

Abstract
Decision-making theories explain animal behaviour, including human behaviour, as a response to estimations about the environment. In the case of collective behaviour, they have given quantitative predictions of how animals follow the majority option. However, they have so far failed to explain that in some species and contexts social cohesion increases when conditions become more adverse (i.e. individuals choose the majority option with higher probability when the estimated quality of all available options decreases). We have found that this failure is due to modelling simplifications that aided analysis, like low levels of stochasticity or the assumption that only one choice is the correct one. We provide a more general but simple geometric framework to describe optimal or suboptimal decisions in collectives that gives insight into three different mechanisms behind this effect. The three mechanisms have in common that the private information acts as a gain factor to social information: a decrease in the privately estimated quality of all available options increases the impact of social information, even when social information itself remains unchanged. This increase in the importance of social information makes it more likely that agents will follow the majority option. We show that these results quantitatively explain collective behaviour in fish and experiments of social influence in humans.
Keywords: decision-making, collective behaviour, collective decisions, panic
1. Introduction
In many social species, individuals in a group make choices that are more similar to each other when conditions are adverse than when they are favourable. This phenomenon is well documented in groups of moving animals, which often form tighter groups in response to the detection of a predator [1–6]; but it also takes place in other adverse conditions, such as in the absence of food [7] or when animals are introduced into an unknown environment [8,9]. In humans, the occurrence of sudden bank runs [10–12] and human stampedes [13–19] suggests increased aggregation in adversity, although data are insufficient to draw definitive conclusions. We will use the term super-aggregation in adversity to describe all these situations, regardless of whether aggregation occurs in physical space (as in groups of prey fleeing from a predator) or in the space of possible choices (as in investors deciding what shares to buy or sell).
Many theories study this phenomenon from a purely social point of view, investigating why an individual benefits from the company of its conspecifics—the intrinsic benefits of belonging to a group (figure 1a). For example, both theory and experiments show that belonging to a group may protect against predators [6,20–23]. In humans, copying others' behaviour can help to deflect the responsibility for an anticipated failure [24,25]. These explanations focus on cases in which aggregation holds an intrinsic benefit (such as collective defence from a predator), and require that this benefit increases in adversity—an increase that is often not obvious. Here we ask whether super-aggregation in adversity may emerge even in the absence of this benefit.
Figure 1.

Super-aggregation in adversity emerges from estimation-based decisions. (a) Scheme of a purely social decision. The focal individual must decide which group to join and only takes into account the groups themselves. (b) Scheme of a more complete decision-making process. The deciding individual must choose which group to join, but these groups are also associated with their non-social circumstances (in this example, they are choosing different doors). (c) Bayesian decision-making predicts super-aggregation in adversity: preference for the majority option (defined as P(Y | B, C)/P(X | B, C) in equation (2.4)), as a function of the privately estimated quality for both options (G = P(X | C) = P(Y | C)).
An indirect advantage of being in a group is that the behaviours of others can inform about the environment. Therefore, even if belonging to a group holds no intrinsic value, copying others' decisions may be the optimal strategy when reacting to an uncertain environment, and this strategy may lead to aggregation. The optimal level of aggregation resulting from this strategy can be calculated using decision-making theory (figure 1b). These types of models successfully explain collective behaviour in many animals, including humans [26–31], but have never been used to investigate super-aggregation in adversity.
Here we show that Bayesian estimation predicts super-aggregation in adversity, which was inadvertently present in some decision-making models [30,31], and absent from others due to simplifying assumptions [26–29]. Furthermore, we find that many non-Bayesian decision-making models may also lead to super-aggregation in adversity, and discuss the conditions in which this will hold. Using simulations, we show that the effect can be strong enough to reproduce typical observations of groups of animals under predation risk, and that its predictions are consistent with existing experimental data.
2. Results
Consider the example of a person who wants to exit a building, and must choose between two identical looking doors (x and y; figure 1b). We define the quality of each option as the probability that it leads safely to the exit. Even assuming that the presence of other individuals holds no intrinsic value, their behaviour may give information about the quality of the two doors: assuming that part of the people also want to exit the building, and that they may have some information about the correct path, a door chosen by the majority has a higher probability of being the correct option.
Bayes' theorem allows computing this probability combining social and private information. According to this theorem, the probability that door y is a good option is
| 2.1 |
where Y stands for ‘y is a good option’ and 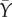 stands for ‘y is a bad option’. B and C represent the social and private information, respectively. P(Y | C) is the probability that option y is good, estimated using only private information; we therefore define the non-social term as
stands for ‘y is a bad option’. B and C represent the social and private information, respectively. P(Y | C) is the probability that option y is good, estimated using only private information; we therefore define the non-social term as 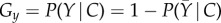 . The terms P(B | Y, C) and
. The terms P(B | Y, C) and 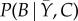 contain all the social information, and we therefore define the social term as
contain all the social information, and we therefore define the social term as 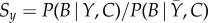 . While this term encapsulates all the social information, it also depends on the non-social information C. An alternative parametrization that separates better the two types of information is possible but less compact, and leads to the same conclusions (electronic supplementary material, section S1). With these definitions, Bayes' theorem in equation (2.1) becomes
. While this term encapsulates all the social information, it also depends on the non-social information C. An alternative parametrization that separates better the two types of information is possible but less compact, and leads to the same conclusions (electronic supplementary material, section S1). With these definitions, Bayes' theorem in equation (2.1) becomes
| 2.2 |
for option y, and similarly for option x. In our previous work, we developed the social terms Sx and Sy, obtaining explicit forms that allow the model's predictions to be tested with experimental data [28,30,31]. This particularization is not necessary here because our results are independent of the exact form of the social terms. It suffices to note that Sy increases when social information indicates that y is a good option (usually as more individuals choose option y), and that Gy increases when private information indicates that y is a good option. By convention we will consider that y is the option chosen by the majority and hence favoured by social information, meaning that Sy > Sx.
Decisions will be based on the estimated probabilities. A simple and widespread decision rule is to choose options according to the ratio of predicted qualities [28,30,32–41]. Then, the probability of choosing option y (Py) is a monotonically increasing function of the ratio of the estimated probabilities,
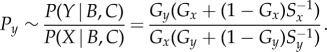 |
2.3 |
When Gx ≠ Gy, private information will bias the decision towards one of the two options. This bias may be strong enough to obscure the effect of social information, and it is generally accepted that social information has more weight when the decision is most uncertain (i.e. when private information does not favour any option, Gx = Gy) [42,43]. We will then focus our analysis on this state of maximum uncertainty, defining G ≡ Gx = Gy. Then, equation (2.3) simplifies to
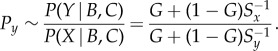 |
2.4 |
We now define adversity as an event that decreases the quality of all options. In our example, we may consider the case of a fire in the building. We assume that the deciding individual receives some information about the adverse event, such as a fire alarm going off. The fire alarm does not help to choose between the two doors (so we still have Gx = Gy ≡ G) but it lowers the estimated probability that either door leads safely to the street, because fire could be encountered on the way (so G decreases).
A simple assumption to explain super-aggregation in adversity is that social information becomes more relevant in this context, which in our model would mean a change in the social terms Sx and Sy. But we aim to show that this change is not necessary for the result, so we will assume that these social terms remain constant (i.e. other individuals are equally reliable with and without the fire). Given that the social terms remain constant and that the fire alarm does not favour one door over another, should we expect super-aggregation around one of the options?
From equation (2.4) we see that, in extremely favourable conditions (G = 1), there will be no preference for either option. As adversity increases (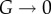 ), so does the preference for the majority option (figure 1c). Super-aggregation in adversity thus emerges, even when the social terms remain constant.
), so does the preference for the majority option (figure 1c). Super-aggregation in adversity thus emerges, even when the social terms remain constant.
More formally, we say that super-aggregation in adversity occurs whenever the probability of choosing the majority option increases when lowering G, or equivalently,
| 2.5 |
By computing the derivative of equation (2.4), we find that ∂Py/∂G has the same sign as (S−1y − S−1x), which is negative as long as y is the majority option (hence Sy > Sx). Therefore, the Bayesian model shows super-aggregation in adversity (see Material and methods for a more general derivation).
This derivation shows that agents following Bayesian estimations show super-aggregation in adversity in a two-option scenario with symmetric private information. We will next illustrate with an spatial example that this result can be generalized to many options and to asymmetric private information. Then we will discuss the mathematical properties that lead to super-aggregation in adversity, and discuss other models that also lead to it (outside Bayesian estimation and without using the ratio of the probabilities to estimate the tendency to choose either of them). Finally, we will contrast our predictions with existing experimental data.
2.1. Spatial super-aggregation in adversity
So far, we have seen that a Bayesian estimation model applied to a two-choice scenario shows super-aggregation in adversity. We now test that an extension of the same model to groups of moving animals gives the increased spatial cohesion typically observed in experiments. Our model draws from extensive work on collective motion [44–48] but, in contrast to most previous studies, our individuals do not react directly to each other. Instead, individuals estimate the quality of all points within a given maximum distance using a many-options version of the Bayesian model. In this model, social information increases the expected quality of the space around each individual, and individuals choose where to go with a probability proportional to each site's estimated quality (see Material and methods for details). In favourable conditions, a point close to other individuals has only slightly higher quality than the background, so the animals remain relatively dispersed. When conditions deteriorate, the estimated quality is high only for high-density regions, so all individuals converge towards them (figure 2a,b; electronic supplementary material, movies S1, S2).
Figure 2.

Spatial super-aggregation in adversity. (a) Four frames of a simulation where private information is identical for all locations and changes suddenly at time t = 150 from favourable conditions (G = 0.1) to adverse conditions (G = 0.0001). The background colour shows the probability that each pixel is a good location, estimated by the blue individual using the Bayesian model (see Material and methods). (b) Average distance among individuals as a function of time, for the same simulation as in (a). Background colour indicates the value of G. Dots mark the times of the frames shown on (a). (c) Same as (a), for a simulation with a predator. (d) Same as (b), for a simulation with a predator.
The model also shows aggregation when the non-social estimate of qualities is asymmetric, as, for example, when a predator approaches the group. We assume that individuals who perceive the predator update their private information to a non-uniform map of qualities whose minimum is at the predator's position. A simple non-social model of predator avoidance in which each individual ran straight away from the predator would predict the group to disperse, its members following diverging trajectories centred on the predator's position. Likewise, in our model the gradient of privately estimated qualities pushes the individuals away from the predator. However, the gradient also decreases the overall quality, producing super-aggregation in adversity and leading to higher aggregation as a net result (figure 2c,d; electronic supplementary material, movie S3).
These results illustrate that decision-making can produce strong spatial super-aggregation in adversity under some conditions. Furthermore, as the effect emerges from the individuals' decision-making algorithm, the prediction is robust to changes in the dynamical details of the model, making it applicable across taxa (electronic supplementary material, figure S1).
2.2. A geometric framework for decision-making
We have seen super-aggregation in adversity in a Bayesian model, applied to a two-choice case and to a spatial version. We are still missing an explanation of the origin of the effect in this model and whether it applies more generally to other models. To answer these questions, we developed a simple framework in which many decision theories can be represented.
We divide the decision in two steps. First, the deciding individual estimates the quality of the available options (Qx and Qy for options x and y). In our Bayesian model, the quality of each option was the probability estimated by equation (2.1), Qy = P(Y | B, C). In general, we will use ‘quality’ as a generic name for whatever is relevant to the decision, including both social and non-social factors. In the context of evolution, quality measures the fitness value of each option. In the language of economic decision-making, quality refers to the utility of each option. These qualities may be estimated with any model relevant for each particular situation.
For two options, we can visualize the estimated qualities in a two-dimensional landscape (figure 3a, left). We still assume symmetric private information (Gx = Gy ≡ G, where G now stands for the privately estimated quality), so the private estimate falls on the landscape's diagonal (figure 3a, red diamond symbol). Social information is then added (figure 3a, left, green arrow) to the private information to reach a final estimate (figure 3a, left, blue diamond symbol).
Figure 3.

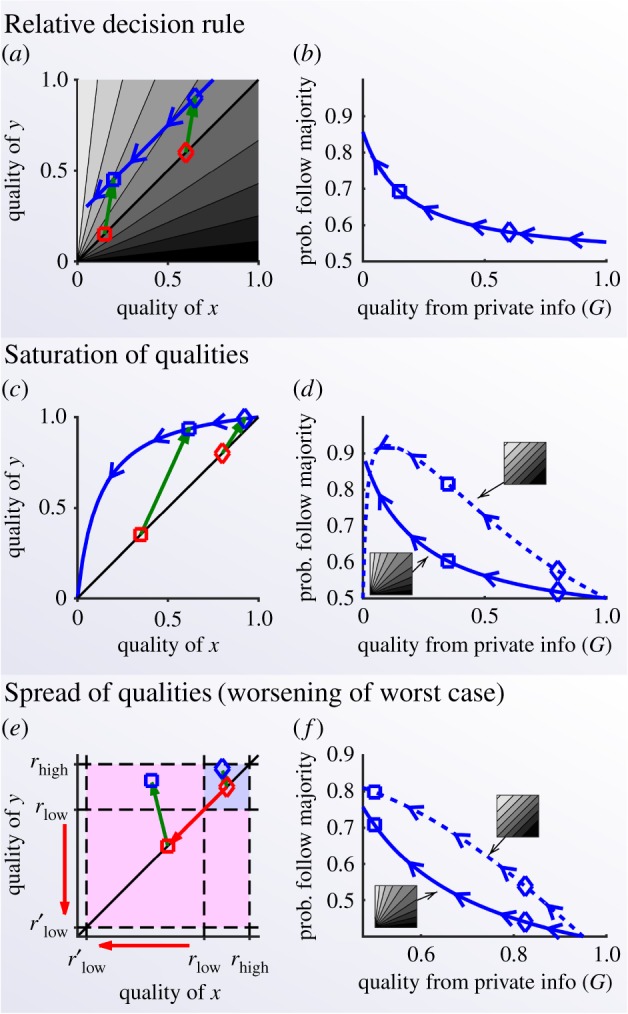
A geometric framework for decision-making. (a) Decision process: in step 1, social and non-social information are integrated to estimate the qualities of the options, Qx and Qy. Red diamond: privately estimated qualities (G). Green arrow: contribution of the social information. Blue diamond: estimated qualities. In step 2, the decision rule gives the probability of choosing each option (Px and Py) given the estimated qualities from step 1. In this example, Py = Qy/(Qx + Qy) and Px = 1 − Py. (b) Example of the change in the estimated qualities when conditions become adverse. Colours as in (a). Diamonds: favourable conditions. Squares: adverse conditions. Blue and red arrowheads point in the direction of increasing adversity. (c) Left: Example of the trajectory followed by the estimated qualities in adversity (arrowheads point towards higher adversity), for three different decision rules: top: relative decision rule (Py = Qy/(Qx + Qy)); middle: absolute decision rule Py = 1/(1 + e−2(Qy−Qx)); bottom: deterministic decision rule (Py = 1 if Qy > Qx, and Py = 0 otherwise). Right: Probability to follow the majority as a function of the privately estimated quality, for the same trajectories and decision rules shown on the left.
In the second step, a decision rule transforms the estimated qualities into the probability of choosing each option (figure 3a, right).
Now, we investigate the effect of adversity on the decision-making process. As before, the effect of adversity is to lower the privately estimated quality G, moving the estimation to a different point of the quality landscape. To illustrate this, we may consider an estimation rule simpler than our Bayesian model: we define the quality of an option as Qy = Gy + Sy, where the social term (Sy) remains constant in adversity (figure 3b). Even in this linear case, and even if the change in non-social information does not favour one option over the other, the change in estimated qualities leads in general to a different probability of choosing each option (figure 3c, top). The only exception is when the estimated qualities run along an isoprobability line of the decision rule (figure 3c, middle). Such a perfect match is unlikely except for decision rules with large regions of constant probability, as, for example, the deterministic rule ‘always choose the option with highest estimated quality’ (figure 3c, bottom). This decision rule is used in many simple models, preventing them from explaining super-aggregation in adversity [26,27].
Another feature that prevents some probabilistic models from predicting super-aggregation in adversity is that they assume mutually excluding options (one of them is good and the other is bad, so P(x is good) = 1 − P(y is good)) [26–28]. These models lack a parameter that measures adversity, which would require lowering P(x is good) and P(y is good) simultaneously, and cannot predict super-aggregation in adversity.
In general, decision rules are not deterministic and options are not mutually excluding, so the probability of following the majority will change with adversity. But why do we usually observe increased (rather than decreased) aggregation in adversity? The geometric framework does not directly answer this question, but will help us visualize how super-aggregation in adversity emerges from different characteristics common to many decision-making models.
2.3. Mechanisms for super-aggregation in adversity
This section will discuss several qualitative mechanisms that lead to super-aggregation in adversity. The mechanism considered in most existing models to describe super-aggregation in adversity [6,20–25] amounts to an explicit change in the social terms that favours the majority option. This change is probably present in many situations, and it is easy to see that it would change the degree of aggregation. Here we will focus on another three mechanisms that are present even when the social terms remain constant.
2.3.1. Relative decision rules
Many decisions depend on the relative value of estimated qualities, rather than on their absolute value. Examples range from bacteria to humans, including rules such as Weber's Law (which depends on the relative difference between qualities (Qy − Qx)/(Qy + Qx)), probability matching (which depends on Qy/(Qx + Qy)), direct ratio rules (Qy/Qx) and others [28,30,32–41]. All these rules share the condition that
| 2.6 |
where Px and Py are the probabilities of choosing x and y, respectively, and f is any monotonically increasing function. When more than two options exist, a relative decision rule must fulfil equation (2.6) for every pair of options.
All relative rules have isoprobability lines identical in shape to those in figure 4a, independently of function f. With these rules, when the effect of social information on the estimation remains the same (figure 4a, green arrows), its impact on the final decision increases in adversity, with a higher probability of following the majority (figure 4b). Even when the influence of social information in the qualities decreases in adversity, the probability to follow the majority will increase as long as the estimated qualities fulfil
| 2.7 |
This condition holds both for the non-optimal estimation rule in figure 4a and for the Bayesian model in equation (2.1) (as illustrated in figure 1c and derived in equation (4.6) in Material and methods).
Figure 4.
Mechanisms responsible for super-aggregation in adversity. (a) Estimated qualities for an additive estimation model (Qx = G + Sx, Qy = G + Sy, with Sx = 0.05, Sy = 0.3). Red: private estimate for favourable conditions (G = 0.6, diamond) and adverse conditions (G = 0.15, square). Green arrows: contribution of the social information. Blue: trajectory of the final estimated qualities when adversity increases (arrows point towards adversity). Background: probability of choosing y for each pair of qualities, for the relative decision rule Py = Qy/(Qx + Qy) (greyscale: black=0, white=1). (b) For the model in (a), probability of choosing the majority option (y), as a function of the privately estimated quality (G). Arrows point in the direction of adversity. Diamond and square correspond to the same conditions as in (a). (c) Estimated qualities for a Bayesian decision-making model (equation (2.2) with Sx = 3, Sy = 9). Colours and symbols as in (a). (d) Probability of choosing the majority option (y) as a function of the privately estimated quality (G), using the Bayesian estimation model in (c) and a relative decision rule (Py = Qy/(Qx + Qy), solid line) or an absolute decision rule (Py = 1/(1 + e−2(Qy−Qx)), dashed line). (e) Estimated qualities for the model with pay-offs (equation (4.17)); rhigh is the pay-off for a good option, rlow the pay-off for a bad option in favourable conditions and r′low the pay-off for a bad option in adverse conditions. Colours and symbols as in (a). (f) Same as (d) but for the model in (e). Quality from private info is defined as G = rlow + (rhigh − rlow)Pprivate, where Pprivate = 0.5 is the privately estimated probability that options have a high reward.
2.3.2. Saturation near the upper bound of qualities
The range of qualities is often bounded, for example, when there is a limit in the amount of food an animal can consume or when qualities are probabilities. In this case, as the privately estimated qualities increase, both the private and the final estimates converge to the upper bound, so the difference between them—the contribution of social information—tends to zero. Adversity lowers the qualities and therefore takes estimation away from the upper bound, and social information can now impact more. This effect takes place in the Bayesian model in equation (2.2), because the qualities are defined as probabilities (figure 4c). Therefore, the Bayesian model may show super-aggregation in adversity not only when coupled with a relative decision rule, but also through the saturation near the upper bound.
To decouple the effects of saturation and relative decision rules, we considered a decision rule that depends on the difference of the qualities, Qy − Qx (Material and methods). With this decision rule, Bayesian estimation predicts super-aggregation in adversity when the initial estimated qualities are high (dashed line in figure 4d). In the range of very low qualities we find the opposite effect, due to the lower bound of the probability. However, social information usually pushes the estimation towards the upper bound, making the range for super-aggregation in adversity wider than the range for the opposite effect, especially for large groups (equation (4.16) in Material and methods).
2.3.3. Spread of the qualities through worsening of the worst-case scenario
A third mechanism was found for the case in which adversity modifies the values of the potential pay-offs behind each option, rather than the probability of reaching them. In our example of two doors, we defined the quality as the probability to reach the street safely. We may build a more detailed model by detaching the probability that each door reaches the street and its consequences (the pay-off behind each option). A fire alarm does not change the probability that each door leads to the street, nor the corresponding pay-off for reaching the street (rhigh). Instead, it decreases the pay-off for choosing the wrong door from a low value rlow (detour to street) to an even lower pay-off r′low < rlow (possibility of dying in a fire). Adversity thus increases the contrast between a good and a bad choice, effectively rescaling the estimation from the region between rlow and rhigh to a wider region of the quality landscape between r′low and rhigh (figure 4e). This rescaling results in a larger contribution of the social information, leading to super-aggregation in adversity for both relative and absolute decision rules (figure 4f) and for all combinations of the parameters (Material and methods).
The opposite effect takes place when adversity affects the gains of a good option, rather than the cost of a bad one (Material and methods). Therefore, among adverse situations, we expect the life-threatening ones—characterized by a deterioration of the worst-case scenario—to produce stronger super-aggregation in adversity.
Each of these three mechanisms can produce super-aggregation in adversity by itself, but in general we may observe several of them reinforcing each other, as, for example, the solid lines in figure 4d,f .
2.4. Contrast with experimental data
We have tested whether decision models showing super-aggregation in adversity compare well against experimental data. We compared the spatial model shown in figure 2 with experimental data of groups of 10 fish (Fundulus diaphanus) [7]. To modify the private information of the fish, the authors sprayed different odours uniformly on the water. Food odour was used to signal favourable conditions, and alarm odour (released when a fish is killed by a predator) to signal adversity. Experimenters then measured the distribution of group sizes in each treatment. They found that odours that signal adversity increased the cohesion in the fish, measured as a higher probability of finding large groups (figure 5a, insets). Our spatial model reproduces these data with an accuracy comparable to that of the model originally proposed to describe them [7]. Our approach has the advantage that the theory indicates what parameter must change across conditions, while in previous models the increase in social attraction could be implemented in several different ways. In our model, all parameters remain constant across conditions except the private information G, which we fitted to the data (figure 5a; see Material and methods for details).
Figure 5.

Experiments are consistent with super-aggregation in adversity emerging from decision-making. (a) Mean group size for 10 fish swimming in a closed space as a function of the privately estimated quality, as predicted by the spatial model. The black dots indicate the experimental mean group sizes [7], and the values of G that best fit the experiments. Insets: distributions of group sizes for the four experiments (dots: experimental data. red line: simulations). (b) Layout of the experiment of Case et al. [49]. (c) Probability of relying on the card choice of another person (a professor for the green data and a student for the black data), as a function of the proportion of red cards (which is equivalent to the probability of getting a good card at random). Dots: experimental data (curved patches indicate experimental uncertainty due to sampling, with width proportional to the probability that the true value falls at each value, and truncated at the 95% CI). Lines: model (equation (4.24)).
These results are too indirect to conclude that fish are effectively implementing a Bayesian model with the values of G recovered by our fit. However, they show that our prediction for super-aggregation in adversity can be strong enough to reproduce experimental results.
Super-aggregation in adversity may also take place in humans, as suggested by the occurrence of sudden bank runs [10–12] and human stampedes [13–19]. It is, however, unclear whether these events actually emerge from super-aggregation, from other causes such as sudden changes in the private information towards a single preferred option, or from a combination of both. Tests in these panic situations are difficult, but our theory suggests that super-aggregation in adversity should also happen when adversity is unrelated to life-threatening situations. In these situations our prediction is easy to test, and we did so using an existing dataset [49].
In this study, the experimental subject had to choose one out of eight face-down cards and got a reward when the chosen card was red. The subject could either choose one card or rely on the opinion of another person—either a professor or a student (figure 5b). Subjects were told the proportion of red cards, so they had private information about the probability of success. For this dataset, the experimenters expected no relation between this probability of success and the probability to rely on the other person's opinion [49]. However, the data show the trend predicted by our theory: when subjects rely more on social information the proportion of good cards is lower (figure 5c; Material and methods).
3. Discussion
Our main result is that estimations and decisions naturally imply, without extra hypotheses, super-aggregation in adversity. It is, therefore, a parsimonious explanation for the generality of super-aggregation in adversity, which should be common to all situations in which estimation plays a role. This is consistent with the general presence of super-aggregation in adversity [1–5,7], but of course does not rule out additional mechanisms in particular situations, such as collective protection or confusion effects in the case of predation risk. Interestingly, our approach also makes predictions that are probably different from other explanations. This is more dramatically seen in those cases in which our approach ceases to predict super-aggregation in adversity. This happens for very adverse situations when the decision rule is not relative (figure 4d). Also, we predict the opposite effect, a form of dispersion in adversity, in the case in which a higher pay-off decreases.
Our results are complementary to other mechanisms that may increase aggregation in adversity in specific situations [20–23], and in fact our geometric framework may naturally include some of these models. For example, it can reproduce the selfish-herd hypothesis [21] when the qualities are given by the probability of surviving a predator attack (electronic supplementary material, figure S2). In general, it is difficult to disentangle different mechanisms in a given situation. For example, the aggregation typically found when animals explore a new set-up can also be due to increased uncertainty in private information; the decreased aggregation found experimentally as a response to food odour may be a mechanism to reduce competition. Our results add a new potential mechanism, to be considered along with the classical ones.
Our results apply to the case when the presence of other individuals in one particular option increases its expected quality (i.e. we assume that Sy > Sx when y is the majority option). This may not be the case when social information is communicated through other means, such as by how insistently an individual prefers one option. In this case, the minority may drive the group towards a given option [50,51] and, while the amplification of the effect of social information will still exist, it may not lead to observable super-aggregation. Super-aggregation in adversity may also not exist if competition is strong, outweighing the benefits of social information. In this case, we might expect different—perhaps even opposite—trends. Some situations may be mixed, with super-aggregation in adversity leading to high density around one of the options, in turn leading to high competition. For example, super-aggregation in adversity may lead to most people choosing the same emergency exit in a building, producing increased competition for space when the crowd reaches the door and obstructs it.
Our results may have implications on the neural architectures behind optimal decisions. Optimal decisions leading to super-aggregation in adversity may not require recomputing the social terms Sx and Sy, opening the possibility of neural systems in which social and non-social information are computed by separate modules, but that can nevertheless combine them optimally and efficiently. This would allow decision-makers to swiftly adapt their social behaviour to adverse conditions. Even in situations in which social information changes substantially, a first-order approximation that would emerge from this architecture would be to update the non-social component and recompute the final decision before updating the social component. Therefore, the additional constraint of making fast decisions preserves super-aggregation in adversity.
Our analysis has focused on symmetric private information (all options have the same privately estimated quality), which corresponds to maximum uncertainty about what option is better. The mechanisms discussed are also at work with asymmetric private information, but in this case it is difficult to decouple the role of private and social information. An additional confounder arises if the asymmetry in private information between the options increases or decreases in adversity, obscuring the effect of social information. For example, many situations are characterized by a sharp increase in asymmetry: people wandering in a building usually have different aims, but a fire alarm will direct everyone towards the exit. This type of aggregation is compatible with our results and fits in our framework, but our results are applicable even when considering symmetric options, as, for example, two identical emergency exits or two equivalent escape routes from a predator. In general, by sticking to the symmetric case, we have shown that super-aggregation in adversity does not require any asymmetry in the private information.
We have seen that super-aggregation in adversity is at the core of decision-making. This finding does not exclude other causes for the observed behaviours, but may be taken as a reference result for decision-making before resorting to more complex explanations.
4. Material and methods
4.1. Formal definition of super-aggregation in adversity
For a given decision-making model, we will say that super-aggregation in adversity occurs whenever
| 4.1 |
where Py is the probability to choose the majority option and G is the privately estimated quality (equal for all options because we consider symmetric private information).
4.2. Super-aggregation in adversity with relative decision rules
We start from the definition of super-aggregation in adversity (equation (4.1)). If there are only two options (x and y), we must have Px = 1 − Py. Therefore, decreasing Py necessarily means decreasing Py/Px, so
| 4.2 |
and from equation (2.6) we have that
| 4.3 |
where f′( · ) is the derivative of f with respect to its argument, which is always positive because f is by definition a monotonically increasing function. Therefore,
| 4.4 |
Putting together equations (4.2) and (4.4), super-aggregation in adversity will take place whenever
| 4.5 |
If the choice is among more than two options, a similar condition is sufficient (but not necessary) to produce super-aggregation in adversity. The probability to choose the majority option must decrease if the ratio of this probability with respect to all other probabilities decreases:
| 4.6 |
With this and equation (4.4) (which is valid for any two options), we have that
| 4.7 |
is a sufficient condition for super-aggregation in adversity when there are more than two options.
For the Bayesian model in equation (2.1), Qy/Qx is given by equation (2.4). Therefore,
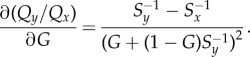 |
4.8 |
This expression is always negative because squared terms are always positive and Sy > Sx because y is the majority option. Therefore, the Bayesian estimation model with a relative decision rule always produces super-aggregation in adversity.
4.3. Absolute decision rules
We say that a decision rule is absolute when the probability to choose option y is of the form
| 4.9 |
where Qx, Qy are the qualities of options x and y, and F is any monotonically increasing function.
Absolute decision rules give super-aggregation in adversity whenever equation (4.1) is fulfilled. From equation (4.9),
| 4.10 |
where F′( · ) is the derivative of F with respect to its argument, which is always positive because F is monotonically increasing. Therefore, ∂Py/∂G < 0 ⇔ ∂(Qy − Qx)/∂G < 0, so super-aggregation in adversity will take place whenever
| 4.11 |
Absolute decision rules may emerge, for example, if the subject chooses y when Qy > Qx + η, with η a random number: let ρ(η) be the probability density function of η, and F(η) be its cumulative distribution. Then, the probability to choose y is equal to the probability to draw a value of η lower than Qy − Qx,
| 4.12 |
We see that F is a cumulative distribution, which is always monotonically increasing. In figures 1 and 4, we have used
| 4.13 |
This function is the cumulative distribution of the logistic distribution, whose probability density function is ρ(η) = e−η/λλ−1(1 + e−η/λ)−2. We have chosen this distribution because its cumulative density function has a simple analytical form; all results hold regardless of the probability distribution that we choose.
When combined with an absolute decision rule, the Bayesian model will show super-aggregation in adversity when
 |
4.14 |
The denominator of this expression is always positive, and Sy − Sx is positive when y is the majority option. Therefore, the whole expression is negative when
| 4.15 |
This inequality has only one solution for G > 0, which is
| 4.16 |
Thus, there is super-aggregation in adversity in the range of high G, and the opposite effect in the range of low G. The higher the SxSy, the wider the range for super-aggregation in adversity.
This result matches the intuition that the upper bound is more important than the lower one because social information tends to move the estimation towards the upper bound. In principle, an individual choosing option x can indicate both that x is a good option and/or that y is a bad one. Therefore, this choice can increase Sx to the same degree as it decreases Sy. However, experimental data show that social information usually has a positive net effect, meaning that an individual that chooses x increases Sx more than it decreases Sy (in our previous work [30] we defined parameter k to measure this effect. All experimental data, from three different species, were consistent with k < 1, meaning that social information has a positive net effect). When social information has a positive net effect, the product SxSy increases as more individuals make choices. Therefore, for large groups (or when behaviours are very informative) the range of super-aggregation in adversity is very wide. For example, in our previous study [30] we found that for zebrafish SxSy = 5n, where n is the total number of individuals that have already chosen one of the two options. Therefore, equation (4.16) tells us that a group of 10 zebrafish will show super-aggregation in adversity for G > 3 × 10−4, and a group of 15 for G > 6 × 10−6. As a reference, in our experiments (that corresponded to an intermediate level of adversity, with the fish in an unknown environment but without any direct threat) we found G ≈ 0.08 [30].
4.4. Model with pay-offs
Let rlow be the reward provided by a bad option, and rhigh be the reward provided by a good one, with rhigh ≥ rlow ≥ 0. The estimated quality of option x is its expected pay-off
| 4.17 |
and similarly for option y. By P(xhigh) we denote the estimated probability that x has a high pay-off (rhigh), and equation (4.17) takes into account that P(xlow) = 1 − P(xhigh). The private estimate of the quality of the options is
| 4.18 |
where Pprivate is the privately estimated probability that an option contains a high reward (equal for all options, by hypothesis). A change in private information may translate into three different changes in the parameters: (i) a change in the probability (Pprivate), (ii) a change in the lower pay-off (rlow) and (iii) a change in the higher pay-off (rhigh). The first type of change will depend on the specific model we use to estimate the probabilities (we may use a Bayesian model as in previous sections, or any other model). Here we will consider the other two cases, in which the new private information changes the values of the rewards that the subject expects to obtain.
First, let us consider the case in which adversity means a decrease in the lower reward (rlow), and the case of a relative decision rule (equation (2.6)). From equation (4.18) we have that ∂G/∂rlow > 0 in all cases. Therefore, any derivative with respect to G will have the same sign as a derivative with respect to rlow, and equation (2.7) is now equivalent to ∂(Qy/Qx)/∂rlow < 0. We compute this derivative from equation (4.17), getting
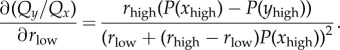 |
4.19 |
The denominator is always positive because it is squared, and rhigh is positive by definition. We see that P(yhigh) > P(xhigh) because y is the majority option, so the derivative is always negative; super-aggregation in adversity always takes place.
We find the same result for an absolute decision rule. To test for super-aggregation in adversity, we use equation (4.11), deriving with respect to rlow instead of G (as explained in the previous paragraph). We get
| 4.20 |
which is always negative because P(yhigh) > P(xhigh) when y is the majority option. Therefore, cohesion always increases with adversity.
By contrast, cohesion decreases in adversity when the higher pay-off changes, keeping all other parameters constant. This has a simple intuitive explanation: in adversity rhigh goes down, becoming more similar to rlow. Therefore, the difference between choosing correctly and choosing incorrectly decreases, making any decision weaker. Mathematically, for relative decision rules we evaluate the condition in equation (2.7) (in this case deriving with respect to rhigh instead of G), finding
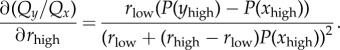 |
4.21 |
The denominator of this expression is always positive, as is rlow by definition. And P(yhigh) > P(xhigh) because y is the majority option, so the derivative is always positive, meaning that cohesion decreases in adversity when using a relative decision rule. Now we consider an absolute decision rule (equation (4.11)):
| 4.22 |
which is always positive because Py > Px when y is the majority option.
4.5. Spatial model
To simulate animals in motion, we discretize the space in pixels (for two-dimensional simulations) or voxels (for three-dimensional simulations). In each iteration, each individual chooses one pixel and accelerates towards it, up to a maximum acceleration (amax) and never exceeding a maximum velocity (vmax). The probability to choose a given pixel is proportional to the probability that it is a good place according to the Bayesian model in equation (2.1). Following Arganda et al. [30], we expand the social term as Sy = sNnear, where y here refers to a single pixel (or voxel), Nnear is the number of individuals within a radius rinfluence from pixel y and s is a parameter measuring the reliability of the other individuals. We, therefore, have
| 4.23 |
We also incorporate a limited field of view for each individual, by assuming that an individual can only choose pixels within a certain radius from itself, rview (this parameter is needed to make the model computationally tractable even when the individuals are not restricted to a finite region).
For the results in figure 3a,b and electronic supplementary material, movie S1, we chose the parameters amax = 0.1, vmax = 0.5, rinfluence = 5, rview = 100, s = 3 and G as indicated in figure 3b (space units are in pixels, and time units in iterations).
For the case of predator avoidance the model confirmed our prediction of increased cohesion in adversity, but was not realistic: in many conditions, when the predator appears, individuals cluster together but fail to run away from it (the social attraction overcomes the repulsion from the predator). To obtain more realistic results, we assume that an individual indicates that the location towards which it is heading (rather than its current location) is a good place. To account for this, we centre the circle of influence of each individual at the position where it will be in tprediction steps in the future (assuming it will keep constant direction and speed), rather than at its current location. With this addition, animals not only cluster together when the predator appears, but also tend to align with each other along the optimal escape route (figure 3c,d; electronic supplementary material, movie S2; simulations with the same parameters as in previous paragraph, but with tprediction = 15).
In fact, alignment arises in adversity when individuals pay attention to future positions rather than current ones (tprediction > 0), even if there is no predator present (electronic supplementary material, movie S3; simulations with same parameters as for electronic supplementary material, movie S1, but with tprediction = 15). Thus, in our model the group does not need the asymmetry created by the predator to reach a consensus direction. But if there is a predator, the consensus direction will head away from it.
To reproduce the experimental data in figure 5a, we adjusted the model parameters to mimic the experimental conditions [7]. The experiments were performed in a 100 × 100 × 10 cm tank, and the experimenters considered that two fish belonged to the same group when they were closer than 16 cm. Assuming a scale of 1 pixel cm−1, we simulated 10 individuals in a closed two-dimensional space of 100 × 100 pixels and set rinfluence = 16 pixels. When performing the analysis, we considered that two fish belonged to the same group when they were within 16 pixels. Then we searched the parameter space manually and non-systematically, finding a good fit for amax = 1, vmax = 12, rview = 30, s = 10, tprediction = 0 and G as in figure 4a.
4.6. Model for the cards experiment
The experimental design presented social information as a separate option (figure 5b), so we have implemented the simplest model that mimics this condition: the subject assumes that the other person (the professor or the student) has a fixed probability of making a correct choice (ξ). And the probability of making a correct choice by choosing a card is nred/8, where nred is the number of red cards. We then consider a nine-choice scenario: the eight cards plus the social option. As the decision rule we use probability matching, where the probability to choose one option is proportional to its corresponding probability of success. Then, the probability to rely on the other's opinion is
| 4.24 |
We fit the parameter ξ to the experimental data by minimizing the sum of the squared errors between the data and the model, getting ξ = 0.624 for the professor and ξ = 0.328 for the student.
Supplementary Material
Acknowledgements
We are very grateful to Sara Arganda, Barrett Deris, Francisco Ferrero-Romero and Raphaël Jeanson for fruitful discussions, and to Trevor I. Case for clarifications about the data in [49].
Data accessibility
Experimental datasets used were obtained from Hoare et al. [7] and Case et al. [49].
Authors' contributions
A.P.-E. designed the project, developed the framework, wrote the software, analysed data and wrote the manuscript. G.G.d.P. designed the project, developed the framework, analysed data and wrote the manuscript.
Competing interests
We declare we have no competing interests.
Funding
We acknowledge an FPU fellowship from Ministerio de Economa y Competitividad, Spain (AP2006-01666 to A.P.-E.), an EMBO fellowship (ALTF818-214 to A.P.-E.), a Human Frontier Science Program fellowship (LT000537/2015 to A.P.-E.), funding from Spanish Plan Nacional BFU2009-09967, BFU2012-33448 and BFU2013-49512-EXP from Ministerio de Economa y Competitividad (to G.G.d.P.), from ERASysBio+ initiative supported under the European Union European Research Area Networks (ERA-NET) Plus scheme in the FP7 Seventh Framework Programme as EUI2009-04090 (to G.G.d.P., including contract to A.P.-E.), from Fundaçao para a Ciência e Tecnologia PTDC/NEU-SCC/0948/2014 (to G.G.d.P.) and Champalimaud Foundation (to G.G.d.P.).
References
- 1.Caraco T, Martindale S, Pulliam HR. 1980. Avian flocking in the presence of a predator. Nature 285, 400–401. ( 10.1038/285400a0) [DOI] [Google Scholar]
- 2.Beauchamp G. 2004. Reduced flocking by birds on islands with relaxed predation. Proc. R. Soc. Lond. B 271, 1039–1042. ( 10.1098/rspb.2004.2703) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Forsman JT, Monkkonen M, Inkeroinen J, Reunanen P. 1998. Aggregate dispersion of birds after encountering a predator: experimental evidence. J. Avian. Biol. 29, 44–48. ( 10.2307/3677339) [DOI] [Google Scholar]
- 4.Carere C, Montanino S, Moreschini F, Zoratto F, Chiarotti F, Santucci D, Alleva E. 2009. Aerial flocking patterns of wintering starlings, Sturnus vulgaris, under different predation risk. Anim. Behav. 77, 101–107. ( 10.1016/j.anbehav.2008.08.034) [DOI] [Google Scholar]
- 5.Bode NWF, Faria JJ, Franks DW, Krause J, Wood AJ. 2010. How perceived threat increases synchronization in collectively moving animal groups. Proc. R. Soc. B 277, 3065–3070. ( 10.1098/rspb.2010.0855) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.King AJ, Wilson AM, Wilshin SD, Lowe J, Haddadi H, Hailes S, Jennifer Morton A. 2012. Selfish-herd behaviour of sheep under threat. Curr. Biol. 22, R561–R562. ( 10.1016/j.cub.2012.05.008) [DOI] [PubMed] [Google Scholar]
- 7.Hoare DJ, Couzin ID, Godin J-GJ, Krause J. 2004. Context-dependent group size choice in fish Anim. Behav. 67, 155–164. ( 10.1016/j.anbehav.2003.04.004) [DOI] [Google Scholar]
- 8.Delaney M, Follet C, Ryan N, Hanney N, Lusk-Yablick J, Gerlach G. 2002. Social interaction and distribution of female zebrafish (Danio rerio) in a large aquarium. Biol. Bull. 203, 240–241. [DOI] [PubMed] [Google Scholar]
- 9.Pérez-Escudero A, Vicente-Page J, Hinz RC, Arganda S, de Polavieja GG. 2014. idTracker: tracking individuals in a group by automatic identification of unmarked animals. Nat. Methods 11, 743–8. ( 10.1038/nmeth.2994) [DOI] [PubMed] [Google Scholar]
- 10.Gorton G. 1988. Banking panics and business cycles. Oxf. Econ. Pap. 40, 751–781. ( 10.1093/oxfordjournals.oep.a041885) [DOI] [Google Scholar]
- 11.Saunders A. 1996. Contagious bank runs: evidence from the 1929–1933 period. J. Financ. Intermediation 423, 409–423. ( 10.1006/jfin.1996.0022) [DOI] [Google Scholar]
- 12.Bougheas S. 1999. Contagious bank runs. Int. Rev. Econ. Finance 8, 131–146. ( 10.1016/S1059-0560(99)00011-8) [DOI] [Google Scholar]
- 13.Ngai KM, Burkle FM Jr, Hsu A, Hsu EB. 2009. Human stampedes: a systematic review of historical and peer-reviewed sources. Disaster Med. Public Health Prep. 3, 191–195. ( 10.1097/DMP.0b013e3181c5b494) [DOI] [PubMed] [Google Scholar]
- 14.Hsieh Y-H, Ngai KM, Burkle FM, Hsu EB. 2009. Epidemiological characteristics of human stampedes. Disaster Med. Public Health Prep. 3, 217–223. ( 10.1097/DMP.0b013e3181c5b4ba) [DOI] [PubMed] [Google Scholar]
- 15.Soomaroo L, Murray V. 2012. Disasters at mass gatherings: lessons from history. PLoS. Curr. 4, RRN1301 ( 10.1371/currents.RRN1301) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Illiyas FT, Mani SK, Pradeepkumar AP, Mohan K. 2013. Human stampedes during religious festivals: a comparative review of mass gathering emergencies in India. Int. J. Disaster. Risk. Reduct. 5, 10–18. ( 10.1016/j.ijdrr.2013.09.003) [DOI] [Google Scholar]
- 17.Johnson NR. 1987. Panic at ‘The Who concert stampede’: an empirical assessment. Soc. Probl. 34, 362–373. ( 10.2307/800813) [DOI] [Google Scholar]
- 18.Mawson AR. 2005. Understanding mass panic and other collective responses to threat and disaster. Psychiatry 68, 95–113. ( 10.1521/psyc.2005.68.2.95) [DOI] [PubMed] [Google Scholar]
- 19.Rogsch C, Schreckenberg M, Tribble E, Klingsch W, Kretz T. 2010. Was it panic? An overview about mass-emergencies and their origins all over the world for recent years. In Pedestrian and evacuation dynamics 2008 (eds Wolfram W.F. Klingsch, Christian Rogsch, Andreas Schadschneider, Michael Schreckenberg), pp. 743–755. Springer; https://link.springer.com/content/pdf/10.1007/978-3-642-04504-2.pdf#page=724. [Google Scholar]
- 20.Miller RC. 1922. The significance of the gregarious habit. Ecology 3, 122–126. ( 10.2307/1929145) [DOI] [Google Scholar]
- 21.Hamilton WD. 1971. Geometry for the selfish herd. J. Theor. Biol. 31, 295–311. ( 10.1016/0022-5193(71)90189-5) [DOI] [PubMed] [Google Scholar]
- 22.Krause J, Ruxton GD. 2002. Living in groups, Oxford series edition Oxford, UK: Oxford University Press. [Google Scholar]
- 23.Ioannou CC, Guttal V, Couzin ID. 2012. Predatory fish select for coordinated collective motion in virtual prey. Science 337, 1212–1215. ( 10.1126/science.1218919) [DOI] [PubMed] [Google Scholar]
- 24.Bradley GW. 1978. Self-serving biases in the attribution process: a reexamination of the fact or fiction question. J. Pers. Soc. Psychol. 36, 56–71. ( 10.1037/0022-3514.36.1.56) [DOI] [Google Scholar]
- 25.Zuckerman M. 1979. Attribution of success and failure revisited, or: the motivational bias is alive and well in attribution theory. J. Pers. 47, 245–287. ( 10.1111/j.1467-6494.1979.tb00202.x) [DOI] [Google Scholar]
- 26.Banerjee AV. 1992. A simple model of herd behavior. Q. J. Econ. 107, 797–817. ( 10.2307/2118364) [DOI] [Google Scholar]
- 27.Bikhchandani S, Hirshleifer D, Welch I. 1992. A theory of fads, fashion, custom, and cultural change as informational cascades. J. Political Econ. 100, 992–1026. ( 10.1086/261849) [DOI] [Google Scholar]
- 28.Pérez-Escudero A, de Polavieja GG. 2011. Collective animal behavior from Bayesian estimation and probability matching. PLoS. Comput. Biol. 7, e1002282 ( 10.1371/journal.pcbi.1002282) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Madirolas G, de Polavieja GG. 2015. Improving collective estimations using resistance to social influence. PLoS Comput. Biol. 11, 1–16. ( 10.1371/journal.pcbi.1004594) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Arganda S, Pérez-Escudero A, de Polavieja GG. 2012. A common rule for decision-making in animal collectives across species. Proc. Natl Acad. Sci. USA 109, 20 508–20 513. ( 10.1073/pnas.1210664109) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Pérez-Escudero A, Miller N, Hartnett AT, Garnier S, Couzin ID, de Polavieja GG. 2013. Estimation models describe well collective decisions among three options. Proc. Natl Acad. Sci. USA 110, E3466–E3467. ( 10.1073/pnas.1309867110) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Escalante-Chong R, Savir Y, Carroll SM, Ingraham JB, Wang J, Marx CJ, Springer M. 2015. Galactose metabolic genes in yeast respond to a ratio of galactose and glucose. Proc. Natl Acad. Sci. USA 112, 1636–1641. ( 10.1073/pnas.1418058112) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Fechner GT. 1966. Elements of psychophysics [Elemente der Psychophysik] (eds DH Howes, EG Boring), vol 1. First published 1860. Translated by HE Adler. New York, NY: Holt, Rinehart and Winston. [Google Scholar]
- 34.Moore AR, Cole WH. 1921. The response of Popillia japonica to light and the Weber–Fechner law. J. Gen. Physiol. 3, 331–335. ( 10.1085/jgp.3.3.331) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Perna A, Granovskiy B, Garnier S, Nicolis SC, Labédan M, Theraulaz G, Fourcassié V, Sumpter DJT. 2012. Individual rules for trail pattern formation in Argentine ants (Linepithema humile). PLoS Comput. Biol. 8, e1002592 ( 10.1371/journal.pcbi.1002592) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Herrnstein RJ. 1961. Relative and absolute strength of response as a function of frequency of reinforcement. J. Exp. Anal. Behav. 4, 267 ( 10.1901/jeab.1961.4-267) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Behrend ER, Bitterman ME. 1961. Probability-matching in the fish. Am. J. Psychol. 74, 542–551. ( 10.2307/1419664) [DOI] [Google Scholar]
- 38.Greggers U, Menzel R. 1993. Memory dynamics and foraging strategies of honeybees. Behav. Ecol. Sociobiol. 32, 17–29. ( 10.1007/BF00172219) [DOI] [Google Scholar]
- 39.Kirk KL, Bitterman ME. 1965. Probability-learning by the turtle. Science 148, 1484–1485. ( 10.1126/science.148.3676.1484) [DOI] [PubMed] [Google Scholar]
- 40.Vulkan N. 2000. An economist's perspective on probability matching. J. Econ. Surv. 14, 101–118. ( 10.1111/1467-6419.00106) [DOI] [Google Scholar]
- 41.Wozny DR, Beierholm UR, Shams L. 2010. Probability matching as a computational strategy used in perception. PLoS Comput. Biol. 6, e1000871 ( 10.1371/journal.pcbi.1000871) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Deutsch M, Gerard HB. 1955. A study of normative and informational social influences upon individual judgment. J. Abnorm. Soc. Psychol. 51, 629–636. ( 10.1037/h0046408) [DOI] [PubMed] [Google Scholar]
- 43.Valone TJ, Templeton JJ. 2002. Public information for the assessment of quality: a widespread social phenomenon. Phil. Trans. R. Soc. Lond. B 357, 1549–1557. ( 10.1098/rstb.2002.1064) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Aoki I. 1982. A simulation study on the schooling mechanism in fish. Bull. Jpn. Soc. Sci. Fisheries 48, 1081–1088. ( 10.2331/suisan.48.1081) [DOI] [Google Scholar]
- 45.Couzin ID, Krause J, James R, Ruxton GD, Franks NR. 2010. Collective memory and spatial sorting in animal groups. J. Theor. Biol. 218, 1–11. ( 10.1006/jtbi.2002.3065) [DOI] [PubMed] [Google Scholar]
- 46.Strombom D. 2011. Collective motion from local attraction. J. Theor. Biol. 283, 145–151. ( 10.1016/j.jtbi.2011.05.019) [DOI] [PubMed] [Google Scholar]
- 47.Calovi DS, Lopez U, Ngo S, Sire C, Chaté H, Theraulaz G. 2014. Swarming, schooling, milling: phase diagram of a data-driven fish school model. New. J. Phys. 16, 015026 ( 10.1088/1367-2630/16/1/015026) [DOI] [Google Scholar]
- 48.Janosov M, Virágh C, Vásárhelyi G, Vicsek T. 2017. Group chasing tactics: how to catch a faster prey. New. J. Phys. 19, 053003 ( 10.1088/1367-2630/aa69e7) [DOI] [Google Scholar]
- 49.Case TI, Fitness J, Cairns DR, Stevenson RJ. 2004. Coping with uncertainty: superstitious strategies and secondary control J. Appl. Soc. Psychol. 34, 848–871. ( 10.1111/j.1559-1816.2004.tb02574.x) [DOI] [Google Scholar]
- 50.Couzin ID, Krause J, Franks NR, Levin SA. 2005. Effective leadership and decision-making in animal groups on the move. Nature 433, 513–516. ( 10.1038/nature03236) [DOI] [PubMed] [Google Scholar]
- 51.Couzin D, Christos C, Demirel G, Gross T, Torney C, Hartnett A, Conradt L, Levin SA, Leonard NE. 2011. Uninformed individuals promote democratic consensus in animal groups. Science 334, 1578–1580. ( 10.1126/science.1210280) [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Experimental datasets used were obtained from Hoare et al. [7] and Case et al. [49].