

Abstract
To boost the power of classifiers, studies often increase the size of existing samples through the addition of independently collected data sets. Doing so requires harmonizing the data for demographic and acquisition differences based on a control cohort before performing disease specific classification. The initial harmonization often mitigates group differences negatively impacting classification accuracy. To preserve cohort separation, we propose the first model unifying linear regression for data harmonization with a logistic regression for disease classification. Learning to harmonize data is now an adaptive process taking both disease and control data into account. Solutions within that model are confined by group cardinality to reduce the risk of overfitting (via sparsity), to explicitly account for the impact of disease on the inter-dependency of regions (by grouping them), and to identify disease specific patterns (by enforcing sparsity via the l0-‘norm’). We test those solutions in distinguishing HIV-Associated Neurocognitive Disorder from Mild Cognitive Impairment of two independently collected, neuroimage data sets; each contains controls and samples from one disease. Our classifier is impartial to acquisition difference between the data sets while being more accurate in diseases seperation than sequential learning of harmonization and classification parameters, and non-sparsity based logistic regressors.
1 Introduction
Popular for improving the power of classifiers is to expand application from a single data set (Fig. 1(a)) to multiple, independently collected sets of the same disease (Fig. 1(b)) [1]. To analyze across multiple sets, neuroimage studies generally first harmonize the data by, for example, regressing out demographic factors from MRI measurements and then train the classifier to distinguish disease from control samples [2]. However, harmonization might mitigate group differences making classification difficult (such as in Fig. 2). To improve classification accuracy, we propose the first approach to jointly learn how to harmonize MR image data and classify disease. Harmonization relies on both controls and disease cohorts to reduce differences in the image based measurements due to acquisition differences between sets while preserving the group separation investigated by the classifier. We evaluate our approach on the challenging task (Fig. 1(c)) of being trained on two data sets differing in their acquisition and diseases they sample, and tested on accurately distinguishing the two diseases while being impartial to acquisition differences, i.e., the controls of the two sets.
Fig. 1.
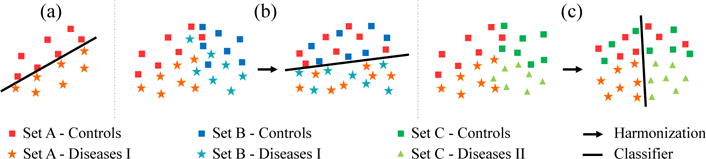
Examples for classifying data: (a) Classification based on a single set, (b) separating healthy and disease based on multiple sets requiring harmonization, and (c) part two disease groups based on harmonizing controls of disease specific data sets.
Fig. 2.
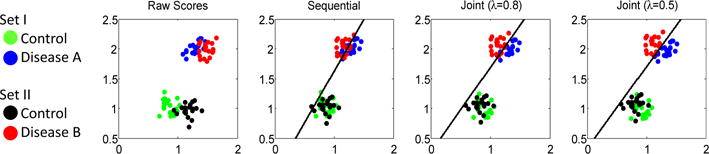
Impact of harmonization on classification (black line) of two synthetic sets. Compared to the raw scores, the Sequential approach mitigated differences between the two disease groups by ‘pushing’ them together. Our joint model with λ = 0.5 is the only approach that is indifferent to controls and correctly labels all disease cases.
Training of our approach is defined by an energy function that combines a linear harmonization model with a logistic regression classifier. Minimizing this function is confined to group cardinality constrained solutions, i.e., labeling is based on a small number of groups of image scores (counted via the l0-‘norm’). Doing so reduces the risk of overfitting, accounts for inter-dependency between regions (e.g., bilateral impact of diseases), and identifies disease distinguishing patterns (defined by non-zero weights of classifiers) that avoid issues of solutions based on relaxed sparsity constraints [3]. Inspired by [4], our method uses block coordinate descent to find the optimal parameters for harmonizing the two data sets and correctly labeling disease samples while being indifferent to control cohorts (i.e., acquisition differences). During testing, we use those parameters to harmonize the image scores before performing classification ensuring that the data set associated with a subject is not part of the labeling decision.
Using 5-fold cross-validation, we measure the accuracy of our method on distinguishing HIV-Associated Neurocognitive Disorder (HAND) from Mild Cognitive Impairment (MCI) of two independently collected data sets; each set contains controls and samples of one disease only. Distinguishing HAND from MCI is clinically challenging due to similarity in symptoms and missing standard protocols for assessing neuropsychological deficits [5]. Not only is our classifier indifferent to the controls from both groups but is also significantly more accurate in distinguishing the two diseases than the conventional sequential harmonization and classification approach and non-sparsity based logistic regression methods.
2 Jointly Learning of Harmonization and Classification
Let a data set consists of set SA of controls and samples with disease A, and an independently collected set SB of controls and samples of disease B. The four subsets are matched with respect to demographic scores, such as age. Each sample s of the joint set is represented by a vector of image features xs and a label ys, where ys = −1 if s ∈ SA and ys = +1 for s ∈ SB. The acquisition differences between SA and SB are assumed to linearly impact the image features. To extract disease separating patterns from this joint set, we review the training of a sequential model for data harmonization and classification, and then propose to simultaneously parameterize both tasks by minimizing a single energy function.
2.1 Sequential Harmonization and Classification
Training the linear regression model for data harmonization results in parameterizing matrix U so that it minimizes the difference (with respect to the l2-norm ‖·‖2) between the inferred values U · [1 ys]⊤ (1 is the bias term of the linear model) and the raw image scores xs across nC controls of the joint data set, i.e.,
| (1) |
A group sparsity constrained logistic regression classifier is trained on the residuals , i.e., harmonized scores, across samples ‘s’ of two groups, which are nD samples of the two disease cohorts. Note, classification based on the inferred values is uninformative as all scores of a region are mapped to two values. Now, let the logistic function be θ(α) := log(1+exp(−α)), the weight vector w encode the importance of each score of rs and v ∈ ℝ be the label offset, then the penalty (or label) function of the classifier is defined by
| (2) |
The search for point minimizing often has to be limited so that conforms to disease specific constraints, such as the bilateral impact of HAND or MCI on individual regions. These constraints can be modeled by group cardinality. Specifically, every entry of w is assigned to one of nG groups . The search space is composed of weights where the number of groups with non-zero weight entries are below a certain threshold k ∈ ℕ, i.e., with ‖·‖0 being the l0-‘norm’. Finally, the training of the classifier is fully described by the following minimization problem
| (3) |
which can be solved via penalty decomposition [4, 6]. Note, that Eq. (3) turns into a sparsity constrained problem if each group gi is of size 1. Furthermore, setting ‘k = nG’ turns Eq. (3) into a logistic regression problem. Finally, Eq. (3) can distinguish a single disease from controls by simply replacing ys in Eq. (2) with a variable encoding assignment to cohorts instead of data sets.
2.2 Simultaneous Harmonization and Classification
We now determine for a single minimization problem composed of the linear (harmonization) and logistic (classification) regression terms, i.e.,
| (4) |
Algorithm 1.
Joint Harmonization and Classification.
| 1: | Set ϱ = 0.1, (according to [4]) and U′ = 0, w′ = 0, q′ = 0, v′ = 1 |
| 2: | Repeat |
| 3: | Repeat (Block Coordinate Descent) |
| 4: | U″ ← U′, w″ ← w′, q″ ← q′, v″ v′ |
| 5: | U′ ←argminU (1 − λ)lD (U, v′, q′) + λhC (U) (via Gradient Descent) |
| 6: | (via Gradient Descent) |
| 7: | Update w′ by |
| Sort groups gj(q′) so that | |
| Define to be the set of indices of q′ associated with groups if ∈ and 0 otherwise. | |
| 8: | Until |
| 9: | ϱ ← σ · ϱ |
| 10: | Until ‖w′ − q′ ‖max <εP. |
where λ ∈ (0, 1). Note, the model fails to classify when λ = 1 ( and are undefined) or harmonize when λ = 0 (entries of are undefined). Motivated by [4], we simplify optimization by first parameterizing the classifier with respect to the ‘unconstrained’ vector q before determining the corresponding sparse solution . The solution to Eq. (4) is estimated by iteratively increasing ϱ of
| (5) |
until the maximum of the absolute difference between elements of wϱ and qϱ is below a threshold, i.e., ‖wϱ−qϱ‖max<εP. (Uϱ,vϱ,wϱ,qϱ) are determined by block coordinate descent (BCD). As outlined in Alg. 1, let (U′, v′, w′, q′) be estimates of (Uϱ, vϱ, wϱ, qϱ), then U′ is updated by solving Eq. (5) with fixed (v′, w′, q′):
| (6) |
As this minimization is over a convex and smooth function, Eq. (6) is solved via gradient descent. Note, that determining U′ is equivalent to increasing the separation between the two disease groups by minimizing lD(·, v′, q′) while reducing the difference between the two control groups by minimizing hC(·).
Next, BCD updates v′ and q′ by keeping (U′, w′) fixed in Eq. (5), i.e.,
| (7) |
This minimization problem is defined by a smooth and convex function. Its solution is thus also estimated via gradient descent. Finally, w′ is updated by solving Eq. (5) with fixed (U′, v′, q′), i.e.,
| (8) |
As shown in [4, 6], the closed form solution of Eq. (8) first computes ‖gi(q′)‖2 for each group i and then sets w′ to the entries of q′, who are assigned to the k groups with the highest norms. The remaining entries of w′ are set to 0. The procedures (6)~(8) are repeated until the relative changes of (U′, v′, w′, q′) between iterations are smaller than a threshold εB. (Uϱ, vϱ, wϱ, qϱ) is updated with the converged (U′, v′, w′, q′), ϱ is increased and another BCD loop is initiated until wϱ and qϱ converge towards each other (see Alg. 1 for details).
Fig. 2 showcases the differences between sequential and joint harmonization and classification. Two synthetic data sets consist of a control and disease cohort, where the raw scores for each cohort are 20 random samples from a Gaussian distribution with the covariance being the identity matrix multiplied by 0.01. The mean of the Gaussian for Disease A of Set I (blue) is (1.3,2) resulting in samples that are somewhat separated from those of Disease B of Set II (mean=(1.5,2), red). The difference in data acquisition between the two sets is simulated by an even larger separation of the means between the two control groups (Set I: mean=(0.9,1), green; Set B: mean=(1.2,1), black). The Sequential method (see Sec. 2.1 without sparsity) harmonizes the scores so that the classifier assigns the controls to one set, i.e., the separating plane (black line) is impartial to acquisition differences. This plane fails to perfectly separate the two disease cohorts as the cohorts are ‘pushed’ together with the mean of Disease B being now to the right of the mean of Disease A. Higher accuracy in disease classification is achieved by our joint model (omitting sparsity) with λ = 0.8. Comparing this plot to the results with λ = 0.5 shows that as λ decreases the emphasis on separating the two disease increases as intended by Eq. (6). The classifier is still impartial to acquisition differences and perfectly labels the samples of the two disease cohort. In summary, the joint model enables data harmonization that preserves group differences, which was not the case for the sequential approach.
3 Distinguishing HAND from MCI
We tested our method on a joint set of two independently collected data sets: the ‘UHES’ set [7] contained cross-sectional MRIs of 15 HAND cases and 21 controls while the ‘ADNI’ set contained MRIs of 20 MCIs and 18 controls. The 4 groups were matched with respect to sex and age. Each MRI was acquired on a 3T Siemens scanner (with the two sets having different acquisition protocols) and was processed by [8] resulting in 102 regional volume scores. We assigned those scores to (nG = 52) groups to account for the bilateral impact of MCI and HAND on both hemispheres. We now review our experimental setup and results highlighting that jointly learning harmonization and classification results in findings that are indifferent to the two control cohorts and more accurate in distinguishing the two disease groups compared to alternative learning models.
To measure the accuracy of our method, we used 5 fold-cross validation with each fold containing roughly 20% of each cohort. On the training sets, we used parameter exploration to determine the optimal group cardinality k ∈ {1, 2, …, 10} and weighing λ ∈ {0.1, 0.2, …, 0.9}. Across all folds and settings, our algorithm converged within 5 iterations while each BCD optimization converged within 500 iterations. For each setting, we then computed the disease accuracy of the classifier by separately computing the accuracy for each cohort (MCI and HAND) to be assigned to the right set (UHES or ADNI) and then averaging the scores to consider the imbalance of cohort sizes. We determined the control accuracy repeating those computations with respect to the two control groups. Since higher control accuracy infers worse harmonization, an unbiased control accuracy, i.e., around 50%, coupled with a high disease accuracy was viewed as preferable. Note, an unbiased control accuracy only qualifies the harmonization in that the remaining acquisition differences do not impact the separating plane (or weights ) of the classifier. For each training set, we then chose the setting (λ, k) with corresponding weights and harmonization parameters that produced the largest difference between the two accuracy scores. This criteria selected a unique setting for 2 folds, 2 settings for 2 folds, and 3 settings for 1 fold.
On the test set, we computed the harmonized scores (residuals) of all samples for each selected setting. We then hid the subjects’ data set associations from the ensemble of selected classifiers by applying the residuals to classifiers parameterized by the corresponding weight settings. Based on those results, we computed control and disease accuracy as well as the corresponding p-values via the Fisher exact test [9]. We viewed p < 0.05 as significantly more accurate than randomly assigning samples to the two sets. An ensemble of classifiers was viewed as informative, if separating HAND from MCI resulted in a significant p-value and a non-significant one for controls.
We repeated the above experiment for the sequential harmonization and classification approach of Section 2.1, called SeqGroup, to show the advantages of our joint learning approach, called JointGroup. To generalize our findings about joint learning of harmonization and classification parameters to non-sparsity constrained models, we also tested the approach omitting the group sparsity constraint, i.e., k = 52. JointNoGroup refers to the results of the corresponding joint method and SeqNoGroup to the sequential results.
Table 1 shows the accuracy scores and p-values of all implementations listed according to the difference between disease and control accuracy. The method with the smallest difference, SeqNoGroup, was the only approach recording a significant control accuracy score (68.4%, p = 0.024). The corresponding separating plane was thus not impartial to acquisition difference so that the relatively high disease accuracy (82.5%) was insignificant. The next approach, SegGroup, obtained non-significant accuracy scores for controls (64.6%) indicating that the group sparsity constrain improved generalizing the results from the relatively small training set to testing. The difference between control (52.8%) and disease accuracy (83.3%) almost doubled (30.5%) for the joint approach JointNoGroup. As reflected in Fig. 2, learning data harmonization separated from classification does not generalize as well as the joint approach, who harmonizes data so that differences between disease groups are preserved. Confirming all previous findings, the overall best approach (i.e., control and disease accuracy differ most) is our proposed JointGroup approach achieving a disease accuracy of 90%.
Table 1.
Implementations listed according to the difference between disease (MCI vs. HAND) and control (UHES controls vs. ADNI controls) accuracy. In bold are the findings that are statistically significant different from chance, i.e., p < 0.05. Our method, JointGroup, achieves the highest disease accuracy and largest spread in scores.
| Classification accuracy | p-value with ground truth | ||||
|---|---|---|---|---|---|
| Disease | Control | Difference | Disease | Control | |
| SeqNoGroup | 82.5 | 68.4 | 14.1 | <0.001 | 0.024 |
| SeqGroup | 80.0 | 64.6 | 15.4 | <0.001 | 0.073 |
| JointNoGroup | 83.3 | 52.8 | 30.5 | <0.001 | 0.753 |
| JointGroup | 90.0 | 52.8 | 37.2 | <0.001 | 0.753 |
The group sparsity constraint aided in separating diseases and identified patterns of regions (i.e., non-zero weights ) impacted by either MCI or HAND (or HIV). Each column of Fig. 3 shows the largest, unique pattern associated with a training set. For those training sets that selected multiple patterns (i.e., settings), patterns with less regions were always included in the largest pattern. The precentral gyrus, cerebellum VIII, and lateral ventricle were parts of all patterns. HIV is known to impact the cerebellum [10] and accelerated enlargement of ventricles is linked to both HIV [11] and MCI [12]. These findings indicate that the extracted patterns are informative with respect to MCI and HAND (and HIV), which requires an in-depth morphemic analysis for confirmation.
Fig. 3.
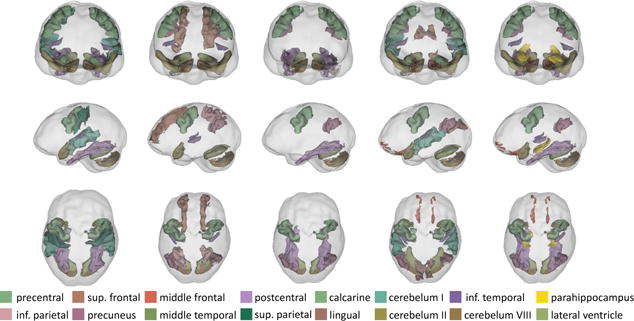
Each column shows the largest, unique pattern extracted by JointGroup on one of the 5 training sets. Identified regions are impacted by HAND, HIV, or MCI.
4 Conclusion
We proposed an approach that simultaneously learned the parameters for data harmonization and disease classification. The search for the optimal separating plane was confined by group cardinality to reduce the risk of overfitting, to explicitly account for the impact of disease on the inter-dependency of regions, and to identify disease specific patterns. On separating HAND from MCI samples of two disease specific data sets, our joint approach achieved better classification accuracy than the non-sparsity based model and sequential approaches.
Acknowledgments
This research was supported in part by the NIH grants U01 AA017347, AA010723, K05-AA017168, K23-AG032872, and P30 AI027767. We thank Dr. Valcour for giving us access to the UHES data set. With respect to the ADNI data, collection and sharing for this project was funded by the NIH Grant U01 AG024904 and DOD Grant W81XWH-12-2-0012. Please see https://adni.loni.usc.edu/wp-content/uploads/how_to_apply/ADNI_DSP_Policy.pdf for further details.
References
- 1.Jovicich J, et al. Multisite longitudinal reliability of tract-based spatial statistics in diffusion tensor imaging of healthy elderly subjects. NI. 2014;101:390–403. doi: 10.1016/j.neuroimage.2014.06.075. [DOI] [PubMed] [Google Scholar]
- 2.Moradi E, et al. Predicting symptom severity in autism spectrum disorder based on cortical thickness measures in agglomerative data. bioRxiv. 2016 doi: 10.1016/j.neuroimage.2016.09.049. [DOI] [PubMed] [Google Scholar]
- 3.Sabuncu M. A universal and efficient method to compute maps from image-based prediction models. MICCAI. 2014 doi: 10.1007/978-3-319-10443-0_45. [DOI] [PubMed] [Google Scholar]
- 4.Zhang Y, et al. Computing group cardinality constraint solutions for logistic regression problems. Medical Image Analysis. 2016 doi: 10.1016/j.media.2016.05.011. In Press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Sanmarti M, et al. HIV-associated neurocognitive disorders. JMP. 2014;2(2) doi: 10.1186/2049-9256-2-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Lu Z, Zhang Y. Sparse approximation via penalty decomposition methods. SIAM J Optim. 2013;23(4):2448–2478. [Google Scholar]
- 7.Nir TM, et al. Mapping White Matter Integrity in Elderly People with HIV. Human Brain Mapping. 2014;35(3):975–992. doi: 10.1002/hbm.22228. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Pfefferbaum A, et al. Variation in longitudinal trajectories of regional brain volumes of healthy men and women (ages 10 to 85 years) measured with atlas-based parcellation of MRI. NI. 2013;65:176–193. doi: 10.1016/j.neuroimage.2012.10.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Fisher R. The logic of inductive inference. J Roy Stat Soc. 1935;1(98):38–54. [Google Scholar]
- 10.Chang L, et al. Impact of apolipoprotein E ε4 and HIV on cognition and brain atrophy: antagonistic pleiotropy and premature brain aging. NI. 2011;4(58) doi: 10.1016/j.neuroimage.2011.07.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Thompson PM, et al. 3D mapping of ventricular and corpus callosum abnormalities in HIV/AIDS. NI. 2006;31(1):12–23. doi: 10.1016/j.neuroimage.2005.11.043. [DOI] [PubMed] [Google Scholar]
- 12.Nestor SM, et al. Ventricular enlargement as a possible measure of alzheimer’s disease progression validated using the alzheimer’s disease neuroimaging initiative database. Brain. 2008;131(9):2443–2454. doi: 10.1093/brain/awn146. [DOI] [PMC free article] [PubMed] [Google Scholar]