminary version of this study was published as an extended abstract in WABI [14].
Preliminaries
Profiles and events
We represent a reference chromosome as a sequence of intervals that we call positions, numbered from 1 to n in left to right order. We consider mutations that amplify or delete contiguous positions. The copy-number profile, or profile for short, of a clone specifies the number of copies of each of the n positions. Formally, a profile is a vector of length n. An entry indicates the number of copies of position s in clone i. For simplicity, we consider a single chromosome only. The results can be easily extended to the case of multiple chromosomes.
An operation, or event, acting on profile increases or decreases copy-numbers in a contiguous segment of . Formally, an event is a triple (s, t, b) where and . If b is positive then profile-valued positions are incremented by b, whereas for negative b the positions are decremented by at most |b|. That is, applying event (s, t, b) to results in a new profile such that
An event with is called an amplification and an event with is called a deletion. As indicated by the condition above, once a position has been lost, i.e. , it can never be regained (or deleted). Therefore, for a pair of profiles there might not exist a sequence of events that transforms one into the other.
The copy-number tree problem
We describe the evolutionary process that led to the tumor clones by a copy-number tree T, which is a rooted full binary tree. As such, each vertex of T has either zero or two children. We denote the vertex set of T by V(T), the root vertex by r(T), the leaf set by L(T) and the edge set by E(T). The vertices of T correspond to clones. Thus, each vertex is labeled by a profile . The root vertex r(T) corresponds to the normal clone, which we assume to be diploid, i.e. for all positions s. Note that we do not require each vertex to be labeled by a unique profile.
Each edge relates a parent clone to its child , and is labeled by a sequence of events that yielded from . These events are applied in order from 1 to q. Since different events in may affect the same position, the order as specified by matters. The cost of an event (s, t, b) is the number of changes and is thus equal to |b|. Therefore, the cost of an edge is the total cost of the events in , i.e.
Note that the cost is not symmetric. The cost of the tree T is the sum of the costs of all edges.
Our observations correspond to the profiles of k extant clones. Under the assumption of parsimony, the goal is to find a copy-number tree of minimum cost whose leaves correspond to the extant clones. Furthermore, we assume that the maximum copy-number in the phylogeny is bounded by . We thus have the following problem.
Problem 1
[Copy-number tree (CNT)] Given profiles on n positions and an integer , find a copy-number tree , vertex labeling and edge labeling such that (1) has k leaves labeled and for all , (2) for all and , (3) for the root r and , and (4) is minimum.
Note that by definition the profile of the root vertex r(T) of any copy-number tree T is the vector whose entries are all 2’s. As such, this must hold as well for the minimum-cost tree , which always exists. Additionally, the requirement of T being a binary tree is without loss of generality as high-degree vertices can be split. Furthermore, the assumption that T is a full binary tree (i.e. each vertex has out-degree either 0 or 2) is also without loss of generality as degree-2 internal non-root vertices can be merged. To account for the case where r(T) has out-degree 1, given an instance we solve a second instance with an additional profile consisting of 2’s. The result is the minimum-cost tree among the two instances.
The copy-number triplet problem
The special case where is the copy-number triplet (CN3) problem. When we consider only two input profiles, it is not necessary to explicitly refer to trees. Thus, we formulate CN3 as follows:
Problem 2
[Copy-number triplet (CN3)] Given profiles and on n positions, find a profile on n positions and sequences of events, an , such that (1) yields from and yields from , and (2) is minimum.
Instances to both CNT and CN3 always have a solution as the diploid profile is an ancestor to any other profile. Next, we present definitions that will allow us to describe results specific to CN3 in a compact manner. We denote the minimum value associated with a solution by . We say that a triple is optimal if it realizes . Note that is symmetric and finite. Moreover, if (resp. ) is finite then (resp. ) gives a trivial solution to CN3. Let denote the maximum copy-number in the input. Finally, given and , we denote the cost of deletions/amplifications affecting position i by
Previous results
We now present three results incorporated in the design of our dynamic programming and ILP algorithms for CN3 and CNT. The first one relies on the observation that if , then , i.e. it is safe to fix . Therefore, we have the following straightforward yet useful result.
Lemma 1
Without loss of generality, it can be assumed that for all , at least one value among and is positive.
This lemma also implies that we can assume that the profile of any optimal triple consists only of positive values (since for a position i such that , it holds that ).
We say that a sequence of events where all of the deletions precede all of the amplifications is sorted. Formally, let be a sequence of events that yields from . Then, if there exist a sequence of deletion events and a sequence of amplification events such that , we say that is sorted. The following lemma states that we can focus on sorted sequences of events:
Lemma 2
[13] Given a sequence of events that yields from , there exists a sorted sequence of cost at most that yields from .
Shamir et al. [13] also showed that the minimum cost of a sequence yielding from is computable by the recursive formula given below. Here, we let G[i, d, a] be the minimum cost of a sequence of events that from the prefix of yields the prefix of and that satisfies and . In case such a sequence does not exist, we let .
Lemma 3
[13] Let and be two profiles, and let . Then,
If and either or : .
Else if and : .
Else if : .
Else: .
where . The minimum cost of a sequence yielding from is .
Complexity
In this section we show that CNT is NP-hard by reduction from the maximum parsimony phylogeny (MPP) problem [15]. In MPP, we seek to find a binary phylogeny T, which is a full binary tree whose vertices are labeled by binary vectors of size n. The cost of a binary phylogeny T is defined as the sum of the Hamming distances between the two binary vectors associated with each edge. The input for MPP are leaves of an unknown binary phylogeny in the form of k binary vectors of size n, and the task is to find a minimum-cost binary phylogeny T with k leaves such that each leaf is labeled by and the root is labeled by a vector of all 0’s. We consider the decision version where we are asked whether there exists a binary phylogeny T with cost at most h. This problem is NP-complete [15].
We start by defining the transformation (Fig. 2). Let be an instance of MPP. The corresponding CNT-instance has parameter and profiles of length . Each input profile , where , is defined as
| 1 |
where
| 2 |
and , called a wall, is a vector of size nk such that for each
| 3 |
Finally, .
Fig. 2.
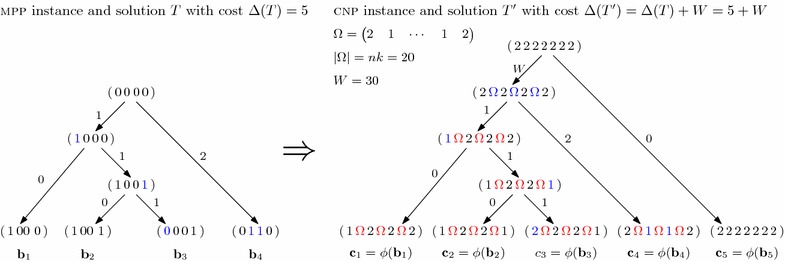
Transformation of an MPP instance to a CNT instance. Left shows an MPP instance and solution T, whereas right shows the corresponding CNT instance and solution . Edges are labeled by the cost of the associated events and their affected positions are colored in blue.
Informally, is defined as a vector consisting of true positions (which correspond to the original values) that are separated by walls (which are vectors of alternating 2, 1 values of length nk). The purpose of wall positions is to prevent an event from spanning more than one true position. Profile plays a role in initializing the wall elements immediately from the all 2’s root. This transformation can be computed in polynomial time, and it is used in the following proof of hardness.
Theorem 4
The CNT problem is NP-hard.
Proof
We claim that MPP instance, composed of such that , admits a binary phylogeny T with cost at most h if and only if the corresponding CNT instance, composed of and such that , admits a copy-number tree with cost at most where . Note that is even, and thus . Intuitively, W represents the cost of ‘initializing’ the wall elements .
Let T be a binary phylogeny with cost . We denote by the binary vector of vertex . For each true position , the corresponding position in the transformation is denoted by . We show that given T we can construct a copy-number tree such that . Tree is composed of a root vertex whose two children correspond to tree T (rooted at r(T)) and an additional leaf w labeled by . The remaining vertices are labeled by [see (1)]. The edge of connects two vertices with the same profile and thus has cost 0. The other edge has cost W, which corresponds to the number of wall positions that need to be initialized to 1 (these are common to all leaves ). Consider an edge of T with Hamming distance . First, observe that the Hamming distance equals the number of flips required to transform into . We describe how to obtain a sequence of events on the corresponding edge in such that . Consider position . A flip from 0 to 1 at position s corresponds to a deletion event . Conversely, a flip from 1 to 0 in position s corresponds to an amplification event . Recall that . It thus follows that . Since , we thus have .
Let be a copy-number tree with cost . We denote by the profile of vertex . We show that can be transformed into a binary phylogeny T such that . We distinguish two cases and .
If , we can construct a naive binary phylogeny T whose internal vertices are labeled with the same binary vector as the root (all 0’s). The cost of T is at most kn since the total number of flips is at most kn, and thus .
-
Consider the case where . We assume without loss of generality that . Now, since for . Hence, . Recall that the root vertex has 2’s at every position including the walls. We claim that has two children, one of which is a leaf labeled by . Assume for a contradiction that this is not the case and that the two children split into two sets and such that and . Thus, there exist two distinct leaves and such that for the respective profiles it holds that and . Now the cost of initializing the wall elements of and is at least 2W, which yields a contradiction. It thus follows that the tree must be composed of a root vertex whose first child corresponds to a tree (rooted at ) and whose second child is a leaf w labeled by . We focus our attention on .
We claim that there is no event in that covers more than one true position. Assume for a contradiction that such an event (s, t, b) exists. By construction, positions s and t span at least one wall . W.l.o.g. assume that both s and t are true positions. In our restricted setting where and where the leaves of do not contain 0’s, the event (s, t, b) can only be applied if all positions from s to t have the same value. As such, this event must be preceded by at least nk / 2 other events to make those positions with the same value and must be followed by at least nk / 2 other events to restore the wall . Thus, there must be at least nk other events (which is the length of a wall ). These events may be on the same edge or any ancestral edge. Therefore, , which is a contradiction. Hence, events in where span at most one true position.
Finally, we show how to construct a binary phylogeny T from such that . T has the same topology of . Moreover, each vertex is labeled by a binary vector such that . Consider an edge of labeled by events and with cost . Each event spans at most one true position (but may contain parts of a wall ). Let be the set of true positions spanned by events in . Observe that since either or . Therefore, the Hamming distance between and is at most |X|. Hence,
Algorithms
Copy-number triplet problem: DP
In this section we develop a DP algorithm, called DP-Alg1, that solves the CN3 problem in time and space . We will assume w.l.o.g. that sequences of events consist only of events of the form (s, t, b) where . Events with can be replaced by |b| events of that form, having the same total cost. Next, we show that DP-Alg1 can be improved to obtain a DP algorithm, called DP-Alg2, that solves the CN3 problem in time and space . We also present in Additional file 1: Appendix B an ILP formulation for CN3 consisting of O(n) variables.
DP-Alg1 is based on Lemma 3 and the following Lemma 5, proved in Additional file 1: Appendix A.
Lemma 5
Let and be two profiles. Then, there exists an optimal triple such that the following conditions hold.
Both and are sorted sequences of events.
For all , . Thus, for all , .
For all , and , .
Let and be the prefixes consisting of the first i positions of and , respectively. We will store costs corresponding to partial solutions in a table L (see Fig. 3). This table has an entry L for all , and . At such an entry, we will store the the minimum total cost, of a triple in the set , which is defined as follows. This set contains all triples such the numbers of deletions/amplifications affecting i are given by , where the notation d/a and indicate whether we consider amplifications or deletions as well as or , and for all , .
Fig. 3.
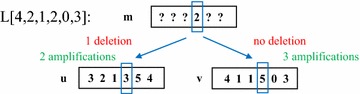
Illustration of an item in the DP table for solving CN3. Given that the 4th position of is 2, one of the combinations considered is 1 deletion and 2 amplifications on the path to , and 3 amplifications on the path to . The best cost of that combination is computed by DP-Alg1 based on the L entries for position 3.
By Lemma 5, is the minimum cost stored in an entry where . Thus, it remains to show how to correctly compute the entries of L efficiently. We use the following base cases, whose correctness follows from Lemma 3:
If , and or : L.
Else if , and or : L.
Else if and : L.
Else if and : L.
Else if : L.
Now, consider entries L that are not filled by the base cases. We compute them using the following formula: as
The correctness of this formula follows from Lemma 3 and since in light of Lemma 5, it exhaustively searches for the best choice for the previous value of . DP-Alg1 computes entries of L iteratively and returns
By computing the entries of L in an ascending order according to their first argument i, we have that the computation of each entry relies only on entries that are computed before it. The table L consists of entries, and each of them can be computed in time . Thus, we obtain the following lemma.
Lemma 6
DP-Alg1 solves CN3 in time and space .
Next, we show that DP-Alg1 can be modified to obtain a DP algorithm, called DP-Alg2, for which we prove the following result.
Theorem 7
DP-Alg2 solves CN3 in time and space .
Recall that Lemma 1 states that we can assume that for all , either or (or both). Now, by the formulas given in the previous subsection, for all , if then we only need to explicitly store the entries L where ; if one accesses an entry L where , we simply return . The symmetric argument holds for all such that . Now, for all , the number of entries is bounded by rather than , and therefore the space complexity is bounded by .
Consider an entry L computed by the recursive formula of the previous subsection. In case , we need only consider the value , since if then L . Symmetrically, in case , we need only consider the value . That is, we have that each entry can be computed in time rather than , and therefore the time complexity is bounded by . We thus obtain an algorithm that solves CN3 in time and space .
Note that the only entries that this algorithm computes in time rather than are those where either or . However, the following lemmas state that these entries can in fact be computed in time .
Lemma 8
Each entry of the form L where and can be computed in time .
Proof
Consider an entry L where and . It is sufficient to show that the calculation of this entry can be modified to depend only on entries of the form L . First, note that since , by Lemma 1 we have that , and therefore we can fix . We now claim that we can also fix and , which will imply that the lemma is correct. To show this, we need to show that there is a triple that minimizes and satisfies and . Since , it is clear that . Moreover, since , each event in whose segment includes i can be elongated to include as well while maintaining optimality (as we do not introduce new events) and that yields from . Therefore, we can assume that and . Furthermore, since , each event in whose segment includes but not i can be modified to exclude as well, as long as it still holds that , while maintaining optimality and that yields from . Therefore, and .
Lemma 9
Each entry of the form L where and can be computed in time .
Proof
The proof is symmetric to the one of Lemma 8.
Thus, we obtain the desired algorithm DP-Alg2 that computes the entries of L iteratively using the latter observations to store only the required entries and efficiently compute them.
Copy-number tree problem: ILP
In this section we describe an ILP for CNT consisting of variables and constraints. Let be an instance of CNT. Recall that we seek to find a full binary tree with k leaves. We define a directed graph G that contains any full binary tree with k leaves as a spanning tree. As such, . The vertex set V(G) consists of a subset L(G) of leaves such that . We denote by the vertex that corresponds to the root vertex. Throughout the following, we consider an order of the vertices in V(G) such that and . The edge set E(G) has edges . We denote by the set of vertices incident to an outgoing edge to j. Conversely, denotes the set of vertices incident to an incoming edge from i. We make the following two observations.
Observation 1
G is a directed acyclic graph.
Observation 2
Any copy-number tree T is a spanning tree of G.
We now proceed to define the set of feasible solutions (X, Y) to a CNT instance by introducing constraints and variables modeling the tree topology, and vertex labeling and edge costs. More specifically, variables encode a spanning tree T of G and variables encode the profiles of each vertex such that X and Y combined induce edge costs. In the following we provide more details.
Tree topology
The goal is to enforce that we select a spanning tree T of G that is a full binary tree. To do so, we introduce a binary variable for each edge indicating whether the corresponding edge is in T. Note that by construction . We require that each vertex has exactly one incoming edge in T.
| 4 |
We require that each vertex has two outgoing edges in T.
| 5 |
Vertex labeling and edge costs
We introduce variables that encode the copy-number state of position s of vertex . Since the profiles of each leaf as well as the root vertex are given, we have the following constraints.
| 6 |
| 7 |
for each and each .
Next, we encode a set of events that transform the profile of into profile of . Recall that an event is a triple (s, t, b) and corresponds to an amplification if and a deletion otherwise. We model the cost of the amplifications and the cost of the deletions covering any position s with two separate variables. Variables correspond to the cost of the amplifications in covering position s. Variables correspond to the cost of the deletions in covering position s.
Now, we consider the effect of amplifications and deletions on a position s. By Lemma 2, we have that there exists an optimal solution such that for each edge there are two sets of events and that yield from by first applying followed by . If a subset of the events in results in position s reaching value 0, the remaining amplifications and deletions will not change the value of that position. We distinguish the following four different cases (Table 1).
and : since both positions have value 0, the number of amplifications and deletions are between 0 and e.
and : since , the number of deletions must be strictly smaller than . Moreover, it must hold that .
and : recall that by Lemma 2 deletions precede amplifications. As such, the number of deletions must be at least .
and : once a position s has been lost it cannot be regained. As such, this case is infeasible.
Table 1.
Case analysis on the values of variables and
| Additional | |||
|---|---|---|---|
| (a) | |||
| (b) | |||
| (c) | |||
| (d) | Infeasible | Infeasible | Infeasible |
To capture the conditions of the four cases, we introduce binary variables and constraints such that iff .
| 8 |
| 9 |
| 10 |
| 11 |
for each , each , and each . Since , the upper bound constraints involving e are covered. In particular, case (a) is captured in its entirety. We capture case (b) with the following constraints.
| 12 |
| 13 |
| 14 |
for each position and each edge . In the case of and , constraints (12) and (13) model the equation , whereas constraints (14) ensure that . Next, we model case (c) using the following constraints.
| 15 |
for each position and each edge . Finally, the following constraints, which encode that if then implies , prevent case (d) from happening.
| 16 |
for each position and each edge .
The cost of a tree T is the sum of the costs of the events associated to each edge . We model the cost of an edge as the sum of the number of amplifications and deletions that start at each position s. Variables and represent the number of new amplifications and deletions, respectively, that start at position s. We model this using the following constraints.
| 17 |
| 18 |
| 19 |
| 20 |
for each position and each edge .
The objective is to minimize the cost of the events of the selected tree T, which corresponds to
| 21 |
We model the product using the following constraint.
| 22 |
for each position , each edge and .
In Additional file 1: Appendix C, we report the complete ILP formulation.
Experimental evaluation
Copy-number triplet (CN3) problem
We compared the running times of our DP and ILP algorithms for the CN3 problem as a function of n and B. Our results on simulations show that while the running time of the DP algorithm highly depends on the copy-number range B, the ILP time is almost independent of B. With the exception of the case of , the ILP is faster (Additional file 1: Figure S1). Additional file 1: Figure S1 presents the average running times of the DP and ILP algorithms on simulated instances.
Copy-number tree (CNT) problem
To assess the performance of the ILP for CNT, we simulated instances by randomly generating a full binary tree T with k leaves. We randomly labeled edges by events according to a specified maximum number m of events per edge with amplifications/deletions ratio . Specifically, we label an edge by d events where d is drawn uniformly from the set . For each event (s, t, b) we uniformly at random draw an interval and decide with probability whether (amplification) or (deletion). The resulting instance of CNT is composed of the profiles of the k leaves of T and e is set to the maximum value of the input profiles.
We considered varying numbers of leaves and of segments . In addition, we varied the number of events and varied the ratio . We generated three instances for each combination of k, n, m and , resulting in a total of 324 instances.
We implemented the ILP in C++ using CPLEX v12.6 (http://www.cplex.com). The implementation is available at https://github.com/raphael-group/CNT-ILP. We ran the simulated instances on a compute cluster with 2.6 GHz processors (16 cores) and 32 GB of RAM each. We solved 302 instances (93.2%) to optimality within the specified time limit of 5 h. Computations exceeding this limit were aborted and the best identified solution was considered. The instances that were not solved to optimality are a subset of the larger instances with and . For these cases, we show in Additional file 1: Figure S2 the gap between the best identified solutions and their computed upper bounds.
For 323 out of 324 instances (99.7%) the tree inferred by the ILP has a cost that was at most the simulated tree cost. The only exception is an instance with leaves and positions that was not solved to optimality, and where the inferred cost was 15 vs. a simulated cost of 14. These results empirically validate the correctness of our ILP implementation.
We observe that the running time increases with the number of leaves and to a lesser extent with the number of positions (Fig. 4a). In addition, we assessed the distance between topologies of the inferred and simulated trees using the Robinson–Foulds (RF) metric [16]. To allow for a comparison across varying number of leaves, we normalized by the total number of splits to the range [0,1] such that a value of 0 corresponds to the same topology of both trees. For 264 instances (81.4%) the normalized RF was at most 0.35. For leaves the median RF value was 0, which indicates that for at least 50% of these instances the simulated tree topology was recovered. Figure 4b shows the distribution of normalized RF values with varying numbers of leaves and positions. Given a fixed number of leaves, the normalized RF value decreases with increasing number of positions. This indicates that the maximum parsimony assumption becomes more appropriate with larger number of positions, which is not surprising since amplifications and deletions are less likely to overlap. In addition, we observed that running time and RF values are not affected by varying values of m and (Additional file 1: Figures S3, S4). In summary, we have shown that our ILP scales to practical problem instance sizes with and up to positions, which is a reasonable size for applications to real data [12, 17].
Fig. 4.
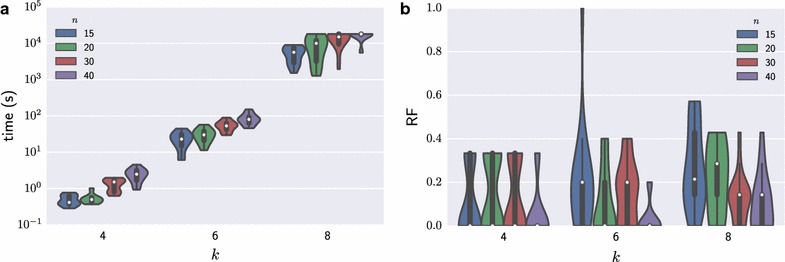
Performance of the ILP algorithm for CNT. Violin plots of running time in seconds (a) and normalized Robinson–Foulds metric for measuring the tree distance (b) for varying number k of leaves and number n of positions. Median values are indicated by a white dot in each plot. Results with positions are shown in Additional file 1: Figures S3 and S4.
Conclusions
In this paper we studied two problems in the evolution of copy-number profiles. For the CN3 problem, we gave a pseudo-polynomial DP algorithm and an ILP formulation, and compared their efficiency on simulated data. Determining the computational complexity of CN3 remains an open problem. We showed that the general CNT problem is NP-hard and gave an ILP solution. Finally, we assessed the performance of our tree reconstruction on simulated data. While all formulations describe copy-number profiles on a single chromosome, our results readily generalize to multiple chromosomes. In addition, while our formulations presently lack the phasing step performed in [12], both the DP algorithm and the ILP formulations can be extended to support phasing.
We note that experiments on real cancer sample data are required to establish the relevance of our formulations. To this end, several extensions to our models might be required. These include handling fractional copy-number values that are a result of most experiments and handling missing data for some positions. Moreover, since tumor samples are often impure, each sample may actually represent a mixture of several clones. In such situations, different objectives might try to decompose the clone mixture in order to reconstruct the evolutionary tree as has been investigated for single-nucleotide variants [3–7].
Authors’ contributions
RS, RS, MZ, and RZ introduced the CN3 problem, designed the DP algorithm and the ILP formulation for this problem, and evaluated both on simulated instances. MEK, BJR, and SZ introduced the CNT problem, analyzed its computational complexity, designed an ILP formulation for this problem, implemented and evaluated the ILP on simulated instances. All authors contributed to writing the manuscript. All authors read and approved the final manuscript.
Acknowledgements
Part of this work was done while M.E-K., B.J.R., R. Shamir, R. Sharan and M.Z. were visiting the Simons Institute for the Theory of Computing.
Competing interests
B.J.R. is a co-founder and consultant at Medley Genomics.
Funding
B.J.R. is supported by a National Science Foundation CAREER Award CCF-1053753, NIH RO1HG005690 a Career Award at the Scientific Interface from the Burroughs Wellcome Fund, and an Alfred P Sloan Research Fellowship. R. Shamir is supported by the Israeli Science Foundation (Grant 317/13) and the Dotan Hemato-Oncology Research Center at Tel Aviv University. R.Z. is supported by fellowships from the Edmond J. Safra Center for Bioinformatics at Tel Aviv University and from the Israeli Center of Research Excellence (I-CORE) Gene Regulation in Complex Human Disease (Center No 41/11). M.Z. is supported by a fellowship from the I-CORE in Algorithms and the Simons Institute for the Theory of Computing in Berkeley and by the Postdoctoral Fellowship for Women of Israel’s Council for Higher Education.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional file
Additional file 1. The appendix contains the proofs omitted from the main text, the ILP formulation for the Copy-Number Triplet Problem, the complete ILP formulation for the Copy-Number Tree Problem, and additional details about the results.
Footnotes
Electronic supplementary material
The online version of this article (doi:10.1186/s13015-017-0103-2) contains supplementary material, which is available to authorized users.
Contributor Information
Mohammed El-Kebir, Email: melkebir@princeton.edu.
Benjamin J. Raphael, Email: braphael@princeton.edu
Ron Shamir, Email: rshamir@post.tau.ac.il.
Roded Sharan, Email: roded@post.tau.ac.il.
Simone Zaccaria, Email: zaccaria@princeton.edu.
Meirav Zehavi, Email: meizeh@post.tau.ac.il.
Ron Zeira, Email: ronzeira@post.tau.ac.il.
References
- 1.Nowell PC. The clonal evolution of tumor cell populations. Science. 1976;194:23–28. doi: 10.1126/science.959840. [DOI] [PubMed] [Google Scholar]
- 2.Felsenstein J. Inferring phylogenies. London: Macmillan Education; 2004. [Google Scholar]
- 3.Popic V, et al. Fast and scalable inference of multi-sample cancer lineages. Genome Biol. 2015;16:91. doi: 10.1186/s13059-015-0647-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.El-Kebir M, et al. Reconstruction of clonal trees and tumor composition from multi-sample sequencing data. Bioinformatics. 2015;31(12):62–70. doi: 10.1093/bioinformatics/btv261. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Yuan K, et al. BitPhylogeny: a probabilistic framework for reconstructing intra-tumor phylogenies. Genome Biol. 2015;16:36. doi: 10.1186/s13059-015-0592-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Jiao W, et al. Inferring clonal evolution of tumors from single nucleotide somatic mutations. BMC Bioinform. 2014;15:35. doi: 10.1186/1471-2105-15-35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Malikic S, et al. Clonality inference in multiple tumor samples using phylogeny. Bioinformatics. 2015. [DOI] [PubMed]
- 8.Ciriello G, et al. Emerging landscape of oncogenic signatures across human cancers. Nat Genet. 2013;45:1127–1133. doi: 10.1038/ng.2762. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Fisher R, et al. Cancer heterogeneity: implications for targeted therapeutics. Brit J Cancer. 2013;108(3):479–485. doi: 10.1038/bjc.2012.581. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Chowdhury S, et al. Algorithms to model single gene, single chromosome, and whole genome copy number changes jointly in tumor phylogenetics. PLoS Comput Biol. 2014;10(7):e1003740. doi: 10.1371/journal.pcbi.1003740. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Zhou J, et al. Maximum parsimony analysis of gene copy number changes. In: WABI. vol. 9289; 2015. p. 108.
- 12.Schwarz R, et al. Phylogenetic quantification of intra-tumour heterogeneity. PLoS Comput Biol. 2014;10(4):e1003535. doi: 10.1371/journal.pcbi.1003535. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Shamir R, et al. A linear-time algorithm for the copy number transformation problem. In: CPM; 2016. [DOI] [PubMed]
- 14.El-Kebir M, Raphael BJ, Shamir R, Sharan R, Zaccaria S, Zehavi M, Zeira R. Copy-number evolution problems: complexity and algorithms. In: International Workshop on algorithms in bioinformatics. Berlin: Springer International Publishing; 2016. p. 137–49.
- 15.Foulds LR, Graham RL. The Steiner problem in phylogeny is NP-complete. Adv Appl Math. 1982;3:43–49. doi: 10.1016/S0196-8858(82)80004-3. [DOI] [Google Scholar]
- 16.Robinson DF, Foulds LR. Comparison of phylogenetic trees. Math Biosci. 1981;53:131–147. doi: 10.1016/0025-5564(81)90043-2. [DOI] [Google Scholar]
- 17.Sottoriva A, et al. A big bang model of human colorectal tumor growth. Nat Genet. 2015;47(3):209–216. doi: 10.1038/ng.3214. [DOI] [PMC free article] [PubMed] [Google Scholar]