

Summary
Prostate cancer patients are closely followed after the initial therapy and salvage treatment may be prescribed to prevent or delay cancer recurrence. The salvage treatment decision is usually made dynamically based on the patient's evolving history of disease status and other time-dependent clinical covariates. A multi-center prostate cancer observational study has provided us data on longitudinal prostate specific antigen (PSA) measurements, time-varying salvage treatment and cancer recurrence time. These data enable us to estimate the best dynamic regime of salvage treatment, while accounting for the complicated confounding of time-varying covariates present in the data. A Random Forest based method is used to model the probability of regime adherence and inverse probability weights are used to account for the complexity of selection bias in regime adherence. The optimal regime is then identified by the largest restricted mean survival time. We conduct simulation studies with different PSA trends to mimic both simple and complex regime adherence mechanisms. The proposed method can efficiently accommodate complex and possibly unknown adherence mechanisms, and it is robust to cases where the proportional hazards assumption is violated. We apply the method to data collected from the observational study and estimate the best salvage treatment regime in managing the risk of prostate cancer recurrence.
Keywords: Causal Inference, Dynamic Treatment Regime, Inverse Probability Weighting, Random Forest, Restricted Mean Survival Time
1. Introduction
Usually after initial treatment, patients with clinically localized prostate cancer are actively monitored for possible cancer recurrence by measuring prostate-specific antigen (PSA). A noticeable rise in the levels of PSA is considered as an indicator for increased risk of cancer recurrence and in these situations salvage androgen deprivation therapy (SADT) would typically be applied to delay the recurrence. The reduction in the hazard of recurrence due to SADT has been estimated using various regression approaches (Kennedy et al., 2010; Taylor et al., 2014). Clinically, “when to start SADT” is hard to determine because early initiation of SADT has both benefits and harms. If SADT is given too early when PSA values are still low, it is wasted during the time when the patient is at low risk, while later on the beneficial effect may wear off as the patient develops resistance. On the other hand if the patient waits to start SADT until PSA is very high, it becomes less effective because by that time the cancer is already well established and may have already spread to other sites.
In this paper, we try to directly address the above question and make recommendations on when would be the optimal time to start SADT in terms of prolonging a patient's cancer recurrence free survival. We use flexible weighting models based on longitudinally collected PSA data to estimate an optimal regime. This situation can be framed as a dynamic treatment regime (DTR) (Murphy, 2003; Robins, 2004), in which dose or treatment is frequently modified according to a patient's current history and disease status. Identifying such optimal dynamic decision rules offers an effective vehicle for personalized management of chronic diseases, for which a patient typically has to be treated at multiple stages.
Although data from sequential multiple assignment randomized trials (SMARTs) are desirable (Murphy, 2005) to evaluate the performance of different DTRs, observational studies are the most common source of data. Careful formulation and assumptions are required to make valid causal inference, especially on how the observational data may restrict the set of DTRs that can be assessed, which are called the feasible (Robins, 1994) or viable (Wang et al., 2012) DTRs. A variety of estimation approaches have been developed for this situation. Murphy (2003) and Robins (2004) generalized the G-estimation method of structural nested models (Robins, 1986) for optimal treatment regime estimation. Furthermore, Q-learning (Watkins, 1989; Watkins and Dayan, 1992; Murphy et al., 2007) and advantage learning (A-learning, Murphy, 2003; Robins, 2004; Blatt et al., 2004) became more and more popular in this field, which are closely related to reinforcement learning methods (Sutton and Barto, 1998) for sequential decision-making in computer science. However, the computational burden of these methods also increases substantially as the number of decision-making stages increases. For chronic diseases, it is common to have a long follow-up period with many clinical visits where new treatment could be initiated dynamically. In these situations, methods based on inverse probability weighting (IPW) are easier to conduct and provide certain robustness against model mis-specifications (Hernán et al., 2006; Robins et al., 2008). But the validity of these approaches still relies on correct model assumptions of the treatment assignment mechanism. This is especially challenging in our prostate cancer study, because the treatment assignment in this observational study is not completely understood, and the nonlinear PSA trend makes it difficult to model the treatment time. Furthermore, the typical proportional hazard assumption is also likely to be violated when comparing different regimes; thus causal differences between regimes may not be well summarized by a single hazard ratio parameter.
The robustness of estimation and model selection for both treatment and outcome models have been discussed in the literature (Mortimer et al., 2005; Neugebauer et al., 2012; Zhang et al., 2013). Nonparametric modeling has been suggested for doubly robust estimators to increase model flexibility and stability (Stitelman et al., 2012). Among which, the successful implementation of Super Learner (Van der Laan et al., 2007) has suggested the potential of machine learning methods to account for the complexity in the underlying mechanism (Neugebauer et al., 2013, 2014). Following the spirit of these researches, we propose to use a flexible approach that imposes minimal model assumptions for the unknown and potentially complicated treatment assignment mechanism. Specifically, we focus on evaluating a class of pre-specified viable DTRs for a time-to-event outcome, with the goal of estimating, from the observational data, the optimal regime to initiate SADT for prolonging the time before cancer recurrence, and we compare different regimes without assuming that the hazards are proportional across regimes. We proceed by artificially censoring subjects when they become noncompliant with a specific regime under investigation (Robins, 2002; Hernán et al., 2006). This censoring potentially induces a bias which we correct using a modified Inverse Probability of Censoring Weighting (IPCW) (Robins, 1993). Then we employ a modified version of Nelson-Aalen estimator with a Random Forest based flexible data driven weighting scheme to (1) accurately estimate the survival distribution under a pre-defined DTR of interest; and (2) compare the survival distribution under different viable DTRs.
In Section 2, we describe the prostate cancer study. In Section 3, we introduce notation under the counterfactual framework of causal inference, followed by the description of the class of DTRs of clinical interest. In Section 4, we present our method of the weighted Nelson-Aalen estimator, where the weights are derived from Random Forest regression. In Section 5, we demonstrate the validity of the proposed method in various simulation scenarios that mimic different treatment/adherence mechanisms, and then we present the analysis results from the prostate cancer data example in Section 6, followed by a discussion in Section 7.
2. The prospective cohort study on prostate cancer recurrence
The data used in this paper come from a prospective study of prostate cancer recurrence. The study enrolled a total of 2781 patients with clinically localized prostate cancer, all of whom were initially treated with external beam radiation therapy (EBRT). Patients came from four cohorts: University of Michigan (Michigan, U.S.A.); Radiation Therapy Oncology Group; Peter MacCallum Cancer Center (Melbourne, Australia); and William Beaumont Hospital (Michigan, U.S.A.). Pretreatment prognostic factors PSA (ng/ml) and T-stages (with value 1-4) were recorded prior to initial EBRT, and then PSAs were monitored at periodic visits throughout follow-up. Each patient enrolled in the study was followed up for at least one year with a minimal of two visits. The median follow-up was 5.2 years, and the median number of PSA measurements (visits) prior to recurrence or SADT was 9. Further description of the data can be found in Proust-Lima et al. (2008). Overall, 11% of the patients received SADT and 12% experienced a recurrence of prostate cancer. A higher level of PSA is considered an important indicator of increasing risk of cancer recurrence; thus a typical regime in clinical practice would be to treat a patient with SADT when his PSA value is increasing and the first time it goes above a certain threshold. However, it is likely that different physicians will have different criteria for when to begin SADT treatment. Moreover, the typical PSA trajectories after initial treatment also have varying and complicated shapes over time, which contribute to the heterogeneity of the observed treatment times in the dataset. We will rely on statistical tools to connect the observed data to various regimes of clinical interest, and to find the optimal one that can be used to guide future clinical practice.
3. Notation and Dynamic Treatment Regimens
Consider a cohort of n patients at baseline t0 = 0. Prior to the cancer recurrence or the patient's dropping out, each patient visits the clinic at regular intervals t1, t2, ⋯, tk, ⋯ until the study end (tK) and has their time-dependent covariates (the PSA level) measured. Treatment decisions, i.e. whether to start SADT, were made soon after each clinic visit and at no other time. Assume that the subjects in the cohort are a random sample from a large population of interest. For patient i at time tk, with i = 1, ⋯, n and k = 0, ⋯, K, let Lk,i = PSAk,i denote the time-dependent covariate observed at tk. In particular, L0,i = (PSA0,i, V0,i) includes baseline PSA as well as other baseline covariates V0,i for patient i. In our study, V0,i denotes indicators for the patient's baseline T-stage. Let Rk,i denote a binary indicator for event occurrence, which takes value 1 if the patient has experienced prostate cancer recurrence by time tk and 0 otherwise. Let Ak,i denote the kth-specific SADT prescription which takes values in a finite set 𝒜k = {0,1}. We further assume that a patient would stay on the treatment once initiated. Following the convention in the literature, we use overbars to denote the history of the variable up to the indexed time. Capital letters are used to refer to random variables or vectors, while lower-case letters are employed to denote the observed values of the corresponding random variables. For example, the observational data for a given patient i up to time tk is denoted as Ōk,i = (O0,i, ⋯, Ok,i) = (R0,i, L0,i, R1,i, L1,i, R2,i, ⋯, Lk−1,i, Rk,i) and a possible observed treatment history up to time tk is denoted as āk,i = (a0,i, ⋯, ak,i) ∈ 𝒜0 × ⋯ × 𝒜k = 𝒜̄k. For simplicity, we will suppress the patient index i in the future when no confusion exists.
Since our interest lies in the outcome when everyone follows the same regime, we define the treatment regime specific counterfactual outcomes under the framework of causal inference (Robins, 1986). For k = 1, ⋯, K, let denote the counterfactual event status that would be observed at time tk were the patient to receive treatment history āk−1 regardless what treatment sequence he actually followed up to tk, and similarly let denote the corresponding counterfactual covariate information at time tk under treatment history āk−1. Then all the counterfactual random variables up to time tK can be denoted as
In our survival outcome setting, the counterfactual observation would only be meaningful up to the time when the counterfactual event occurs, if the counterfactual event happens before tK. So we only include them in Zc for ease of notation.
The SADT treatment process can be formulated as a dynamic treatment regime g = {gk : k = 0, ⋯, K − 1}. The rule for determining the treatment prescription at each time tk, gk ∈ 𝒜k, may depend on part or all of the recorded health information about the patient up to and including time tk. The optimal regime would be a regime that maximizes the expected utility function if all patients in the population follow g. Note that the expected utility can depend on both the rule g as well as the subject-specific ōk, thus it provides a personalized treatment decision. For time-to-event outcomes with right censoring, the Cox model (Cox, 1972) is the most popular choice. However, in our case, it may be unrealistic to expect the proportional hazard assumption to hold across all regimes. Thus, we propose to estimate each regime specific survival curve directly and use the restricted mean survival time (RMST) as the utility function. If we denote the survival time by T, then for some arbitrary time bound Tmax, the RMST can be represented as μ ≡ E {min (T, Tmax)} which equals the area under the survival curve up to Tmax, . Here a large value is commonly chosen for Tmax such as tK. We consider a set of clinically relevant regimes as described earlier where a patient starts SADT when his PSA is increasing and the first time it goes above a threshold b. Practically, we define increasing PSA by its empirical slope, , for k = 1, ⋯, K, i.e. the current PSA value needs to be larger than the value at the previous visit. To formalize this, we consider the class of regimes indexed by b, where at baseline t0 = 0, no salvage treatment would be initiated, i.e. . For tk, k = 1, ⋯, K − 1, the treatment indicator is defined as
| (1) |
where again the superscript b is used to denote the regime gb specific counterfactuals, , , , and . In this setting, a treatment regimen gb is fully defined by cut-off value b. The counterfactual data used in the definition of in (1) is specific to the case where all patients follow gb. If we denote the RMST under regime gb to be μb, then the optimal regime is gopt = arg max{gb∈𝒢} μb.
Definition (1) is based on the assumption that we observe the counterfactual data under all regimes gb ∈ 𝒢. In practice, not all of them can be observed for each patient, because each patient is observed to experience one and only one treatment history. So instead of calculating μb from the counterfactual data , we need to estimate it from the observed data Ōk. To make this possible, we follow Robins (1993) and make the following assumptions. (i) The consistency assumption: for k = 1, ⋯,K; that is, a patient's observed covariates and outcomes are the same as the potential ones in the counterfactual world as long as this person has the same treatment history he actually received. (ii) No unmeasured confounder assumption (NUCA) implies that Ak is independent of ZC conditional on (Ōk, Āk−1) for k = 1, ⋯, K. (iii) The positivity assumption: for a viable regime gb ∈ 𝒢, for k = 1, ⋯, K with probability 1 for an arbitrary small positive constant ε. This essentially guarantees that in the counterfactual world where everyone follows regime gb, if there were patients with history ōk and āk−1 who would be assigned to treatment , then, in the observational world, there must be some actual patients as counterparts who have the same history (ōk and āk−1) and received treatment . Because the treatment can only go from 0 to 1 in our case, we only need to assume the positivity when the patient is not on treatment until tk−1. With the above assumptions, for k = 1, ⋯, K with any fixed under regime gb, we have
where p(·) denotes the probability function, and thus we are able to make inferences on μb using the observational data (Ōk, Āk−1). The validity of this inference can be proved using the similar approach as for a continuous outcome (Robins, 1993; Pearl and Robins, 1995), and the details are provided in Web Appendix A.
4. Method
The assumptions from last section enable us to connect the observational data to the counterfactuals of interest. However, we usually do not know if the decision about treatment initiation was based on a pre-planned regime, instead, we can only judge whether their observed data are compatible with a certain regime at each longitudinal visit. Thus we need to use causal inference tools to estimate the counterfactual survival experiences that the whole cohort of patients would have had if they had truly been adherent to gb.
4.1 Inverse Probability of Adherence Weighting
For a specific regime gb, we proceed by artificially censoring patients at their first nonadherent visit. Let be the indicator of adherence at time tk, k = 0, ⋯, K − 1, which is 1 if the patient's observed treatment status at time tk is the same as the treatment assignment if he followed regime gb (adherent), and 0 otherwise. The patient's data is compatible with regime gb until time tk if , where 1̄ is a vector of 1's with the same length as . The patient is censored at time to create the regime gb adherence dataset, i.e. for a patient who partially follows the regime of interest, we will include him only up to the first time his data is not compatible with following that regime.
Following Robins (1993), we adjust for the bias induced from this artificial censoring by weighting each patient by their Inverse Probability of Adherence Weights as following:
| (2) |
Each adhering patient is essentially weighted at each time point by the inverse probability that he remains adherent given his covariates history, and thus accounts for himself as well as other similar patients who were non-adherent and artificially censored. The probability of adherence for a patient at time tk is calculated as the multiplication of the conditional probabilities of adherence at each time point tj given that he remains adherent up to time tj−1 (j = 1, ⋯, k). A numerator term, which modeled only with baseline covariates, is included to reduce the variability of the weights (Robins and Finkelstein, 2000; Cain et al., 2010).
4.2 Random Forest Regression
Traditionally, the probability models in the numerator and denominator of Equation (2) are estimated by fitting logistic regression models, and if there are multiple time points, the models are usually fitted by pooling data from all possible person-time pieces together (Hernán et al., 2006). In our case, the regime rules are defined based on the PSA value. The non-linear trajectory of PSA and the wide spectrum of regimes from different physicians and different centers leads to some complexity of the treatment mechanism. Although a time-dependent intercept is commonly used in such cases to provide more flexibility for the logistic regression models, it may fail to fully capture the association between adherence and covariates. To this end, we propose to use Random Forest regression to model the probability of treatment in our case and account for things like nonlinear dependence on PSA and interaction between PSA and time.
Random Forests (Breiman, 2001) is a non-parametric classification and regression method. It employs a combination of resampling and ensembles of single tree based models to give superior performance in both classification and regression. Compared to parametric logistic regression, the tree-based regression provides more flexibility in capturing the non-linear effects of the covariates. Furthermore, the resampling in Random Forests also helps to achieve smooth estimates and avoids very extreme probabilities, which is a common problem in using a logistic model to estimate the weights. As a relatively large number of decision points are considered in our case, the number of patients at risk decreases dramatically over time. Thus, it may not be efficient to fit separate conditional probability models at each time point. With Random Forest regression, we can follow the same strategy as in traditional approaches to pool the data of all person-time pieces together, and fit a single model for conditional probabilities at all stages by directly including time as a covariate to account for their variability over stages. Specifically, for the denominator in Equation (2), we fit the model for the observed treatment assignment mechanism, P(Ak = 1|Ōk = ōk, Āk−1 = 0̄), with all the observed data available up to the first time point when the patient is on treatment, i.e. person-time pieces up to t = max{tk : Ak−1 = 0, k ≤ K}. The following property connects the treatment probabilities with the model for the adherence to regime gb.
Property 1: For any patient i = 1, ⋯, n, and k = 1, ⋯, K − 1, we have
A brief derivation of Property 1 is outlined in Web Appendix B. It allows us to calculate the probability of regime adherence from the probabilities of initiating treatment. Since the treatment model for the observational data is the same regardless of which regime is under investigation, this allows us to obtain the probability of adherence for various regimes while only fitting a single pooled Random Forest model. Besides, the treatment model can incorporate information from all the pre-treatment person-time pieces available, which will be more efficient than modeling the regime specific censoring mechanism. However, for the numerator, we may not be able to do the same thing, or the numerator will also depend on the time-dependent confounder Āk. Thus, we proceed by directly modeling in the adherence cohort for each regime of interest. The Random Forest regression is done using the R function randomForest with all default settings except for the number of trees to grow (ntree) and number of candidate variables to include at each split (mtry). We set ntree = 1000, and perform a grid search for mtry from {1, 2, 4} based on the “out-of-bag” prediction error. In both simulation and data application, we end up using mtry = 2. Following the suggestion in Foster et al. (2011), we also include the two-way interactions of all variables in the model for better numerical performance. The treatment/adherence probability estimates are then obtained from the “out-of-bag” predictions.
4.3 Weighted Nelson-Aalen Estimator
For the regime gb adherent cohort, we assign a time-dependent weight to each person-time piece. Then we define the following weighted number of events and the weighted number at risk at time tk (k = 1, ⋯, K) as
and employ the weighted Nelson-Aalen formula for the regime gb-specific survival function as Ŝb(t) = exp{−Λ̂b(t)}, where is the cumulative hazard function. The estimated counterfactual RMST is then given by . Since we have discrete visit times, the integral can be written as .
As a widely used flexible modeling approach, the theoretical properties of Random Forests have been intensively studied and discussed (Lin and Jeon, 2006; Biau and Devroye, 2010; Scornet et al., 2015). They have provided valuable insights on the consistency of the method. Based on the consistency results of Random Forest regression, we have the following property for the weight estimator in Section 4.2.
Property 2: The time-dependent weights estimated through Random Forests are consistent estimators of the true weights given the observed history Ōk,i at tk (k = 1, …, K). That is, as n → ∞, where denotes the measure generated by counterfactual variables observed until tk under the given regime gb, and 𝒫k denotes the corresponding measure generated by observational data Ōk,i up to time tK.
With Properties 1 and 2, we can further investigate the consistency property of the proposed estimator for the counterfactual quantities of interest as following:
Proposition 1: Under assumptions (i) - (iii) and the following regularity conditions:
The observational data (Ōk,i, ĀK−1,i) are independent and identically distributed,
where is the true marginal hazard for any regime gb ∈ 𝒢,
For the true marginal survival function , we assume there exist continuous first-order derivatives in t and bounded second partial derivatives (uniformly in t ∈ (0, tK]). can thus be consistently estimated by the proposed estimator Ŝb(t), and μ̂b is a consistent estimator for true regime specific RMST .
Web Appendix C provides a brief derivation of this proposition. Property 1, Property 2, and Proposition 1 assure that the weights are able to be consistently estimated through the proposed procedure, and then the weighted Nelson-Aalen estimator is consistent for the regime specific counterfactual survival function. Furthermore, the estimation of the utility is also consistent. Thus, we can identify the optimal DTR by maximizing μ̂b within all the gb's that are considered, that is, .
So far we consider the data with only administrative censoring. For more complicated censoring mechanisms, inverse probability of censoring weights could be applied in addition to correct for the possible bias related to censoring. More specifically, one can first model the time-dependent censoring probability in the full dataset using similar strategy via Random Forest regression, then the overall weight for each person-time piece would be the product of the adherence weight and the censoring weight.
5. Simulation
In order to evaluate the performances of the proposed method, we conduct simulation studies where we explicitly model the relationship among time to recurrence, SADT free PSA, and treatment effect. In the simulation studies, we have the fully adherent data available for each defined regime, and thus we can use these simulated counterfactual data as the “gold standard”. Two scenarios are considered, one to mimic a simple case with linear PSA trajectories and the second with a more complicated but more realistic pattern of PSA trajectories. We compare the performance of our proposed method with a naive unweighted estimator and the logistic regression based estimator, where for the denominator of the weight in Equation (2), the treatment probabilities are estimated from
| (3) |
and for the numerator, one fits the regime specific adherence model as
| (4) |
Here, following Hernán et al. (2006), the time-dependent intercepts h1(tj) and h2(tj) are included in (3) and (4) to increase the modeling flexibility. We use cubic splines with 2 internal knots to non-parametrically estimate these intercept terms. The observational data, Ok, include PSAk and the empirical slope at time tk (for Scenario 1, we only consider PSAk). Similar as in Proust-Lima et al. (2008), the PSA values are log-transformed. T-stage at baseline (V0) is represented as a 2-dimensional vector of indicators V0 = (I(T-stage = 2), I(T-stage ≥ 3))T. For each scenario, we simulate 500 datasets each with 2000 subjects.
5.1 Simulation set-up of Scenario 1
5.1.1 Longitudinal PSA Values
During the follow-up period (0, tK], each patient is repeatedly measured every year, and we choose tK = 15 years. Let denote the observed PSA value for patient i measured at tk (tk = k = 0,1, …, 15) if he has not received any SADT treatment. We simulate from the following linear mixed model:
| (5) |
where Xi(t) = (α0 + α0,i) + (α1 + a1,i)t models the underlying true SADT free PSA for t ∈ (0,tK]. (α0, α1) = (−3.0, 0.3) are fixed effect parameters, (a0,i, a1,i) ∼ MVN(0,Σ) are subject-specific random effects, with . We further truncate any a1,i < −0.1 at -0.1 to create increasing PSA trends. At a given time tk, we assume the measurement error εk,i ∼ N(0, σ2) with σ2 = 0.1. Note that we observe before the earliest of either SADT initiation or recurrence, and then will not be observed.
5.1.2 Different Treatment Regimes and Observed Treatment Time
For each patient, we consider 10 regimes with regime-specific thresholds of {b1, b2, ⋯, b10} = {−1.0, −0.5, ⋯, 3.5}. Based on patient i's SADT free PSA trajectory { }, we can calculate the regime specific SADT initiation time as , , ⋯, for all 10 regimes, where is determined from Equation (1) with b = bj (let if ). We generate the index of the observed regime Bi at random from {b1, b2, ⋯,b10} for patient i. Thus, the observed treatment time for patient i who is following gBi , which we denote as Ui for simplicity of notation. Based on this data generation process, both the counterfactual treatment initiation time for each regime of interest and the observed treatment initiation time are determined by the SADT free PSA measurements. We show in Web Appendix D that this procedure helps us to prevent extreme weights among the regimes of interest.
5.1.3 Model for Recurrence and Fully Compliant Data
We simulate the recurrence time for patient i according to a Cox model with hazard function, for t ∈ (0, tK]:
| (6) |
where λ0 = 0.2, θ0 = (0.2, 0.3)T, and θ1 = 0.3. Patient i's baseline T-stage is sampled from {1, 2, 3, 4} with probability p = (0.33, 0.59, 0.07,0.01)T, which is used to generate V0,i. The treatment effect, γi(t), is defined as
| (7) |
where γ0,i = β0 + β1Xi(Ui), with (β0, β1, β2) = (−1.0, −0.4, 0.2). Thus, the initial treatment effect γi(Ui) = γ0,i linearly depends on Xi(Ui), the true SADT free PSA value at the time point Ui. After that, the magnitude of the treatment effect γi(t) decays over time until it shrinks to zero. The time to recurrence is generated for patient i as , where
| (8) |
and Wi ∼ Uniform(0,1), then is rounded up to the closest visit time as Ti, or censored at tK. Similarly, for each regime gbj, j = 1, ⋯, 10, we calculate the time to recurrence for patient i according to the counterfactual treatment initiation time .
5.2 Simulation set-up of Scenario 2: Nonlinear PSA trends and more candidate regimes
To better understand the performance of the proposed method in practice, we consider the following scenario with more realistic PSA trajectories. In addition, we generate the observational data from a larger number of candidate regimes to increase randomness.
5.2.1 PSA Models
In the absence of SADT, a typical trajectory of PSA has three phases (0: starting-value, 1: short-term evolution, 2: long-term evolution). Here we consider a shorter study length with tK = 12 years. Following Proust-Lima et al. (2008) and Taylor et al. (2013), for patient i at t ∈ (0, tK], we simulate SADT free PSA values from the following mixed model to recreate these phases as:
| (9) |
where again Xi(t) is the underlying true SADT free PSA for t ∈ (0, tK], and f(t) = (1 + t)−1.5 − 1 is used to model the short-term decreasing trend, the linear in t term is used to model the long-term increasing trend. (a0,i, a1,i, a2,i) ∼ MVN(0, Σ) are subject-specific random effects with . (α0, α11, α12, α21, α22) are fixed effect parameters with α0 = 1.0, α11 = 1.5, α12 = (0.2, 0.2)T, α21 = 0.1, and α22 = (0.2, 0.5)T, and V0,i is generated the same as in Scenario 1. At a given time tk = k = 0,1, ⋯, 12, we assume εk,i ∼ N(0, σ2) with σ2 = 0.2.
5.2.2 Different Treatment Regimes and Observed Treatment Time
To give more heterogeneity to the treatment assignment mechanism, we generate the observed treatment time and survival outcome for patient i with threshold Bi, which is drawn from a discrete uniform distribution with 100 evenly spaced values {−2.00, −1.95, ⋯, 2.95}. The observed treatment time for patient i is then . Note that in the analysis we still restrict our interest to evaluating the counterfactual outcomes from 10 regimes {b1, b2, ⋯, b10} = {−2.0, −1.5, ⋯, 2.5}.
5.2.3 Model for Recurrence and Fully Compliant Data
Following Proust-Lima et al. (2008), we let the hazard function depend on both true PSA and its slope, for t ∈ (0, tK],
| (10) |
where the true slope of SADT free is the derivative of Xi(t) from Model (9). The time to recurrence Ti is then generated from (7), (8) and (10) with λ0 = 0.15, θ0 = (0.8, 0.9)T, θ1 = 0.1, θ2 = 0.1, β0 = 10.0, β1 = −10.0 and β2 = 0.2. The same models are used to define the counterfactual to recurrence for each regime gbj, j = 1, ⋯, 10.
5.3 Simulation Results
Figure 1 shows the average Nelson-Aalen survival curves for given regimes estimated using different methods. Figures 1a and 1b show the estimation for regime b = 2.0 in Scenario 1, while Figures 1c and 1d show the estimation for b = −1.0 in Scenario 2. As can be seen, the survival curves estimated naively from the observational data without using weights are all biased away from the fully adherent curves. In contrast, both the pooled logistic regression based estimation and the proposed method can help reduce such bias in Scenario 1, where the data generation is relatively simple and thus more consistent with pooled logistic regression. In Scenario 2, the PSA trajectory has a complicated shape, and therefore the treatment adherence mechanism is hard to fit well using the pooled logistic regression method. As shown in Figure 1c and 1d, the survival curve estimated by the proposed method is very close to the counterfactual fully adherent curve, while the curve estimated by the pooled logistic method shows bias compared to the fully adherent curve. Similar results are also observed for other regimes.
Figure 1.
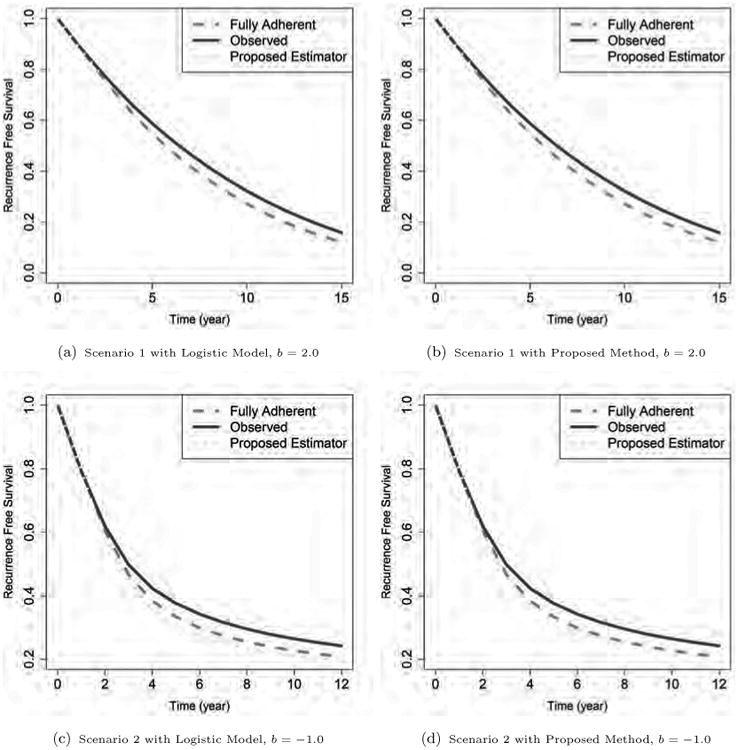
The estimated survival curves for different simulation schemes. The regime specific true curves (obtained from the counterfactual fully adherent cohorts) are shown in dashed lines. The solid lines are unweighted estimates from the observed data (obtained by censoring subjects when they are no longer adherent with given regimes), and the dotted lines are for the proposed weighted estimates. The upper panels are from regime b = 2.0 in Scenario 1, and the lower panels are from regime b = -1.0 in Scenario 2. The two panels on the left show estimation from the pooled logistic method, while the panels on the right show results from the proposed Random Forest based method. All curves are obtained by averaging over 500 simulations.
In both scenarios, we approximate the true RMST, , for any given b by the Monte Carlo simulation of a very large regime specific cohort (n = 107). Figure 2 plots over different b for both scenarios. Among the regimes under consideration, is maximized at around b = 2.0 with years for Scenario 1 (Figure 2a). While for Scenario 2, the optimal DTR is when b = 1.0, which yields the maximum at 5.518 years (Figure 2b). Table 1 summarizes the estimated RMST μ̂ for the regimes of interest. In both scenarios, we can see that 1) μ̂ from the fully adherent cohort is close to in Figure 2, which suggests that these estimates can well approximate the true population quantities in our simulations, and 2) the proposed estimator yields the maximal average μ̂b at true optimal regime and also correctly identifies the true optimal regime with highest frequency.
Figure 2.

True under Scenario 1 (Figure 2a) and Scenario 2 (Figure 2b) in the simulation study. In each figure, The x-axis stands for the regime specific PSA threshold for SADT initiation b, while the y-axis stands for the true regime specific RMST calculated from Monte Carlo method. Each point in the plots above are calculated from 107 Monte Carlo samples.
Table 1. Restricted Mean Survival Time for Regimes of Interest in Simulation Studies.
| Regime | Full Adherent | Unweighted | Pooled Logistic | Proposed Method | |||||
|---|---|---|---|---|---|---|---|---|---|
| μ̂ | opt% | μ̂ | opt% | μ̂ | opt% | μ̂ | opt% | ||
| Scenario 1 | b1 = −1.0 | 4.016 (0.067) | 0% | 4.953 (0.121) | 0% | 4.039 (0.079) | 0% | 4.047 (0.073) | 0% |
| b2 = −0.5 | 4.876 (0.075) | 0% | 5.721 (0.115) | 0% | 4.671 (0.083) | 0% | 4.884 (0.080) | 0% | |
| b3 = 0.0 | 5.920 (0.091) | 0% | 6.578 (0.117) | 0% | 5.563 (0.100) | 0% | 5.918 (0.094) | 0% | |
| b4 = 0.5 | 6.787 (0.103) | 0% | 7.225 (0.124) | 0% | 6.425 (0.121) | 0% | 6.797 (0.107) | 0% | |
| b5 = 1.0 | 7.589 (0.113) | 0% | 7.785 (0.129) | 0% | 7.286 (0.135) | 0% | 7.600 (0.120) | 0% | |
| b6 = 1.5 | 8.340 (0.110) | 0% | 8.407 (0.128) | 0% | 8.159 (0.135) | 0% | 8.335 (0.131) | 0% | |
| b7 = 2.0 | 8.729 (0.114) | 99.6% | 8.919 (0.134) | 3.8% | 8.656 (0.147) | 92.0% | 8.710 (0.146) | 93.6% | |
| b8 = 2.5 | 8.503 (0.116) | 0.4% | 8.949 (0.143) | 96.2% | 8.421 (0.163) | 8.0% | 8.488 (0.158) | 6.4% | |
| b9 = 3.0 | 8.068 (0.114) | 0% | 8.668 (0.148) | 0% | 7.984 (0.175) | 0% | 8.045 (0.171) | 0% | |
| b10 = 3.5 | 7.632 (0.111) | 0% | 8.324 (0.156) | 0% | 7.519 (0.215) | 0% | 7.472 (0.310) | 0% | |
|
| |||||||||
| Scenario 2 | b1 = −2.0 | 4.872 (0.078) | 0% | 5.417 (0.096) | 0% | 4.153 (0.121) | 0% | 4.639 (0.103) | 0% |
| b2 = −1.5 | 4.921 (0.079) | 0% | 5.402 (0.093) | 0% | 4.293 (0.109) | 0% | 4.687 (0.099) | 0% | |
| b3 = −1.0 | 4.991 (0.079) | 0% | 5.410 (0.092) | 0% | 4.544 (0.110) | 0% | 4.829 (0.098) | 0% | |
| b4 = −0.5 | 5.091 (0.078) | 0% | 5.456 (0.091) | 0% | 4.867 (0.106) | 0% | 5.047 (0.093) | 0% | |
| b5 = 0.0 | 5.294 (0.079) | 0% | 5.572 (0.091) | 0% | 5.298 (0.117) | 0.2% | 5.380 (0.095) | 0% | |
| b6 = 0.5 | 5.757 (0.082) | 0.6% | 5.766 (0.093) | 80.4% | 5.891 (0.153) | 30.0% | 5.862 (0.101) | 29.0% | |
| b7 = 1.0 | 5.848 (0.088) | 99.4% | 5.736 (0.096) | 19.6% | 5.927 (0.219) | 50.4% | 5.890 (0.108) | 71.0% | |
| b8 = 1.5 | 5.562 (0.084) | 0% | 5.488 (0.095) | 0% | 5.658 (0.336) | 6.2% | 5.563 (0.112) | 0% | |
| b9 = 2.0 | 5.315 (0.081) | 0% | 5.280 (0.092) | 0% | 5.499 (0.431) | 4.8% | 5.307 (0.120) | 0% | |
| b10 = 2.5 | 5.138 (0.080) | 0% | 5.135 (0.092) | 0% | 5.372 (0.575) | 8.4% | 5.102 (0.134) | 0% | |
Note: The values in parentheses are the empirical standard deviations calculated from 500 MC replications, %opt is the percentage for the given regime to be identified as the optimal regime among the 500 replicates
For Scenario 1, μ̂b from the unweighted dataset shows a notable bias compared to the RMST of the fully adherent data, and it is maximized at regime 8 for most of the replications, which is incorrect. As shown by the frequency of being identified as the optimal regime, over the 500 simulations, 99.6% of the fully adherent datasets yield regime 7 as the true optimal, while only 3.8% pick regime 7 as the optimal using the unweighted method. Both the pooled logistic method and the proposed method can correct the bias and identify regime 7 with b7 = 2.0 as the optimal one with the highest frequency (92.0% and 93.6% respectively). This is not surprising because the data generating process in Scenario 1 can be well approximated by the model specification of the pooled logistic regression. In Scenario 2, the fully adherent data show that regime 7 has the largest μ̂b, and is the optimal regime in 99.4% of the 500 simulations. Again, the unweighted estimator prefers a different regime (regime 6) in 80.4% of the simulations, which is biased. Since in Scenario 2, the data generating process is more complicated and thus the models employed in the pooled logistic regression are misspecified, the pooled logistic method can only identify regime 7 as the optimal in 50.4% of the simulations. In contrast, the proposed method has a much higher rate of correctly identifying the optimal regime (71.0%). Comparing to the estimation from pooled logistic method, the average RMSTs given by the proposed method are also closer to the ones from fully adherent data. Thus we can see that the proposed flexible model works more robustly in correctly picking up the true optimal regime in different scenarios and reduces the bias more effectively when estimating the population survival outcome.
6. Analysis of the Prostate Cancer Data
It is of great interest to learn from the observational data about how different regimes are expected to perform in the future and whether some common guidelines could be suggested. To this end, we apply the proposed method on our prostate cancer recurrence dataset.
There are 2781 patients in the dataset of which 222 patients (< 8.0%) have follow-up time longer than 10 years. Thus, we compare μ̂b with tK = 10 years in the analysis. We consider regular visits at every 0.2 years, which was followed by most patients. For patients who missed visits and thus had interval longer than 2 years, we restrict to the time period when they were actively followed, and arbitrarily censor them at 0.2 years after the last visit before such long interval. Other than that, the last observation is carried forward to impute missing PSA measures. In total, 245 patients (8.8%) received SADT. We consider DTRs gb as defined earlier, where b is the cut-off for the logarithm of (PSA+0.1). In clinical practice, PSA may be considered as in the “alert zone” from 3 ng/ml to 30 ng/ml, and a SADT is commonly seen to be initiated in that zone. Thus, we focus on regimes in that zone with b ∈ {1.1, 1.2, ⋯, 3.5}.
In the dataset, there is a wide range of treatment initiation times and PSA values at the time of initiation. This suggests the need for the treatment initiation model to have flexibility in order to accommodate the unknown relationships. Thus, we estimate the weights through Random Forests with input covariates PSA, empirical slope of PSA (the increment of PSA since the previous visit), baseline T-stage, time t and all two-way interactions. In addition to the regime specific adherence weight , we also account for possible bias from non-administrative censoring by IPCW. If we denote the censoring indicator in the original observational dataset at time tk by Corg,k, then the IPCW weights for k = 1,…, K are
| (11) |
where the censoring probability models in both the numerator and denominator are fitted with the same covariates as we used in the adherence models using Random Forest regression. Thus, the overall weight used in estimation for each person-time piece is .
Figure 3a shows that the regime with b = 1.2 (3.22 ng/ml PSA) is identified as gopt by the proposed method, and the corresponding estimated restricted mean time to recurrence under this regime is μ̂b = 9.46 years. Figure 3b presents the weighted Nelson-Aalen estimators for the estimated optimal regime along with two other regimes. Our results suggest to initiate the SADT at an earlier stage when PSA raises to the “alert zone”, which is consistent with the common understanding of clinical practice.
Figure 3.

The survival estimation for regime specific time to recurrence in the prostate cancer dataset. Panel (a) shows the relationship between the restricted mean time to recurrence estimated by the proposed method μ̂b and the regime specific PSA threshold for SADT initiation b. Panel (b) shows the weighted Nelson-Aalen curves estimated for three regimes, which includes the estimated optimal regime b = 1.2 (solid line), along with two other regimes b = 1.9 (dashed line) and b = 2.7 (dotted line).
7. Discussion
Motivated by the clinical need in prostate cancer treatment, we describe a method to estimate the optimal DTR from observational data that can accommodate complex unknown dependency of the treatment assignment as well as regime adherence mechanism on time-dependent and time-independent covariates. The proposed method provides an extension of the traditional inverse probability weighting method to allow for flexibilities simultaneously in two ways: (1) for the adherence mechanism, the Random Forest regression allows us to capture a large range of different treatment models, and (2) for the survival outcome, the non-parametric estimation allows us to put minimal structure assumptions on the estimator. The proposed estimating procedure can be implemented with most commonly used statistical software. Compared to logistic models for treatment initiation, the bootstrap procedure within the Random Forest regression can effectively avoid unstable and very extreme probability estimates. For example, in the real data application, for the regime b = 1.2 (the estimated optimal) compliant dataset, the estimated weights have a median of 0.91, with 2.5% and 97.5% quantiles as 0.50 and 3.14. Notice that these weights are cumulative products of up to 50 conditional probabilities, which means that most of the estimated probabilities are close to 1. Furthermore, compared to methods involving dynamic programming, the proposed method is computationally feasible even for problems with a relatively large number of decision time points. Thus, it is a powerful tool in clinical studies and public health practice, where there are more than a handful of possible decision points to initiate the treatment or intervention.
One common concern with machine learning based methods is overfitting. Tree size control and pruning procedures are used in tree based models to deal with this issue. In Random Forests, the bootstrap procedure and random selection of covariates for each tree will also help to reduce overfitting. In our simulation studies, we choose the tuning parameters according to the “out-of-bag” errors, which come from data not used for fitting each tree. We find the results very close to the prediction errors given by 5-fold cross-validation in both scenarios. Although larger number of trees are likely to increase accuracy, it will also lead to increased computational burden. In our case, there is no obvious improvement when ntree goes above 1000, so we set ntree = 1000. In general, we recommend cross-validation to select tuning parameters (Van der Laan and Robins, 2002), if there is a large discrepancy between the “out-of-bag” prediction error and the cross-validation prediction error.
One needs to be cautious when instrumental variables (IVs) exist, because including IVs in the weight models may create practical positivity violations and thereby lead to unstable weights, increased variance, and poor confidence interval coverage. From our experience with additional simulations, including IVs in the weight model for the proposed method does not severely affect the results. However, in general, if there is prior knowledge that allows us to identify a variable as an IV rather than a confounder, then it is better to exclude that variable from the weight model.
In this prostate cancer study, the patient's data are only collected at each visit, but the cancer recurrence events are more likely to actually happen at some point in the interval between adjacent visits. Since we are considering time intervals as small as 0.2 years, the bias introduced by treating the events as happening at the visits is likely to be ignorable. However, a more precise model would be desired to handle the event time as interval censored. This would be of more importance when the interval between visits are longer. Additional methodology will also be required to adjust for possible bias in censoring under such settings.
Supplementary Material
Acknowledgments
The authors thank the editor, the associated editor and the anonymous referee for their helpful comments. This research is partially supported by NIH grant CA199338 and CA129102.
Footnotes
Supplementary Materials: Web Appendices referenced in Sections 3, 4, and 5 and the source code for the proposed data analysis procedures are available with this paper at the Biometrics website on Wiley Online Library.
References
- Biau G, Devroye L. On the layered nearest neighbour estimate, the bagged nearest neighbour estimate and the random forest method in regression and classification. Journal of Multivariate Analysis. 2010;101:2499–2518. [Google Scholar]
- Blatt D, Murphy S, Zhu J. A-learning for approximate planning Technical report. The Methodology Center, Pennsylvania State University; 2004. [Google Scholar]
- Breiman L. Random forests. Machine Learning. 2001;45:5–32. [Google Scholar]
- Cain LE, Robins JM, Lanoy E, Logan R, Costagliola D, Hernán MA. When to start treatment? a systematic approach to the comparison of dynamic regimes using observational data. The International Journal of Biostatistics. 2010;6 doi: 10.2202/1557-4679.1212. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cox DR. Regression models and life-tables. Journal of the Royal Statistical Society Series B (Methodological) 1972:187–220. [Google Scholar]
- Foster JC, Taylor JMG, Ruberg SJ. Subgroup identification from randomized clinical trial data. Statistics in Medicine. 2011;30:2867–2880. doi: 10.1002/sim.4322. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hernán MA, Lanoy E, Costagliola D, Robins JM. Comparison of dynamic treatment regimes via inverse probability weighting. Basic Clinical Pharmacology & Toxicology. 2006;98:237–242. doi: 10.1111/j.1742-7843.2006.pto_329.x. [DOI] [PubMed] [Google Scholar]
- Kennedy EH, Taylor JMG, Schaubel DE, Williams S. The effect of salvage therapy on survival in a longitudinal study with treatment by indication. Statistics in Medicine. 2010;29:2569–2580. doi: 10.1002/sim.4017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin Y, Jeon Y. Random forests and adaptive nearest neighbors. Journal of the American Statistical Association. 2006;101:578–590. [Google Scholar]
- Mortimer KM, Neugebauer R, Van der Laan M, Tager IB. An application of model-fitting procedures for marginal structural models. American Journal of Epidemiology. 2005;162:382–388. doi: 10.1093/aje/kwi208. [DOI] [PubMed] [Google Scholar]
- Murphy SA. Optimal dynamic treatment regimes. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2003;65:331–355. [Google Scholar]
- Murphy SA. An experimental design for the development of adaptive treatment strategies. Statistics in Medicine. 2005;24:1455–1481. doi: 10.1002/sim.2022. [DOI] [PubMed] [Google Scholar]
- Murphy SA, Oslin DW, Rush AJ, Zhu J. Methodological challenges in constructing effective treatment sequences for chronic psychiatric disorders. Neuropsychopharmacology. 2007;32:257–262. doi: 10.1038/sj.npp.1301241. [DOI] [PubMed] [Google Scholar]
- Neugebauer R, Fireman B, Roy JA, O'Connor PJ, Selby JV. Dynamic marginal structural modeling to evaluate the comparative effectiveness of more or less aggressive treatment intensification strategies in adults with type 2 diabetes. Pharmacoepidemiology and Drug Safety. 2012;21:99–113. doi: 10.1002/pds.3253. [DOI] [PubMed] [Google Scholar]
- Neugebauer R, Fireman B, Roy JA, Raebel MA, Nichols GA, O'Connor PJ. Super learning to hedge against incorrect inference from arbitrary parametric assumptions in marginal structural modeling. Journal of Clinical Epidemiology. 2013;66:S99–S109. doi: 10.1016/j.jclinepi.2013.01.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Neugebauer R, Schmittdiel JA, Zhu Z, Rassen JA, Seeger JD, Schneeweiss S. High-dimensional propensity score algorithm in comparative effectiveness research with time-varying interventions. Statistics in Medicine. 2014;34:753–781. doi: 10.1002/sim.6377. [DOI] [PubMed] [Google Scholar]
- Pearl J, Robins J. Proceedings of the Eleventh conference on Uncertainty in Artificial Intelligence. Morgan Kaufmann Publishers Inc; 1995. Probabilistic evaluation of sequential plans from causal models with hidden variables; pp. 444–453. [Google Scholar]
- Proust-Lima C, Taylor JMG, Williams SG, Ankerst DP, Liu N, Kestin LL, Bae K, Sandler HM. Determinants of change in prostate-specific antigen over time and its association with recurrence after external beam radiation therapy for prostate cancer in five large cohorts. International Journal of Radiation Oncology Biology Physics. 2008;72:782–791. doi: 10.1016/j.ijrobp.2008.01.056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins J. A new approach to causal inference in mortality studies with a sustained exposure period: application to control of the healthy worker survivor effect. Mathematical Modelling. 1986;7:1393–1512. [Google Scholar]
- Robins J, Orellana L, Rotnitzky A. Estimation and extrapolation of optimal treatment and testing strategies. Statistics in Medicine. 2008;27:4678–4721. doi: 10.1002/sim.3301. [DOI] [PubMed] [Google Scholar]
- Robins JM. Information recovery and bias adjustment in proportional hazards regression analysis of randomized trials using surrogate markers. Proceedings of the Biopharmaceutical Section, American Statistical Association. 1993;24:3. [Google Scholar]
- Robins JM. Correcting for non-compliance in randomized trials using structural nested mean models. Communications in Statistics-Theory and Methods. 1994;23:2379–2412. [Google Scholar]
- Robins JM. Analytic methods for estimating hiv-treatment and cofactor effects. Methodological Issues in AIDS Behavioral Research. 2002:213–288. [Google Scholar]
- Robins JM. Proceedings of the Second Seattle Symposium in Biostatistics. Springer; 2004. Optimal structural nested models for optimal sequential decisions; pp. 189–326. [Google Scholar]
- Robins JM, Finkelstein DM. Correcting for noncompliance and dependent censoring in an aids clinical trial with inverse probability of censoring weighted (ipcw) log-rank tests. Biometrics. 2000;56:779–788. doi: 10.1111/j.0006-341x.2000.00779.x. [DOI] [PubMed] [Google Scholar]
- Scornet E, Biau G, Vert JP. Consistency of random forests. Annals of Statistics. 2015;43:1716–1741. [Google Scholar]
- Stitelman OM, De Gruttola V, Van der Laan MJ. A general implementation of tmle for longitudinal data applied to causal inference in survival analysis. The International Journal of Biostatistics. 2012;8 doi: 10.1515/1557-4679.1334. [DOI] [PubMed] [Google Scholar]
- Sutton RS, Barto AG. Reinforcement learning: An introduction. MIT press; 1998. [Google Scholar]
- Taylor JMG, Shen J, Kennedy EH, Wang L, Schaubel DE. Comparison of methods for estimating the effect of salvage therapy in prostate cancer when treatment is given by indication. Statistics in Medicine. 2014;33:257–274. doi: 10.1002/sim.5890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van der Laan MJ, Polley EC, Hubbard AE. Super learner. Statistical Applications in Genetics and Molecular Biology. 2007;6 doi: 10.2202/1544-6115.1309. [DOI] [PubMed] [Google Scholar]
- Van der Laan MJ, Robins JM. Unified methods for censored longitudinal data and causality. Springer Science & Business Media; 2002. [Google Scholar]
- Wang L, Rotnitzky A, Lin X, Millikan RE, Thall PF. Evaluation of viable dynamic treatment regimes in a sequentially randomized trial of advanced prostate cancer. Journal of the American Statistical Association. 2012;107:493–508. doi: 10.1080/01621459.2011.641416. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Watkins CJ, Dayan P. Q-learning. Machine Learning. 1992;8:279–292. [Google Scholar]
- Watkins CJCH. PhD thesis. University of Cambridge England; 1989. Learning from delayed rewards. [Google Scholar]
- Zhang B, Tsiatis AA, Laber EB, Davidian M. Robust estimation of optimal dynamic treatment regimes for sequential treatment decisions. Biometrika. 2013;100:2. doi: 10.1093/biomet/ast014. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.