

Abstract
Parametric images for dynamic positron emission tomography (PET) are typically generated by an indirect method, i.e., reconstructing a time series of emission images, then fitting a kinetic model to each voxel time activity curve. Alternatively, “direct reconstruction,” incorporates the kinetic model into the reconstruction algorithm itself, directly producing parametric images from projection data. Direct reconstruction has been shown to achieve parametric images with lower standard error than the indirect method. Here, we present direct reconstruction for brain PET using event-by-event motion correction of list-mode data, applied to two tracers.
Event-by-event motion correction was implemented for direct reconstruction in the Parametric Motion-compensation OSEM List-mode Algorithm for Resolution-recovery reconstruction. The direct implementation was tested on simulated and human datasets with tracers [11C]AFM (serotonin transporter) and [11C]UCB-J (synaptic density), which follow the 1-tissue compartment model. Rigid head motion was tracked with the Vicra system. Parametric images of K1 and distribution volume (VT=K1/k2) were compared to those generated by the indirect method by regional coefficient of variation (CoV). Performance across count levels was assessed using sub-sampled datasets.
For simulated and real datasets at high counts, the two methods estimated K1 and VT with comparable accuracy. At lower count levels, the direct method was substantially more robust to outliers than the indirect method. Compared to the indirect method, direct reconstruction reduced regional K1 CoV by 35–48% (simulated dataset), 39–43% ([11C]AFM dataset) and 30–36% ([11C]UCB-J dataset) across count levels (averaged over regions at matched iteration); VT CoV was reduced by 51–58%, 54–60% and 30–46%, respectively. Motion correction played an important role in the dataset with larger motion: correction increased regional VT by 51% on average in the [11C]UCB-J dataset.
Direct reconstruction of dynamic brain PET with event-by-event motion correction is achievable and dramatically more robust to noise in VT images than the indirect method.
Keywords: motion correction, direct PET reconstruction, kinetic modeling
1. Introduction
Kinetic modeling of dynamic positron emission tomography (PET) can produce parametric images characterizing tracer uptake rates, useful in studying a wide variety of physiological functions such as metabolism and receptor pharmacology. Parametric images are typically obtained from dynamic PET data by reconstructing images at multiple time frames, then fitting a kinetic model to each voxel time activity curve (TAC). Often, due to high voxel noise, multiple methods are used to reduce voxel noise in order to produce parametric images with acceptable noise levels [1–4]. An alternative method, “direct reconstruction,” produces parametric images directly from raw data by incorporating the kinetic model into the reconstruction algorithm. Because the image-domain noise distribution is difficult to model, direct reconstruction, using the Poisson model, can achieve lower-variance parameter estimates than the indirect method. Direct reconstruction has been the focus of much recent attention, as computational power has grown to support this large estimation problem; please see recent reviews [5–8].
Motion correction is critical for dynamic brain PET of awake subjects [9, 10]. However, there are very few examples in the literature for which direct reconstruction of brain data has included motion correction. Gravel et al. [11] presented a method for correcting inter-frame motion in direct reconstruction, and evaluated their method in simulated data but not in real data. Jiao et al. [12] also developed a direct reconstruction algorithm to estimate inter-frame motion and kinetic parameters simultaneously from PET sinogram data. Neither of these methods addresses intra-frame motion or takes advantage of measurements from an external motion tracking device, which can be made accurately with high temporal resolution [9]. The work of Jin et al. [10] suggests that, while frame-based motion correction is sufficient for small intra-frame motions (< 5 mm), event-by-event motion correction has universally good performance.
Most published demonstrations of direct reconstruction use sinogram data (e.g., [13–15]), but list mode data is better suited for event-by-event motion correction since continuous motion information can be used [10]. When using list mode data, exact computation of the sensitivity image – the sum of the system matrix, including attenuation and normalization, over all possible lines-of-response (LOR) – is difficult since the locations of the lines-of-response are continuously changing with motion. For the sake of computational feasibility, approximations must be made, particularly when correcting for motion [16, 17]. In this work, we extend the Parametric Motion-compensation OSEM List-mode Algorithm for Resolution-recovery reconstruction for the one-tissue model (PMOLAR-1T) [18–20] to include event-by-event motion for direct reconstruction; this requires a modified approach for estimating the sensitivity image. In the previous initial evaluation of PMOLAR-1T on human data, this effect was ignored for simplicity.
The magnitude by which direct reconstruction outperforms the indirect method will depend on, among other factors, the kinetics of the PET tracer, noise level, kinetic model, and kinetic parameter of interest (see Figure 11 in [8]). Here, we evaluate the performance of this algorithm for two tracers whose kinetics can be modeled with the1-tissue compartment (1T) model, [11C]AFM and [11C]UCB-J. [11C]AFM [21] targets the serotonin (5HT) transporter protein (SERT) and has been applied to the study of psychiatric disorders such as depression and post-traumatic stress disorder. [11C]UCB-J is a new tracer targeting the synaptic vesicle glycoprotein 2A [22] and can be used to measure synaptic density, relevant to a wide range of diseases including epilepsy and Alzheimer’s disease. We quantify the benefit of direct reconstruction, as compared to the indirect method, for each tracer, over a range of count levels. Here we take advantage of list-mode data, which permits the generation of lower-count noise realizations by selectively retaining varying fractions of the events during reconstruction.
2. Methods
2.1 Algorithm
2.1.1 Emission Image Reconstruction
For the indirect approach, an emission image for each frame of the dynamic PET data is independently reconstructed. The list mode EM update equation [23, 24] for the activity λ of each voxel j for a frame f of duration T as implemented in MOLAR [16, 25] is:
| (1) |
where variable definitions are given in Table 1; note that the list mode event index k maps to a particular LOR i and time t within frame f. The terms ckj and Ak are time-dependent to account for motion: each event’s LOR is transformed according to the measured motion at corresponding time index t. Each voxel of the global sensitivity image
| (2) |
is pre-computed using a large number of random LORs as described in [16, 25].
Table 1.
Variable definitions.
| Variable | Unit | Description | |
|---|---|---|---|
| Ait | – | Attenuation along LOR I at time index t | |
| cijt | mm | Contribution of voxel j to LOR i at time index t (includes geometry, resolution, solid angle, and motion effects) | |
| Δt | s | Duration of each time bin (for direct reconstruction; time interval for discretization of the kinetic model, which can theoretically be as small as 1 ms, the timing resolution of the list mode file) | |
| f | – | Frame index (for indirect reconstruction) | |
| G | – | Number of k2 values used to compute sensitivity images with motion correction (Eqs. 16 and 17) | |
| i | – | LOR index | |
| j | – | Voxel index | |
| k | – | List mode event index | |
| K1,j | mL/min/cm3 | Inflow rate constant of 1T model at voxel j | |
| k2,j | 1/min | Outflow rate constant of 1T model at voxel j | |
| Lt | – | Decay factor | |
| λj | Bq/mL | Value of emission image at voxel j | |
|
|
counts | Conditional expectation of complete data at iteration n | |
| n | – | Iteration number | |
| Ni | (counts/s)/(Bq/mL·mm) | Normalization factor for LOR i (in terms of absolute sensitivity) | |
| Pτ | Bq/mL | Value of input function to 1T model at time index τ | |
| Qj | (counts/s)/(Bq/mL) | Sensitivity of voxel j | |
| Rit | counts/s | Randoms rate for LOR i at time index t | |
| Sit | counts/s | Scatter rate for LOR i at time index t | |
| t | – | Time bin index, relative to injection time | |
| T | s | Duration of an emission time frame (for indirect reconstruction) | |
| τ | – | Time bin index of tracer delivery (for discretization of convolution integral) | |
| Xijtτ | counts | Random variable representing counts detected on LOR i at time t, emitted from voxel j for tracer delivered at time index τ (xijtτ denotes a realization of this random variable) | |
| ξijtτ | 1/s | Rate parameter of the Poisson distribution of Xijtτ | |
| Yit | counts | Random variable representing counts detected on LOR i at time index t (yit denotes a realization of this random variable) |
2.1.2 Direct Parametric Reconstruction
The 1T compartment model describing tissue activity concentration CT(t), parameterized by influx and efflux rate constants K1 and k2, is
| (3) |
where CA(t) is the arterial input function (the time-varying tracer concentration in the plasma) and ⊗ is the convolution operator with integration beginning at t=0. The underlying kinetic model, i.e., the emission time course, is not represented as truly continuous, but rather per time epoch Δt. While Δt can be as small as the list mode resolution (1 ms), in this work we set Δt = 6s, which is more than sufficient for normal rates of tracer kinetics based on sampled input functions. PMOLAR-1T (previously described in [20] and reviewed here) is a direct reconstruction algorithm based on expectation maximization (EM), in which update equations are analytically derived for the 1T model. For mathematical clarity, we present the equations for sinogram-based reconstruction, which can be generalized to list mode (the results in this manuscript were generated by the list mode approach). The adaptation to list mode is most simply achieved by directly processing the list mode data of each time bin, where each event index k maps to a particular LOR i and time t, and the count yit=1. The EM complete data space is given by the random emissions detected along LOR i from voxel j at time index t, from tracer input delivered at time τ. Note that for list mode reconstruction, t has the time resolution of the list mode data (1 ms). This random variable Xijtτ describing the EM complete data space is assumed to be Poisson distributed
| (4) |
with rate parameter
| (5) |
(Refer to Table 1 for all variable definitions.) This complete data space decomposes the total counts along LOR i into its spatial components (as in the static EM algorithm) and into its temporal components (based on the convolution equation). The complete-data log likelihood for this Poisson random variable (omitting constant terms) is given by
| (6) |
and the expectation of the complete data at iteration n, including randoms rate Rit and scatter rate Sit, is
| (7) |
The EM surrogate function is the conditional expectation of the kinetic parameters in each voxel, given their current estimates:
| (8) |
The update equation for K1 is found by maximizing the right-hand side of (8) with respect to K1, which gives:
| (9) |
To find the update equation for k2, the partial derivative of (8) with respect to k2 is set to 0 to obtain the intermediate result:
| (10) |
Substituting the result for K1,j from (9) into (10) yields the following:
| (11) |
Here, we define a function H(k2) as the right-hand side of (11):
| (12) |
Because the left-hand side of (11) is dependent only on the data and current parameter estimates, the update equation for k2 is:
| (13) |
As done previously [20], in the absence of motion, cijt and Ait are independent of time, so the update equation for K1 (9) can be simplified to:
| (14) |
and H(k2) (12) can be simplified to:
| (15) |
The terms and can be pre-computed at a set of k2 values for computational efficiency (with the approximation of ignoring time-varying live time correction). Note that H(k2,j) is a monotonically decreasing function; refer to Appendix A in the Supplemental File for the proof.
Here, we have extended the implementation to include motion. Specifically, when there is motion, the sums and from (9) and (12) are not factorable into a sensitivity term Qj and a kinetic model term which is a function of k2. Therefore, we incorporated the kinetic model term into the sensitivity image to produce a “kinetic-sensitivity image” by computing the denominator and numerator terms:
| (16) |
and
| (17) |
at a set of G coarsely sampled k2 values (where subscript g denotes the index into this set), to get two sets of kinetic sensitivity images. This results in a spatially variant :
| (18) |
The Q′ and Q″ images are pre-computed for G k2 values; then is computed for these G k2 values (see Supplementary figure S13), and a linear interpolation between the two values of nearest to is used to solve the following update equation:
| (19) |
The inverse of H′ is implemented as piecewise linear between each pair of k2,g values. In principle, higher order interpolation could be used, but for this application, linear interpolation is likely sufficient (H′(k2) is well approximated by piecewise linear functions for the k2 spacing we selected). See Supplemental Figure S13, which gives an example of H′(k2) for a representative voxel.
The K1 update equation in the presence of motion is then
| (20) |
where again interpolation within the table of G k2 values is used to find Q′ at the current k2 estimate.
2.2 Data Simulation
A 4D simulation (3D + kinetics) was performed to validate the updated equations, specifically the inclusion of the kinetic term in the sensitivity image, in the presence of motion, and to characterize bias in parametric images generated by the indirect and direct methods. Note that nonlinear parameter estimation methods can produce bias simply due to noise. A list mode file was simulated for a 2-hour scan based on [11C]AFM kinetics and the HRRT scanner geometry. Template parametric K1 and k2 images were generated by intensity-based segmentation of parametric images from a real human [11C]AFM scan. These parametric images were used in conjunction with an input function from a human acquisition to calculate the activity image at 6-second intervals, according to the 1T model.
At each timestamp (in ms intervals), a random sampling of LORs was forward projected through the ground truth activity image. This forward projection step yielded an expected value for the counts of each LOR, consistent with the spatial and temporal distribution of activity. Since the LORs are undersampled, an adjustment must be made to the expected value. First, note that a Poisson random variable compounded with a Bernoulli random variable (i.e. an undersampling operator) results in another Poisson random variable. Thus, since the LOR selection process can be approximated as a Poisson random variable, a Bernoulli variate was then produced for each random LOR. The probability parameter of each Bernoulli distribution was specified by the expected value of the counts along that LOR, scaled by the LOR undersampling rate. To improve efficiency, LORs were grouped by similar expected values (approximated from a coarse forward projection of the activity image at regular time intervals), and non-uniformly sampled such that groups with higher expected values were sampled more heavily. LOR sampling rates were set high enough such that the Bernoulli parameter never exceeded 1. Thus, the LOR sampling process varied in space and time to capture the tracer kinetics as well as motion, which was simulated based on Vicra measurements from a real human acquisition, and applied event-by-event. A more detailed description of the simulation methodology can be found in Appendix B presented in the Supplemental file. Randoms and scatter modeling were not included. Attenuation inside the brain was assumed to be uniform. The simulated list mode file contained 837 million true events, which was then downsampled to 5, 10, and 20% count levels as described below for the human datasets.
2.3 Human Data Acquisition
This study is a retrospective analysis of previously acquired datasets of two healthy male subjects, one using tracer [11C]AFM and the other with [11C]UCB-J (see Table 2). Both PET scans were acquired on the high-resolution research tomograph (HRRT) (Siemens Medical Solutions, Knoxville, TN, USA). Transmission scans were acquired for attenuation correction. Input functions were obtained by arterial blood sampling at the radial artery, continuously collected for the first 7 minutes of the PET acquisition at 4 mL/min (PBS-101, Veenstra Instruments, Joure, The Netherlands). Fifteen manual samples were collected over the remainder of the acquisition. Corrections were made for metabolites, decay, dispersion, and delay. The Polaris Vicra tracking system (NDI Systems, Waterloo, Ontario, Canada) [26] was used to measure rigid motion of the head throughout each scan at a frequency of ~30 Hz. These measurements formed a priori knowledge of the motion field, which were provided as input to the reconstruction algorithm as previously described [10, 25]. During reconstruction (both indirect and direct methods), the endpoints of each line of response are corrected according to the most recent measurement from the external tracking device.”
Table 2.
Summary of human acquisitions.
| Subject 1 | Subject 2 | |
|---|---|---|
| Tracer | [11C]AFM | [11C]UCB-J |
| Dose (MBq) | 832 | 650 |
| Scan Duration (h) | 2 | 2 |
| Counts (×109) | 1.2 | 2.3 |
Each list mode file was down-sampled to 5, 10, and 20% of the total counts by applying a repeating sequence of 50 ms gates for the 2-hour scan duration. Respectively, each 20th, 10th, or 5th gate was kept per replicate. Five replicates were reconstructed for each case, as well as the original (full count) datasets.
Reconstruction and Kinetic Modeling
For the indirect method, each frame was initialized to the 1T model evaluated at the frame midpoint with k2=0.02 min−1, K1=0.5 mL/min/cm3. For the direct method, reconstruction initial conditions were set to k2=0.02 min−1, K1=0.5 mL/min/cm3. Both methods used 4 iterations of 20 subsets. Events were sequentially assigned to subsets in the order read in from the list mode file.
To estimate Q or Q′ and Q″ (Eq. 2 for indirect; Eq. 16 and 17 for direct) sensitivity images, random LORs were selected. The number of random LORs was chosen in proportion to the number of events included in the reconstruction (e.g., such that the 10% count level reconstructions used half the number of random LORs for Q estimation as the 20% count level reconstructions). This approach, to scale the number of random LORs based on the number of actual events in the reconstruction, has been shown to balance the amount of noise added by the random Q process vs. computation time. For each real event in the list mode file, a random LOR was chosen, to achieve time-varying sampling according to count rate. To verify that this approach was appropriate, for the [11C]AFM dataset only, the 10% count level datasets were additionally reconstructed with Q generated using double the number of random LORs as list mode events, and the 5% count level datasets with quadruple the number of random LORs (i.e., the same number of random LORs as used in the 20% count level reconstructions). These reconstructions were used to evaluate the impact of the number of LORs used to estimate the sensitivity image on the noise of the parametric images.
For the direct method, Q′ and Q″ (Eqs. 16 and 17) were computed for 12 k2 values distributed linearly between 0.0001 min−1 and 0.078 min−1.
Randoms were estimated based on time-varying block singles rates. Scatter was estimated across coarsely sampled detector space at 10 time points using the single-scatter simulation (SSS) method [27], and iteratively updated at subsets 0, 4, and 10 of the first iteration. Global scatter scale factors for each time point were determined as the ratio between scatter measured outside the attenuation volume and calculated scatter estimate. To determine the scatter estimate for each event, linear interpolation among the 10 estimated timepoints was used [18, 19].
For each down-sampled replicate, dynamic PET sequences of 17 temporal frames (4×30s, 1×1min, 2×2min, 2×5min, 1×7min, 3×10min, 3×15min, 1×20min) beginning one minute after scan start were reconstructed using MOLAR [16], for the indirect method. Post-reconstruction of each iteration of 20 subsets, the 1T model was fit to each voxel using the basis function method [28, 29] with weights based on noise-equivalent counts. The minimal and maximal allowed values of k2 were 0.0001 min−1 and 0.078 min−1, respectively. In previous analyses of these tracers with a more lenient maximum k2 (1.0), fewer than 0.1% of voxels exceeded the maximum set here.
2.4 Quantitative Analysis
The parameters of interest in this study were K1 and volume of distribution, VT=K1/k2, which contains the receptor-related information [30]. Quantitative metrics were summarized regionally, for 8 regions (amygdala, caudate, cerebellum, frontal lobe, hippocampus, occipital lobe, putamen, and thalamus) from the automated anatomical labeling (AAL) template [31] in the Montreal Neurological Institute (MNI) space, which was transformed to the PET space independently for each subject based on co-registered MR images. Regions were eroded by one voxel, and all regions besides the subcortical regions (caudate, putamen, and thalamus) were masked to include only voxels corresponding to gray matter, as determined from the co-registered MRI. For simulated data, percent bias in K1 and VT with respect to the true values was calculated per voxel from the average of the 5 replicates, per count level. Mean parametric images were generated by averaging replicates for each count level, which was followed by averaging within region of interest. Voxelwise coefficient of variation (CoV) for VT could not be reliably estimated using the mean and standard deviations across 5 replicates, due in part to large outliers. Instead, the voxelwise covariance matrix of K1 and k2 was estimated across replicates per count level, and voxelwise VT CoV was estimated by propagation of uncertainty, using the full-count images from direct reconstruction (due to high bias in lower count and indirect images) for the mean voxelwise values of K1 and k2:
| (17) |
where σ1 is the K1 standard deviation, σ2 is the k2 standard deviation, and σ1,2 is the covariance of K1 and k2. Standard deviation images were calculated as standard deviation across 5 replicates, per voxel. The covariance images were computed across 5 replicates, using a 3×3×3 neighborhood at each voxel (for a total of 135 values contributing to the covariance estimate at each voxel). To quantify the advantage of the direct method over the indirect method, we computed the percent reduction in regional VT CoV from indirect to direct, at matched iteration and count level:
| (18) |
3. Results
Changes in regional K1 and k2 means over the final two iterations at the 100% count level for both the indirect and direct methods were small (−1.9±1.5%, see Supplemental Tables S1 and S2); accordingly, whenever results are not shown for all iterations, they are summarized at iteration 2. Most results are presented for a single representative brain region (frontal lobe), with additional regions presented in the Supplemental Data.
3.1 Simulated Data
Simulated and reconstructed images are shown in Fig. 1. The K1 image shows differences based on higher and lower blood flow in gray matter and white matter, respectively. The VT image shows the distribution of serotonin transporter binding which is lowest in the cerebellum and highest in subcortical and midbrain regions.
Figure 1.
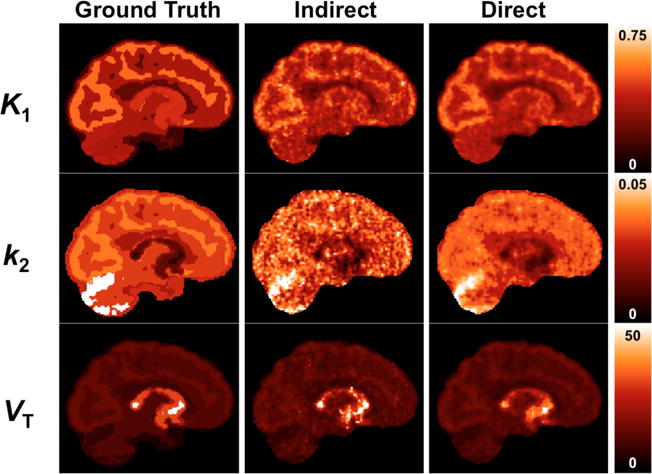
Simulated parametric images. First column shows true images. Second and third columns show reconstructed parametric images by the indirect and direct methods, respectively, at Iteration 2 (20 subsets). These results use the full list mode file (100%-count level). No smoothing has been applied. For a comparison with and without motion correction, see Supplemental Figure S1.
At the full count level, K1 and VT images (Fig. 1) are qualitatively similar between the direct and indirect methods, though indirect had slightly higher noise. The k2 image has notable differences in texture between indirect and direct, with the indirect k2 image showing much higher variability. At iteration 2, the mean regional biases of K1 and VT in the frontal lobe for the full-count dataset were <1% for both the indirect and direct methods (Tables 3 and 4). Bias tended to increase with iteration, particularly for the indirect method. Several small regions (amygdala, caudate, putamen) exhibited significant bias in VT even for the full-count dataset, by the indirect method but not the direct method (Supplemental Tables S3–S5).
Table 3.
Mean bias of K1 in the frontal cortex for the simulated dataset, per count level and iteration, for direct and indirect methods.
| Iter 1 | Iter 2 | Iter 3 | Iter 4 | ||
|---|---|---|---|---|---|
| 100% Counts | Indirect | −0.7 | 0.4 | 1.1 | 1.7 |
| Direct | −1.6 | −0.6 | −0.1 | 0.1 | |
|
| |||||
| 20% Counts | Indirect | 0.6 | 3.2 | 4.8 | 5.9 |
| Direct | −1.4 | −0.03 | 0.6 | 1.0 | |
|
| |||||
| 10% Counts | Indirect | 2.3 | 5.3 | 7.1 | 8.6 |
| Direct | −1.2 | 0.4 | 1.3 | 1.9 | |
|
| |||||
| 5% Counts | Indirect | 4.0 | 7.4 | 9.9 | 12 |
| Direct | −1.4 | 1.0 | 2.6 | 3.5 | |
Table 4.
Mean bias of VT in the frontal cortex for the simulated dataset, per count level and iteration, for direct and indirect methods.
| Iter 1 | Iter 2 | Iter 3 | Iter 4 | ||
|---|---|---|---|---|---|
| 100% Counts | Indirect | −0.3 | 0.8 | 3.2 | 10 |
| Direct | −0.4 | 0.2 | 0.5 | 0.6 | |
|
| |||||
| 20% Counts | Indirect | 5.2 | 116 | 327 | 554 |
| Direct | −0.3 | 0.5 | 1.3 | 2.1 | |
|
| |||||
| 10% Counts | Indirect | 49 | 420 | 779 | 1072 |
| Direct | −0.2 | 1.2 | 4.1 | 7.9 | |
|
| |||||
| 5% Counts | Indirect | 322 | 996 | 1446 | 1740 |
| Direct | 2.0 | 35 | 157 | 261 | |
Across all count levels, bias in frontal lobe K1 was relatively low by both methods across iterations (Table 3): even at iteration 4 at the 5% count level the bias from the indirect method was only 12%. Some other regions showed greater bias in K1 at low counts, even at iteration 2 (Supplemental Table S3).
Results were different for VT (K1/k2). At the subsampled count levels, extreme outliers cause large positive bias in VT images generated by the indirect method, which worsen with increasing iteration and decreasing count level (Fig. 2a, 3a; Table 4). These outliers are due to k2 values approaching the lower bound imposed in model fitting. At the 5% count level, the mean bias in VT in the frontal cortex is ~1000% by the indirect method at iteration 2, however the median VT bias is 15%, due to the asymmetric distribution of estimated values. Bias in VT is much better controlled by the direct method (Fig. 2b, Fig. 3b), and only the 5% count level has significant outliers (mean VT bias at iteration 2 is 35% and median is 4%). Mean and median VT bias for other regions are given in Supplemental Tables S4 and S5. The regions exhibiting greatest bias were primarily those with higher VT values (due to higher concentrations of transporter) and thus very low k2, where errors introduce large bias in VT.
Figure 2.
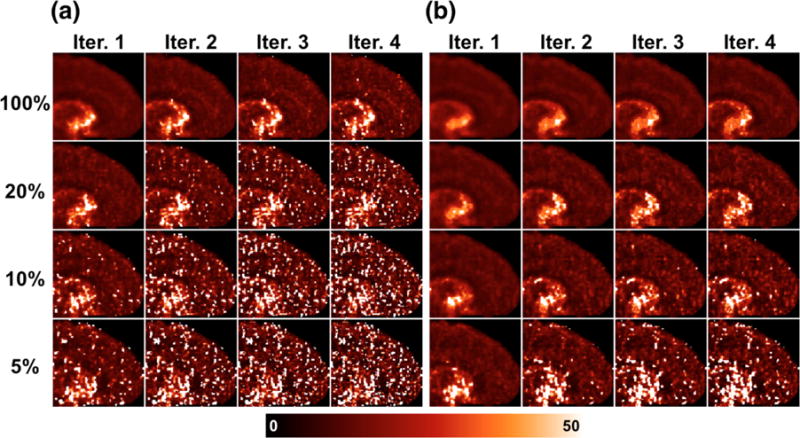
VT parametric maps of one replicate of simulated [11C]AFM dataset per count level (rows), across 4 iterations (columns). (a) Generated by the indirect method. (b) Generated by the direct method.
Figure 3.
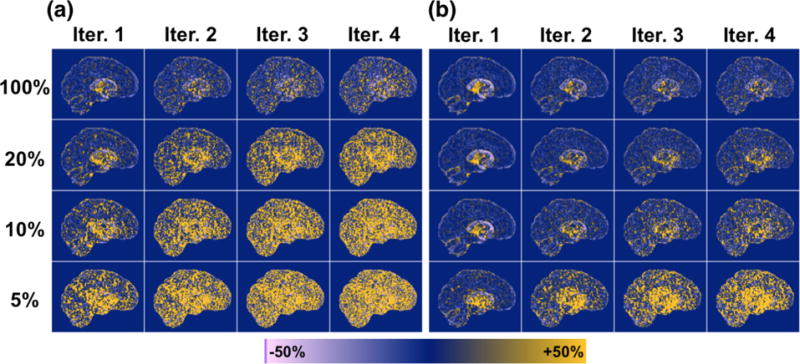
Voxelwise percent bias in VT parametric images, computed from average across 5 replicates of simulated data (except for the 100% count level, which used 1 replicate), per count level (rows) and iteration (columns). (a) Generated by the indirect method. (b) Generated by the direct method.
Fig. 4a shows the regional CoV values for VT in the frontal lobe. Direct reconstruction shows much lower noise than the indirect method. For example, at iteration 2, VT CoV is lower for the 5% count level by direct reconstruction (21%) than that with quadruple the counts by the indirect method (25%) (Fig. 4a). At iteration 2, the percent reduction in regional VT CoV (in the frontal cortex) afforded by direct reconstruction compared to indirect is similar across count levels, ranging from 59% to 64% (Fig. 4b). Percent reduction in VT CoV was similar for other regions, 51–58% (averaged separately per count level, across regions). Percent reduction in K1 CoV was smaller, 35–48% averaged across regions.
Figure 4.
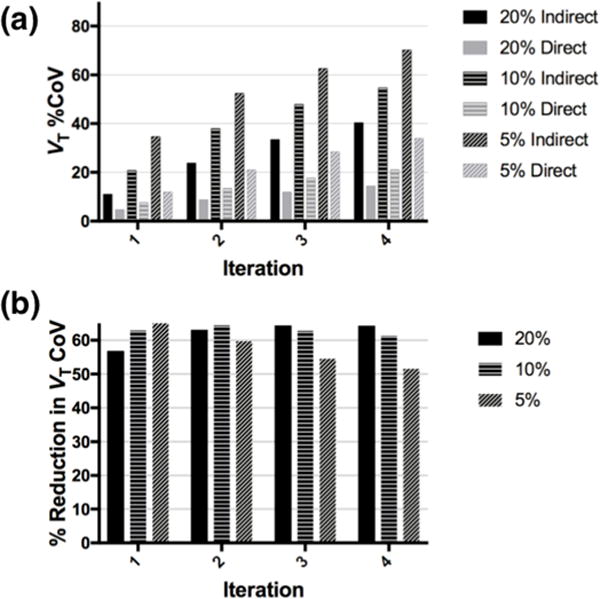
(a) Regional VT %CoV (in the frontal cortex) by iteration and count level for the indirect and direct methods, for the simulated dataset. (b) Percent reduction in regional VT CoV of the direct method relative to the indirect method, by iteration and count level, for the simulated dataset.
3.2 Human Data
To demonstrate the importance of motion correction, one replicate at the 20% count level for each dataset was reconstructed by the direct method, both with and without motion correction (Fig. 5). Motion magnitude over the 2-hour scan duration was summarized quantitatively according to Equation 3 in [10] for each dataset; the average motion was 2.86 mm for the [11C]AFM dataset and 20.1 mm for the [11C]UCB-J dataset. The large motion for the [11C]UCB-J dataset is primarily due to a shift that occurred in the 56th minute. Only subtle differences are present between the corrected and uncorrected images for the [11C]AFM dataset, consistent with the relatively small motion in this acquisition (Fig. 5a). The average VT in the frontal cortex at iteration 2 is 14.6 mL/cm3 without motion correction, and 15.9 mL/cm3 with motion correction. Motion correction had a more pronounced effect on the [11C]UCB-J parametric images when correction was not applied (Fig. 5b). A large vertical shift is evident in the k2 image, which was more greatly impacted by motion than the K1 image. When left uncorrected, the motion in the [11C]UCB-J study results in severe artifacts and widespread elevation in k2, which in turn lowers VT: at iteration 2, the average VT in the frontal lobe is 15.2 mL/cm3 without motion correction, and 25.5 mL/cm3 with motion correction. See Supplemental Table S6 and S7 for other regional values for K1, k2, and VT with and without motion correction.
Figure 5.
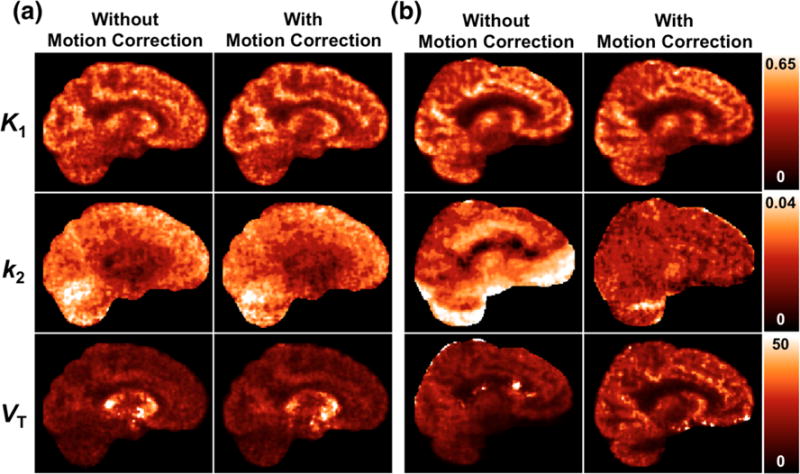
Parametric images generated via direct reconstruction, without and with motion correction. Results are shown at iteration 2, for one replicate at the 20% count level. (a) [11C]AFM dataset (b) [11C]UCB-J dataset
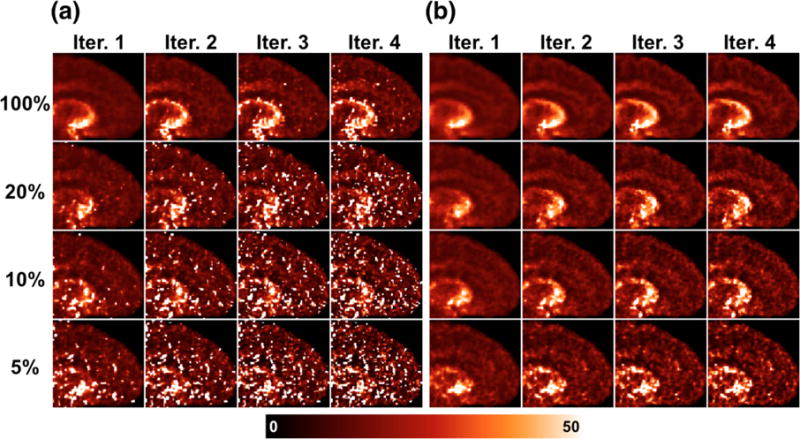
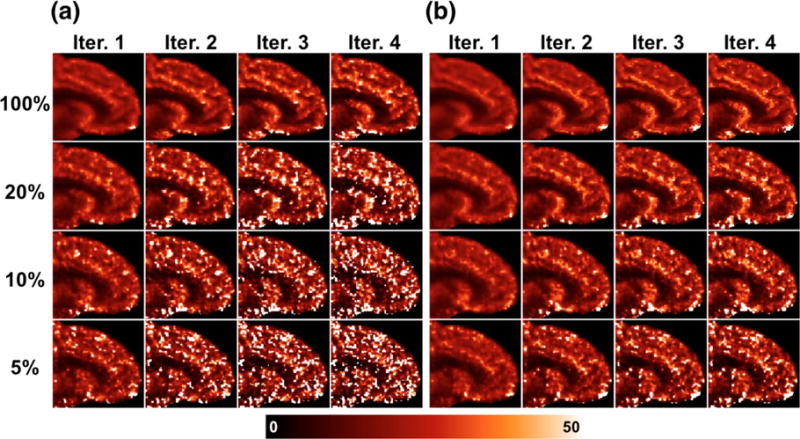
Parametric VT images of single replicates of the [11C]AFM and [11C]UCB-J datasets are shown, respectively in Figures 6 and 7, at each count level and iteration. See Supplemental Figures S2–S5 for K1 and k2 parametric images of each tracer. K1 images are similar between the [11C]AFM and [11C]UCB-J datasets, as they both reflect cerebral blood flow. The k2 image is more uniform across the brain in [11C]UCB-J due to uniformity of binding to synaptic vesicles in gray matter.
Figure 6.
VT parametric maps of one replicate of human [11C]AFM dataset per count level (rows), across 4 iterations (columns). (a) Generated by the indirect method. (b) Generated by the direct method.
Figure 7.
VT parametric maps of one replicate of human [11C]UCB-J dataset per count level (rows), across 4 iterations (columns). (a) Generated by the indirect method. (b) Generated by the direct method.
Full-count images by both methods are mostly free of outliers. Predictably, noise becomes systematically worse with increasing iteration and decreasing count level, and is always higher for the indirect method than the direct method at matched count level and iteration. For both tracers, the noise advantage of the direct method over the indirect method is more visibly apparent in the k2 images than K1.
Mean regional K1 and VT values at iteration 2 for the frontal lobe (averaged across replicates and within region) for the 2 tracers are given in Tables 5 and 6; see Supplemental Tables S8–S11 for other regions. In both datasets, mean K1 values are similar between direct and indirect methods across all count levels, with only slightly greater differences between direct and indirect K1 at the 5% count level compared to the 100% count level. This is consistent with the simulation study, for which bias in K1 was low in all regions for both methods, increasing modestly with decreasing count level for the indirect method (Supplemental Table S3). However, mean VT values are similar between direct and indirect only for the full-count reconstructions. The mean VT is stable across count level for the direct method, with a slight increase at the lowest count levels for [11C-]UCB-J. Mean VT estimated by the indirect method becomes larger with decreasing count level, as a result of noise-induced bias: higher variance in k2 produces more k2 values approaching the lower bound for k2, and thus much higher VT values. Median VT values are less biased since they are less affected by these outliers.
Table 5.
Summary of regional K1 and VT values from [11C]AFM dataset in the frontal lobe at iteration 2 for each count level. Mean and median are computed within region from the mean image across replicates.
| [11C]AFM K1 | [11C]AFM VT | ||||||
|---|---|---|---|---|---|---|---|
|
| |||||||
| Mean | Median | %CoV | Mean | Median | %CoV | ||
| 100% Counts | Indirect | 0.45 | 0.45 | – | 14.8 | 14.5 | – |
| Direct | 0.44 | 0.44 | – | 15.9 | 15.6 | – | |
|
| |||||||
| 20% Counts | Indirect | 0.46 | 0.46 | 17 | 26.1 | 15.0 | 19 |
| Direct | 0.44 | 0.44 | 9 | 15.9 | 15.6 | 10 | |
|
| |||||||
| 10% Counts | Indirect | 0.47 | 0.46 | 24 | 62.5 | 15.6 | 33 |
| Direct | 0.45 | 0.44 | 13 | 16.0 | 15.7 | 14 | |
|
| |||||||
| 5% Counts | Indirect | 0.48 | 0.47 | 32 | 125 | 16.3 | 49 |
| Direct | 0.45 | 0.45 | 18 | 16.1 | 15.8 | 21 | |
Table 6.
Summary of regional K1 and VT values from [11C]UCB-J dataset in the frontal lobe at iteration 2 for each count level. Mean and median are computed within region from the mean image across replicates.
| [11C]UCB-J K1 | [11C]UCB-J VT | ||||||
|---|---|---|---|---|---|---|---|
|
| |||||||
| Mean | Median | %CoV | Mean | Median | %CoV | ||
| 100% Counts | Indirect | 0.43 | 0.43 | – | 25.4 | 25.0 | – |
| Direct | 0.43 | 0.43 | – | 25.0 | 24.7 | – | |
|
| |||||||
| 20% Counts | Indirect | 0.43 | 0.44 | 11 | 30.5 | 25.8 | 17 |
| Direct | 0.43 | 0.43 | 7 | 25.9 | 25.2 | 12 | |
|
| |||||||
| 10% Counts | Indirect | 0.44 | 0.44 | 16 | 54.3 | 26.6 | 27 |
| Direct | 0.43 | 0.43 | 10 | 26.7 | 25.3 | 17 | |
|
| |||||||
| 5% Counts | Indirect | 0.45 | 0.45 | 23 | 120 | 28.4 | 44 |
| Direct | 0.43 | 0.43 | 15 | 30.6 | 25.8 | 23 | |
Qualitative image assessments of noise from Figs. 6 and 7 show clear noise advantage of the direct method; this assessment is supported by the regional estimates of VT %CoV (across replicates) in the frontal lobe (Figs. 8a and 8b). K1 %CoV was lower than VT %CoV, but followed the same trends (Supplemental Figure S6a and b). VT %CoV was relatively uniform throughout most of the brain (see Supplemental Figures S7 and S8 for VT CoV images of each tracer across count levels and iterations), although subcortical VT %CoV appeared to be higher (since VT values there are higher). For [11C]AFM, the direct method at the 5% count level has similar regional VT CoV in the frontal lobe at iteration 2 (21%) as the indirect method at the 20% count level (19%), i.e., with quadruple the counts (Fig. 8a). This agreed well with the simulation results, for which the direct method gave VT CoV of 21% at the 5% count level and the indirect method gave VT CoV of 24% at the 20% count level. For [11C]UCB-J (Fig. 8b), the direct method gives similar regional VT CoV at iteration 2 (23% for the 5% count level, 17% for the 10% count level) as the indirect method does with double the counts (27% for the 10% count level, 17% for the 20% count level).
Figure 8.
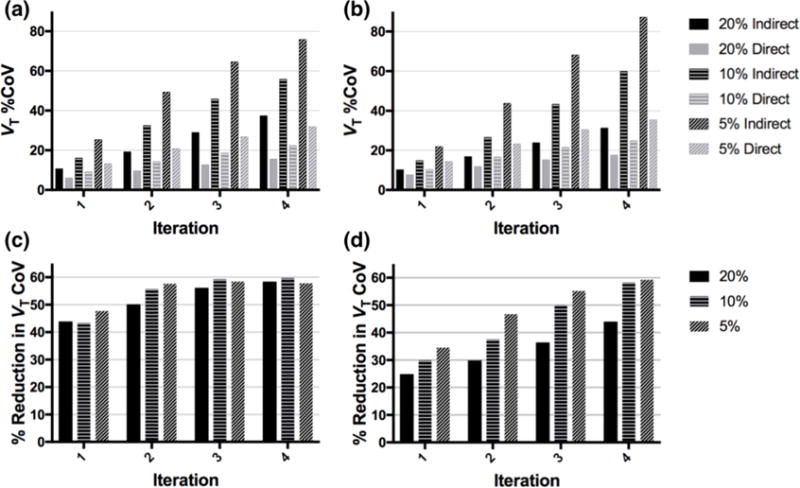
(a,b) Regional VT %CoV (in the frontal cortex) by iteration and count level for the indirect and direct methods, for (a) [11C]AFM and (b) [11C]UCB-J. (c,d) Percent reduction in regional VT CoV of the direct method relative to the indirect method, by iteration and count level, for (c) [11C]AFM and (d) [11C]UCB-J.
For the [11C]AFM dataset, the advantage of direct reconstruction in terms of regional VT CoV reduction, compared to the indirect method, is similar across count levels, for matched iteration (Fig 8c). In the [11C]UCB-J dataset, the advantage of direct reconstruction is consistently greatest for the lowest count level, across all iterations (Fig 8d). The reduction in K1 CoV of direct reconstruction compared to the indirect method followed similar trends (Supplemental Figure S6c,d). At iteration 2, the percent reduction in regional K1 CoV in the frontal lobe between direct and indirect was 43–46% for [11C]AFM and 30–36% for [11C]UCB-J; the percent reduction in regional VT CoV between direct and indirect ranged from 50% to 58% for [11C]AFM, and 30% to 47% for [11C]UCB-J. Similar results were obtained across other regions (Supplemental Figures S9 and S10).
4. Discussion
4.1 Summary
In this work, we demonstrate the application of direct reconstruction with event-by-event motion compensation to simulated and real brain PET data for two tracers with 1T kinetics, across multiple count levels. The primary outcome measure is distribution volume coefficient of variation, which is compared regionally between the direct and indirect methods. Both methods gave comparable regional estimates for K1 across all count levels. The direct method produced more stable estimates of VT across count levels. The direct method consistently gave parametric images with lower CoV than the indirect method.
4.2 Relative Advantage of Direct Reconstruction
While direct reconstruction yielded substantial improvements in CoV for both datasets, the benefit of direct over indirect was greater for the [11C]AFM dataset than for the [11C]UCB-J dataset. The [11C]UCB-J dataset had double the counts of the [11C]AFM dataset, which might contribute to the difference in performance. The weighted least squares fitting used in the indirect method assumes Gaussian noise in image space, which likely becomes a better approximation at higher counts, allowing the indirect method to achieve variance closer to the theoretical minimum.
The benefit of direct reconstruction over the indirect method in terms of parameter CoV, as determined in this study, falls within the range of those previously reported (e.g., see Figure 11 of [8]). However, a more thorough comparison of these results to those in the literature is difficult due to the dependence on tracer, model, parameter of interest, and count level, as well as the inclusion of other factors, such as randoms, scatter, and motion.
4.3 Motion
In previous work using PMOLAR-1T, as well as most other published studies on direct reconstruction, motion has been avoided or ignored. In our data, the parametric images from one of the two evaluated human datasets were not greatly affected by motion (9% increase in frontal lobe VT with motion correction, compared to uncorrected), while those from the second were more severely affected (68% increase in frontal lobe VT with motion correction, compared to uncorrected). Motion can have variable impact on parametric images, depending on motion magnitude, frequency, and time of occurrence. For instance, motion towards the end of an acquisition might be more likely to affect k2 than K1, because the early data has a larger impact on K1 estimation, and the later data have greater sensitivity to k2; this is consistent with the results from the [11C]UCB-J study, which had a large motion an hour into the scan.
4.4 Outlying VT Estimates
The primary outcome measure used here is VT (=K1/k2), a measure of total tracer binding to the target. Because VT is calculated as a ratio, it is prone to large outliers, and increasingly so at lower count levels. Note that in both indirect and direct methods, a fixed range for k2 is established in advance, thus, VT can be constrained by setting a relatively high lower bound for k2, which would result in more visually appealing images. The k2 images from direct reconstruction have much greater precision than those from the indirect method, so the distribution of k2 values did not extend as close to 0 as in the indirect method, despite sharing the same imposed lower bound on k2. Therefore, unlike the lower count indirect VT images, the direct VT images had very few outliers at any count level.
4.5 Stopping Iteration
To determine a stopping criterion for iterative reconstruction methods without regularization, it is common to estimate from simulations the iteration that, for instance, minimizes root-mean-square error, combining the effects of bias and noise. Such an approach was not viable for this application, because both CoV and regional bias in VT increased with each iteration, for all count levels and methods. Moreover, biases at full counts were extremely small at iterations 1 and 2, suggesting that convergence had been reached, at least for the ROIs examined here. Also, we used subsets for computational practicality, so we cannot assess convergence with much granularity. While in some places we have used iteration 2 results as a reasonable stopping point, we do not present any formal stopping criterion for this work.
4.6 Sampling for Sensitivity Image Estimation
In routine reconstructions of HRRT data with MOLAR, in order to properly model continuous motion, the sensitivity image (Eqs. 2, 16, and 17) is determined by sampling LORs, and it is standard practice to use the same number of LORs for estimating the sensitivity image as events in the list mode file, in order to balance noise vs. computation time. Increasing LOR sampling affected indirect and direct VT CoV equally. Iteration 2 regional VT CoV decreases by ~15% for both methods at the 5% count level when the number of sampled LORs is quadrupled; regional VT CoV decreases by 11% for both methods at the 10% count level when the number of sampled LORs is doubled (Supplemental Figure S11). Quadrupling (at the 5% count level) or doubling (at the 10% count level) the number of LORs sampled for estimation of the sensitivity image resulted in a ~20% decrease, in each case, in regional mean VT at iteration 2 for the indirect method, reflecting a reduction in the magnitude of outliers. For the direct method, which did not produce many outlying VT values, increasing the LOR sampling results in virtually no change in mean VT. While increasing the LOR sampling for sensitivity image estimation can indeed reduce noise, the effect is modest, and much smaller than that gained from using direct reconstruction over indirect for matched conditions.
4.7 Limitations
One shortcoming of this work is the limited number of replicates reconstructed per condition. Because replicates were obtained by downsampling real list mode files, we were restricted to 5 (independent) replicates for the 20% count level. At the lower count levels, the decision to use only 5 replicates was driven by considerations for computational burden. The same approach was taken by Gravel and Reader [32] in a similar work evaluating direct reconstruction of binding potential images for raclopride PET. With so few replicates, voxelwise estimates of standard deviation will tend to be biased downwards (sample variances will be unbiased). However, comparing results generated by either 5 or 15 replicates for the simulated data at the 5% count level, we find that regional averages of the voxelwise VT CoV estimates are not greatly affected by number of replicates (see Supplemental Fig. S12). At iteration 2, the VT CoV in the frontal lobe was 12% greater when estimated with 15 replicates versus 5 replicates for the indirect method, and 7% greater for the direct method. Moreover, the pattern of CoV with respect to count level or method was not affected by the small number of replicates.
Because the low count replicates in this study are sub-sampled from real list mode datasets, the randoms rates are still consistent with full count acquisitions. True low count acquisitions would be expected to have fewer random events. Therefore, this approach represents a conservative estimate of performance at low counts.
Inaccurate model specification can cause propagation of bias from regions where the model does not fit, to regions where it should, when parametric images are generated by direct reconstruction [33]. The 1T model has been validated for use in both [11C]AFM and [11C]UCB-J, though some lack of fit was observed for [11C]AFM in regions with relatively low binding [21]. If the regions with poor fits are indeed only those with low activity, the relative magnitude of the residuals due to lack of fit will also likely be low, and error propagation is expected to be minimal. For the full count datasets, there were no substantial differences in regional K1 and k2 values between the indirect and direct methods, suggesting that error propagation is unlikely to be significant.
The 1T compartment model is of course not suitable for modeling the kinetics of all tracers. In principle, the algorithm presented here can be easily extended to the two tissue compartment model by adding a dimension to the EM complete data space specifying compartment number (with an ordering constraint to enforce parameter identifiability), though convergence rate might suffer due to increased parameter correlations. This extension would be similar to what we have previously implemented for direct reconstruction of cardiac PET [34], for which two linear parameters were added to the 1T model to accommodate spillover from the right and left ventricles into myocardial tissue.
5. Conclusion
These results demonstrate the first use of event-by-event motion correction in the direct reconstruction of real PET data. The advantage of direct reconstruction over indirect was substantial at a given iteration and was similar or increased slightly with decreasing count level, as quantified by mean regional VT CoV. Additionally, the direct method was more robust to outliers even at extremely low count levels, where the indirect method suffers from noise-induced bias. The advantage of direct reconstruction is substantial enough to permit greatly reduced doses, compared to what would be required for similar quality parametric images generated by the indirect method.
Supplementary Material
Acknowledgments
This work was supported by NIH grants R01NS058360 from the National Institute of Neurological Disorders and Stroke and F31EB018720 from the National Institute of Biomedical Imaging and Bioengineering. This publication was made possible by CTSA Grant Number UL1 TR000142 from the National Center for Advancing Translational Science (NCATS), a component of the National Institutes of Health (NIH). Its contents are solely the responsibility of the authors and do not necessarily represent the official view of NIH.
References
- 1.Shidahara M, Ikoma Y, Kershaw J, Kimura Y, Naganawa M, Watabe H. PET kinetic analysis: wavelet denoising of dynamic PET data with application to parametric imaging. Annals of nuclear medicine. 2007;21:379–86. doi: 10.1007/s12149-007-0044-9. [DOI] [PubMed] [Google Scholar]
- 2.Floberg JM, Mistretta CA, Weichert JP, Hall LT, Holden JE, Christian BT. Improved kinetic analysis of dynamic PET data with optimized HYPR-LR. Medical physics. 2012;39:3319–31. doi: 10.1118/1.4718669. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Lu L, Karakatsanis NA, Tang J, Chen W, Rahmim A. 3.5 D dynamic PET image reconstruction incorporating kinetics-based clusters. Physics in medicine and biology. 2012;57:5035. doi: 10.1088/0031-9155/57/15/5035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Mohy-ud-Din H, Lodge MA, Rahmim A. Quantitative myocardial perfusion PET parametric imaging at the voxel-level. Physics in medicine and biology. 2015;60:6013. doi: 10.1088/0031-9155/60/15/6013. [DOI] [PubMed] [Google Scholar]
- 5.Tsoumpas C, Turkheimer FE, Thielemans K. A survey of approaches for direct parametric image reconstruction in emission tomography. Medical physics. 2008;35:9. doi: 10.1118/1.2966349. [DOI] [PubMed] [Google Scholar]
- 6.Rahmim A, Tang J, Zaidi H. Four-dimensional (4D) image reconstruction strategies in dynamic PET: Beyond conventional independent frame reconstruction. Med Phys. 2009;36:17. doi: 10.1118/1.3160108. [DOI] [PubMed] [Google Scholar]
- 7.Wang G, Qi J. Direct estimation of kinetic parametric images for dynamic PET. Theranostics. 2013;3:802–15. doi: 10.7150/thno.5130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Reader AJ, Verhaeghe J. 4D image reconstruction for emission tomography. Physics in medicine and biology. 2014;59:R371. doi: 10.1088/0031-9155/59/22/R371. [DOI] [PubMed] [Google Scholar]
- 9.Montgomery AJ, Thielemans K, Mehta MA, Turkheimer F, Mustafovic S, Grasby PM. Correction of head movement on PET studies: comparison of methods. Journal of Nuclear Medicine. 2006;47:1936–44. [PubMed] [Google Scholar]
- 10.Jin X, Mulnix T, Gallezot J-D, Carson RE. Evaluation of motion correction methods in human brain PET imaging—A simulation study based on human motion data. Medical physics. 2013;40:102503. doi: 10.1118/1.4819820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Gravel P, Verhaeghe J, Reader AJ. Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), 2012 IEEE. IEEE; 2012. Direct 4D PET reconstruction of parametric images into a stereotaxic brain atlas for [11 C] raclopride; pp. 3994–8. [Google Scholar]
- 12.Jiao J, Boss A, Thielemans K, Burgos N, Weston P, Markiewicz P, et al. Direct parametric reconstruction with joint motion estimation/correction for dynamic brain PET data. IEEE Transactions on Medical Imaging. 2016 doi: 10.1109/TMI.2016.2594150. [DOI] [PubMed] [Google Scholar]
- 13.Matthews J, Bailey D, Price P, Cunningham V. The direct calculation of parametric images from dynamic PET data using maximum-likelihood iterative reconstruction. Physics in medicine and biology. 1997;42:1155–73. doi: 10.1088/0031-9155/42/6/012. [DOI] [PubMed] [Google Scholar]
- 14.Kamasak ME, Bouman CA, Morris ED, Sauer K. Direct reconstruction of kinetic parameter images from dynamic PET data. Medical Imaging, IEEE Transactions on. 2005;24:636–50. doi: 10.1109/TMI.2005.845317. [DOI] [PubMed] [Google Scholar]
- 15.Wang G, Qi J. Biomedical Imaging: From Nano to Macro, 2008 ISBI 2008 5th IEEE International Symposium on. IEEE; 2008. Iterative nonlinear least squares algorithms for direct reconstruction of parametric images from dynamic PET; pp. 1031–4. [Google Scholar]
- 16.Johnson CA, Thada S, Rodriguez M, Zhao Y, Iano-Fletcher AR, Liow J-S, et al. Nuclear Science Symposium Conference Record, 2004 IEEE. IEEE; 2004. Software architecture of the MOLAR-HRRT reconstruction engine; pp. 3956–60. [Google Scholar]
- 17.Qi J. Calculation of the sensitivity image in list-mode reconstruction for PET. Nuclear Science, IEEE Transactions on. 2006;53:2746–51. [Google Scholar]
- 18.Yan J, Planeta-Wilson B, Gallezot J-D, Carson RE. Nuclear Science Symposium Conference Record (NSS/MIC), 2009 IEEE. IEEE; 2009. Initial evaluation of direct 4d parametric reconstruction with human pet data; pp. 2503–6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Yan J, Planeta-Wilson B, Gallezot J-D, Carson RE. Nuclear Science Symposium Conference Record (NSS/MIC), 2010 IEEE. IEEE; 2010. Evaluation of direct 4D parametric reconstruction with low count human PET data; pp. 2259–62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Yan J, Planeta-Wilson B, Carson RE. Direct 4-D PET list mode parametric reconstruction with a novel EM algorithm. Medical Imaging, IEEE Transactions on. 2012;31:2213–23. doi: 10.1109/TMI.2012.2212451. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Naganawa M, Nabulsi N, Planeta B, Gallezot J-D, Lin S-F, Najafzadeh S, et al. Tracer kinetic modeling of [ 11C] AFM, a new PET imaging agent for the serotonin transporter. Journal of Cerebral Blood Flow & Metabolism. 2013;33:1886–96. doi: 10.1038/jcbfm.2013.134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Finnema SJ, Nabulsi NB, Eid T, Detyniecki K, Lin S-F, Chen M-K, et al. Imaging synaptic density in the living human brain. Science Translational Medicine. 2016;8:348ra96–ra96. doi: 10.1126/scitranslmed.aaf6667. [DOI] [PubMed] [Google Scholar]
- 23.Shepp LA, Vardi Y. Maximum likelihood reconstruction for emission tomography. IEEE transactions on medical imaging. 1982;1:113–22. doi: 10.1109/TMI.1982.4307558. [DOI] [PubMed] [Google Scholar]
- 24.Lange K, Carson R. EM reconstruction algorithms for emission and transmission tomography. J Comput Assist Tomogr. 1984;8:306–16. [PubMed] [Google Scholar]
- 25.Carson RE, Barker WC, Liow J-S, Johnson CA. Nuclear Science Symposium Conference Record, 2003 IEEE. IEEE; 2003. Design of a motion-compensation OSEM list-mode algorithm for resolution-recovery reconstruction for the HRRT; pp. 3281–5. [Google Scholar]
- 26.Lopresti BJ, Russo A, Jones WF, Fisher T, Crouch DG, Altenburger D, et al. Implementation and performance of an optical motion tracking system for high resolution brain PET imaging. IEEE Transactions on Nuclear Science. 1999;46:2059–67. [Google Scholar]
- 27.Watson CC. New, faster, image-based scatter correction for 3D PET. Nuclear Science, IEEE Transactions on. 2000;47:1587–94. [Google Scholar]
- 28.Gunn RN, Lammertsma AA, Hume SP, Cunningham VJ. Parametric imaging of ligand-receptor binding in PET using a simplified reference region model. Neuroimage. 1997;6:279–87. doi: 10.1006/nimg.1997.0303. [DOI] [PubMed] [Google Scholar]
- 29.Lodge MA, Carson RE, Carrasquillo JA, Whatley M, Libutti SK, Bacharach SL. Parametric images of blood flow in oncology PET studies using [15O] water. Journal of Nuclear Medicine. 2000;41:1784–92. [PubMed] [Google Scholar]
- 30.Innis RB, Cunningham VJ, Delforge J, Fujita M, Gjedde A, Gunn RN, et al. Consensus nomenclature for in vivo imaging of reversibly binding radioligands. Journal of Cerebral Blood Flow & Metabolism. 2007;27:1533–9. doi: 10.1038/sj.jcbfm.9600493. [DOI] [PubMed] [Google Scholar]
- 31.Tzourio-Mazoyer N, Landeau B, Papathanassiou D, Crivello F, Etard O, Delcroix N, et al. Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage. 2002;15:273–89. doi: 10.1006/nimg.2001.0978. [DOI] [PubMed] [Google Scholar]
- 32.Gravel P, Reader AJ. Direct 4D PET MLEM reconstruction of parametric images using the simplified reference tissue model with the basis function method for [11C] raclopride. Physics in medicine and biology. 2015;60:4533. doi: 10.1088/0031-9155/60/11/4533. [DOI] [PubMed] [Google Scholar]
- 33.Kotasidis F, Matthews J, Angelis G, Markiewicz P, Lionheart W, Reader A. Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), 2011 IEEE. IEEE; 2011. Impact of erroneous kinetic model formulation in Direct 4D image reconstruction; pp. 2366–7. [Google Scholar]
- 34.Germino M, Sinusas AJ, Liu C, Carson RE. Direct EM reconstruction of kinetic parameters from list-mode cardiac PET. Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), 2014 IEEE. 2014 [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.