

Summary
Motivated by searching for associations between genetic variants and brain imaging phenotypes, the aim of this paper is to develop a groupwise envelope model for multivariate linear regression in order to establish the association between both multivariate responses and covariates. The groupwise envelope model allows for both distinct regression coefficients and distinct error structures for different groups. Statistically, the proposed envelope model can dramatically improve efficiency of tests and of estimation. Theoretical properties of the proposed model are established. Numerical experiments as well as the analysis of an imaging genetic data set obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) study show the effectiveness of the model in efficient estimation. Data used in preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database.
Keywords: Dimension reduction, Envelope model, Grassmann manifold, Reducing subspace
1. Introduction
To motivate the proposed methodology, we consider an imaging genetic data set from 745 subjects collected by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) study (http://www.adni-info.org/) in order to advance the discovery in detection, invention, prevention as well as treatments of the Alzheimer’s disease. Specifically, each subject has brain volumes of 93 regions of interest, single nucleotide polymorphisms (SNPs) on candidate genes of the Alzheimer’s Disease, and other covariates including gender, age, education level, marital status and handedness. Alzheimer’s Disease (AD) is characterized by death of nerve cells and accelerated cerebral atrophy, leading to the shrinkage of various brain volumes, such as hippocampus. Similar to a recent large-scale imaging study for schizophrenia in Franke et al. (2016), we are interested in characterizing the genetic influences of the top 40 AD candidate genes listed on the AlzGene database (www.alzgene.org) as of June 10, 2010 on structural brain phenotypes in ADNI.
A standard model in the imaging genetic literature (Vounou et al., 2010; Thompson et al., 2013; Sun et al., 2015) is the multivariate linear regression given by
| (1) |
where Y is a r × 1 vector of multiple responses (e.g., brain volumes), X is a p × 1 vector of covariates, and the errors ε follows a distribution with mean 0 and positive definite covariance matrix Σ ∈ ℝr×r. Moreover, μ ∈ ℝr and β ∈ ℝr×p are unknown intercept and regression coefficients. It is common to calculate the ordinary least squares estimator of β by regressing each element in Y on the predictors of interest. This method, however, ignores the relationship among different response components. A novel envelope modeling framework introduced in Cook et al. (2010) explicitly uses such relationship to identify a part of the responses that is immaterial to the estimation of β, while bringing extraneous variation. This immaterial part is then accounted for in the subsequent estimation, making the estimation more efficient. After the original development, advances have been taken place to extend the scope of envelope model (Su and Cook, 2011, 2012, 2013; Cook et al., 2013; Cook and Zhang, 2015; Khare et al., 2017).
However, model (1) is not sufficient for addressing a more specific question of interest. Specifically, it is interesting to investigate how the associations between AD genetic variants and sub-cortical volume measures differ across male and female groups. Suppose that we observe imaging genetic data from subjects in L different groups. For each l = 1,…, L, the l−th group has n(l) observations and the total sample size is . By incorporating such group information, we can reformulate model (1) as
| (2) |
where Y(l)j ∈ ℝr is the jth observed response vector in the l−th population, μ(l) ∈ ℝr is the mean of the l−th population, X(l)j ∈ ℝp is the jth observed covariate vector in the l−th population, β(l) ∈ ℝr×p contains the regression coefficients for the l−th population, and ε(l)j follows some distribution with mean 0 and covariance matrix Σ(l). Throughout this paper, we use subscript (l) to denote the l−th population and subscripts without parenthesis to number the observations. Without loss of generality, we assume that , l = 1,…,L are centered at 0 in the sample for each group. Model (2) is referred to as the standard model in later discussion.
The aim of this paper is to develop a new groupwise envelope modelling framework for model (2), which allows for distinct regression coefficients and the heteroscedastic error structure across groups. Compared with the existing literature (Su and Cook, 2013; Cook et al., 2010), we make at least three major contributions. First, we develop an efficient estimation method to estimate distinct genetic-volume associations across groups under the heteroscedastic error structure. In contrast, the existing envelope models assume either a homogenous error structure or distinct means across groups without covariate X. Second, we examine the asymptotic properties of the proposed estimates under some mild conditions. Third, our simulation studies and the ADNI data analysis confirm the efficiency gains obtained by using the groupwise envelope model. An alternative way to gain estimation efficiency in model (2) is to fit a separate envelope model to each group. However, as will be shown in Sections 3 and 5, efficiency is lost due to ignoring the common characteristics in response variables across groups.
The article is organized as follows. Section 2 reviews the envelope model and introduces the groupwise envelope model and its estimation procedure. Section 3 systematically investigates the asymptotic properties of all estimators. Simulation studies are conducted in Section 4. A real data analysis of the imaging genetic data set from ADNI is described in Section 5. Conclusion remarks are given in Section 6.
2. Methods
2.1 A Review of Envelope Models
We first introduce some notation. We use PS to denote the projection matrix onto span(S) or S if S is a matrix or a subspace, and QS = I − PS. With a matrix A ∈ ℝm×n, vec(A) ∈ ℝmn stacks the columns of A into a vector. The Kronecker product is denoted by ⊗, X ∼ Y means X and Y has the same distribution, and X ⫫ Y means that X and Y are independent.
The original envelope model (Cook et al., 2010) was developed for model (1). Under (1), we partition the response vector Y into a material part and an immaterial part, where the distribution of the material part changes with the predictor X and the distribution of the immaterial part does not. More specifically, let be a subspace of ℝr, L be an orthogonal basis of and L0 be an orthogonal basis of . The linear combinations of the responses LTY and are called the material part and the immaterial part if the following two conditions are satisfy: (a) and (b) . Condition (a) indicates that the distribution of the immaterial part does not depend on X, and condition (b) indicates that given X, the material part and immaterial part are uncorrelated. Let . Conditions (a) and (b) are also equivalent to: (I) and (II) (Cook et al., 2010). Condition (I) indicates that the immaterial part does not contain information on β and condition (II) indicates that the variation Σ can be decomposed into the variation due to the material part and the variation due to the immaterial part. When Σ has the structure in condition (II), is a reducing subspace of Σ (Conway, 1990). Then, the Σ-envelope of , denoted by , is defined to be the smallest reducing subspace of Σ containing . Model (1) is called the envelope model when conditions (I) and (II) are imposed.
Let u denote the dimension of , Γ ∈ ℝr×u be an orthogonal basis of , and Γ0 ∈ ℝr×(r−u) be an orthogonal basis of . The coordinate form of the envelope model is
where β = Γη, η ∈ ℝu×p carries the coordinates of β with respect to Γ, and Ω = ΓT ΣΓ and carry the coordinates of Σ with respect to Γ and Γ0, respectively. When u = r, , the envelope model degenerates to the standard multivariate linear regression model. As shown in Cook et al. (2010), the envelope estimator of β is more efficient than or at least as efficient as the standard estimator. The efficiency gains can be substantial when ‖Σ1‖ ≪ ‖Σ2‖, where ‖·‖ denotes the spectral norm of a matrix or vector.
2.2 Formulation of Groupwise Envelop Model
Under model (2), let be a subspace of ℝr, L be an orthogonal basis of and L0 be an orthogonal basis of . Then for each l, the material part LTY(l)j and the immaterial part should satisfy (A) and (B) . From conditions (A) and (B), is a reducing subspace of all Σ(l) and for l = 1,…,L. Therefore, we define the groupwise envelope to be the intersection of all such . More specifically, let denote the collection of all covariance matrices, and . Then the -envelope of , denoted by , is the smallest subspace that reduces each matrix in and contains . When appears in subscripts, it is shortened to . From the definition of , we have
| (3) |
Model (2) is called the groupwise envelope model if conditions in (3) are imposed.
Let Γ ∈ ℝr×u be an orthogonal basis of and Γ0 ∈ ℝr×(r−u) be its completion. The coordinate form of the groupwise envelope model is given by
| (4) |
for each l = 1,…,L, where β(l) = Γη(l), η(l) ∈ ℝu×p carries the coordinate of β(l) with respect to Γ, and Ω(l) ∈ ℝu×u and Ω0 ∈ ℝ(r−u)×(r−u) are symmetric matrices that carry the coordinates of Σ(l) with respect to Γ and Γ0, respectively. The groupwise envelope model degenerates to the envelope model in Cook et al. (2010) if L = 1.
For a fixed dimension u, the number of parameters in the groupwise envelope model (4) is N(u) = Lr + Lup + Lu(u + 1)/2 + (r − u)(r − u + 1)/2 + u(r − u). This is because we need Lr parameters for all μ(l)s′, Lup parameters for all η(l)s′, Lu(u + 1)/2 parameters for all Ω(l)s′, and (r − u)(r − u + 1)/2 parameters for Ω0. The envelope subspace is on an r × u Grassmann manifold, which is the set of all u dimensional subspaces in an r dimensional space, so it has u(r − u) free parameters.
2.3 Estimation Procedure
The groupwise envelope model does not require normality, but we will use the normal likelihood function as a pseudo likelihood function to calculate estimators. Technical details are included in Supplemental Section A. Let θ = (μ, η, Ω, Ω0) be a collection of parameters, where μ = (μ(1),…,μ(L)), η = (η(1),…,η(L)), and Ω = (Ω(1),…,Ω(L)). For a fixed dimension u, u = 0,…,r, the normal log likelihood of the groupwise envelope model is given by
| (5) |
When Γ is fixed, the estimators of μ(l), η(l), Ω(l), and Ω0, which maximize ℓ(θ), can be written as explicit expressions of Γ. Let , and , where is the centered data matrix for X and is the centered data matrix for Y for group l. Substitute them back to ℓ(θ), we get
where denotes the r×u Grassmann manifold. To emphasize that Γ is an orthogonal basis of , we put subscript Γ on . After we obtained , can be any orthogonal basis of . For l = 1,…,L, the estimators for all other parameters are given as follows:
, where ;
;
;
, where is the completion of ;
, where is the ordinary least squares estimator of β(l);
.
To estimate the dimension of , we apply the Bayesian information criterion (BIC). Let l∗(u) be the maximized l for a fixed u, and N(u) be the number of parameters discussed in Section 2.2. We choose a value uopt that minimizes BIC(u) = −2l∗(u) + log(n)N(u).
3. Theoretical Properties
In this section, we examine the theoretical properties of the groupwise envelope estimators. We present the following theoretical properties, whose proofs are included in Supplemental Section B.
Proposition 1
Under the groupwise envelope model (4), assume that the errors are independent and have finite fourth moments. Then is a consistent estimator of β(l) and is a consistent estimator of Σ(l) for l = 1, …, L.
Proposition 1 establishes the consistency of the groupwise envelope estimators. Notice that normality is not required even though the estimators are derived by maximizing the normal likelihood function.
Proposition 2
Suppose that the conditions of Proposition 1 hold and f(l) = n(l)/n does not change with n. Then, converges in distribution to a multivariate normal distribution with mean 0 for each l = 1,…, L. Furthermore, under the normality, we have
where denotes convergence in distribution and for l = 1, …, L, in which T is given by
Proposition 2 provides the asymptotic distribution of the groupwise envelope estimator and derives explicit form of the asymptotic variance under the normality. The first term is the asymptotic variance of for known Γ, and the second term is the cost of estimating the envelope subspace .
Suppose that we fit separate envelope model to the data in each group, and we denote their estimators as for l = 1, …, L. We have the following results.
Proposition 3
Suppose that the conditions of Proposition 1 hold, then converges in distribution to a multivariate normal distribution with mean 0 for l = 1, …, L. Furthermore, under the normality, we have
where for l = 1, …, L, in which .
Corollary 4
V(l),senv ⩾ V(l) for l = 1, …, L.
Proposition 3 gives the asymptotic distribution of . Corollary 4 indicates that the groupwise envelope estimator is more efficient. A close examination reveals that V(l) and V(l),env differ only in terms of T and T2. This suggests that if Γ is known, the asymptotic variance for is the same. However, the cost of estimating is smaller for the groupwise envelope model. This is because that the groupwise envelope model uses all the data to estimate , whereas the separate envelope model only uses the data from the l−th group to estimate . We also notice that with finite sample, the envelope subspace calculated by fitting separate envelope model varies across groups.
4. Simulation Study
In this section, we use Monte Carlo simulations to evaluate the finite-sample performance of the groupwise envelope model (4). We generated the data from model (4) with two groups (L = 2), which have 40% and 60% of the observations. We set r = 10, p = 3, and u = 1. The matrix (Γ, Γ0) was obtained by normalizing an r × r matrix of independent normal variates, μ(1) was a vector of 3 and μ(2) was a vector of 10, η(1) was a vector of independent variates and η(2) was a vector of independent variates. Let A ∈ ℝ (r−u)×(r−u) be a matrix of independent normal (5, 12) variates, Ω(1) and Ω(2) both be variates, and Ω0 = AAT. The predictors were independent normal (0, 52) variates for the first group and independent normal (0, 102) variates for the second group. We varied the sample size from 100, 300, 1000 and 3000. For each sample size, 200 replications were generated. The standard model (2), the envelope model (Cook et al., 2010), separate envelope model and the groupwise envelope model (4) were fit to the data. Standard deviation of each element in β(1) and β(2) was calculated based on the 200 replications for each method at each sample size. We also computed the bootstrap standard deviations of each element in β(1) and β(2) based on 200 bootstrap samples. The results for a randomly chosen element in β(1) and a randomly chosen element in β(2) are summarized in Figure 1. For clarity, we did not draw the line for the standard deviation of the standard model, but only displayed its asymptotic standard deviation.
Figure 1.
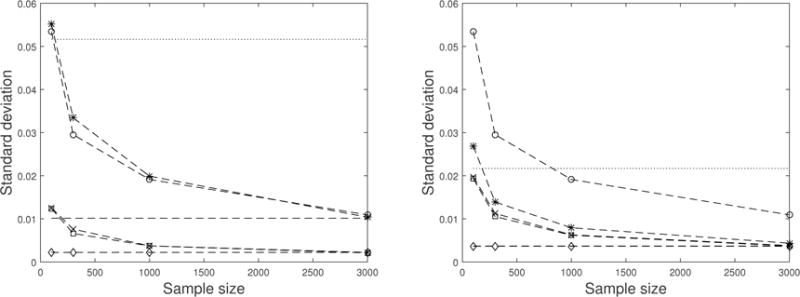
Left panel: Standard deviations for a random picked element in β(1). Right panel: Standard deviations for a random picked element in β(2). The –□–, –x– and –◊– lines mark the actual, bootstrap and asymptotic standard deviations of the groupwise envelope model. The –∗– and – – lines mark the actual and asymptotic standard deviation of the separate envelope model. The –o– line marks the standard deviations of the envelope estimator in Cook et al. (2010). The…line marks the asymptotic standard deviations of the standard model.
We have the following observations from Figure 1. The groupwise envelope estimator is consistent and its standard deviation approaches to the asymptotic standard deviation as sample size increases, which agrees with Proposition 1. It is also observed that the groupwise envelope model achieves substantial efficiency gains over the standard model. Take the element in the right panel of Figure 1 for example, the standard deviation of the groupwise envelope estimator is already smaller than the asymptotic standard deviation of the standard estimator with n = 100. This means by using the groupwise envelope model, with 100 samples we have achieved the efficiency of taking infinity number of samples under the standard model. We also notice that the bootstrap standard deviation is a good estimation of the sample standard deviation. The envelope model with constant covariance structure (Cook et al., 2010) has standard deviation about five times as large as the groupwise envelope model, indicating that accommodating the groupwise error structure brings extra efficiency gains. The separate envelope model also has larger standard deviations than the groupwise envelope model, as asserted in Corollary 4. The difference is more pronounced in one group than the other.
We investigated the numerical properties of the groupwise envelope model under non-normal errors in Web Appendix A and Web Appendix B. In Web Appendix A, we considered the estimation standard deviation of the groupwise envelope model under different non-normal error distributions including t distribution with degrees of freedom 6, uniform distribution defined on the unit interval, and chi-squared distribution with degrees of freedom 4. We examined the selection performance of BIC under non-normal errors in Web Appendix B.
5. The Alzheimer’s Disease Neuroimaging Initiative
We applied the groupwise envelope model to the imaging genetic data set obtained from ADNI study as described in Section 1. We used the image processing pipeline and quality control methods described in Zhu et al. (2014) to process the structural Magnetic Resonance Imaging (MRI) data and genetic data downloaded from the ADNI publicly available database (http://adni.loni.usc.edu/). Our problem of interest is to investigate the genetic effects of the SNPs on the top 40 AD candidate genes on the brain volumes of 93 regions of interest (ROI), whose names and abbreviation are given in the supplementary material in Zhu et al. (2014) across male and female groups. The top 40 AD candidate genes are listed on the AlzGene database (www.alzgene.org) as of June 10, 2010 on the brain volumes of 93 ROIs across male and female groups. The selection of the genes is described in Section 4.1 in Zhu et al. (2014). To correct for normal variation in head size, we used the proportion method to calculate ROI tissue-to-intracranial volume ratios and then took logarithm of these ratios. We selected the 1071 SNPs on the 37 top genes and Apolipoprotein E (APOE) ε4. We first performed a principal component analysis on the 1071 SNP predictors. Figure 2 presents the 1071 × 1071 correlation matrix of all 1071 SNPs. We selected 205 principal components (PCs) whose loadings have corresponding eigenvalues greater than 1, and these 205 PCs explain 89.76% of the total variation of all SNP predictors.
Figure 2.
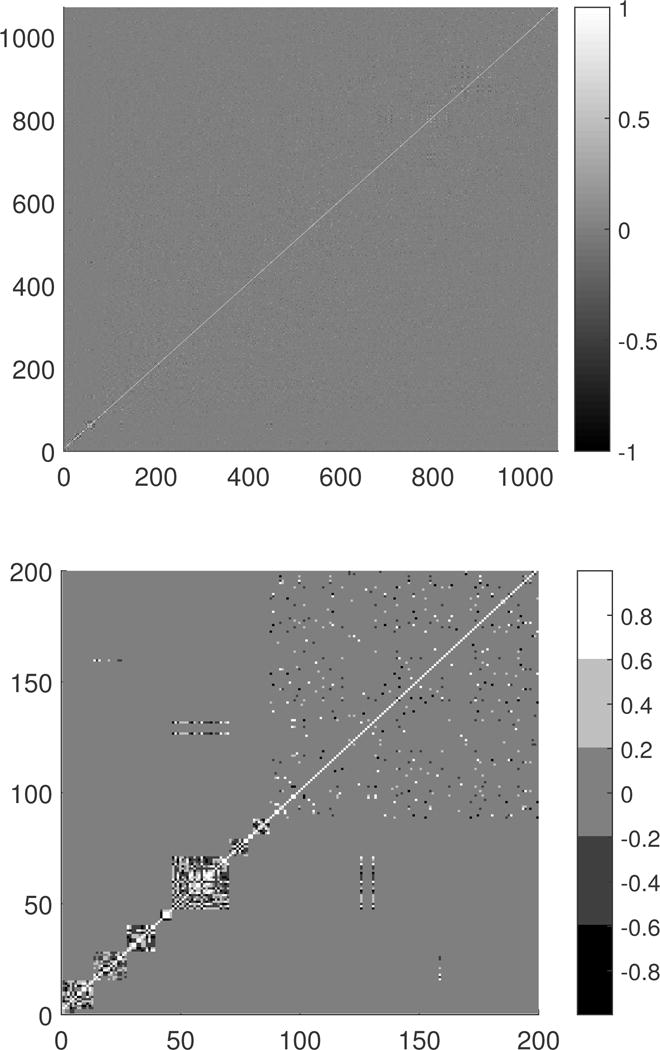
Plot of the correlation matrix. The top panel shows the correlation of 1071 SNPs and the bottom panel is the enlarged version for the first 200 SNPs. This figure appears in color in the electronic version of this article.
We fit a linear regression of the logarithm of the ratios for the brain volumes on five PCs obtained from the entire SNP data accounting for the population stratification. The residuals are used for multivariate responses in the groupwise envelop model (4). We used gender (male versus female) as the group variable and the SNP PCs and all covariates except gender as predictors. Note that the responses are unitless. The covariates include APOE ε4, age (years, from 55 to 91), education level (years, from 6 to 20), marriage status (married, widowed, divorced, other) and handedness (right-handed, other). All variables were standardized. BIC suggests u = 1. For each element in β(l), we computed the ratio of the bootstrap standard deviation under the standard model versus the bootstrap standard deviation under the groupwise envelope model. As demonstrated in Figure 1, this ratio is a good approximation to the ratio of actual standard deviations. The ratios range from 4.56 to 136.80, with an average of 29.71 for the male group, and from 6.06 to 351.82 with an average of 56.99 for the female group. This indicates that the groupwise envelope model obtains substantial efficiency gains over the standard model (2). A boxplot of the ratios is given in Figure 3. The efficiency gains can be explained by the covariance structure: , and . This indicates that the variation of the immaterial part is much larger than that of the material part, and by identifying and accounting for the immaterial variation, the groupwise envelope model achieves substantial efficient estimation in this case. The efficiency gains in estimation lead to better prediction performance. The prediction error is estimated by the average of 50 five-fold cross validations with random splits, and the identity inner product is used to bind the responses. The standard model has a prediction error of 21.27, and the groupwise envelope model has a prediction error of 9.65, which is more than a 50% reduction.
Figure 3.
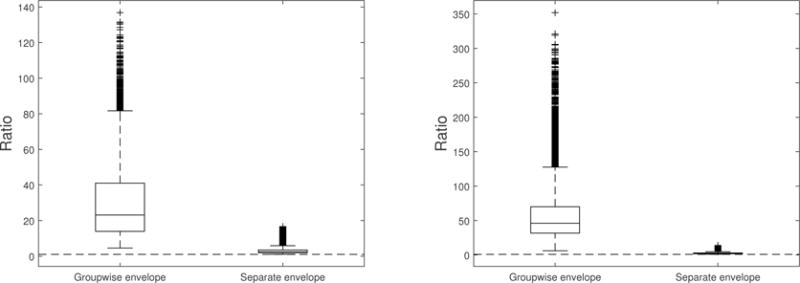
Boxplot of the ratio of the bootstrap standard deviation under the standard model to the bootstrap standard deviation under the groupwise envelope model or separate envelope model. The left panel is boxplot of the ratios for the male group, and the right panel is boxplot of the ratios for the female group. The horizontal line is at 1.
We also fitted the separate envelope model to the data. BIC suggested u = 1 for both male and female groups. The ratios of the bootstrap standard deviation under the standard model to that under the separate envelope model range from 1.05 to 16.63 with an average of 3.16 for the male group, and range from 1.01 to 13.93 with average of 2.68 for the female group. The ratios are also displayed in Figure 3. The boxplot reveals that the groupwise envelope model and the separate envelope model are both more efficient than the standard model. But by using the information from all the groups in the estimation of , the groupwise envelope model achieves substantially more efficiency gains than the separate envelope model, which confirms the results in Corollary 4.
To investigate the genetic effects of the SNPs on the brain volumes of 93 ROIs through the groupwise envelope model, we looked at a submatrix of , say , which consisted of columns corresponding to the 205 PCs and APOE ε4. And we calculated , where denotes the (j, i)th element of and denotes the jth row of , j = 1, …, 93 and i = 1, …, 206. In particular, j = 30 and j = 69 correspond to the right and left part of hippocampal formation region, which are important ROIs. Figure 4 shows c30,i and c69,i for the hippocampal formation region. In particular, the 206th element in the horizontal axis corresponds to APOE ε4. We have c30,206 = c69,206 = 0.077 for the male group and c30,206 = c69,206 = 0.110 for the female group.
Figure 4.
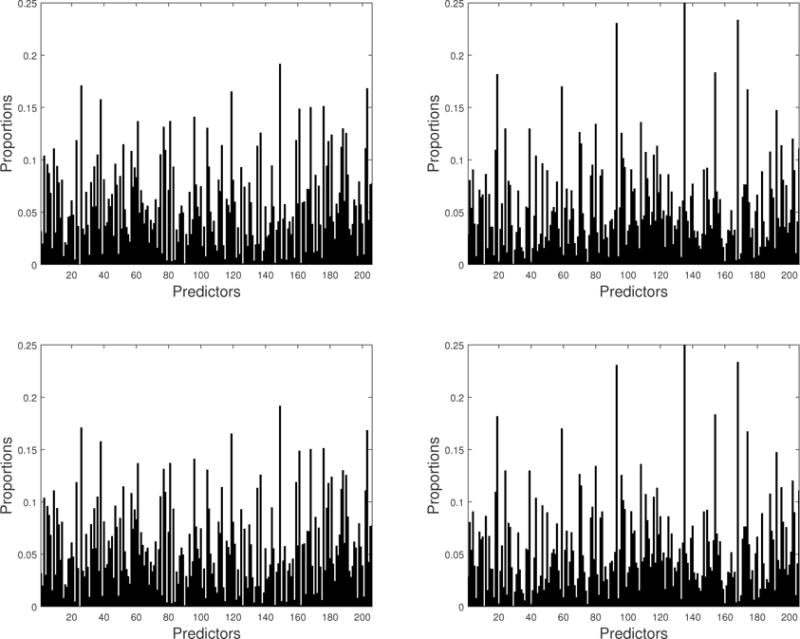
Plot of the proportions of the absolute value of coefficient for SNPs in the Euclidean norm of the coefficient vector corresponding to the region: the last on the horizontal axis denotes APOE ε4 and the remaining is for 205 PCs. The first row is for left hippocampal formation region, and the second row is for the right hippocampal formation region. The left panel is for the male group, and the right panel is for the female group. This figure appears in color in the electronic version of this article.
To consider the relationship between SNPs and ROI volumes in the coefficient matrix, we focused on the PCs with large coefficients based on the 98th quantile of the absolute values of the estimated regression coefficients. After thresholding, 42 PCs were selected for the male group and 49 PCs were selected for the female group. The heatmaps of regression coefficients for each group under the groupwise envelope model and the standard model are displayed in Figure 5. The horizontal axes in Figure 5 include the selected PCs as well as APOE ε4. Under the groupwise envelope model, it is easier to identify the regions with diminishing regression coefficients.
Figure 5.

Heatmaps of the regression coefficients: the last on the horizontal axis denotes APOE ε4 and the remaining is for the selected PCs. The first row is for groupwsie envelope model, and the second row is for the standard model (2). The left panel is for the male group, and the right panel is for the female group. This figure appears in color in the electronic version of this article.
We also tested if a coefficient equals to 0 for all elements in β. An ROI is chosen if at least one of the p-values in the corresponding coefficients is smaller than 0.05. Based on this criterion, all ROIs are selected under the standard model. Under the groupwise envelope model, 41 ROIs are selected for the male group. And eight additional ROIs lat.f-o.gy.R, sup.f.gy.R, hiopp.R, caud.neuc.R, mid.t.gy.L, prec.gy.L, par.lb.WM.R, and ant.caps.R are selected for female group, i.e. 49 ROIs are selected for female group. This indicates that the unselected ROIs are significant under the homogeneous model, but not under the model that considers heteroscedasticity. The selected ROIs are listed in Table 1. Among the selected ROIs, (i) me.f-o.gy.L/R, lat.f-o.gy.R, inf.f.gy.L/R, f.lob.WM.L, sup.f.gy.L/R and me.f.gy.R are related to the function of management (making a decision and carrying out tasks), attention (interest and concentration) and working memory; (ii) tmp.pl.R, sup.gy.R, sup.t.gy.L/R, mid.t.gy.L/R, inf.t.gy.L are related to memory and language; (iii) sup.p.lb.L/R and par.lb.WM.R are related to the sense of the space and size; and (iv) sup.o.gy.L/R, mid.o.gy.R, me.o.gy.L/R are located in the back of the brain playing an important role in vision.
Table 1.
The selected ROIs based on the p-value of βred. The italic ROIs in groupwise envelope model are regions additionally selected from female group except 41 common selected ROIs.
| Groupwise Envelope model | Standard model | |||
|---|---|---|---|---|
| me.f-o.gy.R | pstc.gy.R | me.f-o.gy.R | sup.o.gy.R | tmp.pl.L |
| lat.ve.L | ling.gy.R | mid.f.gy.R | caud.neuc.L | ent.cort.L |
| insula.R | me.f.gy.R | lat.ve.L | sup.gy.L | inf.o.gy.R |
| lat.ve.R | amyg.L | insula.R | ant.caps.L | sup.o.gy.L |
| glob.pal.R | me.o.gy.L | prec.gy.R | oc.lb.WM.R | lat.o.t.gy.R |
| glob.pal.L | mid.t.gy.R | lat.f-o.gy.R | mid.f.gy.L | ent.cort.R |
| inf.f.gy.L | corp.col | cing.R | sup.p.lb.L | hiopp.L |
| ang.gyr.R | sup.t.gy.R | lat.ve.R | caud.neuc.R | thal.L |
| tmp.pl.R | me.o.gy.R | me.f.gy.L | cun.L | par.lb.WM.R |
| nuc.acc.R | thal.R | sup.f.gy.R | prec.L | insula.L |
| f.lob.WM.L | lat.f-o.gy.R | glob.pal.R | par.lb.WM.L | pstc.gy.R |
| subtha.nuc.L | sup.f.gy.R | glob.pal.L | tmp.lb.WM.R | ling.gy.R |
| sup.o.gy.R | hiopp.R | putamen.L | sup.gy.R | me.f.gy.R |
| caud.neuc.L | caud.neuc.R | inf.f.gy.L | sup.t.gy.L | amyg.L |
| sup.p.lb.L | mid.t.gy.L | putamen.R | unc.L | me.o.gy.L |
| prec.L | prec.gy.L | f.lob.WM.R | mid.o.gy.R | parah.gy.R |
| sup.gy.R | par.lb.WM.R | parah.gy.L | mid.t.gy.L | ant.caps.R |
| sup.t.gy.L | ant.caps.R | ang.gyr.R | ling.gy.L | mid.t.gy.R |
| unc.L | tmp.pl.R | sup.f.gy.L | occ.pol.R | |
| mid.o.gy.R | subtha.nuc.R | nuc.acc.L | corp.col | |
| ling.gy.L | nuc.acc.R | oc.lb.WM.L | amyg.R | |
| sup.f.gy.L | unc.R | pstc.gy.L | inf.t.gy.R | |
| nuc.acc.L | cing.L | inf.f.gy.R | sup.t.gy.R | |
| inf.f.gy.R | fornix.L | prec.gy.L | mid.o.gy.L | |
| me.f-o.gy.L | f.lob.WM.L | tmp.lb.WM.L | ang.gyr.L | |
| per.cort.R | pec.R | me.f-o.gy.L | me.o.gy.R | |
| sup.p.lb.R | subtha.nuc.L | per.cort.R | cun.R | |
| per.cort.L | post.limb.L | sup.p.lb.R | lat.o.t.gy.L | |
| inf.t.gy.L | post.limb.R | lat.f-o.gy.L | thal.R | |
| ent.cort.L | hiopp.R | per.cort.L | occ.pol.L | |
| ent.cort.R | inf.o.gy.L | inf.t.gy.L | fornix.R | |
We then use the polygenic score to study the genetic relationship between the SNPs and the brain volumes on 93 ROIs. The genetic effects in our setting are contained in the 205 PCs obtained from the SNPs as well as APOE ε4. Let l be the gender indicator, l = 1 for male and l = 2 for female. Then for group l, Yl = (Yl,1,…, Yl,93)T is the response vector and Zl denotes the vector of 205 PCs and all the covariates. For each response Yl,j, j = 1, …, 93, we fit the linear regression model of Yl,j on Zl, and obtained the estimated coefficients and the p-values for each element in . We set the significance level at 0.05. Suppose are the significant genetic effects and are their coefficients, we can construct the polygenic score as . We then fit the regression of Yl,j on , and calculated the total sum of squares SSTl,j and regression sum of squares SSRl,j. We then computed and . Based on the value of R1 and R2, the genetic effects of SNPs explain 9.55% and 9.60% of the variation in the male and female groups, respectively. The association of the polygenic score with the phenotypical variation is tested based on the chi-squared distribution with non-centrality parameter λl and degrees of freedom 1, where , n(1) = 441 and n(2) = 304. Then the power of the two-tailed chi-squared test with significance level α is obtained from
where Φ is the cumulative distribution function for the standard normal distribution. We found both groups have power 1 with α = 0.05 in the testing.
6. Conclusion
We have proposed a groupwise envelope model, which is an efficient model for estimating regression coefficients for heterogeneous groups. Since the interest of research in heterogeneity soars, such as the great attention in precision medicine, the development of models dealing with heterogeneity is desired in multivariate response analysis. The groupwise envelope model allows for distinct regression coefficients and heteroscedastic error structure for different groups. Our simulation studies and ADNI data analysis demonstrates the efficiency gains obtained by the groupwise envelope model, compared to both standard model and separate envelope model. The groupwise envelope model leads to a better understanding of the genetic effects of the top 40 AD candidate genes for male and female groups on brain volumes of 93 ROIs in the ADNI dataset.
For future research, a sparse groupwise envelope model that pinpoints the immaterial responses is desired for real applications, as it is more interpretable. If we consider the spatial structure of the brains, we would have a multi-dimensional array (tensor) response. Li and Zhang (2016) developed a tensor response envelope model that achieves efficient estimation in tensor regression. We can expand our methodology to handle heteroscedastic error structure in the tensor envelope model. In addition, a Bayesian version of this model that incorporates prior information from earlier studies is also worth exploration. As longitudinal data and missing data appear in Alzheimer’s study, a groupwise envelope model that can handle these data structures would also be of practical use.
Supplementary Material
Acknowledgments
We are grateful to the editor and two referees for their insightful suggestion and comments that helped us improve the paper. We thank Professors Dennis Cook and Hani Doss for helpful discussions. This material was based upon work partially supported by the NSF grant DMS-1127914 to the Statistical and Applied Mathematical Science Institute. This work was partially supported by NIH grants MH086633 and MH092335, NSF grants SES-1357666, DMS-1407460, and DMS-1407655, and a grant from Cancer Prevention Research Institute of Texas. Data used in preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (http://adni.loni.usc.edu). As such, the investigators within the ADNI contributed to the design and implementation of ADNI and/or provided data but did not participate in analysis or writing of this report. A complete listing of ADNI investigators can be found at: http://adni.loni.usc.edu/wp-content/uploads/how_to_apply/ADNI_Acknowledgement_List.pdf.
Appendix
A: Estimation of the groupwise envelope model
we first hold Γ fixed and derive the estimators of parameters μ(l), η(l), Ω(l), l = 1,…, L, and Ω0 as a function of Γ. The derivative of the log likelihood l = l(θ) in (5) with respect to μ(l) is
| (A.1) |
Setting the derivative in (A.1) to 0 and using the fact that is centered at 0, we have . Substitute into the likelihood, we now consider the derivative of l in (5) with respect to η(l):
| (A.2) |
We set the the derivative in (A.2) to be 0 and obtain
where is an n(l) × p matrix with its ith row being , is an n(l) × r matrix with its ith row being . Substitute and to the log likelihood function, we have
| (A.3) |
We can easily get the estimators of Ω(l) and Ω0 by taking the derivatives, and the estimators are
| (A.4) |
Substitution of (A.4) into (A.3) gives
| (A.5) |
By Lemma 6.2 of Cook et al. (2010), we rewrite the function in (A.5) as
Then the objective function for Γ is
and Γ can be obtained by minimizing the preceding objective function.
B: Proofs of theoretical results in Section 3
Proof of Proposition 1 and Proposition 2
For preparation, if A ∈ ℝm×m is a symmetric matrix, vech(A) ∈ ℝm(m+1)/2 denotes the vector that stacks the lower triangle of A into a vector. The notations and are expansion and contraction operators that connect vec and vech: vec(A) = Em vech(A) and vech(A) = Cm vec(A).
We use Proposition 4.1 in Shapiro (1986) to prove Proposition 1. Let h denote the parameters under the standard model, and let ϕ denote the parameters under the groupwise envelope model. Then , and . We use J to denote the Fisher information matrix under the standard model, and G to denote the gradient matrix. Then
where g1=ILr, g2 is a Lpr × Lpu block diagonal matrix whose all diagonal blocks are Ip ⊗ Γ, g3 = (η(1) ⊗ Ir,…,η(L) ⊗ Ir)T, g4 id a Lr(r + 1)/2 × ur block diagonal matrix whose all diagonal blocks are and . Now we match Shapiro’s notations with our notations. Shapiro’s θ is our ϕ; Shapiro’s ξ is our h; Shapiro’s is the standard estimator of h; Shapiro’s Δ is our gradient matrix G; Shapiro’s V is our J; and Shapiro’s discrepancy function F is lmax − l, where l is the log likelihood function and lmax is the maximum value of l attained when h is the standard estimator of h. Specifically,
It is easy to see that lmax − l satisfies the conditions 1 – 4 in Section 3 of Shapiro (1986). Since J is full rank, we have rank (GT JG) = rank (J). As the standard estimator of h is consistent and converges in distribution to a normal distribution with mean 0 and covariance J−1, all the conditions in Proposition 4.1 of Shapiro (1986) are satisfied. Thus, the groupwise envelope estimator is a consistent estimator of h, and has asymptotically normal distribution with mean 0.
When the errors are normally distributed, then J has a closed form:
where f(l) = n(l)/n is the proportion of the l–th population, J1 is a Lr × Lr block diagonal matrix whose diagonal blocks are , J2 is a Lpr × Lpr block diagonal matrix whose diagonal blocks are , and J3 is a {Lr(r + 1)/2} × {Lr(r +1)/2} block diagonal matrix whose diagonal blocks are . The asymptotic variance of under the groupwise envelope model then has a closed form Venv = G(GT JG)†GT, where A† denotes the Moore-Penrose generalized inverse of a matrix A. After some straightforward calculations, the asymptotic variance of vec is and the asymptotic variance of is (1/f(l))Σ(l), for l = 1,…,L.
Proof of Proposition 3
Proof of Proposition 3 follows directly from (5.7) in Cook et al. (2010).
Footnotes
Supplementary Materials
Web Appendix A and Web Appendix B referenced in Section 4 are available with this paper at the Biometrics website on Wiley Online Library. An R package implementing the groupwise envelope model with simulating data is available at https://github.com/BIG-S2/GENV.
References
- Conway J. A course in functional analysis. New York: Springer; 1990. [Google Scholar]
- Cook RD, Helland IS, Su Z. Envelopes and partial least squares regression. Journal of the Royal Statistical Society: Series B. 2013;75:851–877. [Google Scholar]
- Cook RD, Li B, Chiaromonte F. Envelope models for parsimonious and efficient multivariate linear regression (with discussion) Statistica Sinica. 2010;20:927–1010. [Google Scholar]
- Cook RD, Zhang X. Foundations for envelope models and methods. Journal of the American Statistical Association. 2015;110:599–611. [Google Scholar]
- Franke B, Stein JL, Ripke S, Anttila V, Hibar DP, Van Hulzen KJ, Arias-Vasquez A, Smoller JW, Nichols TE, Neale MC, et al. Genetic influences on schizophrenia and subcortical brain volumes: large-scale proof of concept. Nature neuroscience. 2016 doi: 10.1038/nn.4228. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Khare K, Pal S, Su Z. A bayesian approach for envelope models. Annals of Statistics. 2017;45:196–222. [Google Scholar]
- Li L, Zhang X. Parsimonious tensor response regression. Journal of the American Statistical Association. 2016 doi: 10.1080/01621459.2021.1938082. (to appear) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shapiro A. Asymptotic theory of overparameterized structural models. Journal of the American Statistical Association. 1986;81:142–149. [Google Scholar]
- Su Z, Cook RD. Partial envelopes for efficient estimation in multivariate linear regression. Biometrika. 2011;98:133–146. [Google Scholar]
- Su Z, Cook RD. Inner envelopes: efficient estimation in multivariate linear regression. Biometrika. 2012;99:687–702. [Google Scholar]
- Su Z, Cook RD. Estimation of multivariate means with heteroscedastic errors using envelope models. Statistica Sinica. 2013;23:213–230. [Google Scholar]
- Sun Q, Zhu H, Liu Y, Ibrahim JG. Sprem: sparse projection regression model for high-dimensional linear regression. Journal of the American Statistical Association. 2015;110:289–302. doi: 10.1080/01621459.2014.892008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thompson PM, Ge T, Glahn DC, Jahanshad N, Nichols TE. Genetics of the connectome. NeuroImage. 2013;80:475–488. doi: 10.1016/j.neuroimage.2013.05.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vounou M, Nichols TE, Montana G, ADNI Discovering genetic associations with high-dimensional neuroimaging phenotypes: A sparse reduced-rank regression approach. NeuroImage. 2010;53:1147–1159. doi: 10.1016/j.neuroimage.2010.07.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu H, Khondker Z, Lu Z, Ibrahim JG. Bayesian generalized low rank regression models for neuroimaging phenotypes and genetic markers. Journal of the American Statistical Association. 2014;109:977–990. [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.