

Summary
Biological and social systems consist of myriad interacting units. The interactions can be represented in the form of a graph or network. Measurements of these graphs can reveal the underlying structure of these interactions, which provides insight into the systems that generated the graphs. Moreover, in applications such as connectomics, social networks, and genomics, graph data are accompanied by contextualizing measures on each node. We utilize these node covariates to help uncover latent communities in a graph, using a modification of spectral clustering. Statistical guarantees are provided under a joint mixture model that we call the node-contextualized stochastic blockmodel, including a bound on the misclustering rate. The bound is used to derive conditions for achieving perfect clustering. For most simulated cases, covariate-assisted spectral clustering yields results superior both to regularized spectral clustering without node covariates and to an adaptation of canonical correlation analysis. We apply our clustering method to large brain graphs derived from diffusion MRI data, using the node locations or neurological region membership as covariates. In both cases, covariate-assisted spectral clustering yields clusters that are easier to interpret neurologically.
Keywords: Brain graph, Laplacian, Network, Node attribute, Stochastic blockmodel
1. Introduction
Modern experimental techniques in areas such as genomics and brain imaging generate vast amounts of structured data, which contain information about the relationships of genes or brain regions. Studying these relationships is essential for solving challenging scientific problems, but few computationally feasible statistical techniques incorporate both the structure and diversity of these data.
A common approach to understanding the behaviour of a complex biological or social system is to first discover blocks of highly interconnected units, also known as communities or clusters, that serve or contribute to a common function. These might be genes that are involved in a common pathway or areas in the brain with a common neurological function. Typically, we only observe the pairwise relationships between the units, which can be represented by a graph or network. Analysing networks has become an important part of the social and biological sciences. Examples of such networks include gene regulatory networks, friendship networks, and brain graphs. If we can discover the underlying block structure of such graphs, we can gain insight from the common characteristics or functions of the units within a block.
Existing research has extensively studied the algorithmic and theoretical aspects of finding node clusters within a graph, by Bayesian, maximum likelihood, and spectral approaches. Unlike model-based methods, spectral clustering is a relaxation of a cost minimization problem and has been shown to be effective in various settings (Ng et al., 2002; Von Luxburg, 2007). Modifications of spectral clustering, such as regularized spectral clustering, are accurate even for sparse networks (Chaudhuri et al., 2012; Amini et al., 2013; Qin & Rohe, 2013). On the other hand, certain Bayesian methods offer additional flexibility in how nodes are assigned to blocks, allowing for a single node to belong to multiple blocks or a mixture of blocks (Nowicki & Snijders, 2001; Airoldi et al., 2008). Maximum likelihood approaches can enhance interpretability by embedding nodes in a latent social space and providing methods for quantifying statistical uncertainty (Hoff et al., 2002; Handcock et al., 2007; Amini et al., 2013). For large graphs, spectral clustering is one of very few computationally feasible methods that has an algorithmic guarantee for finding the globally optimal partition.
The structured data generated by modern technologies often contain additional measurements that can be represented as graph node attributes or covariates. For example, these could be personal profile information in a friendship network or the spatial location of a brain region in a brain graph. There are two potential advantages of utilizing node covariates in graph clustering. First, if the covariates and the graph have a common latent structure, then the node covariates provide additional information to help estimate this structure. Even if the covariates and the graph do not share exactly the same structure, some similarity is sufficient for the covariates to assist in the discovery of the graph structure. Second, by using node covariates in the clustering procedure, we enhance the relative homogeneity of covariates within a cluster and filter out partitions that fail to align with the important covariates. This allows for easy contextualization of the clusters in terms of the member nodes’ covariates, providing a natural way to interpret the clusters.
Methods that utilize both node covariates and the graph to cluster the nodes have previously been introduced, but many of them rely on ad hoc or heuristic approaches and none provide theoretical guarantees for statistical estimation. Most existing methods can be broadly classified into Bayesian approaches, spectral techniques, and heuristic algorithms. Many Bayesian models focus on categorical node covariates and are often computationally expensive (Chang & Blei, 2010; Balasubramanyan & Cohen, 2011). A recent Bayesian model proposed by Yang et al. (2013) can discover multi-block membership of nodes with binary node covariates. This method has linear update time in the network size, but does not guarantee linear-time convergence. Heuristic algorithms use various approaches, including embedding the network in a vector space, at which point more traditional methods can be applied to the vector data (Gibert et al., 2012), or using the covariates to augment the graph and applying other graph clustering methods that tune the relative weights of node-to-node and node-to-covariate edges (Zhou et al., 2009). A commonly-used spectral approach to incorporate node covariates directly alters the edge weights based on the similarity of the corresponding nodes’ covariates, and uses traditional spectral clustering on the weighted graph (Neville et al., 2003; Gunnemann et al., 2013).
This work introduces a spectral approach that performs well for assortative graphs and another that does not require this restriction. We give a standard definition of an assortative graph here and later define it in the context of a stochastic blockmodel.
Definition 1
(Assortative graph). A graph is assortative if nodes within the same cluster are more likely to share an edge than nodes in two different clusters.
Assortative covariate-assisted spectral clustering adds the covariance matrix of the node covariates to the regularized graph Laplacian, boosting the signal in the top eigenvectors of the sum, which is then used for spectral clustering. This works well for assortative graphs, but performs poorly otherwise. Covariate-assisted spectral clustering, which uses the square of the regularized graph Laplacian, is presented as a more general method that performs well for assortative and non-assortative graphs. A tuning parameter is employed by both methods to adjust the relative weight of the covariates and the graph; in § 2.3 we propose a way to choose this tuning parameter. Research on dynamic networks using latent space models has yielded an analogous form for updating latent coordinates based on a distance matrix and the latent coordinates from the previous time step (Sarkar & Moore, 2006). A similar framework can also be used to cluster multiple graphs (Eynard et al., 2015).
Variants of our methods previously introduced were derived by first considering the problem of minimizing the weighted sum of the 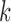 -means and graph cut objective functions and then solving a spectral relaxation of the original problem. Wang et al. (2009) decided against using an additive method similar to covariate-assisted spectral clustering because setting the method’s tuning parameter is a nonconvex problem. They chose to investigate a method that uses the product of the generalized inverse of the graph Laplacian and the covariate matrix instead. Shiga et al. (2007) recognized the advantage of having a tuning parameter to balance the contribution of the graph and the covariates, but did not use the stochastic blockmodel to study their method. The full utility and flexibility of these types of approaches have not yet been presented, and neither paper derives any statistical results about the methods’ performance. Furthermore, they do not consider the performance of these methods on non-assortative graphs. In contrast, we were initially motivated to develop covariate-assisted spectral clustering by its interpretation and propensity for theoretical analysis.
-means and graph cut objective functions and then solving a spectral relaxation of the original problem. Wang et al. (2009) decided against using an additive method similar to covariate-assisted spectral clustering because setting the method’s tuning parameter is a nonconvex problem. They chose to investigate a method that uses the product of the generalized inverse of the graph Laplacian and the covariate matrix instead. Shiga et al. (2007) recognized the advantage of having a tuning parameter to balance the contribution of the graph and the covariates, but did not use the stochastic blockmodel to study their method. The full utility and flexibility of these types of approaches have not yet been presented, and neither paper derives any statistical results about the methods’ performance. Furthermore, they do not consider the performance of these methods on non-assortative graphs. In contrast, we were initially motivated to develop covariate-assisted spectral clustering by its interpretation and propensity for theoretical analysis.
Very few of the clustering methods that employ both node covariates and the graph offer any theoretical results, and, to our knowledge, this paper gives the first statistical guarantee for these types of approaches. We define the node-contextualized stochastic blockmodel, which combines the stochastic blockmodel with a block mixture model for node covariates. Under this model, a bound on the misclustering rate of covariate-assisted spectral clustering is established in § 3.2. The behaviour of the bound is studied for a fixed and an increasing number of covariates as a function of the number of nodes, and conditions for perfect clustering are derived. A general lower bound is also derived, demonstrating the conditions under which an algorithm using both the node covariates and the graph can give more accurate clusters than any algorithm using only the node covariates or the graph.
For comparison, an alternative method based on an adaptation of classical canonical correlation analysis is introduced (Hotelling, 1936), which uses the product of the regularized graph Laplacian and the covariate matrix as the input to the spectral clustering algorithm. Simulations indicate that canonical correlation performs worse than covariate-assisted spectral clustering under the node-contextualized stochastic blockmodel with Bernoulli covariates. However, canonical correlation analysis clustering is computationally faster than our clustering method and requires no tuning. In contrast, covariate-assisted spectral clustering depends on a single tuning parameter, which interpolates between spectral clustering with only the graph and only the covariates. This parameter can be set without prior knowledge by using an objective function such as the within-cluster sum of squares. Some results for determining what range of tuning parameter values should be considered are provided in the description of the optimization procedure in § 2.3. Alternatively, the tuning parameter can be set using prior knowledge or to ensure that the clusters achieve some desired quality, such as spatial cohesion. As an illustrative example, in § 5 we study diffusion magnetic resonance imaging-derived brain graphs using two different sets of node covariates. The first analysis uses spatial location. This produces clusters that are more spatially coherent than those obtained using regularized spectral clustering alone, making them easier to interpret. The second analysis uses neurological region membership, which yields partitions that closely align with neurological regions, while allowing for patient-wise variability based on brain graph connectivity.
2. Methodology
2.1 Notation
Let 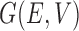 be a graph, where
be a graph, where 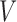 is the set of vertices or nodes and
is the set of vertices or nodes and 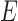 is the set of edges, which represent relationships between the nodes. Let
is the set of edges, which represent relationships between the nodes. Let 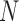 be the number of nodes. Index the nodes in
be the number of nodes. Index the nodes in 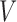 by
by 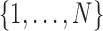 ; then
; then 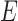 contains a pair
contains a pair 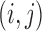 if there is an edge between nodes
if there is an edge between nodes 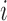 and
and 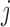 . A graph’s edge set can be represented as the adjacency matrix
. A graph’s edge set can be represented as the adjacency matrix 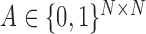 , where
, where 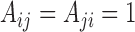 if
if 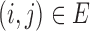 and
and 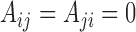 otherwise. We restrict ourselves to studying undirected and unweighted graphs, although with small modifications most of our results also apply to directed and weighted graphs.
otherwise. We restrict ourselves to studying undirected and unweighted graphs, although with small modifications most of our results also apply to directed and weighted graphs.
Define the regularized graph Laplacian as
where 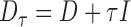 and
and 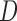 is a diagonal matrix with
is a diagonal matrix with 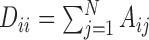 . The regularization parameter
. The regularization parameter 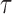 is treated as a constant, and is included to improve spectral clustering performance on sparse graphs (Chaudhuri et al., 2012). Throughout, we shall set
is treated as a constant, and is included to improve spectral clustering performance on sparse graphs (Chaudhuri et al., 2012). Throughout, we shall set 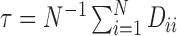 , i.e., the average node degree (Qin & Rohe, 2013).
, i.e., the average node degree (Qin & Rohe, 2013).
For the graph 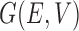 , let each node in the set
, let each node in the set 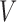 have an associated bounded covariate vector
have an associated bounded covariate vector 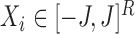 , and let
, and let 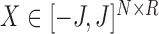 be the covariate matrix where each row corresponds to a node covariate vector. Let
be the covariate matrix where each row corresponds to a node covariate vector. Let  denote the spectral norm and
denote the spectral norm and 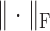 the Frobenius norm. Let
the Frobenius norm. Let 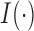 denote the indicator function. For sequences
denote the indicator function. For sequences 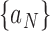 and
and 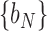 ,
, 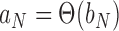 if and only if
if and only if 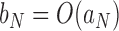 and
and 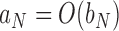 .
.
2.2 Spectral clustering for a graph with node covariates
The spectral clustering algorithm has been employed to cluster graph nodes using various functions of the adjacency matrix. For instance, applying the algorithm to 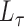 corresponds to regularized spectral clustering, where the value of the regularization parameter is set prior to running the algorithm. All of the methods we consider will employ this algorithm, but will use a different input matrix such as
corresponds to regularized spectral clustering, where the value of the regularization parameter is set prior to running the algorithm. All of the methods we consider will employ this algorithm, but will use a different input matrix such as 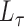 ,
, 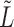 or
or 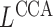 as defined later.
as defined later.
Algorithm 1.
Spectral clustering.
Given input matrix
and number of clusters
:
Step 1. Find eigenvectors
corresponding to the
largest eigenvalues of
.
Step 2. Use the eigenvectors as columns to form the matrix
.
Step 3. Form the matrix
by normalizing each of
’s rows to have unit length.
Step 4. Run
-means clustering with
clusters, treating each row of
as a point in
.
Step 5. If the
th row of
falls in the
th cluster, assign node
to cluster
.
Step 4 of the spectral clustering algorithm uses 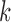 -means clustering, which is sensitive to initialization. In order to reduce this sensitivity, we use multiple random initializations. To take advantage of available graph and node covariate data in graph clustering, it is necessary to employ methods that incorporate both of these data types. As discussed in § 1, spectral clustering has many advantages over other graph clustering methods. Hence, we propose three approaches that use the spectral clustering framework and utilize both the graph structure and the node covariates.
-means clustering, which is sensitive to initialization. In order to reduce this sensitivity, we use multiple random initializations. To take advantage of available graph and node covariate data in graph clustering, it is necessary to employ methods that incorporate both of these data types. As discussed in § 1, spectral clustering has many advantages over other graph clustering methods. Hence, we propose three approaches that use the spectral clustering framework and utilize both the graph structure and the node covariates.
Assortative covariate-assisted spectral clustering uses the leading eigenvectors of
where 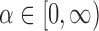 is a tuning parameter. When using
is a tuning parameter. When using 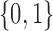 -Bernoulli covariates, the covariate term can be interpreted as adding to each element
-Bernoulli covariates, the covariate term can be interpreted as adding to each element 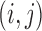 a value proportional to the number of covariates equal to 1 for both
a value proportional to the number of covariates equal to 1 for both 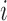 and
and 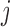 . In practice, the covariate matrix
. In practice, the covariate matrix 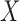 should be parameterized as in linear regression; specifically, categorical covariates should be re-expressed with dummy variables. For continuous covariates, it can be beneficial to centre and scale the columns of
should be parameterized as in linear regression; specifically, categorical covariates should be re-expressed with dummy variables. For continuous covariates, it can be beneficial to centre and scale the columns of 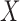 before performing the analysis. The scaling helps satisfy condition (i) in Lemma 1, which ensures that the top
before performing the analysis. The scaling helps satisfy condition (i) in Lemma 1, which ensures that the top 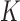 eigenvectors of
eigenvectors of 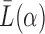 contain block information. As demonstrated in the simulations in § 4, this method is robust and has good performance for assortative graphs, but does not perform well for non-assortative graphs.
contain block information. As demonstrated in the simulations in § 4, this method is robust and has good performance for assortative graphs, but does not perform well for non-assortative graphs.
Covariate-assisted spectral clustering uses the leading eigenvectors of
This approach performs well for non-assortative graphs and nearly as well as our assortative clustering method for assortative graphs. When there is little chance of confusion, 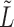 will be used for notational convenience.
will be used for notational convenience.
To run covariate-assisted spectral clustering on the large graphs, such as the brain graphs in § 5, the top 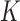 eigenvectors of
eigenvectors of 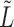 are computed using the implicitly restarted Lanczos bidiagonalization algorithm (Baglama & Reichel, 2006). At each iteration, the algorithm only needs to compute the product
are computed using the implicitly restarted Lanczos bidiagonalization algorithm (Baglama & Reichel, 2006). At each iteration, the algorithm only needs to compute the product 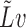 , where
, where 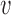 is an arbitrary vector. For computational efficiency, the product is calculated as
is an arbitrary vector. For computational efficiency, the product is calculated as 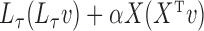 . This takes advantage of the sparsity of
. This takes advantage of the sparsity of 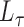 and the low-rank structure of
and the low-rank structure of 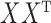 . Ignoring log terms and any special structure in
. Ignoring log terms and any special structure in 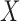 , it takes
, it takes 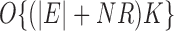 operations to compute the required top
operations to compute the required top 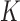 eigenvectors of
eigenvectors of 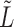 , where
, where 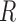 is the number of columns in
is the number of columns in 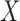 . The graph clusters are obtained by iteratively employing the spectral clustering algorithm on
. The graph clusters are obtained by iteratively employing the spectral clustering algorithm on 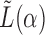 while varying the tuning parameter
while varying the tuning parameter 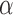 until an optimal value is obtained. The details of this procedure are described in the next section.
until an optimal value is obtained. The details of this procedure are described in the next section.
As an alternative, we propose a modification of classical canonical correlation analysis (Hotelling, 1936) whose similarity matrix is the product of the regularized graph Laplacian and the covariate matrix,
The spectral clustering algorithm is employed on 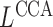 to obtain node clusters when the number of covariates,
to obtain node clusters when the number of covariates, 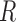 , is greater than or equal to the number of clusters,
, is greater than or equal to the number of clusters, 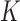 . This approach inherently provides a dimensionality reduction in the common case where the number of covariates is much less than the number of nodes. If
. This approach inherently provides a dimensionality reduction in the common case where the number of covariates is much less than the number of nodes. If 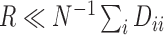 , then spectral clustering with
, then spectral clustering with 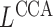 has a faster running time than covariate-assisted spectral clustering.
has a faster running time than covariate-assisted spectral clustering.
2.3 Setting the tuning parameter
In order to perform spectral clustering with 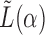 , it is necessary to determine a specific value for the tuning parameter,
, it is necessary to determine a specific value for the tuning parameter, 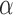 . The tuning procedure presented here presumes that both the graph and the covariates contain some block information, as demonstrated by the simulations in § 4. In practice, an initial test can be used to determine if the graph and the covariates contain common block information, and such a test will be presented in future work. The tuning parameter should be chosen to achieve a balance between
. The tuning procedure presented here presumes that both the graph and the covariates contain some block information, as demonstrated by the simulations in § 4. In practice, an initial test can be used to determine if the graph and the covariates contain common block information, and such a test will be presented in future work. The tuning parameter should be chosen to achieve a balance between 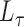 and
and 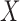 such that the information in both is captured in the leading eigenspace of
such that the information in both is captured in the leading eigenspace of 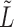 . For large values of
. For large values of 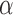 , the leading eigenspace of
, the leading eigenspace of 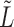 is approximately the leading eigenspace of
is approximately the leading eigenspace of 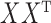 . For small values of
. For small values of 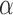 , the leading eigenspace of
, the leading eigenspace of 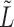 is approximately the leading eigenspace of
is approximately the leading eigenspace of 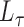 . A good initial choice of
. A good initial choice of 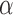 is the value which makes the leading eigenvalues of
is the value which makes the leading eigenvalues of 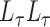 and
and 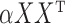 equal, namely
equal, namely 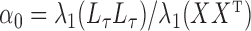 .
.
There is a finite range of 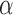 for which the leading eigenspace of
for which the leading eigenspace of 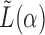 is not a continuous function of
is not a continuous function of 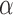 ; outside this range, the leading eigenspace is always continuous in
; outside this range, the leading eigenspace is always continuous in 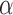 . In simulations, the clustering results are exceedingly stable in the continuous range of
. In simulations, the clustering results are exceedingly stable in the continuous range of 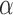 . Hence, only the values of
. Hence, only the values of 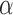 inside a finite interval need to be considered. This section gives an interval
inside a finite interval need to be considered. This section gives an interval 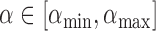 that is computed with only the eigenvalues of
that is computed with only the eigenvalues of 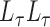 and
and 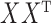 . Within this interval,
. Within this interval, 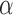 is chosen to minimize an objective function. Empirical results demonstrating these properties are given in the Supplementary Material.
is chosen to minimize an objective function. Empirical results demonstrating these properties are given in the Supplementary Material.
Let 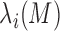 be the
be the 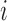 th eigenvalue of matrix
th eigenvalue of matrix 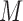 . To find the initial range
. To find the initial range 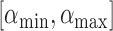 , define a static vector
, define a static vector 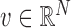 as a vector that satisfies conditions (1) and (2) below. For
as a vector that satisfies conditions (1) and (2) below. For 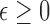 ,
,
| (1) |
| (2) |
The eigenspaces of 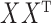 and
and 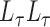 have little overlap along a static vector,
have little overlap along a static vector, 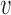 ; perhaps there is a cluster in the graph that does not appear in the covariates, or vice versa. These static vectors produce discontinuities in the leading eigenspace of
; perhaps there is a cluster in the graph that does not appear in the covariates, or vice versa. These static vectors produce discontinuities in the leading eigenspace of 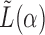 .
.
For example, if 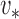 is an eigenvector of
is an eigenvector of 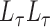 and a static vector of type (1), then as
and a static vector of type (1), then as 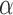 changes, it will remain a slightly perturbed eigenvector of
changes, it will remain a slightly perturbed eigenvector of 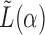 . When
. When 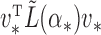 is close to
is close to 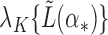 , then, in some neighbourhood of
, then, in some neighbourhood of 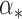 , the slightly perturbed version of
, the slightly perturbed version of 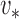 will transition into the leading eigenspace of
will transition into the leading eigenspace of 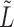 . This transition corresponds to a discontinuity in the leading eigenspace.
. This transition corresponds to a discontinuity in the leading eigenspace.
As shown in the Supplementary Material, the concept of static vectors with 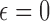 can be used to find a limited range of
can be used to find a limited range of 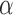 for possible discontinuities. The range of
for possible discontinuities. The range of 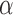 values for which discontinuities can occur is
values for which discontinuities can occur is 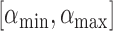 , where
, where
The tuning parameter 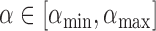 is chosen to be the value which minimizes the
is chosen to be the value which minimizes the 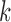 -means objective function, the within-cluster sum of squares,
-means objective function, the within-cluster sum of squares,
where 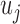 is the
is the 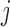 th row of
th row of 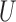 ,
, 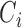 is the centroid of the
is the centroid of the 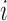 th cluster from
th cluster from 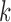 -means clustering, and
-means clustering, and 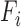 is the set of points in the
is the set of points in the 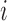 th cluster. Hence, the tuning parameter is
th cluster. Hence, the tuning parameter is 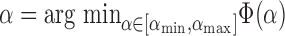 .
.
3. Theory
3.1 Node-contextualized stochastic blockmodel
To illustrate what covariate-assisted spectral clustering estimates, this section proposes a statistical model for a network with node covariates and shows that covariate-assisted spectral clustering is a weakly consistent estimator of certain parameters in the proposed model. To derive statistical guarantees for covariate-assisted spectral clustering, we assume a joint mixture model for the graph and the covariates. Under this model, each node belongs to one of 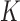 blocks and each edge in the graph corresponds to an independent Bernoulli random variable. The probability of an edge between any two nodes depends only on the block membership of those nodes (Holland et al., 1983). In addition, each node is associated with
blocks and each edge in the graph corresponds to an independent Bernoulli random variable. The probability of an edge between any two nodes depends only on the block membership of those nodes (Holland et al., 1983). In addition, each node is associated with  independent covariates with bounded support, where expectation depends only on the block membership and
independent covariates with bounded support, where expectation depends only on the block membership and  can grow with the number of nodes.
can grow with the number of nodes.
Definition 2
(Node-contextualized stochastic blockmodel). Consider a set of nodes
. Let
assign each of the
nodes to one of the
blocks, where
if node
belongs to block
. Let
be of full rank and symmetric, where
is the probability of an edge between nodes in blocks
and
. Conditional on
, the elements of the adjacency matrix are independent Bernoulli random variables. The population adjacency matrix
fully identifies the distribution of
and
.
Let
be the covariate matrix and
the covariate expectation matrix, where
is the expectation of the
th covariate of a node in the
th block. Conditional on
, the elements of
are independent and the population covariate matrix is
(3)
Under the node-contextualized stochastic blockmodel, covariate-assisted spectral clustering seeks to estimate the block membership matrix 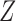 . In the next section, we show that this estimate is consistent. If
. In the next section, we show that this estimate is consistent. If 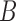 is assumed to be positive definite, the same results hold for assortative covariate-assisted spectral clustering up to a constant factor. These results motivate the definition of an assortative graph in the context of the node-contextualized stochastic blockmodel.
is assumed to be positive definite, the same results hold for assortative covariate-assisted spectral clustering up to a constant factor. These results motivate the definition of an assortative graph in the context of the node-contextualized stochastic blockmodel.
Definition 3
(Assortative graph). A graph generated under the node-contextualized stochastic blockmodel is said to be assortative if the block probability matrix
corresponding to the graph is positive definite. Otherwise, it is said to be non-assortative.
Many common networks are assortative, such as friendship networks or brain graphs. Dating networks are one example of a non-assortative network. Most relationships in a dating network are heterosexual, comprised of one male and one female. In a stochastic blockmodel, where the blocks are constructed by gender, 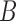 will have small diagonal elements and large off-diagonal elements, producing more relationships between genders than within genders. Such a matrix is not positive definite. More generally, non-assortative stochastic blockmodels will tend to generate more edges between blocks and fewer edges within blocks. These non-assortative blocks appear in the spectrum of
will have small diagonal elements and large off-diagonal elements, producing more relationships between genders than within genders. Such a matrix is not positive definite. More generally, non-assortative stochastic blockmodels will tend to generate more edges between blocks and fewer edges within blocks. These non-assortative blocks appear in the spectrum of 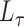 as large negative eigenvalues. By squaring the matrix
as large negative eigenvalues. By squaring the matrix 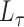 , the eigenvalues become large and positive, matching the positive eigenvalues in
, the eigenvalues become large and positive, matching the positive eigenvalues in 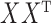 .
.
3.2 Statistical consistency under the node-contextualized stochastic blockmodel
The proof of consistency for covariate-assisted spectral clustering under the node-contextualized stochastic blockmodel requires three results. Lemma 1 expresses the eigendecomposition of the population version of the covariate-assisted Laplacian,
in terms of 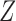 . Theorem 1 bounds the spectral norm of the difference between
. Theorem 1 bounds the spectral norm of the difference between 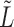 and
and 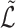 . Then, the Davis–Kahan theorem (Davis & Kahan, 1970) bounds the difference between the sample and population eigenvectors in Frobenius norm. Finally, Theorem 3 combines these results to establish a bound on the misclustering rate of covariate-assisted spectral clustering. The argument largely follows Qin & Rohe (2013). The results provided here do not include the effects of Step 3 in Algorithm 1. The proofs are in the Supplementary Material.
. Then, the Davis–Kahan theorem (Davis & Kahan, 1970) bounds the difference between the sample and population eigenvectors in Frobenius norm. Finally, Theorem 3 combines these results to establish a bound on the misclustering rate of covariate-assisted spectral clustering. The argument largely follows Qin & Rohe (2013). The results provided here do not include the effects of Step 3 in Algorithm 1. The proofs are in the Supplementary Material.
Lemma 1.
Under the node-contextualized stochastic blockmodel, let
,
, and
. Let
, where
and
. Define
with columns containing the top
eigenvectors of
. Assume (i)
; then there exists an orthogonal matrix
such that
. Furthermore,
if and only if
, where
is the
th row of the block membership matrix.
Under assumption (i) the rows of the population eigenvectors are equal if and only if the corresponding nodes belong to the same block. This assumption requires the population eigengap to be greater than the maximum of the absolute difference between the sum of covariate variances within a block and the mean of the sums across all blocks. If all the covariates have equal variance in all blocks, the assumption is trivially true. Since 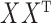 is effectively being used as a measure of similarity between nodes, if the covariate variances across blocks are unequal, the difference in scale makes the blocks more difficult to distinguish. This is evidenced by a reduction in the eigengap proportional to this difference. In practice, this condition is not restrictive since
is effectively being used as a measure of similarity between nodes, if the covariate variances across blocks are unequal, the difference in scale makes the blocks more difficult to distinguish. This is evidenced by a reduction in the eigengap proportional to this difference. In practice, this condition is not restrictive since 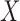 can be centred and normalized. To derive a bound on the misclustering rate, we will need a bound on the difference between the population eigenvectors and the sample eigenvectors. In order to establish this bound, the following theorem bounds the spectral norm of the difference between
can be centred and normalized. To derive a bound on the misclustering rate, we will need a bound on the difference between the population eigenvectors and the sample eigenvectors. In order to establish this bound, the following theorem bounds the spectral norm of the difference between 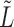 and
and 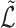 .
.
Theorem 1.
Let
,
,
,
, and
. For any
, if (ii)
and (iii)
, then with probability at least
,
Consider a node-contextualized stochastic blockmodel with two blocks, within-block probabilities 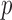 , and between-block probabilities
, and between-block probabilities 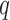 . Condition (ii) holds when
. Condition (ii) holds when 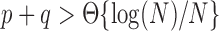 and condition (iii) holds when
and condition (iii) holds when 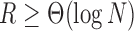 . Hence, condition (ii) restricts the sparsity of the graph, while condition (iii) requires that the number of covariates grow with the number of nodes. Now we use Theorem 1 and the Davis–Kahan theorem to bound the difference between the sample and population eigenvectors.
. Hence, condition (ii) restricts the sparsity of the graph, while condition (iii) requires that the number of covariates grow with the number of nodes. Now we use Theorem 1 and the Davis–Kahan theorem to bound the difference between the sample and population eigenvectors.
Theorem 2.
Let
be the
th largest eigenvalue of
and let
be a rotation matrix. Let the columns of
and
contain the top
eigenvectors of
and
, respectively. Under assumptions (i) in Lemma 1, (ii) and (iii) in Theorem 1, and (iv)
, with probability at least
,
The next theorem bounds the proportion of misclustered nodes. In order to define misclustering, recall that the spectral clustering algorithm uses 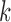 -means clustering to cluster the rows of
-means clustering to cluster the rows of 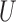 . Let
. Let 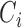 and
and 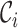 be the cluster centroids of the
be the cluster centroids of the 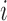 th node generated using
th node generated using 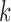 -means clustering on
-means clustering on 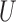 and
and 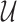 , respectively. A node
, respectively. A node 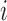 is correctly clustered if
is correctly clustered if 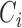 is closer to
is closer to 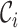 than
than 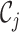 for all
for all 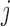 such that
such that 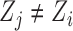 . In order to avoid identifiablity problems and since clustering only requires the estimation of the correct subspace, the formal definition is augmented with a rotation matrix
. In order to avoid identifiablity problems and since clustering only requires the estimation of the correct subspace, the formal definition is augmented with a rotation matrix 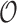 . The following definition formalizes this intuition.
. The following definition formalizes this intuition.
Definition 4.
Let
be a rotation matrix that minimizes
. Define the set of misclustered nodes as
Using the definition of misclustering and the result from Theorem 2, the next theorem bounds the misclustering rate, 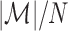 .
.
Theorem 3.
Let
denote the size of the largest block. Under assumptions (i) in Lemma 1, (ii) and (iii) in Theorem 1, and (iv) in Theorem 2, with probability at least
, the misclustering rate satisfies
The asymptotics of the misclustering rate depend on the number of covariates and the sparsity of the graph. This is demonstrated by Corollary 1, which provides insight into how the number of covariates and graph sparsity affect the misclustering rate and the choice of tuning parameter.
Corollary 1.
Assume
and
for all
; in addition, let
,
for all
, and
. For computational convenience, assume that each block has the same number of nodes
and
is a multiple of
, where
is fixed. Let
,
, and
, where
. Then, the misclustering bound from Theorem 3 becomes
If
, then the minimum misclustering rate is
when
. If
, then the minimum misclustering rate is
when
.
These results demonstrate that the tuning parameter 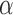 is determined by the balance between the number of covariates and the sparsity of the graph. A nonzero optimal
is determined by the balance between the number of covariates and the sparsity of the graph. A nonzero optimal 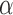 value signifies that including covariates improves the misclustering bound, although it might not improve the asymptotics of the bound. Furthermore, the asymptotic misclustering rate is determined by the asymptotic behaviour of the number of covariates or the mean number of edges, whichever is greater as determined by
value signifies that including covariates improves the misclustering bound, although it might not improve the asymptotics of the bound. Furthermore, the asymptotic misclustering rate is determined by the asymptotic behaviour of the number of covariates or the mean number of edges, whichever is greater as determined by 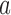 and
and 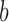 , respectively. For example, if we allow the number of covariates to grow with the number of nodes such that
, respectively. For example, if we allow the number of covariates to grow with the number of nodes such that 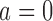 or
or 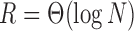 and let the mean number of edges increase such that
and let the mean number of edges increase such that 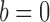 or
or 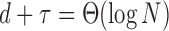 , then the covariates and the graph contribute equally to the asymptotic misclustering rate.
, then the covariates and the graph contribute equally to the asymptotic misclustering rate.
Remark 1.
It is instructive to compare the value of
suggested by the results in Corollary 1 with the possible values of
based on the optimization procedure in § 2.3. Computing
and
with
instead of
, for convenience, gives
and
. Therefore, the optimization procedure will yield
. This agrees with the results of Corollary 1 when the mean node degree and the number of covariates grow at the same rate with respect to the number of nodes or
.
Corollary 2.
Based on Theorem 3, perfect clustering requires
. Under the simplifying assumptions given in Corollary 1, perfect clustering is achieved when the number of covariates is
.
3.3 General lower bound
The next theorem gives a lower bound for clustering a graph with node covariates. This bound uses Fano’s inequality and is similar to that shown in Chaudhuri et al. (2012) for a graph without node attributes. We restrict ourselves to a node-contextualized stochastic blockmodel with 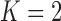 blocks, but allow an arbitrary number of covariates
blocks, but allow an arbitrary number of covariates 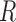 .
.
Theorem 4.
Consider the node-contextualized stochastic blockmodel with
blocks and
such that
. Let the Kullback–Leibler divergence of the covariates be
, where
and
are the distributions of the
th covariate under opposite block assignments, and
. For a fixed
and
, in order to correctly recover the block assignments with probability at least
,
must satisfy
Remark 2.
If
(4)
(5) then only an algorithm that uses both the graph and node covariates can yield correct blocks with high probability. Condition (4) specifies when the graph is insufficient and condition (5) specifies when the covariates are insufficient to individually recover the block membership with high probability.
Remark 3.
The upper bound for covariate-assisted spectral clustering in Theorem 3 can be compared with the general lower bound. Simplifying the general lower bound gives the condition
for perfect clustering with probability
. This is the same condition as for regularized spectral clustering. According to Theorem 3, for this method to achieve perfect clustering with probability
requires
. As highlighted in Corollary 2, this condition cannot be satisfied for a fixed
, so it cannot be shown that covariate-assisted spectral clustering achieves perfect clustering for a fixed number of covariates. This is consistent with similar results for regularized spectral clustering.
4. Simulations
4.1 Varying graph or covariate signal
In these simulations, consider a node-contextualized stochastic blockmodel with 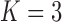 blocks and
blocks and 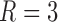 node Bernoulli covariates. Define the block probabilities for the assortative graph, the non-assortative graph, and the covariates as
node Bernoulli covariates. Define the block probabilities for the assortative graph, the non-assortative graph, and the covariates as
| (6) |
where 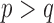 and
and 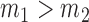 . This implies that for the assortative graph the probability of an edge within a block is
. This implies that for the assortative graph the probability of an edge within a block is 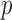 , which is greater than
, which is greater than 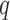 , the probability of an edge between two blocks. The opposite is true for the non-assortative graph. In the
, the probability of an edge between two blocks. The opposite is true for the non-assortative graph. In the 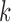 th block, the probability of the
th block, the probability of the 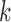 th covariate being 1 is
th covariate being 1 is 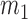 and the probability of the other covariates being 1 is
and the probability of the other covariates being 1 is 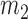 .
.
These simulations compare five methods. The first three are canonical correlation analysis clustering, covariate-assisted spectral clustering, and assortative covariate-assisted spectral clustering, which utilize node edges and node covariates to cluster the graph. The other two methods utilize either the node edges or the node covariates. For the node edges, regularized spectral clustering is used; for the node covariates, spectral clustering on the covariate matrix is used.
The first set of simulations investigates the effect of varying the block signal in the graph on the misclustering rate. This is done by varying the difference in the within- and between-block probabilities,  . The simulations are conducted for the assortative and non-assortative graphs, using
. The simulations are conducted for the assortative and non-assortative graphs, using 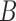 and
and 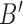 in (6), shown in Fig. 1(a) and (b), respectively. In the assortative case, our assortative clustering method performs better than any of the other methods. Covariate-assisted spectral clustering performs slightly worse than the assortative variant, but still outperforms the other methods. In the non-assortative case, our clustering method has the best performance, while the assortative version always does worse than using only the covariates or the graph.
in (6), shown in Fig. 1(a) and (b), respectively. In the assortative case, our assortative clustering method performs better than any of the other methods. Covariate-assisted spectral clustering performs slightly worse than the assortative variant, but still outperforms the other methods. In the non-assortative case, our clustering method has the best performance, while the assortative version always does worse than using only the covariates or the graph.
Fig. 1.

Average misclustering rate of five clustering methods: covariate-assisted spectral clustering (solid), assortative covariate-assisted spectral clustering (dash), canonical correlation analysis clustering (dot), regularized spectral clustering (dot-dash), and spectral clustering on the covariate matrix (long dash). The fixed parameters are 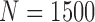 ,
, 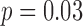 ,
, 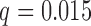 ,
, 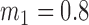 , and
, and 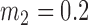 .
.
The second set of simulations investigates the effect of varying the block signal of the covariates on the misclustering rate by changing the difference between the block-specific covariate probabilities, 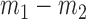 . As shown in Fig. 1(c), assortative covariate-assisted spectral clustering tends to have a better misclustering rate than the other methods. Only when the difference in the covariate block probabilities is very small and
. As shown in Fig. 1(c), assortative covariate-assisted spectral clustering tends to have a better misclustering rate than the other methods. Only when the difference in the covariate block probabilities is very small and 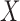 effectively becomes a noise term does regularized spectral clustering outperform our assortative clustering method. For the non-assortative case shown in Fig. 1(d), assortative covariate-assisted spectral clustering performs poorly, while covariate-assisted spectral clustering is able to outperform all other methods for a sufficiently large difference in the covariate block probabilities. This is expected since the covariates in the assortative variant effectively increase the edge weights within a block, which will smooth out the block structure specified by
effectively becomes a noise term does regularized spectral clustering outperform our assortative clustering method. For the non-assortative case shown in Fig. 1(d), assortative covariate-assisted spectral clustering performs poorly, while covariate-assisted spectral clustering is able to outperform all other methods for a sufficiently large difference in the covariate block probabilities. This is expected since the covariates in the assortative variant effectively increase the edge weights within a block, which will smooth out the block structure specified by 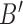 .
.
4.2 Model misspecification
The final simulation considers the case where the block membership in the covariates is not necessarily the same as the block membership in the graph. The node Bernoulli covariates no longer satisfy (3) in Definition 2, but 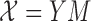 , where
, where 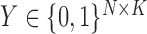 is a block membership matrix that differs from
is a block membership matrix that differs from 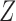 . As such, the underlying clusters in the graph do not align with the clusters in the covariates. This simulation varies the proportion of block assignments in
. As such, the underlying clusters in the graph do not align with the clusters in the covariates. This simulation varies the proportion of block assignments in 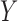 which agree with the block assignments in
which agree with the block assignments in 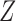 to investigate the robustness of the methods with respect to this form of model misspecification. The results in Fig. 1(e) show that assortative covariate-assisted spectral clustering is robust with respect to covariate block membership model misspecification for the assortative graph. The misclustering rate shown is computed relative to the block membership of the graph. For this case, our assortative clustering method is able to achieve a lower misclustering rate than regularized spectral clustering when the proportion of agreement between the block membership of the graph and the covariates is greater than
to investigate the robustness of the methods with respect to this form of model misspecification. The results in Fig. 1(e) show that assortative covariate-assisted spectral clustering is robust with respect to covariate block membership model misspecification for the assortative graph. The misclustering rate shown is computed relative to the block membership of the graph. For this case, our assortative clustering method is able to achieve a lower misclustering rate than regularized spectral clustering when the proportion of agreement between the block membership of the graph and the covariates is greater than 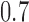 . Since a three-block model is used, the lowest proportion of agreement possible is one third due to identifiability. For the non-assortative graph, Fig. 1(f), covariate-assisted spectral clustering requires a higher level of agreement at
. Since a three-block model is used, the lowest proportion of agreement possible is one third due to identifiability. For the non-assortative graph, Fig. 1(f), covariate-assisted spectral clustering requires a higher level of agreement at 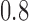 .
.
5. Clustering diffusion MRI connectome graphs
Assortative covariate-assisted spectral clustering was applied to brain graphs recovered from diffusion magnetic resonance imaging (Craddock et al., 2013). Each node in a brain graph corresponds to a voxel in the brain. The edges between nodes are weighted by the number of estimated fibres that pass through both voxels. The centre of a voxel is treated as the spatial location of the corresponding node. These spatial locations were centred and used as the first set of covariates in the analysis. The dataset used in this analysis contains 42 brain graphs obtained from 21 different individuals. Only the largest connected components of the brain graphs were used, ranging in size from 707 000 to 935 000 nodes, with a mean density of 744 edges per node. In addition, the brain graphs contain brain atlas labels corresponding to 70 different neurological brain regions, which were treated as a second set of covariates.
Whereas the simulations attempted to demonstrate the effectiveness of our clustering method in utilizing node covariates to help discover the underlying block structure of the graph, this analysis focuses on the ability of our clustering method to discover highly connected clusters with relatively homogeneous covariates. The node covariates contextualize the brain clusters and improve their interpretability. Like other clustering methods, covariate-assisted spectral clustering is mainly an exploratory tool which may or may not provide answers directly but can often provide insight into relationships within the data. In this example, it is used to examine the relationships between brain graph connectivity, spatial location, and brain atlas labels. The utility of covariate-assisted spectral clustering was explored by partitioning the brain graphs into 100 clusters. The brain graphs in this dataset are assortative, so our assortative clustering method was used in this analysis. Since the brain graphs have heterogeneous node degrees, the rows of the eigenvector matrix were normalized when applying the spectral clustering algorithm to improve the clustering results (Qin & Rohe, 2013). Figure 2 shows a section of a sample brain graph with nodes plotted at their corresponding spatial locations and coloured by cluster membership. For reference, the neurological brain atlas clusters with 70 different regions and an additional category for unlabelled nodes are also plotted. The brain graphs were clustered using three different approaches: regularized spectral clustering, and assortative covariate-assisted spectral clustering with spatial location and with brain atlas membership. The tuning parameter 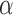 was set using the procedure in § 2.3, and the values were
was set using the procedure in § 2.3, and the values were 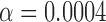 with spatial location covariates and
with spatial location covariates and 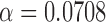 with brain atlas membership covariates.
with brain atlas membership covariates.
Fig. 2.

Brain graph cross-sections with nodes plotted spatially and coloured by cluster membership for three different clustering methods and a brain atlas.
As shown in Fig. 2, regularized spectral clustering yielded spatially diffuse clusters of densely connected nodes. By adding spatial location using covariate-assisted spectral clustering, we obtained densely connected and spatially coherent clusters. Regularized spectral clustering had two clusters of about 80 000 nodes and four clusters with fewer than 1000 nodes, while the largest cluster from our clustering method had fewer than 50 000 nodes and no clusters had fewer than 1000 nodes. Both greater spatial coherence and increased uniformity in cluster size demonstrated by covariate-assisted spectral clustering are important qualities for interpreting the partition. In addition, the clusters have a greater similarity with the brain atlas labels, though this similarity is still not very substantial. This suggests that brain graph connectivity is governed by more than just the neurological regions in the brain atlas.
The relation between the brain atlas and the brain graph was studied further by treating brain atlas membership as the node covariates. This allowed the discovery of highly connected regions with relatively homogeneous graph atlas labels. As shown in Fig. 2, relative to the brain atlas, some of the clusters are broken up, a few are joined together, and others overlap with multiple brain atlas regions, but the high similarity is clearly visible. Importantly, this approach gives us clusters that are highly aligned with known neurological regions while allowing for individual variability of the partitions based on brain graph connectivity. The adjusted Rand index was used to quantify the similarity of the partitions of a brain graph specified by the different clustering methods and the brain atlas in Table 1. The alignment with the partitions based only on spatial location and either covariate-assisted spectral clustering with spatial location or the brain atlas is greater than between the two methods. This indicates that both the clusters from our method and the brain atlas are spatially coherent yet not highly overlapping.
Table 1.
The adjusted Rand index between different partitions
| ACASC-X | Brain atlas | ACASC-BA | SC-X | |
|---|---|---|---|---|
| RSC | 0.095 | 0.082 | 0.085 | 0.092 |
| ACASC-X | - | 0.169 | 0.189 | 0.278 |
| Brain atlas | - | - | 0.838 | 0.226 |
| ACASC-BA | - | - | - | 0.227 |
RSC, regularized spectral clustering; ACASC-X, assortative covariate-assisted spectral clustering with spatial location; ACASC-BA, assortative covariate-assisted spectral clustering with brain atlas membership; SC-X, spectral clustering using spatial location.
Brain graph connectivity appears to be giving the clusters that use spatial location a different configuration from the brain atlas, as seen in Fig. 2. As expected, covariate-assisted spectral clustering with brain atlas membership has the highest adjusted Rand index partition similarity with the brain atlas but low similarity with the regularized spectral clustering partitions. If a more balanced partition alignment is desired, the tuning parameter can be adjusted accordingly.
The relationship between all 42 brain graphs was analysed by using the adjusted Rand index to compare partitions between them, as shown in Fig. 3. To conduct the comparison, the nodes of each brain graph were matched by spatial location, and any nonmatching nodes were ignored. Both regularized spectral clustering and covariate-assisted spectral clustering with spatial location distinguish clearly between individuals based on their brain graph partitions, but the latter gave partitions which are more homogeneous both within and between individuals. This increased partition consistency is favourable since a high degree of variation in the clusters between individuals would make them more difficult to interpret.
Fig. 3.

Heat maps of the adjusted Rand index comparing the partitions of 42 brain graphs. The separate heat maps are based on partitions generated with different methods. Each row and column corresponds to a brain scan and adjacent rows or columns correspond to two scans of the same individual.
6. Discussion
Although the node-contextualized stochastic blockmodel is useful for studying graph clustering methods, data can deviate from the model’s assumptions. More generally, covariate-assisted spectral clustering can be used to find highly connected communities with relatively homogeneous covariates, where the balance between these two objectives is controlled by the tuning parameter and can be set empirically or decided by the analyst. Relatively homogeneous covariates contextualize the clusters, making them easier to interpret and allowing the analyst to focus on partitions that align with important covariates. Beyond its scientific interest, the brain graph analysis demonstrates the computational efficiency of our clustering method, since the analysis could not have been feasibly conducted with existing methods. Nevertheless, determining an optimal tuning parameter still presents a computational burden. Using a low-rank update algorithm for eigenvector decomposition can further reduce this cost.
This work is meant as a step towards statistical understanding of graphs with node covariates. Further work is needed to better understand the use of covariate-assisted spectral clustering for network contextualization. Methods for determining the relative contribution of the graph and the covariates to a graph partition and tests to signify which covariates are informative would be useful. Ultimately, a thorough examination of the relationship between graph structure and node covariates is essential for a deep understanding of the underlying system.
Supplementary Material
Acknowledgement
This research was supported by the U.S. National Institutes of Health, National Science Foundation, and Defense Advanced Research Projects Agency. The authors would like to thank Yilin Zhang, Tai Qin, Jun Tao, Soumendu Sundar Mukherjee, and Zoe Russek for helpful comments.
Supplementary material
Supplementary material available at Biometrika online includes proofs of all the theorems and details about selecting the tuning parameter  .
.
References
- Airoldi E. M., Blei D. M., Fienberg S. E. & Xing E. P. (2008). Mixed membership stochastic blockmodels. J. Mach. Learn. Res. 9, 1981–2014. [PMC free article] [PubMed] [Google Scholar]
- Amini A. A., Chen A., Bickel P. J. & Levina E. (2013). Pseudo-likelihood methods for community detection in large sparse networks. Ann. Statist. 41, 2097–122. [Google Scholar]
- Baglama J. & Reichel L. (2006). Restarted block Lanczos bidiagonalization methods. Numer. Algor. 43, 251–72. [Google Scholar]
- Balasubramanyan R. & Cohen W. W. (2011). Block-LDA: Jointly modeling entity-annotated text and entity-entity links. In Proc. 2011 SIAM Int. Conf. Data Mining, Liu B. Liu H. Clifton C. Washio T. & Kamath C. eds., vol. 11 Philadelphia, PA: SIAM, pp. 450–61. [Google Scholar]
- Chang J. & Blei D. M. (2010). Hierarchical relational models for document networks. Ann. Appl. Statist. 4, 124–50. [Google Scholar]
- Chaudhuri K., Chung F. & Tsiatas A. (2012). Spectral clustering of graphs with general degrees in the extended planted partition model. J. Mach. Learn. Res. 2012, 1–23. [Google Scholar]
- Craddock R. C., Jbabdi S., Yan C.-G., Vogelstein J. T., Castellanos F. X., Di Martino A., Kelly C., Heberlein K., Colcombe S. & Milham M. P. (2013). Imaging human connectomes at the macroscale. Nature Meth. 10, 524–39. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davis C. & Kahan W. M. (1970). The rotation of eigenvectors by a perturbation. SIAM J. Numer. Anal. 7, 1–46. [Google Scholar]
- Eynard D., Kovnatsky A., Bronstein M., Glashoff K. & Bronstein A. (2015). Multimodal manifold analysis by simultaneous diagonalization of laplacians. IEEE Trans. Pat. Anal. Mach. Intel. 37, 2505–17. [DOI] [PubMed] [Google Scholar]
- Gibert J., Valveny E. & Bunke H. (2012). Graph embedding in vector spaces by node attribute statistics. Pat. Recog. 45, 3072–83. [Google Scholar]
- Gunnemann S., Farber I., Raubach S. & Seidl T. (2013). Spectral subspace clustering for graphs with feature vectors. In Proc. IEEE 13th Int. Conf. Data Mining, Ding W. Washio T. Xiong H. Karypis G. Thuraisingham B. Cook D. & Wu X. eds. Los Alamitos, CA: IEEE, pp. 231–40. [Google Scholar]
- Handcock M. S., Raftery A. E. & Tantrum J. M. (2007). Model-based clustering for social networks. J. R. Statist. Soc. A 170, 301–54. [Google Scholar]
- Hoff P. D., Raftery A. E. & Handcock M. S. (2002). Latent space approaches to social network analysis. J. Am. Statist. Assoc. 97, 1090–8. [Google Scholar]
- Holland P. W., Laskey K. B. & Leinhardt S. (1983). Stochastic blockmodels: First steps. Social Networks 5, 109–37. [Google Scholar]
- Hotelling H. (1936). Relations between two sets of variates. Biometrika 28, 321–77. [Google Scholar]
- Neville J., Adler M. & Jensen D. (2003). Clustering relational data using attribute and link information. In Proc. Text Mining and Link Analysis Workshop, 18th Int. Joint Conf. on Artificial Intelligence, Cohn A. ed. San Francisco, CA: Morgan Kaufmann Publishers, pp. 9–15. [Google Scholar]
- Ng A. Y., Jordan M. I. & Weiss Y. (2002). On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems 14, Dietterich T. Becker S. & Ghahramani Z. eds. Cambridge, MA: MIT Press, pp. 849–56. [Google Scholar]
- Nowicki K. & Snijders T. A. B. (2001). Estimation and prediction for stochastic blockstructures. J. Am. Statist. Assoc. 96, 1077–87. [Google Scholar]
- Qin T. & Rohe K. (2013). Regularized spectral clustering under the degree-corrected stochastic blockmodel. In Advances in Neural Information Processing Systems 26, Burges C. Bottou L. Welling M. Ghahramani Z. & Weinberger K. eds. Red Hook, NY: Curran Associates, Inc., pp. 3120–8. [Google Scholar]
- Sarkar P. & Moore A. W. (2006). Dynamic social network analysis using latent space models. In Advances in Neural Information Processing Systems 18, Weiss Y. Schölkopf B. & Platt J. eds. Cambridge, MA: MIT Press, pp. 1145–52. [Google Scholar]
- Shiga M., Takigawa I. & Mamitsuka H. (2007). A spectral clustering approach to optimally combining numerical vectors with a modular network. In Proc.13th ACM SIGKDD Int. Conf. Know. Disc. Data Mining, Berkhin P. Caruana R. Wu X. & Gaffney S. eds. New York, NY: ACM, pp. 647–56. [Google Scholar]
- Von Luxburg U. (2007). A tutorial on spectral clustering. Stat. Comp. 17, 395–416. [Google Scholar]
- Wang F., Ding C. H. & Li T. (2009). Integrated KL (K-means-Laplacian) clustering: A new clustering approach by combining attribute data and pairwise relations. In Proc. 2009 SIAM Int. Conf. Data Mining, Apte C. Park H. Wang K. & Zaki M. J. eds., vol. 9 Philadelphia, PA: SIAM, pp. 38–48. [Google Scholar]
- Yang J., Mc Auley J. & Leskovec J. (2013). Community detection in networks with node attributes. In Data Mining (ICDM), 2013 IEEE 13th Int. Conf., Ding W. Washio T. Xiong H. Karypis G. Thuraisingham B. Cook D. & Wu X. eds. Los Alamitos, CA: IEEE, pp. 1151–6. [Google Scholar]
- Zhou Y., Cheng H. & Yu J. X. (2009). Graph clustering based on structural/attribute similarities. In Proceedings of the Very Large Databases Endowment, Jagadish H. V. Abiteboul S. Milo T. Patel J. & Rigaux P. eds., vol. 2 San Jose, CA: VLDB Endowment, pp. 718–29. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.