

Abstract
Cost-effective yet efficient designs are critical to the success of biomarker evaluation research. Two-phase sampling designs, under which expensive markers are only measured on a subsample of cases and non-cases within a prospective cohort, are useful in novel biomarker studies for preserving study samples and minimizing cost of biomarker assaying. Statistical methods for quantifying the predictiveness of biomarkers under two-phase studies have been proposed (Cai and Zheng, 2012; Liu, Cai and Zheng, 2012). These methods are based on a class of inverse probability weighted (IPW) estimators where weights are ‘true’ sampling weights that simply reflect the sampling strategy of the study. While simple to implement, existing IPW estimators are limited by lack of practicality and efficiency. In this manuscript, we investigate a variety of two-phase design options and provide statistical approaches aimed at improving the efficiency of simple IPW estimators by incorporating auxiliary information available for the entire cohort. We consider accuracy summary estimators that accommodate auxiliary information in the context of evaluating the incremental values of novel biomarkers over existing prediction tools. In addition, we evaluate the relative efficiency of a variety of sampling and estimation options under two-phase studies, shedding light on issues pertaining to both the design and analysis of biomarker validation studies. We apply our methods to the evaluation of a novel biomarker for liver cancer risk conducted with a two-phase nested case control design (Lok et al., 2010).
Keywords: biomarker, prediction accuracy, risk prediction, two-phase study
1. Introduction
Novel biomarkers have the potential to improve risk prediction for diseases such as cancer. Due to the cost associated with biomarker measurement, the improvement in the predictive performance of a model enriched with novel biomarkers over a model with only clinical risk factors, throughout referred to as the incremental value (IncV) of the novel biomarkers, needs to be rigorously assessed before incorporating the enriched risk model into routine clinical practice. A major barrier to validating prediction models is that measuring novel markers from a large prospective cohort study may be too expensive, especially if the event rate is low. Two subcohort sampling designs, the case cohort (CCH) (Prentice, 1986) and nested case control (NCC) (Thomas, 1977), are often employed as cost-effective alternatives to the standard full-cohort design, and have been recently adopted for risk marker evaluation studies (Lok et al., 2010; Wang et al., 2011).
These designs, while cost effective, can be challenging due to the outcome-dependent missingness on the marker information. Statistical methods have been developed to incorporate such missingness in estimating relative and absolute risk parameters (Self et al., 1988; Borgan, Goldstein and Langholz, 1995; Langholz and Borgan, 1997). However, evaluation of the clinical utility of risk markers adds another level of complexity, requiring additional estimation of distribution of risks in the population and its summary indices. Appropriate statistical methods for risk model evaluation under two-phase studies and guidance to efficiently conduct the design are still lacking. Novel statistical tools that can be used for estimating the predictive performance of a single biomarker have also been developed for both CCH and NCC studies (Cai and Zheng, 2012; Liu, Cai and Zheng, 2012). In these approaches, simple inverse probability-weighted (IPW) estimators were considered, with weights as the reciprocals of true selection probabilities calculated based on the observed data and study design.
While such IPW estimators are simple to implement, limitations exist. First, in many practical situations, two-phase sampling plans can be quite complicated, due to practical considerations such as the need to reuse samples previously assayed for other studies or missing measurements due to inadequate samples. Retrieving ‘true’ sampling weights can therefore be considerably difficult in practice. In addition, these simple IPW estimators tend to be quite inefficient because they discard information from individuals without biomarker information. When auxiliary variables related to both outcome and incomplete marker measurement are available from the entire cohort, incorporating such information in estimation may lead to improvement in efficiency (Breslow et al., 2009a,b; Saegusa and Wellner, 2013). In this manuscript we propose novel estimators of prediction performance measures for two-phase studies, aiming to improve efficiency and practicality over existing estimators. Our estimators are based on the idea of augmentation, previously considered for estimating relative risk parameters under case-cohort studies. The augmented estimators adopt the IPW principal but use nonparametrically estimated weights based on auxiliary information.
Our second goal is to address study design issues, particularly regarding the impact of matching on estimation efficiency when the goal is to evaluate the IncV of novel biomarkers. In settings where routine markers or other auxiliary information exist, matching controls to cases on baseline predictors is usually considered. Matching is frequently adopted as a way to improve efficiency, particularly for the estimation of relative risk parameters (Breslow et al., 1980). However, little is known regarding whether matching improves efficiency for the estimation of prediction performance and IncV measures. In addition, it has been previously noted that using augmented weights can lead to the efficiency gain of hazard ratio parameters for the fully observed covariates in a Cox regression model, but not so much for the partially observed biomarkers (Qi, Wang and Prentice, 2005). The extent of efficiency gain due to augmentation for the estimation of prediction performance or IncV parameters has not yet been studied. In this paper, we perform extensive numerical studies to provide insight on the connection between the augmented estimators under minimally matched sampling designs and the simple IPW estimators under matched/stratified designs. We evaluate the relative efficiency of a variety of sampling and estimation options to identify strategies that are both efficient and practical.
2. Model Specification and General Estimation under Two-phase Studies
2.1. Notation
Suppose the full cohort has N individuals from the targeted population followed prospectively. Due to censoring, the underlying full cohort data consist of N i.i.d copies of the vector, , where Xi = min(Ti, Ci), δi = I(Ti ≤ Ci), Ti and Ci denote failure time and censoring time respectively, and subscript i indexes the subjects in the cohort. Here, is the vector of all potential risk predictors, Yoldi includes a set of routine markers available for all, Ynewi represents novel risk markers only ascertained at the second phase for a selected subset of individuals, and Zi represents auxiliary variables including matching and stratification variables available for the entire cohort. While is available for the entire cohort, Ynewi is only available if Vi = 1, where Vi is a binary variable indicating whether subject i is selected to the phase II subcohort. The two-phase sampling only depends on Xi, δi and Zi, with the true sampling probability known by design. We also assume that the risk follows a semi-parametric transformation model (Cheng, Wei and Ying, 1995, 1997; Zeng and Lin, 2006)
| (2.1) |
where H(t) is an increasing function and is a cumulative distributional function. When , the model corresponds to the proportional hazards model (Cox, 1972).
2.2. A General Inverse Probability Weighted Framework for Two-phase Studies
To incorporate outcome dependent missingness in Ynew, estimation of IPW procedures is based on subjects with Vi = 1 and reweight the ith observation by ωi = Vi/πi. Consider a generic IPW statistic , where E(Ri) = 0. An obvious choice for πi is the true sampling probability , which leads to a class of True Weights based IPW (TIPW) statistics . The form of can be obtained explicitly for both stratified CCH (sCCH) (Gray, 2009; Liu, Cai and Zheng, 2012) and NCC (Samuelsen, 1997; Cai and Zheng, 2012) designs. See Appendix A of the supplementary article (Zheng et al., 2017) for details.
When is not directly available from the study and/or to improve efficiency over the simple TIPW estimators, we focus on AIPW estimators that leverage information on auxiliary variables W by non-parametrically estimating πi given Wi. The AIPW approach replaces with an augmented weight , where is an estimate of using Wi. The key to the efficiency gain from the AIPW approach is to choose W and the estimator such that and W is highly correlated with Ri. For example, one may consider for mNCC design, and for sCCH to enable both consistent estimation of the sampling weights and efficiency improvement by leveraging full cohort information on Yoldi.
When Wi is discrete, a natural choice for is the empirical proportion based on the observed data: However, Wi often involves continuous variables. For example, for NCC designs, the sampling is dependent on X; thus, W needs to include X to ensure the consistency of the AIPW estimators. To incorporate continuous W, one may consider the Nadaraya-Watson estimator,
| (2.2) |
where Kh(·) = K(·/h)/h, K is a symmetric kernel density function, and h > 0 is the bandwidth. Selection of appropriate h can follow the recommendations in Wang and Wang (2001) and Qi, Wang and Prentice (2005). Since the IPW estimators could be biased if does not consistently estimate , such a widely applicable nonparametric estimator, applicable to a wide range of practical situations, is appealing.
Asymptotic Behavior of AIPW Estimators
Making inference under a two-phase design with weight is generally difficult because the sampling scheme leads to weak correlation between the Vi’s, which is not ignorable even in large samples. Derivations for the asymptotic properties of the AIPW estimators accounting for such correlations are given in the Appendix B of the supplementary article (Zheng et al., 2017). For ease of presentation, we focus on a setting where all cases are selected and controls are sampled according to the CCH or NCC design without additional matching. We also show in the Appendix B that the variance reduction, is always great than or equal to 0, and thereby justifies the efficiency gain by AIPW estimators over the TIPW estimators.
3. Accuracy and Incremental Value Evaluation
3.1. Parameters of Interest
For any subvector of Y, Y*, and the associated risk model for , Y* affects Dt only through the risk score . Thus, we quantify the predictiveness of Y* based on the predictiveness of . One main goal here is to quantify the prediction performance of a risk score for predicting Dt = I(T ≤ t), for various choices of . An array of measures can be considered for such evaluations. Key summary indices for characterizing the accuracy of in classifying Dt include
where p is a risk threshold that can potentially be used to form different clinical decisions.
The pair of summaries and specifies the cumulative distribution of risks among t-year cases with Dt = 1 and non-cases with Dt = 0, respectively, and is a building block for other measures. For example, taking Dt as a binary outcome for a fixed t, the proportion of t-year cases followed (Pfeiffer and Gail, 2011) can be expressed as , where . Its inverse function is the fraction of the general population at the highest risk that needs to be followed to ensure that a fraction p of the t-year cases will be captured.
When no specific risk thresholds are of key interest, one may consider summary measures to complement the display of case and control risk distributions. For example,
is a time-dependent version of the area under the ROC curve (AUC), which provides a measure of separation between the distributions of among t-year cases and non-cases. Another frequently used prediction performance measure is the difference in mean risks (DMR) between cases and non-cases at time t, which is related to the Integrated Discrimination Improvement (IDI) statistic for comparing risk models (Pencina et al., 2008), .
To quantify the IncV in risk prediction based on a generic prediction summary index denoted by , one may consider , where is evaluated for the updated model constructed with as predictors, and is the corresponding value for the risk model developed using only Yold.
3.2. Estimation and Inference of Accuracy Summaries and IncV
We now investigate the AIPW estimation procedures for the evaluation of IncV under the semi-parametric transformation model as specified in (2·1). Specifically following the approaches taken in Murphy, Rossini and Van der Vaart (1997) and Zeng and Lin (2006), the model parameters can be obtained by maximizing a weighted semiparametric likelihood:
where and λ1(x) = dΛ1(x)/dx, ΔH(x) = H(x) − H(x−). With as estimators for ß, we can calculate , where .
To estimate the pair of key predictive performance summaries, and , for a generic risk function , we first note that under model (2.1),
We assume that (2.1) holds but allow the risk function to be derived from a potentially mis-specified submodel. This along with the AIPW principle motivates us to estimate and respectively as
| (3.3) |
| (3.4) |
where is the estimated risk function derived under the submodel for . Subsequently, we may construct augmented estimators for other risk parameters. For example, we estimate as , and as , where . An estimator for is , with and , and an estimator for is .
For IncV evaluations, we compare the prediction performance of the to that of obtained by fitting (2.1) with Yold only. When the full cohort data are available for Yold, the estimation of model parameters associated with P(Dt = 1 | Yold) can be obtained using the standard procedures as in Zeng and Lin (2006) without weighting.
For a generic prediction accuracy parameter representing either TPRt(p), FPRt(p), PCFt(v), PNFt(p), AUCt or DMRt, let , , and denote the true and estimated accuracy for and , respectively. The IncV with respect to , , can be calculated as .
To construct confidence intervals for the accuracy and IncV parameters, in the supplementary article Appendix C (Zheng et al., 2017), we provide the asymptotic variances of for the CCH and NCC design based on the asymptotic linear expansion of and .
4. Simulations
We conducted simulations to examine the finite sample performances of our proposed procedures under both two-phase designs and the impact of different sampling and analysis strategies on efficiency. With a cohort of size N = 5000, we first generated Yold and Ynew from a zero-mean bivariate normal distribution with unit variances and correlation 0.8. The event time T was generated by conditioning on Yold and , with , where β1 = log(3), β2 = log(2) and α0 was chosen to be (i) 0.1 for studying CCH designs, representing a moderate event rate scenario; and (ii) 0.01 for NCC designs, representing a rare case scenario. The censoring time C was taken to be the minimum of 2 and W, where W followed a gamma distribution, with a shape parameter of 2.5 and a rate parameter of 2. The event rate was about 20% under the setting for studying CCH designs, and 4% under the setting for studying NCC designs. These two full cohort data generating mechanisms were used for all simulation settings, and a variety of sampling strategies were implemented to assemble the phase II data. For each sampling design and parameter of interest, we obtained two IPW estimators: one with true sampling weights, and one with the weights estimated by nonparametrically estimating P(Vi = 1 | W) as in Equation (2.2).
4.1. Finite Sample Performance of the Proposed Estimators
We first assessed the validity of our proposed inference procedures in finite samples. For simplicity, no additional matching variables were used for sampling. For the CCH design, we randomly sampled n1 = 105 cases from {i : δi = 1} and n0 = 3n1 controls from {i : δi = 0}. For the NCC design, we included all individuals with δ = 1 as cases, and for each case, we randomly selected 3 controls from the risk set of the case. To estimate the sampling weights for augmentation, we let W = (δ, Yold)⊤ for CCH and W = (δ, X, Yold)⊤ for NCC.
Based on the results of 5000 simulated datasets as shown in supplementary article Table 1 (Zheng et al., 2017), we found that all point estimates had negligible bias. The asymptotic based standard error estimators approximated the empirical standard errors well with empirical coverage levels of the 95% confidence intervals close to the nominal level for all parameters except NPV under the NCC design. This was not surprising because, in this case, the true NPV levels were extremely close to 1, which made finite sample standard error and interval estimation generally difficult as in any binomial proportion estimation setting (Brown, Cai and Dasgupta, 2002). We also varied the values of bandwidth in the nonparametric kernels to evaluate the robustness of the proposed estimators. Varying bandwidths had little impact on estimates of accuracy summaries in the simulated settings as shown in supplementary article Table 2 (Zheng et al., 2017). Reducing cohort size to 1000 for CCH and 2000 for NCC showed efficiency improvement of AIPW estimators over TIPW estimators, with slightly increasing in bias. See supplementary article (Zheng et al., 2017) Table 3(a) and (b) for details.
4.2. Relative Efficiency of Different Sampling and Analytical Options
We conducted simulation studies to examine the effect of matching or stratification by a discrete variable Z on the efficiency of estimating various accuracy summaries. We let , where yq is the 100qth percentile of Yold and {q1, q2} are chosen as (i) {0.5, 0.75} for the CCH design and (ii) {0.33, 0.66} for the NCC design. We compared the efficiency of AIPW and TIPW estimators obtained with data generated from different sampling designs, with and without matching on Z.
CCH Design
Irrespective of sampling strategy, a total of 150 cases with δ = 1 and 450 controls with δ = 0 were included in the phase II subcohort. Three commonly adopted sampling strategies were considered:
Setting A (random): randomly sampled 150 cases and 450 controls without considering Z.
Setting B (frequency matched): randomly sampled 150 cases, then sampled controls such that the distribution of Z among the selected controls was the same as that of the cases.
Setting C (balanced design): sampled 50 cases and 150 controls from each stratum defined by the level of Z, which design led to oversampling categories with lower prevalence.
Under the CCH design, for any given parameter of interest that is estimated via the TIPW approach as , it is possible to calculate the optimal sampling fractions to minimize the variance of (Borgan et al., 2000). Suppose and the target is to sample n1 cases and n0 controls. Then the optimal sampling fractions that minimize the variance of are and for the cases and controls with Z = l, respectively, where
and . Note that in practice, an estimate of may only be available to assist in study design if preliminary data are available. In addition, such optimal sampling fractions tend to vary by specific measure – the sampling fractions optimal for one measure may not be optimal for the other. Thus, it is not possible to design a study to achieve optimal efficiency simultaneously for all measures. To mimic the most likely scenario in practice, we calculated optimal fractions for βnew and used them as the basis for sampling. The IPW estimators with true weights obtained under such a design (using sampling fraction optimal for βnew), denoted by TIPWopt, were then used as the benchmark for comparing the efficiency of various standard designs and gauging the effect of augmentation.
Figure 1(a) shows the efficiencies of the TIPW and AIPW estimators obtained under various sampling strategies, relative to the TIPWopt estimators. When true weights were used, the frequency matched design had similar efficiency as the optimal design and outperformed the random and balanced designs for a majority of the parameters investigated. However, for the accuracy parameters at various risk threshold levels, the efficiency of the frequency matching was much lower than the optimal design and was comparable to or sometimes worse than the random and balanced designs. On the other hand, the AIPW estimators were substantially more efficient than their corresponding TIPW estimators, except for β2. Interestingly, the AIPW estimators under random sampling had efficiency comparable to or higher than those obtained from TIPWopt for all parameters of interest. When comparing the AIPW estimators obtained across the three designs, the balanced design generally performed the worst. Although the frequency matched design achieves a slightly higher efficiency for a few parameters than the random design, the random design appeared to be much more robust with regard to efficiency of AIPW estimators across different parameters. The results here suggested that, in practice, considering a simple random sampling scheme at the design stage and then utilizing auxiliary information in the analysis step has the advantage in both practical simplicity and statistical efficiency.
Fig 1.
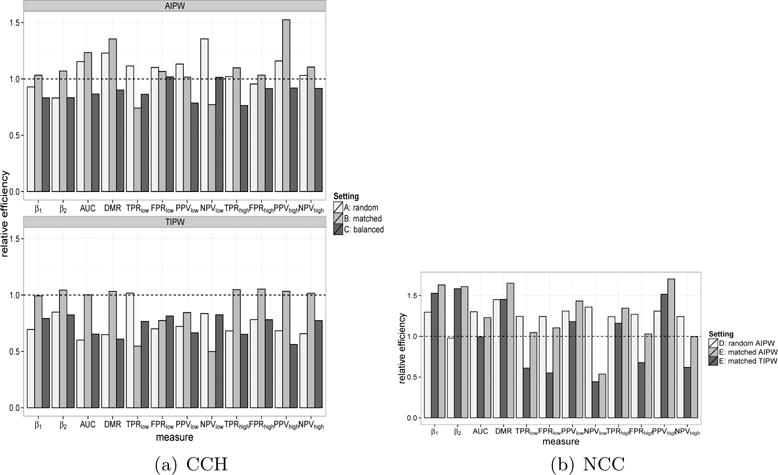
Relative efficiency (RE) of various predictive performance summaries by different designs. Figure (a): results for CCH designs. Setting A: simple random sampling; Setting B: matched design and Setting C: balanced design. TIPW (top panel) and AIPW (bottom pane) estimators for each setting are considered, using TIPWopt as benchmark for efficiency. Figure (b) results for NCC designs. Setting D: simple random sample; Setting E: matched design. TIPW estimator under setting D is the benchmark for efficiency.
NCC design
For the NCC design, all cases were included and 3 controls were sampled from the risk sets of the cases according to the follow two strategies:
Setting D (random): randomly sampled from the risk set of the case;
Setting E (matched): randomly sampled from the case’s risk set and matched on the value of Z of the case.
Since no simple optimal sampling strategies can be implemented for the NCC design, we used the TIPW estimator under random sampling as the benchmark for comparison and present in Figure 1(b) the efficiencies of the TIPW and AIPW estimators obtained under these two designs relative to the benchmark estimator. The matched design led to the most efficient relative risk estimators for β1 and β2, however the efficiency gain did not directly translate to the estimation of performance summary parameters, and it may in fact lead to poorer efficiency compared to a simple random sampling design. Indeed, for a majority of summary performance parameters considered, Setting D, using a simple random sampling design with the proposed AIPW estimators, appeared to be the most efficient. The results further suggested the benefit of employing a simple random design followed by the AIPW estimation procedure. Stratifying/matching based on Yold, while leading to improved efficiency for the regression parameters, could drastically sacrifice the efficiency for various accuracy parameters. On the other hand, the AIPW estimator with random sampling always resulted in efficiency improvement. Numerical results are presented in the supplementary article (Zheng et al., 2017) Table 4(a) and (b).
5. Example
Patients with hepatocellular carcinoma (HCC) often have poor prognosis due to late diagnosis. Since cirrhosis of any cause and chronic infection with hepatitis B virus (HBV) or hepatitis C virus (HCV) are the most common risk factors for HCC, surveillance of high-risk populations may detect tumors at an early stage when curative interventions can be implemented. Alpha fetoprotein (AFP) is the most widely used biomarker for HCC surveillance; however, its sensitivity and specificity in detecting early HCC are low. More reliable biomarkers for HCC surveillance and early detection are sought in order to improve the outcome of the disease.
The Hepatitis C Antiviral Long-Term Treatment against Cirrhosis (HALT-C) Trial included 1050 patients with chronic hepatitis C and bridging fibrosis or cirrhosis who failed to achieve a sustained virologic response (SVR) to combination therapy of pegylated interferon and ribavirin. Patients were randomized to low-dose pegylated interferon or no treatment and examined every 3 months for a total duration of 3.5 years. Blood samples were collected at each visit for subsequent research testing, including assays for HCC biomarkers. Ultrasound examinations were repeated 6 months after enrollment and again every 12 months. Patients with an elevated or rising AFP and those with new lesions detected by ultrasound were evaluated further by CT or MRI.
One goal of the HALT-C Trial was to identify and validate markers for HCC surveillance. As part of the trial, an NCC study was employed to assess and compare the accuracy of AFP and a novel serum biomarker, des-gamma-carboxy prothrombin (DCP), in predicting the risk of HCC. The NCC sub-cohort included all 39 HCC cases diagnosed during the follow-up. For each case, 2 controls without HCC, matched for treatment assignment and presence of cirrhosis on baseline biopsy, were selected from the risk set of the case. This resulted in a total of 77 controls in the NCC subcohort. The biomarkers were evaluated at multiple follow-up visits, and the results on the repeated markers were reported in Lok et al. (2010), where conditional logistic regression models were used to compare characteristics of HCC cases, and matched controls and unconditional logistic regression were used to evaluate the accuracy performance of the biomarkers.
To illustrate our proposed methods, only baseline measurements were considered for risk modeling. Logarithm transformed values were considered for both AFP and DCP, denoted by logAFP and logDCP, respectively. Due to low liver cancer incidence, methods that could improve efficiency would be helpful. For comparison, we obtained parameter estimates using both the TIPW and AIPW approaches, where for the AIPW approach, we let W = (X, δ, log AFP)⊤ for augmentation. To build a risk model with both logAFP and logDCP, we considered fitting a Cox proportional hazards model. We obtained log hazard ratio (logHR) parameter estimates with the conditional logistic regression, TIPW, and AIPW methods. The conditional logistic regression method yielded a logHR estimate of 0.54 with a standard error (SE) of 0.27 for logAFP and 1.54 with a SE of 0.51 for logDCP, suggesting that DCP may serve as an independent risk factor for HCC beyond AFP. The logHR was estimated as 0.61 (SE: 0.22) for logAFP and 2.04 (SE: 0.33) for logDCP based on TIPW, and 0.82 (SE: 0.18) for logAFP and 1.95 (SE: 0.32) for logDCP based on AIPW. These results indicated that that the AIPW method provided more efficient estimates of the logHR parameters when compared to TIPW and conditional logistic regression methods.
We subsequently evaluated the 2-year predictive performance by combining logDCP and logAFP using the measures described in Section 3.1. The results for evaluating the full model with both logAFP and logDCP included are presented in the first two columns of Table 1. Across the measures we considered, point estimates from the two approaches in general were quite close; however, the AIPW estimators had substantially smaller standard errors than that of the TIPW estimators for most of the parameters. Combing AFP and DCP led to a good predictive model for predicting the 2-year risk of HCC, with AUC estimated as 0.81 (95%CI: [0.68,0.94]) based on TIPW, and 0.82 (95%CI: [0.75, 0.90]) based on AIPW. If the top 20% of the population based on the estimated risks is considered of high risks, then the proportion of individuals who will be diagnosed with HCC within two years, captured by the prediction rule, is 64% (95% CI: [38%, 89%]) based on the TIPW estimate, and 68% (95% CI: [53%, 81%]) based on the AIPW estimate.
Table 1.
Evaluation of biomarkers in predicting 2-year liver cancer incidence in Halt-C study. Shown below are TIPW and AIPW estimates along with their corresponding standard errors shown in parenthesis. The log-hazard ratios and accuracy parameters were estimated for 2-year risks estimated based on both (i) the full model with logAFP + logDCP; and (ii) the reduced model with logAFP alone. Also presented are the TIPW and AIPW estimates for IncV parameters of logDCP above and beyond logAFP.
| logAFP + logDCP | logAFP | IncV of logDCP | ||||
|---|---|---|---|---|---|---|
| Parameters | TIPW (SE) | AIPW (SE) | TIPW (SE) | AIPW (SE) | TIPW (SE) | AIPW (SE) |
| β1 | .614 (.221) | .822 (.177) | .542 (.206) | .771 (.168) | – | – |
| β2 | 2.043 (.333) | 1.953 (.316) | – | – | – | – |
| AUC | .809 (.066) | .823 (.040) | .655 (.079) | .694 (.054) | .155 (.129) | .129 (.030) |
| DMR | .155 (.376) | .173 (.193) | .065 (.148) | .112 (.081) | .090 (.473) | .061 (.267) |
| ITPR | .168 (.389) | .188 (.199) | .108 (.036) | .142 (.015) | .060 (.353) | .045 (.193) |
| IFPR | .013 (.013) | .015 (.007) | .043 (.154) | .030 (.087) | −.029 (.126) | −.015 (.082) |
| TPR(.002) | .979 (.023) | .981 (.024) | .986 (.031) | .989 (.021) | −.007 (.031) | −.008 (.023) |
| FPR(.002) | .827 (.123) | .824 (.167) | .928 (.060) | .939 (.066) | −.101 (.073) | −.116 (.125) |
| PPV(.002) | .014 (.004) | .016 (.004) | .016 (.007) | .014(.009) | −.002 (.007) | .002 (.007) |
| NPV(.002) | .999 (.001) | .999 (.001) | .997 (.005) | .998(.005) | .001 (.006) | .001 (.006) |
| TPR(.02) | .529 (.287) | .562 (.083) | .201 (.098) | .328 (.050) | .328 (.292) | .234 (.069) |
| FPR(.02) | .112 (.070) | .114 (.051) | .069 (.328) | .099(.074) | .043 (.249) | .015 (.097) |
| PPV(.02) | .052 (.015) | .063 (.019) | .042 (.041) | .043 (.041) | .011 (.038) | .021 (.055) |
| NPV(.02) | .994 (.003) | .993 (.002) | .987 (.018) | .990 (.006) | .007 (.014) | .003 (.005) |
| PCF(.20) | .636 (.131) | .667 (.071) | .307 (.047) | .453 (.048) | .329 (.117) | .214 (.056) |
| PNF(.85) | .526 (.119) | .570 (.061) | .400 (.051) | .386 (.037) | .125 (.120) | .183 (.067) |
To further evaluate whether adding DCP to the model substantially improves accuracy when compared to the model with AFP alone, we also fit a model with AFP alone and calculated the IncV of DCP with respect to various accuracy parameters as shown in Table 1. The ROC curves and risk distribution for both models are shown Figure 2. As seen in the figures, the enriched model always had higher TPF and higher PCF, but smaller PNF across different risk thresholds p. Formal tests of such observed incremental values for selected p can be based on the results presented in the last two columns in Table 1. For example, was estimated as 12.9% with 95% CI (7.0%, 18.7%) based on AIPW, indicating that adding DCP improved in prediction accuracy beyond AFP. In addition, there was also significant improvement with respect to PCF and PNF, with estimated as 21.4% (95% CI: [10.4%, 32.3%]) and estimated as 18.3% (95% CI: [5.1%, 31.4%]), based on AIPW. The TIPW approach, while generating similar point estimates, did not produce statistically significant IncV estimates for all parameters considered (Table 1). This example demonstrates the advantage of the proposed AIPW method for estimating accuracy summaries and IncV parameters, particularly when there are limited samples with available biomarker measurements.
Fig 2.
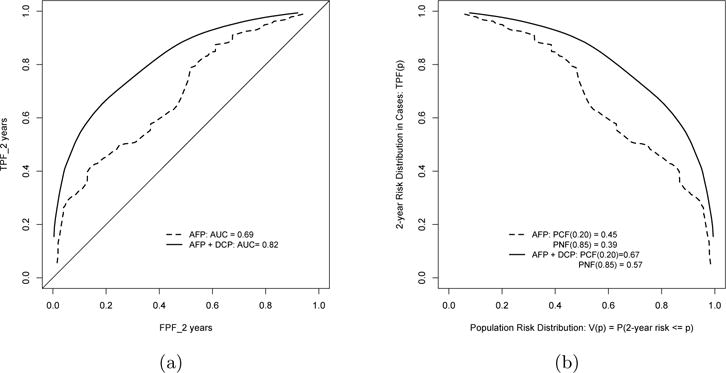
Comparing performance of two prediction models: model with AFP along (solid lines) and model with both AFP and DCP (dashed lines). (a) ROC curves for predicting 2-year risk of HCC with baseline biomarker measurements. (b): risk distribution curves for individuals who diagnosed with HCC in 2 years.
6. Discussion
Large cohort biomarker studies of rare diseases such as cancer require thoughtful planning, from selection of study subjects and measurement of key variables and auxiliary information to analytical strategies. Study design becomes even more demanding in biomarker research, when measurements are based on stored tissue or blood specimens. It is important in this setting to use research resources wisely to achieve optimal efficiency of the study. There is a paucity of appropriate statistical methods for biomarker assessment and guidance on design and analysis strategies to maximize efficiency. Practical and efficient statistical tools can enable clinical investigators to conduct more cost-effective studies and more efficiently allocate research resources.
This manuscript contributes to such an endeavor in two ways. First, we provide a general framework for more efficiently estimating prediction accuracy and IncV parameters via an AIPW approach under two-phase CCH or NCC designs. Our simulation studies and application of Halt-C biomarker validation studies indicate that the use of nonparametric weights to capture design selection is valid and yields significant efficiency gain. Furthermore, the proposed approach also provides a practical solution in study settings where the true design-based sampling probabilities are impractical to ascertain. In addition, previous work on biomarker evaluation with two-phase studies (Cai and Zheng, 2012; Liu, Cai and Zheng, 2012) only considered evaluating the performance of a single marker. We extend the scope of work to the evaluation of multivariate risk models and IncV of novel biomarkers under two-phase designs. Such extensions are non-trivial due to the complex structure induced by both the correlation among different risk markers and the sampling design.
Second, using extensive numerical studies, we demonstrated that stratification sampling for CCH studies or matching for NCC studies can be inefficient in many accuracy summaries when not done optimally. In the absence of preliminary data, it is often unclear what variables for matching, or what sampling fractions should be considered for stratification. A poor choice in matching variables may lead to loss in efficiency and unnecessary complications in analysis. Furthermore, the sampling fractions optimal for one parameter may not be optimal for another, and thus, no sampling strategies would be uniformly optimal across all parameters. Therefore, using a simple sampling scheme at the design stage and then improving estimation efficiency using the proposed augmented estimators in analysis would be a useful alternative to considering matched designs.
We have focused on the estimation of accuracy summaries with a semi-parametric approach to illustrate the AIPW approach. Alternatively, one may consider calculating the accuracy summaries with a nonparametric approach as was previously considered (Cai and Zheng, 2011), without relying on the assumption of Model 2.1. The estimating and inference procedures with AIPW described can be easily adopted to that setting. Our proposed estimators for evaluating the IncV of a new prediction model improves efficiency of the existing IPW-based estimators; however, they do not achieve full efficiency as compared with a full likelihood-based approach (Zeng and Lin, 2014). Future exploration of the additional gain when applying non-parametric likelihood-based procedures is warranted, even at the cost of increased computational burden. Finally, the validity of the class of IPW estimators is based on the assumption that selection is dependent on variables observable from the full cohort. Caution should be taken when the availability of biomarker measurement might be dependent on unmeasured variables.
Supplementary Material
Acknowledgments
The work was partially supported by grants U01 CA86368, P01 CA053996, R01 GM085047, P50 MH106999, and P01 CA134294 awarded by the National Institutes of Health. We thank the editor and anonymous reviewers whose careful guidance led to much improvement of the manuscript.
Footnotes
Conflict of Interest: None declared.
SUPPLEMENTARY MATERIAL
Supplementary Article for “Improving Efficiency in Biomarker Incremental Value Evaluation under Two-phase Study Designs”
(doi: COMPLETED BY THE TYPESETTER; .pdf). We provide theoretical derivations and additional simulation results.
Contributor Information
Yingye Zheng, Public Health Sciences Division, Fred Hutchinson Cancer Research Center, Seattle, WA 98109.
Marshall Brown, Public Health Sciences Division, Fred Hutchinson Cancer Research Center, Seattle, WA 98109.
Anna Lok, Division of Gastroenterology, University of Michigan Ann Arbor, MI 48109.
Tianxi Cai, Department of Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA 02115.
References
- Borgan O, Goldstein L, Langholz B. Methods for the analysis of sampled cohort data in the Cox proportional hazards model. Annals of Statistics. 1995;23:1749–1778. [Google Scholar]
- Borgan O, Langholz B, Samuelsen SO, Goldstein L, Pogoda J. Exposure stratified case-cohort designs. Lifetime Data Analysis. 2000;6:39–58. doi: 10.1023/a:1009661900674. [DOI] [PubMed] [Google Scholar]
- Breslow NE, Day NE, et al. Statistical Methods in Cancer Research 1. International Agency for Research on Cancer; Lyon: 1980. [Google Scholar]
- Breslow NE, Lumley T, Ballantyne CM, Chambless LE, Kulich M. Using the whole cohort in the analysis of case-cohort data. American Journal of Epidemiology. 2009a;169:1398–1405. doi: 10.1093/aje/kwp055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Breslow NE, Lumley T, Ballantyne CM, Chambless LE, Kulich M. Improved Horvitz–Thompson estimation of model parameters from two-phase stratified samples: applications in epidemiology. Statistics in Biosciences. 2009b;1:32–49. doi: 10.1007/s12561-009-9001-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown LD, Cai TT, Dasgupta A. Confidence intervals for a binomial proportion and asymptotic expansions. Annals of Statistics. 2002;30:160–201. [Google Scholar]
- Cai T, Zheng Y. Nonparametric Evaluation of Biomarker Accuracy Under Nested Case-Control Studies. Journal of the American Statistical Association. 2011;106:569–580. doi: 10.1198/jasa.2011.tm09807. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cai T, Zheng Y. Evaluating prognostic accuracy of biomarkers under nested case-control studies. Biostatistics. 2012;13:89–100. doi: 10.1093/biostatistics/kxr021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheng S, Wei L, Ying Z. Analysis of transformation models with censored data. Biometrika. 1995;82:835. [Google Scholar]
- Cheng S, Wei L, Ying Z. Predicting survival probabilities with semi-parametric transformation models. Journal of the American Statistical Association. 1997;92:227–235. [Google Scholar]
- Cox DR. Regression models and life-tables. (Series B (Methodological)).Journal of the Royal Statistical Society. 1972;34:187–220. [Google Scholar]
- Gray RJ. Weighted analyses for cohort sampling designs. Lifetime Data Analysis. 2009;15:24–40. doi: 10.1007/s10985-008-9095-z. [DOI] [PubMed] [Google Scholar]
- Langholz B, Borgan Y. Estimation of absolute risk from nested case-control data. Biometrics. 1997;53:767–774. [PubMed] [Google Scholar]
- Liu D, Cai T, Zheng Y. Evaluating the Predictive Value of Biomarkers with Stratified Case-Cohort Design. Biometrics. 2012;68:1219–1227. doi: 10.1111/j.1541-0420.2012.01787.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lok AS, Sterling RK, Everhart JE, Wright EC, Hoefs JC, Di Bisceglie AM, Morgan TR, Kim HY, Lee WM, Bonkovsky HL, et al. Des-γ-carboxy prothrombin and α-fetoprotein as biomarkers for the early detection of hepatocellular carcinoma. Gastroenterology. 2010;138:493–502. doi: 10.1053/j.gastro.2009.10.031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murphy S, Rossini A, Van der Vaart A. Maximum likelihood estimation in the proportional odds model. Journal of the American Statistical Association. 1997;92:968–976. [Google Scholar]
- Pencina MJ, D’Agostino RB, Sr, D’Agostino RB, Jr, Vasan RS. Evaluating the added predictive ability of a new marker: from area under the ROC curve to reclassification and beyond. Statistics in Medicine. 2008;27:157–172. doi: 10.1002/sim.2929. [DOI] [PubMed] [Google Scholar]
- Pfeiffer R, Gail M. Two criteria for evaluating risk prediction models. Biometrics. 2011;67:1057–1065. doi: 10.1111/j.1541-0420.2010.01523.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Prentice RL. A case-cohort design for epidemiologic cohort studies and disease prevention trials. Biometrika. 1986;73:1. [Google Scholar]
- Qi L, Wang C, Prentice RL. Weighted estimators for proportional hazards regression with missing covariates. Journal of the American Statistical Association. 2005;100:1250–1263. [Google Scholar]
- Saegusa T, Wellner JA. Weighted likelihood estimation under two-phase sampling. Annals of Statistics. 2013;41:269. doi: 10.1214/12-AOS1073. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Samuelsen SO. A pseudolikelihood approach to analysis of nested case-control studies. Biometrika. 1997;84:379–394. [Google Scholar]
- Self SG, Prentice RL, et al. Asymptotic distribution theory and efficiency results for case-cohort studies. Annals of Statistics. 1988;16:64–81. [Google Scholar]
- Thomas DC. Addendum to “Methods of cohort analysis: Appraisal by application to asbestos mining”. Journal of the Royal Statistical Society Series A General. 1977;140:483–485. [Google Scholar]
- Wang S, Wang C. A note on kernel assisted estimators in missing covariate regression. Statistics & Probability Letters. 2001;55:439–449. [Google Scholar]
- Wang T, Rohan TE, Gunter MJ, Xue X, Wactawski-Wende J, Rajpathak SN, Cushman M, Strickler HD, Kaplan RC, Wassertheil-Smoller S, Scherer PE, H GY. A Prospective Study of Inflammation Markers and Endometrial Cancer Risk in Postmenopausal Hormone Nonusers. Cancer Epidemiology Biomarkers & Prevention. 2011;20:971–7. doi: 10.1158/1055-9965.EPI-10-1222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zeng D, Lin D. Maximum likelihood estimation in semiparametric transformation models for counting processes. Biometrika. 2006;93:627–40. doi: 10.1093/biomet/asw013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zeng D, Lin D. Efficient Estimation of Semiparametric Transformation Models for Two-Phase Cohort Studies. Journal of the American Statistical Association. 2014;109(505):371–383. doi: 10.1080/01621459.2013.842172. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zheng Y, Brown M, Lok A, Cai T. Supplement to “improving efficiency in biomarker incremental value evaluation under two-phase study designs”. Annals of Applied Statistics. 2017 doi: 10.1214/16-AOAS997. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.