

Abstract
Efferent modulation has been demonstrated to be very important for speech perception, especially in the presence of noise. We examined the functional relationship between two efferent systems: the rostral and caudal efferent pathways and their individual influences on speech perception in noise. Earlier studies have shown that these two efferent mechanisms were correlated with speech perception in noise. However, previously, these mechanisms were studied in isolation, and their functional relationship with each other was not investigated. We used a correlational design to study the relationship if any, between these two mechanisms in young and old normal hearing individuals. We recorded context-dependent brainstem encoding as an index of rostral efferent function and contralateral suppression of otoacoustic emissions as an index of caudal efferent function in groups with good and poor speech perception in noise. These efferent mechanisms were analysed for their relationship with each other and with speech perception in noise. We found that the two efferent mechanisms did not show any functional relationship. Interestingly, both the efferent mechanisms correlated with speech perception in noise and they even emerged as significant predictors. Based on the data, we posit that the two efferent mechanisms function relatively independently but with a common goal of fine-tuning the afferent input and refining auditory perception in degraded listening conditions.
Keywords: efferent, corticofugal, olivocochlear bundle, otoacoustic emissions, ABR, contextual encoding, brainstem
INTRODUCTION
Attempts to probe into the physiological mechanisms supporting speech perception in noise have revealed the importance of both afferent and efferent auditory pathways in the regulating process (Kumar and Vanaja 2004; Gilbert and Sigman 2007; Davis and Johnsrude 2007; Ziegler et al. 2009; Anderson et al. 2011; Song et al. 2011a). While most initial studies primarily focussed on bottom-up mechanisms and highlighted their importance (Dubno et al. 1984; Batra et al. 1986; Galbraith et al. 1995; Souza et al. 2007), later studies revealed a significant role of even efferent processing mechanisms such as phonological decoding, perceptual cognitive restoration and efferent feedback to be important in regulating auditory perception and speech in noise perception (Giraud et al. 1997a; Gilbert and Sigman 2007; Davis and Johnsrude 2007; Chandrasekaran et al. 2009; Kumar et al. 2010; Ciuman 2010; Andéol et al. 2011; Wersinger and Fuchs 2011; Parbery-Clark et al. 2011). With specific reference to regulating mechanisms within the auditory pathway, studies have demonstrated the contribution of efferent auditory neural pathway in regulating speech perception in noise (Giraud et al. 1997a; Kumar and Vanaja 2004; Chandrasekaran et al. 2009; Strait et al. 2011; Parbery-Clark et al. 2011; Anderson et al. 2013; Mishra and Lutman 2014).
Both caudal and rostral efferent auditory projections (efferent innervations in the rostral and caudal brainstem) have been extensively investigated for their role in modulating auditory perception in noise (Giraud et al. 1997a; May et al. 2004; Gilbert and Sigman 2007; Chandrasekaran et al. 2009; Ciuman 2010; Strait et al. 2011; Andéol et al. 2011; Wersinger and Fuchs 2011; Parbery-Clark et al. 2011). While the caudal efferents (Medial Olivocochlear bundle-MOCB) extend from the superior olivary complex to the outer hair cells and the afferent first-order neurons (Guinan et al. 1983; Kawase et al. 1993; Kawase and Liberman 1993; Liberman et al. 1996; Guinan 2006), the rostral efferents (cortico-thalamic and cortico-collicular) arise from the layers V and VI of the auditory cortex and innervate the inferior colliculus (Luo et al. 2008; Bajo et al. 2010; Stebbings et al. 2014) and medial geniculate body (Budinger et al. 2013). The connections are also found from the medial geniculate body to inferior colliculus (Dragicevic et al. 2015; Terreros and Delano 2015; Aedo et al. 2016).
MOCB is the most studied auditory efferent pathway (see Guinan 2006 for review). In most of the studies, the mechanism of MOCB is documented in terms of the magnitude of suppression of otoacoustic emissions in the presence of contralateral acoustic stimulation. Contralateral suppression of otoacoustic emissions (CSOAEmag) is known to be mediated by medial olivocochlear bundle (MOCB) in humans (Berlin et al. 1993; Giraud et al. 1997b; Kumar and Vanaja 2004; Guinan 2006; Zhao and Dhar 2010). CSOAEmag has been shown to correlate with speech perception in noise (Kumar and Vanaja 2004; de Boer and Thornton 2008; Mishra and Lutman 2014) indicating the regulatory role of MOCB in speech in noise perception. The anti-masking effect resulting from the olivocochlear efferent mechanisms, fine-tunes the ascending input (Guinan 2006) through selective reduction of the cochlear amplification in the side bands. An additional effect is also seen as reduction in nerve firing rate to noises, thus increasing the dynamic range and controlling the line-busy effect. The studies using microelectrical stimulation of corticofugal efferent projections have shown that efferent connections from the cortex influence the functioning of the olivocochlear bundle (Xiao and Suga 2002; León et al. 2012). These involve cortico-thalamo-collicular-cochlear nucleus and cortico-collicular-olivary pathways (Terreros and Delano 2015). The rostral and caudal efferent branches seem to be linked, owing to the fact that electrical activation of both causes change in the response properties of the cochlear hair cells (Xiao and Suga 2002; León et al. 2012; Dragicevic et al. 2015). Suga et al. (2002) suggested that corticofugal pathways form multiple interlinked feedback loops with the ascending auditory pathways and modulate the ascending neural input. Figure 1 shows a simplified illustration of these pathways.
FIG. 1.

A simplified illustration of the descending pathways in the central auditory pathway based on Terreros and Delano (2015) (With permission). The black paths are the afferent paths and the grey paths are the efferent paths. It can be seen that there are many rich interconnections in the efferent auditory pathway. The efferent innervations originating from the cortex and the upper brainstem are operationally termed rostral efferents, and those originating in the lower brainstem are operationally termed the caudal efferents. AC auditory cortex, MGB medial geniculate body, IC inferior colliculus, SOC superior olivary complex, CN cochlear nucleus.
Chandrasekaran et al. (2009), Parbery-Clark et al. (2011), Strait et al. (2011) and Gnanateja et al. (2013) showed electrophysiological evidence for modulation of auditory brainstem responses by rostral efferents. They used an oddball-like stimulus paradigm and found repetition-related enhancement of auditory brainstem responses compared to those elicited in the context of other syllables. Similar to CSOAE, the contextual brainstem encoding was found to be related to speech in noise perception. They attributed this repetition-related enhancement/contextual encoding to the efferent modulation, possibly mediated by the rostral corticofugal pathway. The human auditory system is good at detecting patterns in the auditory scene and extracts information from the relevant patterns (Bregman 1994). The repetition-related effect in brainstem responses leads to tagging on to regularly occurring features in speech (voice pitch) and helps in perceptually separating the competing (irrelevant) features from the auditory stream of interest. Such a phenomenon is important in a cocktail party like situation, i.e., perceiving speech in the presence of noise.
There are several other efferent neural connections (Nuñez and Malmierca 2007; Terreros and Delano 2015; Aedo et al. 2016) in the auditory system, other than those tapped by the two above-mentioned measures. However, most of those are not feasible for studying the efferent mechanisms in human beings due to their invasive nature. The two mechanisms mentioned here are the ones which can be studied in the human auditory system with relative ease non-invasively.
In summary, it appears that the corticofugal (rostral efferents) (Yan and Suga 1998; Suga et al. 2002; Chandrasekaran et al. 2009; Strait et al. 2011; Parbery-Clark et al. 2011; Gnanateja et al. 2013) and the medial olivocochlear pathway (caudal efferents) (Giraud et al. 1997a; Kumar and Vanaja 2004; de Boer and Thornton 2008; Andéol et al. 2011; Mishra and Lutman 2014) share a common objective of fine-tuning the neural responses for better speech in noise perception. However, it is not clear if the rostral and caudal efferent mechanisms function as independent entities or they work in unison and are part of the same neural network. Given the proximity and the numerous inter-connections (illustrated in Fig. 1) between rostral and caudal efferent pathways, it is palpable to assume at the least, that both are a part of the descending pathway serving similar efferent modulatory function. However, it would be erroneous to consider so, without experimental validation.
The relationship between the two efferent mechanisms mentioned above can be probed using a correlational study design in normal hearing individuals with good and poor speech in noise perception. It has been widely reported that older individuals have difficulty perceiving speech in the presence of noise in spite of normal peripheral hearing sensitivity (Crandell et al. 1991; Anderson et al. 2012). Age-related deterioration is also observed in neurophysiological measures of efferent and afferent auditory function (Parthasarathy 2001; Anderson et al. 2012; Lauer et al. 2012; Bidelman et al. 2014 inter alia). Examining the efferent modulatory mechanisms and speech perception in noise in young and older individuals with normal hearing sensitivity would aid in understanding these mechanisms better. We also focussed on the relative contribution of these efferent mechanisms to speech perception in noise. The findings would also be valuable in making clinically relevant decisions in selecting assessment tools for efferent auditory function. In the current study, we used the contextual brainstem encoding and CSOAEmag as non-invasive tools to index rostral and caudal efferent modulatory mechanisms, respectively. We assessed these measures for their correlation with each other and with speech perception in noise. We compared the context-dependent speech evoked auditory brainstem responses, contralateral suppression of otoacoustic emissions and speech perception in noise between adults and older individuals with normal hearing sensitivity. We also assessed the inter-relationship among context-dependent speech evoked auditory brainstem responses, efferent suppression of otoacoustic emission and speech perception in noise.
MATERIALS AND METHODS
Participants
A total of 56 adults participated in the present study. All the participants resided in-and-around Mysore district in Karnataka and were fluent speakers of the Kannada language. They had a minimum educational qualification of tenth grade. All the participants had hearing thresholds below 15 dB hearing level at octave frequencies from 250 Hz through 8000 Hz. We also measured transient evoked otoacoustic emissions to assess cochlear functioning. This was done to ensure that the findings of the study are not affected by peripheral hearing status of the participants. We also ruled out the presence of hypertension, diabetes and other neurological and psychological problems through a structured interview with the participants. Based on their age, we assigned the participants to either ‘older’ or ‘younger’ group. The older group consisted of 29 participants in the age range of 50 to 65 years, while the younger group consisted of 27 participants in the age range of 18 to 30 years. All the participants signed an informed consent form, and the procedures used in the study conformed to the ethical guidelines for bio-behavioural research involving human subjects by the All India Institute of Speech and Hearing, Mysuru (Venkatesan 2009). All the procedures adopted were in line with the declaration of Helsinki (World Medical Association 2013).
Speech Perception in Noise
The signal to noise ratio needed for obtaining 50 % (SNR-50) speech identification scores in the presence of noise was evaluated. SNR-50 for Kannada sentences was evaluated for all the participants using ‘speech perception in noise test–Kannada’ (Methi et al. 2009). The material consisted of Kannada sentences spoken by a male speaker and multi talker (Eight talkers) babble as the background noise. The test consists of seven equivalent lists of seven sentences each. The sentences were presented at SNRs of +20 to −10 dB in steps of 5 dB. These sentences were presented through circumaural Sennheisser HDA200 headphones driven by a standard sound card of an Acer 4820T notebook PC at an intensity of 40 dB HL. Only the left ear of each participant was tested. Only the List 2 of the test was used in the study, to avoid any extraneous effect of list differences on the SNR-50, if any. The total number of words repeated correctly by each participant was noted down, and the SNR-50 was calculated based on the Spearman-Karber equation (eq. 1) metric (Finney 1952; Tillman and Olsen 1973):
| 1 |
Context-Dependent Brainstem Encoding of Speech
Generation and Presentation of Stimuli
Consonant-vowel (CV) syllables /bi/, /bu/, /gi/ and /da/ were chosen to elicit auditory brainstem responses. The syllable /da/ was the stimulus of interest, while the others served only as the contextual stimuli. The contextual stimuli were chosen such that they differed from the /da/ syllable in terms of the vowel, stop burst and the second formant transition (cueing place of articulation). An adult male who was a native speaker of Kannada uttered the chosen CV syllables. The utterances were recorded using a dynamic microphone placed at a distance of six inches from the speaker’s mouth. The microphone output was routed to the Stim2 hardware (Compumedics-Neuroscan, Charlotte, NC, USA) and recorded with a resolution of 16 bits at a sampling rate of 44,100 Hz in the Sound module of the Stim2 software suite. The syllables were trimmed to a duration of 100 ms by deleting the vowel cycles beyond 100 ms at the nearest zero-crossing. The recorded syllables were initially analysed using Speech Processing and Synthesis toolboxes (Childers 1999) incorporating a linear predictive coding algorithm. This was done in order to extract and modify the different acoustic parameters independently. The modified linear predictive coding parameters were then used to synthesize the CV stimuli of 100 ms using the toolboxes. These synthetic speech syllables /ba/, /bu/, /gi/ and /da/ were subjected to a perceptual rating for naturalness and quality by 10 sophisticated listeners with normal hearing. Based on the ratings of the listeners, linear predictive coding parameters were modified to resynthesize the stimuli with higher naturalness. The waveforms, spectrograms and acoustic parameters of the four stimuli are shown in Figure 2.
FIG. 2.

The waveforms and spectrograms of the four stimuli used in the study. The salient acoustic characteristics of each syllable are given in the attached table.
Brainstem responses were recorded in two different paradigms: one repetitive paradigm and the other variable paradigm. The repetitive paradigm involved repetitive presentation of only the /da/ syllable for 6114 sweeps. The variable paradigm involved the presentation of the /da/ syllable in the context of the stimuli /bi/, /bu/ and /gi/. Each stimulus in the variable paradigm had a frequency of occurrence of 25 % of the total 6114 stimulus presentations. Two blocks each of the repetitive and variable paradigm were presented, resulting in a total of 12,228 sweeps per paradigm. The order of these four blocks was randomized across the participants. Stimulus presentation was controlled in the Gentask module of the Stim2 system (Compumedics-Neuroscan, Charlotte, NC, USA). The stimulus presentation sequence was prepared such that two /da/ syllables never occurred consecutively. A schematic representation of the two paradigms is depicted in Figure 3. The stimuli were presented in an alternating polarity through shielded ER-3A (Etymotic Research, Elk Grove Village, USA) insert ear phones (Neuroscan, El paso, Texas) at an intensity of 85 dB sound pressure level monaurally to the left ear of the participants at an inter-stimulus interval of 166.67 ms. Additionally, using a watermelon model, it was ensured that stimulus artifacts were not picked up by the recording apparatus, even when the electrode wire was in contact with the insert ear phone.
FIG. 3.

Schematic representation of the two paradigms used in the study. The upper panel shows the variable paradigm and the lower panel shows the repetitive paradigm.
Recording of AEPs
The participants were made to sit in a reclining chair and ensured for their comfort. During the course of the experiment, participants were shown a captioned movie of their choice. This was done to maintain a passive, yet wakeful state. The scalp EEG responses were picked up from the Cz electrode site using a 64 channel QuickCap™ (Compumedics-Neuroscan, Charlotte, NC, USA) with AgCl sintered electrodes. The electrode cap was adjusted to position the electrodes on the scalp according to the 10–10 EEG placement system (Chatrian et al. 1985). The right ear mastoid was used as the reference channel. The raw EEG output of the electrode cap was recorded in the Acquire module of the Scan 4.4 suite (Compumedics-Neuroscan, Charlotte, NC, USA) interfaced by a Synamps2 DC preamplifier. This was then lowpass filtered at the pre-amplifier with a cutoff of 3500 Hz and converted into a digital signal at a sampling rate of 20,000 Hz in the amplifier. The raw EEG responses were later analysed offline in the Neuroscan Edit 4.4 module (Compumedics-Neuroscan, Charlotte, NC, USA).
Response Analysis
The continuous raw EEG of every participant in each paradigm was subjected to offline processing to extract the averaged brainstem responses time locked to the /da/ syllable in the repetitive and variable paradigms separately. In the offline processing of ABR, to begin with, the raw EEGs were band-pass filtered using an FIR filter with an 80 Hz highpass cutoff and a 1500 Hz lowpass cutoff, each with a slope of 12 dB/octave. The responses to the /da/ syllable in both the paradigms were isolated from those of the other stimuli by extracting the epochs time locked to the /da/ stimulus. The epochs time locked to the three contextual syllables were not considered for analysis. The epochs in the repetitive paradigm corresponding to the order of occurrence of the contextual syllables were discarded. Epochs with peak amplitudes exceeding ±35 μV were rejected, and the rest of the epochs were considered for further analysis. After artifact rejection in the variable paradigm, the sequence of rejected and accepted epochs was used as a template to reject the corresponding epochs in the repetitive paradigm and vice versa (as done in Chandrasekaran et al. 2009; Parbery-Clark et al. 2011). For example, if the response to the /da/ as the 12th stimulus in the variable paradigm was rejected, then the response to the 12th /da/ stimulus in the repetitive paradigm was also rejected. This was done in order to control the effect of variations in stimulus presentation order if any, neural refractoriness and number of sweeps. The epochs were then averaged in the time domain to obtain brainstem responses of good signal to noise ratio and free from stimulus order effects.
The averaged brainstem responses were subjected to spectral analysis to analyse the amplitudes at the spectral components corresponding to the fundamental frequency (F0 = 100 Hz), second Harmonic (H2 = 200 Hz) and third Harmonic (H3 = 300 Hz) of the stimulus. This was done in a custom written program in Matlab 2010 (Mathworks Inc., Natick USA). The waveforms were windowed from 20 to 110 ms using a 10 % tapered Tukey window and zero-padded up to a total duration of 1 s to increase the spectral resolution to 1 Hz. The zero-padded waveforms were then subjected to a fast Fourier transform. The magnitudes at F0 (100 Hz), H2 (200 Hz) and H3 (300 Hz) were then analysed by averaging the magnitudes of ten bins (1 Hz wide) around the F0, H2 and H3 frequencies. These spectral magnitudes were used as the index of brainstem encoding and were subjected to statistical analyses.
Contralateral Suppression of Otoacoustic Emissions
Participants were made to sit on a comfortable chair in a sound-treated room. Oto-acoustic emissions were recorded in an ILO 292-USBII (Otodynamics, Hatfield Herts) system with ILO V6 software. The probe apparatus with an appropriate-sized tip was positioned in the left ear canal. The probe fit was adjusted to ensure that a click stimulus presented at 70 dB pkSPL in the ear had a single peak followed by a single trough with no ringing trail. It was also ensured that the spectrum of click in the ear had relatively flat frequency spectrum across all frequencies. A total of 260 click-trains presented at 70 dB pkSPL served as the test stimuli for evoking transient evoked otoacoustic emissions (TEOAE). Each stimulus train consisted of 4 tokens of 80 μs broadband clicks. The TEOAEs recorded were averaged in two buffers separately such that the odd numbered stimuli were stored in one buffer and the even numbered in the other. The TEOAEs were compared between the groups to ensure that the cochlear functioning did not vary between the two groups.
White noise presented in the right (contralateral) ear served to trigger contralateral suppression. The noise was generated in Adobe Audition version 3.0 and presented to the contralateral ear through Sennheisser HDA200 headphones. The noise was calibrated to produce 40 dB SPL in a 6cc test cavity. In each participant, the middle ear admittance was monitored when the suppressor noise was presented to the contralateral ear, before recording the TEOAEs. This was done to ensure that the TEOAE suppression magnitude was not contaminated by the middle ear muscle reflexes. The TEOAEs were measured in two conditions; with contralateral acoustic stimulus (CAS) condition and a no-CAS condition. The white noise suppressor was presented to the contralateral ear in the CAS condition, while no suppressor was presented in the contralateral ear in the no-CAS condition. The order of TEOAE recording in the two conditions was randomized across the participants. The TEOAEs in the two conditions were recorded twice and averaged separately. The corresponding averaged amplitudes were used for further analysis. A gap of 2 min was given between two consecutive TEOAE recordings.
TEOAEs were analysed offline using the Kresge Echomaster software version 4.0 (Han Wen, 1988-Kresge Hearing Research Laboratory). The software allowed us to analyse the TEOAEs over a specified time scale. The suppression magnitude was analysed in the latency region of 8 to 20 ms post-stimulus onset to minimize the artifactual interference of stimulus ringing. The suppression magnitude was calculated using equation 2.
| 2 |
Here, CSOAEmag is the magnitude of contralateral suppression of OAE in dB (RMS). Subscripts in eq. 2 indicate the without and with contralateral noise conditions. Subscript ‘a’ indicates TEOAEs recorded without CAS, while the subscript ‘b’ indicates TEOAEs recorded with CAS. A and B indicate the odd and even recording buffers, respectively. Each variable in the right hand side of equation is the RMS in dB of the TEOAE response in the respective buffer between 8 and 20 ms post-stimulus onset. The CSOAEmag was analysed as the target parameter, which indexed olivocochlear function.
All the data were tabulated and analysed in SPSS version 17. The figures were made in Matlab v2010, Inkscape v 0.91, SPSS version 17 and Microsoft Office Powerpoint 2010.
RESULTS
To begin with, it was important in the present study to ensure that the peripheral mechanisms are comparable between the two participant groups, prior to any inferences about the central or efferent mechanisms. Therefore, the global OAE amplitudes in quiet in the two groups were compared using independent t test (two-tailed), and the results showed that there was no statistically significant difference between the two groups [t (54) = 1.021, P = 0.312].
Speech Perception in Noise
The mean SNR-50, i.e., the signal-to noise ratio required to perceive 50 % of the sentences presented, is shown in Figure 4. It can be seen from the figure that the mean SNR-50 was lower in the younger group than the older group. An independent t test showed that the difference in mean SNR-50 between the two groups was statistically significant [t (54) = −10.132, P < 0.001].
FIG. 4.

Mean SNR-50 in the two groups. Error bars represent 95 % confidence interval of mean. The older group had higher mean SNR-50 than the younger group. Lower SNR-50 indicates better speech perception in noise and also greater tolerance to disruptive effects of noise.
Context-Dependent Brainstem Encoding of Speech
The repetitive paradigm in the younger group yielded larger mean spectral magnitudes at F0, while there were smaller mean differences in H2 and H3. Also, smaller mean differences were seen in the older group at the three frequencies. To check whether these differences observed were statistically significant, we performed a multivariate repeated measures analysis of variance on the spectral magnitudes (F0, H2 and H3 taken together) of ABR with stimulus paradigm (repetitive vs variable) and group (younger vs older) as within and between-subject factors, respectively. There was a significant main effect of group [F (3,52) = 4.589, P < 0.01] on the spectral magnitudes, while there was no significant main effect of paradigm [F (3,52) = 2.241, P = 0.094]. However, there was a significant interaction [F (3,52) = 3.892, P = 0.01] between group and paradigm. Hence, we used two-tailed paired t tests to compare the spectral magnitudes between paradigms separately in the two groups. Results of paired t tests in the younger group showed a significant effect of paradigm on the spectral magnitudes at F0 [t (26) = 5.419, P < 0.001], while there was no significant effect of paradigm on spectral magnitudes at H2 [t (26) = 0.153, P = 0.879] and H3 [t (26) = −0.692, P = 0.5]. On the other hand, there was no significant effect of paradigm on the spectral magnitudes at F0 [t (28) = −0.318, P = 75], H2 [t (26) = 0.222, P = 0.83] and H3 [t (26) = 0.942, P = 0.35] in the older group. Figure 5 shows the data of contextual brainstem encoding in the two groups.
FIG. 5.
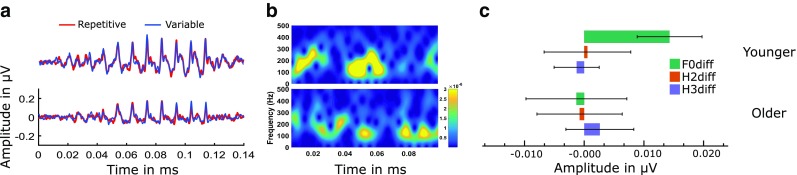
a ABR waveforms in the younger and older groups in the repetitive and the variable paradigms. b A 256 point short-term Fourier transform spectrograms with a 90 % overlapping Tukey window of the difference ABR waveforms (repetitive minus variable) from the repetitive and variable paradigms in the two groups. Warm colours indicate greater contextual effect and cold colours indicate lesser contextual effect. Difference ABR spectrograms show greater contextual effect in younger adults compared to the older adults. c Bar plots of the contextual effect on the spectral magnitudes in the younger and older groups. Error bars represent 95 % confidence interval of mean. It can be seen that the contextual effect on the spectral magnitudes are highest in the younger group at F0 while in the older group, this contextual effect is not present.
Contralateral Suppression of Otoacoustic Emissions
We examined the CSOAEmag by subtracting the magnitude of OAE recorded with contralateral noise from the magnitude of OAE recorded without contralateral noise (equation 2). The mean CSOAEmag in the two groups can be seen in Figure 6. We found that the mean CSOAEmag was higher in the younger group than the older group. An independent t test applied to this data showed that younger group had significantly [t (54) = 5.279, P < 0.001] higher CSOAEmag than the older group.
FIG. 6.

Mean magnitude of contralateral suppression of OAE (CSOAEmag) in the two groups. Error bars represent 95 % confidence interval of mean. It can be seen that the mean CSOAEmag is higher in the younger group when compared to the older group.
Relation Among Efferent Mechanisms and Speech Perception in Noise
Based on the above findings, we considered the CSOAEmag and contextual effect at F0 as indices of efferent functioning. We derived the contextual effect at F0 by subtracting the spectral magnitudes in the variable paradigm from those in the repetitive paradigm. Within-group Pearson’s product-moment correlation coefficient was calculated between the contextual effect at F0, CSOAEmag and the SNR-50. An additional partial correlation was done while controlling for the FFR spectral magnitudes in variable paradigm. The scatter plots and the correlation coefficients are shown in Figure 7. CSOAEmag correlated negatively with SNR-50 in the elder group and not in the younger group. SNR-50 correlated negatively with contextual effect at F0 in the younger group, and not in the older group. The correlation coefficients continued to remain significant even after the effects of the FFR spectral magnitudes recorded in the variable paradigm were controlled using partial correlation. The two efferent indices did not show any significant correlation with each other.
FIG. 7.
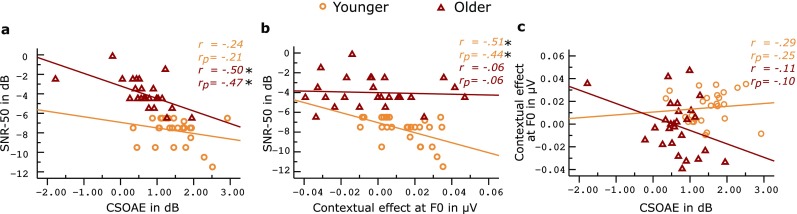
a–c The bivariate scatter plots among the different measures of efferent modulation and speech perception in noise. It can be seen that there is no visible trend between the contextual effect of ABR with that of CSOAE. r depicts the Pearson’s correlation coefficient and r p depicts the partial correlation coefficient, when controlling for the effects of FFR spectral magnitudes (IF0, IH2, IH3) in the variable paradigm. Asterisks show significant pairs with significant correlation at 0.05 level of significance. Removal of the outlier in the elder group changed the CSOAE to SNR-50 correlation coefficient by −0.005, and the CSOAE to contextual effect of ABR by +0.1 (P still not significant); hence, the data was retained.
To estimate the relative contribution of the two efferent mechanisms to speech perception in noise, we carried out a multiple linear regression analysis with SNR-50 as the dependent variable and the CSOAEmag and contextual effect at F0 as the independent variables. The FFR spectral magnitude at F0 (IF0—magnitude at F0 in the FFR recorded in the variable paradigm) in the variable paradigm in the variable paradigm (index of predominantly afferent processing) was also plugged into the model, to estimate the differential weights of afferent and efferent indices in predicting the SNR-50. Results showed that contextual effect at F0 significantly predicted SNR-50 in the younger group [F (3,26) = 3.47, P < 0.05, r 2 = 0.311], while the CSOAEmag predicted SNR-50 in the older group [F (3,28) = 3.82, P < 0.05, r 2 = 0.314]. The results are illustrated in Figure 8. An important result is that the afferent indices did not significantly predict the SNR-50 in both the groups. CSOAEmag and contextual effect at F0 continued to predict the speech perception in noise even after adding the index of the afferent processing as one of the predictors.
FIG. 8.

Figure depicting the results of within-group multiple linear regression predicting the speech in noise perception based on the efferent modulation measures. IF0 indicates the afferent index of processing, i.e., the spectral magnitude at F0 in the variable paradigm. The thick arrows connect the significant predictors of speech perception in noise and corresponding numbers indicate the standardized regression coefficients. The thin arrows connecting to SNR-50 indicate that they were not significant predictors and the corresponding numbers indicate the standardized regression coefficients. An additional multiple linear regression on the data pooled across groups shows that the model significantly predicted SNR-50 (r 2 = 0.622, adjusted r 2 = 0.600). CSOAEmag (β = −0.565, P < 0.05) predicted SNR-50 maximally followed by contextual effect at F0 (β = −0.-0.482, P < 0.05) followed by spectral magnitude at F0 in the variable paradigm (β = −0.272, P < 0.05).
DISCUSSION
To our knowledge, this is the first study investigating the inter-relationship between the two efferent mechanisms functioning at the brainstem and their differential contribution to the perception of speech in the presence of noise in humans. The findings show that both the measures of efferent processing significantly predicted speech perception in noise despite lack of relationship between the two measures with each other. The findings are discussed in detail in the subsequent sections.
Speech Perception in Noise in the Younger and the Older Groups
Because speech perception in noise co varies with the efferent mechanisms (Anderson et al. 2010; Strait et al. 2011; Parbery-Clark et al. 2011), it was important in our study to have at least two groups: one with good speech perception in noise and the other with poor speech perception in noise. We considered an older and a younger group with an a priori assumption supported by literature (Crandell et al. 1991; Pichora-Fuller and Souza 2003) that individuals in the former group would have poorer speech perception in noise compared to the latter group. The results of our study showed that speech perception in noise scores were significantly poorer in older group, in line with the assumption made and earlier studies in literature. The older group in the study needed significantly higher signal to noise ratio to perceive 50 % of the sentences presented when compared to the younger group. We ensured that the older group did not have any significant compromise of peripheral hearing that could have affected their speech perception in noise. Therefore, deficit in older group could be attributed to possible reduction in neural efficiency (Vander Werff and Burns 2011) or decline in cognitive abilities (Pichora-Fuller and Souza 2003) including possible reduction in efficiencies of efferent mechanisms. In the present study, we primarily focussed on two efferent mechanisms (rostral and caudal efferent functioning) which we expected would vary between the two study groups considering their role in speech perception in noise.
Acoustic Context Modulates Brainstem Encoding
We compared the brainstem responses to a repetitively presented syllable /da/ with those obtained using the syllable /da/ embedded in a stream of three other syllables. Results showed better encoding of the F0 (pitch) in the repetitive paradigm. This is consistent with the findings of previous studies (Strait et al. 2011; Parbery-Clark et al. 2011; Gnanateja et al. 2013) wherein it was found that when a sound is presented repetitively, central auditory system can easily predict the next incoming sound based on the on-going sound statistics and can amplify the neural encoding of the incoming sound. This repetition-related enhancement of the brainstem responses has been attributed to the efferent mechanisms of the auditory system, Gao and Suga (1998) used the term ‘egocentric selection’ to explain this process, and demonstrated the role of corticofugal (rostral efferents) modulation in egocentric selection seen in the collicular neurons. Evidence of this egocentric selection at the inferior colliculus has also been demonstrated by Yan and Suga (1998). As the primary generator of the scalp recorded frequency following portion of the auditory brainstem response is the inferior colliculus, the repetition-related enhancement in the brainstem responses found in our study could be attributed to the rostral efferent-mediated modulation of the collicular neurons.
Skoe and Kraus (2010) showed enhancement in the spectral magnitudes of scalp recorded brainstem responses to predictive stimuli (repetitive stimuli being the most predictive). They postulated that this enhancement is a result of the feedback from the cortical centres, which enhances the responses of the sub-cortical nuclei to predictable or behaviourally relevant stimuli. They concluded that the enhancement is not only seen for repeated stimuli but also seen for contextually predictable stimuli (tones in a melody in their study). This emphasizes that the enhancement seen in the brainstem responses serves a behaviourally relevant function. The enhancement seen is not a result of long-term experience related plasticity but is a result of online modulation (Krishnan and Gandour 2009; Strait et al. 2011; Song et al. 2011b). The rostral efferent system is involved in shaping the neural responses in an online fashion as well, over a longer period, based on behaviourally relevant experiences. The modulation effect seen in the current study can be attributed to the online modulatory role of the rostral efferent networks innervating the inferior colliculus.
We found repetition-induced enhancement in the younger group and not in the older group. Chandrasekaran et al. (2009) found reduced repetition-induced enhancement in individuals with dyslexia which correlated with auditory processing difficulties in them. We found a similar result in aged individuals. Ageing is often associated with auditory perceptual difficulties (Pichora-Fuller and Souza 2003; Anderson et al. 2012; Lauer et al. 2012) attributable to decline in the functioning of the afferent as well as efferent functioning in the auditory and other sensory systems (Boyce and Shone 2006; Owsley 2011; Dagnelie 2013). The deficient contextual brainstem encoding in these individuals, as found in our study, is possibly related to their auditory perceptual deficits (poor speech perception in noise). The decline in efferent functioning consequent to ageing is further supported by Lauer et al. (2012) who found an altered pattern of efferent innervation in aged auditory systems. The reduced contextual brainstem encoding indicates affected rostral efferent functioning in the older group. Our study is the first study reporting the affected rostral efferent functioning in humans attributed to ageing without any evident peripheral hearing deficits.
Medial Olivocochlear Functioning in the Older Individuals
The contralateral suppression of otoacoustic emissions has been an important physiological measure to assess the medial olivocochlear pathway (caudal efferents) and has been shown to correlate well with speech perception in noise (Giraud et al. 1997a; Kumar and Vanaja 2004; de Boer and Thornton 2008). The CSOAEmag was higher in the younger group than the older group in the current study. This was consistent with the previous findings of reduced CSOAEmag in aged individuals (Parthasarathy 2001; Kim et al. 2006; Mukari and Mamat 2008). This finding was seen despite equivalent peripheral hearing sensitivity or similar baseline OAE levels in the two groups. The reduced CSOAEmag could be attributed to age-related decline in the functioning of caudal efferent pathway. The normal MOCB helps in auditory perception by modulating the responses in the auditory nerve and causing an anti-masking phenomenon, which helps in enhancing the on-going signal in the presence of noise (Giraud et al. 1997b; Liberman and Guinan 1998). This caudal modulatory mechanism was found to be impaired in the older group, probably being one of the factors affecting auditory perception.
Speech Perception in Noise Correlates with Measures of Rostral and Caudal Efferent Network Function
Speech perception abilities varied as a function of both contextual effects in brainstem responses and the CSOAE suppression magnitude. The two efferent measures emerged as significant predictors of speech perception in noise, which emphasize their role in adaptive fine-tuning of signals in degraded listening conditions. This is in agreement with the findings of the previous studies, which have shown the effect of MOCB (Kumar and Vanaja 2004; Mukari and Mamat 2008; de Boer and Thornton 2008; Mishra and Lutman 2014) and rostral efferents (Chandrasekaran et al. 2009; Strait et al. 2011) on speech perception in noise.
The caudal efferents predicted speech perception in noise in the older group. On the other hand, the rostral efferents predicted speech perception in noise in the younger group. The mechanisms by which the rostral and caudal efferents modulate the afferent input might be driving this finding. The caudal efferents modulate the afferent input by increasing the dynamic range of the afferent hair cell receptor by suppressing the cochlear amplifier gain (see Guinan 2006 for a detailed review). This effect is frequency-specific in nature, and thus applies to the frequency of interest. The rostral efferents function by shifting the best frequency of the other neurons to the frequency of interest (repetitive stimulus in this case), and also suppress the activity of the neurons tuned to the other frequencies (Suga et al. 2002). The repetition-related enhancement has an important role to play in speech perception in noise. In a noisy situation, a listener tends to analyse the sound scene and tag onto repetitively occurring features in the target speech. The repetitively occurring voice features are crucial for object formation and sound stream segregation. The rostral efferents help in extracting speech from the background by voice-tagging which is achieved by analysing the ongoing sound statistics and targeting the repetitively occurring voice features in the sound stream. The effects of the rostral and caudal efferents in modulating the afferent input are different in terms of function and happen at two different levels in the hierarchy (peripheral and central) of the auditory system. Based on the results of the current study, the phenomenon of enhancement of brainstem-neural representation associated with repetitively presented stimuli is impaired in the older group. As this effect itself was not present in the older group, the derived index was not correlated with the speech perception. It can be hypothesized that in a normal auditory system, the efferent systems function in unison, and the effect of the caudal efferents might be masked by the other efferents. In the normal auditory system, the rostral efferents possibly have a more significant role in modulating the afferent input than the caudal efferents. When the rostral efferents are affected (as seen in the older group), the caudal efferents seem to emerge as the significant modulatory mechanisms.
However, these efferent effects have been studied in isolation and therefore the relative weightage of each is not known. In our study, we showed that the relative importance of the efferent modulatory control by the caudal efferent networks is greater than the modulatory control by the rostral efferent networks for speech perception in noise. Our data also shows that decline in neural fine-tuning abilities, modulated by the rostral and caudal pathways, correlates with poorer speech perception in degraded listening situations seen in the older individuals.
Relationship Between Measures of Rostral and Caudal Efferent Modulation
In the current study, the contextual brainstem encoding indexed the functioning of rostral efferent pathway while the CSOAEmag indexed the functioning of caudal efferent pathway. The older group had absent contextual brainstem encoding and reduced CSOAE magnitude suggesting affected rostral and caudal efferent functioning, respectively. However, there was a lack of correlation between indices of the two different pathways in both the groups. This suggests that the two efferent control systems function relatively independent of each other. This was true in spite of both being significant predictors of speech perception in noise. Though both the inferior colliculus and medial superior olivary complex receive innervations from the auditory cortex (Giard et al. 1994; Gao and Suga 1998; Yan and Suga 1998; Perrot et al. 2006; Suga 2012), the results suggest that the efferent effects on the two nuclei do not follow the same pattern.
Earlier, we had predicted that caudal efferent branches and the rostral efferent branches might be functionally linked, owing to the fact that electrical activation of both changes the response properties of the cochlear hair cells (Groff and Liberman 2003; Perrot et al. 2006). The prediction was also based on the presence of multiple interlinked feedback loops (see Fig. 1), of the corticofugal projections via the rostral and caudal efferent connections to the ascending auditory pathways reported in various studies (Dragicevic et al. 2015; Terreros and Delano 2015; Aedo et al. 2016) which are known to modulate the ascending neural input.
However, from our data, it can be construed that the corticofugal connections to the collicular and MSOC neurons are not functionally correlated. It is possible that the cortifugal connections to the MSOC neurons functionally bypass the collicular neurons. The multi-level cortical modulatory control on the brainstem seems to be associated to separate processes in the auditory system. The MOCB (caudal) efferent pathways typically function as inhibitory mechanisms to enhance signal to noise ratio and increase the dynamic range (Scharf et al. 1997; Tan et al. 2008; Perrot and Collet 2014). The rostral efferent networks on the other hand enhance the neural encoding by selectively amplifying the afferent neural input by shifting the best frequency of the neurons to match the afferent input (augmented neural representation) and an associated inhibition of the undesired neural input (Zhang and Suga 1997). The efferent fine-tuning by the anti-masking effect of the MSOC is a predominantly inhibition based process while the rostral efferent modulation is associated with predominantly amplification based process associated with neural inhibition as well.
On similar lines, Dragicevic et al. (2015) showed that the cortico-fugal efferent modulation of the peripheral nerve input and the outer hair cells were not correlated. Studies incorporating invasive cortical activation/inactivation to study efferent effect on the subcortical functioning show conflicting evidences when the effect is compared between collicular and olivocochlear processing. Perrot et al. 2006 found reduced OAE amplitudes following cortical activation, while Zhang and Suga (1997) found reduced collicular responses following cortical inactivation. These data combined with ours helps us deduce that the rostral and olivocochlear (caudal) efferent networks function in separate ways and are age-dependent. However, both the systems appear to have a final goal of facilitating the encoding of the desired sound input. Interestingly, the effect of age showed patterns on the two efferent systems.
In contrast to the findings of our study, de Boer et al. (2012) found that larger CSOAE was associated with poorer speech discrimination and greater noise related latency shifts in the ABR. The methods used in our study in terms of speech perception were very different (syllable discrimination vs sentence identification) than the de Boer et al. study. Additionally, the ABR was used as a measure of afferent function (ipsilateral noise effects on ABR) than the efferent function (context-dependence) as measured in the current study. Thus, it may be suggested that the efferent and afferent related effects might be related to the measures adopted to study these functions. There is a need to explore more such measures to evaluate efferent and afferent functioning to understand such neurophysiological processes in the human auditory system comprehensively.
Relationship Between Altered Afferent Function and the Efferent Measures
The FFRs were significantly lower in amplitude in the older group compared to the younger group. This suggests that the two groups were different in terms of the afferent neural functioning. The measures of efferent functioning considered in the study could have been at least in part be affected by the altered afferent neural input. This factor, however, could not be controlled unlike those in near field animal studies where the function of the efferent pathway can be clearly traced. This being a study in humans we had to work with this limitation. The readers of the article are thus cautioned to interpret the results of the data with this limitation. Notwithstanding the limitation, it can be seen in the Figure 8 that the afferent index (F0 spectral magnitude in the variable paradigm) did not significantly predict SNR-50. This suggests that the trend in the indices of the efferent mechanisms is not due to afferent effects on the efferent functioning. Additionally, we would like to acknowledge that we do not strongly imply mechanistic determinism based on our data; rather, we draw our interpretations based on theoretically driven statistical treatment of the data.
Limitations and Caveats
Generalization of these findings may be done with a few caveats. Enhanced amplitudes of OAE (Giard et al. 1994) and changes in amplitudes in the brainstem frequency following responses (Galbraith and Doan 1995; Galbraith et al. 2003; Lehmann and Schönwiesner 2014) have been shown during active attention tasks. This suggests that attention plays an important role in the rostral efferent modulatory control over the afferent input. We did not employ any active attention tasks in our study. In fact, the participants were shown a movie during the experimental evaluation. Thus, the differential functional relationship between the rostral and caudal efferent networks may or may not follow the same independent trend as seen in the current study. It would be very intriguing to see the effect of attention on the contextual brainstem encoding and its relationship if any with attention effects on the CSOAE. If any relationship is seen, then it can be hypothesized that attention acts as a bridge between these layers of modulatory control.
Further, it should be noted that the differential effects (Fig. 8) of age on the two efferent measures were obscured when data was pooled across age-groups (data in Fig. 8 caption). Thus, an experimental design where pooled data is analysed may lead to slightly different interpretations than those in the current study.
CONCLUSIONS
From our findings, we propose that both rostral and caudal efferent control mechanisms are functionally important for fine-tuning the neural encoding of input speech stream. This fine-tuning is functionally relevant for the segregation of the desired speech from the background. These two mechanisms, however, are relatively independent of each other, and we also found that the medial olivocochlear (caudal) modulation plays a greater role in speech in noise perception than the rostral efferent modulation in the older individuals, while in the younger group, rostral efferent modulation plays a greater role in speech perception than the caudal efferent modulation.
Glossary
- dB pkSPL
Decibel peak sound pressure level
- dB
Decibel
- MOC
Medial olivocohlear pathway
- ms
Millisecond
- μV
Microvolts
Author Contributions
Authors 1 and 2 were involved in the conceptualization, data analysis and manuscript preparation. Author 3 was involved in stimuli and paradigm preparation, data collection, data analysis and manuscript preparation.
Compliance with Ethical Standards
Conflict of Interest
The authors declare that they have no conflict of interest.
Source of Funding
All India Institute of Speech and Hearing Research Fund (ARF4.07, 2011-12 ).
Software Used for Statistical Analysis
SPSS v17.
Software Used for Artwork
SPSS v17, Matlab, Inkscape.
Institutional Review Board
Ethical guidelines for bio-behavioural research involving human subjects–AIISH.
References
- Aedo C, Terreros G, León A, Delano PH. The Corticofugal effects of auditory cortex Microstimulation on auditory nerve and superior Olivary complex responses are mediated via alpha-9 nicotinic receptor subunit. PLoS One. 2016;11 doi: 10.1371/journal.pone.0155991. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Andéol G, Guillaume A, Micheyl C, et al. Auditory efferents facilitate sound localization in noise in humans. J Neurosci. 2011;31:6759–6763. doi: 10.1523/JNEUROSCI.0248-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson S, Parbery-Clark A, White-Schwoch T, Kraus N. Aging affects neural precision of speech encoding. J Neurosci. 2012;32:14156–14164. doi: 10.1523/JNEUROSCI.2176-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson S, Parbery-Clark A, Yi H-G, Kraus N. A neural basis of speech-in-noise perception in older adults. Ear Hear. 2011;32:750–757. doi: 10.1097/AUD.0b013e31822229d3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson S, Skoe E, Chandrasekaran B, Kraus N. Neural timing is linked to speech perception in noise. J Neurosci. 2010;30:4922–4926. doi: 10.1523/JNEUROSCI.0107-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson S, White-Schwoch T, Parbery-Clark A, Kraus N. A dynamic auditory-cognitive system supports speech-in-noise perception in older adults. Hear Res. 2013;300:18–32. doi: 10.1016/j.heares.2013.03.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bajo VM, Nodal FR, Moore DR, King AJ. The descending corticocollicular pathway mediates learning-induced auditory plasticity. Nat Neurosci. 2010;13:253–260. doi: 10.1038/nn.2466. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Batra R, Kuwada S, Maher VL. The frequency-following response to continuous tones in humans. Hear Res. 1986;21:167–177. doi: 10.1016/0378-5955(86)90037-7. [DOI] [PubMed] [Google Scholar]
- Berlin CI, Hood LJ, Wen H, et al. Contralateral suppression of non-linear click-evoked otoacoustic emissions. Hear Res. 1993;71:1–11. doi: 10.1016/0378-5955(93)90015-S. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Villafuerte JW, Moreno S, Alain C. Age-related changes in the subcortical-cortical encoding and categorical perception of speech. Neurobiol Aging. 2014;35:2526–2540. doi: 10.1016/j.neurobiolaging.2014.05.006. [DOI] [PubMed] [Google Scholar]
- Boyce JM, Shone GR. Effects of ageing on smell and taste. Postgrad Med J. 2006;82:239–241. doi: 10.1136/pgmj.2005.039453. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bregman AS. Auditory scene analysis: the perceptual Organization of Sound. Cambridge, Mass: A Bradford Book; 1994. [Google Scholar]
- Budinger E, Brosch M, Scheich H, Mylius J. The subcortical auditory structures in the Mongolian gerbil: II. Frequency-related topography of the connections with cortical field AI. J Comp Neurol. 2013;521:2772–2797. doi: 10.1002/cne.23314. [DOI] [PubMed] [Google Scholar]
- Chandrasekaran B, Hornickel J, Skoe E, et al. Context-dependent encoding in the human auditory brainstem relates to hearing speech in noise: implications for developmental dyslexia. Neuron. 2009;64:311–319. doi: 10.1016/j.neuron.2009.10.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Childers DG. Speech processing and synthesis toolboxes, Har/Cdr edition. New York: John Wiley & Sons; 1999. [Google Scholar]
- Ciuman RR. The efferent system or Olivocochlear function bundle - fine regulator and protector of hearing perception. Int J Biomed Sci. 2010;6:276–288. [PMC free article] [PubMed] [Google Scholar]
- Crandell CC, Henoch MA, Dunkerson KA. A review of speech perception and aging: some implications for aural rehabilitation. J Acad Rehabil Audiol. 1991;24:121–132. [Google Scholar]
- Dagnelie G. Age-related psychophysical changes and low vision. Invest Ophthalmol Vis Sci. 2013;54:ORSF88–ORSF93. doi: 10.1167/iovs.13-12934. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davis MH, Johnsrude IS. Hearing speech sounds: top-down influences on the interface between audition and speech perception. Hear Res. 2007;229:132–147. doi: 10.1016/j.heares.2007.01.014. [DOI] [PubMed] [Google Scholar]
- de Boer J, Thornton ARD. Neural correlates of perceptual learning in the auditory brainstem: efferent activity predicts and reflects improvement at a speech-in-noise discrimination task. J Neurosci. 2008;28:4929–4937. doi: 10.1523/JNEUROSCI.0902-08.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Boer J, Thornton ARD, Krumbholz K. What is the role of the medial olivocochlear system in speech-in-noise processing? J Neurophysiol. 2012;107:1301–1312. doi: 10.1152/jn.00222.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dragicevic CD, Aedo C, León A, et al. The olivocochlear reflex strength and cochlear sensitivity are independently modulated by auditory cortex microstimulation. J Assoc Res Otolaryngol JARO. 2015;16:223–240. doi: 10.1007/s10162-015-0509-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dubno JR, Dirks DD, Morgan DE. Effects of age and mild hearing loss on speech recognition in noise. J Acoust Soc Am. 1984;76:87–96. doi: 10.1121/1.391011. [DOI] [PubMed] [Google Scholar]
- Finney DJ (1952) Statistical method in biological assay. Griffen, London
- Galbraith GC, Arbagey PW, Branski R, et al. Intelligible speech encoded in the human brain stem frequency-following response. Neuroreport. 1995;6:2363–2367. doi: 10.1097/00001756-199511270-00021. [DOI] [PubMed] [Google Scholar]
- Galbraith GC, Doan BQ. Brainstem frequency-following and behavioral responses during selective attention to pure tone and missing fundamental stimuli. Int J Psychophysiol. 1995;19:203–214. doi: 10.1016/0167-8760(95)00008-G. [DOI] [PubMed] [Google Scholar]
- Galbraith GC, Olfman DM, Huffman TM. Selective attention affects human brain stem frequency-following response. Neuroreport. 2003;14:735–738. doi: 10.1097/00001756-200304150-00015. [DOI] [PubMed] [Google Scholar]
- Gao E, Suga N. Experience-dependent corticofugal adjustment of midbrain frequency map in bat auditory system. Proc Natl Acad Sci. 1998;95:12663–12670. doi: 10.1073/pnas.95.21.12663. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Giard M-H, Collet L, Bouchet P, Pernier J. Auditory selective attention in the human cochlea. Brain Res. 1994;633:353–356. doi: 10.1016/0006-8993(94)91561-X. [DOI] [PubMed] [Google Scholar]
- Gilbert CD, Sigman M. Brain states: top-down influences in sensory processing. Neuron. 2007;54:677–696. doi: 10.1016/j.neuron.2007.05.019. [DOI] [PubMed] [Google Scholar]
- Giraud AL, Garnier S, Micheyl C, et al. Auditory efferents involved in speech-in-noise intelligibility. Neuroreport. 1997;8:1779–1783. doi: 10.1097/00001756-199705060-00042. [DOI] [PubMed] [Google Scholar]
- Giraud AL, Wable J, Chays A, et al. Influence of contralateral noise on distortion product latency in humans: is the medial olivocochlear efferent system involved? J Acoust Soc Am. 1997;102:2219–2227. doi: 10.1121/1.419635. [DOI] [PubMed] [Google Scholar]
- Gnanateja GN, Ranjan R, Firdose H, et al. Acoustic basis of context dependent brainstem encoding of speech. Hear Res. 2013;304:28–32. doi: 10.1016/j.heares.2013.06.002. [DOI] [PubMed] [Google Scholar]
- Groff JA, Liberman MC. Modulation of Cochlear afferent response by the lateral Olivocochlear system: activation via electrical stimulation of the inferior Colliculus. J Neurophysiol. 2003;90:3178–3200. doi: 10.1152/jn.00537.2003. [DOI] [PubMed] [Google Scholar]
- Guinan JJ. Olivocochlear Efferents: anatomy, physiology, function, and the measurement of efferent effects in humans. Ear Hear. 2006;27:589–607. doi: 10.1097/01.aud.0000240507.83072.e7. [DOI] [PubMed] [Google Scholar]
- Guinan JJ, Jr, Warr WB, Norris BE. Differential olivocochlear projections from lateral versus medial zones of the superior olivary complex. J Comp Neurol. 1983;221:358–370. doi: 10.1002/cne.902210310. [DOI] [PubMed] [Google Scholar]
- Kawase T, Delgutte B, Liberman MC. Antimasking effects of the olivocochlear reflex. II. Enhancement of auditory-nerve response to masked tones. J Neurophysiol. 1993;70:2533–2549. doi: 10.1152/jn.1993.70.6.2533. [DOI] [PubMed] [Google Scholar]
- Kawase T, Liberman MC. Antimasking effects of the olivocochlear reflex. I. Enhancement of compound action potentials to masked tones. J Neurophysiol. 1993;70:2519–2532. doi: 10.1152/jn.1993.70.6.2519. [DOI] [PubMed] [Google Scholar]
- Kim S, Frisina RD, Frisina DR. Effects of age on speech understanding in normal hearing listeners: relationship between the auditory efferent system and speech intelligibility in noise. Speech Commun. 2006;48:855–862. doi: 10.1016/j.specom.2006.03.004. [DOI] [Google Scholar]
- Krishnan A, Gandour JT. The role of the auditory brainstem in processing linguistically-relevant pitch patterns. Brain Lang. 2009;110:135–148. doi: 10.1016/j.bandl.2009.03.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kumar AU, Hegde M, Mayaleela (2010)Perceptual learning of non-native speech contrast and functioning of the olivocochlear bundle. Int J Audiol 49:488–496. doi:10.3109/14992021003645894 [DOI] [PubMed]
- Kumar UA, Vanaja CS. Functioning of olivocochlear bundle and speech perception in noise. Ear Hear. 2004;25:142–146. doi: 10.1097/01.AUD.0000120363.56591.E6. [DOI] [PubMed] [Google Scholar]
- Lauer AM, Fuchs P, Ryugo DK, Francis HW. Efferent synapses return to inner hair cells in the aging cochlea. Neurobiol Aging. 2012;33:2892–2902. doi: 10.1016/j.neurobiolaging.2012.02.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lehmann A, Schönwiesner M. Selective attention Modulates human auditory brainstem responses: relative contributions of frequency and spatial cues. PLoS One. 2014;9 doi: 10.1371/journal.pone.0085442. [DOI] [PMC free article] [PubMed] [Google Scholar]
- León A, Elgueda D, Silva MA, et al. Auditory cortex basal activity Modulates Cochlear responses in chinchillas. PLoS One. 2012;7 doi: 10.1371/journal.pone.0036203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liberman MC, Guinan JJ. Feedback control of the auditory periphery: anti-masking effects of middle ear muscles vs. olivocochlear efferents. J Commun Disord. 1998;31:471–482. doi: 10.1016/S0021-9924(98)00019-7. [DOI] [PubMed] [Google Scholar]
- Liberman MC, Puria S, Guinan JJ. The ipsilaterally evoked olivocochlear reflex causes rapid adaptation of the 2 f1−f2 distortion product otoacoustic emission. J Acoust Soc Am. 1996;99:3572–3584. doi: 10.1121/1.414956. [DOI] [PubMed] [Google Scholar]
- Luo F, Wang Q, Kashani A, Yan J. Corticofugal modulation of initial sound processing in the brain. J Neurosci. 2008;28:11615–11621. doi: 10.1523/JNEUROSCI.3972-08.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- May BJ, Budelis J, Niparko JK. Behavioral studies of the olivocochlear efferent system: learning to listen in noise. Arch Otolaryngol Head Neck Surg. 2004;130:660–664. doi: 10.1001/archotol.130.5.660. [DOI] [PubMed] [Google Scholar]
- Methi R, Avinash MC, Kumar UA. Development of sentence material for quick speech in noise test (quick SIN) in Kannada. J Indian Speech Hear Assoc. 2009;23:59–65. [Google Scholar]
- Mishra SK, Lutman ME. Top-down influences of the medial Olivocochlear efferent system in speech perception in noise. PLoS One. 2014;9 doi: 10.1371/journal.pone.0085756. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mukari SZ-MS, Mamat WHW. Medial olivocochlear functioning and speech perception in noise in older adults. Audiol Neurootol. 2008;13:328–334. doi: 10.1159/000128978. [DOI] [PubMed] [Google Scholar]
- Nuñez A, Malmierca E. Corticofugal modulation of sensory information. Adv Anat Embryol Cell Biol. 2007;187:1–74. doi: 10.1007/978-3-540-36771-0_1. [DOI] [PubMed] [Google Scholar]
- Owsley C. Aging and vision. Vis Res. 2011;51:1610–1622. doi: 10.1016/j.visres.2010.10.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Parbery-Clark A, Strait DL, Kraus N. Context-dependent encoding in the auditory brainstem subserves enhanced speech-in-noise perception in musicians. Neuropsychologia. 2011;49:3338–3345. doi: 10.1016/j.neuropsychologia.2011.08.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Parthasarathy TK. Aging and contralateral suppression effects on transient evoked otoacoustic emissions. J Am Acad Audiol. 2001;12:80–85. [PubMed] [Google Scholar]
- Perrot X, Collet L. Function and plasticity of the medial olivocochlear system in musicians: a review. Hear Res. 2014;308:27–40. doi: 10.1016/j.heares.2013.08.010. [DOI] [PubMed] [Google Scholar]
- Perrot X, Ryvlin P, Isnard J, et al. Evidence for Corticofugal modulation of peripheral auditory activity in humans. Cereb Cortex. 2006;16:941–948. doi: 10.1093/cercor/bhj035. [DOI] [PubMed] [Google Scholar]
- Pichora-Fuller MK, Souza PE. Effects of aging on auditory processing of speech. Int J Audiol. 2003;42(Suppl 2):2S11–2S16. [PubMed] [Google Scholar]
- Scharf B, Magnan J, Chays A. On the role of the olivocochlear bundle in hearing: 16 case studies 1. Hear Res. 1997;103:101–122. doi: 10.1016/S0378-5955(96)00168-2. [DOI] [PubMed] [Google Scholar]
- Skoe E, Kraus N. Hearing it again and again: on-line subcortical plasticity in humans. PLoS One. 2010;5 doi: 10.1371/journal.pone.0013645. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song JH, Skoe E, Banai K, Kraus N. Perception of speech in noise: neural correlates. J Cogn Neurosci. 2011;23:2268–2279. doi: 10.1162/jocn.2010.21556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song JH, Skoe E, Banai K, Kraus N. Training to improve hearing speech in noise: biological mechanisms. Cereb Cortex. 2011;22:1180–1190. doi: 10.1093/cercor/bhr196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Souza PE, Boike KT, Witherell K, Tremblay K. Prediction of speech recognition from audibility in older listeners with hearing loss: effects of age, amplification, and background noise. J Am Acad Audiol. 2007;18:54–65. doi: 10.3766/jaaa.18.1.5. [DOI] [PubMed] [Google Scholar]
- Stebbings KA, Lesicko AMH, Llano DA. The auditory corticocollicular system: molecular and circuit-level considerations. Hear Res. 2014;314:51–59. doi: 10.1016/j.heares.2014.05.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strait DL, Hornickel J, Kraus N. Subcortical processing of speech regularities underlies reading and music aptitude in children. Behav Brain Funct. 2011;7:44. doi: 10.1186/1744-9081-7-44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suga N. Tuning shifts of the auditory system by Corticocortical and Corticofugal projections and conditioning. Neurosci Biobehav Rev. 2012;36:969–988. doi: 10.1016/j.neubiorev.2011.11.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suga N, Xiao Z, Ma X, Ji W. Plasticity and corticofugal modulation for hearing in adult animals. Neuron. 2002;36:9–18. doi: 10.1016/S0896-6273(02)00933-9. [DOI] [PubMed] [Google Scholar]
- Tan MN, Robertson D, Hammond GR. Separate contributions of enhanced and suppressed sensitivity to the auditory attentional filter. Hear Res. 2008;241:18–25. doi: 10.1016/j.heares.2008.04.003. [DOI] [PubMed] [Google Scholar]
- Terreros G, Delano PH. Corticofugal modulation of peripheral auditory responses. Front Syst Neurosci. 2015 doi: 10.3389/fnsys.2015.00134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tillman TW, Olsen WO (1973) Speech audiometry. In: Jerger J (ed) Modern Developments in Audiology, 2nd edn. Academic, New York, pp 37–74
- Vander Werff KR, Burns KS. Brain stem responses to speech in younger and older adults. Ear Hear. 2011;32:168–180. doi: 10.1097/AUD.0b013e3181f534b5. [DOI] [PubMed] [Google Scholar]
- Venkatesan S (2009) Ethical guidelines for bio-behavioral research involving human subjects. Dr. Vijayalakshmi basavaraj, Director, All India Institute of Speech and Hearing, Manasagangothri, Mysore
- Wersinger E, Fuchs PA. Modulation of hair cell efferents. Hear Res. 2011;279:1–12. doi: 10.1016/j.heares.2010.12.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- World Medical Association (2013) World Medical Association Declaration of Helsinki: ethical principles for medical research involving human subjects. JAMA 310:2191–2194. doi:10.1001/jama.2013.281053 [DOI] [PubMed]
- Xiao Z, Suga N. Modulation of cochlear hair cells by the auditory cortex in the mustached bat. Nat Neurosci. 2002;5:57–63. doi: 10.1038/nn786. [DOI] [PubMed] [Google Scholar]
- Yan W, Suga N. Corticofugal modulation of the midbrain frequency map in the bat auditory system. Nat Neurosci. 1998;1:54–58. doi: 10.1038/255. [DOI] [PubMed] [Google Scholar]
- Zhang Y, Suga N. Corticofugal amplification of subcortical responses to single tone stimuli in the mustached bat. J Neurophysiol. 1997;78:3489–3492. doi: 10.1152/jn.1997.78.6.3489. [DOI] [PubMed] [Google Scholar]
- Zhao W, Dhar S. The effect of contralateral acoustic stimulation on spontaneous Otoacoustic emissions. JARO J Assoc Res Otolaryngol. 2010;11:53–67. doi: 10.1007/s10162-009-0189-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ziegler JC, Pech-Georgel C, George F, Lorenzi C. Speech-perception-in-noise deficits in dyslexia. Dev Sci. 2009;12:732–745. doi: 10.1111/j.1467-7687.2009.00817.x. [DOI] [PubMed] [Google Scholar]